Узнаем как правильно сделать словообразовательный разбор слова в русском языке
Словообразование – неотъемлемая часть языка. Без него не было бы новых слов, профессиональных жаргонов, названий новых изобретений и многого другого. Без словообразования современный язык не был бы настолько богат и удобен для общения, многие слова не канули бы в лету, не стали бы историзмами. Благодаря этому процессу наша повседневная речь усложняется и совершенствуется. Именно поэтому нужно знать законы словообразования и уметь делать словообразовательный разбор слова.
Немного теории
Словообразование (деривация) – процесс создания новых, зачастую более сложных слов из более простых. Этот процесс является неотъемлемой составляющей такой науки, как лингвистика. В разделе словообразования слова делятся на первичные (из которых получают новое слово) и производные (которые получаются при помощи словообразования). Словообразование — сложный процесс, и именно поэтому для него есть несколько методов. О них (или некоторых из них) мы и поговорим в этой статье, а в итоге узнаем, как произвести словообразовательный разбор слова и многое другое. Кроме того, мы узнаем намного больше того, что говорили нам в школе, на уроках русского языка. И, может быть, вы сможете объяснить ребёнку то, что не смог доходчиво объяснить учитель.
О них (или некоторых из них) мы и поговорим в этой статье, а в итоге узнаем, как произвести словообразовательный разбор слова и многое другое. Кроме того, мы узнаем намного больше того, что говорили нам в школе, на уроках русского языка. И, может быть, вы сможете объяснить ребёнку то, что не смог доходчиво объяснить учитель.
Сложение двух основ
В современном мире из-за обилия слов и их спецификации всё чаще используется такой метод словообразования, как сложение двух основ. Чаще всего это сложение происходит так: у двух слов, например, «вода» и «проводить», выделяется корень. Получается: «вод» и «провод». Эти корни соединяются при помощи соединительной гласной «о». Получается новое слово: «водопровод», означающее систему сооружений, чаще всего находящуюся под землёй, доставляющую воду от места «добычи» в места её потребления. Это один из самых простых методов словообразования.
Сложение основы и слова
Разумеется, есть способы и посложнее, чем первый. Допустим, сложение основ и целого слова. Возьмём слово «гидроэлектростанция» и разобьём его на основы. «Гидр», «электр» и «станция». Как вы видите, гласные «о» являются соединительными, от слова «электричество» взяли только корень «электр» (от «электрон»). А вот слово «станция» осталось полноценно жить в данном производном. Так с помощью словообразовательного разбора слова можно определить способ его образования.
Возьмём слово «гидроэлектростанция» и разобьём его на основы. «Гидр», «электр» и «станция». Как вы видите, гласные «о» являются соединительными, от слова «электричество» взяли только корень «электр» (от «электрон»). А вот слово «станция» осталось полноценно жить в данном производном. Так с помощью словообразовательного разбора слова можно определить способ его образования.
Аббревиация
Часто мы используем в своей речи аббревиатуры, а не целые слова. Например, название организаций, учебных заведений и даже стран. Например, «МГУ» – Московский Государственный Университет. Этот способ называется буквенной аббревиацией, т. е. при произнесении аббревиатуры мы обязаны проговаривать буквы слова. Однако есть и звуковая аббревиация, например, «НАТО», «ООН» и «вуз». При такой аббревиации мы произносим звуки, а не буквы. Создание аббревиатур тоже поможет в словообразовательном разборе слова.
Субстантивация
Не стоит бояться этого термина, ведь субстантивацией называют всего лишь такое свойство слов, как переход из одной части речи в другую. Например, «мороженое» (как существительное и как прилагательное), «выходной» (то же самое), «зубной», «жаркое» и т. д. Стоит отметить, что в русском языке переход обычно совершается как раз между существительными и прилагательными. Разумеется, морфемный и словообразовательный разбор слова, которое перешло из одной части речи в другую, будет изменяться.
Например, «мороженое» (как существительное и как прилагательное), «выходной» (то же самое), «зубной», «жаркое» и т. д. Стоит отметить, что в русском языке переход обычно совершается как раз между существительными и прилагательными. Разумеется, морфемный и словообразовательный разбор слова, которое перешло из одной части речи в другую, будет изменяться.
Приставочный
Этот способ мы знаем ещё со школьной скамьи. «Бежал – прибежал», «шёл – отошёл», «дорожный – придорожный» и т. д. Здесь всё просто и понятно. К основе слова добавляется приставка со значением приближения, неполноты действий, близости к предмету и т. п. Часто приставочным способом образуются прилагательные (непричастный — причастный) и местоимения (нигде — где).
Суффиксальный
Обычно эти два способа словообразования изучаются параллельно. Часто этим способом образуются существительные (от глаголов) и такие части речи, как причастие и деепричастие. Например: «положение – положить» и «бегущий – бежать». Здесь, чтобы не путаться, можно выучить суффиксы разных частей речи. Это поможет вам сделать словообразовательный разбор слова и разбор по составу намного быстрее и легче. Например, словообразовательный разбор слова «карманный» будет таким: «карманный –карман» (при помощи суффикса прилагательного -н-).
Здесь, чтобы не путаться, можно выучить суффиксы разных частей речи. Это поможет вам сделать словообразовательный разбор слова и разбор по составу намного быстрее и легче. Например, словообразовательный разбор слова «карманный» будет таким: «карманный –карман» (при помощи суффикса прилагательного -н-).
Приставочно-суффиксальный
Один из самых сложных способов словообразования. Ведь здесь нужно смотреть не только на производное слово, но и на лексическое значение каждой из его морфем. Например, слово «поморье», образовано от слова «море». А вот «приморский» образовано от «морской», а уже оно от «море». Вот такая сложная словообразовательная цепь. Но понять её довольно просто: если слово без приставки или суффикса отдельно не употребляется, тогда способ образования – приставочно-суффиксальный. Если же слово может спокойно существовать без приставки, но с суффиксом, то способ приставочный. Если слово употребляется без суффикса, но с приставкой, то способ суффиксальный. Это всё, что нужно запомнить и уяснить.
Бессуффиксный
Поговорим о таком способе словообразования, как бессуффиксный. Этим способом в русском языке образовано немало имён существительных. Разумеется, они образовываются от глаголов. Каким образом? Возьмём глагол «насыпать» и уберём окончание «ть» и суффикс глагола «а». У нас останется имя существительное женского рода, третьего склонения «насыпь». То есть бессуффиксный способ образования – способ, при котором у глагола отсекается окончание и суффикс, а в итоге получается существительное. Так образованы существительные: «загар» и «просека». Но этим способом имена существительные могут образовываться и от прилагательных, например: «глубь», «тишь», «интеллектуал» и т. д.
Усечение корня
Тут тоже всё понятно. «Танцевальный + пол = танцпол». То есть в этом способе слово отрезается до голой косточки — корня — и в таком виде живёт. Ничего необычного, сложного или специфического. Часто этот способ используется для создания жаргонных слов: «преподаватель – препод», «доктор — док» и т. д. Это, пожалуй, самый простой способ появления на свет новых слов.
д. Это, пожалуй, самый простой способ появления на свет новых слов.
Как сделать словообразовательный разбор слова
После того как мы разобрали основные способы словообразования в русском языке (а те, что мы описали, действительно, лишь основные, а не все способы), нужно разобраться, как же делать словообразовательный разбор слова. Этим и займемся. Для того чтобы всё было понятней, в качестве примера сделаем словообразовательный разбор слова «растапливать». Все данные об этом слове будут помещаться в скобках каждого пункта.
Поэтапный план словообразовательного разбора
- Итак, для начала разбора определяем часть речи (в нашем случае это глагол).
- Разбираем слово по составу, то есть делим его на морфемы. («рас» — приставка, «тап» — корень, «л» — глагольный суффикс, «ива» — суффикс, «ть» — окончание).
- Теперь смотрим, может ли слово существовать без приставки (в нашем случае получается несуществующее слово «тапливать»).
- Определяем способ образования (у нас приставочно-суффиксальный).

- Составляем словообразовательную цепочку, то есть от какого слова образовано. Должно получиться то слово, которое осталось после отделения приставок, суффиксов и т. д. («растапливать – топить»).

Вот так, на несложном примере, легко и просто можно разобраться с тем, как делать словообразовательный разбор. Главное, знать все способы словообразования. Но на этом наш письменный урок не закончен.
Каких ошибок можно избежать, сделав словообразовательный разбор слова по составу
Словообразовательный разбор поможет вам понять, какая перед вами часть речи, и не сделать ошибку по невнимательности. Например, всем известно правило, что в суффиксах –ан- и –ян- у прилагательных пишется одна буква –н-, а у полных страдательных причастий, образованных от глагола совершенного вида, пишется две буквы -нн-. Если же вы составили словообразовательную цепь, то вам сразу станет понятно, что же за часть речи перед вами, и вы не сделаете глупой ошибки.
Как ни странно, словообразование тесно связано и с пунктуацией. Это опять же касается прилагательных, причастных и деепричастных оборотов. Ведь предпоследние выделяются запятыми, если стоят после определяемого слова, а последние – всегда.
Это опять же касается прилагательных, причастных и деепричастных оборотов. Ведь предпоследние выделяются запятыми, если стоят после определяемого слова, а последние – всегда.
Словообразовательная цепочка поможет вам определить и значение слова, а это, в свою очередь, позволит облачить его в грамотную, стилистически нейтральную конструкцию, органично вписать в текст и искусно обыграть слово. Это очень поможет вам при составление речей для публичного выступления и красивой, уверенной речи в повседневной жизни. Ведь у каждой морфемы есть своя смысловая нагрузка, которую она несёт. И забывать об этой важной роли приставок и суффиксов никак нельзя.
Интересные факты о словообразовании
Существует слово, которое нужно произносить три с половиной часа! А для того, чтобы его записать, нужно сто восемьдесят девять тысяч восемьсот девятнадцать знаков алфавита (букв). Это название одного из белков титана. Упрощенное название этого белка читается сравнительно просто и быстро: коннектин.
Английский язык официально признан самым богатым языком в мире. В нём насчитывается четыреста девяносто тысяч слов и ещё триста тысяч профессиональных и технических терминов. Это в несколько раз больше, чем в любом другом языке мира. Учитесь образовывать новые слова у англичан, дамы и господа!
Существуют аспектные словари, которые отражают морфемный состав слова, всевозможные частные признаки этого слова, включая его словообразовательную производность. Вот бы всем такой словарь! Тогда бы проблем с написанием слов и получением оценок ни у кого не было.
И в заключение хотелось бы сказать…
Как вы видите, словообразование – важнейший раздел русского языка, незнание которого может привести к элементарным и даже смешным ошибкам из раздела орфографии, пунктуации, лексики и даже стилистики.
Учите и любите свой родной язык! Не делайте глупых ошибок!
Русский язык неморфологические способы — Altarena.ru — технологии и ответы на вопросы
Содержание
- Способы словообразования. Морфологический и неморфологический способы словообразования.
- Русский язык неморфологические способы
- Презентация по русскому языку «Неморфологический способ образования слов»
- Оставьте свой комментарий
- Подарочные сертификаты
- § 3. Неморфологические способы словообразования
- Курс подготовки к ЕГЭ. Урок 9
- Видео
 Морфологический и неморфологический способы словообразования.
Морфологический и неморфологический способы словообразования.Способы словообразования. Морфологический и неморфологический способы словообразования.
Словообразование – это раздел науки о языке, который изучает строение слов и способы их образования.
Состав слова. Слово состоит из основы и окончания. В основу входят приставка, корень, суффикс. Части слова называются морфемами.
Морфема– это минимальная значимая часть слова, которая не членится на более мелкие единицы того же уровня.
1. Морфологический способ:
2) Суффиксальный способ При суффиксальном способе к основе исходного слова присоединяется суффикс.
Слова, образованные данным способом, могут быть как той же части речи (лес — лесник), так и другой (лес — лесной).
Суффикс присоединяется не к целому слову, а к его основе, при этом иногда основа видоизменяется: может отсекаться часть основы, изменяться звуковой состав, происходит чередование звуков: отливать — отливка, ткач — ткацкий.
5) Сложение целых слов.
Сложение — это образование нового слова путем объединения в одно словесное целое двух слов или двух и более основ. Слова, образованные в результате сложения, называются сложными.
Сложные слова образуются:
1) сложением целых слов: телефон-автомат, школа-интернат;
2) сложением основ: зарплата, завуч;
3) сложением с помощью соединительных гласных О и Е: следопыт, сталевар, земледелие;
4) сложением начальных букв: РГУ, АТС;
5) сложением начальных звуков: тюз, МХАТ.
2. Неморфологический способ— образование новых слов в результате перехода одной части речи в другую за счёт переосмысления понятия слова:
3)Морфолого-синтаксический: образование нового слова путем перехода его из одной части речи в другую: столовая, мороженое. Слово при этом приобретает новые грамматические признаки;
Слово при этом приобретает новые грамматические признаки;
Порядок словообразовательного разбора:
1. Найти слово, от которого образовано данное слово (попробовать объяснить лексическое значение данного для разбора слова через исходное слово).
2. Определить, как образовано данное слово, назвать способ словообразования.
Слово учительницаобразованно от слова учитель при помощи суффикса -ниц.
Этот суффикс используется для обозначения лиц женского пола. Это суффиксальный способ словообразования.
Учительница учитель
Морфемный разбор слова– это выделение всех морфем, из которых состоит слово. Например:
Занимается природоведением, по-моему.
1. Определить, какой частью речи является слово; указать его основу и окончание. (У неизменяемых слов окончания нет.)
(У неизменяемых слов окончания нет.)
2. Указать корень, суффикс и приставки.(Для выделения корня подбираем однокоренные слова. При выделении суффиксов и приставок опираемся на словообразовательный разбор.)
Источник
Русский язык неморфологические способы
В зависимости от используемых средств разделяют два основных способа словообразования:
— морфологический — с помощью различных морфем;
— неморфологический — без помощи морфем.
Каждый из них включает несколько видов.
Способы словообразования
| Морфологический | Неморфологический | |
| Аффиксация | Сложение | |
| • суффиксальный | • сложение слов | Морфолого-синтаксический |
| • приставочный | • сложение основ + интерфиксация | Лексико-синтаксический |
| • приставочно-суффиксальный | • сложение основ + суффиксация (сложносуффиксальный) | Лексико-семантический |
| • бессуффиксный (нулевая аффиксация) | • аббревиация (сложносокращенный) | |
Неморфологическими называются способы образования слов без использования морфем.
В зависимости от конкретных процессов выделяют
морфолого-синтаксический,
лексико-синтаксический,
лексико-семантический способы.
больной (прилагательное) – больной (существительное)
вокруг (наречие) – вокруг (предлог)
Выделяют несколько разновидностей морфолого-синтаксического способа
| переход в существительные | столовая посуда (прил.) – заводская столовая мороженое блюдо (прил.) – ванильное мороженое отдыхающие (прич.) в санатории – отдыхающие гуляли |
| переход в прилагательные | блестящий (прич.) на солнце – блестящие способности любимый (прич.) людьми – любимый человек первый (числ.) в ряду – первый ученик |
| переход в местоимения | определенный (прич.) законом – определенный успех о данных (сущ.) для исследования – о данных событиях |
| переход в наречия | медленным шагом (сущ. ) – ехали шагом ) – ехали шагом лежа (дееприч.) на кровати – думать лежа попали в заключение (сущ.) – скажу в заключение |
| переход в служебные части речи | лагодаря (дееприч.) за помощь – благодаря помощи (предлог) что ты сказал? (предлог) – сказал, что (союз) знает возвратился один (числ.) – один (частица) он знал |
| переход в междометия | кремлевский караул (сущ.) – караул! давай (гл. в повелит. накл.) вещи – давай! (=пока) |
Принадлежность таких слов той или иной части речи определяется только в контексте – в составе словосочетания или предложения.
за благо рассудится – заблагорассудится
с ума сошедший – сумасшедший
вечно зелёный – вечнозеленый
сильно действующий – сильнодействующий
ума лишённый – умалишённый
тяжело раненный – тяжелораненый
многообещающий – обещающий много
вышеуказанный – указанный выше
Слова, образованные морфологическим способом сложения основы и слова, такому изменению не подвергаются: нефтедобыча, сухофрукты, лесозаготовка.
При лексико-семантическом способе новые слова возникают в результате изменения значений уже существующих слов, то есть в результате распада многозначного слова на омонимы. Иными словами, лексический состав языка меняется за счет изменения семантики слов.
Это происходит в результате того, что разные значения многозначного слова со временем утрачивают внутреннюю связь между собой.
Источник
Презентация по русскому языку «Неморфологический способ образования слов»
Описание презентации по отдельным слайдам:
Неморфологический способ образования слов
Неморфологический способ словообразования Неморфологическим называются способ образования слов без использования морфем. В зависимости от конкретных процессов выделяют 3 вида неморфологического образования слов: морфолого-синтаксический, лексико-синтаксический, лексико-семантический способы.
Морфолого-синтаксический неморфологический способ словообразования При морфолого-синтаксическом способе слова образуются путем перехода слов из одной части речи в другую, приобретая новое значение и теряя ряд грамматических признаков. Меняются их морфологические признаки и синтаксическая роль: рядовой (прилагательное) – рядовой (существительное) около (наречие) – около (предлог)
Меняются их морфологические признаки и синтаксическая роль: рядовой (прилагательное) – рядовой (существительное) около (наречие) – около (предлог)
Выделяют несколько разновидностей морфолого-синтаксического способа переход в существительные ванная комната (прил.) – шикарная ванная мороженое блюдо (прил.) – сливочное мороженое заведующий (прич.) складом– заведующий распорядился переход в прилагательные блестящий (прич.) на солнце – блестящие способности любимый (прич.) людьми – любимый человек первый (числ.) в ряду – первый ученик переход в местоимения определенный (прич.) законом – определенный успех (в знач.: некоторый)
Принадлежность таких слов той или иной части речи определяется только в контексте – в составе словосочетания или предложения. переход в наречия медленным шагом (сущ.) – ехали шагом сидя (дееприч.) на диване – читать сидя попали в заключение (сущ.) – скажу в заключение переход в служебные части речи благодаря (дееприч.) за помощь – благодаря помощи (предлог) что ты сказал? (местоимение) – сказал, что (союз) знает возвратился один (числ. ) – один (частица) он знал переход в междометия кремлевский караул (сущ.) – караул! давай (гл. в повелит. накл.) вещи – давай! (=пока)
) – один (частица) он знал переход в междометия кремлевский караул (сущ.) – караул! давай (гл. в повелит. накл.) вещи – давай! (=пока)
Лексико-синтаксический способ При лексико-синтаксическом способе (или сращении) производное слово получается в результате сращения (слияния) целого словосочетания в одно слово. Иначе говоря, при этом способе словообразования появляется новое слово, то есть меняется лексический состав языка, плюс меняется синтаксическая роль бывшего (производящего) словосочетания.
За благо рассудится – заблагорассудится с ума сошедший – сумасшедший вечно зелёный – вечнозелёный сильно действующий – сильнодействующий ума лишённый – умалишённый тяжело раненный – тяжелораненый Части слова-сращения по морфемному составу не отличаются от слов в производящем словосочетании. При перестановке компонентов они легко преобразуются в обычные словосочетания, не требуя никаких изменений. многообещающий – обещающий много вышеуказанный – указанный выше
Лексико-семантический неморфологический способ словообразования При лексико-семантическом способе новые слова возникают в результате изменения значений уже существующих слов, то есть в результате распада многозначного слова на омонимы. Иными словами, лексический состав языка меняется за счет изменения семантики слов. Это происходит в результате того, что разные значения многозначного слова со временем утрачивают внутреннюю связь между собой.
Иными словами, лексический состав языка меняется за счет изменения семантики слов. Это происходит в результате того, что разные значения многозначного слова со временем утрачивают внутреннюю связь между собой.
Номер материала: ДВ-565259
Не нашли то что искали?
Вам будут интересны эти курсы:
Оставьте свой комментарий
Подарочные сертификаты
Ответственность за разрешение любых спорных моментов, касающихся самих материалов и их содержания, берут на себя пользователи, разместившие материал на сайте. Однако администрация сайта готова оказать всяческую поддержку в решении любых вопросов, связанных с работой и содержанием сайта. Если Вы заметили, что на данном сайте незаконно используются материалы, сообщите об этом администрации сайта через форму обратной связи.
Все материалы, размещенные на сайте, созданы авторами сайта либо размещены пользователями сайта и представлены на сайте исключительно для ознакомления.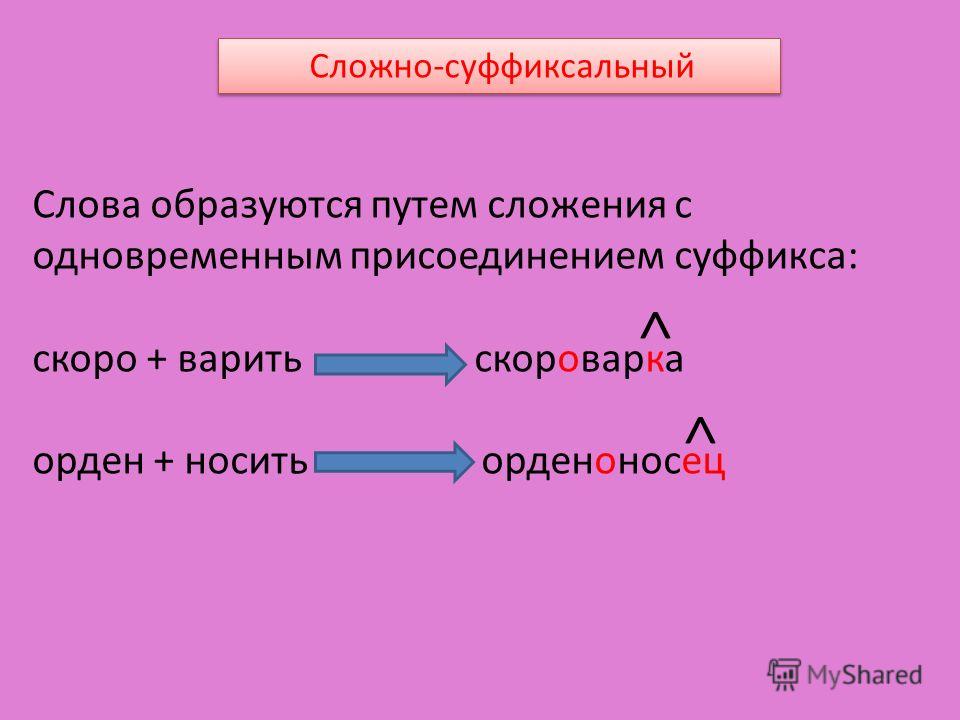 Авторские права на материалы принадлежат их законным авторам. Частичное или полное копирование материалов сайта без письменного разрешения администрации сайта запрещено! Мнение администрации может не совпадать с точкой зрения авторов.
Авторские права на материалы принадлежат их законным авторам. Частичное или полное копирование материалов сайта без письменного разрешения администрации сайта запрещено! Мнение администрации может не совпадать с точкой зрения авторов.
Источник
§ 3. Неморфологические способы словообразования
В словообразовательной системе русского языка существуют три неморфологических способа: лексико-семантический, лексико-грамматический и лексикосинтаксический.
Сущностью лексико-семантического и лексико-грамматического способов является образование новых омонимичных слов в лексической системе языка. Возникновение омонимичных слов в кругу одной и той же части речи (журавль1 — «наименование птицы» и журавль2 — «наименование приспособления для подъема воды из колодца») осуществляется с помощью лексико-семантического способа. Появление омонимичных слов в сфере разных частей речи (мороженое1 мясо — имя прилагательное, полное; вкусное мороженое* — субстантивированное прилагательное) происходит лексико-грамматическим способом.
Сущностью лексико-синтаксического способа является образование новых слов, омонимичных тем словосочетаниям, на почве которых они создаются (вышеуказанный — выше указанный).
Лексико-семантический способ словообразования — это возникновение омонимичных слов в результате появления новых значений в структуре того или иного производящего слова.
В результате появления новых значений в структуре многозначного слова нередко возникают новые омонимичные слова. Именно таким путем возникло существительное гладь в значении «вышивка сплошными, плотно прилегающими друг к другу стежками»1, которое ранее входило в систему значения омонимичного существительного гладь—1) «ровная, гладкая поверхность»; 2) «способ вышивания широкими, плотно прилегающими друг к другу стежками»[38] [39].
При лексико-семантическом способе образование новых омонимичных слов связано лишь с изменением смысловой структуры производящего слова и не затрагивает грамматических свойств или морфемного членения.
Лексико-грамматический способ словообразования — это возникновение омонимичных слов путем изменения значений и грамматических свойств производящего слова.
При переходе слов из одной части речи в другую, естественно, семантические изменения сопровождаются изменением грамматических свойств слова, а иногда и его морфемного состава.
С помощью лексико-грамматического способа пополняются как знаменательные, так и служебные части речи. Наиболее распространен этот способ в системе словообразования имен существительных на почве прилагательных и причастий, т. е. в результате процесса субстантивации. Так, например, существительные столовая (Столовая на ремонте), ученый (большой ученый) отличаются от омонимичных им прилагательных тем, что обозначают не признак предмета, а сам предмет. Они приобретают самостоятельные категории рода, числа и падежа, существенно изменяют свою синтаксическую функцию.
Служебные слова, сложившиеся на основе знаменательных частей речи, уже не обозначают предметов, действий и их признаков. Они становятся показателями различных отношений между предметами, показателями направления действия этих предметов и т. п. Так, например, отыменные и отглагольные предлоги и союзы в силу, несмотря на, благодаря, с тех пор как, спустя, отыменные и отглагольные частицы капельку, чуть-чуть, чуточку, пусть, давай и др. выражают отвлеченные условные, причинные, временные и другие грамматические значения.
п. Так, например, отыменные и отглагольные предлоги и союзы в силу, несмотря на, благодаря, с тех пор как, спустя, отыменные и отглагольные частицы капельку, чуть-чуть, чуточку, пусть, давай и др. выражают отвлеченные условные, причинные, временные и другие грамматические значения.
Служебные слова, сложившиеся на основе знаменательных частей речи, существенно преобразуют свой морфемный состав, а именно: прежде членимые основы, как правило, становятся непроизводными, нечленимыми (сравните: благодар-я—деепричастие и благодаря — предлог).
Лексико-синтаксический способ словообразования представляет собой сращение в одно слово двух или более слов, входящих в состав свободного или устойчивого словосочетания.
Лексико-синтаксическим способом в современной словообразовательной системе образуются главным образом прилагательные, которые соотносятся с тождественными, омонимичными им словосочетаниями, состоящими из прилагательного или причастия в соединении с уточняющим их компонентом, выраженным, как правило, наречием, реже существительным и предлогом: вечнозеленый, малоизученный, вышестоящий, умалишенный, близлежащий.
В результате образования сложных слов лексико-синтаксическим способом происходит утрата семантической, фонетической и грамматической самостоятельности компонентов производящего словосочетания. В структуре новых слов формируется семантическая, фонетическая и грамматическая цельнооформленность (сравните: глубоко уважаемый и глубокоуважаемый).
Все ранее рассмотренные способы производства и образования слов можно представить схематически в следующей таблице:
Источник
Курс подготовки к ЕГЭ. Урок 9
Урок 10. Словообразование. Морфологический и неморфологический способы словообразования
В языковую систему вместе с морфемным уровнем (деление слова по составу на значимые части приставку, корень, суффикс и окончание) входит и словообразовательный уровень. Чтобы определить, каким способом образовано слово, надо:
1) увидеть, есть ли в слове кроме корня ещё значимые части;
2) определить лексическое значение искомого слова в зависимости от лексического значения производящего слова, то есть того, от которого образовано искомое.
Возьмём существительное ноша. Ноша это то, что носят, то есть изначально в сознании людей было зафиксировано значение действия, а затем сформировалось значение предмета как результата этого действия. Следовательно, существительное ноша образовалось путём усечения суффикса от глагола носить.
Внимание! Есть формообразующие морфемы, которые участвуют в образовании грамматических форм, а не новых слов. К ним относятся:
б) формообразующие суффиксы: глагола прошедшего времени -л, глагола повелительного наклонения, глагольных форм причастий и деепричастий, сравнительной степени прилагательных и наречий.
Существует два способа образования в языке новых слов и, следовательно, обогащения лексики: морфологический и неморфологический.
1. Морфологический способ:
5) сложение целых слов, когда новое слово вмещает в себя сумму понятий, выражаемых каждым словом: сорви + голова = сорвиголова; еле + еле = еле-еле;
8) сращение, или слияние в одно слово компонентов словосочетаний: близ + лежащий = близлежащий; с + ума + сшедший = сумасшедший.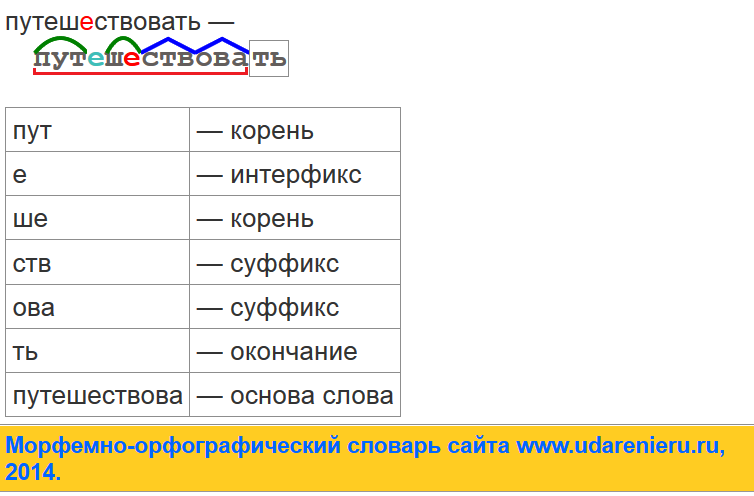
1. Определите способ словообразования слов объективность, лисонька, подоконник, направо. Определите, новые слова или формы слов рисующий, проехала, красивее, переходя.
2. Исправьте ошибки, допущенные в словообразовании выделенных слов. Проверяйте себя по орфографическому словарю.
1) С исчерпывающей полностью Салтыков-Щедрин раскрывает характер Иудушки Головлёва.
2) В литературе ХIХ века народным заступникам был заготовлен трудный путь.
3) Старик Дубровский не мог вынести измываний соседа.
4) Развитие движения разночинцев показано в романе «Отцы и дети» с большой шириной и глубиной.
5) Ехай скорей с горы!
6) Сегодня солнце так и жгёт.
7) Вы не хочете отдохнуть после обеда?
3. Укажите номер (номера), где слово образовано приставочно-суффиксальным способом:
1) разглядеть
2) разговаривать
3) тишь
4) прочитать
5) походка
6) соломенный
7) самолёт
8) прочитанный
Источник
Видео
Все способы словообразования
Русский язык. Способы словообразования в современном русском языке: морфемные и неморфемные
Способы словообразования в современном русском языке: морфемные и неморфемные
Морфемы. Словообразование | Русский язык ЕГЭ, ЦТ
СПОСОБЫ СЛОВООБРАЗОВАНИЯ [IrishU]
Русский язык 10 класс (Урок№11 — Морфология и морфологические нормы.)
Русский язык 6 класс (Урок№29 — Основные способы образования слов в русском языке. Часть 1.)
Морфологическая норма| Русский язык
РАЗРЯДЫ МЕСТОИМЕНИЙ [IrishU]
Синтаксическая норма| Русский язык
ЕГЭ задание 7: Морфологические нормы
Урок в 6-м классе по теме «Словообразовательный разбор»
Цели:
-
закрепить знания, полученные при изучении раздела «Словообразование и орфография»;
-
отрабатывать умения и навыки морфемного и словообразовательного разбора;
-
развивать коммуникативную компетенцию учащихся;
-
воспитывать «чувство языка» у учеников.
Ход урока
I.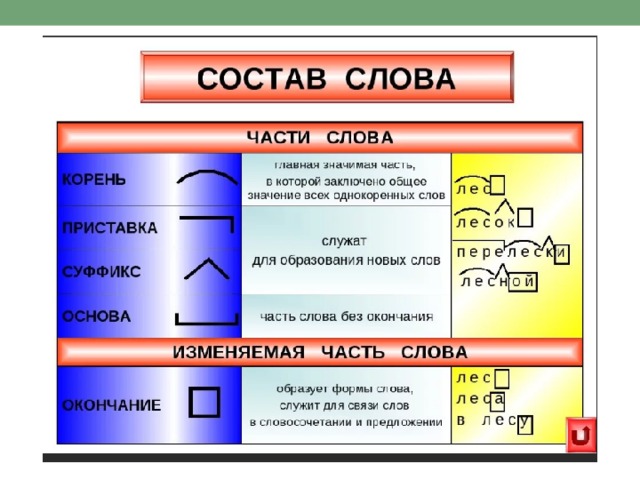 Оргмомент.
Оргмомент.
II. Слово учителя.
Ребята, сегодня произошло неожиданное событие: к нам за помощью обратился юный исследователь Вася Грамматиков. На чердаке своего дома он нашёл странный ящик и записку от дедушки: «Дорогой внук, здесь хранится секрет успеха любого твоего начинания, дела. Но для того, чтобы его разгадать, ты должен проявить смекалку и выполнить ряд заданий». Давайте с вами попробуем помочь Васе. (Слайды 1-3).
- (Слайд 4) Раздел науки о языке, в котором изучается, от чего и с помощью чего образованы слова. (Словообразование).
- (Слайд 5) Что общего между
представленными изображениями. (В
старину столом называли не только то, что
называем мы, но и место, на котором сидел
князь, правитель страны. Город, где он жил,
называли стольным городом, или просто
столицей. Т.е. эти слова были
однокоренными, а теперь они утратили
родство и образовали свои
словообразовательные гнёзда).
 Город, где он жил,
называли стольным городом, или просто
столицей. Т.е. эти слова были
однокоренными, а теперь они утратили
родство и образовали свои
словообразовательные гнёзда).
Город, где он жил,
называли стольным городом, или просто
столицей. Т.е. эти слова были
однокоренными, а теперь они утратили
родство и образовали свои
словообразовательные гнёзда).Ящик открылся.
III. Слово учителя.
Отлично, мы помогли Васе выполнить задания дедушки и добраться до содержимого ящика.
— Какие разделы науки о языке помогли нам справиться с заданиями? (Этимология, словообразование)
— Тема сегодняшнего урока «Словообразовательный разбор». Запишите её.
Но, кажется, Вася снова нуждается в нашей помощи. Свиток старый, чернила побледнели, а кое-где исчезли совсем. Давайте поможем Васе восстановить его. (Слайд 6)
Анализ текста.
Спишите, вставляя пропущенные буквы, графически объясняя их.
Огонь оч.
Кр..сивый, властит..льный, бл..стящий, живой,
Бе(з,с)шумный в мерцании ц..рковной св..чи,Мн..г..шумный в пожаре,
Глухой для м..льбы, мн..г..ликий,
Мн..г..цветный при гибели зданий,
Проворный, в..сёлый и страс..ный,
Так победно-пр..красный,
Что, когда он (з,с)ж..гает моё,
(Не)могу я (не)видеть его крас..ты!
О кр..сивый Огонь, я тебе посв..тил все мечты!
 .стительный, огонь р..ковой,
.стительный, огонь р..ковой,— Итак, текст восстановлен. (Слайд 7)
— Что помогло нам правильно написать слова многошумный, многоликий, многоцветный? (Словообразовательный разбор)
— А какой вид разбора помог в правильном выборе букв в других словах? (Морфемный)
— А что же такое
словообразовательный разбор? Откройте
учебники (Русский язык: учеб. Для 6 кл.
общеобразоват. учреждений/ [М.Т.Баранов, Т.А.Ладыженская,
Л.А.Тростенцова и др.; научн.
— Объясните написание сложных слов. (В сложных словах после твёрдых согласных пишется соединительная о, а после мягких согласных, шипящих и ц – соединительная гласная е)
— Выполните словообразовательный разбор этих слов.
Роковой – рок + (ов) (значение слов) – суффиксальный способ словообразования;
Удивительный – удивить + (тельн)– суффиксальный способ словообразования;
Бесшумный – шум + (бес) + (н) – приставочно-суффиксальный способ словообразования;
Мольба – молить + (б) - суффиксальный способ словообразования;
Красота – красивый + (от) - суффиксальный способ словообразования.
— Назовите ещё слова, образованные по этой модели (доброта, забота).
— Чем объединены эти способы словообразования? (Морфемные)
— А какие способы образования слов вы ещё знаете? (Сложение, неморфологический)
— Назовите слова, образованные
путём сложения основ с соединительной
гласной. (Многошумный, многоликий,
многоцветный)
(Многошумный, многоликий,
многоцветный)
— Выполните их словообразовательный разбор
Многошумный – много+ шум +н - сложносуффиксальный
Многоликий – много+лица – сложение основ с помощью соединительной гласной
Многоцветный – много- цвет + н - сложносуффиксальный
— Как вы считаете, почему автор использует повтор этих однокоренных слов? (Это стилистический приём, «работающий» на эмоциональное воздействие).
— Итак, мы видим, что словообразовательный разбор помогает нам зачастую понять значение слов, но так бывает не всегда. Васе непонятно, что хотел сказать мудрый дедушка. В каком значении употреблено слово огонь? (Огонь души. В переносном значении. Это метафора).
— Как иначе можно выразить мысль текста, о чём он? (О вдохновении)
— Как вы понимаете лексическое значение слова вдохновение.
Толковый словарь Ожегова.
Вдохновенние – творческий подъём, прилив
творческих сил. Сила вдохновения,
побуждающая поэта видеть красоту
окружающего мира.
Сила вдохновения,
побуждающая поэта видеть красоту
окружающего мира.
-Найдите слова, характеризующие огонь? (Очистительный – сжигающий всё нечистое в душе и вне её, роковой – предназначенный провидением, властительный – сильный, весёлый и страстный – вызывающий сильные чувства, победно-прекрасный – чарующий своей красотой. )
— Какими средствами художественной выразительности являются названные слова? (Эпитетами).
— Подберите свои эпитеты к слову огонь, но чтобы в них была орфограммы «Корни с чередованием», «Правописание приставок» (умиротворяющий, причудливый, бесстрашный, прелестный, призывный, оживляющий, озаряющий, исцеляющий)
— Как вы считаете, в каком предложении заключена главная мысль стихотворения? (В последнем).
— Выполните синтаксический
разбор последней предикативной части. (Простое,
повествовательное, восклицательное,
двусоставное, распространённое, осложнено
обращением).
Итог. — Какие разделы науки о языке помогли Васе и вам справиться с заданиями? (Словообразование, этимология, морфемика)
— Какие способы словообразования вы знаете? (Морфемные: приставочный, приставочно-суффиксальный, суффиксальный, бессуффиксный; сложение: сложение целых слов, сложение основ с соединительной гласной, сложение сокращённых основ, сложносуффиксальный; неморфологический: переход их одной части речи в другую).
— Для чего нужно уметь производить словообразовательный разбор? (Для того, чтобы правильно понимать его лексическое значение, правильно его писать).
IV. Слово учителя.
— Какую тайну познал сегодня Вася и вы вместе с ним? (Если в сердце горит благородный огонь, любое дело легко даётся, все преграды преодолеваются).
— Я желаю вам, чтобы огонь в вашей душе не угасал никогда и побуждал вас к новым свершениям.
V. Домашнее задание. Составьте текст из
4-5 предложений по опорным словам великолепно,
преодолеть, благородный на тему «Огонь
вдохновения». Выполните
словообразовательный разбор ключевых слов.
Домашнее задание. Составьте текст из
4-5 предложений по опорным словам великолепно,
преодолеть, благородный на тему «Огонь
вдохновения». Выполните
словообразовательный разбор ключевых слов.
Приложение
Патент США на метод анализа морфем с использованием дополнительной информации и анализатора морфем для выполнения метода. Патент (Патент № 8,554,539, выданный 8 октября 2013 г.)
ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ № 10-2006-0029487, поданной 31 марта 2006 г. в Ведомство интеллектуальной собственности Кореи, раскрытие которой включено в настоящий документ посредством ссылки в его сущность.
УРОВЕНЬ ТЕХНИКИ
1. Область
Настоящее изобретение относится к способу выполнения морфемного анализа и, в частности, к анализу фразы для идентификации ключевого термина из фразы.
2. Обсуждение связанных технологий
Термин «морфема» указывает на минимальный лингвистический элемент, составляющий слово или словосочетание. Морфема может быть разделена на существенную морфему и функциональную морфему. Субстанциальная морфема имеет субстанциальное значение, а функциональная морфема отвечает за функциональный элемент. Разделение морфемы должно быть завершено до анализа морфемы для извлечения индекса. В частности, морфема указывает на минимальный лингвистический элемент, который не может быть разделен в аспекте ни значения, ни функции.
Морфема может быть разделена на существенную морфему и функциональную морфему. Субстанциальная морфема имеет субстанциальное значение, а функциональная морфема отвечает за функциональный элемент. Разделение морфемы должно быть завершено до анализа морфемы для извлечения индекса. В частности, морфема указывает на минимальный лингвистический элемент, который не может быть разделен в аспекте ни значения, ни функции.
Кроме того, анализ морфем указывает на процесс идентификации каждой из морфем, составляющих слово или словосочетание, и восстановления каждой из морфем при неправильном использовании, сокращении или пропуске.
Для извлечения индекса требуется анализ фраз, например, анализ морфем. Существительные обычно используются в качестве указателей и ключевых слов. Для извлечения существительных требуются различные типы служебных слов, других частей речи, морфологическая трансформация и т.п. В случае поисковой системы наиболее важными являются структура индексной базы данных и алгоритм ранжирования. Однако только при сохранении наиболее подходящего и окончательного индекса поисковая машина может иметь превосходную производительность. Когда корейский текст анализируется с использованием только пробела, то есть по единице словосочетания, могут быть получены неудовлетворительные результаты поиска.
Однако только при сохранении наиболее подходящего и окончательного индекса поисковая машина может иметь превосходную производительность. Когда корейский текст анализируется с использованием только пробела, то есть по единице словосочетания, могут быть получены неудовлетворительные результаты поиска.
Соответственно, в методе поиска, использующем метод анализа морфем, анализатор морфем имеет ухудшенную производительность 1) когда существует незарегистрированное слово, 2) когда игнорируется интервал между объектами анализа морфемы или 3) когда одна морфема включает в себя другую морфема. Из-за ухудшения производительности результаты поиска могут быть неудовлетворительными и неточными.
РИС. 1 иллюстрирует пример локального поиска информации с использованием примерного метода анализа морфем. Как показано на фиг. 1, когда ключевое слово GOOKSUHO 101 («GOOKSUHO» — название корейского народа) введен на веб-страницу поиска 100 , метод поиска с использованием метода анализа морфем может выдать результат поиска 102 , который не связан с ключевым словом GOOKSUHO. 101 в аспекте значения. ИНЖИР. 1 показан пример проблемы, которая может возникнуть из-за 2) пробела в целевом анализе морфем, например, DAJEONGOOKSUHOGYEJUM («DAJEONGOOKSUHOGYEJUM» включает несколько корейских слов, где «DAJEON» — торговая марка, «GOOKSU» — название корейской еды что означает «лапша», «HOGYE» — название подрайона, а «JUM» — корейский суффикс, означающий «магазин».), игнорируется и 3) одна морфема, например, GOOKSUHO, включает в себя другую морфема, например, ГООКСУ. (На рис. 1 «GOOKSUHODIDIMDANCETROUPE» включает несколько слов, где «GOOKSUHO» — это название корейского народа, «DIDIM» — торговая марка, а «DANCE» и «TROUPE» — английские слова.)
101 в аспекте значения. ИНЖИР. 1 показан пример проблемы, которая может возникнуть из-за 2) пробела в целевом анализе морфем, например, DAJEONGOOKSUHOGYEJUM («DAJEONGOOKSUHOGYEJUM» включает несколько корейских слов, где «DAJEON» — торговая марка, «GOOKSU» — название корейской еды что означает «лапша», «HOGYE» — название подрайона, а «JUM» — корейский суффикс, означающий «магазин».), игнорируется и 3) одна морфема, например, GOOKSUHO, включает в себя другую морфема, например, ГООКСУ. (На рис. 1 «GOOKSUHODIDIMDANCETROUPE» включает несколько слов, где «GOOKSUHO» — это название корейского народа, «DIDIM» — торговая марка, а «DANCE» и «TROUPE» — английские слова.)
Обсуждение в этом разделе предназначено для предоставления общей справочной информации и не представляет собой признание известного уровня техники.
РЕЗЮМЕ
В одном из аспектов изобретения предлагается способ обработки фразы для ее ключевого термина, включающий: предоставление фразы и данных, связанных с фразой; обработку данных для извлечения множества терминов, включенных в данные; обработку фразы с использованием множества терминов, чтобы определить, включает ли фраза какой-либо из множества терминов, извлеченных из данных, при этом обработка фразы определяет, что фраза включает в себя первый из множества терминов; и связывание первого термина с фразой в качестве ключевого термина фразы.
В описанном выше способе фраза и первый термин могут быть сохранены в доступной для поиска базе данных, где первый термин в качестве ключевого термина сконфигурирован для использования для поиска фразы в ответ на поисковый запрос с использованием первого термина. Способ может дополнительно включать предоставление первого списка справочных терминов, содержащего множество справочных терминов, и при этом обработка данных может включать определение того, включают ли данные в себя какой-либо из множества справочных терминов из первого списка справочных терминов. Способ может дополнительно включать предоставление второго списка опорных терминов, содержащего множество опорных терминов, обработку второго списка опорных терминов, чтобы определить, содержит ли второй список опорных терминов первый термин, при этом обработка второго списка опорных терминов определяет, что второй список ссылочных терминов не содержит первый термин, и добавление первого термина ко второму списку ссылочных терминов после определения того, что второй список ссылочных терминов не содержит первый термин. Способ может дополнительно включать предоставление второго списка справочных терминов, содержащего множество справочных терминов, которые содержат первый термин, и анализ фразы с использованием второго списка справочных терминов, чтобы определить, включает ли фраза в него какой-либо один из множества справочных терминов. терминов второго списка справочных терминов, при этом анализ фразы подтверждает, что фраза включает в себя первый термин.
Способ может дополнительно включать предоставление второго списка справочных терминов, содержащего множество справочных терминов, которые содержат первый термин, и анализ фразы с использованием второго списка справочных терминов, чтобы определить, включает ли фраза в него какой-либо один из множества справочных терминов. терминов второго списка справочных терминов, при этом анализ фразы подтверждает, что фраза включает в себя первый термин.
В соответствии с описанным выше способом способ может дополнительно включать предоставление второго списка справочных терминов, содержащего множество справочных терминов, который содержит второй термин, анализ фразы с использованием второго списка справочных терминов, чтобы определить, входит ли в него фраза любой из множества справочных терминов второго списка справочных терминов, при этом анализ фразы может определить, что фраза включает в себя второй термин, и связывание второго термина с фразой в качестве другого ключевого термина фразы. Способ может дополнительно включать предоставление первого списка справочных терминов, содержащего множество справочных терминов, при этом обработка данных включает определение того, включают ли данные в себя какой-либо из множества справочных терминов из первого списка справочных терминов, предоставление второго списка справочных терминов. содержащий множество опорных терминов, обработку второго списка опорных терминов, чтобы определить, содержит ли второй список опорных терминов первый термин, при этом обработка второго списка опорных терминов определяет, что второй список опорных терминов не содержит первый термин, и добавление первого термина во второй список опорных терминов после определения того, что второй список опорных терминов не содержит первый термин. Способ может дополнительно включать предоставление списка справочных терминов, содержащего множество справочных терминов, при этом обработка данных включает определение того, включают ли данные в себя какой-либо из множества справочных терминов из списка справочных терминов, и анализ фразы с использованием справочного термина.
Способ может дополнительно включать предоставление первого списка справочных терминов, содержащего множество справочных терминов, при этом обработка данных включает определение того, включают ли данные в себя какой-либо из множества справочных терминов из первого списка справочных терминов, предоставление второго списка справочных терминов. содержащий множество опорных терминов, обработку второго списка опорных терминов, чтобы определить, содержит ли второй список опорных терминов первый термин, при этом обработка второго списка опорных терминов определяет, что второй список опорных терминов не содержит первый термин, и добавление первого термина во второй список опорных терминов после определения того, что второй список опорных терминов не содержит первый термин. Способ может дополнительно включать предоставление списка справочных терминов, содержащего множество справочных терминов, при этом обработка данных включает определение того, включают ли данные в себя какой-либо из множества справочных терминов из списка справочных терминов, и анализ фразы с использованием справочного термина. список, чтобы определить, включает ли фраза в себя какой-либо из множества эталонных терминов списка эталонных терминов, при этом анализ фразы определяет, что фраза включает в себя первый термин в нем.
список, чтобы определить, включает ли фраза в себя какой-либо из множества эталонных терминов списка эталонных терминов, при этом анализ фразы определяет, что фраза включает в себя первый термин в нем.
Однако в описанном выше методе первый термин может состоять из двух слов, разделенных пробелом между ними. Первым термином может быть слово, представляющее собой строку букв без пробела между любыми двумя последовательными буквами. Фраза может содержать первое слово и второе слово, разделенные только пробелом между ними, при этом первый термин может быть морфемой первого слова. Фраза может содержать первое слово и второе слово, разделенные только пробелом между ними, при этом первый термин может быть частью первого слова и частью второго слова, разделенных пробелом между ними. Первый термин может содержать имя собственное. Фраза может быть строкой букв без пробела между двумя последовательными буквами. Фраза может содержать название компании. Данные могут включать, по крайней мере, один элемент, выбранный из группы, состоящей из общего названия продукта или услуги, предоставляемых бизнесом, вида общего названия, типа бизнеса и адреса бизнеса.
Кроме того, в вышеизложенном способе способ может дополнительно включать получение от удаленного терминала запроса на поиск с поисковым запросом, анализ поискового запроса для идентификации по меньшей мере одного ключевого слова из поискового запроса, при этом по меньшей мере одно ключевое слово является первым термином, поиск в базе данных информации, связанной по меньшей мере с одним ключевым словом, составляющим первый термин, посредством чего находят фразу, которая связана с первым термином, и передают на удаленный терминал данные для отображения результатов поиска, содержащих фразу.
Другой аспект изобретения обеспечивает компьютерную программу, сконфигурированную для выполнения вышеуказанного способа.
Еще один аспект изобретения обеспечивает систему для обработки фразы для ее ключевого термина, причем система содержит: базу данных, содержащую фразу и данные, связанные с фразой; и вычислительное устройство, подключенное к базе данных, при этом вычислительное устройство сконфигурировано для обработки данных для извлечения множества терминов, включенных в данные, при этом вычислительное устройство сконфигурировано для обработки фразы с использованием множества терминов, чтобы определить, включает ли фраза какой-либо из множества терминов, извлеченных из данных, и при этом после определения того, что первый из множества терминов включен во фразу, вычислительное устройство сконфигурировано для связывания первого термина с фразой как ключевой термин фразы. В вышеупомянутой системе вычислительное устройство может быть выбрано из группы, состоящей из процессора, взаимосвязанной группы процессоров, одного компьютера и взаимосвязанной группы компьютеров.
В вышеупомянутой системе вычислительное устройство может быть выбрано из группы, состоящей из процессора, взаимосвязанной группы процессоров, одного компьютера и взаимосвязанной группы компьютеров.
В одном из аспектов настоящего изобретения предлагается способ выполнения анализа морфем с использованием дополнительной информации.
Другой аспект настоящего изобретения также обеспечивает способ выполнения анализа морфем, который может использовать неполную строку символов дополнительной информации, которая хранится вместе с целью анализа морфемы и обычно включается в цель анализа морфемы, и, таким образом, может выполнять анализ морфем, чтобы слоги словаря, соответствующего частичной строке символов, не могли быть разделены, когда неполная строка символов включена в цель анализа морфем, а также могут повышать точность в процессе поиска с использованием метода анализа морфем.
Другой аспект настоящего изобретения также обеспечивает способ выполнения анализа морфем, который может повысить точность и скорость поиска при локальном поиске или поиске по магазинам за счет использования информации о категории или адресной информации в качестве дополнительной информации при выполнении локального поиска и поиск по магазинам.
Другой аспект настоящего изобретения также обеспечивает способ выполнения анализа морфем, который может создать ключ путем анализа морфемы дополнительной информации и частично решить проблему незарегистрированного слова, используя созданный ключ, и дополнить токенизатор с использованием ключа когда интервал игнорируется.
В соответствии с аспектом настоящего изобретения предложен способ выполнения анализа морфем, включающий: получение цели анализа морфемы и дополнительной информации, связанной с целью анализа морфемы, из данных поискового индекса; создание ключа на основе дополнительной информации; и анализ морфемы объекта анализа морфемы с использованием ключа.
В этом случае создание может включать: создание множества ключей путем выполнения анализа морфем для каждой информации, включенной в дополнительную информацию; и создание комбинированного ключа путем объединения множества ключей. Кроме того, дополнительная информация может включать в себя информацию о категории и адресную информацию, связанную с целью анализа морфемы, и создание множества ключей может включать в себя: создание первого ключа путем анализа морфемы информации о категории; и создание второго ключа путем анализа морфемы адресной информации.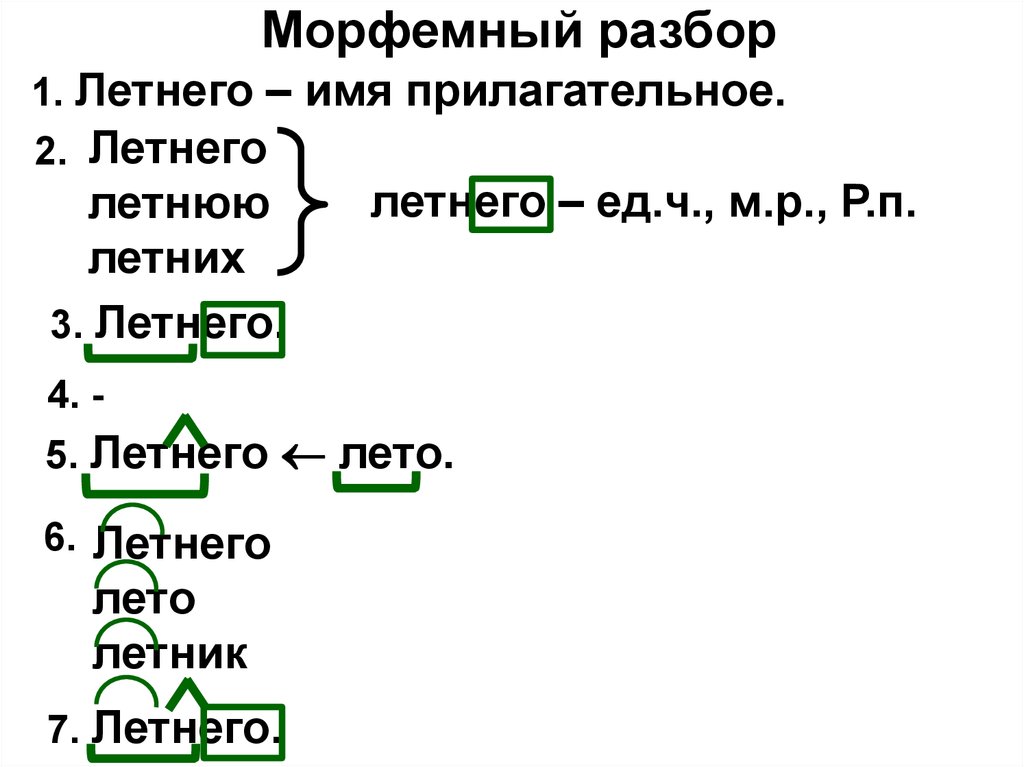 Кроме того, создание комбинированного ключа может включать в себя создание комбинированного ключа путем объединения первого ключа и второго ключа, а анализ морфемы может включать в себя анализ морфемы объекта анализа морфемы с использованием созданного комбинированного ключа.
Кроме того, создание комбинированного ключа может включать в себя создание комбинированного ключа путем объединения первого ключа и второго ключа, а анализ морфемы может включать в себя анализ морфемы объекта анализа морфемы с использованием созданного комбинированного ключа.
В соответствии с другим аспектом настоящего изобретения предоставлен анализатор морфем, включающий в себя: блок сбора информации, сконфигурированный для получения цели анализа морфемы и дополнительной информации, связанной с целью анализа морфемы, из данных поискового индекса; создатель ключа, сконфигурированный для создания ключа на основе дополнительной информации; и блок анализа морфемы, выполненный с возможностью анализа морфемы объекта анализа морфемы с использованием ключа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙВышеупомянутые и другие аспекты и преимущества настоящего изобретения станут очевидными и более понятными из следующего подробного описания, взятого вместе с прилагаемыми чертежами, на которых:
РИС. 1 иллюстрирует пример поиска локальной информации с использованием примерного метода анализа морфем;
1 иллюстрирует пример поиска локальной информации с использованием примерного метода анализа морфем;
РИС. 2 представляет собой блок-схему, иллюстрирующую способ выполнения анализа морфем с использованием дополнительной информации в соответствии с примерным вариантом осуществления настоящего изобретения;
РИС. 3 представляет собой блок-схему, иллюстрирующую внутреннюю конфигурацию анализатора морфем, выполняющего анализ морфем с использованием дополнительной информации, в соответствии с примерным вариантом осуществления настоящего изобретения;
РИС. 4 представляет собой блок-схему, иллюстрирующую способ выполнения анализа морфем с использованием категории и адреса для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения;
РИС. 5 иллюстрирует способ выполнения анализа морфем с использованием дополнительной информации в соответствии с примерным вариантом осуществления настоящего изобретения;
РИС. 6 иллюстрирует первый пример и второй пример в отношении повышения производительности анализа морфем с использованием информации о категории для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения;
6 иллюстрирует первый пример и второй пример в отношении повышения производительности анализа морфем с использованием информации о категории для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения;
РИС. 7 иллюстрирует примеры с первого по третий в отношении повышения производительности анализа морфем с использованием адресной информации для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения; и
РИС. 8 иллюстрирует первый пример частичного решения незарегистрированного слова с использованием дополнительной информации и второй пример дополнения токенизатора согласно примерному варианту осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Теперь будет сделана подробная ссылка на иллюстративные варианты осуществления настоящего изобретения, примеры которых проиллюстрированы на прилагаемых чертежах, на которых одинаковые ссылочные позиции относятся к одинаковым элементам. Типовые варианты осуществления описаны ниже со ссылками на чертежи.
Типовые варианты осуществления описаны ниже со ссылками на чертежи.
В некоторых вариантах осуществления анализ морфем будет обсуждаться в качестве примера анализа фраз. ИНЖИР. 2 представляет собой блок-схему, иллюстрирующую способ выполнения анализа фразы или морфемы с использованием дополнительной или ассоциированной информации в соответствии с примерным вариантом осуществления настоящего изобретения. В эксплуатации S 210 , анализатор морфем, использующий дополнительную информацию, получает цель анализа морфемы и дополнительную информацию, связанную с целью анализа морфемы, из данных поискового индекса. В этом случае цель анализа морфемы может соответствовать цели анализа морфемы поиска, которая выводится поисковой машиной.
В операции S 220 анализатор морфем создает ключ на основе дополнительной информации. В этом случае, как показано на фиг. 2, операции S 221 и S 224 могут быть включены в операцию S 220 и затем выполнены. Кроме того, дополнительная информация может включать информацию о категории или типе бизнеса и адресную информацию, связанную с целью анализа морфем. Кроме того, анализатор морфем может включать в себя часть речевого тегера, который выбирает только один наиболее вероятный результат из множества результатов анализа морфем. В операции S 221 анализатор морфем создает множество ключей, выполняя анализ морфем для каждой информации, включенной в дополнительную информацию. В этом случае, как показано на фиг. 2, операции S 222 и S 223 могут быть включены в операцию S 221 и выполнены.
Кроме того, дополнительная информация может включать информацию о категории или типе бизнеса и адресную информацию, связанную с целью анализа морфем. Кроме того, анализатор морфем может включать в себя часть речевого тегера, который выбирает только один наиболее вероятный результат из множества результатов анализа морфем. В операции S 221 анализатор морфем создает множество ключей, выполняя анализ морфем для каждой информации, включенной в дополнительную информацию. В этом случае, как показано на фиг. 2, операции S 222 и S 223 могут быть включены в операцию S 221 и выполнены.
В операции S 222 анализатор морфем создает первый ключ, анализируя морфему информации о категории. В этом случае информация о категории может быть расширена при выполнении анализа морфем с использованием списка информации о ключевых словах, связанного с информацией о категории. В операции S 223 анализатор морфем создает второй ключ, анализируя морфему адресной информации. В эксплуатации S 224 анализатор морфем создает комбинированный ключ, комбинируя множество ключей. В этом случае комбинированный ключ может быть создан путем объединения первого ключа и второго ключа.
В эксплуатации S 224 анализатор морфем создает комбинированный ключ, комбинируя множество ключей. В этом случае комбинированный ключ может быть создан путем объединения первого ключа и второго ключа.
В операции S 230 анализатор морфем анализирует морфему цели анализа морфемы с помощью ключа. В этом случае, как показано на фиг. 2, операции с S 231 по S 233 могут быть включены в операцию S 230 и затем выполняться. Кроме того, анализатор морфем может анализировать морфему цели анализа морфем с использованием созданного комбинированного ключа. В эксплуатации S 231 , анализатор морфем определяет, включает ли цель анализа морфем неполную строку символов, соответствующую ключу. В операции S 232 анализатор морфем временно добавляет неполную строку символов в словарь морфем, когда цель анализа морфем включает в себя неполную строку символов, соответствующую ключу. Как описано выше, согласно варианту осуществления настоящего изобретения можно временно добавить словосочетание частичной строки символов в словарь морфем без обязательного отделения словосочетания от частичной строки символов. Соответственно можно частично решить проблему незарегистрированных слов. В эксплуатации S 233 , анализатор морфем анализирует морфему цели анализа морфем, обращаясь к словарю морфем.
Как описано выше, согласно варианту осуществления настоящего изобретения можно временно добавить словосочетание частичной строки символов в словарь морфем без обязательного отделения словосочетания от частичной строки символов. Соответственно можно частично решить проблему незарегистрированных слов. В эксплуатации S 233 , анализатор морфем анализирует морфему цели анализа морфем, обращаясь к словарю морфем.
В операции S 240 анализатор морфем добавляет цель анализа морфемы в список часто используемых слов для каждой категории и увеличивает число использований соответствующего слова. В этом случае информация о категории расширяется при выполнении морфемного анализа с использованием информации из часто используемого списка слов.
Как описано выше, метод анализа морфем в соответствии с вариантом осуществления настоящего изобретения использует неполную строку символов, которая хранится вместе с целью анализа морфем, обычно включенной в цель анализа морфем, и, таким образом, выполняет анализ морфем так, чтобы слоги словарь, соответствующий частичной строке символов, не может быть разделен, когда неполная строка символов включена в цель анализа морфем. Соответственно, можно повысить точность процесса поиска, используя метод анализа морфем.
Соответственно, можно повысить точность процесса поиска, используя метод анализа морфем.
РИС. 3 представляет собой блок-схему, иллюстрирующую внутреннюю конфигурацию анализатора , 300, морфем, выполняющего анализ морфем с использованием дополнительной информации в соответствии с примерным вариантом осуществления настоящего изобретения. Анализатор 300 морфем может включать в себя блок 310 сбора информации, генератор 320 ключа и блок 330 анализа морфем. Блок 310 сбора информации получает цель анализа морфемы и дополнительную информацию, связанную с целью анализа морфемы, из данных поискового индекса. В этом случае цель анализа морфемы может соответствовать цели анализа морфемы поиска, которая выводится поисковой машиной.
Создатель ключа 320 создает ключ на основе дополнительной информации. В этом случае, как показано на фиг. 3, создатель , 320, ключа может включать в себя создатель , 321 множественных ключей и создатель комбинированного ключа , 322 . Создатель множества ключей , 321, создает множество ключей, выполняя анализ морфем для каждой информации, включенной в дополнительную информацию. В этом случае создатель множества ключей , 321, может включать в себя первый создатель 9 ключей.0003 321 a и создатель второго ключа 321 b . Создатель первого ключа , 321, , и может создать первый ключ путем анализа морфемы информации о категории. Создатель второго ключа , 321, , b может создать второй ключ, анализируя морфему адресной информации. Создатель комбинированного ключа 322 создает комбинированный ключ путем объединения множества ключей. В этом случае создатель комбинированного ключа 322 может создать комбинированный ключ путем объединения первого ключа и второго ключа.
3, создатель , 320, ключа может включать в себя создатель , 321 множественных ключей и создатель комбинированного ключа , 322 . Создатель множества ключей , 321, создает множество ключей, выполняя анализ морфем для каждой информации, включенной в дополнительную информацию. В этом случае создатель множества ключей , 321, может включать в себя первый создатель 9 ключей.0003 321 a и создатель второго ключа 321 b . Создатель первого ключа , 321, , и может создать первый ключ путем анализа морфемы информации о категории. Создатель второго ключа , 321, , b может создать второй ключ, анализируя морфему адресной информации. Создатель комбинированного ключа 322 создает комбинированный ключ путем объединения множества ключей. В этом случае создатель комбинированного ключа 322 может создать комбинированный ключ путем объединения первого ключа и второго ключа.
Блок анализа морфем 330 анализирует морфему объекта анализа морфем с помощью ключа. В этом случае блок 330 анализа морфем может включать в себя блок 331 определения, сумматор 332 строки неполных символов и блок 333 анализа цели анализа морфем. Кроме того, блок 330 анализа морфем может анализировать морфему цели анализа морфемы с использованием созданного комбинированного ключа. Блок определения 331 определяет, включает ли цель анализа морфем частичную строку символов, соответствующую ключу. Сумматор неполной строки символов 332 временно добавляет неполную строку символов в словарь морфем, когда цель анализа морфем включает неполную строку символов, соответствующую ключу. Как описано выше, согласно варианту осуществления настоящего изобретения можно временно добавить словосочетание частичной строки символов в словарь морфем без обязательного отделения словосочетания от частичной строки символов. Соответственно можно частично решить проблему незарегистрированных слов. Блок анализа 9 целевого объекта анализа морфем0003 333 анализирует морфему объекта анализа морфем, обращаясь к словарю морфем.
Соответственно можно частично решить проблему незарегистрированных слов. Блок анализа 9 целевого объекта анализа морфем0003 333 анализирует морфему объекта анализа морфем, обращаясь к словарю морфем.
Кроме того, блок анализа морфем 330 может дополнительно включать в себя сумматор 334 цели анализа морфемы, который добавляет цель анализа морфемы в список часто используемых слов для каждой категории и увеличивает число использований соответствующего слова. . В этом случае информация о категории расширяется при выполнении анализа морфем за счет использования информации из часто используемого списка слов. В частности, поскольку целевой сумматор 9 для анализа морфем0003 334 добавляет цель анализа морфем в список часто используемых слов для каждой категории, можно повторно использовать информацию, когда анализатор морфем 300 выполняет последующий анализ морфем.
РИС. 4 представляет собой блок-схему, иллюстрирующую способ выполнения анализа морфем с использованием категории и адреса для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения. Как показано на фиг. 4, при выполнении морфемного анализа в локальном поиске адресная информация (928-2 HOGYE 2-DONG, DONGAN-GU, ANYANG-SI, GYEONGGI-DO) 402 («928-2 HOGYE 2-DONG, DONGAN-GU, ANYANG-SI, GYEONGGI-DO» — это адрес бизнес в соответствии с корейской адресной системой, где «HOGYE» — название подрайона, «DONG» — суффикс, означающий «подрайон», «DONGAN» — название района, «GU» — суффикс что означает «район», «АНЬЯН» — название города, «СИ» — суффикс, означающий «город», «КЁНГИ» — название провинции, «ДО» — суффикс, означающий «провинция». ) и информацию о категории (лапша>GOOKSU) 403 используются. В этом случае адресная информация 402 и информация о категории 403 соответствуют дополнительной информации о цели анализа морфем (DAJEONGOOKSUHOGYEJUM) 401 .
Как показано на фиг. 4, при выполнении морфемного анализа в локальном поиске адресная информация (928-2 HOGYE 2-DONG, DONGAN-GU, ANYANG-SI, GYEONGGI-DO) 402 («928-2 HOGYE 2-DONG, DONGAN-GU, ANYANG-SI, GYEONGGI-DO» — это адрес бизнес в соответствии с корейской адресной системой, где «HOGYE» — название подрайона, «DONG» — суффикс, означающий «подрайон», «DONGAN» — название района, «GU» — суффикс что означает «район», «АНЬЯН» — название города, «СИ» — суффикс, означающий «город», «КЁНГИ» — название провинции, «ДО» — суффикс, означающий «провинция». ) и информацию о категории (лапша>GOOKSU) 403 используются. В этом случае адресная информация 402 и информация о категории 403 соответствуют дополнительной информации о цели анализа морфем (DAJEONGOOKSUHOGYEJUM) 401 .
В операции S 401 анализатор морфем создает первый ключ или термин, включая лапшу и GOOKSU, путем анализа морфемы информации о категории 403 . В операции S 402 анализатор морфем создает второй ключ, включающий GYOENGGI, ANYANG, DONGAN и HOGYE, анализируя морфему адресной информации 9.0003 402 . В операции S 403 анализатор морфем создает комбинированный ключ, включающий лапшу, GOOKSU, GYOENGGI, ANYANG, DONGAN и HOGYE, путем объединения первого ключа и второго ключа.
В операции S 402 анализатор морфем создает второй ключ, включающий GYOENGGI, ANYANG, DONGAN и HOGYE, анализируя морфему адресной информации 9.0003 402 . В операции S 403 анализатор морфем создает комбинированный ключ, включающий лапшу, GOOKSU, GYOENGGI, ANYANG, DONGAN и HOGYE, путем объединения первого ключа и второго ключа.
В операции S 404 анализатор морфем извлекает словарь GOOKSU и HOGYE, включая неполную строку символов комбинированного ключа, из цели анализа морфем 401 . В операции S 405 анализатор морфем временно добавляет извлеченный словарь в словарь морфем. В эксплуатации S 406 анализатор морфем выполняет анализ морфем, используя словарь морфем, включая словарь.
Как описано выше, в соответствии с вариантом осуществления настоящего изобретения можно создать ключ, используя адресную информацию 402 и информацию о категории 403 , и временно добавить неполную строку символов ключа, которая включен в цель анализа морфем 401 , в словарь морфем, чтобы слоги не могли быть отделены друг от друга. Благодаря операции точность или скорость поиска локального поиска могут быть улучшены. Кроме того, можно частично решить проблему незарегистрированных слов, используя словарный запас, полученный путем анализа морфем адресной информации 9.0003 402 и информацию о категории 403 . Кроме того, можно дополнить токенизатор, используя словарь, когда пробелы игнорируются.
Благодаря операции точность или скорость поиска локального поиска могут быть улучшены. Кроме того, можно частично решить проблему незарегистрированных слов, используя словарный запас, полученный путем анализа морфем адресной информации 9.0003 402 и информацию о категории 403 . Кроме того, можно дополнить токенизатор, используя словарь, когда пробелы игнорируются.
РИС. 5 иллюстрирует способ выполнения анализа морфем с использованием дополнительной информации в соответствии с примерным вариантом осуществления настоящего изобретения. Как показано на фиг. 5, результаты анализа дополнительной информации 504 могут быть получены путем анализа морфемы дополнительной информации 502 с помощью анализатора 9 морфем.0003 503 перед анализом морфемы объекта анализа морфем 501 . В этом случае дополнительная информация 502 включает в себя информацию о категории или адресную информацию, связанную с целью 501 анализа морфем. Кроме того, когда цель анализа морфем 501 включает в себя результаты анализа дополнительной информации 504 в форме неполной строки символов, результаты анализа цели анализа морфем 505 могут быть получены путем неразделения слогов строки неполных символов при анализе. морфема цели анализа морфем 501 . Благодаря операции точность процесса поиска может быть повышена.
Кроме того, когда цель анализа морфем 501 включает в себя результаты анализа дополнительной информации 504 в форме неполной строки символов, результаты анализа цели анализа морфем 505 могут быть получены путем неразделения слогов строки неполных символов при анализе. морфема цели анализа морфем 501 . Благодаря операции точность процесса поиска может быть повышена.
Если одно из следующих условий: 1) существует незарегистрированное слово, 2) игнорируется интервал между объектами анализа морфем и 3) одна морфема включает в себя другую морфему, анализ морфем может быть выполнен неточно и, таким образом, могут быть получены неудовлетворительные результаты поиска. Однако когда результаты поиска получают посредством метода анализа морфем с использованием дополнительной информации 502 , вышеописанные проблемы с 1) по 3) могут быть решены.
РИС. 6 иллюстрирует первый пример 610 и второй пример 620 в отношении повышения производительности анализа морфем с использованием информации о категории для локального поиска согласно примерному варианту осуществления настоящего изобретения. В первом примере 610 показаны результаты анализа ошибок 611 , где разделены слоги слова «САНБУИНГУА» («САНБУИНГУА» — корейское слово, означающее «акушерство и гинекология»). , и результаты анализа 613 , где слоги неполной строки символов не разделены с использованием информации о категории 612 . Как показано в первом примере 610 , при выполнении локального поиска результаты поиска неполной строки символов «HYOSAN» могут включать результаты анализа ошибок 611 , не связанные со значением цели анализа морфемы. Чтобы решить эту проблему, информация о категории 612 может временно добавить «SANBUINGUA» в словарь морфем, чтобы слоги «SANBUINGUA» не могли быть отделены друг от друга. Соответственно, производительность анализа морфем может быть улучшена. (На рис. 6 «КИМБОНХЁ» — имя врача.)
В первом примере 610 показаны результаты анализа ошибок 611 , где разделены слоги слова «САНБУИНГУА» («САНБУИНГУА» — корейское слово, означающее «акушерство и гинекология»). , и результаты анализа 613 , где слоги неполной строки символов не разделены с использованием информации о категории 612 . Как показано в первом примере 610 , при выполнении локального поиска результаты поиска неполной строки символов «HYOSAN» могут включать результаты анализа ошибок 611 , не связанные со значением цели анализа морфемы. Чтобы решить эту проблему, информация о категории 612 может временно добавить «SANBUINGUA» в словарь морфем, чтобы слоги «SANBUINGUA» не могли быть отделены друг от друга. Соответственно, производительность анализа морфем может быть улучшена. (На рис. 6 «КИМБОНХЁ» — имя врача.)
Во втором примере 620 показаны результаты анализа ошибок 621 , где разделены слоги ‘GOOKSU’, соответствующие частичной строке символов объекта анализа морфемы, и результаты анализа 623 , где слоги частичной строки символов разделены. не разделены с помощью информации о категории 622 . Как показано во втором примере 620 , при выполнении локального поиска результаты поиска частичной строки символов «MIGOOK» («MIGOOK» — корейское слово, означающее «США») могут включать результаты анализа ошибок 621 не связаны со значением цели анализа морфем. Чтобы решить эту проблему, информация о категории 622 может временно добавить «GOOKSU» в словарь морфем, чтобы слоги «GOOKSU» не могли быть отделены друг от друга. Соответственно, производительность анализа морфем может быть улучшена. (На фиг. 6 «POOJIMI» является названием компании).
не разделены с помощью информации о категории 622 . Как показано во втором примере 620 , при выполнении локального поиска результаты поиска частичной строки символов «MIGOOK» («MIGOOK» — корейское слово, означающее «США») могут включать результаты анализа ошибок 621 не связаны со значением цели анализа морфем. Чтобы решить эту проблему, информация о категории 622 может временно добавить «GOOKSU» в словарь морфем, чтобы слоги «GOOKSU» не могли быть отделены друг от друга. Соответственно, производительность анализа морфем может быть улучшена. (На фиг. 6 «POOJIMI» является названием компании).
РИС. 7 показан первый пример 710 , второй пример 720 и третий пример 9.0003 730 в отношении улучшения производительности анализа морфем с использованием адресной информации для локального поиска в соответствии с примерным вариантом осуществления настоящего изобретения. В первом примере 710 точные результаты анализа «SINCHEONGJU/GONGIN/JUNGGYE/SAMUSO» 713 («CHEONGJU» — название города в Корее, «SIN» — префикс, означающий «новый», «GONGIN ” — корейское слово, означающее «уполномоченный», «JUNGGYE» — корейское слово, означающее «маклерство», а «SAMUSO» — корейское слово, означающее «офис».) извлекаются с использованием адресной информации «CHEONGJU» 712 в отношении результатов анализа ошибок «SINCHEONG/JUGONG/IN/JUNGYE/SAMUSO» 711 («SINCHEONG» — корейское слово, означающее «просьба», «заявление» или «ходатайство», «JUGONG» — это аббревиатура названия корейской компании, «IN» может быть бессмысленной последовательностью букв, «JUNGGYE» — корейское слово, означающее «маклерство», а «SAMUSO» — корейское слово, означающее «офис».) Цель анализа морфем «SINCHEONGJUGONGINJUNGGYESAMUSO», которая включает несколько корейских слов.
В первом примере 710 точные результаты анализа «SINCHEONGJU/GONGIN/JUNGGYE/SAMUSO» 713 («CHEONGJU» — название города в Корее, «SIN» — префикс, означающий «новый», «GONGIN ” — корейское слово, означающее «уполномоченный», «JUNGGYE» — корейское слово, означающее «маклерство», а «SAMUSO» — корейское слово, означающее «офис».) извлекаются с использованием адресной информации «CHEONGJU» 712 в отношении результатов анализа ошибок «SINCHEONG/JUGONG/IN/JUNGYE/SAMUSO» 711 («SINCHEONG» — корейское слово, означающее «просьба», «заявление» или «ходатайство», «JUGONG» — это аббревиатура названия корейской компании, «IN» может быть бессмысленной последовательностью букв, «JUNGGYE» — корейское слово, означающее «маклерство», а «SAMUSO» — корейское слово, означающее «офис».) Цель анализа морфем «SINCHEONGJUGONGINJUNGGYESAMUSO», которая включает несколько корейских слов.
Во втором примере 720 точные результаты анализа ‘beer/hunter/CHANGWON/DAEBANGJUM’ 723 («CHANGWON — название города в Корее, «DAEBANG» — название подрайона в CHANGWON , и «JUM» — корейский суффикс, означающий «магазин»). ” — корейский суффикс, означающий «подрайон») по отношению к результатам анализа ошибок «пиво/охотник/ЧАНВОНДАЭ/БАНДЖУМ» 721 («CHANGWONDAE» — это название университета, которое включает в себя название города «CHANGWON», а «BANGJUM» — корейское слово, означающее «отмечающая точка») объекта анализа морфем «beerhunterCHANGWONDAEBANGJUM».
” — корейский суффикс, означающий «подрайон») по отношению к результатам анализа ошибок «пиво/охотник/ЧАНВОНДАЭ/БАНДЖУМ» 721 («CHANGWONDAE» — это название университета, которое включает в себя название города «CHANGWON», а «BANGJUM» — корейское слово, означающее «отмечающая точка») объекта анализа морфем «beerhunterCHANGWONDAEBANGJUM».
В третьем примере 730 точные результаты анализа «UNIGEN/SENGMYUNG/GUAHAK/SEONGNAM/SUJEONG/JISA» 733 («UNIGEN» — название компании, «SENGMYUNG» — корейское слово, означающее «жизнь» , «ГУАХАК» — корейское слово, означающее «наука», «СОННАМ» — название города в Корее, «СУЧЖОН» — название района в СОННАМ, а «ДЖИСА» — корейское слово, означающее «филиал». .) извлекаются с использованием адресной информации «SEONGNAM-SI SUJEONG-GU» 732 («SI» — корейский суффикс, означающий «город», а «GU» — корейский суффикс, означающий «район») в отношении результатов анализа ошибок «UNIGEN/SENGMYUNG/GUAHAKSEONG/NAMSUJEONG/JISA» 731 в отношении цели анализа морфем «UNIGENSENGMYUNGGUAHAKSEONGNAMSUJEONGJISA», которая включает несколько корейских слов.
Как описано выше, поскольку точные результаты анализа получаются с использованием адресной информации, точность результатов локального поиска может быть повышена. ИНЖИР. 8 иллюстрирует первый пример 810 частичного решения незарегистрированного слова с использованием дополнительной информации и второго примера 820 дополнения токенизатора согласно примерному варианту осуществления настоящего изобретения.
В первом примере 810 проблема анализа ошибок ‘GOHYANGMAK/GOOKSU’ 811 цели анализа морфем ‘GOHYANGMAKGOOKSU’, включающая незарегистрированное слово в словаре морфем, временно добавляется в словарь морфем с использованием информации о категории ‘ МАКГУКСУ 812 . («МАКГУКСУ» — блюдо из Корана, разновидность лапши.) Соответственно, можно получить точные результаты поиска «ГОХЯН/МАКГУКСУ» 813 («ГОХЯН» — корейское слово, означающее «родной город»). Проблема с незарегистрированным словом может быть частично решена. Во втором примере 820 точные результаты анализа ‘sky/pcBANG’ 823 извлекаются путем использования информации о категории ‘pcBANG’ 822 («BANG» — корейский суффикс, означающий «магазин») по отношению к проблема анализа ошибок цели анализа морфем ‘skypcBANG’ 821 , где пробел игнорируется. Через операцию токнизер может быть дополнен.
Проблема с незарегистрированным словом может быть частично решена. Во втором примере 820 точные результаты анализа ‘sky/pcBANG’ 823 извлекаются путем использования информации о категории ‘pcBANG’ 822 («BANG» — корейский суффикс, означающий «магазин») по отношению к проблема анализа ошибок цели анализа морфем ‘skypcBANG’ 821 , где пробел игнорируется. Через операцию токнизер может быть дополнен.
Метод анализа морфем с использованием дополнительной информации в соответствии с вышеописанными примерными вариантами осуществления настоящего изобретения может быть записан на машиночитаемом носителе, включая программные инструкции для реализации различных операций, воплощенных в компьютере. Носитель также может включать в себя, отдельно или в сочетании с программными инструкциями, файлы данных, структуры данных и т.п. Примеры машиночитаемых носителей включают магнитные носители, такие как жесткие диски, дискеты и магнитные ленты; оптические носители, такие как диски CD-ROM и DVD; магнитооптические носители, такие как оптические диски; и аппаратные устройства, специально сконфигурированные для хранения и выполнения программных инструкций, такие как постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), флэш-память и т. п. Среда также может быть средой передачи, такой как оптические или металлические линии, волноводы и т. д., включая несущую, передающую сигналы, определяющие программные инструкции, структуры данных и т. д. Примеры программных инструкций включают как машинный код, например, созданный компилятор и файлы, содержащие код более высокого уровня, который может выполняться компьютером с помощью интерпретатора. Описанные аппаратные устройства могут быть сконфигурированы для работы в качестве одного или нескольких программных модулей для выполнения операций вышеописанных примерных вариантов осуществления настоящего изобретения.
п. Среда также может быть средой передачи, такой как оптические или металлические линии, волноводы и т. д., включая несущую, передающую сигналы, определяющие программные инструкции, структуры данных и т. д. Примеры программных инструкций включают как машинный код, например, созданный компилятор и файлы, содержащие код более высокого уровня, который может выполняться компьютером с помощью интерпретатора. Описанные аппаратные устройства могут быть сконфигурированы для работы в качестве одного или нескольких программных модулей для выполнения операций вышеописанных примерных вариантов осуществления настоящего изобретения.
В соответствии с вариантом осуществления настоящего изобретения предоставляется способ выполнения анализа морфем, который может использовать неполную строку символов дополнительной информации, которая хранится вместе с целью анализа морфем и обычно включается в цель анализа морфем. , и, таким образом, может выполнять анализ морфем, так что слоги словаря, соответствующие частичной строке символов, не могут быть разделены, когда неполная строка символов включена в цель анализа морфем, а также может повысить точность процесса поиска с использованием морфемы метод анализа.
Кроме того, в соответствии с вариантом осуществления настоящего изобретения предлагается способ выполнения морфемного анализа, который может повысить точность и скорость поиска при локальном поиске или поиске по магазинам за счет использования информации о категории или информации об адресе в качестве дополнительной информации. при выполнении локального поиска и поиска покупок. Кроме того, согласно варианту осуществления настоящего изобретения предоставляется способ выполнения анализа морфем, который может создать ключ путем анализа морфемы дополнительной информации и частично решить проблему незарегистрированного слова, используя созданный ключ, и дополнить токенизатор, использующий ключ, когда интервал игнорируется.
В приведенном выше корейском языке фразы или слова используются для описания вариантов осуществления изобретения, хотя и не ограничиваются этим. Анализ фраз согласно вариантам осуществления изобретения может быть использован для обработки фраз любых других языков, например, японского, китайского, английского, тайского, вьетнамского, французского, немецкого, итальянского, испанского, тайского и вьетнамского.
Хотя были показаны и описаны примерные варианты осуществления настоящего изобретения, настоящее изобретение не ограничено описанными примерными вариантами осуществления. Вместо этого специалистам в данной области техники будет понятно, что в эти иллюстративные варианты осуществления могут быть внесены изменения без отклонения от принципов и сущности изобретения, объем которого определяется формулой изобретения и ее эквивалентами.
Путешествие слова: практическое исследование морфемного анализа и этимологии для одаренных и талантливых учащихся средней школы
Сара Кэролайн Хэлфорд ◽
Марсия Б. Имбо ◽
Линда Х. Эйлерс
Исследование действий ◽
Одаренный и талантливый ◽
Уровень оценки ◽
Шестой класс ◽
Словарный запас ◽
Вмешательство в грамотность ◽
Исследовательский проект действий ◽
Учащиеся шестого класса ◽
Стратегии анализа ◽
Морфемный анализ
Учащиеся шестого класса, которые были признаны одаренными и талантливыми, участвовали в мероприятии по повышению грамотности, разработанном и реализованном первым автором в рамках исследовательского проекта. Эти учащиеся соответствовали стандартам своего класса по грамотности, поэтому проект был направлен на дальнейшее расширение их словарного запаса, чтобы подготовить их к сложной лексике, с которой они сталкиваются при самостоятельном чтении и назначенных единицах содержания. Это ежедневное вмешательство непосредственно обучало студентов происхождению и истории слов и частей слов из латинского, греческого, германского и французского языков, знакомило их со стратегиями морфемного анализа и давало им методы анализа значений слов на основе этой информации. Словарный запас по конкретному содержанию, а также общий словарный запас учащихся-участников значительно расширились. На протяжении всего вмешательства уверенность учащихся в знании словарного запаса улучшилась, и они стали глубже понимать нюансы языка, поскольку их способность применять эти знания в других контекстах росла и способствовала лучшему пониманию слов, которые они читали.
Эти учащиеся соответствовали стандартам своего класса по грамотности, поэтому проект был направлен на дальнейшее расширение их словарного запаса, чтобы подготовить их к сложной лексике, с которой они сталкиваются при самостоятельном чтении и назначенных единицах содержания. Это ежедневное вмешательство непосредственно обучало студентов происхождению и истории слов и частей слов из латинского, греческого, германского и французского языков, знакомило их со стратегиями морфемного анализа и давало им методы анализа значений слов на основе этой информации. Словарный запас по конкретному содержанию, а также общий словарный запас учащихся-участников значительно расширились. На протяжении всего вмешательства уверенность учащихся в знании словарного запаса улучшилась, и они стали глубже понимать нюансы языка, поскольку их способность применять эти знания в других контекстах росла и способствовала лучшему пониманию слов, которые они читали.
PENERAPAN PENDEKATAN KONTEKSTUAL UNTUK MENINGKATKAN HASIL BELAJAR IPA KELAS VI SD NEGERI 004 TEMBILAHAN KOTA KECATAMATAN TEMBILAHAN
Сармина Сармина
Исследование действий ◽
Результаты обучения ◽
Изучение науки ◽
Контекстный подход ◽
Студенты естественных наук ◽
Студенческая деятельность ◽
Учащиеся шестого класса ◽
Исследования действий в классе
Предпосылкой данного исследования является низкая успеваемость по естественным наукам учащихся 6 класса SDN 004 TembilahanKota. Целью данного исследования является улучшение результатов обучения студентов естественных наук VI класса SDN 004Tembilahan Kota с применением контекстуального подхода. Это исследование было проведено в классе VI SDN004 Тембилахан Кота. Это исследование представляет собой исследование действий в классе с двумя циклами. Субъектами данного исследования являются учащиеся шестого класса учебного года SDN 004 Tembilahan Kota, которые состоят из 30 человек, из них 26 мужчин и 14 женщин. По результатам исследования листы активности учителя появляются на каждой встрече. При первой встрече I цикла 64,3%, при второй встрече I цикла 67,86%. При первом заседании II цикла 71,43%, а при втором заседании II цикла 78,57%. При этом студенческая активность также возрастает с каждой встречей. При первом заседании I цикла 67,86%, при втором заседании I цикла 71,43%. На первом заседании второго цикла 75%, а на втором заседании II цикла 78,57%. Результаты обучения в первом цикле повысились на 12,8% с базового балла 67,83% до 76,5%.
Целью данного исследования является улучшение результатов обучения студентов естественных наук VI класса SDN 004Tembilahan Kota с применением контекстуального подхода. Это исследование было проведено в классе VI SDN004 Тембилахан Кота. Это исследование представляет собой исследование действий в классе с двумя циклами. Субъектами данного исследования являются учащиеся шестого класса учебного года SDN 004 Tembilahan Kota, которые состоят из 30 человек, из них 26 мужчин и 14 женщин. По результатам исследования листы активности учителя появляются на каждой встрече. При первой встрече I цикла 64,3%, при второй встрече I цикла 67,86%. При первом заседании II цикла 71,43%, а при втором заседании II цикла 78,57%. При этом студенческая активность также возрастает с каждой встречей. При первом заседании I цикла 67,86%, при втором заседании I цикла 71,43%. На первом заседании второго цикла 75%, а на втором заседании II цикла 78,57%. Результаты обучения в первом цикле повысились на 12,8% с базового балла 67,83% до 76,5%. Во втором цикле увеличилось на 17,2% до 79.5%.
Во втором цикле увеличилось на 17,2% до 79.5%.
Решающая роль математики начальной школы в уравнивании возможностей
Люси В. Продает
Уровень оценки ◽
Важная роль ◽
Шестой класс ◽
Профессиональные тесты ◽
Лечебные курсы ◽
Начальная школа математики ◽
Предложения работы ◽
Учащиеся шестого класса ◽
Настигнуть
Во многих школьных округах по всей стране назначение учащихся на курсы математики в седьмом, восьмом и девятом классах основано на баллах, полученных на тестах на знание, сдаваемых в шестом классе. Учащиеся, которые серьезно отстают от своего уровня по этим тестам, направляются на корректирующие курсы, чтобы у них была возможность наверстать упущенное. Учащиеся, не овладевшие базовыми навыками, необходимыми для того, чтобы наверстать упущенное, никогда не смогут пройти курсы алгебры и геометрии, необходимые для поступления во многие колледжи и все чаще необходимые для продвижения по техническим специальностям, не требующим диплома колледжа. Таким образом, неспособность овладеть арифметическими навыками на уровне класса представляет собой серьезное препятствие для трудоустройства учащихся.
Таким образом, неспособность овладеть арифметическими навыками на уровне класса представляет собой серьезное препятствие для трудоустройства учащихся.
ВНЕДРЕНИЕ МАЛОЙ ГРУППЫ ПО СОВЕРШЕНСТВОВАНИЮ АНГЛИЙСКОЙ РАЗГОВОРНОСТИ УЧАЩИХСЯ (АКТИВНОЕ ИССЛЕДОВАНИЕ) У ШЕСТОГО КЛАССА ИСЛАМСКОЙ НАЧАЛЬНОЙ ШКОЛЫ MIFTAHUL MUBTADIIEN ISLAMIYAH BANYAKAN KEDIRI В 2013/2014 УЧЕБНОМ ГОДУ
Памадья Витасморо
Начальная школа ◽
Исследование действий ◽
Малая группа ◽
Школьный учитель ◽
Шестой класс ◽
Школа на базе ◽
Класс D ◽
Учащиеся шестого класса ◽
говорящий по-английски ◽
Исследования действий в классе
Говорить – это один из навыков английского языка, которому учат в школе. Это означает, что английский язык можно преподавать в начальной школе в зависимости от потребностей школы. В начальной школе учитель обучает четырем языковым навыкам, таким как: аудирование, разговорная речь, чтение и письмо, чтобы учащиеся могли владеть английским языком, овладев этими четырьмя навыками.
Учащиеся Исламская начальная школа Miftahul Mubtadiien Islamiciyah Banyakan столкнулась с некоторыми проблемами речи, такими как боязнь делать ошибки, они стесняются говорить с другими учениками, и у них низкие разговорные способности.
В этом исследовании применялись исследования действий в классе. Целью этого исследования является описание того, как небольшая группа может улучшить разговорный английский язык учащихся шестого класса исламской начальной школы Miftahul Mubtadiien Islamiciyah Banyakan, Kediri. В шестом классе исследователь обнаружил проблему в классе и попытался найти решение. Учащиеся шестого класса Исламской начальной школы Мифтахул Мубтадиин Исламия Баньякан Кедири. Всего 28 студентов. Делятся на мужские и женские. 12 студентов мужского пола и 16 студенток женского пола. Это проводилось в два цикла: первый цикл состоит из трех встреч, как и второй цикл.
Результаты исследования показывают, что (1) небольшая группа может улучшить разговорные способности учащихся с точки зрения повышения их успеваемости в случае (а) беглость, (б) точность (произношение и интонация) (2) небольшая группа может улучшить ситуацию в классе с точки зрения (а) взаимодействия учащихся при наличии и ответах на вопросы учителя, (б) активности в деятельности малых групп, (в) быть более внимательным к разговорному уроку, (d) и отсутствие учеников, которые опоздали и ушли во время разговорного урока, и (e) незаметное доминирование учителя.
Математика, количественные показатели и показатели отношения для мальчиков и девочек начальной школы
Гейл Фендрих-Салоуи ◽
Мэри Бьюкенен ◽
Клиффорд Дж. Дрю
Начальная школа ◽
Половые различия ◽
Локус контроля ◽
Уровень оценки ◽
Шестой класс ◽
Математические достижения ◽
Интеллектуальная способность ◽
Независимая группа ◽
Учащиеся шестого класса ◽
Ниже уровня оценки
В этом исследовании изучались половые различия в количественных способностях, отношении к арифметике и локусе контроля как переменных, которые могут влиять на математическое обучение. Испытуемыми были 48 учеников пятого и шестого классов одной школы. Уровни интеллектуальных способностей и математических достижений контролировались. Были изучены независимые сравнения групп по полу и уровню успеваемости по математике, чтобы определить, существуют ли между группами существенные различия. Достоверные различия были очевидны только при одном сравнении. Субъекты младшего школьного возраста по математике набрали значительно более низкие баллы, чем школьники на уровне операций Стэнфордского диагностического арифметического теста.
Достоверные различия были очевидны только при одном сравнении. Субъекты младшего школьного возраста по математике набрали значительно более низкие баллы, чем школьники на уровне операций Стэнфордского диагностического арифметического теста.
PENERAPAN МОДЕЛЬ PEMBELAJARAN KOOPERATIF TYPE KEPALA BERNOMOR BERSTRUKTUR UNTUK MENINGKATKAN MOTIVASI BELAJAR PKN SISWA KELAS VI SDN 029 SUNGAI PINANG KABUPATEN KAMPAR
Дагниар Дагниар
Исследование действий ◽
Показатели эффективности ◽
Гражданственное образование ◽
Шестой класс ◽
Классовый иск ◽
Мотивация обучения ◽
Образование Студенты ◽
Учащиеся шестого класса ◽
Очень высоко ◽
Тип головы
Это исследование было мотивировано низкой мотивацией к обучению учащихся шестого класса, обучающихся гражданскому воспитанию, из SDN 029 Sungai Pinang Kabupaten Kampar. Это исследование направлено на улучшение учебной мотивации Pkn посредством применения структурированных моделей совместного обучения типа пронумерованных головок у учащихся шестого класса SDN 029 SungaiPinang Kabupaten Kampar.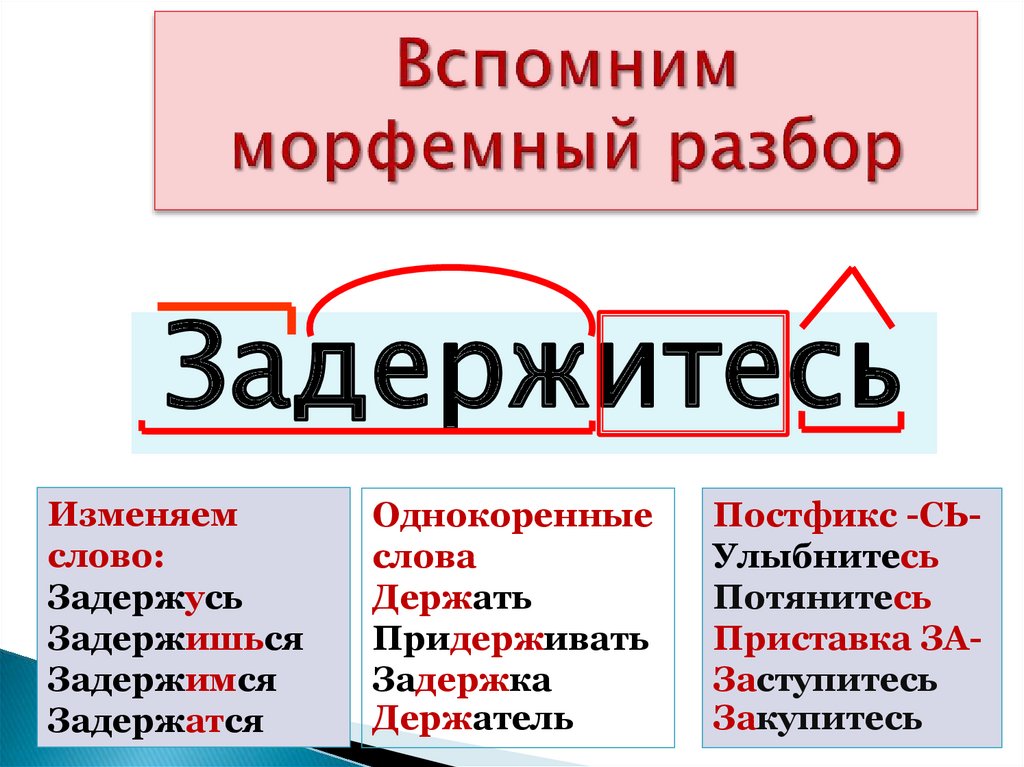 Субъектами этого исследования были все учащиеся шестого класса SDN 029.Сунгай Пинанг Кабупатен Кампар, всего 17 лет, 2016 г. Форма исследования — исследование в классе. Этот исследовательский инструмент состоит из инструментов производительности и инструментов сбора данных в виде листов наблюдений за деятельностью учителя и деятельностью учащихся. Основываясь на результатах исследования и обсуждения, применение структурированной модели обучения с пронумерованными головками может улучшить учебную мотивацию учащихся шестого класса SDN 029 Sungai Pinang Kabupaten Kampar, увидев, что учебная мотивация учащихся в первом цикле набрала 50% в низкая категория, в то время как во втором цикле получили 755% в очень высокой категории. В первом цикле это групповое исследование не было признано успешным, в то время как во втором цикле исследование было успешным с показателем успеха на 75,5%, превышающим показатели эффективности. которые были установлены
Субъектами этого исследования были все учащиеся шестого класса SDN 029.Сунгай Пинанг Кабупатен Кампар, всего 17 лет, 2016 г. Форма исследования — исследование в классе. Этот исследовательский инструмент состоит из инструментов производительности и инструментов сбора данных в виде листов наблюдений за деятельностью учителя и деятельностью учащихся. Основываясь на результатах исследования и обсуждения, применение структурированной модели обучения с пронумерованными головками может улучшить учебную мотивацию учащихся шестого класса SDN 029 Sungai Pinang Kabupaten Kampar, увидев, что учебная мотивация учащихся в первом цикле набрала 50% в низкая категория, в то время как во втором цикле получили 755% в очень высокой категории. В первом цикле это групповое исследование не было признано успешным, в то время как во втором цикле исследование было успешным с показателем успеха на 75,5%, превышающим показатели эффективности. которые были установлены
ПЕНИНГКАТАН КЕМАМПУАН МЕНЬЯМПАЙКАН ИСИ БЕРИТА ДИ СУРАТ КАБАР МЕЛАЛУИ МЕТОД БЕРСЕРИТА СИСВА КЕЛАС ВИ SD НЕГЕРИ 022 РИМБО ПАНДЖАНГ КЕКАМАТАН ТАМБАНГ
Саринан Саринан
Исследование действий ◽
Сбор данных ◽
Шестой класс ◽
Студенческая деятельность ◽
Средняя стоимость ◽
Учащиеся третьего класса ◽
Учащиеся шестого класса ◽
Академический год ◽
Деятельность по сбору данных ◽
III класс
Улучшает предоставление новостного контента в газете с помощью метода рассказывания историй Учащиеся VI класса SD Negeri 022 Rimbo Panjang Kecamatan Tambang.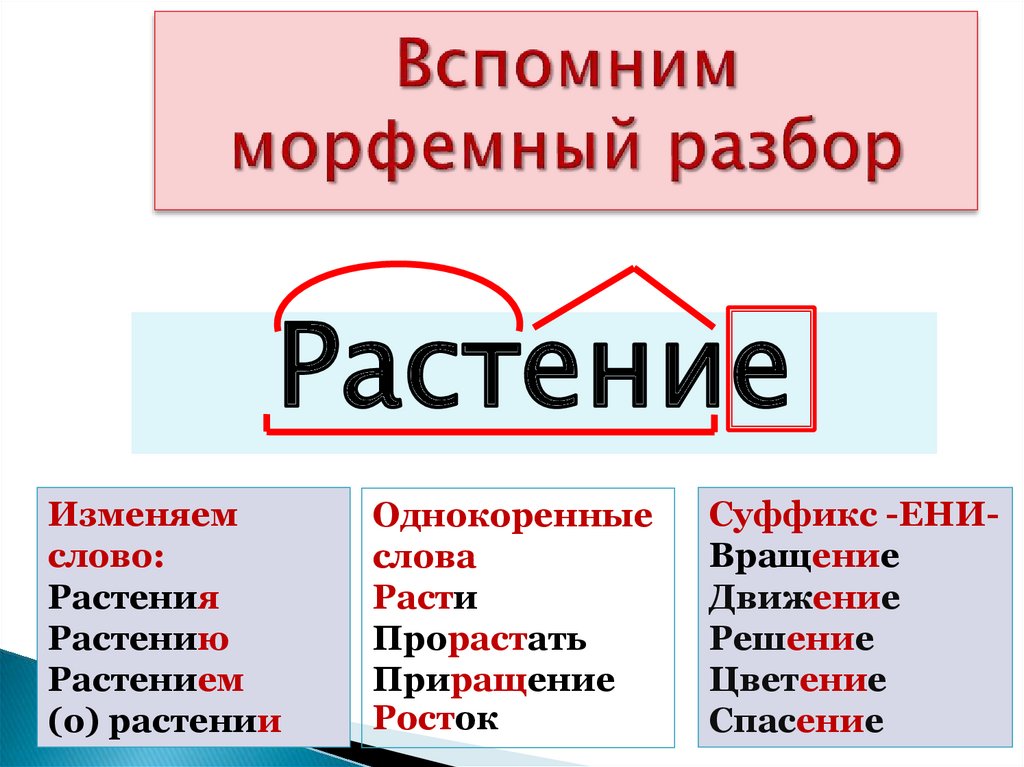 Это исследование мотивировано отсутствием возможности сообщать новости в газетах ученикам третьего класса SD Negeri 022 Rimbo Panjang Kecamatan Tambang. Это исследование направлено на то, чтобы определить, может ли за счет использования метода рассказывания историй улучшить способность учащихся VI класса SD Negeri 022 Rimbo Panjang Kecamatan Tambang в области обучения научиться говорить на индонезийском языке, которое проводится в течение 1 месяца. В качестве испытуемых в данном исследовании выступают учащиеся шестых классов в 2014-2015 учебном году в количестве 15 человек, из них 4 мальчика и 11 девочек. Форма исследования – исследование в классе. Инструмент исследования состоит из инструментов и листа наблюдения за деятельностью по сбору данных о производительности инструментов, формирующих деятельность учителя и ученика. Согласно проведенному исследованию, заключение этого исследования об обновлениях доставляет новости в газету с помощью метода рассказывания историй, уровень III в SD Negeri 022 Rimbo Panjang Kecamatan Tambang.
Это исследование мотивировано отсутствием возможности сообщать новости в газетах ученикам третьего класса SD Negeri 022 Rimbo Panjang Kecamatan Tambang. Это исследование направлено на то, чтобы определить, может ли за счет использования метода рассказывания историй улучшить способность учащихся VI класса SD Negeri 022 Rimbo Panjang Kecamatan Tambang в области обучения научиться говорить на индонезийском языке, которое проводится в течение 1 месяца. В качестве испытуемых в данном исследовании выступают учащиеся шестых классов в 2014-2015 учебном году в количестве 15 человек, из них 4 мальчика и 11 девочек. Форма исследования – исследование в классе. Инструмент исследования состоит из инструментов и листа наблюдения за деятельностью по сбору данных о производительности инструментов, формирующих деятельность учителя и ученика. Согласно проведенному исследованию, заключение этого исследования об обновлениях доставляет новости в газету с помощью метода рассказывания историй, уровень III в SD Negeri 022 Rimbo Panjang Kecamatan Tambang. Среднее значение способностей студентов перед сиклсу I 42,2 на первом цикле, составив 63,9а во втором цикле 84,2 или способность, которая, как ожидается, будет достигнута более чем 70% студентов, набравших верхние баллы KKM, равна 70. Утверждения выше показывают, что способность сообщать новости в газетах может быть усиливается за счет рассказывания историй.
Среднее значение способностей студентов перед сиклсу I 42,2 на первом цикле, составив 63,9а во втором цикле 84,2 или способность, которая, как ожидается, будет достигнута более чем 70% студентов, набравших верхние баллы KKM, равна 70. Утверждения выше показывают, что способность сообщать новости в газетах может быть усиливается за счет рассказывания историй.
Роль фонологической и морфологической грамотности в знании английской лексики корейскими шестиклассниками и понимании прочитанного
Ын Джу Ким
Понимание прочитанного ◽
Морфологическая осведомленность ◽
Шестой класс ◽
Словарный запас ◽
Учащиеся шестого класса
Вклад понимания академической лексики в ответы на вопросы понимания
Джеймс В. Каннингем ◽
Дэвид В. Мур
Понимание прочитанного ◽
Вопрос Ответ ◽
Шестой класс ◽
Словарный запас ◽
Вопрос понимания ◽
Академическая лексика ◽
Независимый фактор ◽
Учащиеся шестого класса ◽
Различия ◽
Словарный субтест
Это исследование было разработано для изучения того, является ли словарь вопросов на понимание письма независимым фактором, определяющим эффективность понимания прочитанного учащимися. Контролируемыми факторами были характеристики читателя, характеристики текста и отношения вопрос-текст-ответ. На наборы совпадающих вопросов на понимание, различающихся только типом словарного запаса (академический или повседневный), ответили 106 учащихся четвертого, пятого и шестого классов. Также были собраны баллы испытуемых по подтесту по смысловому словарному запасу ITBS и неформальному показателю академического словарного запаса. Различия между средними значениями показали, что академическая лексика в вопросах на понимание значительно снижает эффективность ответов на вопросы. Чтобы пролить дополнительный свет на это снижение, была рассчитана серия простых, множественных и получастичных корреляций между показателями словарного запаса и баллами по вопросам понимания. Эти корреляции постоянно поддерживали интерпретацию того, что различия в терминологии между согласованными наборами вопросов объясняют разницу в производительности по вопросам. Обсуждаются возможные направления дальнейших исследований и последствия для практики.
Контролируемыми факторами были характеристики читателя, характеристики текста и отношения вопрос-текст-ответ. На наборы совпадающих вопросов на понимание, различающихся только типом словарного запаса (академический или повседневный), ответили 106 учащихся четвертого, пятого и шестого классов. Также были собраны баллы испытуемых по подтесту по смысловому словарному запасу ITBS и неформальному показателю академического словарного запаса. Различия между средними значениями показали, что академическая лексика в вопросах на понимание значительно снижает эффективность ответов на вопросы. Чтобы пролить дополнительный свет на это снижение, была рассчитана серия простых, множественных и получастичных корреляций между показателями словарного запаса и баллами по вопросам понимания. Эти корреляции постоянно поддерживали интерпретацию того, что различия в терминологии между согласованными наборами вопросов объясняют разницу в производительности по вопросам. Обсуждаются возможные направления дальнейших исследований и последствия для практики.
КОНФЕРЕНЦИОННЫЙ ПОДХОД К ПРОДВИЖЕНИЮ ПИСЬМЕННЫХ СПОСОБНОСТЕЙ: АКЦИОНЕРНОЕ ИССЛЕДОВАНИЕ ЯЗЫКОВОГО ТВОРЧЕСКОГО ПИСЬМА НА ИНДОНЕЗИЙСКОМ ЯЗЫКЕ
Татат Хартати
Исследование действий ◽
Писательское творчество ◽
Навыки письма ◽
Шестой класс ◽
Средний счет ◽
Школьники ◽
Учащиеся шестого класса ◽
Написание стихов ◽
Исследования действий в классе ◽
Влияние
В последнее время наблюдается растущий интерес к изучению творческого письма. Также был изучен ряд подходов к обучению творческому письму. Тем не менее, исследования, посвященные творческому письму, особенно для учащихся начальных классов, практически отсутствуют. Цель настоящего исследования — выяснить, как метод конференц-связи применяется для обучения написанию стихов, и выяснить влияние этого подхода на навыки письма учащихся. В исследовании использовалось исследование действий в классе с участием 30 учеников шестого класса. Чтобы настоящий подход эффективно улучшал успеваемость, в исследовании использовались три цикла этапов обучения, включая классический, групповой и индивидуальный. Также использовались различные средства массовой информации и источники для поддержки учебной деятельности. Результаты исследования показывают, что наблюдается значительное улучшение навыков письма студентов, у которых средний балл третьего цикла был в два раза выше, чем у первого цикла. Это говорит о том, что обучение по конференц-связи было успешным в улучшении навыков письма учащихся. Особое внимание уделялось процессу взаимодействия как между студентами, так и между студентами и преподавателями. Кроме того, педагоги получили опыт аналитической оценки написания стихов по четырем аспектам: творческая мысль, дикция, информация и воображение.
Чтобы настоящий подход эффективно улучшал успеваемость, в исследовании использовались три цикла этапов обучения, включая классический, групповой и индивидуальный. Также использовались различные средства массовой информации и источники для поддержки учебной деятельности. Результаты исследования показывают, что наблюдается значительное улучшение навыков письма студентов, у которых средний балл третьего цикла был в два раза выше, чем у первого цикла. Это говорит о том, что обучение по конференц-связи было успешным в улучшении навыков письма учащихся. Особое внимание уделялось процессу взаимодействия как между студентами, так и между студентами и преподавателями. Кроме того, педагоги получили опыт аналитической оценки написания стихов по четырем аспектам: творческая мысль, дикция, информация и воображение.
MENINGKATKAN PENGUASAAN MENELADANI KHALIHAF ABU BAKAR DAN UMAR MENGGUNAKAN TEKNIK BERCERITA MELALUI TUTOR SEBAYA PADA SISWA KELAS VI SDN 005 BONTANG
Зайтун Зайтун
Исследование действий ◽
Процесс изучения ◽
Шестой класс ◽
Средний счет ◽
Предмет исследования ◽
рассказывание историй ◽
Учащиеся шестого класса ◽
Преподавание ценностей ◽
История ◽
Исследования действий в классе
Это исследование направлено на повышение мастерства в истории обучения ценностям Абу Бакара и Умара бин Хаттаба, императора после Наби Мухаммеда. В исследовании используется исследование действий в классе в качестве дизайна для внедрения репетитора того же возраста с помощью методов рассказывания историй. Используя два цикла, это исследование назначает учащихся шестого класса SDN 005 Botang в качестве объекта исследования. Это исследование обнаруживает, что активность обучения увеличивается, а средний балл увеличивается с 6,5 до 8,2. Участие и участие в процессе обучения также увеличиваются, так что обучение завершается во втором цикле. Это исследование доказывает, что использование наставника того же возраста для обучения персонажей Абу Бакара и Умара как кулафаура расидина является благоприятным.
В исследовании используется исследование действий в классе в качестве дизайна для внедрения репетитора того же возраста с помощью методов рассказывания историй. Используя два цикла, это исследование назначает учащихся шестого класса SDN 005 Botang в качестве объекта исследования. Это исследование обнаруживает, что активность обучения увеличивается, а средний балл увеличивается с 6,5 до 8,2. Участие и участие в процессе обучения также увеличиваются, так что обучение завершается во втором цикле. Это исследование доказывает, что использование наставника того же возраста для обучения персонажей Абу Бакара и Умара как кулафаура расидина является благоприятным.
Почему мы помечаем одни связанные морфемы, а другие нет?
Почему мы помечаем одни связанные морфемы, а другие нет?
Опубликовано по адресу: 2021-01-28
Справочные базы данных SALT используют очень специфический набор соглашений для маркировки связанных морфем. Наши протоколы не являются единственным способом маркировки морфем, но если вы хотите сравнить свой образец с нашими базами данных, важно, чтобы вы использовали те же соглашения. Если вас не интересуют гайки и болты, просто перейдите к разделу «Сводка». Это самая сжатая версия правил SALT для маркировки связанных морфем, с которой мы можем справиться! Поначалу правила SALT для маркировки связанных морфем могут показаться неясными. Но в нашем безумии есть метод. В этом блоге объясняется обоснование соглашений SALT по маркировке связанных морфем. Это выходит за рамки «потому что так было давно, и вот правила, которые нужно запомнить». Или, говоря более клинически, «потому что это морфемы развития, а вот правила для запоминания». При написании этого блога мы надеемся, что, поняв «почему» за соглашениями, правила обретут больше смысла и, надеюсь, их будет легче реализовать. Роджер Браун
Если вас не интересуют гайки и болты, просто перейдите к разделу «Сводка». Это самая сжатая версия правил SALT для маркировки связанных морфем, с которой мы можем справиться! Поначалу правила SALT для маркировки связанных морфем могут показаться неясными. Но в нашем безумии есть метод. В этом блоге объясняется обоснование соглашений SALT по маркировке связанных морфем. Это выходит за рамки «потому что так было давно, и вот правила, которые нужно запомнить». Или, говоря более клинически, «потому что это морфемы развития, а вот правила для запоминания». При написании этого блога мы надеемся, что, поняв «почему» за соглашениями, правила обретут больше смысла и, надеюсь, их будет легче реализовать. Роджер Браун
Гарвардский университет В значительной степени соглашение SALT для маркировки связанных морфем основано на соглашениях, использованных Роджером Брауном (1973) при расчете MLUm (средняя длина высказывания в морфемах) еще на заре языка. анализ проб.
Инфлективные морфемы и деривационные морфемы
Многие пояснения и примеры в этом разделе взяты со следующих веб-сайтов: https://semanticsmorphology.weebly.com/inflectional-and-derivational-morphemes.html http:// www.mathcs.duq.edu/~packer/Courses/Psy598/Ling-Morphology.pdf Браун исключил производные морфемы при расчете MLUm. Чтобы понять почему, нам сначала нужно провести различие между двумя типами связанных морфем – флективными и словообразовательными. Инфлективные морфемы используются, чтобы показать некоторые аспекты грамматической функции слова. Они всегда являются суффиксами и всегда приводят к одной и той же части речи. Мы используем флективные морфемы, чтобы указать, является ли слово единственным или множественным, является ли оно сравнительной или притяжательной формой, а также для обозначения времени. Инфлективные морфемы никогда не изменяют грамматическую категорию (часть речи) слова. Например, обувь и обувь оба являются существительными, высокий и высокий оба являются прилагательными, а смотреть и выглядеть оба являются глаголами. Инфлективные морфемы просто производят разные версии слов. Есть восемь флективных морфем. Они показаны в следующей таблице:
Инфлективные морфемы просто производят разные версии слов. Есть восемь флективных морфем. Они показаны в следующей таблице:
| Флективные морфемы | Добавлено к | Пример | |
| -с, -ес | множественное число | существительные | У меня два черных кота s . |
| -‘с, -с’ | притяжательный | существительные | Моя собака лает очень громко. |
| -эр | сравнительный | прилагательных | У меня длиннее или волос, чем у тебя. |
| -эст | превосходная степень | прилагательных | У него самая большая тыква est . |
| -с | 3 rd лицо единственное число | глагола | Она быстро бежит с . |
| -ред. | прошедшее время | глагола | Он играет изд баскетбол. |
| -en | причастие прошедшего времени | глагола | Она съела и всего. |
| -инг | прогрессивное время | глагола | Он играет в в баскетбол. |
Когда дети используют флективные морфемы, они (как правило) демонстрируют свое знание основного слова , а также их способность кодировать множественное число, притяжательное или время этого корневого слова. Производные морфемы , напротив, используются для образования новых слов или для образования слов другого грамматического класса (части речи) из корневой формы. Например, при добавлении словообразовательной морфемы -er глагол читать становится существительным читать . Добавление -ize изменяет прилагательное нормальный на глагол нормализовать . Точно так же мы можем вывести прилагательные полезный и беспомощный путем добавления -ful и ‑less к существительному помочь . Однако некоторые словообразовательные морфемы не меняют грамматическую категорию слова, но существенно меняют значение слова. Например, мы можем получить существительные окрестности и королевство , добавив производные суффиксы ‑hood и ‑dom к существительным сосед и король . А словообразовательные префиксы, такие как не- и ре-, как правило, не меняют категорию слова, к которому они присоединены. Таким образом, оба счастливый и несчастный — это прилагательные, а наполнить 90 717 и пополнить – это глаголы. Но каждая из этих пар слов, хотя и явно связанных, имеет совершенно разные значения. Производные морфемы могут быть либо суффиксами, либо префиксами и обычно, но не всегда, приводят к другой грамматической категории. В следующей таблице перечислены некоторые распространенные производные морфемы:
Точно так же мы можем вывести прилагательные полезный и беспомощный путем добавления -ful и ‑less к существительному помочь . Однако некоторые словообразовательные морфемы не меняют грамматическую категорию слова, но существенно меняют значение слова. Например, мы можем получить существительные окрестности и королевство , добавив производные суффиксы ‑hood и ‑dom к существительным сосед и король . А словообразовательные префиксы, такие как не- и ре-, как правило, не меняют категорию слова, к которому они присоединены. Таким образом, оба счастливый и несчастный — это прилагательные, а наполнить 90 717 и пополнить – это глаголы. Но каждая из этих пар слов, хотя и явно связанных, имеет совершенно разные значения. Производные морфемы могут быть либо суффиксами, либо префиксами и обычно, но не всегда, приводят к другой грамматической категории. В следующей таблице перечислены некоторые распространенные производные морфемы:
| Общие словообразовательные морфемы (суффиксы) | Добавлено к | Результаты в | Примеры |
| -из | существительных прилагательных | глагола | глаголарезина размер обычный размер |
| -полный | существительные | прилагательных | play ful , help ful, beauti ful |
| -лы | существительных прилагательных | прилагательных наречий | человек ly , друг ly гордый ly |
| -сион | глагола | существительные | дискус сион |
| -капот, -дом | существительные | сосед капот , король дом | |
| Производные суффиксы, которые пересекаются с флективными суффиксами ( хотя они служат другой цели ) | |||
| -эр | глаголов существительных/глаголов | существительных существительных | чтение er град er |
-ред. | глагола | прилагательных | am tir ed , was bor ed |
| -en | глагола | прилагательных | это место так en |
| -инг | существительные/глаголы существительные/глаголы | существительных прилагательных | bik ing это забавный интерес ing история |
| Общие словообразовательные морфемы (префиксы) | Добавлено к | Результаты в | Примеры |
| не-, а- дис-, ре- анти- | Прилагательные глаголы существительные | un happy, a типичный dis like, re fill, re оценить, re view anti -самолет | |
Согласно Брауну, маленькие дети, как правило, не учат базовое слово, а затем применяют производную морфему для кодирования дополнительной информации.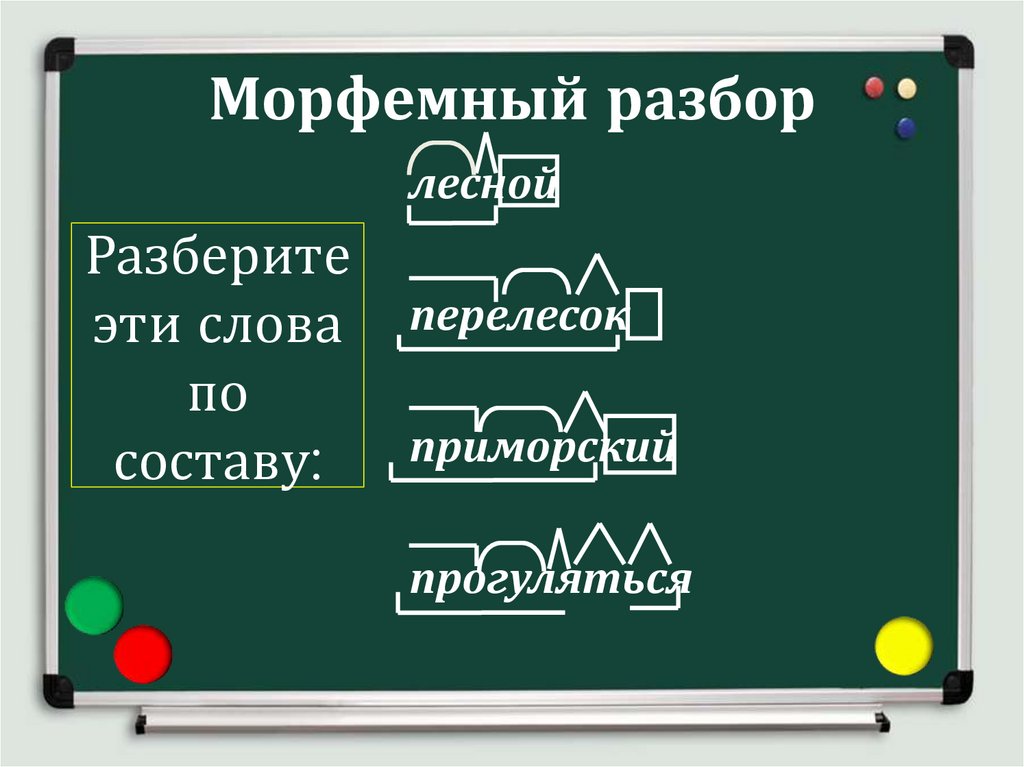 Вместо этого они обычно изучают их как полностью сформированные, независимые слова со своим особым значением. Хотя деривационные морфемы можно логически разделить на корневое слово и префикс или суффикс, эти более мелкие части не имеют значения для говорящего ребенка, и поэтому в данном случае их не следует рассматривать как отдельные морфемы. Го и др. (2018) приводит доказательства этого, в том числе:
Вместо этого они обычно изучают их как полностью сформированные, независимые слова со своим особым значением. Хотя деривационные морфемы можно логически разделить на корневое слово и префикс или суффикс, эти более мелкие части не имеют значения для говорящего ребенка, и поэтому в данном случае их не следует рассматривать как отдельные морфемы. Го и др. (2018) приводит доказательства этого, в том числе:
- Существует множество психолингвистических доказательств того, что базовые слова и производные слова (например, красота , красота ) хранятся как отдельные лексические статьи и должны иметь равный вес.
- Дети могут выучить производное слово (например, красивый, интересный ) перед основным словом (например, красота, интерес ). Кажется маловероятным, чтобы дети добавляли производные морфемы к этим основным словам, чтобы образовать производные слова. Примечание : чтобы проверить это, мы изучили образцы 355 типично развивающихся детей в возрасте до 7 лет, взятые из баз данных SALT Play and Conversation. Производное слово красивый использовалось пять раз, в то время как его основная форма красота использовалась только один раз. А интересное использовалось дважды и не было ни одного экземпляра его базовой формы интересного .
 Производное слово красивый использовалось пять раз, в то время как его основная форма красота использовалась только один раз. А интересное использовалось дважды и не было ни одного экземпляра его базовой формы интересного .
Производное слово красивый использовалось пять раз, в то время как его основная форма красота использовалась только один раз. А интересное использовалось дважды и не было ни одного экземпляра его базовой формы интересного .Они считают, что деривация – это процесс словообразования, а не процесс грамматического кодирования. Следовательно, деривация отражает лексические навыки говорящего, а не грамматические навыки.
Итак, какие правила лежат в основе соглашений ОСВ?
ПРАВИЛО 1: Не отмечайте словообразовательные морфемы . Отметить (большинство) словоизменительные морфемы. Почему ? Короче говоря, мы хотим отметить связанные морфемы, когда они отражают понимание говорящим ребенком того, что префикс/суффикс имеет значение, отличное от корневого слова. При использовании деривационных морфем, выученных как полностью сформированных, независимых слов, говорящий ребенок использует только одно значение. Напротив, при использовании флективной морфемы ребенок использует два значения: корневое слово и закодированное множественное/притяжательное/временное значение. Не отмечая деривационные морфемы, мы не отдаем должное говорящему за связанные морфемы, которые изменяют значение слова (например, счастливый → несчастный) или изменяют его грамматическую категорию (например, друг → дружелюбный). Однако, когда говорящий ребенок, вероятно, понял отдельные значения связанных морфем, мы хотим отметить их. Так мы помечаем большинство флективных морфем. Большинство, но не все… ПРАВИЛО 1а: Не отмечайте сравнительные (флективные) морфемы -er и -est . Почему не ? Хотя -er и -est являются флективными морфемами, Браун не учитывал их, потому что они не являются обязательными. Согласно Guo, et al (2018), это означает, что это стилистический выбор, использовать ли сравнительную и превосходную форму, а не неизменяемое прилагательное. Например, когда ребенку дается выбор из нескольких мячей разного размера, он может выбрать самый большой и сказать: « У меня есть самый большой 9».
Напротив, при использовании флективной морфемы ребенок использует два значения: корневое слово и закодированное множественное/притяжательное/временное значение. Не отмечая деривационные морфемы, мы не отдаем должное говорящему за связанные морфемы, которые изменяют значение слова (например, счастливый → несчастный) или изменяют его грамматическую категорию (например, друг → дружелюбный). Однако, когда говорящий ребенок, вероятно, понял отдельные значения связанных морфем, мы хотим отметить их. Так мы помечаем большинство флективных морфем. Большинство, но не все… ПРАВИЛО 1а: Не отмечайте сравнительные (флективные) морфемы -er и -est . Почему не ? Хотя -er и -est являются флективными морфемами, Браун не учитывал их, потому что они не являются обязательными. Согласно Guo, et al (2018), это означает, что это стилистический выбор, использовать ли сравнительную и превосходную форму, а не неизменяемое прилагательное. Например, когда ребенку дается выбор из нескольких мячей разного размера, он может выбрать самый большой и сказать: « У меня есть самый большой 9». 0717», если не будет предложено провести сравнение. ПРАВИЛО 1b: Не маркируйте неправильные формы . Почему не ? Неправильные формы считаются отдельными морфемами, потому что дети (обычно) учат их как отдельные формы, а не как варианты их базовых форм. В следующей таблице перечислены примеры неправильных слов:
0717», если не будет предложено провести сравнение. ПРАВИЛО 1b: Не маркируйте неправильные формы . Почему не ? Неправильные формы считаются отдельными морфемами, потому что дети (обычно) учат их как отдельные формы, а не как варианты их базовых форм. В следующей таблице перечислены примеры неправильных слов:
| Категория | Примеры неправильных слов |
| во множественном числе | человек → люди, ступня → ступни, кактус → кактусы, олень → олень |
| все притяжательные местоимения | Я → мой, он → его, она → ее, мы → наш, ты → твой, он → его, они → их |
| 3 рд лицо единственное число | есть → есть, есть → было |
| прошедшее время | начало → началось, перерыв → сломалось, пошли → пошли, получили → получили |
| причастие прошедшего времени ( правильная форма настоящего времени + EN как отдельный слог ) | начать → начать, сломать → сломать, идти → уйти, получить → получить, увидеть → увидеть, быть → было |
| отрицание | будет → не будет |
Некоторые слова неправильные, потому что меняется звучание основной формы. Эти слова следуют стандартному написанию флективных или сокращенных слов, но меняют свое звучание. Вот несколько примеров:
Эти слова следуют стандартному написанию флективных или сокращенных слов, но меняют свое звучание. Вот несколько примеров:
| Категория | Примеры измененного звука |
| во множественном числе | лист → листья, волк → волки |
| 3 рд лицо единственное число | делать → делает, говорит → говорит |
| причастие прошедшего времени | диск → привод, запись → запись |
| отрицание | делать → не делать |
ПРАВИЛО 1c: Не отмечайте множественное число для слов, не имеющих формы единственного числа . Почему бы и нет ? Дети не выучили бы форму единственного числа, чтобы затем применить правило для множественного числа. Ниже приведены некоторые примеры:
| Примеры множественного числа без формы единственного числа | |||
| вещи бинокль бриджи ящики для одежды | очки ( очки ) защитные очки трусики пижамы | штаны трусики остаются богатством махинаций | шорты пена колготки брюки пинцет |
ПРАВИЛО 2. Не отмечайте конкатенации . Почему не ? Браун считал конкатенации отдельными морфемами, потому что, как и неправильные формы, дети могли хранить их как целостные фрагменты. Ниже приведен список конкатенаций:
Не отмечайте конкатенации . Почему не ? Браун считал конкатенации отдельными морфемами, потому что, как и неправильные формы, дети могли хранить их как целостные фрагменты. Ниже приведен список конкатенаций:
| Примеры конкатенаций ( означает ) | |||
| держу пари ( держу пари ) | лайкета ( нравится ) | из ( из ) | useta ( используется для ) |
| может ( может иметь ) | посмотри ( посмотри на это ) | должен ( должен иметь ) | хочу ( хочу ) |
| собирается ( переходит на ) | муста ( обязательно ) | спост ( предполагается ) | что за ( ты что ) |
| должен ( попал в ) | надо ( надо ) | трынта ( попытка ) | будет ( будет ) |
| хафта (с по ) | |||
ПРАВИЛО 3: Отмечайте сокращенные слова . Почему ? Сокращения объединяют два слова в одно (например, мы à мы ). Говорящему засчитывается одинаковое количество морфем, независимо от того, использует ли он два слова или одно сокращенное слово.
Почему ? Сокращения объединяют два слова в одно (например, мы à мы ). Говорящему засчитывается одинаковое количество морфем, независимо от того, использует ли он два слова или одно сокращенное слово.
| Схватки | Примеры | |
| -‘т -нет | отрицание | Я могу еще не уйти. Он не знает лучше |
| — | имеет ли нас | пора идти. Он из был болен. Чем и он зарабатывает на жизнь? Отпустите из . |
| — | это | Вы опоздали. |
| -м | утра | Я готов пройти тест. |
| -11 | будет | Я подожду здесь. |
| -‘d | сделал бы | Он сделал бы это. Вам лучше уйти сейчас. Почему — мальчик посмотрел туда? Вам лучше уйти сейчас. Почему — мальчик посмотрел туда? |
| — | есть | У нас много дел. |
Резюме
Эти правила можно резюмировать следующим образом:
- Отметьте только следующие словоизменительные морфемы и сокращения:
| Инфлективные морфемы | Схватки | |||
| /с | множественное число | / нет, / нет | отрицание | |
| /з | притяжательный | / с, / ре, / м | есть, есть, я | |
| /3 с | 3 rd лицо единственное число | /’ll, /’d | будет, будет | |
| / ред. | прошедшее время | / ‘ve, / h’s, / h’d | есть, есть, было | |
| /en | причастие прошедшего времени | / д, / д | делает, делает | |
| / | прогрессивное время | / нас | США | |
- Не отмечайте неправильные формы, конкатенации или формы множественного числа, которые не имеют формы единственного числа.

- Используйте косую черту (/) для связанных морфем, которые следуют за свободной морфемой (суффиксы), и используйте обратную косую черту (\) для связанных морфем, которые предшествуют свободной морфеме (префиксы). Между свободной морфемой и связанной морфемой не должно быть пробелов.
- Когда написание свободной морфемы, такой как CRY, изменяется при добавлении связанной морфемы, используйте корневое написание свободной морфемы (как будто связанной морфемы нет). Затем просто добавьте косую черту и связанную морфему (например, CRY/ED). Если этого не сделать, основной CRI будет рассматриваться как слово, отличное от CRY, и, таким образом, увеличится отношение типа к токену (TTR), а также количество различных слов (NDW).
Если вы хотите увидеть некоторые примеры форматирования для связанных морфем, см. этот PDF-файл: https://saltsoftware.com/media/wysiwyg/tranaids/TranConvSummary.pdf Также попробуйте наш онлайн-курс № 1304: Транскрипция — Соглашения Часть 1: https://saltsoftware.