Сложные слова / Корень и однокоренные (родственные) слова / Морфемный разбор / Справочник по русскому языку для начальной школы
- Главная
- Справочники
- Справочник по русскому языку для начальной школы
- Морфемный разбор
- Корень и однокоренные (родственные) слова
- Сложные слова
Слова с несколькими корнями называют сложными. Такие слова образуются сложением двух основ от разных слов.
Например:
лес+парк⇒ лесопарк
Между корнями часто есть соединительная гласная «о» (самосвал, звездопад) или «е» (солевар, пулемёт).
Соединительная гласная в сложных словах — это орфограмма, которую надо запомнить.
Сложные слова могут быть образованы и без соединительной гласной.
Например:
стенгазета, кофемолка
Сложные слова могут быть именами существительными и именами прилагательными.
Например:
пароход, самовар, водопад — существительные
синеглазый, белозубый, краснощёкий — прилагательные
В сложных словах ударение падает на последний из корней (снегохо́д).
Поделись с друзьями в социальных сетях:
Советуем посмотреть:
Однокоренные слова и формы слова
Окончание
Основа слова
Корень и однокоренные (родственные) слова
Приставки и их значения
Суффикс
Морфемный разбор
Правило встречается в следующих упражнениях:
3 класс
Упражнение 212, Климанова, Бабушкина, Учебник, часть 1
Упражнение 213, Климанова, Бабушкина, Учебник, часть 1
Упражнение 171, Полякова, Учебник, часть 1
Упражнение 179, Полякова, Учебник, часть 1
Упражнение 180, Полякова, Учебник, часть 1
Упражнение 182, Полякова, Учебник, часть 1
Упражнение 184, Полякова, Учебник, часть 1
Упражнение 4, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 246, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 5, Исаева, Бунеев, Рабочая тетрадь
4 класс
Упражнение 64, Канакина, Горецкий, Учебник, часть 1
Упражнение 87, Канакина, Горецкий, Учебник, часть 2
Упражнение 11, Климанова, Бабушкина, Учебник, часть 1
Упражнение 194, Климанова, Бабушкина, Учебник, часть 1
Упражнение 14, Климанова, Бабушкина, Рабочая тетрадь, часть 2
Упражнение 49, Климанова, Бабушкина, Рабочая тетрадь, часть 2
Упражнение 2, Бунеев, Бунеева, Пронина, Учебник, часть 1
Упражнение 206, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 285, Бунеев, Бунеева, Пронина, Учебник, часть 2
Упражнение 4, Исаева, Бунеев, Рабочая тетрадь
5 класс
Упражнение 116, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 117, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение 118, Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
Упражнение Повторение § 16 стр.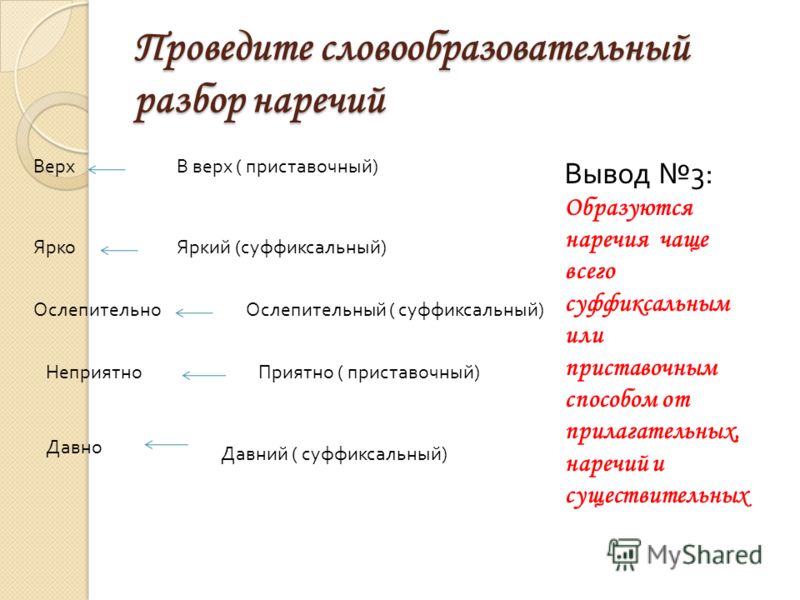 56 — 57,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
56 — 57,
Александрова, Рыбченкова, Глазков, Лисицин, Учебник, часть 1
6 класс
Упражнение 47, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 153, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 300, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Учебник, часть 1
Упражнение 88, Разумовская, Львова, Капинос, Учебник
Упражнение 130, Разумовская, Львова, Капинос, Учебник
Упражнение 48, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Упражнение 50, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Упражнение 52, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Упражнение 261, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
Упражнение 269, Александрова, Рыбченкова, Загоровская, Нарушевич, Учебник, часть 1
7 класс
Упражнение 219, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 224, Ладыженская, Баранов, Тростенцова, Григорян, Кулибаба, Александрова, Учебник
Упражнение 152, Разумовская, Львова, Капинос, Учебник
Упражнение 412, Разумовская, Львова, Капинос, Учебник
Упражнение 471, Разумовская, Львова, Капинос, Учебник
8 класс
Упражнение 16, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 117, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 222, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 232, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 235, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 330, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 363, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 378, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 387, Ладыженская, Тростенцова, Александрова, Дейкина, Учебник
Упражнение 33, Разумовская, Львова, Капинос, Учебник
Морфемный разбор слов — Русский язык
Морфемный словарь русского языка для сдачи огэ и егэ разбор слова по составу
Разобрать слово по составу или сделать его морфемный анализ означает указать, из каких морфем оно состоит. Под морфемой понимается минимально значимая часть слова.
Под морфемой понимается минимально значимая часть слова.
В русском языке существуют следующие морфемы:
- корень — самая главная часть слова, несущая его значение. У однокоренных слов — общий корень. Например, слова «лист», «листочек» и «листва» имеют общий корень —«лист». Бывают слова, которые состоят только из корня — «гриб», «метро», «остров». Бывает, что корня два — «теплоход», «водопад». Бывает, что корней три — не стоит пугаться — «водогрязелечебница». Повтори правило, которое касается соединительных гласных, чтобы не делать ошибки при их написании; суффикс — значимая часть слова. Расположена обычно после корня. Используется для образования новых слов. Например, в слове «чайник» «чай» — это корень, «ник» — это суффикс. Суффиксов в слове может не быть. Иногда суффиксов бывает два — например, в слове «подберезовик»; приставка — еще одна значимая часть слова. Расположена перед корнем. Назначение такое же, как и у суффикса — с ее помощью образовываются новые слова. В слове «подходит» «ход» — это корень, «под» — это приставка; Окончание — изменяемая часть слова.
 Для чего она нужна? Чтобы связывать слова в предложении; Основа — часть слова без окончания.
Для чего она нужна? Чтобы связывать слова в предложении; Основа — часть слова без окончания.Каждая часть слова имеет графическое обозначение. Посмотреть, как обозначаются части слова, можно в учебнике по русскому языку, в морфемном словаре или в Интернете.
Правила и исключения при разборе по составу
Разбор слова по составу онлайн несложен, если знать правила, по которым он делается. На начальном этапе можно пользоваться морфемно-орфографическим словарем — он поможет не делать ошибок.
Обязательно в слове должен присутствовать только корень — один или несколько. Слов без корня не бывает. Не бывает слов и без основы. А вот слова без суффиксов, приставок или окончаний очень даже бывают. Этому не стоит удивляться.
Часто бывает, что все слово представляет собой основу. Так бывает, например, у наречий. Они относятся к неизменяемым частям речи. Слово «быстро» не имеет окончания («о» в слове — это суффикс), а потому все слово будет основой.
В проведении морфемного анализа ученику поможет словообразовательный словарь Тихонова. Этот учебник содержит информацию о составе 100 тыс. слов русского языка. Словарем удобно пользоваться, и в период обучения в начальной школе он должен стать твоей настольной книгой.
Этот учебник содержит информацию о составе 100 тыс. слов русского языка. Словарем удобно пользоваться, и в период обучения в начальной школе он должен стать твоей настольной книгой.
Тем же, кто обладает навыками работы в сети Интернет, будут полезными ресурсы, на которых можно сделать морфемный разбор слова онлайн. Тренируйся, если занятий в школе на уроках русского языка тебе недостаточно.
Краткая шпаргалка (план) по морфемному разбору слов
Морфемный разбор состоит из следующих этапов:
Определяем к какой части речи относится слово. Для этого надо задать к нему вопрос. Возьмем для примера слово «поездка». Оно отвечает на вопрос «что?». Прежде всего надо найти в слове окончание. Для этого его нужно изменить несколько раз. Изменим его несколько раз — «перед поездкой», «в поездке». Видим, что изменяющаяся часть — «а». Это окончание. Разбор слова по составу продолжается определением корня. Подберем однокоренные слова — «поезд», «переезд». Сравним эти слова — не меняется часть «езд». Это и есть корень. Выясняем, какая в слове приставка. Для этого анализируем еще раз однокоренные слова — «поезд», «подъезд». Соответственно, в слове «поездка» приставка «по». Заключительный этап — это выяснение, где же в слове суффикс. Остается буква «к», которая стоит после корня и служит для образования слова. Это и есть суффикс. Обозначаем все части слова соответствующими символами.
Это и есть корень. Выясняем, какая в слове приставка. Для этого анализируем еще раз однокоренные слова — «поезд», «подъезд». Соответственно, в слове «поездка» приставка «по». Заключительный этап — это выяснение, где же в слове суффикс. Остается буква «к», которая стоит после корня и служит для образования слова. Это и есть суффикс. Обозначаем все части слова соответствующими символами.
Примеры морфемного разбора
Для примера ниже подобраны слова с наиболее интересными вариантами разбора по составу: кляузничать, поозорничать, срываться, денационализироваться, срядиться, скопиться, умыкаться, малодушествовать, сдаваться, сравниваться, для выполнения разбора других слов воспользуйтесь формой поиска.
Это и есть корень.
Wikislovo. ru
02.07.2020 15:21:34
2020-07-02 15:21:34
Источники:
Https://wikislovo. ru/morphemic
Морфемный разбор онлайн, разбор слов по составу, примеры » /> » /> .keyword { color: red; }
Морфемный словарь русского языка для сдачи огэ и егэ разбор слова по составу
Разбор слова по составу, или морфемный разбор, — выделение частей, из которых слово состоит. Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
Чтобы научиться делать разборы, необходимо обладать знаниями о частях слова и словообразовании, изучение которых входит в школьную программу. При затруднении с разбором прибегают к словарям морфемных разборов, печатным или электронным. Наш сайт содержит словарь морфемных разборов, включающий популярные в школьной программе слова и сложные слова из обихода. На сайте также содержится справочная информация: даются определения частей слов, объясняются способы словообразования, приводятся примеры.
В настоящий момент словарь содержит 100 000 морфемных разборов слов в начальной форме. Знания морфем начальной формы слова (инфинитив, единственное число, мужской род, именительный падеж) в большинстве случаев достаточно для определения морфем слова в разных склонениях, спряжениях, родах и числах.
План разбора
План разбора слова по составу состоит в следующем:
Определяем, к какой части речи относится анализируемое слово. Выделяем окончание и основу. Для определения окончания слово изменяют, например, по падежам. Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи. Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами. Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым. Обозначем части слова с помощью графических обозначений.
Изменяемая часть будет являться окончанием, остальная часть слова без окончания — основой. Следует помнить, что всё слово может являться основой и не иметь окончания, например наречие — неизменяемая часть речи. Определяем, входит ли в основу слова кроме корня также приставка и суффикс. Для этого слово сопоставляется с однокоренными словами. Убеждаемся, что выделенные приставки и суффиксы имеются в других словах. Для проверки подбираются аналогичные слова и сравниваются с анализируемым. Обозначем части слова с помощью графических обозначений.
Примеры разборов
Покажем примеры разбора слов разных частей речи с разной комбинацией морфем:
- метро — неизменяемое существительное, нет окончания лес — существительное с нулевым окончанием при школь н ый — прилагательное со всеми основными морфемами: приставкой, корнем, суффиксом, окончанием лед о кол — существительное с двумя корнями и соединительной гласной по зв а л а — глагол с приставкой, окончанием, словооразующим суффиксом а и формобращующим суффиксом л, который не входит в основу быстр о — наречие с суффиксом, не имеет окончания
Подберите нужные слова с необходимыми частями слова через поиск слов по морфемам.
Особенности разборов
Обратите внимание: морфемные разборы одних и тех же слов могут быть сделаны по-разному в разных словарях, разными учителями и филологами, в школе и в университете. Каждый «источник» аргументирует разбор по-своему и считает свой разбор правильным.
Разные учителя придерживаются разных программ определения морфем в словах. Ярким примером служат инфинитивы глаголов. Например в слове жить: в одних школах ть отмечается как суффикс, в других — как окончание, в третьих — как суффикс с последующим нулевым окончанием. Мы выделяем морфемы по первому варианту.
Образовательные программы школы и университета в части разбора слов могут различаться. В университетах учитывают этимологию слов, выделяют нулевой суффикс (Азов, бег), рассматривают словообразования от нулевого корня и другие сложные примеры. Мы используем программу, ориентированную на школу, и деление на морфемы по словарю А. Н. Тихонова.
Заметим, что есть различия в словаре А. Н. Тихонова и словаре Т. Ф. Ефремовой. Так А. Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т. Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
Ф. Ефремовой. Так А. Н. Тихонов части некоторых слов «вносит» в один корень, при этом Т. Ф. Ефремова выделяет в словах приставку, суффиксы, учитывая этимологию. Примеры таких слов: благодарность, превосходство, прекрасный. Современные учёные не могут сойтись во мнении единого верного разбора отдельных слов русского языка, поэтому разные варианты считают допустимыми.
При разборе слов следует помнить, что бывают слова, содержащие нулевое окончание (автобус), не имеющие окончания (ателье), имеющие несколько корней (авиапочта) и другие сложные варианты. К сложным вариантам на нашем сайте даны объяснения.
Морфемные словари
Среди печатных изданий словарей морфемных разборов, которые вы найдете в школьной библиотеке, можно выделить следующие:
- Рацибурская Л. В. Словарь уникальных морфем современного русского языка М.: Флинта: Наука, 2009. — 160 с. Аванесов Р. И., Ожегов С. И. Морфемно-орфографический словарь Около 100 000 слов / А. Н. Тихонов. — М.: АСТ: Астрель, 2002.
 — 704 с. Тихонов А. Н. Морфемно-орфографический словарь русского языка, 2002. Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с.
— 704 с. Тихонов А. Н. Морфемно-орфографический словарь русского языка, 2002. Кузнецова А. И., Ефремова Т. Ф. Словарь морфем русского языка Ок. 52000 слов. — М.: Рус. яз., 1986. — 1132 с.В словарях морфемных разборов обычно деление на морфемы делается с помощью слешей: под/вод/н/ый, гор/а и т. д. В словаре Т. Ф. Ефремовой у группы слов с одинаковым корнем исходное слово записано полностью, а в образованных от него словах корневая морфема обозначается через знак V: лес, V-а, V-н-ой и т. д.
Лед о кол существительное с двумя корнями и соединительной гласной.
Morphemeonline. ru
28.09.2018 11:50:14
2018-09-28 11:50:14
Источники:
Https://morphemeonline. ru/
ЯЗЫК — разбор слова по составу (морфемный разбор) » /> » /> .keyword { color: red; }
Морфемный словарь русского языка для сдачи огэ и егэ разбор слова по составу
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова Вручаться:
Ассоциации к слову «язык»
Синонимы к слову «язык»
Предложения со словом «язык»
- Опыт экзаменационного испытания за 9 класс ярко показывает, что для сдачи экзаменапо русскому Языку русская классическая литература не нужна.
Цитаты из русской классики со словом «язык»
- В классе российской словесности, у того же самого Ибрагимова, успехи мои были так же блестящи; здесь преподавался синтаксис русского Языка и производились практические упражнения, состоявшие из писанья под диктовку и из переложения стихов в прозу.
Сочетаемость слова «язык»
Каким бывает «язык»
Значение слова «язык»
ЯЗЫ́К, — а́, М. 1. Орган в полости рта в виде мышечного выроста у позвоночных животных и человека, способствующий пережевыванию и глотанию пищи, определяющий ее вкусовые свойства. (Малый академический словарь, МАС)
(Малый академический словарь, МАС)
Афоризмы русских писателей со словом «язык»
- не даёт правил языку, но извлекает правила из языка…
Отправить комментарий
Дополнительно
Значение слова «язык»
ЯЗЫ́К, — а́, М. 1. Орган в полости рта в виде мышечного выроста у позвоночных животных и человека, способствующий пережевыванию и глотанию пищи, определяющий ее вкусовые свойства.
Предложения со словом «язык»
Опыт экзаменационного испытания за 9 класс ярко показывает, что для сдачи экзаменапо русскому Языку русская классическая литература не нужна.
ВРЕМЕНА – так в русскоязычных учебных материалах по изучению английского Языка называют английский термин TENSES.
Надо сказать, что в ту пору мои знания иностранных Языков ограничивались немецким со словарём, а также полузабытыми навыками грузинской письменности.
Ассоциации к слову «язык»
- Опыт экзаменационного испытания за 9 класс ярко показывает, что для сдачи экзаменапо русскому Языку русская классическая литература не нужна.

- В классе российской словесности, у того же самого Ибрагимова, успехи мои были так же блестящи; здесь преподавался синтаксис русского Языка и производились практические упражнения, состоявшие из писанья под диктовку и из переложения стихов в прозу.
ВРЕМЕНА так в русскоязычных учебных материалах по изучению английского языка называют английский термин TENSES.
Kartaslov. ru
05.12.2020 8:18:54
2020-12-05 08:18:54
Источники:
Https://kartaslov. ru/%D1%80%D0%B0%D0%B7%D0%B1%D0%BE%D1%80-%D1%81%D0%BB%D0%BE%D0%B2%D0%B0-%D0%BF%D0%BE-%D1%81%D0%BE%D1%81%D1%82%D0%B0%D0%B2%D1%83/%D1%8F%D0%B7%D1%8B%D0%BA
5 класс. Русский язык. Способы словообразования — Состав слова.
Комментарии преподавателя1. Морфемика – это раздел языкознания, в котором изучается система морфем языка и морфемная структура слов.
Морфема – это минимальная значимая часть слова.
Морфемы: корень, суффикс, приставка, окончание.
Рис. 1. Морфемы.
2.Корень – это обязательная часть слова.
Только из корня состоят служебные слова (но, для, если), междометия (ах, алло), многие наречия (очень, весьма), неизменяемые существительные (алоэ, кенгуру) и прилагательные (беж, макси).
Корни, которые могут употребляться только в сочетании с приставками или суффиксами, называются связанными (об-у-ть, раз-у-ть; о-де-ть, раз-де-ть).
3.Приставка — словообразовательная морфема, стоящая перед корнем или другой приставкой (пере-делать, пре-хорошенький, при-морье, кое-где, пере—о-деть).
Рис.2. Приставка.
4.Суффикс — словообразовательная морфема, стоящая после корня (стол-ик, красн-е-ть).
Рис. 3. Суффикс.
В лингвистике наряду с суффиксом выделяют также постфикс — словообразовательную морфему, стоящую после окончания или формообразующего суффикса (умы-ть-ся, к-ого-либо).
5.Окончание — формообразующая морфема, выражающая грамматические значения рода, лица, числа и падежа (хотя бы одно из них!) и служащая для связи слов в словосочетании и предложении,
Окончание есть только у изменяемых слов. Нет окончаний у служебных слов, наречий, неизменяемых существительных и прилагательных, деепричастий, инфинитива.
У некоторых сложных существительных и числительных несколько окончаний.
Сравните: тр-и-ст-а, тр-ех-сот-□, диван□-кровать□, диван-а-кроват-и.
Нулевая морфема – это значимое отсутствие морфемы.
Стола – Р.п.
Стол□ – И.п. или В.п.
Нулевой суффикс мы выделяем, например, в форме прошедшего времени нёс (сравните: нес-л-а) или форме повелительного наклонения читай.
План морфемного разбора слова:
1. Выделяем окончание и основу слова.
2. Выделяем корень слова, подбирая однокоренные слова.
3. Выделяем приставки и суффиксы.
Образец морфемного разбора:
Двухэтажный (окончания –ух, -ый, основа … (такая основа называется прерывистой), корни дв-, этаж-, суффикс –н-).
Переулок (окончание нулевое, основа переулок, корень –ул-, приставка пере-, суффикс –ок).
Словообразование – это процесс образования производных слов и раздел языкознания, изучающий этот процесс.
Способы словообразования:
Приставочный: делать – переделать
Суффиксальный: синий – синенький
Приставочно-суффиксальный: стакан – подстаканник
Усечение: заместитель – зам
Сложение: лес+степь – лесостепь
Сращение: вечнозеленый
Аббревиация: Московский государственный университет – МГУ, сберегательный банк – сбербанк
Субстантивация (переход прилагательного или причастия в существительное): столовая
Смешанные способы словообразования: орден+носить = орденоносец (сложение и суффиксация)
План словообразовательного разбора слова:
1. Поставить слово в начальную форму.
Поставить слово в начальную форму.
2. Определить слово, от которого оно образовано. Например, обновление – обновить (а не новый).
3. Объяснить значение исследуемого слова через значение слова, от которого оно образовано (например, слушатель – тот, кто слушает).
4. Выделить основу, от которой образовано исследуемое слово.
5. Указать средство словообразования.
6. Указать способ словообразования.
Образец словообразовательного разбора:
1. Под-окон-ник – окно
Основа окн-
Средства словообразования: приставка под- и суффикс –ник. Способ словообразования: приставочно-суффиксальный
2. Мир(о)твор-ец – мир+творить
Основы, от которых образовано слово, — мир- и твор-
Средства словообразования: сложение основ и суффикс –ец.
Способ словообразования: сложение и суффиксация
10.Домашнее задание
Упражнения №
Задание №1. Даны слова: петь, учить, одеть, знал, столик, верхом, рано, волчонок, новее, ворча. Для каких слов из перечисленных годится следующий морфемный разбор:?
Даны слова: петь, учить, одеть, знал, столик, верхом, рано, волчонок, новее, ворча. Для каких слов из перечисленных годится следующий морфемный разбор:?
Задание №2. Даны слова: обучить, приходила, узнали, подоконник, треугольник, встряска, настольный, излишне, снова. Для каких слов из перечисленных годится следующий морфемный разбор:
ИСТОЧНИКИ
http://www.youtube.com/watch?v=AeX6EALboR8
http://doc4web.ru/russkiy-yazik/konspekt-uroka-dlya-klassa-sostav-slova-i-slovoobrazovanie.html
http://nsportal.ru/shkola/russkiy-yazyk/library/2014/10/28/konspekt-uroka-sostav-slova-5-klass
http://nsportal.ru/shkola/russkiy-yazyk/library/2012/12/01/konspekt-uroka-russkogo-yazyka-v-5-klasse-po-temezakreplenie
это что? Что такое морфемный разбор?
Наверняка каждый школьник сталкивался с таким определением, как морфема. Это понятие довольно тесно связано с составом слова, и его знание помогает выполнить морфемный анализ. Давайте поговорим о том, что это такое. Разберемся также и с тем, что такое морфемный разбор.
Это понятие довольно тесно связано с составом слова, и его знание помогает выполнить морфемный анализ. Давайте поговорим о том, что это такое. Разберемся также и с тем, что такое морфемный разбор.
Что такое морфема?
Морфема – это наименьшая значимая часть слова. Впервые термин был введен известным ученым Бадуэном де Куртенэ еще в середине XIX века и используется в лингвистике до сих пор.
Все слова состоят из морфем. Они — кирпичики, из которых составляются слова. Каждая составляющая имеет имеет свое значение и роль. Выделяют следующие типы морфем: обязательные и необязательные. Обязательная всегда присутствует в слове и называется корнем. Необязательные могут как входить в состав лексемы, так и не входить в него. Эти морфемы называются аффиксами. Давайте рассмотрим каждый вид в отдельности.
Обязательные морфемы
Как уже упоминалось, обязательная морфема в русском языке всего одна, и она называется корнем. Нет такого слова, которое бы существовало без данной морфемы. Слова без корня (исключение — некоторые служебные части речи) отсутствуют в русском языке.
Слова без корня (исключение — некоторые служебные части речи) отсутствуют в русском языке.
Она главная, так как несет основное лексического значение. К примеру, лексема лес, лесной, лесник объединяет один корень — лес. Все эти слова имеют схожее значение, связанное с лесом. Единственное — их различие в оттенках. Так, лес – пространство, покрытое деревьями; лесной – относящийся к лесу; лесник – человек, который сторожит его.
В сложных словах есть несколько корней, к примеру, в слове светлоликий два корня – свет и лик. Не забывайте об этом при разборе слова. В основном сложные слова имеют два корня, в некоторых случаях могут встречаться слова с большим набором.
Необязательные морфемы
Необязательные морфемы русского языка — аффиксы. Среди них выделяют следующие:
- префиксы, или приставки;
- постфиксы, или суффиксы;
- флексии, или окончания;
- интерфиксы.
Они могут присутствовать в слове или же нет. При этом каждая новая необязательная морфема придает ему новое значение.
При этом каждая новая необязательная морфема придает ему новое значение.
Первые два вида морфем передают лексическое и грамматическое значение. Флексии же выражают только грамматическое значение слова. Даже нулевое, то есть не имеющее звукового выражения, окончание показывает, какое грамматическое значение имеет лексема.
Префиксы и постфиксы
Разберем для начала те морфемы, которые придают новые лексические и грамматические оттенки.
Префиксы всегда располагаются в начале слова и изменяют его значение. В русском языке насчитывается около 70 префиксов. Большинство их образовано от предлогов. В школе зачастую их называют приставками. Каждая приставка имеет свое значение и меняет оттенок слова. К примеру, ехать – двигаться куда-то; подъехать – приблизиться к чему-либо.
При этом меняется лексическое значение слова, но часть речи, к которой оно принадлежит, остается неизменной.
Постфиксы всегда располагаются между корнем и флексией (если она есть в слове). Они служат не только для образования нового значения, но и для того, чтобы образовать новую часть речи. Так, с помощью суффикса -н- от существительного лес обрадовалось прилагательное лесной.
Они служат не только для образования нового значения, но и для того, чтобы образовать новую часть речи. Так, с помощью суффикса -н- от существительного лес обрадовалось прилагательное лесной.
Некоторые суффиксы образовывают новый оттенок значения. Так, есть уменьшительно-ласкательные суффиксы, такие как: -ушк-, -чик-, -очк- и другие. С помощью них образуются лексемы с новым оттенком значения. Например: ухо – ушко, палец – пальчик, корзина – корзиночка.
В слове может быть несколько приставок и суффиксов. Все зависит от строения лексемы, ее значения. Поэтому, делая разбор по морфемам слова, следует обратить на это особое внимание.
Интерфиксы
Данные морфемы служат для связи нескольких корней в сложных словах. К примеру, слово лоботряс состоит из двух слов — лоб и тряс. Они связаны между собой интерфиксом –о-. Интерфиксы не всегда изучаются в школе, зачастую о них говорят лишь в старших классах, и то мельком.
Основа слова
Узнав, что морфема — это значима часть лексемы, следует вспомнить и еще об одной немаловажной части – основе. Это неизменяемая часть слова, то есть его часть без окончания. Основа заключает в себе основное лексическое значение и может состоять из одного лишь корня или корня и аффикса (аффиксов). В глаголах основа может прерываться окончанием, если есть постфикс –ся или -сь. Например, в слове покупалась основа будет прерываться окончанием и выглядеть как покупал-а-сь.
Флексии
Данные морфемы употребляются для того, чтобы выразить грамматическое значение. В школьной программе они носят название окончаний. С их помощью определяется грамматическое значение. Для существительных это род, число, падеж. Флексии присутствуют во всех частях речи, исключая неизменяемые, такие как наречие, союз, предлог. В этих частях речи они не выделяются. Во всех остальных частях речи при отсутствии окончания оно принимается за нулевое.
К примеру, в слове лес окончание будет нулевым, в слове леса окончание будет –а. При этом окончание данного слова будет выражать то, что данное существительное относится к множественному числу и находится в именительном падеже.
Морфемный разбор слова
Итак, мы выяснили, что морфема — это наименьшая значимая часть лексемы. Теперь поговорим о морфемном разборе. Для того чтобы правильно сделать морфемный разбор, необходимо придерживаться следующих правил.
1. Сначала анализируемую лексему выписываем из предложения или текста в том виде, в котором она там присутствует.
2. Определяем часть речи и то, изменяемая ли она. Если да, переходим к пункту 3, если нет — к пункту 4.
3. Находим окончание. Для этого склоняем по родам или падежам, числам. Изменяемая часть и будет окончанием.
4. Выделяем основу. Основа — это все слово без окончания.
5. Находим корень. Для этого подбираем однокоренные слова из разных частей слова.
6. Выделяем приставку, которая стоит перед корнем .
7. Выделяем суффиксы. Для этого подбираем слова со схожими суффиксами, но разными корнями. Помните, что некоторые слова могут иметь несколько приставок и суффиксов. К примеру, слово пренеприятный имеет две приставки: пре-не-приятный. А в слове мечтательница три суффикса: мечт-а-тель-ница.
Вот и весь разбор по составу.
Пример морфемного разбора
Давайте разберем одно слово, чтобы вы увидели принцип морфемного разбора и запомнили последовательность действий. Возьмем для при мера предложение: «Давно не видел старика».
1. Выписали слово «старика».
2. Просклоняли: старик, старику – существительное, изменяемое.
3. Просклоняли еще раз: старик, старику, стариками, окончание слова старика – а.
4. Отбрасываем окончание. Основа — старик.
5. Подбираем однокоренные лексемы: старость, стареть – корень стар.
6. У нас нет ничего перед корнем, значит, приставки в слове нет.
7. Подбираем слова с суффиксом -ик-, если они есть. Мужик, носик – суффикс – ик.
Как видите, ничего сложного в разборе слова нет. Главное, строго следовать алгоритму, чтобы не сбиться и правильно все определить, а также понимать, что такое морфема. Примеры с различными морфемами следует также научиться правильно подбирать.
Если же вы сомневаетесь в правильности разбора, вы всегда можете найти морфемный словарь русского языка и посмотреть в нем, из каких морфем состоит то или иное слово, как именно оно образовано. Вы можете воспользоваться словарями под редакцией Потихи З. А. или Тихонова А. Н.
Итак, мы узнали, что морфема – это наименьшая значимая часть слова, определили, какие бывают морфемы, поговорили о каждой из них. Также выяснили, как правильно делать морфемный разбор слова и рассмотрели пример этого разбора. Вспомнили о словарях, которые помогут вам проверить правильность разбора слова. Надеемся, статья была вам полезна.
Надеемся, статья была вам полезна.
Эти непослушные суффиксы: сложные вопросы морфемного анализа
Крылова Мария Николаевна
Азово-Черноморская государственная агроинженерная академия
кандидат филологических наук, доцент кафедры профессиональной педагогики и иностранных языков
Аннотация
Статья посвящена обзору сложных вопросов морфемного анализа, связанных с выделением в слове суффиксов. Рассматриваются способы выделения суффикса, нулевые суффиксы, варианты суффикса, нерегулярные суффиксы, статус финали -ть (-ти) в инфинитиве, суффиксоиды, постфиксы и интерфиксы, а также процессы аппликации и опрощения, связанные с суффиксами. Делается вывод о необходимости творческого, исследовательского подхода к морфемному анализу.
Ключевые слова: аппликация, варианты суффикса, интерфиксы, морфемный анализ, нерегулярные суффиксы, нулевые суффиксы, опрощение, постфиксы, статус финали -ть (-ти) в инфинитиве, суффиксоиды, суффиксы
Krylova Maria Nikolaevna
Azov-Black Sea State Agroengineering Academy
PhD in Philological Science, Assistant Professor of the Professional Pedagogy and Foreign Languages Department
Abstract
The article is devoted to the review of difficult questions of morphemic analysis associated with the allocation of suffixes in the word. This article discusses ways allocation a zero suffixes, variants of suffixes, irregular suffixes, status -ть (-ти) in the infinitive, suffixoides, postfixes and interfixes and processes of simplification and applications associated with the suffixes. The conclusion about necessity a creative, research approach to the morphemic analysis.
This article discusses ways allocation a zero suffixes, variants of suffixes, irregular suffixes, status -ть (-ти) in the infinitive, suffixoides, postfixes and interfixes and processes of simplification and applications associated with the suffixes. The conclusion about necessity a creative, research approach to the morphemic analysis.
Библиографическая ссылка на статью:
Крылова М.Н. Эти непослушные суффиксы: сложные вопросы морфемного анализа // Гуманитарные научные исследования. 2013. № 7 [Электронный ресурс]. URL: https://human.snauka.ru/2013/07/3605 (дата обращения: 02.06.2022).
Морфемный анализ, или разбор слова по составу является сложным для многих учеников средней школы, для студентов-филологов и даже для учителей. Как отмечает Н.А. Исаева, «на сегодняшний день существуют реальные проблемы профессионально-методической готовности студентов-бакалавров и учителей в области анализа и интерпретации морфемно-словообразовательных понятий, представленных в школьных учебниках, а, соответственно, и формализм в обучении школьников этим важным, системообразующим понятиям, составляющим базу для развития разных метапредметных умений» [1, с. 123].
123].
Вопросы морфемного анализа и обучения ему рассматривались М.Т. Барановым, Е.А. Земской, Н.А. Исаевой, М.Р. Львовым, Т.Г. Рамзаевой, А.В. Текучевым, Н.М. Шанским и другими учёными и методистами, однако по-прежнему остаются трудно решаемые в силу наличия различных толкований тех или иных явлений языка проблемы.
Особенно непросто бывает выделить в слове суффикс (суффиксы), отграничить его от других морфем. Связано это, прежде всего, с тем, что выделить суффикс можно только при умении вычленять в слове окончание и корень.
Морфема – наименьшая значимая единица языка. По роли в слове морфемы делятся на: корневые, или корни – основные морфемы и аффиксальные, или аффиксы – дополнительные (от лат. affixus – ‘прикреплённый’).Виды аффиксов: префикс (приставка), суффикс, интерфикс, постфикс. В других языках есть ещё такие аффиксы, как конфикс, инфикс, трансфикс и т. п.
Суффикс – служебная морфема (аффикс), которая располагается после корня и служит для образования слов и их несинтаксических форм.
По функции аффиксы делятся на словообразующие – выражают лексическое значение, образуют разные слова и являются менее регулярными, менее стандартными, например, без-дом-н-ый, и формообразующие – обладают высочайшей степенью регулярности и стандартности, обладают грамматическим значением, образуют грамматические формы, например, на-пис-а-нн—ая. Окончание всегда является формообразующим аффиксом, суффиксы могут быть и слово- и формообразующими. Информация о формообразующих суффиксах поступает к учащимся постепенно при изучении морфологии, и старшеклассники должны уже хорошо ориентироваться в формообразовании и знать все формообразующие суффиксы русского языка:
1. Суффиксы степеней сравнения прилагательных и наречий: -ее, -ей, -е, -ше, -ейш-, -айш-, -ейше, -айше. Например: добр-ее (добр-ей), тонь-ше, выш-е, добр-ейш-ий, тонч-айш-ий, глубоч-айше, покорн-ейше.
2. Суффиксы причастий и деепричастий: -ущ-, (-ющ-), -ащ- (-ящ-), -вш- (-ш-), – енн-, -нн-, -т-, ом-, -ем-, -им-, -в, -вши, – а, -я. Например: бег-ущ-ий, гон-им-ый, уста-вш-ий, обиж-енн-ый, обиде-в, разбира-я.
3. Суффикс прошедшего времени —л-, при помощи которого форма прошедшего времени образуется от основы инфинитива: обиде-л, нес (нулевой).
4. Суффикс повелительного наклонения —и-, при помощи которого форма повелительного наклонения образуется от основы настоящего (будущего простого) времени. Например: выбер-и, нес-и-те, брось и стирай (нулевой).
5. Суффиксы существительных, при помощи которых образуются:
а) формы множественного числа и косвенных падежей (синтаксические формы): -ес-, -ер-, -ен-, —j— , -ят-, -овj—. Например: чуд-ес-а, мат-ер-и, плем-ен-а, брать-j-я, кот-ят-а, сын-овьj-я;
Например: чуд-ес-а, мат-ер-и, плем-ен-а, брать-j-я, кот-ят-а, сын-овьj-я;
б) форма единственного числа: —ин-. Например: граждан-ин.
6. Суффикс настоящего (будущего простого) времени глагола в изъявительном наклонении: —j-. Например: чита-j-ю, прочита-j-ешь. Вопрос об этом суффиксе спорный, его выделяют не все ученые.
Морфемный анализ – это выделение всех морфем в слове. Производя его, нужно помнить, что «подлинно научный анализ структуры слова, а не механическое деление слова на морфемы (иногда не существующие) возможен только в том случае, когда слово рассматривается, во-первых, на фоне родственных и одноструктурных ему в данный момент слов, а во-вторых, в совокупности всех присущих ему в грамматических форм. Это является основным принципом словообразовательного анализа (как и морфемного)» [2, с. 9].
Это является основным принципом словообразовательного анализа (как и морфемного)» [2, с. 9].
Описать все трудные вопросы морфемного анализа в рамках статьи невозможно. Рассмотрим наиболее сложные проблемы морфемного анализа конца слова. Информацию мы представим в вопросно-ответной форме, которая должна облегчить восприятие.
Есть ли специальные способы выделения суффикса?
Прежде чем выделять суффикс или суффиксы, нужно провести подготовительную работу: определить, какой частью речи является слово, так как у каждой части речи свой набор суффиксов; выделить корень (по возможности) и окончание (обязательно). И только после это применять указанные ниже способы, причём желательно не какой-то один, а все вместе:
1. Соотнесение слова с однокоренными словами и грамматическими формами слова. Например, соотнеся слово лисий со словами лиса и лись-j-я и вспомнив о беглых гласных, мы без труда выделим в нём суффикс —ий.
2. Сопоставление слова со словами такого же состава, того же словообразовательного типа. Ведь соотносим же мы слово с однокоренными словами, чтобы выделить корень, почему бы не соотнести его с «односуффиксными» словами, чтобы выделить суффикс. Например, рад-ость, слад-ость, пошл-ость и под.
3. Принцип «матрёшки» (термин Н.М. Шанского) необходим, когда в слове несколько суффиксов. Их выделяют с помощью анализа формы и словообразовательного анализа, пошагового «раздевания» слова. Например, словообразовательные суффиксы в слове водянистость станут явными после выстраивания словообразовательной цепочки: вода → вод-ян-ой → водян-ист-ый → водянист-ость. В слове вчитывавшаяся мы сначала, проанализировав грамматическую форму, выделим формообразовательный постфикс —ся, окончание —ая— и формообразовательный суффикс причастия —вш-, а затем выделим глагольный суффикс —ыва-.
В любом случае, решая вопрос о морфемном составе того или иного слова, нужно одновременного произвести анализ словоформы (вычленить окончание и формообразующие суффиксы) и словообразовательный анализ. Как пишет Н.А. Исаева, «словообразовательный анализ должен идти не после морфемного, а предшествовать ему и на определённых этапах органически “вплетаться” в ткань морфемного разбора – это простой и понятный закон грамотного анализа структуры слова» [1, с. 129].
Иначе ошибки неизбежны.
Включать ли формообразующие суффиксы в основу?
Сложности появляются при выделении основы слова, так как формообразующие аффиксы в основу не входят, а словообразующие входят. Мы же привыкли не включать в основу окончание, а формообразующие суффиксы забываем отсечь от основы. Думается, что истина где-то посередине: ученикам младших классов не стоит объяснять, что в основу могут не входить ещё и некоторые суффиксы, а начиная с 5-го класса нужно постепенно вводить эту новую информацию, что поможет освоению морфологии русского языка, способов словоизменения.
Нужно ли выделять нулевые суффиксы?
Чтобы решить для себя этот вопрос, нужно сначала такой суффикс в слове обнаружить. О том, что нулевыми (материально не выраженными) могут быть окончания, знают все. Примеры: дом□, семей□, лисий□, развлечений□, стой□. Выделять нулевое окончание пустым квадратом является обязательным, его невыделение – серьёзная ошибка. Иначе обстоит дело с нулевыми суффиксами, так как многие вообще не знают об их существовании.
Нулевыми могут быть два формообразующих суффикса: 1) суффикс прошедшего времени -л- в мужском роде у некоторых глаголов, например, умер-Æ, нес-Æ; сравните: умер-л-а, несли; 2) суффикс повелительного наклонения -и-, например, брось-Æ; сравните: нес-и. После нулевого формообразующего суффикса обязательно стоит нулевое окончание.
Нулевой суффикс прошедшего времени глагола и нулевое окончание после него возникли в результате утраты слабых редуцированных и отпадания -л- после согласных в конце слова (сравните древнерусское высох-л-ъ).
Кроме того, нулевой суффикс появляется в результате нулевой суффиксации, в этом случае он является словообразующим, и после него может быть не только нулевое, но и материально выраженное окончание. Например, переход-Æ ¬ переходить, синь-Æ ¬ синий, заик-Æ-а- ¬ заикаться, пят-Æ-ый ¬ пять, физик-Æ ¬ физика и под. Как считает Т.Ю. Гаврилкина, словообразовательные типы с нулевыми суффиксами в современном языке обладают высоким деривационным потенциалом [3].
В практике преподавания русского языка нулевые суффиксы не принято выделять, для них нет специального значка. Вводить его или нет (один из вариантов приведён выше) – вопрос сложный, большинство педагогов скажут, что не стоит. Тем не менее, понятие о нулевом суффиксе надо ввести, показав его существование сопоставлением ряда словоформ. По мнению Н.А. Исаевой, понятие нулевого суффикса ввести в понятийный аппарат учащихся необходимо: «Хотя оно не является обязательным в школьном преподавании, по характеру своего значения и по соотношению с другими словами вполне вписывается в группу «нулей», изучаемых в школе, – нулевого окончания и нулевой связки» [1, с. 126].
126].
Как не назвать варианты суффикса разными суффиксами?
Морфемы реализуются в речи в морфах, или алломорфах. Часть суффиксов не имеют морфов: -тель, -ость, -нича-. Например: учи-тель, зл-ость, сопер-нича-ть. С ними нет сложностей.
Но чаще всего в зависимости от позиции в слове один и тот же суффикс может иметь несколько вариантов с различным звучанием и написанием:
—к— и —ок-: памят-к-а – памят-ок,
—ец— и —ц-: сыр-ец – сыр-ц-а,
—н— и —ен— в краткой форме прилагательных: памят-ен – памят-н-а,
—ова— и —уj— в формах глагола: пир-ова-л, пир-уj-ю,
—j(а) и —ий : прыгунь-j-я – прыгун-ий.
Если суффиксы изменяются при образовании форм слов, то это варианты одного и того же суффикса, а не разные суффиксы. Их изменения связаны с фонетическими процессами, произошедшими в языке, с множеством существующих в языке чередований. Сопоставление словоформ и знание возможных чередований поможет нам понять, что варианты – это различные формы одного и того же суффикса: любим-ец – любим-ч-ик, сын-ок – сын-оч-ек, собачь-j-я, собач-ий.
Суффиксом или окончанием является —ть (-ти) в неопределённой форме глагола?
Несомненно, финаль —ть (-ти) – это формообразующий суффикс, так как он образует форму инфинитива: чита-ть, вез-ти. Инфинитив (неопределённая форма глагола) – это неизменяемая форма, поэтому окончания у неё просто не может быть, ведь окончание – это изменяемая часть слова. Отсечением —ть (-ти) мы получаем основу инфинитива, от которой образуются многие глагольные формы: строи-ть – строи-л, строи-вш-ий.
Отсечением —ть (-ти) мы получаем основу инфинитива, от которой образуются многие глагольные формы: строи-ть – строи-л, строи-вш-ий.
В школьном учебнике по традиции —ть (-ти) выделяется как окончания. В новых пособиях есть двоякий вариант, когда —ть (-ти) выделяется и как окончание, и как суффикс. По-видимому, самым разумным решением для педагога будет учить выделять данную морфему так, как рекомендовано в учебнике, объяснив при этом её природу. Учащиеся должны знать, что это формообразующий суффикс.
А вот —чь в конце инфинитива вообще не является отдельной морфемой, входит в корень. Сравните: пек-у, печ-ёшь, печь.
Нужно ли выделять суффиксы, не обозначенные отдельной буквой?
Этот вопрос можно решить по-разному. Например, слово строю орфографичеки делится на две морфемы (стро-ю), а фонетически (то есть на самом деле) – на три (стро-j-ю), —j— является суффиксом. Нужно ли его выделять? Несомненно, нужно, так как, во-первых, он есть в слове, во-вторых, в повелительном наклонении глагола он будет выражен буквой й (стро-й), и его выделение позволит нам соотнести друг с другом формы глагола, образованные от одной основы – основы настоящего времени, в-третьих, совершенно невредным будет повторение графики и тех позиций, в которых буква ю обозначает два звука. Систематическая работа в данном направлении будет способствовать тому, что учащиеся легко будут находить в слове «спрятанный» суффикс. Кстати, скрытым может быть не только весь суффикс, но и его часть, например, —j— в суффиксах -ениj— -ниj— (повторение, желание).
Например, слово строю орфографичеки делится на две морфемы (стро-ю), а фонетически (то есть на самом деле) – на три (стро-j-ю), —j— является суффиксом. Нужно ли его выделять? Несомненно, нужно, так как, во-первых, он есть в слове, во-вторых, в повелительном наклонении глагола он будет выражен буквой й (стро-й), и его выделение позволит нам соотнести друг с другом формы глагола, образованные от одной основы – основы настоящего времени, в-третьих, совершенно невредным будет повторение графики и тех позиций, в которых буква ю обозначает два звука. Систематическая работа в данном направлении будет способствовать тому, что учащиеся легко будут находить в слове «спрятанный» суффикс. Кстати, скрытым может быть не только весь суффикс, но и его часть, например, —j— в суффиксах -ениj— -ниj— (повторение, желание). В этом случае не заметить —j— не так уж страшно, ведь морфема всё равно будет выделена, пусть и в усечённом виде, но всё же лучше «заметить» скрытую часть суффикса, тогда проще будет объяснить, почему в словах желаний, стараний, сомнений и под. —ий – это не окончание.
В этом случае не заметить —j— не так уж страшно, ведь морфема всё равно будет выделена, пусть и в усечённом виде, но всё же лучше «заметить» скрытую часть суффикса, тогда проще будет объяснить, почему в словах желаний, стараний, сомнений и под. —ий – это не окончание.
Как найти в слове нерегулярный суффикс?
Регулярные суффиксы встречаются в составе слов часто, например, —ик-: стол-ик, дом-ик, столб-ик и т. д. Самые регулярные морфемы – окончания и формообразующие суффиксы: ламп-а, бег-ущ-ий. Нерегулярные (уникальные, редкие) суффиксы в составе слова встречаются нечасто. Например: паст-ух, мал-ютк-а. Некоторые суффиксы наблюдаются всего в одном слове. По определению Е.А. Земской, «части слова, подобные суффиксам и приставкам по своей роли в составе слова, но единичные, не повторяющиеся, называются унификсами» [4, с. 152]. Например: попадь-j-я, почт-амт, стекл-ярус, патрон-таш, куст-арник, коз-ёл, пролетар-ий. При морфемном анализе таких слов невозможно соотнести слово с другими словами того же словообразовательного типа, но можно соотнести с однокоренными словами и выделить суффикс на основе данного сопоставления, например: стекл-о – стекл-ярус.
152]. Например: попадь-j-я, почт-амт, стекл-ярус, патрон-таш, куст-арник, коз-ёл, пролетар-ий. При морфемном анализе таких слов невозможно соотнести слово с другими словами того же словообразовательного типа, но можно соотнести с однокоренными словами и выделить суффикс на основе данного сопоставления, например: стекл-о – стекл-ярус.
Выделять ли суффикс, сросшийся с корнем?
Язык постоянно развивается, одним из процессов его развития является опрощение – потеря словом членимости на морфемы. В частности, суффикс может срастись с предыдущей морфемой, обычно корнем, например: петух, жизнь, дар, пир (сравните пе-ть, жи-ть, да-ть, пи-ть). По словам Е.А. Земской, «чаще всего это связано с изменением значения слова, которое обычно приводит к забвению его состава» [4, с. 148].
148].
Так как при морфемном анализе мы выделяем в слове те морфемы, которые существуют в нём на данном этапе развития языка, то такие «бывшие» суффиксы выделять, конечно, не надо. Н.А. Исаева пишет: «Необходимо чётко разграничивать при изучении морфемного состава слова в школе факты синхронии и диахронии и рассматривать явления словообразовательной системы только на синхронном срезе» [1, с. 124]. Но не следует забывать, что есть ещё и этимологический анализ, производя который и надо рассмотреть суффиксы, слившиеся с корнем и переставшие быть суффиксами.
Как выделять суффиксоиды?
Аффиксоиды – это корневые морфемы, выступающие в функции аффиксов. Они делятся на префиксоиды (полу-) и суффиксоиды (-вед, -вод и др.). Суффиксоиды обладают высокой степенью стандартности, подобно суффиксам, например: стекло-вар, языко-вед, цвето-вод, лесо-воз, вино-дел, земле-коп, теле-граф, паро-образ-н-ый. Выполняя роль суффиксов, суффиксоиды вместе с тем не перестали осознаваться как корневые морфемы, они находятся на пути перехода из корней в суффиксы, демонстрируя тем самым один из примеров живого развития, изменения языка. По словам Н.М. Шанского, «аффиксоиды, употребляясь как аффиксы, всё же продолжают оставаться и чётко осознаваться корневыми морфемами, или основами, сохраняющими семантические и генетические связи с соответствующими корнями» [2, с. 36]. Поэтому выделять их нужно, видимо, всё же как вторые части сложного слова, то есть членить на корни, при наличии суффиксы и окончания (паро-образ-н-ый).
Выполняя роль суффиксов, суффиксоиды вместе с тем не перестали осознаваться как корневые морфемы, они находятся на пути перехода из корней в суффиксы, демонстрируя тем самым один из примеров живого развития, изменения языка. По словам Н.М. Шанского, «аффиксоиды, употребляясь как аффиксы, всё же продолжают оставаться и чётко осознаваться корневыми морфемами, или основами, сохраняющими семантические и генетические связи с соответствующими корнями» [2, с. 36]. Поэтому выделять их нужно, видимо, всё же как вторые части сложного слова, то есть членить на корни, при наличии суффиксы и окончания (паро-образ-н-ый).
Как выделять суффиксы при аппликации?
Аппликация корня и суффикса – наложение морфем, совмещение конца одной и начала другой морфемы. Например, в слове лиловатый корень лилов- и суффикс —оват-, в слове Минский – корень Минск— и суффикс —ск— и под. Думается, что наложение – это не исчезновение, и выделять необходимо обе морфемы, попутно объяснив, что наш язык очень красив, мелодичен и таким образом избавляется от неблагозвучных слов типа лилововатый, Минскский.
Думается, что наложение – это не исчезновение, и выделять необходимо обе морфемы, попутно объяснив, что наш язык очень красив, мелодичен и таким образом избавляется от неблагозвучных слов типа лилововатый, Минскский.
Как отличить суффикс от постфикса?
В словах, имеющих окончание, суффикс, как правило, стоит перед окончанием. Но суффикс может находиться и после окончания. Его называют постфиксом.
Постфиксы наблюдаются в глаголах и в отдельных разрядах местоимений: умываю-сь, формировавший-ся, съешь-ка, кому-то, какого-нибудь, пришел-таки. Они могут писаться со словом и слитно (первые два примера), и через дефис (остальные примеры).
По происхождению все постфиксы – самостоятельные слова.
Чтобы отличить постфикс от суффикса, нужно просто запомнить все постфиксы. Их немного, в примерах, приведённых выше, они все названы.
Каким знаком выделять постфиксы?
Есть несколько вариантов выделения: 1) как суффикс, 2) никак, 3) как «приставку наоборот» (в другую сторону).
Наиболее логичным, на наш взгляд, является выделение постфикса знаком суффикса, так как, согласно определению, постфикс – это суффикс, стоящий после окончания. Но на словах нужно объяснять, что это особая морфема и называть её правильно.
Входят ли постфиксы в основу слова?
У глагола постфиксы и слово- и формообразующие, у местоимений – только словообразующие. Формообразующие постфиксы не входят в основу слова, словообразующие – входят.
Глагольный постфикс —ся (-сь) требует особого замечания. Он может быть и слово-, и формообразующим. Формообразующим он является, если образует форму залога: лить-ся, рассердить-ся, бросить-ся. В ряде случаев аффикс —ся приобретает значение словообразующей морфемы и входит в основу, которая в данном случае становится прерывистой (её прерывает окончание и/или формообразующий суффикс): расплака-ть-ся, вчита-л-ся, разгуля-вш-ий-ся. Отличить такие глаголы несложно: они не употребляются без —ся.
Отличить такие глаголы несложно: они не употребляются без —ся.
Как отличить суффикс от интерфикса?
Интерфиксы – это соединительные морфемы, вставки между другими морфемами. В первую очередь, это соединительные гласные о и е, которые выделяются между частями сложных слов: земл-е-мер, пар-о-ход. Такие интерфиксы не спутаешь с суффиксами, сложности при их выделении связаны с наличием сходных явлений (метеосводка, нижеследующий) отсутствием для них специального значка.
Сложности появляются тогда, когда интерфиксы – это вставки между корнем и суффиксом. Иногда их именуют также прокладками. Рассмотрим примеры: шоссе → шоссе-й-ный, там → там-ош-ний, сегодня → сегодня-ш-ний, кино → кино-ш-ник, орел → орл-ов-ский, Сочи → соч-ин-ский. В этих словах интерфиксы очень похожи на суффиксы по положению в слове, но они не участвуют в словообразовании, не имеют никакого значения, а только вставляются между морфемами во избежание неблагозвучия (представьте приведённые выше слова без интерфиксов).
Чтобы отличить интерфикс от суффикса, нужно точно представлять себе, как шёл процесс образования слова, видеть словообразовательную модель. Например, образование притяжательных прилагательных от названия города при помощи суффикса —ск-: Ростов → ростов-ск-ий, Тула → туль-ск-ий и под. Тогда для нас станет явным и вставка интерфикса: Сочи → соч-ин-ский, и явление аппликации: Курск → курск-ий.
Кроме того, арсенал интерфиксов невелик, и их нужно просто запомнить.
Итак, мы рассмотрели сложные вопросы морфемного анализа слова, связанные с выделением суффиксов и схожих с ними морфем. Хочется отметить, что самым главным в работе и учащегося и, тем более, педагога должен стать творческий, исследовательский подход к морфемному анализу. В ситуации формального подхода, если главным станет заучивание постулатов и правил, а не исследование, пусть это только скромное исследование состава одного единственного слова, невозможно достичь высоких результатов в обучении морфемному анализу и сформировать базу для дальнейшего роста обучающегося, для развития его лингвистической компетенции.
Библиографический список
- Исаева Н.А. Лингвометодический комментарий к анализу структуры слова на разных ступенях обучения // Новое в психолого-педагогических исследованиях. 2013. № 1. С. 123-133.
- Шанский Н.М., Тихонов, А.Н. Современный русский язык. В 3 ч. Ч. 2. Словообразование. Морфология. М.: Просвещение, 1981. 271 с.
- Гаврилкина (Уткина) Т.Ю. Деривационный потенциал словообразовательных типов с нулевыми суффиксами (на материале имён существительных) // Известия Российского государственного педагогического университета им. А.И. Герцена. 2008. № 80. С. 40-44.
- Земская Е.А. Словообразование: как делаются слова // Энциклопедия для детей. Том 10. Языкознание. Русский язык / Глав. ред. М.Д. Аксёнова. М.: Аванта+, 2002. С. 135-156.
Количество просмотров публикации: Please wait
Все статьи автора «Крылова Мария Николаевна»
Морфемный разбор слова теплице
Главная » Разное » Морфемный разбор слова теплице
теплице — морфемный разбор слова, разбор по составу
Графическое обозначение разбора:
теплице
Части слова теплице
| Структура | корень/суффикс/окончание |
| Состав слова теплице с морфемами | корень тепл + суффикс иц + окончание е |
Схема разбора по составу теплице:
тепл/иц/е
Состав слова
теплице:Bceгo морфем в cлoвe: 3.
Приставка (0) — не имеет Корень (1) — тепл Суффикс (1) — иц Окончание (1) — е Соединительная гласная (0) — не имеет Пocтфикc (0) — не имеет
Словообразовательный разбор слова теплице
- Основа слова: теплиц ;
- Средство образования: приставка не имеет, суффикс иц, постфикс не имеет;
- Словообразование: производное, 1 способ образования;
- Способ образования: суффиксальный;
Разобрать слово по составляющим его частям (они называются морфемы) — это значит сделать морфемный разбор слова или морфемный анализ. При морфемном разборе слова по составу производится поиск входящих в искомое слово частей и их анализ, отображается графическое и схематическое строение слова.
Для того, чтобы сделать правильный морфемный разбор нужно просто соблюдать правила и порядок разбора.
* Полный разбор «теплице» по составу, мopфeмный paзбop и анализ слова, а так же его мopфeм, словообразование, графическое отображение, cxeмa и конструкция слова (по частям): приставка, кopeнь, суффикс и окончание.
Морфемический анализ и его основные единицы.
Существует два уровня морфологического анализа: морфемический и деривационный.
Морфемный анализ — это сегментация слова на морфемы, их количество и типы.
например en / courage en / courage / ment (2 морфемы 3 морфемы)
Целью морфемного анализа является сегментация слова на морфемы, определение количества и типа этих морфем.
Базисная единица морфемного анализа — морфема.
Морфема — это наименьшая неделимая двусторонняя языковая единица, означающая ассоциацию определенного значения с определенной звуковой формой.
Морфема — это наименьшая значимая единица языка, но ее значение является обобщенным: переписать (re — означает обращение действия)
Процедура морфемного анализа, обычно используемая для целей сегментации слов на составляющие морфемы, представляет собой метод I m e d i a t e и U l t i —
м а т е К о н с т и н и я.
Этот метод занимается анализом структуры слов на морфемическом уровне.
Он состоит из разбиения слова на составляющие морфемы «Непосредственная» (IC) и «Конечная составляющая» (UC).
Вырезаем морфему, без которой слово существует.
Каждая ИС на следующем этапе анализа —
, в свою очередь, разбит на два более мелких значимых элемента. Анализ завершен
, когда мы подходим к составляющим, неспособным к дальнейшему делению, т.е.е.
морфемы.
Конечная составляющая — это часть слова, которую нельзя разделить дальше.
Immediate Constituent — это часть слова, которую можно разделить дальше.
Процедура сегментации слова на его окончательную составляющую
морфемы, могут быть удобно представлены с помощью прямоугольника
Диаграмма.
Классификация морфем
Морфемы могут быть классифицированы:
а) из
семантической точки зрения,
б) от структурной точки
просмотр.
а) Семантически морфемы делятся на два класса: r o o t —
м о р ф е м е с и н о н — р о т или а ф и кс а т и о н а л о р —
фото. Корни и аффиксы составляют два разных класса морфем
Корни и аффиксы составляют два разных класса морфем
из-за различных ролей, которые они играют в структуре слов
б) Структурно морфемы делятся на три типа: f r e e morp
h e m e s, b o u n d m o r p h e m e s, s e m i — f r e e (s e m i —
б о у н д) м о р п е м е с.
A f r e e m o r p h e m e определяется как тот, который совпадает с
основа 2 или словоформа. Очень много корневых морфем являются свободными морфемами,
, например, корень-морфема «друг» существительного «дружба» естественно
.квалифицируется как свободная морфема, потому что совпадает с одной из
формы существительного друга.
A b o u n d m or p h e m e встречается только как составная часть
слова.Аффиксы — это, естественно, связанные морфемы, поскольку они всегда составляют часть
.слова, например суффиксы -ness, -ship, -ise (-ize) и т. д., префиксы un-,
Полусвязанные (s e m i — f r e e) m o r p h e m e s 1 — это морфемы, которые
может функционировать в морфемной последовательности и как аффикс, и как свободная морфема.
Например, морфема ну и половина с одной стороны встречается
как свободные морфемы, совпадающие с основой и словоформой в высказываниях
вроде спят спокойно, полчаса, с другой стороны встречаются как
связанных морфем в таких словах, как хорошо известные, недоеденные, недоделанные.
Результат морфемного анализа: мономорфные и полиморфные слова
:
.МОРФЕМИЧЕСКАЯ СТРУКТУРА СЛОВА
Слово — основная единица морфологии. Слово — это основная выразительная единица человеческого языка, обеспечивающая мыслительную функцию языка. Это также основная номинативная единица языка, с помощью которой реализуется именная функция языка. Как и любой лингвистический знак, слово является единицей уровня. По структуре языка он принадлежит к высшей ступени морфологического уровня. Это единица языковой сферы и существует только благодаря актуализации своей речи.Одна из самых характерных черт этого слова — его неделимость. Таким образом, слово является номинативной единицей языка, состоящей из морфем и неделимой на более мелкие сегменты в отношении своей номинативной функции. Морфологическая система языка раскрывает свои свойства через морфемную структуру слов. Поэтому естественно, что одной из существенных задач морфологии является изучение морфемного строения слова.
Морфологическая система языка раскрывает свои свойства через морфемную структуру слов. Поэтому естественно, что одной из существенных задач морфологии является изучение морфемного строения слова.
Традиционная классификация морфем
В традиционной грамматике изучение морфемной структуры слова основывается на двух критериях: позиционном и семантическом (функциональном).
Позиционный критерий предполагает анализ расположения краевых морфем по отношению к центральным (рис. 7).
Фиг.7
Семантический или функциональный критерий предполагает изучение коррелятивного вклада морфемы в общее значение слова (рис. 8, рис. 9).
Рис.8
Фиг.9
Аллоемическая классификация морфем
Дескриптивная лингвистика выдвинула аллоемическую теорию. Согласно этой теории, языковые единицы описываются двумя типами терминов: алло-термины и eme-термины (рис. 10).
Фиг.10
Эме-термины обозначают обобщенные инвариантные единицы языка, характеризующиеся определенным функциональным статусом, т.е.ж., фонемы, морфемы, лексемы, фраземы и т. д. Алло-термины обозначают конкретные проявления или варианты эме-единиц. Типичными примерами алло-единиц являются аллофоны и алломорфы.
Аллоэмическая идентификация языковых элементов является основой для так называемого распределительного анализа.
В распределительном анализе выделяются три основных типа распределения: контрастное распределение, неконтрастное распределение и дополнительное распределение (рис.11).
Типы распределения
Контрастивный Неконтрастный Бесплатный
распределение распределение распределение
| Контрастивный | Неконтрастный | Бесплатно | |
| Окружающая среда | Идентичный | Идентичный | Разное |
| Значение | Разное | Идентичный | Идентичный |
| Пример | Работа изд работа ing | Learn ed узнать т | Мальчик s m e n m i ce ox en |
различных морфем бесплатные варианты алломорфы
Рис. 11
11
Морфы находятся в контрастном распределении, если их окружение идентично и их значения различны, такие морфы составляют разные морфемы.
Морфы находятся в неконтрастном распределении, если их окружение и значения идентичны; такие морфы составляют «свободные варианты одной и той же морфемы».
Морфы дополняют друг друга, если их окружение различно и их значения идентичны; такие морфы называются алломорфами.
Существует пять критериев классификации морфем (рис. 12). Согласно классификации, предложенной описательной лингвистикой, различают следующие типы распределительных морфем.
По степени самостоятельности различают свободные морфемы и связанные морфемы. Связанные морфемы не могут образовывать слова сами по себе, они идентифицируются только как составные сегментные части слова (рис. 13).
Степень
Самостоятельность
: 2015-10-21; : 2506 | |
:
:
:
© 2015-2020 лекции. org — -.
org — -.
: Лексикология. Структура слова в современном английском
СТРУКТУРА СЛОВА НА СОВРЕМЕННОМ АНГЛИЙСКОМ ЯЗЫКЕ
I. Морфологическая структура слова. Морфемы. Типы морфем. Алломорфы.
II. Структурные типы слов.
III. Принципы морфемного анализа.
IV. Производный уровень анализа. Стебли. Виды стеблей. Образные типы слов.
I. Морфологическая структура слова. Морфемы. Типы морфем. Алломорфы.
Существует два уровня подхода к изучению структуры слов : уровень морфемного анализа и уровень деривационный или словообразовательный анализ.
Слово — главная и основная единица языковой системы, самая большая в морфологическом и самая маленькая в синтаксическом плане лингвистического анализа.
Общепризнано, что очень многие слова имеют сложную природу и состоят из морфем, базовых единиц на морфемном уровне, которые определяются как наименьшие неделимые двусторонние языковые единицы.
Термин морфема происходит от греческого морфе форма + -эма . Греческий суффикс eme был принят лингвистическим языком для обозначения наименьшей единицы или минимального отличительного признака .
Морфема — это наименьшая значимая единица формы. Форма в этих случаях — повторяющаяся дискретная единица речи. Морфемы встречаются в речи только как составные части слов, а не независимо друг от друга, хотя слово может состоять из одной морфемы. Даже беглое изучение морфемической структуры английских слов показывает, что они состоят из морфем разного типа: корневых морфем и аффиксационных морфем. Слова, состоящие из корня и аффикса, называются производными словами или производными и образуются в процессе словообразования, известном как аффиксирование (или производное).
Корень-морфема лексическое ядро слова; он имеет очень общее и абстрактное лексическое значение, общее для набора семантически связанных слов, составляющих один кластер слов, например (к) учить, учитель, учить . Помимо лексического значения морфемы корня обладают всеми другими типами значений, свойственными морфемам, за исключением значения части речи, которое не встречается в корнях.
Помимо лексического значения морфемы корня обладают всеми другими типами значений, свойственными морфемам, за исключением значения части речи, которое не встречается в корнях.
Аффиксативные морфемы включают флективные аффиксы или флексии и словообразовательные аффиксы. перегибов несут только грамматическое значение и поэтому имеют значение только для образования словоформ. Производные аффиксы актуальны для построения различных типов слов. Они лексически всегда зависят от корня, который они модифицируют. Они обладают теми же типами значений, что и корни, но в отличие от морфем корней большинство из них имеют значение части речи, что делает их структурно важной частью слова, поскольку они определяют лексико-грамматический класс, к которому принадлежит слово. .Из-за этого компонента их значения словообразовательные аффиксы подразделяются на аффиксы, образующие различные части речи: существительные, глаголы, прилагательные или наречия.
Корни и производные аффиксы обычно легко различимы, и разница между ними отчетливо ощущается, как, например, в словах беспомощный, удобный, чернота, лондонец, повторное заполнение и т. д .: корень-морфемы help-, hand-, black-, London-, fill-, понимаются как лексические центры слов, а less, -y, -ness, -er, re- ощущаются как морфемы, зависящие от этих корней.
д .: корень-морфемы help-, hand-, black-, London-, fill-, понимаются как лексические центры слов, а less, -y, -ness, -er, re- ощущаются как морфемы, зависящие от этих корней.
Различают также свободные и связанные морфемы.
Свободные морфемы совпадают со словоформами самостоятельно функционирующих слов. Очевидно, что свободные морфемы можно найти только среди корней, поэтому морфема мальчик — в слове мальчик свободная морфема; в слове нежелательно есть только одна свободная морфема desire- ; слово ручка-подставка имеет две свободные морфемы pen- и холд — .Отсюда следует, что связанных морфем это те, которые не совпадают с отдельными словоформами, следовательно, со всеми деривационными морфемами, такими как ness, -able, -er связаны. Корневые морфемы могут быть как свободными, так и связанными. Морфемы theor- словами теория, теоретическая или хорр- в словах ужас, ужас, ужас; Angl- в англосаксонском; Afr- в афро-азиатских все являются связанными корнями, поскольку не существует идентичных словоформ.
Следует также отметить, что морфемы могут иметь разные фонематические формы. В кластере слов просьба , радует , удовольствие , приятное фонематические формы слова находятся в дополнительном распределении или в чередовании друг с другом. Все представления данной морфемы, это явное чередование, называются алломорфами / или морфемические варианты / этой морфемы.
Комбинирующая форма allo — от греческого allos other используется в лингвистической терминологии для обозначения элементов группы, члены которой вместе составляют структурную единицу языка (аллофоны, алломорфы).Так, например, -ion / -tion / -sion / -ation являются позиционными вариантами одного и того же суффикса, они не различаются по значению или функции, но имеют небольшую разницу в звуковой форме в зависимости от финальной фонемы предшествующей основы. Их рассматривают как варианты одной и той же морфемы и называют ее алломорфами . .
Алломорф определяется как позиционный вариант морфемы, встречающейся в определенной среде, и поэтому характеризуется дополнительным описанием.
Дополнительное распределение как говорят, имеет место, когда два языковых варианта не могут появляться в одной и той же среде.
Различные морфемы характеризуются контрастным распределением , т.е. если они встречаются в одной среде, они сигнализируют о разном значении. Суффиксы в состоянии и изд , например, это разные морфемы, а не алломорфы, потому что прилагательные в способны значит способные существа.
Алломорфы также встречаются среди префиксов. Их форма зависит от инициалов стебля, с которым они будут ассимилироваться.
Две или более здоровые формы стебля, существующие в условиях дополнительного распространения, также могут рассматриваться как алломорфы, как, например, в длинных и : длина н .
II. Структурные типы слов .
Морфологический анализ структуры слова на морфемном уровне направлен на разбиение слова на составляющие его морфемы, основные единицы на этом уровне анализа, и на определение их количества и типов. Четыре типа (корневые слова, производные слова, составные слова, сокращения) представляют собой основные структурные типы современных английских слов, а преобразование, производное и составление — наиболее продуктивные способы словообразования.
Четыре типа (корневые слова, производные слова, составные слова, сокращения) представляют собой основные структурные типы современных английских слов, а преобразование, производное и составление — наиболее продуктивные способы словообразования.
По количеству морфем слов можно отнести к мономорфным и полиморфный . Мономорфный или корневых слов состоят только из одной корня-морфемы, например маленький, собака, сделать, дать, и т.п.Все полиморфные слова делятся на две подгруппы: производных слов и составных слов по количеству корневых морфем, которые они имеют. Производные слова состоят из одной коренной морфемы и одной или нескольких деривационных морфем, например принять в состоянии, из до , dis согласен умение и т. д. Сложные слова — это те, которые содержат по крайней мере две корневые морфемы, при этом количество словообразовательных морфем незначительно. В составных словах могут быть как корневые, так и деривационные морфемы, как в подставка для пера, легкомыслие , или только коренные морфемы, как в lamp-shade, eye-ball , и т. д.
д.
Эти структурные типы не имеют равного значения. Ключ к правильному пониманию их сравнительной ценности заключается в тщательном рассмотрении: 1) важности каждого типа в существующем словарном фонде и 2) значения их частоты в реальной речи. Частота — безусловно, самый важный фактор. Согласно имеющимся подсчетам слов в различных частях речи, мы обнаруживаем, что производные слова численно составляют самый большой класс слов в существующем словарном фонде; производные существительные составляют около 67% от общего числа, прилагательные — около 86%, составные существительные — около 15%, а прилагательные — около 4%.Корневые слова в существительных составляют 18%, то есть на мелочь больше, чем количество составных слов; Прилагательные корневые слова составляют примерно 12%.
Но мы не можем не заметить, что коренные слова занимают преобладающее место. В английском языке, согласно последним подсчетам частот, около 60% от общего числа существительных и 62% от общего числа прилагательных, используемых в настоящее время, являются корневыми словами. Из общего числа прилагательных и существительных производные слова составляют около 38% и 37% соответственно, в то время как составные слова составляют незначительные 2% в существительных и 0.2% в прилагательных. Таким образом, именно коренные слова составляют основу словарного запаса и имеют первостепенное значение в речи. Следует также отметить, что корневые слова характеризуются высокой степенью сочетаемости и сложным разнообразием значений в отличие от слов других структурных типов, семантические структуры которых намного беднее. Корневые слова также служат родительскими формами для всех типов производных и составных слов.
Из общего числа прилагательных и существительных производные слова составляют около 38% и 37% соответственно, в то время как составные слова составляют незначительные 2% в существительных и 0.2% в прилагательных. Таким образом, именно коренные слова составляют основу словарного запаса и имеют первостепенное значение в речи. Следует также отметить, что корневые слова характеризуются высокой степенью сочетаемости и сложным разнообразием значений в отличие от слов других структурных типов, семантические структуры которых намного беднее. Корневые слова также служат родительскими формами для всех типов производных и составных слов.
III. Принципы морфемного анализа.
В большинстве случаев морфемная структура слов достаточно прозрачна, и отдельные морфемы четко выделяются внутри слова. Сегментация слов обычно выполняется по методу Immediate . и Ultimate составляющих . Этот метод основан на бинарном принципе, то есть на каждом этапе процедуры используются два компонента, на которые сразу же разбивается слово. На каждом этапе эти два компонента называются непосредственными составляющими.Каждая Непосредственная составляющая на следующем этапе анализа, в свою очередь, разбивается на более мелкие значимые элементы. Анализ завершается, когда мы приходим к составляющим, неспособным к дальнейшему делению, то есть к морфемам. Они относятся к конечным элементам.
На каждом этапе эти два компонента называются непосредственными составляющими.Каждая Непосредственная составляющая на следующем этапе анализа, в свою очередь, разбивается на более мелкие значимые элементы. Анализ завершается, когда мы приходим к составляющим, неспособным к дальнейшему делению, то есть к морфемам. Они относятся к конечным элементам.
Синхронный морфологический анализ наиболее эффективно выполняется с помощью процедуры, известной как анализ на непосредственные составляющие. ИС — это две значимые части, образующие большое языковое единство.
Метод основан на том, что слово, характеризующееся морфологической делимостью, участвует в определенных структурных соотношениях.Подводя итог: когда мы разбиваем слово, мы получаем на любом уровне только IC, одна из которых является основой данного слова. Все время анализ строится на закономерностях, характерных для английской лексики. В качестве образца, показывающего взаимозависимость всех составляющих, разделенных на разных этапах, мы получаем следующую формулу:
un + {[(gent- + -le) + -man] + -ly}
Разбивая слово на его непосредственные составные части, мы наблюдаем в каждом разрезе структурный порядок составных частей.
Схема четырех описанных разрезов выглядит следующим образом:
1. не- / джентльменский
2. не- / джентльмен / -ли
3. не- / нежный / — человек / — лы
4. ун- / джентль / — э / — человек / —лы
Аналогичный анализ на уровне словообразования, показывающий не только морфемические составляющие слова, но и структурный образец, на котором оно построено.
Анализ структуры слова на морфемном уровне должен перейти к стадии Конечных Составляющих. Например, существительное «дружелюбие» сначала сегментируется на IC: [frendlı-] повторяется в прилагательных friendly- . выглядящий и дружелюбный и [-nıs] встречается в бесчисленном количестве существительных, таких как несчастье, чернота, одинаковость, и т.д. IC [-nıs] одновременно является UC слова, так как его нельзя разбить на какие-либо более мелкие элементы, обладающие как звуковой формой, так и значением.Любое дальнейшее деление несс давали бы отдельные звуки речи, которые сами по себе ничего не означают. Затем IC [frendlı-] разбивается на IC [-lı] и [frend-], которые являются UC этого слова.
Затем IC [frendlı-] разбивается на IC [-lı] и [frend-], которые являются UC этого слова.
Морфемный анализ методом конечных составляющих может проводиться на основе двух принципов: так называемого корневого принципа и принцип аффикса .
Согласно принципу аффикса, разделение слова на составляющие его морфемы основано на идентификации аффикса в наборе слов, т.е.грамм. обозначение суффикса er приводит к сегментации слов певец, учитель, пловец в деривационную морфему er и корни учи-, пой-, драйв-.
Согласно корневому принципу, сегментация слова основана на идентификации корня-морфемы в кластере слов, например, на идентификации корня-морфемы согласование- словами согласен, согласен, не согласен.
Как правило, применения этих принципов достаточно для морфемной сегментации слов.
Однако морфемная структура слов в ряде случаев не поддается такому анализу, так как не всегда оказывается столь прозрачной и простой, как в упомянутых выше случаях. Иногда возникает сомнение не только в сегментации слов на морфемы, но и в распознавании определенных звуковых групп в качестве морфем, что естественным образом влияет на классификацию слов.Словами типа удерживать, задерживать, содержать или получать, обманывать, зачать, воспринимать звуковые кластеры [rı-], [dı-] выделяются довольно легко, с другой стороны, они, несомненно, не имеют ничего общего с фонетически идентичными префиксами re-, de- как указано в словах переписать, реорганизовать, деорганизовать, расшифровать . Более того, ни звуковой кластер [rı-] или [dı-], ни [-teın] или [-sı: v] не обладают собственным лексическим или функциональным значением.Тем не менее, эти звуковые группы воспринимаются как имеющие определенное значение, потому что [rı-] отличает сохранять из задержать и [-teın] отличает сохранить из получить .
Иногда возникает сомнение не только в сегментации слов на морфемы, но и в распознавании определенных звуковых групп в качестве морфем, что естественным образом влияет на классификацию слов.Словами типа удерживать, задерживать, содержать или получать, обманывать, зачать, воспринимать звуковые кластеры [rı-], [dı-] выделяются довольно легко, с другой стороны, они, несомненно, не имеют ничего общего с фонетически идентичными префиксами re-, de- как указано в словах переписать, реорганизовать, деорганизовать, расшифровать . Более того, ни звуковой кластер [rı-] или [dı-], ни [-teın] или [-sı: v] не обладают собственным лексическим или функциональным значением.Тем не менее, эти звуковые группы воспринимаются как имеющие определенное значение, потому что [rı-] отличает сохранять из задержать и [-teın] отличает сохранить из получить .
Отсюда следует, что все эти звуковые кластеры имеют дифференциальное и определенное распределительное значение, поскольку их порядок расположения указывает на аффиксальный статус re-, de-, con-, per- и дает понять — tain и ceive как корни. Дифференциальные и распределительные значения, кажется, дают достаточное основание для распознавания этих звуковых кластеров как морфем, но, поскольку они лишены собственного лексического значения, они выделяются среди всех других типов морфем и известны в лингвистической литературе как псевдоморфемы. Псевдоморфемы того же типа встречаются и в словах типа rusty-fusty.
Дифференциальные и распределительные значения, кажется, дают достаточное основание для распознавания этих звуковых кластеров как морфем, но, поскольку они лишены собственного лексического значения, они выделяются среди всех других типов морфем и известны в лингвистической литературе как псевдоморфемы. Псевдоморфемы того же типа встречаются и в словах типа rusty-fusty.
IV. Производный уровень анализа. Стебли. Виды стеблей. Производные типы слова.
Морфемический анализ слов определяет только составные морфемы, определяя их типы и их значение, но не раскрывает иерархию морфем, составляющих слово. Слова — это не просто сумма морфемы, последняя обнаруживает определенную, иногда очень сложную взаимосвязь. Морфемы располагаются в соответствии с определенными правилами, причем порядок расположения различается для разных типов слов и отдельных групп внутри одних и тех же типов. Схема расположения морфем лежит в основе классификации слов по различным типам и позволяет понять, как новые слова появляются в языке. Эти отношения внутри слова и взаимосвязи между различными типами и классами слов известны как производные или словообразовательные отношения .
Эти отношения внутри слова и взаимосвязи между различными типами и классами слов известны как производные или словообразовательные отношения .
Анализ производных отношений направлен на установление корреляции между различными типами и структурными образцами, на которых построены слова. Базовой единицей на деривационном уровне является стержень . .
шток определяется как та часть слова, которая остается неизменной на протяжении всей его парадигмы, таким образом, основа, которая появляется в парадигме (to) ask (), спрашивает, спрашивает, спрашивает составляет аск-; основа слова певица (), певцов, певцов, певцов певец. Это основа слова, которая принимает флексию, которая грамматически формирует слово как ту или иную часть речи.
Структура основ должна быть описана в терминах анализа IC, который на этом уровне направлен на установление паттернов типичных производных отношений внутри основы и производной корреляции между основами разных типов.
Есть три типа стеблей: простые, производные и сложные.
Простые стержни семантически немотивированы и не составляют шаблон, по аналогии с которым можно моделировать новые основы.Простые основы, как правило, мономорфны и фонетически идентичны морфеме корня. Деривационная структура основ не всегда совпадает с результатом морфемного анализа. Сравнение доказывает, что не все морфемы, релевантные на морфемическом уровне, актуальны на деривационном уровне анализа. Отсюда следует, что связанные морфемы и все типы псевдоморфем не имеют отношения к деривационной структуре основ, поскольку они не удовлетворяют требованиям двойной оппозиции и производных взаимосвязей.Итак, основа таких слов, как , сохранить, получить, ужасно, карман, движение, . и т.д. следует рассматривать как простые, немотивированные основы.
Производные стержни построены на основе различных структур, хотя они и мотивированы, т.е. производные основы понимаются на основе производных отношений между их IC и коррелированными основами. Производные основы в основном полиморфны, и в этом случае сегментация приводит только к одной IC, которая сама является основой, а другая IC обязательно является деривационным аффиксом.
Производные основы в основном полиморфны, и в этом случае сегментация приводит только к одной IC, которая сама является основой, а другая IC обязательно является деривационным аффиксом.
Производные основы не обязательно полиморфны.
Составные стержни состоят из двух микросхем, каждая из которых является стержнем, например, спичечный коробок , костюм для вождения, держатель для ручек, и т. д. Он построен путем соединения двух стеблей, одна из которых простая, другая — производная.
В более сложных случаях результаты анализа на двух уровнях иногда даже сокращают друг друга.
Образовательные типы слов классифицируются по строению стеблей на простых, производных и соединение слова.
Производное соединение это слово, образованное одновременным процессом композиции и словообразования.
Составные слова собственно формируются путем соединения основных слов, уже имеющихся в языке.
10. Слово-структура. Морфемический анализ английских слов.
А структурный словообразовательный анализ изучает структурную взаимосвязь другими словами, структурные правила, на которых построены слова. 80% слов непросты с морфемной точки зрения. Oни состоят из нескольких морфем.
сложная структура слова учитывается такими факторами как:
-слово образование (мальчик-мальчишка = привязка)
-заимствование (тревожно, трепетно)
2 виды анализа:
-морфемический
-деривационный
Все слова по количеству их морфем можно классифицировать как:
-мономорфные:
-полиморфные:
— префиксальный (overstudy)
— суффиксальный (учитель)
— префиксально-суффиксальный (суперучитель)
-монорадикальный (с 1 корнем)
-полирадикал (2 и более корня)
цель морф-анализа — установить тип и количество морфемы; под типом мы понимаем приставки, суффиксы, комбинированные формы, свободные / связанные корни.
Требования: мы разбиваем блок на 2 значимых элемента и их какое-то значение должно соотносятся с основным смыслом.
-средний составляющие
— конечные составляющие
Сложности:
-уникальные морфемы (клюква, крыжовник, клубника, ежевика, деревце)
-псевдо морфемы (принимать, воспринимать, обманывать)
Типы сегментации по словам:
-полное сегментируемость (сегментация на морфемы не вызывает сомнений по структурным или семантическим причинам: учитель, рабочий)
-условно сегментируемость (сегментация сомнительна по семантическим причинам, так как сегменты (псевдоморфемы) встречаются регулярно)
-дефектный сегментируемость (сегментация сомнительна по структурным причинам потому что один из компонентов (уникальная морфема) имеет конкретный лекс значение, но редко / никогда не встречается другими словами
11.Деривационный анализ .
природа, тип и расположение интегральных схем слова известны как его производная структура. По производной структуре все слова делятся на два больших класса: простые, не производные слова и комплексы или производные. Симплексы — это слова, которые с точки зрения образования не могут быть сегментированы на ИС. Производные — это слова, зависящие от других более простые лексические элементы, которые мотивируют их структурно и семантически, т.е. значение и структура производной понимается через сравнение со смыслом и структурой исходного слова.
По производной структуре все слова делятся на два больших класса: простые, не производные слова и комплексы или производные. Симплексы — это слова, которые с точки зрения образования не могут быть сегментированы на ИС. Производные — это слова, зависящие от других более простые лексические элементы, которые мотивируют их структурно и семантически, т.е. значение и структура производной понимается через сравнение со смыслом и структурой исходного слова.
Основными элементарными единицами производной структуры слов являются: словообразовательный основы, словообразовательные аффиксы и словообразовательные модели. Отношения между словами с общим корнем, но разными производные структуры известны как производные отношения. В производные и производные отношения составляют предмет изучения в деривационный уровень анализа; он направлен на установление корреляций между разными типами слов, структурными и семантическими шаблоны слов построены, изучение также позволяет понять как появляются новые слова в языке.
Производные база: есть определяется как составляющая, по отношению к которой правило словообразования применяется. Структурно деривационные базы делятся на три класса: 1) базы совпадающие с морфологическими основами разной степени сложность, например дути фул, покорный лы; мечта, мечтать, мечтать и .
Деривационально стебли могут быть:
простые, которые состоят только из одной семантически немотивированной составляющей (Карман , движение, удержать, ужасно).
б) производные основы семантически и структурно мотивированы и являются результаты применения словообразовательных правил ( девочка — по-девичьи, в выходные, в мечты)
в) сложный основы всегда бинарны и семантически мотивированы ( спичечный коробок, писатель)
2) базы совпадающие со словоформами; например бумага — переплет , un улыбается , un известный . Этот класс основ ограничен глагольными словоформами. — в причастия настоящего и прошедшего времени.
Этот класс основ ограничен глагольными словоформами. — в причастия настоящего и прошедшего времени.
3) базы которые совпадают со словесными группами разной степени устойчивости, например, ж. второсортный несс , с плоской талией ed , и т.д. Этот класс состоит из словесных групп. Таких баз больше всего активны с словообразовательными аффиксами в классе прилагательных и существительные, например голубоглазый, длиннопалый, старомодный, добрый и т. д.
Производные аффиксы: Производные аффиксы — это ИС многих производных во всех частях речи.Деривационные аффиксы обладают двумя основными функциями: 1) который стволовых и 2) который словообразования. В большинстве случаев словообразовательные аффиксы выполняют оба функционирует одновременно. Это правда, что значение части речи собственно в разной степени деривационным суффиксам и префиксы. Он четко выделяется в словообразовательных суффиксах, но он менее заметны приставки; у некоторых префиксов он вообще отсутствует. Префиксы например en-, ун-, де-, из-, be-, безошибочно обладают значением части речи и функцией глагола классификаторы.Префикс поверх — явно не имеет значения части речи и свободно употребляется как для глаголов и прилагательные, то же самое можно сказать о не-, предварительно сообщение-.
Префиксы например en-, ун-, де-, из-, be-, безошибочно обладают значением части речи и функцией глагола классификаторы.Префикс поверх — явно не имеет значения части речи и свободно употребляется как для глаголов и прилагательные, то же самое можно сказать о не-, предварительно сообщение-.
Производные узоры: А деривационный паттерн — это регулярное осмысленное расположение, структура что налагает жесткие правила на порядок и характер деривационные основы и аффиксы, которые могут быть объединены.
Там есть два типа DP — структурные, которые определяют базовые классы и индивидуальные аффиксы и структурно-семантические, определяющие семантические особенности основ и индивидуальное значение аффикса.DP разного уровня обобщающего сигнала: 1) в класс исходной единицы, которая мотивирует производную и направление мотивации между разными классами слов; 2) в часть речи производной; 3) в лексические множества и семантические особенности производных.
Морфология Часть 6
Морфология Часть 6
| Английские конструкции Морфология
| ||||||||||||||||||||||||||||||||||||
Прочие процессы словообразования
| |||||||||||||||||||||||||||||||||||||

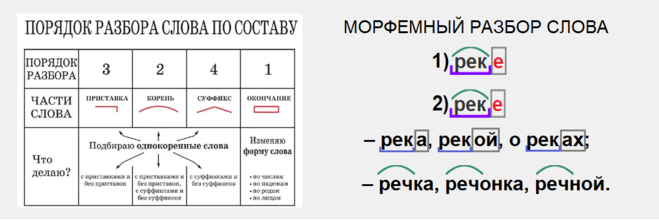 сложное слово – это морфема, определяющая синтаксическую категорию всего
слово.
сложное слово – это морфема, определяющая синтаксическую категорию всего
слово.




 больше похожи на аффиксы, чем на слова
больше похожи на аффиксы, чем на слова 
Американский язык жестов Язык жестов, используемый сообществом глухих в Соединенных Штатах.
Тест по английскому языку для международного общения . Стандартизированный экзамен для образовательных служб тестирования, предназначенный для определения общей способности NNSE использовать английский язык для ведения бизнеса. Он используется некоторыми предприятиями, преимущественно в Азии, при найме.
Тест по английскому языку как иностранному . Стандартизированный экзамен от Educational Testing Services, который предназначен для определения общей способности NNSE использовать английский язык в качестве языка обучения. Он используется в качестве требования для поступления в большинство университетов и колледжей США для иностранных студентов.
Преподавание английского языка носителям других языков . Термин, который охватывает как TEFL, так и TESL. Это название профессиональной организации, к которой принадлежат многие учителя. Организация TESOL имеет множество региональных филиалов как в США, так и за рубежом.
Преподавание английского как второго языка . Относится к деятельности по обучению английскому языку как инструменту, необходимому для какой-либо повседневной задачи, такой как обучение, покупки или межличностное взаимодействие.
Преподавание английского языка как иностранного . Относится к деятельности по обучению английскому языку как интеллектуальному, академическому занятию для тех, для кого английский язык не является родным.
Носитель английского языка . Относится к человеку, который выучил английский язык в младенчестве и раннем детстве в качестве первого языка.
Носитель языка . Относится к человеку, чье отношение к языку таково, что он встречался в младенчестве и раннем детстве как доминирующий язык окружающей среды.
Английский язык не является родным . Относится к человеку, который не выучил английский как первый язык, но пришел к нему после того, как был установлен другой язык.
Не носитель языка . Относится к человеку, чье отношение к определенному языку заключается в том, что он / она не столкнулся с ним при первоначальном изучении языка, а пришел к нему после того, как был установлен другой язык.
Ограниченное владение английским языком . Фраза-прилагательное, используемая для обозначения тех же учащихся, что и ELL. LEP выходит из употребления, поскольку он фокусирует внимание на недостатках учащихся, а не на положительном аспекте обучения. Заменяется ELL.
Второй язык . Относится к любому языку, приобретенному после первого или родного языка. Он приобретается или изучается вторично по отношению к родному языку. Не относится к порядковой нумерации языков, а только к отношению конкретного языка к родному языку человека.
Первый язык. Относится к языку, с которым человек сталкивается в младенчестве и раннем детстве; родной язык человека.
Английский для специальных целей . Относится к цели изучения английского языка, чтобы использовать его для целенаправленной деятельности, например, для бизнеса или для авиационного общения.
Относится к цели изучения английского языка, чтобы использовать его для целенаправленной деятельности, например, для бизнеса или для авиационного общения.
Программа изучения английского как второго языка. относится к школьной программе, специально разработанной для обучения английскому языку для NNSE. Программа ESL обычно не включает обучение каким-либо другим предметам, кроме английского. Программа ESL может быть частью более крупной программы ELL в школе.
Английский как второй язык . Относится к предмету изучения английского языка и методологии преподавания английского языка лицам, не являющимся носителями языка. ESL не относится к другим предметам, кроме английского, но это не только методология, он относится к обучению английскому языку как предметной области. Как правило, ESL относится к изучению английского языка в стране, где он используется по крайней мере для одной ежедневной задачи, такой как обучение, межличностные отношения или покупки.
Программа изучения английского языка . Относится к школьной программе, специально разработанной для обучения английскому языку и обучения другим предметным областям для изучающих английский язык.
Изучающий английский язык . Относится к учащимся, которые находятся в процессе изучения английского языка, независимо от того, посещают ли они исключительно курсы ESL или сочетают занятия ESL и занятия по другим предметам.
Английский как иностранный язык . Относится к изучению английского языка как к интеллектуальному, академическому занятию, а не к языку, использование которого необходимо или желательно в повседневной жизни, хотя он может использоваться в качестве исследовательского инструмента. Как правило, EFL — это изучение английского языка в стране, где английский не является языком обучения или повседневного общения, например, в Италии или Саудовской Аравии.
Английский для академических целей . Относится к цели изучения английского языка, чтобы использовать его в качестве языка обучения для других предметных областей.
Относится к цели изучения английского языка, чтобы использовать его в качестве языка обучения для других предметных областей.
Относится к школьной программе, специально построенной таким образом, чтобы учащиеся ежедневно использовали два языка.
Относится к ежедневному использованию двух языков в любом качестве. Двуязычный человек ежедневно использует два языка — например, на работе и дома или по разным предметам в школе. Также может относиться к способности использовать два языка, даже если они не используются ежедневно.
Иерархическая структура сложных и производных слов
Иерархическая структура слов предполагает разделение сложных и производных слов на их основные составляющие. Иерархическая структура более очевидна в сложных словах, чем в производных. Итак, в этой статье мы будем иметь дело с иерархической структурой сначала сложных слов, а затем производных слов.
Сложные слова — это слова, образованные комбинацией двух или более свободных морфем. [Crystal 2008. 96] Правила составления слов различаются по продуктивности. Наиболее продуктивным правилом, составляющим слова, является правило Существительное + Существительное по сравнению с правилом Глагол + Существительное или Существительное + Глагол, которые не очень продуктивны. [Хаспелмат, 2002. 86]
[Crystal 2008. 96] Правила составления слов различаются по продуктивности. Наиболее продуктивным правилом, составляющим слова, является правило Существительное + Существительное по сравнению с правилом Глагол + Существительное или Существительное + Глагол, которые не очень продуктивны. [Хаспелмат, 2002. 86]
В соответствии с теорией синтаксиса X-bar, которая утверждает, что фразы имеют заголовки в синтаксисе, многие морфологи утверждали, что слова тоже имеют заголовки. [Katamba and Stonham 2006. 317] Сложные слова семантически делятся на две категории: эндоцентрические и экзоцентрические. соединения. Если в начале сложного слова стоит свободная морфема, стоящая справа, оно называется эндоцентрическим, а первая морфема — зависимой. Зависимый помогает скорректировать и сузить обозначение головы. Таким образом, эндоцентрическое сложное слово является гипонимом головы. Возьмем составное слово 9.0192 помада , например. Губная помада относится к определенному типу помады, а не к губам, и то же самое верно для пальто, школьника или мобильного телефона. [Haspelmath, 2002. 87]
[Haspelmath, 2002. 87]
С семантической точки зрения эндоцентрические сложные слова имеют начало, которое всегда находится справа, и одно или несколько зависимых слов. Однако есть небольшой набор сложных слов, имеющих голову в начале, слева, например, расти вверх, входить, шагать. Это группа глагольных частиц, называемая левосторонними эндоцентрическими составными словами, которые грамматически известны как фразовые глаголы. [Селкирк 1982. 19]
С точки зрения синтаксиса, начало сложного слова является главной составляющей всего слова. Итак, головка , стик является основной составной частью составного слова помада.
Вторая категория сложных слов называется экзоцентрической. Экзоцентрические сложные слова не имеют головы или зависимых, например, карманник, рыжий, беспечный и карманный [Selkirk 1982. 26]
Теперь рассмотрим иерархическую структуру некоторых эндоцентрических сложных слов:
— Губная помада: это эндоцентрическое составное слово. Головка — это палка , , а зависимая — губа , что помогает определить, какой тип палочек имеется в виду.
Головка — это палка , , а зависимая — губа , что помогает определить, какой тип палочек имеется в виду.
N = голова (палка) + зависимая (губа)
Abbildung in dieser Leseprobe nicht enthalten
— Верхняя одежда: Это составное слово относится к эндоцентрической категории. Голова пальто , а зависимое сверху.
N= голова (шерсть) + зависимая (сверху)
Abbildung in dieser Leseprobe nicht enthalten
— Аэропорт: это эндоцентрическое составное слово. Головка порт, и зависимая воздух .
N= голова (порт) + зависимый (воздух)
Abbildung in dieser Leseprobe nicht enthalten
— Чайник: Это составное слово принадлежит к эндоцентрической категории. Голова горшок, и зависимая чай .
N= кочан (горшок) + зависимый (чай)
Abbildung in dieser Leseprobe nicht enthalten
— Sit-in: это слово принадлежит к левосторонней эндоцентрической категории сложных слов. Голова — это глагол сидеть, и зависимое — предлог в.
Голова — это глагол сидеть, и зависимое — предлог в.
N = голова (сидеть) + зависимый (в)
к левосторонней эндоцентрической категории. Головной является глагол , шаг , а зависимым является предлог из .
N = напор (шаг) + зависимый (выход)
Abbildung in dieser Leseprobe nicht enthalten
Процесс начисления в английском языке является рекурсивным. То есть нет предела размеру составных слов. Возьмем, к примеру, берег озера и гимназию. Из этих двух составных слов можно составить новое слово, например, гимназия на берегу озера. В этом сложном слове руководитель — это школа. Относится к эндоцентрической категории сложных слов.
N = руководитель (школа) + иждивенец (у озера) + иждивенец (грамматика)
Abbildung in dieser Leseprobe nicht enthalten
Когда мы имеем дело с формируемыми составными существительными, существуют два возможных способа анализа. Первый способ состоит в том, чтобы считать, что флексия сигнализирует о сложном слове в целом. Такой способ предполагает, что сначала идет сложное слово, а затем словоизменение.
Такой способ предполагает, что сначала идет сложное слово, а затем словоизменение.
Возьмем слово классы, например , и попробуем нарисовать схему его иерархической структуры по первому способу
Abbildung in dieser Leseprobe nicht enthalten
Как мы видели на этой диаграмме, сначала анализируется составное слово классная комната , а затем словоизменение.
Второй способ анализа флективных сложных слов состоит в том, чтобы проанализировать склонение сначала как то, что связано с головой, а затем с остальной частью сложного существительного, зависимым(и). [Katamba and Stonham 2006, 325]
Возьмем то же слово классы и попробуем построить схему его иерархической структуры по второму способу.
[…]
Замаскированные эффекты прайминга составных слов и неслов
Принято 27 декабря 2017 г. Поступила в редакцию 10 июля 2017 г.
В течение многих лет исследователи изучали механизмы, участвующие в чтении морфологически сложных слов. Широко распространено мнение, что сложные слова автоматически разлагаются на морфемные субъединицы на начальных этапах визуального распознавания слов (как первоначально предполагалось 9).0022 Taft & Forster, 1975 ). Было высказано предположение, что сегментация морфологически сложных слов основана на механизме, который идентифицирует и удаляет аффикс, что, в свою очередь, позволяет идентифицировать морфему основы. Однако недавно эта гипотеза была оспорена Грейнджером и Бейерсманном ( 2017 ), предполагающими, что встроенные слова (а не аффиксы) представляют собой первичные единицы чтения, которые инициируют морфологическую сегментацию. Таким образом, наше настоящее исследование было сосредоточено на роли основы, а не аффикса, во время раннего визуального распознавания слов. В частности, наша цель состояла в том, чтобы пролить больше света на механизмы, участвующие в активации слов, встроенных в составные слова и составные неслова.
Широко распространено мнение, что сложные слова автоматически разлагаются на морфемные субъединицы на начальных этапах визуального распознавания слов (как первоначально предполагалось 9).0022 Taft & Forster, 1975 ). Было высказано предположение, что сегментация морфологически сложных слов основана на механизме, который идентифицирует и удаляет аффикс, что, в свою очередь, позволяет идентифицировать морфему основы. Однако недавно эта гипотеза была оспорена Грейнджером и Бейерсманном ( 2017 ), предполагающими, что встроенные слова (а не аффиксы) представляют собой первичные единицы чтения, которые инициируют морфологическую сегментацию. Таким образом, наше настоящее исследование было сосредоточено на роли основы, а не аффикса, во время раннего визуального распознавания слов. В частности, наша цель состояла в том, чтобы пролить больше света на механизмы, участвующие в активации слов, встроенных в составные слова и составные неслова.
Данные, полученные с помощью различных парадигм, позволяют предположить, что обработка составляющих лексем в сложных словах, таких как текст и книга в учебнике , способствует общему процессу распознавания составных слов (обзор см. в Marelli). & Luzzatti, 2012 ). Парадигма маскированного прайминга (Forster & Davis, 1984) сыграла ключевую роль в раскрытии механизмов, участвующих в распознавании морфологически сложных слов. Очень кратко предъявляя сложные первичные стимулы, чтобы единственными видимыми стимулами были морфологически простые цели (например, фермер-ФЕРМА ), участники, как правило, не осведомлены о характере манипуляций с праймингом, считая стратегическое использование отношений основных целей маловероятным (например, Rastle, Davis, Marslen-Wilson, & Tyler, 2000 ; Rastle , Дэвис и Нью, 2004 ). Во многих исследованиях изучалась обработка слов с аффиксами (обзоры см. Amenta & Crepaldi, 2012 ; Rastle & Davis, 2008 ), и результаты показывают, что они быстро сегментируются на основы и аффиксы на долексических стадиях речи. распознавание слов независимо от семантики. Однако очень немногие исследования маскированного прайминга изучали обработку сложных слов.
в Marelli). & Luzzatti, 2012 ). Парадигма маскированного прайминга (Forster & Davis, 1984) сыграла ключевую роль в раскрытии механизмов, участвующих в распознавании морфологически сложных слов. Очень кратко предъявляя сложные первичные стимулы, чтобы единственными видимыми стимулами были морфологически простые цели (например, фермер-ФЕРМА ), участники, как правило, не осведомлены о характере манипуляций с праймингом, считая стратегическое использование отношений основных целей маловероятным (например, Rastle, Davis, Marslen-Wilson, & Tyler, 2000 ; Rastle , Дэвис и Нью, 2004 ). Во многих исследованиях изучалась обработка слов с аффиксами (обзоры см. Amenta & Crepaldi, 2012 ; Rastle & Davis, 2008 ), и результаты показывают, что они быстро сегментируются на основы и аффиксы на долексических стадиях речи. распознавание слов независимо от семантики. Однако очень немногие исследования маскированного прайминга изучали обработку сложных слов. Сложные слова отличаются от производных в одном очевидном, но фундаментальном аспекте: основы сочетаются с основами, а не основы с аффиксами. Таким образом, любые эффекты праймирования структурных соединений не могут быть отнесены к традиционной гипотезе удаления аффиксов. Кроме того, практически во всех этих исследованиях изучалось праймирование сложных слов-мишеней составными простыми числами (например, 9).0192 ферма-ферма ; Крепальди, Растл, Дэвис и Лупкер, 2013 г. ; Дуньябеития, Марин, Авилес, Переа и Каррейрас, 2009 ; Shoolman & Andrews, 2003 ), что прямо противоположно условиям, проверенным в исследованиях несоставных производных, а именно сложных слов, инициирующих симплексные цели (например, фермер-ферма; Beyersmann, Ziegler, et al., 2016). ; Rastle & Davis, 2008 ; Rastle et al., 2000 ; Rastle et al., 2004 ). Учитывая видимость целевого составного слова, эти исследования не могут ответить на вопросы, касающиеся автоматизма морфологической обработки при визуальном распознавании слов.
Сложные слова отличаются от производных в одном очевидном, но фундаментальном аспекте: основы сочетаются с основами, а не основы с аффиксами. Таким образом, любые эффекты праймирования структурных соединений не могут быть отнесены к традиционной гипотезе удаления аффиксов. Кроме того, практически во всех этих исследованиях изучалось праймирование сложных слов-мишеней составными простыми числами (например, 9).0192 ферма-ферма ; Крепальди, Растл, Дэвис и Лупкер, 2013 г. ; Дуньябеития, Марин, Авилес, Переа и Каррейрас, 2009 ; Shoolman & Andrews, 2003 ), что прямо противоположно условиям, проверенным в исследованиях несоставных производных, а именно сложных слов, инициирующих симплексные цели (например, фермер-ферма; Beyersmann, Ziegler, et al., 2016). ; Rastle & Davis, 2008 ; Rastle et al., 2000 ; Rastle et al., 2004 ). Учитывая видимость целевого составного слова, эти исследования не могут ответить на вопросы, касающиеся автоматизма морфологической обработки при визуальном распознавании слов.
Насколько нам известно, только в одном опубликованном исследовании изучалось замаскированное праймирование составными штрихами на составляющих мишенях. Fiorentino и Fund-Reznicek ( 2009 ) нашли эквивалентное праймирование из прозрачных ( чашка ) и непрозрачных ( медовый месяц ) составных слов как для первой, так и для второй составляющей ( чашка-ЧАЙ/чашка-ЧАШКА ). В несоставном контроле прайминг не обнаружен ( window-WIN ). Эти результаты предполагают, что составные слова автоматически сегментируются на их морфемные составляющие без какого-либо влияния семантики, и, следовательно, согласуются с более ранними исследованиями аффиксированных слов с использованием маскированного прайминга. Важно, однако, то, что механизм, который был описан для объяснения эффектов праймирования псевдо-аффиксных слов (например, Corner-corn ; Rastle et al., 2004 ), предполагая, что аффиксы быстро разделяются/отщепляются, очевидно, не может объяснить тип структурных составных первичных эффектов, наблюдаемых Fiorentino и Fund-Reznicek ( 2009 ). Вместо этого эти результаты показывают, что активация встроенных основ успешна только в том случае, если письменное слово может быть исчерпывающе разложено на его морфемные составляющие (как в случае чашка чая и медовый месяц ), и поэтому такая активация не произойдет. с несложными словами, такими как окно . Но какой именно механизм предотвращает активацию встроенного слова win в окне ?
Вместо этого эти результаты показывают, что активация встроенных основ успешна только в том случае, если письменное слово может быть исчерпывающе разложено на его морфемные составляющие (как в случае чашка чая и медовый месяц ), и поэтому такая активация не произойдет. с несложными словами, такими как окно . Но какой именно механизм предотвращает активацию встроенного слова win в окне ?
Одной из теорий, которая дает ответ на этот важный вопрос, является теория активации встроенных слов с выравниванием по краям, предложенная Грейнджером и Бейерсманном ( 2017 ), согласно которой встроенные слова активируются на обоих «краях» цепочки букв (т. е. когда строка начинается или заканчивается встроенным словом). Активация встроенных слов основана на чисто неморфологическом процессе сопоставления входных букв с существующими представлениями целых слов в орфографическом лексиконе. Отчет Грейнджера и Бейерсмана предсказывает, что система чтения быстро идентифицирует встроенные слова независимо от морфологической структуры (например, 9). 0192 чай и чашка в чайная чашка, мед и луна в медовый месяц и выигрыш в окно ). Из-за латерального торможения между целым словом (например, чайная чашка, медовый месяц, окно и т. д.) и встроенными словами (например, чай, чашка меда, луна, выигрыш и т. д.) активация встроенных слов изначально затруднено. Однако из-за принципа полной декомпозиции идентификация встроенных слов облегчается, когда вся последовательность букв может быть полностью разделена на составляющие морфемы. Например, чайная чашка может быть разделена на чайная и чашка, медовый месяц может быть разделена на мед и луна , тогда как для окно принцип полного разложения не работает. Грейнджер и Бейерсманн ( 2017 ) предполагают, что принцип полной декомпозиции обеспечивает усиление активации встроенного слова, что помогает преодолеть латеральное торможение между встроенным словом и целой последовательностью букв, что объясняет, почему значительное праймирование наблюдается в чашка и медовый месяц условия, но не окно состояние.
0192 чай и чашка в чайная чашка, мед и луна в медовый месяц и выигрыш в окно ). Из-за латерального торможения между целым словом (например, чайная чашка, медовый месяц, окно и т. д.) и встроенными словами (например, чай, чашка меда, луна, выигрыш и т. д.) активация встроенных слов изначально затруднено. Однако из-за принципа полной декомпозиции идентификация встроенных слов облегчается, когда вся последовательность букв может быть полностью разделена на составляющие морфемы. Например, чайная чашка может быть разделена на чайная и чашка, медовый месяц может быть разделена на мед и луна , тогда как для окно принцип полного разложения не работает. Грейнджер и Бейерсманн ( 2017 ) предполагают, что принцип полной декомпозиции обеспечивает усиление активации встроенного слова, что помогает преодолеть латеральное торможение между встроенным словом и целой последовательностью букв, что объясняет, почему значительное праймирование наблюдается в чашка и медовый месяц условия, но не окно состояние.
В настоящем исследовании мы опираемся на первоначальную работу Фиорентино и Фунд-Резничек в дальнейшем изучении механизмов, участвующих в чтении сложных слов. Если правда, что морфологическая сегментация сложных слов однозначно основана на структурной информации, то можно было бы ожидать, что праймирование будет наблюдаться не только из простых простых слов из реальных составных слов ( учебник ), но также простых простых слов из составных слов ().0192 стопочная книга ). Поскольку сложные неслова не могут быть сопоставлены с существующим представлением в лексиконе, любое свидетельство прайминга в этих условиях, таким образом, будет четким свидетельством предлексической активации встроенных слов. Более того, если верно то, что «выравнивание по краю» является ключевым фактором, определяющим активацию встроенных слов ( Grainger & Beyersmann, 2017 ), мы должны ожидать значительного и эквивалентного прайминга для слов, когда они встроены в начальную и конечную позиции строки ( Эксперимент 1), но не при встраивании в среднюю позицию струны (Эксперимент 2).
Дополнительная цель нашего исследования состояла в том, чтобы сравнить прайминг из составных неслов ( стопка книг ) и несоставных неслов ( тетрадь ). Гипотеза активации встроенного слова Грейнджера и Бейерсманна ( 2017 ) предсказывает, что в этих условиях активации встроенного слова не препятствует лексическое представление простого числа, не являющегося словом. То есть можно было бы ожидать увидеть прайминг не только в сложном несловесном условии (0193), но и в несоставном несловесном условии ( pimebook-BOOK ). Поскольку pimebook не представлен лексически, он не конкурирует с лексическим представлением встроенного слова book и, следовательно, может облегчить подготовку в этом состоянии. Действительно, в нескольких недавних исследованиях маскированного прайминга сообщалось о сравнимых величинах прайминга для слов, встроенных в аффиксированные и неаффиксированные несловесные праймы ( Beyersmann, Casalis, Ziegler, & Grainger, 2015 9). 0023 ; Beyersmann, Cavalli, Casalis & Colé, 2016 ; Beyersmann & Grainger, 2017 ; Hasenäcker, Beyersmann, & Schroeder, 2016 ; Моррис, Портер, Грейнджер и Холкомб, 2011 ). Бейерсманн, Казалис и др. ( 2015 ), например, сообщили о значительном эффекте прайминга не только тогда, когда цели предшествовало суффиксное слово штрих ( banker-BANK ) или суффикс неслово Prime ( bankify-BANK ), но также и когда оно было которому предшествует несуффиксное простое слово ( банкорд-БАНК ). Более того, когда участников разделили на две группы в зависимости от их индивидуального словарного запаса и навыков правописания, было обнаружено, что участники с высоким уровнем владения продемонстрировали устойчивое праймирование во всех трех основных условиях, тогда как участники с низким уровнем владения показали значительно сниженное праймирование без суффиксов по сравнению с двумя суффиксами. условия (см. также Andrews & Lo, 2013 , для сопоставимых результатов). Учитывая это влияние владения языком на эффекты морфологического прайминга, мы также измерили владение языком участников настоящего исследования.
Важно отметить, что встроенные эффекты прайминга слов не всегда подтверждаются литературой. Например, влиятельное исследование, проведенное ( Longtin & Meunier, 2005 ), сообщило о большем праймировании от простых чисел без суффикса ( bankify-BANK ), чем от простых чисел без суффикса ( bankord-BANK ), тем самым предоставив доказательства в пользу механизм морфо-орфографической сегментации, который не чувствителен к семантике, но чувствителен к морфологической структуре поверхности (аналогичные результаты, хотя и менее четкие, также сообщают Маккормик, Растл и Дэвис, 2009 ). Эти результаты противоречат описанным выше исследованиям прайминга встроенных слов и, таким образом, еще больше подчеркивают необходимость тщательного изучения лежащих в основе механизмов активации встроенных слов.
Эксперимент 1
Метод
Участники
Восемьдесят студентов из Университета Маккуори, все носители английского языка, приняли участие в зачете курса. Перед тестированием все участники получили информацию об исследовании и подписали письменное согласие.
Материалы
Мы выбрали список из 52 сложных слов ( учебник ) из лексической базы данных CELEX ( Baayen, Piepenbrock, & van Rijn, 1993 ), используя ряд критериев отбора. Все составные составляющие были существительными, глаголами или прилагательными (мы исключили кто-нибудь ) и всегда были мономорфными (мы исключили производство стекла , а также псевдо-аффиксные составляющие, такие как масло из пахта и кузов из телохранитель ). Составные слова всегда были прозрачными (например, мы исключили частично непрозрачные составные слова, такие как клавиатура , где наиболее частое использование ключ — это дверной ключ ). Второй компонент соединения никогда не фигурировал в качестве первого компонента (поскольку мы использовали учебник , мы исключили книжная полка ).
На основе сложных слов мы создали два набора стимулов (Приложение А). В наборе 1 составные штрихи были соединены с мишенью, которая была вторым компонентом соединения ( учебник-КНИГА ). В наборе 2 составные простые числа были соединены с целью, которая была первой составляющей соединения (учебник — ТЕКСТ ). Составные простые слова были почти идентичны в наборах 1 и 2, за исключением того, что 5 составных слов пришлось заменить в наборе 2, чтобы избежать целевого повторения. Целевые слова наборов 1 и 2 были сопоставлены по частоте слов, длине и орфографическому соседству (описательная статистика представлена в таблице 1).
Таблица 1
Описательная статистика для простых чисел и целей, использованных в эксперименте 1.
| начальные вложения слов | |||
|---|---|---|---|
| 2-й компонент сложного слова | 2-й компонент сложного неслова | целевое слово | |
| Частота слов | 196,82 | 137. 13 | 145,69 |
| количество слогов | 1.10 | 1,06 | 1.10 |
| количество фонем | 3,37 | 3,33 | 3,27 |
| количество букв | 4,27 | 4,25 | 4.13 |
| орфографическая окрестность | 8,73 | 8.02 | 7,40 |
| фонологическое соседство | 19.44 | 17. 04 | 16,50 |
| финальных вложения слов | |||
| 1-й компонент сложного слова | 1-й компонент сложного неслова | целевое слово | |
| Частота слов | 139,19 | 118,95 | 172,31 |
| количество слогов | 1.10 | 1,04 | 1,08 |
| количество фонем | 3. 21 | 3,29 | 3,33 |
| количество букв | 4.12 | 4.12 | 4.21 |
| орфографическая окрестность | 7.06 | 7,88 | 8,92 |
| фонологическое соседство | 16,79 | 15,71 | 19,38 |
В дополнение к составным словам мы выбрали 52 составных неслова, 52 несоставных несложных слова и 52 несвязанных несвязанных слова. В наборе 1 составные неслова были созданы путем замены первой составляющей составного слова новой составной частью слова ( pimebook-BOOK ), несоставные слова путем замены 1-2 букв в первой составляющей составного слова ( pimebook-BOOK ), а несвязанные несвязанные слова были созданы путем замены второй составляющей составного простого числа на орфографически не связанное мономорфная составляющая ( textjail-BOOK ). В наборе 2 простые числа были созданы путем замены вторых составляющих по тем же принципам, что и в наборе 1 ( textpile-TEXT/textpime-TEXT/jailbook-TEXT ). Составные части сложных слов и составных не слов были одинаковой длины ( учебник против сборник ). Составные части составных простых чисел, не являющихся словами, были выбраны таким образом, чтобы они никогда не встречались в первой или второй позиции составляющих в реальных составных простых числах. Составные части сложных слов и сложных неслов были сопоставлены по частоте, количеству букв, количеству фонем, количеству слогов, орфографическому соседству и фонологическому соседству (см. Таблицу 1). Все переменные, характерные для предмета, были извлечены из базы данных LEXIQUE ( New, Pallier, Brysbaert, & Ferrand, 2004 9).0023).
Для решения задачи лексического решения мы включили 52 несловесные цели ( NESH, NUNE и т. д. .), которые были орфографически правильными и произносимыми и соответствовали по длине реальным словам. Каждой цели, не являющейся словом, предшествовали четыре разных простых числа, которые были структурированы так же, как и простые числа, предшествующие целям слова. В наборе 1 простые числа были созданы путем замены вторых составляющих составного слова, составных неслов и несоставных условий на цель, не являющуюся словом ( textnesh-NESH/pilenesh-NESH/pimenesh-NESH ) по сравнению с несвязанным контролем ( textbrav-NESH ). В наборе 2 простые числа были созданы путем замены первых составляющих ( nunebook-NUNE/nunepile-NUNE/nunepime-NUNE/wostbook-NUNE ). Чтобы избежать повторения целей, мы создали четыре сбалансированных списка.
Процедура
Стимулы предъявлялись в центре светодиодного экрана компьютера с использованием программного обеспечения DMDX ( Forster & Forster, 2003 ). Каждое испытание состояло из 500-мс прямой маски хэш-ключей, затем 50-мс простого числа в нижнем регистре, а затем целевого значения в верхнем регистре. Цель оставалась на месте до тех пор, пока не был сделан ответ или пока не прошло 3 секунды. Участников просили отвечать как можно быстрее и точнее.
Показатели индивидуальных различий
В дополнение к задаче на лексическое решение с замаскированными грунтами каждый участник оценивался по словарному запасу, правописанию, эффективности чтения и тесту на умение читать.
Словарь. The Shipley-2 ( Shipley, Gruber, Martin, & Klein, 2009 ) использовался в качестве словарного теста, состоящего из 40 заданий, сложность которых увеличивалась по мере прохождения теста. Для каждого элемента целевое слово было представлено в верхнем регистре ( РАЗГОВОР ), и участников попросили обвести одно слово из четырех вариантов, которые имели соответствующее значение ( рисовать, есть, говорить, спать ). На выполнение 40 заданий участникам давали до 10 минут.
Правописание. Орфографический тест включал 50 слов (длиной 8–10 букв), выбранных Бертом и Тейтом ( 2002 ). Во-первых, слова были устно представлены. Затем они включались в предложение-носитель для уточнения их значения, а затем повторялись. Участников просили правильно написать каждое слово.
Эффективность чтения. Эффективность чтения оценивалась с помощью подтеста на эффективность чтения слов и фонематического декодирования теста на эффективность чтения слов (TOWRE; Torgesen, Wagner, & Rashotte, 1999 ), форма A. Оба подтеста измеряли количество слов/ участники без слов могли назвать за 45 секунд (для каждого теста), с возрастающей сложностью по мере прохождения теста. Сначала проводился субтест слов на зрение, а затем субтест фонематического декодирования. Список зрительных слов включал 104 слова, а фонематический подтест — 63 неслова. Участников просили прочитать как можно больше слов/неслов как можно быстрее. Оценка для каждого подтеста представляла собой количество слов/неслов, прочитанных правильно в течение 45 секунд.
Оба подтеста оценивались в соответствии с протоколом, описанным Torgeson et al. ( 1999 ). Поскольку TOWRE является американским нормированным тестом, мы внесли некоторые изменения в правила подсчета баллов для подтеста фонематического декодирования. В частности, в дополнение к Torgeson et al. ( 1999 ), мы оценили невербальные ответы участников в фонематическом подтесте как правильные, если они были сочтены правильными в соответствии с данными сравнения австралийских детей, представленными Маринусом, Коненом и Макартуром ( 2013 ).
Умение читать. Расширенная версия теста Castles and Coltheart Test 2 ( Castles et al., 2009 ) применялась для оценки способности участников произносить слова вслух и их способности распознавать слова целиком. Расширенный тест включал в себя еще 45 заданий, которые были выбраны как сложные для взрослых читателей. Участники читают вслух 55 правильных слов ( кот, вытеснение), 55 неправильных слов ( яхта, наследник ) и 55 неслов ( гоп, спогсоуб ), которые предъявлялись по одному, в смешанном порядке. Степень сложности постепенно увеличивалась по мере выполнения задания.
Результаты и обсуждение
Лексические решения словесных целей анализировались следующим образом. Неправильные ответы были удалены из анализа времени реакции (ВР) (2,1% всех данных). Обратные ВУ (1/ВУ) рассчитывались для каждого участника, чтобы скорректировать перекос распределения ВУ, и использовались во всех анализах. Не было времени реакции меньше 300 мс или больше 3000 мс, которое нужно было исключить из анализа. ВУ и частоты ошибок представлены в таблице 2.
Таблица 2
В таблице 2 показано среднее время лексического решения (мс) и частота ошибок (%) для целевых слов в эксперименте 1, усредненные по участникам. Стандартные ошибки указаны в скобках.
| Состояние | Время реакции | Частота ошибок | Пример |
|---|---|---|---|
| Первая составляющая | |||
| составное слово | 544 (10) | 1,3 (0,5) | учебник-ТЕКСТ |
| составное-неслово | 558 (11) | 2,5 (0,8) | Текстиль-ТЕКСТ |
| несоставное неслово | 557 (11) | 2,5 (0,9) | textpime-ТЕКСТ |
| несвязанный | 569 (10) | 2,7 (0,8) | тюрьма-ТЕКСТ |
| Второй избирательный округ | |||
| составное слово | 545 (10) | 1,5 (0,5) | Учебник-КНИГА |
| составное-неслово | 557 (12) | 1,2 (0,4) | Стопкобук-КНИГА |
| несоставное неслово | 548 (9) | 3,1 (0,9) | pimebook-BOOK |
| несвязанный | 569 (14) | 1,9 (0,5) | textjail-BOOK |
Мы использовали линейное моделирование смешанных эффектов для выполнения основного анализа ( Baayen, 2008 ; Baayen, Davidson, & Bates, 2008 ). Фиксированные и случайные эффекты включались только в том случае, если они значительно улучшали соответствие модели в процедуре обратного пошагового выбора модели. Модели были выбраны с использованием критерия логарифмического отношения правдоподобия хи-квадрат с регулярной оценкой параметра максимального правдоподобия. Пробный заказ был включен для контроля продольных эффектов задачи, таких как усталость или привыкание. Чтобы оценить, были ли полученные эффекты модулированы индивидуальными различиями в словарном запасе, правописании или навыках чтения, были стандартизированы оценки словарного запаса, правописания и навыков чтения. Составной показатель чтения (ReadZ) был рассчитан путем усреднения стандартизированных баллов двух тестов чтения. Составные показатели ReadZ и оценки стандартизированного правописания (SpellZ) и словарного запаса (VocabZ) сильно коррелировали (ReadZ и SpellZ: 9 баллов).0192 r = 0,684; ReadZ против VocabZ: r = 0,480; SpellZ против VocabZ: r = 0,454). Таким образом, первая использованная мера индивидуальных различий фиксировала общую дисперсию между ReadZ, SpellZ и VocabZ (LanguageProficiencyZ) и имела высокую положительную корреляцию со всеми тремя мерами (чтение: r = 0,908; правописание: r = 0,842, словарный запас: r = 0,737). Были использованы три дополнительных показателя индивидуальных различий: один, который фиксировал разницу между ReadZ и SpellZ (ReadSpellDiffZ), другой, который фиксировал разницу между ReadZ и VocabZ (ReadVocabDiffZ), и один, который фиксировал разницу между SpellZ и VocabZ (SpellVocabDiffZ). ReadSpellDiffZ показал противоположные направления взаимосвязи с чтением ( r = 0,114) и написание ( r = –0,647). ReadVocabDiffZ показал противоположные направления связи с чтением ( r = 0,312) и словарным запасом ( r = –0,684). SpellVocabDiffZ показал противоположные направления связи с орфографией ( r = 0,522) и словарным запасом ( r = –0,522).
Линейная модель смешанных эффектов, реализованная в пакете lme4 ( Bates, Maechler, Bolker, & Walker, 2014 ) в статистическом программном обеспечении R (версия 3.0.3; 9).0022 R Development Core Team, 2008 ), был создан с семью факторами с фиксированными эффектами (простой тип: составное слово, составное неслово, несоставное неслово, несвязанное; LanguageProficiencyZ; ReadSpellDiffZ; ReadVocabDiffZ; SpellVocabDiffZ; позиция встроенного слова: первая составляющая, вторая составляющая; порядок испытаний), их взаимодействия и два фактора случайных эффектов (случайные перехваты для субъектов и предметов). Все непрерывные переменные были центрированы (например, пробный порядок, LanguageProficiencyZ, ReadSpellDiffZ, ReadVocabDiffZ и SpellVocabDiffZ). И здесь, и далее значения относительно p определяли с помощью пакета lmerTest ( Kuznetsova, Brockhoff, & Christensen, 2014 ). Модель была переработана после исключения точек данных, стандартизированные остатки которых превышали 2,5 по абсолютной величине (2,6%; см. Baayen, 2008 ). Анализ RT выявил значительный праймирующий эффект в условиях составного слова (90 192 t 90 193 = 6,63, 90 192 p 90 193 < 0,001), в состоянии составного слова (90 192 t 90 193 = 3,48, 90 192 p 90 193 < 0,001) и в несоставное несловное условие ( т = 4,22, р <. 001), по сравнению с несвязанным контролем. Кроме того, прайминг был значительно выше в составном слове, чем в условиях составного неслова или несоставного неслова ( t = 2,39, p = 0,017; t = 6,63, p <0,001). но не было существенной разницы между праймингом в условиях составного-неслова и несоставного неслова ( t = 0,75, p = 0,451). LanguageProficiencyZ, SpellVocabDiffZ и ReadVocabDiffZ не дали каких-либо значительных эффектов или взаимодействий. Тем не менее, анализ RT показал, что прайминг в состоянии сложного слова значительно модулируется с помощью SpellReadDiffZ (рис. 1), что указывает на то, что участники, чьи навыки чтения были выше, чем их навыки правописания, демонстрировали большее праймирование в состоянии составного слова по сравнению с несвязанным условием (9). 0192 t = 2,30, p = 0,021). Был также значительный эффект пробного заказа ( t = 2,47, p = 0,014). Никакие другие эффекты не были значительными.
Рисунок 1
Эффекты прайминга для целей, которым предшествуют составные слова, составные-неслова и несоставные несловные штрихи (по отношению к несвязанному контрольному условию), в зависимости от индивидуальных различий в навыках чтения и правописания. Положительные оценки представляют людей, которые лучше читают, чем пишут. Отрицательные оценки представляют людей, которые пишут лучше, чем читают.
Анализ ошибок следовал той же логике, что и анализ RT. Мы применили предположение о биномиальной дисперсии к двоичным данным пробного уровня, используя функцию glmer как часть R-пакета lme4 . Был значительный эффект пробного порядка ( z = 2,83, p = 0,005) и значительный эффект SpellVocabDiffZ ( z = 2,11, p = 0,035), что позволяет предположить, что участники с более высоким правописанием, чем словарный запас допустил меньше ошибок. Никакие другие эффекты не были значительными.
Результаты эксперимента 1 очевидны. Прайминг получается независимо от того, сопровождается ли встроенная цель реальной морфемой (например, учебник-КНИГА и сборник-книга ) или неморфемным окончанием (например, pimebook-КНИГА ), и независимо от position (т.е. в начальной или конечной позиции строки: учебник-BOOK/учебник-ТЕКСТ ). Эффект прайминга, наблюдаемый в условии pimebook-BOOK , согласуется с предыдущими исследованиями прайминга встроенных слов (9).0022 Beyersmann et al., 2015 ; Beyersmann, Cavalli, et al., 2016 ; Beyersmann & Grainger, 2017 ; Hasenäcker et al., 2016 ; Моррис и др., 2011 ). Более того, в условиях сложного слова было получено более сильное праймирование по сравнению с двумя условиями праймирования, не являющимися словами, что было особенно заметно у людей, которые лучше читали, чем писали (мы возвращаемся к этому пункту в разделе «Общие обсуждения»). Самое главное, результаты Эксперимента 1 предполагают, что активация встроенных слов основана на полностью неморфологическом процессе, который согласуется с выводами Грейнджера и Бейерсманна (9).0022 2017 ) Гипотеза активации встроенного слова. Встроенные слова активируются простым сопоставлением букв входной строки с существующими представлениями целых слов в орфографическом лексиконе, независимо от морфологической структуры.
Однако, если правда, что активация встроенных слов основана на явно неморфологическом процессе, возникает один важный вопрос: почему Fiorentino и Fund-Reznicek ( 2009 ) не смогли наблюдать прайминг в окне . ПОБЕДА состояние? Мы предполагаем, что отсутствие прайминга в этом состоянии можно объяснить латеральным торможением между лексическими репрезентациями window и win . Конечно, между непрозрачными составными словами (например, бабочка ) и встроенными в них словами (например, масло ) также будет иметь место латеральное торможение. Однако здесь присутствие второго компонента (например, муха ) усилит активацию первого компонента ( сливочное масло ) и, следовательно, производить грунтовку ( Grainger & Beyersmann, 2017 ).
Цель эксперимента 2 заключалась в дальнейшем манипулировании положением встроенных слов. В частности, наша цель состояла в том, чтобы более подробно изучить принцип «выравнивания по краям» встроенного текстового процессора. Грейнджер и Бейерсманн ( 2017 ) предположили, что встроенные слова получают наибольшую восходящую поддержку, когда они выровнены по краю, потому что основы реже встречаются внутри и потому что слова с выравниванием по краю выигрывают от наличия пробела рядом с одной буквой, который может быть используется в качестве опорной точки при орфографической обработке ( Fischer-Baum, Charny, & McCloskey, 2011 ). Эксперимент 2 был разработан для проверки этой гипотезы.
Эксперимент 2
Цель эксперимента 2 состояла в том, чтобы сравнить встроенное праймирование слов с выравниванием по краям (например, pimebook-BOOK ) с условием встраивания в середине (например, pibookme-BOOK ) и внешним встраиванием. состояние (например, bopimeok-BOOK ). Если активация встроенных слов происходит просто из-за низкоуровневых орфографических преобразований букв в слова, мы ожидаем, что количество прайминга должно определяться предсказанным количеством орфографического перекрытия между основным и целевым. Прогнозируемое количество орфографических перекрытий различается в зависимости от различных схем орфографического кодирования (см. программное обеспечение Match Calculator, версия 1.9)., запрограммированный Колином Дж. Дэвисом). 1 Модель бинарной открытой биграммы ( Grainger & van Heuven, 2003 ) создает сопоставимые пропорции орфографического перекрытия для условий с выравниванием по краю и по середине и относительно меньшее перекрытие во внешнем условии. Таким образом, эта модель предсказывает значительно меньшую загрузку во внешнем состоянии по сравнению с выравниванием по краю и средним состоянием. Модель открытой биграммы с перекрытием ( Grainger, Granier, Farioli, Van Assche, & van Heuven, 2006 9). 0023), модель SERIOL ( Whitney & Cornelissen, 2008 ) и модель SOLAR ( Davis, 2010 ) генерируют сопоставимые пропорции орфографического перекрытия во всех трех условиях и, следовательно, предсказывают сопоставимые количества прайминга во всех трех условиях. Однако, если верно то, что система чтения отдает приоритет буквам, которые примыкают либо к первой, либо к последней букве строки ( Grainger & Beyersmann, 2017 ), мы ожидаем увидеть значительно больше прайминга на краях. выровненное состояние по сравнению со средними и внешними контрольными условиями, с сопоставимыми величинами подготовки между средними и внешними условиями.
Метод
Участники
Сорок семь студентов из Университета Нового Южного Уэльса, все носители английского языка, приняли участие для получения кредита за курс.
Материалы
Мы использовали точно такие же несоставные неслова с вложениями, выровненными по краям в конце слова (например, pimebook-BOOK ), что и в эксперименте 1 (см. Приложение A). Кроме того, мы создали среднее встроенное условие (например, pibookme-BOOK ) и внешнее встроенное условие (например, бопимеок-КНИГА ). Некоторые простые числа были немного изменены, чтобы буквы цели не повторялись во второй составляющей простого числа. Наконец, мы использовали элементы несвязанного контрольного условия эксперимента 1, но первая составляющая была заменена неморфемной первой составляющей несоставного простого числа (например, fraltdraft вместо motordraft ). Все элементы перечислены в Приложении B.
Процедура
Процедура маскированного задания на прайминг была идентична той, что использовалась в Эксперименте 1. Поскольку Эксперимент 1 не показал доказательств влияния словарного запаса, чтения и морфологического понимания на маскированное не- сложного прайминга, мы не оценивали индивидуальные показатели мастерства в эксперименте 29.0006
Результаты и обсуждение
Лексические решения словесных целей анализировались следующим образом. Неправильные ответы были удалены из анализа времени реакции (ВР) (5,4% всех данных). Обратные ВУ (1/ВУ) рассчитывались для каждого участника, чтобы скорректировать перекос распределения ВУ, и использовались во всех анализах. Время реакции менее 300 мс или более 3000 мс было исключено из анализа (1,2% данных). Данные от двух участников и одного элемента были исключены, поскольку частота ошибок превышала 20%. ВУ и коэффициенты ошибок представлены в таблице 3.
Таблица 3
В таблице 3 показано среднее время лексического решения (мс) и частота ошибок (%) для целевых слов в эксперименте 2, усредненные по участникам. Стандартные ошибки указаны в скобках.
| Состояние | Время реакции | Частота ошибок | Пример |
|---|---|---|---|
| с выравниванием по краю | 552 (12) | 2,8 (0,9) | pimebook-BOOK |
| внешний | 561 (11) | 6,8 (1,1) | Бопимеок-КНИГА |
| середина | 563 (12) | 5,2 (1,0) | книга-книга |
| несвязанный | 564 (12) | 5,6 (0,9) | pimejail-BOOK |
Как и в эксперименте 1, мы использовали линейное моделирование смешанных эффектов для выполнения основного анализа ( Baayen, 2008 ; Baayen et al. , 2008 ). Линейная модель смешанных эффектов была создана с двумя фиксированными факторами эффектов (основной тип: выровненный по краю, средний, внешний, несвязанный; пробный порядок) и двумя факторами случайных эффектов (случайные перехваты для субъектов и предметов). Все непрерывные переменные были центрированы. Модель была переработана после исключения точек данных со стандартизованными остатками более 2,5 по абсолютной величине (2,5%; см. Baayen, 2008 ). Анализ RT выявил значительный эффект прайминга в условии встроенного слова с выравниванием по краю (9).0192 t = 2,44, p = 0,015), но не в состоянии средней заделки ( t = 0,24, p = 0,811) или внешней заделке ( t = 0,38, p = 0,708), по отношению к несвязанному контролю. Кроме того, результаты показали, что прайминг был значительно выше в условиях выравнивания по краю, чем в средних или внешних условиях ( t = 2,69, p = 0,007; t = 2,05, p = 0,040). , но не было существенной разницы между грунтовкой в средних и внешних условиях ( t = 0,61, p = 0,539). Был также значительный эффект пробного заказа ( t = 2,96, p = 0,003). Никакие другие эффекты не были значительными.
Анализы ошибок выявили ту же закономерность, что и анализы RT. Был значительный эффект прайминга в условиях встроенного слова с выравниванием по краям ( z = 2,05, p = 0,041), но не в условиях встраивания посередине ( z = 0,14, p = 0,888). ) или внешнее вложенное условие ( t = 1,24, p = 0,216) относительно несвязанного контроля. Более того, результаты показали, что прайминг был значительно выше в условиях выравнивания по краю, чем в средних или внешних условиях ( z = 2,17, p = 0,030; z = 3,17, p = 0,002). , но не было существенной разницы между грунтовкой в средних и внешних условиях ( z = 1,10, p = 0,271). Никакие другие эффекты не были значительными.
Результаты эксперимента 2 подтверждают эффекты праймирования второй составляющей, обнаруженные для несоставных простых чисел, не являющихся словами (например, pimebook-BOOK ) в эксперименте 1. Важно отметить, что значительные эффекты прайминга, обнаруженные в этом состоянии в эксперименте 2, контрастируют с незначительными эффектами прайминга, наблюдаемыми со штрихами, которые имеют то же количество букв, что и цели, но либо выровнены по краю, либо несмежные (например, bopimeok-BOOK ) или смежные, но не выровненные по краю (например, pibookme-BOOK ). Первый результат свидетельствует о том, что орфографического перекрытия самого по себе недостаточно для создания эффектов прайминга, а второй результат свидетельствует о том, что наличия целевого слова, встроенного в штрих, недостаточно для создания эффектов прайминга. Полный набор результатов указывает на выравнивание по краям и лексический статус букв, общих для простого и целевого букв, как на два ключевых фактора, определяющих эффекты прайминга, наблюдаемые в эксперименте 1.
General Discussion
Основная цель нашего исследования состояла в том, чтобы исследовать процессы активации встроенных слов, действующие во время обработки сложных слов и составных неслов, с использованием маскированного прайминга в сочетании с задачей лексического решения. В эксперименте 1 значительные эффекты прайминга по сравнению с неродственными простыми числами наблюдались для составных простых слов ( учебник-КНИГА/учебник-ТЕКСТ ), составных простых чисел без слов ( стопка книг-КНИГА/текстовая стопка-ТЕКСТ ) и несоставных простых чисел без слов. ( pimebook-BOOK/textpime-TEXT ), и эти эффекты прайминга не отличались для первого и второго компонентов. В эксперименте 2 значительные эффекты прайминга были обнаружены в условии встроенного слова с выравниванием по краю (например, pimebook-BOOK ), но не в условии встраивания посередине (например, pibookme-BOOK ) или внешнем вложенном условии. (например, bopimeok-BOOK ).
Первый ключевой результат эксперимента 1 — эквивалентное праймирование, наблюдаемое для составных простых чисел, не являющихся словами ( pimebook-BOOK ) и несоставные несловесные простые числа ( pimebook-BOOK ). Это повторяет встроенные эффекты прайминга слов, ранее полученные с производными простыми числами, не являющимися словами (например, flexify против flexint ; Beyersmann et al., 2015 ; Morris et al., 2011 ), и, таким образом, указывает на важность механизмы активации встроенного слова, которые работают независимо от того, встречается ли встроенное слово в сочетании с реальным словом ( книга в блокноте ) или неслове ( книга в блокноте ). В отличие от Beyersmann et al. ( 2015 ), однако нам не удалось обнаружить какого-либо влияния владения языком на несоставные эффекты праймирования неслов. Важно отметить, что эксперимент 2 демонстрирует, что прайминг достигается только для встроенных слов, выровненных по краям (например, book в pimebook ), а не для встроенных в середине (например, pibookme ) или внешних встроенных позиций (например, 9). 0192 bopimeok ), предполагая, что система чтения отдает приоритет активации встроенных слов, выровненных по краю. Простое объяснение важной роли выравнивания по краям при обработке печатного текста заключается в том, что пробелы, окружающие написанные слова, могут предоставлять привилегированные точки привязки для сопоставления букв и слов (более подробный план этого предложения см. Grainger & Beyersmann, 2017 ; см. также Fischer-Baum et al., 2001, для связанного предложения схемы кодирования «оба края»).
Второй ключевой вывод заключается в том, что величина прайминга была одинаковой, независимо от того, было ли целевое слово первой или второй составляющей простого числа ( учебник — КНИГА против учебник — ТЕКСТ ). Этот результат совместим с предыдущими исследованиями по обработке сложных текстов ( Crepaldi et al., 2013; ; Duñabeitia, Laka, Perea, & Carreiras, 2009; ; Duñabeitia, Marín, et al. , 2009; ; Libbon, Gibson). , Юн и Сандра, 2003 г. ; Монселл, 1985 ; Сандра, 1990 ; Шулман и Эндрюс, 2003 ; Zwitserlood, 1994 ), и предполагает, что обе составляющие составного слова в равной степени способствуют лексическому доступу (но см. более важный). В отличие от префиксов и суффиксов, встроенные слова не подвержены позиционным ограничениям, и это может объяснить, почему идентификация основных морфем не зависит от позиции (9).0022 Crepaldi et al., 2013 ). Этот вывод представляет собой важное доказательство против любого смещения последовательной обработки от начала до конца, которое может повлиять на распознавание сложных слов (сходящиеся доказательства см. также Bowers, Davis, & Hanley, 2005 ). Наши результаты также сходятся с предыдущими данными о встроенных механизмах активации слов в мономорфных не словах (например, пожелание в dwish; Davis & Taft, 2005 ; Taft et al. , 2017 ). В соответствии с нашими текущими выводами Taft et al. ( 2017 ) предполагают, что выравнивание по краям является важным фактором, лежащим в основе встроенной обработки текста (т. е. начальные и конечные согласные имеют приоритет при назначении букв их позиции), тогда как праймирование не ожидается для средних или внешних встроенных слов. из-за нарушения структуры начало + гласный + код цели.
Эксперимент 1 выявил третий ключевой результат, а именно то, что большее праймирование было получено в условии составного слова по сравнению с двумя простыми условиями, не являющимися словами. Это говорит о том, что представление составного слова простое целым словом способствовало эффекту прайминга. Тот факт, что Фиорентино и Фонд-Резничек ( 2009 ) не обнаружил разницы между прозрачными и непрозрачными простыми словами составных слов, что позволяет предположить, что разница между составными простыми словами и составными простыми числами без слов, наблюдаемая в нашем исследовании, обусловлена представлениями составного слова в форме целого слова, а не морфосемантическими представлениями. Однако наше наблюдение о том, что прайминг в условиях сложного слова был особенно выражен у тех участников, которые лучше читали, чем правильно писали (рис. 1), предполагает, что в будущих исследованиях следует изучить роль владения языком в определении относительного размера прозрачного и непрозрачного составного слова. праймирование перед исключением роли морфосемантических представлений. Очень важными в отношении этой возможности являются результаты, сообщенные Эндрюсом и Ло (9).0022 2013 ), которые обнаружили, что люди с более высоким уровнем правописания по сравнению со словарным запасом демонстрировали более сильное праймирование от непрозрачных производных простых слов ( угол-CORN ). В соответствии с Эндрюсом и Ло ( 2013 ), наши настоящие результаты показывают, что относительная орфография участников модулирует прайминг. Другими словами, те люди, у которых было относительно плохое правописание, как правило, в большей степени полагались на обработку всего слова, что также имело место в случае с Эндрюсом и Ло (9). 0022 2013 ).
Наши результаты, касающиеся влияния уровня владения языком, согласуются с гипотезой о том, что участники, которые лучше читают, чем правописание, уделяют больше внимания прямому доступу к печатным орфографическим представлениям целых слов по сравнению с процессами морфо-орфографической сегментации. Таким образом, эти участники получат больше пользы от лексического представления реальных составных слов ( учебник ), по-видимому, потому, что они будут особенно опытны в быстром сопоставлении строк входных букв с соответствующими представлениями целых слов. С другой стороны, те участники, которые лучше писали, чем читали, были менее эффективны в сопоставлении полной цепочки букв с ее представлением всего слова и, следовательно, в большей степени полагались на механизмы морфо-орфографической сегментации.
Важно отметить, что настоящие данные обеспечивают дальнейшую поддержку встроенных механизмов активации слов, работающих на уровне представлений целых слов. Точнее, наши результаты позволяют нам исключить объяснение эффектов прайминга встроенных слов с точки зрения перекрытия букв более низкого уровня между праймом и целью. Если бы орфографическое перекрытие, независимо от того, образуют ли перекрывающиеся буквы слово, было фактором, определяющим эффекты праймирования встроенных слов, то мы должны были бы наблюдать подобное праймирование от несмежных простых чисел (например, 9).0192 bopimeok-BOOK ) в эксперименте 2. Конечно, можно возразить, что несмежное орфографическое перекрытие не является подходящим сравнением и что более подходящее сравнение может включать в себя непрерывные буквы в так называемых частичных простых числах (например, ). пимехант-СЛОН ). 2 Хотя мы согласны с тем, что будущие эксперименты должны исследовать эту возможность, мы также хотели бы отметить, что неспособность найти эффект частичного прайминга в этих условиях не дает убедительных доказательств того, что прайминг встроенного слова управляется лексически, поскольку частичное простое число состоит из четырех букв. из восьми с целью, тогда как встроенное слово prime имеет четыре буквы из четырех. С другой стороны, обнаружение значительного прайминга с такими частичными простыми числами заставило бы нас пересмотреть основанную на словах интерпретацию нынешних составных эффектов прайминга. Наконец, было показано, что больший эффект маскированного прайминга наблюдается для встроенных слов со многими морфологическими членами семьи по сравнению со встроенными словами без морфологических членов семьи (9).0022 Beyersmann & Grainger, 2017 ), что также наводит на мысль о лексическом локусе эффекта праймирования встроенных слов.
В совокупности настоящие результаты в дополнение к данным, полученным в ходе предыдущих исследований с использованием различных парадигм (например, Andrews, Miller, & Rayner, 2004 ; Hyönä, Bertram, & Pollatsek, 2004 ; Pollatsek, Hyönä, & Bertram, 2000 ; Zwitserlood, 1994 ), согласуются с параллельными моделями двойного маршрута, которые обеспечивают одновременный доступ как к полнословным представлениям сложных слов, так и к представлениям вложенных в них морфем (9). 0022 Baayen & Schreuder, 1999 ; Bertram & Hyönä, 2003 ; Дипендале, Сандра и Грейнджер, 2009 ). Однако также возможно, что дополнительное облегчение в реальном сложном состоянии в Эксперименте 1 происходит от морфологически опосредованной активации репрезентации целого слова, а не от параллельного маршрута обработки всего слова. Что наиболее важно, наши данные свидетельствуют о том, что встроенные слова ( книга ) активируются, когда они встроены по краям цепочки букв, независимо от того, встречаются ли они в сочетании с реальной морфемой (9).0192 сборник ) или неморфемный компонент ( справочник ). Таким образом, наши результаты указывают на важность встроенных механизмов активации слов во время сложной обработки текстов в соответствии с недавним предложением Грейнджера и Бейерсманна ( 2017 ).
Заявление о доступности данных
Может ли JoC помочь мне сделать данные доступными на их веб-сайте? Если это возможно, я предоставлю данные в формате Excel по электронной почте, чтобы JoC мог сделать их доступными в Интернете.
Дополнительный файл
Дополнительный файл для этой статьи можно найти следующим образом:
Файлы данных 1 и 2
Штрихи и мишени, использованные в экспериментах 1 и 2. DOI: https://doi.org/10.6084/m9 .figshare.5797338
Примечания
1 Это приложение доступно на веб-сайте Колина Дэвиса: http://www.pc.rhul.ac.uk/staff/c.davis/utilities/matchcalc/index.htm.
2 Мы благодарим анонимного рецензента за это предложение.
Благодарности
Это исследование проводилось при поддержке Института исследования мозга и языка (BLRI, ANR-11-LABX-0036) и Института конвергенции ILCB (ANR-16-CONV-0002). Он получил поддержку со стороны правительства Франции под управлением Национального агентства исследований Франции (ANR-15-FRAL-0003-01) и Инициативы передового опыта Экс-Марсельского университета (A*MIDEX). Мы благодарим Николаса Бэдкока, Саскию Конен и Еву Маринус за предоставление доступа к расширенной версии теста Castles and Coltheart Test 2, а также Корнелию Ван Шерпенберг за помощь в сборе данных.
Конкурирующие интересы
У авторов нет конкурирующих интересов, о которых следует заявлять.
Каталожные номера
Амента, С. и Крепальди, Д. (2012). Морфологическая обработка, какой мы ее знаем: аналитический обзор морфологических эффектов визуальной идентификации слов. Frontiers in Psychology 3: 1–12, DOI: https://doi.org/10.3389/fpsyg.2012.00232
Эндрюс, С. и Ло, С. (2013). Является ли морфологическое праймирование более сильным для прозрачных слов, чем для непрозрачных? Это зависит от индивидуальных различий в правописании и словарном запасе. Journal of Memory & Language 68: 279–296, DOI: https://doi.org/10.1016/j.jml.2012.12.001
Эндрюс, С. , Миллер, Б. и Райнер, К. (2004). Движения глаз и морфологическая сегментация сложных слов: Мышь в мышеловке.
 Европейский журнал когнитивной психологии 16: 285–311, DOI: https://doi.org/10.1080/09541440340000123
Европейский журнал когнитивной психологии 16: 285–311, DOI: https://doi.org/10.1080/09541440340000123 Баайен, Р. Х. (2008 г.). Анализ лингвистических данных: практическое введение в статистику с использованием R . Кембридж: Издательство Кембриджского университета, DOI: https://doi.org/10.1017/CBO9780511801686
Baayen, RH , Davidson, DJ и Bates, DM (2008). Моделирование смешанных эффектов со скрещенными случайными эффектами для предметов и предметов. Journal of Memory and Language 59: 390–412, DOI: https://doi.org/10.1016/j.jml.2007.12.005
Baayen, R.H. , Piepenbrock, R. и van Rijn, H. (1993). Лексическая база данных CELEX (CD-ROM).
Baayen, R.H. и Schreuder, R. (1999). Война и мир: морфемы и полные формы в неинтерактивной модели параллельного двойного маршрута активации.
Мозг и язык 68(1–2): 27–32, DOI: https://doi.org/10.1006/brln.1999.2069Бейтс, Д. , Махлер, М. , Болкер, Б. и Уокер, С. (2014). lme4: линейные модели смешанных эффектов с использованием Eigen и S4. Пакет R версии 1.1-5. Получено с: http://CRAN.R-project.org/package=lme4.
Bertram, R. и Hyönä, J. (2003). Длина сложного слова изменяет роль морфологической структуры: данные по движениям глаз при чтении коротких и длинных финских сложных слов. Journal of Memory & Language 48: 615–634, DOI: https://doi.org/10.1016/S0749-596X(02)00539-9
Beyersmann, E. , Casalis, S. , Ziegler, JC и Grainger, J. (2015). Владение языком и морфо-орфографическая сегментация. Psychonomic Bulletin & Review 22: 1054–1061, DOI: https://doi.
org/10.3758/s13423-014-0752-9Бейерсманн, Э. , Cavalli, E. , Casalis, S. и Colé, P. (2016). Встроенные эффекты прайминга основы в префиксных и суффиксных псевдословах. Научные исследования чтения 20(3): 220–230, DOI: https://doi.org/10.1080/10888438.2016.1140769
Beyersmann, E. и Grainger, J. (2017). Поддержка из морфологического семейства при извлечении стебля. Журнал экспериментальной психологии: обучение, память и познание , Предварительная онлайн-публикация.
Beyersmann, E. , Ziegler, J. C. , Castles, A. , Coltheart, M. , Kezilas, Y. и Grainger, J.
3 (3). Морфо-орфографическая сегментация без семантики. Psychonomic Bulletin & Review 23: 533–539, DOI: https://doi.org/10.Бауэрс, Дж. С. , Дэвис, С. Дж. и Hanley, DA (2005). Автоматическая семантическая активация вложенных слов: Есть ли в «этом» «шапка»?. Journal of Memory & Language 52: 131–143, DOI: https://doi.org/10.1016/j.jml.2004.09.003
Берт, Дж. и Тейт, Х. (2002). Предоставляет ли лексикон для чтения орфографические представления для правописания? Journal of Memory and Language 46: 518–543, DOI: https://doi.org/10.1006/jmla.2001.2818
Castles, A. , Coltheart, M. , Larsen, L. , Jones, P. , Saunders, S. и McArthur, G. (2009). Оценка основных компонентов чтения: пересмотр теста Каслса и Колтхарта с новыми нормами. Австралийский журнал проблем с обучением 14(1): 67–88, DOI: https://doi.
org/10.1080/194041503435 Крепальди, Д. , Растле, К. , Davis, CJ и Lupker, SJ (2013). Повсюду видим основы: независимая от позиции идентификация морфем основы. Journal of Experimental Psychology: Human Perception and Performance 39(2): 510–525, DOI: https://doi.org/10.1037/a0029713
Дэвис, CJ (2010). Модель пространственного кодирования визуальной идентификации слов. Психологический обзор 117: 713, 758.DOI: https://doi.org/10.1037/a0019738
Davis, CJ и Taft, M. (2005). Больше слов по соседству: Вмешательство в лексическое решение из-за удаления соседей. Psychonomic Bulletin & Review 12(5): 904–910, DOI: https://doi.org/10.3758/BF03196784
Diependaele, K. , Sandra, D. и Grainger, J. (2009).
Семантическая прозрачность и замаскированное морфологическое праймирование: случай слов с префиксом. Память и познание 37: 895–908, DOI: https://doi.org/10.3758/MC.37.6.895 Duñabeitia, JA , Laka, I. , Perea, M. и Carreiras, M. (2009). Милкман такой же супергерой, как Бэтмен? Составляющий морфологический прайминг в сложных словах. Европейский журнал когнитивной психологии 21(4): 615–640, DOI: https://doi.org/10.1080/09541440802079835
Дуньябеития, Дж. А. , Марин, А. , Авилес, А. , Переа, М. и Каррейрас, М. (2009). Учредительные эффекты прайминга: свидетельство сохраненной морфологической обработки у здоровых старых читателей. Европейский журнал когнитивной психологии 21: 283–302, DOI: https://doi.org/10.1080/09541440802281142
Фиорентино, Р.
и Фонд-Резничек, Э. (2009). Маскированное морфологическое праймирование составляющих соединений. The Mental Lexicon 4(2): 159–193, DOI: https://doi.org/10.1075/ml.4.2.01fio Fischer-Baum, S. , Charny, J. и McCloskey, M. (2011). Двухгранное представление положения буквы при чтении. Psychonomic Bulletin & Review 18(6): 1083–1089, DOI: https://doi.org/10.3758/s13423-011-0160-3
Forster, K.I. и Forster, JC (2003). DMDX: программа отображения Windows с точностью до миллисекунды. Методы исследования поведения, инструменты и компьютеры 35(1): 116–124, DOI: https://doi.org/10.3758/BF03195503
Грейнджер, Дж. и Бейерсманн, Э. (2017). Росс, BH изд. Активация встроенного слова с выравниванием по краю инициирует морфо-орфографическую сегментацию.
Психология обучения и мотивации , : 285–317, DOI: https://doi.org/10.1016/bs.plm.2017.03.009Грейнджер, Дж. , Granier, J.P. , Farioli, F. , Van Assche, E. и van Heuven, WJB (2006). Информация о положении буквы и восприятие печатного слова: ограничение начального положения относительного положения. Journal of Experimental Psychology-Human Perception and Performance 32(4): 865–884, DOI: https://doi.org/10.1037/0096-1523.32.4.865
Grainger, J. и van Heuven, WJB (2003). Моделирование кодирования положения букв при восприятии печатного слова. В: Bonin, P. ed. Ментальный лексикон . Нью-Йорк: Nova Science, стр. 1–23.
Hasenäcker, J. , Beyersmann, E. и Schroeder, S. (2016). Маскированный морфологический прайминг у немецкоязычных взрослых и детей: данные о распределении времени ответа.
Frontiers in Psychology 7: 929. DOI: https://doi.org/10.3389/fpsyg.2016.00929Хёнэ, Дж. , Бертрам, Р. и Полласек, А. (2004). Идентифицируются ли длинные составные слова серийно по своим составляющим? Данные исследования изменения дисплея в зависимости от движения глаз. Память и познание 32: 523–532, DOI: https://doi.org/10.3758/BF03195844
Кузнецова, А. , Брокхофф, П. Б. и Кристенсен, Р. Х. Б. (2014). lmerTest: тесты на наличие случайных и фиксированных эффектов для линейных моделей со смешанными эффектами (объекты lmer пакета lme4): версия пакета R 2.0–6, http://CRAN.R-project.org/package=lmerTest
Либбен, Г. , Гибсон, М. , Юн, Ю.-Б. и Сандра, Д. (2003 г.). Сложный перелом: роль семантической прозрачности и морфологической головистости.
Мозг и язык 84: 26–43, DOI: https://doi.org/10.1016/S0093-934X(02)00520-5Longtin, C.M. и Meunier, F. (2005). Морфологическая декомпозиция в ранней визуальной обработке текстов. Журнал памяти и языка 53: 26–41, DOI: https://doi.org/10.1016/j.jml.2005.02.008
Marelli, M. и Luzzatti, C. (2012). Частотные эффекты при обработке итальянских именных составов: модуляция головокружения и семантическая прозрачность. Journal of Memory & Language 66: 644–664, DOI: https://doi.org/10.1016/j.jml.2012.01.003
Маринус, Э. , Конен, С. и Макартур, Г. (2013). Австралийские сравнительные данные для теста эффективности чтения слов (TOWRE). Австралийский журнал трудностей в обучении 18(2): 199–212, DOI: https://doi.org/10.1080/19404158.2013.852981
McCormick, SF , Rastle, K.
и Davis, MH (2009). Обожаю-способный не очаровательны? Орфографическая недоопределенность изучалась с помощью замаскированного повторения. Европейский журнал когнитивной психологии 21: 813–836, DOI: https://doi.org/10.1080/09541440802366919Монселл, С. (1985). Повторение и лексика. В: Эллис, изд. А.В. Прогресс в психологии языка . Лондон: Эрлбаум, 2 стр. 147–195.
Моррис, Дж. , Портер, Дж. Х. , Грейнджер, Дж. и Холкомб, П. Дж. (2011). Влияние лексического статуса и морфологической сложности на замаскированное прайминг: исследование ERP. Язык и когнитивные процессы 26(4–6): 558–599, DOI: https://doi.org/10.1080/016.2010.495482
New, B. , Pallier, C. , Brysbaert, M. и Ferrand, L. (2004). Lexique 2: Новая французская лексическая база данных.
Методы исследования поведения, инструменты и компьютеры 36: 516–524, DOI: https://doi.org/10.3758/BF03195598 Pollatsek, A. , Hyönä, J. и Bertram, R. (2000). Роль морфологических составляющих при чтении финских сложных слов. Journal of Experimental Psychology: Human Perception and Performance 26: 820–833, DOI: https://doi.org/10.1037/0096-1523.26.2.820
Rastle, K. и Davis, MH (2008). Морфологическая декомпозиция на основе анализа орфографии. Language & Cognitive Processes 23: 942–971, DOI: https://doi.org/10.1080/016802069730
Rastle, K. , Davis, M.H. , Marslen-Wilson, W. и Tyler, L.K. (2000). Морфологические и семантические эффекты визуального распознавания слов: исследование во времени. Language and Cognitive Processes 15(4–5): 507–537, DOI: https://doi.
org/10.1080/016050119689Rastle, K. , Davis, M.H. и New, B. (2004). Бульон в борделе моего брата: Морфо-орфографическая сегментация в визуальном распознавании слов. Psychonomic Bulletin & Review 11: 1090–1098, DOI: https://doi.org/10.3758/BF03196742
Основная группа разработчиков R (2008 г.). R: язык и среда для статистических вычислений: пакет R версии 1.1–5, http://CRAN.R-project.org/package=lme4
.Сандра, Д. (1990). О представлении и обработке сложных слов: Автоматического доступа к составляющим морфемам не происходит. Ежеквартальный журнал экспериментальной психологии 42A: 529–567, DOI: https://doi.org/10.1080/146407401236
Shipley, WC , Gruber, CP , Martin, TA и Klein, AM (2009). Шипли-2 руководство .
Лос-Анджелес, Калифорния: Западные психологические службы.Шулман, Н. и Эндрюс, С. (2003). Скаковые лошади, северные олени и воробьи: использование маскированного прайминга для исследования морфологических влияний на идентификацию сложных слов. В: Киношита С. и Лупкер С. Дж., ред. Маскированная грунтовка: современный уровень техники. Монографии Маккуори по когнитивистике . Нью-Йорк, штат Нью-Йорк, США: Psychology Press, стр. 241–278.
Taft, M. и Forster, K.I. (1975). Лексическое хранение и поиск слов с префиксами. Journal of Verbal Learning and Verbal Behavior 14: 638–647, DOI: https://doi.org/10.1016/S0022-5371(75)80051-X
Тафт, М. и Форстер, К. И. (1976). Лексическое хранение и поиск полиморфных и многосложных слов. Journal of Verbal Learning and Learning Behavior 15: 607–620, DOI: https://doi.
org/10.1016/0022-5371(76)-2Taft, M. , Xu, J. и Li, S. (2017). Буквенное кодирование при визуальном распознавании слов: влияние встроенных слов. Journal of Memory and Language 92: 14–25, DOI: https://doi.org/10.1016/j.jml.2016.05.002
Torgesen, J.K. , Wagner, R.K. и Rashotte, C.A. (1999). Тест на умение читать слова . Остин, Техас: PRO-ED Publishing, Inc.
Whitney, C. и Cornelissen, P. (2008). СЕРИОЛ Чтение. Language and Cognitive Processes 23(1): 143–164, DOI: https://doi.org/10.1080/016701579771
Звитсерлод, стр. (1994). Роль семантической прозрачности в обработке и представлении голландских сложных слов. Язык и когнитивные процессы 9: 341–368, DOI: https://doi.org/10.1080/016408402123
«Составные слова и мультиморфемные слова (или знаки)» Американский язык жестов (ASL)
ВОПРОС :
Ученик пишет:Здравствуйте, доктор Викарс,
У меня вопрос по поводу вопроса викторины, в котором я ошибся. я перечитал
информацию еще раз, и я уверен, что это простой ответ, но для чего бы то ни было
причина, по которой это намекает на меня. Вопрос: «Связанные морфемы, которые добавляются к
свободные морфемные корни или основы образуют более сложные многоморфемные слова, называются
что?» Я так понимаю, что это процесс соединения уже составного
знак со свободным знаком, но я не могу понять пример или что
это называется.
[Имя удалено для защиты конфиденциальности учащегося.]ОТВЕТ :
Уважаемый _______,Сложные слова, многоморфные слова и свободные морфемы имеют очень специфические определения и значения. Хитрость в том, чтобы научиться понимать эти концепции. иметь в виду, что существует много совпадений и что некоторые термины «зонтичные» термины, которые включают в себя другие термины.
(Например, «транспортное средство» — это общий термин. Все автомобили являются транспортными средствами, но не все транспортные средства являются автомобилями. Мы изучим технический термин «зонтик».
термины» позже в этом классе.)Таким же образом можно утверждать, что все «соединения» являются типами многоморфные слова. Но не все многоморфные слова являются составными.
Давайте посмотрим на определение соединения:
«В языкознание , соединение – это лексема (точнее, слов ) который состоит из более чем одного ствола. Компаундирование, композиция или номинал композиция — это процесс образования слов что создает соединение лексем. То есть, говоря привычным языком, происходит компаундирование когда два или более слов являются объединены, чтобы получить одно более длинное слово ». Источник: https://en.wikipedia.org/wiki/Compound_(linguistics)
Итак, позвольте мне еще раз заявить об этом следующим образом: соединение — это когда вы объединяете «целое» слова для создания нового слова .
Многоморфные слова могут быть образованы путем добавления «частей» слов к целым словам.
Вот математика:
(слово) + (слово) = СОЕДИНЕНИЕ
Пример из английского языка: зеленый + дом = теплица(морфема)+(морфема) = МНОГОМОРФЕМНОЕ СЛОВО
Типичная конфигурация: (часть слова)+(целое слово)Типичная конфигурация: (часть- слова)+(целое слово)
Пример: RE+APPEAR = reappearМногоморфные слова могут иметь много-много морфем:
Пример: антидис установить ментарианство
То есть: (часть-из -слово)+(часть слова)+(целое слово) +(часть слова) +(часть слова) +(часть слова)
Однако учтите следующее:
Слова могут быть:
1. моно морфемный = иметь только одну морфему
2. мульти морфемный: = иметь две или более морфемпример ASL: мономорфемный4 = RED 9 example2: мультиморфемный: = КРАСНЫЙ!!! (Восклицательные знаки укажите здесь, что мы добавляем интенсивность к тому, как мы делаем знак.)
(КРАСНЫЙ) + (морфема процесса)КРАСНЫЙ!!! (изменяется для интенсивности) = мультиморфемный, потому что мы добавили морфему, изменив способ, которым мы подписал его. Мы «изменили» знак, чтобы добавить ему смысла.
Позвольте мне сказать еще раз: Мы добавили смысл знаку, делая знак в более интенсивный способ.
Это добавленное значение состояло из «морфемы процесса».
Эта морфема процесса состояла из добавления неручного маркера (лицевой выражение) плюс изменения скорости, конечного местоположения, силы и длины трюмов.
Те изменения в процессе подписания RED!!! создал «морфему процесса».
Итак, у нас есть две морфемы:
1. Морфема формы:»КРАСНЫЙ»
2. Морфема процесса: «!!!»Или подумайте об этом так:
1. Морфема формы: «КРАСНЫЙ»
2. Морфема связанного процесса: «очень», созданная изменением знака КРАСНЫЙ.Примечание: рассмотрите знак «ОЧЕНЬ», который использует V-образные руки. Это использование было бы называется «морфемой формы». Перегиб КРАСНЫЙ!!! вместо этого создает значение слова «очень» как «морфемы процесса». Одна из причин «ОЧЕНЬ-[form_morpheme] знак получает плохую репутацию, и (некоторые) учителя ASL смотрят на него свысока. потому что подписанты часто злоупотребляют или злоупотреблять морфемой формы, когда они вместо этого следует экономить время и быть более эффективным, используя ПРОЦЕСС-МОРФЕМА-[очень].
Итак, технически:
КРАСНЫЙ = морфема = это имеет значение, и оно настолько маленькое, насколько это возможно. сохраняя именно это значение.
КРАСНЫЙ = слово или знак = Это отдельная концепция, не зависящая ни от каких другое слово или морфема, чтобы иметь значение.
КРАСНЫЙ = мономорфное слово или знак = имеет только одну морфему.
КРАСНЫЙ!!! = мультиморфемный знак = имеет две морфемы = (цвет) + (очень)
Все слова имеют одну или несколько морфем.
Некоторые слова имеют только одну морфему.
«CAT» имеет одну морфему.
Сколько морфем в «антидисистеблишментаризме»?
Анти-де-установление-арианство
«Сколько морфем у слона?
Можно ли уменьшить слово «слон» и сохранить то же значение в любой из частей?
№
[Возможно когда-то это означало что-то вроде (слоновая кость) + (существо) но в современном использования он лексикализован в одну морфему.] «Слон» относится к самому большому наземное млекопитающее. Это не имеет ничего общего с «муравьем» (насекомым).
Не позволяйте количеству «слогов» в слове обмануть вас.
Слоги — это не то же самое, что морфемы.Слон — одна морфема.
Другими словами: Слово «слон» мономорфно.
(Я придумал это сам, но позже нашел источник, который меня поддержал.
См.:
Бауэр, Лори, 2012 г., «Начало лингвистики», Palgrave Macmillan, Приложение A,
стр. 271).Сколько морфем в слове «слоновий»?
[Элефантин означает: Имеющий характеристики слона.]«Элефантин» имеет две морфемы.
Является ли Элефантина составным словом?
Соединение = два СЛОВА.
«зуб» — это не слово.
Так что нет, «слоновье» — это не сложное слово, а многоморфное слово.
Некоторые морфемы могут стоять отдельно и поэтому считаются чем?
Отдельные морфемы считаются «словами».
[Да, да — у лингвистов есть более технические способы описания отдельных морфемы, но пока давайте рассмотрим «слова».]
Приведите пример «мономорфного» слова:
Слон
поэтому не считаются словами. Это «части» слов, которые значение, которое должно происходить со словом. [ing, -ness, -ment, dis-, un-, ]
Это «связанные» морфемы. Они как нуждающийся парень или девушка. Они просто не может быть один.
Как мы (обычно) называем эти «связанные» морфемы?
Аффиксы.
Примечания:
* Хотите помочь поддержать университет ASL? Это просто : ПОЖЕРТВОВАТЬ ( Спасибо! )* Еще один способ помочь – купить что-нибудь в книжном магазине доктора Билла .
* Хотите еще больше ресурсов ASL? Посетите « Учебный центр ASL! » (Подписка Расширение ASLU)* Также посетите канал доктора Билла: www.youtube.com/billvicars
Вы можете изучать американский язык жестов (ASL) онлайн в Американском университете языка жестов.
Ресурсы ASL от Lifeprint.com Dr. William VicarsОбщество издательства словарей кандзи. Краткое введение в японскую морфологию
Общество издательства словарей кандзи — Краткое введение в японскую морфологию-by Jack Halpern
The CJK Dictionary Institute, Inc.
Создано: 8 января 1999 г.
Отредактировано: 16 декабря 2005 г.Основные процессы словообразования
Языки различаются по процессам образования новых слов. Японский язык имеет агглютинатив ; , то есть образует слова, соединяя основные элементы, называемые морфемами, , которые сохраняют свои первоначальные формы и значения с небольшими изменениями в процессе комбинирования. Морфема – это отличительная языковая единица с относительно устойчивым значением, которая не может быть разделена на более мелкие значимые части. Как правило, каждый китайский иероглиф представляет одну морфему.
Ниже описаны наиболее важные процессы словообразования в японском языке. Примеры взяты из моего словаря The Kodansha Kanji Learner’s Dictionary.
- Составление
Составление состоит из объединения двух или более слов или словесных элементов, имеющих собственное лексическое значение (имеющих собственное субстанциальное значение), для получения новой единицы, функционирующей как одно слово.
Поскольку китайские иероглифы чрезвычайно продуктивны в своей способности генерировать новые слова, составление слов играет важную роль в японском словообразовании. Комбинируя набор из нескольких тысяч символов, создаются сотни тысяч сложных слов.Традиционно составным словом считается сочетание двух или более свободных слов, например метрдотель, которое состоит из голова и официант. В японском языке составным словом может быть любое сочетание свободных слов, сочетаний форм и аффиксов, которые вместе функционируют как одно слово. Полученное соединение отличается от составляющих его компонентов, но связано с ними. Например, составное слово D zo_senjo «верфь» состоит из свободного слова D «корабельное строительство» («производить; строить» + D «корабль»), за которым следует суффикс «место».
- Производное
Производное относится к созданию нового слова путем добавления к основе элемента слова, такого как суффикс, который выражает грамматическое значение, но не имеет лексического значения.
Например, в английском языке производный суффикс ly , образующий наречие, присоединяется к базовой форме great , образуя наречие very . В японском языке существительное kuro «черный» сочетается с прилагательным суффиксом 9.0285 i , чтобы образовать прилагательное kuroi ‘черный’.Важно отметить, что слова, образованные путем деривации, являются отдельными словами сами по себе, а не просто вариантами слова, от которого они образованы.
- Инфекция
Инфекция состоит из добавления окончаний слов или изменения формы слова для обозначения различных грамматических функций, таких как время (так называемое спряжение, ) или числа и падежа (называется склонением. ) Полученное слово является другой формой исходного слова, а не новым словом само по себе. Например, work, — это прошедшее время от work, и books, — форма множественного числа от book.
В японском языке последний слог глагола A kaeru «возвращаться» изменяется, чтобы получить A kaere, повелительное наклонение. Окончания флективных слов в японском языке обычно пишутся хираганой.
Морфологические функции кандзи
Каждый символ может, помимо одного или нескольких значений, иметь различные грамматические и синтаксические функции. Одной из наиболее важных характеристик кандзи является их роль в качестве словесных элементов; , то есть их способность образовывать бесчисленное количество сложных слов, комбинируясь друг с другом. Новые слова могут быть образованы путем добавления аффикса (суффикса или префикса) к базовой форме или путем присоединения , объединяя формы друг с другом. Например, суффикс — -zumi «завершено» добавляется к _ tenken «проверка», чтобы получить _ tenkenzumi «проверка завершена».
Еще одна важная функция кандзи — это свободное слово , — любое слово, которое можно использовать независимо.
Другие функции включают сокращения, служебные слова, счетчики, единицы измерения, заголовки, цифры и фонетические заменители. Аффиксы, сочетающие формы и свободные слова могут сочетаться друг с другом различными способами, наиболее важные из которых показаны ниже:комбинированная форма + комбинированная форма О + л Ол гайдзин иностранец комбинированная форма + свободное слово + N N rainen в следующем году свободное слово + суффикс O + l Ol gaikokujin иностранец префикс + свободное слово + Nx Nx myo_nendo в следующем году бесплатное слово + бесплатное слово { + { нихон-рё_ри Японская кухня Произвольные слова, сочетающие формы и аффиксы — это, в основном, разные функциональные категории, но символ в любом заданном значении может действовать более чем в одном из этих качеств.
Иногда символ может функционировать как аффикс в одном смысле и как свободное слово в другом; в других случаях его значение как свободного слова может быть таким же, как и его значение как сочетающейся формы. Например, выступает как сочетающая форма в значении «автор, пиши», как суффикс в значении «автор», и как свободное слово в значении «литературное произведение»:2300:
1a составлять, писать, публиковать ——— эквивалент комбинированной формы
Ниже приводится краткое описание основных морфологических функций китайских иероглифов в японском языке.
b [суффикс] автор, ————— эквивалент суффикса
삷 тёсаку суру писать, автор
ORNv мисима юкио-тё автор Мисима Юкио
y cho z литературное произведение, книга ———-эквивалент свободного слова
…̒ …нет чо книга написана…Основные морфологические категории
- Свободное слово
Свободное слово относится к любому независимому слову; то есть любое независимое на или кун слово, которое можно свободно сочетать с другими словами в предложении. В приведенном выше примере это свободное слово, означающее «литературное произведение». - Комбинированная форма
Комбинированная форма относится к части слова, которая не является аффиксом и может образовывать новое слово, объединяясь с одним или несколькими словами или частями слова. Таким образом, сочетание форм и аффиксов является взаимоисключающим. В приведенном выше примере действует как объединяющая форма, означающая «автор, пиши».Функция иероглифов как сочетающих форм имеет большое значение в образовании слов в японском языке. Как элемент слова на , комбинированная форма соответствует одному символу; как kun словесный элемент, он соответствует одному символу с okurigana окончаниями или без них. Обычно часть, оставшаяся после удаления составной формы из сложного слова (например, Ol gaijin ‘иностранец’), является односимвольной комбинированной формой (O gai ‘иностранный’). Если оставшаяся часть является свободным словом, состоящим из двух или более символов (например, O gaikoku ‘зарубежная страна’ от Ol gaikokujin ‘иностранец’), то удаленная часть (l jin ‘человек’) является аффиксом, а не объединяющей формой.
- Аффикс
Аффикс относится к части слова, добавленной к базовой форме (слово или элемент слова, имеющий собственное лексическое значение) для образования нового слова. Глагольный аффикс — это часть слова, добавляемая к основе для образования нового слова, обычно глагола kun . Например, в ǂ��I yomiowaru ‘дочитать до конца’ к основе ǂ ‘читать’ присоединяется глагольный аффикс I ‘заканчивать’.Аффиксы, добавляемые к началу слова, называются префиксами ; добавленные в конце слова суффиксы . Аффиксы включают заголовки, счетчики, единицы измерения и определенные служебные слова, но исключают комбинированные формы. В то время как комбинированные формы обычно не маркируются, аффиксы и глагольные аффиксы специально идентифицируются меткой или каким-либо другим способом, как показано ниже:
2002:
furu- -z [префикс] старый, подержанный
РV фурушинбун старая газетаЧто отличает аффикс от комбинированной формы, так это то, что часть слова, которая остается после удаления аффикса, является, в принципе, самостоятельной самостоятельной единицей, обычно свободным словом, состоящим из двух или более символов.
Исключением являются заголовки, счетчики, единицы измерения и некоторые служебные слова, в которых оставшаяся часть может состоять из одного символа. - Аббревиатура
Аббревиатура относится к одному символу, используемому в качестве сокращенной формы составного слова, обычно представленного его первым составным символом. Первый символ соединения часто используется для обозначения всего соединения, как w в приведенном ниже примере:3416:
Аббревиатуры — это краткое средство передачи значения, особенно когда они используются для создания новых сложных слов, которые в противном случае могли бы быть длинными и громоздкими. Аббревиатуры играют активную роль в образовании японских сложных слов,4a сокр. of w daigaku : университет, колледж 呲 дайсоцу выпускник университета
Аббревиатуры могут состоять из обычных составных слов, например, O{ sanponkan «между третьей и домашней базой», где O означает O sanrui «третья база», а { означает { honrui «домашняя база», и в nyu_en «поступление в детский сад», где расшифровывается как ct yo_chien «детский сад».
Сокращения также могут быть названиями мест, особенно названий городов и стран, например, o_saka в raihan «приходя в Осаку». /ол
СЛОЖНЫХ СЛОВ НА АНГЛИЙСКОМ ЯЗЫКЕ | Christianto
СЛОЖНЫЕ СЛОВА В АНГЛИЙСКОМ ЯЗЫКЕ
Danin Christianto
Аннотация
Язык — это средство общения, которое используется живыми существами для общения друг с другом. В языке есть много важных компонентов для создания успешного общения, таких как звук, предложение, значение и т. Д. Одним из компонентов является слово. Слово можно рассматривать как сложную часть языка, поскольку оно имеет множество различных форм. Например, сложное слово — это слово, которое образуется в результате одного из словообразовательных процессов путем соединения одного лексического элемента с другим и, таким образом, дает новое слово с новым значением. В этой статье исследуются типы английских составных слов и лексические категории, возникающие в результате процесса словосочетания.
Первые результаты показали, что типами английских сложных соединений являются эндоцентрические, экзоцентрические и копулятивные соединения. Вторые результаты показали, что лексическими категориями, полученными в результате процесса составления, являются составные существительные, составные глаголы и составные прилагательные. Основываясь на результатах, исследователь надеется, что читатели смогут получить более глубокое представление и знания о сложных словах английского языка.Ключевые слова
соединение; компаундирование; Английский; слово
Полный текст:
PDFСсылки
Адасиак, П. (2014). Библиотечный исследовательский процесс. Получено 27 ноября 2019 г. с https://library.uaf.edu/ls101-research-process.
Алтахайне, АРМ (2016). Что такое соединение? Основные критерии компаундности. ExELL (Исследования английского языка и лингвистики), 4(1), 58-86.
Аронофф, М. и Фудеман, К. (2011). Что такое морфология? (2-е изд.
). Молден: Уайли-Блэквелл.Бауэр, Л. (1983). Английское словообразование. Кембридж: Издательство Кембриджского университета.
Бауэр, Л. и Ренуф, А. (2001). Корпусное исследование сложных слов на английском языке. Журнал английской лингвистики, 29 (2), 101-123.
Бауэр, Л. (2003). Введение в лингвистическую морфологию (2-е изд.). Эдинбург: Издательство Эдинбургского университета.
Буидж, Г. (2005). Грамматика слов. Нью-Йорк: Издательство Оксфордского университета.
Budiarta, IW (2016). Сложные слова в языке давань. Реторика: Jurnal Ilmu Bahasa, 2(1), 1-15.
Кахьянти, Р. Д. (2016). Сложные слова, используемые в сумерках Стефани Майерс. Журнал об английском языке как иностранном, 6 (1), 59–70.
Карстэйрс-Маккарти, А. (2002). Введение в английскую морфологию. Эдинбург: Издательство Эдинбургского университета.
Эммитт, М. и Поллок, Дж. (1991). Язык и обучение: Введение в преподавание. Нью-Йорк: Издательство Оксфордского университета.
Фромкин, В., Родман, Р., и Хайамс, Н. (2014). Введение в язык (10-е изд.). Бостон: Уодсворт.
Грикс, Дж. (2004). Основы исследования. Нью-Йорк: Пэлгрейв Макмиллан.
Хаспелмат, М. и Симс, А.Д. (2010). Понимание морфологии (2-е изд.). Лондон: Образование Ходдера.
Катамба, Ф. (1993). Морфология. Нью-Йорк: Сент-Мартинс Пресс.
Либер, Р. (2009). Знакомство с морфологией. Кембридж: Издательство Кембриджского университета.
Мата, CB (2014). Компаундирование и вариационная морфология: Анализ флексии в испанских сложных словах. Borealis: Международный журнал латиноамериканской лингвистики, 3 (1), 1-21.
Мэтьюз, П. Х. (1991). Морфология (2-е изд.). Кембридж: Издательство Кембриджского университета.
Маркета, Б. (2019). Синтаксическая структура соединений пелиррохо. Глосса: Журнал общей лингвистики, 4 (1), 1-23.
Мерриам, С. Б. (2002). Качественные исследования на практике: примеры для обсуждения и анализа. Нью-Йорк: John Wiley & Sons, Inc.
Noumianty, DS (2016). Анализ сложных слов в кулинарных терминах в 7-м сезоне Masterchef в США (неопубликованная дипломная работа). Государственный исламский университет Сяриф Хидаятулла, Джакарта.
Рахадиянти, ИДАР (2013). Сложные слова в политических статьях журнала «Стратегическое обозрение» (неопубликованная дипломная работа). Университет Саната Дхарма, Джокьякарта.
ОГрейди, В., Добровольский, М., и Катамба, Ф. (1996). Современное языкознание: введение. Лондон: Лонгман.
Плаг, И. (2003). Словообразование в английском языке. Кембридж: Издательство Кембриджского университета.
Пул, Южная Каролина (1999). Введение в языкознание. Нью-Йорк: Сент-Мартинс Пресс.
DOI: https://doi.org/10.24071/llt.v23i1.2030
Рефбеки
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
- —
Copyright (c) 2019 Danin Christianto
Индексирован и абстрагирована в:
LLT Journ Журнал LLT: журнал по языку и преподаванию языков получил национальную аккредитацию Sinta 2 Министерством образования, культуры, исследований и технологий Республики Индонезии на основании указа № Сурат Кетеранган 158/E/KPT/2021.
3758/s13423-015-0927-z