Морфологический разбор глагола «попробовал» онлайн. План разбора.
Для слова «попробовал» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «попробовал» — глагол - Морфологические признаки.
- попробовать (инфинитив)
- Постоянные признаки:
- 1-е спряжение
- переходный
- совершенный вид
- изъявительное наклонение
- единственное число
- прошедшее время
- мужской род.
Но вначале попробовал зайти издалека.
Выполняет роль сказуемого.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.

- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)

Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
14 голосов, оценка 4. 714 из 5
714 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «попробовал» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Морфологический разбор слова попробовать онлайн
Слово ‘попробовать’
Слово попробовать является Глаголом (это самостоятельная часть речи, которая отвечает на вопросы «что делать?», «что сделать?»). У глагола попробовать есть постоянные признаки:
У глагола попробовать есть постоянные признаки:
- Возвратный/Невозвратный — слово ‘попробовать’ является невозвратный;
- Переходный/Непереходный — слово ‘попробовать’ это переходный глагол. ; Глагол ‘попробовать’ относится к несовершенному виду.
- Пример изъявительного наклонения: Женщина снова попробовала объяснить, что пока молчать нужно, не то совсем голос потеряет.
- Пример cослагательного наклонения: Попробовал бы кто-нибудь про нашего папу такое сказать – я бы в жизни не простила.;
- Пример повелительного наклонения: Пусть повязка будет у тебя, если хочешь, но сейчас попробуй открыть оба глаза.;
- Род слова определить не возможно потому, что глагол является Инфинитивом.
- Лицо — не определяется в инфинитиве;
- У данного слово время не определяется потому, что слово попробовать является Инфинитивом;
Слово «попробовать» значит:
- Сделать попытку, приложить усилие, постараться.
- Съесть небольшую порцию кушанья для ознакомления и оценки.
- Испытать, проверить.

«ПОПРОБОВАТЬ» — это Глагол. Обозначающая действие предмета и отвечает на вопросы «Что делать?» или «Что сделать?». В предложении обычно выполняет роль сказуемого.
попрОбовать
Ударение падает на слог с буквой О. На пятую букву в слове.
Слово «попробовать» — род не определяется в инфинитиве
Глагол ‘попробовать’ является несовершенным видом.
Переходность глагола «попробовать» — переходный
Лицо у глагола «попробовать» — не определяется в инфинитиве
Пример использования наклонений
Изъявительное
Женщина снова попробовала объяснить, что пока молчать нужно, не то совсем голос потеряет.
Сослагательное (условное)
Попробовал бы кто-нибудь про нашего папу такое сказать – я бы в жизни не простила.
Повелительное
Пусть повязка будет у тебя, если хочешь, но сейчас попробуй открыть оба глаза.
Время глагола «попробовать» — не определяется в инфинитиве
Слово «попробовать» — относится к Первому спряжению
Она (ед. число)
число)
Оно (ед. число)
Они (мн. число)
- разнести
- драпировать
- подмочить
- пересохнуть
- твердить
- шиковать
- спекулировать
- разнять
- наняться
- увести
Морфологический разбор глагола Попробовал.
 Начальная форма, часть речи, постоянные и непостоянные признаки
Начальная форма, часть речи, постоянные и непостоянные признаки Выполним онлайн морфологический разбор слова «попробовал» (часть речи: глагол) в
соответствии с правилами русского языка.
Слово состоит из четырех слогов.
Ударение в слове «попр
Часть речи
глагол
Синтаксическая роль
В зависимости от контекста
Морфологические признаки
| Постоянные признаки | переходный, совершенный вид, 1 спряжение |
| Непостоянные признаки | прошедшее время, изъявительное наклонение, единственное число, мужской род |
| Начальная форма | попробовать |
Фонетический (звуко-буквенный) разбор слова
папр`обавал
Слово по слогам (4)
по-про-бо-вал
Перенос слова
по-пробовал, поп-робовал, попро-бовал, попробо-вал
Данный разбор был сделан с помощью искусственного интеллекта и может быть не правильным.
 Результаты разбора могут быть использованы исключительно для самопроверки.
Если вы нашли ошибку, оставьте комментарий в форме ниже.
Результаты разбора могут быть использованы исключительно для самопроверки.
Если вы нашли ошибку, оставьте комментарий в форме ниже.Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Спасибо за комментарий, он будет опубликован после проверки
«Попробовать» или «попробывать»: как писать правильно?
На чтение 2 мин Просмотров 29 Опубликовано
Чтобы правильно написать слово – «попробовать» или «попробывать», нужно знать правило о выборе гласных в суффиксах глаголов. Давайте вспомним орфограмму и выберем правильный вариант написания.
Как правильно пишется?
В соответствии с правилом орфографии, пишется – попробовать.
Глагол совершенного вида «попробовать» употребляется в значениях – «испытать или проверить что-либо»; «съесть немного чего-нибудь»; «сделать попытку, постараться что-либо сделать». Образован он приставочным способом от инфинитива «пробовать». Суффикс в глагольной форме «попробовать» находится в безударной позиции, поэтому произносится не совсем отчетливо. И поэтому возникает сомнение, какую гласную писать в нём – «о» или «ы».
Образован он приставочным способом от инфинитива «пробовать». Суффикс в глагольной форме «попробовать» находится в безударной позиции, поэтому произносится не совсем отчетливо. И поэтому возникает сомнение, какую гласную писать в нём – «о» или «ы».
Чтобы не допускать ошибок в суффиксе, нужно знать орфограмму № 49. В этой орфограмме сказано, если в 1 л., ед. ч. глагол теряет «-ова-/-ева-», то он сохраняется в гл. сов. вида.
Суффикс «-ова-» не сохраняется в указанной форме – попробую, значит, он нужно писать – попробовать.
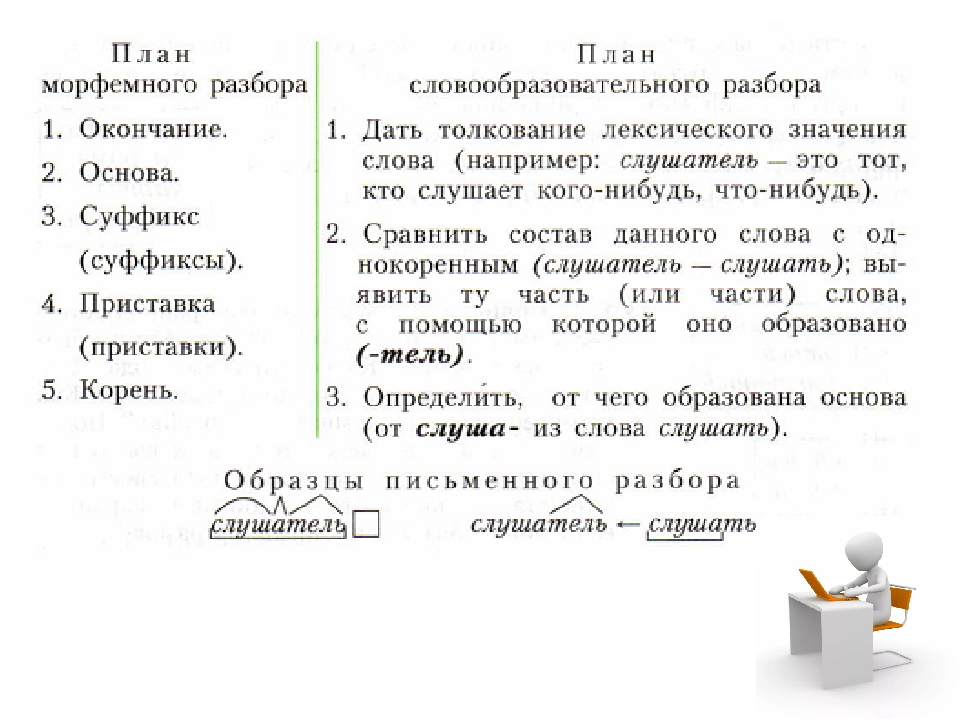
Морфемный разбор слова «попробовать»
Схема разбора:
попробовать.
Состоит из префикса «по-», корня «-проб-», суффикса «-ова-», флексии «-ть».
«Попробова» – основа.
Часть речи – глагол; части слова – по/проб/ова/ть.
Способ образования глагола – префиксальный.
Примеры предложений
- Я не прочь попробовать это вкусно пахнущее блюдо.
- Нужно попробовать сделать такую же поделку.
- Прежде чем сесть и поехать, нужно попробовать восстановить автомобиль.

Синонимы слова «попробовать»
Слова и выражения, близкие по лексическому значению слову «попробовать»:
попытаться, проверить, испытать, познать, опробовать что-либо, отважиться на что-то, отведать что-либо, вкусить что-то, испробовать, перепробовать, испить, изведать что-либо, дерзнуть, полакомиться чем-либо, навидаться, протестировать что-то, откушать; пуститься наудачу, почувствовать на своей шкуре, предпринять попытку, сделать какое-то поползновение, подвергнуть что-либо проверке, узнать на своем опыте, испытать счастье, собраться с духом.
Ошибочное написание слова «попробовать»
Ошибка – писать глагол с буквой «ы» в суффиксе, а также с «а» в первом слоге – попробывать, папробовать.
Заключение
При написании «попробовать» или «попробывать» нужно помнить, что в глаголах пишутся – «-ОВА/ЕВА-», если в форме 1 л. , ед. ч. они не сохраняются.
, ед. ч. они не сохраняются.
Разбор слова по составу, морфемный разбор онлайн — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Как разобрать по составу слово «изображение»? — 4 info
Как разобрать по составу слово «изображение»?
В данном вопросе требуется разобрать по составу слово изображение.
Вот так мы это сделаем ниже.
Слово изображение. Основа этого слова ИЗОБРАЖЕНИ. Слово изображение является существительным. Оно состоит из корня ИЗОБРАЖ, суффикса ЕНИ и окончания Е. В итоге получается корень-суффикс-окончание, а именно ИЗОБРАЖ — ЕНИ — Е.
Слово Изображение отвечает на вопрос Что? и оказывается существительным среднего рода (Изображение — оно мое), которое обладает окончанием -Е: Изображение-Изображения-Изображению-Изображение-Изображением-Изображении.
Однокоренными словами оказываются: Изображение-Изображать-Отображать-Образ.
Следовательно корнем слова будет морфема -ОБРАЖ-/ОБРАЗ-, часто выделяется корень ИЗОБРАЖ-.
Далее выделим в составе слова приставку ИЗ- и суффикс существительного -ЕНИ-.
Получаем: ИЗ-ОБРАЖ-ЕНИ-Е (приставка-корень-суффикс-окончание), основа слова: ИЗОБРАЖЕНИ-.
Пример предложения: Изображение было получено с помощью фотоаппарата, который был напечатан с помощью принтера.
Слово «изображение» имя существительное (Что?), неодушевлнное, среднего рода единственного числа, винительный падеж.
Части слова изображение имеет вид: изображ/ени/е.
Разбор по составу слова:
изображ это корень;
ени суффикс;
е окончание.
Основа слова является изображени .
Слово «нововведение» — это имя существительное второго склонения, среднего рода, употреблено в форме именительного или винительного падежа, единственного числа.
Окончание выделяется по-разному. В упрощенном виде должно быть выделено -е (ср.: изображени-я, изображени-ю, изображени-ем и др.). Но для профессионально или углубленно изучающих русский язык должно быть ясно, что буква е здесь обозначает два звука: jэ (йэ), из них только второй ходит в окончание, а j остается в основе: изображениj-а (изображения), изображениj-у (изображению), изображениj-эм (изображением) и т. д.
д.
Корень слова -ображ- (родственные слова — образ, изобразить, изображенный, преобразить, образец, образчик, вообразить и др.; присутствует чередование зж).
Приставка из- (значение внешнего выражения; присутствует также в словах «исходить», «изложить», «исполнить» и др.; присутствует чередование сз).
Суффикс (в зависимости от выбора окончания -ени- (-ениj-).
Основа изображени(j).
Морфемная структура слова следующая: приставкакореньсуффиксокончание. Из-ображ-ени(j)-э.
Слово «изображение» является существительным среднего рода в единственном числе.
Разбор по составу слова «изображение»:
Части слова изображение: изображ/ени/е
Состав слова:
изображ корень,
ени суффикс,
е окончание,
изображени основа слова.
Урока русского языка «Разбор слова по составу»
Приложение 2
ЗАЯВКА
участника конкурса для учителей начальных классов
«Новое качество урока. Работаем по ФГОС»
Работаем по ФГОС»
Приложение 3
Форма технологической карты урока
Анисимова Ольга Борисовна
ФИО участника
Невский район, ГБОУ СОШ№20
Район, название ОУ (кратко)
Начальная школа XXI века
Используемый УМК (учебно-методический комплекс)
русский язык
Учебный предмет
3
Класс
«Лучший урок русского языка»
Номинация, подноминация
Тип: урок отработки умений и рефлексииЦель урока: отработать алгоритм разбора слова по составу
Планируемые результаты
Предметные: разбирать слово по составу, определять способ словообразования, составление слова из заданных морфем
Метапредметные: составлять план работы над упражнением, работать по алгоритму, осуществлять самопроверку результата учебных действий
Личностные: интерес к происхождению слов
Ресурсы урока: интерактивная доска, анимированные изображения в PowerPoint, ЭФУ, учебник
Ход урока:
Содержание деятельности учителя
Содержание деятельности обучающихся
Мотивация к деятельности
На экране изображения: ягода и конфета (подписи под изображениями «ягода», «конфета») под изображениями суффиксы
-К-, -ИЩ-
Задает вопрос классу: «Какой суффикс надо выбрать, чтобы уменьшить изображение?. .. А для того чтобы увеличить?»
.. А для того чтобы увеличить?»
— Как с помощью суффикса изменялось значение слов?
— Зачем нужны суффиксы? (Помогает сформулировать ответ)
Уточняет название темы урока: «Состав слова и словообразование»
Дети отвечают, что суффикс –к- уменьшит предмет, а суффикс –ищ- — увеличит.
Подходят к интерактивной доске и выбирают суффикс.
Если выбран суффикс -к- на экране появляется уменьшенное изображение и запись: например: «ягодка», затем «конфетка»
Для того, чтобы увеличить изображение нужно выбрать суффикс –ищ-, тогда появится увеличенное изображение и запись «ягодища», затем «конфетища».
— Суффиксы –к- и –ищ- изменяли значения слов: большой предмет или маленький предмет. Суффиксы нужны для образования новых слов
Приводят примеры: рыбка дорожка, волчище, медведище
Предлагают варианты темы урока. Формулируют цели урока: повторить как разбирать слово по составу, узнать о том, как образуются новые слова
Актуализация необходимых знаний
Организует письменную работу детей, при необходимости напоминает о правильности посадки при письме, о правильном оформлении числа, записи «Классная работа».
Вызывает к доске трех сильных учеников, для написания однокоренных слов на доске.

— Приведите примеры других слов с использованными суффиксами
Предлагает разобрать слово загородный по составу. Для этого нужно вспомнить алгоритм разбора слова, изученного на уроке 8.
Вызывает к доске сильного ученика, помогает ему сформулировать алгоритм разбора слова.
Записывает на доске схематичный порядок разбора слова по составу.
На дороге суффикс –ищ-
Там за деревом волчище
На тропинке суффикс –к-
В норке спряталась лисичка
На ладошку мне упал суффикс –инк-
А с ним дождинка
Пролетает суффикс –ок-
Это легкий ветерок.
Подобрать слово с заданным корнем, подходящее по значению
Записать в тетрадь
Выделить корень и суффикс
Один из сильных учеников разбирает слово загородный у доски, комментируя свои действия.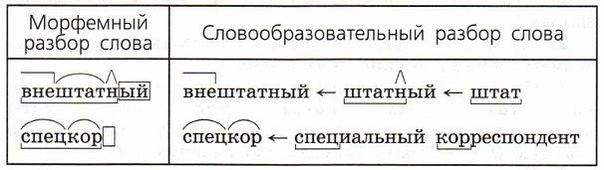
Находим окончание, изменяя форму слова, с помощью вспомогательных слов: нет загородного, любуюсь загородным, выделяем основу слова – часть слова без окончания
Находим корень слова, подбирая однокоренные слова город, городок. Выделяем корень.
Выделяем суффикс – часть слова между корнем и окончанием, приводим примеры слов с таким же суффиксом
Выделяем приставку, приводим примеры слов с такой же приставкой.
Шагают, при слове суффикс, ладошки домиком над головой
Повторяют движения за учителем
Организация познавательной деятельности
Предлагает самостоятельно разобрать по составу слова березка и стирка, пользуясь алгоритмом написанным на доске.
Организует фронтальную проверку
Задает вопрос о значении суффикса –к- в слове берзка, называя слова с таким же суффиксом – конфетка, ямка, кроватка.
Спрашивает о значении суффикса –к- в слове стирка, называя слова с этим суффиксом: варка, глажка, засолка. Поясняет, что в этих словах значение суффикса не уменьшительное, а произведенное действие.
Поясняет, что в этих словах значение суффикса не уменьшительное, а произведенное действие.
- Предлагает детям проверить как Вова справился с заданием, найти ошибки в его работе. Придумать и записать по два своих примера. Упражнение 4 на с.30.
Проводит фронтальную проверку, придуманных примеров.
Задание выделить синим цветом слова с приставками.
Нажимает на кнопку «Проверить». Если верно, появляется надпись «Молодец», если есть ошибки, предлагает их найти.
Задает домашнее задание: записать в тетрадь и разобрать по составу слова: настольный, пальто, начало, старушка, ручка, строитель, кенгуру. Слова напечатаны на листочках.
Отвечают, что в слове «березка», суффикс –к- имеет значение «маленький», а в слове стирка, суффикс –к- имеет другое значение
Находят ошибки в работе Вовы, устно, фронтальная работа.
Придумывают и записывают свои примеры. Желающие пишут на доске.
Остальные по очереди читают свои примеры слов.
 Остальные по очереди читают свои примеры слов.
Остальные по очереди читают свои примеры слов.Выходят к доске по цепочке, выделяя синим цветом, слова с приставками.
Рефлексия деятельности-Чему сегодня научились?
-Что было интересным на уроке?
Предлагает оценить свою работу на уроке:
С помощью цветного кружка.
«зеленый» — не возникло затруднений
«желтый» — возникли трудности
«красный» — было трудно и непонятно
Отвечают на вопросы.
Поднимают цветные кружки.
Приложение 4
Форма экспертного заключения
(первый этап Конкурса)
_____________________________________________________________________________
ФИО участника
_____________________________________________________________________________номинация, подноминация
Баллы:
0 – отсутствие данного критерия
1 – частичное наличие данного критерия
2 – наличие данного критерия
Баллы выставляются по каждому критерию
Член жюри:______________________/____________________________/ Дата ___________Приложение 5
Форма экспертного заключения
по итогам проведения мастер-класса
_____________________________________________________________________________
ФИО участника
_____________________________________________________________________________номинация, подноминация
Баллы:
0 – отсутствие данного критерия
1 – частичное наличие данного критерия
2 – наличие данного критерия
Баллы выставляются по каждому критерию
Член жюри:______________________/____________________________/ Дата ___________
«знакомстве» — морфемный разбор слова, разбор по составу (корень суффикс, приставка, окончание)
Оля Бережная. Екатерина Майская запись закреплена три часа назад. Ищу компанию на погулять в выходные. Нина Королькова. Екатерина Майская. Нина , может Сокольники,может Измайловский. Сколько карандашей на фото? Сначала старые. Bahtiyor Boboev. Светлана Светлана запись закреплена три часа назад.
Екатерина Майская запись закреплена три часа назад. Ищу компанию на погулять в выходные. Нина Королькова. Екатерина Майская. Нина , может Сокольники,может Измайловский. Сколько карандашей на фото? Сначала старые. Bahtiyor Boboev. Светлана Светлана запись закреплена три часа назад.
Истинная любовь приходит случайно, там где ты её не ждёшь. И она может быть не идеальная, как и сам человек. И все мы не идеальны, но встречаем друг друга.. Я бы всем пожелала искать отношения сердцем, а не умом по списку качеств. Юлия Антонова.
Знакомства после 40. Тренд современности: женщина старше мужчины
А я вообще не могу понять, как можно искать любовь она или есть или ее нет. Это непредсказуемо, вообще Виктория Чел. Юлия , думаю, имеется в виду как-то заявить о себе не сидеть дома и не ждать. Но в то же время и на Берлин не идти. Юлия Антонова ответила Виктории.
Виктория , наверное. Красивые слова!. Екатерина Майская запись закреплена вчера в Мужчины,что должна уметь или обладать какими качествами женщина,чтобы вы влюбились в неё? Евгений Лисицын ответил 9 ответов Показать следующие комментарии. Алексей Велесов. Екатерина Майская ответила 3 ответа Показать следующие комментарии. Доброго времени суток познакомлюсь с девушкой лет для серьезных отношений!!! Андрей Сутягин запись закреплена вчера в Только девушки. Что сегодня Вас заставило улыбнуться?
Красивые слова!. Екатерина Майская запись закреплена вчера в Мужчины,что должна уметь или обладать какими качествами женщина,чтобы вы влюбились в неё? Евгений Лисицын ответил 9 ответов Показать следующие комментарии. Алексей Велесов. Екатерина Майская ответила 3 ответа Показать следующие комментарии. Доброго времени суток познакомлюсь с девушкой лет для серьезных отношений!!! Андрей Сутягин запись закреплена вчера в Только девушки. Что сегодня Вас заставило улыбнуться?
Владимир Крузо. Ольга Сукач ответила 10 ответов Показать следующие комментарии. Евгения Родина. Сегодня у меня все плохо.
Знакомства от 40 до 50
Евгения , тогда вам срочно необходимы обнимашки со слоненком Евгения Родина ответила Евгению. Евгений , да мне срочно нужны обнимашки. Ольга Сукач. Её записи проданы тиражом млн альбомов и более 55 миллионов синглов по всему миру «Чем меньше думаешь о годах, чем меньше смотришься в зеркало, тем лучше выглядишь. Mireille Mathieu. Tous les enfants chantent avec moi.
Мирей Матье. Sous Le siel De Paris. Ciao, Bambino, Sorry Пока, милый, прости. La Paloma adieu. Une Femme Amoureuse Der Pariser Tango. Я уже долго тебя ищу, моя милая, дорогая женщина.
Так как я ни разу тебя не видел и не знаю. Возможно мы уже не раз проходили мимо друг- друга, В нашем городе, мы может быть живём, с тобой на одной улице, а может на разных берегах, нашего могучего Енисея.
Женщины за 40, не старайтесь подстраиваться под мужчину!
Показать полностью… Пусть я не знаю, как ты выглядишь, но для меня ты самая красивая и желанная. Ты умная, начитана, с хорошим вкусом и чёткой жизненной позицией. У тебя правильная система ценностей, ты ненавидишь ложь, предательство. Возможно тебя уже предавали, твой самый близкий для тебя человек, возможно потушил в тебе веру в мужчин. Жив будь доселе царь Додон, одной тобой он был бы опьянён. Ему б не нужно было ни сребра ни злата, но ты одна была бы виновата. Что он не устерёг своих границ пока перед тобою падал ниц!
Анатолий 2 года назад. Ты очень красивая! Может познакомимся? Батыр Гулматов 2 года назад. Александр Докукин 2 года назад. Сергей 2 года назад. Arthur 2 года назад. Оксана Гирич 2 года назад. Сергей Трусов 2 года назад.
Ты очень красивая! Может познакомимся? Батыр Гулматов 2 года назад. Александр Докукин 2 года назад. Сергей 2 года назад. Arthur 2 года назад. Оксана Гирич 2 года назад. Сергей Трусов 2 года назад.
Артур Хачатурян 3 года назад. Александр Кузнецов 4 года назад. Артур Хачатурян Александр Кузнецов 3 года назад. Комментарий удален. Селиван Осьмаков 4 года назад.
Первые «Быстрые свидания» в Баку: как это было?
Зарабатывай реальные деньги в играх онлайн. Без ограничений. Serg Thirteenth 4 года назад. Mishqa 4 года назад. Михаил 4 года назад. Показать ещё 24 комментария из Российские Флинстоуны: по Челябинску ездит маршрутка с дырой в полу.
Узбекские знакомства | стр.3
Хотите познакомиться с женщиной лет в Москве? 35–40 лет для представительниц слабого пола – возраст достижения духовной зрелости. Знакомства женщин от 40 до 50 лет из любого города для серьёзных отношений, брака или дружбы, я страница результатов поиска.
Вот это разворот! В Ейске пострадала автомобилистка. Инвалиды, потерявшие конечности, но не чувство юмора. Почему в армии нельзя носить бороду? Подборка демотиваторов на злобу дня. Распродажа квартир в новостройках: в чем обман? Стань лицом с обложки диска!
Инвалиды, потерявшие конечности, но не чувство юмора. Почему в армии нельзя носить бороду? Подборка демотиваторов на злобу дня. Распродажа квартир в новостройках: в чем обман? Стань лицом с обложки диска!
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Сделайте морфемный разбор слов (разобрать слова по составу) : Учительница, пришкольный,
Определи вариант где верно образованные личные формы глагола.Определи вариант, где верно образованы личные формы глаголов. дарить – дарю, даришь, даюл
… юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
дарить – дарю, даришь, даюл
… юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
Распределительная работа. Раскрывая скобки, запишите данные выражения группами, исходя из часте-речной принадлежности слова. Объясните правила написан … ия частиц не.
РЕБЯТА ДАЮ 50 БАЛОВ!!!!!!!!! НАПИСАТЬ СОЧИНЕНИЕ С ОТВЕТОМ НА ВОПРОС «ПРАВИЛЬНО ЛИ ПОСТУПИЛ БОРИС, КОТОРЫЙ ОСТАВИЛ РЫСЬ?» ПО РАССКАЗУ Е.МАРЫСЕВУ
Упражнение 500. Назовите стороны света, запишите их.Образец: Юго-запад.быстрее кто ответить тому лучший ответтт
Русский язык сор 7 класс 4 четверть, срочно.Вот мой номер:87074206310 напишите
Определите, к каким частям речи относятся слова из текста, и расположите их в следующей последовательности: А) прилагательное, Б) существительное, В) … глагол, Г) местоимение, Д) существительное, Е) предлог, Ж) наречие, З) прилагательное, К) существительное 1) животными, 2) количествах, 3) растительная, 4) пища, 5) используется 6) в, 7) небольших, 8) очень, 9) этими
Читательская грамотностьПрочитай текст «Про ежей» и ответы на вопросы. Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
прочитайте. Назовите лишние слова. Можно ли их заменить?пожалуйста помогите ❣
Слово в прямом значении: a) Добрая семечка b) Добрые книжки c) Добрая девочка d) Добрый вечер e) Доброе утро
Можете ответить на вопрос пожалуйста
Разобрать по составу слова:рыбка, тишина, лесною.
Определи вариант где верно образованные личные формы глагола.Определи вариант, где верно образованы личные формы глаголов.дарить – дарю, даришь, даюл … юбить – люблю, любишь, любитносить – носи, несет, носишьдерзить – держу, держишь, дерзит
Распределительная работа. Раскрывая скобки, запишите данные выражения группами, исходя из часте-речной принадлежности слова. Объясните правила написан … ия частиц не.
РЕБЯТА ДАЮ 50 БАЛОВ!!!!!!!!! НАПИСАТЬ СОЧИНЕНИЕ С ОТВЕТОМ НА ВОПРОС «ПРАВИЛЬНО ЛИ ПОСТУПИЛ БОРИС, КОТОРЫЙ ОСТАВИЛ РЫСЬ?» ПО РАССКАЗУ Е.МАРЫСЕВУ
Упражнение 500. Назовите стороны света, запишите их.Образец: Юго-запад.быстрее кто ответить тому лучший ответтт
Русский язык сор 7 класс 4 четверть, срочно.Вот мой номер:87074206310 напишите
Определите, к каким частям речи относятся слова из текста, и расположите их в следующей последовательности: А) прилагательное, Б) существительное, В) … глагол, Г) местоимение, Д) существительное, Е) предлог, Ж) наречие, З) прилагательное, К) существительное 1) животными, 2) количествах, 3) растительная, 4) пища, 5) используется 6) в, 7) небольших, 8) очень, 9) этими
Читательская грамотностьПрочитай текст «Про ежей» и ответы на вопросы. Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
Изображение домовитых ежей, которые несут на своих колючкахяблоки, мы все хорошо
… знаем. Но ёж всю зиму пребывает в спячке и ничегоза это время не ест.Возникает простой вопрос: «Зачем же сжу яблоки?» Растительнаяпиша используется этими животными в очень небольших количествах.Основа рациона ежей — ящерицы и змеи. Яблоки же необходимы ежамтолько в Гигиенических целях.Когда эти животные путешествуют по лесу и цепляются иголками затраву и ветки, они собирают на себя большое количество насекомых. Этинасекомые кусаются и вызывают у ежей страшный зуд. Чтобы избавиться отэтих мучителей, ежи накалывают на свой игольчатый панцирь яблоки,Кислый сок этих яблок уничтожает блох и клещей.По материалам журнала «Вокруг света»Вопросы и задання по тексту1. Согласны ли вы с данными утверждениямиУтвержденияДа Нет1. Благодаря яблокам у ежейобостряется слух.2. Путешествуя лесу,цепляютсятраву иветки.3. Насекомые вызывают у ежей зуд.Поежииголкамиза
прочитайте. Назовите лишние слова. Можно ли их заменить?пожалуйста помогите ❣
Слово в прямом значении: a) Добрая семечка b) Добрые книжки c) Добрая девочка d) Добрый вечер e) Доброе утро
Можете ответить на вопрос пожалуйста
Два изображения, три слова и отпечатки пальцев обнаружили под «Черным квадратом»
Информация о том, что под красочным слоем «Черного квадрата» Казимира Малевича обнаружено изображение и три слова, неделю назад стала сенсацией. Тогда сотрудники Третьяковской галереи, где и прошло исследование картины, отложили комментарии до официальной презентации. Об этом «Ведомости», получившие разъяснения от музея, писали 12 ноября.
Тогда сотрудники Третьяковской галереи, где и прошло исследование картины, отложили комментарии до официальной презентации. Об этом «Ведомости», получившие разъяснения от музея, писали 12 ноября.
Несмотря на то что мир волнуют уже другие, очень далекие от искусства проблемы, в здании Третьяковской галереи на Крымском Валу в зале Малевича собралось очень много журналистов. Им показали, как выглядит рентгенограмма картины, что видно на холсте при макрофотосъемке с помощью бинокулярного микроскопа и что получается, если «скомпоновать результаты съемок на рентгеновских пленках в единую композицию».
Получаются очень, надо сказать, эффектные изображения. Интригующе выглядит как черно-белая рентгенограмма, так и цветная реконструкция первоначальной композиции, поверх которой и написан черный квадрат. Причем и эти краски были наложены не одновременно, так что, возможно, изображений два. Также исследователи предполагают, что возникшие на холсте кракелюры являются следствием толщины красочного слоя. Очевидно поэтому картина постепенно теряла также свою черноту. На полотне, что было известно и раньше, до нынешнего исследования, оставались следы авторской реставрации. Через 14 лет после написания «иконы супрематизма» (это случилось, как доказала Александра Шатских, 8 июня 1915 г.) картина должна была быть выставлена на персональной выставке Малевича в Третьяковской галерее. Очевидно, тогда заведующий отделом нового русского искусства Алексей Федоров-Давыдов и попросил художника написать авторскую копию картины. Легко предположить, что физическое состояние оригинала казалось ему не слишком надежным.
Очевидно поэтому картина постепенно теряла также свою черноту. На полотне, что было известно и раньше, до нынешнего исследования, оставались следы авторской реставрации. Через 14 лет после написания «иконы супрематизма» (это случилось, как доказала Александра Шатских, 8 июня 1915 г.) картина должна была быть выставлена на персональной выставке Малевича в Третьяковской галерее. Очевидно, тогда заведующий отделом нового русского искусства Алексей Федоров-Давыдов и попросил художника написать авторскую копию картины. Легко предположить, что физическое состояние оригинала казалось ему не слишком надежным.
Кроме того, в результате исследований было обнаружено, что квадрат написан двумя черными красками, разными по составу. То есть, насколько и как черен черный квадрат, Малевичу было небезразлично. Другое дело, что исследуемый «Черный супрематический квадрат», который впервые был выставлен в декабре 1915 г., могут видеть только посетители Третьяковской галереи. На многочисленные выставки посылается как раз вариант 1929 г. этого самого востребованного произведения музея, потому что первый нетранспортабелен.
этого самого востребованного произведения музея, потому что первый нетранспортабелен.
Что же касается надписи из трех слов, которая так заинтриговала публику, то она была сделана поверх окончательного красочного слоя карандашом и могла, как сказала научный сотрудник музея Ирина Вакар, быть сделана кем угодно, например посетителем выставки. Хотя исследователи склонны к заключению, что, судя по почерку, написал ее сам Малевич. Почему и зачем – неизвестно. Из трех слов два прочитаны сотрудниками музея как «Битва негров…», третье разобрать трудно. Но, как и писали «Ведомости», нельзя точно сказать, знал ли художник о том, что французский остроумец Альфонс Алле выставил в 1882 г. черный прямоугольник в раме, названный «Битва негров в пещере ночью». Вакар также напомнила, что шуточные надписи на полях были популярны в то время у художников-футуристов.
Еще при исследовании на картине обнаружены отпечатки пальцев Малевича, что вполне естественно. Как ни пытали журналисты вопросами научных сотрудников Третьяковской галереи и ее директора Зельфиру Трегулову, никаких однозначных выводов, сделанных по результатам исследования, они не высказали. Разве что окрепла уверенность, что «Черный квадрат» был написан художником не случайно, а в результате размышлений и поисков, что, впрочем, было известно и без высокотехнологичной аппаратуры.
Разве что окрепла уверенность, что «Черный квадрат» был написан художником не случайно, а в результате размышлений и поисков, что, впрочем, было известно и без высокотехнологичной аппаратуры.
«Черному супрематическому квадрату» Казимира Малевича исполнилось в этом году 100 лет. И, как показали последние события, он до сих пор способен вызвать сенсацию. Которой, к слову, не было, когда его впервые показали публике на выставке «0,10». Но что, в сущности, такого – под красочным слоем знаменитой картины нашли ранние изображения, три слова и отпечатки пальцев художника? Никак это причины славы произведения не проясняет, а хотелось бы.
Image to Text: как извлечь текст из изображения
Представьте, что существует простой способ получить или извлечь текст из изображения, отсканированного документа или файла PDF и быстро вставить его в другой документ.
Хорошая новость заключается в том, что вам больше не нужно тратить время на ввод всего текста, потому что есть программы, использующие оптическое распознавание символов (OCR) для анализа букв и слов на изображении, а затем их преобразования в текст.
Существует ряд причин, по которым вы можете захотеть использовать функцию OCR для копирования текста из изображения или PDF.
- Вставьте текст с изображения или снимка экрана в Microsoft Office или другой документ.
- Сохранение текста в сообщении об ошибке, всплывающем окне или меню, где текст не может быть выделен.
- Захватить текст в каталоге файлов (имя файла, размер файла, дата изменения).
Независимо от вашей ситуации, этот тип функциональности может быть полезен, особенно когда вам нужно скопировать информацию из папки с файлами или снимка экрана веб-сайта, что обычно требует от вас значительного количества времени для повторного ввода всего текста.
К счастью, есть чрезвычайно простой способ сохранить текст или преобразовать изображение текста в редактируемый текст. С Snagit достаточно всего нескольких шагов, чтобы быстро извлечь текст с изображения.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Вот все, что вам нужно знать о том, как снимать текст с экрана компьютера или извлекать текст из изображения.
Как записать текст в Windows или Mac
Шаг 1. Настройте параметры захвата.
Чтобы захватить текст, откройте окно захвата, выберите вкладку «Изображение» и установите для выбора значение «Захватить текст».
Вы также можете ускорить процесс с помощью предустановки «Захват текста».
Шаг 2. Сделайте снимок экрана
Начните захват, затем с помощью перекрестия выберите область экрана с нужным текстом.
Snagit анализирует выбранный вами текст и отображает отформатированный текст.
Если указанный шрифт не установлен на вашем компьютере, Snagit заменит его системным шрифтом аналогичного стиля.
Выделите текст, который хотите скопировать, или нажмите «Копировать все…», чтобы скопировать весь текст в буфер обмена.
Шаг 3. Вставьте текст
Наконец, вы можете вставить текст в документ, презентацию или любое другое место назначения.
Изображение в текст: как извлечь текст из изображения с помощью OCR
Шаг 1. Найдите свое изображение
Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе.
Шаг 2. Откройте текст для захвата в Snagit
Открыв изображение в редакторе Snagit, перейдите в меню «Правка» и выберите «Захватить текст».
Или просто щелкните изображение правой кнопкой мыши или щелкните изображение и выберите «Захватить текст».
Шаг 3. Скопируйте текст
Затем скопируйте текст и вставьте его в другие программы и приложения.
И все. Извлечение текста из изображений, PDF-файлов или отсканированных документов не требует особых усилий.
Извлеките текст сегодня!
Загрузите бесплатную пробную версию Snagit, чтобы быстро и легко извлекать текст из изображений.
Скачать бесплатную пробную версию
Часто задаваемые вопросы
Как преобразовать изображение в текст?Загрузите ваше изображение в Snagit. Затем щелкните правой кнопкой мыши в любом месте изображения и выберите «Захватить текст». Это сканирует ваше изображение и преобразует его в текст.
Как извлечь текст из изображения в Windows?Сначала используйте Snagit, чтобы сделать снимок экрана своего изображения или загрузить его в редактор.
Snagit использует программное обеспечение оптического распознавания символов, или OCR, для распознавания и извлечения текста из изображения на компьютере с Windows.
Как извлечь текст из отсканированного PDF-файла? Вы можете захватить текст из отсканированного изображения, загрузить файл изображения со своего компьютера или сделать снимок экрана на рабочем столе. Затем просто щелкните изображение правой кнопкой мыши и выберите «Захватить текст».
Затем просто щелкните изображение правой кнопкой мыши и выберите «Захватить текст».
Текст из отсканированного PDF-файла можно затем скопировать и вставить в другие программы и приложения.
Как скопировать текст с изображения?Воспользуйтесь окном захвата изображения Snagit. Затем в раскрывающемся списке выберите «Захватить текст». По завершении появится окно со всем текстом, готовым для копирования и вставки.
Примечание редактора. Этот пост был первоначально опубликован в 2017 году и был обновлен для обеспечения точности и полноты.
Копирование текста с изображений и распечаток файлов с помощью OCR в OneNote
OneNote поддерживает оптическое распознавание символов (OCR), инструмент, который позволяет копировать текст с изображения или распечатки файла и вставлять его в заметки, чтобы вы могли вносить изменения в слова. Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или в другую программу, например Outlook или Word.
Это отличный способ делать такие вещи, как копирование информации с отсканированной визитки в OneNote. После извлечения текста вы можете вставить его в другое место в OneNote или в другую программу, например Outlook или Word.
Извлечь текст из одного изображения
Щелкните изображение правой кнопкой мыши и выберите Копировать текст с изображения .
Примечание. В зависимости от сложности, разборчивости и количества текста, отображаемого на вставленном вами рисунке, эта команда может быть недоступна сразу в меню, которое появляется при щелчке правой кнопкой мыши на изображении.Если OneNote все еще читает и преобразует текст на изображении, подождите несколько секунд и повторите попытку.
Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.

Извлечь текст из изображений распечатанного многостраничного файла
Щелкните правой кнопкой мыши любое изображение и выполните одно из следующих действий:
Нажмите Копировать текст с этой страницы распечатки , чтобы скопировать текст только с текущего выбранного изображения (страницы).
Нажмите Копировать текст со всех страниц распечатки , чтобы скопировать текст со всех изображений (страниц).
 org/ListItem»>
org/ListItem»>Щелкните место, куда вы хотите вставить скопированный текст, а затем нажмите Ctrl + V.
Примечание. Эффективность оптического распознавания символов зависит от качества изображения, с которым вы работаете.После вставки текста с изображения или распечатки файла рекомендуется просмотреть его и убедиться, что текст распознан правильно.
Пусть этот AI-бот превратит ваши слова в расплывчатые картинки
Лаборатория
Интерпретация ИИ фразы: «лаборатория». Искусственный интеллект уже влияет на большую часть нашей жизни разными способами, например, помогает водить машину, украшает наши фото в Instagram с едой и даже помогает диагностировать болезни.ИИ обрабатывает данные иначе, чем люди, поэтому общение с ним на нашем странном, непоследовательном языке может привести к таким дурацким результатам. Последняя коллекция странных творений искусственного интеллекта поступает из сети Attentional Generative Adversarial Network, которая переводит напечатанные слова в визуальное изображение.
Кристобаль Валенсуэла, создающий инструменты машинного обучения, создал сайт, чтобы продемонстрировать, как ИИ может анализировать слова и пытаться передать их значение визуально.
Впервые он был замечен в отличном блоге AI Weirdness, который кратко описывает весь процесс как «визуальный чат-бот в обратном порядке.«Вместо того, чтобы пытаться рассказать вам, что изображено на картинке, алгоритм пытается создать картинку из того, что вы ему рассказываете. Концепция основана на исследовании из опубликованной в прошлом году статьи под названием AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
.Бот рисует из набора объектов, на которых он был обучен. В результате он намного точнее работает с повседневными предметами, которые легко переводятся в картинку. Вещи становятся намного более абстрактными, когда вы начинаете кормить их туманными терминами, сложными концепциями или, как мне кажется, дурацкой чепухой.
Мы ввели в инструмент некоторые научные термины, чтобы увидеть, на что он способен. Результаты предсказуемо странные, по крайней мере, для моего мозга, не являющегося роботом.
Результаты предсказуемо странные, по крайней мере, для моего мозга, не являющегося роботом.
Вы можете попробовать свои собственные фразы здесь, но имейте в виду, что большой трафик из Twitter сделал службу немного ненадежной.
Вторичные материалы
Интерпретация AI фразы: «Вторичные материалы».Химическая реакция
Интерпретация AI фразы: «Химическая реакция.”Марсоход
Интерпретация ИИ фразы: «Марсоход».Поле астероидов
Интерпретация ИИ фразы: «Поле астероидов».Большой взрыв
Интерпретация ИИ фразы: «Большой взрыв».Внеземная жизнь
Интерпретация ИИ фразы: «Внеземная жизнь».Изменение климата
Интерпретация AI фразы: «Изменение климата».Космический корабль
Интерпретация AI фразы: «Космический корабль.”Как Evernote делает текст внутри изображений доступным для поиска — справочный центр Evernote
Как Evernote делает текст внутри изображений доступным для поиска
Знаете ли вы, что когда вы делаете снимок или прикрепляете изображение к заметке, Evernote может найти и идентифицировать текст, включая рукописный текст, внутри этого изображения?
Как это работает
Машинописный текст и рукописные заметки в формате JPG, PNG или GIF оцениваются нашей системой индексирования. Текст, найденный в изображении, будет оцениваться, если он соответствует одной из следующих ориентаций в пределах нескольких градусов:
Текст, найденный в изображении, будет оцениваться, если он соответствует одной из следующих ориентаций в пределах нескольких градусов:
- 0 ° — нормальная горизонтальная ориентация
- 90 ° — вертикальная ориентация
- 270 ° — вертикальная ориентация
Текст, не соответствующий одной из этих ориентаций, будет проигнорирован (включая диагональный и инвертированный текст). Когда изображения индексируются, они могут показывать несколько результатов. Например, система индексации может взглянуть на слово и решить, что это «кошка», «летучая мышь» или «3at».
Лучший способ убедиться, что почерк, в частности, найден и проиндексирован, — это следовать этим рекомендациям:
- Изображения, содержащие рукописный текст, следует добавлять в Evernote как изображения JPG, а не в формате PDF. Файлы PDF являются предпочтительным форматом для машинописных документов или отсканированных страниц, содержащих машинописный текст. Рукописный ввод не индексируется в файлах PDF.
- Чем четче почерк, тем больше вероятность, что он будет точно проиндексирован для поиска. Если почерк трудно читается, то Evernote будет труднее различать написанные слова.
- Имейте в виду, что вместо того, чтобы генерировать одно совпадение для данного рукописного слова, Evernote будет генерировать несколько возможных совпадений для этого слова. Например, слово «плоский» в формате JPG может быть проиндексировано как «плоский», «плавающий» или «фиатный».

В настоящее время Evernote может индексировать 28 машинописных языков и 11 рукописных языков. Вы можете выбрать, какой язык будет использоваться при индексировании, изменив параметр «Язык распознавания» в настройках своей учетной записи.
Подробнее о том, как работает распознавание изображений Evernote
Примеры
- Делайте снимки меню ресторана (включая меню на вынос) и сохраняйте их в своей учетной записи Evernote для использования в будущем.
- Делайте фотографии винных и пивных этикеток, чтобы отслеживать свои любимые товары и любые дегустационные заметки.
- Делайте фотографии подарочных карт и подарочных сертификатов, чтобы всегда знать, где можно потратить лишние деньги.
- Делайте снимки рукописных поздравительных открыток и просматривайте их, когда душе угодно.
- Фотографируйте гарантии, инструкции по уходу за продуктами и любую другую полезную информацию, которую вы встретите в бумажной форме.

LANGUAGES_SUPPORT LANGUAGES_INCLUDE = ms
Ключевые слова:
- текстовый поиск
- поисковый текст
- текст в изображениях
- индекс
- индексирование изображений
- окр
- распознавание изображений
- распознавание текста
- индексных изображений
- почерк
- рукописный
— Ruby: синтаксический анализ / извлечение изображений и объектов из файла docx
Я пытаюсь открыть и прочитать.docx с помощью Ruby, извлеките части текста и объектов / изображений и сохраните их в другом (не .docx) файле.
Используя Nokogiri, я могу правильно извлекать текст и разбивать документ на разделы, которые мне нужны через:
zip = Zip :: File. open file_path
doc = zip.find_entry ("word / document.xml")
xml = Nokogiri :: XML.parse (doc.get_input_stream)
wt = xml.root.xpath ("// w: t", {"w" =>
"http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
 open file_path
doc = zip.find_entry ("word / document.xml")
xml = Nokogiri :: XML.parse (doc.get_input_stream)
wt = xml.root.xpath ("// w: t", {"w" =>
"http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
open file_path
doc = zip.find_entry ("word / document.xml")
xml = Nokogiri :: XML.parse (doc.get_input_stream)
wt = xml.root.xpath ("// w: t", {"w" =>
"http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
Если я сделаю это вместо этого:
xml.root.xpath ("// w: body", {"w" => "http://schemas.openxmlformats.org/wordprocessingml/2006/main"})
Я вижу объекты в xml как:
, но не знаю, как преобразовать это во что-то, что позже можно будет использовать для отображения в html. Преобразование в svg таким образом, чтобы его можно было отображать вместе с текстом в html, было бы идеальным.
Спасибо за любую помощь.
python — как реализовать макет для анализа значений и получения файла взамен?
После более чем 30-часовой попытки реализовать python_-docx и docxtpl для определенных функций (и при этом совершенно неуспешно) я решил зайти сюда за советом.
Мой текущий проект состоит из различных изображений (.png), форматированного текста (т.е. полужирный, тень, шрифт, цвет и т. Д.) И т. Д. — теперь эти элементы нужно расположить / вписать в аккуратный шаблон. Сначала я попробовал подушка , создав холст и добавив все эти элементы каждый. Само решение чрезвычайно подвержено ошибкам и не поддерживает все функции, касающиеся текста. Затем я создал шаблон .docx (расположение изображений, текста, включая шрифт, стиль и т. Д.)) и реализовать ценности таким образом — это сработало! … кроме того, что он не поддерживает более одного элемента изображения / мультимедиа на странице Word!)
В демонстрационных целях я попытался набросать рабочий процесс:
Теперь должно быть очевидно, почему я попробовал Word — простую программу для редактирования слов, в которой я смог отформатировать все по своему желанию (хотя Python API не работал, следовательно, он бесполезен) — в демонстрационных целях, вот фрагмент псевдокода:
# КОД ПСЕВДО
из docxtpl import DocxTemplate
tpl = DocxTemplate ('файл. docx ')
tpl.replace_media ('dummy.png', 'pic1.png')
tpl.replace_media ('dummy2.png', 'pic2.png')
tpl.save ('out.docx')
 docx ')
tpl.replace_media ('dummy.png', 'pic1.png')
tpl.replace_media ('dummy2.png', 'pic2.png')
tpl.save ('out.docx')
docx ')
tpl.replace_media ('dummy.png', 'pic1.png')
tpl.replace_media ('dummy2.png', 'pic2.png')
tpl.save ('out.docx')
В зависимости от настройки он либо заменяет None, либо оба изображения одним из них. Согласно различным вопросам и темам StackOverflow, более одного изображения невозможно ! Поэтому слово «подход» бесполезно.
Во всяком случае, я ничего не знаю. Любые предложения о том, как достичь такого рабочего процесса, то есть иметь простой редактируемый макет, в котором мне просто нужно проанализировать определенные значения и получить .docx , .png , .pdf , что угодно ..
Извлечение текста из изображений с помощью Tesseract OCR, OpenCV и Python
Людям легко понять содержимое изображения, просто взглянув на него. Вы можете распознать текст на изображении и без особого труда понять его. Однако компьютеры работают иначе. Они понимают только организованную информацию. И именно здесь на сцену выходит оптическое распознавание символов. В моем предыдущем блоге я объяснил основы OCR и 3 важные вещи, о которых вам следует знать. Как и обещал моим читателям, я вернулся со своим вторым блогом. На этот раз я собираюсь подробнее рассказать об оптическом распознавании текста, особенно об извлечении информации из изображения. И, как всегда, с автоматизацией вы можете вывести это на новый уровень. Автоматизация задачи извлечения текста из изображений поможет вам вести и анализировать записи. В этом блоге основное внимание уделяется областям приложений OCR с использованием Tesseract OCR, OpenCV, установке и настройке среды, кодированию и ограничениям Tesseract.Итак, приступим.
В моем предыдущем блоге я объяснил основы OCR и 3 важные вещи, о которых вам следует знать. Как и обещал моим читателям, я вернулся со своим вторым блогом. На этот раз я собираюсь подробнее рассказать об оптическом распознавании текста, особенно об извлечении информации из изображения. И, как всегда, с автоматизацией вы можете вывести это на новый уровень. Автоматизация задачи извлечения текста из изображений поможет вам вести и анализировать записи. В этом блоге основное внимание уделяется областям приложений OCR с использованием Tesseract OCR, OpenCV, установке и настройке среды, кодированию и ограничениям Tesseract.Итак, приступим.
Тессеракт OCR
Tesseract — это движок распознавания текста с открытым исходным кодом, доступный по лицензии Apache 2.0, и его разработка спонсируется Google с 2006 года. В 2006 году Tesseract считался одним из самых точных движков OCR с открытым исходным кодом. Вы можете использовать его напрямую или можете использовать API для извлечения печатного текста из изображений. Самое приятное то, что он поддерживает большое количество языков. Именно через оболочки Tesseract можно сделать совместимым с различными языками программирования и фреймворками.В этом блоге я буду использовать оболочку Python под названием pytesseract. Он используется для распознавания текста из большого документа или его также можно использовать для распознавания текста из изображения одной текстовой строки. Ниже представлено визуальное представление архитектуры Tesseract OCR, представленной в исследовательском документе по системе OCR на основе голосования.
Самое приятное то, что он поддерживает большое количество языков. Именно через оболочки Tesseract можно сделать совместимым с различными языками программирования и фреймворками.В этом блоге я буду использовать оболочку Python под названием pytesseract. Он используется для распознавания текста из большого документа или его также можно использовать для распознавания текста из изображения одной текстовой строки. Ниже представлено визуальное представление архитектуры Tesseract OCR, представленной в исследовательском документе по системе OCR на основе голосования.
Говоря о Tesseract 4.00, он имеет настроенный распознаватель текстовых строк в своей новой подсистеме нейронной сети. В наши дни люди обычно используют сверточную нейронную сеть (CNN) для распознавания изображения, содержащего один символ.Текст произвольной длины и последовательность символов решается с использованием рекуррентной нейронной сети (RNN) и долговременной краткосрочной памяти (LSTM), где LSTM является популярной формой RNN. Входное изображение Tesseract в LSM обрабатывается построчно в прямоугольниках, которые вставляются в модель LSTM и выдают выходные данные.
Входное изображение Tesseract в LSM обрабатывается построчно в прямоугольниках, которые вставляются в модель LSTM и выдают выходные данные.
По умолчанию Tesseract рассматривает входное изображение как страницу текста в сегментах. Вы можете настроить различные сегменты Tesseract, если хотите захватить небольшую область текста с изображения.Вы можете сделать это, назначив ему режим —psm . Tesseract полностью автоматизирует сегментацию страниц, но не выполняет ориентацию и обнаружение скриптов. Различные параметры конфигурации для Tesseract упомянуты ниже:
Режим сегментации страниц (—psm): Настроив это, вы можете помочь Tesseract в том, как он должен разделять изображение в форме текста. Справка командной строки имеет 11 режимов. Вы можете выбрать тот, который лучше всего подходит для ваших требований, из приведенной ниже таблицы:
| режим | Рабочее описание |
| 0psm | Только ориентация и обнаружение сценария (OSD) |
| 1 | Автоматическая сегментация страниц с помощью экранного меню |
| 2 | Автоматическая сегментация страниц без экранного меню или OCR |
| 3 | Полностью автоматическая сегментация страниц, без экранного меню (по умолчанию) |
| 4 | Предположим, что один столбец текста переменного размера |
| 5 | Предположим, что это один однородный блок с вертикально выровненным текстом |
| 6 | Предположим, что один однородный блок текста |
| 7 | Обрабатывать изображение как одну текстовую строку |
| 8 | Обрабатывать изображение как одно слово |
| 9 | Для обработки изображения как отдельного слова в круге |
| 10 | Считать изображение одним символом |
| 11 | Разрезанный текст. Найдите как можно больше текста не в определенном порядке Найдите как можно больше текста не в определенном порядке |
| 12 | Разреженный текст с экранным меню |
| 13 | Сырая линия. Рассматривайте изображение как одну текстовую строку, избегайте взлома, специфичного для Tesseract. |
Engine Mode (—oem): Tesseract имеет несколько режимов двигателя с разной производительностью и скоростью. Tesseract 4 представил дополнительный режим нейтральной сети LSTM, который работает лучше всего. Следуйте таблице, приведенной ниже, для различных режимов двигателя OCR:
| Режим двигателя OCR | Рабочее описание |
| 0 | Только устаревший двигатель |
| 1 | Только нейронная сеть LSTM |
| 2 | Legacy + только режим LSTM |
| 3 | По умолчанию, в зависимости от того, что в настоящее время доступно |
OpenCV
OpenCV (библиотека компьютерного зрения с открытым исходным кодом), как следует из названия, представляет собой компьютерное зрение с открытым исходным кодом и библиотеку программного обеспечения для машинного обучения. OpenCV был создан для предоставления общей инфраструктуры для приложений компьютерного зрения. Помимо этого, это также ускоряет использование машинного восприятия в коммерческих продуктах. OpenCV является продуктом с лицензией BSD, поэтому он может пригодиться компаниям для использования и модификации кода. Библиотека включает более 2500 оптимизированных алгоритмов, которые имеют полный набор как классического, так и современного компьютерного зрения, а также алгоритмы машинного обучения. Эти алгоритмы могут использоваться для обнаружения и распознавания лиц, классификации действий человека в видео, извлечения 3D-моделей объектов и многого другого.Здесь я буду использовать его для предварительной обработки, чтобы определить текст из файла изображения. Tesseract требует чистого изображения для обнаружения текста, здесь OpenCV играет важную роль, поскольку он выполняет операции с изображением, такие как преобразование цветного изображения в двоичное изображение, регулировка контрастности изображения, обнаружение краев и многое другое.
OpenCV был создан для предоставления общей инфраструктуры для приложений компьютерного зрения. Помимо этого, это также ускоряет использование машинного восприятия в коммерческих продуктах. OpenCV является продуктом с лицензией BSD, поэтому он может пригодиться компаниям для использования и модификации кода. Библиотека включает более 2500 оптимизированных алгоритмов, которые имеют полный набор как классического, так и современного компьютерного зрения, а также алгоритмы машинного обучения. Эти алгоритмы могут использоваться для обнаружения и распознавания лиц, классификации действий человека в видео, извлечения 3D-моделей объектов и многого другого.Здесь я буду использовать его для предварительной обработки, чтобы определить текст из файла изображения. Tesseract требует чистого изображения для обнаружения текста, здесь OpenCV играет важную роль, поскольку он выполняет операции с изображением, такие как преобразование цветного изображения в двоичное изображение, регулировка контрастности изображения, обнаружение краев и многое другое.
Теперь переходим к следующему разделу, который посвящен установке и настройке среды для выполнения задачи распознавания текста.
Установка и настройка среды
Здесь я буду использовать Python в качестве языка программирования для выполнения задачи распознавания текста.Я проведу вас через процедуру настройки среды для Python OCR и установки библиотек в вашей системе Linux.
Во-первых, настройте среду Python в Ubuntu с помощью команды, приведенной ниже:
virtualenv -p python3 ocr_env
Примечание: Убедитесь, что в вашей системе установлен Python версии 3 или более поздней версии.
Теперь активируйте свою среду с помощью следующей команды в терминале:
источник ocr_env / bin / activate
Теперь вы готовы к установке OCR и Tesseract, используйте команды, указанные ниже, одну за другой:
pip install opencv-python
pip install pytesseract
Теперь, когда установка и настройка среды, наконец, завершены, перейдем к части кодирования.
Кодирование
Здесь я буду использовать следующий образец изображения квитанции:
Образец изображения чека
Первая часть — это пороговая обработка изображений. Ниже приведен код, который можно использовать для определения порога:
.1 | # импорт модулей
2 | импорт cv2
3 | импортный питессеракт
5 | # чтение изображения с помощью opencv
6 | image = cv2.imread (sample_image.png ’)
7 | # преобразование изображения в изображение в оттенках серого
8 | gray_image = cv2.cvtColor (изображение, cv2.COLOR_BGR2GRAY)
9 | # преобразование его в двоичное изображение с помощью Thresholding
10 | # этот шаг требуется, если у вас есть цветное изображение, потому что если вы пропустите эту часть
11 | # тогда tesseract не сможет правильно определить текст, и это даст неверный результат
11 | threshold_img = cv2.threshold (gray_image, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) [1]
12 | # отобразить изображение
13 | cv2.
14 | # Сохранять окно вывода, пока пользователь не нажмет клавишу
15 | cv2.waitKey (0)
16 | # Уничтожение текущих окон на экране
17 | cv2.destroyAllWindows ()
 imshow («пороговое изображение», threshold_img)
imshow («пороговое изображение», threshold_img) После установки порога изображения выходное изображение будет таким:
Изображение после порога
Теперь вы можете увидеть разницу между исходным изображением и изображением с пороговым значением. Изображение с пороговым значением показывает четкое разделение между белыми и черными пикселями. Таким образом, если вы доставите это изображение в Tesseract, он легко обнаружит текстовую область и даст более точные результаты.Для этого следуйте командам, приведенным ниже:
13 | # настройка параметров для tesseract
14 | custom_config = r '- oem 3 --psm 6'
15 | # теперь загружаем изображение в тессеракт
16 | details = pytesseract.image_to_data (threshold_img, output_type = Output.DICT, config = custom_config, lang = ’eng’)
17 | печать (details.
 keys ())
keys ())
Если вы распечатываете детали, это ключи словаря, которые будут содержать соответствующие детали:
dict_keys ([‘level’, ‘page_num’, ‘block_num’, ‘par_num’, ‘line_num’, ‘word_num’, ‘left’ , ‘верх’, ‘ширина’, ‘высота’, ‘conf’, ‘текст’])
В приведенном выше словаре содержится информация о вашем входном изображении, такая как обнаруженная текстовая область, информация о положении, высота, ширина, оценка достоверности и т. Д.Теперь нарисуйте ограничивающую рамку на исходном изображении, используя приведенный выше словарь, чтобы узнать, насколько точно Tesseract работает как сканер текста для обнаружения текстовой области. Следуйте приведенному ниже коду:
18 | total_boxes = len (подробности ['текст'])
19 | для sequence_number в диапазоне (total_boxes):
20 | if int (подробности ['conf'] [sequence_number])> 30:
21 | (x, y, w, h) = (подробности ['left'] [sequence_number], details ['top'] [sequence_number], details ['width'] [sequence_number], подробности ['height'] [sequence_number] )
22 | threshold_img = cv2.
23 | # отобразить изображение
24 | cv2.imshow («захваченный текст», threshold_img)
25 | # Сохранять окно вывода, пока пользователь не нажмет клавишу
26 | cv2.waitKey (0)
27 | # Уничтожение текущих окон на экране
28 | cv2.destroyAllWindows ()
 прямоугольник (threshold_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
прямоугольник (threshold_img, (x, y), (x + w, y + h), (0, 255, 0), 2) Примечание: На шаге 20 учитывайте только те изображения, для которых показатель достоверности больше 30. Получите это значение, вручную просмотрев сведения о текстовом файле словаря и показатель достоверности.После этого убедитесь, что все текстовые результаты верны, даже если их оценка достоверности находится между 30-40. Вам необходимо проверить это, потому что изображения состоят из цифр, других символов и текста. И в Tesseract не указано, что поле содержит только текст или только цифры. Предоставьте весь документ как есть в Tesseract и дождитесь, пока он покажет результаты в зависимости от значения, принадлежит ли он тексту или цифрам.
Изображение после рисования ограничительной рамки
Теперь, когда у вас есть изображение с ограничивающей рамкой, вы можете перейти к следующей части, которая должна упорядочить захваченный текст в файл с форматированием, чтобы легко отслеживать значения.
Примечание: Здесь я написал код на основе текущего формата изображения и вывода из Tesseract. Если вы используете какой-либо другой формат изображения, вам необходимо написать код в соответствии с этим форматом изображения.
Приведенный ниже код предназначен для преобразования результирующего текста в формат, соответствующий текущему изображению:
29 | parse_text = []
30 | word_list = []
31 | last_word = ''
32 | на слово в деталях ['текст]:
33 | если слово! = '':
34 | список слов.добавить (слово)
35 | last_word = word
36 | if (last_word! = '' и word == '') или (word == details ['text'] [- 1]):
37 | parse_text.append (список_слов)
38 | word_list = []
Следующий код преобразует текст результата в файл:
39 | импорт csv
40 | с open (result_text.
41 | csv.writer (файл, delimiter = "") .writerows (parse_text)
 txt ',' w ', newline = "") как файл:
txt ',' w ', newline = "") как файл: Пришло время сравнить выходной текстовый файл и входное изображение.
Теперь, если вы сравните оба изображения, можно сделать вывод, что почти все значения верны. Таким образом, можно сказать, что в данном тестовом примере Tesseract дал точный результат около 95%, что весьма впечатляет.
Однако у Tesseract есть некоторые ограничения, давайте посмотрим, что это такое.
Ограничения Tesseract
- Точность распознавания текста не так высока по сравнению с некоторыми коммерческими решениями, доступными в настоящее время.
- Не распознает рукописный текст.
- Если документ содержит языки, которые не поддерживаются Tesseract, результаты будут плохими.
- Требуется четкое изображение на входе. Сканирование низкого качества может привести к плохим результатам при распознавании текста.
- Он не дает точных результатов для изображений, на которые влияют артефакты, включая частичное перекрытие, искаженную перспективу и сложный фон.
- Не подходит для анализа нормального порядка чтения документов. Например, вы можете не распознать, что документ содержит два столбца, и можете попытаться объединить текст в этих столбцах.
- Не раскрывает текстовую информацию о семействе шрифтов.

В итоге можно сделать вывод, что Tesseract идеально подходит для сканирования чистых документов, и вы можете легко преобразовать текст изображения из OCR в word, pdf в word или в любой другой требуемый формат. Имеет довольно высокую точность и вариативность шрифтов. Это очень полезно в случае учреждений, где задействовано много документации, таких как правительственные учреждения, больницы, учебные заведения и т. Д.
SEM1A5 — Часть 2 — Морфологический анализ
SEM1A5 — Часть 2 — Морфологический анализМорфологический анализ
Этот раздел состоит из трех частей. В первой части вводятся некоторые основные морфологические термины, в частности, морфема , аффикс, префикс , суффикс , связанный и свободный формы. Во втором рассматриваются традиционные способы группировки языков, такие как , изолирующий , , агглютинативный и , склоняющий .В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
Во втором рассматриваются традиционные способы группировки языков, такие как , изолирующий , , агглютинативный и , склоняющий .В последнем разделе рассматриваются некоторые морфологические процессы, концентрируясь только на тех, которые имеют большее отношение к инженерии естественного языка.
Некоторая терминология
Лингвистика стремится описывать язык. Любое описание требует некоторой терминологии для его описания. Мы можем рассматривать это как технический словарь дисциплины. В естественных языках есть свои термины для описания самих себя. Например, мы в разговорной речи говорим о «словах», «фразах», «предложениях» и «абзацах».Знаем ли мы, что означают эти слова?
Мы рассмотрим только определение этого слова. В таком тексте мы можем легко обнаружить «слова», потому что они отделены друг от друга пробелами или знаками препинания. Однако, если вы запишете обычную разговорную речь, вы обнаружите, что между словами нет разрывов. Несмотря на это, мы могли снова и снова выделять единицы, которые мы используем в речи, но в разных комбинациях. Это говорит о том, что существует небольшая единица чего-то вроде слова. Но как определить «слово»? Мы все согласимся, что черный и птица — это слова. blackbird — одно или два слова? blackbird s — это то же слово, что и blackbird , или отдельное слово?
Несмотря на это, мы могли снова и снова выделять единицы, которые мы используем в речи, но в разных комбинациях. Это говорит о том, что существует небольшая единица чего-то вроде слова. Но как определить «слово»? Мы все согласимся, что черный и птица — это слова. blackbird — одно или два слова? blackbird s — это то же слово, что и blackbird , или отдельное слово?
На эти вопросы нет простых ответов. Ситуация более сложная, потому что
- лингвистическая теория также должна учитывать, как звуки ( фонология ) связаны со «словами»
- , потому что английский на данный момент является относительно простым языком: в других языках есть гораздо более сложные способы изменения форм слов, чем в английском.
Морфология — это изучение структуры и образования слов. Его наиболее важной единицей является морфема , которая определяется как «минимальная единица значения». (Учебники лингвистики обычно определяют его немного иначе как «минимальную единицу грамматического анализа». ) Рассмотрим такое слово, как «несчастье». Он состоит из трех частей:
) Рассмотрим такое слово, как «несчастье». Он состоит из трех частей:
Есть три морфемы, каждая из которых несет определенное значение. un означает «нет», а ness означает «находиться в состоянии или состоянии». Happy — это бесплатная морфема , потому что она может появляться сама по себе (как «слово» само по себе). Связанные морфемы должны быть присоединены к свободной морфеме, и поэтому не могут быть словами сами по себе. Таким образом, у вас не может быть предложений на английском языке, таких как «Джейсон чувствует себя сегодня очень беспомощным».
Вооружившись этими определениями, мы можем взглянуть на способы, используемые для классификации языков в соответствии с их морфологической структурой.
Классификация морфологических структурных типов
Выше было высказано предположение, что английский с морфологической точки зрения является довольно простым языком.Подразумевается, что другие языки ведут себя по-другому, и это является основой данной схемы классификации. Лингвисты предыдущих поколений были весьма заинтересованы в создании генеалогических деревьев языков, чтобы показать, какие современные языки произошли от каких более ранних, и, возможно, даже иметь возможность восстановить утраченные языки. Морфологическая структура — это всего лишь один из способов группировки языков.
Лингвисты предыдущих поколений были весьма заинтересованы в создании генеалогических деревьев языков, чтобы показать, какие современные языки произошли от каких более ранних, и, возможно, даже иметь возможность восстановить утраченные языки. Морфологическая структура — это всего лишь один из способов группировки языков.
В этой классификации обычно три класса.
- Изолирующие языки
- Слова изолирующего языка неизменны.Другими словами, он состоит из свободных морфем, поэтому здесь нет морфем, указывающих на такую информацию, как грамматическое число (например, множественное число) или время (прошлое, настоящее, будущее). В качестве примера такого языка часто приводят мандаринский китайский (хотя некоторые утверждают, что вьетнамский является лучшим примером). Транслитерированное предложение:
gou bú ài chi qingcài
дословно можно перевести как:собака не любит есть овощи
В зависимости от контекста это может означать любое из четырех следующих предложений:собака не любит есть овощи
собаки не любят есть овощи
собаки не любят есть овощи
собаки не любят есть овощи - Агглютинативные языки
- Мой словарь дает определение агглютината как «соединить как с клеем; (языка) объединять простые слова без изменения формы для выражения сложных идей». Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
- ler = множественное число
- i = притяжательный (например, его, ее, его )
- den = аблатив (например, грамматическое окончание «падежа», показывающее источник, например из дома).
Чтобы завершить наш пример, нам понадобится турецкое существительное, в данном случае ev , что означает «дом».Из этого существительного можно составить следующие слова:
- ev: дом
- evler: домов
- evi: его / ее дом
- evleri: его дома, их дома
- evden: от дома
- evlerden: от домов
- evinden: из его дома
- evlerinden: из своих домов, из своих домов
(Обратите внимание, что за притяжательной морфемой i обычно следует n перед den.
)В этом примере важно заметить, как все морфемы представляют «единицу значения» и как они остаются абсолютно идентифицируемыми в структуре слов. Это контрастирует с тем, что происходит в последнем классе: склоняющиеся языки.
- Изменяющиеся языки
- Слова в флективных языках имеют разные формы, и можно разбить слова на более мелкие единицы и пометить их так же, как турецкий пример был представлен выше.Однако результат — очень запутанный и противоречивый отчет. Обычные примеры основаны на латыни и основаны на знании латинского грамматического примера, которого нет у большинства английских студентов. В качестве простого примера, на латыни «я люблю» это амо. Это означает, что окончание o используется для выражения значений, от первого лица, («я» или «мы»), в единственном числе, в настоящем времени, и других значений.
 Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы:
Примеры из учебников обычно основаны на турецком или суахили, из которых мы будем использовать первый. В нашем примере мы будем использовать следующие морфемы: )
) В этой классификации всего три класса.Действительно ли возможно объединить все языки мира в три класса? С одной стороны, невозможно поместить какой-либо из языков в какой-либо из классов, потому что каждый язык нечист. То есть, если вы посмотрите достаточно внимательно, вы обнаружите словоизменение в основном в агглютинативных языках, флексию в изолирующих языках, агглютинацию в флективных языках и т.д.
То есть, если вы посмотрите достаточно внимательно, вы обнаружите словоизменение в основном в агглютинативных языках, флексию в изолирующих языках, агглютинацию в флективных языках и т.д.
Какие уроки мы можем извлечь из этого? Я думаю, что стоит отметить два момента. Во-первых, языки сильно различаются, и обобщения, основанные на опыте владения только одним языком (например, английским), могут быть легко противопоставлены другим языкам.Во-вторых, язык — это естественное явление, и «инструменты», которые мы используем для его изучения (например, классификации и технические термины), — всего лишь инструменты, которые могут быть несовершенными попытками описать что-то слишком сложное для нашей современной науки.
Морфологические процессы
В приведенном выше примере несчастья, мы видели два вида аффиксов: префикс и суффикс. Чтобы показать, что языки действительно сильно различаются, есть также инфиксы.Например, язык Bontoc с Филиппин использует инфикс um для преобразования прилагательных и существительных в глаголы.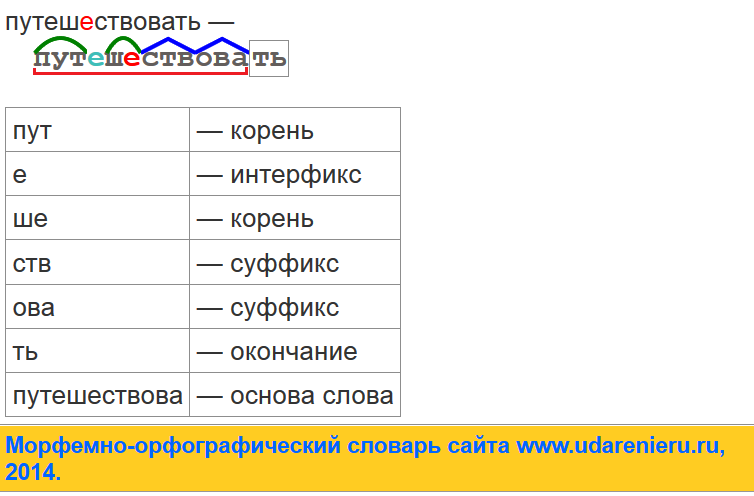 Таким образом, слово fikas, , что означает «сильный», преобразовано в глагол «быть сильным» путем добавления инфикса: f-um-ikas.
Таким образом, слово fikas, , что означает «сильный», преобразовано в глагол «быть сильным» путем добавления инфикса: f-um-ikas.
Существует ряд морфологических процессов, некоторые из которых более важны для НЛП, чем другие. Представленный здесь отчет является выборочным и необычным, поскольку он указывает на практические аспекты выбранных процессов.
- Перегиб
- Флексия — это процесс изменения формы слова так, чтобы оно выражало такую информацию, как число, личность, падеж, пол, время, настроение и аспект, но синтаксическая категория слова остается неизменной. Например, форма множественного числа существительного в английском языке обычно образуется из формы единственного числа путем добавления s.
- легковых / легковых
- стол / столы
- собака / собаки
Не нужно много времени, чтобы найти примеры, где приведенное выше простое правило не подходит.
Итак, есть меньшие группы существительных, образующих множественное число по-разному:- волк / волки
- нож / ножи
- переключатель / переключатели.
Еще немного подумайте, и мы сможем подумать о совершенно неправильных формах множественного числа, таких как:
- фут / фут
- ребенок / дет.
Английские глаголы относительно просты (особенно по сравнению с такими языками, как финский, в котором более 12 000 глагольных перегибов).
- косилка — штанга
- mow s — третье лицо единственного числа, настоящее время
- mow ed — прошедшее время и причастие прошедшего времени
- косить ing — настоящее непрерывное время
Аспекты НЛП
Такие языки, как французский или немецкий, имеют гораздо больше интонаций, чем английский, поэтому принято включать морфологические анализаторы в системы, которые обрабатывают эти языки. Системы НЛП для английского языка часто не включают каких-либо морфологических процессов, особенно если это небольшие системы. В тех случаях, когда системы, основанные на английском языке, включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), в то время как исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы необходимо вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации. - Вывод
- Как было показано выше, словоизменение не меняет синтаксическую категорию слова.Деривация не меняет категорию . Лингвисты классифицируют словообразование в английском языке в зависимости от того, вызывает ли оно изменение произношения. Например, добавление суффикса ity изменяет произношение корня active , поэтому ударение находится на втором слоге: activity. Добавление суффикса al к Approve не меняет произношения корня: Approve.
Аспекты НЛП
Очевидное использование деривационной морфологии в системах НЛП состоит в том, чтобы уменьшить количество сохраняемых форм слов.Таким образом, если уже существует запись для базовой формы глагола sing, , тогда должна быть возможность добавить правила для сопоставления существительных singers и singers одной и той же записи. Проблема в том, что обнаружение производных певца от певца должно также позволить морфологическому анализатору вносить информацию, которая является особенной для певца . Это кажется немного непонятным, но пример прояснит это. Добавление к слову или указывает на то, что действие совершает человек.Эта семантическая информация должна быть добавлена к сохраненной информации из словарной статьи для корневой формы и , чтобы можно было найти правильное значение предложения. Кажется, это нормально, но предположим, что следующие два слова: рекордер и драгстер. Использование морфемы er не может обязательно означать кого-то, кто предпринимает действие, представленное корневой формой.Любая лингвистическая обработка может привести к обнаружению потенциальной двусмысленности, особенно там, где люди этого не ожидают.Деривационные морфологические анализаторы могут сделать это довольно легко, потому что они всегда пытаются сократить слова до более мелких единиц. Таким образом, слово на самом деле может быть проанализировано как на самом деле (т.е. само слово), так и как относительно + союзник. Эта введенная двусмысленность может быть устранена с помощью более поздней синтаксической обработки, но, тем не менее, это означает, что требуется больше обработки (и, следовательно, более медленная система).
Деривационная морфология особенно полезна для машинного перевода.Успешный МП должен обрабатывать большие объемы текста, который может содержать много ранее невидимых слов. Некоторые слова являются неологизмами (то есть новыми словами). Если анализатор сможет преобразовать эти слова в их базовую форму, он сможет перевести это и, по сути, создать новое слово на целевом языке, просто следуя правилам. Приведу пару примеров: неологизмы часто имеют в качестве корня собственное имя. Знание того, как Thatcherite и Majorism образовались из имен собственных, могло позволить системе машинного перевода перевести их в идиоматический эквивалент на целевом языке.
- Полуаффиксы и комбинированные формы
- Полуаффиксы — это связанные морфемы, сохраняющие словесное качество. Примеры: анти-, контр-, -подобный и -достойный. Итак, мы можем иметь:
- против часовой стрелки или против часовой стрелки
- контрпример или контрпример
- Птичий или Птичий
- заслуживает внимания или заслуживает внимания
Комбинированные формы даже более похожи на слова, чем полуаффиксы, и часто встречаются в технической литературе, например индоевропейский или гастроэнтерит. Некоторые слова могут состоять полностью из связанных форм, но без свободной морфемы, например franco-phile.
Аспекты НЛП
Как и в случае деривационной морфологии, полуаффиксы и комбинирующие формы могут быть проанализированы в их морфемы и, как и в случае деривационной морфологии, могут быть использованы для анализа ранее невидимых слов. Расстановка переносов представляет собой особую проблему для таких языков, как английский и немецкий, и понимание полуаффиксов и комбинирования форм может способствовать выявлению необязательных и вероятных точек переноса при обработке текста. - Клитицизация
- Клитика — это элемент, который ведет себя как аффикс и слово. Однако они довольно сложны, поскольку также являются частью словообразования. В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии.
Мы подробно остановимся на этом.
- «Клитика — это элемент, который ведет себя как аффикс и слово.«
- Английский язык имеет очевидную клитику, « ‘s », используемую для обозначения притяжательного падежа (иногда известного как родительный падеж). Лингвисты называют его энклитикой , что означает, что это клитика, которая прикрепляется справа от слова, как и суффикс.
- «Однако они довольно сложны в том, что они также являются частью словообразования».
- « ‘s » присоединяется («наклеивается») к слову или фразе, к которым относится притяжательное.
- «В отличие от других морфологических явлений, клитики встречаются в синтаксической структуре, и их привязка к словам не является частью правил словообразования, как остальная часть морфологии».
- « ‘s » присоединяется к определенному составному элементу независимо от того, где он встречается в предложении. В следующих двух примерах « ‘s » сначала присоединяется к существительному, а затем к предлогу:
- девочка пингвин
- машина, в которую я врезался фарами
Английский также показывает другой источник клитификации. Некоторые слова можно сократить до более короткой формы. Например, Я в Бирмингеме можно уменьшить до Я м в Бирмингеме и Это весенний цыпленок можно уменьшить до Я весенний цыпленок. Обратите внимание, что сокращаемое слово имеет свою собственную синтаксическую категорию и будет фигурировать само по себе при любом синтаксическом анализе предложения.
Аспекты НЛП
Клитизация — интересная проблема для НЛП.Обычные системы НЛП являются модульными и поэтому имеют различные модули морфологической, синтаксической и семантической обработки. Однако такие клитики, как «‘s », не могут быть удовлетворительно проанализированы только на одном уровне. Морфологический анализатор должен уметь отделить клитику от присоединенной к ней морфемы, но он не может сделать это правильно, если не знает синтаксической структуры высказывания. В традиционной архитектуре системы НЛП синтаксическая структура недоступна морфологическому анализатору.Существуют различные методы, которые можно использовать для решения этой проблемы, например, передача как можно большего числа альтернатив от морфологического анализатора синтаксическому анализатору и надежда, что последний сможет разрешить неоднозначности. Другой метод может заключаться в попытке провести морфологический и синтаксический анализ параллельно — или, возможно, морфология и синтаксис являются несовершенными способами описания языка, и мы должны найти лучшую описательную модель.
 Итак, есть меньшие группы существительных, образующих множественное число по-разному:
Итак, есть меньшие группы существительных, образующих множественное число по-разному: В тех случаях, когда системы, основанные на английском языке, включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), в то время как исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы необходимо вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации.
В тех случаях, когда системы, основанные на английском языке, включают анализ флексии, обычные формы слов анализируются с использованием одного из стандартных методов (например, конечных автоматов), в то время как исключения (неправильные слова) перечисляются индивидуально. Это означает, что обычные формы необходимо вводить в словарь только один раз, что может сэкономить много места и сэкономить ввод данных, если словарь содержит много синтаксической и семантической информации.
Критика морфологии Морфология была частью основной лингвистики на протяжении шестидесяти или более лет.Как, по-видимому, происходит со всеми лингвистическими теориями, время служит только для выявления все новых и новых недостатков в теории и дальнейших разработок, направленных на укрепление исходной теории — даже до той стадии, когда она настолько обременена, что рушится полностью.
Морфология, безусловно, расширилась и представляет собой отдельную область с обширным техническим словарем, таким как morph и allomorph (упомянем только два наиболее распространенных). Более подробное описание см. В Lyons (1968; стр. 180-194), а описание некоторых трудностей с морфемами см. В Palmer (1971, стр. 187-199), который писал:
«Однако сегодня ясно, что концепция морфемы имеет лишь ограниченную ценность.Он, безусловно, может отображать минимальные единицы грамматического анализа в огромном количестве языковых данных. В конце концов, неправильного английского языка не так уж и много. И когда дело доходит до анализа агглютинативных языков, концепция морфемы неоценима, поскольку эти языки как бы специально созданы для нее. Но когда мы рассматриваем трудности морфемной идентификации в целом … становится ясно, что это понятие не такое всеобъемлющее, как это иногда представляется ».
© П[email protected]
Тщательно разбираем наши слова — CSMonitor.com
В журналистике три точки данных могут составить тренд. Я собираюсь снизить планку здесь: если в одном утреннем выпуске новостей я дважды слышу один и тот же необычный глагол в совершенно разных контекстах, возможно, это стоит отметить.
Это случилось на днях, и глагол parse . В своем первоначальном значении parse , как говорят глаголы, является довольно специализированным, лексическим эквивалентом рыбного ножа.
Но, проверив онлайн, я обнаружил, что parse отображается в различных контекстах.
«Исследователи пытаются понять значение решения секретного режима выпустить в эфир сильно отредактированную версию« Bend It Like Beckham »о молодом футболисте, который оказался между этим видом спорта и ожиданиями ее южноазиатской семьи», — сообщает Los Angeles Times. трансляции часовой версии фильма правительством Северной Кореи.
Обозреватель Национального журнала Элиза Ньюлин Карни недавно написала: «Мы предоставим ученым-конституционистам возможность разбираться, действительно ли лидер большинства Гарри Рид, демократия Невесты., может возобновить первый законодательный день в Сенате (который начался 5 января), когда сенаторы вновь соберутся 24 января и позволят преобладать лишь 51 голосу «.
И далеко от мира компьютерных фанатов, как недавно сообщал TradingMarkets.com,» Motorola Solutions представляет решения нового поколения для розничной торговли. «В рассказе о новом портативном компьютере говорится, что он» предлагается с дополнительным встроенным механизмом синтаксического анализа для чтения и анализа штрих-кодов PDF417 на водительских правах в США «.
I ‘ Сделаем отступление, чтобы отметить, что двигатель прошел долгий путь с начала 14 века, когда он означал просто «механическое устройство».«Сегодняшние« движки », скорее всего, будут виртуальными штуковинами, строками компьютерного кода, в конечном счете. Но синтаксический анализ тоже прошел некоторое расстояние.
Parse восходит к 1550-м годам, когда он означал« излагать части речи в Среднеанглийское слово pars , от древнефранцузского, было существительным, означающим «часть речи». Следуя схеме, все еще широко распространенной сегодня, pars существительное превратилось в parse глагол. как я глагол существительного, мы можем поговорить позже.)
Когда студенты 16 века разбирали предложения, это было в ответ на вопрос, все еще задаваемый на латыни: Quae pars orationis? «Какая часть речи?»
Я никогда не изучал латынь, но я знаю речь , когда вижу ее. Внезапно задача придирчивого грамматика по анализу предложений и построению диаграмм оказывается связана с ораторским искусством, и не зря эта базовая классификация слов называется «части речи ». Цицерон, Цезарь, Марк Антоний, вы слушаете?
В наши дни буквальный процесс синтаксического анализа оставил нам полезную метафору для анализа, точно так же, как стереотипы, когда-то считавшиеся респектабельной квалифицированной профессией, теперь стали полезным термином для обозначения дурной привычки мыслить.
Когда наблюдатели из Северной Кореи «разбирают» призыв Пхеньяна к «Бекхэму», они анализируют его. Обозреватель Национального журнала г-жа Карни использовала термин «синтаксический анализ» аналогичным образом, но контекст подсказывает решение, основанное на классификации: уловка г-на Рейда либо конституционна, либо нет.
«Его предложения не разбираются». Так коллега успокоил какого-то общественного деятеля, который несколько лет назад вызывал у нас изжогу. Он имел в виду, что этот человек не был слишком умным, но конкретным подтекстом было то, что его публичные высказывания не выдерживали грамматического анализа, не говоря уже о политическом анализе.
Это похоже на то, как английский майор говорит: «Эта собака не будет охотиться». Помните это? И теперь, когда я размышляю, этот коллега был по специальности английский. Это разбирает?
Журнал неврологии и неврологии | Рецензирование
Импакт-фактор журнала: 1,45 *, 1,21 (5-летний импакт-фактор)
Глобальный импакт-фактор: 0,654
Journal of Neurology and Neuroscience (ISSN: 2171-6625) — это международный циркулирующий рецензируемый журнал с открытым доступом, в котором представлены оригинальные исследовательские работы и научные достижения в области неврологии и нейробиологии.
Journal of Neurology & Neuroscience направлен на содействие исследовательским коммуникациям и обеспечение форума для врачей, исследователей, врачей и медицинских работников, где они могут найти самые последние достижения во всех областях неврологии и неврологии. Неврология и нейронауки решительно поддерживают научный рост и укрепление в соответствующем научно-исследовательском сообществе, расширяя доступ к рецензируемым научным литературным произведениям.
Journal of Neurology & Neurosciences принимает оригинальные исследовательские статьи, обзоры, мини-обзоры, отчеты о случаях и быстрое общение, охватывающие все аспекты неврологии и нейробиологии.
Журнал неврологии и неврологиипомогает студентам, исследователям, клиницистам и другим специалистам в области здравоохранения находить самую свежую информацию по функциональной неврологии, хирургической неврологии, неврологической реабилитации, поведенческой неврологии, черепно-мозговой травме, неврологии головного мозга, неврологическим расстройствам мозга, клинической неврологии и т. Д. Дегенеративная неврология, экспериментальная неврология и новые открытия в области нервного развития, регенерации, пластичности, трансплантации, концептуальные подходы к улучшению регенерации и реабилитации и многие другие интересные темы исследований в области неврологии и неврологии.
Отправьте рукопись на https://www.imedpub.com/submissions/neurology-neuroscience.html или напишите нам по адресу [электронная почта защищена]
Функциональная неврология
Функциональная неврология — это исследование взаимосвязей отдельных нейронных систем в контексте их общего состояния здоровья. Используя анатомические и эмбриологические взаимосвязи, функциональный невролог диагностирует дисфункции внутри систем и использует эти взаимосвязи для изменения нервной оси.Основным принципом функциональной неврологии является нейропластичность. Традиционно неврология имеет тенденцию рассматривать заболевание нервной системы как черно-белое, причем одна сторона представляет собой оптимальную неврологическую функцию, а другая — неврологические заболевания, такие как опухоли, инсульты и т. Д. Функциональная неврология рассматривает дисфункцию нервной системы в различных оттенках. серого в поисках тонких изменений в нервной системе, прежде чем они станут явными патологиями. Вы часто слышите, как функциональный невролог говорит, что нейроны нуждаются в топливе и активации, чтобы процветать и выжить.Топливо можно определить как кислород, глюкозу и основные питательные вещества. Активация относится к стимуляции нервной системы, которая вызывает изменения в структуре и метаболизме нервной клетки. В последнее время практикующие специалисты по функциональной неврологии также занимаются устранением возможных негативных воздействий на нейроны, таких как токсины, инфекционные агенты и иммунные реакции.
Связанные журналы функциональной неврологии
Журнал неврологии и неврологии, Insights in Neurosurgery, Journal of Neuropsychiatry, Insights in Clinical Neurology, Functional Neurology, Restorative Neurology and Neuroscience, Romanian Journal of Neurology Revista Romana de Neurologie, Семинары по неврологии, Семинары по детской неврологии, Международные семинары по детской неврологии Neuroscientist — обзорный журнал, посвященный нейробиологии, неврологии и психиатрии, Annals of Indian Academy of Neurology, Annals of Neurology, Behavioral Neurology, BMC Neurology, Brain, журнал неврологии, сердечно-сосудистой психиатрии и неврологии, отчеты о клинических случаях в неврологии, Китайский журнал современного Неврология и нейрохирургия, Китайский журнал неврологии
Когнитивная неврология
Когнитивная неврология — это мультидисциплинарная область исследований, охватывающая системную нейробиологию, вычисления и когнитивную науку.Его цель — углубить наше понимание взаимосвязи между когнитивными явлениями и основным физическим субстратом мозга. Область когнитивной нейробиологии касается научного изучения нейронных механизмов, лежащих в основе познания, и является отраслью нейробиологии. Задача исследования — найти способы улучшить функции разума и мозга. Основное внимание уделяется аспектам речи, языка (включая концептуальные способности, необходимые для мышления), а также обучению и памяти. В настоящее время мы работаем с людьми с аутизмом (особенно с мало речью или без нее), афазией, амнезией, с возрастными заболеваниями (включая болезнь Альцгеймера), женщинами, прошедшими химиотерапию, и здоровыми людьми с различными способностями.
Связанные журналы когнитивной неврологии
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Международный журнал анестезиологии и медицины боли, Журнал неврологии и клинических исследований, Журнал когнитивной неврологии, Журнал когнитивной нейробиологии, Когнитивная нейронаука развития, Когнитивная нейронаука
Нейронауки развития
Он описывает клеточные и молекулярные механизмы, с помощью которых возникают сложные нервные системы во время эмбрионального развития и на протяжении всей жизни.Нейробиология развития охватывает все стадии развития мозга беспозвоночных, позвоночных и человека. Исследование сосредоточено на оригинальных исследованиях как основных, так и клинических аспектов развивающейся нервной системы, начиная от более простых систем беспозвоночных и нейронных моделей in vitro до моделей регенерации, хронических неврологических заболеваний и старения. Его основные цели будут заключаться в облегчении передачи базовой информации для клинических приложений и в содействии пониманию фундаментальных механизмов роста, развития и патологии нервной системы.
Связанные журналы неврологии развития
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Клиническая и экспериментальная нейроиммунология, Международный журнал детской неврологии, Международный журнал нейробиологии развития, Текущие отчеты о неврологии и нейробиологии, Текущие протоколы в неврологии, Актуальные темы в поведенческой нейронауке, когнитивной нейронауке развития, нейробиологии развития, диалогах в клинической неврологии, диалогах в клинической неврологии
Нейропсихиатрия и клиническая неврология
Это интерфейс между неврологией и поведенческими расстройствами.Это исследование по эффективной диагностике и лечению пациентов с психоневрологическими расстройствами. В нем рассматриваются важные темы, такие как болезнь Альцгеймера, черепно-мозговые травмы, болезнь Паркинсона, эпилепсия и судорожные расстройства, и посвящены сообщениям об открытиях в клинической нейробиологии, которые имеют отношение к пониманию расстройств мозга пациентов. Журнал нейропсихиатрии фокусируется на фундаментальных исследованиях, а также на прикладных клинических исследованиях, которые будут стимулировать систематические экспериментальные, когнитивные и поведенческие исследования, а также улучшат эффективность, диапазон и глубину клинической практики.Область клинической нейропсихиатрии, которая занимается, в частности, течением болезни и эффективностью лечения. Клинические аспекты психиатрических и неврологических расстройств, такие как лекарственные препараты, используемые для лечения, и их эффективность у пациентов, рассматриваются в рамках клинической нейропсихиатрии.
Связанные журналы нейропсихиатрии и клинической неврологии
Журнал нейропсихиатрии, клинической психиатрии, психического здоровья в семейной медицине, Международный журнал анестезиологии и медицины боли, Когнитивная нейропсихиатрия, клиническая нейропсихиатрия, Журнал нейропсихиатрии и клинической неврологии, нейропсихиатрии, психиатрии и клинической неврологии
0300030002
Поведенческая неврология — это раздел неврологии, изучающий неврологические основы поведения, памяти и познания, влияние неврологических повреждений и заболеваний на эти функции, а также методы лечения.Поведенческая неврология — это специальность, которая занимается изучением неврологических основ поведения, памяти и познания, а также их влияния на повреждения, болезни и лечение. Поведенческая неврология и нейропсихиатрия определяется как медицинская специальность, направленная на лучшее понимание связей между нейробиологией и поведением, а также на помощь людям с неврологическими поведенческими расстройствами. Обучение поведенческой неврологии и нейропсихиатрии влечет за собой приобретение знаний о клинических и патологических аспектах нейронных процессов, связанных с познанием, эмоциями, поведением и элементарными неврологическими функциями, овладение клиническими навыками, необходимыми для оценки и лечения людей с такими проблемами, развитие уровня профессионализма, межличностных и коммуникативных навыков, а также практических и системных компетенций, необходимых для практики по данной медицинской специальности.
Связанные журналы по поведенческой неврологии
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Когнитивная и поведенческая неврология, Когнитивная, аффективная и поведенческая нейронауки in Behavioral Neuroscience, Handbook of Behavioral Neuroscience, Hispanic Journal of Behavioral Sciences, Интегративная психологическая и поведенческая наука, Международный журнал поведенческого развития, Международный журнал поведенческой медицины, Международный журнал поведенческого питания и физической активности, Иранский журнал психиатрии и поведенческих наук, Журнал прикладных биоповеденческих исследований, Журнал принятия поведенческих решений, Журнал поведенческого образования, Журнал поведенческих финансов
Аффективная неврология
Аффективная неврология — это изучение нервных механизмов эмоций.Эта междисциплинарная область сочетает неврологию с психологическим изучением личности, эмоций и настроения. Исследование посвящено научным компетенциям в области аффективной нейробиологии, а также последним достижениям в этой области, преподаваемым ведущими учеными. Материалы, несмотря на то, что они натуральные или синтетические, помогают заменять или лечить ткани мозга при взаимодействии с биологическими системами. Они содержат биоразлагаемые материалы, которые легко растворяются в организме.
Связанные журналы аффективной неврологии
Журнал неврологии и неврологии, Международный журнал анестезиологии и медицины боли, Insights in Clinical Neurology, Journal of Neuropsychiatry, Journal of Clinical and Experimental Neuroimmunology, International Journal of Pediatric Neurosciences, Current Neurology and Neuroscience Reports, Current Protocols in Neuroscience, Current Topics в области поведенческой нейронауки, когнитивной нейробиологии развития, нейробиологии развития, диалога в клинической нейробиологии, диалога в клинической неврологии
Нейронауки ЦНС
Когнитивная нейробиология — это междисциплинарная область исследований, охватывающая системную нейробиологию, вычисления и когнитивную науку.Его цель — углубить наше понимание взаимосвязи между когнитивными явлениями и основным физическим субстратом мозга. Изучение когнитивных процессов и их реализации в головном мозге. Когнитивные нейробиологи используют методы, основанные на повреждении головного мозга, нейропсихологии, когнитивной психологии, функциональной нейровизуализации и компьютерном моделировании.
Связанные журналы нейробиологии ЦНС
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Международный журнал анестезиологии и медицины боли, нейробиологии и клинических исследований, нейробиотехнологии, нейронауки и терапии ЦНС, поведенческой нейробиологии, компьютерного интеллекта и нейробиологии, текущих протоколов неврологии и нейронауки
Неврология
Неврология. Техническое изучение нервной системы — это раздел биологической науки.Однако, учитывая текущие достижения в этой области, оно было переопределено как междисциплинарное знание, которое взаимодействует с областями медицины, генетики, психиатрии, химии, информатики, инженерии и смежных дисциплин психологии.
Связанные журналы неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Международный журнал анестезиологии и медицины боли, нейронауки и клинических исследований, нейроинфекционных заболеваний, фундаментальной и клинической неврологии, фундаментальной и клинической нейробиологии, поведенческой нейронауки , BMC Neuroscience, Клиническая ЭЭГ и нейронаука, Когнитивная нейронаука, Аффективная и поведенческая нейронауки, Вычислительный интеллект и нейронаука, Текущие отчеты по неврологии и нейробиологии, Текущие протоколы в нейробиологии, Текущие темы в поведенческой нейронауке, Когнитивная нейронаука в области развития Неврология, диалоги в клинической неврологии
Интервенционная неврология
Интервенционная неврология — это исследование клинических и диагностических исследований эндоваскулярных методов и других интервенционных исследований в лечении инсульта с особым вниманием к неврологическим расстройствам.Это исследование обеспечит передовое лечение инсульта и заболеваний головы, шеи и позвоночника с помощью малоинвазивных методов визуализации под контролем.
Связанные журналы интервенционной неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Международный журнал анестезиологии и медицины боли Журнал визуализации и интервенционной радиологии , Interventional Pediatrics Нейропсихиатрия, Нейробиотехнология, Неврология и нейрофизиология, Детская неврология и медицина, Текущие отчеты по неврологии и нейробиологии, Текущее мнение в области неврологии, медицины развития и детской неврологии, Египетский журнал неврологии, психиатрии и нейрохирургии, Европейский журнал неврологии, Frontiers in Neurology, Frontiers in Neurology , Future Neurology, Handbook of Clinical Neurology, Hot Topics in Neurology and Psychiatry
Сосудистая неврология
Сосудистая неврология специализируется на отдельных неврологических расстройствах, затрагивающих центральную нервную систему, вызванных ишемическими или геморрагическими событиями или нервно-сосудистыми расстройствами.Сосудистая неврология требует междисциплинарного подхода, который включает знания в соответствующих аспектах фундаментальной науки, эпидемиологии, клинической неврологии, диагностической и интервенционной радиологии, нейросонологии, мозгового кровотока / метаболизма, неврологической критической помощи, нейроповеденческой и нейрореабилитации.
Связанные журналы сосудистой неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Журнал сосудистой и эндоваскулярной хирургии, Международный журнал сердечно-сосудистых исследований, Сердечно-сосудистая патология: открытый доступ, Сердечно-сосудистая фармакология: открытый доступ, Журнал сосудистой медицины и хирургии, Детская неврология, Прогресс в неврологии и психиатрия, восстановительная неврология и неврология, Румынский журнал неврологии / Revista Romana de Neurologie, Семинары по неврологии, Невролог: обзорный журнал, посвященный нейробиологии, неврологии и психиатрии, Анналам неврологии, поведенческой неврологии, сердечно-сосудистой психиатрии и неврологии Современная неврология и нейрохирургия, Текущие отчеты по неврологии и нейробиологии, Текущее мнение в области неврологии, медицины развития и детской неврологии
Комплексная неврология
Неврологические проблемы могут быть пугающими как для взрослых, так и для детей, поэтому очень важно начать лечение как можно раньше.Это исследование неврологической помощи как взрослым, так и детям. Он включает в себя осмотр, тестирование, диагностику и лечение пациента.
Связанные журналы комплексной неврологии
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Международный журнал анестезиологии и медицины боли, Нейробиотехнологии, нейроинфекционных заболеваний, неврологии и нейрофизиологии, CONTINUUM Отчеты о непрерывном обучении в неврологии и неврологии , Текущее мнение в неврологии, Текущие варианты лечения в неврологии, медицине развития и детской неврологии, Египетский журнал неврологии, психиатрии и нейрохирургии, Европейский журнал неврологии, Европейский журнал детской неврологии, Европейская неврология, экспериментальная неврология, Frontiers in Neurology, Frontiers of неврология и нейробиология, функциональная неврология, будущая неврология, Справочник по клинической неврологии, Горячие темы в неврологии и психиатрии, Иранский журнал детской неврологии, JAMA Neurology, Journal of Child Neurology, Journal of Clinical Neurology
Human Brain Mapp ing
Brain Mapping — это набор нейробиологических методов, основанных на отображении биологических величин или свойств на пространственные представления человеческого мозга, в результате чего создаются карты.Картирование мозга далее определяется как исследование анатомии и функции головного и спинного мозга с помощью визуализации (включая интраоперационную, микроскопическую, эндоскопическую и мультимодальную визуализацию).
Связанные журналы картирования человеческого мозга
Журнал неврологии и нейробиологии, Поведенческая неврология, Журнал нейропсихиатрии, Психическое здоровье в семейной медицине, Картирование мозга человека, Журнал науки о мозге, Метаболические заболевания мозга, Неврология, психиатрия и исследования мозга, Прогресс в исследованиях мозга, Поведенческие и мозговые функции, Поведенческие функции Исследования мозга, Мозг и познание, Мозг и развитие, Мозг и язык, Визуализация мозга и поведение, Нарушение мозга, Патология мозга, Исследования мозга, Бюллетень исследований мозга, Журнал исследований мозга, Стимуляция мозга, Структура и функции мозга, Топография мозга, Опухоль головного мозга Патология, Патология опухолей головного мозга, Гены, Мозг и поведение, Религия, Мозг и поведение, Мозг и нерв = Shinkei kenkyu no shinpo, Травма головного мозга, Мозг: журнал неврологии
Неврология мозга
Здесь мы можем изучать мозг и другие элементы нервной системы.Мозг — самая сложная часть человеческого тела. Этот трехфунтовый орган является средоточием интеллекта, интерпретатором чувств, инициатором движения тела и регулятором поведения. Это дает нам основную информацию о человеческом мозге. Это может помочь нам понять, как работает здоровый мозг, как сохранить его здоровым и что происходит, когда мозг болен или дисфункционален.
Связанные журналы неврологии головного мозга
Журнал неврологии и неврологии, Поведенческая неврология, Журнал нейропсихиатрии, Психическое здоровье в семейной медицине, Картирование мозга человека, Журнал науки о мозге, Метаболические заболевания мозга, Неврология, психиатрия и исследования мозга, Прогресс в исследованиях мозга, Религия, мозг и поведение, Поведенческие и мозговые функции, Поведенческие науки и исследования мозга, Поведенческие исследования мозга, Мозг и познание, Мозг и развитие, Мозг и язык, Мозг и нерв = Shinkei kenkyu no shinpo, Визуализация и поведение мозга, Нарушение мозга, травмы мозга, Патология мозга Исследования, Бюллетень исследований мозга, Журнал исследований мозга, Стимуляция мозга, Структура и функции мозга, Топография головного мозга, Патология опухолей головного мозга, Мозг: неврологический журнал
Клиническая неврология
Обзор соответствующих аспектов эпидемиологии, клинических проявлений, основных механизмов заболевания, диагностических подходов и вариантов лечения наиболее распространенных неврологических заболеваний.Этот курс предоставит базовый обзор наиболее распространенных и важных неврологических заболеваний и состояний, влияющих на людей во всем мире: инсульт, эпилепсия, головная боль, боль в спине, нейродегенеративные заболевания, двигательные расстройства, изменения сознания, инфекции нервной системы, черепно-мозговые травмы и нервно-мышечные болезни.
Связанные журналы клинической неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Clinical & Experimental Neuroimmunology, Neuroscience & Clinical Research, Clinical Neurology, Clinical Neurology and Neurosurgery, Clinical Neuropathology Clinical Neuropharmacology, Clinical Neurophysiology, Clinical Neuropsychiatry, 9000 Нейрохирургия
Это исследование клинических аспектов неврологии и нейрохирургии.Клиническая нейрохирургия — это медицинская специальность, занимающаяся профилактикой, диагностикой, лечением и реабилитацией заболеваний, которые влияют на любую часть нервной системы, включая головной, спинной мозг, периферические нервы и экстрачерепную цереброваскулярную систему.
Связанные журналы клинической нейрохирургии
Журнал неврологии и нейробиологии, Insights in Clinical Neurology, Clinical & Experimental Neuroimmunology, Neuroscience & Clinical Research, Clinical Neurology, Clinical Neurology and Neurosurgery, Clinical Neuropsychiatry, Clinical Neurosurgery
Degenerative Neurology
Это известно как прогрессирующая потеря структуры или функции нейронов, включая гибель нейронов.Заболевания, вызванные нейродегенерацией, неизлечимы и часто поражают пожилых людей и характеризуются прогрессирующим разрушением нервных клеток, что в конечном итоге приводит к их гибели. Дегенеративные неврологические состояния могут включать рассеянный склероз, нервно-мышечные расстройства (например, мышечную дистрофию), болезнь двигательных нейронов, болезнь Хантингтона и болезнь Паркинсона.
Связанные журналы дегенеративной неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Journal of Neuropsychiatry, Психическое здоровье в семейной медицине, Международный журнал анестезиологии и медицины боли, Нейродегенеративные заболевания, нейродегенеративные заболевания, ЦНС и неврологические расстройства — мишени для лекарств, терапевтические достижения в неврологических расстройствах
Очаговая неврология
Очаговая неврологическая недостаточность состоит из набора симптомов или признаков, причина которых может быть локализована в анатомическом участке центральной нервной системы.Внезапное развитие очагового неврологического дефицита свидетельствует о сосудистой ишемии, например, инфаркте. Хронически ухудшающийся очаговый неврологический дефицит может быть вызван расширяющимся внутричерепным поражением, таким как первичное или метастатическое новообразование.
Связанные журналы по фокальной неврологии
Журнал неврологии и неврологии, Insights in Clinical Neurology, Neurology, Brain: журнал неврологии, Annals of Neurology, Lancet Neurology, JAMA Neurology, Journal of Comparative Neurology, Journal of Neurology, Neurosurgery and Psychiatry, Experimental Neurology
CS440
CS440 Лекции CS 440 / ECE 448
Осень 2020
Маргарет Флек
Естественный язык 3
Боути Макбоутфейс (от BBC)
Поиск морфем
Итак, теперь давайте предположим, что у нас есть чистая последовательность слов.Под словом я подразумеваю кусок размера, удобного для последующих алгоритмов (например, синтаксический анализ, перевод). Это может быть выход распознавателя речи. Или же, поскольку многие системы естественного языка не начинаются с речи, поток слов может быть (очищенный) письменный текст.
Затем эти слова необходимо разделить на морфемы с помощью алгоритма «морфологии». Слова на некоторых языках могут быть очень длинными (например, турецкий), что затрудняет для дальнейшей обработки, если они (хотя бы частично) не разделены в морфемы.Например:
безответный -> не отвечающий
предварительных условий -> предварительные условия
Или рассмотрим следующее известное китайское слово:
Чжун + гуу
В современном китайском это одно слово («Китай»). И наша система искусственного интеллекта вероятно, сможет собрать достаточно информации о Китае с помощью рассматривая его как одно двухсложное слово. Но исторически (и в письменной форме system) состоит из двух морфем («середина» и «страна»).Это то, что называется «прозрачное соединение», то есть говорящий на языке будет в курсе отдельных частей. Это знание внутреннего слова структура позволила бы человеку угадать что менее распространенное слово, оканчивающееся на «гуо», также может быть названием страна.
Иногда связанные слова образуются другими процессами, кроме конкатенации, например изменение внутреннего гласного в английском «foot» vs. «feet». Когда это является обычным явлением в языке, мы можем пожелать использовать более абстрактное представление на основе признаков, e.грамм.
стопа -> стопа + ЕДИНИЦЫ
футов -> стопа + МНОЖЕСТВЕННОЕ ЧИСЛО
Иногда соответствующее разделение зависит от приложения. Итак, английское притяжательное окончание «s» традиционно пишется как часть предыдущего слова. Однако часто бывает удобно выделить его как отдельное слово при дальнейшей обработке.
POS-теги
Чтобы сгруппировать слова в более крупные единицы (например, предложные фразы), Первым шагом обычно является присвоение тега «части речи» (POS) каждому слову.Вот пример текста из корпуса Брауна, который содержит очень чистые письменный текст.
Северные либералы — главные сторонники гражданских прав и интеграция. Они также привели нацию к государство всеобщего благосостояния.
Вот версия с тегами. Например, «либералы» — это ННС, которая существительное во множественном числе. «Северный» — прилагательное (JJ). Наборы тегов должны различать основные типы слов (например, существительные и прилагательные) и основные варианты, например единственное и множественное число существительных, настоящее vs.глаголы прошедшего времени. Также есть несколько специальных тегов ключевые функциональные слова, такие как HV для «иметь», и пунктуация (например, точка).
Северные / jj либералы / nns являются / ber сторонниками / at вождя / jjs / nns из / в гражданских / jj прав / nns и / cc of / в интеграции / nn ./. Они / ppss иметь / hv также / rb led / vbn the / at nation / nn in / in / in the / at direction / nn из / в а / при социальном обеспечении / нн государстве / нн ./.
У большинства слов есть только одна общая часть речи. Итак, мы можем подняться до точность около 91% при использовании простого «базового» алгоритма, который всегда угадывает наиболее распространенную часть речи для каждого слова.Однако у некоторых слов может быть несколько тегов, например «либеральный» может быть существительным или прилагательным. Чтобы понять это правильно, мы можем использовать алгоритмы вроде скрытых марковских моделей (следующая лекция). На чистом тексте хорошо настроенный POS-теггер может обеспечить точность около 97%. Другими словами, POS-тегеры достаточно надежны и в основном используются в качестве стабильная отправная точка для дальнейшего анализа.
Мелкие системы
Многие полезные системы можно построить, используя только простой локальный анализ. слова поток, e.грамм. слова, биграммы слов, морфемы, теги POS, возможно, неглубокий синтаксический анализ (см. ниже). Эти алгоритмы обычно делают «марковское предположение», т. Е. Предполагают, что только несколько последних пунктов имеют значение для следующего решения. Например.
- Решаете, вставлять ли границу слова? Посмотрите на последние 5-7 символов.
- Решаете, какой тег POS поставить на следующее слово? Посмотрите на последние 1-3 слова.
Конкретные методы включают конечные автоматы, скрытые марковские модели (HMM) и повторяющиеся нейронные сети (РНС).Позже в этом курсе мы увидим скрытые марковские модели.
Один очень старый тип мелководья система орфографической коррекции. Полезные апгрейды (которые часто работают) включать обнаружение грамматических ошибок, добавление гласных или диакритических знаков на языке (например, арабском), где они часто опускаются. Передовые исследовательские задачи включают автоматическую оценку эссе, ответы на стандартные тесты. Распознавание речи использовалось для оценки английского беглость речи и обучение детей чтению (e.грамм. вслух). Успех зависит от очень сильных ожиданий относительно того, что человек скажет.
Перевод часто выполняется поверхностными алгоритмами. Чтобы узнать, как делать перевод, мы можем выровнять пары предложений на разных языках, сопоставляя соответствующие слова.
Английский: 18-летние не могут покупать алкоголь.
французский язык: Les 18 ans ne peuvent pas acheter d’alcool
| 18 | год | лет | банка | ‘т | купить | спирт | |||
| Лес | 18 | и | ne | peuvent | па | ахетер | д ‘ | спирт |
Обратите внимание, что некоторые слова не имеют совпадений на другом языке.Для других пар в языках может произойти радикальное изменение порядка слов.
Корпус совпадающих пар предложений может быть использован для создания словарей переводов (для фразы, а также слова) и извлекать общие сведения об изменениях в порядке слов.
Разбор
Если у нас есть теги POS для слов, мы можем собрать слова в дерево разбора. Есть много стилей построения деревьев синтаксического анализа. Здесь — это дерево избирательных округов из Penn treebank (от Митча Маркуса).
Дерево синтаксического анализа в стиле Penn treebank (от Митча Маркуса)
Альтернативой является дерево зависимостей , подобное приведенным ниже из Лаборатории Google. Достаточно недавний парсер из них называется «Парси МакПарсфейс», после Великобритании Боути Макбоутфейс, показанный выше.
В этом примере левое дерево показывает правильное вложение для слов «в ее машине», то есть изменение слова «водил». Правое дерево показывает интерпретацию, в которой улица находится в машине.
Лингвисты (вычислительные и другие) вели длительные споры по поводу лучший способ нарисовать эти деревья. Однако закодированная информация всегда довольно похожи и в первую очередь связаны с объединением слов которые образуют связные фразы, например «государство всеобщего благосостояния». Это довольно похоже к разбору языков программирования, кроме программирования языки были разработаны, чтобы упростить синтаксический анализ.
«Мелкий синтаксический анализатор» строит только самые нижние части такого дерева.Так что может группировать слова в существительные, предложные фразы и сложные глаголы (например, «идет»). Извлекать эти фразы намного проще чем построение всего дерева синтаксического анализа, и может быть чрезвычайно полезно для строительство неглубоких систем.
Как и низкоуровневые алгоритмы, парсеры часто принимают решения, используя только небольшое количество предшествующего (и, возможно, опережающего) контекста. Однако «один элемент» контекста может быть целым кусок дерева синтаксического анализа. Например, «юную леди» можно считать единый блок.Алгоритмы синтаксического анализа обычно должны учитывать широкий спектр вариантов, например множество вариантов частично построенного дерева. Поэтому они обычно используют поиск луча, т.е. сохраняйте только фиксированное количество гипотез с наилучшей оценкой. Новые методы также попробуйте разделить древовидную структуру между конкурирующими альтернативами (например, динамическое программирование) чтобы они могли хранить больше гипотез и избегать дублирования работы.
Парсеры делятся на три категории
- Unlexicalized: используйте только теги POS для построения дерева.
- По классам: вне части речи определить общий тип объект или действие (например, человек против транспортного средства)
- Лексикализованный: также включить некоторую информацию о слове идентичность / значение
Ценность лексической информации иллюстрируется предложениями. как это, в котором изменение существительная фраза меняет предложную фразу изменяет:
Она шла по улице ..в ее грузовике. (изменяет идущий)
в новом наряде.(изменяет тему)
в Южном Чикаго. (изменяет улицу)
Лексикализованы лучшие парсеры (точность до 94% от Google). Парсер «Parsey McParseface»). Но неясно, сколько информации о слова и их значения. Например, должна ли «машина» всегда вести себя как «грузовик»? Более подробная информация помогает принимать решения (особенно вложение) но требует больше данных для обучения.
Подробнее о наборах ярлыков
Обратите внимание, что набор тегов для корпуса Brown был несколько специализированным. для английского языка, в котором формы «иметь» и «быть» играют важную синтаксическую роль.Для наборов тегов для других языков потребуются некоторые из тех же тегов (например, для существительные), но и категории для типы служебных слов, которые не используются в английском языке. Например, для набора тегов для китайцев или майя потребуется тег для числовых значений. классификаторы, то есть слова, которые идут с числами (например, «три»). для указания приблизительного типа перечисляемого объекта (например, «table» может потребоваться классификатор для больших плоских объектов). Непонятно, лучше ли иметь специализированные наборы тегов. для определенных языков или один универсальный набор тегов, который включает основные функциональные категории для всех языков.
Наборы тегов различаются по размеру в зависимости от теоретических предубеждений люди, создающие аннотированные данные. Меньшие наборы этикеток передают только основная информация о типе слова. Более крупные наборы включают информацию о том, какую роль играет слово в окружающем контексте. Образец размеры
- Penn treebank 36
- Коричневый корпус 87
- «универсал» 12
Разговорный разговорный язык также включает в себя функции, которых нет в письменной речи.В приведенном ниже примере (из корпуса Switchboard) вы можете увидеть заполненную паузу «э-э», а также обрыванное слово «т-». Также обратите внимание на то, что первое предложение разбито на парантийный комментарий («вы знаете»), и третье предложение обрывается в конце. Такие функции усложняют анализ разговорной речи, чем письменный текст.
Я был бы очень осторожен и проверял их. Нашей, пришлось поместить мою мать в дом престарелых. У нее был довольно массивный инсульт о … о …
Я / PRP ‘d / MD быть / VB очень / RB очень / RB осторожно / JJ и / CC, /, ээ / UH, /, вы / PRP знаете / VBP, /, проверяете / VBG them / PRP out / RP./. Э-э / э-э, /, наш / PRP $, /, имел / VBD t- / TO, /, place / VB my / PRP $ mother / NN in / IN a / DT сестринский уход / NN дом / NN ./. Она / ПРП была / ВБД а / ДТ вернее / РБ массивная / JJ ход / НН о / РБ, /, ух / УХ, /, про / РБ — /:
Семантика
Представление смысла менее изучено. В современных системах значение индивидуального основы слов (например, «кошка» или «прогулка») основаны на их наблюдаемом контексте. Посмотрим подробности позже в срок. Но эти значения не связаны или слабо связаны с Физический мир.Способы объединения значений отдельных слов в единое значение (например, «рыжий кот») так же хрупки. Очень немногие системы пытаются понять сложные конструкции, включающие кванторы («Сколько стрел не попало в цель?») или относительные предложения. (Примером относительного предложения является «что даст …» в приведенный выше пример синтаксического анализа банка дерева Penn.)
Особая проблема даже для простых приложений состоит в том, что отрицание легко для людей, но трудно для людей. компьютеры.Например, запрос Google по запросу «Африка, а не франкоязычный» возвращает информацию о франкоязычных частях Африки. И это пример циркулярного перевода показывает, что Google выполняет следующее преобразование, которое отменяет полярность совета.
- Ввод: «Так что не пытаюсь через 3 часа».
- Вывод: «Попробуй через 3 часа».
Приложения, которые могут хорошо работать с ограниченным пониманием включают
- группирование документов по темам, разделение документов в местах, где они меняют тему
- анализ настроений: сценаристу нравится этот фильм или этот ресторан?
Три типа поверхностного семантического анализа оказались полезными и почти в пределах имеющихся возможностей:
- классы слов: какие слова похожи друг на друга (например,грамм. люди против овощей)?
- значение смысла слова: какое было предполагаемое прочтение слова с несколькими значениями (например, «банк»)?
- Маркировка семантических ролей: мы знаем, что именная фраза X связана на глагол Y. Является ли X субъектом / действующим лицом? объект, который действие было сделано? инструмент, используемый для помощи в действии?
- разрешение сопутствующего эталона (см. Ниже)
Разметка семантических ролей включает в себя определение того, как основные словосочетания предложение относится к глаголу.Например, в «Джон вел машину» «Джон» — это субъект / агент, а «машина» — это управляемый объект. Эти отношения не всегда являются объектом, например кто ест кто в «мост поедания грузовиков»? (Поищи в Гугле.)
В настоящее время наиболее популярным представлением классов слов является «вложение слов». Вложения слов дают каждому слову уникальное местоположение в многомерном евклидовом пространстве, настроенном так, чтобы похожие слова близко друг к другу. Подробности увидим позже. Популярный алгоритм — word2vec.
Текущий текст содержит ряд «именованных сущностей», то есть существительных, местоимений и существительные, относящиеся к людям, организациям и местам. Совместное разрешение пытается идентифицировать какие именованные сущности относятся к одному и тому же. Например, в этом тексте из Википедии у нас есть определила три сущности как относящиеся к Мишель Обаме, два как Барак Обама, и три как места, которые ни то, ни другое их. Один из источников сложности — это такие предметы, как последний «Обама», который внешне выглядит так, будто мог бы быть любой из них.
[Мишель ЛаВон Робинсон Обама] (родился 17 января 1964 г.) американский юрист, администратор университета и писатель. кто служил [Первая леди США] из С 2009 по 2017 год. Замужем за [44-й президент США], [Барак Обама], и была первой афроамериканской первой леди. Поднят на южной стороне [Чикаго, Иллинойс], [Обама] является выпускник [Университет Принстона] а также [Гарвардская школа права].
Согласованность диалога
С самого раннего возраста люди обладают сильной способностью управлять взаимодействия в течение длительного периода времени.Например. мы можем продолжать говорить на связную тему (например, политику) на весь вечер. Мы может задать дополнительные вопросы, чтобы построить мысленную модель, в которой все части подходят друг к другу. Мы ожидаем, что все части будут соответствовать друг другу при чтении романа. Даже лучшие современные системы искусственного интеллекта пока не могут сделай это.
Одна из конкретных задач — «согласованность диалога». Например, Предположим, вы задаете Google домой вопрос типа «Сколько калорий в банане?» Вы могли бы продолжить с «Как насчет апельсина?» Но большинство этих систем обрабатывают каждый запрос отдельно.Исключения могут содержать только очень краткую теорию контекста или (например, системы обслуживания клиентов) работают в очень ограниченной области. Более интересным примером поддержания согласованности в ограниченной области был Система ILEX для предоставления информация о музейных экспонатах. ( ссылка на оригинал статьи)
Новейшая нейросетевая система GPT-3 обладает сильной способностью поддерживать локальную согласованность в сгенерированном тексте и диалогах. Однако это происходит Стоимость. Поскольку у него нет реальной модели мира или собственных убеждений, это может быть сбиты с толку наводящими вопросами.
Введение в обработку естественного языка (NLP)
Обработка естественного языка (NLP) — это область информатики и искусственного интеллекта, связанная с взаимодействием между компьютерами и людьми на естественном языке. Конечная цель НЛП — помочь компьютерам понимать язык так же хорошо, как и мы. Это движущая сила таких вещей, как виртуальные помощники, распознавание речи, анализ тональности, автоматическое суммирование текста, машинный перевод и многое другое.В этом посте мы рассмотрим основы обработки естественного языка, погрузимся в некоторые из ее методов, а также узнаем, как НЛП помогло последним достижениям в области глубокого обучения.
Содержание
- Введение
- Почему НЛП сложно
- Синтаксический и семантический анализ
- Техники НЛП
- Глубокое обучение и NLP
- Список литературы
I. Введение
Обработка естественного языка (NLP) — это пересечение компьютерных наук, лингвистики и машинного обучения.Эта область фокусируется на общении между компьютерами и людьми на естественном языке, а НЛП — на том, чтобы заставить компьютеры понимать и генерировать человеческий язык. Применения методов НЛП включают голосовых помощников, таких как Amazon Alexa и Apple Siri, а также такие вещи, как машинный перевод и фильтрация текста.
NLP сильно выиграл от последних достижений в области машинного обучения, особенно от методов глубокого обучения. Поле разделено на три части:
- Распознавание речи — Перевод устной речи в текст.
- Natural Language Understanding — Способность компьютера понимать то, что мы говорим.
- Генерация естественного языка — Генерация естественного языка компьютером.
II. Почему НЛП сложно
Человеческий язык особенный по нескольким причинам. Он специально разработан, чтобы передать смысл говорящего / писателя. Это сложная система, хотя маленькие дети могут освоить ее довольно быстро.
Еще одна замечательная вещь в человеческом языке — это то, что все дело в символах.По словам Криса Мэннинга, профессора машинного обучения из Стэнфорда, это дискретная, символическая, категориальная сигнальная система. Это означает, что мы можем передавать одно и то же значение по-разному (например, речь, жест, знаки и т. Д.). Кодирование человеческим мозгом представляет собой непрерывный паттерн активации, посредством которого символы передаются через непрерывные звуковые и визуальные сигналы.
Понимание человеческого языка считается сложной задачей из-за его сложности. Например, существует бесконечное количество различных способов расположить слова в предложении.Кроме того, слова могут иметь несколько значений, и для правильной интерпретации предложений необходима контекстная информация. Каждый язык более или менее уникален и неоднозначен. Достаточно взглянуть на следующий заголовок в газете «Папа папа наступает на геев». Это предложение явно имеет две очень разные интерпретации, что является довольно хорошим примером проблем в НЛП.
Обратите внимание, что идеальное понимание языка компьютером привело бы к созданию ИИ, способного обрабатывать всю информацию, доступную в Интернете, что, в свою очередь, вероятно, привело бы к созданию общего искусственного интеллекта.
III. Синтаксический и семантический анализ
Синтаксический анализ (синтаксис) и семантический анализ (семантический) — это два основных метода, которые приводят к пониманию естественного языка. Язык — это набор правильных предложений, но что делает предложение действительным? Синтаксис и семантика.
Синтаксис — это грамматическая структура текста, а семантика — это передаваемое значение. Однако синтаксически правильное предложение не всегда является семантически правильным.Например, фраза «коровы в высшей степени текут» грамматически корректна (подлежащее — глагол — наречие), но не имеет никакого смысла.
Синтаксический анализСинтаксический анализ, также называемый синтаксическим анализом или синтаксическим анализом, — это процесс анализа естественного языка с использованием правил формальной грамматики. Грамматические правила применяются к категориям и группам слов, а не к отдельным словам. Синтаксический анализ в основном придает тексту семантическую структуру.
Например, предложение включает подлежащее и сказуемое, где подлежащее — это существительная фраза, а предикат — глагольная фраза.Взгляните на следующее предложение: «Собака (существительная фраза) ушла (глагольная фраза)». Обратите внимание, как мы можем комбинировать каждую именную фразу с глагольной фразой. Опять же, важно повторить, что предложение может быть синтаксически правильным, но не иметь смысла.
Семантический анализТо, как мы понимаем сказанное кем-то, — это бессознательный процесс, основанный на нашей интуиции и знаниях о самом языке. Другими словами, то, как мы понимаем язык, во многом зависит от значения и контекста.Однако к компьютерам нужен другой подход. Слово «семантический» является лингвистическим термином и означает «относящийся к значению или логике».
Семантический анализ — это процесс понимания значения и интерпретации слов, знаков и структуры предложения. Это позволяет компьютерам частично понимать естественный язык так, как это делают люди. Я говорю отчасти потому, что семантический анализ — одна из самых сложных частей НЛП, и она еще не решена полностью.
Распознавание речи, например, стало очень хорошим и работает почти безупречно, но нам все еще не хватает такого уровня знаний в понимании естественного языка.Ваш телефон в основном понимает то, что вы сказали, но часто ничего не может с этим поделать, потому что не понимает стоящего за этим смысла. Кроме того, некоторые технологии только заставляют вас думать, что они понимают значение текста. Подход, основанный на ключевых словах или статистике, или даже на чистом машинном обучении, может использовать метод сопоставления или частоты для подсказок о том, «о чем» текст. Эти методы ограничены, потому что они не рассматривают истинный смысл.
IV.Способы понимания текста
Давайте рассмотрим некоторые из самых популярных методов, используемых при обработке естественного языка. Обратите внимание, как некоторые из них тесно взаимосвязаны и служат только подзадачами для решения более крупных проблем.
РазборЧто такое парсинг? Согласно словарю, синтаксический анализ означает «разложить предложение на составные части и описать их синтаксические роли».
Это на самом деле прибило, но могло бы быть немного более исчерпывающим.Под синтаксическим анализом понимается формальный анализ предложения компьютером на его составные части, в результате которого создается дерево синтаксического анализа, показывающее их синтаксические отношения друг с другом в визуальной форме, которое можно использовать для дальнейшей обработки и понимания.
Ниже представлено дерево синтаксического анализа для предложения «Вор ограбил квартиру». Включено описание трех различных типов информации, передаваемых в предложении.
Буквы непосредственно над отдельными словами показывают части речи для каждого слова (существительное, глагол и определитель).Уровень выше — это некая иерархическая группировка слов во фразы. Например, «вор» — это существительное, «ограбил квартиру» — глагольное словосочетание, и, сложив вместе эти две фразы, образуют предложение, которое отмечается на один уровень выше.
Но что на самом деле означает существительное или глагольная фраза? Существительные фразы — это одно или несколько слов, которые содержат существительное и, возможно, некоторые дескрипторы, глаголы или наречия. Идея состоит в том, чтобы сгруппировать существительные со словами, которые к ним относятся.
Дерево синтаксического анализа также предоставляет нам информацию о грамматических отношениях слов из-за структуры их представления.Например, в структуре мы видим, что «вор» является субъектом «ограблен».
Под структурой я подразумеваю, что у нас есть глагол («ограблен»), который отмечен буквой «V» над ним и буквой «VP» над ним, которая связана буквой «S» с подлежащим («вор» ), над которым стоит «NP». Это похоже на шаблон для отношений подлежащее-глагол, и есть много других для других типов отношений.
СтволСтемминг — это метод, основанный на морфологии и поиске информации, который используется в НЛП для предварительной обработки и повышения эффективности.В словаре это определяется как «возникать или быть вызванным».
По сути, выделение корней — это процесс сокращения слов до их основы. «Основа» — это часть слова, которая остается после удаления всех аффиксов. Например, основа слова «тронут» — «прикоснуться». «Прикосновение» также является основой «прикосновения» и так далее.
Вы можете спросить себя, зачем нам вообще ствол? Итак, основа необходима, потому что мы встретимся с разными вариантами слов, которые на самом деле имеют одну основу и одно и то же значение.Например:
Я ехал на машине.
Я ехал в машине.
Эти два предложения означают одно и то же, и использование этого слова идентично.
А теперь представьте себе все английские слова в словаре со всеми их различными фиксациями в конце. Для их хранения потребуется огромная база данных, содержащая множество слов, которые на самом деле имеют одинаковое значение. Это решается путем сосредоточения внимания только на основе слова.Популярные алгоритмы выделения включают алгоритм вывода Портера из 1979 года, который до сих пор хорошо работает.
Сегментация текстаСегментация текста в НЛП — это процесс преобразования текста в значимые единицы, такие как слова, предложения, различные темы, лежащее в основе намерение и многое другое. В основном текст разбивается на составляющие слова, что может быть сложной задачей в зависимости от языка. Это опять же из-за сложности человеческого языка. Например, в английском языке относительно хорошо работает разделение слов пробелами, за исключением таких слов, как «icebox», которые принадлежат друг другу, но разделены пробелом.Проблема в том, что люди иногда также пишут это как «ледяной ящик».
Признание именной организации
Распознавание именованных объектов (NER) концентрируется на определении того, какие элементы в тексте (то есть «именованные объекты») могут быть обнаружены и классифицированы по заранее определенным категориям. Эти категории могут варьироваться от имен людей, организаций и местоположений до денежных значений и процентов.
Например:
До NER: Мартин купил 300 акций SAP в 2016 году.
После NER: [Мартин] Человек купил 300 акций [SAP] организации за [2016] Время.
Извлечение отношений
Извлечение отношений берет названные объекты NER и пытается идентифицировать семантические отношения между ними. Это может означать, например, выяснение, кто с кем женат, что человек работает в определенной компании и так далее. Эта проблема также может быть преобразована в проблему классификации, и модель машинного обучения может быть обучена для каждого типа отношений.
Анализ тональности
С помощью анализа настроений мы хотим определить отношение (то есть настроение) говорящего или писателя по отношению к документу, взаимодействию или событию. Следовательно, это проблема обработки естественного языка, когда текст необходимо понимать, чтобы предсказать основное намерение. Настроения в основном делятся на положительные, отрицательные и нейтральные категории.
С помощью анализа настроений, например, мы можем захотеть спрогнозировать мнение и отношение клиента к продукту на основе написанного ими обзора.Анализ тональности широко применяется к обзорам, опросам, документам и многому другому.
Если вам интересно использовать некоторые из этих методов с Python, взгляните на Jupyter Notebook о наборе инструментов естественного языка Python (NLTK), который я создал. Вы также можете ознакомиться с моим сообщением в блоге о построении нейронных сетей с помощью Keras, где я обучаю нейронную сеть выполнять анализ настроений.
V. Глубокое обучение и НЛП
Центральное место в глубоком обучении и естественном языке занимает «значение слова», когда слово и особенно его значение представлены в виде вектора действительных чисел.С помощью этих векторов, которые представляют слова, мы помещаем слова в многомерное пространство. Интересно то, что слова, представленные векторами, будут действовать как семантическое пространство. Это просто означает, что слова, которые похожи и имеют похожее значение, имеют тенденцию группироваться вместе в этом многомерном векторном пространстве. Вы можете увидеть визуальное представление значения слова ниже:
Вы можете узнать, что означает группа сгруппированных слов, выполнив анализ главных компонентов (PCA) или уменьшение размерности с помощью T-SNE, но иногда это может вводить в заблуждение, поскольку они упрощают и оставляют много информации на стороне.Это хороший способ начать работу (например, логистическая или линейная регрессия в науке о данных), но он не является передовым и можно сделать это лучше.
Мы также можем думать о частях слов как о векторах, которые представляют их значение. Представьте себе слово «нежелательность». Используя морфологический подход, который включает в себя различные части, которые имеет слово, мы могли бы думать, что оно состоит из морфем (частей слова), например: «Un + желание + способность + ity». Каждая морфема получает свой вектор. Исходя из этого, мы можем построить нейронную сеть, которая может составить значение более крупной единицы, которая, в свою очередь, состоит из всех морфем.
Глубокое обучение также может определять структуру предложений с помощью синтаксических анализаторов. Google использует подобные методы анализа зависимостей, хотя и в более сложной и крупной манере, с их «McParseface» и «SyntaxNet».
Зная структуру предложений, мы можем начать пытаться понять смысл предложений. Мы начинаем со значения слов, являющихся векторами, но мы также можем сделать это с целыми фразами и предложениями, где значение также представлено в виде векторов.И если мы хотим знать взаимосвязь предложений или между ними, мы обучаем нейронную сеть принимать эти решения за нас.
Глубокое обучение также хорошо подходит для анализа настроений. Возьмем, к примеру, этот обзор фильма: «Этот фильм не заботится об остроумии, с каким-либо другим умным юмором». Традиционный подход попался бы в ловушку, думая, что это положительный отзыв, потому что «сообразительность или любой другой вид интеллектуального юмора» звучит как положительное намерение, но нейронная сеть распознала бы его реальное значение.Другие приложения — это чат-боты, машинный перевод, Siri, предлагаемые ответы в почтовом ящике Google и так далее.
Также произошел огромный прогресс в машинном переводе благодаря появлению рекуррентных нейронных сетей, о которых я также написал сообщение в блоге.
В машинном переводе, выполняемом с помощью алгоритмов глубокого обучения, язык переводится, начиная с предложения и генерируя векторные представления, которые его представляют. Затем он начинает генерировать слова на другом языке, содержащие ту же информацию.
Подводя итог, НЛП в сочетании с глубоким обучением — это все о векторах, которые представляют слова, фразы и т. Д. И до некоторой степени их значения.
VI. Список литературы
Никлас Донгес — предприниматель, технический писатель и эксперт в области искусственного интеллекта. В течение 1,5 лет он работал в команде SAP в области искусственного интеллекта, после чего основал компанию Markov Solutions. Компания из Берлина специализируется на искусственном интеллекте, машинном обучении и глубоком обучении, предлагая индивидуальные программные решения на базе искусственного интеллекта и консалтинговые программы для различных компаний.
СвязанныеПодробнее о Data Science
Blog — страница 8 — NYU MorphLab
Я не могу вспомнить номер телефона ни на секунду, а когда меня знакомят с людьми, я теряю начало их имен к тому времени, когда они доходят до конца (кажется, даже для односложных имен). Таким образом, любое изложение истоков Halle & Marantz обязательно потребует рациональной реконструкции того, что должно было происходить в начале 1990-х годов. При этом внимание к тексту раскрывает многие силы, которые привели к структуре и содержанию статьи и, следовательно, к структуре канонической распределенной морфологии.Здесь я хочу сосредоточиться на взаимосвязи между целями статьи и различными техническими частями раннего DM — почему происходит морфологическое слияние, добавление словарного запаса, обеднение, расщепление и слияние.
Из количества страниц, посвященных H&M грузинскому языку и, в частности, Potawatomi, должно быть ясно, что основная направленность статьи является ответом на морфологию морфологии Стива Андерсона. Следуя идеям Роберта Бирда о «сепарационистской» морфологии, мы хотели показать, что морфология элементов и аранжировок может иметь свой реализационизм (разделение синтаксических и семантических характеристик морфем от их фонологической реализации) и также есть его.Итак, как мы более прямо заявили в «Ключевые особенности распределенной морфологии», целью было объединение Роберта Бирда по разделению и Шелли Либер по синтаксическому словообразованию — Поздняя вставка и Syntax All The Way Down.
Однако не следует забывать, что в начале 1980-х я написал очень длинную диссертацию, перевернувшуюся книгу, которая касалась взаимосвязи между словообразованием и синтаксисом. Работа называется «О природе грамматических отношений», потому что это в некотором смысле гимн реляционной грамматике.Он повторно рассматривает некоторые проблемы хлеба с маслом в RG (каузативное придаточное объединение, аппликативы (продвижение до 2), восхождения) в рамках более стандартной генеративной структуры, с особым акцентом на связи между словообразованием и синтаксисом. Таким образом, морфологическое слияние высшей каузативной главы и встроенного глагола может быть как причиной словообразования (глагол с каузативным суффиксом), так и редукцией структуры, связанной с объединением каузативных придаточных предложений (или «реструктуризацией»). В этих рамках морфологическое слияние отличается от традиционного перескока аффиксов и от подъема головы, которые сами по себе не вызывают редукции структуры.Последующая работа Бейкера над «Инкорпорацией» пыталась — и, на мой взгляд, безуспешно — объединить подъем головы с сокращением структуры, связанным с морфологическим слиянием. Эти вопросы все еще актуальны — см., Например, работу Матушанки о движении головы.
В наши дни было бы полезно пересмотреть работу начала 1980-х годов по словообразованию и синтаксису. Работы Ричарда Спроута являются здесь образцовыми. Те из нас, кто серьезно задумывается над проблемами, явно связали «парадоксы заключения в скобки» перегиба (перескок аффиксов создает локальную связь между заголовком и перегибом, когда синтаксический и семантический объем перегиба является фразовым, а не совмещенным) с аналогичными несоответствиями между морфологическая и синтаксическая / семантическая область, в частности, примером которой являются клитики (так «играл» = «шляпа королевы Англии»).Хотя можно думать обо всех этих несоответствиях в скобках как о возникающих постсинтаксически в результате операции морфологического слияния на стороне PF, в моей книге была исследована возможность того, что та же операция словообразования слияния может подпитывать синтаксис, приводя к синтаксической реструктуризации в случае причинных конструкций. , Например. Это может быть, а может и не быть на правильном пути, но, как поясняет Матушанский, любой синтаксис типа минималистской программы на основе фаз использует подход к цикличности, который позволяет морфологическому слиянию, управляемому PF, отражаться в синтаксисе.
Довольно примечательно, что, учитывая мою предвзятость к морфологическому слиянию и его потенциальному взаимодействию с синтаксисом, H&M пишет, как если бы поле было объединено вокруг вывода о том, что синтаксическое словообразование в значительной степени является результатом движения (подъема) головы и присоединения . Я напишу об этом позже, но с практической точки зрения принятие этого предположения о словообразовании позволило провести прямое сравнение между DM и лексикалистской синтаксической теорией того времени Хомского в последнем разделе статьи.Тем не менее, H&M полагает, что для создания фонологических слов было необходимо нечто вроде морфологического слияния / смены аффиксов / понижения. Итак, для ключевой особенности DM «синтаксическая структура вниз», H&M продвигает движение головы и присоединение, а также морфологическое слияние. H&M оставляет в стороне любые вопросы о том, может ли морфологическое слияние подпитывать синтаксис.
Для ключевой функции «поздней вставки» H&M предлагает особую технологию вставки словаря.Эмпирическая цель здесь — контекстная алломорфия и (локальные) блокирующие отношения. Таким образом, можно сделать вывод, что ядром DM являются механизмы синтаксического словообразования и механизмы реализации PF, а механизмы, предложенные в H&M, были предметом непрерывных исследований в течение последних 25 лет.
Что же тогда насчет расщепления, слияния и обнищания? Для этих механизмов были задействованы две движущие силы: эмпирические области, представляющие интерес для морфологов, и конкретные исследования Эулалии Бонет и Рольфа Нойера, в которых мы были убеждены.Расщепление — это особый подход к появлению множественной экспоненциальности, который Нойер умело применил в своем анализе семитских словесных соглашений. Fusion включает в себя прямую работу над кажущимися объемными элементами словарного запаса. Чтобы вывести наш анализ синкретизма, нам потребовалось однозначное соединение терминальных узлов с элементами словарного запаса, а Fusion, по сути, был механизмом грубой силы для покрытия ситуаций, в которых, возможно, несколько терминальных узлов обеспечивают вставку одного элемента словарного запаса.Обнищание объясняет два типа явлений. Примером первого является работа Бонета над каталонскими клитиками: использование немаркированного словарного элемента в отмеченной среде. Я по-прежнему считаю, что анализ обеднения необходим для отделения стандартной контекстной алломорфии, когда отмеченный ВП появляется в отмеченной среде (а более общий ВП встречается где-то еще), от ситуаций, в которых более общий ВП встречается в определенной среде — главный аргумент. заключается в том, что среда для ВИ и, следовательно, контекстная алломорфия является локальной, тогда как обнищание может происходить на расстоянии.Другое использование обнищания — для систематических парадигматических пробелов, когда, например, гендерные различия теряются во множественном числе, скажем. Здесь обозначений признаков ВП достаточно для создания форм без обеднения, но обнищание явно указывает на лежащее в основе обобщение (например, отсутствие гендерных различий в контексте множественного числа).
Йохен Троммер и другие показали, что, играя с механизмами вставки словаря и допущениями о синтаксической структуре, ни один из этих механизмов не требуется для охвата эмпирических областей, для которых они использовались в H&M.То, что они не нужны, не означает, что они на самом деле не являются частью грамматики — возможно, они были правильным подходом к явлениям, к которым они были применены. Лично я считаю, что доказательства обнищания убедительны, но я больше не использую Fission и Fusion в своей работе (хотя я с радостью поддержу их в работе других).
Подводя итог, H&M закладывает основу для синтаксической теории словообразования и поздней вставки DM, описывая механизмы движения головы и присоединения и морфологического слияния для словообразования и механизмы словарной вставки для поздней вставки.В статье гораздо больше интересного, поскольку она в основном является ответом на A-морфологию и на тогдашнюю версию лексикализма Хомского для флективной морфологии. Чего, к сожалению, по большей части не хватает, так это того, что касается «природы грамматических отношений» — точного взаимодействия словообразования и синтаксиса.
морфем: примеры, определение и типы — видео и стенограмма урока
Типы морфем
В лингвистике мы бы далее классифицировали морфемы как фонем (наименьшие единицы грамматики, распознаваемые по звуку) или графемы (наименьшие единицы письменного языка).Для наших целей мы сосредоточимся на графемах.
Давайте рассмотрим слово nonperishable , проанализируем его, а затем обсудим связанные с ним термины.
Nonperishable состоит из трех морфем: non- , perish и -able . На самом деле в нем пять слогов, что является хорошим примером того, почему морфемы и слоги не являются синонимами.
- не является примером префикса или морфемы, которая предшествует базовой морфеме
- погиб является примером базовой морфемы , так как она придает слову его основное значение
- -able является примером суффикса или морфемы, которая следует за базовой морфемой
И non-, и -abl e являются примерами аффикса , морфемы, присоединенной до или после основы, которая не может функционировать независимо как слово.
Мы также можем взглянуть на эту диаграмму, чтобы увидеть некоторые примеры того, как работают морфемы:
Морфема как слово
Когда мы можем взять морфему независимо и использовать ее как отдельное слово в предложении, это называется базисом. Как показано в таблице, это могут быть существительные, глаголы, прилагательные, союзы, предлоги или определители. Мы также классифицируем морфему, которая может функционировать как отдельное слово, как free .
В предложении:
Птичий человек почти не прикасался к своей еде за обедом.
Всего существует двенадцать морфем, десять из двенадцати — свободные:
- (статья)
- птица (существительное)
- как (прилагательное)
- man (имя существительное)
- жесткий (прилагательное)
- касаться (глагол)
- его (определитель)
- food (имя существительное)
- на (предлог)
- ужин (существительное)
Две другие морфемы, -ed и -ly , являются типами аффиксов, которые подводят нас к нашей следующей теме.
Морфема как аффикс
Аффикс — это морфема , привязанная к , что означает, что она исключительно для значения прикреплена к свободной морфеме. Префиксы и суффиксы — самые распространенные примеры.
- Общие префиксы: re-, sub-, trans-, in-, en-, ad-, dis-, con-, com-
- Общие суффиксы: -s, -es, -able, -ance, -ity, -less, -ly, -tion
Производные морфемы могут быть суффиксом или префиксом, и они могут преобразовывать либо функцию, либо значение слова.Примером может быть добавление суффикса без к существительному , что означает . Затем суффикс делает слово противоположным самому себе, тем самым резко меняя значение.
Примеры морфем
Давайте пройдемся по нескольким предложениям и разберем их морфемные структуры.
1. Это были лучшие времена; это были худшие времена. — Чарльз Диккенс
В этой знаменитой цитате всего четырнадцать морфем. Двенадцать свободных морфем таковы: оно было, лучшее, время, оно, было, худшее, время. Единственные две связанные морфемы — суффиксы -s на времени .
В следующем предложении давайте займемся кое-чем хитрым:
Если вы не посеете семя, растение никогда не вырастет.
В этом предложении одиннадцать морфем. Мы могли бы задаться вопросом, действительно ли у него есть десять морфем, поскольку без и без являются обычными аффиксами. Однако минус функционирует как прилагательное, которое является разновидностью свободной морфемы.
Краткое содержание урока
Лингвисты или те, кто изучает язык, разработали категорию для наименьшей единицы грамматики: морфем .Морфемы служат основой языка и синтаксиса. Синтаксис — это расположение слов и предложений для создания смысла. В лингвистике мы далее классифицируем морфемы как фонем (наименьшие единицы грамматики, распознаваемые по звуку) или графем (наименьшие единицы письменного языка).
Префикс — это морфема, которая предшествует базовой морфеме. Базовая морфема дает слову его основное значение.Суффикс — это морфема, которая следует за базовой морфемой. Аффикс — это морфема, прикрепленная до или после основы, которая не может функционировать независимо как слово. Мы классифицируем морфему, которая может функционировать как отдельное слово, как free . Аффикс — это связанная с морфема , что означает, что он прикреплен исключительно к свободной морфеме для значения.
Флективные морфемы могут быть только суффиксами, и они преобразуют функцию слова. Деривационные морфемы могут быть суффиксом или префиксом, и они могут преобразовывать либо функцию, либо значение слова.
Морфемы
| Определение | Классификации и типы |
|---|---|
| Наименьшая единица грамматики | Классифицируется как фонемы или графемы. Связанный, свободный, словоизменительный и словообразовательный — это типы морфем. |
Результаты обучения
Когда вы закончите, вы сможете:
- Вспомнить определение морфемы
- Обсудить типы морфем
- Определить морфемы в предложении