Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: понич сейчас либретто сейчас п а р о л о д и сейчас р е м о е т сейчас крсутер сейчас автокран сейчас деесуижн сейчас т и о а м р н м з сейчас антклон сейчас отпадение сейчас с о ю з н и к сейчас перепрядаю сейчас рпмйнёс лпммёлуйг сейчас камте сейчас р е к а т 1 секунда назад
Морфемный разбор
Электронный ресурс
цифровой образовательной среды СПО
Рейтинг издания
Морфемный разбор
| Подзаголовок: | Памятка для начальной школы |
| Издательство: | Феникс |
| Авторы: | Матёкина Э. И. И. |
| Год издания: | 2016 |
| ISBN: | |
| Тип издания: | учебно-методическое пособие |
| Гриф: |
Библиографическая запись
Матёкина, Э. И. Морфемный разбор : памятка для начальной школы / Э. И. Матёкина. — Ростов-на-Дону : Феникс, 2016. — 32 c. — ISBN 2227-8397. — Текст : электронный // Электронный ресурс цифровой образовательной среды СПО PROFобразование : [сайт]. — URL: https://profspo.ru/books/60723 (дата обращения: 14.03.2023). — Режим доступа: для авторизир. пользователей
Об издании
В данной памятке представлены морфологические разборы слов в разделе программы школьного курса по русскому языку, предусмотренные программой начальной школы. В памятке даны определения важнейших понятий, а также приведены основные правила и методические рекомендации по выполнению заданий, которые помогут учащимся правильно в устной и письменной форме производить морфологический разбор слова.
Скачать библиографическую запись
Учебные проекты по технологии. 5 класс
Смелова В.Г.
Сопротивление материалов в примерах и задачах. Расчетно-графические работы. В 2 частях. Часть 2
English for service and tourism industry = Английский язык в сфере обслуживания и туризма
Раптанова И.Н., Чапалда К.Г.
Организация строительства и эксплуатации волоконно-оптических линий передачи. В 2 частях. Ч. 2. Строительство и техническая эксплуатация волоконно-оптических линий передачи
В 2 частях. Ч. 2. Строительство и техническая эксплуатация волоконно-оптических линий передачи
Горлов Н.И., Бутенков В.В., Первушина Л.В.,…
Векторная графика. CorelDRAW X6
Левковец Л.Б.
Самостоятельные занятия физическими упражнениями студентов специальной медицинской группы
Насырова Г.Х.
Основы программирования на C# 2.0
Марченко А.Л.
Основы телевизионной техники
Лузин В.И., Никитин Н.П., Шестаков А.А.,…
[PDF] Трехмерная параметризация для анализа морфологически богатых языков
- title={Трехмерная параметризация для разбора морфологически богатых языков},
автор = {Реут Царфати и К.
 Симаан},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {2007}
}
Симаан},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {2007}
} Текущие параметры точных нелексикализованных синтаксических анализаторов, основанных на вероятностных контекстно-свободных грамматиках (PCFG), образуют двумерную сетку, в которой события перезаписи обусловлены как горизонтальной (головой наружу), так и вертикальной (родительской) историей. В семитских языках, где аргументы могут перемещаться довольно свободно, а фразовые структуры часто неглубоки, существуют дополнительные морфологические факторы, управляющие процессом порождения. Здесь мы предлагаем, чтобы признаки согласования просачивались вверх по дереву синтаксического анализа…
View on ACL
dl.acm.orgWord Segmentation, Unknown-word Resolution, and Morphological Agreement in a Hebrew Parsing System
- Yoav Goldberg, Michael Elhadad
Computer Science
CL
- 2013
В этой работе показано, что производительность синтаксического анализа может быть повышена за счет использования языкового ресурса, внешнего по отношению к банку деревьев, в частности, морфологического анализатора на основе лексики.
Реляционно-реализационный анализ
- Реут Царфати, К. Симаан
Информатика
COLING
- 2008
допускают вариативность структуры фразы и морфологически-синтаксическое взаимодействие.
Единая генеративная модель для совместной морфологической сегментации и синтаксического анализа
- Йоав Голдберг, Реут Царфати
Лингвистика
ACL
- 2008
Предлагается единая совместная модель для выполнения как морфологической сегментации, так и синтаксического устранения неоднозначности, которая обходит связанную цикличность.
UvA-DARE ( Digital Academic Repository ) Relational-realizational parsing
- Tsarfati
Computer Science
- 2008
The Relational-Realizational approach to parsing is developed, in which the projection of grammatical functions and their means реализации распутаны, чтобы учесть вариативность фразовой структуры и морфо-синтаксическое взаимодействие.
Морфологически богатые языки. проблемы, связанные с синтаксическим анализом ряда морфологически богатых языков (MRL), а также описывает проблемы с синтаксическим анализом MRL и обрисовывает в общих чертах вклад статей в специальном выпуске.
На основе слов или морфем? Аннотация Стратегии для современной еврейской клитики
- Реут Царфати, Йоав Гольдберг
Лингвистика
LREC
- 2008
лучшая способность устранения неоднозначности PP-прикрепления и лучшее согласование с исходными поверхностными формами.
Статистический анализ морфологически богатых языков (SPMRL) What, How and Whither
- Реут Царфати, Джаме Седдах, Л. Тунси
Информатика, лингвистика
SPMRL@NAACL-HLT
- 2010
Настоящий рабочий документ по арабскому языку, синтезу немецкого языка и арабскому языку.
, иврит, хинди и корейский, чтобы указать на общие решения для разных языков и стать источником направлений для будущих исследований.— 1-Автоматическая аннотация морфосинтаксических зависимостей в современном иврите
- Treebank
Лингвистика
- 2008
Морфо-синтаксические зависимости между составными частями предложения являются неотъемлемой частью синтаксического анализа, в частности, в семитских языках. На этих языках из-за относительно свободного порядка…
Автоматическая аннотация морфо-синтаксических зависимостей в дереве дерева современного иврита
- Ноэми Гутманн, Юваль Кримоловски, Ади Милеа, Йоад Винтер
Лингвистика
- 2008
Разрабатывая метод автоматического добавления аннотаций зависимостей к банку деревьев современного иврита, проект MHT стремился внести свой вклад в развитие банка деревьев для семитских языков, а также для других языков.
Анализ зависимостей современного стандартного арабского языка с лексическими и флективными особенностями
Показано, что качество анализа в прогнозируемом состоянии может значительно улучшиться за счет обучения комбинированному золотому + прогнозируемому состоянию, а также вклада лингвистических знаний в наборы тегов и выявленные особенности выходят за рамки конкретных экспериментальных настроек и могут быть информативными для других синтаксических анализаторов и морфологически богатых языков.
ПОКАЗАНЫ 1–10 ИЗ 33 ССЫЛОК
СОРТИРОВАТЬ ПО Релевантности Наиболее влиятельные статьи Недавность
Управляемые головой статистические модели для анализа естественного языка
Описаны три статистические модели для анализа естественного языка, что привело к подходам, в которых дерево анализа представляется последовательность решений, соответствующая центрированному нисходящему построению дерева.
Обучение точной, компактной и интерпретируемой аннотации дерева
- Слав Петров, Леон Барретт, Р. Тибо, Д. Кляйн
Информатика
ACL
- 2006
Мы представляем автоматический подход к аннотации дерева, в котором основные нетерминальные символы попеременно разделяются и объединяются вероятность тренировочного дерева. Начиная с простой X-bar…
Управляемые головкой PCFG со статистикой скрытой головы
- D. Prescher
Информатика
IWPT
- 2005
В этой статье показано, как индуцировать управляемые головкой вероятностные синтаксические анализаторы со скрытыми головками из банка деревьев, не прибегая к полной лексикализации, и производительность уже лучше, чем у ранних лексикализированных парсеров.
Сложности модели синтаксического анализа Коллинза
Большой набор до сих пор неопубликованных деталей, которые Коллинз использовал в своем синтаксическом анализаторе, представляет собой документы, так что, наряду с тезисом Коллинза (1999), эта статья содержит всю информацию, необходимую для дублирования результатов тестов Коллинза.
PCFG-модели представлений лингвистических деревьев
- Марк Джонсон
Информатика
Вычисл. Лингвистика
- 1998
Описано простое преобразование перемаркировки узлов, которое улучшает среднюю точность и полноту синтаксического анализатора на основе банка деревьев PCFG примерно на 8%, или примерно на половину разницы в производительности между простой моделью PCFG и лучшей моделью с широким охватом. доступные сегодня парсеры.
Точный нелексикализованный синтаксический анализ
- Д. Кляйн, Кристофер Д. Мэннинг
Информатика
ACL
- 2003
расщепления, разрушающие ложную независимость…
Вероятностная компьютерная графика со скрытыми аннотациями
- Такуя Мацудзаки, Юсуке Мияо, Джуничи Цудзи
Информатика
ACL
- 2005
В этой статье определяется порождающая вероятностная модель деревьев разбора, которую мы называем PCFG-LA.
Эта модель является расширением PCFG, в котором нетерминальные символы дополнены скрытыми переменными.…Интегрированная морфологическая и синтаксическая неоднозначность для современного иврита
- Реут Царфати
Лингвистика, информатика
9007ACL
Эта работа представляет собой первую попытку моделирования морфолого-синтаксического взаимодействия в генеративно-вероятностной структуре, позволяющей анализировать MH, и показывает, что морфологическая информация, выбранная в тандеме с синтаксическими категориями, полезна для анализа семитских языков.
Вероятностный анализ для немецкого языка с использованием зависимостей сестрин-головы
- Amit Dubey, Frank Keller
Компьютерные науки
ACL
- 2003
Эта модель превзошла базовую, а также запоминающуюся сцену и запоминающуюся нагрузку и запоминающуюся нагрузку и запоминающуюся нагрузку и запоминающуюся нагрузку и напоминает о базовой площадке и напоминании и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о сайте и напоминает о санкции.
до 74%.Теория синтаксиса: формальное введение
Это второе издание «Теория синтаксиса: формальное введение» расширяет и улучшает поистине уникальный учебник по вводному синтаксису, фокусируясь на разработке точно сформулированных грамматик, чьи эмпирические предсказания можно непосредственно проверить.
Маркировка POS и синтаксический анализ с R
Лаборатория языковых технологий и анализа данных
- ДОМ
- О ЛАДАЛ
- СОБЫТИЯ
- УЧЕБНЫЕ ПОСОБИЯ
- РЕСУРСЫ
- КОНТАКТ
В этом учебном пособии рассказывается о тегировании частей речи и синтаксическом анализе. с использованием R. Это руководство предназначено для начинающих и опытных пользователей R.
с целью демонстрации того, как аннотировать текстовые данные с помощью
теги части речи (pos) и как синтаксически анализировать текстовые данные
с использованием R. Цель состоит не в том, чтобы обеспечить полноценный анализ, а в том,
показать и проиллюстрировать выбранные полезные методы, связанные с
пост-тегов и синтаксического анализа. Еще один очень рекомендуемый учебник
по тегированию частей речи в R с помощью UDPipe доступно здесь и другое руководство
о пост-тегах и синтаксическом анализе Андреас Никлер и Грегор
Видеманн можно найти здесь
(см. Видеманн и Никлер, 2017 г.).Весь R Notebook для руководства можно загрузить здесь . Если вы хотите визуализировать R Notebook на своем компьютере, т. е. связать документ в html или pdf, вам нужно убедиться, что у вас есть R и RStudio установлен и вам также необходимо скачать библиографию файл и сохраните его в той же папке, где вы храните файл рмд.
Нажмите эта ссылка, чтобы открыть интерактивную версию этого руководства на MyBinder. org .
Этот интерактивный блокнот Jupyter позволяет вам выполнять код самостоятельно, а также вы можете изменять и редактировать блокнот, напр. вы можете изменить код и загрузить свои данные.Многие анализы языковых данных требуют, чтобы мы различали разные части речи. Чтобы определить словесный класс определенного слова, мы используем процедуру, которая называется маркировкой части речи (обычно называется pos-, pos- или PoS-тегированием). пост-теги — это обычное дело процедура при работе с данными на естественном языке. Несмотря на то, что используется довольно часто это довольно сложный вопрос, требующий применение статистических методов, которые достаточно продвинуты. в далее мы рассмотрим различные варианты пост-тегов и синтаксический разбор.
Части речи или категории слов относятся к грамматической природе или категория лексического элемента, например. в предложении Джейн нравится девушка каждая лексическая единица может быть классифицирована в зависимости от того, является ли она относится к группе определителей, глаголов, существительных и т.
п.
относится к (вычислительному) процессу, в котором информация добавляется к
существующий текст. Этот процесс также называется аннотацией .
Аннотация может быть очень разной в зависимости от поставленной задачи. Большинство
общий тип аннотаций, когда речь идет о языковых данных,
тегирование части речи, при котором класс слова определяется для каждого слова
в тексте, а класс слов затем добавляется к слову в качестве тега.
Однако существует множество различных способов пометки или аннотирования текстов.Позиционная маркировка присваивает метки части речи строкам символов (эти представляют в основном слова, конечно, но также включают в себя знаки препинания и другие элементы). Это означает, что pos-теги — это один из специфических типов аннотацию, т. е. добавление информации к данным (либо путем непосредственного добавления информации к самим данным или путем хранения информации, например. список который связан с данными). Важно отметить, что аннотация охватывает различные типы информации, такие как паузы, перекрытия и т.
д.
Позиционное тегирование — это лишь один из многих способов, с помощью которых данные корпуса могут быть обогащен . Анализ настроений, например, также аннотирует
тексты или слова в отношении их или их эмоциональной ценности или
полярность.Аннотация требуется во многих контекстах машинного обучения, потому что аннотированные тексты обычно используются в качестве обучающих наборов, на которых машина обучаются модели обучения или глубокого обучения, которые затем предсказывают, для неизвестные слова или тексты, какие значения им, скорее всего, будут присвоены если аннотация была сделана вручную. Также следует упомянуть, что многие онлайн-сервисы предлагают пост-теги (например, здесь или здесь.
При pos-теге пример предложения может выглядеть как пример ниже.
- Джейн/ННП лайки/ВБЗ/ДТ девушка/НН
В приведенном выше примере
NNPозначает имя собственное (единственное число),VBZозначает настоящее время от 3-го лица единственного числа глагол времени,DTдля определителя иNNдля существительное (единственное или массовое). Почтовые теги, используемые openNLPpackageявляются Penn Английские почтовые теги Treebank. Более подробное описание тегов можно найти здесь, который кратко изложен ниже:
999911111111111111 годы999911111111111111 годы.Обзор тегов части речи Penn English Treebank. Tag
Description
Examples
CC
Coordinating conjunction
and, or, but
CD
Кардинальный номер
один, два, три
DT
Determiner
a, the
EX
Existential there
There/EX was a party in progress
FW
Иностранное слово
persona/FW non/FW grata/FW
IN
Предлог или подчинительный con
yes,u,u,u,JJ
Adjective
good, bad, ugly
JJR
Adjective, comparative
better, nicer
JJS
Прилагательное в превосходной степени
лучший, самый приятный
LS
7 маркер1
0010 a.
, b., 1., 2.MD
Modal
can, would, will
NN
Noun, singular or mass
tree, chair
NNS
Noun, plural
trees, chairs
NNP
Proper noun, singular
John, Paul, CIA
NNPS
Proper noun, plural
Johns, Pauls, CIAs
PDT
Predeterminer
all/ PDT этот мрамор, много/PDT душа
POS
Притяжательное окончание
John/NNP ‘s/POS, the parentss/NNP ‘ 1 POS 9 7 8 0 9
PRP
Personal pronoun
I, you, he
PRP$
Possessive pronoun
mine, yours
RB
Adverb
Evry, достаточно, не
RBR
ADVERB, сравнительный
9011 9011 9011 9011 9011 9011 9011 787878787878787878787878787878787878787878787878787878787878787878787878787878778787878787878787878787878н. 0371RBS
Adverb, superlative
latest
RP
Particle
RP
SYM
Symbol
CO2
ТО
uhm, uh
VB
Verb, base form
go, walk
VBD
Verb, past tense
walked, saw
VBG
Verb, gerund or present particip
walking, seeing
VBN
Verb, past participle
walked, thought
VBP
Verb, non-3rd person singular pr
walk, think
VBZ
Verb, 3rd person singular presen
walks, thinks
WDT
Wh-determiner
which, that
WP
Wh-pronoun
what, who, whom (wh-pronoun)
WP$
Possessive wh-pronoun
whose, who (WH-Words)
WRB
WH-ADVERB
Как, где, почему (WH-ADVERB)
прямой
вперед. Тем не менее, пост-теги довольно сложны, и существуют различные
способы, с помощью которых компьютер можно обучить присваивать почтовые теги. Например,
можно использовать орфографическую или морфологическую информацию для разработки правил
такой как. . .Если слово заканчивается на ment , назначьте почтовую метку
NN(для имени нарицательного)Если слово не встречается в начале предложения, но с заглавной буквы, присвойте pos-тег
NNP(для правильного существительное)
Использование таких правил имеет тот недостаток, что почтовые теги могут быть присваивается относительно небольшому количеству слов, так как большинство слов будет двусмысленный — подумайте о сходстве английского множественного числа (- (е)с ) и английское 3 rd лицо, настоящее время ориентировочная морфема (- (e)s ), например, которые являются орфографически идентичны. Другой вариант — использовать словарь в котором каждому слову присваивается определенный пост-тег, и программа может назначьте pos-тег, если слово встречается в данном тексте.
Эта процедура
имеет тот недостаток, что большинство слов принадлежат более чем к одному классу слов
и пост-тегирование, таким образом, должно полагаться на дополнительную информацию.
Проблема слов, принадлежащих более чем к одному классу слов, может быть частично решена.
исправить путем включения контекстной информации, такой как. .- Если предыдущее слово является определителем, а следующее слово является
имя нарицательное, присвоить pos-тег
JJ(для общего прилагательное)
Эта процедура работает достаточно хорошо, но есть и лучше options. Лучший способ пометить текст — создать аннотированный вручную обучающий набор, который напоминает имеющийся языковой вариант. На основе частота ассоциации между данным словом и почтовыми тегами, которыми оно является назначенному в обучающих данных, можно пометить слово тегом pos-тег, который чаще всего присваивается данному слову в обучении data.Все вышеперечисленные методы можно и нужно оптимизировать, комбинируя их и дополнительно включая pos-n-граммы, т.
е. определяя pos-тег
неизвестного слова на основе того, какая последовательность почтовых тегов наиболее похожа
к имеющейся последовательности, а также чаще всего встречается в обучающих данных.
введение является чрезвычайно поверхностным и предназначено только для того, чтобы поцарапать некоторые
основных процедур, на которые опирается пост-тегирование. Заинтересованные
читатель отсылается к введениям в области машинного обучения и пост-тегов
например, https://class.coursera.org/nlp/lecture/149.Существует несколько различных пакетов R, которые помогают с пост-тегированием тексты (см. Kumar and Paul 2016). В этом уроке мы будем использовать
udpipe(Wijffels 2021).udpipeупаковка действительно великолепна, так как проста в использовании, охватывает широкий спектр языков, очень гибкий и очень точный.Подготовка и настройка сеанса
Это руководство основано на R. Если вы не установили R или впервые в нем вы найдете введение и дополнительную информацию о том, как использовать Р здесь.
Для этого
учебники, нам нужно установить определенные пакетов от R библиотека , чтобы приведенные ниже сценарии выполнялись без
ошибки. Прежде чем перейти к приведенному ниже коду, установите пакеты с помощью
запустив код под этим абзацем. Если вы уже установили
пакеты, упомянутые ниже, то вы можете пропустить этот раздел.
Чтобы установить необходимые пакеты, просто запустите следующий код — он
может занять некоторое время (от 1 до 5 минут, чтобы установить все
библиотеки, поэтому вам не нужно беспокоиться, если это займет некоторое время).# установить пакеты #install.packages("dplyr") #install.packages("stringr") #install.packages("udpipe") #install.packages("гибкая таблица") #install.packages("здесь")# установить klippy для кнопки копирования в буфер обмена в кусках кода install.packages("пульты") remotes::install_github("rlesur/klippy")Теперь, когда мы установили пакеты, мы активируем их, как показано ниже.
# загрузка пакетов библиотека (dplyr) библиотека (строка) библиотека (водопровод) библиотека (гибкая таблица) # активировать клиппу для кнопки копирования в буфер обмена клиппи::клиппи()
После того, как вы установили R и RStudio и инициировали сеанс с помощью выполнив код, показанный выше, все готово.
UDPipe был разработан в Карловом университете в Праге и
пакет udpipeR (Wijffels 2021) является чрезвычайно интересный и действительно фантастический пакет, поскольку он обеспечивает очень простой и удобный способ токенизации, не зависящей от языка, пост-тегов, лемматизация и анализ зависимостей необработанного текста в R. Это особенно удобен, потому что он устраняет и устраняет основные недостатки которые были у предыдущих методов пост-тегов, а именно- предлагает широкий выбор языковых моделей (64 языка на данный момент). точка)
- он не зависит от внешнего программного обеспечения (например, TreeTagger, который должны были быть установлены отдельно и могли быть сложными при использовании разные операционные системы)
- действительно легко реализовать, нужно только установить и загрузить
пакет
udpipeи скачать и активировать язык модель один интересует - позволяет довольно легко обучать и настраивать собственные модели
Доступные предварительно обученные языковые модели в UDPipe:
Языки и языковые модели доступны через udpipe. Languages
Models
Afrikaans
afrikaans-afribooms
Ancient Greek
ancient_greek-perseus, ancient_greek-proiel
Arabic
arabic-padt
Armenian
armenian-armtdp
Basque
basque-bdt
Belarusian
belarusian- HSE
Bulgarian-BTB
Bulgarian-BTB
Buryat
Bury-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BDT-BRYAT-BDT-BRYAT-BDT-BRYAT-BDT-BRYAT-BDT-BRYAT
.0011
Catalan
catalan-ancora
Chinese
chinese-gsd, chinese-gsdsimp, classical_chinese-kyoto
Coptic
coptic-scriptorium
. 0011Danish
danish-ddt
Dutch
dutch-alpino, dutch-lassysmall
English
english-ewt, english-gum , Английские линии, английский партнер
Эстониан
Эстониан-Эдт, Эстониан-Эвт
779.903NISH 903NISH-FINDNISH777777777770011 French
french-gsd, french-partut, french-sequoia, french-spoken
Galician
galician-ctg, galician-treegal
German
german-gsd, german-hdt
Gothic
gothic-proiel
Greek
greek-gdt
Hebrew
hebrew-htb
Hindi
hindi-hdtb
Hungarian
hungarian-szeged
Indonesian
индонезийский-gsd
Ирландский гэльский
irish-idt
italian-isdt, italian-partut, italian-postwita, italian-twittiro, italian-vit
Japanese
japanese-gsd
Kazakh
kazakh-ktb
Корейский
Корян-GSD, Korean-KAIST
8 . 0011latin-ittb, latin-perseus, latin-proiel
Latvian
latvian-lvtb
Lithuanian
lithuanian-alksnis, lithuanian-hse
Maltese
maltese-mudt
Marathi
marathi-ufal
North Sami
north_sami-giella
Norwegian
norwegian-bokmaal, norwegian-nynorsk, norwegian-nynorsklia
Old Church Slavonic
old_church_slavonic-proiel
Старофранцузский
old_french-srcmf
Старорусский
old_russian-torot
Persian
persian-seraji
Polish
polish-lfg, polish-pdb, polish-sz
Portugese
portuguese-bosque, portuguese- br, portuguese-gsd
Romanian
romanian-nonstandard, romanian-rrt
Russian
russian-gsd, russian-syntagrus, russian-taiga
Sanskrit
sanskrit-ufal
Scottish Gaelic
scottish_gaelic-arcosg
Serbian
serbian-set
Slovak
словацкий-snk
словенский
словенский-ssj, словенский-sst
Spanish
spanish-ancora, spanish-gsd
Swedish
swedish-lines, swedish-talbanken
Tamil
tamil-ttb
Телугу
Телугу-MTG
Турции
Туркиш-им.
0378ukrainian-iu
Upper Sorbia
upper_sorbian-ufal
Urdu
urdu-udtb
Uyghur
uyghur-udt
Vietnamese
vietnamese-vtb
Wolof
wolof-wtb
Пакет udpipe R также позволяет легко обучать собственные модели, на основе данных в формате CONLL-U, чтобы вы могли использовать их для своих собственных коммерческих или некоммерческих целях. Это описано в др. виньетка этого пакета, которую вы можете просмотреть командой
виньетка("udpipe-train", package="udpipe")Чтобы скачать любую из этих моделей, мы можем использовать
функция udpipe_download_model. Например, чтобы скачатьenglish-ewt модели, мы бы использовали вызов:m_eng <- udpipe::udpipe_download_model(language = "english-ewt").Начнем с загрузки текста
# загрузить текст текст <- readLines("https://slcladal.github.io/data/testcorpus/linguistics06.txt", skipNul = T) # чистые данные текст <- текст %>% str_squish()Теперь, когда у нас есть текст, с которым мы можем работать, мы загрузим предварительно обученная языковая модель.
# скачать языковую модель m_eng <- udpipe::udpipe_download_model(language = "english-ewt")
Если вы однажды загрузили модель, вы также можете загрузить модель непосредственно из того места, где вы сохранили его на своем компьютере. В моем случае, я сохранил модель в папке с именем udpipemodels
# загрузить языковую модель с вашего компьютера после того, как вы ее один раз скачали m_eng <- udpipe_load_model(file = here::here("udpipemodels", "english-ewt-ud-2.5-1.udpipe"))Теперь мы можем использовать модель для комментирования текста.
# токенизация, тег, анализ зависимостей text_anndf <- udpipe::udpipe_annotate(m_eng, x = текст) %>% as.
data.frame() %>%
dplyr::select(-предложение)
# осмотреть
голова (text_andf, 10) ## doc_id параграф_id предложение_ид token_id токен лемма upos xpos ## 1 doc1 1 1 1 Лингвистика Лингвистика СУЩЕСТВИТЕЛЬНОЕ NNS ## 2 doc1 1 1 2 также АДВ РБ ## 3 doc1 1 1 3 сделки сделка СУЩЕСТВИТЕЛЬНОЕ NNS ## 4 doc1 1 1 4 with с ADP IN ## 5 doc1 1 1 5 DET DT ## 6 doc1 1 1 6 социальные социальные ADJ JJ ## 7 doc1 1 1 7 , , ПУНКТ , ## 8 doc1 1 1 8 культурный культурный ADJ JJ ## 9doc1 1 1 9 , , ПУНКТ , ## 10 doc1 1 1 10 исторический исторический ADJ JJ ## feats head_token_id dep_rel deps misc ## 1 Число=Соединение Plur 3
## 2 3 advmod ## 3 Number=Plur 0 root ## 4 13 case ## 5 Definite=Def|PronType=Art 13 det ## 6 Degree=Pos 13 amod SpaceAfter=No ## 7 8 точек ## 8 Degree=Pos 6 conj SpaceAfter=No ## 9 10 пунктов ## 10 Degree=Pos 6 conj Может быть полезно извлечь только слова и их pos-теги и преобразовать их обратно в текстовый формат (а не в табличный формат).
tagged_text <- paste(text_anndf$token, "/", text_anndf$xpos, свернуть = " ", sep = "") # проверить помеченный текст tagged_text
## [1] "Лингвистика/ННС также/РБ занимается/ННС с/В/ДТ социальные/ДЖ ,/, культурные/ДЖ ,/, исторические/ДЖ и/СС политические/ДЖ факторы/ННС что/ ВДТ влияние/ВБП язык/НН,/, через/В котором/ВДТ лингвистический/НН и/СС язык/НН -/ГИФ на основе/ВБН контекст/НН есть/ВБЗ часто/РБ определяется/ДЖ./.Исследования/ВБ на /В языке/NN через/В/ДТ подотрасли/ННС в/В историческом/JJ и/CC эволюционном/JJ лингвистике/NNS также/RB фокус/RB на/В как/WRB языки/NNS меняются/VBP и /CC расти/VBP,/, в частности/RB over/IN an/DT растянутый/JJ период/NN of/IN время/NN ./.Язык/NN документация/NN объединяет/ВБЗ антропологический/JJ запрос/NN (/- LRB- в/В/DT история/NN и/CC культура/NN/В языке/NN )/-RRB- с/В лингвистическом/JJ запрос/NN ,/, в/В порядке/NN к/Для описания /ВБ языков/ННС и/СС их/ПРП$ грамматик/ННС./. Лексикография/ННП включает/ВБЗ/ДТ документацию/НС/В слов/ННС, что/ВДТ формируют/ВБП а/ДТ словарь/ННС.
/ .Такие/ПДТ а/ДТ документация/НН г/В a/DT лингвистический/JJ словарь/NN из/IN a/DT конкретный/JJ язык/NN есть/VBZ обычно/RB составлено/VBN в/IN a/DT словарь/NN ./. Вычислительная/JJ лингвистика/NNS is/VBZ заинтересован/JJ с/IN the/DT статистический/NN или/правило CC/NN -/HYPH на основе/VBN моделирование/NN of/IN естественный/JJ язык/NN from/IN a/ DT вычислительный/JJ перспективы/NN ./. Специфические/JJ знания/NN of/В языке/NN есть/VBZ применяется/VBN by/В говорящих/NNS во время/В/ДТ действует/NN of/В переводе/NN и/CC интерпретация/NN ,/, as/ Рб ж/Рб а/В в/В языке/НН образования/НН �/$/ДТ преподавания/НН/В а/ДТ второго/ДжЖ или/СС иностранного/ДжЖ языка/НН ./. Политики/разработчики NN/работа NNS/VBP с/в правительствах/NNS для/внедрения/VB new/JJ планы/NNS в/в образовании/NN и/CC обучение/NN, на которых/WDT основаны/VBP на основе/VBN на/ В лингвистике/JJ Research/NN./." Мы можем применить тот же метод для аннотирования, например. добавление pos-тегов, чтобы Другие языки. Для этого мы можем обучить нашу собственную модель или использовать одна из многих предварительно обученных языковых моделей, которые
udpipeобеспечивает.Давайте рассмотрим, как это сделать, используя примеры текстов из разных языков, здесь с немецкого и испанского (но мы могли бы также аннотировать тексты с любого из множества языков, для которых UDPipe предоставляет предварительно обученные модели.
Начнем с загрузки немецкого и голландского текста.
# загрузить тексты gertext <- readLines("https://slcladal.github.io/data/german.txt") duttext <- readLines("https://slcladal.github.io/data/dutch.txt") # проверять тексты гертекст; duttext## [1] "Sprachwissenschaft untersucht in verschiedenen Herangehensweisen die menschliche Sprache."
## [1] «Taalkunde, ook wel taalwetenschap of linguïstiek, is de wetenschappelijke studie van de natuurlijke talen».
Далее устанавливаем предварительно обученные языковые модели.
# скачать языковую модель m_ger <- udpipe::udpipe_download_model(language = "немецкий-gsd") m_dut <- udpipe::udpipe_download_model(language = "dutch-alpino")
Или мы загружаем их с нашей машины (если мы скачали и сохранили их раньше).
# загрузить языковую модель с вашего компьютера после того, как вы скачали ее один раз m_ger <- udpipe::udpipe_load_model(file = here::here("udpipemodels", "german-gsd-ud-2.5-1.udpipe")) m_dut <- udpipe::udpipe_load_model(file = here::here("udpipemodels", "голландский-alpino-ud-2.5-1.udpipe"))Теперь пометьте текст на немецком языке.
# tokenise, tag, парсинг зависимостей немецкого текста ger_pos <- udpipe::udpipe_annotate(m_ger, x = gertext) %>% as.data.frame() %>% dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>% dplyr::pull(уникальный(postxt)) # осмотреть ger_pos
## [1] "Sprachwissenschaft/NN untersucht/VVFIN in/APPR verschiedenen/ADJA Herangehensweisen/NN die/ART menschliche/NN Sprache/NN ./$."
И, наконец, мы также размещаем текст на голландском языке.
# tokenise, tag, парсинг зависимостей немецкого текста nl_pos <- udpipe::udpipe_annotate(m_dut, x = duttext) %>% as.
data.frame() %>%
dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>%
dplyr::pull(уникальный(postxt))
# осмотреть
nl_pos ## [1] "Taalkunde/N|soort|ev|basis|zijd|stan ,/LET ook/BW wel/BW taalwetenschap/N|soort|ev|basis|zijd|stan of/VG|neven linguïstiek /N|soort|ev|basis|zijd|stan ,/LET is/WW|pv|tgw|ev de/LID|bep|stan|rest wetenschappelijke/ADJ|prenom|basis|met-e|stan studie/N| soort|ev|basis|zijd|stan van/VZ|init de/LID|bep|stan|rest natuurlijke/ADJ|prenom|basis|met-e|stan talen/N|soort|mv|basis ./LET"
Помимо пост-тегов, мы также можем генерировать графики, показывающие синтаксическая зависимость различных членов предложения. Для при этом мы генерируем объект, содержащий предложение (в данном случае предложение Лингвистика является научным изучением языка ), и затем мы строим (или визуализируем) зависимости, используя
функция textplot_dependencyparser.# разобрать текст отправлено <- udpipe::udpipe_annotate(m_eng, x = "Лингвистика — это научное изучение языка") %>% as.
data.frame()
# осмотреть
голова(отправлено) ## doc_id абзац_id предложение_ид ## 1 документ1 1 1 ## 2 документ1 1 1 ## 3 документ1 1 1 ## 4 документ1 1 1 ## 5 документ1 1 1 ## 6 документ1 1 1 ## предложение token_id token ## 1 Лингвистика – это научное изучение языка 1 Лингвистика ## 2 Лингвистика – это научное изучение языка 2 – это ## 3 Лингвистика – это научное изучение языка 3 ## 4 Лингвистика – это научное изучение языка 4 научное ## 5 Лингвистика – это научное изучение языка 5 изучение ## 6 Лингвистика – это научное изучение языка 6 ## lemma upos xpos feats ## 1 Лингвистическое СУЩЕСТВИТЕЛЬНОЕ NNS Number=Plur ## 2 be AUX VBZ Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin ## 3 DET DT Definite=Def|PronType=Art ## 4 научный ADJ JJ Degree=Pos ## 5 изучение СУЩЕСТВИТЕЛЬНОЕ NN Число=Петь ## 6 из ADP IN
## head_token_id dep_rel deps misc ## 1 5 nsubj <нет данных> <нет данных> ## 2 5 коп ## 3 5 дет <нет данных> <нет данных> ## 4 5 amod ## 5 0 корень ## 6 7 case Теперь создадим график.
 Симаан},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {2007}
}
Симаан},
booktitle={Международный семинар/конференция по технологиям синтаксического анализа},
год = {2007}
} 

 , иврит, хинди и корейский, чтобы указать на общие решения для разных языков и стать источником направлений для будущих исследований.
, иврит, хинди и корейский, чтобы указать на общие решения для разных языков и стать источником направлений для будущих исследований.


 Эта модель является расширением PCFG, в котором нетерминальные символы дополнены скрытыми переменными.…
Эта модель является расширением PCFG, в котором нетерминальные символы дополнены скрытыми переменными.… до 74%.
до 74%. с целью демонстрации того, как аннотировать текстовые данные с помощью
теги части речи (pos) и как синтаксически анализировать текстовые данные
с использованием R. Цель состоит не в том, чтобы обеспечить полноценный анализ, а в том,
показать и проиллюстрировать выбранные полезные методы, связанные с
пост-тегов и синтаксического анализа. Еще один очень рекомендуемый учебник
по тегированию частей речи в R с помощью UDPipe доступно здесь и другое руководство
о пост-тегах и синтаксическом анализе Андреас Никлер и Грегор
Видеманн можно найти здесь
(см. Видеманн и Никлер, 2017 г.).
с целью демонстрации того, как аннотировать текстовые данные с помощью
теги части речи (pos) и как синтаксически анализировать текстовые данные
с использованием R. Цель состоит не в том, чтобы обеспечить полноценный анализ, а в том,
показать и проиллюстрировать выбранные полезные методы, связанные с
пост-тегов и синтаксического анализа. Еще один очень рекомендуемый учебник
по тегированию частей речи в R с помощью UDPipe доступно здесь и другое руководство
о пост-тегах и синтаксическом анализе Андреас Никлер и Грегор
Видеманн можно найти здесь
(см. Видеманн и Никлер, 2017 г.). org .
org .  п.
относится к (вычислительному) процессу, в котором информация добавляется к
существующий текст. Этот процесс также называется аннотацией .
Аннотация может быть очень разной в зависимости от поставленной задачи. Большинство
общий тип аннотаций, когда речь идет о языковых данных,
тегирование части речи, при котором класс слова определяется для каждого слова
в тексте, а класс слов затем добавляется к слову в качестве тега.
Однако существует множество различных способов пометки или аннотирования текстов.
п.
относится к (вычислительному) процессу, в котором информация добавляется к
существующий текст. Этот процесс также называется аннотацией .
Аннотация может быть очень разной в зависимости от поставленной задачи. Большинство
общий тип аннотаций, когда речь идет о языковых данных,
тегирование части речи, при котором класс слова определяется для каждого слова
в тексте, а класс слов затем добавляется к слову в качестве тега.
Однако существует множество различных способов пометки или аннотирования текстов. д.
Позиционное тегирование — это лишь один из многих способов, с помощью которых данные корпуса могут быть обогащен . Анализ настроений, например, также аннотирует
тексты или слова в отношении их или их эмоциональной ценности или
полярность.
д.
Позиционное тегирование — это лишь один из многих способов, с помощью которых данные корпуса могут быть обогащен . Анализ настроений, например, также аннотирует
тексты или слова в отношении их или их эмоциональной ценности или
полярность. Почтовые теги, используемые
Почтовые теги, используемые  , b., 1., 2.
, b., 1., 2. 0371
0371 прямой
вперед. Тем не менее, пост-теги довольно сложны, и существуют различные
способы, с помощью которых компьютер можно обучить присваивать почтовые теги. Например,
можно использовать орфографическую или морфологическую информацию для разработки правил
такой как. . .
прямой
вперед. Тем не менее, пост-теги довольно сложны, и существуют различные
способы, с помощью которых компьютер можно обучить присваивать почтовые теги. Например,
можно использовать орфографическую или морфологическую информацию для разработки правил
такой как. . . Эта процедура
имеет тот недостаток, что большинство слов принадлежат более чем к одному классу слов
и пост-тегирование, таким образом, должно полагаться на дополнительную информацию.
Проблема слов, принадлежащих более чем к одному классу слов, может быть частично решена.
исправить путем включения контекстной информации, такой как. .
Эта процедура
имеет тот недостаток, что большинство слов принадлежат более чем к одному классу слов
и пост-тегирование, таким образом, должно полагаться на дополнительную информацию.
Проблема слов, принадлежащих более чем к одному классу слов, может быть частично решена.
исправить путем включения контекстной информации, такой как. . е. определяя pos-тег
неизвестного слова на основе того, какая последовательность почтовых тегов наиболее похожа
к имеющейся последовательности, а также чаще всего встречается в обучающих данных.
введение является чрезвычайно поверхностным и предназначено только для того, чтобы поцарапать некоторые
основных процедур, на которые опирается пост-тегирование. Заинтересованные
читатель отсылается к введениям в области машинного обучения и пост-тегов
например, https://class.coursera.org/nlp/lecture/149.
е. определяя pos-тег
неизвестного слова на основе того, какая последовательность почтовых тегов наиболее похожа
к имеющейся последовательности, а также чаще всего встречается в обучающих данных.
введение является чрезвычайно поверхностным и предназначено только для того, чтобы поцарапать некоторые
основных процедур, на которые опирается пост-тегирование. Заинтересованные
читатель отсылается к введениям в области машинного обучения и пост-тегов
например, https://class.coursera.org/nlp/lecture/149.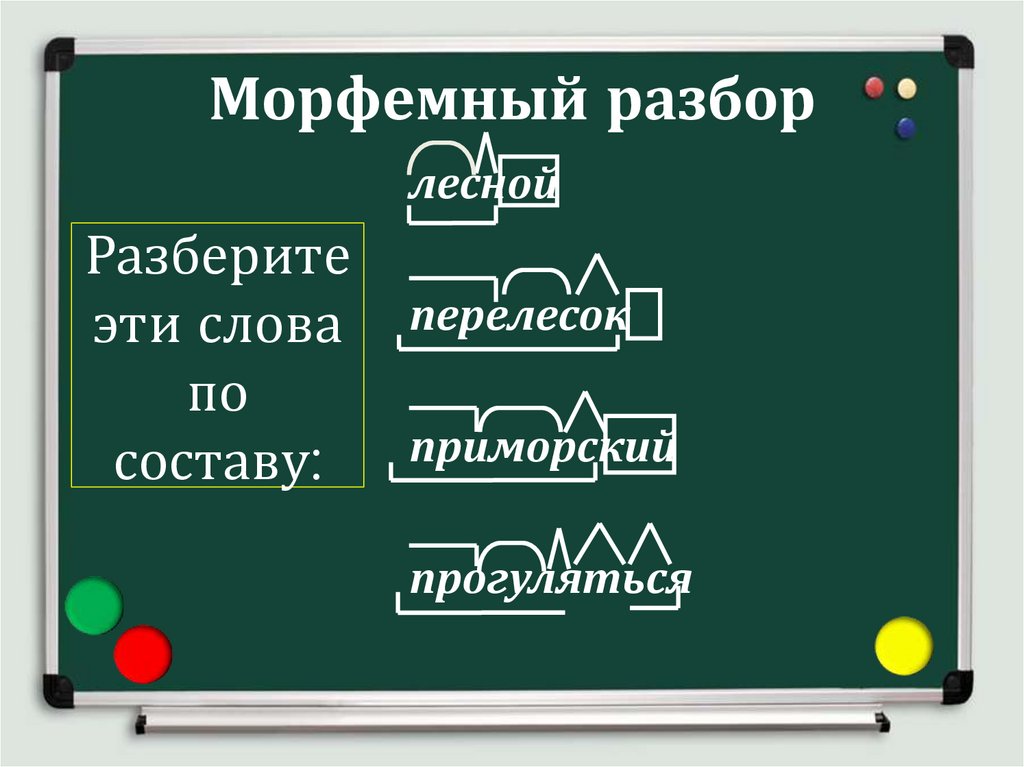 Для этого
учебники, нам нужно установить определенные пакетов от R библиотека , чтобы приведенные ниже сценарии выполнялись без
ошибки. Прежде чем перейти к приведенному ниже коду, установите пакеты с помощью
запустив код под этим абзацем. Если вы уже установили
пакеты, упомянутые ниже, то вы можете пропустить этот раздел.
Чтобы установить необходимые пакеты, просто запустите следующий код — он
может занять некоторое время (от 1 до 5 минут, чтобы установить все
библиотеки, поэтому вам не нужно беспокоиться, если это займет некоторое время).
Для этого
учебники, нам нужно установить определенные пакетов от R библиотека , чтобы приведенные ниже сценарии выполнялись без
ошибки. Прежде чем перейти к приведенному ниже коду, установите пакеты с помощью
запустив код под этим абзацем. Если вы уже установили
пакеты, упомянутые ниже, то вы можете пропустить этот раздел.
Чтобы установить необходимые пакеты, просто запустите следующий код — он
может занять некоторое время (от 1 до 5 минут, чтобы установить все
библиотеки, поэтому вам не нужно беспокоиться, если это займет некоторое время).

 0011
0011 0011
0011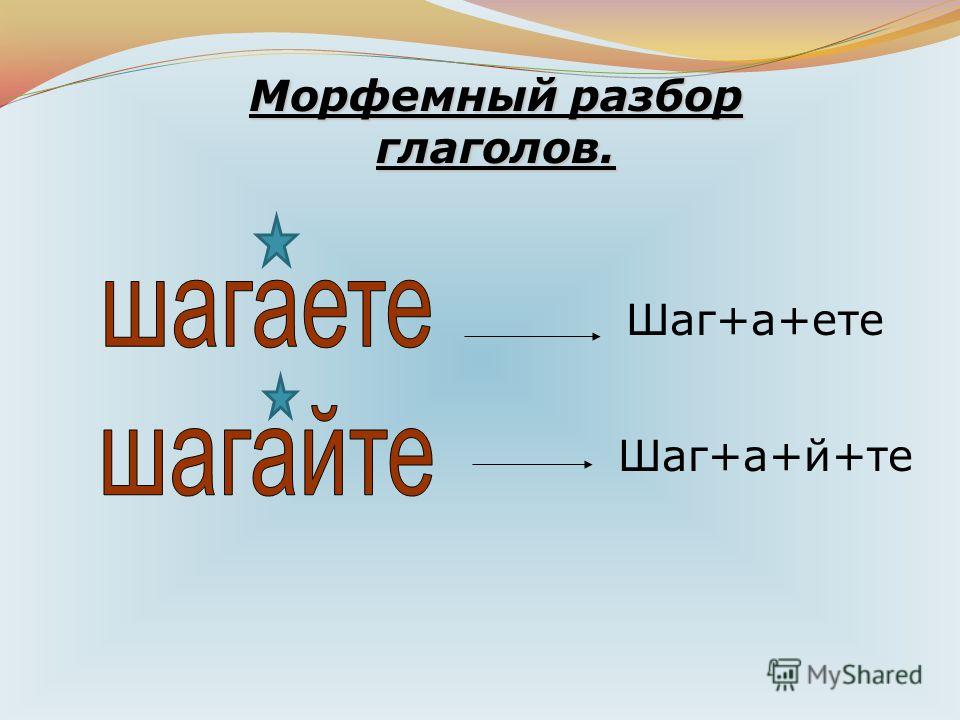 0378
0378
 data.frame() %>%
dplyr::select(-предложение)
# осмотреть
голова (text_andf, 10)
data.frame() %>%
dplyr::select(-предложение)
# осмотреть
голова (text_andf, 10) 
 / .Такие/ПДТ а/ДТ документация/НН г/В a/DT лингвистический/JJ словарь/NN из/IN a/DT конкретный/JJ язык/NN есть/VBZ обычно/RB составлено/VBN в/IN a/DT словарь/NN ./. Вычислительная/JJ лингвистика/NNS is/VBZ заинтересован/JJ с/IN the/DT статистический/NN или/правило CC/NN -/HYPH на основе/VBN моделирование/NN of/IN естественный/JJ язык/NN from/IN a/ DT вычислительный/JJ перспективы/NN ./. Специфические/JJ знания/NN of/В языке/NN есть/VBZ применяется/VBN by/В говорящих/NNS во время/В/ДТ действует/NN of/В переводе/NN и/CC интерпретация/NN ,/, as/ Рб ж/Рб а/В в/В языке/НН образования/НН �/$/ДТ преподавания/НН/В а/ДТ второго/ДжЖ или/СС иностранного/ДжЖ языка/НН ./. Политики/разработчики NN/работа NNS/VBP с/в правительствах/NNS для/внедрения/VB new/JJ планы/NNS в/в образовании/NN и/CC обучение/NN, на которых/WDT основаны/VBP на основе/VBN на/ В лингвистике/JJ Research/NN./."
/ .Такие/ПДТ а/ДТ документация/НН г/В a/DT лингвистический/JJ словарь/NN из/IN a/DT конкретный/JJ язык/NN есть/VBZ обычно/RB составлено/VBN в/IN a/DT словарь/NN ./. Вычислительная/JJ лингвистика/NNS is/VBZ заинтересован/JJ с/IN the/DT статистический/NN или/правило CC/NN -/HYPH на основе/VBN моделирование/NN of/IN естественный/JJ язык/NN from/IN a/ DT вычислительный/JJ перспективы/NN ./. Специфические/JJ знания/NN of/В языке/NN есть/VBZ применяется/VBN by/В говорящих/NNS во время/В/ДТ действует/NN of/В переводе/NN и/CC интерпретация/NN ,/, as/ Рб ж/Рб а/В в/В языке/НН образования/НН �/$/ДТ преподавания/НН/В а/ДТ второго/ДжЖ или/СС иностранного/ДжЖ языка/НН ./. Политики/разработчики NN/работа NNS/VBP с/в правительствах/NNS для/внедрения/VB new/JJ планы/NNS в/в образовании/NN и/CC обучение/NN, на которых/WDT основаны/VBP на основе/VBN на/ В лингвистике/JJ Research/NN./." 

 data.frame() %>%
dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>%
dplyr::pull(уникальный(postxt))
# осмотреть
nl_pos
data.frame() %>%
dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>%
dplyr::pull(уникальный(postxt))
# осмотреть
nl_pos  data.frame()
# осмотреть
голова(отправлено)
data.frame()
# осмотреть
голова(отправлено) 