§ 17. Словообразовательный разбор
Словообразовательный
разбор — это определение способа
образования слова, т. е. выяснение, от
чего и с помощью чего происходит
образование конкретного слова. При
словообразовательном разборе слова
обычно устанавливается последовательность
присоединения суффиксов и приставок к
исходному слову в процессе его
образования.
Примечание. При морфемном и словообразовательном
разборе иногда необходимо учитывать
фонетические особенности данного
слова.
Например,
притяжательные прилагательные типа волчий образованы от соответствующих
существительных с помощью суффикса -ий- (волчий волк
+ -ий-) и имеют нулевое окончание (ср. волчий ,
волчь[й’ь]го, волчь[й’ь]му). Слово бездорожье образовано от слова дорога с помощью приставки без- и суффикса -й-, т. е.
приставочно-суффиксальным
способом.
План
словообразовательного
разбора 1.
Различие между морфемным и словообразовательным разборами
План разбора слова по составу (морфемный разбор):
1. Определить, к какой части речи
относится данное слово.
2. Вспомнить особенности строения слов, относящихся к данной части речи:
3. Записать данное слово (или его начальную форму).
4. Обозначить окончание (если оно есть в слове). См. в каких словах нет окончаний?
5. Обозначить формообразующие суффиксы и постфиксы (если они есть в слове).
6. Обозначить основу слова.
7. Обозначить в основе слова приставку (если она есть в слове).
8. Обозначить в основе слова суффикс (если он есть в слове).
9. Обозначить в основе слова постфикс (если он есть в слове).
10. Обозначить в основе корень слова;
11. Если в слове два (и более)
корня, обозначить
Примечания:
В одном слове могут быть два и более корня, суффикса, приставки, окончания, соединительные морфемы. См.
 Может
ли в одном слове быть два и более
окончания?
Может
ли в одном слове быть два и более
окончания?
 Может
ли в одном слове быть два и более
окончания?
Может
ли в одном слове быть два и более
окончания?13
Словообразовательный разбор слова — Уроки Русского
Словообразовательный разбор предполагает установление, от какого производящего слова с помощью каких словообразовательных морфем и каким способом образовано производное слово.
Производящее слово – это слово, от которого образовано другое слово.
Производное слово – это слово, которое образовалось от другого слова.
Особенности словообразования
- Для проведения словообразовательного разбора, слово необходимо поставить в начальную форму.
- Чтобы найти слово, от которого образовано данное, нужно определить лексическое значение производного слово через однокоренное. Нужно ответить на вопрос:
Что данное слово обозначает? (Что это? Кто это? Какое оно?)
Ответ обязательно должен содержать однокоренное слово. Например, найдем производящие слова для слов лесник, пригород, упростить:
Например, найдем производящие слова для слов лесник, пригород, упростить:
Лесник – это кто?~ Это тот, кто работает в лесу.
Лесник ←лес
Слово лесник образовано от слова лес.
Пригород – это что?~ Это местность возле города.
Пригород ← город
Слово пригород образовано от слова город
Упростить – что значит?~ Значит, сделать простым.
Упростить ← простой
Слово упростить образовано от слова простой.
- В образовании слова одновременно участвуют только разные морфемы. От двух одинаковых морфем слово не может быть образовано (от двух приставок, от двух суффиксов).
- Если при образовании слова изменилась часть речи, значит, в словообразовании участвовал суффикс (либо один, либо в сочетании с другой морфемой). При этом суффикс может быть нулевым. Например:
 При этом суффикс может быть нулевым. Например:
При этом суффикс может быть нулевым. Например:грушевый ←груша
Прилагательное грушевый образовано от существительного груша при помощи суффикса – ев-.
повысить ←высокий
Глагол повысить образован от прилагательного высокий при помощи приставки по— и суффикса –и-.
- Существительные, обозначающие лиц женского пола, обычно образованы от существительных мужского пола. Например:
учительница ← учитель
Слово учительница образовано от слова учитель.
- Существительные, обозначающие качество, признак образованы, как правило, от прилагательных. Например:
доброта ← добрый
Слово доброта образовано от слова добрый.
смелость ← смелый
Слово смелость образовано от слова смелый.
- Существительные со значением действия, как правило, образуются от глаголов. Например:
ожидание ← ожидать
Слово ожидание образовано от слова ожидать.
- Глаголы с суффиксами –ва-, -ива-, -ыва— чаще всего образуются от соответствующих им глаголов без данных суффиксов. Суффикс –ва— ударный, —ива-, -ыва— – безударные.
зашивать ← зашить
Глагол зашивать образован от глагола зашить
замариновывать ← замариновать
Глагол замариновывать образован от глагола замариновать.
- Наречия на –о, -е образуются от прилагательных. Например:
Горячо ← горячий
Наречие горячо образовано от прилагательного горячий.
Алгоритм проведения словообразовательного
- Поставить слово в начальную форму.
- Найти производящее слово.
- Определить, с помощью каких морфем данное слово образовано.
- Определить способ образования слова.

Робеет. Начальная форма – робеть. Что это значит?~ Значит, быть робким. Глагол робеть образован от прилагательного робкий при помощи суффикса –е— суффиксальным способом.
Робеет – робеть.
Робеть ← робкий (суффиксальный сп.)
Повторим
Словообразовательный разбор предполагает установление, от какого производящего слова с помощью каких словообразовательных морфем и каким способом образовано производное слово.
Производящее слово – это слово, от которого образовано другое слово.
Производное слово – это слово, которое образовалось от другого слова.
Особенности словообразования
- Для проведения словообразовательного разбора, слово необходимо поставить в начальную форму.
- Чтобы найти слово, от которого образовано данное, нужно определить лексическое значение производного слово через однокоренное.
- В образовании слова одновременно участвуют только разные морфемы.
- Если при образовании слова изменилась часть речи, значит, в словообразовании участвовал суффикс . Суффикс может быть нулевым.
- Существительные, обозначающие лиц женского пола, обычно образованы от существительных мужского пола.
- Существительные, обозначающие качество, признак образованы, как правило, от прилагательных.
- Существительные со значением действия, как правило, образуются от глаголов.
- Глаголы с суффиксами –ва-, -ива-, -ыва— чаще всего образуются от соответствующих им глаголов без данных суффиксов. Суффикс –ва— ударный, —ива-, -ыва— – безударные.
- Наречия на –о, -е образуются от прилагательных.

Алгоритм проведения словообразовательного разбора.
- Поставить слово в начальную форму.
- Найти производящее слово.
- Определить, с помощью каких морфем данное слово образовано.
- Определить способ образования слова.
морфем как необходимая концепция для обнаружения структур из немаркированных корпусов
- ID корпуса: 14162301
title={Морфемы как необходимая концепция для обнаружения структур из неразмеченных корпусов},
автор={Херв},
год = {1998}
} - Herv
- Опубликовано в 1998 г.
- Лингвистика
В этой статье дается обзор метода, позволяющего обнаруживать синтаксические структуры из немаркированных корпусов. Он состоит из трех основных этапов: открытие грамматических морфем языка. Затем построение чанков, представляющих собой многоязычный понятийный уровень, позволяющий обойти хромающее понятие слов. И, наконец, открытие отношений между чанками. Мы даем обзор различных реализованных процедур и особенно описываем открытие…
Мы даем обзор различных реализованных процедур и особенно описываем открытие…
Простая маркировка морфем в неконтролируемом анализе морфем
- D. Bernhard
Лингвистика
CLEF
- 2007
Система для непреднамеренного анализа Morphem слов в качестве входных данных и возвращает список помеченных морфемных сегментов для каждого слова.
Неконтролируемое открытие морфем
- Матиас Кройц, К. Лагус
Информатика
SIGMORPHON
- 2002
Два метода неконтролируемой сегментации слов на морфемоподобные единицы представлены на основе принципа минимальной длины описания (MDL) и оптимизации максимального правдоподобия (ML).
Jonáš Vidra Морфологическая сегментация чешских слов Института формальных и
Информатика
- 2018
Задача этой диссертации состоит в том, чтобы создать автоматический метод для сегментации чешских слов в сети производных морфем, пригодный для использования в деривационных морфемах. отношения DeriNet, а также создать нейронную сеть, предназначенную для совместного прогнозирования сегментации и деривационных родителей.
отношения DeriNet, а также создать нейронную сеть, предназначенную для совместного прогнозирования сегментации и деривационных родителей.
Unsupervised models for morpheme segmentation and morphology learning
- Mathias Creutz, K. Lagus
Computer Science, Linguistics
TSLP
- 2007
Morfessor can handle highly inflecting and compounding languages where words can consist of lengthy последовательностей морфем, и показано, что он работает очень хорошо по сравнению с широко известным эталонным алгоритмом на финских данных.
Установление морфологических компонентов тамильского языка с использованием неконтролируемого подхода
- Ананти Шешасайи, Анджела Дипа. V.R
Лингвистика, информатика
2016 г. Международная онлайн-конференция по «зеленой» инженерии и технологиям (IC-GET)
- 2016 г.
В этом документе основное внимание уделяется неконтролируемым средствам сегментации словарей тамильского языка по различным параметрам и новому алгоритму. показывает многообещающий результат в пользу идентификации морфем с их суффиксами.
показывает многообещающий результат в пользу идентификации морфем с их суффиксами.
Улучшение охвата слов с помощью неконтролируемого морфологического анализатора
- К. Сунита, Н. Кальяни
Информатика, лингвистика
- 2009
В этой работе представлен подход к овладению морфологией флективного языка, такого как хинди, неконтролируемого обучения с богатым подходом, подходящим для языков конкатенативная морфология и развивает морфологическую сегментацию, которая не зависит от языка.
Вклад медицинской терминологии в ресурсы обработки медицинского языка: эксперименты по извлечению морфологических знаний из тезаурусов
- Пьер Цвайгенбаум, Н. Грабарь
Компьютерные науки, лингвистика
- 1999
знания.
Изучение морфологии без учителя с использованием синтаксических категорий
- Burcu Can, S. Manandhar
Информатика
CLEF
- 2009
 Manandhar
ManandharМетод неконтролируемого изучения морфологии, который использует синтаксические категории слов и использует синтаксическую информацию, т. е. метки частей речи (PoS) слов для облегчения морфологического анализа.
Индуцирование морфем с помощью световых знаний
- Майкл Теппер, Ф. Ся
Информатика
TALIP
- 2010
Переписывание небольшого количества орфографических правил в гибридной форме для лингвистических правил помочь уточнить существующую сегментацию, произведенную MI, чтобы изучить морфемы и получить базовый анализ морфов из существующей сегментации поверхностных морфов, и из них изучить сегментацию на уровне морфем.
Stemmer без присмотра для улучшения анализатора морфологии на основе правил словоизменяется многими морфемами, которые можно было выделить для тех слов, которые изначально не были распознаны морфологическим анализатором, основанным на правилах.

ПОКАЗАНЫ 1-7 ИЗ 7 ССЫЛОК
От грамматики к лексике: изучение лексического синтаксиса без учителя
- М. Брент
Лингвистика
Вычисл. Лингвистика
- 1993
В этой статье описывается подход, основанный на двух принципах: полагаться на локальные морфосинтаксические сигналы для структурирования, а не пытаться анализировать целые предложения, и рассматривать эти сигналы как вероятностные, а не абсолютные индикаторы синтаксической структуры.
Обнаружение морфемных суффиксов Практический пример в индукции MDL
- M. Brent, Sreerama K. Murthy, A. Lundberg
Лингвистика
- 1995
Предметом исследования в этой статье является открытие морфемных суксов, таких как английский {ing и {ly метод широко применим к проблемам изучения языка.
От фонемы к морфеме
- З. Харрис
Языкознание
- 1955
 Харрис
ХаррисКонструктивная процедура, сегментирующая высказывание таким образом, чтобы он соответствовал определенным границам слова и морфемы высказывание за раз.
Автоматическая индукция грамматики и синтаксический анализ произвольного текста: подход, основанный на преобразовании
- Э. Брилл
Информатика
ACL
- 1993 5 бинарно-ветвящиеся синтаксические деревья с непомеченными нетерминалами, а для уменьшения ошибки можно применить набор простых структурных преобразований.
- C. D. Marcken
Информатика
ArXiv
- 1995
- A. Ross
Лингвистика
Nature
- 1953
Когнитивная наука
- 1990
Неконтролируемое приобретение лексики из непрерывной речи
Мы представляем алгоритм обучения без учителя, который извлекает словарь естественного языка из необработанной речи. Алгоритм основан на оптимальном кодировании последовательностей символов в рамках MDL, и…
Структурная лингвистика
 Ross
RossМетоды в конструкции L -Zerlingby S. . Стр. xv + 384. (Чикаго: University of Chicago Press; Лондон: Cambridge University Press, 19).51.) 56с. 6д. сеть.
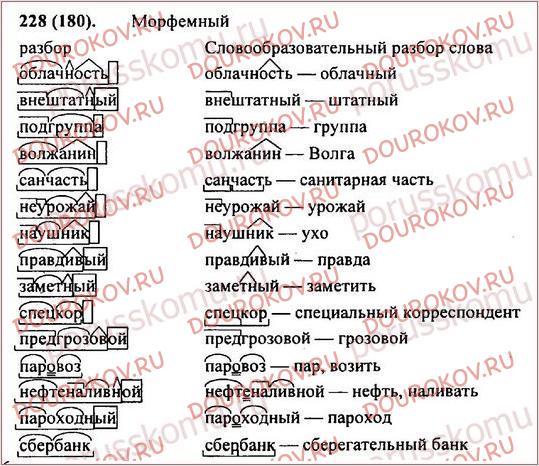
Нахождение нахождения во времени
Морфологический паран для инфлекционных языков с использованием глубокого обучения (Часть I)
Willem Van Peursen, Martijn Naaijer, Constantijn Sikkel, Mathias. «Как мы можем создать парсер на основе машинного обучения (ML) для морфологии флективных языков?» Этот вопрос стал отправной точкой для проекта «Морфологический анализатор флективных языков с использованием глубокого обучения» ETCBC и Центра электронных наук Нидерландов.
Отчасти этот проект преследовал практическую цель: создание базы данных ETCBC еврейской Библии со всеми ее уровнями лингвистического анализа, начатое в 1970-х годах, заняло около четырех десятилетий. С нашим намерением расширить наши возможности на другие корпуса, такие как Пешитта и даже более обширные части огромного количества сирийской литературы, нам необходимо ускорить процесс лингвистического кодирования текстов.
С нашим намерением расширить наши возможности на другие корпуса, такие как Пешитта и даже более обширные части огромного количества сирийской литературы, нам необходимо ускорить процесс лингвистического кодирования текстов.
Однако самой интересной частью этого проекта была не его практическая применимость для ускорения процесса кодирования. Скорее, мы хотели внести свой вклад в поиск ответов на основные вопросы, такие как: как можно сделать метод лингвистического кодирования, разработанный в ETCBC, полезным для других языков, которые также имеют богатую морфологию? Какой вклад наша работа может внести в обширную область корпусной лингвистики, в которой в значительной степени преобладает изучение английского языка с относительно плохой морфологией?
Из-за преобладания английского языка лингвистические корпуса обычно анализируются на уровне слов. Например, в английском предложении «он сказал» первое слово аннотировано как местоимение 3 rd лица мужского рода единственного числа, а второе слово — как простое прошедшее время слова «говорить». Это прекрасно работает для таких языков, как английский. Однако для языков с богатой морфологией, называемых «флективными» (например, семитские языки, санскрит) и «агглютинативными» (например, турецкий), полезно брать в качестве основных единиц морфемы, а не слова. Сравните еврейское слово וַיַּמְלִכֵהוּ (2 Царств 2:9).). На иврите это всего одно графическое слово (то есть последовательность букв между пробелами), но оно соответствует пяти словам в английском переводе: «и поставили его царем».
Это прекрасно работает для таких языков, как английский. Однако для языков с богатой морфологией, называемых «флективными» (например, семитские языки, санскрит) и «агглютинативными» (например, турецкий), полезно брать в качестве основных единиц морфемы, а не слова. Сравните еврейское слово וַיַּמְלִכֵהוּ (2 Царств 2:9).). На иврите это всего одно графическое слово (то есть последовательность букв между пробелами), но оно соответствует пяти словам в английском переводе: «и поставили его царем».
По этой причине ETCBC разработала систему кодирования, в которой кодируются не слова, а отдельные морфемы. Кроме того, существует важное различие между агглютинативными и флективными языками. Оба вида языков имеют богатую морфологию, но в агглютинативном языке, таком как турецкий, все морфемы связаны. Отсюда и слово
anlamıyorum ‘Я не понимаю’
состоит из глагольной основы anla-, отрицательного суффикса –m(ı), индикатора длительного времени первого лица настоящего времени –(i)yor и маркера первого лица –( у) м. [2]
[2]
Во флективных языках, однако, наблюдается слияние морфем, что требует маркировки не только морфем, но и связи между парадигматической формой каждой морфемы и ее реализацией. Именно это и делается при морфологическом кодировании ETCBC. Приведем один пример: еврейское слово וַיֹּ֥ולֶד «и он родил» (Быт. 5:3) показывает слияние префикса несовершенного, префикса каузативной основы и первого корня глагольной лексемы. Более того, с правильными глаголами парадигматически ожидаемая буква, следующая за флективным префиксом, является первым радикалом корня (например, Mem в וַיַּמְלִ֥יכוּ в Судей 9:6), но в этом глаголе мы находим не йод, а вав перед вторым корнем. В морфологической кодировке ETCBC это становится
W:n-!J!](H](J&WLD[
В этой кодировке комбинация ](H] указывает, что это форма каузативной основы, даже если это не просматривается в консонантном каркасе этой формы (в отличие от префикса в перфекте хифил) и сочетания (J&W указывает на то, что здесь вместо парадигматически ожидаемой буквы йод присутствует вав, которая не реализуется в поверхностной форме (а явление, типичное для класса глаголов пе-йод). За вариацией между парадигматическими формами и реализованными формами могут стоять всевозможные механизмы, такие как фонетические правила или исторические изменения. В обсуждаемом примере можно даже утверждают, что с исторической точки зрения вау парадигматически ожидается, потому что в иврите этот глагол пе-йод происходит от глагола пе-вау (ср. арабский валада ).
За вариацией между парадигматическими формами и реализованными формами могут стоять всевозможные механизмы, такие как фонетические правила или исторические изменения. В обсуждаемом примере можно даже утверждают, что с исторической точки зрения вау парадигматически ожидается, потому что в иврите этот глагол пе-йод происходит от глагола пе-вау (ср. арабский валада ).
Соответственно, морфологическая кодировка ETCBC дает много лингвистической информации. Он включает в себя все функции слова, а также полный словарь, поскольку связывает реализацию слова или морфемы с его парадигматической формой. За последние десятилетия многие исследования в ETCBC были сосредоточены на выводах, которые это кодирование дало для лексикографии и грамматики, например, в отношении лексемного статуса суффиксов, трактовки слов мужского и женского рода в словарях, трактовки чисел и глагольных основ. и так далее. Это относится к следующему вопросу: почему в большинстве словарей иврита и сирийского языка есть записи для слов (однобуквенных предлогов или союзов), которые стоят перед последующим словом, но не для слов (местоименных суффиксов), которые присоединяются к предыдущему слову. ? Почему слова женского рода (например, королева или львица) иногда включаются в статью своего аналога мужского рода, тогда как в тех же словарях они получают свою собственную статью в других случаях? Должны ли так называемые шафельские формы рассматриваться как четырехкоренные глаголы, подлежащие перечислению под шином, или, скорее, под трехкоренным корнем, от которого они происходят? Почему десятки (например, «сорок») иногда указываются в словарных статьях их основных (например, «четыре»), тогда как в противном случае они получают свою собственную статью?
? Почему слова женского рода (например, королева или львица) иногда включаются в статью своего аналога мужского рода, тогда как в тех же словарях они получают свою собственную статью в других случаях? Должны ли так называемые шафельские формы рассматриваться как четырехкоренные глаголы, подлежащие перечислению под шином, или, скорее, под трехкоренным корнем, от которого они происходят? Почему десятки (например, «сорок») иногда указываются в словарных статьях их основных (например, «четыре»), тогда как в противном случае они получают свою собственную статью?
В этом посте мы не будем подробно объяснять роль восклицательных знаков, дефисов, квадратных скобок и косых черт, которые используются в приведенном выше примере кодирования. (Подробности см. в «Кратком описании морфологического кодирования» Константина Сиккеля). Однако важно отметить, что различные элементы слов (например, префикс жен. 3 rd синг. несовершенный) маркируются в соответствии с определенными соглашениями и что благодаря этому кодированию грамматические функции слова могут рассчитываться по правилам.