“Листья” фонетический разбор | Грамота
Государственные экзамены – экзамены, которые необходимо сдать каждому. В процессе подготовки к ЕГЭ многие забывают про такую важную тему, как фонетический разбор.
Целиком данная тема не встречается в единых государственных экзаменах, но встречаются части данного анализа. Сделаем звуко-буквенный анализ слова “листья” и подробно разберём каждый этап.
Фонетический разбор
Как правило, в начале нужно определить сколько букв и звуков в слове “листья”:
- Слово “листья” – двусложное: лис/тья.
- Данное слово состоит из 6 букв (из них 2 гласных, 3 согласных и мягкий знак), 6 звуков.
- Положение ударения: ли́стья.
- Возможный переносы: лис-тья, ли-стья.
Транскрипция слова
Транскрипция слова “листья” выглядит следующим образом: [л’ист’й’а].
Звуко-буквенный разбор
- л-[л’] — согласный, звонкий без пары, мягкий (имеет пару)
- и́-[и́] — гласный, под ударением
- с-[с] — согласный, глухой с парой, твёрдый парный
- т-[т’] — согласный, глухой (имеет пару), мягкий с парой
- – ь — не представляет из себя звука
- я-[й’] — согласный, звонкий без пары, мягкий (нет пары)
- -[а] — гласный, без ударения
Проверь себя: “Флаг” фонетический разбор слова
Гласные: По правилам русского языка, стоящая после мягкого знака буква “я” образует двойной йотированный звук [й’а].
Согласные: Буква “л” стоит перед смягчающей буквой “и”, поэтому обозначает единицу речи [л’]. Мягкий знак сам по себе не образует звука, но смягчает перед ним стоящую единицу письма “т”.
Раздел: ФонетикаВсе же или всеже как правильно?
Правильно Все же – единственно правильный вариант написания словосочетания в русском языке, пишется отдельно. Состоит из слов принадлежащих к разным частям речи. «Все» -это местоимение, «же» – частица. Согласно правилам русского языка частица «же» с местоимениями пишется отдельно. Коля вышел из дома рано, но все же опоздал. Дождей было мало,… Читать дальше »
Состоит из слов принадлежащих к разным частям речи. «Все» -это местоимение, «же» – частица. Согласно правилам русского языка частица «же» с местоимениями пишется отдельно. Коля вышел из дома рано, но все же опоздал. Дождей было мало,… Читать дальше »
Фонетический разбор слова — презентация онлайн
Звукобуквенныйразбор
На старой яблоне висит
один плот.
Машенька легла на
бачок и сладко уснула.
На старой яблоне висит
один плод.
плот.
бачок
Машенька легла на бочок
и сладко уснула.
В русском языке 33 буквы.
А О У Э Ы
Я Ё Ю Е И
Й
В русском языке 6 гласных звуков.
Если буквы Е, Ё, Ю, Я стоят в начале слова или
после другой гласной, они обозначают по два
звука: [й’э], [й’о], [й’у], [й’а].
Если буквы Е, Ё, Ю, Я стоят после согласной, то
чаще всего согласный звучит мягко, а после
него мы слышим гласные [э], [о], [у], [а].
Ж
Ш
Ъ
Ц Ч Щ Ь
В русском языке 33 буквы.
А О У Э Ы
Я Ё Ю Е И
Й
Ж
Ш
В русском языке 6 гласных звуков.
Многие согласные буквы могут обозначать по два звука –
твёрдый или мягкий.
Ъ
Ц Ч Щ Ь
В русском языке 33 буквы.
А О У Э Ы
Я Ё Ю Е И
Й
Ж
Ш
В русском языке 6 гласных звуков.
Многие согласные буквы могут обозначать по два звука –
Ъ
Ц Ч Щ Ь
Будем учиться выполнять
Фонетика
– это раздел
науки
звуко-буквенный
разбор
слов
На
старой
яблоне
висит
о
языке,
в
котором
изучаются
(фонетический).
один
плод.
звуки
речи.
Слово «фонетика» происходит от
древнегреческого слова
Разберём,
чем отличается
Машенька
легла на
«φωνητικός», то есть «звуковой»,
орфографическая
запись
бочок и Исладко
«голосовой».

от словауснула.
«φωνή» –
слова от фонетической.
«голос», «звук».
Орфографическая запись
д
д – плоды
плод
о
о – бок
бочок
ед. ч.
мн. ч.
Фонетическая запись
плот
[плот]
’
[бач’ок]
На старой яблоне висит
один плод.
Машенька легла на бочок
и сладко уснула.
Звуко-буквенный (фонетический) разбор слов
1. Произносим слово.
2. Произносим слово по слогам и определяем количество слогов.
3. Находим ударный слог.
4. Называем звуки по порядку и каждому из них даём характеристику.
Звуки
Гласные
Ударные
Безударные
Согласные
Звонкие
Парные
Непарные
Твёрдые
Глухие
Мягкие
Звуко-буквенный (фонетический) разбор слов
1. Произносим слово.
2. Произносим слово по слогам и определяем количество слогов.
3. Находим ударный слог.
4. Называем звуки по порядку и каждому из них даём характеристику.
Звуки
Гласные
Ударные
Безударные
Согласные
Звонкие
Парные
Непарные
Твёрдые
5. Определяем количество букв и количество звуков в слове.
Глухие
Мягкие
плот
Плод [плот]
п л о т – 1 слог.
[п] – согласный, глухой парный,
твёрдый парный,
обозначается буквой «п».
[л] – согласный, звонкий непарный,
обозначается буквой «л».
[о] – гласный, ударный,
обозначается буквой «о».
[т] – согласный, глухой парный,
твёрдый парный,
обозначается буквой «д».
4 буквы, 4 звука
[П] – [П’]
б а ч’о к – 2 слога.
Бо чок [бач’ок]
Бочок
[б] – согласный, звонкий парный,
твёрдый парный,
обозначается буквой «б».
[а] – гласный, безударный,
обозначается буквой «о».
[ч’] – согласный, глухой непарный,
мягкий непарный,
обозначается буквой «ч».
[о] – гласный, ударный,
обозначается буквой «о».
[к] – согласный, глухой парный,
твёрдый парный,
обозначается буквой «к».

5 звуков, 5 букв
[Б] – [Б’]
Зной — фонетический (звуко-буквенный) разбор слова
Многие родители считают, что фонетический разбор слов – ненужное, пустое занятие, перегружающее детей лишней информацией. Чтобы это мнение изменилось, надо понять, зачем такой разбор нужен.
В русском языке звучание и написание слов часто не совпадают. Этим вызваны трудности с орфографией у многих детей. Именно знание законов фонетики позволяет правильно оценить позицию звука в слове и выбрать правильный вариант написания. Ребенок знает, что происходит со звуком в слабой позиции (оглушение, смягчение и другие процессы), и не допустит ошибку, правильно проверив слово или применив знание других законов фонетики.
Фонетическая транскрипция
Зной — [зной’]
Слово состоит из одного слога, ударение падает на гласный «О»
Характеристики
На данном этапе ребенок должен дать полную характеристику звукам, из которых состоит слово. Важно, чтобы не путались характеристики звуков и букв:
з — [з] – согласный, звонкий, твердый
н — [н] – согласный, звонкий, твердый
о — [о]- гласный, ударный
й — [й’] – согласный, звонкий, мягкий
В слове 4 буквы и 4 звука
Обратите внимание ребенка, что прилагательные, обозначающие характеристики звуков, стоят в мужском роде: «согласный, звонкий, твердый». Частой ошибкой детей бывает употребление этих слов в женском роде, потому что дети сбиваются со звуков на буквы. «Буква» — слово женского рода, потому ребенку и хочется написать или сказать у доски: «согласная, звонкая, мягкая».
Речь именно о звуке, а слово «ЗВУК» мужского рода. Поэтому и определения при слове «звук» должны стоять в мужском роде.
Гласные
Ученик должен охарактеризовать каждый гласный звук в слове, обращая внимание на особенности позиции звука:
В слове «ЗНОЙ» один гласный звук «О». Он стоит в сильной позиции, потому что является ударным. А ударение для любого гласного звука – это сильная позиция, в которой этот звук не требует проверки.
Количество звуков совпадает с количеством букв.
Согласные
Для согласных звуков русского языка основными характеристиками являются следующие:
- Звонкость – глухость
- Мягкость – твердость
В слове «ЗНОЙ» три согласных звука. Все согласные в этом слове звонкие, звуки «З» и «Н» твердые, а «Й» — мягкий
Примеры разбора
Ученик должен уметь оформить фонетический разбор слова письменно или дать устный ответ.
Устный разбор
Слово «ЗНОЙ» состоит из одного слога, в котором под ударением стоит гласный звук «О». В слове «ЗНОЙ» три согласных звука:
- Звук «з» — звонкий и твердый
- Звук «н» — звонкий и твердый
- Звук «й» — звонкий и мягкий
В разбираемом слове 4 буквы и 4 звука
Идеальным вариантом будет формулировка по образцу: «Буква «З» обозначает звук «з», который является согласным, звонким и твердым».
Важно помнить, что название букв произносится в алфавитном (азбучном) варианте — [зэ], а звук произносится так, как он слышится в слове — [з].
Письменный разбор слова
Зной – 1 слог
з — [з] – согласный, звонкий, твердый
н — [н] – согласный, звонкий, твердый
о — [о] – гласный, ударный
й — [й’] – согласный, звонкий, мягкий
В слове 4 буквы и 4 звука
Предыдущий разбор: ВЕ́К — [в’эк]
Как выполнять звуко-буквенный разбор слова
Изучение русского языка в школе предполагает у ребенка формирование навыков звуко-буквенного разбора слов. Не секрет, что буква обозначает звук на письме, и далеко не всегда слова пишутся так, как мы их произносим. Число букв и звуков могут не совпадать.
При этом многие школьники и родители искренне не понимают, зачем вообще нужно изучать фонетику, ведь это наш родной язык, мы умеем на нем разговаривать, написание слов можно просто запомнить. То есть если изучение орфографии, морфологии и синтаксиса вообще не вызывает сомнений и нареканий, то фонетика многими воспринимается как некая пустая трата времени.
Как выполняется разбор
Фонетический разбор слова начинается с его написания. Далее нужно произнести слово и попытаться услышать, как именно оно произносится, словно разложить по звукам. Например, мы пишем слово «солнце», но произносим его совершенно иначе, ведь буква «л» не образует звука вообще, а на конце слова слышится звук «э».
Нужно записать все буквы слова в столбик, а затем напротив каждой буквы указать в квадратных скобках тот звук, который образуется при устной речи.
Когда записаны все звуки, напротив них записываются их характеристики:
- гласный или согласный;
- если гласный, то ударный или безударный;
- если согласный, то парный или непарный, звонкий или глухой, твердый или мягкий;
- обозначаются шипящие звуки.
Все звуки их нюансы их произношения формируют транскрипцию — символическая запись того, как произносится слово. Транскрипция записывается напротив слова полностью, указывается количество слогов, букв и звуков в слове.
Как вы видите, чтобы разобраться с фонетическим разбором, нужно уметь правильно произносить слова и чувствовать нюансы произношения, а также разобраться в характеристиках различных звуков русского языка. Иногда это бывает сложно для ребенка, например, буква «я» может давать сразу два звука «й» и «а». Если возникают сложности, воспользуйтесь специальным сервисом для разбора, это поможет отточить самостоятельные навыки.
«Выход» фонетический звуко-буквенный разбор слова
Фонетическим анализом слова “выход” называют определение характеристики звуковых и письменных единиц.
Помимо этого, он включает в себя методы транскрипции, постановку ударения (согласно правилам орфоэпии), сравнение буквенного и звукового анализа, дробление на слоги, возможные варианты переноса слова через строку.
Во избежание ошибок следует придерживаться плана, которые прослеживает логическую связь между пунктами разбора. В качестве примера проделаем фонетический разбор языковой единицы “выход”.
Фонетический разбор
- Начнём с самой сложной задачи в этом этапе разбора слова “выход” определим звуковой и буквенный состав по количеству: 5 букв (2 гласных, 3 согласных), 5 звуков.
- Далее проанализируем место ударения: вЫход. Ударность акцентирует первом слоге.
- Всего в слове “выход” два слога по количеству слогообразующих гласных. Произведём дробление на слоги: вы/ход.
- Способы переноса через строку соответствуют слоговому делению.
Транскрипция слова
Многие считают этот этап разбора самым сложным, потому что он имеет больше всего нюансов, на которые в дальнейшем делает упор звуко-буквенный анализ.
Повторим анализируемое слово несколько раз вслух, после запишем все звуки в квадратных скобках: [выхат].
Звуко-буквенный разбор
- в — [в] — принято считать согласным, здесь представлен в звонкой твёрдой форме
- ы — [ы] — имеет признаки гласного, ударность делает акцент
- х — [х] — принято считать согласным, здесь представлен в глухой твёрдой форме
- о — [а] — имеет признаки гласного, ударность не делает акцент
- д — [т] — принято считать согласным, здесь представлен в глухой твёрдой форме
Проверь себя: “Столб” фонетический разбор слова
Если на букве “о” не присутствует ударение, то она обозначает звук [а].
Так как буква “д” стоит в конце, то она оглушается до звука [т].
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «пословица», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ПОСЛОВИЦА, ы, ж. Краткое народное изречение с назидательным содержанием, народный афоризм. Русские пословицы и поговорки. П. не мимо молвится
• Войти в пословицу 1) стать общеизвестным благодаря своей характерности. Упрямство осла вошло в пословицу; 2) о чьих-н. словах, речениях: войти в общее употребление. Многие строки басен И. А. Крылова вошли в пословицу.
| прил. пословичный, ая, ое. Пословичное выражение.
Фонетический (звуко-буквенный) разбор
по́словица
пословица — слово из 4 слогов: по-сло-ви-ца. Ударение падает на 1-й слог.
Транскрипция слова: [послав’ица]
п — [п] — согласный, глухой парный, твёрдый (парный)
о — [о] — гласный, ударный
с — [с] — согласный, глухой парный, твёрдый (парный)
л — [л] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
в — [в’] — согласный, звонкий парный, мягкий (парный)
и — [и] — гласный, безударный
ц — [ц] — согласный, глухой непарный, твёрдый (непарный, всегда произноится твёрдо)
а — [а] — гласный, безударный
В слове 9 букв и 9 звуков.
Цветовая схема: пословица
Разбор слова «пословица» по составу
пословица
Части слова «пословица»: пословиц/а
Состав слова:
пословиц — корень,
а — окончание,
пословиц — основа слова.
Онлайн тест по Русскому языку по теме Морфемика
Морфемой во всех языках называют минимальную единицу, несущую смысловую нагрузку. То есть это не символ, а их совокупность, из которой далее могут образовываться похожие по смыслу слова. Часто морфема выступает в слове корнем, поскольку, как мы уже и сказали, новое слово было образовано из простейшей частицы. Раздел языкознания, который занимается изучением этих единиц называется Морфемикой.
То есть это не символ, а их совокупность, из которой далее могут образовываться похожие по смыслу слова. Часто морфема выступает в слове корнем, поскольку, как мы уже и сказали, новое слово было образовано из простейшей частицы. Раздел языкознания, который занимается изучением этих единиц называется Морфемикой.
Именно о нем и пойдет речь в этом тесте на нашем сайте. Вам придется дать базовые определения термину и ответить на остальные теоретические вопросы, связанные с этой областью русского языка. Существуют разные приемы, использующиеся для разбора слов, а вам нужно будет вспомнить, какой из них применяется чаще всего в определенных ситуациях, поняв суть поставленного вопроса.
Морфемику начинают изучать в 6 классе средней школы на уроках русского языка, где сначала проходят азы этого раздела, а затем углубляются в более детальное освоение, производят различные разборы слов и их анализы. В следующих классах тоже приходится сталкиваться с этой областью, ведь без морфемы не обходится практически ни одно слово. Вам предстоит вспомнить параграфы из учебников, посвященные морфемики, чтобы правильно ответить на все пять вопросов.
Раздел морфемики огромен, а его изучением занимаются многие языковеды, поэтому мы не стали брать сложные вопросы, не касающиеся школьной программы, а остановились только на базовых правилах и понятиях русского языка. Поэтому наш тест отлично подойдет ученикам и тем, кто только окончил школу для того, чтобы проверить свои знания после изучения этого раздела или вспомнить уже давно пройденный материал, отталкиваясь от наших замечаний и описаний для успешных ответов на все вопросы.
Пройти тест онлайн
Может быть интересно
Ещё никто не оставил комментария, вы будете первым.
Написать комментарий
Спасибо за комментарий, он будет опубликован после проверки
Разбор транскрипций IPA
Телефоны — это основная единица транскрипции IPA. Они состоят из гласной или согласной (или базовый глиф ) вместе с дополнительными диакритическими знаками. Диакритические знаки бывают следующих видов: приставка
(например, преназализация), комбинирование (например, деформация), длина, суффикс (например, стремление) и
тон. В следующих разделах описывается каждая часть отдельного телефона.
Они состоят из гласной или согласной (или базовый глиф ) вместе с дополнительными диакритическими знаками. Диакритические знаки бывают следующих видов: приставка
(например, преназализация), комбинирование (например, деформация), длина, суффикс (например, стремление) и
тон. В следующих разделах описывается каждая часть отдельного телефона.
Префикс диакритический
Префиксный диакритический знак должен стоять перед основным глифом.Телефон может иметь несколько префиксов диакритические знаки.
Базовый символ
Базовый глиф может быть любой гласной или согласной IPA.
Сочетание диакритических знаков
Комбинированные диакритические знаки должны стоять сразу после основного глифа; любое количество может использоваться сочетание диакритических знаков. Комбинирование диакритических знаков также может быть добавлено к диакритические знаки префикса и суффикса.Примечание. Некоторые варианты сочетания диакритических знаков могут вызывать проблемы с рендерингом в зависимости от выбранного шрифта IPA.
Длина
Длина телефона указывается с помощью символа 0x02D0 (длинный) и 0x02D1 (полудлинный). диакритические знаки должны стоять после телефона, которому они принадлежат.
Суффикс диакритический
Диакритический суффикс должен стоять после основного глифа.Телефон может иметь несколько суффиксов диакритические знаки.
Номер тона
Номер тона указывается с помощью надстрочных цифр и должен отображаться как
последний элемент в телефоне. Номер тона применяется ко всем элементам внутри
слоговая единица и может встречаться в любом элементе слога. (Если тон
числовые диакритические знаки появляются более чем на одном элементе, числа объединены.)
Номер тона применяется ко всем элементам внутри
слоговая единица и может встречаться в любом элементе слога. (Если тон
числовые диакритические знаки появляются более чем на одном элементе, числа объединены.)
b²a¹⁴ имеет номер тона ‘214’
% PDF-1.4 % 1 0 obj > / ProcSet [/ PDF / Text] >> / FormType 1 / Тип / XObject / BBox [0 0 595,28 841,89] >> транслировать xM 0E, 3`ә4I.`p.F) j * m + Qp3; {KYF (, Zbdi҆B \ 1wa {NyG7fH! S * QJ% 4 ݴ 4 o_p ys} CYv6 IU ַ @ WgcHsLī `@xAxC ֿ z> K.y» pAE конечный поток эндобдж 4 0 obj > / ProcSet [/ PDF / Text] >> / FormType 1 / Тип / XObject / BBox [0 0 595,28 841,89] >> транслировать xM 0E, 3’4I.pW} ݄ n0QP! T_a_ | K% S $ 6AG конечный поток эндобдж 6 0 obj > / ProcSet [/ PDF / Text] >> / FormType 1 / Тип / XObject / BBox [0 0 595,28 841,89] >> транслировать xM 0E, 3`ә4I.`p.F) j * m + Qp3; {KYF (, Zbdi҆B \ 1wa {N L «i> dJ% «R2KnR # o /` (nFA «8P 㲪 CH} iNIxw> U_7ho; (} WW’RG g% oA? конечный поток эндобдж 7 0 объект > / ProcSet [/ PDF / Text] >> / FormType 1 / Тип / XObject / BBox [0 0 595,28 841,89] >> транслировать xM 0E, 3`ә4I.`p.F) j * m + Qp3; {KYF (, Zbdi҆B \ 1wa {NL «i> dJ% «R2KnR # o /` (nFA «8P 㲪 CH} iNIxw> U_7ho; (} WW’RG g% oA @ конечный поток эндобдж 8 0 объект > / ProcSet [/ PDF / Text] >> / FormType 1 / Тип / XObject / BBox [0 0 595.? OϒK AC конечный поток эндобдж 3 0 obj > эндобдж 2 0 obj > эндобдж 12 0 obj [333 333 500 675 250 333250 278 500 500 500 500 500 500 500 500 500 500 333 333 675 675 675 500 920 611 611 667 722 611 611 722 722 333 444 667 556833 667 722 611 722 611 500 556722 611 833 611 556 556 389 278 389 422 500 333 500 500 444 500 444 278 500 500 278 278 444 278 722 500 500 500 500 389 389 278] эндобдж 11 0 объект > эндобдж 13 0 объект > эндобдж 15 0 obj [500 500 500 500 500 500 500 500 500 500] эндобдж 14 0 объект > эндобдж 16 0 объект > транслировать x ڭ uUT ܒ upw! [@ kwww,; wg ^ fCSԮi) UY & @ i] 5qrT * YԀNrc + ƃLK +
Статистический анализ корпуса орфографических и фонематических языков для моделирования польского языка на основе слов и фонем | Журнал EURASIP по обработке звука, речи и музыки
Л. Рабинер, Б. Хуанг, Основы распознавания речи.Обработка сигналов Prentice Hall серии (PTR Prentice Hall, США, 1993).
Рабинер, Б. Хуанг, Основы распознавания речи.Обработка сигналов Prentice Hall серии (PTR Prentice Hall, США, 1993).
Google Scholar
JR Bellegarda, C Monz, Современные статистические методы обработки речи и языка. Comput. Speech Lang. 35: , 163–184 (2016).
Артикул Google Scholar
Л. Рабинер, Б. Хуанг, Энциклопедия языка и лингвистики, Статистические методы распознавания и понимания речи (Elsevier, Амстердам, 2005).
Google Scholar
С. Сакти, К. Марков, С. Накамура, В. Минкер, в Включение источников знаний в статистическое распознавание речи, том 42 конспектов лекций по электротехнике . Статистическое распознавание речи (Springer USUSA, 2009), стр. 19–53.
Google Scholar
Дж. Беллегарда, Распознавание речи с большим словарным запасом с использованием многоязыковых статистических языковых моделей.IEEE Transa. Речевой аудиопроцесс. 8: , 76–84 (2000).
Артикул Google Scholar
P Kłosowski, в Computer Nerworks vol 79 Коммуникаций в компьютерных и информационных науках , изд. Авторы: A Kwiecien, P Gaj и P Stera. Приложение для обработки речи на основе фонетики и фонологии польского языка. 17-я Международная конференция Компьютерные сети, Устронь, Польша, 15-19 июня (Springer-VerlagBerlin, 2010), стр.236–244.
Google Scholar
Клосовский П., Улучшение обработки речи на основе фонетики и фонологии польского языка. Przegląd Elektrotechniczny. 89: , 303–307 (2013).
Google Scholar
J Izydorczyk, P Kłosowski, Акустические свойства польских гласных. Бык. Pol. Акад. Sci. Tech. Sci. 47 (1), 29–37 (1999).
Sci. Tech. Sci. 47 (1), 29–37 (1999).
Google Scholar
J Izydorczyk, P Kłosowski, в Международная конференция Программируемые устройства и системы PDS2001 Семинар IFAC, Гливице 22–23 ноября .Основные акустические свойства польской речи (IFACGliwice, 2001), стр. 61–66.
Google Scholar
P Kłosowski, A Dustor, J Izydorczyk, J Kotas, Slimok J, в Computer Networks, CN 2014. vol 431 of Communications in Computer and Information Science , ed. Авторы: A Kwiecien, P Gaj и P Stera. Распознавание речи на основе программного обеспечения для обработки речи с открытым исходным кодом. 21-я Международная научная конференция по компьютерным сетям (CN), Брунов, Польша, 23-27 июня (Springer-VerlagBerlin, 2014), стр.308–317.
Google Scholar
A Dustor, Kłosowski P, в Computer Networks, CN 2013. vol 370 of Communications in Computer and Information Science , ed. Авторы: A Kwiecien, P Gaj и Stera P. Биометрическая идентификация голоса на основе нечеткого классификатора ядра. 20-я Международная конференция по компьютерным сетям (CN), Львовек-Слёнски, Польша, 17-21 июня (Springer-VerlagBerlin, 2013), стр. 456–465.
Google Scholar
A Dustor, P Kłosowski, J Izydorczyk, в Международная конференция по мультимедийным вычислениям и системам 2014 г. (ICMCS) .Система распознавания дикторов с хорошими обобщающими свойствами. Международная конференция по мультимедийным вычислениям и системам (ICMCS), Марракеш, Марокко, 14–16 апреля (IEEEUSA, 2014), стр. 206–210.
Google Scholar
A Dustor, P Kłosowski, J Izydorczyk, в Computer Networks, CN 2014. vol 431 of, Communications in Computer and Information Science , ed. Авторы: A Kwiecien, P Gaj и P Stera. Влияние размерности функции и сложности модели на производительность проверки докладчика.21-я Международная научная конференция по компьютерным сетям (CN), Брунов, Польша, 23–27 июня (Springer-VerlagBerlin, 2014), стр. 177–186.
Влияние размерности функции и сложности модели на производительность проверки докладчика.21-я Международная научная конференция по компьютерным сетям (CN), Брунов, Польша, 23–27 июня (Springer-VerlagBerlin, 2014), стр. 177–186.
Google Scholar
P Kłosowski, A Dustor, J Izydorczyk, в Computer Networks, CN 2015. vol 522 of Communications in Computer and Information Science , ed. пользователя P Gaj, A Kwiecien и P Stera. Оценка эффективности проверки выступающих на основе программного обеспечения для обработки речи с открытым исходным кодом и корпуса Timit Speech.22-я Международная конференция по компьютерным сетям (CN), Брунов, Польша, 16-19 июня (Springer-VerlagBerlin, 2015), стр. 400–409.
Google Scholar
A Dustor, P Kłosowski, J Izydorczyk, R Kopanski, в Computer Networks, CN 2015. vol 522 of Communications in Computer and Information Science , ed. пользователя P Gaj, A Kwiecien и P Stera. Влияние размера корпуса на проверку докладчика. 22-я Международная конференция по компьютерным сетям (CN), Брунов, Польша (Springer-VerlagBerlin, 2015), стр.242–249.
Google Scholar
P Kłosowski, Dustor A, в Computer Networks, CN 2013. vol 370 of Communications in Computer and Information Science , ed. Авторы: A Kwiecien, P Gaj и P Stera. Автоматическая сегментация речи для автоматического перевода речи. 20-я Международная конференция по компьютерным сетям (CN), Львовек-Слёнски, Польша, 17-21 июня (Springer-VerlagBerlin, 2013), стр. 466–475.
Google Scholar
Елинек Ф., Статистические методы распознавания речи.Язык, речь и общение: книга Брэдфорда (MIT Press, США, 1997).
Google Scholar
S Furui, Недавний прогресс в распознавании спонтанной речи на основе корпуса. IEICE Trans. Инф. Syst. E88D: , 366–375 (2005).
IEICE Trans. Инф. Syst. E88D: , 366–375 (2005).
Артикул Google Scholar
M Adda-Decker, Corpus для автоматического распознавания речи. Revue Francaise De Linguistique Appliquee. 12: , 71–84 (2007).
Google Scholar
A Przepiórkowski, M Bańko, RL Górski, B Lewandowska-Tomaszczyk, Национальный корпус польского языка (на польском языке: Narodowy Korpus Języka Polskiego) (Wydawnictwo Naukzowe Polskiego) (Wydawnictwo Naukzowe Polskiego)
Google Scholar
A Przepiórkowski, RL Górski, B Lewandowska-Tomaszczyk, aziński M, in Proceedings of the Sixth International Conference on Language Resources and Evaluation, LREC 2008 .К национальному корпусу польского языка (MarrakechELRA, 2008).
Google Scholar
RL Górski, B Lewandowska-Tomaszczyk, M Bańko, P Pęzik, M aziński, A. Przepiórkowski, Практические применения Национального корпуса польского языка. Prace Filologiczne. 63: , 231–240 (2012).
Google Scholar
Дж. Хиршберг, К. Д. Мэннинг, «Достижения в обработке естественного языка».Наука. 349: , 261–266 (2015).
MathSciNet Статья МАТЕМАТИКА Google Scholar
Международная фонетическая ассоциация, Справочник Международной фонетической ассоциации: руководство по использованию международного фонетического алфавита. Публикация Regents (Cambridge University Press, Великобритания, 1999).
Google Scholar
R Sussex, P Cubberley, Славянские языки.Cambridge Language Surveys (Издательство Кембриджского университета, Великобритания, 2006 г.).
Google Scholar
Дж. Уэллс, в «Справочнике стандартов и ресурсов для систем разговорного языка» . Том Часть IV, раздел B , изд. Д. Гиббона, Р. Мура и Р. Вински. Фонетический алфавит, читаемый компьютером SAMPA (Mouton de GruyterBerlin and New York, 1997).
Уэллс, в «Справочнике стандартов и ресурсов для систем разговорного языка» . Том Часть IV, раздел B , изд. Д. Гиббона, Р. Мура и Р. Вински. Фонетический алфавит, читаемый компьютером SAMPA (Mouton de GruyterBerlin and New York, 1997).
Google Scholar
М. Разави, Р. Расипурам, М. М. Досс, Преобразование графемы в фонемы на основе акустических данных в рамках вероятностного лексического моделирования.Речь общ. 80: , 1–21 (2016).
Артикул Google Scholar
Р. М. Каплан, М. Кей, Регулярные модели систем фонологических правил. Comput. Лингвист. 20: , 331–378 (1994).
Google Scholar
М. Штеффен-Батог, Проблема автоматической фонематической транскрипции письменного польского языка. Биулетин Фонографический. 14: , 75–86 (1973).
Google Scholar
M Steffen-Batóg, in Польский: Automatyzacja transkrypcji fonematycznej tekstów polskich . Автоматическая фонематическая транскрипция польских текстов (Wydawnictwo Naukowe PWNWarszawa, 1975).
Google Scholar
M Steffen-Batóg, Nowakowski P, в Studia Phonetica Posnaniensia. Vol. 3 , изд. М. Штеффен-Батог, В. Аведик.Алгоритм фонетической транскрипции орфографических текстов на польском языке (Wydawnictwo Naukowe UAMPoznań, 1993).
Google Scholar
W Jassem, Механизм определения фонематической транскрипции и деления слогов (Исследовательский коллоквиум Onomastica-Copernicus, Эдинбург, 1996).
Google Scholar
P Kłosowski, in Proceedings of 20 IEEE International Conference Signal Processing Algorithms, Architectures, Arrangements, and App. lations, 21-23 сентября . Алгоритм и реализация автоматической фонематической транскрипции для польского языка (Познанский технологический университет, Познань, 2016), стр. 298–303.
lations, 21-23 сентября . Алгоритм и реализация автоматической фонематической транскрипции для польского языка (Познанский технологический университет, Познань, 2016), стр. 298–303.
Google Scholar
М. Выпич, в Речевые и языковые технологии. Vol. 3 . Реализация алгоритма фоненной транскрипции (на польском языке: Implementacja algorytmu transkrypcji fonematycznej) (Polskie Towarzystwo FonetycznePoznań, 1999).
Google Scholar
Г. Деменко, М. Выпич, Е. Барановска, Реализация правил преобразования графемы в фонемы и расширенного алфавита SAMPA в синтезе текста речи на польском языке.Speech Lang. Technol. 7 (17) (2003).
P Przybysz, W. Kasprzak, в 2013 6-я Международная конференция по взаимодействию человеческих систем (HSI) , изд. по WA Paja, BM Wilamowski. Генерация правил преобразования букв в звук для преобразования графемы в фонемы. Конференция по взаимодействию человеческих систем. Gdansk Univ Technol; Унив информационных технологий и менеджмента; IEEE Ind Elect Soc (Гданьский технологический университет, Гданьск, 2013 г.), стр. 292–297.
Google Scholar
D Skurzok, B Ziółko, Ziółko M, в 7-я языковая и технологическая конференция, Познань .Ortfon2 — инструмент для орфографической и фонетической транскрипции (Университет Адама Мицкевича в Познани, Познань, 2015).
Google Scholar
D Koržinek, Ł Brocki, Marasek K, Польский инструмент и сервис преобразования графемы в фонемы, цифровой репозиторий CLARIN-PL (2016). http://hdl.handle.net/11321/295, (онлайн: 2016.08.01).
Викисловарь, Словарь польского языка (2015). https://pl.wiktionary.org/. По состоянию на 17 февраля 2017 г.
W Jassem, Podstawy fonetyki akustycznej (англ. «Зачатки акустической фонетики») (PWN, Warszawa, 1973).
«Зачатки акустической фонетики») (PWN, Warszawa, 1973).
P obacz, W Jassem, Fonotaktyczna analiza mówionego tekstu polskiego (англ. Фонотаксический анализ устных польских текстов). Biuletyn Polskiego Towarzystwa Ję. 32: , 179–195 (1974).
Google Scholar
C Basztura, Rozmawiac z komputerem (англ.Говорить с компьютерами) , (1992).
B Ziółko, J Gałka, S. Manandhar, RC Wilson, M Ziółko, в Human Language Technology: Challenges of the Information Society. Том 5603 конспектов лекций по искусственному интеллекту , изд. пользователя Z Vetulani, H Uszkoreit. Статистика по трифону для польского языка. 3-я конференция по языкам и технологиям 2007 г., Познань, Польша, 5–7 октября (2009 г.), стр. 63–73.
B Ziółko, J Gałka, M Ziółko, Польская статистика фонем, полученная на большом наборе письменных текстов.Comput. Sci. (AGH). 10: , 97–106 (2009).
Google Scholar
B Ziółko, Gałka J, in Computer Science and Information Technology (IMCSIT), Proceedings of the 2010 International Multiconference on . Статистика польских телефонов (AGH Univesity of Science and TechnologyKrakow, 2010), стр. 561–565.
Google Scholar
B Ziółko, P Zelasko, Skurzok D, in 2014 XXII Annual Pacific Voice Conference (PVC) .Статистика наличия дифонов и трифонов на границах слов в польском языке. Приложения к ASR. Ежегодная конференция Pacific Voice, AGH; Pacific Voice Speech Fdn, 2014. 22-я ежегодная конференция Pacific Voice (PVC) (KrakowAGH Univesity of Science and Technology, 2014).
Google Scholar
Д. Лайтфут, Развитие языка: приобретение, изменение и эволюция (Wiley-Blackwell, Hoboken, 1999).
Google Scholar
Д. Бибер, С. Конрад, Р. Репп. En, Corpus linguistics: Investigating language structure and use (Cambridge University Press, Cambridge, 1998).
Бибер, С. Конрад, Р. Репп. En, Corpus linguistics: Investigating language structure and use (Cambridge University Press, Cambridge, 1998).
Google Scholar
Р. Факкинетти, М. Риссанен, Основанные на корпусе исследования диахронического английского языка, т. 31 (Питер Ланг, 2006).
Г. К. Ципф, Человеческое поведение и принцип наименьших усилий.J. Clin. Psychol. 6 (3), 306–306 (1950).
Google Scholar
Y Tambovtsev, C. Martindale, Частоты фонем подчиняются распределению юлей. SKASE J. Theor. Лингвист. 4 (2) (2008).
ST Piantadosi, Закон частоты слов Ципфа в естественном языке: критический обзор и направления на будущее. Психонимический бык. Ред. 21: , 1112–1130 (2014).
Артикул Google Scholar
А. Коррал, Г. Боледа, Р. Феррер-и Канчо, Закон Ципфа для частотности слов: словоформы против лемм в длинных текстах.Plos ONE. 10 (7), e0129031 (2015). DOI: 10.1371 / journal.pone.0129031.
Артикул Google Scholar
GU Yule, Математическая теория эволюции, основанная на выводах доктора Дж. К. Уиллис, F.R.S. Фил. Пер. R. Soc. Лондон B Biol Sci. 213 (402-410), 21–87 (1925).
Артикул Google Scholar
S Dziadzio, A NaboŻny, A Smywiński-Pohl, B Ziółko, в Computer Science and Information Systems (FedCSIS) 2015 Federated Conference on .Сравнение языковых моделей, обученных письменным текстам и транскриптам речи в контексте автоматического распознавания речи (Лодзинский технологический университет, Лодзь, 2015), стр. 193–197.
Google Scholar
С. Такахаши, Т. Моримото, в Международная конференция по обработке азиатских языков, 2012 г. (IALP 2012), , изд. Авторы: D Xiong, E Castelli, M Dong и PTN Yen. Модель языка N-грамм, основанная на выражениях из нескольких слов в веб-документах для распознавания речи и скрытых субтитров (Университет Сучжоу, Китай, 2012 г.), стр.225–228.
(IALP 2012), , изд. Авторы: D Xiong, E Castelli, M Dong и PTN Yen. Модель языка N-грамм, основанная на выражениях из нескольких слов в веб-документах для распознавания речи и скрытых субтитров (Университет Сучжоу, Китай, 2012 г.), стр.225–228.
Google Scholar
А Хатами, А Акбари, Б. Насершариф, в 2013 21-я Иранская конференция по электротехнике (ICEE) . Адаптация N-грамм с использованием языковой модели класса Дирихле на основе части речи для распознавания речи (Университет Фирдоуси, Мешхед, Машхадм, 2013).
Google Scholar
M Bahrani, H Sameti, N Hafezi, S Momtazi, в New Frontiers в приложении.лгал искусственный интеллект, том 5027 конспектов лекций по искусственному интеллекту , изд. Н. Т. Нгуен, Л. Борземски, А. Гжех и М. Али. Новый метод кластеризации слов для построения языковых моделей n-грамм в системах распознавания слитной речи (SpringerBerlin, 2008), стр. 286–293.
Google Scholar
B Рапп, в Международная мультиконференция по компьютерным наукам и информационным технологиям, 2008 г. (IMCSIT), тома 1 и 2 , изд.М. Ганжа, М. Папжицкий и Т. Пелех-Пилиховский. N-граммы языковых моделей для польского языка. Основные концепции и приложения в системах автоматического распознавания речи (IEEE Computer Society PressLos Alamitos, 2008), стр. 295–298.
Google Scholar
Д. Клаков, П. Йохен, Проверка корреляции частоты ошибок по словам и недоумения. Речь общ. 38 (1–2), 19–28 (2002).
Артикул МАТЕМАТИКА Google Scholar
T Cover, J Thomas, Серия Wiley в области телекоммуникаций: элементы теории информации (John Wiley and Sons, США, 1991).
Google Scholar
П Ю, FTB Seide, в Interspeech . Гибридное приложение, основанное на словах и фонемах, для улучшенного независимого от словаря поиска в спонтанной речи (CiteseerJeju Island, 2004).
Гибридное приложение, основанное на словах и фонемах, для улучшенного независимого от словаря поиска в спонтанной речи (CiteseerJeju Island, 2004).
Google Scholar
V Chunwijitra, A. Chotimongkol, C. Wutiwiwatchai, Гибридная рекуррентная нейронная сеть входного типа для моделирования языка lvcsr. ЕВРАЗИП Дж.Аудио речевой музыкальный процесс. 2016 (1), 15 (2016).
Артикул Google Scholar
А. Язган, М. Сараклар, в Акустика, речь и обработка сигналов, 2004. Труды (ICASSP’04). Международная конференция IEEE по . Гибридные языковые модели для обнаружения слов вне словарного запаса при распознавании разговорной речи с большим словарным запасом. том 1 (IEEE, 2004), стр. I – 745.
М. Ларсон, Языковые модели на основе вложенных слов для распознавания речи: значение для речевого поиска документов.Whorkshop по языковому моделированию и поиску информации (2001).
A Czardybon, O Hellwig, W. Petersen, в книге «Достижения в области обработки естественного языка». том 8686 конспектов лекций по искусственному интеллекту , изд. Авторы: А. Пржепорковский, М. Огродничук. Статистический анализ взаимосвязи между порядком слов и определенностью в польском языке. Polish Acad Sci, Inst Comp Sci, 2014. 9-я Международная конференция по обработке естественного языка (NLP), Варшава, Польша, 17-19 сентября (Польская академия наук, Институт компьютерных технологий, Варшава, 2014), стр.144–150.
Google Scholar
P Mandera, E Keuleers, Z Wodniecka, M Brysbaert, Subtlex-pl: оценки частоты слов на основе субтитров для польского языка. Behav. Res. Методы. 47: , 471–483 (2015).
Артикул Google Scholar
Дж. Р. Беллегарда, Распознавание речи с большим словарным запасом с использованием многоязыковых статистических языковых моделей. IEEE Trans. Речевой аудиопроцесс. 8: , 76–84 (2000).
IEEE Trans. Речевой аудиопроцесс. 8: , 76–84 (2000).
Артикул Google Scholar
H Schwenk, Модели языка непрерывного пространства. Comput. Speech Lang. 21 (3), 492–518 (2007).
Артикул Google Scholar
МАБ Шайк, Э. Д. Амуза, Р. Шлютер, Х. Ней, в INTERSPEECH . Гибридные языковые модели с использованием смешанных типов сублексических единиц для открытого словарного запаса немецкого языка LVCSR (Международная ассоциация речевой коммуникации (ISCA) Baixas, 2011), стр.1441–1444.
Google Scholar
Преобразование графемы в фонемы для добавления фонематической транскрипции в словарные статьи и учебные пособия — тема исследовательской работы в области компьютерных и информационных наук. Скачайте научную статью в формате PDF и читайте ее бесплатно в открытом научном центре CyberLeninka.
Доступно на сайте www.sciencedirect.com
ScienceDirect
Процедуры — социальные и поведенческие науки 103 (2013) 473 — 484
13-я Международная конференция по образовательным технологиям
Улучшение учебных материалов турецкого языка: преобразование графемы в фонемы для добавления фонематической транскрипции в словарные статьи и учебники
Özgün KO§ANER * a, Cagdas Can BRANTb, Özlem AKTA§b
a Университет Докуз Эйлул, факультет писем, факультет лингвистики, Измир 35260, Турция _a Университет Докуз Эйлул, инженерный факультет, факультет компьютерной инженерии, Измир 35260, Турция_
Аннотация
В материалах курса для преподавания турецкого как второго языка отсутствует информация о произношении турецкого языка.В этих материалах есть главы об алфавите и произношении букв, но в них отсутствует обозначение фонематической транскрипции. Также в турецких словарях отсутствует информация о фонематической транскрипции из-за ложного мнения, что турецкий алфавит является фонематическим. Однако нет однозначного соответствия между буквами алфавита и фонемами турецкого языка. В этом отношении данное исследование направлено на разработку инструмента преобразования графемы в фонему / аллофон для турецкого языка. Выходные данные программного обеспечения могут быть использованы в материалах курса для обучения турецкому как второму языку, а также в турецких словарях для учащихся.
Также в турецких словарях отсутствует информация о фонематической транскрипции из-за ложного мнения, что турецкий алфавит является фонематическим. Однако нет однозначного соответствия между буквами алфавита и фонемами турецкого языка. В этом отношении данное исследование направлено на разработку инструмента преобразования графемы в фонему / аллофон для турецкого языка. Выходные данные программного обеспечения могут быть использованы в материалах курса для обучения турецкому как второму языку, а также в турецких словарях для учащихся.
© 2013 Авторы, опубликовано ElsevierLtd.
Отбор и экспертная оценка под ответственностью Ассоциации науки, образования и технологий-TASET, Sakarya Universitesi, Турция.
Ключевые слова: словарь; материалы курса; фонематическая транскрипция; преобразование графемы в фонемы
1. Введение
Турецкий язык стал очень популярным благодаря огромному потенциалу Турции как глобального игрока и ворот на новые развивающиеся рынки в Центральной Азии.Правительство США включило турецкий язык в список критически важных языков ЦРУ (CIA Values Language Capabilities Among Employees, 2009), а университеты США (Бостонский университет, Техасский университет A&M, Университет Питтсбурга и т. Д.) Начали новые программы по Турецкая история, культура и история или улучшили их существующие. Эти недавние события сделали турецкий язык многообещающим языком для будущего, и многие студенты со всего мира начали изучать турецкий как
* Корреспондент ozgunkosaner @ gmail.com
1877-0428 © 2013 Авторы. Опубликовано Elsevier Ltd.
Отбор и экспертная оценка под ответственностью Ассоциации науки, образования и технологий-ТАСЕТ, Сакарья
Universitesi, Турция.
DOI: 10.1016 / j.sbspro.2013.10.363
в своих странах, а также в государственных и частных учреждениях Турции. Чтобы удовлетворить потребность в изучении турецкого языка как иностранного, многие университеты Турции начали выпускные программы по преподаванию турецкого языка как иностранного (Университет Докуз Эйлул, Стамбульский университет, Университет Хаджеттепе, Университет Йылдыз Текник и т. Д.). Однако в учебных материалах, особенно в турецких словарях, отсутствует одна из самых важных сведений о языке — его произношение. В материалах курса турецкого есть главы об алфавите и произношении букв, но в них отсутствует запись в качестве фонематической транскрипции. Также в турецких словарях отсутствует информация о фонематической транскрипции из-за ложного убеждения, что турецкий алфавит является фонематическим. Однако нет однозначного соответствия между буквами алфавита и фонемами турецкого языка.В этом отношении данное исследование направлено на разработку инструмента преобразования графемы в фонему / аллофон для турецкого языка для решения проблемы, упомянутой выше. Выходные данные этого программного обеспечения будут напрямую доступны пользователю и понятны любому преподавателю языка, знакомому с фонетическими символами, используемыми в алфавите IPA (Международной фонетической ассоциации).
Чтобы удовлетворить потребность в изучении турецкого языка как иностранного, многие университеты Турции начали выпускные программы по преподаванию турецкого языка как иностранного (Университет Докуз Эйлул, Стамбульский университет, Университет Хаджеттепе, Университет Йылдыз Текник и т. Д.). Однако в учебных материалах, особенно в турецких словарях, отсутствует одна из самых важных сведений о языке — его произношение. В материалах курса турецкого есть главы об алфавите и произношении букв, но в них отсутствует запись в качестве фонематической транскрипции. Также в турецких словарях отсутствует информация о фонематической транскрипции из-за ложного убеждения, что турецкий алфавит является фонематическим. Однако нет однозначного соответствия между буквами алфавита и фонемами турецкого языка.В этом отношении данное исследование направлено на разработку инструмента преобразования графемы в фонему / аллофон для турецкого языка для решения проблемы, упомянутой выше. Выходные данные этого программного обеспечения будут напрямую доступны пользователю и понятны любому преподавателю языка, знакомому с фонетическими символами, используемыми в алфавите IPA (Международной фонетической ассоциации).
Исследование организовано следующим образом: сначала дается несколько основных определений понятий, часто используемых в исследовании, и лингвистических данных, которые используются в качестве основы исследования.Далее представлен краткий обзор литературы по преобразованию графемы в фонему / аллофон. После обзора литературы подробно обсуждается алгоритм программного обеспечения, разработанного в этом исследовании. В последнем разделе представлены результаты и общая производительность программного обеспечения с примерами.
2. Основные определения и турецкие лингвистические данные
Чтобы объяснить процесс преобразования графемы в фонему / аллофон, представлены некоторые основные концепции, которые будут использоваться в исследовании, чтобы объяснить, что мы намереваемся использовать в этих концепциях.
2.1. Графемы и турецкая письменность
Графема — это минимальная контрастирующая единица в системе письма языка, которая может быть реализована в нескольких формах и обычно заключена в угловые скобки (Crystal, 2003). Например, графема может быть реализована как A, a или a. В турецком алфавите 29 букв; однако турецкая система письма состоит из 32 графем, 29 форм букв, представленных в турецком алфавите, и графем , и , образованных добавлением диакритического знака с циркумфлексом (A) к графемам , и (ТДК Язим Килавузу, 2013).
2.2. Фонема
Фонема — это наименьшая отдельная звуковая единица языка (Matthews 1997), способная различать значения. Например, фонемы / s / и / f / различают слова sap и jap. Различные источники (Ergenf, 2002; Ozsoy, 2004; Goksel & Kerslake, 2005) представляют разные классификации и, следовательно, разное количество фонем для турецкого языка. В этом исследовании мы используем единый подход и объединяем данные из всех этих ресурсов.В нашей классификации 32 фонемы турецкой звуковой системы. Равенство между количеством графем и фонем не должно приводить нас к выводу, что турецкий язык имеет однозначное соответствие между графемами и фонемами, поскольку некоторые графемы могут представлять более одной фонемы. Список турецких фонем представлен в таблице ниже с соответствующими графемами и примерами.
Таблица 1. Фонемы в турецком
Графемы Фонемы
Прописные буквы Строчные
А а а / а
г г г / л
I i UI
К к к / к
л л 1 / л
Ö ö 0
§ 5 J «
Ü ü y
ДА *
* Эти графемы не имеют фонематических соответствий; однако они могут вызывать фонологические явления, такие как удлинение гласной.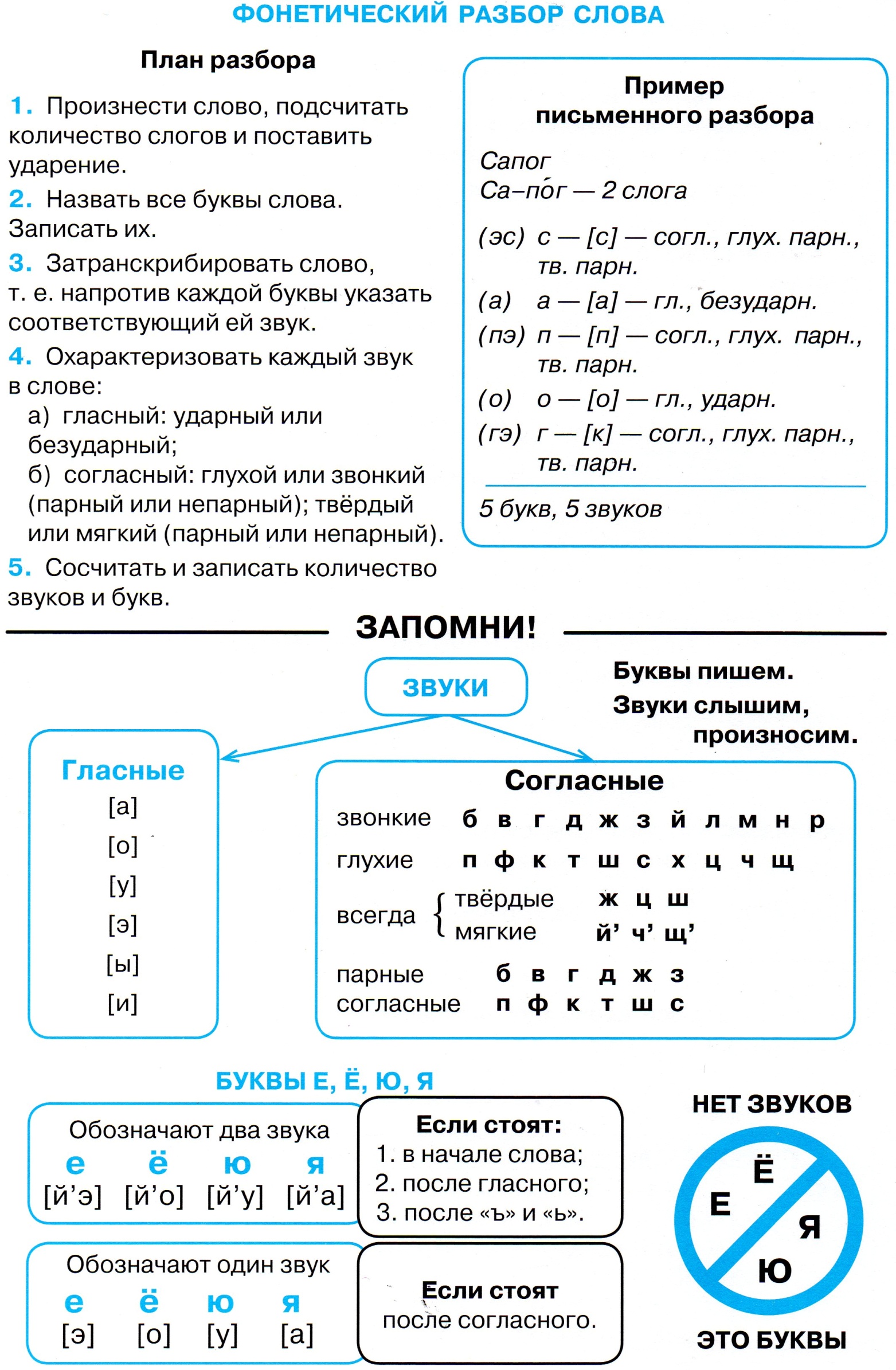
Как видно из Таблицы 1, турецкие фонемы и графемы не всегда соответствуют взаимно однозначному соответствию. Некоторые графемы представляют более одной фонемы, а некоторые графемы не имеют фонематического соответствия, они могут иметь аллофоническое соответствие, которое будет обсуждаться в следующих разделах.
2.3. Аллофон
Аллофон — это отчетливо различимый вариант фонемы (Matthews, 1997). Аллофоны — это связанные звуки, происходящие от одной и той же фонемы.Например, турецкая фонема / n / имеет три варианта, другими словами, три аллофона [n], [i)] и | ji]. Эти варианты используются в отношении фонетической среды, в которой они встречаются, как показано ниже:
<бак> [тай) к]
Эта аллофоническая вариация представлена как правило аллофонии, которое охватывает все аллофоны фонемы и условия их возникновения.i] встречается перед гласным передним взрывным согласным, как в cenk.
Как видно из одного примера, турецкая фонология имеет множество нюансов для большинства фонем. Фонемы и их аллофоны представлены с примерами в Таблице 2 ниже. Из-за нехватки места правила аллофонии, объясненные на примере выше, подробно не представлены.
Таблица 2. Аллофонические вариации в турецком языке
Графемы Фонемы Аллофоны
Прописные буквы Строчные
А а а а а а ä
Б б б б
С с *
Ç ç f Î
Д д д д
E e e e £ ë e «
F f f f i
г г г / мкг J
г г * *
H h h h x ç
I i UI ra m ra «
я я я я я р
Дж к 3 3
К к к / к к к к ч
л л в / л 1 л
М м м м п)
N n n n Ji 5
O o o o 5 o
Ö ö 0 0 œ œ
P P P P стр.
R r r r f r
с с с
S 5 с S
т т т т ф
U u u u ü u «
Ü ü y y y y «
В v v v P
Г г г дж
Z z z z
В *
Я * *
ед. * *
2.4.
Графема
• Удлиняет предыдущий гласный заднего ряда, когда он стоит в конце слога или слова.Эффект удлинения представлен символом: в фонетическом алфавите IPA: yagmur [ja: mur], dag [da:];
• Может произноситься как небное скольжение, когда предшествующий гласный является передним: eglen [эйлен];
• Не слышно между одинаковыми гласными заднего ряда, удлиняя первую гласную: ugur [u: r]; сигил [си: л];
• Если он находится между двумя гласными и эти гласные имеют разные отличительные особенности, другими словами, они не идентичны, это вызывает сдвиг гласных.Сдвиг гласных обозначается символом • в фонетическом алфавите IPA: agit [a’int], oge [0’e «].
2,5. Слоги и структура слогов в турецком
Слог — основная единица речи или произношения (Bussmann, 1998: 1155). Исследования G2P, а также фонологии показывают, что в большинстве случаев информация о положении границы слога необходима для определения правильных областей для фонологических и фонетических правил (van den Bosch & Daelemans, 1993; Demberg, Schmid & Mohler, 2007). Как упоминалось в литературе, в турецком слоге в основном используются фонологические правила и аллофонические вариации. Например, гласная, предшествующая носовой согласной в том же слоге, становится назализованной. Однако гласная, предшествующая носовой согласной, не превращается в носовую гласную.
Как упоминалось в литературе, в турецком слоге в основном используются фонологические правила и аллофонические вариации. Например, гласная, предшествующая носовой согласной в том же слоге, становится назализованной. Однако гласная, предшествующая носовой согласной, не превращается в носовую гласную.
пистолет [гын] гуну [гы.ны «]
Как видно из приведенных выше примеров, гласная / y / (u) становится назализованной, когда она предшествует согласной в том же слоге; но тот же гласный, предшествующий тому же согласному, но на этот раз в другом слоге (граница слога представлена точкой), не превращается в свой носовой аналог.Для более точного определения фонем и аллофонических вариаций следует учитывать структуру слогов. Ozsoy (2004) дает подробный отчет о слогах в турецком языке; и в этом исследовании использовались правила, представленные в Ozsoy. Структуру слога в турецком языке можно резюмировать следующим образом (Ozsoy, 2004: 97-98, 101): Турецкий язык имеет шесть разных слогов:
• V o
• CV бу
• VC aç
• Токен CVC
• VCC alt
• CVCC sarp
Группы согласных состоят из двух согласных и ограничиваются только двумя согласными: Türk, * plan,
турецких слога — это в основном открытые слоги.Когда слово, оканчивающееся на согласную, добавляется, происходит процесс повторного слогового суффикса, начинающийся с гласной, и согласная в конце первого слога переходит в следующий слог и становится началом. aç — im — »a + çim
Турецкий язык имеет несколько заимствованных структур слогов для заимствований.
VCC CCV
акс про
• CCVC
• CCCVC
Стразбург
3.Обзор литературы
Для преобразования графем в фонематические символы используется компьютерный процесс, называемый преобразованием графемы в фонемы. Преобразование графемы в фонему (G2P) — это базовый модуль любой системы преобразования текста в речь, который преобразует письменный текст в синтезированный речевой сигнал. G2P — это задача преобразования строки графем (букв, используемых при письме) в строку фонетических символов (букв, используемых для представления звуков речи) (Demberg, Schmid & Möhler, 2007: 96).G2P применяется во многих областях, таких как распознавание речи, автоматические диалоговые системы и системы транслитерации (системы, которые обеспечивают преобразование из одной алфавитной системы в другую, например, из кириллицы в латиницу).
Преобразование графемы в фонему (G2P) — это базовый модуль любой системы преобразования текста в речь, который преобразует письменный текст в синтезированный речевой сигнал. G2P — это задача преобразования строки графем (букв, используемых при письме) в строку фонетических символов (букв, используемых для представления звуков речи) (Demberg, Schmid & Möhler, 2007: 96).G2P применяется во многих областях, таких как распознавание речи, автоматические диалоговые системы и системы транслитерации (системы, которые обеспечивают преобразование из одной алфавитной системы в другую, например, из кириллицы в латиницу).
В литературе есть многочисленные исследования G2P для различных языков, в которых системы G2P используются как модули в системах преобразования текста в речь, так и в качестве независимого программного обеспечения (Daelemans & van den Bosch, 1993; Kienappel & Kneser, 2001; Demberg, Schmid & Möhler, 2007; Bisani and Ney, 2008).Системы G2P, разработанные в этих исследованиях, также используются для транслитерации языков с различной орфографией.
СистемыG2P также представлены в национальной литературе (Salor, 1999; Bozkurt, 2000; Sak, 2000; §ayli, 2002; Salor, 2005; Sak, Güngör & Safkan, 2006; Görmez & Görmez, 2008; Yilmaz, 2009; Акбулут, Адигузель и Йылмаз 2011). Однако все эти системы являются частями систем преобразования текста в речь или речи в текст, и их выходные данные доступны только для компьютерных систем и не могут быть доступны и использоваться пользователем.ma Dili ve Türkfenin Söyleyij Sözlügü «, словарь произношений Эргенфа (2002). Однако эта публикация доступна только в печатном виде, и для ее оцифровки с помощью методов OCR требуются большие усилия. Поэтому ее нелегко использовать в материалах курса и в турецких словарях.
При обзоре литературы по преобразованию графемы в фонемы можно увидеть, что эта задача может быть выполнена с использованием либо подхода, основанного на правилах (знаниях), либо подхода, основанного на данных (Kienappel & Kneser. 2001):
2001):
Подход, основанный на правилах;
• требует больших усилий и опыта, а также явно закодированных, языковых, лингвистических источников знаний,
• не может быть легко применен к новым задачам и языкам,
• имеет неотъемлемые проблемы с обслуживанием, трудно изменить некоторые правила, не вызывая нежелательных побочных эффектов.
• демонстрирует впечатляющую производительность для некоторых задач,
С другой стороны, подход, основанный на данных;
• требует написания слов с соответствующим произношением в фонематическом или фонетическом алфавите
• очень гибкий
• автоматически создается для языка в соответствии с правилами, неявными в обучающих данных, без явного моделирования лингвистических знаний
4.Метод
В подходе, основанном на правилах, к проектированию модулей графема-фонема, для выполнения задачи необходимы явно закодированные, зависящие от языка, лингвистические источники знаний. Однако для создания такого модуля и адаптации этого модуля к новому языку или задаче требуются большие усилия и опыт (Kienappel & Kneser, 2001). В подходе, управляемом данными, который использует методы контролируемого обучения, основанные на корпусе транскрибированных слов, можно достичь такой же даже лучшей производительности без явного моделирования лингвистических знаний (van den Bosch & Daelemans, 1993).ma Dili ve Turkfenin Soyleyi§ Sozlugu «, словарь произношения, разработанный Эргенфом (2002). Однако эта публикация доступна только в печатном виде, и для ее оцифровки с помощью методов OCR требуются большие усилия. Вместо этого мы намерены начать с нуля, создание настраиваемой архитектуры, которая будет хранить перечень графем турецкого алфавита, фонем и фонологических правил фонологии в базе данных.
5. Программное обеспечение G2P на основе правил для турецкого языка
Программное обеспечение G2P на основе правил для турецкого языка
Архитектура разработанного программного обеспечения следующая:
В соответствии с этой архитектурой в инструменте преобразования G2P для турецкого языка модуль Parser на первом этапе принимает в качестве входных данных любой турецкий текст и разбирает этот текст на предложения и слова.
В модуле силлабификатора это проанализированное написание слов разбивается на слоги, поскольку в большинстве случаев информация о положении границы слога необходима для определения надлежащих областей для фонологических и фонетических правил (van den Bosch & Daelemans, 1993 ; Demberg, Schmid & Möhler, 2007).
Позже в модуле конвертера G2P графемы в этих слоговых словах сопоставляются с их символами фонем, используя фонологические правила, хранящиеся в инвентаре.
/ ТЕКСТ y /
Рис. 1. Архитектура G2P Software
На последнем этапе модуль Mapper сопоставляет написание слова и фонематическую транскрипцию попарно и выдает на выходе корпус слов с их транскрипцией.
5.1. Модуль парсера
Модуль синтаксического анализатора использует алгоритм определения границ предложения, предложенный Akta§ (2006) и Akta§ & Demir (2006) для синтаксического анализа файлов простого текста на предложения и слова.Он хранит эти аннотированные данные в формате XML. Этот модуль работает онлайн как веб-сервис.
5.2. Модуль силлибификатора
Этот модуль разбивает проанализированные слова на слоги с использованием алгоритма слоговой классификации, разработанного с использованием фонологических правил, упомянутых выше.
Для оценки точности модуля силлабификатора случайным образом были выбраны 5000 слов (два или более слога) из турецкого словаря TDK.Результаты оценки следующие:
Таблица 3. Показатель точности для модуля Syllibificator
Показатель точности для модуля Syllibificator
Количество слов 5000
Количество неправильно разобранных слогов 22
Количество правильно разобранных слогов 4978
Точность 99,56
Как упоминалось ранее, силлабификация необходима для определения надлежащих областей для фонологических и фонетических правил, и в турецкой фонологии в большинстве случаев границы слогов важны для определения фонематической среды, а именно контекста, в котором встречается фонема.
5.3. Конвертер G2P
Модуль преобразованияG2P принимает на вход проанализированные и слоговые слова и, используя данные из инвентарных наборов графем, фонем и фонологических символов, преобразует графемы в фонемы в соответствии с фонологическими правилами. Этот модуль сначала сопоставляет графемы с соответствующими фонематическими символами в алфавите IPA. После этого первого шага модуль применяет фонологические правила к этим фонематическим символам и возвращает окончательные символы, измененные в соответствии с аллофоническими вариациями, представленными в правилах.В своей работе модуль использует три набора данных, а именно перечень графем, перечень фонем и перечень фонологических правил
.5.4. Картограф
МодульMapper принимает проанализированный текст и выходные данные модуля G2P в качестве входных данных и объединяет эти данные в корпус слов с их транскрипцией, с точкой слога (.) И без нее.
6. Общая оценка программного обеспечения G2P для турецкого языка
Программное обеспечение было реализовано в соответствии со структурой, упомянутой в предыдущей главе, после создания реестра графем и фонем.Позже фонологические правила были собраны из ресурсов и закодированы таким образом, чтобы программа могла понять эти правила.
Программное обеспечение использует систему кодирования Unicode UTF-8 при представлении символов IPA для фонем благодаря широкой поддержке Unicode символов IPA и простоте использования для конечных пользователей, которые, скорее всего, знакомы с символами в IPA.
Программа принимает любые фрагменты текста в качестве ввода через поле «Ввод текста» или из обычного текстового файла, закодированного в кодировке UTF-8 Unicode.UWh WtH j
Рис. 2. Скриншот пользовательского интерфейса программы G2P
Программа сохраняет вывод пословно, с фонематической транскрипцией каждого слова, как с границами слогов, так и без них. Этот метод сохранения предпочтительнее для будущих исследований; особенно система G2P, которая использует для процесса подход, основанный на данных. Таким образом, выходные данные программы сохраняются в такой структуре, что любое управляемое данными программное обеспечение G2P может иметь доступ к данным графемы, данным фонем и, кроме того, к данным слогов слов в текстовом файле.ilerfn
7. дилбилимин — dn.bi.li.mrn. — diTbilimrn
Рис. 3. Скриншот выходного файла
Программное обеспечение было протестировано с использованием выборки из 1000 слов, выбранных из турецкого словаря TDK. Слова состоят минимум из двух слогов. 1000 слов, выбранных для выборки, содержали 7894 графемы. Результаты оценки точности выходных данных программного обеспечения приведены в Таблице 4 ниже.
Таблица 4.Показатель точности ПО G2P
Количество слов 1000
Число графем 7894
Число правильно проанализированных графем 7588
Число неправильно проанализированных графем 306
Уровень точности 96.12
7. Заключение
Программное обеспечение, реализованное в этом исследовании, представляет собой основанную на правилах систему из графемы в фонемы, которая преобразует турецкие графемы в соответствующие им фонемы.Процесс реализации заключался в сборе списка графем, фонем и фонологических правил в базу данных. Полученное программное обеспечение тестируется на списке слов, состоящем из статей Турецкого словаря, полученного от TDK. Результаты программы успешны, и список слов с их фонетической транскрипцией будет представлен TDK для использования в их онлайн-словарях. Выходные данные программы могут использоваться в системах преобразования текста в речь и речи в текст, которые стали популярными в последнее время.Полученные результаты также могут быть использованы в программах обучения турецкому как иностранному или в других лингвистических исследованиях фонологических свойств турецкого языка. Программное обеспечение G2P, разработанное в этом исследовании, представляет собой основанную на правилах систему G2P и, таким образом, является первым шагом в процессе преобразования графемы в фонемы для турецкого языка. Программное обеспечение может уступить место другому программному обеспечению, например, реализациям G2P, управляемым данными, или может использоваться как встроенный модуль в системах преобразования текста в речь.
Результаты программы успешны, и список слов с их фонетической транскрипцией будет представлен TDK для использования в их онлайн-словарях. Выходные данные программы могут использоваться в системах преобразования текста в речь и речи в текст, которые стали популярными в последнее время.Полученные результаты также могут быть использованы в программах обучения турецкому как иностранному или в других лингвистических исследованиях фонологических свойств турецкого языка. Программное обеспечение G2P, разработанное в этом исследовании, представляет собой основанную на правилах систему G2P и, таким образом, является первым шагом в процессе преобразования графемы в фонемы для турецкого языка. Программное обеспечение может уступить место другому программному обеспечению, например, реализациям G2P, управляемым данными, или может использоваться как встроенный модуль в системах преобразования текста в речь.
Благодарности
Работа поддержана Университетом Докуз Эйлул, проект №: 2012.КБ.S0S.3
Список литературы
Акбулут, А., Адигузель, Т., Йилмаз, А. Э. (2011). Статистический анализ слогов для обнаружения и разрешения неоднозначности произношения в приложениях для преобразования текста в речь: пример на турецком языке. ActaPolytechnica Hungarica, Том 8, № 5. Akta§, O. & Demir, U. (2006). Turk§e i§in Cumle Sonu Belirleme Yontemine Yeni bir Bakis. Статья представлена в ASYU 2006-Akilli Sistemlerde Yenilikler ve Uygulamalari Sempozyumu, Технический университет Йылдыз, Стамбул.турулмаси. Неопубликованная рукопись.
Бисани М. и Ней Х. (2008). «Совместные модели последовательностей для преобразования графемы в фонемы». Речевая коммуникация, том 50, выпуск 5, стр. 434-451.
Бостонский университет (2013). Получено с: http://www.bu.edu/mlcl/home/why-study-turkish/
. Бозкурт Б. (2000). Пособие по чтению для слабовидящих: разработка турецкой системы преобразования текста в речь. Неопубликованная кандидатская диссертация. Буссманн, Х. (1998). Словарь по языку и лингвистике.Лондон: Рутледж.
Неопубликованная кандидатская диссертация. Буссманн, Х. (1998). Словарь по языку и лингвистике.Лондон: Рутледж.
ЦРУ ценит языковые способности сотрудников. (2009). Получено с: https://www.cia.gov/news-information/featured-story-
.архив / 2010-Feature-Story-archive / cia-values-language-features.html
Кристалл, Д. (2003). Словарь лингвистики и фонетики. Молден: издательство Blackwell Publishing.
Daelemans, W. & van den Bosch. (1993). A. TABTALK: возможность повторного использования в ориентированном на данные преобразовании графемы в фонемы.Proceedings of Eurospeech 1993, Berlin, pp.1459-1466.
Демберг В., Шмид Х. и Мёлер Г. (2007). Фонологические ограничения и морфологическая предварительная обработка для преобразования графемы в фонему
Конверсия. В материалах 45-го ежегодного собрания Ассоциации компьютерной лингвистики, стр. 96-13.
Эрген§, И. (2002). Kontffma Dili ve Türkgenin Söyleyig Sözlügü. Стамбул: многоязычный.
Гёксель, А.И Керслейк, С. (2005). Турецкий. Комплексная грамматика. Лондон / Нью-Йорк: Рутледж.
Гёрмез З. и Орхан З. (2008). TTTS: турецкая система преобразования текста в речь. 12-я Международная конференция WSEAS по КОМПЬЮТЕРАМ, Ираклион, остров Крит / Греция, июнь. 2008, Материалы 12-й Международной конференции WSEAS по КОМПЬЮТЕРАМ, стр. 977-982. Международная фонетическая ассоциация. http ..// www.langsci.ucl.ac.uk/ipa/ 06.08.2012
Киенаппель, А. К. и Кнезер, Р. (2001).Разработка очень компактных деревьев решений для транскрипции графемы в фонемы. Статья представлена в 7-м
Европейская конференция по речевой коммуникации и технологиям 2-е мероприятие INTERSPEECH. EUROSPEECH-2001, стр. 1911-1914. Мэтьюз, П. Х. (1997). Краткий словарь лингвистики Oxfor. Оксфорд: издательство Oxfor University Press. Озсой, С. (2004). Türkgenin Yapisi 1 Sesbilim. Стамбул: Bogazi§i Üniversitesi Yayinevi.
Озсой, С. (2004). Türkgenin Yapisi 1 Sesbilim. Стамбул: Bogazi§i Üniversitesi Yayinevi.
Сак, Х., Гюнгор, Т. и Сафкан, Ю. (2006).Система конкатенативного синтеза речи на основе корпуса для турецкого языка. Турецкий журнал электротехники и компьютерных наук, 14 (2): 209-223.
Salor, Ö. (1999). Аспекты обработки сигналов синтезатора текста в речь на турецком языке. Неопубликованная кандидатская диссертация.
Salor, Ö. (2005). Преобразование голоса и разработка инструментов анализа связанной речи для турецкого языка. Неопубликованная кандидатская диссертация.
SAMPA (Фонетический алфавит для оценки речи) (2013).Получено с: http://www.phon.ucl.ac.uk/home/sampa/index.html
§айли, Ö. (2002). Анализ продолжительности и моделирование для синтеза речи турецкого языка. Неопубликованная кандидатская диссертация.
Техасский университет A&M. (2013). Получено с: http://studyturkish.tamu.edu/
.Тюрк Дил Куруму. (2013). http://www.tdk.gov.tr/index.php?option=com_gts&arama=gts&guid= TDK.GTS.501f72499ea1a8.98681729 Университет Питтсбурга. (2013).Получено с: http://www.lctl.pitt.edu/turkish.html
.Ван Баел, К. П. Дж. (2007). Проверка, автоматическое создание и использование широких фонетических транскрипций. Неопубликованная диссертация. Radbound Universiteit Nijmegen.
van den Bosch, A. & W. Daelemans (1993). Методы преобразования графемы в фонемы, ориентированные на данные. Труды Европейского отделения ACL, Утрехт, 45-53.
Yilmaz, A. E. (2009) Türk§e Metinden Konu§ma Senztezleme Uygulamalari i§in bir Veri Sözlük Seti ve Yazilim Qer§ivesi.Gazi ÜniversitesiMühendislikveMimarhkDergisi, Cilt 24, № 4, стр. 735-744.
Уэллс, Дж. К. (1996). Почему важна фонетическая транскрипция. В: Malsori (Журнал фонетического общества Кореи) 31–32, стр. 239–242.
239–242.
% PDF-1.6 % 32 0 объект > эндобдж 29 0 объект > поток 2009-07-02T10: 36: 26-05: 002010-04-14T12: 45: 30-04: 002010-04-14T12: 45: 30-04: 00Adobe Acrobat 8.17 Подключаемый модуль захвата бумаги / pdfuuid: def5b1a8-521f -cf41-b67a-506d81d67710uuid: 2b198267-3aa2-6246-91e1-767d6cc68456 конечный поток эндобдж 33 0 объект > / Кодировка >>>>> эндобдж 28 0 объект > эндобдж 34 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 1 0 obj > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 4 0 obj > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 7 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 10 0 obj > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 13 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 16 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 19 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 22 0 объект > / Font> / ProcSet [/ PDF / Text / ImageB] >> / Type / Page >> эндобдж 110 0 объект > поток HWkoG_O ~
Изучение китайской кодировки для определения фонетического сходства
6 ноября 2018 г. | Автор: Редакция IBM Research
| Автор: Редакция IBM Research
Категории: IBM Research-Almaden
Поделитесь этим постом:
Выполнение мысленной гимнастики по фоенетическому различению слов и фраз, таких как «Я слышу» и «Я здесь» или «Я не могу так, но тонны» на «Я не могу пришивать пуговицы» — это знакомы всем, кто сталкивался с автокорректированными текстовыми сообщениями, короткими сообщениями в социальных сетях и т.п.Хотя на первый взгляд может показаться, что фонетическое сходство можно измерить количественно только для слышимых слов, эта проблема часто присутствует в чисто текстовых пространствах.
ПодходыAI для синтаксического анализа и понимания текста требуют чистого ввода, что, в свою очередь, подразумевает необходимый объем предварительной обработки необработанных данных. Неправильные омофоны и синофоны, использованные по ошибке или в шутку, должны быть исправлены так же, как и любая другая форма орфографической или грамматической ошибки. В приведенном выше примере точное преобразование слов «слышать» и «так» в их фонетически схожие правильные аналоги требует надежного представления фонетического сходства между парами слов.
Большинство алгоритмов фонетического сходства основаны на примерах использования английского языка и предназначены для индоевропейских языков. Однако многие языки, например китайский, имеют другую фонетическую структуру. Звук речи китайского иероглифа представлен одним слогом в пиньинь, официальной системе латинизации китайского языка. Слог пиньинь состоит из: начального (необязательного) (например, «б», «чж» или «х»), финального (например, «а», «оу», «вай» или «юань»). и тон (их пять).Сопоставление этих звуков речи с английскими фонемами приводит к довольно неточному представлению, а использование индоевропейских алгоритмов фонетического сходства еще больше усугубляет проблему. Например, два хорошо известных алгоритма, Soundex и Double Metaphone, индексируют согласные, игнорируя гласные (и не имеют понятия о тонах).
Например, два хорошо известных алгоритма, Soundex и Double Metaphone, индексируют согласные, игнорируя гласные (и не имеют понятия о тонах).
Поскольку слог пиньинь представляет собой в среднем семь различных китайских иероглифов, преобладание омофонов даже больше, чем в английском. Между тем, использование пиньинь для создания текста чрезвычайно распространено в мобильных приложениях и приложениях для чата, как при использовании преобразования речи в текст, так и при прямом наборе текста, поскольку более практично вводить слог пиньинь и выбирать нужный символ.В результате ошибки ввода на основе фонетики чрезвычайно распространены, что подчеркивает необходимость в очень точном алгоритме фонетического сходства, на который можно положиться для исправления ошибок.
Визуализация, представляющая фонетическое кодирование инициалов пиньинь.
Руководствуясь этим вариантом использования, который распространяется на многие другие языки, которые не легко вписываются в фонетический шаблон английского языка, мы разработали подход к изучению n-мерного фонетического кодирования для китайского языка. Важной характеристикой пиньинь является то, что три компонента слог (начальный, конечный и тональный) следует рассматривать и сравнивать независимо.Например, фонетическое сходство финальных слов «ie» и «ue» идентично в парах пиньинь {«xie2», «xue2»} и {«lie2», «lue2»}, несмотря на разные инициалы. Таким образом, сходство пары слогов пиньинь — это совокупность сходств между их инициалами, финалами и тонами.
Однако искусственное ограничение пространства кодирования до низкого уровня (например, индексация каждого инициала до одного категориального или даже числового значения) ограничивает точность захвата фонетических вариаций.Поэтому правильный подход, основанный на данных, состоит в том, чтобы органически изучить кодировку соответствующей размерности. Модель обучения получает точные кодировки путем совместного рассмотрения лингвистических характеристик пиньинь, таких как место артикуляции и методы произношения, а также высококачественные аннотированные наборы обучающих данных.
Таким образом, изученные кодировки могут использоваться, например, для принятия слова в качестве входных данных и возврата ранжированного списка фонетически похожих слов (ранжированных по уменьшению фонетического сходства).Ранжирование важно, потому что последующие приложения не будут масштабироваться для учета большого количества альтернативных кандидатов для каждого слова, особенно при работе в режиме реального времени. В качестве примера из реальной жизни мы оценили наш подход к созданию ранжированного списка кандидатов для каждого из 350 китайских слов, взятых из набора данных социальных сетей, и продемонстрировали 7,5-кратное улучшение по сравнению с существующими подходами фонетического сходства.
Мы надеемся, что улучшения, внесенные в эту работу для представления фонетического сходства для конкретных языков, повысят качество множества многоязычных приложений для обработки естественного языка.Эта работа, являющаяся частью проекта IBM Research SystemT, была недавно представлена на конференции SIGNLL 2018 по вычислительному изучению естественного языка, и предварительно обученная модель китайского языка доступна исследователям для использования в качестве ресурса при создании чат-ботов, приложений для обмена сообщениями, средств проверки орфографии и любые другие соответствующие приложения.
Документ: DIMSIM: точный китайский алгоритм фонетического сходства, основанный на выученном кодировании большого размера
Фонетическое соответствие | Справочное руководство по Apache Solr 6.6
Примеры использования этой кодировки в анализаторе см. В разделе «Фильтр Морзе Бейдера» в разделе «Описание фильтров».
Фонетическое сопоставление по Бейдеру-Морзе (BMPM) — это «похожий на звук» инструмент, который позволяет выполнять поиск с использованием новой системы фонетического сопоставления. BMPM помогает вам искать личные имена (или просто фамилии) в индексе Solr / Lucene и намного превосходит существующие фонетические кодеки, такие как обычный звуковой сигнал, метафон, каверфон и т. Д.
Д.
Как правило, фонетическое соответствие позволяет искать в списке имен имена, фонетически эквивалентные желаемому имени.BMPM похож на поиск soundex в том, что точное написание не требуется. В отличие от soundex, он не генерирует большого количества ложных срабатываний.
По написанию имени BMPM пытается определить язык. Затем он применяет фонетические правила для этого конкретного языка, чтобы транслитерировать имя в фонетический алфавит. Если невозможно определить язык с достаточной степенью уверенности, вместо этого используется общая фонетика. Наконец, он применяет независимые от языка правила в отношении таких вещей, как звонкие и глухие согласные и гласные, чтобы еще больше гарантировать надежность совпадений.
Например, предположим, что совпадения, найденные при поиске Стивена в базе данных, — это «Стефан», «Стеф», «Стивен», «Стив», «Стивен», «Плита» и «Stuffin». «Стефан», «Стивен» и «Стивен», вероятно, уместны, и это имена, которые вы хотите видеть. Однако «Stuffin», вероятно, не имеет отношения к делу. Также отклонены были «Стеф», «Стив» и «Плита». Из них «Плита», наверное, не та, которую мы бы хотели. Но, возможно, вас заинтересуют «Стеф» и «Стив».
Для Solr поиск BMPM доступен для следующих языков:
Английский
Французский
Немецкий
Греческий
Еврейские буквы, написанные еврейскими буквами
Венгерский
Итальянский
Польский
Румынский
Русский кириллицей
Русская транслитерация английскими буквами
Испанский
Турецкий
Сопоставление имен также применимо к нееврейским фамилиям из стран, в которых говорят на этих языках.
.