Страница не найдена
wordmap
Данная страница не найдена или была удалена.
Только что искали:
поставившийся 1 секунда назад
заключающею 1 секунда назад
льняными 2 секунды назад
сматывать кабель 2 секунды назад
сладостнее 4 секунды назад
закрасить 4 секунды назад
выхлопотанных 4 секунды назад
мапротилин 6 секунд назад
заморить 6 секунд назад
миловидна 7 секунд назад
портретирует 8 секунд назад
бесценнейшего 8 секунд назад
иссохшаяся 10 секунд назад
пенгили 10 секунд назад
пенятуллин 11 секунд назад
Последние игры в словабалдучепуху
| Имя | Слово | Угадано | Откуда | |
|---|---|---|---|---|
| Игрок 1 | кукушечка | 10 слов | 93.80.183.175 | |
| Игрок 2 | скипидар | 58 слов | 93. 80.183.175 80.183.175 |
|
| Игрок 3 | розарий | 13 слов | 93.80.183.175 | |
| Игрок 4 | доктор | 27 слов | 93.80.183.175 | |
| Игрок 5 | жёсткий | 0 слов | 89.23.157.58 | |
| Игрок 6 | секвестрация | 1 слово | 217.66.156.145 | |
| Игрок 7 | сопроводительница | 333 слова | 93.80.183.175 | |
| Играть в Слова! | ||||
| Имя | Слово | Счет | Откуда | |
|---|---|---|---|---|
| Игрок 1 | вруша | 13:14 | 94.245.134.239 | |
| Игрок 2 | бадан | 34:36 | 94. 245.134.239 245.134.239 |
|
| Игрок 3 | щечка | 26:27 | 94.245.134.239 | |
| Игрок 4 | кокос | 50:53 | 94.245.134.239 | |
| Игрок 5 | порка | 54:53 | 94.245.134.239 | |
| Игрок 6 | ручей | 0:0 | 94.245.134.239 | |
| Игрок 7 | фляга | 48:45 | 176.59.100.70 | |
| Играть в Балду! | ||||
| Имя | Игра | Вопросы | Откуда | |
|---|---|---|---|---|
| Люблю люблю вову | На двоих | 5 вопросов | 178.120.55.226 | |
| Маша | На одного | 20 вопросов | 93. 157.255.240 157.255.240 |
|
| Таня | На одного | 10 вопросов | 93.157.255.240 | |
| Ш | На одного | 5 вопросов | 109.252.189.106 | |
| Вика | На двоих | 5 вопросов | 178.72.77.88 | |
| Говно | На одного | 10 вопросов | 217.66.156.162 | |
| Тамара | На одного | 10 вопросов | 212.164.64.214 | |
| Играть в Чепуху! | ||||
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
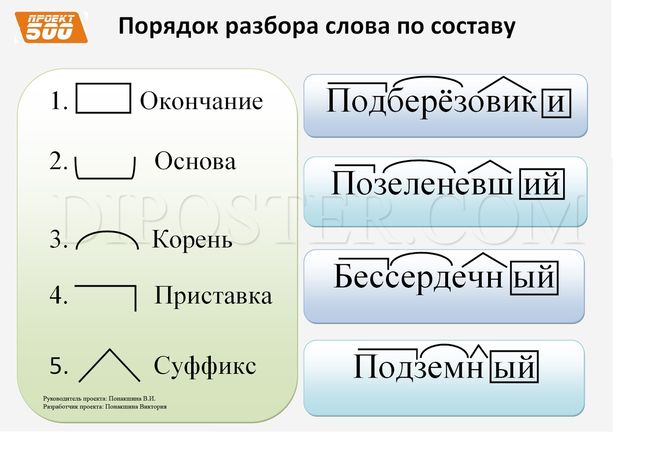
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н., Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
| Вопрос 1 из 20 Разведка полезных ископаемых при помощи сети шурфов | |
| буксование | шурфование |
| буртование | мудрование |
Только что искали: марка сейчас минамяч сейчас ооторб сейчас анмркиод сейчас аирбк сейчас плитокнс сейчас напорд 1 секунда назад блокнот 1 секунда назад трксьаа 1 секунда назад с т к о р а е 1 секунда назад гулнор 1 секунда назад р б и з ю п а 1 секунда назад стокпнек 1 секунда назад капризн 1 секунда назад магнуст 1 секунда назад
Сопоставление с образцом и анализ
Оказывается, сопоставление с образцом и декомпозиция структуры данных
являются прекрасным инструментом для разбора нерегулярных грамматик (таких как
уценка).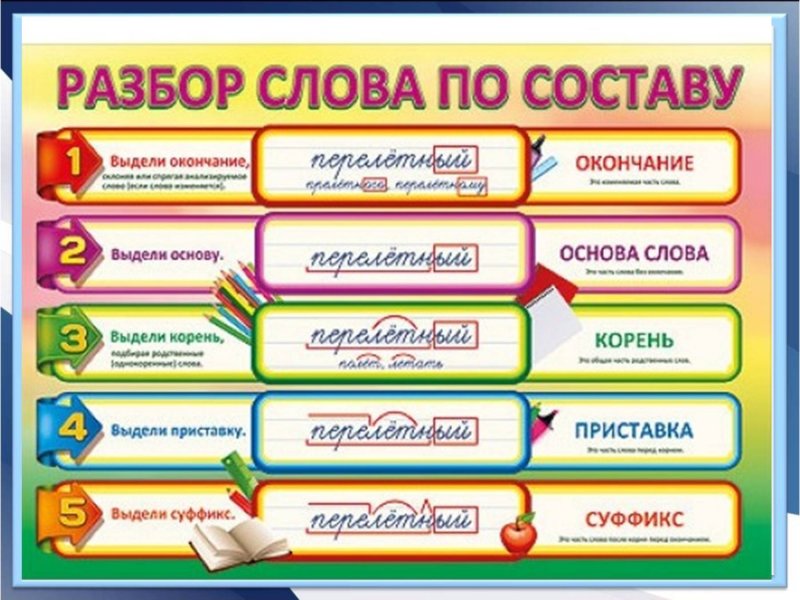
Я работаю над написанием парсера Markdown в Эликсир языка. Это что-то я делать на новых языках, когда у меня есть время, потому что синтаксический анализ Markdown нетривиальный — синтаксис явно нерегулярный.
Так или иначе, я взломал (и выбросил) Ruby и Javascript реализации, и решил попробовать Эликсир.
Большинство парсеров Markdown используют обычные выражения для сканирования и преобразования их ввода. 1 Я начал делать то же самое, но быстро наткнулся на всю гадость этого подхода влечет за собой.
Потом я понял, что так называемые блочные элементы Markdown могут разбирать по-разному. Вместо того, чтобы пытаться сделать это за один проход, я взяв два.
При первом проходе я просто просматриваю каждую строку, распределяя ее по категориям. Типичный категории могут быть пустой строкой , правило , заголовок и так далее. Но есть вещи, которые нельзя решить, глядя только на один линия. Например, заголовок setext выглядит так:
и здесь заканчивается абзац.Это заголовок ==================== А вот и тело…
 Это заголовок
====================
А вот и тело…
Это заголовок
====================
А вот и тело…
То есть заголовок это пустая строка, строка текста, строка содержащий знаки равенства (или дефисы) и еще одну пустую строку.
В дизайне, с которым я играю, такие заголовки (и другие структуры, для анализа которых требуется больше контекста, чем одна строка). распознается вторым проходом по линиям.
Драйвер верхнего уровня
Код верхнего уровня выглядит примерно так:
def categorize(lines) do Stream.concat([[""], lines, [""]]) # начинается и заканчивается пустой строкой |> Enum.map(&type_of/1) |> merge_compound_lines конец
Первая строка функции берет список строк и превращает их во что-то потоковое. В то же время он предшествует и добавляет пустую строку, потому что пустые строки действуют как разделители для множество структур блочного уровня.
Строка map применяет функцию type_of к каждой строке.
Первый проход — присвоение типа каждой строке
Функция type_of
 Например,
пустая строка будет возвращена как
Например,
пустая строка будет возвращена как [type: :blankline] и в стиле atx
заголовок ### Заключение будет возвращен как [type: :heading, level:
3, текст: «заключение»] . Код, который выполняет это сопоставление,
тривиально: 9(=|-)+\s*$/, строка) ->
[_, тип] = совпадение
level = if(String.starts_with?(type, «=»), do: 1, else: 2)
[тип: :setext_underline_heading, уровень: уровень]
правда ->
[тип:: textline, текст: строка] Второй проход — объединение линий в блоки
Итак, теперь у нас есть список типов линий. Нам нужно искать такие вещи как заголовок в стиле setext. И оказывается, что структура декомпозиция позволяет нам сделать это довольно безболезненно. Вот код для заголовки:
def merge_compound_lines(lines), do: merge_compound(lines, [])
def merge_compound([], результат), do: Enum.reverse(результат)
def merge_compound([ [тип: :blankline] = пусто,
[тип: :textline, текст: заголовок],
[тип: :setext_underline_heading, уровень: уровень],
[тип: :blankline]
| отдых
],
результат)
делать
merge_compound (остальное,
[ пустой,
[тип: :заголовок, уровень: уровень, текст: заголовок],
пустой
| результат])
конец
Первая функция — это просто удобство, вызов настоящего работника
с дополнительным параметром для хранения результата.
Тогда у нас есть
функция merge_compound , которая рекурсивно обрабатывает строки.
Здесь интересно то, что заголовок функции начинается с строка 5. Помните, мы говорили, что заголовок setext — это пустая строка, строка текста, строка знаков равенства и еще одна пустая строка. Видеть как декомпозиция структуры и сопоставление с образцом позволяют выразить это прямо в коде:
def merge_compound([ [type: :blankline] = пусто,
[тип: :textline, текст: заголовок],
[тип: :setext_underline_heading, уровень: уровень],
[тип: :blankline]
|
отдых], результат) делать
Эта конкретная функция будет вызываться только в том случае, если передан список который начинается с этих четырех элементов.
Затем, распознав его, тело функции заменяет сопоставил строки с новыми строками — пробел, заголовок и еще один пробел. Мы добавьте эти три в список результатов, рекурсивно вызвав себя:
merge_compound(остальное,
[ пустой,
[тип: :заголовок, уровень: уровень, текст: заголовок],
пустой
|
результат
])
То же самое относится и к другим типам сложных блоков.
Сопоставление с образцом — это анализ потока
В функциональном программировании ваш код в основном выглядит следующим образом:
Затем вы используете композицию, чтобы последовательно разбить some_function на
более низкие уровни абстракции, пока вы не имеете дело с примитивными
значения и встроенные функции, после чего декомпозиция может
останавливаться.
ввод → некоторая_функция → вывод
__/ \__
/ \
→ фн1 → фн2 →
___ / \__
/ \
→ фн3 → фн4 →
Если вы посмотрите на это таким образом, ваша программа в основном представляет собой конвейер. Поток данных поступает в него, анализируется, разбивается, через последовательность функций, отображаемых во что-то другое, и снова собран в выходной файл.
Вот тут-то и появляется сопоставление с образцом, разрушающее поток данных и выбор функций для применения.
И это самое интересное. Если вы думаете о своем коде таким образом, то
вы фактически используете сопоставление с образцом для анализа потока данных как
оно проходит. Если вы можете выразить свой вклад как своего рода
грамматики, то ваша программа — это то, что преобразует данные,
соответствует этой грамматике.
Если вы можете выразить свой вклад как своего рода
грамматики, то ваша программа — это то, что преобразует данные,
соответствует этой грамматике.
Это не просто какая-то причудливая абстракция, потому что зная грамматика, с которой вы работаете, может значительно упростить ваш код. Для например, если вы знаете, что ваши бизнес-правила зависят от контекста бесплатно, тогда вы также знать, что код, который анализирует и обрабатывает соответствующие данные могут работать изолированно — они автоматически разъединяются.
Я так писал код на Эликсире, но особо не думал об этом в плане разбора до сих пор. Теперь я начинаю видеть больше и многое другое из того, что я делаю с точки зрения грамматики и правил производства.
В стороне — слушая ангела на плече (или собаку на коврике)
Это написание синтаксического анализатора Markdown — это CodeKata, что я делаю периодически. Написание Эликсир, я уверенно пошел по той же дороге, что и с Javascript-версия.
Теперь Elixir не так естественен в обработке строк, как Javascript. Как
В результате дорога стала немного извилистой. я обнаружил, что делаю
нефункциональные вещи. Я обнаружил, что пишу длинные функции. я
обнаружил, что беспокоюсь об эффективности различных операций.
Как
В результате дорога стала немного извилистой. я обнаружил, что делаю
нефункциональные вещи. Я обнаружил, что пишу длинные функции. я
обнаружил, что беспокоюсь об эффективности различных операций.
И я продолжал. Я не собирался сдаваться. Это казалось неправильным, но Я НЕ СОБИРАЛАСЬ БИТЬ.
::: заголовок @source/posts/images/Rubber_duck_assisting_with_debugging.jpg Том Моррис (Собственная работа) CC-BY-SA-3.0 или GFDL, через Wikimedia Commons :::
Раньше я описывал свои проблемы с программированием резиновая утка. Настоящее время Я перешел к Мусу, двенадцатилетнему чернокожему лабрадору, чья способность смотреть отвращение к путям людей непревзойденно. Когда я ворчал о проблемах, которые у меня были с Мусом, он просто поднял бровь, перевернулся и снова заснул. Что, конечно, является сокращением для «если код говорит вам, что это трудно сделать таким образом, остановитесь делать это таким образом».
Итак, я выбросил, возможно, дневную работу и переделал ее, используя
сопоставление с образцом и потоки через час или два.
Просто стало намного лучше.
И это одна из причин, по которой нужно завести привычку практиковаться в программировании. ката. Тот факт, что потребовался день, чтобы понять, что я направляюсь в болото очень грустно, но ката позволила мне сделать эту ошибку в некритическая среда.
Я выполнял ката Markdown в n th раз. Этот время, когда я научился не впадать в рутину, делая это одинаково каждый время, и я ушел, пообещав себе, что прислушаюсь к этому чувству беспокойства скорее в будущем.
Конечно, есть исключения. Существует несколько парсеров уценки PEG и несколько классных реализаций на Haskell и (мой любимый) OCaml. ↩
стратегия синтаксического анализа, реализуемая левой передней височной долей – Лаборатория вычислительной нейролингвистики
Джонатан Р. Бреннан публикации
Многие предыдущие исследования связывают части левой височной и левой лобной долей с аспектами понимания предложений. Но процедура, проводимая в этих регионах, не исследована. В новой статье мы тестируем конкретный алгоритм обработки предложений, реализованный в этих регионах. Вместе с Лииной Пюлкканен мы смоделировали две стратегии синтаксического анализа, одну предсказательную «левый угол» и одну менее предсказательную «восходящую» стратегию, и проверили, какая стратегия лучше согласуется с активностью мозга, зарегистрированной с помощью МЭГ. Активность в левой передней височной доле коррелирует с количеством узлов, предсказуемо постулированных синтаксическим анализатором левого угла, начиная примерно через 350 мс после начала слова.
Бреннан, Дж. Р. и Пюлкканен, Л. (ожидается). Свидетельство МЭГ о возрастающем составе предложений в передней височной доле. Когнитивные науки [ссылка]
Ознакомьтесь с абстрактной и ключевой цифрой ниже
Исследования, изучающие мозговую основу понимания языка, связывают левую переднюю височную долю (ATL) с комбинаторикой на уровне предложений. С помощью магнитоэнцефалографии (МЭГ) мы тестируем стратегию разбора, реализованную в этой области мозга. Количество дополнительных шагов синтаксического анализа при использовании прогнозирующей стратегии анализа левого угла, которая поддерживается психолингвистическими исследованиями, сравнивается с таковым при использовании менее предиктивной стратегии. Мы проверяем корреляцию между этапами синтаксического анализа и активностью MEG, локализованной в источнике, записанной, когда участники читают историю. Шаги синтаксического анализа в левом углу коррелируют с активностью в левом ATL примерно через 350–500 мс после начала слова. Никаких других корреляций, характерных для понимания предложений, не наблюдалось. Эти данные показывают, что левый ATL участвует в комбинаторной обработке, которая хорошо характеризуется прогнозирующей стратегией синтаксического анализа левого угла.
С помощью магнитоэнцефалографии (МЭГ) мы тестируем стратегию разбора, реализованную в этой области мозга. Количество дополнительных шагов синтаксического анализа при использовании прогнозирующей стратегии анализа левого угла, которая поддерживается психолингвистическими исследованиями, сравнивается с таковым при использовании менее предиктивной стратегии. Мы проверяем корреляцию между этапами синтаксического анализа и активностью MEG, локализованной в источнике, записанной, когда участники читают историю. Шаги синтаксического анализа в левом углу коррелируют с активностью в левом ATL примерно через 350–500 мс после начала слова. Никаких других корреляций, характерных для понимания предложений, не наблюдалось. Эти данные показывают, что левый ATL участвует в комбинаторной обработке, которая хорошо характеризуется прогнозирующей стратегией синтаксического анализа левого угла.
 Строка 2: Расчетные эффекты (коэффициенты β) для взаимодействия блока стимула с резидуальными шагами синтаксического анализа левого угла (rLC). Строка 3: предполагаемые эффекты взаимодействия блока стимула с остаточными шагами анализа снизу вверх (rBU). Строка 4: предполагаемые основные эффекты шагов синтаксического анализа rBU. Серая заливка указывает на стандартные ошибки коэффициента ±1,64. Положительное значение для эффектов взаимодействия, показанных в строках 2 и 3, указывает на больший эффект для шагов синтаксического анализа в левом углу или снизу вверх в блоке STORY. «*» указывает промежуток времени со статистически значимым эффектом на основе теста непараметрической перестановки. Поиск
Строка 2: Расчетные эффекты (коэффициенты β) для взаимодействия блока стимула с резидуальными шагами синтаксического анализа левого угла (rLC). Строка 3: предполагаемые эффекты взаимодействия блока стимула с остаточными шагами анализа снизу вверх (rBU). Строка 4: предполагаемые основные эффекты шагов синтаксического анализа rBU. Серая заливка указывает на стандартные ошибки коэффициента ±1,64. Положительное значение для эффектов взаимодействия, показанных в строках 2 и 3, указывает на больший эффект для шагов синтаксического анализа в левом углу или снизу вверх в блоке STORY. «*» указывает промежуток времени со статистически значимым эффектом на основе теста непараметрической перестановки. Поиск- Увидимся в Питтсбурге на HSP 2023
Мы с нетерпением ждем HSP2023 в Питтсбурге! Обязательно ознакомьтесь с последними новостями от членов лаборатории о межъязыковых грамматических репрезентациях, моделировании интерференции при поиске и магистерской диссертации Цзюнюаня (психолингвистика MPI) об отслеживании кортикальных фраз! И не забудьте проверить работу […]
- Два препринта: отделение инкрементной композиции от предсказуемости и локализация обработки зависимостей между языками
Я все еще наверстываю упущенное в наших предновогодних усилиях. К ним относятся два (2) препринта статей, в которых используются наборы данных Little Prince. Сначала: Милош Станоевич (DeepMind) и я руководили проектом, в котором […]
- Д-р Тамара Хильдебрандт защищает диссертацию
Поздравляем новоявленного кандидата наук. Тамара Хидлебрандт, успешно защитившая диссертацию 19 декабря! В диссертации описывается множество экспериментов, сочетающих суждения о приемлемости, эксперименты по самостоятельному чтению и ЭЭГ для исследования тонкой взаимосвязи между грамматическими […]
- Бумага и данные: наборы данных фМРТ и лингвистические аннотации из естественного прослушивания на английском, китайском и французском языках
Цзисин Ли поручила большой команде подготовить эти уникальные нейролингвистические наборы данных.
Говорящие на английском (49), китайском (35) или французском (28) слушали 1,5-часовую аудиокнигу «Маленький принц» во время фМРТ-сканирования. Выпущены полные наборы данных МРТ […] - Презентация на AMLAP2022
Цзы-Юн Тунг будет на встрече Архитектуры и механизмов обработки речи в 2022 году, чтобы представить некоторые из своих диссертационных исследований по извлечению памяти во время понимания языка с использованием комбинации данных ЭЭГ и вычислительных моделей. . Проверьте это! […]
- Увидимся в Филадельфии на SNL2022!
Мы с нетерпением ждем возможности поделиться некоторыми из наших исследований на SNL2022, в том числе: Чонхва Чо: нейронное декодирование грамматических чисел внутри и между языками (постер B11 на постерной сессии B и приеме, четверг, 6, 6 октября :30 – 20:30 по восточноевропейскому времени, […]
- Рэйчел Вайслер поступит на факультет Орегонского университета!
 Говорящие на английском (49), китайском (35) или французском (28) слушали 1,5-часовую аудиокнигу «Маленький принц» во время фМРТ-сканирования. Выпущены полные наборы данных МРТ […]
Говорящие на английском (49), китайском (35) или французском (28) слушали 1,5-часовую аудиокнигу «Маленький принц» во время фМРТ-сканирования. Выпущены полные наборы данных МРТ […]