это 📕 что такое КОВШ
plunge basin гидр., bowl, bucket, cup, dipper, ladle, pan, plunge pool, scoop, energy dissipating trench
* * *
ковш м.1. метал. ladle
2. () bucket, dipper; () scoop
бетоноразда́точный ковш — placing bucket
двухчелюстно́й ковш — two-leaf grab [clamshell] bucket
доза́торный ковш — weigh bucket
ковш дра́глайна — dragline bucket
забра́сывать ковш дра́глайна в рабо́чее положе́ние — swing the (dragline) bucket to the digging position
забра́сывать ковш дра́глайна да́льше головы́ стрелы́ — throw the (dragline) bucket beyond the end of the boom
опора́жнивать ковш дра́глайна — let the (dragline) bucket dump its contents
подтя́гивать ковш дра́глайна к стреле́ — pull the (dragline) bucket toward(s) the machine
золотопромы́вочный ковш — gold pan
лите́йный ковш — foundary ladle
лите́йный, ручно́й ковш — shank ladle
ковш механи́ческой лопа́ты — shovel dipper
ковш промежу́точный метал. — intermediate [pony] ladle
— intermediate [pony] ladle
ковш скре́пера — bowl (of a scraper), scraper bowl
ковш скре́пера среза́ет грунт посло́йно — the scraper bowl removes a strip of earth at a time
ковш скре́пера с элева́торной загру́зкой — elevating scraper bowl
сталеразли́вочный ковш — casting [pouring, teeming] ladle
сталеразли́вочный, бараба́нный ковш — barrel-type ladle
сталеразли́вочный ковш на теле́жке — bogie-mounted steel-teeming ladle
сталеразли́вочный ковш с двумя́ сто́порными устро́йствами — double nozzle-and-stopper steel ladle
сталеразли́вочный ковш со шлакоотдели́телем — skimming ladle
сталеразли́вочный, сто́порный ковш — bottom-tap [bottom-pour] ladle
сталеразли́вочный, теле́жечный ковш — truck ladle
сталеразли́вочный, ча́йниковый ковш — teapot-spout ladle
ковш транспортё́ра — conveyer bucket
ковш фронта́льного одноковшо́вого погру́зчика — bowl
чугуново́зный ковш — hot-metal transfer ladle
шла́ковый ковш — slag [cinder] ladle, slag thimble
ковш экскава́тора — excavator bucket, dipper
заполня́ть ковш экскава́тора — fill the dipper
ковш экскава́тора вхо́дит в грунт — the dipper bites into soil
ковш экскава́тора выгружа́ется в отва́л — the dipper dumps the load
ковш экскава́тора набира́ет грунт — the dipper picks up soil
ковш экскава́тора получа́ет напо́рное движе́ние — the dipper is given a crowding force, a crowding force is applied to the dipper
ковш элева́тора — elevator cup
* * *
scoop
Синонимы:
вакуум-ковш, гитерс, дуршлаг, ковшик, ковшичек, корец, корчик, кюбель, плица, промковш, самолов, скип, скопкарь, сосуд, стальковш, сулойник, хамыяк, черпак, черпалка, черпало, шабала, электроковш, янга
Фонетический разбор имен и фамилий: %d0%9a%d0%be%d0%b2%d1%88%d0%be%d0%b2/
Фонетический разбор имени или фамилии %d0%9a%d0%be%d0%b2%d1%88%d0%be%d0%b2/

% — без звука буква
D — без звука буква
0 — без звука буква
% — без звука буква
9 — без звука буква
A — без звука буква
% — без звука буква
D — без звука буква
0 — без звука буква
% — без звука буква
B — без звука буква
E — без звука буква
% — без звука буква
D — без звука буква
0 — без звука буква
% — без звука буква
B — без звука буква
2 — без звука буква
D — без звука буква
1 — без звука буква
% — без звука буква
8 — без звука буква
8 — без звука буква
% — без звука буква
D — без звука буква
0 — без звука буква
% — без звука буква
B — без звука буква
E — без звука буква
% — без звука буква
D — без звука буква
0 — без звука буква
% — без звука буква
B — без звука буква
2 — без звука буква
/ — без звука буква
Прокомментируйте или поделитесь с друзьями:
Фонетический разбор слова — буквенно-звуковой анализ, то есть определение количества букв, звуков, слогов, выделение гласных и согласных звуков и т.
Правила для фонетического разбора слов
Гласные буквы: А, Е, Ё, И, О, У, Ы, Э, Ю, Я.
Гласные буквы А, О, У, Ы, Э — обозначают твёрдость предыдущих согласных звуков, Е, Ё, И, Ю, Я — обозначают мягкость предыдущих согласных звуков.
В русском языке всего 6 гласных звуков: [а], [о], [у], [и], [ы], [э].
Гласный звук может быть ударным (на который падает ударение) и безударным.
Гласные буквы Е, Ё, Ю, Я обозначают 2 звука (согласный звук [й’] + гласный звук) в следующих случаях: в начале слова, после разделительных мягкого и твёрдого знаков Ь и Ъ, а также после гласной.
Согласные буквы: Б, В, Г, Д, Ж, З, Й, К, Л, М, Н, П, Р, С, Т, Ф, Х, Ц, Ч, Ш, Щ.
Звонкие: [б], [в], [г], [д], [ж], [з], [й], [л], [м], [н], [р].

Глухие: [к], [п], [с], [т], [ф], [х], [ц], [ч], [ш], [щ].
Большинство согласных звуков образуют пары по твёрдости-мягкости: [б] — [б’], [в] — [в’], [г] — [г’], [д] — [д’], [з] — [з’], [к] — [к’], [л] — [л’], [м] — [м’], [н] — [н’], [п] — [п’], [р] — [р’], [с] — [с’], [т] — [т’], [ф] — [ф’], [х] — [х’].
Не образуют пар по твёрдости-мягкости: твёрдые [ж], [ш], [ц] и мягкие [ч’], [щ’], [й’].
Непарные звонкие звуки [й’], [л], [л’], [м], [м’] [н], [н’] [р], [р’] называют сонорными.
Некоторые согласные звуки образуют пары по звонкости-глухости: [б]—[п], [в]—[ф], [г]—[к], [д]—[т], [з]—[с], [ж]—[ш].
Слова делятся на слоги (один звук или несколько звуков, произносимых одним выдыхательным толчком воздуха). Гласные звуки образуют слоги, поэтому в слове столько слогов, сколько в нём гласных звуков.
Комментарии
Не отображается форма? Обновить комментарии.Диктанты по русскому языку 3 класс
Контрольная работа по русскому языку №1. Диктант. 3 класс.
Диктант. 3 класс.
Тема: «Повторение орфограмм корня»
Одинокий.
Поздняя осень. За редкими берёзками видна полоска звёздного неба. В вышине плывёт журавлиная стая.
Близко слышу зов журавля. Вижу одинокую фигуру в низине. Почему он один? Почему не летит со всеми?
Журавль с опаской глядит на меня. Вот он разбежался и легко взлетел. Звучит его грустный крик.
Грамматическое задание.
1 вариант.
1.Выпиши из текста 3-4 слова с проверяемой безударной гласной в корне. Рядом запиши проверочное слово, поставь ударение, отметь корень в словах, подчеркни проверяемую гласную. Образец: слова — слово.
2.Среди данных слов найди и запиши только те, в которых на месте пропуска надо писать букву т.
Счас…ливый, интерес…ный, облас…ной, ус…ный, небес…ный, ненас…ный, ужас…ный, мес…ный, древес…ный, чес…ный
2 вариант.
Выпиши из текста 3-4 слова с проверяемой согласной в корне слова. Рядом напиши проверочные слова. Образец: беседка – беседовать.
Рядом напиши проверочные слова. Образец: беседка – беседовать.
2.Среди данных слов найди и запиши только те, в которых на месте пропуска надо писать букву о.
См…треть, повт…рить, з…нты, стр…на, сл…нёнок, в…л…синка, гл…зок, нас…лить, ч…сы, под…рить, выл…вить
Контрольная работа по русскому языку №2. 3 класс.
Тема: «Фонетический анализ слова, разбор слова по составу»
1 вариант.
1.Раздели слова на слоги.
Теремок, ягода, мельник, читать, стриж
2.Выпиши слова, в которых радом находятся звонкий и глухой согласные звуки.
Место, плавучий, ускакать, дочка, болтун, лилия, детвора
3.Сделай фонетический разбор слова клоун.
4.Выпиши слова с одинаковыми приставками.
Добрый, добежать, дорасти, доска, добраться, домик, доучить
5.Разбери по составу слово пылинка.
2 вариант.
1.Раздели слова на слоги.
Уважение, май, сосульки, змейка, лодочка
2. Выпиши слова, в которых радом находятся два глухих согласных звука.
Выпиши слова, в которых радом находятся два глухих согласных звука.
Место, плавучий, ускакать, союз, дочка, болтун, обжигать, детвора
3.Сделай фонетический разбор слова грязь.
4.Выпиши однокоренные слова.
Боль, больница, больше, болеть, болт, больно, хворать
5.Разбери по составу слово крикун.
Контрольная работа по русскому языку №3. Диктант. 3 класс
Тема: «Простое предложение»
Чижи.
У меня жили чижи – Чижик и Пыжик. Они любили летать по комнатам и сидеть на полках. Там у меня хранились лесные орешки, птичьи гнёздышки, охотничьи ружья.
Иногда чижи ссорились. Бывало взъерошат перья, раскроют клювы и шипят друг на дружку. Но ссоры быстро кончались. Птицы садились на полку и начинали дружно петь.
Слова для справок: ссорились, ссоры, птицы.
Грамматическое задание.
1 вариант
1.Спиши предложения и выдели подлежащее и сказуемое.
Сухая трава побелела от инея.
Лужи затянул тонкий ледок.
2 вариант.
1.Спиши предложения и выдели подлежащее и сказуемое.
С болота донёсся журавлиный клич.
Холодный ветер легко продувает плащ.
Завтра мы пойдём в музей.
Итоговая контрольная работа за 1 четверть по русскому языку №4. Диктант. 3 класс
Тема: «Орфограммы, изученные во втором классе»
Белки.
В еловой чаще с утра до позднего вечера хлопочут ловкие белки.
В развилине дерева повесили сушить маленькие грибки. В лесных кладовых спрятали вкусные орешки. Осенью переменят зверьки свои платьица на серые зимние шубки.
В вершинах густых ёлок устроены у белок тёплые гнёзда. Дно гнёздышка укрыто мягким мхом.
Проворна и весела умница белка.
Грамматическое задание.
1 вариант.
Запиши слова в два столбика:
1) слова с гласной а в приставке;
2)слова с гласной о в приставке;
Н…ступить, …блететь, …тъехать, н…дрезать, д…писать, п…лить, з…вернуть, н…помнить, …бъяснение
2 вариант.
Составь и запиши десять слов с приставками без-, бес-, из-, ис-, раз-, рас- . Отметь приставки в словах.
— ветреный, -винить, -пустить, -шумный, -полезный, -править, -глядеть, -пугать, -толковый, -гладить
Контрольная работа по русскому языку №5. Диктант. 3 класс.
Тема: «Правописание слов, образованных сложением. Буквы о,ё после шипящих. Буква ы после ц».
Август.
Конец лета. Тише стали щёлкать птицы. Громче шорох сухих травинок. Поспел крыжовник. Заалели яркие гроздья ягод на калине.
В лесу прохладно и сыро. Надеваю капюшон и сапоги. Щёголь мухомор стоит на тропинке. Слышны удары лесоруба. Скоро листопад. Берёзки стоят совсем жёлтые. Дуб усыпан золотыми желудями.
Мы говорим шёпотом. Боимся спугнуть тишину.
Примечание: Выделенные написания чётко проговариваются учителем.
Орфографические задания.
1 вариант.
1.Выпиши из диктанта три слова с двумя корнями, подчеркни соединительные гласные.
2.Запиши слова в два столбика: 1) слова с пропущенной буквой е;2)слова с пропущенной о.
Ш…лк, ш…фёр, ч…рный, ш…ссе, реш…тка, уч…ба, ш…в, ш…рты
2 вариант.
1.Выпиши из диктанта три слова с орфограммой «Буквы о,ё после шипящих в корне слова».
2.Запиши слова в два столбика: 1) слова с пропущенной буквой и;2)слова с пропущенной ы
Ц..плёнок, станц..я, традиц…я, ц…ган, ц…рк, (царские) дворц…, (пушистые) зайц…
Контрольная работа по русскому языку №6. 3 класс.
Тема: «Простое предложение; члены простого предложения».
1 вариант.
1.Из предложений выпиши грамматические основы.
Сухая трава побелела от инея. Лужи затянул тонкий ледок. К вечеру небо посветлело.
2.Спиши предложения, найди и подчеркни все обстоятельства.
Мы любили играть под липами. Ярко светит летнее солнышко.
3.запиши предложения. На месте пропусков напиши подходящие по смыслу слова. Подчеркни их как члены предложения.
Я люблю читать (что?)… и мечтать (о чём?) … .
Я выполнил рисунок (чем?) … .
4.Запиши предложения. Определи, каким членом предложения является слово ель.
Ель растёт во влажных лесах. Игрушки висят на ели. На поляне дети увидели ель.
5.Придумай и запиши предложение, чтобы данные слова были указанными членами предложения. Охарактеризуй предложение по цели высказывания и интонации.
Сундук — _______ лежать — ________ старый — чердак — _ _ _ _ _
6(дополнительное).Прочитай текст. Найди и запиши предложение, которое соответствует схеме: _________ _____________ .
Я лежу в душистой траве на лугу. Качаются над головой золотые цветы. Трепещут лёгкие стрекозы. Пробегают по невидимым тропкам муравьи. В небе над облаками кружат быстрые ласточки.
Контрольная работа по русскому языку №6. 3 класс.
3 класс.
Тема: «Простое предложение; члены простого предложения
2вариант.
1.Из предложений выпиши грамматические основы.
С болота донёсся журавлиный клич. Холодный ветер легко продувает плащ. В кустах за поляной раздался посвист рябчика.
2.Спиши предложения, найди и подчеркни все обстоятельства.
Летом под липами ветерок колыхал лиловые колокольчики. Завтра мы пойдём в музей.
3.Запиши предложения, найди и подчеркни все дополнения.
Дуб боится крепких морозов. Отец быстро вскопал грядку.
4.Запиши предложения. Определи, каким членом предложения является слово ёлка .
Возле ёлки разгуливает румяный Дед Мороз. Ребятишки украшают ёлку разноцветными игрушками. Высокие ёлки окружили полянку зелёным хороводом.
5.Придумай и запиши предложение, чтобы данные слова были указанными членами предложения. Охарактеризуй предложение по цели высказывания и интонации.
Сорока — _______ ухаживать — ________ потомство — _ _ _ _ _ _ _ _ заботливо — _ _ _ _ _ _ свой —
6(дополнительное). Прочитай текст. Найди и запиши предложение, которое соответствует схеме: _________ _ _ _ _ _ _____________ .
Прочитай текст. Найди и запиши предложение, которое соответствует схеме: _________ _ _ _ _ _ _____________ .
Я лежу в душистой траве на лугу. Качаются над головой золотые цветы. Трепещут лёгкие стрекозы. Пробегают по невидимым тропкам муравьи. В небе над облаками кружат быстрые ласточки.
Утверждаю
Директор __________________
Контрольная работа по русскому языку №7.
Итоговый диктант за 1 полугодие
Тема: «Орфограммы изученные в 1 и 2 четвертях 3-го класса».
Кормушка.
Зима. Стоит чудесный денёк. Ребята сделали для птиц кормушку, насыпали хлебных крошек и повесили её на берёзу. Для синиц они привязали на дерево кусочки сала.
К кормушке подлетели снегири, воробьи, голуби. На ветку берёзы сели прелестные птички. На голове чёрная шапочка. Спина, крылья, хвостик и головка синие. Это синицы. Радостно им иметь хороших друзей.
Орфографическое задание.
1 вариант.
1. Во втором предложении найди и подчеркни однородные члены предложения.
2.Запиши слова в 3 столбика: 1-й слова, с орфограммой в приставке, 2-й с орфограммой в корне, 3-й с орфограммой в суффиксе. Буквы –орфограммы подчеркни.
Полёты, поляна, звёздный, ключик, жучок, шёлк, подъём, отставил, сказка, зайчонок.
2 вариант.
1. В пятом предложении найди и подчеркни однородные члены предложения.
2. Запиши слова в 3 столбика: 1-й слова, с орфограммой в приставке, 2-й с орфограммой в корне, 3-й с орфограммой в суффиксе. Буквы –орфограммы подчеркни.
Помыл, зимой, вкусный, замочек, мышонок, шорты, подъехал, отклеил, пробка, бычок
Контрольная работа по русскому языку №8. Диктант. 3 класс.
Тема: «Суффиксы»
Весенняя поездка.
В субботу мы всем классом ездили за город. Учительница Алла Петровна хотела показать нам цветущий вишнёвый сад. Посадка занимала большую территорию. Роскошь цветущих деревьев околдовала нас.
Учительница повела нас к роднику. Она взяла ковш, зачерпнула холодной родниковой водицы. Какой вкусной она была!
Вечерело. Луч солнца тронул вершинки вишенок. Пора домой. Надолго запомнили мы чудесную поездку.
Слова для справок: всем, цветущий, околдовала, вечерело.
1 вариант.
1.От данных слов образуй и запиши слова с сочетанием -ечк- или –ичк-.
Единица, книжка, пташка, страница, ложка, подушка, чашка, шишка.
2.Спиши слова. Вставь, где это необходимо, мягкий знак.
Стриж…, дрож…, падеж…, мяч…, лож…, экипаж…, тиш…, ключ…,
2вариант.
1.От данных слов образуй и запиши слова с сочетанием -енк- или –инк-.
Тропа, вишня, солома, сосна, царапина, башня, трещина, смородина
2.Спиши слова. Вставь, пропущенные буквы.
Букаш…чка, рубаш…чка, кош…чка, чаш…чка, сит…чко, врем…чко, сем…чко, пугов…чка
Контрольная работа по русскому языку №9.Контрольное изложение. 3 класс.
3 класс.
Весна идёт.
Весна. Оживает природа. Скоро зазвучит над проталинкой первая песня жаворонка. Вот-вот талая вода затопит луга и леса, раздвинет узкие берега ручьёв и превратит лужицы в озёра, а озёра в моря.
Сухие соломинки потревожил лёгкий ветерок, и они кланяются, встречают весну. Поднимаю палый листик, а там спит жучок, не проснулся ещё.
Пройдёт месяц и ландыш нарушит лесную тишь звоном фарфоровых колокольчиков, зажужжат пчёлы, зашелестит листва.
Контрольная работа по русскому языку №10. Диктант. 3 класс.
Тема: «Правописание окончаний имён существительных»
Енот.
Живёт енот в дупле, а ночью бродит по болотам, берегам рек и озёр. Шёрстка у него длинная, густая. На хвостике окраска кольцами то светлее, то темнее. На морде шерсть чёрная с белой оторочкой.
Поймает енот лягушку, рака, мышь, ящерицу и сначала полощет их в воде. За это назвали его енотом-полоскуном. Енот, и жёлуди, и орехи, и ягоды тоже моет. Заодно и лапки помоет перед едой.
Енот, и жёлуди, и орехи, и ягоды тоже моет. Заодно и лапки помоет перед едой.
Контрольная работа по русскому языку №11. 3 класс.
Итоговый диктант за 3-ю четверть.
Тема: «Правописание окончаний имён существительных»
Кукушонок.
На вершине ели было гнездо. Рядом с маленькими яичками там лежало одно большое. Его подкинула кукушка.
Птенцы вылупились. Родители усердно кормили птенцов. Кукушонок стал выталкивать братьев из гнезда.
Мой внучок забрал подкидыша домой. Кукушонок поселился в старом птичьем гнезде. Кошки Мурки тогда в доме не было. Птенец без страха летал по комнате. Скоро пушок на крылышках сменили перья. Мы выпустили кукушонка на волю.
Слова для справок: яички, его
Орфографическое задание. 1 вариант
1.От данных слов образуй и запиши слова с сочетанием –инк- или –енк-.
Проталина, спальня, вишня, царапина, башня, сосна, калина
2.Поставь каждое слово в форму творительного падежа, единственного числа. Отметь окончания.
Отметь окончания.
Душ, камыш, палец, сердце, кольцо, улица, кирпич, птица,
Образец: товарищ – товарищем (Т.п., ед. ч.).
2 вариант
1. От данных слов образуй и запиши слова с суффиксами -ок-, -ик- или –ек-.
Чеснок. Сад, рог, горох, чердак, сук, кусок, конверт
2.Поставь каждое слово в форму дательного падежа, единственного числа. Отметь окончания.
Цель, степь, туча, ночь, сестра, роща, печь, мышь
Образец: сестра – сестре (Д. п., ед. ч.).
Контрольная работа по русскому языку №12. Списывание. 3 класс.
Тема: «Орфограммы в корне слова»
Спиши текст. Выпиши из текста по два примера на каждую указанную орфограмму. Буквы орфограммы подчеркни.
«Звонкие и глухие согласные в корне слова».
«Безударные гласные в корне слова».
«Буквы ё и о после шипящих в корне слова».
Мышь – малютка.
Мышь – малютка – самый маленький грызун в лесу. Весит она всего несколько граммов. Шёрстка у неё коричневая, глазки чёрные, грудка белая. Мышь- малютка ловко лазает по высоким стеблям, листьям и кустам. В высокой траве зверёк сплетает из травинок чудесное гнёздышко-шалашик. Оно подвешено на стебельке высоко над землёй. Не страшен мышке ветер и мороз. Утеплила она гнёздышко внутри мягкими былинками. Скоро там появятся крошечные мышата.
Весит она всего несколько граммов. Шёрстка у неё коричневая, глазки чёрные, грудка белая. Мышь- малютка ловко лазает по высоким стеблям, листьям и кустам. В высокой траве зверёк сплетает из травинок чудесное гнёздышко-шалашик. Оно подвешено на стебельке высоко над землёй. Не страшен мышке ветер и мороз. Утеплила она гнёздышко внутри мягкими былинками. Скоро там появятся крошечные мышата.
Контрольная работа по русскому языку №13. 3 класс.
Тема: «Имя прилагательное и его грамматические признаки»
1 вариант.
1.Запиши словосочетания, в которых имена прилагательные стоят в женском роде.
Высокий дом, железная лестница, синее море, королевская конница, тёмный чердак, зелёное растение, звонкая песня, строгий учитель, доброе лицо, летняя веранда.
2.Спиши словосочетания. В скобках укажи род, число и падеж имён прилагательных.
Старый ослик, на верхней полке, тёмной ночью, для первого класса
3. Спиши предложения, подчеркни все имена прилагательные как члены предложения.
Спиши предложения, подчеркни все имена прилагательные как члены предложения.
Летним днём мы шли по сосновому лесу. Белый туман расстилается над тихими лугами.
4.Выпиши только качественные имена прилагательные, письменно подбери антоним к каждому записанному слову.
Большой, лисий, бумажный, узкий, апельсиновый, острый, папин
5.Запиши данные имена прилагательные в краткой форме, в мужском роде, в единственном числе.
Грубый, умный, седой, сильный
Образец: красивый – красив (м. р., ед.ч.)
6(дополнительное). Спиши текст. Найди притяжательные прилагательные, подчеркни их как члены предложения, определи род, число и падеж этих прилагательных.
Протянулся через дорогу и скрылся в густом ельнике заячий след. Тонкий лисий след вьётся вдоль дороги. Шустрая белка махнула пушистым хвостиком и прыгнула на ёлку.
Контрольная работа по русскому языку №13. 3 класс.
Тема: «Имя прилагательное и его грамматические признаки»
2 вариант.
1.Запиши словосочетания, в которых имена прилагательные стоят в мужском роде. Чёрные брюки, ёлочная игрушка, высокое дерево, хороший прыжок, райская птица, старое здание, широкий проспект, трудное правило, зимние вечера, новое упражнение, верный друг, дальняя дорога, воскресный день
2.Выпиши из текста имена прилагательные вместе с существительными, от которых они зависят. Отметь окончания имён прилагательных, в скобках укажи род, число и падеж. Зима завалила деревню пушистым снегом. Веточки берёз украсил белый иней. С верхушки старой ёлки сорвалась птица. Снег белой бахромой осел на тонких веточках сирени.
3.Спиши предложения, подчеркни все имена прилагательные как члены предложения. По вечерам мама накидывала старый бабушкин пуховый платок и читала нам сказки. Серый осенний дождь грустно стучит по мокрой крыше.
4.Выпиши только относительные имена прилагательные. Рядом запиши слова, от которых они образовались. Лимонный, широкий, высокий, птичий, шёлковый, кислый, дедушкин, настенный
5. Выпиши имена прилагательные в краткой форме, женского рода, единственного числа. Ласковы, ласкова, ласковая, наимудрейшая, мудрая, мудрее, мудра, аккуратная, аккуратен, аккуратна, Внимательная, внимательна, внимателен, прекрасная, прекраснейшая, прекрасна, прекраснее
Выпиши имена прилагательные в краткой форме, женского рода, единственного числа. Ласковы, ласкова, ласковая, наимудрейшая, мудрая, мудрее, мудра, аккуратная, аккуратен, аккуратна, Внимательная, внимательна, внимателен, прекрасная, прекраснейшая, прекрасна, прекраснее
6(дополнительное). Спиши текст. Найди качественные имена прилагательные, подчеркни их как члены предложения, определи род, число и падеж этих прилагательных.
Протянулся через дорогу и скрылся в густом ельнике заячий след. Тонкий лисий след вьётся вдоль дороги. Шустрая белка махнула пушистым хвостиком и прыгнула на ёлку.
Итоговая контрольная работа по русскому языку №14 за 3 класс.
Тема: «Орфограммы, изученные в 3 классе»
1 вариант.
1. Сделай фонетический разбор слова лень.
2.Разбери по составу слово белизна.
3.Спиши словосочетания, определи склонение и падеж имён существительных.
Добраться до города, поделиться с сестрой, услышать в тиши
4. Спиши предложения. Определи род, число и падеж всех имён прилагательных.
Спиши предложения. Определи род, число и падеж всех имён прилагательных.
Жаркий июльский день угасает. Косой солнечный луч золотит вершину молодой сосны. Не слышно птичьих голосов.
5.Спиши. Подчеркни члены предложения и определи известные тебе части речи.
Младшая сестра учится в музыкальной школе. Летний дождь барабанит в окно.
6(дополнительное). Прочитай текст и выпиши слово с такой характеристикой: имя существительное, женского рода, 3-го склонения, стоит в форме единственного числа, винительного падежа, в предложении является обстоятельством.
Узкая тропинка привела нас в лесную глушь. На изумрудных полянках играет солнечный луч. На листочках дрожат прозрачные капельки росы.
Итоговая контрольная работа по русскому языку №14 за 3 класс.
Тема: «Орфограммы, изученные в 3 классе»
2 вариант.
1. Сделай фонетический разбор слова пляж.
2.Разбери по составу слово часовой.
3.Спиши предложение, определи склонение и падеж имён существительных.
Из Москвы на север летит быстрый самолёт
4.Выпиши из текста качественные имена прилагательные с существительными, от которых они зависят. Определи род, число и падеж этих прилагательных.
Жаркий июльский день угасает. Косой солнечный луч золотит вершину молодой сосны. Не слышно птичьих голосов.
5.Спиши. Подчеркни члены предложения и определи известные тебе части речи.
Холодом дышит звёздное небо. Я читаю книги перед сном.
6(дополнительное). Прочитай текст и выпиши слово с такой характеристикой: имя существительное, женского рода, 1-го склонения, стоит в форме множественного числа, предложного падежа, в предложении является обстоятельством.
Узкая тропинка привела нас в лесную глушь. На изумрудных полянках играет солнечный луч. На листочках дрожат прозрачные капельки росы.
Итоговая контрольная работа по русскому языку №15 за 3 класс.
Диктант.
Лето.
Коротка летняя ночь. Заиграл первый луч солнца. Подул ветерок. Зашелестели листики. Всюду проснулась жизнь. На зелёный лужок прилетели пчёлы. Жужжат, торопятся к цветам мохнатые шмели.
К лесной опушке слетаются птицы. Звенят в воздухе их радостные песенки. Прибегают на полянку лесные зверьки. Слышны разные звуки, шорохи, голоса. Вот белочка в рыжей шубке сделала лёгкий прыжок и оказалась на вершине сосенки. Ёжик пробежал в своё жилище. Хлопочут усердные муравьи.
Орфографическое задание.
1 вариант.
1.Допиши окончания, в скобках укажи падеж и склонение имён существительных.
В кроват… — в кроватк…, о мам… — о матер…, для мышк… — об мышк…
2 вариант.
1.Допиши окончания, в скобках укажи падеж и склонение имён существительных.
В кроват… — в кроватк…, о мам… — о матер…, для мышк… — об мышк…
В каком слове все согласные звуки глухие: чеснок, салат, капуста картофель?
Чтобы выполнить фонетический разбор слова программистка, вначале разделю его на слоги и поставлю ударение:
про-гра-мми-стка.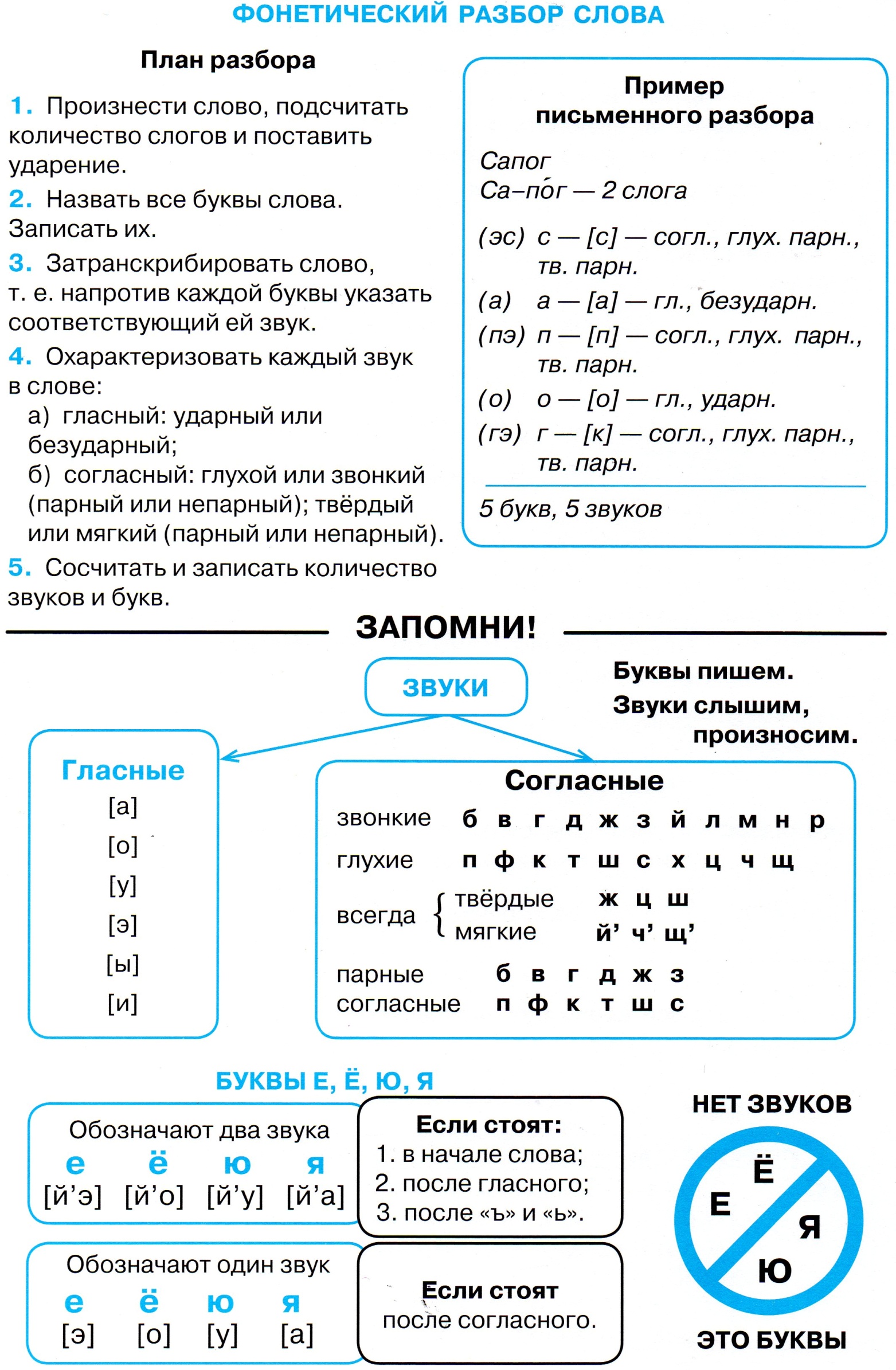 (Двойной согласный звучит как один длинный звук и образует самостоятельный слог).
(Двойной согласный звучит как один длинный звук и образует самостоятельный слог).
При произношении этого существительного ударным является гласный третьего слога, из-за чего первый гласный искажается. Сделаю запись звучания слова:
[п р а г р а м’ и с т к а].
Далее распишу все звуки вертикально и дам им фонетическую характеристику:
В конце звуко-буквенного разбора подсчитаем количество букв и звуков. Их оказалось поровну:
12 букв и 12 звуков.
Чтобы выполнить фонетический разбор слова полёвка, отметим вначале, что ударным является второй слог:
по-лё-вка.
Из-за этого в первом предударном слоге неясно слышится гласный. А перед глухим согласным [к] оглушается звонкий [в], в результате чего это сществительное имеет вот такое звучание:
[п а л’ о ф к а].
Запишем звуки слова вертикально и дадим им фонетическую характеристику:
В конце фонетического разбора рассматриваемого существительного подсчитаем количество букв и звуков, которых оказалось поровну:
7 букв и 7 звуков.
Выполним фонетический (звуко-буквенный) разбор слова «динозавр«:
- в данном слове три слога: ди-но-завр.
- ударение падает на третий слог, на букву «а»: динозАвр (ударная буква выделена заглавной и жирным шрифтом).
- слово может переноситься следующим образом: ди-нозавр, дино-завр.
- транскрипция выглядит так: [д’иназавр].
- в слове 8 букв (из них 5 соглас/х и 3 гласных) и 8 звуков, где также 5 соглас/х и 3 гласн.
- часть речи: существительное.
Охарактеризуем каждый звук:
Букве «Д» соответствует звук_[д’]_согласн., мягк.парн., звонк.парн.
Букве «И» соответствует звук_[и]_гласн., безударн.
Букве «Н» соответствует звук_[н]_согласн., звонк.непарн., твёрд.парн., сонорн.
Букве «О» соответствует звук_[а]_гласн., безударн.
Букве «З» соответствует звук_[з]_согласн. , звонк.парн., твёрд.парн.
, звонк.парн., твёрд.парн.
Букве «А» соответствует звук_[а]_гласн., ударн.
Букве «В» соответствует звук_[в]_согласн., звонк.парн., твёрд.парн.
Букве «Р» соответствует звук_[р]_согласн., звонк.непарн., твёрд.парн., сонорн.
Выполним фонетический (звуко-буквенный) разбор слова «жёлтый«:
- в данном слове два слога: жёл-тый.
- ударение падает на первый слог, на букву «ё»: жЁлтый (ударная буква выделена заглавной и жирным шрифтом).
- слово может переноситься следующим образом: жёл-тый.
- транскрипция выглядит так: [жолтый’].
- в слове 6 букв (из них 4 соглас/х и 2 гласн.) и 6 звуков, где также 4 согл/х и 2 гласн.
- часть речи: прилагательное (отвечает на вопрос «какой?»).
Охарактеризуем каждый звук:
Букве «Ж» соответствует звук_[ж]_согласн., тверд.непарн., звонк.парн.
Букве «Ё» соответствует звук_[о]_гласн., ударн.
Букве «Л» соответствует звук_[л]_согласн., звонк.непарн., твёрд.парн., сонорн.
Букве «Т» соответствует звук_[т]_согласн., глух.парн., твёрд.парн.
Букве «Ы» соответствует звук_[ы]_гласн., безударн.
Букве «Й» соответствует звук_[й’]_согласн., звонк.непарн., мягк.непарн., сонорн.
Выполним фонетический (звуко-буквенный) разбор слова «ковш»:
- в данном слове один слог: ковш.
- ударение падает на букву «о»: кОвш (ударная буква выделена заглавной и жирным шрифтом).
- слово не переносится, пишется полностью: ковш.
- транскрипция выглядит следующим образом: [кофш].
- в слове 4 буквы (из них 3 соглас/х и 1 гласн.) и 4 звука, где также 3 согл/х и 1 гласн.
- часть речи: существительное (отвечает на вопрос «что?»).
Охарактеризуем каждый звук:
Букве «к» соответствует звук_[к]_согласн. , твёр.пар., глух.пар.
, твёр.пар., глух.пар.
Букве «о» соответствует звук_[о]_гласн., ударн.
Букве «в» соответствует звук_[ф]_согласн., глух.пар., тверд.парн.
Букве «ш» соответствует звук_[ш]_согласн., глух.парн., твёрд.непар.
Тест по русскому языку. Фонетика, орфография, графика. 10 класс. Ответы. на Сёзнайке.ру
1 вариант
1. Какой раздел языкознания изучает звуковую сторону языка?
А) морфология,
Б) орфография,
В) графика,
Г) фонетика,
Д) словообразование.
2. Что такое транскрипция?
А) перевод слова на русский язык,
Б) орфографическое письмо,
В) форма передачи звучащей речи графическими средствами,
Г) разбор слова по составу,
Д) морфемный анализ слова.
3. Какие буквы не участвуют в русской транскрипции?
А) ы, я, ю.
Б) а,о,у,
В) ч, ж, х,
Г) ц, ф, э,
Д) я, ю, е, ё.
4. На какие группы делятся все звуки?
На какие группы делятся все звуки?
А) прописные и строчные;
Б) ударные и безударные,
В) звонкие и глухие,
Г) мягкие и твердые,
Д) гласные и согласные.
5. На какие группы делятся согласные звуки?
А) звонкие/глухие, твердые/мягкие,
Б) звонкие/мягкие, глухие/твердые,
В) ударные и безударные,
Г) звонкие/твердые, глухие/мягкие,
Д) прописные и строчные.
6. На какие группы делятся гласные звуки?
А) прописные и строчные,
Б) звонкие/мягкие, глухие/твердые,
В) звонкие/глухие, твердые/мягкие,
Г) звонкие/твердые, глухие/мягкие,
Д) ударные и безударные.
7. Что такое словесное ударение?
А) выделение одного слога в слове,
Б) минимальная звуковая единица,
В) акустические свойства звука,
Г) выделение одного слова в предложении,
Д) максимальная звуковая единица.
8. Что изучает орфоэпия?
А) словарный состав языка,
Б) звуковую сторону языка,
В) звуки и буквы,
Г) способы образования слов,
Д) части речи и их формы.
9. Укажите верный вариант транскрипции слова яблонька:
А) [‘йаблан’ка],
Б) [яблон’ка],
В) [‘йаблон’ка],
Г) [‘йаблонка],
Д) [‘йаблонька].
10. Укажите верный вариант переноса слова:
А) брат-ство, мор-ской, разъ-яс-нить,
Б) судь-ба, класс-ный, чер-вя-чка,
В) расс-каз, клас-сный, е-дин-ство,
Г) бегс-тво, е-динс-тво, су-дьба,
Д) бра-тство, морс-кой, ра-зъяс-нить.
11. Выберите вариант с непроверяемой безударной гласной в корне слова:
А) башмак, человек, корабль,
Б) неспроста, ослепительный, создавать,
В) ворона, воробей, сорока,
Г) руководить, капуста, знобит,
Д) безразлично, лошадка, полотно.
12. Подумайте, какой вариант здесь лишний:
А) загар, изложение, заря,
Б) росток, постелить, обжигать,
В) рядовой, рассказать, приласкать,
Г) плавать, собирать, равнина,
Д) вытер, прикоснуться, умереть.
13. Какую гласную и почему вы напишите в словах пр..брежный, пр..клеить, пр..встать?
А) –и, т.к. приставки близки по значению к слову «очень»,
Б) –е, т.к. можно заменить приставкой пере-,
В) –е, т.к. приставки близки по значению к слову «очень»,
Г) –и, т.к. приставки обозначают присоединение, неполное действие, близость к чему- либо,
Д) –и, т.к. т.к. можно заменить приставкой пере-.
14. В каком слове Ь служит для обозначения формы слова?
А) мощь,
Б) моль,
В) возьми,
Г) колье,
Д) пьеса.
15. Выберите верный вариант написания слов:
А) конечный результат, папин плащ, настежь,
Б) лес дремуч, намажьте маслом, много училищь,
В) замуж, портьера, пустош,
Г) невтерпежь, испечь, хорош,
Д) среди тучь, почки, сможешь
16. В каких словах есть Ъ?
А) п..еса, об..ект, с..узить,
Б) пред. .октябрьский, трех..этажный, без..аварийный,
.октябрьский, трех..этажный, без..аварийный,
В) с..экономил, сверх..интересно, от..утюжить,
Г) сверх..естественно, пред..январский, трех..ярусный,
Д) пред..юбилейный, барел..еф, из..ясняться.
17. Укажите вариант с О после шипящих:
А) ш..пот, круч..ный, щ..лочь,
Б) береж..т, туш..нка, ж..лудь, печ..ный,
В) стаж..р, реш..тка, освещ..нный, ещ..,
Г) изж..га, лодч..нка, свеж.., смеш..н,
Д) холщ..вый, зайч..нок, ч..ткий.
18. Выделите вариант с непроизносимой согласной:
А) словес..ный, безопас..ный,
Б) вкус..ный, прекрас..ный,
В) горес..ный, радос..ный,
Г) искус..ный, ровес..ник, чудес..ный,
Д) ше..ствие, че..ствовать, блес..нуть.
19. Выберите строку с приставкой без-:
А) бе..граничный, бе..заветный,
Б) бе..крайний, бе..цельный,
В) бе..конечный, бе..толковый,
Г) бе..правный, бе..совестный,
Д) бе..словесный, бе. .шумный.
.шумный.
20. Найдите вариант слова с ударением на последнем слоге:
А) центнер,
Б) копировать,
В) начал,
Г) газопровод,
Д) камбала.
2 вариант
1.Назовите непарный по глухости – звонкости согласныйА) [ т ]
Б) [ к ]
В) [ х ]
Г) [ с ]
Д) [ ф ]
2. В разделе «Фонетика» изучается:
А) правописание слов
Б) постановка знаков препинания
В) словарный состав языка
Г) состав слова
Д) звуки речи
3. В каком слове звуков больше, чем букв?
А) яблоки
Б) пень
В) день
Г) соловьи
Д) скворцы
4. Раздел «Орфоэпия» изучает:
А) состав слова
Б) звуки речи
В) правописание слов
Г) словосочетание
Д) произношение слов
5. В каком слове буква Ё обозначает один звук?
А) пьёт
Б) ёжик
В) ёлка
Г) объём
Д) полёт
6. Назовите основные средства графики.
Назовите основные средства графики.
А) звуки
Б) буквы
В) слоги
Г) ударение
Д) произношение
7. Звуком речи является:
А) минимальная звуковая единица, которая выделяется при звуковом членении слова,
Б) специальный вид письма
В) совокупность норм речи
Г) система ударений
Д) фиксация речи
8. Что называется графикой?
А) акустические свойства
Б) звуки человеческой речи
В) классификация звуков
Г) способы образования звуков
Д) совокупность средств письменности, используемых для фиксации речи
9 . Найдите вариант только со звонкими согласными:
А) р,й,з,г,ж
Б) к,г,ж,д,в
В) м,ч,ш,щ,л
Г) д,т,з,к,ф
Д) н,б,ц,в,м
10 . Какая буква обозначает два звука?
А) э
Б) у
В) ю
Г) ы
Д) и
11. В каком сочетании предлог С произносится звонко?
А) с ошибкой
Б) с реки
В) с крылом
Г) с горы
Д) с языком
12. Укажите слово, в котором есть звук О:
Укажите слово, в котором есть звук О:
А) отлив
Б) огурец
В) слепок
Г) Москва
Д) кровля
13. Назовите слово с безударной гласной в корне, проверяемой ударением:
А) бетон
Б) печаль
В) трясина
Г) портфель
Д) капуста
14 .В каком слове ударение падает на второй слог?
А) квартал
Б) каталог
В) дозвонишься
Г) средства
Д) некролог
15.Укажите слово с равным количеством букв и звуков:
А) лечить
Б) ядерный
В) лень
Г) стажёр
Д) святое
16. Укажите слова, в которых происходит оглушение:
А) фуражка, грибков
Б) сдача, сбить
В) сбегать, сделать
Г) сгоряча, сдвинуть
Д) сгореть, сгиб
17. Укажите слово с Ъ (твёрдым знаком):
А) вороб…и
Б) п…едестал
В) ин…екция
Г) бул…он
Д) уст…е
18. В каком слове все согласные звуки твёрдые:
А) след
Б) ртуть
В) ножик
Г) один
Д) сварщик
19. Выделите вариант с непроизносимой согласной:
Выделите вариант с непроизносимой согласной:
А) словес…ный, безопас…ный
Б) вкус…ный, прекрас…ный
В) горес…ный, радос…ный
Г) искус…ный, ровес…ник
Д) чудес…ный, блес…нуть
20. Укажите вариант с О после шипящих:
А) изж..га, лодч..нка, свеж.., смеш..н,
Б) береж..т, туш..нка, ж..лудь, печ..ный,
В) стаж..р, реш..тка, освещ..нный, ещ..,
Г) ш..пот, круч..ный, щ..лочь,
Д) холщ..вый, зайч..нок, ч..ткий.
Ответы
1 вариант
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Г |
В |
Д |
Д |
А |
Д |
А |
Б |
А |
А |
|
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
А |
В |
Г |
А |
А |
Г |
Г |
В |
А |
Г |
2 вариант
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
В |
Д |
А |
Д |
Д |
Б |
А |
Д |
А |
В |
|
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
Г |
Д |
В |
А |
Г |
А |
В |
В |
В |
А |
определение, произношение, транскрипция, словоформы, примеры
существительное
— примерно цилиндрический сосуд, открытый вверху (син . : ведро)
: ведро) — количество, содержащееся в ведре (синоним: ведро)
глагол
— положить в ведро
— нести в ведро
Дополнительные примеры
Мы использовали два ведра с краской, чтобы покрасить гостиную.
…сделали ведра денег на фондовом рынке …
… набирая воду из колодца, мы помчались тушить пожар …
… посадка войск на ковшовые десантные катера оказалась сложной задачей …
Греческий, тот великий колодец, откуда мы ведем наши условия.
Пили пиво ведрами.
На сделке они заработали кучу денег.
Мы устанавливаем ловушку, балансируя ведро с водой на верхней части двери, чтобы она упала на него, когда он войдет.
Ведро воды и замша
Она смотрела, как в ведре течет вода.
В ведре дыра, и вода вытекает.
Он опустил ведро в колодец.
Он стоял с ведром с ледяной водой в одной руке и влажной губкой в другой.
Просто зацепите ведро за веревку и опустите вниз.
Возьмите ведро, чтобы промыть двор.
Формы слова
глагол
I / you / we / they: bucket
he / she / it: buckets
причастие настоящего времени: ведение
прошедшее время: разделенное
причастие прошедшего времени: разделенное
существительное
единственное число: ведро
множественное число: ведра
bucket_1 существительное — определение, изображения, произношение и примечания по использованию
- [счетное] открытый контейнер с ручкой, используемый для переноски или хранения жидкостей, песка и т.
 Д.синоним ведро
Д.синоним ведро- пластиковое ведро
- (британский английский) Они играли на пляже своими ведрами и лопатками.
- Дети сбегали на пляж со своими ведрами и лопатками.
- Уборщик отложил швабру и ведро и сел.
- Песок просыпался из пожарного ведра.
- помойное ведро, полное остатков еды
- быть полным чем-то
- содержать что-то
- держать что-то
- …
- in a / the bucket
- ведро
- ведро и лопата
- швабра и ведро
- [исчисляемый] большой контейнер, который является частью крана или экскаватора и используется для подъема вещей
- [исчисляемый] количество, содержащееся в ведре
- два ведра / полных ведра воды
- ведро / полное ведро Использовали пить чай ведрами (= в больших количествах).
- Она вылила ведро с грязной водой в канализацию.
- ведро овса для лошадей
- большие ведра попкорна и колы
- быть полным чем-то
- содержать что-то
- держать что-то
- …
- в / Ведро
- ведро
- ведро и лопата
- швабра и ведро
ведра
[множественное число] (неофициальное) большое количество- Чтобы добиться успеха в шоу-бизнесе, вы нужны ведра уверенности.
- Плакали ведрами.
- К концу гонки он сильно вспотел.
- Дождь лил ведрами (= шел очень сильный дождь).
 Д.синоним ведро
Д.синоним ведро
Происхождение слова Среднеанглийский язык: от англо-нормандского французского buquet «ванна, ведро», возможно, от древнеанглийского būc «живот, кувшин».
(британский английский капля в море)
- количество чего-то слишком маленького или неважного, чтобы реально изменить ситуацию
- Сумма денег поднятый был каплей в море по сравнению с тем, что нам было нужно.
- (неформальный или юмористический) to die
(PDF) Фонетические модели для создания вариантов орфографии.
3.1.3 Реализация
Мы используем пакет GIZA ++ [Och and Ney, 2003] для обучения
наших моделей перевода. Мы получаем выравнивание между
буквами и фонемами в обоих направлениях с помощью GIZA ++
, а затем на основе выравнивания строим мод перевода
els как для «текста в речь», так и для «речи в текст».
Мы используем статистическую языковую модель CMU-Cambridge —
ing toolkit4 для построения языковых моделей. Мы используем языковые модели на основе триграммы
Мы используем языковые модели на основе триграммы
как для букв, так и для фонем.
Следуя Knight и Graehl [1997], мы представляем каждую
наших языковых моделей как взвешенный конечный автомат
(WFSA) и каждую из наших моделей перевода как взвешенный преобразователь конечных состояний
(WFST).Затем мы используем набор инструментов преобразователя конечного состояния USC / ISI
Carmel5 для определения положения com-
между соответствующими WFST и WFSA до
, чтобы получить два декодера WFST на основе шумных каналов — один переходит от букв к фонемам (текст в речь), а другой —
от фонем к буквам (речь к тексту).
Чтобы получить варианты написания для данного имени, мы помещаем
два декодера WFST на основе шумных каналов в каскад.
сначала генерирует n-лучший список произношений для заданного имени входа
. Второй затем создает n-лучший список заклинаний —
олов для каждого произношения. Затем мы объединяем n-
Затем мы объединяем n-
лучших вариантов написания, сгенерированных каждым из произношений, и
ранжируем объединенный вывод, сортируя его на основе (а) увеличения-
порядка изменения расстояния редактирования от исходного имени, (б) удаления.
порядок сгибания веса, который вариант имени получает от декодера
, и (c) порядок убывания количества раз, когда вариант
генерируется при различных произношениях.Связи, если есть
, разрываются случайным образом.
3.2 Список методов Soundex
В этом методе мы используем огромную базу данных имен, объединенных
с алгоритмом сопоставления фонетических звуков Soundex
, чтобы найти варианты написания.
3.2.1 Создание списка имен
Интернет содержит множество имен собственных. Можно искать
и создавать базы данных имен, вручную собирая различные списки имен, такие как списки детских имен, списки переписи и т. Д.
Мы обнаружили, что попытка создания списков имен вручную
не только утомительная задача, но также приводит к очень редко заполняемым спискам
. Даже лучший ресурс имен, о котором мы знаем
Даже лучший ресурс имен, о котором мы знаем
, список имен переписи населения США, содержит менее
100 000 имен, и это только имена США. Помимо
, это списки, составленные вручную и тщательно подготовленные экспертами
, в основном хорошо написанные имена.Нас интересует
, обнаруживающий распространенные орфографические ошибки в именах.
Чтобы преодолеть эти ограничения, мы решили создать список
имен автоматически. Используя корпус, содержащий около
10 ГБ английского текста, собранный из Интернета в предыдущем проекте
[Ravichandran et al., 2005], мы применили BBN
IdentiFinder, современную систему извлечения именованных сущностей.
тем [Bikel et al., 1999], к нему. Мы извлекли все сущности
, которые экстрактор именованных сущностей пометил как «имена людей».
Это дало нам список из примерно 7,3 миллиона уникальных имен.
4 http://svr-www.eng.cam.ac.uk/~prc14/toolkit.html
5 http://www. isi.edu/licensed-sw/carmel
isi.edu/licensed-sw/carmel
3.2.2 Алгоритм Soundex
Расстояние Левенштейна или расстояние редактирования [Hall and Dowling,
1980] — это мера сходства между двумя строками, измеряемая с учетом количества вставок, удалений и замен
, необходимых для преобразования строки в другую.
Традиционно для обнаружения и исправления ошибок правописания использовалось расстояние редактирования.
Обнаружение и исправление ошибок [Кукич, 1992]. Мы можем использовать
такое же расстояние редактирования в качестве меры для поиска имен, которые
близки к заданному имени, выполнив поиск в списке имен.
Но вычисляемое расстояние редактирования между двумя строками составляет O (n2) в
длине строк. На практике невозможно использовать
эту меру при сравнении с большим списком.Нам нужно
, чтобы получилось лучше. Мы должны, по крайней мере, сначала сократить наши даты кандидатов
, а затем использовать расстояние редактирования в этом сокращенном списке из
кандидатов.
Алгоритм Soundex [Knuth, 1973], впервые запатентованный в
1918 Маргарет О’Делл и Робертом К. Расселом, представляет собой приблизительный алгоритм сопоставления строк
. Он производит грубое (
) представление для строки с использованием шести фонетических классов
звуков человеческой речи (двухгубных, губно-зубных, зубных, альвео-
ларных, велярных и голосовых).Представление состоит из первой буквы слова
, за которой следуют три цифры, которые вместе
представляют фонетический класс этого слова.
Мы используем Soundex, чтобы разделить наш огромный список имен на
ячеек с похожими по звучанию именами, а затем проиндексировать наш список по
, четырехзначному коду Soundex. Теперь, когда мы получаем имя
, варианты которого необходимо найти, мы можем смотреть только на
, соответствующий Soundex-bin, а не на весь список, таким образом,
делает поиск вариантов возможным на практике.
3. 2.3 Реализация
2.3 Реализация
Мы используем систему извлечения именованных сущностей BBN Identi-
finder для идентификации именованных сущностей в нашем корпусе. Затем мы собираем
все имена «людей» из помеченного корпуса и находим
все уникальные имена вместе с их частотами корпуса.
Затем мы запускаем Soundex в списке имен и делим затем
на ячейки с похожими по звучанию именами. Мы получаем около 7000
ящиков, в среднем по 1000 наименований в каждой ячейке.
Чтобы получить варианты имени, мы сначала находим код Soun-
dex для этого имени. Затем в соответствующем бине Soundex-
мы находим n-лучших вариантов, сортируя их на основе (а)
в порядке увеличения расстояния редактирования от исходного имени и
(б) в порядке убывания частоты в корпусе. Связи, если таковые имеются,
разрываются случайным образом.
4 Эксперименты
4.1 Экспериментальная установка
Не сразу понятно, как можно оценить генератор орфографии имени
. Поэтому мы проводим эксперименты, чтобы
Поэтому мы проводим эксперименты, чтобы
измерить производительность различных методов в задаче создания вариантов орфографии
.
Сначала мы случайным образом выбираем 30 американских имен из списка
детских имен. Мы запускаем каждую из систем (включая базовый уровень
) для этих имен и генерируем 25 лучших вариантов
для каждого из этих имен. Затем мы просим человека посмотреть на
имен, сгенерированных каждой системой, и отметить их как хорошие или
Агрегирование гистограммы | Руководство по Elasticsearch [7.13]
Агрегирование гистограммы
Агрегирование значений на основе источника с несколькими сегментами, которое может применяться к извлеченным числовым значениям или значениям числового диапазона.
из документов. Он динамически создает сегменты фиксированного размера (также известные как интервал) по значениям. Например, если
в документах есть поле, содержащее цену (числовую), мы можем настроить эту агрегацию для динамического создания корзин с
интервал 5 (в случае цены может составлять 5 долларов). Когда выполняется агрегирование, поле цены каждого документа
будет оцениваться и округляться до ближайшего к нему сегмента — например, если цена составляет
Когда выполняется агрегирование, поле цены каждого документа
будет оцениваться и округляться до ближайшего к нему сегмента — например, если цена составляет 32 , а размер ведра
равно 5 , тогда округление даст 30 , и, таким образом, документ «упадет» в корзину, связанную с
ключ 30 .Чтобы сделать это более формальным, вот используемая функция округления:
bucket_key = Math.floor ((значение - смещение) / интервал) * интервал + смещение
Для значений диапазона документ может быть разделен на несколько сегментов. Первый сегмент вычисляется из нижнего граница диапазона точно так же, как вычисляется сегмент для одного значения. Последний сегмент вычисляется в том же путь от верхней границы диапазона, и диапазон считается во всех сегментах между ними и включая эти два.
Интервал должен быть положительным десятичным числом, а смещение должно быть десятичным в [0, интервал) (десятичное число больше или равно 0 и меньше интервал )
Следующий фрагмент «ведра» товаров на основе их цены с интервалом 50 :
POST / sales / _search? Size = 0
{
"aggs": {
"Цены": {
"гистограмма": {
"поле": "цена",
«интервал»: 50
}
}
}
} И ответ может быть следующий:
{
. ..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0,0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 100,0,
«doc_count»: 0
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
}  ..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0,0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 100,0,
«doc_count»: 0
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
}
..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0,0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 100,0,
«doc_count»: 0
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
} Минимальное количество документов
Ответ, приведенный выше, показывает, что ни один из документов не имеет цены в диапазоне [100, 150) .По умолчанию
ответ заполнит пробелы в гистограмме пустыми сегментами. Можно изменить это и запросить сегменты с
более высокое минимальное количество благодаря настройке min_doc_count :
POST / sales / _search? Size = 0
{
"aggs": {
"Цены": {
"гистограмма": {
"поле": "цена",
«интервал»: 50,
«min_doc_count»: 1
}
}
}
} Ответ:
{
. ..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0.0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
}  ..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0.0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
}
..
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0.0,
«doc_count»: 1
},
{
«ключ»: 50,0,
«doc_count»: 1
},
{
«ключ»: 150,0,
«doc_count»: 2
},
{
«ключ»: 200,0,
«doc_count»: 3
}
]
}
}
} По умолчанию гистограмма возвращает все сегменты в пределах диапазона самих данных, то есть документы с
наименьшие значения (на которых с гистограммой) будут определять минимальный сегмент (сегмент с самым маленьким ключом) и
документы с наивысшими значениями определяют максимальный сегмент (сегмент с самым высоким ключом).Часто, когда
при запросе пустых корзин это вызывает путаницу, особенно когда данные также фильтруются.
Чтобы понять, почему, давайте рассмотрим пример:
Допустим, вы фильтруете свой запрос, чтобы получить все документы со значениями от 0 до 500 , кроме того, вы хотите
чтобы разрезать данные по цене, используя гистограмму с интервалом 50 . Вы также указываете
Вы также указываете "min_doc_count": 0 , как вы
люблю получать все ведра, даже пустые.Если случится так, что все товары (документы) имеют цены выше 100 ,
первое ведро, которое вы получите, будет с ключом 100 . Это сбивает с толку, как часто вам хотелось бы
чтобы получить эти ведра от 0 до 100 .
С настройкой extended_bounds теперь вы можете «принудительно» агрегировать гистограмму, чтобы начать построение сегментов на определенном мин. Значение , а также продолжать наращивать ведра до значения макс. (даже если документов больше нет).С использованием extended_bounds имеет смысл только тогда, когда min_doc_count равно 0 (пустые сегменты никогда не будут возвращены, если min_doc_count больше 0).
Обратите внимание, что (как следует из названия) extended_bounds — это , а не сегменты фильтрации. Это означает, что если extended_bounds. больше
чем значения, извлеченные из документов, документы по-прежнему будут определять, какой будет первая корзина (и
то же самое касается  min
min extended_bounds.max и последнее ведро). Для фильтрации сегментов следует вложить агрегацию гистограммы
под диапазоном фильтруйте агрегацию с соответствующими настройками от / до .
Пример:
POST / sales / _search? Size = 0
{
"запрос": {
"constant_score": {"filter": {"range": {"price": {"to": "500"}}}}
},
"aggs": {
"Цены": {
"гистограмма": {
"поле": "цена",
«интервал»: 50,
"extended_bounds": {
«мин»: 0,
«макс»: 500
}
}
}
}
} При агрегировании диапазонов сегменты основываются на значениях возвращенных документов.Это означает, что ответ может включать
сегменты вне диапазона запроса. Например, если ваш запрос ищет значения больше 100, и у вас есть диапазон
охватывающий от 50 до 150 и интервал 50, этот документ будет разделен на 3 сегмента — 50, 100 и 150. Как правило, это
лучше всего рассматривать шаги запроса и агрегирования как независимые — запрос выбирает набор документов, а затем
агрегация группирует эти документы независимо от того, как они были выбраны.
См. Примечание о диапазоне ковша
поля для получения дополнительной информации и примера.
Как правило, это
лучше всего рассматривать шаги запроса и агрегирования как независимые — запрос выбирает набор документов, а затем
агрегация группирует эти документы независимо от того, как они были выбраны.
См. Примечание о диапазоне ковша
поля для получения дополнительной информации и примера.
hard_bounds является аналогом extended_bounds и может ограничивать диапазон сегментов в гистограмме. это
особенно полезно в случае диапазонов открытых данных, которые могут привести к очень большому количеству сегментов.
Пример:
POST / sales / _search? Size = 0
{
"запрос": {
"constant_score": {"filter": {"range": {"price": {"to": "500"}}}}
},
"aggs": {
"Цены": {
"гистограмма": {
"поле": "цена",
«интервал»: 50,
"hard_bounds": {
«мин»: 100,
«макс»: 200
}
}
}
}
} В этом примере, даже если диапазон, указанный в запросе, составляет до 500, гистограмма будет иметь только 2 сегмента, начиная с 100 и 150. Все остальные сегменты будут опущены, даже если документы, которые должны попасть в эти сегменты, присутствуют в результатах.
Все остальные сегменты будут опущены, даже если документы, которые должны попасть в эти сегменты, присутствуют в результатах.
По умолчанию возвращенные сегменты сортируются по их ключу по возрастанию, хотя поведение порядка можно контролировать с помощью
установка порядка . Поддерживает те же функции порядка , что и Terms Aggregation .
По умолчанию ключи сегмента начинаются с 0, а затем продолжаются с равными интервалами. интервала , эл.грамм. если интервал равен 10 , первые три сегмента (при условии
внутри них есть данные) будет [0, 10) , [10, 20) , [20, 30) . Ведро
границы могут быть смещены с помощью параметра смещение .
Лучше всего это проиллюстрировать на примере. Если имеется 10 документов со значениями от 5 до 14, использование интервала 10 приведет к
два ведра по 5 документов в каждом. Если используется дополнительное смещение 5 , будет только один сегмент [5, 15) , содержащий все 10
документы.
По умолчанию сегменты возвращаются в виде упорядоченного массива. Также возможно запросить ответ в виде хеша вместо ключа ведра ключи:
POST / sales / _search? Size = 0
{
"aggs": {
"Цены": {
"гистограмма": {
"поле": "цена",
«интервал»: 50,
"keyed": правда
}
}
}
} Ответ:
{
...
"агрегаты": {
"Цены": {
"buckets": {
"0.0": {
«ключ»: 0,0,
«doc_count»: 1
},
«50.0 ": {
«ключ»: 50,0,
«doc_count»: 1
},
"100.0": {
«ключ»: 100,0,
«doc_count»: 0
},
"150.0": {
«ключ»: 150,0,
«doc_count»: 2
},
"200.0": {
«ключ»: 200,0,
«doc_count»: 3
}
}
}
}
} Параметр отсутствует параметр определяет, как следует обрабатывать документы, в которых отсутствует значение.
По умолчанию они будут игнорироваться, но их также можно рассматривать как если бы они
имел значение.
POST / sales / _search? Size = 0
{
"aggs": {
"количество": {
"гистограмма": {
"поле": "количество",
«интервал»: 10,
«пропавших без вести»: 0
}
}
}
} Документы без значения в поле количества |
При выполнении агрегирования гистограммы по полям гистограммы вычисляется общее количество отсчетов для каждого интервала.
Например, выполнение агрегирования гистограммы по следующему индексу, в котором хранятся предварительно агрегированные гистограммы. с показателями задержки (в миллисекундах) для разных сетей:
PUT metrics_index / _doc / 1
{
"network.name": "net-1",
"latency_histo": {
"значения": [1, 3, 8, 12, 15],
«считает»: [3, 7, 23, 12, 6]
}
}
PUT metrics_index / _doc / 2
{
"network. name": "net-2",
"latency_histo": {
"значения": [1, 6, 8, 12, 14],
«считает»: [8, 17, 8, 7, 6]
}
}
POST / metrics_index / _search? Size = 0
{
"aggs": {
"latency_buckets": {
"гистограмма": {
"поле": "latency_histo",
«интервал»: 5
}
}
}
}  name": "net-2",
"latency_histo": {
"значения": [1, 6, 8, 12, 14],
«считает»: [8, 17, 8, 7, 6]
}
}
POST / metrics_index / _search? Size = 0
{
"aggs": {
"latency_buckets": {
"гистограмма": {
"поле": "latency_histo",
«интервал»: 5
}
}
}
}
name": "net-2",
"latency_histo": {
"значения": [1, 6, 8, 12, 14],
«считает»: [8, 17, 8, 7, 6]
}
}
POST / metrics_index / _search? Size = 0
{
"aggs": {
"latency_buckets": {
"гистограмма": {
"поле": "latency_histo",
«интервал»: 5
}
}
}
} Гистограмма агрегация будет суммировать счетчики каждого интервала, вычисленные на основе значений , и
верните следующий вывод:
{
...
"агрегаты": {
"Цены": {
"ведра": [
{
«ключ»: 0,0,
«doc_count»: 18
},
{
«ключ»: 5,0,
«doc_count»: 48
},
{
«ключ»: 10,0,
«doc_count»: 25
},
{
«ключ»: 15,0,
«doc_count»: 6
}
]
}
}
} Агрегация гистограмм — это агрегация сегментов, которая разбивает документы на сегменты, а не вычисляет показатели по таким полям, как
агрегации показателей делают. Каждая корзина представляет собой набор документов, на которых могут работать субагрегации.
С другой стороны, поле гистограммы — это предварительно агрегированное поле, представляющее несколько значений внутри одного поля:
ведра числовых данных и количество предметов / документов для каждого ведра. Это несоответствие между ожидаемыми входными данными гистограммы.
(ожидаются необработанные документы) и поле гистограммы (которое предоставляет сводную информацию) ограничивают результат агрегации
только количество документов для каждого сегмента.
Каждая корзина представляет собой набор документов, на которых могут работать субагрегации.
С другой стороны, поле гистограммы — это предварительно агрегированное поле, представляющее несколько значений внутри одного поля:
ведра числовых данных и количество предметов / документов для каждого ведра. Это несоответствие между ожидаемыми входными данными гистограммы.
(ожидаются необработанные документы) и поле гистограммы (которое предоставляет сводную информацию) ограничивают результат агрегации
только количество документов для каждого сегмента.
Следовательно, при выполнении агрегации гистограммы над полем гистограммы никакие субагрегации не допускаются.
Кроме того, при выполнении агрегирования гистограммы по полю гистограммы не поддерживается отсутствующий параметр .
Ансамблевой подход к крупномасштабному нечеткому сопоставлению имен | Пиюш Сагар мишра | BCG GAMMA
, Ранджан Кант и Пиюш Сагар Мишра
Базы данных являются частью жизни каждого — от использования карт для утреннего кофе до размещения фотографий бранча на выходных; от проверки банковского баланса до совершения покупок в Интернете — мы работаем с базами данных в течение всего дня. Изменение бизнес-требований и развитие Интернета привели к появлению новых типов баз данных, включая тесно связанные реляционные базы данных, системы хранения документов, хранилища значений ключей и хранилища с широкими столбцами. По мере того, как потребители принимают новые форматы данных, такие как структурированные, текстовые, изображения, видео, аудио и машинные журналы, предприятия наблюдают пересечение бизнес-требований и развивающихся форматов данных и, в ответ, интегрируют новые алгоритмы и технологические структуры в свои экосистемы.
Изменение бизнес-требований и развитие Интернета привели к появлению новых типов баз данных, включая тесно связанные реляционные базы данных, системы хранения документов, хранилища значений ключей и хранилища с широкими столбцами. По мере того, как потребители принимают новые форматы данных, такие как структурированные, текстовые, изображения, видео, аудио и машинные журналы, предприятия наблюдают пересечение бизнес-требований и развивающихся форматов данных и, в ответ, интегрируют новые алгоритмы и технологические структуры в свои экосистемы.
Поскольку количество и типы данных продолжают экспоненциально увеличиваться, возникло множество проблем, чаще всего в зависимости от масштаба и шума в данных. Одной из таких задач является приблизительное сопоставление строк или нечеткое сопоставление имен, в котором цель по имени или списку имен состоит в том, чтобы найти наиболее похожие имена из другого списка. Область нечеткого сопоставления имен не нова, но с появлением мобильных и веб-приложений, платформ социальных сетей, новых служб обмена сообщениями, журналов устройств и других форматов открытых данных нюансы данных выросли, что усложняет задачу сопоставления имен. сложный.
сложный.
Чтобы оценить проблему, представьте, что вы являетесь владельцем международной логистической компании. Ваша служба доставки получает несколько тысяч посылок каждый день. Для каждого из них они должны отсканировать штрих-код посылки и проверить детали доставки через онлайн-портал, а затем ввести имя и адрес в службе GPS, чтобы начать процесс доставки. После тщательного наблюдения за этим процессом, время отправки значительно задерживается из-за проблем, вызванных вводимой вручную информацией, такой как примечания отправителя или системные записи.Некоторые из распространенных проблем, с которыми команда, отвечающая за ввод этих данных, может сталкиваться ежедневно:
- Компании с разными префиксами или суффиксами: PT Indo Tambangraya Megah, Tbk vs. Tamban Graya Megah, Индонезия .
- Сокращенные названия: MSFT Corp vs. Microsoft Corporation.
- Имена, в которых название региона сопровождает основное название: Suzhou Synta Optical Technology.
- Языки и скрипты, которые различаются в зависимости от региона: Colgate vs. 高露洁 (gāo lù jié)
- Имена в системе с ошибками: Giordano International Limited, HK vs. . Gordano Intl ‘Ltd., Гонконг
- Информация, которая существует в базе данных в различных форматах: Ключевые продукты — железная руда, медь vs. «… занимается экспортом железной руды и меди. … »
- Имена с лишними или отсутствующими пробелами: Chu Kong Passenger Transport Co Ltd .по сравнению с ChuKong Passenger Trans. Co.

Если бы таких записей было всего несколько сотен, ваша группа могла бы сопоставить имена вручную, сравнивая каждую строку со всеми другими строками и выбирая похожие. Но ваша логистическая компания имеет дело с миллионами таких записей. Сопоставление вручную было бы не просто непрактично, но и невозможно вообразить. (Для более строгой формулировки проблемы, пожалуйста, обратитесь к [1], [2] и [3].) Эти строки текста являются вашей единственной объединяющей точкой для этих записей, поэтому правильное сопоставление похожих строк жизненно важно.Дублирующиеся записи о клиентах могут вызвать плохой таргетинг (повторяющиеся имена клиентов), слабую доставку (неверные результаты поиска) или неправильный маркетинг (разные продукты, проданные одному и тому же клиенту, или возможность рассылки спама).
Сопоставление вручную было бы не просто непрактично, но и невозможно вообразить. (Для более строгой формулировки проблемы, пожалуйста, обратитесь к [1], [2] и [3].) Эти строки текста являются вашей единственной объединяющей точкой для этих записей, поэтому правильное сопоставление похожих строк жизненно важно.Дублирующиеся записи о клиентах могут вызвать плохой таргетинг (повторяющиеся имена клиентов), слабую доставку (неверные результаты поиска) или неправильный маркетинг (разные продукты, проданные одному и тому же клиенту, или возможность рассылки спама).
Несмотря на то, что проблема сопоставления этих строк практически вездесуща и очень важна для обслуживания клиентов, растущая изменчивость и сложность текстовых данных по-прежнему делает сопоставление строк сложной задачей. Хотя на рынке существует множество инструментов поиска, поиск по имени — это совсем другое дело, и он требует принципиально иного подхода.
В следующей статье мы расскажем, как приручить этого зверя. «Ансамблевой» подход к нечеткому сопоставлению имен обеспечивает ту точность, которая необходима, чтобы избежать проблем с клиентами, и делает это в масштабе предприятия. Мы использовали этот подход с клиентом BCG, в данном случае с крупным корпоративным банком. Перед тем, как мы начали процесс, банку требовалась команда из 10 человек для выполнения сопоставления строк в наборе данных, который был в 100 раз меньше, чем полная база данных клиентов банка.
«Ансамблевой» подход к нечеткому сопоставлению имен обеспечивает ту точность, которая необходима, чтобы избежать проблем с клиентами, и делает это в масштабе предприятия. Мы использовали этот подход с клиентом BCG, в данном случае с крупным корпоративным банком. Перед тем, как мы начали процесс, банку требовалась команда из 10 человек для выполнения сопоставления строк в наборе данных, который был в 100 раз меньше, чем полная база данных клиентов банка.
Существующий в банке процесс ручной проверки очень хорошо помогал возвращать очень качественные спички.Проблема заключалась в том, что после того, как команда базы данных отфильтровала имена по качеству, группа продаж получила только десятки потенциальных клиентов. После того, как мы внедрили механизм ансамблевого сопоставления нечетких имен, результаты соответствовали тому же стандарту точности, что и ручной процесс, но увеличили количество качественных потенциальных клиентов в 500 раз, и это увеличение произошло в течение месяца после запуска двигателя. При наличии механизма согласования в течение всего времени проекта всего три месяца банк пережил резкий скачок в количестве потенциальных клиентов, потребовал меньшего количества сотрудников для достижения лучших результатов, мог более эффективно распределять ценное время специалистов по анализу данных и испытал меньшее количество потенциальных клиентов. операционные расходы.В этой статье будет подробно описано, как наша команда BCG достигла всех этих результатов для нашего клиента.
При наличии механизма согласования в течение всего времени проекта всего три месяца банк пережил резкий скачок в количестве потенциальных клиентов, потребовал меньшего количества сотрудников для достижения лучших результатов, мог более эффективно распределять ценное время специалистов по анализу данных и испытал меньшее количество потенциальных клиентов. операционные расходы.В этой статье будет подробно описано, как наша команда BCG достигла всех этих результатов для нашего клиента.
Проблема сопоставления строк не ограничивается конкретной отраслью. От интернет-магазинов, которые должны сопоставить миллионы входящих поисковых запросов с каталогами продуктов, до крупных государственных организаций, которые должны сопоставлять имена и адреса для таких случаев использования, как управление идентификацией и отслеживание списков наблюдения, крупномасштабная система нечеткого сопоставления — это современное предприятие. необходимость. В глобальных условиях растущее словарное содержание и гибкость словарного запаса между языками и диалектами означает, что механизмы нечеткого сопоставления должны решать множество сложных проблем, в том числе:
1. Фонетические вариации: Kohl’s против Coles
Фонетические вариации: Kohl’s против Coles
2. Типографические ошибки : Microsoft vs. Microsft
3. Контекстные различия : Компания vs. Организация
4. Условия изменения порядка : Sam Hopkins vs. Hopkins Sam
5. Префиксы и суффиксы : AJO Technology Company Limited vs. AJO tech Private Co., Ltd.
6. Аббревиатуры, псевдонимы и инициалы : AJ Wilson vs. Alex Jane Wilson
7. Межъязыковая семантика: Private limited vs. 私人
8. Различия в транслитерации: Традиционный китайский и пиньинь
9. Усеченные буквы и пропущенные или лишние пробелы : Chu Kong Transport Company vs. ChuKong Transport Co. Ltd. Разрешение, связь с записями и другие проблемы) сталкиваются как компании, так и научные круги в течение нескольких лет. Благодаря развитию Python и связанных с ним библиотек машинного обучения теперь существует несколько подходов к решению таких проблем. Проблема в том, что большинство известных фреймворков (как автономных, так и гибридных) либо подходят для конкретного варианта использования, либо требуют значительной настройки перед развертыванием в корпоративной среде. Крупные организации, такие как Amazon, Google и Microsoft, вложили много времени и усилий в создание механизмов, которые ищут шаблоны в запросах, сопоставляют шаблоны с поиском или контекстом пользователя, а затем предоставляют результаты или предложения.Однако менее капитализированные организации все еще пытаются овладеть искусством и наукой выполнения приблизительного сопоставления строк в масштабе. Некоторые из наиболее распространенных подходов, которые организации используют для выполнения сопоставления строк, включают (подробнее здесь):
Благодаря развитию Python и связанных с ним библиотек машинного обучения теперь существует несколько подходов к решению таких проблем. Проблема в том, что большинство известных фреймворков (как автономных, так и гибридных) либо подходят для конкретного варианта использования, либо требуют значительной настройки перед развертыванием в корпоративной среде. Крупные организации, такие как Amazon, Google и Microsoft, вложили много времени и усилий в создание механизмов, которые ищут шаблоны в запросах, сопоставляют шаблоны с поиском или контекстом пользователя, а затем предоставляют результаты или предложения.Однако менее капитализированные организации все еще пытаются овладеть искусством и наукой выполнения приблизительного сопоставления строк в масштабе. Некоторые из наиболее распространенных подходов, которые организации используют для выполнения сопоставления строк, включают (подробнее здесь):
- Метод общего ключа для фонетического или информационного сходства: Суть этого подхода заключается в сокращении строк до ключа на основе их произношения. или языковая семантика. Некоторые из наиболее распространенных алгоритмов, используемых в этом подходе, включают Soundex, Metaphone, Double Metaphone, Beider-Morse.
- Метод расстояния редактирования: Этот метод является одним из наиболее часто используемых подходов для решения проблемы нечеткого сопоставления и входит в качестве стандартного модуля в большинство платформ аналитики / бизнес-аналитики, которые поддерживают параметры обработки данных / ETL. Основной подход алгоритмов, которые принадлежат этому методу, состоит в том, чтобы посмотреть, сколько изменений символов (количество вставок, удалений или транспозиций символов) необходимо для перехода от одного имени к другому. Отраслевые стандарты, такие как расстояние Левенштейна, расстояние Яро – Винклера и коэффициент подобия Жаккара, подпадают под этот метод.
- Подходы со статистическим сходством: Статистический подход использует большое количество совпадающих пар имен (обучающий набор) и обучает модель распознавать, как выглядят два «похожих имени», чтобы модель могла взять набор из двух имен и назначить оценка сходства. Эти статистические подходы очень хорошо работают для серьезных проблем, а также могут поддерживать имена в разных скриптах. Недостатком является то, что они имеют высокий барьер для входа, поскольку подготовка обучающего набора данных с совпадающими именами требует значительных ручных усилий и значительного времени.
- Методы внедрения слов: Нюансы в наборах данных не всегда связаны с содержанием: они также могут возникать из-за контекста, в котором появляется информация. Например, «лекарство» и «фармацевтика» означают одно и то же в контексте фармацевтических компаний, но обычные подходы нечеткого сопоставления, основанные на фонетике, расстоянии редактирования или списках, не улавливают это сходство. Эта проблема обычно наблюдается при работе с названиями организаций, а не с именами собственными, и усложняется по мере увеличения количества и длины слов в строке.Встраивание слов — числовое векторное представление семантического значения слова — может выявить подобные различия, глядя на сходство между математическим представлением двух слов. Если два слова или документа имеют похожее вложение, они будут считаться семантически похожими. Например, вложения «женщина» и «девушка» близки друг к другу с точки зрения векторных представлений, что означает, что они будут считаться семантически похожими. Применительно к организациям метод встраивания слов может распознать, например, что JDR Drugs и JDR Pharmaceuticals , скорее всего, являются одной и той же компанией.
- Разное: Помимо обычно используемых подходов, выделенных выше, компании могут также использовать собственные алгоритмы, основанные на одном или нескольких из вышеперечисленных методов, или они могут использовать другие методы, такие как методы кластеризации с общим ключом или короткого текста.
 или языковая семантика. Некоторые из наиболее распространенных алгоритмов, используемых в этом подходе, включают Soundex, Metaphone, Double Metaphone, Beider-Morse.
или языковая семантика. Некоторые из наиболее распространенных алгоритмов, используемых в этом подходе, включают Soundex, Metaphone, Double Metaphone, Beider-Morse. Эти статистические подходы очень хорошо работают для серьезных проблем, а также могут поддерживать имена в разных скриптах. Недостатком является то, что они имеют высокий барьер для входа, поскольку подготовка обучающего набора данных с совпадающими именами требует значительных ручных усилий и значительного времени.
Эти статистические подходы очень хорошо работают для серьезных проблем, а также могут поддерживать имена в разных скриптах. Недостатком является то, что они имеют высокий барьер для входа, поскольку подготовка обучающего набора данных с совпадающими именами требует значительных ручных усилий и значительного времени. Если два слова или документа имеют похожее вложение, они будут считаться семантически похожими. Например, вложения «женщина» и «девушка» близки друг к другу с точки зрения векторных представлений, что означает, что они будут считаться семантически похожими. Применительно к организациям метод встраивания слов может распознать, например, что JDR Drugs и JDR Pharmaceuticals , скорее всего, являются одной и той же компанией.
Если два слова или документа имеют похожее вложение, они будут считаться семантически похожими. Например, вложения «женщина» и «девушка» близки друг к другу с точки зрения векторных представлений, что означает, что они будут считаться семантически похожими. Применительно к организациям метод встраивания слов может распознать, например, что JDR Drugs и JDR Pharmaceuticals , скорее всего, являются одной и той же компанией.Было проведено несколько сравнительных экспериментов для оценки пригодности алгоритмов ([4] и [5]), и почти во всех алгоритмах ни одна модель не способна решить все проблемы. Несмотря на то, что производительность каждого алгоритма зависит от контекста проблемы, используемого языка или требований к объему и времени выполнения, большинство проблем сопоставления имен можно резюмировать следующим образом:
- Неспособность обрабатывать несколько сценариев: Большинство известных алгоритмов связаны ограничением скриптов. Некоторые подходят только для латыни, в то время как другие могут пересекаться с алфавитом. Но большинство этих алгоритмов могут одновременно обрабатывать только один сценарий. Таким образом, организации, которые работают с многоязычными источниками или каналами данных, не могут использовать эти алгоритмы как есть.
- Компромисс между отзывом и точностью : Хотя подходы, основанные на общих ключах или методах на основе списков, предлагают очень высокий уровень отзыва, их точность крайне низка в корпусах с высокой дисперсией. Подходы со статистическим подобием также обеспечивают очень высокую точность, но работают намного медленнее и требуют большого объема высококачественных обучающих данных.
- Высокие вычислительные ресурсы и время выполнения: Требования к вычислениям для современных современных технологий продолжают расти в геометрической прогрессии. Несмотря на то, что с этой проблемой можно довольно легко справиться, время выполнения остается серьезной проблемой, особенно для компаний электронной коммерции, клиенты которых требуют мгновенных результатов и мгновенного удовлетворения.
- Отсутствие обратной связи : Большинство подходов к сопоставлению имен имеют одну общую черту: со временем все они ограничивают автоматические улучшения.Эвристика может применяться для конкретных случаев, когда конкретный алгоритм не работает должным образом, но такие исправления могут очень быстро привести к чрезвычайно сложным и трудоемким проектам.
- Сложность интерпретации стоп-слов : Организации обычно настраивают пользовательские стоп-слова для очистки строк перед выполнением операций сопоставления. Даже в этом случае многие стоп-слова могут играть решающую роль в семантике. В большинстве случаев организации призывают включить или исключить стоп-слово, исходя из приблизительной доли затронутых совпадений.
- Обработка нескольких ключей соединения : Некоторые организации могут иметь дело с наборами данных, включающими несколько ключей, каждый из которых сформирован из строкового поля, такого как имя и адрес клиента; или название, описание и другие атрибуты продукта. В таких случаях механизм должен быть достаточно гибким, чтобы обрабатывать различные конвейеры сопоставления строк, а затем агрегировать баллы по каждому атрибуту, чтобы получить единую оценку и вернуть список совпадений.
- Кандидатам без рейтинга необходим эвристический уровень для определения наилучших совпадений: Во многих случаях пользователь ожидает получить не просто список, а ранжированный список, который определяет «наилучшее совпадение», «второе наилучшее совпадение, » и так далее.Ранжированные результаты обычно обрабатываются с помощью ручных правил или пороговых значений, которые настраиваются с течением времени. Однако небольшие изменения в распределении входных данных или пороге сходства могут нарушить всю логику, деликатно предсказанную на обучающем наборе данных.
- Контекстуальные сходства не имеют себе равных: Все методы, основанные на содержании, не учитывают совпадение или контекстное сходство и, таким образом, не могут идентифицировать похожие сущности, такие как «лекарство» и «фармацевтика». Несмотря на то, что эти различия возникают только для второстепенных строк в именах (на нарицательные существительные эти проблемы не влияют), вспомнить общий метод очень плохо.
 Некоторые подходят только для латыни, в то время как другие могут пересекаться с алфавитом. Но большинство этих алгоритмов могут одновременно обрабатывать только один сценарий. Таким образом, организации, которые работают с многоязычными источниками или каналами данных, не могут использовать эти алгоритмы как есть.
Некоторые подходят только для латыни, в то время как другие могут пересекаться с алфавитом. Но большинство этих алгоритмов могут одновременно обрабатывать только один сценарий. Таким образом, организации, которые работают с многоязычными источниками или каналами данных, не могут использовать эти алгоритмы как есть.
 В таких случаях механизм должен быть достаточно гибким, чтобы обрабатывать различные конвейеры сопоставления строк, а затем агрегировать баллы по каждому атрибуту, чтобы получить единую оценку и вернуть список совпадений.
В таких случаях механизм должен быть достаточно гибким, чтобы обрабатывать различные конвейеры сопоставления строк, а затем агрегировать баллы по каждому атрибуту, чтобы получить единую оценку и вернуть список совпадений. Несмотря на то, что эти различия возникают только для второстепенных строк в именах (на нарицательные существительные эти проблемы не влияют), вспомнить общий метод очень плохо.
Несмотря на то, что эти различия возникают только для второстепенных строк в именах (на нарицательные существительные эти проблемы не влияют), вспомнить общий метод очень плохо. В нашем недавнем проекте упомянутый выше крупный банк хотел ускорить свой рост на высококонкурентных рынках (тех, на которых средний размер конкурентов был значительно больше, чем у указанного банка). Одним из вариантов использования, определяющих общее видение, было выявление новых потенциальных клиентов для их набора решений, состоящего из более чем 50 продуктов. Чтобы привлечь потенциальных клиентов, наша команда BCG сравнила более 200 открытых, социальных и сторонних источников данных. Из них мы отобрали 45 источников данных, включая внутренние наборы данных, такие как транзакции, профиль и исторические интересы.Поскольку внимание клиента было сосредоточено на рынках Азиатско-Тихоокеанского региона, некоторые источники данных были доступны только на региональных языках, таких как китайский, тайский и бахаса. Наша конечная цель состояла в том, чтобы подготовить витрину данных, которая могла бы способствовать генерированию информации и идентификации профилей для более чем десяти миллионов компаний, а затем помочь нашим клиентам составить короткий список и расставить приоритеты для потенциальных клиентов.
Наша конечная цель состояла в том, чтобы подготовить витрину данных, которая могла бы способствовать генерированию информации и идентификации профилей для более чем десяти миллионов компаний, а затем помочь нашим клиентам составить короткий список и расставить приоритеты для потенциальных клиентов.
При создании такого актива данных было пять основных проблем:
- Идентификация одних и тех же компаний в наборах данных: Это была основная задача всего проекта, и она является предметом основной части данной статьи.Имея объем данных, охватывающий несколько форматов, мы столкнулись с огромной проблемой в выявлении одних и тех же компаний в разных сценариях. Для этого мы реализовали ряд подмодулей:
- Нормализовать названия и адреса компаний во всех наборах данных и привести их в стандартный формат.
- Удаление шума из имен в виде префиксов, суффиксов, стоп-слов, региональных дополнений и других параметров.
- Сопоставление названий компаний в разных наборах данных.
- Учитывайте языковые различия между отдельными частями информации компании, представленной на латыни, мандаринском, тайском, бахасском и других региональных языках.

- Выбор наиболее значимой информации для каждой записи в наборе данных: Наша вторая серьезная проблема заключалась в интерпретации полезности конкретного поля с точки зрения полноты, охвата, удобства использования и правильности. Это было настолько сложно, потому что почти все наборы данных содержали одну и ту же информацию, представленную в нескольких областях: ключевые руководители vs.ключевое руководство, акционеры и ключевые руководители, покупатели / поставщики и сеть цепочки поставок.
- Обработка текста в каждом отдельном наборе данных для нормализации полей: Каждый из 45 наборов данных имел свои нюансы:
- Наборы данных содержали информацию в различных текстовых форматах: в некоторых наборах данных ключевые продукты существовали как ключевые слова ( меди , железная руда ), в то время как в других они существовали как предложения ( «… занимается экспортом меди, железной руды…» ).
- Адреса были неполными, удаленными или непонятными в нескольких местах. Например, « 234-xxx, Cecil Street, Alexandra Ro» или «Patin Majar, 23/245 / xxx, Tanjong Pagar, Central Sing».
- Текст хранился с использованием разных разделителей (запятые, вертикальная черта и другие специальные символы, такие как ‘,’ «, ‘-‘) и предоставлялся поставщиками в разных форматах (JSON, CSV, XLSX, SQLDB, MongoDB и т. Д.) .

- Агрегирование информации из разных источников данных: Клиент ожидал, что основная база данных будет содержать более 1000 полей информации для более чем 10 000 000 компаний.Эти поля включали такие детали, как профиль компании, адрес, ключевые руководители, акционеры, финансовые показатели, ключевые покупатели, поставщики, описания продуктов, конкуренты и последние отраслевые разработки. После того, как мы связали все идентичные компании, нашим следующим шагом было перенести необходимую информацию из всех наборов данных на витрину агрегированных данных.
- Создание механизма аудита и обратной связи: Поскольку клиент ожидал, что структура будет самодостаточно генерировать потенциальных клиентов, одной из наших ключевых задач была разработка информационного аудита (качество входных данных, отображаемой информации о потенциальных клиентах для пользователя на уровне представления) и уровень обратной связи, который будет постоянно улучшать логику и улучшать качество потенциальных клиентов.

Поскольку мы знали об имеющихся ограничениях и имеющихся каркасах решений, лучшим способом для нас построить крупномасштабную систему нечеткого сопоставления было «перейти на гибрид». В ходе процесса, который длился три месяца для сквозной разработки, мы повторили более 50 различных компонентов и протестировали их в широком диапазоне сценариев использования (граничные условия, переполнения, исключения формата и т. Д.), Прежде чем разработать окончательный вариант. Механизм нечеткого сопоставления, который состоял из пяти основных модулей:
Модуль 1: Определение языка и транслитерация: Как отмечалось ранее, данные распределяются по нескольким географическим регионам и сценариям, делая большинство существующих алгоритмов непригодными для использования без настройки. Поскольку нюансы различались для разных языков, нашим первым шагом было определение языка входящей строки и создание переводов на другие языки. Мы протестировали несколько подходов к нормализации языка / сценария. Разработанные нами модули выполняли следующие задачи:
Поскольку нюансы различались для разных языков, нашим первым шагом было определение языка входящей строки и создание переводов на другие языки. Мы протестировали несколько подходов к нормализации языка / сценария. Разработанные нами модули выполняли следующие задачи:
- Обнаружение языка строки, переданной : Мы использовали две основные библиотеки, langdetect и spacy , в качестве основы, и построили вокруг них специальную оболочку для повышения точности строк на разных языках.
- Нормализованные языки : небольшое количество поставщиков данных предоставляют названия компаний и адреса на нескольких языках (например, EMIS предоставляет названия компаний на китайском и тайском языках, а также на английском языке). Другие, такие как CapIQ , делают имена и адреса доступными только на одном языке. Для точности было критично то, что мы убедились, что доступная информация может быть отображена на всех языках, поэтому мы создали слой транслитерации, который мог сделать информацию на одном языке доступной для всех других. Для создания этого уровня мы построили трехэтапный конвейер:
- Простой текстовый перевод с использованием Google Translate API для существительных: Для источников данных с информацией только на одном языке мы использовали Google Translate API для перевода каждой сущности в другую. два соответствующих языка. Например, мы могли бы преобразовать название компании с традиционного китайского языка в английский и тайский и добавить преобразования в другие корпуса.
- Максимальное соответствие на основе слогов для выравнивания слов : Мы использовали комбинацию подходов максимального соответствия на основе прямого и обратного слогов для транслитерации длинных имен и адресов.Наша основная идея с этим подходом состояла в том, чтобы создать сопоставление между слогами английского и других языков, подготовив лексикон для выявления потенциальных совпадений, а затем использовать комбинацию алгоритмов прямого и обратного максимального сопоставления. Наконец, мы будем использовать логику ранжирования для подготовки транслитерированного текста.
- Подготовка встраивания слов / символов для многоязычного сравнения второстепенных слов («Компания», «Оптика», «Электричество» и т. Д.): Только 30 процентов всех поставщиков, включенных в короткий список, предоставили информацию о компании на нескольких языках.Следовательно, было критически важно создать автономный набор данных, который позволял бы сравнивать межъязыковые строки. Мы использовали два механизма для решения этой проблемы. Во-первых, мы использовали 30-процентные наборы данных на нескольких языках (например, EMIS предоставляет названия компаний как на китайском, так и на тайском языках, а также на английском языке). Затем мы подготовили пользовательские модели word2vec для создания отношений между словами и символами на разных языках и использовали эти матрицы сходства для транслитерации.Наш второй механизм заключался в использовании некоторых предварительно обученных моделей (здесь и здесь) для выполнения сегментации и сопоставления на уровне слов и символов. Затем мы использовали последнее встраивание, которое мы получили для сопоставления строк и распознавания именованных сущностей.
 Для создания этого уровня мы построили трехэтапный конвейер:
Для создания этого уровня мы построили трехэтапный конвейер: Наконец, мы будем использовать логику ранжирования для подготовки транслитерированного текста.
Наконец, мы будем использовать логику ранжирования для подготовки транслитерированного текста. Затем мы использовали последнее встраивание, которое мы получили для сопоставления строк и распознавания именованных сущностей.
Затем мы использовали последнее встраивание, которое мы получили для сопоставления строк и распознавания именованных сущностей.Модуль 2: Предварительная обработка текстовых данных: Мы очистили текст от пробелов, ложно проанализированного текста и специальных символов, используя стандартный конвейер, который обрабатывает различные поля, используя комбинацию этих параметров:
- Нормализация регистра
- Токенизация выполняется на уровне слова, сегмента или символа в зависимости от сценария
- Специальные символы, обрабатываемые с использованием настраиваемого списка, подготовленного для каждого языка
- Создание основы с использованием Porter Stemmer по умолчанию, с использованием Regexp Stemmer для нелатинских языков
- Обработка стоп-слова : Мы внедрили в движок три уникальных набора стоп-слов:
- Динамический калькулятор важности слова / символа.В зависимости от сценария мы, как правило, выбирали слова для латиницы и символы для китайского и тайского языков, чтобы получить первые n слов в каждом корпусе для каждого атрибута (имя, адрес, адрес электронной почты и ключевые банковские продукты). (Обратите внимание, что для простоты мы использовали слова и символы как взаимозаменяемые в следующих разделах.)
- Список стандартных префиксов / суффиксов / географических регионов на китайском, тайском, бахасском и английском языках
- Заменяемые слова: Мы внес в движок некоторые замены для нормализации контента (например,грамм. coltd as co. ltd.) и определили замещающие ключевые слова на основе исследовательского анализа с использованием частотности / совпадения слов и бизнес-эвристики.
 (Обратите внимание, что для простоты мы использовали слова и символы как взаимозаменяемые в следующих разделах.)
(Обратите внимание, что для простоты мы использовали слова и символы как взаимозаменяемые в следующих разделах.) Модуль 3: Распознавание и классификация именованных организаций (NERC) : Одна из наших ключевых задач заключалась в том, чтобы идентифицировать сущности в именах и описаниях, которые могли бы помочь связать компании в цепочке поставок и установить отношения между покупателем и поставщиком (в отношении товары и услуги). Наша цель состояла в том, чтобы использовать этот установленный поток товаров и денег для выявления ценных потенциальных клиентов (больше связей, больше продуктовых линеек и т. Д.). NERC — это процесс распознавания информационных единиц, таких как имена, включая имена людей, организаций и местоположений; числовые выражения, включая время, дату и деньги; и процентные выражения из неструктурированного текста. Нашей целью было разработать практические и независимые от предметной области методы, которые позволили бы нам автоматически обнаруживать именованные объекты с высокой точностью. Поскольку ни одна из существующих библиотек (NLTK, Spacy, SciPy) не предоставляла готовую маркировку NER для нашего варианта использования, мы создали специальный механизм NER для классификации информации о компании и описании продукта в полях как Product, Company Feature, Предлагаемая услуга или «Прочие» атрибуты.Чтобы создать словарь для стандартных продуктов и услуг, мы собрали информацию из кодов глобальной отраслевой классификации, таких как SIC (Стандартная отраслевая классификация) и NAICS (Североамериканская отраслевая классификация), и региональных стандартов, таких как HSIC (Стандартная отраслевая классификация Гонконга).
Д.). NERC — это процесс распознавания информационных единиц, таких как имена, включая имена людей, организаций и местоположений; числовые выражения, включая время, дату и деньги; и процентные выражения из неструктурированного текста. Нашей целью было разработать практические и независимые от предметной области методы, которые позволили бы нам автоматически обнаруживать именованные объекты с высокой точностью. Поскольку ни одна из существующих библиотек (NLTK, Spacy, SciPy) не предоставляла готовую маркировку NER для нашего варианта использования, мы создали специальный механизм NER для классификации информации о компании и описании продукта в полях как Product, Company Feature, Предлагаемая услуга или «Прочие» атрибуты.Чтобы создать словарь для стандартных продуктов и услуг, мы собрали информацию из кодов глобальной отраслевой классификации, таких как SIC (Стандартная отраслевая классификация) и NAICS (Североамериканская отраслевая классификация), и региональных стандартов, таких как HSIC (Стандартная отраслевая классификация Гонконга). )
)
Модуль 4: Нечеткое сопоставление: Фактическое сопоставление мы выполнили в два этапа; конвейер хеширования с низкой точностью и конвейер высокоточных вычислений:
- Конвейер хеширования: Наша цель для этого первого конвейера состояла в том, чтобы идентифицировать почти определенные совпадения и подготовить хэши, которые можно было бы использовать во втором конвейере для более точного ( но медленнее) совпадение.Мы собрали четыре отдельных потока для параллельной работы и выполнения следующих операций:
- Для первого потока мы выполнили кластеризацию HDBSCAN для названий компаний и адресов (отдельный корпус). HDBSCAN — это чрезвычайно быстрый подход к кластеризации, который использует плотность векторов на основе входных строк для создания кластеров. Чтобы сгенерировать матрицу для кластеризации, мы создали n-граммы на уровне символов (для нелатинских шрифтов) и биграммы и триграммы на уровне слов (по умолчанию). Мы использовали векторизатор tf-idf для подготовки входной матрицы для упражнения по кластеризации и расширение HDBSCAN для создания различных кластеров, так что количество кластеров эвристически определялось на основе размера словаря.
- Для второго потока мы использовали оболочку вокруг подхода кластеризации Fasttext по умолчанию. Затем мы внесли две модификации в оболочку для оптимизации скорости и точности, индексируя записи словаря по n-граммам, содержащимся в них, чтобы обеспечить быстрый поиск по словарю, и ограничили процесс сопоставления словами, которые имели хотя бы одну n-грамм. вместе с другими словами.
- Затем мы выполнили фонетическое хеширование с помощью NYSIIS и Double Metaphone, чтобы сгенерировать хэш из 2 пар для каждой строки.Мы выбрали эти алгоритмы, потому что они создают кодировку для английских слов. Например, «Двойной метафон» выводит первичную кодировку и вторичную кодировку.
- Для вспомогательного сопоставления (продукты и услуги) мы использовали комбинацию NERC и встраивания Word для создания хэшей для полей с описаниями продуктов / услуг. Блок NERC сгенерировал список релевантных ключевых слов для каждой компании, который мы затем передали механизму встраивания. Оболочка Word2Vec вычисляла оценку для каждого слова в списке и сравнивала ее поэлементно с элементами в предварительно вычисленной матрице для создания двух выходных данных: общие элементы из парного списка и общие элементы из перекрывающейся оценки.
- Процессор для конвейера этапа 2: Он состоял из механизма управления правилами, который выполнял базовое матричное умножение выходных матриц из конвейера этапа 1, чтобы сгенерировать окончательный хэш для этапа 2. Это упражнение проверялось на наличие парных вхождений во всем конвейере. подходы и подготовили объединенный хэш за 2 шага:
- Если, например, строки A и B были спарены как совпадения в кластере 2 в подходе 1, кластере 4 в подходе 2 и кластере 7 в подходе 3, то был подготовлен 1-й хэш как «247.»
- Окончательный хэш для каждой строки был подготовлен с использованием 2-битных комбинаций предыдущего хеша (например,« 24 »,« 47 »,« 27 »в приведенном выше случае)
- High-Precision Pipeline: Выполнены два ансамбля параллельно для каждого хэша, полученного на предыдущем шаге. Количество параллельных потоков динамически регулировалось при каждом запуске в зависимости от количества уникальных хешей, а также среднего размера и дисперсии компаний, распределенных по разным хешам. В первом ансамбле использовалось сочетание четырех различных методов редактирования, по одному для каждого типа строки в зависимости от длины строки, количества соответствующих слов и сценария.Второй ансамбль использовал конвейер машинного обучения и использовался для проверки устранения неоднозначности ложных совпадений.
- Ансамбль 1: Мы запустили четыре различных метода редактирования параллельно, используя модуль многопроцессорности, и вычислили чистую оценку с использованием подхода базового взвешивания, сформулированного с использованием одной или нескольких из этих функций логита:
- Jaro-Winkler
- Hamming
- Damerau-Levenshtein
- Levenshtein
- Постпроцессор: Мы использовали динамический порог для каждой пары, чтобы придумать строгий, приблизительный или неудачный тег. Пороговое значение было функцией перекрестной проверки для каждой партии и случайно выбранного фрагмента, который небольшая команда затем проверила вручную (в течение месяца после обучения модели мы смогли уменьшить количество сотрудников, необходимое для этой задачи, с 4 до 1). . Для каждой пары мы умножили оценки на этапах 1 и 2, а ансамбль-1 и ранг упорядочили их логарифмические оценки. Мы создали две границы (строгий к приближению и приблизительный к отказу) во всем распределении и передали в ансамбль-2 каждую сущность в «приблизительном» сегменте.
- Ensemble-2: Это слой статистической модели, который мы разработали для жесткой проверки приблизительных совпадений, полученных на предыдущем шаге. Ансамбль использовал комбинацию машин опорных векторов и логистической регрессии (на основе длины строки) и дал окончательные результаты. Мы использовали несколько шагов для обучения модели:
- Во-первых, мы подготовили собственный конструктор функций , который сгенерировал более 30 функций, используя помеченные данные для сопоставления. Мы создали обучающие данные с использованием семи наборов данных, которые позволяли делать общие ссылки по имени веб-сайта и данным электронной почты (точное совпадение строк).Мы использовали около 11 000 компаний со сбалансированным набором вопросов (сокращения, префиксы / суффиксы и т. Д.) Для создания функций и последующего обучения моделей классификации. Вот некоторые из важных функций, подготовленных в ходе упражнения:
- Изменить оценку расстояния
- Соотношения символов
- Обнаружение вышедших из строя компонентов ( PT Indonesia Batin Technology Pvt Ltd по сравнению с Batin Technology, Индонезия, Pte Ltd. , PT )
- Отсутствует имя (двоичный флаг)
- Первичные и вторичные хэши на основе двойного метафона
- Длина строки, количество отдельных слов
- Длина адреса
- Усеченное имя (двоичный флаг)
- Корневой текст в адресе ( идентифицированы с использованием списка регионов и сопоставлены с использованием метода списка)
- Обучение модели : Мы подготовили этап модели с использованием случайного леса, GBM и XGBoost, с оптимизацией гиперпараметров, используя стандартный sklearn’s GridSearchCV. Мы протестировали различные функции потерь в зависимости от скрипта и длины текста. Мы сделали окончательный выбор на основе средней точности и ее отклонения между прогонами, изменив метод оценки по умолчанию в GridSearchCV в соответствии с бизнес-требованиями.

 Оболочка Word2Vec вычисляла оценку для каждого слова в списке и сравнивала ее поэлементно с элементами в предварительно вычисленной матрице для создания двух выходных данных: общие элементы из парного списка и общие элементы из перекрывающейся оценки.
Оболочка Word2Vec вычисляла оценку для каждого слова в списке и сравнивала ее поэлементно с элементами в предварительно вычисленной матрице для создания двух выходных данных: общие элементы из парного списка и общие элементы из перекрывающейся оценки. Количество параллельных потоков динамически регулировалось при каждом запуске в зависимости от количества уникальных хешей, а также среднего размера и дисперсии компаний, распределенных по разным хешам. В первом ансамбле использовалось сочетание четырех различных методов редактирования, по одному для каждого типа строки в зависимости от длины строки, количества соответствующих слов и сценария.Второй ансамбль использовал конвейер машинного обучения и использовался для проверки устранения неоднозначности ложных совпадений.
Количество параллельных потоков динамически регулировалось при каждом запуске в зависимости от количества уникальных хешей, а также среднего размера и дисперсии компаний, распределенных по разным хешам. В первом ансамбле использовалось сочетание четырех различных методов редактирования, по одному для каждого типа строки в зависимости от длины строки, количества соответствующих слов и сценария.Второй ансамбль использовал конвейер машинного обучения и использовался для проверки устранения неоднозначности ложных совпадений. Пороговое значение было функцией перекрестной проверки для каждой партии и случайно выбранного фрагмента, который небольшая команда затем проверила вручную (в течение месяца после обучения модели мы смогли уменьшить количество сотрудников, необходимое для этой задачи, с 4 до 1). . Для каждой пары мы умножили оценки на этапах 1 и 2, а ансамбль-1 и ранг упорядочили их логарифмические оценки. Мы создали две границы (строгий к приближению и приблизительный к отказу) во всем распределении и передали в ансамбль-2 каждую сущность в «приблизительном» сегменте.
Пороговое значение было функцией перекрестной проверки для каждой партии и случайно выбранного фрагмента, который небольшая команда затем проверила вручную (в течение месяца после обучения модели мы смогли уменьшить количество сотрудников, необходимое для этой задачи, с 4 до 1). . Для каждой пары мы умножили оценки на этапах 1 и 2, а ансамбль-1 и ранг упорядочили их логарифмические оценки. Мы создали две границы (строгий к приближению и приблизительный к отказу) во всем распределении и передали в ансамбль-2 каждую сущность в «приблизительном» сегменте. Мы создали обучающие данные с использованием семи наборов данных, которые позволяли делать общие ссылки по имени веб-сайта и данным электронной почты (точное совпадение строк).Мы использовали около 11 000 компаний со сбалансированным набором вопросов (сокращения, префиксы / суффиксы и т. Д.) Для создания функций и последующего обучения моделей классификации. Вот некоторые из важных функций, подготовленных в ходе упражнения:
Мы создали обучающие данные с использованием семи наборов данных, которые позволяли делать общие ссылки по имени веб-сайта и данным электронной почты (точное совпадение строк).Мы использовали около 11 000 компаний со сбалансированным набором вопросов (сокращения, префиксы / суффиксы и т. Д.) Для создания функций и последующего обучения моделей классификации. Вот некоторые из важных функций, подготовленных в ходе упражнения: Мы протестировали различные функции потерь в зависимости от скрипта и длины текста. Мы сделали окончательный выбор на основе средней точности и ее отклонения между прогонами, изменив метод оценки по умолчанию в GridSearchCV в соответствии с бизнес-требованиями.
Мы протестировали различные функции потерь в зависимости от скрипта и длины текста. Мы сделали окончательный выбор на основе средней точности и ее отклонения между прогонами, изменив метод оценки по умолчанию в GridSearchCV в соответствии с бизнес-требованиями.Модуль 5: Уровень обратной связи: Поскольку конвейер охватывал как детерминированный, так и вероятностный подходы к сопоставлению строк, нам требовался уровень обратной связи, который мог бы сообщать команде о потенциальных изменениях и запускать предупреждения в случае серьезного дисбаланса.Для этого мы создали автоматизированный уровень описательной отчетности в трех модулях и отправили отчеты группе, которая затем проверила эти отчеты и соответствующим образом настроила параметры конвейера. Эти три модуля включали:
- Распознавание именованных сущностей : запланированная доставка наиболее несбалансированных сущностей (одинаковые вероятности для большинства различных классов) и изменчивых сущностей (сущностей, которые меняют свой назначенный класс в ходе последовательных запусков).
- Параметры кластеризации : сводка производительности по известным совпадениям и несоответствиям, а также отчет о показателях производительности кластера при повторных запусках (недоумение, силуэт и т. Д.)).
- Пороговые значения для приблизительного и определенного совпадения : Список наиболее часто встречающихся терминов на границе порогового значения и их оценки для каждой отдельной модели (метода).

Итоговый стек с рабочим процессом можно увидеть ниже (рис. 1). Обратите внимание, что для конфиденциальности мы скрыли некоторые дополнительные конвейеры, такие как ETL, нормализация и создание функций. Был развернут еженедельный график обучения основных моделей с настройкой пороговых значений каждые две недели.Проверка и повторная настройка набора правил (при необходимости) выполняется специалистами по данным. Весь рабочий процесс автоматизирован с помощью Luigi. Управление памятью для больших матричных вычислений выполняется с помощью Dask. Модуль регистрации ядра Python используется вместе с smtplib для создания автоматических отчетов о производительности конвейера. Мы также использовали Flask (облегченный фреймворк Python для разработки API) для создания уровня обслуживания, который может обрабатывать тысячи запросов в секунду (легко масштабируется до 7000 запросов в секунду в текущем формате), что представляет собой значительный объем по сравнению с типичные требования корпоративной банковской среды.
Модуль регистрации ядра Python используется вместе с smtplib для создания автоматических отчетов о производительности конвейера. Мы также использовали Flask (облегченный фреймворк Python для разработки API) для создания уровня обслуживания, который может обрабатывать тысячи запросов в секунду (легко масштабируется до 7000 запросов в секунду в текущем формате), что представляет собой значительный объем по сравнению с типичные требования корпоративной банковской среды.
Рисунок 1 — Архитектура процесса ансамбля нечеткого сопоставления
В дополнение к резкому увеличению числа потенциальных покупателей в 500 раз, наш проект крупномасштабного механизма нечеткого сопоставления имен также соответствовал целям наших клиентов с точки зрения как скорости, так и точность. Дизайн достиг точности 0,99 на тестовом наборе для того же языка и 0,96 на кросс-языковом наборе тестов. В обоих случаях мы получили отзыв более 0,92. В типичном ежедневном сценарии механизм выполняет сопоставление более 5 миллионов строк менее чем за два часа, и хотя мы не выполняли ручную проверку содержимого, превышающего 8000 строк, наша точность в каждом обзоре составляла от 94 до 99 процентов. .
.
Помимо этих итоговых преимуществ, наше трехмесячное взаимодействие с клиентами также привело к ряду идей, которые, по нашему мнению, имеют большое значение для любой компании, которая намеревается решить загадку приблизительного сопоставления строк или нечеткого сопоставления имен.
- Как бы банально это ни звучало, ни один метод сопоставления имен не может учесть все нюансы, обнаруженные в текстовых данных. Большинство методов позволяют выполнить 80 процентов проектного решения. Это последние 20 процентов, которые требуют опыта и изобретательности.
- Путь к таким проектам может быть чрезвычайно сложным. Поначалу каждый поток в конвейере кажется пугающим — длительное время для обучения модели и выполнения стресс-тестов, исключения после изменения каждого компонента в проекте и ручная рутинная работа по просмотру списков соответствий для настройки пороговых значений и определения новые методы для принятия. Решение этих текущих проблем требует значительного терпения и целеустремленности.
- Крайне важно заранее приложить усилия для создания хорошего набора данных для тестирования / валидации — такого, который охватывает все возможные варианты.Не менее важно поддерживать достаточный размер выборки для применения вероятностных методов.
- Управление небольшими блоками, такими как стоп-слова, настройка пороговых значений и параметры кластеризации, требует значительных умственных усилий. Границы, в которых требуется ручное вмешательство, являются наиболее сложными. Чтобы успешно справиться с этой задачей, требуется сильное сообщество участников бизнеса, носителей языка и специалистов по обработке данных.
- Создание ранжированных списков — нелегкая задача.Хотя в некоторых случаях может быть достаточно идентифицировать совокупность всех возможных совпадений, необходимость упорядочивания ранжирования увеличивает сложность на несколько ступеней. Предварительное понимание случаев, в которых требовались ранжированные / нерейтинговые результаты, может значительно улучшить процесс проектирования.
- Настройка автоматических тестов в начале может значительно сэкономить усилия. Как наблюдается в крупных программных проектах, сложные ансамблевые методы, подобные описанному выше, нуждаются в значительной структуре и готовности во всех частях.Наш дизайн включал более 150 автоматизированных тестов, от небольших модульных тестов для оценки языка до крупных интеграционных тестов для разных движков. Несмотря на то, что тесты можно настроить в любое время в процессе, выполнение этой работы на более ранних этапах процесса дает огромные преимущества при отладке, масштабировании и пользовательском тестировании.
- Неанглийские строки (особенно китайские) были узким местом до последней недели разработки. До самого конца мы потратили значительное количество времени на внедрение методов сопоставления китайского и мандаринского языков, тестирование новейших библиотек, таких как Jieba, подготовили большое пользовательское встраивание word2vec и перебирали Google Translate.Это ценные инструменты, но мы отмечаем, что существует огромный потенциал для дальнейшего повышения точности всех этих методов.



- Алгоритмы приблизительного сопоставления строк: https://www.sciencedirect.com/science/article/pii/S0019995885800462
- Экскурсия по приблизительному сопоставлению строк: https://www.dcc.uchile.cl/TR /1999/TR_DCC-1999-005.pdf
- Приблизительные алгоритмы сопоставления строк: краткий обзор и сравнение: https://www.semanticscholar.org/paper/Approximate-String-Matching-Algorithms%3A-A-Brief-and -Hasan-Ahmed / 209963725178129edba7463e2269bb4343758114
- Гибридный подход к поиску нечетких имен, включающий языковые и текстовые принципы: https: // журналы.sagepub.com/doi/10.1177/0165551506068146
- Методы индексирования для приблизительного сопоставления строк: https://users.dcc.uchile.cl/~gnavarro/ps/deb01.pdf
- Обработка естественного языка для сопоставления нечетких строк с помощью Python: https://towardsdatascience.com/natural-language-processing-for-fuzzy-string-matching-with-python-6632b7824c49
- Обзор методов нечеткого сопоставления: https://www. rosette.com/blog/overview- методы сопоставления нечетких имен /
- Сравнение алгоритмов приблизительного сопоставления строк: http: // www.cs.hut.fi/u/tarhio/papers/jtu.pdf
- Сверхбыстрое сопоставление строк в python: https://bergvca.github.io/2017/10/14/super-fast-string-matching.html
- GridSearch CV: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
- Предварительно обученные векторы для 30+ языков: https: // github .com / Kyubyong / wordvectors
- Сегментация китайского текста Jieba: https://github.com/fxsjy/jieba
- Быстрое приблизительное сопоставление строк в словаре: https: // users.dcc.uchile.cl/~gnavarro/ps/spire98.2.pdf
- Предварительно обученные представления ELMo для многих языков: https://github.com/HIT-SCIR/ELMoForManyLangs
 rosette.com/blog/overview- методы сопоставления нечетких имен /
rosette.com/blog/overview- методы сопоставления нечетких имен /КНИГИ НА ПИНГВИНЕ
ЧТЕНИЕ В МОЗГЕ
Французский ученый Станислас Деэн получил образование математика и психолога, прежде чем стал одним из самых активных исследователей когнитивной нейробиологии языка и обработки чисел в человеческом мозге. Он является директором отделения когнитивной нейровизуализации в Сакле, Франция; профессор экспериментальной когнитивной психологии в Коллеж де Франс; и член как Французской Академии наук, так и Папской Академии наук.Он много публиковался в рецензируемых научных журналах и является автором нескольких книг, в том числе The Number Sense .
Он является директором отделения когнитивной нейровизуализации в Сакле, Франция; профессор экспериментальной когнитивной психологии в Коллеж де Франс; и член как Французской Академии наук, так и Папской Академии наук.Он много публиковался в рецензируемых научных журналах и является автором нескольких книг, в том числе The Number Sense .
Похвала за Чтения в мозгу
A Washington Post Лучшая научная книга 2009 года
A Library Journal Лучшая научно-техническая книга 2009 года
«В его великолепном чтении В книге «Brain » французский нейробиолог Станислас Дехаен показывает, как десятилетия низкотехнологичных экспериментов и высокотехнологичных исследований мозга раскрыли тайну чтения и раскрыли его составные части.. . . Приятно читать. [Дехаин] никогда не упрощает; он находит время, чтобы рассказать всю историю, и он рассказывает ее грамотно ».
— The Wall Street Journal
«Увлекательно. . . Изучая мокрый материал внутри нашей головы, мы можем начать понимать, почему это предложение имеет такую структуру и почему эта буква, вот эта, имеет свою форму. . . . Красноречиво. . . Предоставьте множество доказательств ».
. . Изучая мокрый материал внутри нашей головы, мы можем начать понимать, почему это предложение имеет такую структуру и почему эта буква, вот эта, имеет свою форму. . . . Красноречиво. . . Предоставьте множество доказательств ».
—Jonah Lehrer
«Мастерскую книгу Дехайна приятно читать, и она точна с научной точки зрения.»
— Nature
« Объединив исследования и повествование, Дехаен создает увлекательное объяснение того, как префронтальная кора использовала первобытные неврологические пути, чтобы научиться уникальному человеческому умению ».
— Seed
«За прозрачным и автоматическим подвигом понимания прочитанного скрываются сложные биологические усилия, умело проанализированные в этом увлекательном исследовании. . . . Этот живой и ясный трактат еще раз доказывает, что Дехаэн — один из наших самых одаренных толкователей науки; он делает работу разума менее загадочной, но не менее чудесной.»
— Publishers Weekly
« Щедро вознаграждение ».
— Kirkus Reviews
«[Дехаен] — та редкая птица: ученый, который умеет писать».
— The Globe and Mail (Торонто)
«Вдохновите [s] чувство удивления сложностью задач, которые читатели выполняют, просто сканируя от страницы к странице».
—А.В. Club.com
«Нам повезло, что Станислас Дехане, ведущий специалист в области нейронауки языка, также является прекрасным писателем.Его Чтение в мозгу объединяет когнитивные, культурные и неврологические аспекты в элегантном, убедительном повествовании. Это откровение ».
—Oliver Sacks, M.D.
«В тот момент, когда знание о читающем мозге может быть ключом к его сохранению, книга Станисласа Дехайна представляет собой следующую важную ступеньку этих знаний. Он делает это благодаря пониманию, полученному в результате его собственных плодотворных исследований, благодаря своему всеобъемлющему пониманию нейробиологии и благодаря уникальному сочетанию здравого смысла и мудрости, которое пронизывает каждую главу.
—Марианна Вольф, автор книги «Пруст и кальмар: история и наука о читающем мозге»
«Станислас Дехаене отправляет нас в путешествие в науку чтения. Мы путешествуем мимо активирующих нейронов у обезьян, моделей активации мозга у людей, людей с повреждениями мозга и культуры в целом. Это активный и приятный синтез огромного количества информации с правильным балансом между получением правильных фактов и их доступностью для непрофессиональных читателей.
— Джозеф Леду, профессор Нью-Йоркского университета и автор Synaptic Self и The Emotional Brain
« Чтение в мозгу — это не просто чтение. Это ближе, чем все, что я встречал, к объяснению того, как люди думают, и делает это с простой элегантностью, понятной как ученым, так и не ученым. Дехайн дает представление о неврологической основе впечатляющих когнитивных навыков, которые характерны для нашего вида.Не только изучающие человеческую эволюцию найдут Reading in the Brain увлекательным. Родители, педагоги и все, кто заботится о интеллектуальном развитии детей, не могут позволить себе игнорировать наблюдения Дехена о лучших методах обучения их чтению! »
Родители, педагоги и все, кто заботится о интеллектуальном развитии детей, не могут позволить себе игнорировать наблюдения Дехена о лучших методах обучения их чтению! »
—Дин Фальк, автор книги Finding Our Tongues: Mothers, Infants, and the Origins of Language
«Сложное партнерство глаза и разума, которое преобразует печатные символы в звук, музыку и значение и дает начало мысли , является предметом этого интригующего исследования.Это чудесное путешествие: как путешествие крепкого Кортеса, как поиск Х. М. Стэнли доктора Дэвида Ливингстона, как следующий потрясающий зонд в открытый космос ».
—Говард Энгель, соавтор «Человек, который забыл, как читать»
Чтение в мозгу
Новая наука
о том, как мы читаем
СТАНИСЛАС ДЕХАН
ВВЕДЕНИЕ
Новая наука о чтении
Заброшенный в мир этой пустыни вместе с некоторыми книгами, немногочисленными, но мудрыми, я живу в разговоре с умершими и слушаю мертвых своими глазами.
—FRANCISCO DE QUEVEDO
В этот самый момент ваш мозг совершает удивительный подвиг — читает.Ваши глаза просматривают страницу короткими судорожными движениями. Четыре или пять раз в секунду ваш взгляд останавливается на время, достаточное для того, чтобы распознать одно или два слова. Вы, конечно, не подозреваете об этом отрывистом приеме информации. Только звуки и значения слов достигают вашего сознательного разума. Но как могут несколько черных отметин на белой бумаге, проецируемые на вашу сетчатку, вызвать целую вселенную, как это делает Владимир Набоков в первых строках Лолиты :
Лолита, свет моей жизни, огонь моих чресл.Мой грех, моя душа. Ло-ли-та: кончик языка совершает три шага вниз по небу, чтобы постучать в три ступени по зубам. Ло. Ли. Та.
Мозг читателя содержит сложный набор механизмов, превосходно приспособленных к чтению. Этот талант долгие века оставался загадкой. Сегодня черный ящик мозга взломан, и зарождается настоящая наука о чтении. Достижения в области психологии и нейробиологии за последние двадцать лет начали раскрывать принципы, лежащие в основе цепей чтения мозга.Современные методы визуализации мозга теперь всего за несколько минут выявляют области мозга, которые активируются, когда мы расшифровываем написанные слова. Ученые могут отследить напечатанное слово по мере его прохождения от сетчатки глаза через цепочку этапов обработки, каждый из которых отмечен элементарным вопросом: это буквы? На что они похожи? Это слово? На что это похоже? Как это произносится? Что это значит?
Достижения в области психологии и нейробиологии за последние двадцать лет начали раскрывать принципы, лежащие в основе цепей чтения мозга.Современные методы визуализации мозга теперь всего за несколько минут выявляют области мозга, которые активируются, когда мы расшифровываем написанные слова. Ученые могут отследить напечатанное слово по мере его прохождения от сетчатки глаза через цепочку этапов обработки, каждый из которых отмечен элементарным вопросом: это буквы? На что они похожи? Это слово? На что это похоже? Как это произносится? Что это значит?
На этой эмпирической основе материализуется теория чтения. Он постулирует, что схема мозга, унаследованная от эволюции приматов, может быть использована для распознавания печатных слов.Согласно этому подходу наши нейронные сети буквально «перерабатываются» для чтения. Понимание того, как грамотность меняет мозг, коренным образом меняет наше представление об образовании и неспособности к обучению. Разрабатываются новые программы реабилитации, которые должны со временем справиться с изнурительной неспособностью расшифровать слова, известные как дислексия.
Моя цель в этой книге — поделиться своими знаниями о недавних и малоизвестных достижениях науки о чтении. В двадцать первом веке средний человек все еще лучше понимает, как работает машина, чем о внутреннем функционировании своего мозга — любопытное и шокирующее положение вещей.Лица, принимающие решения в нашей образовательной системе, колеблются взад и вперед вместе с меняющимися ветрами педагогической реформы, часто явно игнорируя то, как мозг на самом деле учится читать. Родители, педагоги и политики часто признают, что существует разрыв между образовательными программами и самыми последними открытиями в области нейробиологии. Но слишком часто их представление о том, как эта область может способствовать прогрессу в образовании, основывается только на нескольких цветных изображениях работы мозга. К сожалению, методы визуализации, которые позволяют нам визуализировать деятельность мозга, неуловимы и иногда вводят в заблуждение.Новая наука о чтении настолько молода и быстро развивается, что до сих пор остается относительно неизвестной за пределами научного сообщества. Моя цель — дать простое введение в эту увлекательную область и повысить осведомленность об удивительных способностях нашего читающего мозга.
От нейронов к образованию
Приобретение навыков чтения — важный шаг в развитии ребенка. Многие дети изначально испытывают трудности с чтением, и опросы показывают, что примерно каждый десятый взрослый не может овладеть даже элементарными знаниями текста.Требуются годы упорной работы, прежде чем механизм мозга, похожий на часовой, который поддерживает чтение, заработает настолько гладко, что мы забудем о его существовании.
Почему так сложно освоить чтение? Какие глубокие изменения в мозговых схемах сопровождают приобретение навыков чтения? Некоторые стратегии обучения лучше адаптированы к детскому мозгу, чем другие? Какие научные причины, если таковые имеются, объясняют, почему фоника — систематическое обучение буквенно-звуковому соответствию — кажется, работает лучше, чем обучение целиком? Хотя многое еще предстоит открыть, новая наука о чтении теперь дает все более точные ответы на все эти вопросы.В частности, в нем подчеркивается, почему ранние исследования чтения ошибочно поддерживали подход целого слова — и как недавние исследования сетей чтения мозга доказывают, что это неверно.
Понимание того, что входит в чтение, также проливает свет на его патологии. В наших исследованиях разума и мозга читателя вы познакомитесь с пациентами, которые внезапно потеряли способность читать после инсульта. Я также проанализирую причины дислексии, церебральные основы которой постепенно выявляются.Теперь ясно, что мозг, страдающий дислексией, неуловимо отличается от мозга нормального читателя. Идентифицировано несколько генов предрасположенности к дислексии. Но это ни в коем случае не повод для уныния или отставки. В настоящее время определяются новые терапевтические методы лечения. Интенсивное обучение языку и схемам чтения привело к значительным улучшениям в детском мозге, которые можно легко отслеживать с помощью изображений мозга.
Включение нейронов в культуру
Наша способность читать заставляет нас лицом к лицу сталкиваться с особенностями человеческого мозга.Почему Homo sapiens — единственный вид, который активно обучается? Почему он уникален в своей способности передавать сложную культуру? Как биологический мир синапсов и нейронов соотносится со вселенной культурных изобретений человека? Чтение, а также письмо, математика, искусство, религия, сельское хозяйство и городская жизнь резко увеличили естественные способности нашего мозга приматов. Только наш вид поднимается над своим биологическим состоянием, создает для себя искусственную культурную среду и обучает себя новым навыкам, таким как чтение.Эта уникальная человеческая компетенция вызывает недоумение и требует теоретического объяснения.
Одна из основных техник в наборе инструментов нейробиолога состоит в том, чтобы «поместить нейроны в культуру» — позволить нейронам расти в чашке Петри. В этой книге я призываю к иной «культуре нейронов» — новому взгляду на культурную деятельность человека, основанному на нашем понимании того, как они отображаются на поддерживающие их сети мозга. Общепризнанная цель неврологии — описать, как элементарные компоненты нервной системы приводят к поведенческим закономерностям, которые можно наблюдать у детей и взрослых (включая продвинутые когнитивные навыки).Чтение является одним из наиболее подходящих полигонов для этого «нейрокультурального» подхода. Мы все больше осознаем, как такие разные системы письма, как китайский, иврит или английский, вписываются в контуры нашего мозга. В случае чтения мы можем четко провести прямые связи между нашей природной нейронной архитектурой и нашими приобретенными культурными способностями, но есть надежда, что этот нейробиологический подход распространится на другие основные области человеческого культурного самовыражения.
Тайна читающей обезьяны
Если мы хотим пересмотреть отношения между мозгом и культурой, мы должны решить загадку, которую я называю парадоксом чтения : Почему наш мозг приматов читает? Почему у него есть склонность к чтению, хотя это культурное мероприятие было изобретено всего несколько тысяч лет назад?
Есть веские причины, по которым этот обманчиво простой вопрос заслуживает того, чтобы называться парадоксом.Мы обнаружили, что грамотный мозг содержит специализированные корковые механизмы, которые точно настроены на распознавание написанных слов. Еще более удивительно то, что одни и те же механизмы у всех людей систематически размещаются в идентичных областях мозга, как если бы это был мозговой орган для чтения.
Но письмо зародилось всего пятьдесят четыреста лет назад на Плодородном полумесяце, а самому алфавиту всего тридцать восемьсот лет. С точки зрения эволюции, эти промежутки времени — пустяк.Таким образом, у эволюции не было времени разработать специализированные схемы считывания в Homo sapiens . Наш мозг построен на генетической схеме, которая позволила нашим предкам-охотникам-собирателям выжить. Нам доставляет удовольствие читать Набокова и Шекспира, используя мозг приматов, изначально созданный для жизни в африканской саванне. Ничто в нашей эволюции не могло подготовить нас к восприятию языка через видение. Тем не менее, изображения мозга демонстрируют, что мозг взрослого человека содержит фиксированные схемы, прекрасно приспособленные к чтению.
Парадокс чтения напоминает притчу преподобного Уильяма Пэли, направленную на доказательство существования Бога. В своей книге Natural Theology (1802 г.) он представил, что в пустынной пустоши на земле были найдены часы со сложной внутренней конструкцией, явно предназначенной для измерения времени. Разве это не станет, утверждал он, четким доказательством того, что существует умный часовщик, дизайнер, который специально создал часы? Точно так же Пейли утверждал, что замысловатые устройства, которые мы находим у живых организмов, такие как удивительные механизмы глаза, доказывают, что природа — это работа божественного часовщика.
Чарльз Дарвин классно опроверг Пэли, показав, как слепой естественный отбор может создавать высокоорганизованные структуры. Даже если на первый взгляд биологические организмы кажутся созданными для определенной цели, более тщательное изучение показывает, что их организация не соответствует тому совершенству, которого можно было бы ожидать от всемогущего архитектора. Всевозможные несовершенства свидетельствуют о том, что эволюция не направляется разумным творцом, а следует случайным путем в борьбе за выживание. В сетчатке, например, кровеносные сосуды и нервные кабели расположены на впереди фоторецепторов, таким образом частично блокируя входящий свет и создавая слепое пятно — действительно очень плохая конструкция.
Следуя по стопам Дарвина, Стивен Джей Гулд привел множество примеров несовершенного результата естественного отбора, в том числе большой палец панды.1 Британский эволюционист Ричард Докинз также объяснил, как тонкие механизмы глаза или крыла могли возникнуть только через естественным отбором, или являются результатом работы «слепого часовщика» 2. Эволюционизм Дарвина кажется единственным источником очевидного «замысла» в природе.
Однако, когда дело доходит до объяснения чтения, притча Пейли проблематична в несколько ином смысле.Механизмы мозга, напоминающие часовой механизм, поддерживающие чтение, безусловно, сравнимы по сложности и конструкции с часами, брошенными в пустоши. Вся их организация стремится к единственной очевидной цели — как можно быстрее и точнее расшифровать написанные слова. Однако ни гипотеза разумного творца, ни гипотеза о медленном появлении в результате естественного отбора, похоже, не дают правдоподобного объяснения происхождения чтения. Времени было слишком мало, чтобы эволюция могла разработать специализированные схемы считывания.Как же тогда наш мозг приматов научился читать? Наша кора головного мозга является результатом миллионов лет эволюции в мире без письма — почему она может адаптироваться к конкретным проблемам, возникающим при распознавании письменных слов?
Биологическое единство и культурное разнообразие
В социальных науках приобретение культурных навыков, таких как чтение, математика или изобразительное искусство, редко, если вообще когда-либо, связано с биологическими терминами. До недавнего времени очень немногие социологи считали, что биология мозга и теория эволюции имеют отношение к их областям.Даже сегодня большинство неявно придерживаются наивной модели мозга, неявно рассматривая ее как бесконечно пластичный орган, чьи способности к обучению настолько широки, что не накладывают никаких ограничений на сферу человеческой деятельности. Это не новая идея. Его можно проследить до теорий британских эмпириков Джона Локка, Дэвида Юма и Джорджа Беркли, которые утверждали, что человеческий мозг следует сравнивать с чистым листом, который постепенно поглощает отпечаток естественной и культурной среды человека через пять органов чувств. .
Этот взгляд на человечество, который отрицает само существование человеческой природы, часто принимается безоговорочно. Он принадлежит к стандартной «стандартной модели социальных наук» 3, которую разделяют многие антропологи, социологи, некоторые психологи и даже несколько нейробиологов, которые рассматривают поверхность коры головного мозга как «в значительной степени равноценную и свободную от доменно-специфической структуры» 4. природа конструируется постепенно и гибко через культурное оплодотворение. В результате, согласно этой точке зрения, дети, рожденные у инуитов, охотников-собирателей Амазонки или в семье Верхнего Ист-Сайда в Нью-Йорке, имеют мало общего.Даже восприятие цвета, музыкальное восприятие или представления о добре и зле должны варьироваться от одной культуры к другой просто потому, что человеческий мозг имеет несколько стабильных структур, кроме способности к обучению.
Эмпирики далее утверждают, что человеческий мозг, не ограниченный биологическими ограничениями и в отличие от мозга любого другого вида животных, может впитывать любую форму культуры. С этой теоретической точки зрения говорить о мозговых основах культурных изобретений, таких как чтение, совершенно неуместно — во многом как анализ атомного состава пьесы Шекспира.
В этой книге я опровергаю этот упрощенный взгляд на бесконечную приспособляемость мозга к культуре. Новые данные о мозговых цепях чтения демонстрируют, что гипотеза об эквипотентности мозга неверна. Конечно, если бы мозг был неспособен к обучению, он не смог бы адаптироваться к определенным правилам письма на английском, японском или арабском языках. Однако это обучение жестко ограничено, а сами его механизмы жестко определены нашими генами. Архитектура мозга аналогична у всех членов семейства Homo sapiens и лишь незначительно отличается от таковых у других приматов.Во всем мире одни и те же области мозга активируются для декодирования написанного слова. Будь то французский или китайский язык, обучение чтению обязательно проходит по генетически ограниченному контуру.
На основе этих данных я предлагаю новую теорию нейрокультурных взаимодействий, радикально противоположную культурному релятивизму и способную разрешить парадокс чтения. Я называю это гипотезой «рециклинга нейронов». Согласно этой точке зрения, архитектура человеческого мозга подчиняется строгим генетическим ограничениям, но некоторые цепи эволюционировали, чтобы допускать небольшую изменчивость.Например, часть нашей зрительной системы не зашита, но остается открытой для изменений в окружающей среде. В рамках хорошо структурированного мозга визуальная пластичность дала древним писцам возможность изобрести чтение.
В общем, ряд мозговых цепей, определяемых нашими генами, обеспечивает «предварительные представления» 5 или гипотезы, которые наш мозг может использовать в отношении будущих событий в окружающей его среде. Во время развития мозга механизмы обучения выбирают, какие предварительные представления лучше всего подходят для данной ситуации.Культурное освоение опирается на эту границу пластичности мозга. Наш мозг не только не чистый лист, который поглощает все, что окружает его, но и адаптируется к определенной культуре, минимально изменяя свои предрасположенности для другого использования. Это не tabula rasa , в которой собираются культурные сооружения, а очень тщательно структурированное устройство, которое позволяет преобразовать некоторые его части для нового использования. Когда мы изучаем новый навык, мы повторно используем некоторые из наших старых цепей мозга приматов — если, конечно, эти цепи могут выдержать изменения.
A Reader’s Guide
В следующих главах я объясню, как повторное использование нейронов может объяснить грамотность, ее механизмы в мозге и даже ее историю. В первых трех главах я анализирую механизмы чтения у взрослых экспертов. В главе 1 начинается рассмотрение чтения с психологической точки зрения: насколько быстро мы читаем и каковы основные факторы, определяющие читательское поведение? В главе 2 я перехожу к областям мозга, которые работают, когда мы читаем, и к тому, как их можно визуализировать с помощью современных методов визуализации мозга.Наконец, в главе 3 я перехожу к уровню отдельных нейронов и их организации в цепи, распознающие буквы и слова.
Я решительно занимаюсь анализом механически. Я предлагаю обнажить шестеренки мозга читателя примерно так же, как преподобный Пейли предлагал разобрать часы, брошенные на вересковой пустоши. Однако мозг читателя не откроет никакой совершенной часовой механики, созданной божественным часовщиком. Наши схемы чтения содержат множество недостатков, которые выдают наш мозг компромисс между тем, что необходимо для чтения, и доступными биологическими механизмами.Своеобразные характеристики зрительной системы приматов объясняют, почему чтение не работает как быстрый и эффективный сканер. Когда мы перемещаем взгляд по странице, каждое слово медленно переносится в центральную область нашей сетчатки, а затем разрывается на бесчисленное множество фрагментов, которые позже наш мозг собирает вместе. Только потому, что эти процессы стали автоматическими и бессознательными, благодаря многолетней практике, мы находимся в иллюзии, что чтение — это просто и без усилий.
Парадокс чтения выражает неоспоримый факт, что наши гены эволюционировали не для того, чтобы мы могли читать.Мои доводы перед лицом этой загадки довольно просты. Если мозг не развивался для чтения, должно быть верно обратное: системы письма должны были развиваться в рамках ограничений нашего мозга. Глава 4 пересматривает историю письма в этом свете, начиная с первых доисторических символов и заканчивая изобретением алфавита. На каждом этапе есть свидетельства постоянных культурных изменений. На протяжении многих тысячелетий писцы изо всех сил пытались разработать слова, знаки и алфавиты, которые соответствовали бы возможностям нашего мозга приматов.По сей день мировые системы письма по-прежнему имеют ряд конструктивных особенностей, которые в конечном итоге можно отнести к ограничениям, налагаемым цепями нашего мозга.
Продолжая идею о том, что наш мозг не предназначен для чтения, но использует некоторые из его схем для этой новой культурной деятельности, в главе 5 исследуется, как дети учатся читать. Психологические исследования показывают, что существует не так много способов превратить мозг приматов в мозг опытного читателя. В этой главе довольно подробно исследуется единственная существующая траектория развития.Школам можно посоветовать использовать эти знания для оптимизации обучения чтению и смягчения драматических последствий неграмотности и дислексии.
Я также продолжу показывать, как нейробиологический подход может пролить свет на более загадочные особенности приобретения навыков чтения. Например, почему так много детей часто пишут свои первые слова справа налево? Вопреки общепринятой идее, эти ошибки зеркальной инверсии не являются первыми признаками дислексии, а являются естественным следствием организации нашего зрительного мозга.У большинства детей дислексия связана с другой, довольно отчетливой аномалией в обработке звуков речи. Описание симптомов дислексии, их церебральных основ и самых последних открытий, касающихся ее генетических основ, рассматривается в главе 6, а глава 7 дает представление о том, какие ошибки зеркала могут сказать нам о нормальном визуальном распознавании.
Наконец, в главе 8 я вернусь к удивительному факту, что только наш вид способен на такие изощренные культурные изобретения, как чтение, — уникальный подвиг, не имеющий себе равных среди других приматов.В полной противоположности стандартной модели социальных наук, где культура получает бесплатный проезд на чистом мозгу, чтение демонстрирует, как культура и организация мозга неразрывно связаны. На протяжении своей долгой культурной истории люди постепенно открывали, что они могут повторно использовать свои визуальные системы в качестве суррогатных языковых входов, таким образом достигая навыков чтения и письма. Я также кратко расскажу, как другие основные черты человеческой культуры могут быть подвергнуты аналогичному анализу. Математику, искусство, музыку и религию можно также рассматривать как усовершенствованные устройства, сформированные веками культурной эволюции, посягнувшие на мозг наших приматов.
Остается последняя загадка: если обучение существует у всех приматов, почему Homo sapiens — единственный вид с развитой культурой? Хотя этот термин иногда применяется к шимпанзе, их «культура» едва ли выходит за рамки нескольких хороших приемов для колки орехов, мытья картофеля или ловли муравьев палкой — ничто не сравнимо с кажущимся бесконечным человеческим производством взаимосвязанных условностей и систем символов, включая языки. , религии, формы искусства, спорт, математику или медицину.Нечеловеческие приматы могут медленно научиться распознавать новые символы, такие как буквы и цифры, но они никогда не думают их изобретать. В заключение я предлагаю некоторые предварительные идеи об особенностях человеческого мозга. Уникальность нашего вида может проистекать из комбинации двух факторов: теории разума (способности воображать разум других) и сознательного глобального рабочего пространства (внутреннего буфера, в котором бесконечное разнообразие идей может быть рекомбинировано). Оба механизма, заложенные в наших генах, делают нас единственным культурным видом.Кажущееся бесконечным разнообразие человеческих культур — это всего лишь иллюзия, вызванная тем фактом, что мы заперты в когнитивном порочном круге: как мы можем вообразить формы, отличные от тех, которые способен представить наш мозг? Чтение, хотя и было недавним изобретением, тысячелетиями бездействовало в пределах возможностей, заложенных в нашем мозгу. За очевидным разнообразием систем письма человека скрывается базовый набор универсальных нейронных механизмов, которые, как водяной знак, раскрывают ограничения человеческой природы.
ГЛАВА 1
Как мы читаем?
Обработка текстов начинается у нас на глазах. Только центр сетчатки, называемый ямкой, имеет достаточно высокое разрешение, чтобы можно было распознать мелкий шрифт. Поэтому наш взгляд должен постоянно перемещаться по странице. Когда наши глаза останавливаются, мы узнаем только одно или два слова. Затем каждый из них разделяется нейронами сетчатки на бесчисленные фрагменты и должен быть снова соединен, прежде чем его можно будет распознать. Наша зрительная система постепенно извлекает графемы, слоги, префиксы, суффиксы и корни слов.В конечном итоге в игру вступают два основных параллельных маршрута обработки: фонологический путь, который преобразует буквы в звуки речи, и лексический путь, который дает доступ к мысленному словарю значений слов.
Существование текста — это безмолвное существование, безмолвное до того момента, когда его прочитает читатель. Текст оживает только тогда, когда умный глаз соприкасается с отметками на планшете. Все написание зависит от щедрости читателя.
—ALBERTO MANGUEL, ИСТОРИЯ ЧТЕНИЯ
На первый взгляд чтение кажется почти волшебным: наш взгляд останавливается на слове, и наш мозг без труда дает нам доступ к его значению и произношению.Но, несмотря на внешность, процесс далеко не простой. Попадая на сетчатку, слово разбивается на множество фрагментов, так как каждая часть визуального изображения распознается отдельным фоторецептором. Начиная с этого ввода, настоящая задача состоит в том, чтобы собрать части вместе, чтобы расшифровать, какие буквы присутствуют, выяснить порядок, в котором они появляются, и, наконец, идентифицировать слово.
В течение последних тридцати лет когнитивная психология работала над анализом механики чтения.Его цель — взломать «алгоритм» визуального распознавания слов — серию этапов обработки, которые опытный читатель применяет к проблеме распознавания написанных слов. Психологи относятся к чтению как к проблеме информатики. Каждый читатель похож на робота с двумя камерами — двумя глазами и сетчаткой. На них нарисованы слова, которые мы читаем. Сначала они появляются только как светлые и темные пятна, которые нельзя напрямую интерпретировать как языковые знаки. Визуальная информация должна быть перекодирована в понятный формат, прежде чем мы сможем получить доступ к соответствующим звукам, словам и значениям.Таким образом, у нас должен быть алгоритм дешифрования или рецепт обработки, подобный программному обеспечению автоматического распознавания символов, которое принимает пиксели на странице в качестве входных данных и производит идентичность слов в качестве выходных данных. Чтобы совершить этот подвиг, без нашего ведома, наш мозг выполняет сложный набор операций декодирования, принципы которых только начинают понимать.
Глаз: плохой сканер
Сказка о чтении начинается, когда сетчатка принимает фотоны, отраженные от написанной страницы.Но сетчатка не является однородным сенсором. Только ее центральная часть, называемая ямкой, плотна в клетках с высоким разрешением, чувствительных к падающему свету, тогда как остальная часть сетчатки имеет более грубое разрешение. Ямка, занимающая около 15 градусов поля зрения, — единственная часть сетчатки, действительно полезная для чтения. Когда информация о фовеа отсутствует, будь то из-за поражения сетчатки, из-за инсульта, разрушившего центральную часть зрительной коры, или из-за экспериментального трюка, который выборочно блокирует визуальные входы в фовеа, чтение становится невозможным.6
Необходимость поместить слова в ямку объясняет, почему наши глаза находятся в постоянном движении, когда мы читаем. Ориентируя взгляд, мы «сканируем» текст наиболее чувствительной частью нашего зрения, единственной, которая имеет разрешение, необходимое для определения букв. Однако наши глаза не путешествуют по странице постоянно7. Как раз наоборот: они движутся небольшими шагами, называемыми саккадами. В этот самый момент вы делаете четыре или пять таких резких движений каждую секунду, чтобы донести новую информацию до своей фовеа.
Даже внутри ямки визуальная информация не отображается с одинаковой точностью во всех точках. В сетчатке, а также в последующих визуальных ретрансляторах таламуса и коры, количество клеток, выделенных для данной части визуальной сцены, постепенно уменьшается по мере удаления от центра взгляда. Это вызывает постепенную потерю визуальной точности. Визуальная точность оптимальна в центре и плавно снижается к периферии. У нас есть иллюзия, что мы видим всю сцену перед нами с такой же фиксированной точностью, как если бы она была снята цифровой камерой с однородным массивом пикселей.Однако, в отличие от камеры, наш датчик глаза точно определяет только ту точку, в которую попадает наш взгляд. Окружающее пространство теряется во все более туманной размытости (рис. 1.1) .8
Рис. 1.1 Сетчатка сетчатки строго фильтрует то, что мы читаем. В этом моделировании страница из книги Сэмюэля Джонсона The Adventurer (1754) была отфильтрована с использованием алгоритма, который копирует уменьшающуюся остроту человеческого зрения в сторону от центра сетчатки. Независимо от размера, можно идентифицировать только буквы, близкие к фиксации.Вот почему мы постоянно изучаем страницы, когда читаем, отрывистыми движениями глаз. Когда наш взгляд останавливается, мы можем определить только одно или два слова.
Можно подумать, что в этих условиях именно абсолютный размер напечатанных символов определяет легкость, с которой мы можем читать: маленькие буквы должны быть труднее читать, чем большие. Однако, как ни странно, это не так. Причина в том, что чем крупнее символы, тем больше места они занимают на сетчатке. Когда все слово печатается более крупными буквами, оно перемещается на периферию сетчатки, где даже большие буквы трудно различить.Эти два фактора почти точно компенсируют друг друга, так что огромное и малюсенькое слово по существу эквивалентны с точки зрения точности определения сетчатки. Конечно, это верно только при условии, что размер символов остается больше абсолютного минимума, который соответствует максимальной точности, достигаемой в центре нашей ямки. При снижении остроты зрения, например, у пожилых пациентов, вполне логично рекомендовать книги с крупным шрифтом.
Поскольку наши глаза устроены таким образом, наши способности восприятия зависят исключительно от количества букв в словах, а не от места, которое эти слова занимают на нашей сетчатке.9 Действительно, наши саккады при чтении различаются по абсолютной величине, но постоянны при измерении числами букв. Когда мозг готовится переместить наши глаза, он адаптирует расстояние, которое нужно преодолеть, к размеру персонажей, чтобы гарантировать, что наш взгляд всегда продвигается примерно на семь-девять букв. Эта удивительно малая величина, таким образом, приблизительно соответствует информации, которую мы можем обработать в ходе фиксации одного глаза.
Чтобы доказать, что мы видим только очень маленькую часть каждой страницы за раз, Джордж У.МакКонки и Кейт Рейнер разработали экспериментальный метод, который мне нравится называть «картезианским дьяволом». В своих «Метафизических размышлениях » Рене Декарт вообразил, что злой гений играет с нашими чувствами:
Тогда я предположу, что не тот Бог, который в высшей степени добрый и источник истины, а какой-то злой гений, не менее могущественный, чем лживый, использовал всю свою энергию, чтобы обмануть меня; Я буду считать, что небеса, земля, цвета, фигуры, звук и все другие внешние вещи не что иное, как иллюзии и мечты, которыми воспользовался этот гений, чтобы расставить ловушки для моей доверчивости.Я буду считать себя не имеющим ни рук, ни глаз, ни плоти, ни крови, ни каких-либо чувств, но ложно верю, что обладаю всем этим.
Подобно суперкомпьютеру в фильмах Matrix , злой гений Декарта создает псевдореальность, бомбардируя наши чувства сигналами, тщательно продуманными для создания иллюзии реальной жизни, виртуальной сцены, истинная сторона которой остается навсегда скрытой. Более скромно, Макконки и Рейнер разработали «движущееся окно», которое создает иллюзию текста на экране компьютера.10 Метод заключается в оснащении человека-добровольца специальным устройством, отслеживающим движения глаз и способным изменять визуальное отображение в реальном времени. Устройство можно запрограммировать на отображение только нескольких символов слева и справа от центра взгляда, в то время как все оставшиеся буквы на странице заменяются строками x:
Как только глаза двигаются, компьютер незаметно обновляет изображение. отображать. Его цель — показать соответствующие буквы в том месте, куда смотрит человек, и строки из x везде:
С помощью этого устройства Макконки и Райнер сделали замечательное и парадоксальное открытие.Выяснилось, что участники манипуляции не заметили. Пока достаточно букв представлено слева и справа от фиксации, читатель не может обнаружить уловку и считает, что он смотрит на совершенно нормальную страницу текста.
Эта удивительная слепота возникает из-за того, что глаз достигает максимальной скорости в момент смены букв. Этот трюк затрудняет обнаружение изменения букв, потому что в этот самый момент все изображение сетчатки становится размытым из-за движения. Когда взгляд приземляется, все выглядит нормально: внутри ямки ожидаемые буквы находятся на своих местах, а остальная часть поля зрения на периферии все равно не может быть прочитана.Таким образом, эксперимент Макконки и Рейнера доказывает, что мы сознательно обрабатываем лишь очень небольшую часть наших визуальных входов. Если компьютер оставляет четыре буквы слева от фиксации и пятнадцать букв справа, скорость чтения остается нормальной.11 Короче говоря, мы извлекаем очень мало информации за один раз из записанной страницы. Злой гений Декарта должен был отображать только двадцать букв на каждую фиксацию, чтобы заставить нас поверить, что мы читаем Библию или Конституцию США!
Двадцать букв — это, по сути, завышение.Мы идентифицируем только десять или двенадцать букв на саккаду: три или четыре слева от фиксации и семь или восемь справа. Помимо этого, мы в значительной степени нечувствительны к буквенной идентичности и просто кодируем наличие пробелов между словами. Предоставляя подсказки о длине слова, пробелы позволяют нам подготовить движения глаз и гарантировать, что наш взгляд попадет ближе к центру следующего слова. Эксперты продолжают спорить о том, в какой степени мы извлекаем информацию из предстоящего слова — возможно, только из первых нескольких букв.Однако все согласны с тем, что направление чтения вносит асимметрию в наш кругозор. На Западе визуальный охват гораздо больше по направлению к правой стороне, но у тех, кто читает арабский или иврит, когда взгляд просматривает страницу справа налево, эта асимметрия меняется на противоположную12. больше, саккады короче и зрительный охват соответственно сокращается. Таким образом, каждый читатель адаптирует свою стратегию визуального исследования к своему языку и сценарию.
Используя тот же метод, мы также можем оценить, сколько времени необходимо для кодирования идентичности слов.Компьютер можно запрограммировать так, чтобы по истечении заданного времени все буквы заменялись цепочкой из x, даже в ямке. Этот эксперимент показывает, что пятидесяти миллисекунд презентации достаточно, чтобы чтение продолжалось в нормальном темпе. Это не означает, что все мыслительные операции, связанные с чтением, выполняются за одну двадцатую секунды. Как мы увидим, целый конвейер психических процессов продолжает работать по крайней мере полсекунды после того, как слово было представлено.Однако первоначальное получение визуальной информации может быть очень кратким.
Таким образом, наши глаза накладывают множество ограничений на процесс чтения. Структура наших зрительных датчиков заставляет нас сканировать страницу, дергая глазами каждые две или три десятых секунды. Чтение — это не что иное, как пословное мысленное восстановление текста через серию снимков. Хотя некоторые небольшие грамматические слова, такие как «the», «it» или «is», иногда можно пропустить, почти все содержательные слова, такие как существительные и глаголы, должны быть зафиксированы хотя бы один раз.
Эти ограничения являются неотъемлемой частью нашего зрительного аппарата и не могут быть устранены тренировкой. Конечно, можно научить людей оптимизировать паттерны движения глаз, но большинство хороших читателей, которые читают от четырехсот до пятисот слов в минуту, уже близки к оптимальным. Учитывая имеющийся в нашем распоряжении датчик сетчатки глаза, вероятно, сделать что-то лучше не получится. Простая демонстрация доказывает, что движение глаз ограничивает скорость чтения.13 Если полное предложение представлено, слово за словом, именно в той точке, где фокусируется взгляд, что позволяет избежать движения глаз, хороший читатель сможет прочитать с ошеломляющей скоростью — в среднем одиннадцать сотен слов в минуту и до шестисот слов в минуту для лучших читателей, что составляет примерно одно слово каждые сорок миллисекунд и в три-четыре раза быстрее, чем при обычном чтении! С помощью этого метода, называемого быстрым последовательным визуальным представлением, или RSVP, идентификация и понимание остаются удовлетворительными, что позволяет предположить, что продолжительность этих центральных шагов не налагает сильных ограничений на нормальное чтение.Возможно, этот компьютеризированный режим презентации представляет будущее чтения в мире, где экраны постепенно заменяют бумагу.
В любом случае, пока текст представлен на страницах и строках, получение посредством взгляда замедлит чтение и наложит неизбежное ограничение. Таким образом, методы быстрого чтения, рекламирующие увеличение скорости чтения до одной тысячи слов в минуту или более, должны рассматриваться со скептицизмом14. Без сомнения, можно несколько расширить визуальный охват, чтобы уменьшить количество саккад в строке и также можно научиться избегать моментов регресса, когда взгляд возвращается к словам, которые он только что прочитал.Однако физические ограничения глаз не могут быть преодолены, если только кто-то не хочет пропускать слова и, таким образом, рисковать недопониманием. Вуди Аллен прекрасно описал эту ситуацию: «Я прошел курс скорочтения и смог прочитать Война и мир за двадцать минут. Это касается России ».
Поиск инвариантов
Умеешь читать, Любин?
Да, я могу читать печатные буквы, но я никогда не умел читать почерк.
—MOLIÈRE, GEORGES DANDIN
Чтение представляет собой сложную проблему восприятия.Мы должны идентифицировать слова независимо от того, как они выглядят, напечатаны ли они или написаны от руки, в верхнем или нижнем регистре и независимо от их размера. Это то, что психологи называют проблемой инвариантности : нам нужно распознать, какой аспект слова не меняется — последовательность букв — несмотря на тысячу и одну возможную форму, которую могут принимать реальные символы.
Если перцепционная инвариантность является проблемой, то это потому, что слова не всегда находятся в одном месте, в одном и том же шрифте или в одном и том же размере.Если бы это было так, просто перечисление того, какие из ячеек сетчатки активны, а каких нет, было бы достаточно для декодирования слова, подобно тому, как черно-белое компьютерное изображение определяется списком его пикселей. На самом деле, однако, сотни различных изображений сетчатки могут означать одно и то же слово, в зависимости от того, в какой форме оно написано (рисунок 1.2). Таким образом, одним из первых шагов в чтении должно быть исправление огромного разнообразия этих поверхностных форм.
Рис. 1.2 Визуальная неизменность — одна из основных характеристик системы чтения человека.Наше устройство распознавания слов отвечает двум, казалось бы, противоречивым требованиям: оно игнорирует несущественные вариации в форме символов, даже если они огромны, но усиливает соответствующие различия, даже если они крошечные. Без нашего ведома, наша визуальная система автоматически компенсирует огромные различия в размере или шрифте. Тем не менее, это также касается незначительных изменений формы. Превращая «s» в «e» и, следовательно, «взгляд» в «восемь», один знак радикально переориентирует цепочку обработки в сторону совершенно разных произношений и значений.
Некоторые подсказки предполагают, что наш мозг применяет эффективное решение этой проблемы инвариантности восприятия. Когда мы держим газету на разумном расстоянии, мы можем читать как заголовки, так и тематические объявления. Размер слова может варьироваться в пятьдесят раз, не оказывая особого влияния на нашу скорость чтения. Эта задача не сильно отличается от задачи распознавания того же лица или объекта на расстоянии двух футов или тридцати ярдов — наша зрительная система допускает значительные изменения в масштабе.
Вторая форма неизменности позволяет нам игнорировать расположение слов на странице.Когда наш взгляд просматривает страницу, центр нашей сетчатки обычно оказывается немного левее центра слов. Однако наш таргетинг далек от совершенства, и наши глаза иногда доходят до первой или последней буквы, и это не мешает нам распознать слово. Мы даже можем читать слова, представленные на периферии нашего поля зрения, при условии, что размер букв увеличен, чтобы компенсировать потерю разрешения сетчатки. Таким образом, постоянство размера идет рука об руку с нормализацией пространственного положения.
Наконец, распознавание слов также во многом зависит от формы символа.Теперь, когда программное обеспечение для обработки текстов вездесуще, широко доступны технологии, которые раньше были доступны лишь небольшой элите типографов. Всем известно, что существует множество наборов символов, называемых «шрифтами» (термин, оставшийся с тех времен, когда каждый символ должен был быть отлит в литейном цехе перед отправкой в печать). В каждом шрифте также есть два типа символов, называемых «регистрами»: ВЕРХНИЙ и нижний регистр (изначально регистр представлял собой плоский прямоугольник, разделенный на множество отсеков, в которых сортируются ведущие символы; «верхний регистр» был зарезервирован для заглавных букв, а «верхний регистр» был зарезервирован для заглавных букв, а « нижний регистр »для остальных).Наконец, можно выбрать «вес» шрифта (обычный или полужирный, символа), его наклон ( курсив, , первоначально изобретенный в Италии), подчеркнут он или нет, а также любую комбинацию из этих вариантов . Однако эти хорошо откалиброванные варианты шрифтов — ничто по сравнению с огромным разнообразием стилей письма. Рукописный почерк, очевидно, выводит нас на новый уровень изменчивости и неоднозначности.
Несмотря на все эти вариации, то, как именно наша зрительная система учится классифицировать формы букв, остается в некоторой степени загадочным.Часть этой проблемы инвариантности можно решить с помощью относительно простых средств. Например, гласную «о» можно легко распознать, независимо от ее размера, регистра или шрифта, благодаря ее уникальной замкнутой форме. Таким образом, создать визуальный детектор не составляет особого труда. Однако другие письма создают определенные проблемы. Рассмотрим, например, букву «r». Хотя кажется очевидным, что формы r, R и все представляют одну и ту же букву, тщательное изучение показывает, что эта ассоциация полностью произвольна — например, форма e может служить так же, как и строчная версия буквы «R.«Только исторические случайности оставили нам эту культурную странность. В результате, когда мы учимся читать, мы должны не только узнать, что буквы соответствуют звукам языка, но и что каждая буква может принимать множество разных форм. Как мы увидим, наша способность делать это, вероятно, проистекает из существования абстрактных детекторов букв, нейронов, которые могут распознавать идентичность буквы в ее различных обличьях. Эксперименты показывают, что для декодирования достаточно очень небольшого обучения, при существенном незначительном затрате времени, предприятия, которые принимают меры, принимаемые в качестве альтернативы в повышении эффективности и в низкоэнергетическом секторе.15 В компьютере «злого гения» Макконки и Райнера это чередование букв можно менять между каждой глазной саккадой, совершенно незаметно для читателя! Процессы нормализации букв настолько эффективны, что легко сопротивляются такому преобразованию.
Между прочим, эти эксперименты демонстрируют, что глобальная форма слова не играет никакой роли в чтении. Если мы можем сразу же распознать идентичность «слов», «СЛОВ» и «WoRdS», то это потому, что наша зрительная система не обращает внимания на контуры слов или на схему восходящих и нисходящих букв: ее интересуют только буквы, которые они содержат.Очевидно, наша способность распознавать слова не зависит от анализа их общей формы.
Усиление различий
Хотя наша визуальная система эффективно отфильтровывает визуальные различия, не имеющие отношения к чтению, такие как различие между «R» и «r», было бы ошибкой думать, что она всегда отбрасывает информацию и упрощает формы. Напротив, во многих случаях он должен сохранять и даже усиливать мельчайшие детали, которые отличают два очень похожих слова друг от друга.Рассмотрим слова «восемь» и «взгляд». Мы сразу же получаем доступ к их очень разным значениям и произношению, но только когда мы внимательно смотрим на них, мы понимаем, что разница составляет всего несколько пикселей. Наша зрительная система чрезвычайно чувствительна к незначительной разнице между «восьмеркой» и «зрением» и усиливает ее, чтобы посылать входные данные в совершенно разные области семантического пространства. В то же время он уделяет очень мало внимания другим, гораздо более значительным различиям, таким как различие между «восьмеркой» и «восьмеркой».”
Как и в случае с инвариантностью кейса, эта способность обращать внимание на важные детали является результатом многих лет обучения. Тот же читатель, который сразу заметит разницу между буквами «е» и «о» и отсутствие разницы между «а» и « a », может не заметить, что еврейские буквы и резко различаются, факт, который кажется очевидным. любому читающему на иврите.
Каждое слово — это дерево
Наша визуальная система решает проблему инвариантного распознавания слов с помощью хорошо организованной системы.Как мы подробно увидим в главе 2, поток нейронной активности, поступающей в зрительный мозг, постепенно сортируется по значимым категориям. Формы, которые кажутся очень похожими, такие как «восьмерка» и «зрение», просеиваются через серию все более и более тонких фильтров, которые постепенно разделяют их и прикрепляют к отдельным статьям в мысленном лексиконе, виртуальном словаре всех слов, которые мы когда-либо использовали. столкнулся. И наоборот, такие формы, как «восьмерка» и «ВОСЕМЬ», которые состоят из различных визуальных характеристик, изначально кодируются разными нейронами в первичной визуальной области, но постепенно перекодируются, пока не становятся практически неразличимыми.Детекторы признаков распознают сходство букв «i» и «I». Другие, немного более абстрактные детекторы букв классифицируют «e» и «E» как две формы одной и той же буквы. Несмотря на первоначальные различия, зрительная система читателя в конечном итоге кодирует саму суть буквенных последовательностей «восемь» и «восемь», независимо от их точной формы. Он дает этим двум строкам один и тот же мысленный адрес, абстрактный код, способный ориентировать остальную часть мозга на произношение и значение слова.
Как выглядит этот адрес? Согласно некоторым моделям, мозг использует своего рода неструктурированный список, который просто представляет собой последовательность букв E-I-G-H-T. В других случаях он основан на очень абстрактном и традиционном коде, похожем на случайный шифр, с помощью которого, скажем, [1296] будет словом «восемь», а [3452] словом «взгляд». Однако современные исследования подтверждают другую гипотезу. Каждое написанное слово, вероятно, закодировано иерархическим деревом, в котором буквы сгруппированы в единицы большего размера, которые сами сгруппированы в слоги и слова — так же, как человеческое тело может быть представлено как набор ног, рук, туловища и головы. , каждую из которых можно разбить на простые части.
Хороший пример мысленного разложения слов на соответствующие единицы можно найти, если проанализировать слово «расстегивание». Сначала мы должны убрать префикс «un» и знакомый суффикс или грамматическое окончание «ing». Оба обрамляют центральный элемент, слово внутри слова: корень «кнопка». Все три этих компонента называются «морфемами» — мельчайшими единицами, несущими какое-то значение. На этом уровне каждое слово характеризуется тем, как складываются его морфемы. Разделение слова на его морфемы даже позволяет нам понимать слова, которые мы никогда раньше не видели, такие как «повторное нажатие» или «деглохизация» (мы понимаем, что это отменяет действие «глохинга», что бы это ни было) .В некоторых языках, таких как турецкий или финский, морфемы могут быть собраны в очень большие слова, которые передают столько же информации, сколько и полное английское предложение. В этих языках, но также и в нашем, разложение слова на его морфемы является важным шагом на пути, ведущем от видения к значению.
Множество экспериментальных данных показывают, что наша зрительная система очень быстро и даже совершенно бессознательно вырезает морфемы слов. Например, если бы я высветил слово «отъезд» на экране компьютера, вы позже произнесли бы слово «отъезд» немного быстрее, когда столкнетесь с ним.Представление «ухода», кажется, предварительно активирует морфему [уход], тем самым облегчая доступ к ней. Психологи говорят о «стимулирующем» эффекте: чтение слова способствует распознаванию связанных с ним слов, так же как и насос. Важно отметить, что этот эффект прайминга не зависит исключительно от визуального сходства: слова, которые выглядят совершенно по-разному, но имеют общую морфему, такую как «может» и «мог бы», могут служить друг другу, в то время как слова, которые выглядят одинаково, но не имеют интимной морфологической связи, такие как «аспирин» и «аспирин» — нет.Прайминг также не требует сходства на смысловом уровне; такие слова, как «сложно» и «вряд ли» или «уйти» и «отдел», могут быть взаимно связанными, даже если их значения по существу не связаны17. Переход на уровень морфем, кажется, имеет такое важное значение для нашей системы чтения. что он готов делать предположения о разложении слов. Наш читающий аппарат разбирает слово «отдел» на [отъезд] + [мент] в надежде, что это будет полезно для следующих операторов, вычисляющих его значение.18 Неважно, что это работает не всегда: «вялый» человек — это не тот, кто ждет списка покупок, и совместное использование «квартиры» не означает, что вы и ваш партнер скоро будете жить отдельно. Такие ошибки синтаксического анализа придется обнаруживать на других этапах процесса анализа слов.
Если продолжать раздевать слово «расстегивание», морфема [кнопка] сама по себе не является неделимым целым. Он состоит из двух слогов, [bΛ] и [ton], каждый из которых может быть разбит на отдельные согласные и гласные: [b] [Λ] [t] [o] [n] ».Здесь находится еще одна важная единица нашей системы чтения: графема, буква или ряд букв, которые отображаются на фонему целевого языка. Обратите внимание, что в нашем примере две буквы «tt» отображаются на один звук t .19 Действительно, отображение графем на фонемы не всегда является прямым процессом. Во многих языках графемы могут быть построены из группы букв. English имеет особенно обширную коллекцию сложных графем, таких как «ough», «oi» и «au».
Наша визуальная система научилась обращаться с этими группами букв как с добросовестными единицами до такой степени, что мы больше не обращаем внимания на их фактическое содержание букв.Давайте проведем простой эксперимент, чтобы доказать это. Изучите следующий список слов и отметьте те, которые содержат букву «а»:
гараж
металл
люди
пальто
пожалуйста
мясо
Чувствовали ли вы, что вам нужно немного замедлить темп? из последних трех слов: «пальто», «пожалуйста» и «мясо»? Все они содержат букву «а», но она встроена в сложную графему, которая не произносится как «а». Если бы мы полагались только на детекторы букв для обнаружения буквы «а», разбор слова на его графемы не имел бы никакого значения.Однако фактическое измерение времени отклика ясно показывает, что наш мозг не останавливается на однобуквенном уровне. Наша визуальная система автоматически перегруппировывает буквы в графемы более высокого уровня, тем самым усложняя нам задачу увидеть, что группы букв, такие как «еа», на самом деле содержат букву «а». 20
В свою очередь, графемы автоматически группируются в слоги. Вот еще одна простая демонстрация этого факта. Вы увидите пятибуквенные слова. Некоторые буквы набраны жирным шрифтом , другие — обычным шрифтом.Сосредоточьтесь исключительно на средней букве и попробуйте решить, напечатана ли она обычным или жирным шрифтом:
Список 1: HO RNY RID ER GR AVY FIL ET
Список 2: VOD KA ME TRO HAN DY SU PER
Считаете ли вы, что первый список был немного сложнее второго? В первом списке жирные символы не соответствуют границам слогов — например, в « RID ER» буква «D» напечатана жирным шрифтом, а остальная часть слога — обычным шрифтом.Наш разум имеет тенденцию группировать вместе буквы, составляющие слог, тем самым создавая конфликт с жирным шрифтом, который приводит к измеримому замедлению реакции.21 Этот эффект показывает, что наша зрительная система не может избежать автоматического разделения слов на их элементарные составляющие. даже тогда, когда лучше этого не делать.
Природа этих компонентов остается актуальной темой исследований. Казалось бы, могут сосуществовать несколько уровней анализа: одна буква на самом низком уровне, затем пара букв (или «биграмма», важная единица, к которой мы вернемся позже), графема, слог, морфема, и наконец все слово.На последнем этапе визуальной обработки слово разбирается в иерархическую структуру — дерево, состоящее из ветвей увеличивающихся размеров, листьями которых являются буквы.
Сокращенная до скелета, лишенная всех его несущественных функций, таких как шрифт, регистр и размер, буквенная строка, таким образом, разбита на элементарные компоненты, которые будут использоваться остальной частью мозга для вычисления звука и значения.
Тихий голос
Письмо — это гениальное искусство рисования слов и речи для глаз.
—ЖОРЖ ДЕ БРЕБЕФ (ФРАНЦУЗСКИЙ ПОЭТ, 1617–1661)
Когда он нанес визит Амвросию, тогдашнему епископу Милана, Августин заметил явление, которое он счел достаточно странным, чтобы о нем упомянуть в своих мемуарах:
Когда [Амвросий] читал, его глаза сканировали страницу, и его сердце искало смысл, но его голос был беззвучен, а его язык был неподвижен. Любой мог свободно подойти к нему, и гостей обычно не объявляли, так что часто, когда мы приходили к нему в гости, мы видели, что он читает это в тишине, потому что он никогда не читал вслух.22
В середине седьмого века богослов Исидор Севильский аналогичным образом удивлялся тому, что «буквы обладают властью молча передавать нам высказывания тех, кто отсутствует». В то время было принято читать вслух на латыни. Формулирование звуков было социальной условностью, но также и реальной необходимостью: сталкиваясь со страницами, на которых слова были склеены вместе, без пробелов, на языке, который они плохо знали, большинству читателей приходилось бормотать тексты, как маленькие дети.Вот почему немое чтение Амвросия было таким удивительным, даже если для нас оно стало привычным опытом: мы можем читать, не произнося звуков.
Идет ли когда-нибудь наш разум прямо от написанного слова к его значению без доступа к произношению, или он неосознанно преобразует буквы в звук, а затем звук в значение, было темой значительных дискуссий. разделял психологическое сообщество более тридцати лет.Некоторые думали, что преобразование печатного текста в звук было существенным — письменный язык, по их мнению, является всего лишь побочным продуктом разговорного языка, и поэтому мы должны озвучивать слова через фонологический маршрут , прежде чем у нас появится какая-либо надежда восстановления их значения. Для других, однако, фонологическое перекодирование было лишь чертой новичка, характерной для юных читателей. У более опытных читателей эффективность чтения была основана на прямом лексическом маршруте прямо от строки букв к ее значению.
В настоящее время сложился консенсус: у взрослых существуют оба пути чтения, и оба они одновременно активны. У всех нас есть прямой доступ к значениям слов, что избавляет нас от мысленного произношения слов, прежде чем мы сможем их понять. Тем не менее даже опытные читатели продолжают использовать звуки слов, даже если они этого не осознают. Не то чтобы мы произносили слова тайно — нам не нужно шевелить губами или даже готовить намерение сделать это. Однако на более глубоком уровне информация о произношении слов извлекается автоматически.И лексические, и фонологические пути действуют параллельно и усиливают друг друга.
Существует множество доказательств того, что мы автоматически получаем доступ к звукам речи во время чтения. Представьте, например, что вам представлен список строк и вы должны решить, является ли каждая из них настоящим английским словом или нет. Имейте в виду, вам нужно только решить, соответствуют ли буквы английскому слову. Вот и все:
кролик
bountery
culdolt
money
dimon
karpit
nee
Возможно, вы колебались, когда буквы звучали как настоящее слово — например, «демон», «ковер» или «колено.«Этот эффект интерференции можно легко измерить с точки зрения времени отклика. Это означает, что каждая строка преобразуется в последовательность звуков, которая оценивается как реальное слово, даже если процесс идет вразрез с запрошенной задачей.23
Мысленное преобразование в звук играет важную роль, когда мы читаем слово в первый раз. — скажем, шнурок «Калашников». Изначально мы не можем напрямую получить доступ к его значению, поскольку никогда не видели, чтобы это слово было написано по буквам. Все, что мы можем сделать, — это преобразовать его в звук, обнаружить, что звуковой образец понятен, и с помощью этого косвенного пути прийти к пониманию нового слова.Таким образом, звучание часто является единственным решением, когда мы встречаем новое слово. Это также незаменимо, когда мы читаем слова с ошибками. Рассмотрим малоизвестную историю Эдгара Аллана По под названием «Ангел странностей». В нем странный персонаж таинственным образом вторгается в квартиру рассказчика, «персонаж невзрачный, хотя и не совсем неописуемый», с немецким акцентом, густым, как британский туман:
«Кто вы, молитесь?» сказал я, с большим достоинством, хотя несколько озадаченный; «как вы сюда попали? И о чем ты говоришь? »
«Я уже слышал, — ответила фигура, — не говоря уже о твоей пикантности; и как vor vat я говорю, я говорю о vat, я говорю правильно; И, как я бы ни был, это очень важно, чтобы я пришёл сюда для того, чтобы позволить тебе задуматься над самим собой.. . . Посмотри на меня! Зи! Я ангел ов те странный.
«И довольно странно», — рискнул я ответить; «Но мне всегда казалось, что у ангела есть крылья».
«Крылышко!» — воскликнул он в ярости. — Vat I pe do mit te wing? Mein Gott! Ты возьмешь меня за курицу?
Читая этот отрывок, мы возвращаемся к стилю, который мы давно забыли, который восходит к нашему детству: фонологический путь или медленное преобразование совершенно новых цепочек букв в звуки, которые чудесным образом становятся понятными, как будто кто-то шепчет их у нас.
А как насчет повседневных слов, которые мы встречали уже тысячу раз? У нас не создается впечатление, что мы медленно декодируем посредством мысленного произнесения. Однако умные психологические тесты показывают, что мы по-прежнему активируем их произношение на бессознательном уровне. Например, предположим, что вас просят указать, какие из следующих слов относятся к частям человеческого тела. Все это очень знакомые слова, поэтому вы можете сосредоточиться на их значении и пренебречь их произношением.Попробуйте:
колено
нога
стол
голова
самолет
ведро
заяц
Возможно, вам захотелось ответить на слово «заяц», которое звучит как часть тела. Эксперименты показывают, что мы замедляемся и делаем ошибки в словах, которые звучат как элемент целевой категории24. Непонятно, как мы могли бы распознать эту гомофонию, если бы мы сначала не восстановили в уме произношение слова. Только внутреннее преобразование в звуки речи может объяснить этот тип ошибки.Наш мозг не может не преобразовать буквы «h-a-r-e» во внутреннюю речь, а затем связать ее со смыслом — процесс, который может пойти не так в редких случаях, когда строка звучит как другое хорошо известное слово.
Конечно, этот несовершенный дизайн также доставляет нам одно из величайших удовольствий жизни: каламбуры или «радость текста», как выразился юморист Ричард Ледерер. Без дара преобразования буквы в звук мы не смогли бы насладиться остротой Мэй Уэст («Она из тех девушек, которые поднялись по лестнице успеха неправильно за ошибкой») или шуткой зятя Конан Дойля (« нет такой полиции, как Холмс »).Без «безмолвного голоса» Августина нам было бы отказано в удовольствии от рискованных двусмысленностей:
Поклонник говорит президенту Линкольну: «Разрешите мне представить мою семью. Моя жена, миссис Бейтс. Моя дочь, мисс Бейтс. Мой сын, мастер Бейтс.
«О боже!» — ответил президент.25
Еще одно доказательство того, что наш мозг автоматически получает доступ к звуковым образцам слова, получено в результате подсознательного прайминга. Предположим, я показываю вам слово «ПОЗДНЕЕ», сразу за которым следует слово «мат», и прошу вас прочитать второе слово как можно быстрее.Слова показаны в другом регистре, чтобы избежать визуального сходства на низком уровне. Тем не менее, когда первое слово звучит и произносится как второе, как в этом примере, мы наблюдаем значительное ускорение времени чтения по сравнению с ситуацией, когда два слова не связаны друг с другом («ЧАША» с последующим « приятель»). Частично это облегчение проистекает из сходства только на уровне орфографии. Мигание «MATH» облегчает распознавание «мат», даже если две струны звучат совершенно по-разному.Однако, что очень важно, можно найти еще большее облегчение, когда два слова имеют одинаковое произношение («ПОЗДНЕЕ» с последующим «спаривание»), и это основанное на звуке праймирование работает даже тогда, когда написание совершенно разное («ВОСЕМЬ» с последующим «спаривание» ). Таким образом, кажется, что произношение извлекается автоматически. Однако, как и следовало ожидать, орфография и звук не кодируются одновременно. Нашему мозгу требуется всего двадцать или тридцать миллисекунд просмотра слова, чтобы автоматически активировать написание слова, но дополнительные сорок миллисекунд для его преобразования в звук, как показывает появление звуковой прайминга.26
Таким образом, простые эксперименты позволяют нам очертить целый поток последовательных стадий в мозгу читателя, от отметок на сетчатке глаза до их преобразования в буквы и звуки. Любой опытный читатель легко и неосознанно быстро превращает строки в звуки речи.
Пределы звука
Скрытый доступ к произношению написанных слов — это автоматический шаг при чтении, но это преобразование может быть необязательным. Преобразование речи в звук часто происходит медленно и неэффективно.Таким образом, наш мозг часто пытается восстановить значение слова, используя параллельный и более прямой путь, который ведет прямо от буквенной строки к соответствующей записи в лексиконе разума.
Чтобы улучшить нашу интуицию о прямом лексическом пути, мы должны рассмотреть тяжелое положение воображаемого читателя, который был бы способен только мысленно произносить написанные слова. Для него было бы невозможно различить омофонические слова, такие как «горничная» и «сделал», «поднять» и «сравнять», «доска» и «скучно» или «мускулы» и «мидии».«Чисто на основе звука он мог бы подумать, что серийные убийцы ненавидят кукурузные поля и что бриллианты в один карат имеют странный оттенок оранжевого. Сам факт того, что мы легко распознаем множественные значения таких омофонических слов, показывает, что мы не обязаны их произносить — доступен другой путь, который позволяет нашему мозгу разрешить любую двусмысленность и сразу перейти к их значению.
Еще одна проблема существует для чисто звуковых теорий чтения: путь от орфографии к звуку не является высокоскоростным шоссе, лишенным препятствий.Вывести произношение слова из последовательности букв зачастую невозможно без дополнительной помощи. Рассмотрим слово «кровь». Кажется очевидным, что его следует произносить как blud и что оно рифмуется со словом «бутон» или «грязь». Но откуда мы это знаем? Почему не следует рифмовать слово «кровь» с «едой» или «добром»? Почему это не звучит как «цветение» или «цветение»? Даже один и тот же корень слова может произноситься по-разному, например, «знак» и «подпись». Некоторые слова настолько необычны, что трудно понять, как их произношение соотносится с составляющими их буквами («полковник», «яхта», «хотя».. .). В таких случаях невозможно вычислить произношение слова без предварительного знания слова.
Английская орфография с неровностями. Действительно, разрыв между письменным и устным языком насчитывает столетия, о чем свидетельствует Уильям Шекспир в книге «Потерянные усилия любви », где педант Олоферн говорит:
Я ненавижу такие фанатичные фантазии, таких малодушных и изобретательных товарищей; такие вымогатели орфографии, чтобы говорить dout , хорошо, когда он должен сказать сомневаюсь ; det , когда он должен произнести долга —d, e, b, t, но не d, e, t: он кусает теленка, cauf ; половина , га ; сосед вокатур сосед ; neigh сокращенно ne .Это отвратительно — то, что он назвал бы отвратительным : это намекает на безумие.
Английский — отвратительно нерегулярный язык. Джордж Бернард Шоу указал, что слово «рыба» может быть написано ghoti : gh как «достаточно», o как «женщины» и ti как «лосьон»! Шоу настолько ненавидел неправильное написание английского языка, что в своем завещании он объявил конкурс на разработку нового и полностью рационального алфавита под названием «шавиан».К сожалению, он никогда не имел особого успеха, вероятно, потому, что он слишком сильно отличался от всех других существующих орфографических систем27.
Конечно, пример Шоу надуман: никто никогда не прочитал бы ghoti как «рыба», потому что буква «g», помещенная в начало слова, всегда произносится как жесткое g или j , но никогда как f . Точно так же, вопреки Шекспиру, в современном английском языке буквы «alf» в конце слова всегда произносятся как af , как в «теленок» и «половина».«Если буквы взяты в контексте, часто можно выявить некоторые закономерности более высокого порядка, которые упрощают отображение букв на звуки. Однако даже в этом случае исключения остаются многочисленными — «has» и «was», «tough» и «dough», «мука» и «tour», «header» и «reader», «choir» и «Chair», « друг »и« дьявол ». Для большинства нерегулярных слов восстановление произношения, которое далеко не является источником понимания слова, похоже, зависит от его результата: только после того, как мы распознаем идентичность слова «тесто», мы можем восстановить его звуковой образец.
Скрытая логика нашей системы правописания
Можно задаться вопросом, почему английский язык придерживается такой сложной системы правописания. Действительно, итальянцы не сталкиваются с такими проблемами. Их написание прозрачно: каждая буква отображается на одной фонеме, практически без исключений. В результате, чтобы научиться читать, требуется всего несколько месяцев. Это дает итальянцам огромное преимущество: их дети по навыкам чтения превосходят наши на несколько лет, и им не нужно тратить часы в школе на диктовку и правописание вслух.Более того, как мы обсудим позже, дислексия — гораздо менее серьезная проблема для них. Может быть, нам следует последовать примеру Италии, сжечь все наши словари и разработать систему noo speling, даже не имеющую отношения к древнему tchaild cood eezilee reed.
Нет сомнений в том, что правописание английского языка можно упростить. Вес истории объясняет многие его особенности — сегодняшние ученики должны оплакивать поражение в битве при Гастингсе, потому что последовавшая за этим смесь французского и английского языка является причиной многих наших проблем с орфографией, таких как использование буквы «c» »Для звука с (как в« cinder »).Века академического консерватизма, иногда граничащего с педантизмом, заморозили наш словарь. Ученые из лучших побуждений даже вводили нелепые орфографические ошибки, такие как «s» в слове «остров», ошибочная попытка эпохи Возрождения восстановить этимологию латинского слова insula . Хуже всего то, что английская орфография не смогла развиться, несмотря на естественный дрейф устной речи. Введение иностранных слов и спонтанные сдвиги в английской артикуляции создали огромный разрыв между тем, как мы пишем, и тем, как мы говорим, что вызывает годы ненужных страданий для наших детей.Короче говоря, разум требует радикального упрощения английского правописания.
Тем не менее, прежде чем вносить какие-либо изменения, важно полностью понять скрытую логику нашей системы правописания. Орфографические ошибки — это не просто вопрос условности. Они также берут начало в самой структуре нашего языка и нашего мозга. Два пути чтения, от орфографии к звуку или от орфографии к значению, накладывают сложные и часто несовместимые ограничения на любую систему письма.Лингвистические различия между английским, итальянским, французским и китайским языками таковы, что ни один вариант написания не может удовлетворить их всех. Таким образом, ужасающая неправильность написания английского языка кажется неизбежной. Хотя реформа орфографии крайне необходима, ей придется столкнуться с множеством ограничений.
Прежде всего, неясно, может ли английское правописание, как и итальянское, приписывать отдельную букву каждому звуку и фиксированный звук каждой букве. Это будет непросто, потому что английский язык содержит гораздо больше звуков речи, чем итальянский.Количество английских фонем колеблется от сорока до сорока пяти, в зависимости от говорящих и методов подсчета, в то время как в итальянском их всего тридцать. Гласные и дифтонги особенно распространены в английском языке: есть шесть простых гласных (как в bat , bet , bit , but , good и pot ), а также пять долгих гласных (как в говядине , сапоге , птице , барде и лодке ) и не менее семи дифтонгов (как в залив , мальчик , палец , купить , корова , пиво , медведь ).Если бы каждому из этих звуков был предоставлен собственный письменный символ, нам пришлось бы изобретать новые буквы, что возложило бы дополнительную нагрузку на наших детей. Мы могли бы рассмотреть возможность добавления акцентов к существующим буквам, например ã, õ или ü. Однако совершенно утопично представить универсальный алфавит, который мог бы транскрибировать все языки мира. Такая система правописания действительно существует: она называется Международный фонетический алфавит и играет важную роль в технических публикациях фонологов и лингвистов.Однако эта система письма настолько сложна, что будет неэффективна в повседневной жизни. Международный фонетический алфавит состоит из 170 знаков, некоторые из которых особенно сложны. Даже специалистам очень трудно свободно читать без словаря.
Чтобы избежать изучения чрезмерного количества форм символов, языки с большим количеством фонем, такие как английский и французский, все прибегают к компромиссу. Они обозначают определенные гласные или согласные, используя специальные символы, такие как ü, или группы букв, такие как «oo» или «oy».Такие особенности, присущие любому конкретному языку, отнюдь не являются ненужным украшением: они играют важную роль в «умственной экономии» чтения и должны найти свое место в любой реформе орфографии.
Хотя мы не можем легко назначить форму одной буквы каждому звуку речи, мы могли бы попробовать обратное. Многих орфографических ошибок можно было бы избежать, если бы мы систематически записывали каждый звук фиксированной буквой. Например, если бы мы не записывали звук f одновременно с буквой «f» и «ph», жизнь была бы намного проще.Нет никаких сомнений в том, что мы могли бы легко избавиться от этой и многих других бесполезных излишеств, приобретение которых съедает многие годы детства. Фактически, это робкое направление, которое взяла американская реформа орфографии, когда она упростила неправильное британское написание слов «поведение» или «анализировать» на «поведение» и «анализировать». В том же направлении можно было бы предпринять еще много шагов. Как опытные читатели, мы перестаем осознавать абсурдность написания. Даже такая простая буква, как «x», не нужна, поскольку она обозначает две фонемы ks , которые уже имеют собственное написание.В Турции принимают «такси». Эта страна, которая в течение одного года (1928–29) приняла латинский алфавит, резко упростила его написание и научила читать три миллиона человек, являясь прекрасным примером осуществимости реформы орфографии.
И здесь снова нужна большая осторожность. Я подозреваю, что любая радикальная реформа, цель которой состояла бы в обеспечении четкой однозначной транскрипции английской речи, обречена на провал, потому что роль орфографии , а не просто для обеспечения точной транскрипции звуков речи.Вольтер ошибся, заявив элегантно, но ошибочно, что «письмо — это картина голоса: чем больше оно похоже, тем лучше». Письменный текст не является записью с высокой точностью воспроизведения. Его цель не в том, чтобы воспроизводить речь, как мы ее произносим, а в том, чтобы закодировать ее на достаточно абстрактном уровне, чтобы позволить читателю быстро понять ее значение.
Ради аргументации, мы можем попытаться представить себе, как могла бы выглядеть чисто фонетическая система письма, которую Вольтер мог бы счесть идеальной.Когда мы говорим, мы меняем произношение слов в зависимости от окружающих их звуков. Было бы катастрофой, если бы орфография отражала тупые лингвистические явления так называемой коартикуляции, ассимиляции и ресиллабификации, о которых большинство говорящих обычно не подозревает. В зависимости от контекста одно и то же слово будет написано по-разному. Должны ли мы, например, использовать различные знаки для различного произношения множественного числа? Должны ли мы писать «cap driver» под предлогом того, что звук b , за которым следует d , имеет тенденцию произноситься как p ? С одной стороны, следует ли учитывать акцент говорящего («Вы меня принимаете за болвана?»).Это будет апсурд (да, мы произносим это слово со звуком p ). Основная цель письма — максимально эффективно передать смысл. Любая сервильная транскрипция звуков отвлекает от этой цели.
Английское правописание часто предпочитает прозрачность корней слов за счет регулярности звуков. Слова «безумие» и «безумие», например, настолько тесно связаны со своим значением, что было бы глупо писать их по-другому из-за их немного другого произношения.Точно так же логично сохранить молчание n в конце «колонка», «осень» или «осуждать», учитывая, что эти слова вызывают «обозреватель», «осенний» или «осуждение».
Транскрипция значений также объясняет, по крайней мере частично, почему в английском языке одни и те же звуки произносятся разными способами. Английские слова, как правило, компактны и односложны, поэтому очень часто встречается омофония (например, «глаз» и «я», «ты» и «овца»). Если бы эти слова были фонетически расшифрованы, их нельзя было бы отличить друг от друга.Правила правописания развивались с учетом этого ограничения. Отличительное написание одних и тех же звуков усложняет диктовку, но упрощает задачу для читателя, который может быстро уловить предполагаемый смысл. Студенты, которые жалуются на бесчисленные формы написания звука и , например, «два», «тоже», «к» или «тушить», должны понимать, что эти украшения необходимы для скорости, с которой мы читаем. Без них любой письменный текст превратился бы в непрозрачный ребус. Благодаря правилам правописания, письменный английский прямо указывает на смысл.Любая реформа правописания должна поддерживать это тонкое равновесие между звуком и значением, потому что этот баланс отражает гораздо более глубокий и жесткий феномен: два маршрута чтения нашего мозга.
Невозможная мечта о прозрачном правописании
Соперничество между чтением ради звука и чтением смысла существует во всем мире. Все системы письма должны каким-то образом решать эту проблему. Какой компромисс лучше всего зависит от языка, на котором будет транскрибироваться. Жизнь, безусловно, была бы проще, если бы правописание английского языка было таким же легким в изучении, как итальянское или немецкое.Однако эти языки обладают рядом характеристик, которые позволяют легко преобразовать их в письменную форму. В итальянском, как и в немецком, слова обычно длинные, часто состоящие из нескольких слогов. Грамматическое согласие хорошо обозначено резонансными гласными. В результате омонимы встречаются довольно редко. Таким образом, возможна чисто регулярная транскрипция звуков. Итальянский и немецкий могут позволить себе довольно прозрачную систему правописания, где почти каждая буква соответствует уникальному звуку.
На другом конце континуума есть случай китайского языка.Подавляющее большинство китайских слов состоит только из одного или двух слогов, а поскольку их всего 1239 слогов (410, если не учитывать тональные изменения), каждый из них может относиться к десяткам различных понятий (рис. 1.3). Таким образом, чисто фонетическая система письма будет бесполезна в китайском языке — каждый ребус можно понимать сотнями различных способов! Вот почему тысячи символов мандаринского алфавита в основном транскрибируют слова или, скорее, их морфемы — основные элементы значения слова.Китайское письмо также опирается на несколько сотен фонетических маркеров, которые дополнительно определяют, как следует произносить данный корень, и помогают читателю понять, какое слово имеет в виду. Иероглиф, например, который означает «мать» и произносится как ma , состоит из морфемы = «женщина» и фонетического маркера = mă . Таким образом, вопреки распространенному мнению, даже китайский язык не является ни чисто идеографическим письмом (символы которого представляют концепции), ни логографическим письмом (знаки которого относятся к отдельным словам), а смешанной «морфосиллабической» системой, в которой некоторые знаки относятся к морфемам слова и другие к их произношению.28
Конечно, научиться читать по-китайски труднее, чем по-итальянски. Необходимо выучить несколько тысяч знаков вместо нескольких десятков. Таким образом, эти два языка находятся на двух концах непрерывной шкалы прозрачности правописания, где английский и французский занимают промежуточные позиции.29 Как в английском, так и во французском языке слова, как правило, короткие, и поэтому омофоны встречаются относительно часто («правильно», « пиши »,« обряд »). Чтобы приспособиться к этим ограничениям, правила орфографии на английском и французском языках включают смесь фонетической и лексической транскрипции — источник трудностей для писателя, но простота для читателя.
Короче говоря, мы только начали расшифровывать множество ограничений, которые формируют систему правописания английского языка. Сможем ли мы когда-нибудь его реформировать? Моя личная точка зрения на этот счет такова, что резкое упрощение неизбежно. Мы в долгу перед нашими детьми, которые тратят сотни часов на эту жестокую игру. Более того, некоторые из них могут никогда не выздороветь, будучи инвалидами на всю жизнь из-за дислексии или просто потому, что выросли в малообеспеченных или многоязычных семьях. Это настоящие жертвы нашей архаичной орфографической системы.Я надеюсь, что следующее поколение настолько привыкнет к сокращенному написанию, благодаря сотовым телефонам и Интернету, что перестанет относиться к этой проблеме как к табу и соберет достаточно силы воли, чтобы решить ее рационально. Однако проблема никогда не будет решена простым постановлением, устанавливающим фонологическое правописание. Английский никогда не будет таким простым, как итальянский. Мечта о правильном написании — это что-то вроде иллюзии, как было указано в брошюре, которая некоторое время ходила в Европе:
Рисунок 1.3 Орфографические ошибки не так иррациональны, как кажутся. Например, хотя китайская письменность использует до двадцати или тридцати разных символов для одного и того же слога, избыточность далеко не бессмысленна. Напротив, это очень полезно для китайских читателей, потому что китайский язык включает в себя множество омофонов — слов, которые звучат одинаково, но имеют разные значения, например, английские «один» и «победил». Здесь весь китайский рассказ был написан со звуком «ши»! Любой китайский читатель может понять этот текст, что было бы явно невозможно, если бы он был фонетически транскрибирован как «ши ши ши.. . » Китайские иероглифы устраняют неоднозначность звуков, используя разные символы для разных значений. Точно так же омофония объясняет, почему в английском языке используется так много разных вариантов написания одних и тех же звуков («Я кричу для мороженого»).
Комиссары Европейского Союза объявили, что было достигнуто соглашение о принятии английского языка в качестве предпочтительного языка для европейских коммуникаций, а не немецкого, что было другой возможностью. В ходе переговоров британское правительство признало, что правописание английского языка можно улучшить, и приняло пятилетний поэтапный план для того, что будет известно как евро-английский (сокращенно евро).
В первый год вместо мягкого «c» будет использоваться буква «s». Конечно, госслужащие с радостью примут это известие. Кроме того, жесткая буква «c» будет заменена на «k». Это не только устранит путаницу, но и на пишущей машинке кан будет на одну букву меньше. В следующем году общественный энтузиазм будет расти, когда назойливое «ph» будет заменено на «f». Это сделает такие слова, как «фотография», на 20% короче.
В Кембриджской энциклопедии языка (Crystal, 1988) пример неоднозначного ответа дает Дельфийский оракул, когда один из генералов спрашивает, следует ли ему отправиться в экспедицию.Ответ Оракула можно было истолковать двояко: Domine stes («Мастер, оставайся») или Domi ne stes («Не оставайся дома»). В беглой речи отдельные слова, фразы и предложения сливаются друг с другом, и между ними нет настоящих разрывов — их изолировать — задача слушателя. Как отмечает Харли (2005, с. 237), в обычной речи строки «Я кричу» и «мороженое» звучат неразличимо. Таким образом, эта двусмысленность связана с проблемой границ слов; он появляется в разговорной речи и является частью более широкого явления неоднозначности, связанного с сегментацией речи (Harley, 2005; Norris, McQueen, Cutler, & Butterfield, 1997).
Целью настоящего исследования было определить, разрешается ли неоднозначность, возникающая в результате размытия границы слова, немедленно из-за сентенциального контекста, в котором она возникает, или оба значения доступны одновременно. Лексический доступ — фундаментальная проблема в истории исследований как лексической двусмысленности (концепция слова, имеющего два или более возможных значения), так и синтаксической неоднозначности (концепция, согласно которой предложения или фразы могут быть интерпретированы двумя или более способами из-за их грамматической структура и синтаксическая функция содержащихся в них слов).
Лексическая двусмысленность — это, с одной стороны, особая проблема теории ментальной лексики и вопрос о том, как хранить значения. С другой стороны, результаты исследований по этой теме повлияли на создание различных моделей лексического доступа, которые объясняют процесс активации слов при использовании языка (распознавание и запоминание слов, когда мы слушаем или читаем, когда мы говорим или пишем) (см. Reeves, Hirsh-Pasek, & Golinkoff, 1998). Часто выделяется (например,, Gleason & Ratner, 1998), исследования, посвященные управлению синтаксической двусмысленностью, обогащают знания о процессе синтаксического анализа, вычисляя синтаксическую структуру предложения. Как отмечает Харли (2005, с. 264), «большая часть свидетельств, лежащих в основе современных теорий синтаксического анализа, исходит из исследований синтаксической двусмысленности».
Основные вопросы обработки, связанные с неоднозначностью: как выбрать подходящее значение, какую роль играет контекст в разрешении неоднозначности и на каком этапе используется контекст? (Харлей, 2005).Выбираем ли мы сразу соответствующее чувство (модель прямого доступа) или обращаемся ко всем чувствам, а затем выбираем между ними (двухступенчатая модель)? В случае лексической двусмысленности модель прямого доступа предполагает, что одно значение быстро выбирается на основе контекста и частоты значений. Согласно двухэтапной модели, все значения неоднозначных слов сначала активируются, а затем отбрасываются на более позднем этапе (т. Е. Контекст очень быстро используется для выбора подходящего смысла) (Davis, Marslen-Wilson, & Gaskell, 2002; Мартин, Ву, Келлас и Меткалф, 1999; Симпсон, 1984).
Вышеупомянутый ответ, предоставленный Oracle of Delphi, является случаем синтаксической двусмысленности, которая возникает из-за проблемы сегментации. Проблема сегментации связана с неоднозначностью границ фраз и порождает некоторые типы синтаксической неоднозначности (см. Allbritton, McKoon & Ratcliff, 1996; Harley, 2005; Lyons, 1977). Частным случаем неоднозначности, связанной с сегментацией речи в процессе разговора, является неоднозначность границ слова (WBA). Как упоминалось ранее, когда мы говорим, слова сливаются, что порождает разные значения (например,g., «ведерко со льдом» vs. «красивое ведро»). Это может быть основой для создания каламбуров и шуток, таких как шутка, в которой учитель спрашивает ученика: «Что вы знаете о французском синтаксисе?» и ученик отвечает: «Черт возьми, я не знал, что они должны платить за свое веселье». Условием понять эту шутку является обнаружение гетерографических омофонов («синтаксис» и «налог на грех» звучат одинаково) и неоднозначности границ слов (см. Shultz & Scott, 1974). В повседневном общении семантический и ситуативный контекст, а также просодические сигналы (Marslen-Wilson, Tyler, Warren, Grenier, & Lee, 1992) обычно помогают нам правильно понять значение утверждений (для обзора сегментации слов, см. Davis et al., 2002).
Феномен неоднозначности границ слова (WBA) можно рассматривать в контексте проблемы обработки предложений, то есть вопроса о том, как пользователь языка может быстро определить структуру предложения и понять его значение в целом (несмотря на высокая скорость беглости речи и слияние отдельных слов, так как часто нет пробелов между словами, фразами и предложениями). Одна из основных проблем в исследовании языка и коммуникации касается взаимосвязи между синтаксическим и семантическим уровнями обработки предложений.Есть две основные позиции — автономная и интерактивная модели парсинга. Первая модель использует принцип синтаксической автономии — синтаксическая обработка должна предшествовать и происходить независимо от семантического анализа предложений (концепция модульности). Хотя интерактивная модель предполагает, что семантическая обработка происходит одновременно с синтаксической, с каждым словом, получатель обрабатывает услышанный материал как синтаксически, так и семантически, насколько это возможно. В контексте синтаксической двусмысленности в исследованиях синтаксического анализа преобладали две модели; модель садовой дорожки (автономная двухступенчатая модель) (см. Frazier, 1987; Rayner, Carlson, & Frazier, 1983) и модель на основе ограничений (интерактивная модель) (см. Harley, 2005, стр.283; Макдональд, Перлмуттер и Зайденберг, 1994; Trueswell & Tanenhaus, 1994).
Существует небольшое эмпирическое исследование обработки неоднозначности границ слов. Davis et al. (2002) интересовались вопросом сегментации и неоднозначности, создаваемой встроенными словами. Однако их исследование не касалось доступа к значениям, относящимся к WBA, а скорее касалось распознавания слов, которые встроены в начало других слов. Ян и Клигл (2016) проверили, влияет ли двусмысленность границ слов при чтении предложений на китайском языке на движения глаз (выбор цели саккады).Неоднозначность границ слова обычно возникает в китайском языке из-за отсутствия явного интервала между словами. Это похоже на другие несегментированные языки, такие как японский (Kudo, Yamamoto, & Matsumoto, 2004). Однако в этих исследованиях не рассматривался вопрос о доступе к значениям, связанным с неоднозначностью границ слов.
Основная тема данной статьи — доступность значений такого рода двусмысленности. Как упоминалось выше, проблема доступности значений (как слов, так и предложений) является одним из важнейших вопросов в исследованиях лексической и синтаксической неоднозначности.Интересно посмотреть, можно ли применить двухэтапную модель (или модель множественного доступа) к обработке неоднозначности, связанной с границами слов.
Конечно, WBA касается синтаксической двусмысленности; в случае WBA двусмысленность возникает не из-за того, что два слова имеют одинаковое значение, а из-за того, что граница между словами нечеткая, и синтаксическая функция любого слова, таким образом, также может быть нечеткой. Главный вопрос заключается в том, происходит ли процесс синтаксического анализа предложений с неоднозначностью границ слов в соответствии с автономной или интерактивной моделью синтаксического анализа.
Стоит подчеркнуть, что синтаксическая и лексическая двусмысленность могут рассматриваться как одно и то же явление со схожими механизмами обработки (см. MacDonald et al., 1994). Как отмечают Макдональд и его коллеги, «как лексическая, так и синтаксическая неоднозначность регулируются одними и теми же типами представления знаний и механизма обработки» (стр. 682), а «синтаксическая неоднозначность вызвана неоднозначностью, связанной с лексическими элементами» (стр. 676 ).
Мой исследовательский подходВышеупомянутое предположение послужило вдохновением для разработки исследования, в котором я использовал кросс-модальную парадигму семантического прайминга.В классическом исследовании обработки лексической двусмысленности Суинни (1979) использовал технику кросс-модального прайминга, чтобы показать, что слушание неоднозначных слов приводит к активации всех их значений; например, результаты показали, что слово «ошибка» обеспечивает мгновенный доступ к двум возможным значениям («насекомое» и «шпионский гаджет»), даже если слово было представлено в четком контексте. Затем контекст используется для выбора правильного значения; неправильные значения быстро подавляются. Это исследование поддержало модель множественного доступа, которая в своей крайней форме предполагает, что все значения неоднозначных слов активируются параллельно и в одинаковой степени, и что эта активация не зависит как от частоты значений, так и от контекста (Onifer & Swinney , 1981; Суинни, 1979).
Я решил использовать технику кросс-модального прайминга, чтобы проверить, произойдет ли подобное явление, как в исследовании Суинни (1979), в случае неоднозначности границ слов. Парадигма семантического прайминга основана на семантических связях между отдельными словами (Field, 2004). Семантический прайминг означает, что если слова со связанными значениями встречаются последовательно, то обработка первого слова облегчит распознавание следующего. Lexical Decision Tasks часто используются при исследовании неоднозначности в парадигме семантического прайминга; участники должны решить, является ли строка букв, видимая на экране, словом или неслово (группа букв, которая не является словом на данном языке).Время реакции измеряется для каждой цепочки букв. Предполагается, что более быстрое распознавание данного слова означает, что его мысленное представление более доступно (см. Reeves et al., 1998).
Мой исследовательский подход состоял во введении сильного предвзятого контекста, связанного с одним значением неоднозначности границы слова, представленной на польском языке (пример на английском языке: В этом зоопарке есть большая обезьяна или В этом диктофоне есть серая лента). Второе значение было вложено в предложение.Проблема исследования заключалась в том, будут ли активированы оба значения двусмысленности, возникающие на границах слов (особенно контекстуально несоответствующее значение двусмысленности).
Проблема, которую я стремился изучить в своем исследовании, лежит в контексте спора между автономной и интерактивной моделями синтаксического анализа (а также двухэтапной моделью и моделью прямого доступа). Мое предположение заключалось в том, что произойдет эффект семантического прайминга, то есть целевые слова, относящиеся к значению фразы, обозначенной контекстом предложения, будут распознаваться быстрее, чем нейтральные слова.Это предположение будет означать, что после того, как вы услышите предложение В этом зоопарке есть большая обезьяна, буквенная строка ANIMAL будет распознаваться быстрее как слово, чем контрольное слово, то есть слово, не связанное с контекстом предложения, например HOLIDAY . Мой главный вопрос заключался в том, будет ли активировано второе значение, которое не было обозначено контекстом предложения (в данном случае серая лента).
В представленном материале пропозициональный контекст появляется перед двусмысленностью и указывает, каким может быть значение последней фразы, которая включала WBA.Интерактивная модель предполагает, что предыдущие семантические операции облегчают принятие последующих решений относительно синтаксического анализа. Следовательно, на основе этой модели можно ожидать, что значение, указанное в контексте, будет активировано. Это означает, что целевые слова, относящиеся к значению фразы, обозначенной контекстом предложения, будут распознаваться быстрее, чем целевые слова, относящиеся ко второму значению неоднозначной фразы. С другой стороны, согласно автономной модели, на первом этапе обработки ограничивающее влияние контекста не произойдет, и оба значения могут быть активированы и влиять на лексические решения.Таким образом, прогнозируется, что оба значения неоднозначной фразы будут активированы, что означает более быстрое распознавание слов, относящихся к обоим значениям (например, ЖИВОТНОЕ и КАССЕТА), чем контрольные слова (например, ПРАЗДНИК).
Метод УчастникиВсего в исследовании приняли участие 180 студентов (124 женщины и 56 мужчин); их средний возраст составлял от 18 до 28 лет (M = 21,0; SD = 1,8). Участники были волонтерами, не получившими компенсации за участие, финансовой или иной.В рамках процедуры согласия до участия им напомнили, что они могут отказаться от участия в любое время. Процедура, включая письменное согласие, была одобрена этическим комитетом Института психологии Ягеллонского университета.
Материалы, процедура и дизайнИсследование проводилось с использованием парадигмы семантического прайминга кросс-модальности. Перед участниками стояли две задачи. Во-первых, они должны были слушать через наушники польские предложения, содержащие неоднозначные границы слов, например, zasłona (занавес) vs.za słona (слишком соленый), для которого сентенциальный контекст предлагал одно из значений (например, для «слишком соленого» фраза была «суп был слишком соленым [za słona]»; для «занавески» «На окне там была завеса [заслона] »). Неоднозначное слово всегда было в конце предложения. Впоследствии участников попросили посмотреть на экран, на котором отображались цепочки букв (например, ТАБЛИЧКА) сразу после прослушивания предложения (интервал времени 100 мс). Задача участников заключалась в том, чтобы решить и указать, нажимая правую или левую клавишу Control, является ли представленная цепочка букв фактическим словом (задача лексического решения).Буквенная строка, которая была целевым словом, была тематически связана с тем или иным значением ранее представленной неоднозначной фразы, контрольного слова (например, PEPPER, относящегося к «слишком соленому»; DRAPERY, относящегося к «занавесу»; ДЕНЬГИ — контрольное слово) или неслово (например, PALTE). Важно отметить, что неслова использовались только в качестве заполнителей, чтобы не дать участникам понять, что все стимулы были словами, тем самым сохраняя задачу лексического решения. Неслова не были тематически связаны с другими стимулами, и время реакции (RT) для неслов не входило в анализ.
Было выбрано десять неоднозначных фраз. Для каждой фразы были созданы два предложения, которые указывали на одно или другое неоднозначное значение (например, для английского языка большая обезьяна против серой ленты, предложения могли быть такими: В этом зоопарке есть большая обезьяна против В этом диктофоне есть это серая лента). Для каждого неоднозначного предложения были подготовлены три целевых слова (представленные визуально) для задачи лексического решения: 1) слово, имеющее отношение к значению, предложенному контекстом предложения (например, ОБЕЗЬЯНА), 2) слово, относящееся ко второму значению слова. двусмысленная фраза (эл.g., RIBBON) и 3) управляющее слово (не связанное ни с одним из значений). Целевые слова были выбраны таким образом, чтобы они не различались по длине (два или три слога) или частоте использования (частота употребления слов оценивалась с помощью Частотного словаря польского языка; влияние частоты и длины в лексических решениях необходимо учитывать. в уме; см. Whaley, 1978). Все целевые слова были выбраны на основе пилотного исследования, чтобы обеспечить одинаковую базовую скорость лексических решений. Поскольку время, затрачиваемое на лексические решения, было измерено, я определил, что проблема частоты использования касается целевых слов (лексических стимулов принятия решений), а не двусмысленных фраз (без измерения RT).Поэтому для целевых слов я выбрал слова, соответствующие следующим критериям: а) это были существительные в именительном падеже; б) они были лексически связаны либо с первым, либо со вторым значением двусмысленной фразы, либо с нейтральным значением; в) они были одинаковой длины; г) они имели одинаковую частоту использования на основе данных из частотного словаря; e) они продемонстрировали аналогичные требования к лексическому времени принятия решения в пилотных исследованиях.
Проблема с польским синтаксисом может частично касаться предложений с неоднозначностью границ слова.Польский язык характеризуется продуманным и сложным изгибом, который использовался в этом исследовании: неоднозначные предложения содержали более длинные или более короткие слова, которые образовывали идентичные слуховые стимулы. Более коротким словом было существительное в предложной фразе (например, «na wóz / на повозке», «za pałki / для дубинок»). После соединения существительного и предлога образовалось более длинное слово, которое само было существительным («nawóz / удобрение», «zapałki / спички»). Таким образом генерировались неоднозначности границ слова.Эти неоднозначные фразы в разговорной речи звучат одинаково. В качестве экспериментальных стимулов я выбрал существительные, которые имели ту же форму в предложной фразе, что и в именительном падеже (например, «On mocno trzyma zapałki» / «Он крепко держит спички» против «Policjanci chwycili za pałki») / «Полицейские потянулись за дубинками». Только в двух случаях более короткое слово (в предложной фразе) принадлежало другой части речи, чем более длинное слово; в этих случаях более длинным словом было существительное («zasłona / занавес »), а более короткое слово было прилагательным в предложной фразе (« za słona / слишком соленый »).
Тот факт, что использовались более длинные и короткие слова, важен только при рассмотрении их письменной формы. Как указывалось выше, слуховые стимулы были идентичны, хотя их значение менялось между существительным + предлогом (отдельные слова) и одним «более длинным» словом. Различить эти стимулы можно было только в зависимости от контекста. Приведенные выше примеры только демонстрируют, как бы выглядели слова, если бы они были написаны, и как были созданы различия в значениях. Без контекста произносимая фраза «na wóz» была бы неотличима от «nawóz», так же как английское слово «колибри» (Trochilidae) неотличимо от фразы «колибри» (Mr.Птица мычит).
Было применено полное уравновешивание, так что одно из трех целевых слов (Контекст 1, Контекст 2, Несвязанный) появлялось после каждого неоднозначного предложения. Таким образом, для десяти предложений, указывающих одно значение слова, были созданы три экспериментальные серии (для трех уравновешивающих процедур). Для второй группы предложений, где контекст подразумевал второе неоднозначное значение, также были подготовлены три экспериментальные серии. Шесть вариаций происходят от факторной комбинации переменных: значение, полученное как от слухового стимула (2x), так и от целевого визуального стимула (связанное со значением 1 / значением 2 / несвязанным) (3x).Таким образом, было создано шесть экспериментальных наборов по 30 участников в каждом. Для каждого участника экспериментальная сессия состояла из 30 слуховых предложений и 30 визуальных стимулов, каждый из которых должен был быть оценен как слово или неслово, при этом участники реагировали на одну задачу лексического решения после каждого предложения. Слуховые или визуальные стимулы не повторялись для одного и того же участника. Среди 30 представленных целевых стимулов только 10 были словами, относящимися либо к первому, либо ко второму значению слуховой фразы (или не связанным) — единственными стимулами, использованными в анализе.Остальные 20 фраз и визуальных стимулов представляли собой слова или неслова в сочетании с недвусмысленными фразами (наполнителями), чтобы участники действительно рассматривали неслова как возможность, тем самым создавая задачу лексического решения. Например, участник получил 10 двусмысленных фраз (пять с контекстным значением 1 и пять со значением контекста 2), за каждой из которых следовали визуальные стимулы (три согласованных по значению, три несоответствующие по значению, четыре несвязанные со смыслом) и 20 заполнителей. , за каждым из которых следует слово или неслово (10 слов, 10 неслов), всего 30 предложений и задач лексического решения.Они были представлены в случайном порядке, так что двусмысленные предложения были смешаны с заполнителями.
ОбсуждениеКогда мы говорим, наша артикуляция плавная и непрерывная; В отличие от письменной речи, произносимые слова обычно не содержат ключей, которые определяют начало и конец слова или разделяют различные фонетические сегменты. Отсутствие четких границ граничных форм может порождать неоднозначные сообщения. Темой настоящего исследования была обработка неоднозначности, возникающей на границе слова, в связи с проблемой фонетической сегментации.Целью этого исследования было выяснить, происходит ли одновременный доступ к обоим значениям такого рода двусмысленности, когда сентенциальный контекст указывает на одно из этих значений. Несколько десятилетий исследований по разрешению лексической и синтаксической неоднозначности дали множество результатов, которые используются для создания моделей лексической доступности и моделей анализа синтаксической структуры. Однако, казалось бы, вопрос о лексическом доступе в процессе обработки предложений с неоднозначностью границ слов до сих пор не рассматривался в экспериментальных исследованиях.
В настоящем исследовании использовалась парадигма семантического прайминга кросс-модальности, которая ранее использовалась с целью изучения обработки лексической неоднозначности. Результаты показали, что лексические решения (распознавание визуальных слов) были облегчены для слов, связанных с каждым значением представленной двусмысленности — как со значением, установленным сентенциальным контекстом, так и со встроенным значением. Это говорит о том, что оба значения такой синтаксической двусмысленности активируются немедленно и автоматически, независимо от семантического контекста.Эти результаты соответствуют модели множественного доступа (которая касается лексической неоднозначности) и автономной модели синтаксического анализа. Согласно автономному взгляду, мы автоматически получаем доступ к нескольким значениям утверждения. Контекст используется для выбора подходящего значения двусмысленности. Согласно интерактивным моделям, семантическая информация может влиять на синтаксический процессор на ранней стадии; контекст, который предшествует слову, оказывает значительное влияние на скорость и легкость распознавания слова, услышанного среди других слов.Это означает более сильную активацию смысла, указанного в контексте. Таким образом, кажется, что полученные результаты подтверждают автономную модель. Эти результаты также согласуются с когортной моделью распознавания устных слов, предложенной Марслен-Уилсон и его коллегами (Marslen-Wilson, 1989, 1990). Центральная идея модели состоит в том, что, когда мы слышим речь, мы создаем когорту возможных элементов, которые могут быть представлены словом.
Как отмечают Гаскелл и Марслен-Уилсон (1999), временная неоднозначность (которая является критическим свойством восприятия произносимых слов) улавливается путем параллельной активации множественных лексических представлений.Кажется, что утверждение, сделанное, среди прочего, Макдональдом и его коллегами (1994) о том, что как лексическая, так и синтаксическая неоднозначность регулируются одним и тем же типом представления знаний и механизмов обработки (стр. 682), подтверждается в случае неоднозначности границ слов.
Эмпирические исследования обработки неоднозначности границ слов могут касаться тех же вопросов, что и те, которые предпринимаются в случае лексической двусмысленности. Таким образом, возникает множество вопросов. При каких условиях наблюдается влияние семантического контекста? Какова роль временного расстояния между неоднозначной фразой и целевым словом, и модифицирует ли этот фактор влияние пропозиционального контекста на активацию значений? Зависит ли доступ к одному значению неоднозначной фразы от частоты его использования? Другая возможная область интереса — роль просодии в разрешении неоднозначности границ слов.Другие типы синтаксической двусмысленности легче разрешаются в речи, чем в письменной форме, благодаря сигналам просодии (см. Marslen-Wilson et al., 1992). Неопределенность границ слов проявляется при слушании, а не при чтении; таким образом, роль просодических сигналов особенно разительна.
Как однажды заметил Симпсон (1984), несовместимость результатов и разнообразие моделей, доступных в исследованиях лексической двусмысленности, обусловлены использованием различных парадигм исследования, предпочтением различных методов и использованием различных экспериментальных задач.Было бы интересно посмотреть, будут ли воспроизведены эффекты, полученные в этом исследовании, при использовании других методов, кроме лексических задач принятия решений.
.