Слова «язык» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «язык» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «язык» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «язык».
Содержимое:
- 1 Слоги в слове «язык» деление на слоги
- 2 Как перенести слово «язык»
- 3 Морфологический разбор слова «язык»
- 4 Разбор слова «язык» по составу
- 5 Сходные по морфемному строению слова «язык»
- 6 Синонимы слова «язык»
- 7 Ударение в слове «язык»
- 8 Фонетическая транскрипция слова «язык»
- 9 Фонетический разбор слова «язык» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «язык»
- 11 Сочетаемость слова «язык»
- 12 Значение слова «язык»
- 13 Склонение слова «язык» по подежам
- 14 Как правильно пишется слово «язык»
- 15 Ассоциации к слову «язык»
Слоги в слове «язык» деление на слоги
Количество слогов: 2
По слогам: я-зык
Как перенести слово «язык»
язык
Морфологический разбор слова «язык»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: мужской;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
язык
Разбор слова «язык» по составу
| язык | корень |
| ø | нулевое окончание |
язык
Сходные по морфемному строению слова «язык»
Сходные по морфемному строению слова
Синонимы слова «язык»
1. телугу
телугу
2. балочи
3. филиппино
4. кашмири
5. пиджин
6. бейсик
7. иврит
8. санскрит
9. каннара
10. волапюк
11. идо
12. пали
13. пасилингва
14. пехлеви
15. пракрит
16. эсперанто
17. хиндустани
18. интерлингва
19. малаялам
20. маратхи
21. ория
22. урду
23. говор
24. наречие
25. диалект
26. слог
27. стиль
28. язычок
29. метаязык
30. суахили
31. идиш
32. кобол
33. фотран
34. праязык
35. субпродукт
36. суперстрат
37. фарси
38. фортран
39. ладино
40. жало
41. латынь
42. речь
43. автокод
44. алгол
45. ассемблер
46. кави
47. койне
48. кечуа
49. язычина
50. язычишко
51. язычище
52. бамана
53. банту
54. висайя
55. луганда
56. галла
57. гуарани
58. зулу
59. ибо
ибо
60. йоруба
61. каннада
62. канури
63. ква
64. киконго
65. кикуйю
66. кимбунду
67. киноязык
68. кирунди
69. коми
70. конго
71. кру
72. кхаси
73. луба
74. майя
75. майя-соке
76. макроассемблер
77. малинке
78. манде
79. мандинго
80. манипури
81. маори
82. масаи
83. мунда
84. невари
85. нуэр
86. ньянджа
87. пано
88. панджаби
89. хауса
90. пушту
91. руанда
92. рунди
93. тсонга
94. тукано
95. сантали
96. си
97. синдхи
98. сомали
99. нация
100. веник
101. звякало
102. квакало
103. метла
104. чесалка
105. шлепалка
106. шлепало
107. пленный
108. аймара
109. синтол
110. африкаанс
111. барбакоа
112. бенгали
113. дари
114. тумак
115. лизун
116. лопата
117. терка
терка
118. било
119. клепало
120. коса
121. пищик
122. задвижка
Ударение в слове «язык»
язы́к — ударение падает на 2-й слог
Фонетическая транскрипция слова «язык»
[й’из`ык]
Фонетический разбор слова «язык» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| я | [й’] | согласный, звонкий непарный (сонорный), мягкий | я |
| [и] | гласный, безударный | ||
| з | [з] | согласный, звонкий парный, твёрдый, шумный | з |
| ы | [`ы] | гласный, ударный | ы |
| к | [к] | согласный, глухой парный, твёрдый, шумный | к |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 4 буквы и 5 звуков.
Буквы: 2 гласных буквы, 2 согласных букв.
Звуки: 2 гласных звука, 3 согласных звука.
Предложения со словом «язык»
А это латинист, а это учитель русского
Источник: А. Н. Анненская, В чужой семье, 1889.
Чтобы книгу, скажем, русского писателя прочли на английском языке, её надо прежде перевести и издать.
Источник: Сергий Чернец, Собрание сочинений. Том третий. Рассказы и эссе.
Впереди не самый простой месяц. Необходимо найти общий язык с окружением, но подчас это будет очень нелегко.
Источник: Татьяна Борщ, Лунный календарь для женщин на 2016 год + календарь стрижек, 2015.
Сочетаемость слова «язык»
1. русский язык
2. общий язык
3. английский язык
4. язык тела
язык тела
5. язык жестов
6. языки огня
7. кончик языка
8. изучение языка
9. знание языка
10. язык заплетался11. язык проглотил
12. язык говорит
13. говорить на чьём-либо языке
14. найти общий язык
15. не знать языка
16. (полная таблица сочетаемости)
Значение слова «язык»
ЯЗЫ́К , -а́, м. 1. Орган в полости рта в виде мышечного выроста у позвоночных животных и человека, способствующий пережевыванию и глотанию пищи, определяющий ее вкусовые свойства. (Малый академический словарь, МАС)
Склонение слова «язык» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | кто? | язык | языки |
| РодительныйРод. | кого? | языка | языков |
ДательныйДат. | кому? | языку | языкам |
| ВинительныйВин. | кого? | языка | языков |
| ТворительныйТв. | кем? | языком | языками |
| ПредложныйПред. | о ком? | языке | языках |
Как правильно пишется слово «язык»
Правильно слово пишется: язы́к
Нумерация букв в слове
Номера букв в слове «язык» в прямом и обратном порядке:
- 4
я
1 - 3
з
2 - 2
ы
3 - 1
к
4
Ассоциации к слову «язык»
Диалект
Программирование
Грамматик
Наречие
Гортань
Преподавание
Латынь
Письменность
Словесность
Перевод
Произношение
Сосок
Глагол
Кончик
Алфавит
Словарь
Пламя
Венгерское
Говор
Переводчик
Жаргон
Соска
Филолог
Незнание
Народность
Языковой
Латинский
Тюркский
Языковый
Ломаный
Английский
Арабский
Гласный
Русский
Португальский
Гортанный
Шершавый
Славянский
Чешский
Филологический
Греческий
Говорящий
Казахский
Иностранный
Древнерусский
Эстонский
Башкирский
Кельтский
Древнегреческий
Немецкий
Испанский
Болтливый
Французский
Румынский
Азербайджанский
Литературный
Родной
Нидерландский
Тибетский
Корейский
Молдавский
Финский
Болгарский
Хорватский
Персидский
Заплетаться
Прикусить
Ворочать
Высунуть
Раздвоить
Изъясняться
Трепать
Лизать
Лизнуть
Переводиться
Чесать
Выучить
Облизывать
Молоть
Придержать
Вывалить
Вертеться
Издаваться
Развязывать
Пересохнуть
Распускать
Распухнуть
Откусить
Облизать
Преподавать
Заимствовать
Развязать
Ласкать
Перевести
Произноситься
Владеть
Облизнуть
Поворачиваться
По-немецки
По-французски
На учи.
 ру Олимпиада по русскому языку и литературе ответы
ру Олимпиада по русскому языку и литературе ответыС 6 сентября по 3 октября 2022 года на образовательном портале учи.ру новая Олимпиада по русскому языку и литературе для учеников 1-9 класса, но также интересна будет и взрослым.
10 заданий на разные темы, на решение которых даётся 60 минут, по окончанию олимпиады появятся баллы, но нет конкретных ответов на вопросы. Олимпиада нацелена на проверку знание русского языка и литературы, начитанность, внимание и логику.
Ниже рассмотрим задания всех классов, как их решать и какие правильные ответы, сразу хотелось бы отметить тот факт, что в некоторых заданиях допущены ошибки, но нет времени на выяснения, что там не правильно. Чтобы не допускать ошибок при решении олимпиады, рекомендую предварительно ознакомиться с ответами или самим проверить. Если будет такая возможно, при наличии ошибок, сообщите об этом в комментариях.
Содержание
- Фильмы по книгам
- В каких книгах были такие герои (лягушка, лиса, медведь, баба-яга, старуха)?
- В каких книгах были такие герои (леший, казак, крестьянский мальчик, офицер, князь)?
- Ложные факты
- Выбери все ложные факты о К.
 И. Чуковском.
И. Чуковском. - Выбери все ложные факты об А. С. Пушкине.
- Выберете все ложные факты о И.А Крылове.
- Поговорка-лабиринт
- Связи между словами
- Рифмы-ударения
- Птицы с буквами
- Зашифрованный язык
- Настоящие книги
- Краткое содержание
- Литературные жанры
 И. Чуковском.
И. Чуковском.Фильмы по книгам
Пример задания:
В каких книгах была героиня лиса? Отправь её на съёмки фильмов по этим книгам.
Дано на экране выбрать две книги, отправляем лису в обе и далее переходим к утке.
- «Лиса и журавль», народная сказка — лиса
- «Серая шейка», Д. Н. Мамин-Сибиряк — лиса
Отлично, теперь отправь утку на съёмки
- «Серая шейка», Д. Н. Мамин-Сибиряк — утка
Переходим к основному заданию для всех классов, ищите свои варианты.
В каких книгах были такие герои (
лягушка, лиса, медведь, баба-яга, старуха)?Отправь их на съёмки фильмов по этим книгам.
- «Гуси-лебеди», народная сказка — баба-яга
- «Теремок», народная сказка — лиса, медведь и лягушка
- «Царевна-лягушка», народная сказка — баба-яга и лягушка
- «Квартет», И.А. Крылов — медведь
- «Колобок», народная сказка — лиса, медведь и старуха
- «Елена Премудрая», сказка — старуха
- «Каша из топора» — солдат и старуха
- «Сказка о рыбаке и рыбке», A. С. Пушкин — старуха

В каких книгах были такие герои (леший, казак, крестьянский мальчик, офицер, князь)?
Отправь их на съёмки фильмов по этим книгам.
- «Ночь перед Рождеством», Н. В. Гоголь — казак
- «Песнь о вещем Олеге», А. С. Пушкин — князь
- «Филипок» Л. Н. Толстой — крестьянский мальчик
- «Бежин луг», И. С. Тургенев — крестьянский мальчик
- «Тарас Бульба», Н. В. Гоголь — казак
- «Кавказский пленник», Л. Н. Толстой — казак, офицер и крестьянский мальчик
- «Капитанская дочка», А. С. Пушкин — казак и офицер
Вот так выглядит ответ:
Ложные факты
Писатели написали посты с фактами о себе. Некоторые из фактов ложные. Нажми на любое фото, чтобы открыть пост. И далее надо выбрать (ВНИМАНИЕ!) только ложные факты, их я выделил жирным шрифтом.
Выбери все ложные факты о К. И. Чуковском.
- По мотивам моих книг создают мультфильмы.
- Я написал книгу «Гарри Поттер».
- Я придумал Мойдодыра.
- Я часто участвую в дуэлях.
- На самом деле меня зовут Николай Корнейчуков.
Выбери все ложные факты об А. С. Пушкине.
- Меня воспитывала няня.
- Я пишу только о реально существовавших людях.
- Я пишу сказки.
- Я написал сказку «Лиса и журавль».
- Я учился в лицее.
- Я начал писать «Сказку о рыбаке и рыбке» в 15 лет, а закончил в 51.
Выберете все ложные факты о И.А Крылове.
- Я восхищаюсь творчеством Агнии Барто.
- «Лисица и журавль» — мое произведение.
- Я придумал жанр басни.
- В моих произведениях часто встречаются герои-животные.
- Фразы из моих произведений стали крылатыми.

Вот так выглядит ответ:
Поговорка-лабиринт
Соедини буквы в лампочках так, чтобы получилось слово. Всё достаточно проще, чем кажется на первый взгляд, гадо только начало найти, а далее линии не пересекаются и составление идёт в основном к ближайшим группам.
Соедини все буквы так, чтобы получилось слово.
АН-ЗН-ИЯ — Знания
Соедини все буквы так, чтобы получилась пословица.
ЧТ-ИП-ОЖ-НЁ-ОП-ШЬ-ШЬ,-ТО-ЕЕ-ОС — Чтопосеешь,тоипожнёшь — Что посеешь, то и пожнёшь
КБ-ПЕ-ЕР-КТ-ОМ-ЬШ-ОЛ-РИ-ЮП-НЬ-ДЁ-ТИ-УМ-ЕН-ЬЕ — Кбольшомутерпениюпридётиуменье — К большому терпению придёт и уменье
ПО-ПЫ-АН-ЫТ-АС-ТК-ЕП-КА,-ДА-БЕ-ОС-ПР-НЕ — Попытканепытка,аспронебеда — Попытка не пытка, а спрос не беда
Вот так выглядит ответ:
Связи между словами
Вроде как задание не сложное, но что-то много ошибок было, так что смотрите внимательно. Вот пример (начало задания):
Соедини зефирки со словами.
птица — «живёт в» или «ест» — гнездо
птица — «живёт в» — гнездо
человек — «живёт в» — еда или дом или говорить
человек — «живёт в» — дом
- Корова — телёнок
Лошадь — выбрать из слов: стойло или жеребёнок или ягнёнок или грива или бык
Лошадь — жеребёнок - Кошка — шерсть
Окунь — выбрать из слов: рыба или река или чешуя или вода
Окунь — чешуя - Яйцо — скорлупа
Картофель — выбрать из слов: курица или салат или грядка или капуста или кожура
Картофель — кожура - Ухо — слышать
Зубы — выбрать из слов: щётка или рот или жевать или лечить или чистить
Зубы — ? - Свинец — тяжёлый
Пух — выбрать из слов: перья или трудный или материал или лёгкий или поросёнок
Пух — лёгкий - Железо — кузнец
Дерево — выбрать из слов: мастерская или кабельщик или пень или столяр или кора
Дерево — столяр - Пробка — плавать
Камень — выбрать из слов: тонуть или каменщик или строить или возить или плавание
Камень — тонуть - Дерево — сук
Рука — выбрать из слов: перчатка или рукав или нога или топор или палец
Рука — палец
Вот пример, выдал ошибку, поменял на зубах жевать на чистить, всё-равно ошибка, так что не пойму в чём дело
Рифмы-ударения
Выбери рифму с верным ударением (ударение в слове выделено заглавной буквой)
Под первую строчку: Надели банты
Надо выбрать из предложенных вариантов:
И играем в фАнты — выбрать
И открыли зонтЫ
Под первую строчку: Открываем ворота,
Надо выбрать из предложенных вариантов:
Ведь сегодня суббОта — выбрать
Доставайте паспортА
Под первую строчку: Мы купили торты
Надо выбрать из предложенных вариантов:
И для Вали шОрты — выбрать
И для Вали цветЫ
Под первую строчку: Лук в тарелку клала,
Надо выбрать из предложенных вариантов:
С яйцами мешАла — выбрать
Его с рынка принеслА
Под первую строчку: Мои новые шарфы,
Надо выбрать из предложенных вариантов:
Прямо как к МАрфы — выбрать
Привезли мне из УфЫ
Под первую строчку: Меня там очень баловали,
Надо выбрать из предложенных вариантов:
Не зря туда пожАловала
Вместо супа торт давАли — выбрать
Под первую строчку: Маленькая искра
Надо выбрать из предложенных вариантов:
отлетела от кострА
Улетела бЫстро — выбрать
Под первую строчку: Опустела кладовая.
Надо выбрать из предложенных вариантов:
Я иду в столОвую
Что стоишь, зевАя? — выбрать
Вот пример ответа на это задание:
Птицы с буквами
Фраза — это сочетание слов, которое выражает законченную мысль.
Расставь гнёзда на месте пробелов, чтобы составить несколько фраз. Количество гнёзд на одну фразу ограничено.
ПОДНИМИХЛЕБ (3 фразы)
Подними хлеб, под ним и хлеб, под ними хлеб
НАШЛАСЬТАМАРКА (3 фразы)
Нашлась Тамарка, нашлась та марка, нашлась там арка
СУТКАМИЕМХЛЕБСУХОЙ (4 фразы)
Сутками ем хлеб сухой, с утками ем хлеб сухой, с утками ем хлеб с ухой, сутками ем хлеб с ухой
ПОДНИМИТЕПЕРЬЯ (6 фраз)
Поднимите перья, под ними теперь я, подними теперь я, подними те перья, под ним и те перья, под ним и теперь я
Вот пример ответа:
Зашифрованный язык
В примерах надо слово разобрать по слогам и найти такие же слога в задании, подставить иероглифы.
Найди логику в подсказке и зашифруй слово «рама».
Найди логику в подсказке и зашифруй слово «макароны». (обратите внимание на точку, это ударение, чтобы её получить, надо нажать на символ).
Найди логику в подсказке и зашифруй фразу «начала шипеть».
Найди логику в подсказке и зашифруй фразу «она начала шипеть».
Настоящие книги
Распредели книги. Одних нет в русской литературе, другие есть.
ЕСТЬ:
Федорино горе
Тараканище
Крокодил Гена и его друзья
Серая шейка
Лев и собачка
Малахитовая шкатулка
Сестрица Аленушка и братец Иванушка
Белый Бим, Чёрное ухо
Севастопольские рассказы
Властителям и судьям
Хорошее отношение к лошадям
Недоросль
Песнь о вещем Олеге
Мартышка и очки
Каштанка
Свинья под дубом
Двенадцать месяцев
НЕТ:
Кукушка-путешественница
Емеля
Непонимайка
Серый хвостик
Цветик-шестицветик
Телефонище
Царь Салтан
Мартышкины очки
Алёша Попович и Соловей Разбойник
Белкин
Майский полдень
Пугачев
Старушка Изергиль
Кавказская пленница
Капитанская дочь
Сказка о царе Гвидоне
Бедный всадник
Попрыгунья стрекоза
Сказка о царе и султане
Пример ответа:
Краткое содержание
Ребята рассказывают тебе краткие содержания книг. Нажимай на аватарки и определяй, где какое произведение.
Нажимай на аватарки и определяй, где какое произведение.
Мальчик много хвастался и попал в неловкую ситуацию.
«Англичанин Павля», В. Ю. Драгунский
Очень отзывчивого человека все о чём-то просят.
«Телефон», К. И. Чуковский
История о том, как легкомысленно вообще не думать о будущем.
«Стрекоза и муравей», И. А. Крылов
История о том, что не стоит судить кого-то по внешности.
«Царевна-лягушка», русская народная сказка
Смешная история о том, как два друга напрасно испугались.
«Живая шляпа», Н. Н. Носов
Сказка о том, что случилось с мальчиком-грязнулей.
«Мойдодыр», К. И. Чуковский
Сказка о том, что случилось с мальчиком-грязнулей.
«Мойдодыр», К. И. Чуковский
История о вторжении в чужой дом.
«Три медведя», Л. Н. Толстой
Героиня этой истории не достигла цели из-за своего хвастовства.
«Лягушка-путешественница», В. М. Гаршин
Помощь настоящего друга помогла герою справиться со сложными испытаниями.
«Конёк-Горбунок», П. П. Ершов
П. Ершов
Герой спасает волшебное существо и за это получает необычные способности, но это портит его характер.
«Чёрная курица», А. Погорельский
Двое героев отправились за едой и столкнулись с природными опасностями.
«Кладовая солнца», М. М. Пришвин
Юный герой заблудился, но благодаря своим знаниям и сообразительности нашёл дорогу домой.
«Васюткино озеро», В. П. Астафьев
Пример ответа:
Литературные жанры
Ответь на вопросы о литературных жанрах. Верный ответ пометил жирным.
Может ли вся сказка быть написана в стихах? Да/нет
Что важнее в стихотворении? Вымысел/Рифма и ритм
Могут ли у героя стихотворения быть волшебные способности? Да/нет
Обязательно ли герой стихотворения должен кого-то победить в конце? Да/нет
Можно ли использовать эпитеты в стихотворении? Да/нет
Кто более вероятно станет главным героем исторического романа?
Может ли в романе быть только один герой и одна сюжетная линия? Да/нет
К какому роду литературы относится исторический роман? Эпос/Драма
Могут ли в историческом романе также быть вымышленные персонажи? Да/нет
Должны ли в конце исторического романа быть назидание читателю, мораль? Да/нет
Пример ответа:
Happy
32
Sad
11
Excited
24
Sleepy
7
Angry
47
Surprise
11
«Знания хадисов «Сахих аль-Бухари» нужно получать от учителя, а не только из книги» 12.
 09.2022
09.2022Общество 08:17 | 12 сентября
5
Автор материала: Ильнур Ярхамов
Специалист отдела по вопросам шариата ДУМ РТ в интервью KazanFirst объяснил, как правильно познать религиозные сборники.
Недавнее решение Лаишевского суда по запрету одного из переводов на русский язык сборника хадисов «Сахих аль-Бухари» было истолковано некоторой частью общественности несколько превратно. Почему-то кто-то понял, что суд запретил обширнейший сборник хадисов «Сахих аль-Бухари», хотя речь шла непосредственно о переводе некоторой части сборника на русский язык.
Тем временем в Казани начались публичные чтения сборника хадисов «Сахих аль-Бухари» в мечети «Зангар». Лекции ведет специалист отдела по вопросам шариата ДУМ РТ Нурислам хазрат Валиулла. Причем хадисы в мечети будут зачитываться по арабскому тексту и сопровождаться подробным разъяснением Нурислама хазрата. В интервью KazanFirst богослов рассказал, почему при постижении мусульманином хадисов Пророка Мухаммада очень важна фигура учителя-устаза, имама мечети, то есть человека, который не один год посвятил изучению мусульманских наук.
В интервью KazanFirst богослов рассказал, почему при постижении мусульманином хадисов Пророка Мухаммада очень важна фигура учителя-устаза, имама мечети, то есть человека, который не один год посвятил изучению мусульманских наук.
Нурислам хазрат в интервью также объяснил, почему нужно быть аккуратным с переводами хадисов на русский язык, что механический перевод без компетенций в мусульманском праве неприемлем и может привести к искажениям смыслов.
Наша справка
Уроки по толкованию хадисов «Сахих аль-Бухари» будут проходить еженедельно по средам в мечети «Зангар», расположенной по адресу ул. Сары Садыковой, 8/19. Начало — в 18.30, вход – свободный для всех желающих.
Запись каждого урока будет выложена в Телеграм-канале мечети.
— В мечети «Зангар» проводят лекции по хадисам «Сахих аль-Бухари». Расскажите об этом подробнее.
— Мы в прошлом году начинали читать хадисы. Мы проходили сборник хадисов, составленный татарским ученым Галимджаном Баруди для шакирдов медресе. В книге, в которой Баруди собрал хадисы, есть 11 глав, одна из которых как раз состоит из избранных хадисов из «Сахих аль-Бухари». То есть Галимджан Баруди читал «Сахих аль-Бухари», выбрал оттуда 40 самых нужных хадисов. И мы 10 глав из книги Баруди уже прочитали. Баруди составил сборник хадисов с пояснениями на арабском языке.
В книге, в которой Баруди собрал хадисы, есть 11 глав, одна из которых как раз состоит из избранных хадисов из «Сахих аль-Бухари». То есть Галимджан Баруди читал «Сахих аль-Бухари», выбрал оттуда 40 самых нужных хадисов. И мы 10 глав из книги Баруди уже прочитали. Баруди составил сборник хадисов с пояснениями на арабском языке.
— Что такое «Сахих аль-Бухари»? Это сборник хадисов? Серия книг? Какой-то вид исламской литературы?
— «Сахих аль-Бухари» — это самая достоверная книга, которая признается всеми мусульманами мира. На самом деле у этой книги полное название более длинное — «Аль-джами‘ аль-муснад ас-сахих аль-мухтасар мин умури-расули-Ллах, салляллаху алейхи ва саллям, ва сунани-хи ва айами-хи». Здесь «аль-джами» переводится как «собрание», «аль-муснад» — «непрерывная цепочка до Пророка салляллаху алейхи ва саллям», «ас-сахих» — «достоверных», «аль-мухтасар» — «короткое изложение», «мин умур расули-Ллах» — из жизни Пророка Мухаммада, «ва сунани-хи» — «его пути», «ва айами-хи» — «как он проводил свои дни». В итоге получается перевод смысла названия примерно такой — «Собрание некоторых достоверных сообщений, переданных непрерывной цепочкой о жизни Пророка Мухмаммада, да благословит его Аллах и приветствует». Вот такое название дал книге собиратель этих сообщений-хадисов Мухаммад аль-Бухари примерно в IX веке по григорианскому летоисчислению.
В итоге получается перевод смысла названия примерно такой — «Собрание некоторых достоверных сообщений, переданных непрерывной цепочкой о жизни Пророка Мухмаммада, да благословит его Аллах и приветствует». Вот такое название дал книге собиратель этих сообщений-хадисов Мухаммад аль-Бухари примерно в IX веке по григорианскому летоисчислению.
— На лекциях вы хадисы из «Сахих аль-Бухари» читаете с переводом на русский язык?
— Да. Мы изучаем хадисы «Сахих аль-Бухари» из сборника, который составил в XIX веке ученый дагестанского происхождения Умар Зияуддин ад-Дагестани. Его сборник называется «Зубдат аль-Бухари», который является кратким содержанием самого «Сахих аль-Бухари».
— Почему так получается, что вы читаете краткое изложение сборника «Сахих аль-Бухари»? Не исказятся ли от этого смыслы сообщений-хадисов? Почему вы не читаете непосредственно сам «Сахих аль-Бухари»?
— Сам сборник «Сахих аль-Бухари» составлен в очень ранний период, в III веке по хиджре. В этой книге каждый хадис приводится с цепочкой передатчиков. Как минимум в цепочке передатчиков будет три человека, не считая самого Пророка Мухаммада, да благословит его Аллах и приветствует. Обычно в цепочках передатчиков присутствует по 5-6 человек. Количество передатчиков равно с объемом самого текста сообщения-хадиса, но бывают и случаи, когда цепочка передатчиков объемнее самого сообщения в несколько раз. Поэтому мы пользуемся краткими сборниками. На лекциях мы хадисы будем читать непосредственно на самом арабском языке, с переводом на русский язык.
В этой книге каждый хадис приводится с цепочкой передатчиков. Как минимум в цепочке передатчиков будет три человека, не считая самого Пророка Мухаммада, да благословит его Аллах и приветствует. Обычно в цепочках передатчиков присутствует по 5-6 человек. Количество передатчиков равно с объемом самого текста сообщения-хадиса, но бывают и случаи, когда цепочка передатчиков объемнее самого сообщения в несколько раз. Поэтому мы пользуемся краткими сборниками. На лекциях мы хадисы будем читать непосредственно на самом арабском языке, с переводом на русский язык.
Ад-Дагестани, чтобы написать свой сборник, получается, как раз и перечитал эти семь тысяч с половиной хадисов из «Сахих аль-Бухари». И затем он некоторые хадисы включил в свой сборник. По факту он сделал анализ, перечитал все хадисы, убрал повторяющиеся хадисы, убрал цепочки передатчиков сообщений, в итоге составил то, что у него получилось.
— То есть ад-Дагестани систематизировал сообщения-хадисы и сделал их более удобочитаемыми?
— Да. Книга «Сахих аль-Бухари» на самом деле очень большая. Чтобы ознакомить людей с хадисами из «Сахих аль-Бухари», которая является основной книгой после Корана, Умар ад-Дагестани составил краткий сборник в 1500 хадисов. Во время одной лекции можно разобрать по 10-12 хадисов. Для этого нам понадобится около года, если не больше.
Книга «Сахих аль-Бухари» на самом деле очень большая. Чтобы ознакомить людей с хадисами из «Сахих аль-Бухари», которая является основной книгой после Корана, Умар ад-Дагестани составил краткий сборник в 1500 хадисов. Во время одной лекции можно разобрать по 10-12 хадисов. Для этого нам понадобится около года, если не больше.
— Почему мы обращаемся к сборнику именно ад-Дагестани? Разве татарские богословы не составляли свои сборники хадисов? Тот же, например, Галимджан Баруди?
— У Галимджана Баруди сборник только в 40 хадисов. Мы его в первую очередь прочитали. Мы пока не смогли найти сборники татарских ученых из сообщений-хадисов из «Сахих аль-Бухари». Может быть, они ещё обнаружатся, Иншаллах!
Но сейчас надо пользоваться тем, что известно, а именно сборником ад-Дагестани. Кстати, некоторые татарские богословы в свое время тоже учились в Дагестане и дагестанские ученые приезжали в Казань. Так что контакт и обмен знаниями между нашими учеными был. У нас единая умма-община мусульман России. Книга ад-Дагестани принимается везде, его издают и читают в арабских странах, Турции.
Книга ад-Дагестани принимается везде, его издают и читают в арабских странах, Турции.
— Как примерно выглядят ваши занятия по публичному чтению хадисов в мечети «Зангар»?
— Мы зачитываем хадис на арабском языке, потом я его перевожу на русский язык. А после этого разъясняю, какие выводы, какая польза для мусульман выносится из зачитанного хадиса. Рассказываю, как этот хадис толковали мусульманские ученые. Необходимо читать сам хадис на арабском языке, чтобы человек слышал, какие именно слова произносил Пророк Мухаммад, да благословит его Аллах и приветствует, как эти слова звучат, как слышатся. Затем нужно разбирать отдельные слова хадиса, чтобы человек знал перевод этих слов и научился арабскому языку. Также будут пояснения, как этот хадис нужно правильно понимать.
— Можете привести пример хадиса, который вы зачитываете с прихожанами мечети и слушателями лекции? Можете привести пример хадиса, который не так просто понять самому?
— Например, книга начинается с изречения об имане, то есть о вере самого человека. Например, хадис, что ислам зиждется на пяти основах: 1) шахада «Ля иляха илля Аллах, Мухаммад Расул ли-Ллах» («Нет достойного поклонения, кроме Аллаха, и Мухаммад — его Пророк», 2) выстаивание молитвы, 3) закят — то есть пожертвования, 4) хадж, 5) пост в месяц Рамадан. То есть это всё — обязанности мусульманина. Если человек, имея возможности, эти обязанности не совершил, то он сделал большой грех. А если же человек совершал это, то он войдет в Рай.
Например, хадис, что ислам зиждется на пяти основах: 1) шахада «Ля иляха илля Аллах, Мухаммад Расул ли-Ллах» («Нет достойного поклонения, кроме Аллаха, и Мухаммад — его Пророк», 2) выстаивание молитвы, 3) закят — то есть пожертвования, 4) хадж, 5) пост в месяц Рамадан. То есть это всё — обязанности мусульманина. Если человек, имея возможности, эти обязанности не совершил, то он сделал большой грех. А если же человек совершал это, то он войдет в Рай.
— Это общая тема для мусульман. Допустим, к вам придет на лекции человек, которого волнует вопрос, что его друг просит деньги взаймы. И вот человек думает, дать или не дать деньги в долг, как дать в долг. На такие темы у вас есть хадисы?
— Конечно! Ответы на эти вопросы есть в хадисах. Пророк Мухаммад, да благословит его Аллах и приветствует, говорил, что давать деньги в долг даже лучше, чем давать милостыню. Если дать в долг, то человек будет стараться вернуть деньги, будет работать, приобретать для этого имущество, долг для него станет стимулом. Если же ты дашь просто милостыню, то он может перестать работать. Таким образом, слова Пророка Мухаммада, да благословит его Аллах и приветствует, в хадисах — это ценный довод.
Если же ты дашь просто милостыню, то он может перестать работать. Таким образом, слова Пророка Мухаммада, да благословит его Аллах и приветствует, в хадисах — это ценный довод.
— У вас на лекции хадисы только на арабском языке. А если мусульманин захочет приобщиться к хадисам сам — прийти домой, открыть сборник хадисов уже на русском языке — тогда, на ваш взгляд, как сейчас обстоят дела с переводами хадисов на русский язык?
— Сборник хадисов «Сахих аль-Бухари» на русском языке, выпущенный издательством «Хузур», считается одним из самых лучших.
— Насколько важна личность имама мечети, устаза, хадисоведа в процессе познания хадисов мусульманином? Или человек самостоятельно может постичь сборники хадисов?
— Простой верующий хадисы может неправильно понять. Знания нужно получать от учителя, а не только из книги. Почему? Так всегда было. Всевышний ведь тоже мог только книгу Коран ниспустить мусульманам, мол, вот вам книга, читайте её.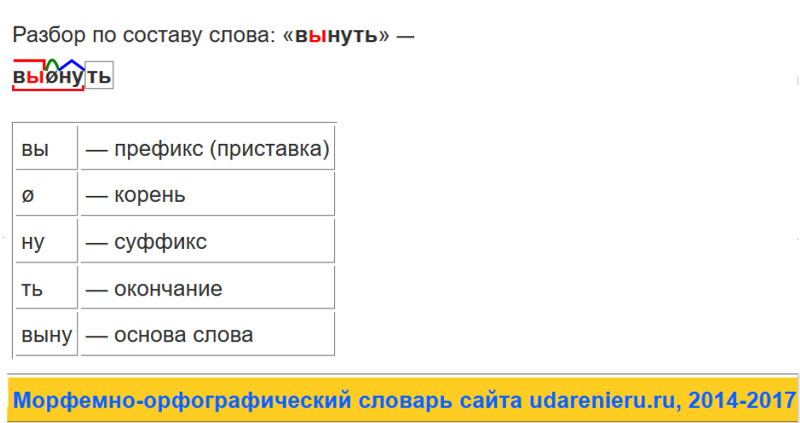 Но нет. Всевышний направил к Пророку Мухаммаду, да благословит его Аллах и приветствует, ангела Джибрила, который её разъяснил. А потом сам Пророк Мухаммад, да благословит его Аллах и приветствует, уже разъяснял всё своим сподвижникам.
Но нет. Всевышний направил к Пророку Мухаммаду, да благословит его Аллах и приветствует, ангела Джибрила, который её разъяснил. А потом сам Пророк Мухаммад, да благословит его Аллах и приветствует, уже разъяснял всё своим сподвижникам.
Поэтому неправильно, когда человек самостоятельно открывает книгу и читает хадисы. У него же нет специальных знаний, при каких обстоятельствах был сказан тот или иной хадис, зачем он был сказан, что об этом хадисе считают другие мазхабы, какова цепочка передатчиков этого хадиса. У простого человека нет вот этих специфических знаний. Ведь получается, что человек читает слова, понятия, мысли, которые были сказаны более 1400 лет тому назад. Ведь этот человек не первый, кто обратился к тому или иному хадису, ведь до него тоже были люди, которые этот хадис читали. Например, есть хадис: «Нет намаза у того человека, который соседствует с мечетью, кроме как в мечети». Если этот хадис понимать дословно, то мусульманин может посчитать, совершение намаза дома недействительно, а действительно только в мечети.
Но ведь все мазхабы, то есть правовые исламские школы, единогласны в том, что намаз, прочитанный дома, действителен. Этот хадис надо понимать так, что Пророк Мухаммад, да благословит его Аллах и приветствует, стимулирует человека читать намаз в мечети, так как за совершение намаза в мечети увеличивается награда в 27 раз.
Есть хадисы, в которых сообщается, что Пророк Мухаммад, да благословит его Аллах и приветствует, знал, что человек прочитал намаз дома, и он не повелел ему, чтобы он перечитал намаз в мечети. Когда мы все вот эти хадисы о намазе соединяем вместе, то у нас общая картина получается, что этот хадис на самом деле лишь побуждает людей читать намазы в мечети, но никак не запрещает намазы дома.
— На сайте муфтията сообщается, что после прослушивания ваших лекций о хадисах можно получить иджазу. Что это такое? И почему важно её получать?
— Хадисы передаются от человека к человеку, то есть цепочки передатчиков. Имам аль-Бухари, написавший свою книгу-сборник во III веке по хиджре, преподавал эту самую книгу своим ученикам. Ученики эту книгу передавали дальше своим ученикам. И вот так эта книга дошла до наших дней.
Ученики эту книгу передавали дальше своим ученикам. И вот так эта книга дошла до наших дней.
Я вместе с учителем-устазом прочитал вот эту книгу «Сахих аль-Бухари», и устаз мне передал специальный список передатчиков хадисов до самого имама аль-Бухари в виде документа. В иджазе написано, что мне дано разрешение на преподавание хадисов. Это получается своеобразный диплом-разрешение, который показывает, что я достиг такого уровня знания, что могу дальше передавать это знание. Но иджаза также дается для того, чтобы была какая-то письменная связь с нашим любимым Пророком, да благословит его Аллах и приветствует.
— Человек, который впервые услышит, увидит информацию о ваших лекциях, который поверхностно прочтет наше интервью, задастся вопросом: «У мусульман уже есть книга Коран, где всё написано. Зачем мусульманам ещё какие-то многотомные сборники хадисов?».
— Коран достаточен. Но как выполнять некоторые положения, упомянутые в Коране? Они детально не разъяснены в нем. Например, в Коране написано: «Совершайте намаз». Но как совершать намаз? В Коране это не разъяснено. Поэтому все условия и порядок совершения намаза разъясняются в хадисах. В Коране про закят есть упоминание. Но как платить закят, кому, кем? При каком имуществе платить закят? Ответы на эти вопросы есть в хадисах.
Например, в Коране написано: «Совершайте намаз». Но как совершать намаз? В Коране это не разъяснено. Поэтому все условия и порядок совершения намаза разъясняются в хадисах. В Коране про закят есть упоминание. Но как платить закят, кому, кем? При каком имуществе платить закят? Ответы на эти вопросы есть в хадисах.
— Есть ли сборники хадисов, имеющие какую-то тематическую направленность? Скажем, сборник, посвященный только торговле, внутрисемейным отношениям, ведению хозяйства?
— Как раз в «Сахих аль-Бухари» все хадисы распределены по таким важным темам, в этом удобство сборника «Сахих аль-Бухари»: хадисы о намазе, хадисы о тахарате… и так далее. Конечно, есть другие отдельные сборники хадисов, скажем, о никахе, о торговле и так далее. У Галимджана Баруди сборник хадисов общего характера.
— Допустим, человек после прочтения нашего интервью заинтересуется хадисами, захочет найти хадисы на конкретные интересующие только его темы. Найдет переводы хадисов на русский язык в интернете. На что должен обратить внимание мусульманин, чтобы вот этот текст, который будет у него перед глазами, не ввел его в заблуждение?
На что должен обратить внимание мусульманин, чтобы вот этот текст, который будет у него перед глазами, не ввел его в заблуждение?
— Самое первое, что нужно сделать мусульманину, — найти учителя-устаза. Нужно найти того, с кем человек изучит основы ислама, фикх (т.е. право. — Ред.). Только после этого я могу посоветовать человеку начать читать хадисы. Без знания акыды (т.е. вероубеждение. — Ред.), без знания фикха человек некоторые хадисы может понять неправильно. Фикх состоит из разных правовых школ. Человек может запутаться, скажем, в ритуале омовения, потому для разных правовых школ — разные практики, а в самом хадисе сообщается лишь только, что «Пророк Мухаммад протер голову». Скажем, по ханафитскому мазхабу протирать нужно четверть головы от лба, по маликитскому мазхабу нужно протереть полностью всю голову. Если мусульманин полностью голову не протрет по маликитскому мазхабу, то его намаз будет недействительным. И таких нюансов и деталей в толковании хадисов, в их разъяснениях очень много, и они все есть в многочисленной литературе по фикху. Разве простой человек может, не зная мусульманского права, сделать правильный вывод лишь только по одному хадису, по одному сообщению, хотя бы касательно вопроса омовения-тахарата? Нет. Для этого ему нужны годы образования, подготовки, получения знания и, конечно же, ему нужен учитель-устаз.
Разве простой человек может, не зная мусульманского права, сделать правильный вывод лишь только по одному хадису, по одному сообщению, хотя бы касательно вопроса омовения-тахарата? Нет. Для этого ему нужны годы образования, подготовки, получения знания и, конечно же, ему нужен учитель-устаз.
— А качество перевода? Насколько серьезен вопрос передачи смысла хадиса с арабского языка на русский язык?
— Качество переводов хадисов может вызывать серьезные вопросы. Мало того что для толкования, для понимания хадисов нужно изучать акыду, фикх, надо ещё и глубоко разбираться в тонкостях арабского языка.
— То есть простого знания арабского языка, умения разговаривать, писать, читать на арабском языке, чтобы потом делать переводы хадисов, — этого недостаточно?
— Да, например арабское слово istawa… У этого слова есть больше 10 вариантов перевода на русский язык: утвердился, возвысился, что-то под владением кого-то, возможность управления, выпрямился, что-то одно сравнялось с чем-то другим, по отношению к еде — что она приготовилась. И какой из этих вариантов переводов выберет переводчик? Очевидно же, что переводчик не только должен быть филологом в арабском языке, также ему нужны очень глубокие знания по акыде, по фикху. Механически хадисы переводить нельзя — они неправильно будут поняты.
И какой из этих вариантов переводов выберет переводчик? Очевидно же, что переводчик не только должен быть филологом в арабском языке, также ему нужны очень глубокие знания по акыде, по фикху. Механически хадисы переводить нельзя — они неправильно будут поняты.
Теги:
хадисы, мусульмане, Сахих аль-Бухари, ислам, религия, интервью, Нурислам хазрат Валиулла, просвещениеОпыт работы репетитором
Мария Беликова
собрала истории
Профиль автора
Репетиторами работают студенты, школьные учителя и просто те, кто считает, что хорошо разбирается в предмете.
Читатели Тинькофф Журнала, которые дают индивидуальные уроки, рассказали, где ищут учеников, как выстраивают план уроков и сколько зарабатывают.
Это истории из Сообщества. Редакция задала наводящие вопросы, бережно отредактировала и оформила по стандартам журнала.
ИСТОРИЯ № 1
«Хочу, чтобы дети из регионов могли качественно готовиться и получать высокие баллы»Лера Илюхина
преподает русский язык в мини-группах
Профиль автора
Почему решила стать репетитором. В начале первого курса я познакомилась с парнем, который обожал книжки по саморазвитию. Еще больше он любил раздавать советы после их прочтения. Мне он сказал: «Ты же сдала ЕГЭ на высокие баллы, помнишь, к чему и как готовиться. И почему еще сидишь? Занимайся репетиторством, делись знаниями».
Сначала я отнеслась к этому скептически: не было образования и опыта, переполнял страх. Казалось, любой человек с улицы может объяснять так же, как я. Но все-таки решила попробовать. Рассматривала свою деятельность как подработку, которая разовьет навыки преподавания.
Поиск учеников. В начале пути кажется, что найти их крайне сложно. Но наш верный друг и помощник — сарафанное радио. При любом разговоре и в каждом деле нужно заявлять близким о том, что ты хочешь чем-то заняться, в перспективе они твои агенты по продвижению. Я сказала о репетиторстве маме, и дело не заставило себя долго ждать. Ее коллега перед началом учебного года искала репетитора по русскому языку для сына. Мама, естественно, порекомендовала меня. Так я нашла первого ученика.
В начале пути кажется, что найти их крайне сложно. Но наш верный друг и помощник — сарафанное радио. При любом разговоре и в каждом деле нужно заявлять близким о том, что ты хочешь чем-то заняться, в перспективе они твои агенты по продвижению. Я сказала о репетиторстве маме, и дело не заставило себя долго ждать. Ее коллега перед началом учебного года искала репетитора по русскому языку для сына. Мама, естественно, порекомендовала меня. Так я нашла первого ученика.
На специальных платформах типа «Репетит-ру» и «Профи-ру» тоже регистрировалась. За два года нашла там только одного ученика, потому что заявок было мало. Зато благодаря «Профи-ру» со мной познакомился молодой человек. Он узнал мое имя на фестивале КВН, вбил его в поисковик, попал на мой профиль и оставил заявку на занятия русским языком. Мы обменялись номерами телефонов и начали общаться. Сейчас думаем о свадьбе.
«Профи-ру» не принес мне учеников, зато подарил любимого человекаМетодика занятий. К концу первого года репетиторства я занималась с двумя младшими школьниками и двумя выпускниками. За месяц до экзамена подумала, что последним перед ЕГЭ нужна постоянная практика — чтобы настроить мозг на быструю деятельность и выработать привычку прорешивать тесты. Программа у всех одна, правила разбирали те же, так что мы попробовали собраться в «Дискорде» и позаниматься сразу втроем.
За месяц до экзамена подумала, что последним перед ЕГЭ нужна постоянная практика — чтобы настроить мозг на быструю деятельность и выработать привычку прорешивать тесты. Программа у всех одна, правила разбирали те же, так что мы попробовали собраться в «Дискорде» и позаниматься сразу втроем.
Пробное групповое занятие всем очень понравилось, и я придумала план ускоренного повторения: учимся три дня подряд перед экзаменом по четыре часа с перерывами. Ребята были в восторге, даже писали: «Лера, а можно к нам еще Кирилл подключится? А можно и Эдик?» Так в группе стало четыре ученика.
Тогда я увидела, насколько эффективны групповые занятия: школьники вовлечены в процесс, мотивированы и сконцентрированы. Из-за того, что они знакомы друг с другом, им важно не опозориться — подумать чуть дольше перед ответом, ответственнее отнестись к решению. Они быстрее и правильнее выполняли задания — помогла здоровая конкуренция, и это здорово сказалось на результате.
/distant-success/
Удобный стул и никакого буллинга: 11 причин, почему дистанционное обучение лучше для всех
С младшеклассниками я, наоборот, занимаюсь очно: так им проще сконцентрироваться. Мы разбираем грамматику, делаем творческие задания. Рано или поздно всем придется сесть за сочинения, и можно написать текст о том, «как я провел лето», а можно придумать что-то поинтереснее.
Мы разбираем грамматику, делаем творческие задания. Рано или поздно всем придется сесть за сочинения, и можно написать текст о том, «как я провел лето», а можно придумать что-то поинтереснее.
С одним мальчиком мы разбирали структуру сочинения — вступление, основную часть и заключение — на примере текста про НЛО. После этого он писал для меня фантастические рассказы с сюжетом на уровне «Аватара». Главное — никого и ни в чем не ограничивать.
Иногда мы с учеником работаем по такой методике: он надевает наушники, а я рассказываю правила в провод. Так информация, по его мнению, попадает прямо в уши. Действительно работает!Доход. Сначала я занималась в свое удовольствие, и деньги не были первостепенной задачей. Брала по минимуму — 500 Р за час. Цен меньше я никогда и не видела. Пару раз даже опаздывала на очный урок и заказывала такси, которое стоило больше, чем само занятие, — отменять его было уже неприлично.
А в середине учебного года мне позвонила крестная и попросила подготовить к ЕГЭ ее сына. Для качественной подготовки с нуля на высокий балл трех месяцев крайне мало, но я все же взялась. Экзамен он в итоге сдал хорошо и поступил на бюджет в тот вуз, в который хотел.
Для качественной подготовки с нуля на высокий балл трех месяцев крайне мало, но я все же взялась. Экзамен он в итоге сдал хорошо и поступил на бюджет в тот вуз, в который хотел.
С ним мы занимались вообще бесплатно. Мне казалось, что нельзя брать деньги с родственников. Сейчас понимаю, что все это глупости, нужно просто назначать цену чуть меньше обычной. Но такой опыт мне сильно помог в другом плане.
Для подготовки к занятиям я использую интернет-ресурсы, варианты ЕГЭ прошлых лет, контрольно-измерительные материалы и печатные справочникиСын крестной стал рассказывать одноклассникам о наших уроках. Так у меня появилось еще несколько учеников-старшеклассников, с которых я брала уже по 600 Р в час. За четырехчасовое групповое занятие мне платили 1200 Р с человека. Со всей группы получалось 3600 Р, так как с сына крестной деньги я не брала.
В прошлом учебном году ежемесячный доход был небольшим из-за того, что я намеренно не набирала много учеников. Я не заморачивалась и ставила занятия в удобные дни, потому что зависела от университета и КВН. Договаривалась об уроках накануне, буквально за день. Выходило около 10 000 Р в месяц.
Договаривалась об уроках накануне, буквально за день. Выходило около 10 000 Р в месяц.
Общение с учениками. Мне комфортно, когда для учеников я Лера, но обращаются они ко мне на «вы». Таким образом мы сохраняем субординацию. Я Лера — потому что молодая и на одной волне с ребятами, на «вы» — потому что преподаватель, которого нужно уважать.
Разумеется, близкое общение присутствует. Все-таки русский — предмет, в котором необходимо открываться. Мы пишем сочинения и делимся мыслями, обсуждаем поступки героев, оцениваем литературу — это довольно интимные вещи. С некоторыми ребятами становимся настоящими друзьями. Один ученик на каждом занятии дарит мне оригами. За два года я собрала целую коллекцию: в основном это котики, но есть еще дракон и пистолет.
Композиция с оригами-котенком и сказками, который придумал мой ученикМинусы того, чтобы «быть на короткой ноге», тоже имеются. Мне пару раз звонили с вопросами в 12 ночи. А я рефлекторно отвечаю на сообщения и звонки и в личное время, хотя делать этого не следовало бы.
Учеба — это не линейная диаграмма, постоянно растущая вверх, а взлеты и падения. На успеваемость влияют многие факторы — от ситуации в семье до переживаний из-за любимого сериала. И нельзя сказать, что в плохих результатах всегда виноват родитель или учитель.
К спадам я отношусь с пониманием. Главное — быть внимательным к ребенку. У меня был одиннадцатиклассник Шамиль. Когда он перестал сдавать сочинения вовремя, оказалось, что его предал близкий друг. Разумеется, такие ситуации заставляют опустить руки. Но в его случае это затянулось, и мне пришлось раскладывать все по полочкам. Мы долго обсуждали его страхи перед трудностями и потерю мотивации. И решили бороться с этим вместе, чтобы прийти к отличному результату.
А недавно у меня был тяжелый период, когда ничего не хотелось делать — только лежать в кровати и спать. Тогда мне пришло сообщение от мальчика, с которым мы готовились к ЕГЭ в группе, раньше он жил в поселке городского типа далеко от Москвы, а потом поступил сюда в университет: «Лера, привет, давай встретимся. Хочу вживую увидеть человека, благодаря которому я оказался в столице». Такие ситуации избавляют от выгорания и мотивируют работать.
Хочу вживую увидеть человека, благодаря которому я оказался в столице». Такие ситуации избавляют от выгорания и мотивируют работать.
Коммуникация с родителями. В моей практике они не принимают особого участия: мы обсуждаем оплату и расписание, но потом я переписываюсь с учениками лично.
В начале работы всегда предлагаю пробное бесплатное занятие — вдруг ребенку не подойдет мой темп речи или манера объяснения. Хотя еще ни разу не было такого, чтобы от занятий впоследствии отказывались. Это тоже помогает наладить доверие.
Успеваемостью родители напрямую не интересуются, дети рассказывают все сами. Если они хорошо работают — хвалю. Если плохо себя ведут — промолчу или обсужу с ними напрямую. Я всегда стороне ученика, и жаловаться маме нет смысла. Все моменты можно разобрать тет-а-тет — это учит ответственности и дисциплине.
Сочинение на тему «Почему я не сделал домашнее задание». Оказывается, во всем виновата летающая тарелкаЦели на будущее. Изначально репетиторство было для меня подработкой, а сейчас стало основным занятием, которое я хочу развивать. Мне кажется, что групповые занятия — это замечательная вещь. Так что основная цель — набирать группы подготовки к ЕГЭ и готовить стобалльников. Планирую сфокусироваться именно на ребятах из регионов, потому что ситуация с репетиторами в маленьких городах и селах сложная: обычно репетиторов там немного, чаще всего это учителя на пенсии, которые не в курсе современных стандартов. Я хочу, чтобы дети из регионов могли качественно готовиться к экзаменам и получать высокие баллы.
Изначально репетиторство было для меня подработкой, а сейчас стало основным занятием, которое я хочу развивать. Мне кажется, что групповые занятия — это замечательная вещь. Так что основная цель — набирать группы подготовки к ЕГЭ и готовить стобалльников. Планирую сфокусироваться именно на ребятах из регионов, потому что ситуация с репетиторами в маленьких городах и селах сложная: обычно репетиторов там немного, чаще всего это учителя на пенсии, которые не в курсе современных стандартов. Я хочу, чтобы дети из регионов могли качественно готовиться к экзаменам и получать высокие баллы.
Ставку я тоже думаю повысить, потому что не могу жить на 600 Р в час. Но точно оставлю ее ниже 1000 Р, потому что в реалиях деревень с небольшими зарплатами платить больше проблематично.
ИСТОРИЯ № 2
«Учу смотреть фильмы глазами режиссера и сценариста»Александр Елизаров
готовит к творческим испытаниям в вузах
Профиль автора
Почему решил стать репетитором. Мысль о преподавании пришла ко мне во время работы грузчиком. Я разбирал мебель, перетаскивал коробки, обматывал зеркала пленкой — и вдруг вспомнил, что умею грамотно разговаривать и знаю кое-что из литературы. В старшей школе писал рецензии, публиковался в журналах, участвовал в научной деятельности и отлично знал гуманитарные предметы. В момент тотальной усталости мне захотелось вернуться к прошлым увлечениям. Я зарегистрировался на специальных интернет-платформах и начал откликаться на заявки по русскому языку и литературе.
Мысль о преподавании пришла ко мне во время работы грузчиком. Я разбирал мебель, перетаскивал коробки, обматывал зеркала пленкой — и вдруг вспомнил, что умею грамотно разговаривать и знаю кое-что из литературы. В старшей школе писал рецензии, публиковался в журналах, участвовал в научной деятельности и отлично знал гуманитарные предметы. В момент тотальной усталости мне захотелось вернуться к прошлым увлечениям. Я зарегистрировался на специальных интернет-платформах и начал откликаться на заявки по русскому языку и литературе.
Сейчас работаю в небольшой нише: даю частные занятия по кинорежиссуре и драматургии. В основном готовлю к вступительным испытаниям для творческих вузов и киношкол, но есть и ученики, которые занимаются из-за личного интереса к сфере.
Фотография с фестиваля «Горький fest». Преподавание подарило мне возможности для творчества и самореализации в любимых сферах — кинематографе и сценарном искусствеПоиск учеников. Моим первым учеником был мальчик Аяз, который жил на окраине Петербурга и очень плохо говорил по-русски. Вторым — абитуриентка Санкт-Петербургского государственного института кино и телевидения. С ней мы несколько месяцев разбирали кинорежиссуру и драматургию, а потом она поступила на бюджет. Это добавило мне уверенности в работе.
Вторым — абитуриентка Санкт-Петербургского государственного института кино и телевидения. С ней мы несколько месяцев разбирали кинорежиссуру и драматургию, а потом она поступила на бюджет. Это добавило мне уверенности в работе.
С поиском учеников помогает только «Профи-ру», там удобная система отзывов и откликов. Но роботизированные ответы поддержки и комиссия — отдельная тема. Представьте: вы провели занятие, у человека поменялись планы и он передумал продолжать, а от вас требуют комиссию 70% от заказа! Но в целом заказов оттуда поступает много. С «Репетит-ру» или «Авито» ученики почти не приходят, хотя анкеты у меня активные и с большим количеством положительных отзывов.
Первое время я проводил бесплатные пробные уроки, но теперь отказался от этой идеи. Подготовка к ним требует ничуть не меньше сил и времени. За час нужно успеть познакомиться, понять ожидания ученика и уровень его подготовки. Так что оплата такого занятия — нормальная практика, которой не нужно стесняться.
Методика занятий. Я не просто рассказываю ребятам о драматургии — так они запишут факты и забудут, — а стараюсь научить их мыслить самостоятельно. Учу читать книги так, чтобы в голове оставались важные идеи, смотреть фильмы глазами режиссера и сценариста, писать как репортер и публицист. Специализируюсь на нестандартных заданиях.
Часто ученики ждут от преподавателя невероятного. Думают, что он будет все рассказывать, они — раз в неделю слушать и зазубривать материал, и 100 баллов обеспечены! Этого быть не может. Я как преподаватель только направляю и подсказываю. К примеру, с каких фильмов начать изучение кино. Популярные российские кинотопы плохи, современные фильмы — довольно низкого уровня. И мне часто приходится объяснять, почему не стоит погружаться в кинематограф с того, что показывают поисковые алгоритмы.
Если же старшеклассник хочет писать рассказы, то я, основываясь на увлечениях и характере, предлагаю нескольких авторов, которые могли бы его заинтересовать. Мы их читаем, обсуждаем, делаем пометки, а потом пробуем сочинять в том же стиле. Еще учу каждого относиться к собственным работам критически: ищем золотую середину, не заваливаясь в сторону излишней похвалы или самобичевания.
Мы их читаем, обсуждаем, делаем пометки, а потом пробуем сочинять в том же стиле. Еще учу каждого относиться к собственным работам критически: ищем золотую середину, не заваливаясь в сторону излишней похвалы или самобичевания.
Никаких заготовок, кроме списка обязательных к прочтению книг, у меня нет. Материал подбираю в зависимости от целей. В этом и состоит принцип изучения творческих дисциплин, у которых нет четких правил.
Мое рабочее местоНекоторым слушателям необходимо время, чтобы прочесть повесть или небольшой роман, поэтому занятия мы проводим раз в две недели. За этот период нужно все проанализировать, изложить мысли в заметке и придумать вопросы для обсуждения. Но обычно уроки проводятся чаще — один или два раза в неделю. На них я смотрю, как человек понял прочитанное, а потом перехожу к разговору о произведении. Сначала мы находим общий язык, чтобы убедиться, что одинаково поняли автора, а уже потом углубляемся в детали.
По сути, задача наших занятий — научиться слышать друг друга и смотреть на искусство глазами авторов, а не зрителей. В какой это будет форме — не имеет значения. Если для понимания Лавкрафта необходимо написать эпигонский рассказ — хорошо. Тексты мы разбираем по предложениям, пьесы — по структурным элементам, фильмы — по кадрам, сценам, эпизодам.
В какой это будет форме — не имеет значения. Если для понимания Лавкрафта необходимо написать эпигонский рассказ — хорошо. Тексты мы разбираем по предложениям, пьесы — по структурным элементам, фильмы — по кадрам, сценам, эпизодам.
Если ученик не выполняет домашнее задание — это его недоработка. Я не сторонник репрессивного контроля за свободным временем своих слушателей. Сама идея дополнительных упражнений должна исходить из желания расширить новые знания самостоятельной работой. Если этого нет, значит, что-то идет не так.
Общение с учениками. Со всеми учениками у нас доверительные отношения. Несколько раз случалось, что подростки на занятиях начинали плакать из-за проблем с родителями или чувства неуверенности. Такое было на уроке с девочкой, профессионально занимавшейся фигурным катанием: в какой-то момент она разрыдалась от сильной нагрузки и бесконечных тренировок. Обсуждение переживаний хоть и забирает какую-то часть урока, но снимает внутреннее напряжение и возвращает интерес к предмету.
Бывают, конечно, и исключения. Пару лет назад мне позвонила выпускница Литературного института. Она искала преподавателя, с которым могла бы обсуждать литературу. Мы договорились о занятии и решили разобрать на нем повесть Леонида Андреева. Через несколько дней начали делиться мыслями о книге. «Одна строчка Достоевского стоит всей прозы Андреева», — заявила она, а я пытался понять, чем ее так разозлила повесть. Так и не понял, но все равно вел конструктивный диалог, анализировал текст. После занятия пришло уведомление об отзыве на сайте репетиторов, что я ей не подошел, потому что не преподаю в Литинституте. Зачем оставляла заявку, зная, что я не оканчивал Литинститут, непонятно.
/find-repetitor/
Как найти хорошего репетитора
Коммуникация с родителями. Одно время я занимался русским языком с маленькими детьми, и третьеклассник назвал меня папой. Я, конечно, опешил, но урок продолжил. Такие ученики, на мой взгляд, нуждаются не в репетиторе, а в поддержке и внимании, поэтому преподаватель начальных классов становится вторым родителем. А это очень плохо, потому что акцент с предмета смещается на личные отношения. Малыши занимаются не для того, чтобы узнать что-то новое, а чтобы угодить маме и папе. На моей практике таких историй было много.
А это очень плохо, потому что акцент с предмета смещается на личные отношения. Малыши занимаются не для того, чтобы узнать что-то новое, а чтобы угодить маме и папе. На моей практике таких историй было много.
Большинство современных подростков, на мой взгляд, болезненно зависимы от родителей. В этом случае коммуникация с ними становится действительно сложной. Я как-то выбрал книгу для разбора, но маме ученика показалось, что она слишком «взрослая» и «жестокая». Конечно, я не против вмешательств в учебный процесс, но они должны быть обоснованы. От такой работы мне комфортнее отказаться.
Доход. За четыре года репетиторства моя ставка выросла в три раза. Сейчас я ориентируюсь на базовую цену — 1500 Р в час. Она может повыситься в зависимости от трудности заказа: например, если цель — поступление, личный интерес или скорый экзамен. К тому же частные уроки имеют большой риск срыва или переноса по разным причинам клиента. Поэтому я не приравниваю почасовую оплату к стабильному доходу. На этой неделе заработаю 10 000 Р, на следующей — 2000 Р. Да и творческие экзамены — это не ЕГЭ по русскому языку, которое обязан сдавать каждый школьник. В один год на режиссерский факультет поступают десять человек, в другой — один. Так что мой доход сильно варьируется.
На этой неделе заработаю 10 000 Р, на следующей — 2000 Р. Да и творческие экзамены — это не ЕГЭ по русскому языку, которое обязан сдавать каждый школьник. В один год на режиссерский факультет поступают десять человек, в другой — один. Так что мой доход сильно варьируется.
/prepod-italianskogo/
Я преподаю итальянский язык и зарабатываю 120 000 Р в месяц
Не могу назвать конкретную сумму еще и потому, что нынешние расценки не совсем актуальны: некоторые ученики уехали и прекратили занятия, количество заказов упало. Это заставляет задуматься над тем, чтобы расширить поле своей деятельности — например, организовывать групповые занятия.
Цели на будущее. Опыт частной практики подарил мне вдохновение, и я создал собственный бесплатный образовательный проект «Новая школа притч». В нем я рассказываю о фильмах и литературе: разбираю «Брата» с точки зрения американских комиксов, объясняю финальную сцену «Июльского дождя», делюсь мыслями о культуре отмены в российском кино — это может пригодиться как для вступительных экзаменов в вузе, так и для общего развития.
Я хотел бы сосредоточиться на придумывании материала для школы и поиске людей, заинтересованных в кинодраматургии. На лекциях делюсь многим из того, о чем говорю на индивидуальных занятиях. А некоторые выпуски напрямую связаны с тем, что мне пришло в голову во время уроков с абитуриентами.
Кадр из видеолекции, в которой я сравниваю фильм «Июльский дождь» с повестью «Посторонний»Что касается репетиторства — буду так же проводить индивидуальные занятия, позволяющие моим слушателям иначе смотреть на привычные вещи, обучаться процессу просмотра кино, чтению книг, написанию сценариев. Это очень большое поле для работы.
К тому же я продолжаю работать над своими фильмами и пьесами, хочу чаще участвовать в фестивалях и получать награды.
ИСТОРИЯ № 3
«Не каждый готов платить за разбор лексики из сериалов и мультиков»Иман Абдалла
преподает английский по мемам и сериалам
Профиль автора
Почему решила стать репетитором. Я билингв и всю жизнь говорю на английском. После того как выпустилась из школы, захотела поделиться опытом с другими людьми. Но только не в привычном формате разбора грамматики и разбора заданий. Это не мое! Я мечтала сделать упор на акценты и разговорные фразы. И искала людей, которым это интересно.
Я билингв и всю жизнь говорю на английском. После того как выпустилась из школы, захотела поделиться опытом с другими людьми. Но только не в привычном формате разбора грамматики и разбора заданий. Это не мое! Я мечтала сделать упор на акценты и разговорные фразы. И искала людей, которым это интересно.
Репетиторство в качестве полноценной работы я не рассматривала. Большинство учеников интересует подготовка к ЕГЭ, а мне к экзаменам готовить не хотелось. Безусловно, не каждый готов платить за разбор лексики из сериалов и мультиков — желающих заниматься в таком формате мало. Так что для меня это всегда будет подработкой.
Поиск учеников. У моей мамы много подруг с детьми школьного возраста, которым нужна языковая практика. Первое время я брала всех учеников, независимо от возраста. Сейчас занимаюсь только с ребятами старше девятого класса.
С теми, кто младше, заниматься не могу: сложно. У меня было такое, когда ребенка заставляли родители: ему это было ни фига не интересно, заниматься он не хотел. Так что хочешь быть гением английского — с удовольствием помогу им стать. Но если этого хочет только твоя мама — умываю руки.
Так что хочешь быть гением английского — с удовольствием помогу им стать. Но если этого хочет только твоя мама — умываю руки.
/list/hear-me-out/
Как научиться понимать устную англоязычную речь: 5 советов
Методика занятий. На уроках я показываю «живой», разговорный английский. В этом помогают мемы, тиктоки, блоги, фильмы, сериалы. Недавно занималась с девочкой, которой была нужна медицинская лексика. Мы взяли несколько сериалов — «Доктора Хауса», «Анатомию Грей», «Хорошего доктора» — и выписывали оттуда предложения с классной грамматикой и новыми словами.
В качестве домашки я даю упражнения по лексике, ищу аудирования и тексты из видеоблогов и форумов. Если есть вопросы по временам или построению фраз, мы разбираем правила из учебника English Grammar in Use — это база. Иногда прорабатываем грамматику на BBC Learning English. Там даются правила, квизы, тесты и другие интерактивные задания по пройденному материалу.
Пример упражнений из моего любимого учебника English Grammar in UseПрогресс отслеживаю по беглости, произношению и уверенности речи — со стороны очень заметно, когда человек понимает, о чем говорит, а не зазубривает фразы. Со временем ученики начинают употреблять фразовые глаголы, идиомы и коллокации — устойчивые сочетания. Это тоже показатель того, что уровень английского повышается.
Со временем ученики начинают употреблять фразовые глаголы, идиомы и коллокации — устойчивые сочетания. Это тоже показатель того, что уровень английского повышается.
У ребят с низким уровнем языка другая программа: мы начинали с мультфильмов по типу «Свинки Пеппы», «Губки Боба», «Смешариков». Последние, кстати, по-английски называются Kikoriki. Слушаем по фразе, останавливаем и переводим. За пару месяцев очень круто прокачивается понимание речи. Работаем мы всегда в «Зуме», общаемся в «Телеграме», смотрим сериалы на «Кинопоиске», присылаем друг другу всякие приколы в «Тиктоке».
Все занятия я провожу в онлайне, это офигенно удобно: я получаю два образования одновременно и дорога на очные уроки забирала бы у меня последние силы.
Рабочий стол ученика во время занятий: «Зум», сериал, учебник и тетрадка с ручкой для записи незнакомых выраженийОбщение с учениками. Я нестандартный преподаватель. Ни разу не встречала людей, которые преподают английский по сериалам и фильмам. Поэтому слово «репетитор» не про меня, скорее — english buddy или english mate, «братан» по изучению языка.
Поэтому слово «репетитор» не про меня, скорее — english buddy или english mate, «братан» по изучению языка.
Всех учеников прошу обращаться ко мне на «ты», создаю дружественную атмосферу. Когда есть классный вайб, тогда есть и результат.
Доход. Я трачу много сил на подготовку, иногда ищу материал несколько дней. Поэтому, несмотря на то, что я еще студентка, беру 1000 Р за час. Средний доход зависит от количества учеников. Летом не работаю, потому что все в разъезде, но связь мы все равно поддерживаем — скидываю всем материалы и полезные слова.
С сентября по май у меня было три ученика, с каждым занимались раз в неделю. В месяц выходило около 13 000 Р.
Мем, который я отправила своей ученице. Перевод: американцы, когда видят, что кто-то использует «км/ч», а не «глазированные пончики в белоголовых орлах»В том году я пробовала себя в роли обычного учителя — отправила резюме в языковую онлайн-школу. За каждое занятие обещали небольшую зарплату, 300 Р в час, но с постоянными бонусами за проверку домашек. Как будто это онлайн-казино, а не школа. В месяц выходило бы около 10 000 Р с максимальной загруженностью. Те же деньги можно получать на частных занятиях при меньших трудозатратах. Так что репетиторство forever, в очередной раз в этом убедилась.
Как будто это онлайн-казино, а не школа. В месяц выходило бы около 10 000 Р с максимальной загруженностью. Те же деньги можно получать на частных занятиях при меньших трудозатратах. Так что репетиторство forever, в очередной раз в этом убедилась.
Цели на будущее. Я учусь в двух университетах, подрабатываю администратором в салоне красоты, и времени на репетиторство просто не хватает. Но бросать преподавание не планирую — для меня это как тренировка, которая помогает не забывать английский язык и постоянно его практиковать.
/exam-tutor/
5 историй о трудоустройстве и работе в онлайн-школах подготовки к ЕГЭ
ИСТОРИЯ № 4
«Хочу открыть свою онлайн-школу в ближайшие три года»kate_smartduckenglish
стала блогером — репетитором по английскому
Профиль автора
Почему решила стать репетитором. Еще в университете в родном Мурманске я занималась со школьниками за небольшую плату. После окончания вуза переехала в Москву и стала преподавателем в языковой школе. Там я учила абсолютно всех: и детей четырех лет, и взрослых.
После окончания вуза переехала в Москву и стала преподавателем в языковой школе. Там я учила абсолютно всех: и детей четырех лет, и взрослых.
После пяти лет работы преподавателем меня назначили директором: я составляла расписание, проводила тренинги, придумывала мероприятия, связывалась с родителями, контролировала успеваемость. За это время поняла, что мне нравится организация и у меня это прекрасно получается! А потом я ушла в декрет. Долго просидеть дома, конечно же, не получилось.
Когда передо мной встал вопрос возвращения на работу по найму, я поняла, что моих навыков достаточно, чтобы преподавать самостоятельно. При этом хотелось уделять достаточное время ребенку. Так моя старая студенческая подработка стала источником постоянного заработка.
Фотография со времен работы в языковой школеПоиск учеников. Когда я еще не работала и сидела с маленьким сыном, знакомая дала мой номер девочке, которой нужно было сдать IELTS. К экзамену мы подготовились, она успешно его сдала и уехала учиться в Польшу.
Потом написал ее одногруппник, который тоже хотел учить английский. Через несколько месяцев я рассказала друзьям, что даю частные уроки, и они порекомендовали меня своим знакомым и коллегам. Так через год у меня сформировалось полностью загруженное расписание. Удивительно, но я до сих пор ни разу не искала учеников специально на какой-либо платформе — они мне просто звонят сами. Еще я веду канал в «Телеграме» и на «Ютубе», блог в «Инстаграме» — часто люди находят меня там.
Соцсеть «Инстаграм» принадлежит компании Meta — организации, деятельность которой признана экстремистской и запрещена на территории РФ
Во время работы в языковой школе я предлагала руководству завести видеоканал с примерами наших уроков, но они идею не оценили. Реализовать это я смогла, только когда начала работать на себя. Было много сомнений, кому это вообще нужно, но потом появились реакции и комментарии, причем их писали не мои родители и друзья. Незнакомые люди просили разобрать определенные темы, записывать больше видео. Тогда я поняла, что хочу продолжать.
Тогда я поняла, что хочу продолжать.
Методика занятий. Я занимаюсь и с детьми, и со взрослыми, и ко всем нужен свой подход. Ко мне часто обращаются предприниматели, которым в связи с релокацией бизнеса нужно подтянуть язык в краткие сроки; моряки, изучающие английский для трудоустройства; студенты-медики, готовящиеся к аспирантуре за границей. У каждого свой запрос и сроки. От этого зависит метод преподавания.
Вначале мы с учеником созваниваемся, определяем основную цель обучения, проводим бесплатный письменный и устный тест, чтобы определить уровень знаний. Исходя из полученной информации, я составляю индивидуальный план занятий.
Чаще всего сперва мы закрепляем уже знакомые грамматические темы, затем берем новые: разбираем правила, выполняем упражнения из сборников. Слушаем аудирование с разными акцентами, читаем публицистические и художественные тексты, пишем пробные варианты IELTS или TOEFL. Через пару месяцев устраиваем пробный экзамен с выставлением баллов.
Через пару месяцев устраиваем пробный экзамен с выставлением баллов.
8 простых неадаптированных книг на английском
Большая часть моих учеников занимается онлайн — по «Скайпу» или «Зуму». В онлайне принципиально не занимаюсь только с малышами: для них эффективнее, когда преподаватель физически находится рядом. Я учу моего сына и еще двух девочек, которые живут по соседству, в отдельной группе. Так совмещаю работу и общение со своим ребенком, да еще и зарабатываю деньги. Но это исключение, все остальные занятия провожу дистанционно.
Основная занятость у меня по выходным. В субботу и воскресенье работаю с девяти утра и до девяти вечера. Остальные занятия раскиданы в течение недели — по три-четыре урока в день. Довольно лайтовый режим, очень удобно! А понедельник всегда посвящен отдыху.
Доход. В начале карьерного пути я назначала очень низкую цену за занятие — 500 Р в час. Когда только приехала в Москву и работала в школе, зарплаты не хватало на оплату съемной квартиры, поэтому в выходные я давала частные уроки. Трудилась совсем без отдыха.
Трудилась совсем без отдыха.
Впоследствии ставку определяла так: сравнивала среднюю стоимость на рынке и сопоставляла с моим уровнем владения языком. У меня С2 Proficiency и большой опыт преподавания — есть студенты с хорошими результатами. Поэтому часто ставила высокую цену: 1500 Р за час, 2000 Р за полтора и 2500 Р за два.
/list/alternative-english/
3 способа сдать международный экзамен по английскому языку
За 10 лет, с 2011 года, моя ставка выросла в четыре раза. Больше увеличивать ее я не планирую.
На платформах для репетиторов не сижу, поэтому не плачу проценты за заказы. Рекламой моего инстаграма бесплатно по знакомству занималась подруга. Еще были траты на маркерную доску и фломастеры. А учебники и пособия есть в интернете. Так что трачу больше времени, чем денег.
Соцсеть «Инстаграм» принадлежит компании Meta — организации, деятельность которой признана экстремистской и запрещена на территории РФ
Один из минусов репетиторства — нестабильный доход. Заработок зависит от месяца. Во время учебного года, с сентября по май, выходит около 120 000 Р в месяц. В летние месяцы, когда ученики разъезжаются, меньше — около 70 000 Р. С учетом того, что я сижу дома и не трачусь на проезд и обеды, получается очень даже достойная зарплата. На жизнь и отпуск два раза в год хватает. На свою квартиру в Москве — пока нет.
Заработок зависит от месяца. Во время учебного года, с сентября по май, выходит около 120 000 Р в месяц. В летние месяцы, когда ученики разъезжаются, меньше — около 70 000 Р. С учетом того, что я сижу дома и не трачусь на проезд и обеды, получается очень даже достойная зарплата. На жизнь и отпуск два раза в год хватает. На свою квартиру в Москве — пока нет.
Общение с учениками. Не люблю, когда учитель ставит себя выше ребенка, поэтому с детьми всегда общаюсь на равных, но показываю, что контролирую процесс именно я. В ходе работы замечаю, как раскрываются ученики. Узнаю об их увлечениях, мечтах, целях — они рассказывают об этом на английском языке. Я тоже делюсь с ними своими историями. Это совсем другой формат, не как в школе, где близко познакомиться со всеми не получится. На частных уроках рождаются доверительно-теплые отношения. Ребята даже подготовили мне на день рождения уточку — я их коллекционирую.
Подарок от учениковСо своей стороны я могу лишь заинтересовать ребенка: найти классные задания, энергично провести урок. Для взрослых устраиваю челленджи: если мы быстро закончим этот уровень, то на следующий будет скидка. Безотказно работает!
Для взрослых устраиваю челленджи: если мы быстро закончим этот уровень, то на следующий будет скидка. Безотказно работает!
В ситуациях, когда нет прогресса, чаще всего бывает так: первые несколько занятий ученик делает все задания, потом понимает, что за два месяца заговорить по-английски не получится, и стимул у него пропадает. Обучение языку — долгий процесс, требующий усидчивости: нужно постоянно зубрить слова, преодолевать барьеры. Если желания работать нет, поможет только время. Возможно, через какой-то период человек все-таки созреет, чтобы продолжить занятия.
Коммуникация с родителями. Во время работы директором в языковой школе я решала конфликты с мамами и папами детей. Неприятных случаев было много: кто-то был недоволен обучением, кто-то — преподавателем. Этот опыт помог мне лучше понимать людей и научил грамотному общению.
Сейчас во взаимодействии с родителями я придерживаюсь принципа открытости. Я всегда на связи — можно писать и задавать вопросы в любое время. А когда мамы видят результаты своих детей и их радостные эмоции от занятий, то никаких проблем возникнуть и не может.
А когда мамы видят результаты своих детей и их радостные эмоции от занятий, то никаких проблем возникнуть и не может.
Цели на будущее. Хочу открыть свою онлайн-школу в ближайшие три года. Это требует серьезной подготовки и больших финансовых вложений. И я маленькими шажками иду к цели.
Кроме желания создать собственный бизнес, есть стремление активнее развивать свои аккаунты, посвященные английскому языку. Сейчас не получается вести их стабильно из-за большого количества учеников и воспитания сына. Мне кажется, если есть инструменты для развития и помощи другим, то этим обязательно нужно пользоваться. К тому же соцсети помогают оставаться на одной волне с ребятами.
Подрабатываете репетитором и учитесь в университете? Расскажите о своем вузе и станьте героем следующего материала
Рассказать
Как компьютеры разбирают слова с неоднозначным значением?
Если вы один из 2,4 миллионов подписчиков в Твиттере импресарио Hamilton Лин-Мануэля Миранды, вы ожидаете восхитительного потока наблюдений, в том числе твитов с записью разговоров с его сыном Себастьяном, которому сейчас 3 года. Ранее в этом месяце Миранда предложила один такой обмен под названием «S’MORES. Реальная одноактная пьеса».
Ранее в этом месяце Миранда предложила один такой обмен под названием «S’MORES. Реальная одноактная пьеса».
Я: Итак, это зефир, но ты будешь есть его с этим крекером и шоколадом.
[Мой сын смотрит на меня так, будто я самый тупой человек на свете.]
Себастьян: Нет, я съем это РОТОМ.
[Конец пьесы.]
Очаровательный кусочек жизни, что и говорить. Но в этом кратком разговоре юный Себастьян Миранда также непреднамеренно наткнулся на своего рода двусмысленность, которая многое говорит о том, как люди изучают и обрабатывают язык, и о том, как мы можем научить компьютеры делать то же самое.
Неверная интерпретация, на которой держится история s’mores, скрывается в скромном предлоге с . Представьте, как можно закончить это предложение:
Я съем этот зефир с…
объект предлога с . Но если вы хотите разделить зефир с другом, вы можете сказать, что собираетесь съесть его «с моим приятелем Чарли». Если вы только неохотно едите этот зефир, вы можете сказать, что собираетесь есть его «с большой неохотой». Или вы можете сказать «моими руками» (или «моим ртом», как молодой Себастьян), если вы сосредоточены на способе еды.
Если вы только неохотно едите этот зефир, вы можете сказать, что собираетесь есть его «с большой неохотой». Или вы можете сказать «моими руками» (или «моим ртом», как молодой Себастьян), если вы сосредоточены на способе еды.
Каким-то образом носители английского языка осваивают эти многочисленные варианты использования слова с , и никто специально не разъясняет это для них. По крайней мере, так обстоит дело с носителями языка — на уроках английского как иностранного учитель, скорее всего, разберет эти нюансы. Но что, если вы хотите предоставить такое же лингвистическое образование машине?
Случилось так, что всего через несколько дней после того, как Миранда отправила свой твит, специалисты по вычислительной лингвистике представили доклад на конференции, в котором подробно исследуется, почему такой неоднозначный язык является сложной задачей для компьютерной системы. Исследователи сделали это с помощью онлайн-игры, которая служит удобным введением в интересную работу, проводимую в настоящее время в области обработки естественного языка (NLP).
Игра под названием Madly Ambiguous была разработана лингвистом Майклом Уайтом и его коллегами из Университета штата Огайо. В нем вам дается задание: поставить в тупик бота по имени Мистер Компьютерный Голова, заполнив пропуск в предложении Джейн съела спагетти с ____________ . Затем компьютер пытается определить, какой тип с вы имели в виду. Игривые изображения доводят до конца суть. В предложении Джейн ела спагетти вилкой , мистер Компьютерный руководитель должен быть в состоянии понять, что вилка — это посуда, а не что-то, что едят в дополнение к спагетти.
Айда ГёкченАналогично, если предложение Джейн ела спагетти с фрикадельками , должно быть очевидно, что фрикадельки являются частью блюда, а не инструментом для поедания спагетти.
Ajda Gokcen В дополнение к этим двум возможностям, существительное (или словосочетание), следующее за и , может также указывать способ ( Джейн ела спагетти с удовольствием ) или компанию ( Джейн ела спагетти с Мэри ).
Мистер Компьютерный Голова пытается провести различие между этими потенциальными семантическими ролями двумя способами. В базовом режиме программа использует подход, основанный на правилах, который традиционно использовался в НЛП, сначала обнуляя главное существительное, а затем просматривая его в семантической базе данных под названием WordNet. Если существительное классифицируется как артефакт, то компьютер предполагает, что роль инструментальная (например, 9).0003 вилка ). Если это вид еды, то предполагается роль части блюда (например, фрикадельки ). Если существительное кажется своего рода чувством, то оно соответствует роли манеры (например, gusto ). Если это что-то еще, мистер Компьютерный Голова предполагает, что это существительное относится к компании, которую Джейн составляет, пока ест спагетти.
В расширенном режиме Mr. Computer Head использует более передовую технику НЛП, известную как встраивание слов. В этом подходе слова и фразы отображаются в геометрическом пространстве, известном как векторное пространство, которое фиксирует степени сходства между различными словами в корпусе (большой коллекции текстов). Подобные слова кажутся ближе друг к другу в векторном пространстве. Мистер Голова Компьютера сопоставляет слова во входной фразе с группами слов, соответствующими различным возможным интерпретациям — скажем, комбинация инструментов, группа манер и так далее.
Подобные слова кажутся ближе друг к другу в векторном пространстве. Мистер Голова Компьютера сопоставляет слова во входной фразе с группами слов, соответствующими различным возможным интерпретациям — скажем, комбинация инструментов, группа манер и так далее.
Уайт представил результаты исследования команды Madly Ambiguous на ежегодной конференции Североамериканского отделения Ассоциации вычислительной лингвистики: технологии человеческого языка. Они обнаружили, что как базовый, так и расширенный подходы работают довольно хорошо, несмотря на то, что пользователи пытаются поставить систему в тупик. С тех пор как игра была запущена около года назад, Mr. Computer Head совпадал с оценками пользователей в 64 процентах случаев в базовом режиме и в 70 процентах случаев в расширенном режиме. Если вы введете, например, «этот крекер Грэма и шоколад», оба режима правильно распознают, что эта фраза должна быть частью блюда, а не каким-то способом еды, как, кажется, думал Себастьян в истории о s’mores.
Компьютерная система никогда не может быть идеальной, поскольку некоторые неясности не могут быть устранены с помощью какого-либо формального анализа. В предложении Джейн ела спагетти с удовольствием , относится ли удовольствие к приправе или к восторженному удовольствию? Интерпретация удовольствия может иметь больше смысла, если вы знаете из реального мира, что релиш не является типичной приправой для спагетти. Но если бы предложение было Джейн съела хот-дог с удовольствием , двусмысленность была бы еще более явной.
По правде говоря, люди все время садятся на мель из-за двусмысленных выражений. Взгляните на заголовок Associated Press: «Верховный суд вынес узкое решение в отношении пекаря из Колорадо, который не готовил однополый свадебный торт». Когда Дональд Трамп-младший столкнулся с этим предложением в Твиттере, он неверно истолковал слово как узкое . «Я читаю о голосовании 7–2. Уверен, что не узко», — написал он в Твиттере. Если бы он удосужился прочитать дальше заголовка, то узнал бы, что решение было принято на узких основаниях, хотя само голосование не было узким.
Если бы он удосужился прочитать дальше заголовка, то узнал бы, что решение было принято на узких основаниях, хотя само голосование не было узким.
Контекст действительно является ключом к разрешению большей части лингвистической двусмысленности, и Себастьян Миранда постепенно усвоит этот урок. Он также узнает, что «есть что-то ртом» — это не то, что люди обычно указывают. (Если бы г-н Компьютерный Голова искал такое употребление в корпусе, оно, вероятно, было бы найдено только в определенных выражениях, таких как риторический вопрос после того, как кто-то сказал что-то непристойное: «Вы едите этим ртом?»)
Для вычислительных систем, чтобы лучше справляться с проблемами двусмысленности языка, исследователи НЛП должны будут вооружить их теми же типами контекстуального мышления, которые развивает молодой Себастьян.
API — Как я могу получить содержание слов из Викисловаря?
Как API Викисловаря можно использовать для определения того, существует ли слово?
- API
- Словарь
- mediawiki-api
- Викисловарь
3
API Викисловаря можно использовать для запроса о том, существует ли слово.
Примеры существующих и несуществующих страниц:
http://en.wiktionary.org/w/api.php?action=query&titles=testhttp://en.wiktionary.org/w/api.php?action=query&titles=testx
Первая ссылка содержит примеры других типов форматов, которые могут быть проще для анализа.
Чтобы получить данные о слове в небольшом формате XHTML (если требуется больше, чем существует), запросите версию страницы для печати:
http://en.wiktionary.org/w/index.php?title=test&printable=yeshttp://en.wiktionary.org/w/index.php?title=testx&printable=yes
Затем их можно проанализировать с помощью любого стандартного анализатора XML.
9
Есть несколько предостережений, связанных с простой проверкой того, что в Викисловаре есть страница с искомым именем:
Предостережение №1 : Все Викисловари, включая английский Викисловарь, на самом деле имеют целью включить каждое слово на каждом языке, поэтому если вы просто используете вышеуказанный вызов API, вы будете знать, что слово, о котором вы спрашиваете, является словом по крайней мере на одном языке, но не обязательно на английском: http://en. wiktionary.org/w/api.php?action=query&titles =дикаре
wiktionary.org/w/api.php?action=query&titles =дикаре
Предостережение № 2 : Возможно существует перенаправление с одного слова на другое. Это может быть из-за альтернативного написания, но может быть и из-за какой-то ошибки. Приведенный выше вызов API не различает перенаправление и статью: http://en.wiktionary.org/w/api.php?action=query&titles=profilemetry
Предостережение №3 : Некоторые Викисловари, включая английский Викисловарь, включают «распространенные орфографические ошибки»: http://en.wiktionary.org/w/api.php?action=query&titles=fourty
Предостережение № 4 : Некоторые Викисловари допускают записи-заглушки, в которых мало или совсем нет информации о термине. Раньше это было обычным явлением в нескольких Викисловарях, но не в английском Викисловаре. Но, похоже, теперь он распространился и на английский Викисловарь: https://en.wiktionary.org/wiki/%E6%99%B6%E7%90%83 (постоянная ссылка, когда заглушка заполнена, чтобы вы все еще могли видеть как выглядит заглушка: https://en. wiktionary.org/w/index.php?title=%E6%99%B6%E7%90%83&oldid=39757161)
wiktionary.org/w/index.php?title=%E6%99%B6%E7%90%83&oldid=39757161)
Если они не включены в то, что вы хотите , вам придется загружать и анализировать сам викитекст, что является нетривиальной задачей. 9[:space:][:punct:]]*‘ | sed ‘s:.*
3
Если вы используете Python, вы можете использовать WiktionaryParser от Suyash Behera.
Вы можете установить его с помощью
sudo pip install wiktionaryparser
Пример использования:
>>> from wiktionaryparser import WiktionaryParser
>>> парсер = WiktionaryParser()
>>> слово = parser.fetch('тест')
>>> другое_слово = parser.fetch('тест', 'французский')
>>> parser.set_default_language('французский')
Вы можете использовать ревизии API:
https://en.wiktionary.org/w/api.php?action=query&prop=revisions&titles=test&rvslots=*&rvprop=content&formatversion=2
Или разбор API:
https://en. wiktionary.org/w/api.php?action=parse&page=test&prop=wikitext&formatversion=2
wiktionary.org/w/api.php?action=parse&page=test&prop=wikitext&formatversion=2
Дополнительные примеры приведены в документации.
1
Как упоминалось ранее, проблема с этим подходом заключается в том, что Викисловарь предоставляет информацию обо всех словах всех языков . Таким образом, подход к проверке существования страницы с использованием API Википедии не будет работать, потому что существует много страниц для неанглийских слов. Чтобы преодолеть это, вам нужно проанализировать каждую страницу, чтобы выяснить, есть ли раздел, описывающий английское слово . Разобрать викитекст — задача нетривиальная, хотя в вашем случае не так уж и плохо. Чтобы охватить почти все случаи, вам нужно просто проверить, содержит ли викитекст Английский заголовок . В зависимости от языка программирования, который вы используете, вы можете найти некоторые инструменты для создания AST из викитекста. Это будет охватывать большинство случаев, но не все из них, потому что Викисловарь содержит некоторые распространенные орфографические ошибки.
Это будет охватывать большинство случаев, но не все из них, потому что Викисловарь содержит некоторые распространенные орфографические ошибки.
В качестве альтернативы вы можете попробовать использовать Lingua Robot или что-то подобное. Lingua Robot анализирует содержимое Викисловаря и предоставляет его в виде REST API. Непустой ответ означает, что слово существует. Обратите внимание, что, в отличие от Викисловаря, сам API не содержит ошибок (по крайней мере, на момент написания этого ответа). Также обратите внимание, что Викисловарь содержит не только слова, но и многословные выражения. 9\/\|]+)\/?\|lang=ru}}/, (_, $1) => {
значение = $1
тип = ‘га’
})
// {{a|GA}} {{IPA|/ˈhæpi/|lang=en}}
// * {{a|RP}} {{IPA|/pliːz/|lang=en}}
// * {{a|GA}} {{enPR|plēz}}, {{IPA|/pliz/|[pʰliz]|lang=en}}
если (!вал)
возвращаться
вернуть {значение, тип}
}
функция parseEtymologyPiece(piece) {
пусть части = piece.split(‘|’)
parts.shift() // Первый игнорируется.
пусть лс = []
если (языки [части [0]]) {
ls. push(parts.shift())
}
если (языки [части [0]]) {
ls.push(parts.shift())
}
пусть l = ls.pop()
пусть t = parts.shift()
вернуть [л, т]
// {{inh|en|enm|poisoun}}
// {{m|enm|poyson}}
// {{der|en|la|pōtio|pōtio, pōtiōnis|t=напиток, глоток, ядовитый глоток, зелье}}
// {{m|la|pōtō|t=я пью}}
// {{der|en|enm|счастливый||удачный, счастливый}}
// {{cog|это|heppinn||повезло}}
}
push(parts.shift())
}
если (языки [части [0]]) {
ls.push(parts.shift())
}
пусть l = ls.pop()
пусть t = parts.shift()
вернуть [л, т]
// {{inh|en|enm|poisoun}}
// {{m|enm|poyson}}
// {{der|en|la|pōtio|pōtio, pōtiōnis|t=напиток, глоток, ядовитый глоток, зелье}}
// {{m|la|pōtō|t=я пью}}
// {{der|en|enm|счастливый||удачный, счастливый}}
// {{cog|это|heppinn||повезло}}
}
Вот более конкретизированная суть.
2
Твой ответ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Обработка естественного языка — разбор текста
Введение
Введение
Обработка естественного языка (NLP) приобрела большую популярность как подобласть искусственного интеллекта. Он направлен на то, чтобы компьютеры могли понимать и обрабатывать человеческие языки. Некоторые распространенные приложения включают чат-ботов, анализ настроений, перевод, классификацию спама и многие другие.
Он направлен на то, чтобы компьютеры могли понимать и обрабатывать человеческие языки. Некоторые распространенные приложения включают чат-ботов, анализ настроений, перевод, классификацию спама и многие другие.
Однако существует значительная разница между НЛП и традиционными задачами машинного обучения: первые имеют дело с неструктурированными текстовыми данными, а вторые — со структурированными табличными данными. Следовательно, необходимо понять, как работать с текстом, прежде чем применять к нему методы машинного обучения. Здесь на помощь приходит разбор текста.
Итак, что такое разбор текста? Проще говоря, это обычная задача программирования, которая разделяет данную последовательность текста на более мелкие компоненты на основе некоторых правил. Его применение варьируется от анализа документов до глубокого обучения НЛП.
В этом руководстве мы будем применять богатые функциональные возможности, доступные в Python, для анализа текста. Двумя популярными вариантами являются регулярные выражения и токенизация слов.
Регулярные выражения
Регулярные выражения или регулярные выражения — это строки со специальным синтаксисом, которые позволяют нам сопоставлять шаблоны в других строках. В питоне есть модуль под названием re для работы с регулярными выражениями. Некоторые из распространенных шаблонов регулярных выражений и их использование показаны ниже:
‘\d’: соответствует любой десятичной цифре; например, 5. Вариантом этого является ‘\D’, который соответствует любому нецифровому символу.
‘\s’: соответствует любому пробелу; Например, ». Вариантом этого является ‘\S’, который соответствует любому непробельному символу.
‘\w’: соответствует любому буквенно-цифровому символу; например, «Плюралсайт». Вариантом этого является ‘\W’, который соответствует любому небуквенно-цифровому символу.
‘+ или *’: выполняет жадное сопоставление. Например, «ееееее».
‘a-z’: соответствует группам в нижнем регистре.
‘A-Za-z’: соответствует верхнему и нижнему регистру английского алфавита.
‘0-9’: соответствует числам от 0 до 9.

Вот некоторые из многих доступных шаблонов регулярных выражений. Мы лучше поймем регулярное выражение в последующих разделах этого руководства с помощью примеров. Мы начнем с импорта относительно модуля , который выполняется в первой строке кода ниже. Нам также понадобится текстовый объект или корпус, для которого мы используем краткое описание популярного фильма «Мстители». Мы храним этот текст в корпусе ‘regex_example’. Делается это в второй строке кода .
1импорт 2regex_example = «Мстители: Война Бесконечности» — американский фильм о супергероях 2018 года, основанный на супергеройской команде Marvel Comics «Мстители». Это 19-й фильм в Кинематографической вселенной Marvel (MCU). Продолжительность фильма составила 149 секунд.минут, а кассовые сборы составили около 2 миллиардов долларов.
 (Источник: Википедия)"
3print(regex_example)
(Источник: Википедия)"
3print(regex_example) питон
Вывод: «Мстители: Война бесконечности» — американский супергеройский фильм 2018 года, основанный на супергеройской команде Marvel Comics Мстители. Это 19-й фильм в кинематографической вселенной Marvel (MCU). Продолжительность фильма составила 149 минут, а кассовые сборы составили около 2 миллиардов долларов. (Источник: Википедия)
Общие методы регулярных выражений Python
re.findall()
Метод re.findall() возвращает все шаблоны в строке. В случае несоответствия возвращается пустой список.
Первая строка кода ниже извлекает числа из текста ‘regex_example’, который мы создали ранее.
Теперь поработаем со словами и попробуем найти количество гласных в тексте. Эту задачу выполняют вторая и третья строки кода. В тексте 87 вхождений гласных.
Предположим, вы хотите найти, сколько раз слово «Мстители» использовалось в корпусе. Это достигается за счет четвертая строка кода и ответ 2.
Это достигается за счет четвертая строка кода и ответ 2.
Мы также можем найти все слова с заглавной буквы и вывести результат, что делается в пятой и шестой строках кода. Вывод содержит только заглавные слова корпуса.
1print(re.findall('\d+', regex_example)) #line1
2
3vowels = re.findall('[aeiou]', regex_example) #line2
4print(len(гласные)) #строка 3
5
6print(len(re.findall('Мстители', regex_example))) #строка 4
7
8capitalwords = "[A-Z]\w+" #строка 5
9print(re.findall(capitalwords, regex_example)) #line 6 python
Вывод:
1['2018', '19', '149', '2'] 287 32 4[«Мстители», «Бесконечность», «Война», «Американка», «Марвел», «Комиксы», «Мстители», «Оно», «Марвел», «Кинотеатр», «Вселенная», «КВМ», 'The', 'Source', 'Wikipedia']
re.split()
Другим полезным методом является re.split(), который разбивает строку в случае совпадения. В случае отсутствия совпадения он возвращает список, содержащий пустую строку.
В нашем примере давайте применим этот метод и разделим корпус с помощью шаблона чисел. Фрагмент кода ниже выполняет эту задачу и печатает вывод.
1print(re.split(r"\d+", regex_example))
python
Результат:
1'Мстители: Война Бесконечности. Мстители. Это 1-й фильм в кинематографической вселенной Marvel (MCU). Продолжительность фильма составила ',' минут, а кассовые сборы составили около ',' миллиардов долларов. (Источник: Википедия)'
Приведенный выше вывод показывает, что разделение было выполнено по цифрам. В метод re.split() можно добавить аргумент «maxsplit», который указывает максимальное количество возможных разделений. Значение по умолчанию равно нулю. В приведенном ниже коде значение maxsplit равно 2, и метод разделяет только первую пару вхождений цифр.
1print(re.split(r"\d+", regex_example,2))
python
Вывод:
1'Мстители: Война Бесконечности' — американский фильм о супергероях, основанный на комиксах Marvel.
 команда Мстителей. Это 1-й фильм в кинематографической вселенной Marvel (MCU). Продолжительность фильма 149минут, а кассовые сборы составили около 2 миллиардов долларов. (Источник: Википедия)'
команда Мстителей. Это 1-й фильм в кинематографической вселенной Marvel (MCU). Продолжительность фильма 149минут, а кассовые сборы составили около 2 миллиардов долларов. (Источник: Википедия)' Другим применением может быть разделение корпуса на пробелы. Это достигается с помощью приведенного ниже кода.
1print(re.split(r"\s+", regex_example))
python
Вывод: ‘Мстители:’, ‘Бесконечность’, ‘Война’, ‘было’, ‘а’, ‘2018’, ‘американец’, ‘супергерой’, ‘фильм’, ‘по мотивам’, ‘на’, ‘на’, ‘ Marvel», «Комиксы», «супергерой», «команда», «то», «Мстители», «Оно», «это», «19», «фильм», «в», «то». ‘, ‘Marvel’, ‘Кинематографический’, ‘Вселенная’, ‘(MCU)’, », ‘работа’, ‘время’, ‘из’, ‘то’, ‘фильм’, ‘было’, ‘ 149’, ‘минуты’, ‘и’, ‘тот’, ‘ящик’, ‘офис’, ‘коллекция’, ‘было’, ‘около’, ‘2’, ‘миллиард’, ‘долларов’, ‘(Источник :’, ‘Википедия)’
re.sub()
Этот метод используется для замены совпавшего текста содержимым переменной replace. Если шаблон не найден, возвращается исходная строка.
Если шаблон не найден, возвращается исходная строка.
В нашем примере заменим слово «Мстители» на «А». Фрагмент кода ниже выполняет эту задачу.
1print(re.sub("Мстители", "A", regex_example)) python
Продукт:
1A: Infinity War) — американский фильм о супергероях 2018 года, основанный на комиксах Marvel о команде супергероев A. Это 19-й фильм в Кинематографической вселенной Marvel (MCU). Продолжительность фильма составила 149 минут, а кассовые сборы составили около 2 миллиардов долларов. (Источник: Википедия)
re.search()
Этот метод используется для поиска шаблона в строке и возврата объекта соответствия в случае успеха. Если поиск не удался, возвращается None.
Давайте разберемся с этим в приведенном ниже примере, где мы попытаемся найти, находится ли слово «Python» в начале предложения «Scikit Learn — отличная библиотека Python». В нашем примере, поскольку поиск не удался, вывод «Нет».
1example = "Scikit Learn — отличная библиотека Python"
2match = re.search('\APython', пример)
3print(match) питон
Вывод: Нет
Регулярные выражения — это огромная область, и невозможно охватить ее все в одном руководстве. Тем не менее, у нас есть общее представление о наиболее часто используемых методах регулярных выражений и их работе в Python, что будет полезно в большинстве случаев. Давайте теперь обратимся к другому важному методу разбора текста под названием 9.0003 токенизация слов .
Токенизация слов
Токенизация — это процесс преобразования текста или корпуса в токены (более мелкие фрагменты). Конвертация в токены осуществляется по определенным правилам. Используя регулярное выражение, также можно создавать собственные правила. Токенизация помогает в задачах предварительной обработки текста, таких как сопоставление частей речи, поиск и сопоставление общих слов, очистка текста и подготовка данных для передовых методов анализа текста, таких как анализ тональности.
Python имеет очень популярную библиотеку инструментов естественного языка, называемую «nltk», которая имеет богатый набор функций для выполнения многих задач НЛП. Его можно скачать через pip, а также он входит в дистрибутив Anaconda.
Мы будем работать над распространенными приложениями токенизации слов с помощью nltk. Для начала нам нужно импортировать библиотеку nltk. Затем мы импортируем функции sent_tokenize и word_tokenize. Это делается в коде ниже.
1# Импорт необходимых модулей 2импорт нлтк 3из импорта nltk.tokenize send_tokenize, word_tokenize
python
Теперь мы получим текст. Мы будем использовать следующий текст для наших примеров:
1textdata = «Pluralsight — это платформа технологических навыков. Она предлагает более 6000 курсов и более 1100 сотрудников. Штаб-квартира Pluralsight находится в Юте, и более 1500 экспертов разрабатывают высококачественные курсы. Pluralsight выросла на 161 процент в период с 2014 по 2017 год, что принесло компании место в списке Deloitte Technology Fast 500 в течение пяти лет подряд».
 2print(текстовые данные)
2print(текстовые данные) python
Вывод:
1Pluralsight — это платформа технологических навыков. В нем более 6000 курсов и более 1100 сотрудников. Pluralsight со штаб-квартирой в штате Юта насчитывает более 1500 экспертов, разрабатывающих высококачественные курсы. Pluralsight выросла на 161 процент в период с 2014 по 2017 год, что принесло компании место в списке Deloitte Technology Fast 500 в течение пяти лет подряд.
Теперь мы будем выполнять задачи токенизации слов для этих текстовых данных. Наиболее распространенными формами токенизации являются слова и предложения.
Первый код ниже разбивает текст на слова и печатает вывод. Второй код также выполняет токенизацию, но на этот раз это делается для предложений.
1print(word_tokenize(textdata))
python
Вывод:
1'Pluralsight', 'есть', 'то', 'технология', 'навыки', 'платформа', '.', ' Это», «имеет», «больше», «чем», «6000», «курсы», «и», «1100+», «сотрудники», «.
 », «Pluralsight», «есть», «штаб-квартира ', 'в', 'Юта', 'и', 'имеет', 'более', '1500', 'эксперты', 'авторство', 'высокое', 'качество', 'курсы', '.', «Pluralsight», «вырос», «161», «процент», «между», «2014», «и», «2017», «,», «прибыль», «компания», «а». ', 'место', 'в', 'то', 'Делойт', 'Технологии', 'Быстро', '500', 'список', 'за', 'пять', 'последовательно', 'лет', '.'
», «Pluralsight», «есть», «штаб-квартира ', 'в', 'Юта', 'и', 'имеет', 'более', '1500', 'эксперты', 'авторство', 'высокое', 'качество', 'курсы', '.', «Pluralsight», «вырос», «161», «процент», «между», «2014», «и», «2017», «,», «прибыль», «компания», «а». ', 'место', 'в', 'то', 'Делойт', 'Технологии', 'Быстро', '500', 'список', 'за', 'пять', 'последовательно', 'лет', '.' 1print(sent_tokenize(textdata))
python
Вывод:
‘Pluralsight — это платформа технологических навыков.’, ‘У нее более 6000 курсов и более 1100 сотрудников.’, ‘Pluralsight находится в штаб-квартире Utah. и имеет более 1500 экспертов, разрабатывающих высококачественные курсы». «Pluralsight выросла на 161 процент в период с 2014 по 2017 год, что принесло компании место в списке Deloitte Technology Fast 500 в течение пяти лет подряд».
Важно понимать разницу между двумя функциями «word_tokenize» и «sent_tokenize». В приведенных выше выходных данных мы видели, что обе функции создают разные выходные данные (токены) для одних и тех же входных данных (текстовых данных) из-за различий в их функциях.
Теперь мы рассмотрим уникальные токены, сгенерированные обоими методами в двух строках кода ниже. В первом выводе ниже термин «Pluralsight» появляется только один раз, так как это токен на уровне слова. Однако во втором выводе термин появляется много раз, потому что токенизация произошла на уровне предложения.
1print(set(word_tokenize(textdata)))
python
Вывод:
1{'технология', 'штаб-квартира', '.', 'качество', '161', 'пять', ' 2017», «Оно», «место», «свыше», «технология», «навыки», «процент», «лет», «500», «платформа», «последовательно», «имеет», «1500» , «заработок», «,», «the», «Deloitte», «1100+», «вырос», «6000», «в», «между», «чем», «курсы», «Pluralsight», '2014', 'авторство', 'Юта', 'а', 'список', 'есть', 'и', 'быстро', 'еще', 'для', 'эксперты', 'высокий', 'сотрудники ', 'компания'} 1print(set(sent_tokenize(textdata)))
python
Вывод:
1{'Pluralsight вырос на 161 процент в период с 2014 по 2017 год, пять раз подряд зарабатывая место в списке Deloitte Technology Fast 500 лет. », «Pluralsight — это платформа технологических навыков», «У нее более 6000 курсов и более 1100 сотрудников», «Штаб-квартира Pluralsight находится в Юте, и более 1500 экспертов разрабатывают высококачественные курсы».}  », «Pluralsight — это платформа технологических навыков», «У нее более 6000 курсов и более 1100 сотрудников», «Штаб-квартира Pluralsight находится в Юте, и более 1500 экспертов разрабатывают высококачественные курсы».}
», «Pluralsight — это платформа технологических навыков», «У нее более 6000 курсов и более 1100 сотрудников», «Штаб-квартира Pluralsight находится в Юте, и более 1500 экспертов разрабатывают высококачественные курсы».} Давайте посчитаем количество уникальных токенов, сгенерированных с использованием обеих функций, «word_tokenize» и «sent_tokenize», что делается в две строки кода ниже. Существует 45 уникальных токенов «слов», в то время как уникальных токенов «предложений» всего 4.
1print(len(set(word_tokenize(textdata)))) 2print(len(set(sent_tokenize(textdata))))
python
Вывод:
145 24
У нас есть четкое представление о токенизации. Теперь мы добавим некоторую визуализацию для токенизации с помощью мощной библиотеки Python, matplotlib. первая строка кода импортирует библиотеку matplotlib, а вторая строка создает токены слов и сохраняет их в объекте ‘t’. Третья строка вычисляет количество вхождений каждого слова в корпус. Четвертая и пятая строки кода отображают гистограмму. Мы видим, что есть много слов, которые повторяются довольно много раз.
Четвертая и пятая строки кода отображают гистограмму. Мы видим, что есть много слов, которые повторяются довольно много раз.
1 # Сочетание извлечения данных НЛП с построением графика 2из matplotlib импортировать pyplot как plt #line 1 3t = word_tokenize (текстовые данные) 4wordlen = [len(w) для w в t] 5plt.hist(слово) 6plt.show()
питон
Вывод:
Заключение
В этом руководстве мы прошли долгий путь от понимания основных регулярных выражений до токенизации слов и предложений. Мы узнали, как использовать две мощные библиотеки Python, re и nltk , используя интересные текстовые примеры. Мы также научились создавать визуализации токенов слов с помощью nltk и matplotlib.
Как Regex, так и NLTK могут играть жизненно важную роль на этапе предварительной обработки текста. Тем не менее, область применения этих методов слишком велика, чтобы охватить ее в одном руководстве, которое должно стать хорошим строительным блоком для тех, кто хочет начать работать с задачами обработки естественного языка с помощью встроенных библиотек Python. 9Определение 0005
9Определение 0005
в кембриджском словаре английского языка
Примеры разбора
разбора
Мы будем разбирать это некоторое время.
Из хроники Сан-Франциско
Но отношение эукариот к другим группам было трудно разобрать .
Из Арс Техника
Это действительно добросовестное (так сказать) усилие разбор этого спора.
Из Чикаго Трибьюн
Но операционные группы центров обработки данных не имеют возможности анализировать все это.
Из Арс Техника
Этот документ анализируется людьми, извлекается людьми, и они оценивают его.
От местного канала CBS
Как будто после разбора нет никакой надежды на дальнейшее понимание.
Из Лос-Анджелес Таймс
Слова и образы анализируются, протестуют и часто извиняются.
Из Лос-Анджелес Таймс
Судите сами по этим комментариям и разобрать слова, если хотите, но «извинение» кажется подходящей их характеристикой.
Из Вашингтон Пост
Когда промышленность и даже правительство анализируют статистику , чтобы отбросить региональные аварии со смертельным исходом, члены семей жертв приходят в ярость по понятным причинам.
От ВРЕМЕНИ
Но давайте разберем эту награду чуть более тщательно.
С холма
Когда вы пытаетесь разобрать сложных варианта, однако вам часто дается всего несколько секунд, и кажется, что время мгновенно испаряется.
Из проводного
Parse в настоящее время имеет более 60 000 приложений и примерно столько же разработчиков.
От TechCrunch
Что мы собираемся сделать здесь, так это разобрать из этого сложного набора отношений, используя информацию, которая у нас есть.
Из Вашингтон Пост
Parse еще очень молод, но он явно нашел свое место в мире.
Из проводного
Ученые разбирают его гневный и часто жестокий язык.
От OregonLive.com
Эти примеры взяты из корпусов и источников в Интернете. Любые мнения в примерах не отражают мнение редакторов Кембриджского словаря, издательства Кембриджского университета или его лицензиаров.
Переводы parse
на китайский (традиционный)
對(句子)作文法分析…
Подробнее
на китайском (упрощенном)
对(句子)作语法分析…
Узнать больше
Нужен переводчик?
Получите быстрый бесплатный перевод!
Как произносится 9?0003 разобрать ?
Обзор
попугай
парировать
парирование
парс
разбор
парсек БЕТА
проанализировано
парсер БЕТА
Парси
Проверьте свой словарный запас с помощью наших веселых викторин по картинкам
- {{randomImageQuizHook. copyright1}}
- {{randomImageQuizHook.copyright2}}
 copyright1}}
copyright1}}Авторы изображений
Попробуйте пройти викторину
Слово дня
попугай
тропическая птица с изогнутым клювом, которую часто держат в качестве домашнего питомца и обучают копировать человеческий голос
Об этом
Блог
Нестандартное мышление: говорим о творчестве.
Подробнее
New Words
микромобильность
В список 9 добавлены новые слова
0005
Наверх
Содержание
EnglishExamplesTranslations
Что означает слово разбор?
Вопрос задан: Ода Джаст
Оценка: 4,1/5 (45 голосов)
Частота: Анализ определяется как разбиение чего-либо на части, особенно для изучения отдельных частей. Примером разбора является разбивка предложения, чтобы объяснить кому-то каждый элемент. … Синтаксический анализ разбивает слова на функциональные единицы, которые можно преобразовать в машинный язык .
Примером разбора является разбивка предложения, чтобы объяснить кому-то каждый элемент. … Синтаксический анализ разбивает слова на функциональные единицы, которые можно преобразовать в машинный язык .
Что значит синтаксический анализ на английском языке?
Синтаксический разбор — это грамматическое упражнение, включающее разбиение текста на составные части речи с объяснением формы, функции и синтаксических отношений каждой части , чтобы текст можно было понять. Термин «разбор» происходит от латинского pars, означающего «часть (речи)».
Что означает разбор в Библии?
Разбор включает разбиение слова на составные грамматические части . При работе с ивритом это очень важно, поскольку одно слово на иврите может содержать множество элементов, которые могут соответствовать ряду слов в английском языке.
Что означает синтаксический анализ имени?
Разбор имени — это процесс разделения строки имени на компоненты .
Что является синонимом для разбора?
Синонимы и близкие синонимы для разбора. анализировать, препарировать .
Что такое синтаксический анализ? Объяснение синтаксического анализа, определение синтаксического анализа, значение синтаксического анализа
Найдено 44 связанных вопроса
Что противоположно синтаксическому анализу?
В терминологии компилятора противоположным является « unparse» . В частности, разбор превращает поток токенов в абстрактные синтаксические деревья, а разбор превращает абстрактные синтаксические деревья в поток токенов.
Что такое пример разбора?
Анализ определяется как разбиение чего-либо на части, особенно для изучения отдельных частей. Примером разбора является , чтобы разбить предложение, чтобы объяснить кому-то каждый элемент . … Синтаксический анализ разбивает слова на функциональные единицы, которые можно преобразовать в машинный язык.
Что означает синтаксический анализ в кодировании?
Разбор — это разбиение предложения или группы слов на отдельные компоненты , включая определение функции или формы каждой части. … Парсинг используется во всех языках программирования высокого уровня. Такие языки, как C++ и Java, анализируются соответствующими компиляторами перед преобразованием в исполняемый машинный код.
Что значит разобрать файл?
Разбор по существу означает «разложить (предложение) на его составные части и описать их синтаксические роли» . В вычислительной технике синтаксический анализ — это «действие синтаксического анализа строки или текста». [Google Dictionary]Синтаксический анализ файлов на компьютерном языке означает придание значения символам текстового файла в соответствии с формальной грамматикой.
[Google Dictionary]Синтаксический анализ файлов на компьютерном языке означает придание значения символам текстового файла в соответствии с формальной грамматикой.
Что такое разбор по-гречески?
Разбор. Разобрать греческий глагол означает идентифицировать эти пять качеств – Person, Number, Tense, Mood, Voice – для любой заданной формы глагола. Например, конкретная форма глагола может быть: Третье лицо. Единственное число.
Что означает синтаксический анализ пакета?
Проблема при синтаксическом анализе пакета представляет собой ошибку типа , которая в основном возникает на смартфонах Android, и мы можем легко ее решить. «Проблема с анализом пакета» является частью мобильной безопасности. Потому что он защищает ваш мобильный телефон от незарегистрированного мобильного приложения и загрузки его из неизвестных источников.
Что означает синтаксический анализ в wow?
Анализ — это показатель вашего DPS в конкретном бою (или в ходе рейда) по сравнению со всеми журналами, которые были загружены на веб-сайт для этого конкретного боя или рейда, и представлены в двух формах: исторический или текущий.
Как вы используете слово анализ?
Пример предложения синтаксического анализа
- Это не означает, что не важно правильно форматировать файл, чтобы читатели каналов могли анализировать содержимое. …
- Благодаря своим способностям анализировать и переводить языки она сыграла ключевую роль в разработке галактического переводчика. …
- Затем он мог проанализировать их, чтобы извлечь необходимую информацию.
Что значит синтаксический анализ на латыни?
Термин синтаксический анализ происходит от латинского pars (orationis), означает часть (речи) . Термин «разбор» происходит от латинского pars, означающего «часть (речи)».
Что такое синтаксический анализ текста?
Разбор текста — это общая задача программирования, которая разбивает заданную последовательность символов или значений (текст) на более мелкие части на основе некоторых правил . Он использовался в самых разных приложениях, начиная от простого разбора файлов и заканчивая крупномасштабной обработкой естественного языка.
Что такое синтаксический анализ простыми словами?
Разбор, синтаксический анализ или синтаксический анализ — это процесс анализа строки символов либо на естественном языке, либо на компьютерных языках, либо в структурах данных, в соответствии с правилами формальной грамматики. Термин синтаксический анализ происходит от латинского pars (orationis), что означает часть (речи).
Какова цель синтаксического анализа?
Разбор — это процесс анализа текста, состоящего из последовательности токенов, для определения его грамматической структуры по отношению к данной (более или менее) формальной грамматике . Затем синтаксический анализатор строит структуру данных на основе токенов.
Зачем нужен парсинг?
По сути, синтаксический анализ необходим , потому что разным объектам нужны данные в разных формах . Синтаксический анализ позволяет преобразовывать данные таким образом, чтобы их могло понять конкретное программное обеспечение. Очевидным примером являются программы — они написаны людьми, но должны выполняться компьютерами.
Очевидным примером являются программы — они написаны людьми, но должны выполняться компьютерами.
Как вы используете синтаксический разбор в предложении?
Пример предложения синтаксического анализа
- В действии принятия синтаксический анализатор объявляет об успешном завершении синтаксического анализа. …
- Поэт получает огромное удовольствие, собирая воедино кажущиеся несопоставимыми слова и вызывая разрозненное целое, смягчающее кажущееся несоответствием.
Что такое синтаксический анализ и типы синтаксического анализа?
Parser — это компилятор, который используется для разбиения данных на более мелкие элементы, полученные на этапе лексического анализа. Синтаксический анализатор принимает входные данные в виде последовательности токенов и выдает выходные данные в виде дерева синтаксического анализа. Парсинг бывает двух видов: анализ сверху вниз и анализ снизу вверх .
Как еще называется разбор McQ?
Объяснение: Также известен как синтаксический анализатор сдвига и уменьшения .
Какой синоним слова нахмурился?
глагол. 1’она вызывающе на него нахмурилась’ сердитый взгляд , хмуриться, сверлить взглядом, сердито смотреть на кого-то, сердито смотреть на кого-то, бросать на кого-то черный взгляд. сделать гримасу, скривиться, опустить уголки рта, надуться.
Какой синоним к слову преобладал?
Надеюсь, им удастся договориться. Синонимы. триумф , победа, победа.
Похожие вопросы
- 15Что такое синтаксический анализ в программировании?
- 28Почему используется синтаксический анализ?
- 19Выполняется ли проверка типов перед синтаксическим анализом?
- 18В чем смысл синтаксического анализа?
- 37Вы имеете в виду разбор?
- 31Для синтаксического анализа приоритета оператора, какой из них верен?
- 30Разбор языка?
- 19Почему нажимать хорошо?
- 27Когда используется синтаксический анализ?
Реклама
Популярные вопросы
- 31Личи растет на Филиппинах?
- 43Что такое узор вечерней звезды?
- 43Законно ли расчет по экодизелю?
- 23Где находится Атлантида?
- 43Как использовать великодушный в предложении?
- 25Что едят бодибилдеры?
- 33Поддерживает ли фазмофобия контроллер?
- 38Кто воздушные нити вплетает в уток?
- 32Потребуется ли храмовому университету вакцина против коронавируса?
- 25Как получают нитролим?
Анализ зависимостей в НЛП (обработка естественного языка)
Расширенный NLP
Эта статья была опубликована в рамках блога о науке о данных
Введение Pure Language Processing — это междисциплинарная концепция, в которой используются основы вычислительной лингвистики и синтетического интеллекта, чтобы понять, как человеческие языки взаимодействуют с технологиями.
Чтобы применить НЛП к сценариям реального мира, необходимо хорошо разбираться в различных терминах и идеях. Среди них некоторые из важных концепций: маркировка половинной речи (POS), статистическое моделирование языка, синтаксическая, семантическая оценка и оценка тональности, нормализация, токенизация, анализ зависимостей и анализ групп.
В этой статье мы рассмотрим принципы синтаксического анализа зависимостей, чтобы лучше понять, как они применяются в обработке естественного языка.
Анализ зависимостейТермин анализ зависимостей (DP) относится к процессу изучения зависимостей между фразами предложения с целью определения его грамматической структуры. Предложение делится на множество разделов, основанных в основном на этом. Процесс основан на предположении, что существует прямая связь между каждой языковой единицей в предложении. Эти гиперссылки называются зависимостями.
Рассмотрим следующее утверждение: «Я предпочитаю утренний рейс через Денвер».
На приведенной ниже диаграмме поясняется структура зависимости предложения:
ИЗОБРАЖЕНИЕ – 1В структуре письменной зависимости отношения между каждой языковой единицей или фразой в предложении выражаются направленными дугами. Корень дерева «предпочтение» варьируется от вершины предыдущего предложения, как показано на иллюстрации.
Тег зависимости указывает на связь между двумя фразами. Например, слово «рейс» меняет значение существительного «Денвер». В результате можно выявить зависимость от
Рейс-> Денвер, где полет — это вершина, а Денвер — ребенок или иждивенец. Он представлен nmod, что означает номинальный модификатор.
Это отличает сценарий зависимости между двумя фразами, где одна служит вершиной, а другая — зависимой. В настоящее время таксономия Common Dependency V2 состоит из 37 общих синтаксических отношений, как показано в таблице ниже:
| Тег зависимости | Описание |
| клаузальный модификатор существительного (придаточное предложение) | |
| акл:рекл | модификатор относительного предложения |
| добавочный | модификатор придаточного предложения |
| адвмод | наречный модификатор |
| адвмод:emph | подчеркивающая фраза, усилитель |
| адвмод:lмод | местный наречный модификатор |
| амод | модификатор прилагательного |
| приложение | аппозиционный модификатор |
доп. | вспомогательный |
| доп:перемещение | пассивный вспомогательный |
| кейс | маркировка корпуса |
| куб.см | координационное соединение |
| куб.см:прекондж | предварительно соединенный |
| комп | clausal дополнение |
| clf | классификатор |
| соединение | соединение |
| компаунд: lvc | нежное построение глагола |
| соединение:prt | частица фразового глагола |
| соединение: редуп | повторных соединений |
| соединение: СВК | серийных глагольных соединений |
| соединение | соединение |
| коп | связка |
| csubj | предметная тема |
| csubj: перемещение | клаузальная пассивная тема |
отд. | неуказанная зависимость |
| от | определитель |
| дет:нумгов | местоименный определитель, определяющий падеж существительного |
| дет.:nummod | местоименный квантификатор, соответствующий падежу существительного |
| дет:поз | притяжательный определитель |
| дискурс | ингредиент дискурса |
| перемещенный | вывихнутые части |
| доп. | ругательство |
| экспл:имперс | безличное ругательство |
| экспл:переместить | возвратное местоимение, используемое в возвратном пассиве |
| экспл:пв | возвратная клитика с возвратным по своей сути глаголом |
| установленный | смонтированное многословное выражение |
| плоский | плоское многословное выражение |
| квартира: за рубежом | зарубежных фраз |
| квартира:титул | имен |
| идет с | идет с |
| iobj | косой объект |
| Контрольный список | контрольный список |
| знак | маркер |
| нмод | номинальный модификатор |
| нмод:возможно | притяжательный именной модификатор |
| nmod:tmod | временной модификатор |
| nsubj | именная тема |
| nsubj: переместить | пассивная номинальная тема |
| числовой мод | числовой модификатор |
| nummod:gov | числовой модификатор, определяющий падеж существительного |
| объект | объект |
| обл | непрямой номинальный |
| обл:агент | модификатор агента |
| обл:арг | косвенный аргумент |
| обл:мод | местный модификатор |
| обл:тмод | временной модификатор |
| сирота | сирота |
| паратаксис | паратаксис |
| пункт | пунктуация |
| репарандум | переопределенная неграмотность |
| корень | корень |
| звательный падеж | звательный падеж |
| xcomp | открытое дополнение |
Пакет Pure Language Toolkit (NLTK) будет использоваться для синтаксического анализа зависимостей, который представляет собой набор библиотек и кодов, используемых во время статистической обработки Pure Language Processing (NLP) человеческого языка.
Мы можем использовать NLTK для разбора зависимостей одним из следующих способов:
1. Вероятностный анализатор проективных зависимостей : Эти анализаторы предсказывают новые предложения, используя данные человеческого языка, полученные из предложений, проанализированных вручную. Известно, что они допускают ошибки и работают с ограниченным набором коучинговой информации.
2. Стэнфордский синтаксический анализатор : Это чисто языковой синтаксический анализатор на основе Java. Вы хотели бы, чтобы синтаксический анализатор Stanford CoreNLP выполнял синтаксический анализ зависимостей. Парсер поддерживает ряд языков, включая английский, китайский, немецкий и арабский.
Вот как вы должны использовать парсер:
из импорта nltk.parse.stanford StanfordDependencyParser path_jar = ‘path_to/stanford-parser-full-2014-08-27/stanford-parser.jar’ path_models_jar = ‘path_to/stanford-parser-full-2014-08-27/stanford-parser-3.Анализ избирательных округов Анализ избирательных округов
 4.1-models.jar’
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
последствие = dep_parser.raw_parse('Я застрелил слона во сне')
зависимость = последствие.последующий()
контрольный список (зависимость.triples())
Ниже приведен вывод вышеуказанной программы:
[
((у’шот’, у’ВБД’), у’нсубж’, (у’И’, у’ПРП’)),
((у’шот’, у’ВБД’), у’добж’, (у’слон’, у’НН’)),
((у’слон’, у’НН’), у’дет’, (у’ань’, у’ДТ’)),
((у’шот’, у’ВБД’), у’преп’, (у’ин’, у’ИН’)),
((у’ин’, у’ИН’), у’побж’, (т’сон’, у’НН’)),
((ты спишь, и'NN'), ты можешь, (ты мой', ты'PRP$'))
]
4.1-models.jar’
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
последствие = dep_parser.raw_parse('Я застрелил слона во сне')
зависимость = последствие.последующий()
контрольный список (зависимость.triples())
Ниже приведен вывод вышеуказанной программы:
[
((у’шот’, у’ВБД’), у’нсубж’, (у’И’, у’ПРП’)),
((у’шот’, у’ВБД’), у’добж’, (у’слон’, у’НН’)),
((у’слон’, у’НН’), у’дет’, (у’ань’, у’ДТ’)),
((у’шот’, у’ВБД’), у’преп’, (у’ин’, у’ИН’)),
((у’ин’, у’ИН’), у’побж’, (т’сон’, у’НН’)),
((ты спишь, и'NN'), ты можешь, (ты мой', ты'PRP$'))
] основан на контекстно-свободных грамматиках. Для разбора текста используются контекстно-свободные грамматики. Здесь дерево синтаксического анализа включает предложения, разбитые на подфразы, каждая из которых принадлежит к разным грамматическим классам. Конечный узел — это лингвистическая единица или фраза, которая имеет материнский или отцовский узел и тег части речи.
Например, «кошка» и «коробка под кроватью» являются именными словосочетаниями, а «написать письмо» и «водить машину» — глагольными словосочетаниями.
Рассмотрим следующий пример предложения: «Я застрелил слона в пижаме». Дерево синтаксического анализа избирательного округа показано графически следующим образом:
ИЗОБРАЖЕНИЕ – 2Дерево синтаксического анализа слева представляет собой поимку слона, несущего пижаму, а дерево синтаксического анализа справа представляет собой поимку слона в его пижаме.
Все предложение разбивается на подфазы, пока не останутся конечные фразы. VP обозначает словосочетания глаголов, тогда как NP обозначает словосочетания существительных.
Синтаксический анализатор Stanford также будет использоваться для анализа избирательных округов. Он начинается с разбора фразы с помощью синтаксического анализатора избирательных групп, а затем преобразует дерево синтаксического анализа избирательных групп в дерево зависимостей.
Если ваша основная цель состоит в том, чтобы прервать предложение на подфразы, идеальным вариантом будет реализовать синтаксический анализ групп. Однако синтаксический анализ зависимостей — лучший метод обнаружения зависимостей между фразами в предложении.
Давайте посмотрим на пример, чтобы понять, в чем разница:
Дерево синтаксического разбора групп обозначает разделение текста на подфразы. Нетерминалы дерева — это разные фразы, терминалы — это слова предложения, а ребра не помечены. Парсинг избирательного округа для простого утверждения «Джон видит Билла» будет следующим:
Анализ зависимостей связывает слова вместе на основе их связей. Каждая вершина в дереве соответствует слову, дочерние узлы — словам, которые зависят от родителя, а ребра — отношениям. Анализ зависимостей для «Джон видит Билла» выглядит следующим образом:
Вы должны выбрать тип парсера, который наиболее тесно связан с вашей целью. Если вы ищете подфразы внутри предложения, вас определенно интересует синтаксический анализ избирательного округа. Если вас интересует связь между словами, вас, вероятно, интересует синтаксический анализ зависимостей.
Если вас интересует связь между словами, вас, вероятно, интересует синтаксический анализ зависимостей.
Организации ищут новые методы использования компьютерных технологий по мере того, как они выходят за искусственные пределы. Значительный рост вычислительных скоростей и мощностей привел к разработке новых и высокоинтеллектуальных программных систем, некоторые из которых готовы заменить или улучшить человеческие услуги.
Одним из лучших примеров является рост обработки естественного языка (NLP) с умными чат-ботами, готовыми изменить мир обслуживания клиентов и не только.
Таким образом, человеческий язык поразительно сложен и разнообразен.
Помимо помощи в разрешении лингвистической неоднозначности, НЛП имеет важное значение, поскольку предлагает полезную математическую основу для различных последующих приложений, таких как распознавание голоса и анализ текста.
Чтобы понять НЛП, важно иметь хорошее представление об основах, анализ зависимостей является одним из них.