Как разобрать слово по составу?
Разобрать слово по составу следует, указав следующие морфемы: приставку, корень, суффикс, окончание, соединительную морфему, постфикс.
Окончание в составе слова
Выполнение разбора слова по составу, обычно необходимо начинать с выделения окончания, которое не входит в его основу. Для этого определим, изменяемое ли слово перед нами, есть ли у него окончание. С этой точки зрения важно, к какой части речи относится анализируемая лексема.
Помним, что у неизменяемых частей речи и форм слов нет окончания:
1. у несклоняемых существительных
- драже, метро, такси, рагу, каноэ, боа.
2. У несклоняемых прилагательных
- платье миди,
- юбка гофре,
- язык ханты,
- вес нетто,
- брюки хаки.
3. У наречий на конце вычленим только суффиксы:
- быстро
- неспроста
- врукопашную
- по-польски
4. В морфемном составе деепричастий имеются формообразующие суффиксы:
В морфемном составе деепричастий имеются формообразующие суффиксы:
- гулять — гуляя
- сбежать — сбежав
- открыть — открывши
- нести — нёсши
5. В форме простой сравнительной степени прилагательных и наречий вычленим суффиксы:
- ходить тише,
- стало радостнее,
- говорите громче.
Основа слова
Выделив окончание в изменяемом слове, которое склоняется, спрягается или изменяется по родам и числам, остальную часть лексемы обозначим как основу слова.
- создание
- красивый
- двадцатый
- отправим
Помним, что в основу слова не входят формообразующие суффиксы причастий, деепричастий, формы прошедшего времени глагола, постфикс формы повелительного наклонения глагола -те, суффиксы простой сравнительной степени прилагательных и наречий.
Примеры
- лелеющий ребенка
- вылинявшая рубашка
- видимый издали
- задуманный проект
- растертый в порошок
- гуляя по набережной
- открыв книгу
- вычертила график
- нарежьте кусочками
- шагать веселее
- стал слаще
Приставка в составе слова
Затем выделим приставку в слове, если она есть. Чтобы убедиться, есть ли эта морфема в слове, можно убрать ее и посмотреть, существует ли в лексике русского языка такое самостоятельное слово, или, второй вариант проверки, — менять предполагаемую приставку на другую:
сорвать — рвать, оторвать, надорвать, перервать, урвать.
Результативным способом определения приставки в составе слова является подбор лексем с такой же приставкой:
содрать, собрать, совместить, согласиться.
В морфемном составе лексемы может быть несколько приставок, тогда целесообразно составить словообразовательную цепочку и добраться до первого производящего слова:
небезынтересный — безынтересный — интересный.
Суффикс в составе слов
Теперь займемся суффиксом слова. Посмотрим, существует ли слово без такого суффикса:
- седина — седой,,
- вкладчик — вклад,
- бодрость — бодр, бодрый.
Подберем слова с таким же суффиксом и убедимся, что такой суффикс существует:
бодрость — нежность, весёлость, радость.
И теперь после последовательного вычленения всех морфем осталась главная часть слова — корень. Чтобы точно определить границы корня и убедиться, правильно ли мы его выделили, займемся подбором родственных слов. Как известно, общая часть родственных слов, в которой заключено основное лексическое значение слова, и есть корень.
Бодрость — бодрый, бодро (шагать), бодренький, бодриться.
Пример разбора слова по составу
Рассмотрим в качестве примера морфемный разбор слова «безрадостный».
Это изменяемое прилагательное, значит, вычленим окончание -ый, сравнив его формы:
- безрадостная неделя,
- безрадостное настроение,
- безрадостные новости.
Определим основу слова — безрадостн-:
безрадостный
Далее укажем приставку без-, как и в составе слов:
- бездомный
- безработный
Чтобы вычленить суффиксы в слове «безрадостный», восстановим словообразовательную цепочку:
безрадостный ← радостный ← радость ← рад (нет полной формы прилагательного).
Как видим, в составе прилагательного можем выделить суффиксы -ость-, -н-.
Оставшаяся часть слова -рад- является корнем, который прослеживается в родственных словах:
- радость
- радостный
- радовать (ся)
Закончим разбор по составу итоговой записью:
безрадостный — приставка/корень/суффикс/суффикс/окончание
Видеоуроки
Разбор глагола по составу
Нечего сказать текст песни Мирель
Посмотреть все тексты песен Mirèle
Мне нечего сказать, у меня нет слов
Все что звучало – правда, и теперь сон
Не различаю линии сюжета
Как будто все это уже было где-то
Мне нечего сказать, у меня нет слов
Мне нечего сказать, у меня нет слов
Мне нечего сказать, у меня нет слов
Мне нечего сказать
Желтые полосы на ногах
Порваны кроссы, ветер в волосах
Не знаю кто этот человек в зеркале
Почему он смотрит так пристально, медленно
Двигаясь в разные стороны
Кроме того, повторяя губами слова
Которые я не могу разобрать
Я таких не слышала никогда
В последнее время все стало сливаться
Не знаю, когда уходить полагается
Завтрак, обед или ужин – не помню
Радуга в небе теперь в монохроме
Мне нечего сказать, у меня нет слов (молчи)
Все что звучало – правда, и теперь сон (проснись)
Как будто все это уже было (где-то)
Понравился текст песни?
Оставьте комментарий ниже
Исправить текстПосмотреть все тексты песен Mirèle
Поделитесь ссылкой на текст:
Рейтинг текста:
- Text-pesni.
 com
com - M
- Mirèle
- Нечего сказать (Мирель)
 com
comПопулярные тексты и переводы песен исполнителя Mirèle:
Нечего сказать (Мирель)
Я — сила
Mirèle
Частица (ft. Кирилл Иванов)
Mirèle
Мне нравится так
Mirèle
Mirèle
Популярные тексты и переводы песен:
ЛП (ft.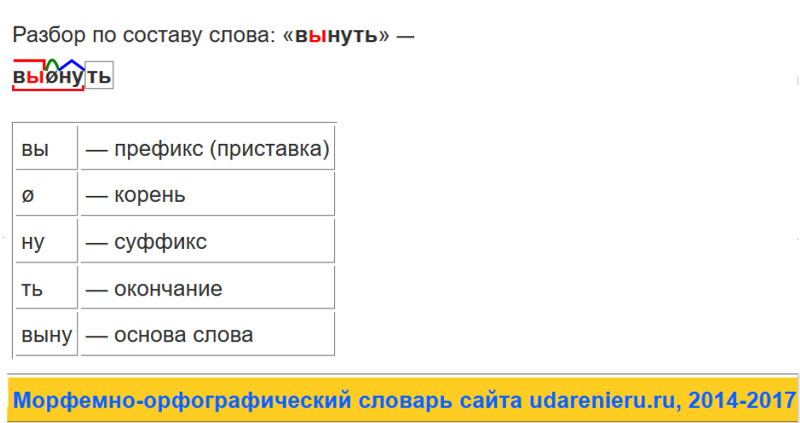 Milana Star)
Milana Star)
Милана Хаметова
Черная Любовь (ft. MONA)
ELMAN
Канги
Ұстазым (Устазым, Ұстазым менің ұстазым)
Ақбота Керімбекова
Твоя нежная походка (Той зимой недалекой)
Тимур Муцураев
JANAGA
А река течёт (из к/ф «Родные»)
Любэ
Малиновая лада (Пусть луна нам светит ярко)
GAYAZOV$ BROTHER$
Учителя (Ермолов, Пора наступает осенняя)
Школьные песни
Нити
Loc-Dog
Лучшие тексты и переводы песен:
Сияй (Рамиль)
Ramil’
Дико тусим (ft.
Даня Милохин
Если тебе будет грустно (ft. NILETTO, Рауф и Фаик, Нилетто)
Rauf & Faik
Юность (Добро, Звук поставим на всю соседи не спят)
Dabro
Лютики (Я смотрю наши старые мультики)
Просто Лера
Снова я напиваюсь (Слава Марлов)
Slava Marlow
Fendi (Рахим Фенди худи Гуччи Прада Луи на мне)
Rakhim
Поболело и прошло (Да подальше все пошло)
HENSY
неболей (ft. Zivert, Зиверт, не болей, С неба лей)
Zivert, Зиверт, не болей, С неба лей)
Баста
Танцевать вот так (Из тик тока Дрим Тима)
Ваша Маруся
Похожие тексты и переводы песен:
Нечего сказать (Мирель)
Mirèle
нечего сказать
маяк
Истина (Мирель)
Mirele
Выпускной (Мирель)
Mirele
Эстетика Грустных Людей (Мирель)
Mirele
Новинки музыки сентября 2022 года: слушаем онлайн новые альбомы «Аквариума» и «ДДТ», 25/17, Bjork и других — обзор — 30 сентября 2022
Афиша Plus
Музыка
Куда пойдем сегодня
30 сентября 2022, 17:57
4 комментарияФото: кадр из клипа/björk/YouTubeПоделиться
В сентябрьском обзоре новинок от музыкального продюсера Дениса Рубина Mars Volta атакует, Оззи Осборн собирает ветеранов сцены, Suede играет панк, Editors упражняются в синти-попе, группа «Диктофон» экспериментирует «в полях» постпанка, Jane Air «убирает» всю нью-металлическую молодежь, а известный пока в узких кругах дуэт Norway. Today записывает одну из самых интересных пластинок осени.
Today записывает одну из самых интересных пластинок осени.
Аквариум. «Дом всех святых»
Автор: Борис Гребенщиков/YouTube
В силу известных причин многие ожидали от Бориса Борисовича острого социального высказывания. Но сила БГ — не в ведении хроники, а в предсказаниях. И свои необходимые предсказания по данному поводу он уже сделал давно, еще в альбоме «Сестра Хаос». А сейчас он выражает свою позицию и свое отношение к происходящему, выпуская альбом в поздних традициях «Аквариума», смешав в одном культурном котле цитаты из современности и религиозных трудов, стилизации под русские народные песни и игры с абсурдом.
В музыкальном плане «Дом всех святых», как и положено альбомам позднего «Аквариума», являет собой высокую эклектику, в которой на равных основаниях замешано все, что вдохновляет Гребенщикова — от регги и фольклора до арт-рока и городского романса. Большой музыкальный котел, в котором варится давно знакомое блюдо, и вкус его все еще никому не надоел.
Большой музыкальный котел, в котором варится давно знакомое блюдо, и вкус его все еще никому не надоел.
«Аквариум» делает сейчас, возможно, самое важное для жизни дело, оставаясь самим собой, являя образец нерушимости. И если даже реальность под личиной дрона-камикадзе и залетает вдруг в одну из песен, она быстро превращается в мифологему. Все еще оставаясь провидцем, БГ сообщает нам, что жизнь, даже в самых страшных и повседневных ее проявлениях, все-таки наполнена и озарена смыслом верхнего мира, отголоски и отсветы которого «Аквариум» аки медиум и пытается донести до нас на протяжении многих десятилетий.
Jane Air. «Миелофон»
Автор: JANE AIR/YouTube
Поклонникам Jane Air можно поблагодарить коллектив Little Big за его вынужденную эмиграцию. Благодаря ей второй фронтмен коллектива, а по первому своему призванию лидер Jane Air, Антон Лиссов, наконец, освободил свое время от бесконечных концертных туров, а следовательно Jane Air смогли приступить к записи студийного альбома. Тем более, что материала за последнее время у группы набралось достаточно: концертную свою жизнь, несмотря на плотный график лидера, они не прекращали.
Тем более, что материала за последнее время у группы набралось достаточно: концертную свою жизнь, несмотря на плотный график лидера, они не прекращали.
Альбом с первой же песни «убирает» всех конкурентов на поле нью-метал, и сразу становится понятно, что молодые да ранние представители жанра оказались в топе лишь потому, что Jane Air дали им эту фору.
Альбом сыгран мощно, напористо и сверхпрофессионально. Дурацкое определение «фирмовый звук» подходит ему на сто процентов. Если не вслушиваться в русский текст, полное ощущение, что вы слушаете западных монстров рока, и слушаете их не где-нибудь, а на забитом под завязку стадионе. При этом тексты органично вписываются в музыку и ни разу не вызывают отторжения.
Очень радует, что на этом альбоме коллектив не замкнулся в узкие жанровые рамки, а уже с четвёртой песни пошел в экспериментальный разнос, явив поклонникам дэнс-панк-боевик, своеобразный ответ теперь уже заокеанским коллегам Little Big, только сделанный более изобретательно и жестко. И таких упражнений в прекрасном на альбоме несколько.
И таких упражнений в прекрасном на альбоме несколько.
В общем, если вы вдруг решили, что тяжёлый современный метал можно сдавать в архив, вам обязательно надо слушать новый альбом Jane Air — лихой, взрывной и талантливый.
25/17. «Одолень»
Автор: 25/17 (official channel)/YouTube
Возможно, это самые сильные и самые философски подкованные российские рэперы. Коллектив традиционно любят за сочетание бойкого и ритмичного слова с изобретательной музыкальной основой, в которой традиционный хип-хоп бит на равных соседствует с роковыми риффами и народными мотивами.
Последний альбом проекта, не говоря об этом прямо, буквально пропитан текущими событиями. Но не с точки зрения социальной рефлексии, а в каком-то хтоническом и эсхатологическом смысле. Он начинается с практически фольклорного ужастика по мотивам русской сказки «Колобок», который музыканты смогли разогнать до трагических вершин обобщения. И дальше следует, не сбавляя оборотов: иногда прикидываясь документальным чернушным повествованием в духе «Ноггано», иногда — вообще эксплуатируя нынешние сладкоголосые поп-каноны, но какими-то косвенными способами, нагнетая атмосферу и дух страшного мифа, особенный ужас которого заключается в том, что он превращается в повседневность.
И дальше следует, не сбавляя оборотов: иногда прикидываясь документальным чернушным повествованием в духе «Ноггано», иногда — вообще эксплуатируя нынешние сладкоголосые поп-каноны, но какими-то косвенными способами, нагнетая атмосферу и дух страшного мифа, особенный ужас которого заключается в том, что он превращается в повседневность.
И самое интересное заключается в том, что парней из 25/17 никак нельзя назвать чернушниками. Они, скорее, летописцы этого смутного времени и одновременно герои собственной летописи. Если бы Егор Летов дожил до наших дней, его легко можно было бы представить в рядах данного коллектива — и по духу, и по таланту, и по позиции.
Диктофон. «Звуки природы»
Автор: Диктофон/YouTube
Антон Макаров, тихий и незаметный эстет от музыки, много лет сочиняющий удивительные песни и, что особенно ценно, очень талантливо их исполняющий и записывающий, постепенно входит на территорию популярной русской музыки. При этом не заметно какой-то особой продюсерской стратегии в его действиях. Он просто последовательно и не изменяя себе сочиняет новый качественный материал, а параллельно с этим выступает в качестве музыканта с такими грандами, как Найк Борзов, Саша Гагарин или группа «Свидание». И каждый такой опыт использует прежде всего как источник новых музыкальных идей и в сочинительстве, и в аранжировке, и в манере сценического поведения.
При этом не заметно какой-то особой продюсерской стратегии в его действиях. Он просто последовательно и не изменяя себе сочиняет новый качественный материал, а параллельно с этим выступает в качестве музыканта с такими грандами, как Найк Борзов, Саша Гагарин или группа «Свидание». И каждый такой опыт использует прежде всего как источник новых музыкальных идей и в сочинительстве, и в аранжировке, и в манере сценического поведения.
Новый альбом группы «Диктофон» — чистое и беспримесное эстетство в формате постпанк. Антону Макарову как-то удалось сделать очень плотный и жирный звук каждой песни, от прослушивания которых получаешь практически физиологическое наслаждение. Но отходя от строгих канонов постпанка (и это следующий сюрприз альбома), Макаров придумал совершенно особенную манеру пения и обработки голоса, которая сначала кажется чужеродной для заявленного материала, но с каждой следующей песней превращается в его уникальную особенность. В этой манере продумано все, даже то обстоятельство, что какие-то отдельные слова крайне сложно разобрать «с лёта», остаются смысловые лакуны, недосказанности и пространство для вариаций.
Таким образом, Антон в данном релизе просто решил сыграть с нами в игру под названием «постпанк» и попробовать ее на излом. Но как музыкант, он выше стиля, оставляя за собой право в следующий раз уйти в любую другую сторону, в том направлении, которое вдохновит его на очередные музыкальные открытия.
Norway.Today. «космос там»
Автор: Norway.Today — тема/YouTube
В последнее время на нашей сцене появилось много интереснейших музыкальных проектов, созданных театральными артистами, режиссерами, драматургами. Почти всегда этот «артистический флер» можно опознать: театральные предлагаемые обстоятельства — сила настолько мощная и заразительная, что просачивается сквозь любую фактуру. Но есть и исключения из этого правила, что кажутся, скорее, плюсом нежели минусом. Одно из таких исключений — молодой дуэт Norway. Today, созданный двумя московскими актерами.
Today, созданный двумя московскими актерами.
Название никак не определяет то, что делают ребята, и вообще ничего не говорит, хотя и выглядит достаточно модно и многозначительно. Но дело тут не в названии. У молодых музыкантов получилась цельная, зрелая и драматически безупречная пластинка, полная и музыкальной, и поэтической мысли.
Стиль проекта можно описать как органичное сочетание Radiohead и «Аукцыона». Хотя, конечно, никакие определения, состоящие из отсылок к авторитетам, не могут быть до конца точными.
Ребята сумели соединить в единое органичное целое сложносочиненную музыку, достойные тексты, в которые действительно хочется вникать, какую-то тревожную вибрирующую материю аранжировок и вокальную манеру Леонида Федорова, которую они не копируют, а как бы «имеют в виду». Удивительным образом среди большого количество релизов сентября от маститых и достойных артистов самую интересную пластинку сделали именно эти ребята.
ДДТ. «Творчество в пустоте-2»
Автор: officialddt/YouTube
 youtube.com/embed/LHaWaU-r_l4″ frameborder=»0″ allowfullscreen=»allowfullscreen» scrolling=»no»/>
youtube.com/embed/LHaWaU-r_l4″ frameborder=»0″ allowfullscreen=»allowfullscreen» scrolling=»no»/>
ДДТ находится в какой-то невероятной форме. Юрий Юлианович выпустил альбом, в котором словно вернулся к корням и записал песни, равные по силе и эмоциональному воздействию ранним своим хитам. Только теперь эти новые хиты стали звучать в миллион раз профессиональнее и убедительнее.
Альбом большой, и в нем нашлось место очень разным по стилю и духу высказываниям. Здесь есть и жесткие сатирические боевики, и гимны, и рок-баллады.
В отличие от некоторых своих поздних экспериментов, здесь Юрий Юлианович ушел от упражнений в генерировании потоков сознания. Каждая песня, как и должно быть у старого доброго ДДТ, это еще и поэтически выверенный текст, в котором есть место и образу, и подвигу.
От Шевчука, возможно, больше чем от других ожидали прямого высказывания про настоящее. Но Юрий Юлианович оказался более крут — он сказал обо всем, но совсем другим способом. Через фигуры умолчания, через те пустоты в смыслах, которые предстоит заполнить нам самим. И сделал он это не по осторожности, а потому, что прекрасно отдает себе отчет — искусство должно действовать другими способами и входить в наши сердца не газетными заголовками и не плакатными изображениями. Иначе.
И сделал он это не по осторожности, а потому, что прекрасно отдает себе отчет — искусство должно действовать другими способами и входить в наши сердца не газетными заголовками и не плакатными изображениями. Иначе.
Каждая песня в альбоме словно пробует слушателя на излом с разных сторон, подбирает к нему поочередно свой собственный ключ. И будьте уверены, рано или поздно, но точно до конца альбома, этот ключ будет найден, и песни войдут в вас через открытую настежь дверь.
Ozzy Osbourne. Patient Number Nine
Старина Оззи, несмотря на преклонный возраст и постоянную борьбу со своими болячками, все еще находит в себе силы для мощного музыкального высказывания. И для особенной убедительности собирает под свои знамена практически всех ветеранов рока: от Эрика Клэптона и Джеффа Бека до Трухильо, Чеда Смита и Джоша Хомме.
На новом альбоме нет никаких откровений и экспериментов со стилем. Это по-прежнему добротный хард-н-хеви, оснащённый не только тяжелыми риффами, но и попсовыми гармониями. В этом, собственно, и состоит неподражаемое мастерство маэстро — ни разу не изменив себе, встроиться в комфортную повестку популярной музыки.
В этом, собственно, и состоит неподражаемое мастерство маэстро — ни разу не изменив себе, встроиться в комфортную повестку популярной музыки.
Обилие приглашенных звезд, каждая из которых вносит свою лепту, приводит к тому, что последняя пластинка Осборна напоминает его творческий вечер, бенефис. Жанр этот всегда особенно приветствуется преданными поклонниками. С одной стороны, здесь все как будто до боли знакомое, наполненное самоцитированием и зашитыми в песенную ткань сюрпризами для своих, с другой — очевидное доказательство, что кумир еще ого-го и дает прикурить.
Bjork. Fossora
Автор: björk/YouTube
Bjork — это то, чем могла бы стать наша Агузарова, если бы бессознательное повело ее в правильную сторону. Но там, где Агузарова инкапсулируется и замыкается на себе, лишь изображая эксцентрику, Bjork эксцентрична по-настоящему. Ее талант центробежен, а потому развивается бесконечно и непредсказуемо. Артистка виртуозно управляется с двумя категориями, на которых строится все ее творчество, — собственно, на музыке и на высоко контролируемом безумии.
Ее талант центробежен, а потому развивается бесконечно и непредсказуемо. Артистка виртуозно управляется с двумя категориями, на которых строится все ее творчество, — собственно, на музыке и на высоко контролируемом безумии.
Fossora — десятый альбом певицы, выпущенный после пятилетнего перерыва, квинтэссенция ее опыта, помноженная на личное горе. Он посвящён умершей в 2018 году матери Bjork. Название — придуманное певицей слово, означающее «копающаяся в земле», и она здесь действительно «роет землю», вскрывая один культурный слой за другим — фольклорные распевы, пульсация земного ядра, грибы, ритуальные кровопролития.
Альбом начинается с джазового рейва, продолжается атональной фри-классикой, на мгновение притормаживает на короткую акапельную паузу и несётся дальше, вбирая в себя все большее музыкальное сумасшествие. На Fossora Bjork снова, как она часто делала и раньше, перепридумывает фольклор, джаз, классику и электронику. И складывает из них то, что следует называть «новым неповторимым стилем Bjork». Здесь нет ни одного хита в общеупотребительном смысле слова, но от альбома невозможно оторваться.
Здесь нет ни одного хита в общеупотребительном смысле слова, но от альбома невозможно оторваться.
Особенное свойство Bjork — в своей творческой практике она вообще не повторяется. Не эксплуатирует свои проверенные формулы, а открывает их заново. И даже если кажется, что она все время ходит кругами, впечатление это обманчиво, Bjork путешествует только по спирали. И спираль эта раскручивается в бесконечность.
Suede. Autofiction
Автор: Suede HQ/YouTube
В свое время группа Бретта Андерсона была включена в число хедлайнеров молодого и бодрого брит-поп-двжиения. При этом всегда стояла несколько особняком. Слишком вычурное эстетство и особая тонкость музыки и слов отделяла Suede от своих более дерзких товарищей по цеху. В общем, это была самая британская команда из всей британской волны. Денди и аристократы среди парней с рабочих окраин.
С точки зрения популярности, подобная позиция Suede сослужила им не лучшую службу. Они смогли выпустить несколько по-настоящему культовых альбомов, но культ этот не превратился в массовое поклонение, а, скорее, остался ритуалом для посвященных. Ровно поэтому, пока длилось затяжное молчание коллектива, никто особенно не удивлялся, и даже самые преданные фанаты давно перестали ждать продолжения.
Но все ошибались — постаревшие, но не утратившие благородной осанки джентльмены, снова взялись за гитары и записали на удивление хороший и бодрый альбом. Во всех своих интервью они заявили, что на этот раз решили добиться от самих себя панковского звучания. Но ожидаемо — играть в панк у аристократов получается не слишком хорошо. Сырой и грязный звук, свойственный стилю, здесь, скорее, обозначен, чем по-настоящему прожит. Хотя где-то Андерсон действительно умудряется кричать на разрыв, а гитары набрасывают шумные и небрежные аккорды.
Однако неудавшийся заход в панк-рок не делает альбом плохим. Его интересно слушать, и главное, он не похож на попытку реконструкции самих себя двадцатилетней давности. Это новая и честная музыка пожилых джентльменов, которым наконец снова в кайф собираться и хулиганить вместе.
Его интересно слушать, и главное, он не похож на попытку реконструкции самих себя двадцатилетней давности. Это новая и честная музыка пожилых джентльменов, которым наконец снова в кайф собираться и хулиганить вместе.
Mars Volta. Mars Volta
Автор: The Mars Volta/YouTube
Еще один неожиданный камбэк. Предыдущий альбом Mars Volta выпускал целых десять лет назад, после чего коллектив благополучно распался и, кажется, не изъявлял никакого желания собираться вновь. Но, похоже, времена пандемии (помните еще это время?) и вынужденное безделье сделали свое дело, и два товарища с длинными экзотическими именами вновь собрались под вывеской Mars Volta.
И это только первая сенсация. А вторая — звучание альбома, которое может довести до инфаркта преданного поклонника. Всю свою музыкальную жизнь, с момента появления до предпоследнего релиза Mars Volta по праву считались самыми крутыми экспериментаторами в деле тяжелого прогрессивного рока и умели лихо выворачивать наизнанку тяжеленный звук, превращая его в интеллектуальную и суперсложную музыку, но на свежем релизе тяжелый рок ушел от слова «совсем». Почти все критики и фанаты дружно стали сравнивать новые песни с произведениями попсового латино-гитариста Сантаны, с одной лишь поправкой: тяжесть ушла, а вот психоделия никуда не делась.
Почти все критики и фанаты дружно стали сравнивать новые песни с произведениями попсового латино-гитариста Сантаны, с одной лишь поправкой: тяжесть ушла, а вот психоделия никуда не делась.
Невероятным образом, вообще отойдя от своего фирменного стиля, Mars Volta смогли записать удивительно цельный и захватывающий альбом, формально вообще не имеющий ничего общего с той музыкой, за которую их полюбили. Но благодаря какому-то надмузыкальному подходу к песням, вы все равно понимаете, что подобное сумасшествие могли сделать только эти два ненормальных.
Editors. EBM
Автор: Editors/YouTube
Коллектив — из числа тех, кто лет пятнадцать назад возрождал популярность постпанка и был по этому поводу на коне, но с каждым новым альбомом все больше уходил в тень. Начинали Editors крайне бодро, и все специалисты прочили их в качестве достойной замены топовых тогда Interpol. Однако на олимпе, по сути, не удержались ни первые, ни вторые. Альбомы выходили более-менее регулярно, но аудитория постепенно скукоживалась.
Однако на олимпе, по сути, не удержались ни первые, ни вторые. Альбомы выходили более-менее регулярно, но аудитория постепенно скукоживалась.
И вот, в 2022 году, сначала достаточно ярко в поле зрения вернулись Interpol, а вслед за ними подтянулись и Editors. Безусловный плюс их нынешнего положения в том, что от них ничего особо уже и не ждут, а значит, нет необходимости думать, как не обмануть надежды поклонников. И можно экспериментировать с музыкой так, как хочется. И в данном случае, похоже, у музыкантов Editors получилось отдаться своей guilty pleasure — тайной, но страстной любви к синти-попу и electric-body music (EBM, кстати, именно так и называется альбом, все по-честному).
Товарищи с нескрываемым наслаждением записали пачку песен, накаченных синтезаторными битами и ритмами, которые подошли бы скорее Erasure или Pet Shop Boys, чем Joy Division, с которыми обычно и привычно их сравнивали. И эта странная музыкальная перверсия оказалась действенной, альбом получился крепким и добротным, а в пиковые свои моменты — дерзким и захватывающим дух. Вряд ли когда-нибудь эту пластинку поставят в дискографии Editors на призовое место, но и стыдиться ее наличия они точно не будут.
Вряд ли когда-нибудь эту пластинку поставят в дискографии Editors на призовое место, но и стыдиться ее наличия они точно не будут.
Денис Рубин, специально для «Фонтанки.ру»
По теме
- Музыка августа: троллинг от Muse, стабильный «Пикник», «Ничего святого» у Хмырова и другие
29 августа 2022, 20:24
- Музыка июля: музыкальная пьеса Найка Борзова, повзрослевшие «Кис-Кис», посмертный альбом Петра Мамонова и другое
31 июля 2022, 18:02
- Музыка июня: тихие проповеди Ника Кейва, саундтрек от Shortparis и многое другое
30 июня 2022, 13:05
- Музыка мая: слушаем и обсуждаем новые альбомы Тома Йорка, Kendrick Lamar и не только
31 мая 2022, 10:10
- Музыка апреля: слушаем и обсуждаем новые альбомы RHCP, Гуфа, Ic3peak и других
30 апреля 2022, 11:25
УДИВЛЕНИЕ0
ПЕЧАЛЬ0
Комментарии 4
читать все комментариидобавить комментарийПРИСОЕДИНИТЬСЯ
Самые яркие фото и видео дня — в наших группах в социальных сетях
- ВКонтакте
- Телеграм
- Яндекс. Дзен
 Дзен
ДзенУвидели опечатку? Выделите фрагмент и нажмите Ctrl+Enter
Новости СМИ2
сообщить новость
Отправьте свою новость в редакцию, расскажите о проблеме или подкиньте тему для публикации. Сюда же загружайте ваше видео и фото.
- Группа вконтакте
Новости компаний
Комментарии4
Новости компаний
20 и 21 сентября – «Турандот» и «Золушка» Ростовского музыкального театра на сценах Мариинского театра
С 20 по 22 сентября в Санкт-Петербурге состоятся Дни культуры Ростовской области. В честь 85-летия, которое в этом году отмечает Ростовская область, ведущие учреждения культуры Дона представят свое творчество на одних из крупнейших площадках Северной столицы. В Мариинском театре две свои яркие премьеры покажет Ростовский музыкальный театр. Оперу «Турандот» Дж.Пуччини ростовчане покажут 20 сентября на сцене Маринский-2. В ростовской постановке задействованы видеопроекция и LED-экраны, неон, мобильные двухуровневые декорации, футуристичные…
В ростовской постановке задействованы видеопроекция и LED-экраны, неон, мобильные двухуровневые декорации, футуристичные…
Заслуженный коллектив России исполнит две великие симфонии ХХ века
7 и 13 февраля в Большом зале Петербургской филармонии Заслуженный коллектив России выступит под управлением народного артиста России Николая Алексеева. Прозвучат две великие симфонии XX века — Девятая Густава Малера и Пятая Дмитрия Шостаковича. Концерт Заслуженного коллектива 7 февраля входит в цикл «Филармония — 100. История в зеркале десятилетий», посвященный 100-летию Петербургской филармонии, которое она отмечает в 2021 году. Цикл объединяет программы знаменитых дирижеров, исполненные в разное время в Большом зале. 7 февраля прозвучат…
В Петербурге пройдет выставка архивных фотографий «Пять веков истории Парнаса»
Компания «Главстрой Санкт-Петербург» представит выставку архивных фотографий Парнаса — территории, на которой сегодня реализуется жилой комплекс «Северная долина».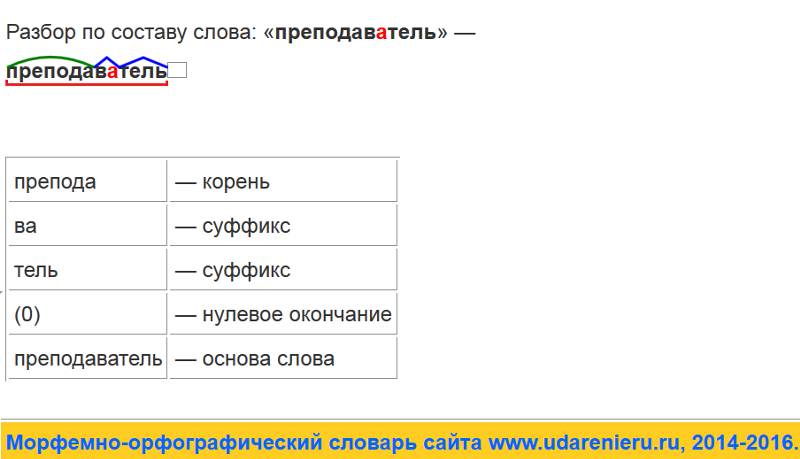 Более пятисот лет истории разместятся на двенадцати информационных стендах на улице Федора Абрамова. Выставка пройдет с 15 марта по 30 апреля (0+). Жилой комплекс «Северная долина», компании «Главстрой Санкт-Петербурга», расположен в одном из самых исторически «древних» мест Петербурга. Первое упоминание о Парголове прозвучало еще в переписной окладной книге Водской пятины…
Более пятисот лет истории разместятся на двенадцати информационных стендах на улице Федора Абрамова. Выставка пройдет с 15 марта по 30 апреля (0+). Жилой комплекс «Северная долина», компании «Главстрой Санкт-Петербурга», расположен в одном из самых исторически «древних» мест Петербурга. Первое упоминание о Парголове прозвучало еще в переписной окладной книге Водской пятины…
ТОП 5
1Новая карта Российской Федерации
159 049
272Военкомат Петербурга: Мобилизации подлежат только категории А и Б, повестки разосланы 8 тысячам горожан
137 603
793Не только в центре Петербурга. Голая дамочка прошлась по Комендантскому
96 639
344В Петербурге суд зарегистрировал первое исковое заявление мобилизованного к военкомату
87 056
305Шел четвертый день. Они готовятся к сражению
Они готовятся к сражению
84 352
14Новости компаний
Решено: Как разобрать слова из чисел
core.noscript.текст
5 ОТВЕТОВ 5
Этикетки
- ААХ
1 - Добро пожаловать
2 - Академия
21 - АДАПТ
87 - Добавить столбец
1 - Добавить новый столбец
1 - Настройки администратора
1 - Администрация
32 - Adobe
161 - Расширенная аналитика
1 - Появление кода
5 - Псевдоним Менеджер
95 - Альтерикс
1 - Альтерикс 2020.1
4 - Академия Альтерикс
3 - Альтерикс Аналитика
1 - Центр аналитики Alteryx
2 - Введение в сообщество Alteryx — студент MSA в CSUF
1 - Альтерикс Коннект
1 - Альтерикс Дизайнер
79 - Альтерикс Двигатель
1 - Галерея Альтерикс
1 - Концентратор Alteryx
1 - альтерикс с открытым исходным кодом
1 - Alteryx Post ответ
1 - Альтерикс Практика
129 - Alteryx SDK API
1 - Команда Альтерикс
1 - Инструменты Alteryx
1 - АльтериксФорГуд
1 - Амазонка с3
181 - Двигатель AMP
95 - АНАЛИТИКА ИННОВАЦИЙ
1 - Поддержка аналитических приложений
1 - Аналитические приложения
18 - Аналитические приложения ACT
1 - Аналитика
2 - Анализатор
19 - Объявление
4 - API
1192 - Приложение
2 - Добавить поля
1 - Приложения
1379 - Процесс архивации
1 - АРИМА
1 - Присвоение метаданных CSV
1 - Аутентификация
4 - Автоматическое обновление
1 - Банковское дело
1 - Кодировка Base64
1 - Базовая отчетность по таблицам
1 - Пакетный макрос
1279 - Новичок
1 - Анализ поведения
235 - Передовой опыт
2527 - BI + аналитика + наука о данных
1 - Книжный червь
2 - Ошибка
626 - Ошибки и проблемы
1 - Расчет рабочих дней
1 - Калгари
87 - КАСС
70 - Кошка Человек
1 - Категория Приложения
1 - Категория Соединители
1 - Категория Документация
1 - Категория Вход Выход
2 - Категория Прогноз
1 - Категория Пространственная
1 - Категория Временной ряд
3 - Категория Трансформация
1 - Сертификация
4 - Связанное приложение
250 - Вызов
17 - Диаграмма
1 - Клиенты
5 - Кластеризация
1 - Общие случаи использования
3428 - Связь
1 - Сообщество
262 - Объединить
1 - Условный столбец
1 - Условный оператор
1 - СОЕДИНИТЕ И РЕШИТЕ
1 - Соединители
1284 - Содержит
1 - Содержание
1 - Управление контентом
8 - Конкурс
6 - Начало разговора
22 - копия
1 - COVID-19
4 - Создайте новую электронную таблицу, используя существующий набор данных
. 1 - Управление учетными данными
3 - Любопытный*Маленький
1 - Функция пользовательской формулы
1 - Пользовательские инструменты
1389 - Создание приборной панели
1 - Анализ данных
1 - Анализ данных
2 - Аналитика данных
1 - Вызов данных
103 - Очистка данных
5 - Соединение данных
1 - Исследование данных
2659 - Загрузка данных
1 - Наука о данных
31 - Подключение к базе данных
2343 - Подключения к базе данных
6 - Наборы данных
4042 - Дата
2 - Дата и время
3 - формат даты
1 - Выбор даты
2 - Дата Время
2,696 - Формат даты
1 - даты
1 - дата и время разбор
2 - Дефект
10 - Демографический анализ
197 - Конструктор
1 - Дизайнерское облако
109 - Интеграция дизайнера
107 - Разработчик
3121 - Инструменты разработчика
2640 - Обсуждение
2 - Документация
467 - Человек-собака
3 - Скачать
1076 - Дублирует строки
1 - Дублирование строк
1 - Динамический
1 - Динамический ввод
1 - Динамическое имя
1 - Динамическая обработка
2622 - динамическая замена
1 - динамически создавать таблицы для входных файлов
1 - Электронная почта
712 - Уведомление по электронной почте
1 - Инструмент электронной почты
2 - Вставить
1 - встроенный
1 - Двигатель
86 - Улучшение
4 - Улучшения
2 - Сообщение об ошибке
2244 - Сообщения об ошибках
6 - ЭТС
1 - События
204 - Эксель
1 - Excel динамически объединять
1 - Макрос Excel
1 - Пользователи Excel
1 - Исследователь
5 - Выражение
1592 - извлечь данные
1 - Запрос функции
4 - Фильтр
1 - фильтр присоединиться
1 - Финансовые услуги
1 - гурман
4 - Формула
2 - формула или фильтр
1 - Инструмент Формула
4 - Формулы
2 - Веселье
5 - Нечеткое совпадение
703 - Нечеткое соответствие
1 - Галерея
568 - Общий
175 - Общее предложение
4 - Генерация строковых и многострочных формул
1 - Создать строки
1 - Начало работы
1 - Google Аналитика
182 - группировка
1 - Рекомендации
16 - Всем привет !
2 - Справка
3608 - Как раскрасить поля в строке на основе значения в другом столбце
1 - Как сделать
1 - Хаб 20. 4
2 - Я новичок в Альтерикс.
1 - идентификатор
1 - В базе данных
1117 - В базе данных
1 - Введите
3966 - Входные данные
2 - Вход Выход
3 - Вставка новых строк
1 - Установить
4 - Установка
404 - Интерфейс
3 - Инструменты интерфейса
1655 - Введение
7 - Итеративный макрос
975 - Соединитель Jira
1 - Присоединяйтесь к
1756 - база знаний
1 - Лицензии
1 - Лицензирование
245 - Список бегунов
1 - Погрузчики
18 - Загрузчики SDK
3 - Оптимизатор местоположения
79 - Поиск
1 - Машинное обучение
170 - Макрос
2 - Макросы
2739 - Картирование
1 - Маркето
25 - соответствие
1 - Слияние
1 - МонгоДБ
83 - Создание нескольких переменных
1 - MultiRowFormula
1 - Нужна помощь
1 - нужна помощь: как найти определенную строку во всех столбцах excel и вернуть этот clmn
1 - Нужна помощь по Formula Tool
1 - сеть
1 - Эквивалент функции NetworkDays
1 - Новый инструмент
1 - Новости
1 - Не твое дело
1 - Не по теме
15 - Управление финансов
1 - Нефть и газ
1 - Оптимизация
693 - Любитель активного отдыха
1 - Выход
4599 - Выходные данные
1 - пакет
1 - Разобрать
2007 - Сопоставление с образцом
1 - Люди Человек
5 - процентили
1 - PowerBI
194 - практические упражнения
1 - Предиктивный
2 - Прогнозный анализ
1261 - Прогнозная аналитика
1 - Препарат
4985 - Предписывающая аналитика
235 - Опубликовать
275 - Питон
645 - Qlik
57 - квартили
1 - Вопрос
13 - Вопросы
2 - Квадратные значения R
1 - Инструмент R
679 - RE GEX конвертировать
1 - обновить проблему
1 - Регулярное выражение
1,896 - Удалить столбец
1 - Отчет
2042 - Ресурс
16 - RestAPI
1 - Управление ролями
3 - Выполнить команду
561 - Запуск рабочих процессов
12 - Время выполнения
1 - Продажи
300 - Расписание
1 - Расписание рабочих процессов
3 - Планировщик
440 - Ученый
3 - Поиск
3 - Поиск отзывов
16 - Сервер
457 - Настройки
911 - Установка и конфигурация
93 - SFTP
1 - Sharepoint
436 - Делюсь
2 - Смартлист
1 - Снежинка
1 - Пространственный
1 - Пространственный анализ
783 - Студент
9 - Проблема со стилем
1 - Итого
1 - Системное администрирование
2 - Таблица
543 - Столы
1 - Технология
1 - Интеллектуальный анализ текста
292 - Миниатюра
1 - Четверг Мысль
11 - Временной ряд
437 - Прогнозирование временных рядов
1 - Советы и рекомендации
3775 - Улучшение инструмента
9 - Инструменты
1 - Интересующая тема
44 - Трансформация
2926 - Транспонировать
1 - Твиттер
50 - Удасити
138 - Уникальный
2 - Не уверен на подходе
1 - Обновления
3 - Обновления
1 - URL-адрес
1 - Варианты использования
1 - Дизайн взаимодействия с пользователем
2 - Пользовательский интерфейс
45 - Управление пользователями
5 - Видео
2 - ВидеоID
1 - ВПР
1 - Еженедельное испытание
1 - Распределение Вейбулла Weibull. Dist
1 - Количество слов
1 - Рабочий процесс
7449 - Рабочие процессы
1 - Годфрак
1 - Ютуб
1 - YTD и QTD
1
 1
1 4
4  Dist
Dist - « Предыдущий
- Следующий »
Разделить строку по разделителю или шаблону, разделить текст и числа
В этом руководстве объясняется, как разделить ячейки в Excel с помощью формул и функции «Разделить текст». Вы узнаете, как отделять текст запятой, пробелом или любым другим разделителем, а также как разбивать строки на текст и числа .
Разделение текста из одной ячейки на несколько ячеек — это задача, с которой время от времени сталкиваются все пользователи Excel. В одной из наших предыдущих статей мы обсуждали, как разделить ячейки в Excel с помощью 9Функция 0978 Text to Column , надстройка Flash Fill и Split Names . Сегодня мы подробно рассмотрим, как можно разбивать строки с помощью формул и функции Разделить текст .
Сегодня мы подробно рассмотрим, как можно разбивать строки с помощью формул и функции Разделить текст .
- Как разделить ячейки в Excel с помощью формул
- Разделить строку запятой, двоеточием, косой чертой, тире или другим разделителем
- Разделить строку разрывом строки
- Формулы для разделения текста и чисел
- Как разделить ячейки с помощью функции «Разделить текст»
- Разделить ячейку по символу
- Разделить ячейку по строке
- Разделить ячейку по маске (шаблону)
Как разделить текст в Excel с помощью формул
Чтобы разделить строку в Excel, вы обычно используете функцию ВЛЕВО, ВПРАВО или СРЕДНЯЯ в сочетании с НАЙТИ или ПОИСК. На первый взгляд некоторые формулы могут показаться сложными, но на самом деле логика довольно проста, и следующие примеры дадут вам некоторые подсказки.
Разделить строку запятой, двоеточием, косой чертой, тире или другим разделителем
При разделении ячеек в Excel важно определить положение разделителя в текстовой строке. В зависимости от вашей задачи, это можно сделать с помощью SEARCH без учета регистра или FIND с учетом регистра. Получив позицию разделителя, используйте функцию ВПРАВО, ВЛЕВО или СРЕДНЯЯ, чтобы извлечь соответствующую часть текстовой строки. Для лучшего понимания рассмотрим следующий пример.
Предположим, у вас есть список SKU шаблона Item-Color-Size , и вы хотите разделить столбец на 3 отдельных столбца:
- Чтобы извлечь имя элемента (все символы до первого дефиса), вставьте следующую формулу в ячейку B2 и скопируйте ее вниз по столбцу:
=ВЛЕВО(A2, ПОИСК("-",A2,1)-1)В этой формуле ПОИСК определяет позицию 1-го дефиса («-«) в строке, а функция ВЛЕВО извлекает все оставшиеся символы (вы вычитаете 1 из позиции дефиса, потому что не хотите извлекать сам дефис).
- Чтобы извлечь цвет (все символы между 1-м и 2-м дефисом), введите следующую формулу в C2, а затем скопируйте ее в другие ячейки:
=СРЕДН(A2, ПОИСК("-",A2) + 1, ПОИСК("-",A2,ПОИСК("-",A2)+1) - ПОИСК("-",A2) - 1)В этой формуле мы используем функцию Excel MID для извлечения текста из A2.
Начальная позиция и количество извлекаемых символов рассчитываются с помощью 4 различных функций ПОИСК:
- Начальный номер — это позиция первого дефиса +1:
ПОИСК("-",A2) + 1 - Количество символов для извлечения : разница между положением дефиса 2 nd и дефиса 1 st минус 1:
ПОИСК("-", A2, ПОИСК("-",A2)+1) - ПОИСК("-",A2) -1
- Начальный номер — это позиция первого дефиса +1:
- Чтобы извлечь размера (все символы после третьего дефиса), введите в D2 следующую формулу:
=ВПРАВО(A2,ДЛСТР(A2) - ПОИСК("-", A2, ПОИСК("-", A2) + 1))В этой формуле функция ДЛСТР возвращает общую длину строки, из которой вычитается положение дефиса 2 и . Разница заключается в количестве символов после дефиса 2 nd , и функция ПРАВИЛЬНО извлекает их.

Аналогичным образом можно разделить столбец по любому другому символу. Все, что вам нужно сделать, это заменить «-» на нужный разделитель, например пробел (» «), косая черта («/»), двоеточие («;»), точка с запятой («;») и так далее.
Совет. В приведенных выше формулах +1 и -1 соответствуют количеству символов в разделителе. В данном примере это дефис (1 символ). Если ваш разделитель состоит из 2 символов, например. запятую и пробел, затем поставьте только запятую («,») в функцию ПОИСК и используйте +2 и -2 вместо +1 и -1.
Как разделить строку по разрыву строки в Excel
Чтобы разбить текст по пробелу, используйте формулы, аналогичные показанным в предыдущем примере. Единственное отличие состоит в том, что вам понадобится функция CHAR для ввода символа разрыва строки, поскольку вы не можете ввести его непосредственно в формулу.
Предположим, что ячейки, которые вы хотите разделить, выглядят примерно так:
Возьмите формулы из предыдущего примера и замените дефис («-») на CHAR(10), где 10 — код ASCII для перевода строки.
- Чтобы извлечь наименование товара :
=ВЛЕВО(A2, ПОИСК(СИМВОЛ(10),A2,1)-1) - Чтобы извлечь цвет :
=СРЕДН(A2, ПОИСК(СИМВОЛ(10),A2) + 1, ПОИСК(СИМВОЛ(10),A2,ПОИСК(СИМВОЛ(10),A2)+1) - ПОИСК(СИМВОЛ(10),A2) - 1) - Чтобы извлечь размер :
=ВПРАВО(A2,ДЛСТР(A2) - ПОИСК(СИМВОЛ(10), A2, ПОИСК(СИМВОЛ(10), A2) + 1))
Вот как выглядит результат:
Как разделить текст и числа в Excel
Начнем с того, что не существует универсального решения, которое работало бы для всех буквенно-цифровых строк. Какую формулу использовать, зависит от конкретного шаблона строки. Ниже вы найдете формулы для двух распространенных сценариев.
Какую формулу использовать, зависит от конкретного шаблона строки. Ниже вы найдете формулы для двух распространенных сценариев.
Разделить строку шаблона «текст + число»
Предположим, у вас есть столбец строк с комбинацией текста и чисел, где число всегда следует за текстом. Вы хотите разбить исходные строки, чтобы текст и числа отображались в отдельных ячейках, например:
Результат может быть достигнут двумя различными способами.
Метод 1: Подсчитайте цифры и извлеките такое количество символов
Самый простой способ разделить текстовую строку, в которой число идет после текста, заключается в следующем: получить общее число и вернуть столько символов с конца строки.
С исходной строкой в A2 формула выглядит следующим образом:
=ПРАВИЛЬНО(A2,СУММ(ДЛСТР(A2) - ДЛСТР(ПОДСТАВИТЬ(A2, {"0","1","2","3","4","5","6","7 ","8","9"},""))))
Чтобы извлечь текст , вы вычисляете, сколько текстовых символов содержит строка, вычитая количество извлеченных цифр (C2) из общей длины строки. исходная строка в A2. После этого вы используете функцию LEFT, чтобы вернуть столько символов с начала строки.
исходная строка в A2. После этого вы используете функцию LEFT, чтобы вернуть столько символов с начала строки.
=LEFT(A2,LEN(A2)-LEN(C2))
Где A2 — исходная строка, а C2 — извлеченное число, как показано на снимке экрана:
Способ 2: определение позиции 1
st цифры в строкеАльтернативным решением может быть использование следующей формулы для определения позиции первой цифры в строке:
=MIN(ПОИСК ({0,1,2,3,4,5,6,7,8,9},A2&"0123456789"))
Подробное объяснение логики формулы можно найти здесь.
Как только положение первой цифры найдено, вы можете разделить текст и числа, используя очень простые формулы ВЛЕВО и ВПРАВО.
для извлечения Текст :
= слева (A2, B2-1)
для извлечения Номер :
= справа (A2, Len (A2) -B2+1)
, где где A2 — исходная строка, а B2 — позиция первого числа.
Чтобы избавиться от вспомогательного столбца, содержащего позицию первой цифры, вы можете вставить формулу МИН в функции ВЛЕВО и ВПРАВО: ПОИСК({0,1,2,3,4,5,6,7,8,9},A2&»0123456789″))-1)
Формула для извлечения чисел :
=ПРАВО(A2,ДЛСТР(A2)-МИН(ПОИСК({0,1,2,3,4,5) ,6,7,8,9},A2&"0123456789"))+1)
Разделить строку шаблона «число + текст»
Если вы разделяете ячейки, в которых текст стоит после числа, вы можете извлечь числа по следующей формуле:
=ЛЕВЫЙ(A2, СУММ(ДЛСТР(A2) - ДЛСТР(ПОДСТАВИТЬ(A2, {"0","1","2","3","4","5" ,"6","7","8","9"},""))))
Формула аналогична той, что рассматривалась в предыдущем примере, за исключением того, что вы используете функцию ВЛЕВО вместо функции ВПРАВО, чтобы получить число с левой стороны строки.
Когда у вас есть числа, извлеките текст , вычитая количество цифр из общей длины исходной строки:
=ПРАВО(A2,ДЛСТР(A2)-ДЛСТР(B2))
Где A2 — исходная строка, а B2 — извлеченное число, как показано на снимке экрана ниже:
Совет. Чтобы получить число из в любой позиции текстовой строки , используйте либо эту формулу, либо инструмент «Извлечь».
Вот как вы можете разделить строки в Excel, используя различные комбинации различных функций. Как видите, формулы далеко не очевидны, поэтому вы можете загрузить образец книги Excel с разделенными ячейками, чтобы изучить их поближе.
Если вы не любите разбираться в хитросплетениях формул Excel, вам может понравиться визуальный метод разделения ячеек в Excel, который демонстрируется в следующей части этого руководства.
Как разделить ячейки в Excel с помощью функции «Разделить текст»
Альтернативным способом разделения столбца в Excel является использование функции «Разделить текст», включенной в наш Ultimate Suite for Excel, которая предоставляет следующие параметры:
- Разделить ячейку по персонаж
- Разделить ячейку по строке
- Разделить ячейку по маске (шаблону)
Чтобы было понятнее, давайте подробнее рассмотрим каждую опцию по отдельности.
Разделить ячейки по символу
Выберите эту опцию, если вы хотите разделить содержимое ячейки по каждому вхождению указанного символа .
Для этого примера возьмем строки шаблона Item-Color-Size , который мы использовали в первой части этого урока. Как вы помните, мы разделили их на 3 разных столбца, используя 3 разные формулы. И вот как вы можете добиться того же результата за 2 быстрых шага:
- Предполагая, что у вас установлен Ultimate Suite, выберите ячейки для разделения и нажмите 9Значок 1028 Split Text на вкладке Ablebits Data .
- Панель Split Text откроется в правой части окна Excel, и вы выполните следующие действия:
- Разверните группу Разделить по символу и выберите один из предопределенных разделителей или введите любой другой символ в поле Пользовательский .
- Выберите, следует ли разбивать ячейки на столбцы или строки.
- Просмотрите результат в разделе Предварительный просмотр и щелкните значок 9. 1028 Сплит кнопка.
 1028 Сплит кнопка.
1028 Сплит кнопка.Наконечник. Если в ячейке может быть несколько последовательных разделителей (например, более одного пробела), установите флажок Считать последовательные разделители одним полем .
Готово! Задача, для которой требовалось 3 формулы и 5 различных функций, теперь выполняется всего за пару секунд и нажатие кнопки.
Разделить ячейки по строке
Эта опция позволяет разделить строки, используя любую комбинацию символов в качестве разделителя. Технически вы разбиваете строку на части, используя одну или несколько различных подстрок в качестве границ каждой части.
Например, чтобы разделить предложение с помощью союзов « и » и « или «, разверните группу Разделить по строкам и введите строки-разделители, по одной в строке:
В результате, исходная фраза отделяется при каждом появлении каждого разделителя:
Совет. Символы «или», а также «и» часто могут быть частью таких слов, как «апельсин» или «Андалусия», поэтому не забудьте ввести цифру 9. 1028 пробел до и после и и или для предотвращения разделения слов.
1028 пробел до и после и и или для предотвращения разделения слов.
А вот еще пример из жизни. Предположим, вы импортировали столбец дат из внешнего источника, который выглядит следующим образом:
5.1.2016 12:20
5.2.2016 14:50
функции даты распознают любой из элементов даты или времени. Чтобы разбить день, месяц, год, часы и минуты на отдельные ячейки, введите следующие символы в поле 9.0978 Разделить по строкам поле:
- Точка (.) для разделения дня, месяца и года
- Двоеточие (:) для разделения часов и минут
- Пространство для разделения даты и времени
Нажмите кнопку Разделить , и вы сразу же получите результат:
Разделить ячейки по маске (шаблону)
Разделение ячейки по маске означает разделение строки на основе шаблона .
Эта опция очень удобна, когда вам нужно разбить список однородных строк на несколько элементов или подстрок. Сложность заключается в том, что исходный текст не может быть разделен при каждом появлении данного разделителя, а только в некоторых конкретных случаях. Следующий пример облегчит понимание.
Сложность заключается в том, что исходный текст не может быть разделен при каждом появлении данного разделителя, а только в некоторых конкретных случаях. Следующий пример облегчит понимание.
Предположим, у вас есть список строк, извлеченных из какого-то файла журнала:
Что вам нужно, так это иметь дату и время, если они есть, код ошибки и сведения об исключении в 3 отдельных столбцах. Вы не можете использовать пробел в качестве разделителя, потому что между датой и временем есть пробелы, которые должны отображаться в одном столбце, а в тексте исключения есть пробелы, которые также должны отображаться в одном столбце.
Решение разбивает строку по следующей маске: *ОШИБКА:*Исключение:*
Где звездочка (*) обозначает любое количество символов.
Двоеточия (:) включены в разделители, потому что мы не хотим, чтобы они появлялись в результирующих ячейках.
А теперь разверните раздел Разделить по маске на панели Разделить текст , введите маску в поле Введите разделители и нажмите Разделить :
Результат будет выглядеть примерно так:
Примечание. Разделение строки по маске равно с учетом регистра . Поэтому обязательно вводите символы в маске точно так же, как они появляются в исходных строках.
Разделение строки по маске равно с учетом регистра . Поэтому обязательно вводите символы в маске точно так же, как они появляются в исходных строках.
Большим преимуществом этого метода является гибкость. Например, если все исходные строки имеют значения даты и времени и вы хотите, чтобы они отображались в разных столбцах, используйте эту маску:
* *ERROR:*Exception:*
В переводе на простой английский маска указывает надстройке разделить исходные строки на 4 части:
- Все символы до первого пробела в строке (дата)
- символов между пробелом 1 st и словом ОШИБКА: (время)
- Текст между ОШИБКА: и Исключение: (код ошибки)
- Все, что идет после Исключение: (текст исключения)
Надеюсь, вам понравился этот быстрый и простой способ разделения строк в Excel. Если вам интересно попробовать, ознакомительная версия доступна для скачивания ниже. Я благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Я благодарю вас за чтение и надеюсь увидеть вас в нашем блоге на следующей неделе!
Доступные загрузки
Формулы Excel с разделенными ячейками (файл .xlsx)
Ultimate Suite, 14-дневная полнофункциональная версия (файл .zip)
Вас также может заинтересовать
Unscramble PARSE — Расшифровано 68 слов из букв в PARSE
РАЗБОР расшифровывает и составляет 68 слов!Начинается с
Заканчивается на
Содержит
Реклама:
68 Расшифрованные слова с использованием букв РАЗБОРСлова из 5 букв, составленные из расшифрованных букв РАЗБОР
- аперсы
- апрес
- согласно
- очищает
- разобрать
- груши
- празе
- преса
- изнасилования
- пожинает
- спаер
- запасной
- копье
Слова из 4 букв, составленные из расшифровки букв PARSE
- апер
- обезьяны
- апсида
- арес
- жопа
- уши
- эпохи
- чистить
- парс
- шаг
- груша
- горох
- изнасилование
- рэп
- поднять
- рашпиль
- пожинать
- повторения
- обжигать
- сыворотка
- спа
- лонжерон
Слова из 3 букв, составленные из расшифровки букв PARSE
- обезьяна
- находятся
- арс
- жерех
- ухо
- eas
- эпоха
- эры
- номинал
- па
- горох
- за
- pes
- до
- рэп
- рас
- представитель
- разрешение
- саэ
- сок
- сар
- море
- сер
- спа
Слова из 2 букв, образованные расшифровкой букв PARSE
- э
- ар
- в качестве
- шт.
- э
- эс
- па
- ре
- ре

Сколько слов можно составить из PARSE?
Выше приведены слова, полученные путем расшифровки PARS E (AEPRS) . Наш поисковик слова расшифровал эти буквы, используя различные методы, чтобы сгенерировать 68 слов ! Наличие такого инструмента для расшифровки, как наш, поможет вам во ВСЕХ играх со словами!
Сколько слов можно составить из PARSE?
Чтобы еще больше помочь вам, вот несколько списков слов, связанных с буквами PARSE
- Слова из 5 букв
- Слов, Начинающихся с Р
- Слов, Оканчивающихся на Е
- Слова, начинающиеся на ПАРСЕ
- Слова, содержащие ПАРСЕ
- Слова, оканчивающиеся на ПАРСЕ
- Различные способы шифрования PARSE
Значения букв P A R S E в Word Scrabble и Words With Friends
Вот значения букв P A R S E в двух самых популярных играх со словами.
Эрудит
Буквы РАЗБОР стоят 7 очков в Scrabble
- P 3
- А 1
- Р 1
- С 1
- Е 1
Words With Friends
Буквы PARSE стоят 8 баллов в Words With Friends
- P 4
- А 1
- Р 1
- С 1
- Е 1
Если расшифровать PARSE… Что это значит?
Определение PARSE в расшифрованном виде
Если мы расшифруем эти буквы, PARSE, то это и составит несколько слов. Вот одно из определений слова, в котором используются все незашифрованные буквы:
аперсов
- Извините. У меня нет значения этого слова.
- Щелкните здесь для полного значения apers
- Является ли apers словом Scrabble?
- это apers слово Words With Friends?
Дополнительная информация о буквах
PARSE- Перестановки PARSE
- Анаграммы PARSE
- слов с буквами
Расшифровка PARSE для других игр Word Scramble
- Расшифровка PARSE для игр Word Scramble
- Расшифровать буквы PARSE для анаграмм
- РАЗБОР в Text Twist
- РАЗБОР в Эрудит
- РАЗБОР в словах с друзьями
- РАЗБОР в Jumble
- Расшифруй слово PARSE
- PARSE Расшифровать для всех словесных игр
Шифрование букв в PARSE
Согласно нашему другому производителю слова, PARSE можно зашифровать разными способами. Различные способы перестановки слова называются «перестановками» слова.
Различные способы перестановки слова называются «перестановками» слова.
Согласно Google, это определение перестановки:
способ, особенно один из нескольких возможных вариантов, в котором можно упорядочить или расположить набор или количество вещей.
Чем это полезно? Ну, он показывает вам анаграммы разбора , зашифрованные разными способами, и помогает вам легче распознавать набор букв. Это поможет вам в следующий раз, когда эти буквы P A R S E появятся в игре со словами.
ПАРЕ АСПРЭ РПСАЭ РСПАЭ PRSAE ПРЕЙС АРПСЕ РАПС ЗАПАСНОЙ СРППЭ PSARE PSRAE САПРЕ СПРЭ РПАСЕ СРАПЕ АПСРЕ АПРСЕ
Мы остановились на 18, но есть так много способов зашифровать РАЗБОР !
Word Scramble Words
- иелопеги
- рвиусавс
- тициллай
- тетейджирр
- пнеймерг
- нткрабпус
- Ирлипоти
- нкдбаху
- хнимойибе
- Инлейвийг
- дтеломсис
- пахойтдил
- лишобвек
- хонецимун
- дийннумак
- аэрикаса
- клинокклиа
- nodeocnmr
- aeunrghcr
- нейтомзис
Расшифруй эти буквы, чтобы получились слова.

Все слова были зашифрованы с помощью скремблера слов…
нифет гларн часовня Брани качественно чамт комок саткег дирмель румтия тихо глаупе изменять глубочайший плюти хор средство для удаления gotoes слова rfteer dtroaw Клисек накл читы соника искатель беспорядок рнбда zugea тоари litfeu помощник все cinlpe рхогт dirsua
Объединить слова
Птица + Утка = Бик
Apple + Honor = Aplonor
Hand + Locker = Handocker
Combine Names
Brad + Angelina = Brangelina
Robert + Katelyn = Robyn
Грегори + Джанет = Гране
Объединяйте слова и имена с помощью нашего Word Combiner
Вы расшифровали PARSE!
Теперь, когда PARSE расшифрован, что делать? Это просто, иди и выиграй свою игру в слова!
Python 3 Примечания[ ГЛАВНАЯ | ЛИНГ 1330/2330] | Разделение и объединение строк<<Предыдущее примечание Следующее примечание >> | ||||||||||||||||||||||||
На этой странице: . split(), .join() и list(). split(), .join() и list().Разделение предложения на слова: .split()Ниже мэрия представляет собой одну строку. Несмотря на то, что это предложение, слова не представлены как дискретные единицы. Для этого вам нужен другой тип данных: список строк, где каждая строка соответствует слову. .split() — это метод для использования:
 .split() разделяет любую комбинированную последовательность этих символов: .split() разделяет любую комбинированную последовательность этих символов:
Разделение на определенную подстрокуУказав необязательный параметр, .split(‘x’) можно использовать для разделения строки на определенную подстроку ‘x’. Без указания ‘x’ .split() просто разбивается на все пробелы, как показано выше.
Строка в список символов: list()Но что, если вы хотите разбить строку на список символов? В Python символы — это просто строки длины 1. Функция list() превращает строку в список отдельных букв:
Соединение со списком строк: .join()Если у вас есть список слов, как вы соедините их в одну строку? .join() — это используемый метод. Вызывается по строке-разделителю ‘x’, ‘x’. join(y) объединяет каждый элемент в списке y, разделенный ‘x’. Ниже слова в mwords соединяются обратно в строку предложения с пробелом между ними: join(y) объединяет каждый элемент в списке y, разделенный ‘x’. Ниже слова в mwords соединяются обратно в строку предложения с пробелом между ними:
|
 split('\n') # разделяется только на '\n'
['Здравствуй, мама', 'Привет, отец.']
split('\n') # разделяется только на '\n'
['Здравствуй, мама', 'Привет, отец.']
 join(hichars)
'Привет, мир'
join(hichars)
'Привет, мир'
Разбор строк в Swift | Swift by Sundell
Почти каждой программе на планете так или иначе приходится иметь дело со строками, поскольку текст играет фундаментальную роль в том, как мы общаемся и представляем различные формы данных. Но обработка и синтаксический анализ строк таким образом, чтобы они были надежными и эффективными, иногда могут быть очень сложными. Хотя некоторые строки представлены в очень строгом и удобном для компьютера формате, таком как JSON или XML, другие строки могут иметь более 9 форматов.0978 хаотичный .
На этой неделе давайте рассмотрим различные способы анализа и извлечения информации из таких строк, а также то, как различные методы и API приводят к различным компромиссам.
В некотором смысле Swift заработал репутацию устройства, с которым сложно работать, когда дело доходит до синтаксического анализа строк. Хотя верно то, что реализация Swift String не предлагает такого же количества удобства , как многие другие языки (например, вы не можете просто случайным образом получить доступ к заданному символу, используя целое число, например string[7] ), это упрощает написание правильного кода разбора строки .
Потому что, хотя приятно иметь возможность случайного доступа к любому заданному символу в строке на основе его воспринимаемой позиции, многоязычный (или, возможно, emoji-lingual ?) мир, в котором мы живем сегодня, делает такие API очень подверженными ошибкам. , поскольку то, как символ представляет в текстовом пользовательском интерфейсе, во многих случаях сильно отличается от того, как на самом деле хранится в строковом значении.
В Swift строка состоит из набора значений символов , сохраненных с использованием кодировки UTF-8 . Это означает, что если мы перебираем строку (например, используя цикл для ), каждый элемент будет символом , который может быть буквой, смайликом или какой-либо другой формой символа. Для идентификации групп символов (таких как буквы или цифры) мы можем использовать CharacterSet , который можно передать нескольким различным API на Строка и связанные с ней типы.
Допустим, мы работаем над приложением, позволяющим нескольким пользователям совместно работать над документом, и мы хотим реализовать функцию, позволяющую пользователям упоминать других людей, используя синтаксис @упоминание в стиле Twitter.
Определение пользователей, которые были упомянуты в данной строке, — это задача, которая на самом деле очень похожа на то, что должен делать компилятор Swift при идентификации различных частей в строке кода — процесс, известный как lexing или tokenizing — вот только наша реализация будет на порядки проще, так как нам нужно искать только один вид токена.
Первоначальная реализация может выглядеть примерно так: вычисляемое свойство String , в котором мы разбиваем строку на основе @ символов, отбрасываем первый элемент (поскольку это будет текст перед первым @- знак), а затем compactMap над результатом — идентифицирующие строки непустых буквенных символов:
строка расширения {
var упомянутые имена пользователей: [строка] {
пусть части = разделить (разделитель: "@"). dropFirst()
// Наборы символов могут быть инвертированы, чтобы идентифицировать все
// символы, которые *не* входят в набор.
пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
}  dropFirst()
// Наборы символов могут быть инвертированы, чтобы идентифицировать все
// символы, которые *не* входят в набор.
пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
}
dropFirst()
// Наборы символов могут быть инвертированы, чтобы идентифицировать все
// символы, которые *не* входят в набор.
пусть delimiterSet = CharacterSet.letters.inverted
return parts.compactMap {часть в
// Здесь мы берем первую последовательность букв справа
// после знака @ и проверяем, что он не пустой.
пусть имя = part.components(separatedBy: delimiterSet)[0]
вернуть name.isEmpty ? ноль: имя
}
}
} Приведенная выше реализация довольно проста и использует некоторые действительно полезные функции Swift, такие как изменение коллекций, использование compactMap для отбрасывания значений nil и так далее. Но у него есть одна проблема — требуется три итерации , одна для разделения строки на основе @ символов, одна для итерации по всем этим частям, а затем одна для разделения каждой части на основе небуквенных символов.
Пока каждая итерация меньше предыдущей (поэтому сложность нашего алгоритма не совсем O(3N) ), многократные итерации чаще всего приводят к некоторой форме узких мест по мере роста набора входных данных. В нашем случае это может стать проблемой, так как мы планируем применить этот алгоритм к документам любого размера (может быть, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), так что давайте посмотрим, сможем ли мы что-то сделать. оптимизировать его.
В нашем случае это может стать проблемой, так как мы планируем применить этот алгоритм к документам любого размера (может быть, некоторые пользователи будут вместе работать над книгой, используя наше приложение, кто знает?), так что давайте посмотрим, сможем ли мы что-то сделать. оптимизировать его.
Вместо того, чтобы разбивать нашу строку на компоненты, а затем перебирать эти компоненты, давайте пройдемся по нашей строке за один раз — перебирая ее символы. Хотя для этого потребуется немного больше кода для ручного синтаксического анализа, это позволит нам сократить наш алгоритм до одной итерации — например:
строка расширения {
var упомянутые имена пользователей: [строка] {
// Настройка нашего состояния, которое представляет собой любое частичное имя, которое мы
// текущий анализ и массив всех найденных имен.
var partialName: Строка?
имена переменных = [Строка]()
// Вложенная функция разбора, которую мы применим к каждому
// символ внутри строки.
func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено.
если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
}  func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено.
func parse(_ символ: Символ) {
если имя переменной = частичное имя {
охранять character.isLetter еще {
// Если мы встретим небуквенный символ
// при разборе имени это означает, что
// имя готово, и мы можем добавить его в
// наш массив (если не пустой):
если !name.isEmpty {
имена.добавлять(имя)
}
// Сбросить наше состояние и разобрать символ
// еще раз, так как это может быть @-знак.
частичное имя = ноль
вернуть синтаксический анализ (символ)
}
name.append(символ)
частичное имя = имя
} иначе, если символ == "@" {
// Устанавливаем пустое состояние, чтобы сигнализировать нашему выше
// код, что пора начинать парсить имя.
частичное имя = ""
}
}
// Применяем нашу функцию разбора к каждому символу
для каждого (разбор)
// Когда мы дойдем до конца, мы обязательно
// захватить любое имя, которое было ранее найдено. если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
}
если пусть lastName = частичное имя, !lastName.isEmpty {
имена.append(фамилия)
}
вернуть имена
}
} Обратите внимание, что приведенный выше isLetter API для Character был добавлен в Swift 5.
Хотя вышеприведенная реализация намного сложнее, чем наша первоначальная — она примерно в два раза быстрее (в среднем), что дает нам наш первый очевидный компромисс : выбираем ли мы более простое решение за счет потенциальной потери производительности — или мы выбираем более сложный, а также более эффективный алгоритм?
Обсуждение того, какой компромисс принять, становится еще более интересным по мере роста нашего списка требований. Допустим, после успешного развертывания функции упоминания для наших пользователей мы начинаем получать запросы на добавление поддержки хэштегов, и мы решили сделать именно это.
Поскольку обнаружение и имени пользователя, и хэштега — одна и та же проблема (отличается только начальный символ — @ против # ), имеет смысл использовать одну и ту же реализацию для обнаружения обоих. Чтобы это произошло, давайте сначала определим тип
Чтобы это произошло, давайте сначала определим тип Symbol , который мы будем использовать для представления упоминания или хэштега:
struct Symbol {
enum Kind {упоминание регистра, хэштег}
пусть вид: Вид
переменная строка: строка
} Хотя у нас могло бы быть вместо этого использовал перечисление со связанными строковыми значениями — поскольку и упоминания, и хэштеги имеют одну и ту же структуру, наш алгоритм немного упростится, если мы будем использовать структуру. Однако, чтобы Symbol можно было использовать в стиле enum , мы также можем добавить некоторые статические фабричные методы, чтобы упростить создание значений с использованием точечного синтаксиса:
extension Symbol {
упоминание статической функции (_ строка: строка) -> символ {
return Symbol (вид: .mention, строка: строка)
}
статическая функция хэштега (_ строка: строка) -> символ {
вернуть символ (вид: .хэштег, строка: строка)
}
} Имея все вышеизложенное, давайте теперь обновим наш упомянутый алгоритм для обнаружения символов, а не только имен пользователей:
extension String {
var символы: [Символ] {
var partialSymbol: Символ?
символы var = [Символ]()
func parse(_ символ: Символ) {
если символ var = partialSymbol {
охранять character. isLetter еще {
если !symbol.string.isEmpty {
символы .append(символ)
}
частичный символ = ноль
вернуть синтаксический анализ (символ)
}
symbol.string.append(символ)
частичный символ = символ
} еще {
// Вот единственная реальная разница по сравнению с
// предыдущая версия, так как мы сейчас решим
// на основе какого символа мы разбираем
// его ведущий символ:
переключить символ {
кейс "@":
частичное символ = .упоминание ("")
кейс "#":
частичный символ = .хэштег ("")
дефолт:
ломать
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы . append (последний символ)
}
символы возврата
}
}  isLetter еще {
если !symbol.string.isEmpty {
символы .append(символ)
}
частичный символ = ноль
вернуть синтаксический анализ (символ)
}
symbol.string.append(символ)
частичный символ = символ
} еще {
// Вот единственная реальная разница по сравнению с
// предыдущая версия, так как мы сейчас решим
// на основе какого символа мы разбираем
// его ведущий символ:
переключить символ {
кейс "@":
частичное символ = .упоминание ("")
кейс "#":
частичный символ = .хэштег ("")
дефолт:
ломать
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы .
isLetter еще {
если !symbol.string.isEmpty {
символы .append(символ)
}
частичный символ = ноль
вернуть синтаксический анализ (символ)
}
symbol.string.append(символ)
частичный символ = символ
} еще {
// Вот единственная реальная разница по сравнению с
// предыдущая версия, так как мы сейчас решим
// на основе какого символа мы разбираем
// его ведущий символ:
переключить символ {
кейс "@":
частичное символ = .упоминание ("")
кейс "#":
частичный символ = .хэштег ("")
дефолт:
ломать
}
}
}
для каждого (разбор)
если пусть lastSymbol = partialSymbol, !lastSymbol.string.isEmpty {
символы . append (последний символ)
}
символы возврата
}
}
append (последний символ)
}
символы возврата
}
} С указанным выше изменением разница между нашей первоначальной реализацией, основанной на разделении строк, и нашим последним алгоритмом становится еще больше — поскольку, если бы мы должны были токенизировать имена пользователей и хэштеги путем разделения строк, нам потребовалось бы 6 различных итераций (2 раза). 3) — два из которых будут полными проходами через исходную строку.
Однако было бы неплохо, если бы мы смогли найти нечто среднее между простотой нашей первоначальной реализации и мощью нашего ручного алгоритма. Одним из способов сделать это может быть введение абстракции, которая разделяет токенизация часть нашего алгоритма из логики фактической работы с любыми найденными токенами.
Для этого давайте переместим большую часть нашего последнего алгоритма в метод tokenize , который принимает словарь обработчиков, хешированный на основе того, какой символ они обрабатывают, например:
extension String {
func tokenize (используя обработчики: [Character: (String) -> Void]) {
// Нам больше не нужно поддерживать массив символов,
// но нам нужно отслеживать как текущую
// разбираемый символ, а также для какого он обработчика.
var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse(_ символ: Символ) {
если var data = parsingData {
охранять character.isLetter еще {
если !data.symbol.isEmpty {
data.handler(данные.символ)
}
парсингданные = ноль
вернуть синтаксический анализ (символ)
}
data.symbol.append(символ)
синтаксический анализ = данные
} еще {
// Если у нас есть обработчик для данного символа,
// тогда мы его разберем.
защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
}  var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse(_ символ: Символ) {
если var data = parsingData {
охранять character.isLetter еще {
если !data.symbol.isEmpty {
data.handler(данные.символ)
}
парсингданные = ноль
вернуть синтаксический анализ (символ)
}
data.symbol.append(символ)
синтаксический анализ = данные
} еще {
// Если у нас есть обработчик для данного символа,
// тогда мы его разберем.
защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
}
var parsingData: (символ: String, обработчик: (String) -> Void)?
func parse(_ символ: Символ) {
если var data = parsingData {
охранять character.isLetter еще {
если !data.symbol.isEmpty {
data.handler(данные.символ)
}
парсингданные = ноль
вернуть синтаксический анализ (символ)
}
data.symbol.append(символ)
синтаксический анализ = данные
} еще {
// Если у нас есть обработчик для данного символа,
// тогда мы его разберем.
защитный пусть обработчик = обработчики [символ] else {
возвращаться
}
parsingData = ("", обработчик)
}
}
для каждого (разбор)
если пусть lastData = parsingData, !lastData.symbol.isEmpty {
lastData.handler(lastData.symbol)
}
}
} Описанное выше не только немного очищает нашу реализацию, но и дает нам гораздо больше гибкости, поскольку теперь мы можем повторно использовать один и тот же алгоритм токенизации во многих различных контекстах и выбирать, как каждый токен должен обрабатываться на сайте вызова.
Теперь мы можем сократить наш код разбора символов до следующего:
extension String {
var символы: [Символ] {
символы var = [Символ]()
токенизировать (используя: [
"@": {символы.добавление(.упоминание($0))},
"#": {символы.приложение(.хэштег($0))}
])
символы возврата
}
} Очень красиво и чисто! 👍 Но, как и прежде, есть ряд компромиссов. Хотя абстракции — отличный способ скрыть сложную логику за гораздо более удобным API — они не бесплатны. Фактически, наша последняя версия требует примерно на 40% больше времени для запуска по сравнению с тем, когда алгоритм был встроен в свойство символов . Тем не менее, это все еще примерно в два раза быстрее, чем делать то же самое, разделяя строки, поэтому на самом деле это может быть та золотая середина, которую мы искали.
До сих пор мы в основном сравнивали ручную итерацию символов строки с разбиением ее на компоненты, но, как и во многих других случаях, есть и другие варианты, которые следует учитывать.
Одним из таких вариантов является использование сканера Foundation типа для непрерывного сканирования строки для идентификации искомых токенов. Как и в нашей последней реализации, она позволяет нам полагаться на абстракцию (на этот раз предоставленную Apple) для обработки большей части нашего алгоритма.0978 «тяжелый подъем» . Вот как может выглядеть такая реализация:
extension String {
var символы: [Символ] {
пусть сканер = Сканер (строка: сам)
пусть symbolSet = CharacterSet (charactersIn: "@#")
символы var = [Символ]()
var symbolKind: Symbol.Kind?
// Сканер не предоставляет API, похожий на последовательность, а скорее
// требует, чтобы мы проверили его текущее состояние, чтобы принять решение
// когда итерация закончилась.
в то время как !scanner.isAtEnd {
если пусть вид = symbolKind {
символВид = ноль
// Так как Scanner на самом деле просто интерфейс Swift
// для класса NSScanner Objective-C требуется
// нам передать указатель NSString, который
// записываем результат в.
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
Продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора.
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
}  результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
Продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора.
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
}
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
Продолжать
}
символы.append (Символ (вид: вид, строка: строка как строка))
} еще {
// Здесь мы сканируем, пока не найдем либо @, либо
// символ #, а затем использовать этот символ
// при назначении вида символа для разбора.
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
}
}
символы возврата
}
} Хотя «Objective-C-ness» из Scanner может сделать наш код немного хуже «Swifty» , это допустимый вариант для такого рода задач — и его характеристики производительности находятся на одном уровне. с нашей реализацией, основанной на ручной итерации, из предыдущей. Можно также утверждать, что использование
с нашей реализацией, основанной на ручной итерации, из предыдущей. Можно также утверждать, что использование Scanner дает немного более читаемый код, поскольку в его API явно указано, что мы сканируем для заданной строки в каждой части алгоритма, но это будет очень субъективно.
Давайте взглянем на последний вариант оптимизации — использование ленивых коллекций . До этого момента все реализации, которые мы исследовали, имели одну общую черту — все они сразу анализировали всю строку. Хотя это совершенно нормально для случаев использования, которые также будут потреблять все результаты немедленно, мы могли бы потенциально оптимизировать вещи, вместо этого выполняя наш синтаксический анализ более ленивым способом .
Как мы рассмотрели в «Быстрые последовательности: искусство быть ленивым» , откладывая вычисление элемента в последовательности до тех пор, пока он не станет действительно необходимым , иногда может дать нам прирост производительности, особенно если вызывающий объект будет потреблять только подмножество нашей последовательности.
Давайте обновим нашу последнюю реализацию на основе Scanner , чтобы она выполнялась лениво. Для этого мы обернем наш алгоритм в AnySequence и AnyIterator , что позволит нам формировать ленивые последовательности, не требуя реализации нового типа с нуля:0004
строка расширения {
var символы: AnySequence {
// Поскольку наш набор символов является константой, мы можем вычислить
// это немедленно, вне нашей итерации закрытия.
пусть symbolSet = CharacterSet (charactersIn: "@#")
// AnySequence позволяет нам использовать замыкания для определения обоих
// наша последовательность и лежащий в ее основе итератор.
return AnySequence { () -> AnyIterator в
пусть сканер = Сканер (строка: сам)
var symbolKind: Symbol.Kind?
// Мы немного переработали наш алгоритм, чтобы вместо этого
// используем вложенную функцию, которая будет вызываться
// итератор для извлечения следующего элемента (или nil, как только
// мы достигли конца последовательности).
func iterate() -> Символ? {
охранять !scanner.isAtEnd еще {
вернуть ноль
}
охранять let kind = symbolKind else {
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
}  func iterate() -> Символ? {
охранять !scanner.isAtEnd еще {
вернуть ноль
}
охранять let kind = symbolKind else {
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
}
func iterate() -> Символ? {
охранять !scanner.isAtEnd еще {
вернуть ноль
}
охранять let kind = symbolKind else {
Scanner.scanUpToCharacters (из: symbolSet, в: nil)
если scan.scanString ("@", в: ноль) {
вид символа = .упоминание
} иначе если scan.scanString("#", into: nil) {
вид символа = .хэштег
}
вернуть итерацию ()
}
символВид = ноль
результат var: NSString?
scan.scanCharacters(из: .letters, в: &result)
охранять пусть строка = результат иначе {
вернуть итерацию ()
}
return Symbol (вид: вид, строка: строка как строка)
}
вернуть AnyIterator (повторить)
}
}
} С указанным выше изменением мы теперь получим довольно значительное повышение производительности для кода, подобного этому, который выполняет только итерацию по нашей последовательности из символов до заданной точки:
let firstHashtag = string.
 symbols.first { $0. kind == .hashtag }
symbols.first { $0. kind == .hashtag } И это ставит нас перед окончательным компромиссом для этой статьи — готовы ли мы принять дополнительную сложность (и, возможно, немного более сложную отладку), чтобы сделать более короткие итерации более производительными?
Как и при написании любого типа алгоритмов, конкретная реализация, которая будет наиболее подходящей, сильно зависит как от того, с какой проблемой мы имеем дело, насколько велики наборы данных, на которых мы планируем ее запустить, и как результат будет съеден.
Конечно, в Swift есть много других способов анализа строк, которые не были рассмотрены в этой статье, например, использование регулярных выражений или углубление для анализа на базовом уровне Unicode, но, надеюсь, он дал вам обзор около инструментов и методов, находящихся в нашем распоряжении, и различные компромиссы, с которыми они все связаны.
Мой личный подход почти всегда состоит в том, чтобы начинать с простейшей возможной реализации и, постоянно измеряя результаты и характеристики производительности моих алгоритмов, масштабировать их по мере необходимости — как в этой статье. Мы также более подробно рассмотрим, как именно измерять наш код по различным показателям производительности, в следующей статье.
Мы также более подробно рассмотрим, как именно измерять наш код по различным показателям производительности, в следующей статье.
Что вы думаете? Есть ли у вас любимый способ разбора строк в Swift или вы попробуете один из методов из этой статьи в следующий раз, когда столкнетесь с проблемой такого рода? Дайте мне знать — вместе с вашими вопросами, комментариями и отзывами — в Твиттере @johnsundell или связавшись со мной.
Спасибо за внимание! 🚀
Примеры «разделения строки» в Scala (разделитель полей, разделитель)
Часто задаваемые вопросы о строке Scala: как разделить строку в Scala на основе разделитель полей , например строка, которую я получаю из значения, разделенного запятыми (CSV), или файла с разделителями вертикальной черты.
Решение
Используйте один из методов split , доступных для объектов Scala/Java String . В этом примере показано, как разделить строку на основе пробела:
scala> "привет мир".
 split(" ")
res0: Array[java.lang.String] = Array(hello, world)
split(" ")
res0: Array[java.lang.String] = Array(hello, world) Метод split возвращает массив из String элемента, которые затем можно рассматривать как обычный массив Scala :
scala> "привет, мир".split(" ").foreach(println)
привет
world Пример из реальной жизни
Вот пример из реальной жизни, который показывает, как разделить строку в кодировке URL, которую вы можете получить в веб-приложении, указав символ & в качестве разделителя полей или разделителя:
scala> val result = "oauth_token=FOO&oauth_token_secret=BAR&oauth_expires_in=3600" 9Результат 2312: java.lang.String = oauth_token=FOO&oauth_token_secret=BAR&oauth_expires_in=3600
scala> val nameValuePairs = result.split("&")
nameValuePairs: Array[java.lang.String] = Array(oauth_token=FOO, oauth_token_secret=BAR, oauth_expires_in=3600) Как вы можете видеть во второй строке, я вызываю метод split , говоря ему использовать & символ, чтобы разделить мою строку на несколько строк. Как вы можете видеть в выводе REPL, переменная
Как вы можете видеть в выводе REPL, переменная nameValuePairs — это тип Array of String , и в данном случае это пары имя/значение, которые мне нужны.
Разделение строки CSV
Вот пример, который показывает, как разделить строку CSV на массив строк:
scala> val s = "яйца, молоко, масло, кокосовые хлопья"
s: java.lang.String = яйца, молоко, масло, кокосовые хлопья
// 1-я попытка
scala> s.split(",")
res0: Array[java.lang.String] = Array(яйца, "молоко", "масло", "кокосовые слойки") Обратите внимание, что при использовании этого подхода лучше обрезать каждую строку. Это показано в следующем коде, где я использую метод map для вызова trim для каждой строки перед возвратом массива:
// 2-я попытка, очищено
scala> s.split(",").map(_.trim)
res1: Array[java.lang.String] = Array(яйца, молоко, масло, кокосовые хлопья) Примечание. Это не идеальное решение, поскольку строки CSV могут содержать дополнительные запятые внутри кавычек. Я просто пытаюсь показать, как этот подход обычно работает.
Это не идеальное решение, поскольку строки CSV могут содержать дополнительные запятые внутри кавычек. Я просто пытаюсь показать, как этот подход обычно работает.
Разделение с помощью регулярных выражений
Вы также можете разделить строку на основе регулярного выражения (regex). В этом примере показано, как разбить строку на пробелы:
scala> "привет, мир, это Эл".split("\\s+")
res0: Array[java.lang.String] = Array(hello, world, this, is, Al) Дополнительные примеры регулярных выражений см. в классе Java Pattern или в моих общих примерах регулярных выражений Java.
Откуда взялся метод «разделения»
Метод разделения перегружен, некоторые версии метода взяты из класса Java String , а некоторые — из класса Scala StringLike . Например, если вы вызываете split с аргументом Char вместо аргумента String , вы используете метод split из StringLike :
.
 // разделить с аргументом String
scala> "привет мир".split(" ")
res0: Array[java.lang.String] = Array(привет, мир)
// разделить с помощью аргумента Char
scala> "привет мир".split(' ')
res1: Array[String] = Array(hello, world)
// разделить с аргументом String
scala> "привет мир".split(" ")
res0: Array[java.lang.String] = Array(привет, мир)
// разделить с помощью аргумента Char
scala> "привет мир".split(' ')
res1: Array[String] = Array(hello, world) Тонкая разница в этом выводе — Array[java.lang.String] против Array[String] — намекает на то, что что-то отличается, но с практической точки зрения это не важно. Кроме того, с проектом Scala IDE, интегрированным в Eclipse, вы можете видеть, откуда берется каждый метод, когда отображается диалоговое окно «помощь по коду» Eclipse. (IntelliJ IDEA и NetBeans могут отображать аналогичную информацию.)
Примечание. Фактический класс Scala, содержащий метод
split, может со временем измениться. На момент написания этой статьи методsplitнаходится в классеStringLike, но по мере реорганизации библиотек Scala это может измениться.
