| ЗВУКО-БУКВЕННЫЙ АНАЛИЗ СЛОВ Воспитатель: Ильинская Диана Витальевна МАДОУ «ДС № 48» СЕВЕРСК ТОМСКАЯ ОБЛАСТЬ Цели и задачи: развитие звукобуквенного анализа и синтеза слов; учить соотносить звук с буквой и символом. Обучения детей грамоте в детском саду осуществляется аналитико-синтетическим методом. Это означает, что детей знакомят сначала со звуками родного языка, а потом с буквами. Современная школа, согласно ФГОС, требует от детей, поступающих в первый класс, не столько какой-либо суммы знаний и умений, сколько способности к действию в умственном плане, которая формируется в процессе усвоения системы знаний в той или иной области действительности. Поэтому уже в дошкольном возрасте надо помочь детям овладеть определенной системой знаний, которая станет основой будущего изучения предмета. Звуковой анализ — это определение, во-первых, порядка звуков в слове, во-вторых, выделение отдельных звуков, в-третьих, различение звуков по их качественным характеристикам. Для русского языка свойственно противопоставление гласных и согласных звуков, твердых и мягких согласных. Умение слышать и выделять все звуки по порядку предупреждает в будущем при письме пропуск букв. Дети пяти лет после занятий в средней группе подготовлены к овладению звуковым анализом: они умеют интонационно выделить звук и определить первый звук в словах. Но чтобы ребенок мог проанализировать слово, его звуковой состав должен быть материализован. Сказанное слово ускользает, и выделить в нем на слух какие-то части, элементы ребенку очень трудно. Его нужно показать дошкольникам в предметном плане, представив звуковую структуру в виде модели. С этой целью используется картина-схема звукового состава слов. На ней изображается предмет, слово-название которого ребенок разбирает и ставит ряд фишек под рисунком по количеству звуков в слове. Рисунок помогает все время видеть предмет, название которого анализируется. Схема дает возможность определить количество звуков в слове и проконтролировать правильность ее заполнения фишками. Основной вид упражнений, развивающий фонетические способности учащихся, – это фонетический разбор. Знакомство с учебной программой показывает, что под фонетическим разбором понимается звуко-буквенный разбор. Однако в методике различают собственно фонетический (или звуковой, и фонетико-графический (или звуко-буквенный)) разбор. Собственно звуковой разбор дети выполняют в подготовительный период обучения грамоте. С переходом к изучению букв звуковой анализ несправедливо почти полностью исключается из употребления. Однако, отмечая важность собственно фонетического разбора, нельзя не признавать, естественным, что основным видом упражнений с момента знакомства детей с буквами становится звуко-буквенный разбор в своих двух разновидностях. Если мы хотим добиться, чтобы ребенок реально оперировал звуками, то есть чтобы развивался его фонетический слух, целесообразно проводить звуковой разбор в такой последовательности.
Прокомментируем каждый пункт этого плана.
Звуко-буквенный анализ — один из важнейших видов работы, который способствует формированию в дальнейшем орфографической зоркости, развитию фонематического слуха; развитию умений вычленить звуки в слове, правильно их назвать и охарактеризовать; умения соотнести слово с его звуковой схемой и многому другому. Работу звукобуквенного анализа слова я провожу следующим образом: I.Раздаю карточки: II. Выясняю:
В своей работе опирались на исследования: А. М. Бородич, Г. С. Швайко, А. И. Максаковой, А. Н. Гвоздева, Е. В. Колесниковой, Г. Г. Голубевой, Г. А. Тумаковой, В. В. Гербовой, Т. А. Ткаченко, А. К. Бондаренко, Е. А Стребелевой, Т. Б. Филичевой, Н. В. Новоторцевой и др., использую таблицы: Список использованной литературы.
Колесникова Е. В. «Развитие звуко-буквенного анализа у детей 5-6 лет». М.: изд. «Ювента», 2003г. 7. Колесникова Е. В. «Развитие фонематического слуха у дошкольников». М.: изд. «Ювента» 2005г. 8. Куликовская Т. А. «Лучшие логопедические игры и упражнения для развития речи» ООО изд-во АСТРЕЛЬ М. 9. Максакова А. И. «Правильно ли говорит ваш ребёнок» — М.: Мозаика – Синтез, 2005 10. Максакова А. И. «Развитие правильной речи ребёнка в семье» — М.: Мозаика – Синтез, 2005г.
|
 Письменная речь формируется на базе устной. И первыми шагами к обучению грамоте должно быть не знакомство с буквами, а усвоение звуковой системы языка.
Письменная речь формируется на базе устной. И первыми шагами к обучению грамоте должно быть не знакомство с буквами, а усвоение звуковой системы языка.
 Так, при анализе слова «ЖУК»
Так, при анализе слова «ЖУК» Это наш ребенок уже умеет — научился на первом этапе обучения. «д-дом», -старательно произносит малыш. — «Какой первый звук?» — «Д». — «Очень хорошо! Давай закроем первую клеточку фишкой, это будет какой звук?» — «Д».
Это наш ребенок уже умеет — научился на первом этапе обучения. «д-дом», -старательно произносит малыш. — «Какой первый звук?» — «Д». — «Очень хорошо! Давай закроем первую клеточку фишкой, это будет какой звук?» — «Д». Палец держим на второй клеточке схемы, а вы вместе с ребенком долго тянете «до-о-ом»
Палец держим на второй клеточке схемы, а вы вместе с ребенком долго тянете «до-о-ом» «А теперь, — говорите вы, — я буду называть звук, а ты будешь снимать его обозначение со схемы. Посмотрим, какой ты внимательный. Убери, пожалуйста, обозначение звука «д» (фишка синего цвета)
«А теперь, — говорите вы, — я буду называть звук, а ты будешь снимать его обозначение со схемы. Посмотрим, какой ты внимательный. Убери, пожалуйста, обозначение звука «д» (фишка синего цвета) Сначала предложите ему найти в слове гласный звук и заменить нейтральную фишку на красную.
Сначала предложите ему найти в слове гласный звук и заменить нейтральную фишку на красную. Поначалу детям лучше давать для анализа простые односложные или двухсложные слова, например их имена: Ваня, Катя, Аня и другие.
Поначалу детям лучше давать для анализа простые односложные или двухсложные слова, например их имена: Ваня, Катя, Аня и другие.
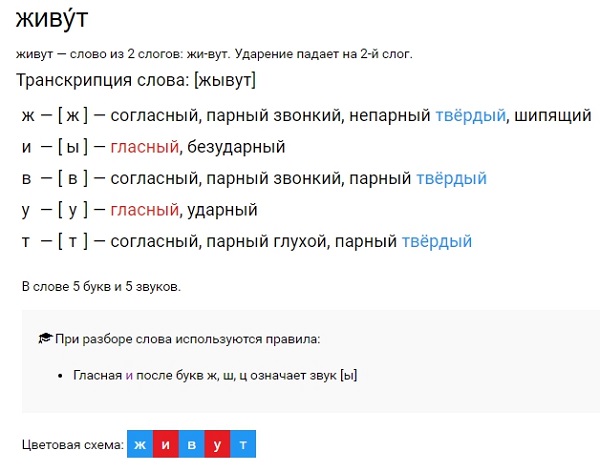 10 см Комплект на каждого ребенка 2 см 2 см. По 4 каждого цвета (черная –1)
10 см Комплект на каждого ребенка 2 см 2 см. По 4 каждого цвета (черная –1)
 Л-твердый согласный звук, обозначаем синей фишкой.
Л-твердый согласный звук, обозначаем синей фишкой.
 -М.,2001г.
-М.,2001г.

 Цель первого – характеристика звуковой структуры слова без обращения к буквам, второй включает в себя собственно фонетический разбор лишь как свою первоначальную ступень, так как главной задачей он имеет выяснение соотношение звуковой структуры слова с её буквенным обозначением.
Цель первого – характеристика звуковой структуры слова без обращения к буквам, второй включает в себя собственно фонетический разбор лишь как свою первоначальную ступень, так как главной задачей он имеет выяснение соотношение звуковой структуры слова с её буквенным обозначением. Послушай, получилось ли слово.
Послушай, получилось ли слово. Второй раз слово произносится по слогам.
Второй раз слово произносится по слогам.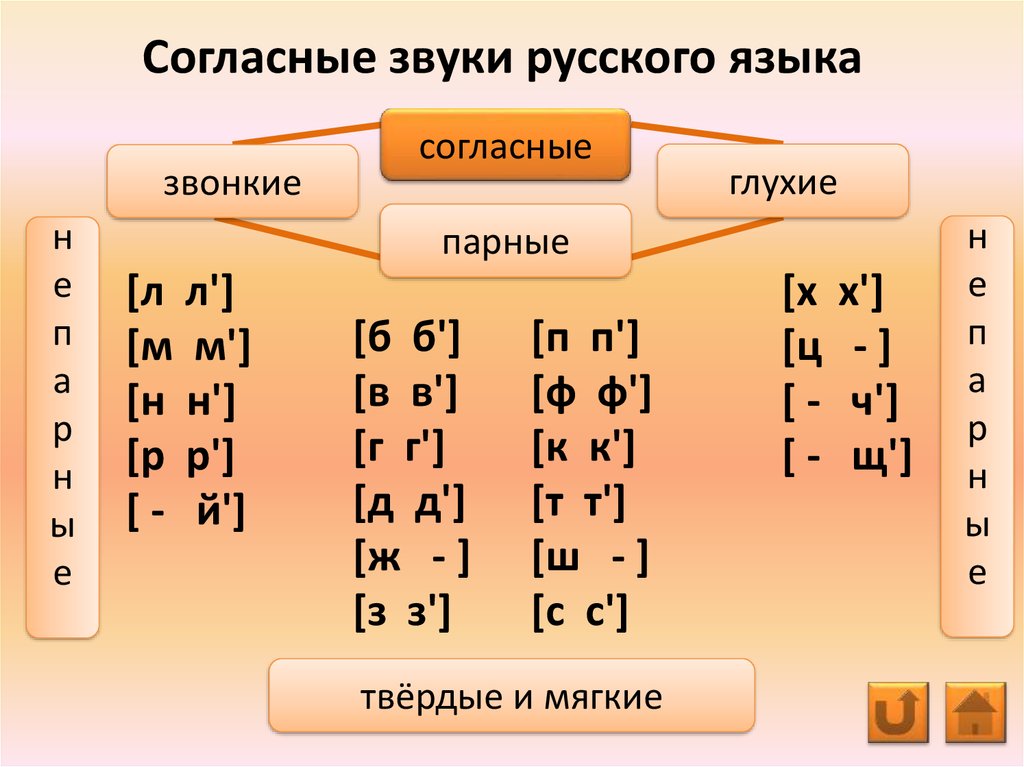

 В. «Живые звуки или фонетика для дошкольников» // «Ребёнок в детском саду». -2005. — №5, 6, 7, 8.
В. «Живые звуки или фонетика для дошкольников» // «Ребёнок в детском саду». -2005. — №5, 6, 7, 8. : 2009г.
: 2009г.
antlr4 — Разбор одного слова на несколько токенов с пропуском пробелов
спросил
Изменено 4 года, 3 месяца назад
Просмотрено 114 раз
У меня есть язык, в котором пробелы не важны, поэтому я его пропускаю. Вот подмножество грамматики, которая у меня есть:
запуск: выражение; выражение : атом | выражение '|' выражение | выражение выражение+ | '{' выражение '}' ; атом : АТОМ_ТОКЕН ; фрагмент БУКВА: [a-zA-Z]; фрагмент ЦИФРА: [0-9]; ATOM_TOKEN: (БУКВА | ЦИФРА)+; WS: [ \r\n\t]+ -> пропустить;
При выполнении на следующем вводе (обратите внимание на пробелы и их отсутствие) он правильно создает желаемое ожидаемое дерево синтаксического анализа:
{hello42 | привет мир}|{до свидания} красный синий зеленый
Моя проблема в том, что в идеале я хотел бы сделать атом вложенное правило, чтобы я мог выбрать репрезентативные части.
Вот пример грамматики:
atom: atomToken+;
атомтокен
: БУКВЫ
| ЦИФРЫ
;
БУКВЫ: БУКВА+;
ЦИФРЫ: ЦИФРА+;
и результат прогонки через него he11o (примечание 1 вместо L):
Проблема с этим подходом заключается в том, что, поскольку пробелы игнорируются, что-то вроде he11o world теперь будет анализироваться как один атом .
Есть ли что-то очевидное, что я упустил? Из моего исследования вытекает несколько возможностей.
- Напишите вторичную грамматику для использования, когда мне действительно нужно извлечь части
атома. Это кажется самым простым решением. - Реализовать своего рода инъекцию токена, создав подкласс сгенерированного Lexer. Это кажется очень хакерским, и я хотел бы избежать этого, если нет лучшего варианта.
- Сделать что-нибудь с лексическими модами или каналами, чтобы пробелы пропускались только условно? Я почти уверен, что это не сработает, поскольку контекст для запуска этого будет исходить от синтаксического анализатора, и, насколько я знаю, вы не можете изменить поведение лексера с помощью правил синтаксического анализатора.

- Не пропускайте пробелы, а вместо этого засоряйте основную грамматику всеми возможными пробелами.

Любая помощь приветствуется.
- antlr4
2
Зарегистрируйтесь или войдите в систему
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
[PDF] Сравнительная оценка методов преобразования букв в звуки для синтеза речи на английском языке
- Идентификатор корпуса: 7024640
title={Сравнительная оценка методов преобразования букв в звуки для синтеза английского текста в речь},
автор = {Роберт И. Дампер, Янник Маршан, Мартин Дж. Адамсон и Кьелл Густафсон},
booktitle={Мастерская синтеза речи},
год = {1998}
}  Дампер, Янник Маршан, Мартин Дж. Адамсон и Кьелл Густафсон},
booktitle={Мастерская синтеза речи},
год = {1998}
}
Дампер, Янник Маршан, Мартин Дж. Адамсон и Кьелл Густафсон},
booktitle={Мастерская синтеза речи},
год = {1998}
} - Р. Дампер, Ю. Маршан, К. Густафсон
- Опубликовано в Speech Synthesis Workshop 1998
- Информатика
Поиск по словарю является основной стратегией получения произношения для входных слов в системе преобразования текста в речь (TTS). Эта стратегия точна для словарных слов, но не является полной: невозможно исчерпывающе перечислить все входные слова. Правильная обработка «неизвестных» слов в настоящее время является нерешенной проблемой синтеза TTS. Существует множество конкурирующих методов преобразования букв в звуки, и разработчик системы должен сделать рациональный выбор среди них. Однако непонятно…
Просмотр бумаги
isca-speech.org
Использование фонетических знаний в инструментах и ресурсах для обработки естественного языка и оценки произношения
- Gustavo Augusto de Mendonça Almeida
Computing Science, лингвистика
.
В диссертации представлены инструменты и ресурсы для разработки приложений в области обработки естественного языка и обучения произношению, а также гибридный преобразователь графем в фонемы для бразильского португальского языка под названием Aeiouadô, который использует как ручные правила транскрипции, так и деревья классификации и регрессии для определения телефона. транскрипция.Преобразование арабского графемы в фонему на основе совместной многограммовой модели
- Эль-Хади Черифи, М. Гуэрти
Информатика, лингвистика
International Journal of Speech Technology
- 0421 This work предлагает подход к арабскому G2P-преобразованию, основанный на вероятностном методе: совместная мультиграммная модель (JMM), которая вполне удовлетворительна на словаре, принятом для тестирования и обучения, и на корпусе непрерывной речи с оценкой чуть более 11. % ПЕР.
ПРЕОБРАЗОВАНИЕ ПИСЬМА В ЗВУК ДЛЯ СИСТЕМ TTS GALICIAN
- Д. Брага, Л. Коэльо
Информатика
- 2006
) описан алгоритм преобразования для галисийского языка. Полный набор правил фонологической транскрипции для галисийского языка…
Диалектная вариация в языке боро и правила преобразования графемы в фонемы для обработки лексического поиска не работают в системе Boro TTS
- К. Сарма, П. Талукдар
Лингвистика
- 2012
Невозможно включить все слова естественного языка в общую систему преобразования текста в речь. Система преобразования графема-тофонема необходима для произнесения слова, которого нет в словаре.…
Повторяющаяся адаптация английского акцента в системе синтеза речи
- Крейг Олински, Фред Камминс
Информатика
Труды 2002 года IEEE Workshop on Синтез речи, 2002.
- 2002
Предложенный алгоритм обобщается и представлены результаты оценки скорости обучения произношению и обобщения, возможного с помощью этого метода, в частности, в отношении выбора целевой речевой базы данных соответствующего размера для обучения.
Обратимое преобразование звука в букву/буквы в звук на основе структуры слога
- С. Сенефф
Лингвистика
NAACL
- 2007
Контекстно-свободная грамматика используется для разбора слов на их базовую слоговую структуру, а набор единиц «спеллнема» подслова, кодирующих как фонематическую, так и графемическую информацию, может быть автоматически получен из проанализированных слов.
Объединение лингвистических знаний и акустической информации при автоматическом создании словаря произношения
- Грейс Чанг, Чао Ван, С. Сенефф, Эдвард Филиско, М. Танг
Информатика, лингвистика
INTERSPEECH
- 2004
В этом документе описывается несколько экспериментов, направленных на достижение долгосрочной цели — дать системе разговорной речи возможность автоматически улучшать свой словарный запас с течением времени посредством прямого…
Использование гибридного подхода для создания словаря произношения для бразильского португальского
- Gustavo Mendonça, S. Aluísio
Информатика
INTERSPEECH
- 2014
Метод, используемый для создания машиночитаемого словаря фонем, основанный на преобразовании graphes в бразильский португальский язык, основан на гибридном фонемном подходе, основанном на преобразовании фонем для бразильского португальского языка. ручные правила транскрипции и алгоритмы машинного обучения.
Преобразование графемы в фонему в эпоху глобализации
- Полякова Татьяна
Языкознание
- 2015
носителям языка, который необходимо адаптировать, или носителям этого языка со средним или низким уровнем владения.
Надежная модель слогоцентрического произношения для тамильского синтезатора речи
- Vaibhavi Rajendran, G.B. Kumar
Информатика
- 2019
В настоящей работе сформулирован новый слогоцентрический подход, основанный на правилах, с более расширенным набором правил, чем существующие в литературе базы правил.
и превосходит существующие системы, основанные на правилах, с низкой частотой ошибок символов и высокой средней оценкой сходства.ПОКАЗЫВАЕТСЯ 1-10 ИЗ 27 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантностьНаиболее влиятельные статьиНовости
Правила преобразования букв в звуки для автоматического перевода английского текста в фонетику
- Х. Эловиц, Р. Джонсон, А. Макхью, Дж. Шор
Лингвистика
- 1976
- Майкл Дж. Дедина, Х. Нусбаум
Лингвистика
- 1991
Информатика
Речь Комм.
- 1990
59 В этом техническом отчете описывается использованный подход и разработанное вспомогательное оборудование и программное обеспечение, а также приведены общие показатели производительности, подробная статистика, показывающая важность каждого правила, а также списки программ перевода и других программ, используемых при разработке правил.
Проверка преобразования текста в речь для английского языка.
В этом обзоре прослеживается ранняя работа по разработке синтезаторов речи, открытие минимальных акустических сигналов для фонетических контрастов, эволюция программ фонематических правил, внедрение просодических правил и разработка методов анализа текста.
Фонематическая транскрипция по аналогии в синтезе речи: новое произношение слов и сжатие лексики может производить транскрипцию с достаточной скоростью, чтобы поддерживать обработку в режиме реального времени в системе преобразования текста в речь.
Перцептивные эксперименты для диагностического тестирования систем преобразования текста в речь
Описываются перцептивные методы диагностики проблем в системах преобразования текста в речь и обсуждается ряд экспериментальных парадигм, которые касаются различных аспектов качества и разборчивости речи.
Произношение по аналогии: влияние выбора реализации на производительность
Произношение по аналогии (PbA) — это новый, основанный на данных метод с потенциальным применением в системах преобразования текста в речь (TTS), а также влиятельная психологическая модель чтения вслух.…
Произношение: программа для произношения по аналогии
Оценка систем преобразования текста в речь: некоторые методологические аспекты
6 Р.0046Система для преобразования английского текста в речь
- W. Ainsworth
Лингвистика
- 1973
. данные были исследованы, и разборчивость полученной синтетической речи оценивалась с помощью тестов на слух.
Параллельные сети, которые учатся произносить текст на английском языке
- Т. Сейновски, Чарльз Р. Розенберг
Информатика
Комплексные сист.
- 1987
Методы иерархической кластеризации, примененные к NETtalk, показывают, что эти разные сети имеют схожие внутренние представления буквенно-звуковых соответствий внутри групп процессорных единиц, что позволяет предположить, что инвариантные внутренние представления могут быть обнаружены в промежуточных скоплениях нейронов.
- Д. Брага, Л.
 В диссертации представлены инструменты и ресурсы для разработки приложений в области обработки естественного языка и обучения произношению, а также гибридный преобразователь графем в фонемы для бразильского португальского языка под названием Aeiouadô, который использует как ручные правила транскрипции, так и деревья классификации и регрессии для определения телефона. транскрипция.
В диссертации представлены инструменты и ресурсы для разработки приложений в области обработки естественного языка и обучения произношению, а также гибридный преобразователь графем в фонемы для бразильского португальского языка под названием Aeiouadô, который использует как ручные правила транскрипции, так и деревья классификации и регрессии для определения телефона. транскрипция. Коэльо
Коэльо
 Aluísio
Aluísio и превосходит существующие системы, основанные на правилах, с низкой частотой ошибок символов и высокой средней оценкой сходства.
и превосходит существующие системы, основанные на правилах, с низкой частотой ошибок символов и высокой средней оценкой сходства. Нусбаум
Нусбаум