Морфологический разбор глагола «изображались» онлайн. План разбора.
Для слова «изображались» найден 1 вариант морфологического разбора
- Часть речи. Общее значение
Часть речи слова «изображались» — глагол - Морфологические признаки.
- изображаться (инфинитив)
- Постоянные признаки:
- 1-е спряжение
- непереходный
- несовершенный вид
- изъявительное наклонение
- множественное число
- прошедшее время.
Боги и богини часто изображались в виде животных.
Выполняет роль сказуемого.
Поделитесь страницей с друзьями — это лучшая благодарность
Морфологический разбор другого слова
План разбора глагола
- Часть речи. Общее значение
- Морфологические признаки.
- Начальная форма (инфинитив)
- Постоянные признаки:
- Вид (совершенный (что сделать?) или несовершенный (что делать?)
- переходный (употребляется с сущeствительным в винительном падеже без предлога)/ непереходный (не употребляется с существительным в винительном падеже без предлога).
- Спряжение
- Наклонение в зависимости от вопроса:
- Изъявительное — что делал? что делает? что сделает?
- Повелительное — что делай?
- условное — что делал бы? что сделал бы?
- Число
- Время (если есть)
- Лицо (если есть)
- Род (если есть)
- Синтаксическая роль (подчеркнуть как член предложения, является главным или второстепенным членом предложения)
Поделитесь страницей с друзьями — это лучшая благодарность
Оцени материал
6 голосов, оценка 4. 167 из 5
167 из 5
План разбора составлен на основе общих правил, в зависимости от класса и предпочтений учителя ответ может отличаться. Если ваш план разбора отличается от представленного, просто сопоставьте его с данными нашего ответа.
Если морфологический разбор глагола «изображались» имеет несколько вариантов, то выберите наиболее подходящий вариант разбора исходя из контекста предложения.
Разборы производились исходя из заложенного программного алгоритма, результаты в редких случаях могут быть недостоверны, если вы нашли несоответствие пожалуйста сообщите нам. Представленный результат используется вами на свой страх и риск.
Морфологический разбор слова изображение онлайн
Слово ‘изображение’
Слово изображение является Именем существительным (это самостоятельная, склоняемая часть речи). Оно неодушевленное и употребляется в среднем роде. Разряд по значению:абстрактное. Второе склонение (т.к. в им. падеже, в мужском роде окончание нулевое или в среднем роде окончания: ‘о’ или ‘е’). Относится к Нарицательным именам существительным. Множественная форма слова ‘изображение’ является ‘-‘
- В Именительном падеже, слово изображение(-) отвечает на вопросы: кто? что?
- Родительный падеж (Кого? Чего?) — изображения(-)
- Дательный падеж (Кому? Чему?) — Дать изображению(-)
- Винительный падеж (Кого? Что?) — Винить изображение(-)
- Творительный падеж (Кем? Чем?) — Доволен
- Предложный падеж (О ком? О чём?) — Думать об изображении(-)
- Действие по значению глаголу изображать.
- Результат такого действия.
Слово «изображение» является Именем существительным
Слово «изображение» — неодушевленное
изображЕние
Ударение падает на слог с буквой Е. На восьмую букву в слове.
На восьмую букву в слове.
Слово «изображение» — средний
Слово «изображение» — абстрактное
Слово «изображение» — 2 склонение
Слово «изображение» — нарицательное
Единственное число
Множественное число
Именительный п.
Изображение окрестностей не заняло много времени.
Родительный п.
Для изображения полуразрушенной церкви художнику потребовалось около двух недель.
По изображению каждой детали видна увлечённость художника его работой.
Винительный п.
Однако Васнецов отказался писать изображение Волги.
Творительный п.
Он как раз занимался изображением мелких деталей на картине.
об изображении
Осталось только согласовать некоторые условия об изображении дворовой челяди на картине.
- благодать
- спелеолог
- инки
- наклонность
- предрассудок
- бриг
- неистовство
- иудушка
- аллопат
- кабаре
Морфологический разбор слова «изображение»
Часть речи: Существительное
ИЗОБРАЖЕНИЕ — неодушевленное
Начальная форма слова: «ИЗОБРАЖЕНИЕ»
| Слово | Морфологические признаки |
|---|---|
| ИЗОБРАЖЕНИЕ |
|
| ИЗОБРАЖЕНИЕ |
|
Все формы слова ИЗОБРАЖЕНИЕ
ИЗОБРАЖЕНИЕ, ИЗОБРАЖЕНЬЕ, ИЗОБРАЖЕНИЯ, ИЗОБРАЖЕНЬЯ, ИЗОБРАЖЕНИЮ, ИЗОБРАЖЕНЬЮ, ИЗОБРАЖЕНИЕМ, ИЗОБРАЖЕНЬЕМ, ИЗОБРАЖЕНИИ, ИЗОБРАЖЕНЬИ, ИЗОБРАЖЕНИЙ, ИЗОБРАЖЕНИЯМ, ИЗОБРАЖЕНЬЯМ, ИЗОБРАЖЕНИЯМИ, ИЗОБРАЖЕНЬЯМИ, ИЗОБРАЖЕНИЯХ, ИЗОБРАЖЕНЬЯХ
Разбор слова по составу изображение
| Основа слова | изображени |
|---|---|
| Корень | изображ |
| Суффикс | ени |
| Окончание | е |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ИЗОБРАЖЕНИЕ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «изображение»
1
Поэтому поляризованное изображение раздваивается – настоящее изображение смещено от повторного изображения на некотором удалении.
Евангелие Царства Божия, Виктор Васильевич Дрожжин2
Теперь быстро прокрутил изображение, нашёл место передачи сигнала, затормозил изображение.
Двугорбый Янус. «Человек не властен над духом, чтобы удержать дух, и нет власти у него над днем смерти, и нет избавления в этой борьбе, и не спасет нечестие нечестивого» Экклезиаст 8:1—17, Сергей Юрьевич Буянов3
Есть образы сложные, к примеру изображение человеческого лица, или даже реалистичное изображение какого – либо животного.
В начале были… Знак, звук, слово, Виктор Васильевич Дрожжин4
Его настоящее изображение скрыто, а мнимое изображение легко просматривается.
5
Изображение в зеркале – это мнимое изображение.
Записки атеиста. Рассказы и повести, Юрий БерковНайти еще примеры предложений со словом ИЗОБРАЖЕНИЕ
Трудности, возникающие при выделении суффикса в морфемном разборе
Необходимо помнить, что в притяжательных прилагательных типа лисий морфема –ий является суффиксом, а не окончанием, сл-но, в форме лисий нулевое окончание, окончание-буква появляется в таком прилагательном при изменении формы слова: лисья, лисьего. А гласная
Трудности возникают при одинаковом графическом изображении суффиксов и окончаний: сем-ей-ٱ, голуб-ей. Здесь тоже нужно разбираемую форму сравнивать с другими, и только после этого решать, что перед вами: суффикс или окончание.
Трудно бывает отграничить один суффикс от другого (мечтательница, бесчувственность, предшественник) – возникает 2 соблазна: 1) выделить все это как один суффикс, 2) выделить как можно больше суффиксов.
Для того чтобы не
ошибиться в подобном случае нужно
выстроить словообразовательную цепочку,
решить, от чего образовано данное слово,
и мотивировать свое решение. Мечтательница – женщина-мечтатель,
можно выделить суффикс –ниц-. Мечтатель – это тот, кто мечтает, можно выделить
суффикс –тель. Мечтать – иметь в голове мечты – выделяем
суффикс –а-.
Мечтать – иметь в голове мечты – выделяем
суффикс –а-.
Предшественник – это тот, кто кому-то предшествует, а не какой-то предшественный человек, поэтому в этом слове выделяем суффикс –енник. Шествие – это отвлеченное существительное обозначает действие, хождение, родственное слово — шел, значит, в сущ-ном выделяется суффикс –ств-.
Богатство суффиксальной системы русского языка дает возможность выразить не только оттенки значений, но и тонкие стилистические оттенки слов: мамочка, маменька, мамаша, мамуся, мамуля; девочка, девушка, деваха, девчина, девчушка, девчушечка, девонька, девица, девчонка, девчоночка, девчурка, девчурочка.
Постфикс
Постфикс (лат. post– «после» иfexus– «прикрепленный») – аффикс, находящийся после окончания в абсолютном конце слова.
В русском языке 5 постфиксов: 2 глагольных (-ся / -сь, -те: бороться, борюсь, учите) и 3 местоименных (-то, -либо, -нибудь: кто-то, какой-нибудь, чей-либо).
В школьных учебниках термин «постфикс» не употребляется. Аффиксы такого типа отнесены к суффиксам.
Все перечисленные аффиксы (кроме -те) словообразовательные. Так, постфикс–сяпридает глаголампереписываться, ссориться значение взаимности, а местоимения и наречия с постфиксами–то, -либо, -нибудь (кто-то, где-либо, когда-нибудь)имеют значение неопределенности.
Постфикс –ся / -сьможет выполнять и словоизменительную функцию: он используется для образования форм страдательного залога. Например:Рабочие строят дом. – Дом строится рабочими.
Словоизменительный постфикс –тев форме повелительного наклонения глагола выражает грамматическое значение множественного числа:думай-те, запоминай-те.
В формах повелительного наклонения может быть 2 постфикса: задумайтесь, улыбнитесь.
Постфиксы совмещают в себе признаки
приставок и суффиксов. Они занимают
позицию справа от корня, как и суффиксы,
но в словообразовательном отношении
ведут себя как приставки: при постфиксации
(т. е. образовании нового слова только
при помощи постфикса: мыть – мыться,
учить — учиться) присоединяются ко
всему слову в целом и не изменяют его
частеречной принадлежности. Глаголы
остаются глаголами, местоимения –
местоимениями (начинать – начинаться,
какой – какой-либо).
е. образовании нового слова только
при помощи постфикса: мыть – мыться,
учить — учиться) присоединяются ко
всему слову в целом и не изменяют его
частеречной принадлежности. Глаголы
остаются глаголами, местоимения –
местоимениями (начинать – начинаться,
какой – какой-либо).
Присоединение постфикса к слову приводит к образованию прерывистой основы: что-то, начинается.
С суффиксами постфикс, кроме места в слове, сближает и поведение в смешанных способах словообразования, где в качестве словообразовательного средства выступает не только постфикс, но и суффикс. В таком случае постфикс присоединяется не к слову в целом, а к основе и изменяет частеречную принадлежность и грамматические свойства слова.
Например, от сущ-го колоспутем прибавления к нему суффикса–и-и постфикса–сяобразуется глаголколоситься.Так же образован глаголскупиться, а глаголприземлиться образован с помощью сложного форманта, в состав которого входят приставка, суффикс и постфикс.
Морфологический разбор слов ночующий и белеющих
Его слова следует понимать двояко.
Собравшись вдесятером, ребята отправились в турпоход.
2. Какой-либо человек,мог выйти из этого крыла.
3.Несколько девушек видели,как Иосив наблюдал за птицей.
4.Некто по имени Мария,не имела ни малейшего шанса увидеть актрису.
5.Он просил хоть сколько-нибуть денег,на рубашку для отца.
6.Некоторый из толпы,был против такого решения.
7.Что-то не совсем разумное,заставило его оставить свою любовь.
Гроздь так как это слово женского рода а остальные-мужского
Лиза вспыхнула, лицо покрылось, она сделала. [- =, — =, и — =]
[- =, — =, и — =]
Стало, не дрожать, Максим уговаривал
[=, =], [- =: — =, -, — -]
Не уверена что правильно
Я учусь в 9 классе , изучаю много интересных предметов . Преподают эти предметы нам учителя . Но среди них у меня есть любимая учительница , ее зовут Татьяна Александровна . Я очень люблю слушать ее уроки . Стараюсь всегда быть подготовленной к уроку . Татьяна Николаевна ведёт русский язык и русскую литературу , она очень доступно и понятно объясняет темы . Приводит очень легкие и понятные примеры . По литературе Татьяна Николаевна задаёт нам самые интересные рассказы , красивые стихи известных писателей , рассказывает нам их биографии … Татьяна Николаевна мой любимый учитель ( или можно » моя любимАЯ учительница )
я постаралась , так как ничего не знаю о ней )) Если не очень скажи . ок ?
просто я в 6 классе , может надо было какими-то другими словами
Morpheme — обзор | Темы ScienceDirect
3 Предварительная обработка документа
Мы начинаем этот раздел с определения терминологии. Индексирование — это процесс создания как представления для документов, так и связанных структур данных для хранения и извлечения представления. Именно это представление используется для определения релевантности документа запросу пользователя. Например, инвертированный индекс — одно из таких представлений (обсуждается в разделе 6).
3.1 Гранулярность документа
Первой задачей IR-системы является предварительная обработка документов. В этом контексте мы рассматриваем следующие вопросы: детализация документа, токенизация и нормализация. Напомним, что основная цель IR-системы — извлекать соответствующие документы по запросу пользователя из большой коллекции документов. Что такое документ? Считается ли вся книга одним документом? Или каждая глава книги — это документ? В качестве другого примера рассмотрим цепочку сообщений электронной почты.Является ли вся цепочка одним документом или каждое электронное письмо в цепочке — отдельным документом? Понятие документа важно почти для всех IR-систем, таких как Elasticsearch (Gheorghe et al., 2015). Каждому документу присваивается уникальный идентификатор, и он образует базовую единицу с точки зрения поиска. Исключением является система Wumpus IR (Университет Ватерлоо, 2018), которая рассматривает всю коллекцию документов как один мегадокумент, а каждый отрывок в мегадокументе является единицей текста для поиска.Для других документов, таких как статьи журнала, каждый компонент документа — заголовок, аннотация, ключевые слова и остальная часть статьи — представляет собой отдельную единицу для поиска. Это позволяет осуществлять выборочный поиск по заголовку, аннотации или основной части статьи.
Что такое документ? Считается ли вся книга одним документом? Или каждая глава книги — это документ? В качестве другого примера рассмотрим цепочку сообщений электронной почты.Является ли вся цепочка одним документом или каждое электронное письмо в цепочке — отдельным документом? Понятие документа важно почти для всех IR-систем, таких как Elasticsearch (Gheorghe et al., 2015). Каждому документу присваивается уникальный идентификатор, и он образует базовую единицу с точки зрения поиска. Исключением является система Wumpus IR (Университет Ватерлоо, 2018), которая рассматривает всю коллекцию документов как один мегадокумент, а каждый отрывок в мегадокументе является единицей текста для поиска.Для других документов, таких как статьи журнала, каждый компонент документа — заголовок, аннотация, ключевые слова и остальная часть статьи — представляет собой отдельную единицу для поиска. Это позволяет осуществлять выборочный поиск по заголовку, аннотации или основной части статьи.
Точность и отзыв — два параметра эффективности поиска. Точность относится к тому, сколько из извлеченных документов актуально для пользователя, тогда как отзыв относится к тому, какая часть извлеченных релевантных документов в коллекции. Степень детализации индексирования относится к размеру / компоненту документа, выбранному для индексирования. Если степень детализации индексации высокая (например, вся книга рассматривается как один документ), это может привести к увеличению количества ложных срабатываний (т. Е. Низкой точности). С другой стороны, если детализация документа слишком велика, это повлечет за собой низкий уровень отзыва. Это связано с тем, что важные отрывки будут упущены, поскольку термины словаря отрывка разделены по мини-документам.
3.2 Токенизация
Документ рассматривается как последовательность байтов.В кодировке ASCII используется один байт на символ, и этого достаточно для английского языка. Другие схемы кодирования, такие как Unicode UTF-8, используют от одного до четырех байтов для представления 1112 064 различных кодов для размещения символов на всех письменных языках. Маркер соответствует последовательности байтов. Например, в «семи чудесах света» пять жетонов, и каждый жетон разного типа. С другой стороны, в «быть или не быть» есть семь токенов, но только пять различных типов токенов.Типы токенов «to» и «be» имеют по два экземпляра. Обратите внимание, что «,» — это знак препинания. Демаркация токенов на основе пробелов работает на таких языках, как английский. Даже в этих языках возникают проблемы, когда фразы типа «Нью-Йорк» и «Северная Каролина» сегментируются. Эти фразы следует сегментировать как отдельные токены. Правила, зависящие от языка, эффективны при распознавании однолинейных фраз. Во многих других языках составные слова изобилуют, и разделение их на отдельные токены нетривиально.Текст «Aliikusersuillammassuaanerartassagaluarpaalli» с западно-гренландского языка переводится как «Однако они скажут, что он великий артист, но…». Это типично для полисинтетических языков, где несколько морфем (то есть наименьшие единицы значения в языке) соединяются вместе, чтобы образовать более крупные слова.
Маркер соответствует последовательности байтов. Например, в «семи чудесах света» пять жетонов, и каждый жетон разного типа. С другой стороны, в «быть или не быть» есть семь токенов, но только пять различных типов токенов.Типы токенов «to» и «be» имеют по два экземпляра. Обратите внимание, что «,» — это знак препинания. Демаркация токенов на основе пробелов работает на таких языках, как английский. Даже в этих языках возникают проблемы, когда фразы типа «Нью-Йорк» и «Северная Каролина» сегментируются. Эти фразы следует сегментировать как отдельные токены. Правила, зависящие от языка, эффективны при распознавании однолинейных фраз. Во многих других языках составные слова изобилуют, и разделение их на отдельные токены нетривиально.Текст «Aliikusersuillammassuaanerartassagaluarpaalli» с западно-гренландского языка переводится как «Однако они скажут, что он великий артист, но…». Это типично для полисинтетических языков, где несколько морфем (то есть наименьшие единицы значения в языке) соединяются вместе, чтобы образовать более крупные слова.
Другие проблемы токенизации включают работу с апострофами (например, O’Brian, Carolina’s), сокращениями (I’ll) и словами, написанными через дефис (now-a-days). Акронимы также создают проблемы (У.S.A / США, Лос-Анджелес / Лос-Анджелес, Луизиана / Лос-Анджелес). Нормализация токенов относится к канонизации токенов, чтобы совпадения происходили, несмотря на внешние различия (Manning et al., 2008). Нормализация токенов также называется классификацией эквивалентности токенов . Например, различные формы даты, такие как 04/01/2018, 2018/04/01 и 4 апреля 2018 года, обозначают одну и ту же дату и, следовательно, являются членами одного класса эквивалентности. Для определения классов эквивалентности используются правила сопоставления, зависящие от домена.В качестве альтернативы, отношений между ненормализованными токенами поддерживаются с использованием составленного вручную списка синонимов. Например, синонимы слова «ускорять» включают в себя «продвигаться», «ускорять», «спешить», «спешить», «ускорять», «шагать вперед» и «стимулировать». Предположим, что термин ускорять встречается в документе d 1 . Этот термин в ненормализованной форме используется для индекса d 1 . Также предположим, что пользователь выдает запрос, который содержит только термин , ускорить .IR-система может добавлять дополнительные термины в список синонимов , ускорять к первоначальному запросу, и запрос обрабатывается как дизъюнкция синонимов. То есть расширенный запрос: ускорить или ускорить или продвинуть или спешить или спешить или ускорить или увеличить или стимулировать. Альтернативой расширению запроса является индексирование d 1 с использованием термина ускорять , а также всех терминов в его списке синонимов — продвигать, ускорять, ускорять, спешить, ускорять, повышать и стимулировать.
Например, синонимы слова «ускорять» включают в себя «продвигаться», «ускорять», «спешить», «спешить», «ускорять», «шагать вперед» и «стимулировать». Предположим, что термин ускорять встречается в документе d 1 . Этот термин в ненормализованной форме используется для индекса d 1 . Также предположим, что пользователь выдает запрос, который содержит только термин , ускорить .IR-система может добавлять дополнительные термины в список синонимов , ускорять к первоначальному запросу, и запрос обрабатывается как дизъюнкция синонимов. То есть расширенный запрос: ускорить или ускорить или продвинуть или спешить или спешить или ускорить или увеличить или стимулировать. Альтернативой расширению запроса является индексирование d 1 с использованием термина ускорять , а также всех терминов в его списке синонимов — продвигать, ускорять, ускорять, спешить, ускорять, повышать и стимулировать.
3.3 Выделение корней и лемматизация
Морфология — это изучение слов, их образования и их взаимосвязи с другими словами того же языка. Есть два типа морфологии — словоизменительная и деривационная. Флективная морфология производит разные формы одного и того же слова, а не разные слова. Флективные категории включают, среди прочего, число, время, личность, падеж, пол. Например, листья производятся из листа, и как исходное, так и новое слово принадлежат к одной и той же категории слов — существительным.Напротив, словообразовательная морфология часто включает добавление словообразовательных аффиксов, а аффиксирование влечет за собой разные категории для новых слов. Например, суффикс «-ive» изменяет слово select на selected .
Другие подходы к классификации эквивалентности включают выделение корней и лемматизацию. Stemming — это грубый эвристический процесс, который сворачивает словообразовательно связанные слова до их основы, основы или корневой формы. Есть два вида стеммеров: алгоритмические и словарные.Алгоритмические основы слова (например, Портера) применяют набор правил для сведения слова к его основной форме. В отличие от этого, словарный стеммер просматривает словарь, чтобы найти основу для данного слова. Учитывая предложение «Другие подходы к классификации эквивалентности включают основание и лемматизацию», алгоритм Портера сводит его к следующей форме: Другой подход к эквивалентному классу включает основание и леммат . Лемматизация включает в себя полный морфологический анализ слов, чтобы свести флективно связанные, а иногда и деривационно связанные формы к их базовой форме — лемме.То же предложение в приведенном выше примере сводится к следующей форме посредством лемматизации: Другой подход к классу эквивалентности включает выделение корней и лемматизацию . И стемминг, и лемматизация помогают улучшить запоминание, снижая точность.
Есть два вида стеммеров: алгоритмические и словарные.Алгоритмические основы слова (например, Портера) применяют набор правил для сведения слова к его основной форме. В отличие от этого, словарный стеммер просматривает словарь, чтобы найти основу для данного слова. Учитывая предложение «Другие подходы к классификации эквивалентности включают основание и лемматизацию», алгоритм Портера сводит его к следующей форме: Другой подход к эквивалентному классу включает основание и леммат . Лемматизация включает в себя полный морфологический анализ слов, чтобы свести флективно связанные, а иногда и деривационно связанные формы к их базовой форме — лемме.То же предложение в приведенном выше примере сводится к следующей форме посредством лемматизации: Другой подход к классу эквивалентности включает выделение корней и лемматизацию . И стемминг, и лемматизация помогают улучшить запоминание, снижая точность.
3.4 Стоп-слова, акценты, складывание регистра и определение языка
Стоп-слова — это грамматические функциональные слова, например, a, an и, be, int, not, of, off, over, out, to, the, and under. Ранняя система IR отбрасывала стоп-слова, поскольку они не несут содержания и существуют только для удовлетворения грамматических требований.Если стоп-слова удалены, такие фразы, как «быть, а не быть, вот в чем вопрос», не будут правильно проиндексированы. Кроме того, для запросов фраз (раздел 6) наличие стоп-слов способствует лучшему запоминанию. Современные IR-системы, включая поисковые системы, не исключают из индексации стоп-слова.
Акценты и диакритические знаки могут игнорироваться в английском тексте, но они могут иметь большое значение для поиска на других языках, таких как испанский. Складывание ящика — еще одна задача нормализации.Слова в начале предложения могут быть в нижнем регистре без последствий для поиска. Однако термины в середине предложения следует писать с заглавной буквы. Аналогичные проблемы возникают с аббревиатурами.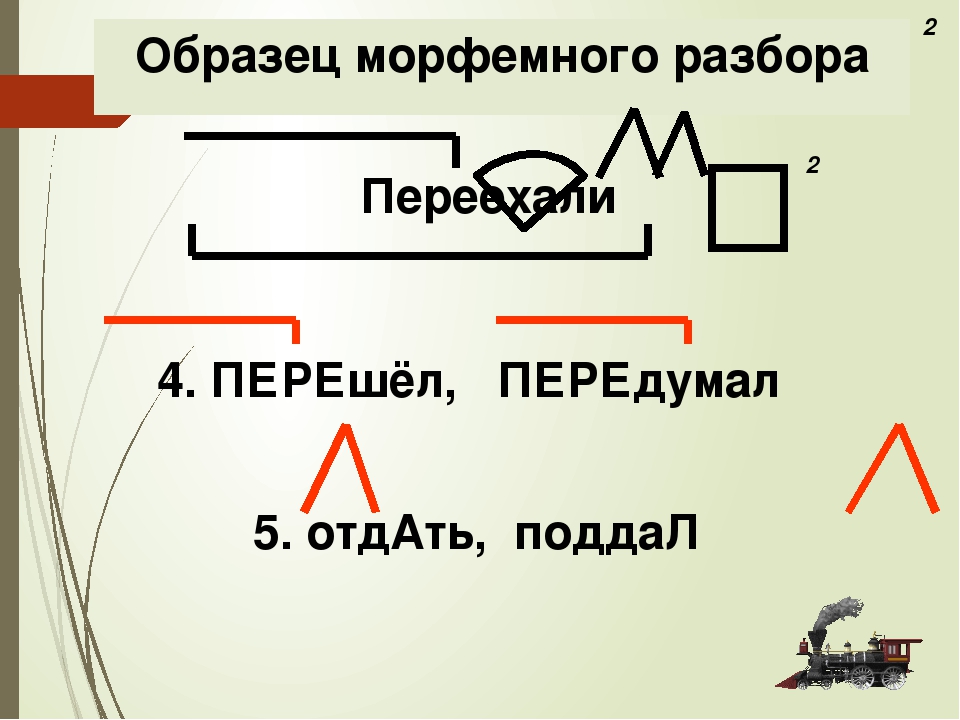 Для таких приложений, как поисковые системы в Интернете, перевод всего в нижний регистр является прагматичным решением, поскольку пользователи практически не используют заглавные буквы в своих запросах.
Для таких приложений, как поисковые системы в Интернете, перевод всего в нижний регистр является прагматичным решением, поскольку пользователи практически не используют заглавные буквы в своих запросах.
Системы написания языков также создают проблемы для извлечения токенов. В некоторых системах письма одни читают слева направо, в других — справа налево и смешанно (как слева направо, так и справа налево), а в третьих.Хотя большинство документов в Интернете написано на английском языке, в последнее время все большее распространение получают веб-документы, написанные на других языках. В таких случаях первая задача — определить язык документа — идентификацию языка (LID). Короткие последовательности символов служат отличительными образцами подписи для задачи LID. Проблема LID была решена с высокой степенью точности как проблема классификации с использованием подходов контролируемого машинного обучения. Однако документы на разных языках, в которых смешана небольшая часть слов из другого языка, могут создавать проблемы для LID.
Прогнозный подход в JSTOR
Abstract В этой статье мы представляем эффективную модель морфологического анализа корейского языка, которая производит все возможные последовательности морфем данного входного слова. Эта модель детерминирована в применении правил орфографии и работает с небольшой вычислительной избыточностью при обработке сложных и неоднозначных слов. Вычислительная эффективность стала возможной благодаря трем новым методам: во-первых, метод интерпретации и составления правил орфографии; во-вторых, приложение правил прогнозирования, которое ограничивает правила написания, подходящие для входного слова; в-третьих, синтаксический анализ морфологической диаграммы, который позволяет анализатору избежать повторного вычисления анализируемых подстрок в случае, если входное слово морфологически неоднозначно.Наша модель была протестирована со словами, отобранными из корпуса корейских начальных учебников. Результаты экспериментов показывают, что наша модель гарантирует быструю и надежную обработку.
Результаты экспериментов показывают, что наша модель гарантирует быструю и надежную обработку.
Изучение языков Восточной Азии, особенно китайского, японского и корейского, существует уже давно как область, о чем свидетельствует наличие программ в большинстве высших учебных заведений и исследовательских программ, которые включают эти языки в качестве основных. составная часть.Люди, говорящие на этих трех языках, в процессе развития своих языков разделили значительную часть лингвистического наследия благодаря культурным контактам, в дополнение к возможной генеалогической связи. Соответственно, эти языки обладают различными общими чертами. Еще один важный фактор, который связывает их вместе как область, заключается в том, что они разделяют общую традицию лингвистических исследований, традицию, которая отличается от изучения западных языков. Вопреки этой традиции, многие недавние работы подошли к этим языкам с более широкой точки зрения за пределами области, рассматривая их в контексте общих теоретических исследований, открывая новые возможности для старых проблем в этой области и способствуя текущим вопросам лингвистической теории.Но у ученых, работающих с таким подходом, по-прежнему есть веские причины проявлять особый интерес к работе друг друга. Область теоретической восточноазиатской лингвистики быстро растет, особенно с учетом количества последних теоретических работ по этим языкам. Цель Журнала восточноазиатской лингвистики — предоставить общий форум для такой научной деятельности и способствовать дальнейшему развитию, который позволит этой области больше извлекать пользу из лингвистической теории сегодняшнего дня и позволит языкам играть более важную роль в формирование лингвистической теории завтрашнего дня.
Информация об издателе Springer — одна из ведущих международных научных издательских компаний, издающая более 1200 журналов и более
3000 новых книг ежегодно, охватывающих широкий круг предметов, включая биомедицину и науки о жизни, клиническую медицину,
физика, инженерия, математика, компьютерные науки и экономика.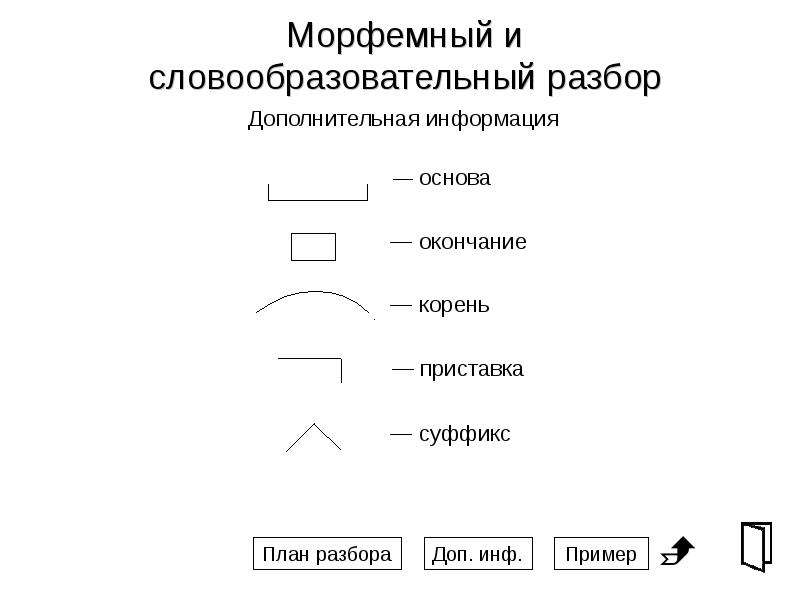
определение морфемы по Медицинскому словарю
Это можно рассматривать как свидетельство того, что в этих школьных классах у ребенка достаточно опыта чтения, чтобы во время чтения разложить слова на их морфемические компоненты.Только два исследования словарного запаса включали как словарный запас, так и показатель понимания прочитанного, а величина эффекта для студентов, получивших комбинацию инструкций по морфемному и контекстному анализу, варьировалась от -0,004 до -0,16, в результате чего практически не оказывалось никакого эффекта на понимание текста (Baumann et al., 2002; Baumann et al., 2003) Таким образом, на каждом уровне языка, фонетическом, морфемическом, синтаксическом, семантическом, прагматическом и т. Д., Наиболее вероятно, существует по крайней мере две строки информации, одна константа, одна экспоненциально возрастающая (см. показатель степени в логарифме), сами уровни чередуются по форме и содержанию (за исключением прагматического уровня, где форма и значение сливаются вместе, создавая лингвистический эффект): такие дифтонги не включены в список гласных хиндко, потому что они не являются отдельными фонемами, так как большинство из них возникают из-за морфемических операций при определенных условиях или в результате из-за каких-либо elisi о процессе, как показано ниже: Один генеративный подход, который потенциально может быть использован для обучения словарного запаса, необходимого учащимся с ограниченными возможностями обучения (LD) для того, чтобы выучить значение тысяч слов, называется инструкцией по морфемному анализу (Blachowicz & Fisher, 2000). ; Эбберс и Дентон, 2008 г .; Могилы, 1986; Надь и Скотт, 2000).Таким образом, в морфемном анализе это слово обозначается как морфема неединичного агента. Ключевые слова: переключение кода, соглашение, урду / хинди-английский, внутриклаузальный, внутрифразовый, морфемический. Глубина знания слов включает в себя все характеристики слова, такие как фонематические, графемные, морфемические, синтаксические, семантические, словосочетания и фразеологические свойства (Quian, 2002). Кроме того, жизненно важны наши убеждения, которые иногда составляют нашу идентичность, а также нашу систему ценностей нашему существованию, что отсутствие структурированного языка с «его семантическими, синтаксическими, фонетическими, морфемическими и семиотическими измерениями» (Ozumba 2004: 18) может испортить его существование, непрерывность и даже его значимость.лексический анализ, морфемы и морфемный анализ. Никакой фонематический, морфемный, синтаксический или семантический анализ любого высказывания не описывает работу языка в мозгу, так же как разложение события на секунды, минуты и часы отображает работу времени в мозгу. В таких случаях изучающий язык навязчиво прибегает к смене выражения, от морфемного до текстового.
Кроме того, жизненно важны наши убеждения, которые иногда составляют нашу идентичность, а также нашу систему ценностей нашему существованию, что отсутствие структурированного языка с «его семантическими, синтаксическими, фонетическими, морфемическими и семиотическими измерениями» (Ozumba 2004: 18) может испортить его существование, непрерывность и даже его значимость.лексический анализ, морфемы и морфемный анализ. Никакой фонематический, морфемный, синтаксический или семантический анализ любого высказывания не описывает работу языка в мозгу, так же как разложение события на секунды, минуты и часы отображает работу времени в мозгу. В таких случаях изучающий язык навязчиво прибегает к смене выражения, от морфемного до текстового.Извлечение морфем и лемматизация для тамильского языка с использованием машинного обучения
слово в предложении нетривиально, так как, например, глагольные вставки
для маркеров времени и человеко-число-пол отличаются от
, как и существительные в выражениях для числа и case, с
необязательными модификациями в корневых окончаниях.Морфологический анализатор
должен обрабатывать изменения правописания, которые могут произойти
из-за присоединения морфемы.
Для разработки морфологических анализаторов на разных языках приняты разные методологии. Конвенция
, основанная на теоретических правилах, в основном используется для разработки системы морфологического анализатора
. В настоящее время для решения морфологической задачи анализатора
внедрены статистические методы
.Например, тайский морфологический анализ
, основанный на теоретических основах Conditional Ran-
dom Fields (CRF), формулирует несегментированный язык как
— задачу последовательного обучения с учителем [15]. Обучение на основе памяти
было успешно применено для морфологического анализа
в западных и восточноевропейских языках [6].
Обучение на основе памяти — это класс индуктивного контролируемого алгоритма обучения ma-
, который учится, сохраняя в памяти примеры
задачи. Морфологический анализатор на основе корпуса
Морфологический анализатор на основе корпуса
для невокализованного современного иврита разработан путем объединения статистических методов
с синтаксическим анализом на основе правил [13].
Джон Голдсмит (2001) [12] показывает, как основы и метки
могут быть выведены из большого неотмеченного корпуса. Для анализа морфологии древнегреческого языка используется метод Data-
[4].
Акшар Бхарати и др. (2001) [5] разработали алгоритм для
неконтролируемого обучения морфологическому анализу и генерирования функционально насыщенных языков
.Этот алгоритм использует частоту появления словоформ в исходном корпусе
. Un-
контролируемое обучение и морфологическое усвоение [21] из
текст также реализован для сильно измененного языка.
Различные методы были использованы для разработки morpho-
логических анализаторов для тамильского языка. Васу Ранганатан
(2001) [20] построил тамильский теггер, реализовав теорию лексической фонологии и морфологии
.Finite State Au-
томаты [24] [17] и подходы, основанные на парадигмах [23], были использованы для анализа морфологического паттерна тамильских слов.
Parameswari.K (2010) [18] разработал тамильский морфологический анализатор и генератор
cal, используя набор инструментов APERTIUM.
Ganesan (2007) [10] разработал морфологический анализатор для
Tamil для анализа корпуса CIIL. При построении логического анализатора morpho-
для тамильского языка учтены фонологические и морфо-
фонематические правила.K.Rajan и др. (2009) [19] разработали
применили неконтролируемый подход к сегментированию тамильских морфем
с использованием подхода, основанного на буквенных преемниках (LSV) и N-грамм
. Ананд Кумар и др. [2] разработали новый подход к изучению последовательности
для тамильского морфологического анализатора
.
3. КРАТКОЕ ОПИСАНИЕ ТАМИЛЬСКОГО
МОРФОЛОГИЯ
В тамильском языке каждый корень фиксируется несколькими морфемами, чтобы
генерировать слово. В общем, оно постпозиционно воздействует на корневое слово
В общем, оно постпозиционно воздействует на корневое слово
.Каждое корневое слово может принимать более десяти
тысяч измененных словоформ. Тамильский язык имеет как лексическую, так и функциональную морфологию
. Лексическая морфология
изменяет значение слова и его класс, добавляя к корню словообразовательные и сложные морфемы
.
Например, тамильское наречие ேவகமாக ‘vEkamAka’ (быстро)
образовано от существительного ேவக ‘vEkam’ (скорость) и морфемы
‘’. Интерактивная морфология изменяет форму
слова и добавляет дополнительную информацию к слову
, добавляя интерактивные морфемы к корню.Например,
, тамильское существительное ழைத ‘kuzawthaikku’ (ребенок) — это
, образованное от существительного ‘kuzawthai’ (ребенок) и морфемы
‘’.
Тамильские слова состоят из лексических корней, за которыми следует один
или более знаков. Лексические корни и аффиксы — это
наименьших значимых единиц, которые называются морфемами. Таким образом, тамильские слова
состоят из морфем, соединенных в серию
друг с другом. Первым в конструкции является
, всегда лексическая морфема (лексический корень).За этим может следовать или не следовать за
другие функциональные или грамматические фемы
. Например, слово ‘puththakangkaL’
(Книги) на тамильском языке можно осмысленно разделить на
‘puththakam’ и ‘க’ ‘kaL’. В этом примере தக
«puththakam» — это лексический корень, представляющий сущность
реального мира, а «kaL» — это маркер множественного числа (su ffi x).
க ‘kaL’ — грамматическая морфема, которая связана с лексическим корнем
, чтобы добавить множественность к лексическому корню.В отличие от En-
glish, тамильские слова могут иметь большую последовательность морфем.
Например,
தககைள ‘puththakangkaLai’ = தக ‘puththakam’
+ க ‘kaL’ + ஐ ‘ai’
Тамильские существительные могут принимать падежные суффикс после маркера множественного числа.
После этого они также могут иметь должности. Тамильские слова
состоят из лексического корня, к которому прикреплены один или несколько букв
. Большинство тамильских аффексов — суки. Тамильские суффиксы
могут быть деривациями, которые либо изменяют часть
речи слова или его значение, либо функциональные суффиксы
, которые отмечают такие категории, как личность, число, настроение, время
и т. Д.Слова могут быть проанализированы так же, как и слово выше
, путем идентификации составляющих морфем, и их особенности
могут быть идентифицированы. Суффиксы используются для выполнения функций
падежей или послелогов. Традиционные грамматики пытались сгруппировать различные суффиксы
в восемь падежей, соответствующих
падежам, используемым в санскрите. Это были именительный падеж, образный падеж
и дательный, социативный, родительный падеж, инструментальный падеж, местный падеж
и аблативный падеж.Различные формы тамильских существительных показаны
в Таблице 1. В таблице представлены единственная и множественная форма слова «எ» eli (крыса) с отметками
в единственном и множественном числе.
В тамильских глаголах используются суффиксы. Тамильские глаголы
могут иметь как конечные, так и не конечные формы. Конечные глагольные формы встречаются в
главном предложении предложения, а не конечные формы встречаются в
как сказуемое придаточных или вложенных предложений. Мор-
физиологически конечные глагольные формы влияют на время, наклонение, вид
, лицо, число и род.
Таблица 1: Знаки падежа существительных
Падеж Единственного числа Множественное число
Именительный падеж eli eli-kaL
Винительный падеж eli-ai eli-kaL-ai
Дательный падеж eli-uku eli-kaL-uku
uku eli-kaL-ukk-Aka
Instrumental eli-Al eli-kaL-Al
Sociative-Odu eli-Odu eli-kaL-Odu
Sociative-udan eli-udan eli-kaL-udan
Locative eli-il eli-kaL-il
Ablative eli-il-iruwthu eli-kaL-il-iruwthu
Родительный падеж eli-in-athu eli-kaL-in-athu
113
Совместные переходные модели для морфо-синтаксического анализа : Стратегии анализа MRL и пример современного иврита | Труды Ассоциации компьютерной лингвистики
Исследования НЛП в последние годы показали возрастающий интерес к синтаксическому анализу типологически различных языков, о чем свидетельствует, например, инициатива универсальных зависимостей 1 Nivre et al. (2016). В частности, большое внимание уделяется синтаксическому анализу морфологически богатых языков (MRL), которые существенно отличаются от английского по своей структуре и характеристикам (Tsarfaty et al., 2010).
(2016). В частности, большое внимание уделяется синтаксическому анализу морфологически богатых языков (MRL), которые существенно отличаются от английского по своей структуре и характеристикам (Tsarfaty et al., 2010).
В MRL грамматическая информация, обычно выражаемая с использованием порядка слов в английском языке, часто проявляется во внутренней сложной структуре слов. Слова в MRL могут содержать, помимо лексического содержания, функциональные аффиксы и клитики, которые соответствуют дополнительной информации.В современном иврите, например, глагол со склонением « ahbtih » 2 (любимый + 1pers.singular.past + 3pers.feminine.singular) соответствует трем различным грамматическим функциям: подлежащему «I», сказуемому «Любил» и прямой объект «ее». Точно так же испанский dámelo соответствует предикату, косвенному объекту и прямому объекту, например, «дай мне». Таким образом, в MRL морфологический анализ (MA), который переводит необработанные токены, разделенные пробелами, в синтаксически релевантные «словесные» единицы, является необходимым условием для любой синтаксической или семантической последующей задачи.
Однако необработанные токены с разделителями-пробелами в MRL часто очень неоднозначны. В иврите, арабском и других семитских языках ситуация осложняется еще и тем, что в письменных текстах отсутствуют диакритические знаки. Еврейский знак «fmn», , например, может быть прочитан как существительное «масло», прилагательное «жир», глагол «смазанный», последовательность «тот» + «из» или фраза «их». + «Имя», только одно из которых имеет отношение к в контексте .Это имеет явные последствия для синтаксического анализа зависимостей. На рисунке 1 показана решетка, которая отражает все возможные анализы еврейской фразы «bclm hneim», буквально: «в их тени — приятное», переведенное «в их приятной тени». Каждая дуга решетки соответствует потенциальному узлу в дереве зависимостей. Темными кружками отмечены границы морфем, двойные кружки — границы токенов. Верхнее дерево отображает правильный синтаксический анализ. В нижнем дереве неправильно разрешенные токены приводят к неправильному синтаксическому анализу.
Каждая дуга решетки соответствует потенциальному узлу в дереве зависимостей. Темными кружками отмечены границы морфем, двойные кружки — границы токенов. Верхнее дерево отображает правильный синтаксический анализ. В нижнем дереве неправильно разрешенные токены приводят к неправильному синтаксическому анализу.
Рисунок 1:
Морфологические и синтаксические взаимодействия при анализе фразы на иврите « bclm hneim » согласно аннотации SPMRL на иврите.
Рисунок 1:
Морфологические и синтаксические взаимодействия при анализе фразы на иврите « bclm hneim » согласно аннотации SPMRL на иврите.
Предыдущие кампании по оценке анализа зависимостей (Buchholz and Marsi, 2006; Nivre et al., 2007) предположили, что правильный морфологический анализ и устранение неоднозначности (MA&D) входного потока известны заранее. Однако в реалистичных сценариях сквозного анализа это, конечно, не так. Чтобы преодолеть это, были созданы конвейерные архитектуры, в которых MA&D предшествует синтаксическому анализу. Эти конвейеры неоптимальны, так как они страдают от распространения ошибок, и поскольку локальный линейный контекст, доступный для автоматической MA&D, может быть недостаточным для точного морфологического устранения неоднозначности.Для этого может потребоваться реальный синтаксический контекст (Царфаты, 2006). Чтобы разрешить эту очевидную петлю, в которой для синтаксического синтаксического анализа требуется морфологический анализ и , синтаксический анализ требуется для морфологического устранения неоднозначности , Царфати (2006) выдвинул гипотезу, что суставов морфосинтаксического анализа, где морфологическая информация может помочь в устранении синтаксической неоднозначности и наоборот. может быть лучше подходит.
Эта совместная морфосинтаксическая гипотеза была принята и успешно подтверждена в контексте синтаксического анализа фразовой структуры семитских языков (Goldberg and Tsarfaty, 2008; Cohen and Smith, 2007; Green and Manning, 2010). Для анализа зависимостей Bohnet and Nivre (2012) и Bohnet et al. (2013) представляют не зависящие от языка фреймворки на основе переходов для совместного синтаксического анализа и маркировки входных слов, но без решения сложной проблемы ретокенизации неоднозначных входных токенов. Совсем недавно Seeker и Centinoglu (2015) представили основанную на графах структуру для решетчатого синтаксического анализа турецкого языка, также охватывающую морфологическую сегментацию. В их системе используется подход «продукта экспертов», в котором морфологические пути и деревья зависимостей обрабатываются с помощью двух различных моделей (линейная модель над биграммами для MD и модель дугового фактора для зависимостей), достигая согласия через установку двойной декомпозиции.
Для анализа зависимостей Bohnet and Nivre (2012) и Bohnet et al. (2013) представляют не зависящие от языка фреймворки на основе переходов для совместного синтаксического анализа и маркировки входных слов, но без решения сложной проблемы ретокенизации неоднозначных входных токенов. Совсем недавно Seeker и Centinoglu (2015) представили основанную на графах структуру для решетчатого синтаксического анализа турецкого языка, также охватывающую морфологическую сегментацию. В их системе используется подход «продукта экспертов», в котором морфологические пути и деревья зависимостей обрабатываются с помощью двух различных моделей (линейная модель над биграммами для MD и модель дугового фактора для зависимостей), достигая согласия через установку двойной декомпозиции.
В этой работе мы представляем новую, не зависящую от языка, основанную на переходах структуру для сквозного морфосинтаксического анализа зависимостей. Платформа объединяет морфологический и синтаксический компоненты в общий синтаксический анализатор, охватывающий единую систему переходов, единую целевую функцию, совместное обучение и совместное декодирование. Мы применяем эту систему для анализа современного иврита и эмпирически подтверждаем, что прогнозирование MA&D в совместных настройках улучшается по сравнению с автономным MA&D и недавно опубликованными результатами MA&D на иврите.Наша система дополнительно улучшает результаты сквозного синтаксического анализа зависимостей по сравнению с существующими современными синтаксическими анализаторами в сценариях конвейера, она значительно превосходит совместный синтаксический анализатор Seeker и Centinoglu (2015) и значительно превосходит синтаксический анализатор зависимостей Голдберг и Эльхадад (2010) до сих пор считались стандартом де-факто для анализа зависимостей на иврите.
Таким образом, вклад этой статьи тройной. Во-первых, мы определяем не зависящий от языка морфосинтаксический синтаксический анализатор суставов во фреймворке на основе переходов. Во-вторых, мы эмпирически подтверждаем, что MA&D выигрывает от синтаксического анализа, а в реалистичных сценариях сквозного синтаксического анализа также и наоборот. Наконец, мы представляем новый набор сильных результатов сквозного синтаксического анализа иврита и предлагаем реализацию совместного синтаксического анализатора с открытым исходным кодом, не зависящую от языка, для дальнейшего исследования совместных стратегий морфосинтаксического синтаксического анализа. Эта статья организована следующим образом.В разделе 2 мы представляем нашу формальную структуру (2.1), морфологическую модель (2.2), синтаксическую модель (2.3) и совместную структуру (2.4). В разделах 3 и 4 представлены наши эксперименты и анализ соответственно. В Разделе 5 обсуждаются связанные и будущие работы, а в Разделе 6 подводятся итоги.
Во-первых, мы определяем не зависящий от языка морфосинтаксический синтаксический анализатор суставов во фреймворке на основе переходов. Во-вторых, мы эмпирически подтверждаем, что MA&D выигрывает от синтаксического анализа, а в реалистичных сценариях сквозного синтаксического анализа также и наоборот. Наконец, мы представляем новый набор сильных результатов сквозного синтаксического анализа иврита и предлагаем реализацию совместного синтаксического анализатора с открытым исходным кодом, не зависящую от языка, для дальнейшего исследования совместных стратегий морфосинтаксического синтаксического анализа. Эта статья организована следующим образом.В разделе 2 мы представляем нашу формальную структуру (2.1), морфологическую модель (2.2), синтаксическую модель (2.3) и совместную структуру (2.4). В разделах 3 и 4 представлены наши эксперименты и анализ соответственно. В Разделе 5 обсуждаются связанные и будущие работы, а в Разделе 6 подводятся итоги.
Мы приводим сквозной морфосинтаксический синтаксический анализ как функцию предсказания структуры F: X → Y, где x∈X — это последовательность необработанных входных токенов, а y∈Y — представление зависимости, где узлы в дереве соответствуют однозначным морфосинтаксические единицы мы обозначаем как морфем . 3
Мы предполагаем, что F реализован в структуре на основе переходов, дополненной методом прогнозирования структуры Zhang and Clark (2011). Начнем с совершенно общего определения переходной системы как четверной S = ( C , T , c s , C t ), с C — набор конфигураций, T — набор переходов, c s — функция инициализации и C t ⊂ C — набор конфигураций клемм. Затем мы определяем различные экземпляры S для различных ( морфологических, синтаксических, морфосинтаксических ) задач синтаксического анализа. В каждом экземпляре последовательность переходов y для x представляет собой последовательность конфигураций, которые получаются последовательным применением переходов t 1 … t n ∈ T . То есть, начиная с начальной конфигурации c 0 = c s ( x ), мы находим y = c 0 ,…, c n , что c i +1 = t i +1 ( c i ) и c n ∈ C т .Таким образом, каждые x изображают последовательность решений, которая создает достоверный анализ для x на соответствующем лингвистическом уровне.
Затем мы определяем различные экземпляры S для различных ( морфологических, синтаксических, морфосинтаксических ) задач синтаксического анализа. В каждом экземпляре последовательность переходов y для x представляет собой последовательность конфигураций, которые получаются последовательным применением переходов t 1 … t n ∈ T . То есть, начиная с начальной конфигурации c 0 = c s ( x ), мы находим y = c 0 ,…, c n , что c i +1 = t i +1 ( c i ) и c n ∈ C т .Таким образом, каждые x изображают последовательность решений, которая создает достоверный анализ для x на соответствующем лингвистическом уровне.
F (x) = argmaxy∈GEN (x) Оценка (y) = argmaxy∈GEN (x) Φ (y) ⋅ω → = argmaxy∈GEN (x) ∑cj∈y∑iωiφi (cj).
Для вычисления Score ( y ), y отображается в глобальный вектор признаков Φ ( y ) размера d , умноженный на вектор весов ω → того же размера. Глобальный вектор признаков Φ ( y ) состоит из локальных векторов признаков, каждый из которых определяется с помощью набора функций {φi: C → N} i = 1d, которые подсчитывают вхождения заранее заданного шаблона в данной конфигурации в y .Следуя Чжану и Кларку (2011), мы изучаем вектор весов ω → ∈Rd с помощью обобщенного персептрона , используя усредненный вариант раннего обновления Коллинза и Рорка (2004).
Декодирование основано на алгоритме поиска луча , в котором в луче поддерживается ряд последовательностей-кандидатов с высокими показателями, чтобы уменьшить безвозвратные ошибки прогнозирования, которые характеризуют процедуры жадного поиска.На каждом этапе система переходов применяет все переходы ко всем кандидатам и оставляет B кандидатов с наивысшей оценкой. Во время обучения алгоритм персептрона проходит через корпус с золотыми аннотациями. Каждое предложение анализируется (декодируется) с использованием последних известных весов, и если результат анализа отличается от золотого, веса обновляются. Обучение прекращается, когда начинается переобучение.
Наша отправная точка для морфологического устранения неоднозначности (MD) — это переходная система Мора и Царфати (2016), которая в настоящее время признана современной для ивритского MA&D. 4 Вход в систему представляет собой решетку L , которая фиксирует диапазон допустимых морфологических анализов для входных токенов x = x 1 ,…, x k , как показано в середине рисунка 1. Цель системы MD состоит в том, чтобы выбрать последовательность смежных дуг в L , которая представляет морфологическое устранение неоднозначности x в контексте.
Формально мы определяем для каждого токена x i его решетку-токен L i = MA ( x i ), где каждая решетка arc5 в L i соответствует потенциальному узлу в дереве зависимостей.Каждая дуга решетки имеет морфосинтаксическое представление (MSR), которое мы определяем как кортеж m = ( b , e , f , t , g ) с b и . e — индексы начала и конца в L , f — форма, t — тег части речи и g — набор грамматических свойств attribute: value. L = MA ( x ) — решетка предложений, полученная объединением решеток токенов сверху вниз L = MA ( x 1 ) ∘… ∘ MA ( x к ).Теперь L представляет собой полный спектр действительных морфологических анализов, применимых к x . 5
e — индексы начала и конца в L , f — форма, t — тег части речи и g — набор грамматических свойств attribute: value. L = MA ( x ) — решетка предложений, полученная объединением решеток токенов сверху вниз L = MA ( x 1 ) ∘… ∘ MA ( x к ).Теперь L представляет собой полный спектр действительных морфологических анализов, применимых к x . 5
MD: (L, p, i, M) → (L, q, j, M∪ {m}).
(1) Этот переход выбирает одну дугу решетки в заданной позиции.Теперь, если p — наше текущее положение в решетке, а m = ( p , q , f , t , g ) — выбранная дуга, тогда j = i + 1, если q находится на границе токена (двойной круг), и j = i , если это не так.
Набор конфигурации терминала определяется как C t = {( L , верх ( L ), | x |, M )}, где M = { м 1 , м 2 ,…., м l } содержит полностью устраненный путь от MSR (выбранных дуг) до L .
Чтобы найти этот путь на основе данных, мы определяем параметрическую модель, которая оценивает все переходы, которые могут быть применены на каждом шаге. Мы определяем свойства f (форма), t (тег pos), g (морфологический атрибут: пары значений), путь (путь в ранее устраненных неоднозначных решетках токенов) и морфов ( набор исходящих морфем текущего узла), и мы используем комбинации этих свойств униграммы, биграммы и триграммы в качестве функций для модели обучения. 6 Затем наш декодер поиска луча применяет в каждой точке решетки все возможные переходы и в этой точке выбирает кандидатов с наивысшей оценкой B . Те, которые не достигают отметки B , падают с балки.
Важно, | M |, количество дуг решетки в пути на каждом этапе, заранее неизвестно, так как различные решения по устранению неоднозначности между границами маркеров могут иметь разную длину пути.Это можно увидеть на решетке на рис. 1, где длина пути варьируется от 4 до 7 дуг. Это сложный вопрос, поскольку он нарушает основное предположение декодирования поиска луча — что количество переходов является детерминированной функцией входа и известно заранее. Такие несоответствия длины могут привести к предпочтению коротких последовательностей в луче из-за раннего достижения конечной цели или к предпочтению длинных последовательностей из-за искусственного завышения оценок на основе множества функций.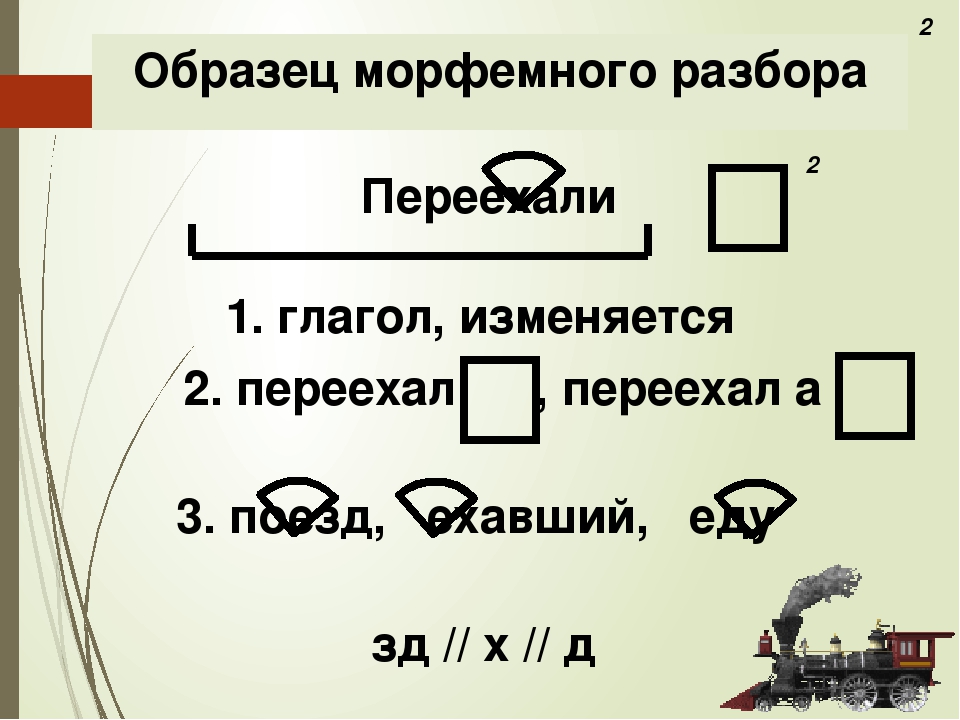
ET: (L, n, i, M) → (L, n, i + 1, M).
(2) В отличие от других переходов, ET имеет свой собственный набор функций (размером d ‘). Помимо увеличения i , ET вызывает переупорядочение кандидатов в луче на каждой границе маркера. Мор и Царфати (2016) показывают, что при использовании этого якоря особенности перехода ET обеспечивают противовес эффектам последовательностей различной длины и повышают точность MD на иврите. Последовательность перехода MD, таким образом, становится объединением непересекающихся наборов конфигураций y = y md ∪ y et , и Score ( y ) выглядит следующим образом, где ωjmdφmd конфигурации очков, полученные в результате переходов MD, а также ωjetφet для переходов ET:Score (y) = ∑i = 1dωimdφimd (ymd) + ∑j = 1d′ωjetφjet (пока)
= ∑ck∈ymd∑i = 1dωimdφimd (ck) + ∑cl∈yet∑j = 1d′ωjetφjet (cl).
(3) Учитывая последовательность выбранных дуг решетки для входной последовательности x , мы можем определить синтаксическое представление зависимости для x как дерево зависимостей, где каждая дуга решетки соответствует узлу в дереве зависимостей. Пусть R будет набором типов зависимости и пусть M = m 1 … m l будет последовательностью l дуг, выбранных компонентом MD. 8 Обозначим график зависимости для последовательности M = м 1 … м l как G M = ( V M , A M ), где V M — набор узлов, соответствующих дугам M и A M ⊆ V M × R × V M представляет собой набор маркированных дуг между элементами V M .
Конфигурация представляет собой частичный анализ входного предложения, где морфемы в стеке σ — это частично обработанные морфемы, морфемы в буфере β — это те, которые ожидают обработки, а набор дуг A представляет собой частично построенное дерево зависимостей (Kübler et al., 2009, глава 3). Если не указано иное, набор конфигураций клемм: C t = {( σ , β , A )}, где β = [] и | σ | = 1. 9
В литературе по синтаксическому анализу зависимостей для английского языка есть различные варианты определения переходов по таким конфигурациям. В частности, три системы перехода были успешно применены к английскому, а также к другим языкам (см. Ballesteros and Nivre [2016]):
Arc Standard: Простой метод пошагового увеличения слева направо снизу вверх. синтаксический анализ, предложенный в Nivre (2004).Мы принимаем определение Кюблера и др. (2009).
Arc Eager: Следуя Abney и Johnson (1991), Arc Eager определяет вариант Arc Standard, который позволяет легко прикреплять правого иждивенца к его голове, позволяя присоединяться к нему большему количеству иждивенцев.
 Мы принимаем определение Кюблера и др. (2009).
Мы принимаем определение Кюблера и др. (2009).Arc (Z) Eager: При воспроизведении современных результатов, представленных Zhang и Nivre (2011) для английского языка, мы обнаружили в коде вариант Arc Eager, который мы называем Arc (Z) Eager, который имеет интересные тонкие вариации от Arc Eager, включая второй стек, содержащий головные узлы, и определенные жесткие ограничения на применение нескольких переходов. 10
 Мы принимаем определение Кюблера и др. (2009).
Мы принимаем определение Кюблера и др. (2009).Эмпирическое исследование, проведенное Nivre (2008), сравнивает производительность Arc Standard и Arc Eager для 13 языков, среди которых арабский и турецкий, оба считаются MRL с некоторой степенью свободы порядка слов. Для этих языков Arc Standard немного превзошел Arc Eager. С другой стороны, наши предварительные эксперименты с английским и ивритом показывают, что вариант Arc ZEager всегда превосходит Arc Eager.Однако вопрос, какой из двух, Arc-Standard или Arc-ZEager, больше подходит для синтаксического анализа иврита, остается открытым для нашего эмпирического исследования в разделе 3.
Существенным вкладом Zhang и Nivre (2011) является их предложение набора из богатых нелокальных функций (RNF) для Arc ZEager, добавление информации более высокого порядка, ранее обнаруживаемой только в анализаторах на основе графов. Чтобы облегчить справедливое сравнение Arc Standard и Arc (Z) Eager, мы должны адаптировать набор функций Zhang and Nivre (2011) к другой системе дуги (насколько это возможно) и к другому типу языка. .В частности, набор RNF зависит от порядка слов за счет явного кодирования направления дуги. Мы обращаемся к зависимости RNF от порядка путем определения параллельного набора функций, который подходит для более гибкого порядка слов в MRL и применим к Arc-Standard. Мы называем этот набор функций rich linguistic features (RLF). Суть этих двух наборов функций одинакова, но мы заменяем функции, основанные на позициях узлов, на функции, основанные на , помеченных грамматическими функциями этих узлов. 11
Суть этих двух наборов функций одинакова, но мы заменяем функции, основанные на позициях узлов, на функции, основанные на , помеченных грамматическими функциями этих узлов. 11
Для построения наших характеристик мы определяем свойства, которые фиксируют лингвистическую информацию выборочных предпочтений и фреймов подкатегории (Tesnière, 1959; Chomsky, 1965). Чтобы захватить распределительную характеристику кадров субкадра, мы определяем sf p как мультимножество тегов части речи зависимых от данной головы.Чтобы захватить функциональную характеристику кадров субкадра, мы определяем sf f , ссылаясь на мультимножество функциональных меток всех зависимых от данной головки. Для валентности мы определяем свойства v sf , относящиеся к количеству иждивенцев данной главы. Для захвата предпочтений выбора в средах с гибким порядком слов мы определяем не зависящие от порядка двухкомпонентные признаки меченой зависимости, генерируемые отдельно для каждого зависимого.
Наконец, мы дополняем синтаксические особенности морфологическими свойствами. Наш оператор дополнения позволяет создавать несколько экземпляров одного и того же объекта с морфологическими свойствами и без них.
Учитывая наши морфологические и синтаксические компоненты, мы стремимся к такой интеграции, чтобы морфологическая информация способствовала устранению синтаксической неоднозначности и наоборот.
Мы предлагаем буквально встроить две автономные конфигурации в единую конфигурацию, а для применения переходов с помощью согласованной логики мы называем стратегию , которая выбирает, какой процессор применять в данном состоянии.
cj = (cmd, cdep) = ((L, n, i, M), (σ, β, A)).
(4)Мы инициализируем встроенную конфигурацию MD c md с функцией инициализации системы перехода MD, как определено в разделе 2.2, но оставляем c dep пустым, с σ = β = [] пустой стек и буфер.Также, как и раньше в c dep , A = ∅ . Конфигурация c j является терминальной тогда и только тогда, когда c md и c dep являются конфигурациями терминала своих соответствующих систем.
Пусть T = (Tmd, Tdep) — пара наборов переходов системы переходов MD и анализа зависимостей, соответственно, пусть C = {Cmd, Cdep} содержит наборы возможных нетерминальных конфигураций, и пусть Ct = {Ctmd , Ctdep} содержат соответствующие наборы конфигураций терминала.Совместная стратегия — это функция, которая, учитывая нетерминальную конфигурацию сустава, выбирает ровно одну систему перехода для воздействия: В MRL токены вне словарного запаса (OOV) представляют собой серьезную проблему для синтаксического анализа. Необработанный токен мог не наблюдаться во время обучения, хотя все его морфемы наблюдались в других контекстах. Чтобы оценить влияние таких элементов OOV на качество синтаксического анализа иврита, мы оцениваем систему в двух разных сценариях. В первом сценарии с добавлением мы проверяем, что каждая решетка содержит морфологический анализ золота. То есть, если золотой путь отсутствует в L = MA ( x ) (следовательно, OOV), мы автоматически вливаем золотой путь в L . Мы сравниваем это с несвязанными сценариями , где мы используем реалистичный морфологический анализатор с его (неполным) лексическим охватом как есть, в соответствии с Adler and Elhadad (2006).
В первом сценарии с добавлением мы проверяем, что каждая решетка содержит морфологический анализ золота. То есть, если золотой путь отсутствует в L = MA ( x ) (следовательно, OOV), мы автоматически вливаем золотой путь в L . Мы сравниваем это с несвязанными сценариями , где мы используем реалистичный морфологический анализатор с его (неполным) лексическим охватом как есть, в соответствии с Adler and Elhadad (2006).
Во всех экспериментах мы использовали луч размером 64, который в наших предварительных экспериментах на dev дал лучшие результаты для совместных моделей, чем луч 32, и в любом случае не хуже, чем луч 128.Чтобы избежать переобучения и недообучения, мы определяем условие остановки для процедуры обучения, которое мы тестируем на каждой итерации обучения. Во время обучения мы используем скользящее окно из трех итераций и выбираем первую модель, которая предшествует двум последовательным падениям оценок при разработке.
Для моделей конвейера мы тестируем различные условия остановки для морфологической и синтаксической моделей, каждая из которых основана на своих собственных автономных оценках.Для совместных моделей мы проверяем условие остановки относительно единой общей зависимости F 1 балла, которую мы вскоре определим.
Оценка совместной морфо-синтаксической зависимости при синтаксическом анализе производительности является нетривиальной задачей, потому что золотые деревья и деревья синтаксического анализа могут иметь разное количество узлов, что исключает применение стандартных оценок привязанности; достаточно, чтобы некорректная сегментация произошла в начале последовательности, тогда отдельные индексы в оставшейся части предложения считают остальные дуги неверными (Царфати и др. , 2012).
, 2012).
Проиллюстрируем этот эффект. Рассмотрим фразу на иврите « бит » (в переводе «в доме»), которая появляется как один символ, разделенный пробелами. Теперь рассмотрим две следующие альтернативы MD, с скрытым определенным артиклем на иврите и без него. Мы также включаем сюда индексы неоднозначных морфем в их линейном порядке:
Далее предположим, что оба дерева зависимостей Gold и Predicted содержат правильных дуг зависимости между b («in») и бит («house») с меткой pobj .Проще говоря, дуги, которые будут сравниваться с целью оценки:
Gold Dep: pobj (1,3), det (3,2)
Predicted Dep: pobj ( 1,2).
Таким образом, предсказанная дуга pobj будет считаться ошибкой, даже если соотношение между формами правильное, и, соответственно, UAS и LAS будут равны 0.
Чтобы решить эту проблему, мы определяем меру точности F 1 по отношению к формам ребер дуги, а не их индексам узлов .Формально пусть M p будет прогнозируемым морфологическим разрешением x , а A p будет прогнозируемым деревом зависимостей для M p . Аналогично, пусть M g , A g будет золотым стандартом морфологического разрешения неоднозначности и дерева зависимостей x . Теперь заменяем индекс каждого узла в дугах A p , A g с формой соответствующей морфемы в M p и M г . Пусть J p , J g будет основанными на форме (а не на основе индексов) дугами предсказанного и золотого представлений x . Мы сообщаем как о маркированном, так и о немаркированном F 1 как: 15
Пусть J p , J g будет основанными на форме (а не на основе индексов) дугами предсказанного и золотого представлений x . Мы сообщаем как о маркированном, так и о немаркированном F 1 как: 15 Pr = | Jp∩Jg || Jp |; Re = | Jp∩Jg || Jg |; F1 = 2 × Pr × RePr + Re.
В нашем примере измененные дуги теперь будут:Gold Dep: pobj (b, bit), det (bit, h)
Predicted Dep: pobj (b, bit).
Теперь синтаксическому анализатору будет засчитано, что он правильно определил дугу pobj , по желанию, и оценки зависимости будут: Pr = 1, Re = 0,5 и F 1 = 0,67.
Таблица 4:Совместный морфо-синтаксический анализ набора для современного иврита с незаплавленных (реалистичных) решеток.
| Стратегия . | Система . | MD F 1 Полный / POS . | Dep F 1 Без / с маркировкой . | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Автономный | M&T 2016 | 84,89 / 87,53 | н / п / н / д | ||||||||||||
| Трубопровод | Стандарт 84 | 2 | ,570 / 67,83 | ||||||||||||
| Трубопровод | ZEager | 84,89 / 87,53 | 74,43 / 68,33 | ||||||||||||
| MDFirst | /8 | 998 | 9 85,49 MDFirstZEager | 85,92 / 89,02 | 75,37 / 69,28 | ||||||||||
| ArcGreedy 3 | Стандартный | 85. 98 / 89,08 98 / 89,08 | 75,73 /69,23 | ||||||||||||
| ArcGreedy 3 | ZEager | 85,85 / 88,92 | 75,30 / 69,13 | Система . | MD F 1 Полный / POS . | Dep F 1 Без / с маркировкой . | |||||||||
| Автономный | M&T 2016 | 84.89 / 87,53 | н / п / н / д | ||||||||||||
| Трубопровод | Стандартный | 84,89 / 87,53 | 73,70 / 67,83 | ||||||||||||
| Трубопровод4E | |||||||||||||||
| MDFirst | Standard | 85,79 / 88,81 | 75,49 / 69,41 | ||||||||||||
| MDFirst | ZEager92 / 89,02 | 75,37 / 69,28 | |||||||||||||
| ArcGreedy 3 | Стандартный | 85,98 / 89,08 | 75,73000 /6914,23 | 2 | 9142 9142 9142 9142 | 2 | 9 | 85,85 / 88,92 | 75,30 / 69,13 |
В таблице 1 представлены результаты анализа для инфузированных морфологических решеток; то есть неоднозначные решетки МА, которые гарантированно включают в себя правильный путь MD.В этих экспериментах мы видим, что результаты MD в совместных стратегиях синтаксического анализа (MDFirst, ArcGreedy) всегда улучшают результаты автономного / конвейерного анализа MD. В частности, все результаты MD по совместным стратегиям очень близки. Мы наблюдаем лишь незначительное преимущество Arc-Zeager перед Arc-Standard для обеих совместных стратегий. К сожалению, это повышение точности MD происходит за счет синтаксиса, где мы наблюдаем небольшое снижение (до 0,5 балла в [un] с меткой F 1 ) при переключении от конвейерной стратегии к совместной.
К сожалению, это повышение точности MD происходит за счет синтаксиса, где мы наблюдаем небольшое снижение (до 0,5 балла в [un] с меткой F 1 ) при переключении от конвейерной стратегии к совместной.
Мы подтверждаем эту тенденцию на тестовом наборе в таблице 2, где мы используем те же модели в настройках , встроенных в , для анализа стандартного тестового набора . Для MD все совместные результаты лучше, чем соответствующие конвейеры (хотя теперь Arc-Standard немного улучшает Arc-Zeager в стратегии ArcGreedy), в то время как результаты анализа зависимостей падают в совместных сценариях (немного больше, чем в dev).
Таблицы 3 и 4 представляют результаты синтаксического анализа для более интересного сценария, реалистичного сценария синтаксического анализа, в котором мы используем незаполненных решеток — неоднозначных решеток, полученных с помощью существующего морфологического анализатора с широким охватом, которые не всегда (и не могут быть) гарантированы всегда. укажите правильный путь. Как и ожидалось, как в наборе для разработчиков (таблица 3), так и в тестовом наборе (таблица 4) результаты падают по сравнению с соответствующими сценариями с добавлением (таблицы 1 и 2 соответственно), поскольку некоторые элементы из правильных путь и дерево больше не доступны в области поиска.В то же время интересно отметить, что как для dev , так и для test , все оценки MD (Full / POS) , а также оценок зависимостей (без / помеченных) лучше при совместном разборе. Конкретные различия между объединенными стратегиями и системами перехода не имеют большого значения — устойчивая эмпирическая тенденция состоит в том, что переключение с конвейера на соединение улучшает производительность как MD, так и анализа зависимостей.
Интересно спросить, почему в сценарии infused , как в dev , так и в test , результаты синтаксического анализа зависимостей в совместных стратегиях падают относительно соответствующих конвейеров.Оказывается, в случае, если правильный анализ редкого (OOV) токена был искусственно введен в решетку, обучение на этих решетках может оказаться неверным. Внедрение правильного, но редкого MSR может привести к искусственной «уверенности» в его подходящем синтаксическом контексте. Затем, если синтаксический анализатор не применяет надежную статистику к общему поведению редких элементов / элементов OOV в различных синтаксических контекстах (как это было бы в случае совместных несвязанных сценариев ), выбор введенного MD может привести к неверному синтаксическому решению.
Главный вывод наших экспериментов заключается в том, что совместное морфологическое устранение неоднозначности и синтаксический анализ в этой основанной на переходах структуре предпочтительнее, чем настройки конвейера, в соответствии с гипотезой о том, что синтаксическая информация помогает устранению морфологической неоднозначности. Кроме того, обнадеживает тот факт, что при анализе незаполненных решеток , как и в более реалистичном сценарии, результаты анализа зависимостей улучшаются для сценариев конвейера, подтверждая выводы Seeker и Centinoglu (2015) в основанных на графах структурах и Коэна и Смита. (2007) и Goldberg and Tsarfaty (2008) в синтаксическом анализе фразеологической структуры.
Чтобы пролить больше света на конкретные способы, которыми объединенная система улучшает производительность по конвейеру, мы провели качественный анализ ошибок в 100 предложениях из стандартного набора для разработки Modern Hebrew при анализе в более реалистичном сценарии unfused . Более конкретно, мы выбрали 100 предложений из проанализированного корпуса, и лингвист вручную отнес каждую ошибку к одной из 10 лингвистических категорий.Затем мы сгруппировали категории по четырем различным типам.
Более конкретно, мы выбрали 100 предложений из проанализированного корпуса, и лингвист вручную отнес каждую ошибку к одной из 10 лингвистических категорий.Затем мы сгруппировали категории по четырем различным типам.
- •
Ошибки ТИПА 1 включают истинную семантическую неоднозначность, когда для устранения неоднозначности требуются дополнительные семантические и мировые знания.
- •
Ошибки ТИПА 2 включают категории, выходящие за пределы различных уровней лингвистической структуры, например, когда ошибки морфологической сегментации влияют на синтаксическое устранение неоднозначности.
- •
Ошибки ТИПА 3 включают ошибки синтаксического анализа, которые проистекают из идиосинкразии данных и особенностей схемы аннотаций SPMRL,
- •
Ошибки ТИПА 4 (другие) включают ошибки синтаксического анализа, относящиеся к лингвистическим структурам, характеризующим семитские явления.
Таблица 8 показывает для каждой категории ошибок количество (и процент) появления этой ошибки в конвейере по сравнению с параметрами соединения. Наиболее результат заключается в том, что тип, который показывает наибольшее уменьшение совместных сценариев по сравнению с конвейерными сценариями, принадлежит ТИПУ 2, отражая явления, непосредственно связанные с морфо-синтаксическим интерфейсом. Более того, мы также видим уменьшение количества ошибок, связанных с лексико-синтаксическим интерфейсом (например,g., устранение неоднозначности прикрепления PP), которые, как оказалось, также выигрывают от совместных настроек. С другими типами ошибок нет явного преимущества для совместного анализа, и мы не ожидаем его. Ошибки ТИПА 3 связаны с несогласованностью наборов поездов, неполными спецификациями или ошибками в золотых деревьях. Ошибки ТИПА 4 проистекают из лингвистических явлений, которые труднее устранить неоднозначность, и они одинаково трудны для разных сценариев.
Monolingual MA&D для современного иврита ранее рассматривался в автономных настройках с использованием скрытых марковских моделей (Bar-haim et al. , 2008; Адлер, 2007). Хотя эти результаты подходят для некоторых последующих приложений, использование MA&D Адлера для анализа зависимостей, например, значительно снижает производительность анализа (Goldberg and Elhadad, 2010). Совсем недавно Мор и Царфати (2016) представили автономную MA&D на основе переходов, которая совместно решает морфологическую сегментацию, тегирование и присвоение признаков, представив новую современную MA&D на иврите, что послужило отправной точкой для нашего исследования.
, 2008; Адлер, 2007). Хотя эти результаты подходят для некоторых последующих приложений, использование MA&D Адлера для анализа зависимостей, например, значительно снижает производительность анализа (Goldberg and Elhadad, 2010). Совсем недавно Мор и Царфати (2016) представили автономную MA&D на основе переходов, которая совместно решает морфологическую сегментацию, тегирование и присвоение признаков, представив новую современную MA&D на иврите, что послужило отправной точкой для нашего исследования.
Что касается сквозного синтаксического анализа зависимостей для иврита, Голдберг и Эльхадад (2010) были первыми, кто оценил влияние предсказанной морфологии по сравнению с морфологией золота в различных (основанных на переходах, графических, простых) фреймворках. .Они продемонстрировали значительную потерю точности для всех моделей в условиях прогнозируемой морфологии и в заключение предложили попробовать совместную обработку. Недавно Straka et al. (2016) представили UDPipe, набор инструментов с автономными компонентами для морфологического анализа, сегментации, тегирования, назначения функций и анализа зависимостей — опять же с использованием конвейерной архитектуры, без возможности чередования различных решений, как мы стремимся сделать здесь. Эта работа направлена на то, чтобы охватить все этапы UDPipe, но в рамках общей архитектуры , что позволяет использовать информацию с любого уровня при устранении неоднозначности другого.
Совместная морфологическая и синтаксическая обработка была рассмотрена в контексте синтаксического анализа фразовой структуры для семитских языков, показывая эмпирические преимущества перед конвейерными архитектурами (Goldberg and Tsarfaty, 2008; Cohen and Smith, 2007; Green and Manning, 2010). В контексте анализа зависимостей Bohnet and Nivre (2012) и Bohnet et al. (2013) интегрировали теги и синтаксический анализ зависимостей, улучшив современную точность для набора типологически разных языков. Andor et al. (2016) используют систему совместных переходов, предложенную Bohnet и Nivre (2012), и улучшают ее с помощью глобально нормализованной нейронной сети. Эти системы обращаются к совместному морфо-синтаксическому анализу неоднозначных слов, но без решения проблемы сегментации и устранения неоднозначности необработанных входных токенов.
Andor et al. (2016) используют систему совместных переходов, предложенную Bohnet и Nivre (2012), и улучшают ее с помощью глобально нормализованной нейронной сети. Эти системы обращаются к совместному морфо-синтаксическому анализу неоднозначных слов, но без решения проблемы сегментации и устранения неоднозначности необработанных входных токенов.
Seeker и Centinoglu (2015) исследуют идею совместного морфологического и синтаксического анализа, включая морфологическую сегментацию, в графической структуре.Их система объединяет два автономных компонента, которые достигают согласия через установку двойной декомпозиции. Однако они сообщают о неоптимальной производительности в стандартном тесте для иврита. Было показано, что для различных задач синтаксического анализа китайского языка совместные системы сегментации слов и синтаксического синтаксического анализа превосходят параметры конвейера (Li et al., 2011; Zhang et al., 2014), но эти системы предполагают переходы по последовательностям на основе символов одинаковой длины. , и поэтому они не применимы к настройке решетчатых путей переменной длины, как показано на рисунке 1.
С ростом интереса к глубокому обучению для НЛП (Goldberg, 2016) исследования в области анализа зависимостей стремятся заменить спроектированные модели функций нейронными сетями, которые автоматически создают модель (Chen and Manning, 2014; Zhou et al., 2015; Andor и др., 2016). Кроме того, концепция вложения слов, введенная Миколовым и др. (2013) позволяет словам иметь векторные представления, так что синтаксические и семантические сходства воплощаются в векторном пространстве.Однако такие архитектуры не сразу применимы к синтаксическому анализу иврита и других MRL. Предварительное обучение встраиванию слов нетривиально для неоднозначных входных токенов, если только не прибегать к конвейерным сценариям «сначала сегментация». Точно так же архитектуры синтаксического анализа, основанные на RNN, требуют морфологически неоднозначных форм в качестве входных данных, что не позволяет синтаксису улучшать морфологическое разрешение неоднозначности, как мы здесь утверждаем.
Точно так же архитектуры синтаксического анализа, основанные на RNN, требуют морфологически неоднозначных форм в качестве входных данных, что не позволяет синтаксису улучшать морфологическое разрешение неоднозначности, как мы здесь утверждаем.
В будущем мы намерены дополнить архитектуру, которую мы представляем здесь, моделями нейронных сетей как для морфологических, так и для синтаксических моделей таким образом, чтобы они могли эффективно взаимодействовать и влиять друг на друга, в надежде привести к дальнейшим улучшениям в обе задачи.
% PDF-1.7
%
1107 0 объект
>
эндобдж
xref
1107 139
0000000016 00000 н.
0000004062 00000 н.
0000004298 00000 н.
0000004342 00000 п.
0000004379 00000 п.
0000004840 00000 н.
0000004956 00000 н.
0000005072 00000 н.
0000005187 00000 н.
0000005303 00000 н.
0000005419 00000 н.
0000005534 00000 н.
0000005650 00000 н.
0000005766 00000 н.
0000005874 00000 н.
0000005984 00000 п.
0000006094 00000 н.
0000006204 00000 н.
0000006311 00000 н.
0000006420 00000 н.
0000006530 00000 н.
0000006615 00000 н.
0000006700 00000 н.
0000006783 00000 н.
0000006866 00000 н.
0000006949 00000 н.
0000007033 00000 н.
0000007117 00000 н.
0000007200 00000 н.
0000007283 00000 н.
0000007366 00000 н.
0000007450 00000 н.
0000007533 00000 н.
0000007617 00000 н.
0000007701 00000 п.
0000007784 00000 н.
0000007868 00000 н.
0000007952 00000 н.
0000008036 00000 н.
0000008119 00000 н.
0000008202 00000 н.
0000008284 00000 н.
0000008366 00000 н.
0000008451 00000 п.
0000008537 00000 н.
0000008622 00000 н.
0000008708 00000 н.
0000008793 00000 н.
0000008878 00000 н.
0000008963 00000 н.
0000009082 00000 н.
0000009144 00000 н.
0000009301 00000 п.
0000009350 00000 н.
0000009386 00000 п.
0000009806 00000 н.
0000010338 00000 п.
0000011093 00000 п.
0000011549 00000 п.
0000011759 00000 п. 0000011932 00000 п.
0000012166 00000 п.
0000012363 00000 п.
0000012652 00000 п.
0000012717 00000 п.
0000013143 00000 п.
0000013222 00000 п.
0000014222 00000 п.
0000014446 00000 п.
0000015096 00000 п.
0000015301 00000 п.
0000015598 00000 п.
0000015668 00000 п.
0000015850 00000 п.
0000016066 00000 п.
0000017122 00000 п.
0000017312 00000 п.
0000017475 00000 п.
0000018595 00000 п.
0000018999 00000 п.
0000019223 00000 п.
0000019509 00000 п.
0000019885 00000 п.
0000020280 00000 п.
0000020492 00000 п.
0000020789 00000 п.
0000020873 00000 п.
0000021555 00000 п.
0000022828 00000 п.
0000023996 00000 п.
0000024862 00000 п.
0000025116 00000 п.
0000025470 00000 п.
0000026329 00000 п.
0000027168 00000 п.
0000033108 00000 п.
0000034471 00000 п.
0000035102 00000 п.
0000038185 00000 п.
0000039913 00000 н.
0000040294 00000 п.
0000046643 00000 п.
0000047505 00000 п.
0000052908 00000 п.
0000102170 00000 н.
0000132252 00000 н.
0000132797 00000 н.
0000132929 00000 н.
0000148246 00000 н.
0000148287 00000 н.
0000148353 00000 п.
0000148473 00000 н.
0000148554 00000 н.
0000148623 00000 н.
0000148708 00000 н.
0000148793 00000 н.
0000148878 00000 н.
0000148939 00000 н.
0000149197 00000 н.
0000149311 00000 п.
0000149415 00000 н.
0000149545 00000 н.
0000149706 00000 н.
0000149896 00000 н.
0000150038 00000 н.
0000150193 00000 н.
0000150309 00000 н.
0000150473 00000 н.
0000150628 00000 н.
0000150800 00000 н.
0000150934 00000 н.
0000151072 00000 н.
0000151206 00000 н.
0000151342 00000 н.
0000151468 00000 н.
0000151590 00000 н.
0000151754 00000 н.
0000151928 00000 н.
0000003076 00000 н.
трейлер
] >>
startxref
0
%% EOF
1245 0 объект
> поток
x ڤ T [LSY]; Z ((
{@ 茴 {C & ؒ t | d * RuD001A
&> & cLLH ~ _ ~ & kL & m | 97g {g0x
+ 0cjr [} ՝ Jmcji9az {c = XuL *? 8] cnkk: ғ] ۣ ކ MMxwGpӮnhs0’rewhzZFv * kOPN «LcUp ‘; b5] ݿ l5? KnB-L
0000011932 00000 п.
0000012166 00000 п.
0000012363 00000 п.
0000012652 00000 п.
0000012717 00000 п.
0000013143 00000 п.
0000013222 00000 п.
0000014222 00000 п.
0000014446 00000 п.
0000015096 00000 п.
0000015301 00000 п.
0000015598 00000 п.
0000015668 00000 п.
0000015850 00000 п.
0000016066 00000 п.
0000017122 00000 п.
0000017312 00000 п.
0000017475 00000 п.
0000018595 00000 п.
0000018999 00000 п.
0000019223 00000 п.
0000019509 00000 п.
0000019885 00000 п.
0000020280 00000 п.
0000020492 00000 п.
0000020789 00000 п.
0000020873 00000 п.
0000021555 00000 п.
0000022828 00000 п.
0000023996 00000 п.
0000024862 00000 п.
0000025116 00000 п.
0000025470 00000 п.
0000026329 00000 п.
0000027168 00000 п.
0000033108 00000 п.
0000034471 00000 п.
0000035102 00000 п.
0000038185 00000 п.
0000039913 00000 н.
0000040294 00000 п.
0000046643 00000 п.
0000047505 00000 п.
0000052908 00000 п.
0000102170 00000 н.
0000132252 00000 н.
0000132797 00000 н.
0000132929 00000 н.
0000148246 00000 н.
0000148287 00000 н.
0000148353 00000 п.
0000148473 00000 н.
0000148554 00000 н.
0000148623 00000 н.
0000148708 00000 н.
0000148793 00000 н.
0000148878 00000 н.
0000148939 00000 н.
0000149197 00000 н.
0000149311 00000 п.
0000149415 00000 н.
0000149545 00000 н.
0000149706 00000 н.
0000149896 00000 н.
0000150038 00000 н.
0000150193 00000 н.
0000150309 00000 н.
0000150473 00000 н.
0000150628 00000 н.
0000150800 00000 н.
0000150934 00000 н.
0000151072 00000 н.
0000151206 00000 н.
0000151342 00000 н.
0000151468 00000 н.
0000151590 00000 н.
0000151754 00000 н.
0000151928 00000 н.
0000003076 00000 н.
трейлер
] >>
startxref
0
%% EOF
1245 0 объект
> поток
x ڤ T [LSY]; Z ((
{@ 茴 {C & ؒ t | d * RuD001A
&> & cLLH ~ _ ~ & kL & m | 97g {g0x
+ 0cjr [} ՝ Jmcji9az {c = XuL *? 8] cnkk: ғ] ۣ ކ MMxwGpӮnhs0’rewhzZFv * kOPN «LcUp ‘; b5] ݿ l5? KnB-L
B- ሀ Ȯʳvpyɸ! ~ tʐiwGHeWyc \ J ሐ-] R &.q: s`EaMqM
(In) изменчивость в самоанском интерфейсе синтаксиса / просодии и последствия для синтаксического анализа
Ан, Б. (2016a). Роль синтаксиса в правиле ядерного стресса. Материалы речевой просодии. Бостон, MA8: 203–206, DOI: https://doi.org/10.21437/SpeechProsody.2016-42
(2016a). Роль синтаксиса в правиле ядерного стресса. Материалы речевой просодии. Бостон, MA8: 203–206, DOI: https://doi.org/10.21437/SpeechProsody.2016-42
Ан, Б. (2016b). Синтаксически-фонологическое отображение и тонганское DP. Glossa 1 (1): 4.1–36.
Бекман, М. и Элам, Г.А. (1997). Указания по маркировке ToBI ,
Beckman, M. и Pierrehumbert, J. (1986). Интонационная структура на японском и английском языках. Фонологический ежегодник 3: 255–309, DOI: https://doi.org/10.1017/S095267570000066X
Bennett, R. , Elfner, E. и McCloskey, J. (2016). Самый светлый справа: очевидно аномальное смещение на ирландском языке. Лингвистический справочник 47 (2): 169–234, DOI: https://doi.org/10.1162/LING_a_00209
Bittner, M. и Hale, K. (1996). Ergativity: К теории неоднородного класса. Лингвистический справочник 27: 531–604.
Bobaljik, J. D. (2008). Где ϕ? Соглашение как постсинтаксическая операция В: Harbour, D., Adger, D. and Béjar, S. eds. Философия . Оксфорд: Издательство Оксфордского университета, стр.295–328.
Boersma, P. и Weenink, D. (2012). Praat: выполнение фонетики с помощью компьютера (версия 5.3.18) [компьютерная программа], http://www.praat.org
Брюс, Г. (1977). Шведские ударения слов в перспективе предложения . Лунд: CWK Gleerup.
Büring, D. (2003). На D-деревьях, фасоли и B-акцентах. Лингвистика и философия 26 (5): 511–545, DOI: https: // doi.org / 10.1023 / A: 1025887707652
Calhoun, S. (2015). Взаимодействие просодии и синтаксиса в самоанской маркировке фокуса. Lingua 165 (Часть B): 205–229.
(2015). Взаимодействие просодии и синтаксиса в самоанской маркировке фокуса. Lingua 165 (Часть B): 205–229.
Calhoun, S. (2017). Эксклюзивные, эквивалентные и просодические фразы на самоанском языке. Glossa 2 (1): 11.1–43.
Cheng, L. L.-S. и Даунинг, Л. Дж. (2009). Где эта тема по-зулусски? Лингвистический обзор 26: 207–238, DOI: https://doi.org/10.1515/tlir.2009.008
Cheng, L. L.-S. и Даунинг, Л. Дж. (2016). Фазальный синтаксис = циклическая фонология ?. Синтаксис 19 (2): 156–191, DOI: https://doi.org/10.1111/synt.12120
Хомский, Н. (1955). Логическая структура лингвистической теории (Ред. На микрофильмах) . Кембридж, Массачусетс: Гуманитарная библиотека Массачусетского технологического института.
Чанг, С. (1978). Падежные знаки и грамматические отношения в полинезийском . Остин, Техас: Техасский университет Press.
Клеменс, Л. и Кун, Дж. (2016). Keough, M. ed. Просодическая составляющая глагольных начальных предложений в Ch’ol. Труды 21-го семинара по структуре и контингенту языков Северной и Южной Америки ,
Клифтон, К. мл., Карлсон, К. и Фрейзер, Л. (2002). Информативные просодические границы. Язык и речь 45 (2): 87–114, DOI: https://doi.org/10.1177/0023830
50020101
Коллинз, Дж. Н. (2014). Арка, И. В. и Индравати, Н. Л. К. М., ред. Распределение немаркированных случаев в Самоа. Материалы 12-й Международной конференции по австронезийской лингвистике. 2: 93–110.
Коллинз, Дж. Н. (2015). Steindl, U. et al. Диагностика предикатного фронтинга в Самоа. Труды 32-й конференции Западного побережья по формальной лингвистике. Скоро.
Steindl, U. et al. Диагностика предикатного фронтинга в Самоа. Труды 32-й конференции Западного побережья по формальной лингвистике. Скоро.
Коллинз, Дж. Н. (2016). Самоанский предикат начальный порядок и позиции объекта. Естественный язык и лингвистическая теория 35 (1): 1–59, DOI: https://doi.org/10.1007/s11049-016-9340-1
Константа , № (2014). Контрастная тема: смыслы и реализации (Неопубликованная докторская диссертация).Амхерст, Массачусетс: Амхерстский университет Массачусетса.
Deal, A. R. (2015). Ergativity In: Alexiadou, A. and Kiss, T. eds. Синтаксис — теория и анализ. Международный справочник . Берлин: Mouton de Gruyter, 1pp. 654–707.
Добаши Ю. (2004). Множественное правописание, синтаксис без меток и PF-интерфейс. Исследования в английской лингвистике 19: 1–47.
Добаши, Ю. (2009). Множественная орфография, проблема сборки и сопоставление синтаксиса и фонологии В: Grijzenhout, J. and Kabak, B. eds. Исследование интерфейсов: Фонологические области: Универсалии и отклонения . Берлин, Германия: Mouton de Gruyter, стр. 195–220, DOI: https://doi.org/10.1515/9783110219234.2.195
Duranti, A. (1981). Самоанский фоно: социолингвистическое исследование (№ 80) . Канберра, Австралия: Лингвистический круг Канберры.
Duranti, A. (1990). Переключение кода и управление конфликтами в самоанском многостороннем взаимодействии. Тихоокеанские исследования 14 (1): 1–30.
Эльфнер, Э. (2012). Взаимодействия синтаксиса и просодии на ирландском языке (неопубликованная докторская диссертация). Амхерст, Массачусетс: Амхерстский университет Массачусетса.
Эльфнер, Э. (2015). Рекурсия в просодической формулировке: свидетельства из Connemara Irish. Естественный язык и лингвистическая теория 33: 1169–1208, DOI: https: // doi.org / 10.1007 / s11049-014-9281-5
Элордиета, г. (2008). Обзор теорий интерфейса синтаксис-фонология. Журнал баскской лингвистики и филологии 42: 209–286.
Феррейра, Ф. и Карими, Х. (2015). Просодия, производительность и когнитивные навыки: свидетельства индивидуальных различий В: Frazier, L. and Gibson, E. eds. Явная и неявная просодия в обработке предложений .Швейцария: Springer, стр. 119–132.
Fodor, J. D. (1998). Учимся разбирать ?. Журнал психолингвистических исследований 27 (2): 285–319, DOI: https://doi.org/10.1023/A:1023258301588
Fougeron, C. и Jun, S. (1998). Оцените влияние на французскую интонацию: просодическая организация и фонетическая реализация. Фонетический журнал 26 (1): 45–69, DOI: https://doi.org/10.1006/jpho.1997.0062
Ghini, M. (1993a). Фи-образование по-итальянски: Новое предложение. Рабочие документы Торонто по лингвистике 12: 41–77.
Ghini, M. (1993b). Фонологическое фразеобразование в итальянском языке (Неопубликованная кандидатская диссертация). Торонто, Канада: Университет Торонто.
Галле, М. (1978). Неизученные и неизученные знания В: Halle Morris, B.J. и Miller, G.А. ред. Лингвистическая теория и психологическая реальность . Кембридж, Массачусетс: MIT Press, стр. 294–303.
Harkema, H. (2000). Распознаватель минималистичных грамматик. Шестой международный семинар по технологиям парсинга, IWPT’00, http://www. informatics.susx.ac.uk/research/groups/nlp/carroll/iwpt2000/after.html
informatics.susx.ac.uk/research/groups/nlp/carroll/iwpt2000/after.html
Harkema, H. (2001). Разбор минималистских языков (неопубликованная докторская диссертация).Лос-Анджелес, Калифорния: Калифорнийский университет.
Hayes, B. и Lahiri, A. (1991). Бенгальская интонационная фонология. Естественный язык и лингвистическая теория 9: 47–96, DOI: https://doi.org/10.1007/BF00133326
Heath, J. и McPherson, L. (2013). Тоносинтаксис и референсное ограничение в НЧ догонов. Язык 89 (2): 265–295, DOI: https://doi.org/10.1353/lan.2013.0020
Hellmuth, S. (2009). (Отсутствие) просодических рефлексов данного / нового информационного статуса в египетском арабском языке In: Owens, J. and Elgibali, A. eds. Информационная структура на разговорном арабском . Оксфорд: Рутледж, стр. 165–188.
Хельмут, С. Дж. (2006). Распределение интонационного тонального акцента в египетском арабском языке (неопубликованная докторская диссертация). Школа восточных и африканских исследований Лондонского университета.
Hirsch, A. и Wagner, M. (2015). Озилдиз Д. и Буй Т. под ред. Движение вправо влияет на просодическую фразировку. Материалы 45-го собрания Северо-Восточного лингвистического общества.
Хуанг, З. и Харпер, М. (2010). Правильно обработанные просодические разрывы помогают синтаксическому анализу PCFG. Труды NAACL-HLT. Лос-Анджелес, Калифорния: 37–45.
Хантер Т. и Дайер, К. (2013). Распределения по минималистским грамматическим выводам. Труды, математика языка ,
Хайман, Л. М. (2011). Тон: Это другое? В: Goldsmith, J., Riggle, J. and Yu, A.C.L., ред. Справочник по фонологической теории . Wiley-Blackwell, стр. 197–239.
М. (2011). Тон: Это другое? В: Goldsmith, J., Riggle, J. and Yu, A.C.L., ред. Справочник по фонологической теории . Wiley-Blackwell, стр. 197–239.
Хайман, Л. М. и Монака, К. К. (2011). Тональная и нетональная интонация в Шекгалагари In: Frota, S., Elordieta, G. и Prieto, P. eds. Просодические категории: производство, восприятие и осмысление . Дордрехт: Springer, стр. 267–289, DOI: https://doi.org/10.1007/978-94-007-0137-3_12
Jackendoff, R. (1972). Семантическая интерпретация в порождающей грамматике . Кембридж, Массачусетс: MIT Press.
Джун, С.-А. (1996). Фонетика и фонология корейской просодии: интонационная фонология и просодическая структура (неопубликованная докторская диссертация).Колумбус, Огайо: Университет штата Огайо.
Джун, С. и Флетчер, Дж. (2014). Методика изучения интонации: от сбора данных к анализу данных В: Jun, S.-A. изд. Просодическая типология II: Фонология и фонетика интонации и фразировки . Оксфорд, Англия: Oxford University Press, стр. 493–519, DOI: https://doi.org/10.1093/acprof:oso/9780199567300.003.0016
Кан, Дж. Г. , Лизинг, М., Charniak, E. , Johnson, M. и Ostendorf, M. (2005). Эффективное использование просодии при разборе разговорной речи. Труды конференции по технологиям человеческого языка и конференции по эмпирическим методам в естественном языке. : 233–240, DOI: https://doi.org/10.3115/1220575.1220605
Kaisse, E. M. (1985). Связная речь: взаимодействие синтаксиса и фонологии . Орландо, Флорида и Лондон: Academic Press.
Kaisse, E.M. и Zwicky, A. M. (1987). Введение: синтаксические влияния на фонологические правила. Phonology Yearbook January 19874: 3–11, DOI: https://doi.org/10.1017/S0952675700000749
M. (1987). Введение: синтаксические влияния на фонологические правила. Phonology Yearbook January 19874: 3–11, DOI: https://doi.org/10.1017/S0952675700000749
Кавари, Дж. У. , Мартен, Л. и ван дер Валь, Дж. (2012). Случаи тона в Отджигереро: отношения между головой и дополнением, линейный порядок и информационная структура. Africana Linguistica 18: 315–353.
Хан, С. (2008). Интонационная фонология и фокусная просодия бенгальского (неопубликованная докторская диссертация). Калифорнийский университет в Лос-Анджелесе.
Хан, С. (2014). Интонационная фонология стандартного бангладешского бенгальского языка In: Jun, S.-A. изд. Просодическая типология II: фонология и фонетика интонации и фразировки . Оксфорд, Англия: Oxford University Press, стр. 81–117, DOI: https: // doi.org / 10.1093 / acprof: oso / 9780199567300.003.0004
Кобеле, Г. М. , Реторе, К. и Сальвати, С. (2007). Роджерс, Дж. И Кепсер, С. ред. Теоретико-автоматный подход к минимализму. Теоретико-модельный синтаксис в 10, ESSLLI’07 ,
Купман, Х. (2012). Самоанская эргативность как двойная пассивизация В: Функциональные главы: Картография синтаксических структур . Оксфорд: Издательство Оксфордского университета, 7 стр.168–180, DOI: https://doi.org/10.1093/acprof:oso/9780199746736.003.0013
Kraljic, T. и Brennan, S.E. (2005). Просодическое разрешение синтаксической структуры: для говорящего или для адресата ?. Когнитивная психология 50: 194–231, DOI: https://doi.org/10.1016/j.cogpsych.2004.08.002
Kratzer, A. и Selkirk, E. (2007). Теория фаз и просодическое правописание: случай глаголов. Лингвистический обзор 24: 93–135, DOI: https://doi.org/10.1515/TLR.2007.005
Теория фаз и просодическое правописание: случай глаголов. Лингвистический обзор 24: 93–135, DOI: https://doi.org/10.1515/TLR.2007.005
Кривокапич, J. (2007). Просодическое планирование: влияние длины и сложности фразы на продолжительность паузы. Фонетический журнал 35: 162–179, DOI: https://doi.org/10.1016/j.wocn.2006.04.001
Ladd, D. R. (2008). Интонационная фонология . 2-е изд. Издательство Кембриджского университета, DOI: https: // doi.org / 10.1017 / CBO9780511808814
Legate, J. A. (2008). Морфологический и абстрактный случай. Лингвистический справочник 29 (1): 55–101, DOI: https://doi.org/10.1162/ling.2008.39.1.55
Liberman, M. и Pierrehumbert, J. (1984). Интонационная инвариантность при изменении диапазона и длины тона В: Звуковая структура языка . Кембридж, Массачусетс: MIT Press, стр. 157–233.
Маранц, А. (1991). Вестфаль Г. Ф., Ао Б. и Чаэ Х.-Р. ред. Кейс и лицензирование. Труды Восьмой конференции по лингвистике восточных государств, ESCOL ’91. : 234–253.
Massam, D. (2001). Объединение псевдо-существительных на Ниуэ. Естественный язык и лингвистическая теория 19 (1): 153–197, DOI: https://doi.org/10.1023/A:1006465130442
Massam, D. (2006). Ни абсолютив, ни эргативный падеж не являются именительным или винительным падежом In: Johns, A., Massam, D. и Ndayiragije, J. eds. Эргативность: возникающие проблемы . Dordrecht: Springer, стр. 26–46, DOI: https://doi.org/10.1007/1-4020-4188-8_2
Massam, D. (2012). Структура (не) эргативов. Протоколы AFLA 16 ,
Майер, Дж. Ф. (2001). Переключение кода на Самоанском языке: t-стиль и k-стиль (неопубликованная докторская диссертация). Гавайский университет.
(2001). Переключение кода на Самоанском языке: t-стиль и k-стиль (неопубликованная докторская диссертация). Гавайский университет.
Макферсон, Л. и Хит, Дж. (2016). Фразовый грамматический тон в языках догонов: роль ограничения взаимодействия. Естественный язык и лингвистическая теория 34: 593–639, DOI: https://doi.org/10.1007/s11049-015-9309-5
Michaelis, J. (1998). Деривационный минимализм умеренно контекстно-зависимый. Труды, Логические аспекты компьютерной лингвистики, LACL’98. NYSpringer: 179–198.
Милнер, Г.Б. (1993). Самоанский словарь: самоанско-английский, англо-самоанский . Окленд, Новая Зеландия: Polynesian Press.
Mosel, U. и Hovdhaugen, E. (1992). Справочная грамматика Самоа . Осло: Scandinavian University Press.
Myrberg, S. (2013). Сестричество в просодическом ветвлении. Фонология 30 (1): 73–124, DOI: https://doi.org/10.1017/S0952675713000043
Неспор, М. и Vogel, I. (1986). Просодическая фонология . Дордрехт, Нидерланды: Публикации Foris.
Ochs, E. (1982). Эргативность и порядок слов в самоанском детском языке. Язык 58 (3): 646–671, DOI: https://doi.org/10.2307/413852
Ochs, E. (1988). Культура и языковое развитие: овладение языком и языковая социализация в самоанской деревне .Кембридж, Великобритания: Издательство Кембриджского университета.
Odden, D. (1987). Киматуумби фразовая фонология. Phonology Yearbook , январь 19874: 13–36, DOI: https://doi.org/10.1017/S0952675700000750
Орфителли Р. и Ю. К. (2009). Интонационная фонология Самоа. Представлено Австронезийской ассоциацией формальной лингвистики XVI. Санта-Крус, Калифорнийский университет,
и Ю. К. (2009). Интонационная фонология Самоа. Представлено Австронезийской ассоциацией формальной лингвистики XVI. Санта-Крус, Калифорнийский университет,
Пак, М. (2008). Постсинтаксическая деривация и ее фонологические рефлексы (неопубликованная докторская диссертация). Филадельфия, Пенсильвания: Пенсильванский университет.
Пейт, Дж. К. и Голдуотер, С. (2013). Неконтролируемый анализ зависимостей с помощью акустических сигналов. Труды Ассоциации компьютерной лингвистики 1: 63–74.
Pierrehumbert, J. (1980). Фонология и фонетика английской интонации (Неопубликованная докторская диссертация).Кембридж, Массачусетс: MIT.
Prieto, P. (2005). Синтаксические и ритмические ограничения на формулировку решений на каталонском языке. Studia Linguistica 59 (2/3): 194–222, DOI: https://doi.org/10.1111/j.1467-9582.2005.00126.x
Prieto, P. , D’Imperio, M. , Elordieta, G. , Frota, S. и Vigário, M. (2009). Доказательства «мягкого» предварительного планирования в тональной постановке: начальное масштабирование в романсе.Материалы конференции Speech Prosody 2009. : 803–806.
Prieto, P. , Shih, C. и Nibert, H. (1996). Нисходящий тренд на испанском языке. Фонетический журнал 24 (4): 445–473, DOI: https://doi.org/10.1006/jpho.1996.0024
R Core Team (2014). Р: Язык и среда для статистических вычислений [Руководство по компьютерному программному обеспечению] В: Австрия: Вена. Получено с: http: // www.R-project.org/ ..
Селкирк, Э. (2000). Взаимодействие ограничений на просодическую фразировку В: Horne, M. ed. Просоды: теория и эксперимент . Дордрехт: Kluwer Academic Publishers, стр. 231–261, DOI: https://doi.org/10.1007/978-94-015-9413-4_9
Селкирк, Э. (2003). Фонология предложения In: Frawley, W. ed. Международная энциклопедия языкознания . 2-е изд. Нью-Йорк: Oxford University Press, (4) стр.41–42.
Селкирк, E. (2011). Интерфейс синтаксис-фонология В: Goldsmith, J., Riggle, J. and Yu, A.C. L. eds. Справочник по фонологической теории . Wiley-Blackwell, стр. 435–484, DOI: https://doi.org/10.1002/9781444343069.ch24
Селкирк, Э. О. (1978/1981). О просодической структуре и ее связи с синтаксической структурой В: Fretheim, T. ed. Скандинавская просодия II . Тронхейм, Норвегия: ТАПИР, стр.111–140.
Shriberg, E. , Stolcke, A. , Hakkani-Tür, D. и Tür, G. (2000). Автоматическая сегментация речи на предложения и темы на основе просодии. Речевое общение 32: 127–154, DOI: https://doi.org/10.1016/S0167-6393(00)00028-5
Шу, Ю.-Л. , Китинг, П. , Висеник, К. и Ю., К. (2011). Voicesauce: программа для анализа голоса. Труды ИФЗ XVI ,
Snedeker, J. и Trueswell, J. (2003). Использование просодии во избежание двусмысленности: влияние осведомленности говорящего и референтного контекста. Журнал памяти и языка 48: 103–130, DOI: https://doi.org/10.1016/S0749-596X(02)00519-3
Speer, S. R. и Foltz, A. (2015). Неявная просодия корректирующего контраста подготавливает зонды с соответствующей интонацией В: Frazier, L.и Гибсон, Э. ред. Явная и неявная просодия в обработке предложений . Швейцария: Springer, стр. 263–285, DOI: https://doi.org/10.1007/978-3-319-12961-7_14
Stabler, E. P. (2010). Вычислительные перспективы минимализма In: Boeckx, C. ed. Оксфордский справочник минимализма . Оксфорд: Издательство Оксфордского университета, стр. 617–641.
Stabler, E. P. (2013). Две модели минималистского инкрементального синтаксического анализа. Темы когнитивной науки 5 (3): 611–633, DOI: https://doi.org/10.1111/tops.12031
Стидман, М. (2000). Информационная структура и синтаксически-фонологический интерфейс. Лингвистический справочник 31 (4): 649–689, DOI: https://doi.org/10.1162/0024384505
Толлан Р. (2015). Неэргативы и раздельная эргативность на самоанском языке. NELS 46 ,
Торр, Дж. и Stabler, E. (2016). Согласование в минималистской грамматике. Труды 12-го ежегодного семинара по грамматикам, примыкающим к деревьям, и связанным с ними формализмам (TAG +) ,
Вагнер, М. (2005). Просодия и рекурсия (неопубликованная докторская диссертация). Массачусетский Институт Технологий.
Вагнер, М. (2010). Просодия и рекурсия в координатных структурах и за их пределами. Естественный язык и лингвистическая теория Январь 2010 г. 28 (1): 183–237, DOI: https: // doi.org / 10.1007 / s11049-009-9086-0
Wickham, H. (2009). ggplot2: элегантная графика для анализа данных . Springer.
Ю., К. М. (2011). Лима, С., Маллин, К. и Смит, Б., ред. Звук эргативности: отображение морфосинтаксиса и просодии на самоанском языке. Материалы 39-го ежегодного собрания Северо-восточного лингвистического общества.