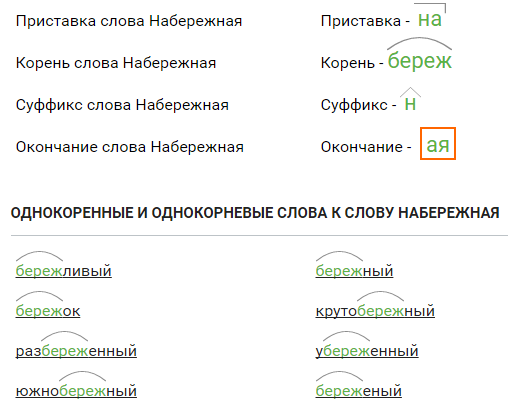
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться.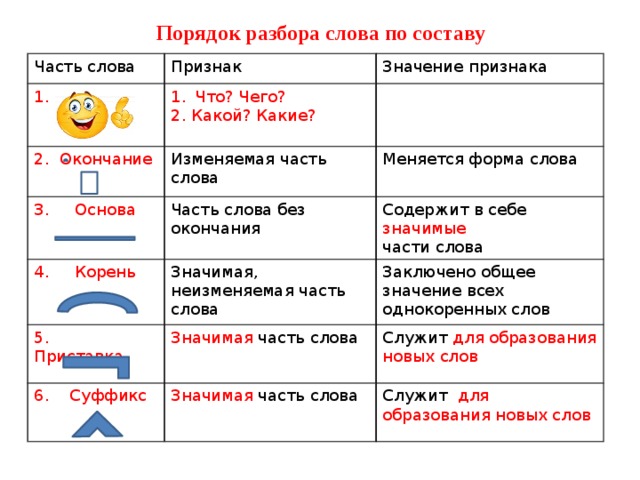 Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: нетамлра сейчас н е ц п р и а е ч сейчас факира 1 секунда назад г и е т о р я н з 1 секунда назад а о в к ч а л 1 секунда назад к о н ц е р т 1 секунда назад рукопашка 1 секунда назад а н ь д м л и 1 секунда назад эль куэту 1 секунда назад м е т и з а 1 секунда назад ореннй 1 секунда назад с о н е т 1 секунда назад мелодия 1 секунда назад к в и д м у щ ы 2 секунды назад раккмо 2 секунды назад
Слова «искусственный» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «искусственный» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «искусственный» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «искусственный».
Содержимое:
- 1 Слоги в слове «искусственный»
- 2 Как перенести слово «искусственный»
- 3 Морфемный разбор слова «искусственный» по составу
- 4 Сходные по морфемному строению слова «искусственный»
- 5 Синонимы слова «искусственный»
- 6 Антонимы слова «искусственный»
- 7 Ударение в слове «искусственный»
- 8 Фонетическая транскрипция слова «искусственный»
- 9 Фонетический разбор слова «искусственный» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «искусственный»
- 11 Сочетаемость слова «искусственный»
- 12 Значение слова «искусственный»
- 13 Склонение слова «искусственный» по подежам
- 14 Как правильно пишется слово «искусственный»
Слоги в слове «искусственный»
Количество слогов: 4
По слогам: и-ску-сстве-нный
По правилам школьной программы слово «искусственный» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Например, такой:
ис-кус-ствен-ный
По программе института слоги выделяются на основе восходящей звучности:
и-ску-сстве-нный
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
сдвоенные согласные сс не разбиваются при выделении слогов и парой отходят к следующему слогу
сдвоенные согласные нн не разбиваются при выделении слогов и парой отходят к следующему слогу
Как перенести слово «искусственный»
ис—кусственный
искус—ственный
искусст—венный
искусствен—ный
Морфемный разбор слова «искусственный» по составу
| искусственн | корень |
| ый | окончание |
искусственный
Сходные по морфемному строению слова «искусственный»
Сходные по морфемному строению слова
Синонимы слова «искусственный»
1. неестественный
неестественный
2. раздутый
3. поддельный
4. вставной
5. деланный
6. ненатуральный
7. жеманный
8. манерный
9. нарочитый
10. наигранный
11. театральный
12. натянутый
13. напряженный
14. принужденный
15. насильственный
16. вымученный
17. аффективный
18. аффектированный
19. цирлих-манирлих
20. ненастоящий
21. суррогатный
22. напускной
23. декоративный
24. неподлинный
25. притворный
26. неискренний
27. артифициальный
28. невзаправдашний
29. невзаправдашный
30. неправдашний
31. неправдашный
32. фальшивый
33. синтетический
34. изломанный
35. не натуральный
Антонимы слова «искусственный»
1. натуральный
2. естественный
3. настоящий
4. неподдельный
Ударение в слове «искусственный»
иску́сственный — ударение падает на 2-й слог
Фонетическая транскрипция слова «искусственный»
[иск`ус тв’ин ый’]
Фонетический разбор слова «искусственный» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| и | [и] | гласный, безударный | и |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| к | [к] | согласный, глухой парный, твёрдый, шумный | к |
| у | [`у] | гласный, ударный | у |
| с | [с] | согласный, глухой парный, твёрдый, долгий | с |
| с | — | не образует звука | с |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| в | [в’] | согласный, звонкий парный, мягкий | в |
| е | [и] | гласный, безударный | е |
| н | [н] | согласный, глухой парный, твёрдый, долгий | н |
| н | — | не образует звука | н |
| ы | гласный, безударный | ы | |
| й | [й’] | согласный, звонкий непарный (сонорный), мягкий | й |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 13 букв и 11 звуков.
Буквы: 4 гласных буквы, 9 согласных букв.
Звуки: 4 гласных звука, 7 согласных звуков.
Предложения со словом «искусственный»
В принципе ничего не мешает задать такой вопрос искусственному интеллекту напрямую.
Источник: Андрей Кананин, Нереальная реальность-3.
Лежат на соседних кроватях, оба подключённые к аппаратуре искусственного дыхания.
Источник: Павел Рупасов, Записки санитара.
Метеориты и другие мелкие тела облетали меня стороной, а вот от искусственных спутников и летающих тарелок приходилось уворачиваться.
Источник: Владимир Кириллов, Калейдоскоп, 2013.
Сочетаемость слова «искусственный»
1. искусственный интеллект
2. искусственное дыхание
3. искусственные цветы
4. аппарат искусственного дыхания
аппарат искусственного дыхания
5. искусственный спутник земли
6. искусственная вентиляция лёгких
7. делать искусственное дыхание
8. казаться искусственными
9. создать искусственный интеллект
10. (полная таблица сочетаемости)
Значение слова «искусственный»
ИСКУ́ССТВЕННЫЙ , -ая, -ое; -вен, -венна, -венно. 1. только полн. ф. Сделанный наподобие настоящего, природного. Искусственное волокно. Искусственные зубы. Искусственное орошение. Искусственное освещение. (Малый академический словарь, МАС)
Склонение слова «искусственный» по подежам
| Падеж | Единственное числоЕд.ч. | Множественное числоМн.ч. | ||
|---|---|---|---|---|
| Мужской родМ.р. | Женский родЖ.р. | Средний родС.р. | ||
| ИменительныйИм. | какой? | какая? | какое? | какие? |
| искусственный | искусственная | искусственное | искусственные | |
РодительныйРод.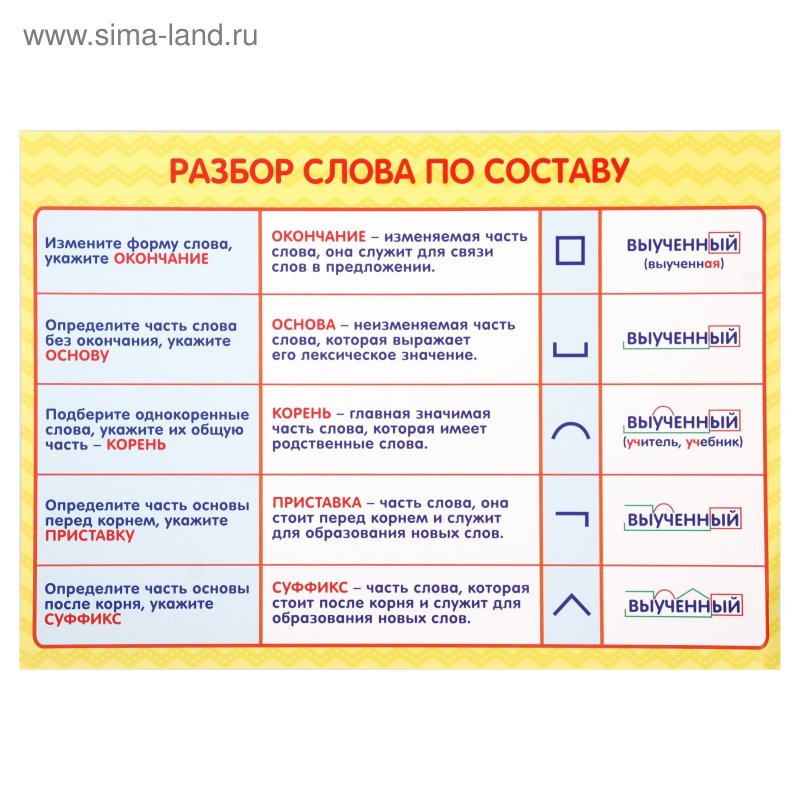 | какого? | какой? | какого? | каких? |
| искусственного | искусственной | искусственного | искусственных | |
| ДательныйДат. | какому? | какой? | какому? | каким? |
| искусственному | искусственной | искусственному | искусственным | |
| Винительный (одушевленное)Вин. одуш. | какого? | какую? | какого? | каких? |
| искусственного | искусственную | искусственное | искусственных | |
| Винительный (неодушевленное)Вин. неодуш. | какой? | какую? | какое? | какие? |
| искусственный | искусственную | искусственное | искусственные | |
| ТворительныйТв. | каким? | какой? | каким? | какими? |
| искусственным | искусственной, искусственною | искусственным | искусственными | |
ПредложныйПред. | о каком? | о какой? | о каком? | о каких? |
| искусственном | искусственной | искусственном | искусственных | |
Как правильно пишется слово «искусственный»
Правописание слова «искусственный»
Орфография слова «искусственный»
Правильно слово пишется: иску́сственный
Нумерация букв в слове
Номера букв в слове «искусственный» в прямом и обратном порядке:
- 13
и
1 - 12
с
2 - 11
к
3 - 10
у
4 - 9
с
5 - 8
с
6 - 7
т
7 - 6
в
8 - 5
е
9 - 4
н
10 - 3
н
11 - 2
ы
12 - 1
й
13
Smart Ways to Document Parsing
Современные технологии анализа документов, как правило, достаточно умны, чтобы понимать суть документов. Они могут читать для точного смысла и понимать широкий контекст. Однако интеллектуальный анализ документов требует, чтобы программы использовали возможности, доступные в современном программном обеспечении, для чтения, импорта, управления и обмена документами. Более интеллектуальный анализ документов означает, например, возможность создавать объединенные версии для копирования и печати вместо практики создания нескольких версий одного документа или бумажного вывода.
Однако интеллектуальный анализ документов требует, чтобы программы использовали возможности, доступные в современном программном обеспечении, для чтения, импорта, управления и обмена документами. Более интеллектуальный анализ документов означает, например, возможность создавать объединенные версии для копирования и печати вместо практики создания нескольких версий одного документа или бумажного вывода.
Например, IBM Document Conversion Workbench (DCW), Java Developer Kit (JDK) 6, включает API-интерфейс Document Parser, упрощающий задачу создания программного обеспечения для чтения текстовых или HTML-файлов. В этом блоге разъясняются любые вопросы об умном способе синтаксического анализа документов, и он должен стать прекрасной отправной точкой, если вы хотите узнать об этом больше.
Источник: Towards Data Science
Что такое синтаксический анализ документов? Синтаксический анализ документов — это процесс извлечения информации из электронного документа. Он может быть как структурированным, так и неструктурированным.
Он может быть как структурированным, так и неструктурированным.
Бумаги в различных формах, включая документы Word, файлы PDF, файлы XML и HTML-страницы
Оптическое распознавание символов (OCR) — это электронное преобразование отсканированных печатных материалов в редактируемый и доступный для поиска текст. Целью OCR является сортировка документов со сплошным шрифтом путем извлечения текстового содержимого и превращения его в документ, который легко редактировать и искать.
Например, изображения, преобразованные в текст с помощью OCR, включают печатные документы, рукописные документы, фотографии и рукописные знаки. Этот процесс извлекает символы определенного шрифта из изображения, чтобы преобразовать его в другую форму представления, обычно в набор символов компьютера по умолчанию.
Это способ обработки текста, который позволяет всесторонне понять документы. Это можно упростить, чтобы объяснить это более простыми словами. Система использовала разделенную бумагу для извлечения различных алгоритмов, реализованных в правилах. Эта система может быть сложной или простой, в зависимости от того, планируете ли вы вести веб-сайт электронной коммерции или простой блог-сайт.
Эта система может быть сложной или простой, в зависимости от того, планируете ли вы вести веб-сайт электронной коммерции или простой блог-сайт.
Интеллектуальный анализ документов используется в бизнесе, образовании и медицине. Это помогает представлять информацию в структурированном формате для лучшего понимания данных. По данным Valuates, ожидается, что мировой рынок распознавания изображений вырастет на 589 долларов США.20 миллионов к 2026 году по сравнению с 20720 миллионами долларов США в 2019 году.
Как это работает?Работа по анализу документов начинается с извлечения данных из существующих документов или файлов. Извлечение данных обычно включает оптическое распознавание символов (OCR). Во-первых, он распознает текст на изображениях и в файлах PDF, HTML и других документах. Затем он преобразует его в машиночитаемый текст и использует индекс или базу данных, чтобы найти, где он находится в более крупной композиции.
Анализ документов включает в себя извлечение таких документов, как электронные письма, текстовые сообщения, телефонные звонки и другие заметки. Кроме того, синтаксический анализ документов используется для таких задач, как анализ тональности (определение субъективного «ощущения» от документа), поиск конкретной информации в копии и категоризация данных в соответствии с набором документов, помеченных как принадлежащие к определенной категории.
Кроме того, синтаксический анализ документов используется для таких задач, как анализ тональности (определение субъективного «ощущения» от документа), поиск конкретной информации в копии и категоризация данных в соответствии с набором документов, помеченных как принадлежащие к определенной категории.
Парсер — это программа, которая читает текст и извлекает данные. Корпус — это тело текста, используемое синтаксическим анализатором для обучения удалению этих данных. Большинство людей знакомы с поисковыми системами, наиболее распространенным типом синтаксического анализатора — поисковым роботом.
Согласно новому отчету Reports and Data, глобальная обработка естественного языка (NLP) в здравоохранении и медико-биологических науках, по прогнозам, достигнет 4 799,6 млн долларов США к 2028 году.
Зачем нам нужен анализ документов? Анализ документов необходим почти для всех компаний, таких как банки, страховые компании и авиакомпании. Парсинг документов включает в себя извлечение информации из доступных документов, таких как чеки, контракты.
База данных будет хранить извлеченные данные. Нам нужен синтаксический анализ документов для извлечения данных из документов и создания индекса, по которому мы можем позже выполнять поиск. Большинство современных задач поиска и анализа требуют от нас более эффективного извлечения и анализа контента.
Умные синтаксические анализаторы документовПомимо глупых синтаксических анализаторов документов, блестящие синтаксические анализаторы документов являются первыми. Добейтесь ума, вызывая внешний синтаксический анализатор, чтобы получить дополнительную информацию о синтаксическом анализе определенного раздела документа. В свою очередь, это создает мощный интеллектуальный анализатор документов в руках опытного пользователя.
Visionify Document Parsing Решения Visionify для анализа документов на основе API анализируют любое изображение документа (PDF, PNG, JPEG) и превращают его в интеллектуальный текст. Например, традиционный синтаксический анализ документа может предоставить вам прочитанный текст; API-интерфейсы Visionify дадут вам заголовки, подразделы, таблицы, рисунки. Кроме того, у нас есть индивидуальные решения для анализа этикеток, которые будут декодировать штрих-коды, QR-коды и предоставлять простую в использовании конечную точку для интеграции с вашей ERP: платформа сканирует, конвертирует, индексирует и архивирует документы для извлечения из хранилища. В результате Visionify упрощает процесс управления документами, обеспечивая максимальный контроль хранения, точность и эффективность.
Кроме того, у нас есть индивидуальные решения для анализа этикеток, которые будут декодировать штрих-коды, QR-коды и предоставлять простую в использовании конечную точку для интеграции с вашей ERP: платформа сканирует, конвертирует, индексирует и архивирует документы для извлечения из хранилища. В результате Visionify упрощает процесс управления документами, обеспечивая максимальный контроль хранения, точность и эффективность.
Текст, таблицы, диаграммы и фотографии извлекаются из любого документа PDF с помощью API. Кроме того, он автоматически распознает макет страницы и предоставляет простое для понимания дерево страниц с точными размерами.
Intelligent Document Quality Processor Google Intelligent Document Quality Processor — это платформа искусственного интеллекта, разработанная Google Brain Institute. Это для выявления ошибок в тексте. Для этого он использует нейронную сеть для выявления орфографических и грамматических ошибок и даже неподходящих источников. Он делает это путем сканирования работ на наличие шаблонов, связанных с конкретными ошибками.
Он делает это путем сканирования работ на наличие шаблонов, связанных с конкретными ошибками.
Компания Google создала программу для автоматизации проверки фактов, но у нее есть много других потенциальных применений, включая стилистический анализ и редактирование текста. Этот инструмент предназначен для пакетной обработки большого количества документов. Этот инструмент находит некорректный контент в определенном формате документа в масштабе. Процессор Google Intelligent Document Quality обеспечивает почти 100-процентную точность аннотаций документов.
Например, Document Quality Processor — это первый шаг новой инициативы Google по борьбе со спамом. Речь идет о лучшем понимании текста электронного письма, рассмотрении каждого предложения на предмет полярности, тональности, синтаксиса, ключевых терминов и многого другого. Цель состоит в обучении сотен тысяч заспамленных документов для создания классификатора, способного идентифицировать спам с достаточной точностью.
Источник: Google
Понимание документов UiPath Понимание документов UiPath работает на основе глубокого обучения, обработки естественного языка и набора алгоритмов компьютерного зрения и обработки изображений.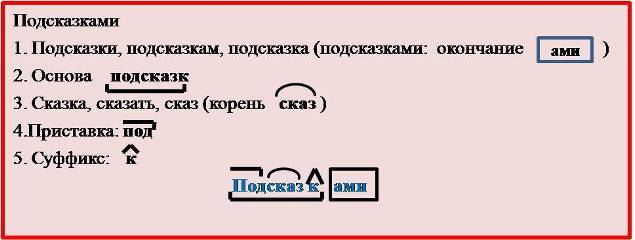 Вместе это лучший способ оптического распознавания символов на бумаге, небрежно нацарапанных или иным образом трудно читаемых.
Вместе это лучший способ оптического распознавания символов на бумаге, небрежно нацарапанных или иным образом трудно читаемых.
Платформа понимания документов UiPath — это часть UiPath Studio, позволяющая анализировать текст из отсканированных документов, визитных карточек, записей клиентов, электронных медицинских отчетов и других ресурсов. Вы можете заручиться поддержкой этого фреймворка, чтобы вашему роботу было проще читать документы и понимать их содержание.
Анализ документов с помощью языков программирования Анализ PDF-файлов с помощью Python PDF-файлы повсюду. Если у вас есть большое количество PDF-файлов и вы хотите извлечь из них информацию либо для своих целей, либо в качестве услуги другим, хорошей идеей будет научиться анализировать их с помощью Python. Возможность анализировать PDF-файлы необходима, если вы ведете бизнес, связанный с какими-либо публикациями, будь то технические руководства или научно-исследовательские работы. Для Cairo такие программы, как PDFMiner и pdf, решают эту проблему, добавляя специфичную для Python библиотеку для взаимодействия с PDF.
Для Cairo такие программы, как PDFMiner и pdf, решают эту проблему, добавляя специфичную для Python библиотеку для взаимодействия с PDF.
XML — это формат документов, который становится все более и более популярным. В результате XML является неотъемлемой частью веб-архитектуры обмена данными. Однако использование Javascript позволяет анализировать файлы XML с помощью DOM (объектная модель документа). Затем загрузите файл XML и отобразите всю информацию файла XML в виде таблицы HTML.
ЗаключениеАнализ документов распознает, что делать, предоставляет пользователю необходимую информацию и помогает ему в процессе. Он также должен убедиться, что все необходимые исследования прошли успешно. Мы можем назвать этот подход умным способом разбора документов.
Девиз Visionify — сделать системы визуализации документов более эффективными во всех аспектах. Мы постоянно сотрудничаем с нашими клиентами для разработки новых концепций и методов. Это приведет к созданию более эффективных систем обработки изображений документов и более высокой производительности на протяжении всего жизненного цикла рабочих процессов обработки изображений документов. Свяжитесь с нами, чтобы получить живую демонстрацию.
Это приведет к созданию более эффективных систем обработки изображений документов и более высокой производительности на протяжении всего жизненного цикла рабочих процессов обработки изображений документов. Свяжитесь с нами, чтобы получить живую демонстрацию.
Наоаки Окадзаки — Дом
Works
Основы обработки естественного языка
Это японский учебник по основам обработки естественного языка на основе глубокого обучения. Эта книга предназначена в первую очередь для новичков, которые начинают исследования в области НЛП, и разработчиков программного обеспечения, которые хотят укрепить теоретические аспекты.
Упражнение НЛП 100
Упражнение НЛП 100 — это учебный лагерь, предназначенный для обучения навыкам программирования, анализа данных и исследовательской деятельности путем выполнения практических и увлекательных заданий. Он охватывает команды UNIX, регулярные выражения, теги частей речи, синтаксический анализ зависимостей, встраивание слов и глубокую нейронную сеть для исследования и разработки обработки естественного языка.
Записная книжка для машинного обучения
Записная книжка для машинного обучения предназначена для реализации «заметки» для обучения машинному обучению в виде новой формы записной книжки, улучшенной с помощью компьютеров. Он охватывает теории и реализации методов машинного обучения, таких как регрессия, классификация, кластеризация и анализ основных компонентов. Он используется в лекции «Машинное обучение» (CSC.T254) Токийского технологического института.
Введение в глубокое обучение
На этом сайте представлены слайды и блокноты Jupyter Notebooks об обработке естественного языка на основе глубокого обучения, включая встраивание слов, RNN, LSTM, CNN, модели последовательностей, механизм внимания, Transformer, GPT и BERT. . Он используется во второй половине лекции «Расширенное машинное обучение» (ART.T458) Токийского технологического института.
Краткий справочник по Python
Краткий справочник по Python содержит записные книжки Jupyter для быстрого ознакомления с программами Python и их выполнением. Он охватывает основы Python, а также полезные библиотеки, такие как NumPy и Matplotlib. Начать изучение Python можно в Google Colaboratory и Amazon SageMaker Studio Lab.
Он охватывает основы Python, а также полезные библиотеки, такие как NumPy и Matplotlib. Начать изучение Python можно в Google Colaboratory и Amazon SageMaker Studio Lab.
CRFsuite
CRFSuite — это реализация условных случайных полей (CRF) для задач последовательной маркировки. Он не поддерживает глубокое обучение, но был разработан для быстрого обучения модели на одноядерном процессоре.
libLBFGS
libLBFGS — это C-порт реализации метода Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) с ограниченной памятью, написанный Хорхе Носедалом на FORTRAN. В отличие от кодов C, автоматически сгенерированных f2c (преобразователь Fortran 77 в C), этот порт включает изменения, основанные на моих интерпретациях, улучшениях, оптимизации и улучшениях.
SimString
SimString представляет собой реализацию простого и эффективного алгоритма приблизительного сопоставления строк, который извлекает из базы данных строки, сходство которых со строкой запроса не меньше порогового значения.
Биография
- 2017-: профессор, лаборатория Оказаки, курс искусственного интеллекта, факультет компьютерных наук, школа вычислительной техники, Токийский технологический институт
- 2011-2017: доцент, лаборатория Инуи-Окадзаки, Высшая школа информационных наук, Университет Тохоку
- 2007–2011: Исследователь, лаборатория Tsujii, Высшая школа информационных наук и технологий, Токийский университет .
- 2003–2007: Курс докторантуры, факультет информационных и коммуникационных технологий, Высшая школа информационных наук и технологий, Токийский университет
- 2001–2003: Магистерский курс, факультет информационных и коммуникационных технологий, Высшая школа информационных наук и технологий, Токийский университет
- 1997-2001: Бакалавриат, факультет информационных и коммуникационных технологий, Инженерная школа, Токийский университет
Награда
- Награда за лучшую статью (первое место), 29-е ежегодное собрание Ассоциации обработки естественного языка, DREEAM: Направление внимания с помощью доказательств для улучшения извлечения отношений на уровне документа (2023)
- Награда за лучшую статью, 29-е ежегодное собрание Ассоциации обработки естественного языка, семантическая специализация для устранения неоднозначности смысла слов на основе знаний (2023 г.
 )
) - Спонсорская награда (Hitachi), 29-е ежегодное собрание Ассоциации обработки естественного языка, предложения запросов и обобщения: создание пар запрос-резюме для обобщения, ориентированного на запрос (2023)
- Награда Специального комитета, 29-е ежегодное собрание Ассоциации обработки естественного языка, Решение проблем НЛП посредством взаимодействия человека и системы: подход, основанный на обсуждении (2023)
- Награда за лучшую статью (первое место), Ассоциация обработки естественного языка, Оптимизация сегментации слов для последующих задач путем взвешивания текстового вектора (2022)
- Награда за лучшую статью, 28-е ежегодное собрание Ассоциации обработки естественного языка, IMPARA: Метрики на основе воздействия для GEC с использованием данных PARAllel (2022)
- Награда Специального комитета, 28-е ежегодное собрание Ассоциации обработки естественного языка, неавторегрессивное создание с использованием ближайшего соседа (2022)
- Награда Специального комитета, 28-е ежегодное собрание Ассоциации обработки естественного языка, Выборочное прогнозирование для оценки уверенности в знании языковых моделей (2022 г. )
- Награда Специального комитета, 28-е ежегодное собрание Ассоциации обработки естественного языка, Метод автоматического выбора миниатюры изображения с использованием названия фильма (2022)
- Награда AKBC2021 за выдающуюся работу, поведенческое тестирование моделей встраивания графов знаний для предсказания ссылок (2021)
- Награда за лучшую статью, 27-е ежегодное собрание Ассоциации обработки естественного языка, обнаружение гипонимии с использованием иерархического обучения коду (2021)
- Специальная награда комитета, 27-е ежегодное собрание Ассоциации обработки естественного языка, создание заголовков, которые надежно содержат указанные слова (2021)
- Награда спонсора, 27-е ежегодное собрание Ассоциации обработки естественного языка, создание заголовков, которые надежно содержат указанные слова (2021)
- Премия TokyoTech Education Award 2020, Общеуниверситетская образовательная программа по науке о данных и искусственному интеллекту для аспирантов (2021)
- Премия за презентацию, 15-я конференция NTCIR, WER99 на Классификационной задаче NTCIR-15 QA Lab-PoliInfo-2 (2020)
- Победа в конкурсе машинного перевода с видеоуправлением (VMT) 2020, Сегментация ключевых кадров и позиционное кодирование для конкурса машинного перевода с видеоуправлением 2020 (2020)
- Награда за языковые ресурсы, 26-е ежегодное собрание Ассоциации обработки естественного языка, передача стиля для абстрактного обобщения в маломасштабном ресурсе (2020 г. )
- Награда за лучшую статью, 240-е собрание специальной группы по обработке естественного языка (SIGNL), Японского общества обработки информации (IPSJ), «Пересмотр задачи создания заголовков на основе текстового представления» (2019)
- Премия JSAI 2018 за лучшую статью, Обучение составлению распределенных представлений реляционных шаблонов (2018)
- Награда за лучшую статью, 24-е ежегодное собрание Ассоциации обработки естественного языка, Сокращение нечетного поколения при генерации заголовков с помощью нейронных сетей (2018 г.)
- Премия Microsoft Research Award 2016 в области обработки информации (2017)
- PACLIC-30 Best Paper Honorable Mentions, Распознавание отношений открытого словаря между объектами в изображениях (2016)
- 15-я научная премия Funai (2016 г.)
- Премия для молодых ученых, Почетная грамота министра образования, культуры, спорта, науки и технологий (2016 г.)
- Награда за лучшую статью (высшая), 22-е ежегодное собрание Ассоциации обработки естественного языка, Модель выборочного предпочтения с использованием контекстной информации на основе распределенного представления (2016 г. )
- Награда за лучшую статью, 22-е ежегодное собрание Ассоциации обработки естественного языка, динамическое распределенное представление местного контекста в дискурсе (2016)
- Награда за исследования, IPSJ SIG обработки естественного языка, Контекстуализация модели выбора предпочтений на основе распределенного представления (2016)
- Премия PACLIC-29 за лучшую статью (вычисления), сокращение лексических признаков при синтаксическом анализе с помощью встраивания слов (2015)
- Премия Docomo Mobile Science за передовые технологии (2015 г.)
- Награда за исследования, IPSJ SIG обработки естественного языка, аддитивная композиция логарифма вектора совпадения (2015)
- Награда за лучшую статью (высшая), 21-е ежегодное собрание Ассоциации обработки естественного языка, Семантическое вычисление моделей отношений на основе композиционности (2015)
- Награда за исследования для молодых ученых, Фонд Минору Исида (2014 г. )
- Награда за исследования, ARG SIG Web Intelligence and Intraction (WI2), Последующий анализ твитов, касающихся обложки японского журнала «Искусственный интеллект» (2014 г.)
- Награда AMT2014 за лучшую статью, Добыча ложной информации в Твиттере о ситуации крупного бедствия (2014)
- Награда за лучшую статью (высшая), 20-е ежегодное собрание Ассоциации обработки естественного языка, дистрибутивного семантического представления слов и фраз на основе распределения Гаусса (2014)
- Награда за лучшую статью, Журнал обработки естественного языка, Извлечение ложной информации в Твиттере и анализ процессов ее распространения с использованием лингвистических шаблонов для исправления (2014)
- Награда за лучшую статью, 26-е ежегодное собрание Японского общества анализа рисков, анализ и противодействие слухам о персиках, выращенных в префектуре Фукусима, на основе Twitter (2013)
- Награда за лучшую статью, Журнал обработки естественного языка, Обобщение семантических ролей в автоматической маркировке семантических ролей (2011)
- Награда за лучшую статью для молодого исследователя Национального собрания IPSJ, Быстрый алгоритм приблизительного сопоставления словарей (2011)
 )
) )
) )
) )
) )
)Услуги (международные)
Руководители
- Расширенные члены (MAL), Азиатская федерация обработки естественного языка (AFNLP) (2017–2018)
Международные журналы
- Редколлегия Computational Intelligence (2015-)
- Группа постоянных рецензентов, Transactions of the Association for Computational Linguistics (2014-)
- Рецензент, AI Communications (2014)
- Рецензент, IEEE/ACM Transactions on Audio Speech and Language (2019)
- Рецензент Американского общества информационных наук и технологий (2009 г. )
- Рецензент, Прикладная клиническая информатика (2014)
- Рецензент, Биоинформатика (2016, 2017)
- Рецензент, BMC Bioinformatics (2010)
- Рецензент, Химинформатика (2014)
- Рецензент компьютерной речи и языка (2022)
- Рецензент, Computational Intelligence (2011, 2012, 2013)
- Рецензент, Компьютеры в промышленности (2015)
- Рецензент, Data and Knowledge Engineering (2016)
- Рецензент, IEICE Transaction on Information and Systems (2010, 2012, 2016)
- Рецензент, IEEE Transaction on Neural Networks and Learning Systems (2016)
- Рецензент, обработка информации (2015)
- Рецензент, Журнал обработки информации (2017)
- Рецензент, обработка информации и управление (2011)
- Рецензент, информационные науки (2011)
- Рецензент, системы, основанные на знаниях
- Рецензент, Журнал химинформатики (2014)
- Рецензент, Языковые ресурсы и оценка (2012, 2019)
- Рецензент, Исследования в области машинного обучения (2009, 2012, 2015, 2016)
- Рецензент, Новое поколение вычислений (2019)
- Рецензент, Труды Ассоциации компьютерной лингвистики (2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021)
- Рецензент, Transactions on Knowledge and Data Engineering (2012)
- Рецензент, Операции в информационных системах управления (2013)
- Рецензент журнала медицинских интернет-исследований (2017, 2019)
- Рецензент, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2021, 2022)
 )
)Международные конференции
- Председатель программы, ACL 2023
- Учебный стул, ACL 2022
- Стул для мастерских, EMNLP-IJCNLP 2019
- Стул для мастерских, IJCNLP 2013
- Стул для публикаций, EMNLP-CoNLL 2012
- Районный стул, ACL 2012, 2016, 2021
- Редактор действий, ACL Rolling Review (ARR) 2021, 2022
- Районный стул, EMNLP 2022
- Зональный стул, LREC 2022
- Старший программный комитет (SPC), AAAI 2021, 2022, 2023
- Старший программный комитет (SPC), IJCAI 2020, 2021, 2022
- Программный комитет, AAAI 2011, 2014, 2015, 2017, 2018, 2019, 2020
- Программный комитет, AACL 2020
- Программный комитет, ACL 2009, 2010, 2013, 2015, 2016, 2017, 2018, 2019, 2020
- Программный комитет, Непрерывный обзор ACL (ARR) 2021
- Программный комитет, BigComp 2015, 2016
- Программный комитет, БиоНЛП 2011, 2013, 2015, 2016, 2017, 2018, 2020
- Программный комитет, BioTxtM 2012, 2014, 2016
- Программный комитет, Coling 2008, 2010, 2012, 2014, 2016, 2018, 2020, 2022
- Программный комитет, CoNLL 2014, 2015
- Программный комитет, DTMBIO 2012
- Программный комитет, EACL 2012, 2014, 2017
- Программный комитет, ЕАБР 2016
- Программный комитет, EMNLP 2010, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021
- Программный комитет, GeCKo 2020
- Программный комитет, ICLR 2020, 2021, 2022
- Программный комитет, IJCAI 2011, 2016, 2018, 2019
- Программный комитет, IJCNLP 2011, 2017
- Программный комитет, KIKE 2016
- Программный комитет, LOUHI 2018
- Программный комитет, LREC 2018, 2020
- Программный комитет, NAACL 2016, 2018, 2021
- Программный комитет, NeurIPS 2021, 2022
- Программный комитет, NewSum 2021
- Программный комитет, SemEval 2020
- Программный комитет, СМБМ 2010, 2012
- Программный комитет, SPNLP 2022
- Программный комитет, W-NUT 2016, 2017, 2018, 2020, 2021
- Генеральный председатель Симпозиума молодых исследователей по обработке естественного языка, 2016 г.