Тренинг «Морфемный разбор» / Морфемный разбор / Русский на 5
Выполняй морфемный разбор слова. Проверяй себя по ответам:
Задание 1
Слова для разбора:
1) замаскироваться, 2) восток, 3) жгу, 4) жжёшь, 5) вполуха
Ответ:
1) замаскироваться, 2) восток , 3) жгу, 4) жжёшь, 5) вполуха
Задание 2
Слова для разбора:
1) англо-русский, 2) выдохнуться, 3) ждать, 4) жгут (существительное), 5) жгут (глагольная форма)
Ответ:
1) англо-русский, 2) выдохнуться, 3) ждать, 4) жгут , 5) жгут
Задание 3
Слова для разбора:
1) кино, 2) заунывный, 3) заунывно, 4) наследница, 5) бил
Ответ:
1) кино, 2) заунывный, 3) заунывно, 4) наследница, 5) бил
Задание 4
Слова для разбора:
1) насекомое, 2) организационно, 3) спят, 4) пекарня, 5) пилотаж
Ответ:
1) насеком
Задание 5
Слова для разбора:
1) пилотирование, 2) понизу, 3) помимо, 4)мять, 5) мну
Ответ:
1) пилотирование,* 2) понизу, 3) помимо, 4) мять, 5) мну
* Точнее: пилотирова[н’ий’+э], то есть [й] отходит к суффиксу, а [э] — это окончание.
Задание 6
Слова для разбора:
1) справа, 2) пригнать, 3) приворотить, 4) рученька, 5) пять
Ответ:
1) справа, 2) пригнать, 3) приворотить, 4) рученька, 5) пять
Задание 7
Слова для разбора:
1) русифицированный, 2) рядышком, 3) ряби´на (дерево), 4) рябина´ (неровность, пятнистость), 5) русский
Ответ:
1) русифицированный, 2) рядышком, 3) ряби´на (дерево), 4) рябина´ (неровность, пятнистость), 5) русский
Задание 8
Слова для разбора:
1) шить, 2) шитьё, 3) бра, 4) мяу, 5) очищу
Ответ:
1) шить, 2) шитьё,* 3) бра, 4) мяу, 5) очищу
* Точнее: шить[й’о], [й’] — суффикс, а [о] — окончание.
Задание 9
Слова для разбора:
1) репетировать, 2) схитрить, 3) вот, 4) сыгранность, 5) сызмальства
Ответ:
1) репетировать, 2) схитрить, 3) вот, 4) сыгранность , 5) сызмальства
Задание 10
Слова для разбора:
1) себя, 2) себялюбец, 3) вру, 4) дал, 5) поучительный
Ответ:
1) себя, 2) себялюбец , 3) вру, 4) дал , 5) поучительный
Смотрите также
— Понравилась статья?:)Мой мир
Вконтакте
Одноклассники
Google+
Карточки » Разбор слова по составу» | Методическая разработка по русскому языку (2 класс) на тему:
Фамилия,имя______________________ Разбери по составу: Травушка травинка молоденький
рассвет светлячок ветерок моряк полюшко рысёнок самовар золотые побережье бережок небо небеса голуби прибрежная полоска лисята лесник город | Фамилия,имя______________________ Разбери по составу: Времена перевязь глазной глоток гнёздышко горный давний далёкий подарок денёк детёныш длинный дождливый вздох дочурка дровишки дроздовый еловый жарища желток котёнок ночник выпечка плясун |
Фамилия,имя______________________ Разбери по составу: Зелёный зеркальный позолота ловец замазка игривый игрушка качка носишко конина котёнок красивый лесник крикливый
кровинка ледник летучий ловушка овчина парник перина мировая низина новизна | Фамилия,имя______________________ Разбери по составу: Плечистый пчелиный пятнашки робкий садовый свинина свисток божок бочар больной силач синева ходули подсказка скворушка снежинка хитрый травинка тропинка сосновый соринка |
КАРТОЧКИ ДЛЯ РАЗБОРА СЛОВ ПО СОСТАВУ
1. ПОМОЩНИК СДВИГ НАКЛОН
ПОМОЩНИК СДВИГ НАКЛОН
ВЫСТАВКА КАЧКА ДРУЖОЧЕК
ШКОЛЬНИК НАКИПЬ БАБУШКА
_____________________________________________________________________
2. СГИБ ДЕДУШКА КНИЖЕЧКА
ПОМОЩНИЦА СОСЕДКА КОРАБЛИК
БЕЛИЛА ШАЛУН СТОЛЯР
_____________________________________________________________________
3. ШАЛОСТЬ СТРЕЛОК ОТМЕТКА
ПЕРЕБЕЖКА ПАРОХОД ЗАМАЗКА
КРИКУН ПОЛОВИКИ ГОРСТКА
_____________________________________________________________________
4. ОБЛАЧКО ОЗИМЬ ПРИЗВАНИЕ
ПОЕЗД ГОРСТКА ОЧИСТКИ
ГНЕЗДЫШКО ДВЕРКА ДРУЖОК
_____________________________________________________________________
5. НАГРУЗКА РАЗГОВОР МАСТЕРСТВО
НАГРУЗКА РАЗГОВОР МАСТЕРСТВО
ОХРАНА ЗАГЛЯДЕНИЕ ВЕТОЧКА
СКОРЛУПКА ДУБОК ЗИМУШКА
_____________________________________________________________________
6. ГРАДУСНИК ЕЖИКИ НАКЛОН
ТРЯСКА БЕЛИЗНА ЗАБОЛЕВАНИЕ
ГЛАЗОК ПОЛЯНА ТИШИНА
7. СЕРДЕЧНЫЙ ТИГРЕНОК САРАЙ
ЗВЕРЕК СЛОВЕЧКО МОРСКАЯ
ЧАСОВЩИК РАСТЕНИЕ РУССКИЙ
_____________________________________________________________________
8. РАССКАЗ ПОДДЕРЖКА ЦИРКАЧ
ВЕСЕЛЬЕ ПОБЕДА ДЕЛОВЫЕ
ЗВЕРИНЕЦ СНЕГОВИКИ СКРИПУЧАЯ
_____________________________________________________________________
9. ГРУЗОВОЕ КОРМУШКА ПОВАРЕНОК
ГРУЗОВОЕ КОРМУШКА ПОВАРЕНОК
ЗАВЯЗКА ЛЯГУШЕЧКА ДЕВОЧКА
ОТГАДКА СИНЕНЬКИЕ ПРИБРЕЖНАЯ
_____________________________________________________________________
10. ПЕРЕХОД ПОЖАР ТРАВУШКА
КАРТИНА ПЕСЕНКА КРЫЛАТЫЕ
ЗАМЕСТИТЕЛЬ РАЗЛИНОВКА ПРОЕЗД
_________________________________________________________________
11. ХВАСТЛИВАЯ СЕНОКОС ДОРОЖКА
ПАРОХОД МАЛЕНЬКИЕ ЕЛЬ
СОЛНЦЕ ЛОШАДКА ВОДОПАД
_________________________________________________________________
12. КРЕПОСТЬ ПОГРАНИЧНИК ПЫЛЕСОС
МУДРАЯ МОРОЗНЫЕ ПИРОЖОК
ЛЕДОХОД ЧАЙНИК СДАЧА
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «интересный», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ИНТЕРЕСНЫЙ, ая, ое; сен, сна.
1. Возбуждающий интерес (в 1 знач.), занимательный, любопытный. И. спектакль. Интересно (нареч.) рассказывать.
2. Красивый, привлекательный. Интересная внешность.
| сущ. интересность, и, ж.
Фонетический (звуко-буквенный) разбор
интере́сный
интересный — слово из 4 слогов: ин-те-ре-сный. Ударение падает на 3-й слог.
Транскрипция слова: [ин’т’ир’эсный’]
и — [и] — гласный, безударный
н — [н’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
т — [т’] — согласный, глухой парный, мягкий (парный)
е — [и] — гласный, безударный
р — [р’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
е — [э] — гласный, ударный
с — [с] — согласный, глухой парный, твёрдый (парный)
н — [н] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
ы — [ы] — гласный, безударный
й — [й’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (непарный, всегда произносится мягко)
В слове 10 букв и 10 звуков.
Цветовая схема: интересный
Разбор слова «интересный» по составу
интересный
Части слова «интересный»: интерес/н/ый
Состав слова:
интерес — корень,
ый — окончание,
интересн — основа слова.
Как Разбирать Предложения по Составу+ ТОП-5 примеров
СохранитьSavedRemoved 3
Из чего состоит предложение? Как правильно выделять члены предложения? – из статьи ниже, вы научитесь делать разбор предложения по составу, а также узнаете о типичных ошибках при разборе.
Содержание этой статьи:
Члены предложения
Это интересно: Как сделать правильно проект «Моя семья» для первого класса + ОБРАЗЦЫ, пошаговая ИНСТРУКЦИЯ и 75 ФОТО
вернуться к меню ↑Главные
Подлежащее
Отвечает на вопросы: кто? Что?
Примеры: Аня, Мама, Алексей Иванович, погода и т.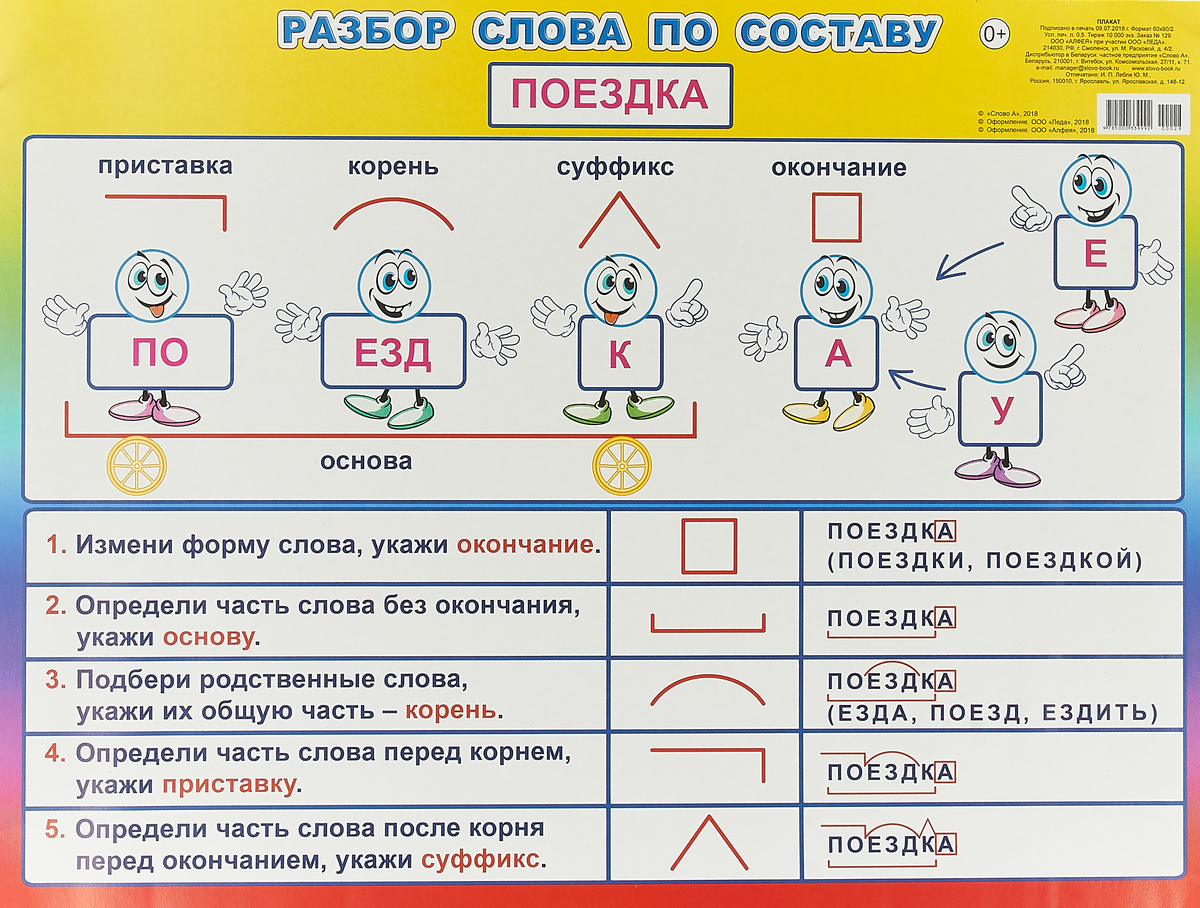 п.
п.
Подлежащим может быть любое существительное, местоимение, совершающее действие в предложение:
«Я помыл руки»; «Погода нас порадовала»; «Мама попросила сходить в магазин»; «Алексей Иванович не любит гостей»; «Аня посмотрела на письмо и заплакала».
Подлежащее может стоять в начале предложения, в середине, в конце. Его выделяют прямой чертой.
Сказуемое
Отвечает на вопросы: Что делает? Что сделает?
Примеры: пишет, читает, разговаривает, любит.
Сказуемое – это глагол. Сказуемое всегда совершает действие и связано с подлежащим:
«Мы выписали важную информацию в тетрадь»; «Зачем ты испытываешь мое терпение?»; «Я вдруг почувствовала на себе взгляд соседского мальчишки и мне стало не по себе.»
Выделяют двумя чертами.
Согласование глагольного сказуемого с подлежащим
Подлежащее и сказуемое согласованы между собой в числе, роде и лице. Нельзя выделить основу: «Собака жили»; Можно выделить основу «собака жила». Если подлежащее и сказуемое не согласуются между собой, то либо вы нашли существительное неправильно, либо в предложении несколько грамматических основ.
Если подлежащее и сказуемое не согласуются между собой, то либо вы нашли существительное неправильно, либо в предложении несколько грамматических основ.
Второстепенные
Второстепенные члены предложения
Дополнение
Указывает на результат совершенного действия, либо на предмет, с которым совершается действие. Выделяется пунктиром.
«Я устала от одиночества» — процитировала Аню сестра» — фраза принадлежит Ане, сестра ее процитировала, значит, дополнением служит «Аню» (кого?).
«Миша ненавидел среды из-за уроков французского» — Из-за чего Миша ненавидел среды? – из-за уроков французского, значит, это дополнение.
Чтобы не перепутать дополнение с обстоятельством и определением, важно перечитывать предложение и задавать правильные вопросы. Важен контекст, поэтому вслепую выделять дополнение нельзя.
Определение
Показывает качества, свойства и признак предмета. В предложении выделяют волнистой линией.
В предложении выделяют волнистой линией.
«Кот Тимофей лег на коврик и показал свой пушистый бочок.» — бочок какой? – пушистый.
«Сотри свои красные губы, они тебе совершенно не идут!» — губы какие? – красные.
«Интересно, как может такой красивый, интересный и интеллигентный человек, согласится на такое отвратительное предложение?» — «красивый, интересный и интеллигентный» — качества, определяющие описываемого человека.
«Отвратительное» — признак, описывающий предложение, поступившее человеку, о котором ведется повествование. Следовательно, в предложении 4 определения.
Обстоятельство
Зависит от сказуемого и выражает признак действия или предмета. Выделяют пунктиром с точкой.
«Встреча была назначена вечером, в холле нашего отеля» — когда была назначена встреча? – вечером; где назначена встреча? – в холле отеля.
«Я путешествую только поездами, так как самолеты кажутся мне небезопасными» — как ты путешествуешь? – только поездами. В предложении одно обстоятельство.
В предложении одно обстоятельство.
«Он поехал в Европу, ему нужно срочно увидеть что-то красивое» — куда он поехал? – в Европу; увидеть как? – срочно. В предложении два обстоятельства.
Существует несколько видов обстоятельств:
- Времени
- Места
- Цели
- Сравнения
- Условия
- Уступки
- Меры и степени
- Причины
Виды обстоятельств по значению
Каждый вид выделяется одинаково – пунктиром с точкой.
вернуться к меню ↑ вернуться к меню ↑Как сделать разбор предложения по составу
Выделяем главные членыПодлежащее и сказуемое должно согласовываться по числу и роду. Если получается нескладная грамматическая основа: она писали, семья решил и т.п. – основа выделена неверно.
Выделяем второстепенные члены От главных членов задаем вопросы к второстепенным. Они также должны согласовываться между собой.Разбор по составу – несложный процесс, главное – правильно задать вопрос и определить главные члены. Если первый пункт выполнен верно, то найти второстепенные члены будет легко.
Если первый пункт выполнен верно, то найти второстепенные члены будет легко.
Обращаем внимание на согласованность каждого члена по роду, числу и падежу.
вернуться к меню ↑ вернуться к меню ↑Топ-5 примеров
Главные и второстепенные члены предложения
1«Когда я вышла ночью в поле, я впервые ощутила настоящую тишину!»
Я (что сделала?) вышла – первая грамматическая основа; (вышла когда?) ночью (куда?) в поле – обстоятельства;
Я (когда?) впервые (что сделала?) ощутила (какую?) настоящую (что?) тишину – перед нами вторая грамматическая основа, обстоятельство, определение и дополнение.
2«Я пробуждаюсь несколько раз за ночь и тревожусь в течение всего дня, мне срочно нужно отдохнуть».
Я пробуждаюсь и тревожусь – подлежащее и 2 сказуемых; несколько раз за ночь – обстоятельство; в течение всего дня – обстоятельство времени; мне нужно отдохнуть – 2 грамматическая основа; срочно – обстоятельство.
3«Когда я перешел порог новой школы, я испытал приступ сильнейшего волнения, все закружилось перед глазами, и я отчаянно пытался успокоиться».
Я перешел – грамматическая основа; порог школы – дополнение; новой – определение;
Я испытал – вторая грамматическая основа; приступ – дополнение; сильнейшего – определение; волнения – дополнение;
Все закружилось – третья грамматическая основа; перед глазами – обстоятельство;
Я пытался успокоиться – четвертая грамматическая основа; отчаянно – обстоятельство.
4«Лиза чувствовала себя особенной, ведь она единственная в классе умела играть на скрипке и читать 220 слов в минуту».
Лиза чувствовала – первая грамматическая основа; себя – дополнение; особенной – определение;
Она умела играть и читать – вторая грамматическая основа; на скрипке – дополнение; 220 слов в минуту – обстоятельство.
5«Леша с удовольствием читал книгу»
Леша читал – грамматическая основа; книгу – дополнение; с удовольствием – обстоятельство.
Типичные ошибки
Разбор предложения по членам
1Несколько подлежащих
В сложном предложении действительно может быть несколько подлежащих. Если мысленно поделить предложение на несколько частей, то можно разбить его на короткие предложения:
«Мы уговаривали родителей остаться, но они упрямо нам отказывали, ссылаясь на необходимость уехать».
В данном примере, всего 2 подлежащих – «мы» и «они». Если мысленно разделить предложение на 2 части, то получится: Мы уговаривали родителей остаться. Они упрямо нам отказывали, ссылаясь на необходимость уехать».
Некоторые выделяют в качестве подлежащего все местоимения и существительные:
«Мы не понимали, что могло испортить им вечер, поэтому попросили пришедших гостей удалиться на серьезный разговор».
Подлежащее совершает действие, остальное – второстепенные части речи: обстоятельства, дополнения, определения.
2Грамматическая основа может быть только одна
В сложных предложениях, может быть более 2 грамматических основ.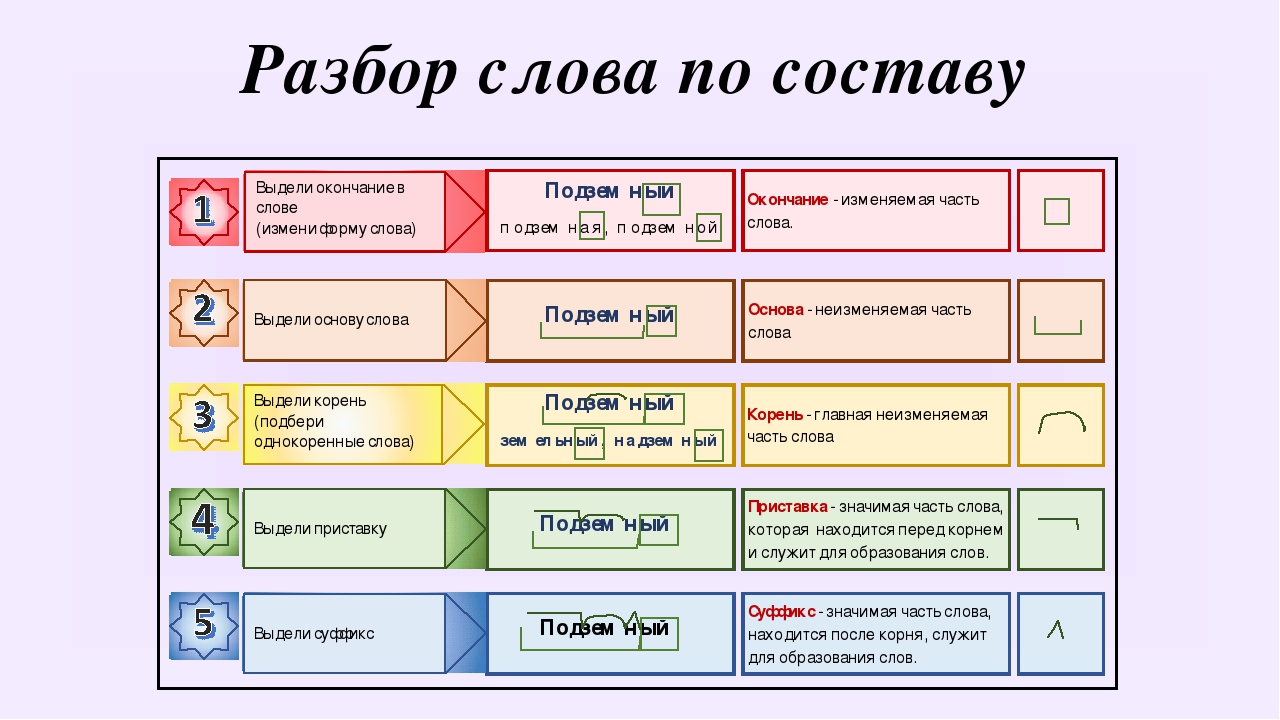
3Если рядом в предложении стоит несколько одинаковых членов предложения, то их нельзя выделять вместе
Например, если стоит несколько определений через запятую: красивый, умный и добрый (человек). В таком случае, выделить все определения одной волнистой линией – не ошибка.
Если между одинаковыми членами предложения стоят запятые, либо они отсутствуют, их можно выделить одной чертой. Оформление в данном случае ни на что не влияет. Однако, будет ошибкой, если между членами предложения есть и другие, но их игнорируют. Пример:
«День был весенний, солнечный, я люблю теплые дни». – В данном случае между определениями есть грамматическая основа, ее игнорировать нельзя.
4Глагол – всегда сказуемое
«Семья уехала отдыхать на море» — распространенной ошибкой считается выделение сказуемого «уехала отдыхать». Однако, «отдыхать на море» — обстоятельство цели. Семья уехала (куда? с какой целью?) отдыхать на море.
5Разбор без дополняющих вопросов
Чтобы правильно разбирать предложение, важно задавать вопросы и понимать контекст, а не расставлять грамматические основы по логике «существительное – подлежащее, а глагол – сказуемое».
Перечитывая предложение несколько раз и задавая правильные вопросы, вы сможете безошибочно делать разбор по составу. Обращайте внимание на согласованность каждого члена друг с другом.
вернуться к меню ↑ВИДЕО: Главные и второстепенные члены предложения
вернуться к меню ↑Как понять – это обстоятельство (места, времени и т.д.) или дополнение
Смотрите контекст – обстоятельство всегда объясняет совершаемое событие, добавляет ясности, объясняет причины. Дополнение же дополняет уже имеющуюся информацию, уточняет.
Обстоятельством может стать любая часть речи, даже фразеологизм. В классическом виде это наречия, поэтому лучше начинать разбор предложения с поиска обстоятельства, а не дополнения.
Дополнениями зачастую становятся числительные, местоимения, наречия и фразеологизмы. Если перед вами спорное слово, похожее на обстоятельство, но обстоятельные вопросы задать невозможно, то перед вами на 100% дополнение.
Существуют ли ограничения на члены предложения в количестве
Не смущайтесь, если в предложении более 5 одинаковых членов. Все зависит от автора, например, у Л.Н. Толстого есть предложения с огромным количеством грамматических основ (более 6), не говоря уже о второстепенных членах.
Если вы самостоятельно составляете текст и хотите сделать его складным и удобочитаемым, то стремитесь писать предложения с умеренным количеством второстепенных членов. Для удобства чтения, лучше разбить одно большое предложение на несколько маленьких – так, вы с меньшей вероятностью ошибетесь.
Ресурс для разбора предложения онлайн: goldlit.ru
вернуться к меню ↑ВИДЕО: Синтаксический разбор предложения часть
8 Общий Балл
Чтобы разбирать предложения по составу, нужно хорошо чувствовать язык и знать правила русского языка. Выучив один раз вопросы каждого члена предложения, вы сможете правильно и быстро разбирать предложение по составу. Если вы не согласны с рейтингом статьи, то просто поставьте свои оценки и аргументируйте их в комментариях. Ваше мнение очень важно для наших читателей. Спасибо!
Если вы не согласны с рейтингом статьи, то просто поставьте свои оценки и аргументируйте их в комментариях. Ваше мнение очень важно для наших читателей. Спасибо!
Достоверность информации
8
Актуальность информации
8.5
Раскрытие темы
7.5
Доступность применения
9
Плюсы
- Разбирать предложения по составу довольно легко
Минусы
- Сначала школьнику может понадобиться помощь учителя
Гайд по комиксам про Мстителей от Джейсона Аарона
Мстители, к разбору!
Серии Могучих Героев Земли с незапамятных времен были и остаются линейками-хэдлайнерами: именно от их авторских составов и сюжетного развития зависит актуальное состояние и статус-кво крайне разношерстного и местами рваного мира Marvel Comics. И в этом, говоря откровенно, есть своя неоспоримая логика: ведь именно в сюжетах «Мстителей» всегда участвовали самые основные герои вселенной, будь то Капитан Америка, Железный Человек, Тор, Халк или Паучок, – отсюда же «росли ноги» у всевозможных глобальных событий и кроссоверов, меняющих привычный уклад Земли-616 на n-нное количество времени. Таким образом вселенную медленно, но верно «двигали» по заранее обсужденному и проработанному направлению, при этом не растрачивая много сил и средств на проработку каждого отдельного персонажа – ведь про них можно существуют сольные онгоинги. В общем, супергеройские капустники тащат развитие – и делают это относительно хорошо и качественно.
Таким образом вселенную медленно, но верно «двигали» по заранее обсужденному и проработанному направлению, при этом не растрачивая много сил и средств на проработку каждого отдельного персонажа – ведь про них можно существуют сольные онгоинги. В общем, супергеройские капустники тащат развитие – и делают это относительно хорошо и качественно.
Данная тенденция сохранялась десятки лет вплоть до «Secret Wars» Джонатана Хикмана: после тамошних событий онгоинг «Avengers» утратил весомую часть значимости для тогдашнего контьюнити, заимев в названии ненужные и путающие молодых читателей приставки вроде «All-New All-Different». Под руководством одного из культовых сценаристов Большой Двойки, Марка Уэйда («The Flash», «Daredevil»), начались эксперименты с составом команды, фундаментальными тезисами и остросоциальным посылом, который далее перекочует в онгоинг «Champions», пришедший на замену всевозможных «Молодых Мстителей» и «Академий».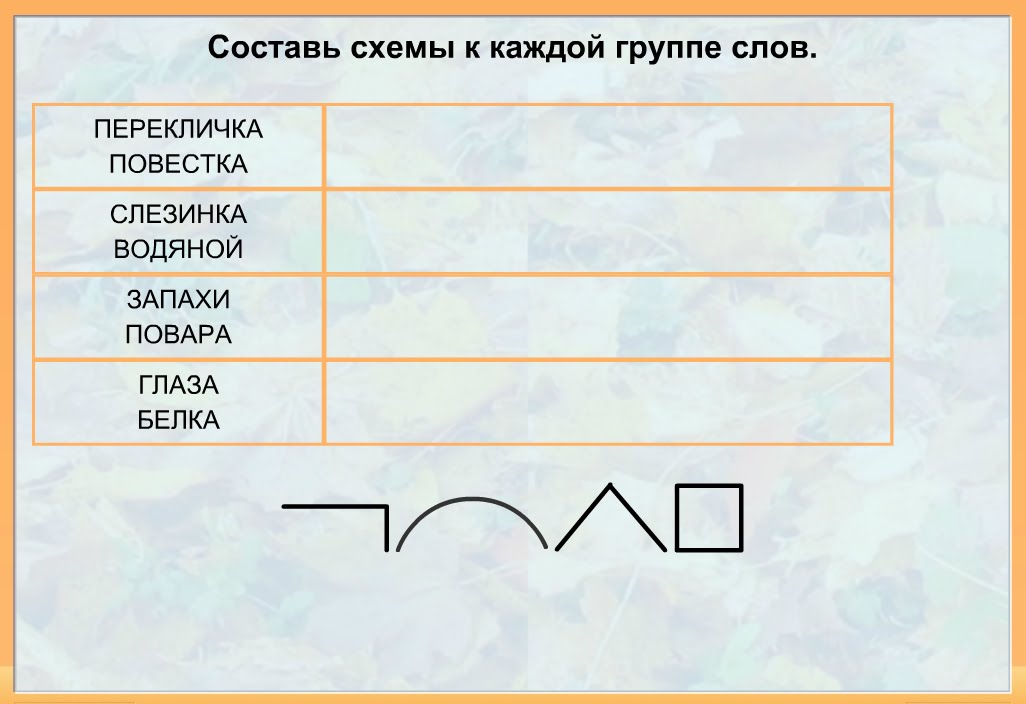 Конечно, неприятные изменения были и до него – однако именно при Уэйде серия окончательно потеряла собственный неповторимый шарм, скатившись до уровня блеклой линейки второго эшелона про очередную супергеройскую команду.
Конечно, неприятные изменения были и до него – однако именно при Уэйде серия окончательно потеряла собственный неповторимый шарм, скатившись до уровня блеклой линейки второго эшелона про очередную супергеройскую команду.
Подобное не могло продолжаться слишком долго – хотя бы из-за серьезного спада продаж серии. Это понимал и ныне бывший главный редактор «издательства чудес» Аксель Алонсо: путем очередного масштабного кроссовера, «Avengers: No Surrender», в принудительном порядке были «подчищены» лишние онгоинги, чьи продажи оставляли желать лучшего. Параллельно с этим за написание спецвыпуска «Marvel Legacy» #1, инициативы конца 2017 года с обновлением нумерации номеров основных серий издательства, взялся автор крайне успешных серий о Торах и не менее успешных «Wolverine» и «Punisher MAX» – Джейсон Аарон. Уже отметившийся в Marvel написанием одного из глобальных событий десятых, «Original Sin», сценарист вдохнул в мифологию несколько устаревшего и закаменелого капустника героев новые элементы.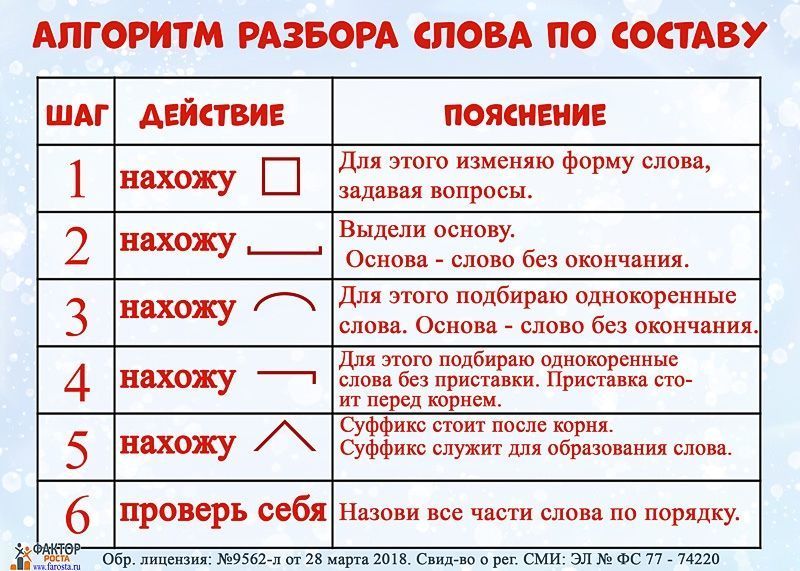
Таким образом, уже в мае 2018 года читатели получили обновленную линейку «Avengers». Аарон, незадолго до этого обзаведшийся поддержкой и протекцией пришедшего на смену Алонсо Ч. Б. Себульски, получил насиженное место главного сценариста и идейного двигателя актуальной вселенной Marvel, а заодно, судя по качеству дальнейших сюжетов, полноценный карт-бланш на неограниченное количество ретконов и переосмыслений. Благодаря этому кажущаяся еще в далеком 2017-ом году «незначительной» история о Доисторических Мстителях предстала подспорьем для формирования новой команды и появления очередного бессмертного антагониста. Да, благодаря этому интернет получил бесконечное число мемов про Мефисто еще задолго до премьеры «ВандаВижн».
И раз уж в самом разгаре ивент «Heroes Reborn», плотно подвязанный к насыщенному на события комиксу Джейсона, не вижу смысла не поговорить об одном из самых спорных, противоречивых и ненавистных онгоингов Marvel последних лет.
Вы будете смеяться, кричать и плакать – но, уверяю вас, равнодушными вы не останетесь.
Важное примечание! Цель данного текста: упростить путь «изучения» для незнакомых с серией «Avengers» читателей, сократив несколько монотонно тянущихся лет Земли-616 до формата одного относительно компактного лонгрида. Само собой, это означает, что впереди будут спойлеры – как незначительные, так и крупные. Если у вас появилось (или, может, появится по ходу чтения статьи) желание ознакомиться с комиксом самостоятельно – дерзайте, не откладывая прочтение в долгий ящик. Так или иначе я вас известил.
Первое, с чего стоит начать, – предупреждение. К сожалению или к счастью, «Мстители» Аарона затрагивают почти каждого важного (и не только) для мира Marvel персонажа, посему глупо было бы ожидать, что за десятками выпусков читателей не подстерегают, так сказать, «критичные для восприятия» ретконы. Посему если вы идентифицируете себя как ярого фаната Тора, Призрачного Гонщика, Феникса, Лунного Рыцаря или Черной Пантеры – готовьтесь к локальному разрыву шаблонов. Отдельного внимания заслуживают люди, которые настойчиво игнорируют актуальные для Тони Старка изменения – для вас, говорю абсолютно серьезно, путь к серии «Avengers» 2018-го бесповоротно закрыт. Не читайте этот текст, забудьте об этом комиксе и постарайтесь не думать о том, что происходит в современных сериях про вашего любимого персонажа. Уверяю, и на вашей улице однажды наступит праздник.
Отдельного внимания заслуживают люди, которые настойчиво игнорируют актуальные для Тони Старка изменения – для вас, говорю абсолютно серьезно, путь к серии «Avengers» 2018-го бесповоротно закрыт. Не читайте этот текст, забудьте об этом комиксе и постарайтесь не думать о том, что происходит в современных сериях про вашего любимого персонажа. Уверяю, и на вашей улице однажды наступит праздник.
«Marvel Legacy» #1 и «FCBD 2018: Avengers»По такому случаю хочу передать привет Кристоферу Кантвеллу. Если хотите почитать хороший и, что самое главное, новый комикс про Железного Человека – прошу пройти в одноименную серию конца 2020 года.
Рисунок: Эсад Рибич, Стивен МакНивен, Сара Пикелли и др.
Пролог к основному онгоингу, в котором кратко рассказывают об актуальном состоянии команды Могучих Героев Земли, знакомят с Доисторическими Мстителями и всеми силами пытаются завлечь в тернии новой серии с измененной хронологией событий.
Говоря подробнее, после событий «No Surrender» команда в очередной раз находится в упадке: Роджерс лишился титула Капитана Америка и колесит по Штатам, пытаясь очистить свое доброе имя от приписываемых ему «заслуг» в «Secret Empire», Железный Человек оправляется от двухлетнего нахождения в коме (об этом читайте в «Civil War II»), а Тор страдает от очередной потери Мьельнира и статуса наследного принца Асгарда (про это – в «Original Sin», «The Unworthy Thor» и финальном сюжете «The Mighty Thor» с Джейн Фостер).
Меж тем читатель испытывает первые впечатления от знакомства с «новыми» аватарами уже привычных героев: в команде Доисторических Мстителей состоят известные по другим сериям Marvel персонажи вроде Агамотто (первый Верховный Чародей Земли, чей глаз находится в попечении Доктора Стрэнджа), молодого Одина, Призрачного Наездника, Звездного Клейма и других. Подробнее о каждом из них вы узнаете из спецвыпусков, заботливо размазанных тонким слоем по всему хронометражу онгоинга.
Данный элемент истории несет в себе важное примечание: актуальный для нас состав Мстителей будет состоять преимущественно из «наследников» доисторической команды. Для большинства это вряд ли станет серьезной проблемой, однако познакомиться с новыми героями для неподготовленных читателей все же не помешает: к примеру, прочитать первый сюжет «All-New Ghost Rider», чтобы понять «что это вообще за Робби Рейес такой».
«Avengers» vol. 8 #1-6: сюжет «The Final Host»Рисунок: Эд МакГинесс
Первая ласточка новой серии. В течение сюжета участники новообразованной команды знакомятся друг с другом, сражаются с очередной космической угрозой в лице «Последнего Войска» Целестиалов и примиряются с дальнейшей необходимостью совместно бороться с общим врагом, долгие годы манипулирующем как судьбами героев, так и душами обычных людей.
Читатели в свою очередь узнают первопричину засилья всесильных существ, мутантов и всевозможных генетически «девиантных» личностей на Земле: дело в том, что неожиданный эволюционный скачок планете задала нелепая случайность – падший Целестиал, кровоточащий в момент формирования первых тектонических плит и примитивной жизни.
Именно из-за выделений космического божества, охватывающих только-только зарождающеюся планету, биология современных (и не только, как оказалось по итогу) людей обрела разнообразные «отклонения» от нормы вроде гена «X», присущего «homo superior» с Кракоа.
«Avengers» #7: спецвыпуск Призрачного НаездникаИ для объяснения этого мне потребовались всего пара предложений в одном абзаце. В самом же комиксе данную мысль пытаются растянуть на все шесть выпусков первого сюжета, задев также остальные номера линейки. Так что если вздумаете лезть в тернистые дебри под названием «Avengers», будьте готовы к затянутым монологам и длинным рассуждениям о, казалось бы, достаточно простых и понятных концепциях с нагнетанием ненужной интриги.
Рисунок: Сара Пикелли
Первый из целой серии ваншотов номер, посвященный рождению Духа Мщения. Ничего интересного, не считая «обязательного» появления Мефисто в качестве триггера истории.
Как не трудно догадаться по косвенным (пока что) признакам, именно любимый всеми со времен «One More Day» демон занял место главного антагониста серии Мстителей и ключевую роль во всех современных комиксах Marvel.
«Avengers» #8-12: сюжеты «Avengers World Tour» и «The Agents of Wakanda»Забавно, что именно при Себульски Мефисто резко активизировался: появившись в качестве противника «Полуночных Сынов» в «Doctor Strange: Damnation», он продолжает светиться во всех сколько-нибудь важных сериях издательства, будь то «The Amazing Spider-Man» Спенсера или «Ghost Rider» Бриссона. Судя по происходящим событиям, новый главный редактор поставил перед собой задачу вознести «мистическую» часть вселенной на пьедестал, уделив ей бóльшую часть свободного времени и линеек. И на самом деле, даже спасибо за это – именно этого не доставало фанатам последнюю декаду.
Рисунок: Эд МакГинесс, Кори Смит и др.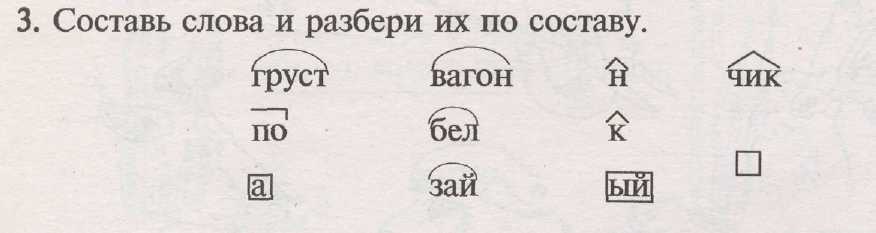
Молодая команда наживает себе врагов по всему свету, пытаясь сформироваться в нечто сколько-нибудь презентабельное. Параллельно с этим новый состав Мстителей выбирает себе лидера – им становится Черная Пантера. Решая больше не ограничиваться геройством в пределах США, Т’Чалла созывает международный форум сверхлюдей со всего света, который, само собой, заканчивается плачевно: отныне Мстителям противостоит не только всемогущий демон, но и старые знакомые в лице Зимней Гвардии со стороны России и Верховного Эскадрона со стороны Америки. Вместе с тем Нэмор вновь решает уничтожить сушу и собирает «Защитников Днища» («Defenders of the Deep»), пока в Румынии готовится претворить свои зловещие планы Граф Дракула с армией подконтрольных ему вампиров.
Проще говоря, в рамках сюжета «Avengers World Tour» Мстители оказываются под перекрестным огнем, а Джейсон Аарон продолжает вешать всевозможные ружья в ожидании дальнейших арок с прямыми конфронтациями между объединениями героев. По итогу выходит динамичный, пускай местами и слишком, триллер про то, как Могучих Героев Земли сделали «крайними» во всем мире и за его пределами.
По итогу выходит динамичный, пускай местами и слишком, триллер про то, как Могучих Героев Земли сделали «крайними» во всем мире и за его пределами.
Спецвыпуск «The Agents of Wakanda», как можно понять из названия, сосредоточен на сборе локальной шпионской организации Пантерой для дальнейшей работы на Мстителей. В общем, еще один филлер, чья задача ограничивается потребностью в «перерывах» между работой над крупными арками.
«Avengers» #13: спецвыпуск Железного КулакаК слову, 10-ый номер стал юбилейным для серии Мстителей: линейка «Avengers» наконец перешагнула рубеж в семь сотен выпусков. По такому случаю в серию и Колсона вернули (и не абы откуда, а аж из мертвых), и новых персонажей ввели. В общем, пропускать, если любите серию величайшей команды Marvel Comics, крайне не советую.
Рисунок: Андреа Соррентино
Ваншот, рассказывающий о первом Железном Кулаке. Попытки «сбить с праведного пути» еще неокрепшую разумом девушку от Мефистофиля, решение проблем самоидентификации в обществе пещерных людей, а также встреча с Доисторическими Мстителями и присоединение к команде – все, как вы могли заметить, по уже знакомой структуре седьмого номера.
Попытки «сбить с праведного пути» еще неокрепшую разумом девушку от Мефистофиля, решение проблем самоидентификации в обществе пещерных людей, а также встреча с Доисторическими Мстителями и присоединение к команде – все, как вы могли заметить, по уже знакомой структуре седьмого номера.
Даже и сказать не о чем. Хотя, конечно, приятно видеть Соррентино в числе художников спешлов.
«Avengers» #14-17: сюжет «War of the Vampires»Рисунок: Дэвид Маркез
В 12-ом выпуске серии к героям присоединяется Блэйд. Само собой, не просто так: персонажи намерены избавиться от Дракулы и полчищ кровососов, захвативших Европу.
Крайне скупая на события история, интригующая разве что действиями Зимней Гвардии и ее дальнейшим влиянием на сюжет линейки. Ненужная и безумно затянутая интрига прилагается.
«Avengers» #21: сюжет «The Day after a Day unlike any other»Выпуски с 18-го по 20-ый мы пропускаем, потому что тай-ин к «War of the Realms».
Во-первых, из-за того, что «Война Царств» – это «поле» Тора, а не Мстителей. Во-вторых, сюжет не несет смысловой нагрузки и максимально незначителен в контексте онгоинга. В-третьих, будем считать это штрафом Аарону за то, что он, сволочь такая, решил назвать два соседствующих сюжета созвучными, безликими и почти идентичными сочетаниями слов «War of the…». Ему и офису редакторов весело, а нам потом разбираться с этими «Войнами» и их последствиями.
 Во-первых, из-за того, что «Война Царств» – это «поле» Тора, а не Мстителей. Во-вторых, сюжет не несет смысловой нагрузки и максимально незначителен в контексте онгоинга. В-третьих, будем считать это штрафом Аарону за то, что он, сволочь такая, решил назвать два соседствующих сюжета созвучными, безликими и почти идентичными сочетаниями слов «War of the…». Ему и офису редакторов весело, а нам потом разбираться с этими «Войнами» и их последствиями.
Во-первых, из-за того, что «Война Царств» – это «поле» Тора, а не Мстителей. Во-вторых, сюжет не несет смысловой нагрузки и максимально незначителен в контексте онгоинга. В-третьих, будем считать это штрафом Аарону за то, что он, сволочь такая, решил назвать два соседствующих сюжета созвучными, безликими и почти идентичными сочетаниями слов «War of the…». Ему и офису редакторов весело, а нам потом разбираться с этими «Войнами» и их последствиями.Рисунок: Джейсон Мастэрс
Выпуск-последствие «War of the Realms», в котором команда сидит в джакузи и пытается отвлечься от обилия потрясений, настигших их за последний год.
Забавный филлер, значимый для нас в первую очередь Т’Чаллой, нащупывающим связь между не так давно воскресшим Колсоном, Верховным Эскадроном, Нэмором, Зимней Гвардией и «неизвестным злодеем-кукловодом».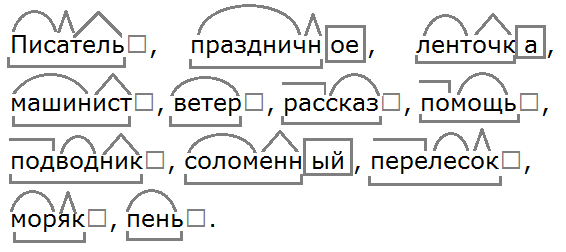
«Avengers» #22-25: сюжет «Challenge of the Ghost Riders»Да, это все еще Мефисто. Без моих подсказок вы бы догадались об этом еще на первом десятке выпусков, но, видимо, в Marvel принимают своих читателей и целевую аудиторию комиксов за детей, неспособных к построению простейших причинно-следственных цепочек. Прям как DC десятки лет назад, когда Ли активно поносил издательство-конкурента за «наивные и вылизанные до блеска» истории про Супермена, Бэтмена и Чудо-Женщину. Туше.
Рисунок: Стефано Казелли
Джонни Блейз медленно, но верно утрачивает контроль над преисподней и ее обитателями. Чтобы сохранить мир в дьявольском прибежище и увеличить свою силу, новый Король Ада решает устроить турнир Призрачных Гонщиков, в котором победителю достанется сила всех прошлых Духов Мщения.
Арка, рассчитанная в первую очередь на фанатов «мистической» части мира Marvel: тут вам и обезумевший Блейз, и Рейес, и его поехавший дядя-маньяк (не видели его со времен все того же «All-New Ghost Rider») в теле Целестиала, и даже Космический Призрачный Гонщик, перекочевавший из «Guardians of the Galaxy» Донни Кейтса! В общем, настоящий «пир» для людей, в открытую признающихся в любви Призрачным Гонщикам. Можете заодно воспринимать как пролог к одноименной серии Эда Бриссона.
Можете заодно воспринимать как пролог к одноименной серии Эда Бриссона.
«Avengers» #26: спецвыпуск Звездного КлеймаХотите узнать, что произошло с Джонни Блейзом и альтернативном Фрэнком Каслом дальше? Читайте гайд, посвященный актуальным сериям Духов Мщения.
Рисунок: Дейл Киоун, Андреа Соррентино
Представьте, что вы – типичный житель доисторической Земли. Большинство представителей вашего племени не способно ни к чему, что не подразумевает под собой охоту, а за проявление смекалки и простейших способностей к речи прилюдно казнят, выбрасывая на съедение монстрам каменного века.
А теперь представьте, что вы – веган, который проявляет симпатию к представителю своего пола. Несладко вам бы было, да? Об этом, собственно, и весь выпуск. На мой субъективный взгляд, один из самых слабых ваншотов Аарона, сделанный словно впопыхах перед следующим крупным сюжетом, который в свою очередь посвящен Звездному Клейму. И что-то мне подсказывает, что данное соседство отнюдь не простое совпадение.
И что-то мне подсказывает, что данное соседство отнюдь не простое совпадение.
Рисунок: Эд МакГинесс
Звездное Клеймо бороздит просторы космоса, выбирая себе нового аватара в лице заключенной ши’арской тюрьмы. По итогу Мстители будут втянуты в межгалактическое сражение, в котором каждый из участников столкновения жаждет заполучить космическую силу Клейма (или, по крайней мере, хотя бы избавиться от нее на какое-то время). Таким образом, Аарон наконец вводит в состав команды нового Старбрэнда – им оказывается новорожденная девочка, которую вынашивала землянка во время своего пребывания в инопланетном заключении.
Разумеется, для Героев Земли космическая потасовка заканчивается, мягко говоря, не идеально: команда сломлена и «зализывает раны» после получения права на воспитание нового Клейма, сражение за космические силы аватаров продолжится уже через несколько выпусков, а Тони Старк все еще не найден. Да, так уж получилось, что герой пропал в конце «Испытания Гонщиков» – и команда до сих пор не имеет ни малейшего понятия о том, куда же запропастился герой. Но об этом далее.
Да, так уж получилось, что герой пропал в конце «Испытания Гонщиков» – и команда до сих пор не имеет ни малейшего понятия о том, куда же запропастился герой. Но об этом далее.
Очередная бестолковая арка, основной целью которой становится введение в серию последнего из аватаров-преемников Доисторических Мстителей. Для полного состава не хватает только Феникса, о котором речь пойдет спустя еще пару филлеров и один большой сюжет про Хонсу.
«Avengers» #31: сюжет «The Temptation of Antony Stark»Рисунок: Джерардо Заффино, Симон Кудрански и др.
Помните, я предупреждал поклонников Тони Старка? Так вот это оно.
Железный Человек магическим образом перемещается в каменный век (прям как в «Astonishing Spider-Man & Wolverine» все того же Джейсона), истошно борется за выживание, встречается с «оригинальными» Мстителями и возвращается в свое время, вламываясь в камеру Мефисто в Лас-Вегасе (в которой он сидит еще с финала «Damnation»).
В этом же выпуске читатели узнают, что Мефисто одновременно существует во всех измерениях и временных линиях, находясь в постоянной суперпозиции относительно других персонажей Marvel. Внезапно оказывается, что демон не просто «руководит» действиями героев извне, но и активно втирается в доверие к сотням и тысячам людей, собирая вокруг себя культ сатанистов-фанатиков. Одним из приверженцев секты имени нового Короля Ада оказывается Говард Старк, который на протяжении многих лет был «правой рукой» демона. Крайне болезненный, пускай и, как по мне, интересный плот-твист.
«Avengers» #32: сюжет «Earth’s Mightiest Villains»А учитывая события того же «Tony Stark: Iron Man» и «Iron Man 2020», воспринимается сей сценарный ход и вовсе как глоток свежего воздуха: все лучше, чем наблюдать за постоянной рефлексией Тони и безбожно нудными приключениями Арно в роли Железного Человека 2020.
Рисунок: Эд МакГинесс, Франческо Манна
Как и полагается перед очередной крупной аркой, ваншот-филлер. В нем вы узнаете, что Агент Колсон уже на протяжении нескольких лет служит Мефисто (сразу после возвращения из мертвых в 700-ом номере), а Верховный Эскадрон, Зимняя Гвардия, Нэмор и Дракула все это время играли роль пешек в затянувшейся партии Дьявола против Мстителей.
В нем вы узнаете, что Агент Колсон уже на протяжении нескольких лет служит Мефисто (сразу после возвращения из мертвых в 700-ом номере), а Верховный Эскадрон, Зимняя Гвардия, Нэмор и Дракула все это время играли роль пешек в затянувшейся партии Дьявола против Мстителей.
В общем, пафосное название номера подошло как нельзя кстати.
«Avengers» #33-37: сюжет «The Age of Khonshu»Рисунок: Хавьер Гаррон
На мой крайне субъективный и предвзятый взгляд, один из крупнейших гвоздей в крышку гроба серии. Если вы читали «Moon Knight» Лемира, отойдите от экрана или закройте статью.
Марк Спектор, движимый очередной «хотелкой» Хонсу, отбирает силы актуального состава Мстителей и преемников доисторической команды, убивает Мефисто и ввергает мир в Эру Луны, порабощая Землю. Прям всю и сразу, да. Впоследствии читателю объяснят, что Бог Луны в панике забился в угол, рыдая у подножия собственного храма, и буквально умолял Марка помочь ему «спасти мир» от демона.
Разумеется, не обошлось без форс-мажоров: желая избавиться от зла, Хонсу и Спектор были вынуждены убивать тысячи вариаций Мефисто из альтернативных миров, конца и края которым нет так же, как нет конца и края лимиткам про Дэдпула. Параллельно с этим незадачливый «защитник ночных путников» устраивает из «приключения на двадцать минут» апокалипсис с тоталитарным режимом и захватывает власть над всей планетой, пытаясь заодно откачать силы у зажатых в подполье членов Мстителей-ополченцев. Короче, хотели как лучше, а получилась очередная Эра – спасибо, что хоть не Альтрона (хотя, ориентировочно, тоже на неделю-другую).
Тут-то и возникают мои претензии.
Начать стоит хотя бы с того, что Хонсу на протяжении долгого времени оставался лишь одним из «симптомов» больного разума Спектора – нигде прямо не говорилось, что Бог Луны был реален и обладал силами, собственно, Бога. У Бендиса упоминания Хонсу сводились к небольшим камео, у Вуда он представлял собой внеземную концепцию с, опять же, обязательными для существования «аватарами», а Бимис так и вовсе свел значимость бессмертного пришельца до «еще одной личности» в голове Марка.
В конечном счете, мы даже не трогаем ран Джеффа Лемира, который поставил жирную точку в многолетнем развитии отношений Лунного Рыцаря и Хонсу – допустим, в Marvel все-таки не решились сделать историю о психбольнице полноценным каноном для персонажа. Но вспомним серию в рамках «Marvel Legacy»: Марк сам рассуждает о том, что по «неведомой ему причине» у него отсутствуют какие-либо «лунные» сверхсилы, хотя у земного воплощения Ра есть способности к управлению огнем – его врожденной стихией.
Все это наталкивало на простую и понятную мысль, озвученную в дальнейших выпусках как Марком, так и второстепенным кастом: Спектор, как и Пациент 86, – самые обычные психопаты. Просто одному из них, судя по всему, повезло родиться с необходимым для драматизма геном мутанта – для мира Marvel это, говоря откровенно, не такая уж и редкость.
Что делает Аарон? Плюет на десятки лет проработки героя и его личностных качеств, внутренний конфликт, взаимоотношения с Хонсу и саму концепцию бессмертного и всемогущего существа, который остается за гранью понимания обычных смертных. Вместо этого Покровитель Ночи повторяет судьбу Мефисто: его избивают, унижают и арестовывают герои, среди которых есть, к примеру, Блэйд и Старк. Несуществующего Бога Луны. Арестовывают. Персонажи, чьи силы ограничены, видимо, лишь задумками автора.
Вместо этого Покровитель Ночи повторяет судьбу Мефисто: его избивают, унижают и арестовывают герои, среди которых есть, к примеру, Блэйд и Старк. Несуществующего Бога Луны. Арестовывают. Персонажи, чьи силы ограничены, видимо, лишь задумками автора.
«Avengers» #38: сюжет «The Fly That Laid a Billion Maggots»Помимо этого в сюжете происходит еще целая куча нелепицы, обсуждать которую нет ни сил, ни желания. О самом известном просчете редакторов Marvel и Джейсона Аарона можете почитать в рамках этой статьи – думаю, вам будет интересно.
Рисунок: Эд МакГинесс
Логическое продолжение 32-го номера, в котором нам досконально разжевывают планы Мефисто и кормят многообещающей интригой вокруг старшего Старка. Нагнетающий саспенса выпуск, который прекрасно вписывается в контекст «сквозняка» Аарона.
«Avengers» #39: спецвыпуск ФениксРисунок: Дейл Киоун
Рассказ о доисторических племенах мутантов и очередном рыжеволосом телепате с «X»-геном – видимо, сформировавшийся веками практики строго обязательный фетиш Огненной Птицы, без которого она уже жить не может.
Рисунок: Хавьер Гаррон
Спустя десяток выпусков Феникс добирается до Земли и устраивает локальную «Королевскую Битву» с супергероями для того, чтобы найти себе нового «достойного» носителя. В ходе сюжета читателя кормят всевозможными сочетаниями героев и крайне завораживающими баталиями (проще говоря, Джейсон начинает писать сценарий для кооперативного файтинга под аркадные автоматы), который переходит в очередной неловкий плот-твист: как оказалось, все это время матерью Тора была Феникс, с которой Один непринужденно флиртовал еще с самого первого совместного появления в серии. Приятно, что хотя бы к этому читателей подготовили заранее.
Вот, к примеру, диалог Одина с Феникс из первого номера онгоинга.
Занятный, пускай и вновь бессмысленный поворот, сделанный Аароном словно в назидание читателям, мол «да, именно я писал серии Бога Грома последний десяток лет». Теперь же, сдерживаемый лишь собственной (на мой взгляд, крайне извращенной) фантазией, сценарист посчитал Асгард и мифологию Marvel Comics «частной собственностью», с которой он может поступать так, как ему заблагорассудиться. Ненависти это вызывает, конечно, чуть меньше, чем схожий сюжетный троп в «Эре Хонсу», но, думается мне, где-то здесь фанаты окончательно смирились с происходящими в онгоинге событиями. И это, конечно же, очень печально.
Теперь же, сдерживаемый лишь собственной (на мой взгляд, крайне извращенной) фантазией, сценарист посчитал Асгард и мифологию Marvel Comics «частной собственностью», с которой он может поступать так, как ему заблагорассудиться. Ненависти это вызывает, конечно, чуть меньше, чем схожий сюжетный троп в «Эре Хонсу», но, думается мне, где-то здесь фанаты окончательно смирились с происходящими в онгоинге событиями. И это, конечно же, очень печально.
Далее идет 45-ый выпуск, который вновь стал тай-ином к глобальному событию – на этот раз к «King in Black» Донни Кейтса. О нем, как, собственно, и об основной линейке «Короля в Черном», поговорим отдельным текстом когда-нибудь потом.
И на этом все. Поздравляю: теперь вы обладаете бесценными знаниями и способны объяснить коллегам, друзьям и приятелям, почему восьмой том «Avengers» не стоит потраченного времени и сил.
Перед нами масштабная, эпическая, но от того не менее несуразная история, которая то и дело спотыкается на самых простых и, казалось бы, очевидных вещах. В попытках сделать каждый отдельный сюжет «глобальным ивентом», Джейсон Аарон погряз в однотипной формуле, вынуждающей его писать «обязательные» спецвыпуски и прологи к новым сюжетам вместо того, чтобы сделать одну сколько-нибудь законченную историю. По итогу читатели получают десятки «номеров-событий», от размаха которых быстро наскучиваешь, и пачку спецвыпусков, чье написание, уверен, самому Аарону не доставляло никакого удовольствия – это можно проследить хотя бы по резкому падению качества самой проработки «доисторического сквозняка» после истории с Кулаком.
В попытках сделать каждый отдельный сюжет «глобальным ивентом», Джейсон Аарон погряз в однотипной формуле, вынуждающей его писать «обязательные» спецвыпуски и прологи к новым сюжетам вместо того, чтобы сделать одну сколько-нибудь законченную историю. По итогу читатели получают десятки «номеров-событий», от размаха которых быстро наскучиваешь, и пачку спецвыпусков, чье написание, уверен, самому Аарону не доставляло никакого удовольствия – это можно проследить хотя бы по резкому падению качества самой проработки «доисторического сквозняка» после истории с Кулаком.
В настоящий момент онгоинг находится на хиатусе, а основные события и действующие лица перекочевали, как я уже и говорил, в лимитированную серию «Heroes Reborn» – сухую, блеклую и откровенно душную кальку с классического «House of M», на этот раз с Блейдом, Мефисто и Верховным Эскадроном у руля. Что до продолжения: уже в июле стартует сюжет «World War She-Hulk», в котором Аарон попытается переписать культовую «Мировую Войну Халка», на этот раз сделав изгоем в глазах читателей Дженнифер Уолтерс. Стоит ли ждать от арки чего-то феноменально нового? Думаю, вы уже и сами знаете ответ.
Стоит ли ждать от арки чего-то феноменально нового? Думаю, вы уже и сами знаете ответ.
Хочется сказать лишь одно: не тратьте свое время попусту, пока есть люди, которые тратят его за вас. Конечно, читать (или не читать) серию «Avengers» 2018-го года – это личный выбор каждого фаната комиксов Marvel. Однако пока, говоря объективно, мы имеем одну из самых спорных, странных, до нелепого масштабных и глупых серий про Могучих Героев Земли за долгие годы. А это о чем-то, да говорит.
Батыры как ОПГ, олигархи как туленгуты, слабые ханы, трайбализм, непотизм и другие параллели казахской истории
Про традиционный и современный трайбализм, происхождение и генетику казахских родов, чёрную и белую кость Казахской степи, шапрашты и чингизидов, Сатпаева и Джакишева поговорила Гульнара Бажкенова с Жаксылыком Сабитовым – казахстанским учёным нового поколения, работающим на стыке наук истории, медиевистики и генетики.
Жаксылык, раз уж мы с вами решили поговорить про казахские роды возле памятника батыру Райымбеку, давайте разберёмся, как они возникают. Вот здесь, насколько я помню, сначала было место поклонения, потом появился памятник и вся композиция приобрела сакральное значение. Почему именно здесь? Как это работает?
Вот здесь, насколько я помню, сначала было место поклонения, потом появился памятник и вся композиция приобрела сакральное значение. Почему именно здесь? Как это работает?
На самом деле, Райымбек – это один из батыров рода Албан, населяющего окрестности Алматы и имеющего большое количество представителей в самом городе. Соответственно, он — свой для большого количества людей, живущих в Алматы. Исходя из этого, появляются люди с положением, которые, используя своё влияние, могут раскачать эту тему, сказать, что вот этот герой очень важен для нас, и, опираясь на общественную поддержку, сделать его как минимум локальным героем или разнести славу до национального уровня. Это зависит от того, сколько представителей данного рода живёт на конкретной территории и как они относятся к этой памяти. Потому что есть рода, потерявшие свою идентичность, сильно атомизированные, а есть такие, которые при своей многочисленности ещё имеют некую структуру, их объединяющую и позволяющую им делать такие вещи, условно говоря.
А как рождается легенда, что такое-то место связано с таким-то батыром?
За каждой легендой стоят реальные вещи, факты, события. То есть это всё документально обосновано, но впоследствии может обрастать мифами. Всё-таки человеческое мышление оно такое, что мифологизирует некоторые понятия. Профессиональным историкам потом важно разделять, что — правда, а что — миф.
Это трудно? В нашем случае понимать и разделять, где миф, а где реальность?
Да, довольно-таки трудно и на самом деле не очень-то интересно. Некоторые мифы поддерживаются государством, а против государственного мифа идти сложнее, чем против мифа, который ещё не получил поддержку государства.
Вот тут на дощечке написаны слова Жамбыла Жабаева про батыра Райымбека. Они были из одного рода?
Нет, Жамбыл Жабаев – шапырашты. Известный представитель шапырашты. А Райымбек – албан.
Про Жамбыла Жабаева мы все знаем и понимаем, что он — выдающийся поэт, хоть и шапрашты. А как в случае с батыром? Его поднял род албан. А если исторически: он реально был таким героем?
А как в случае с батыром? Его поднял род албан. А если исторически: он реально был таким героем?
С точки зрения своего рода, он, конечно, был героем. Но тут нужно чётко понимать, какого уровня. Нужно документально исследовать исторические материалы периода его жизнедеятельности. Важно абстрагироваться от политических моментов. А это очень сложно сейчас. Если вы интересуетесь, сильно ли мифологизирована персона, имейте ввиду, что представители рода могут и в суд подать. Такие случаи уже были: с тем же Жамбылом Жабаевым, когда многие обиделись на некоторые исследования и засудили журналиста, кажется.
Получается, самый великий батыр будет тот, чей род самый влиятельный. Это так?
Нет, это не так. Это батыр во многом определял место своего рода в иерархии. Вообще батыры сделали большое дело для казахов. У Радика Темиргалиева есть хорошая книга «Эпоха последних батыров». Считаю, на сегодня это лучшая книга. Она описывает, как казахи с помощью батыров и родов сделали большое благо для всего народа. Дело в том, что власть в степи была сильно децентрализованной. Хан не мог ничего сказать роду. Если тот занял какую-то позицию, то всё бесполезно. Ханская власть была слабой, и батыры, пользуясь этим и поддержкой своего рода, постоянно расширяли владения казахов. И в конце концов расширили до тех пределов, которые мы сейчас имеем. Если бы власть была более централизованной, то вполне вероятно, что мы имели бы территорию гораздо меньше.
Дело в том, что власть в степи была сильно децентрализованной. Хан не мог ничего сказать роду. Если тот занял какую-то позицию, то всё бесполезно. Ханская власть была слабой, и батыры, пользуясь этим и поддержкой своего рода, постоянно расширяли владения казахов. И в конце концов расширили до тех пределов, которые мы сейчас имеем. Если бы власть была более централизованной, то вполне вероятно, что мы имели бы территорию гораздо меньше.
Может быть, некорректное сравнение и не всем понравится, но, по сути, батыры и их ополчения – это ОПГ 90-х годов. Они были сами по себе, сами все организовывали, обеспечивали социальную справедливость своих родов, сражались, погибали и зарабатывали что-то. И в итоге, в условиях неразберихи XVIII века сделали большое благо, расширив территории Казахстана максимально, насколько это было возможно.
А как вообще становились батырами? Как присваивался этот статус? Эти мужчины были богатыми или просто обладали большой физической силой?
Это так и не так. Тут на самом деле не сила, а харизма и уверенность человека. Тот же Абылай хан был невысокого роста, беззубый, хромой…
Тут на самом деле не сила, а харизма и уверенность человека. Тот же Абылай хан был невысокого роста, беззубый, хромой…
Ну он же был ханом, а не батыром?
Ханом был, но я к тому, что всё решало внутреннее содержание. Батыром мог стать кто угодно при наличии персональной храбрости и харизмы. Если у тебя есть внутренний стержень, который тебя держит, тогда неважно, кто ты, хоть метр пятьдесят с кепкой, но с помощью своего стержня ты можешь многое. И когда хаос, неразбериха, берёшь в руки оружие и с помощью него всё решаешь. Но помимо храбрости нужны были ещё мозги. На самом деле выживали и выбивались вверх не только самые храбрые, но и самые умные. Таким образом, качества, необходимые для того, чтобы стать батыром – харизма, мозги, храбрость и определённая сила.
Так всё работало тогда, в прошлом, но история не всегда справедлива, и почётное место в ней не всегда занимают самые достойные. Тем более в нашем случае отсутствия собственных письменных источников и документальных свидетельств. Не получается ли так, что самые великие батыры у тех родов, у которых — самый мощный пиар?
Не получается ли так, что самые великие батыры у тех родов, у которых — самый мощный пиар?
Знаете, есть родовые объединения, которые маскируются под имена прославленных соотечественников, но являются объединениями какого-то рода, по сути. Если они хорошо организованы, если у них крепкие социальные контакты, то могут раскрутить своих родовых героев до уровня, минимум, локального, максимум — национального. Если род не сильно пострадал в результате русификации и советской власти, то он более сплочённый. Конечно, это не тот классический трайбализм, который мы наблюдали в средневековье, но всё равно действует, и социальные сети развиваются за счёт этого.
И какие роды у нас наиболее самоорганизованные и наименее пострадавшие?
К сожалению, без научных исследований я не могу этого сказать. Тут надо придумывать какую-то шкалу, методологию, говорить на глаз всё-таки не научно.
Ну вы этим занимаетесь — научными исследованиями, поэтому мы с вами сегодня общаемся, поэтому я задаю вопросы, которые нас интересуют.
Если так посмотреть, то наиболее организованные рода всё-таки на юге Казахстана. Там у каждого родового объединения есть свой президент. И когда они собираются, это так называемый саммит президентов. Это интересно. Вы можете с ними встретиться, поговорить, некоторые проблемы через них даже скорее решаются, чем через акимат. Но говоря про родовые объединения, надо иметь в виду, что большое значение имеет социальный компонент. То есть когда представители одного рода общаются, все они — представители одного класса. Представителю низкого социального класса очень трудно попасть в их круг, который называется родовым объединением, и занять какое-либо положение. Я бы сказал, это закрытые группы по интересам, у которых есть свой социальный и экономический ценз.
В одном интервью вы заявили, что в Казахстане нет трайбализма, а есть непотизм. Что у нас скорее двигают братьев и родственников, нежели представителей своего рода. Но разве родственники не являются представителями одного рода и клана?
Тут такой момент.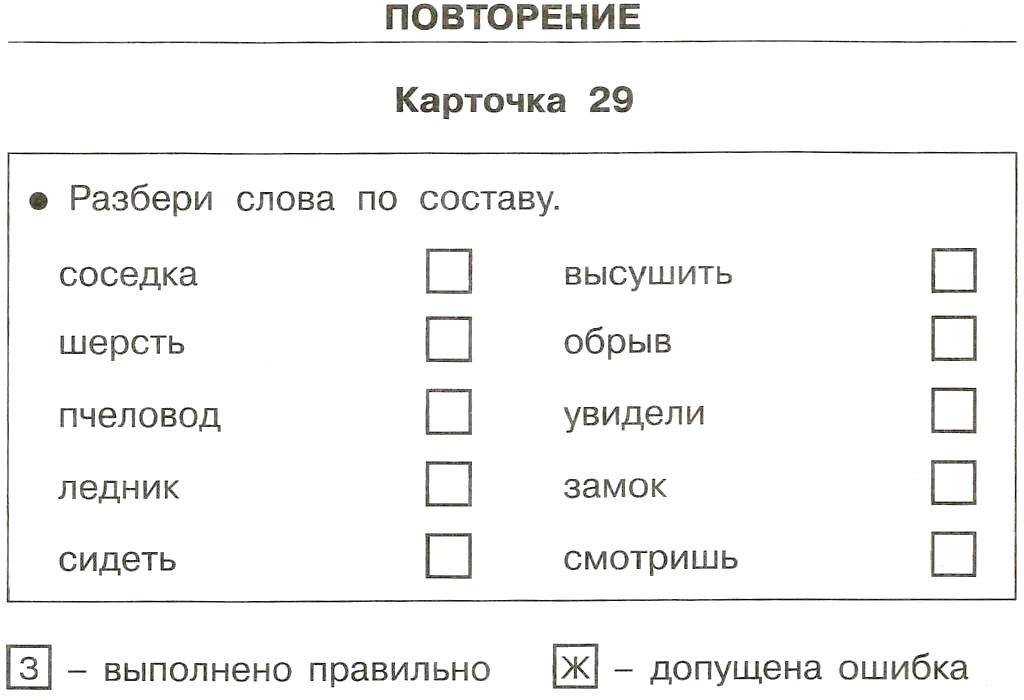 Когда мы говорим о трайбализме, это объединение родственников по прямой мужской линии. Это очень жёсткий момент. Там даже внук от дочери называется «жиен», и он — не свой. Там нет такого влияния женской стороны. Но наше общество европеизируется. Роль женщины растёт. Часто в семье она даже больше рулит, чем мужчина. Поэтому мы видим, что в городах внука от дочери уже называют немере, хотя, по старым понятиям, он — жиен, не свой. А в современных реалиях — свой. И разницы между внуками от сыновей и дочерей не делают. Соответственно, рулит больше непотизм нежели трайбализм. Трайбализм – это когда у тебя есть пятиюродный брат по отцу и двоюродный брат по матери, и ты всегда отдаёшь приоритет пятиюродному брату по отцу, потому что он — одного с тобой рода. А непотизм — это когда ближе тот, с кем ты рос, кого ты видишь чаще, чем пятиюродного брата.
Когда мы говорим о трайбализме, это объединение родственников по прямой мужской линии. Это очень жёсткий момент. Там даже внук от дочери называется «жиен», и он — не свой. Там нет такого влияния женской стороны. Но наше общество европеизируется. Роль женщины растёт. Часто в семье она даже больше рулит, чем мужчина. Поэтому мы видим, что в городах внука от дочери уже называют немере, хотя, по старым понятиям, он — жиен, не свой. А в современных реалиях — свой. И разницы между внуками от сыновей и дочерей не делают. Соответственно, рулит больше непотизм нежели трайбализм. Трайбализм – это когда у тебя есть пятиюродный брат по отцу и двоюродный брат по матери, и ты всегда отдаёшь приоритет пятиюродному брату по отцу, потому что он — одного с тобой рода. А непотизм — это когда ближе тот, с кем ты рос, кого ты видишь чаще, чем пятиюродного брата.
У нас, наверное, накладывается одно на другое…
Надо сказать, что накладывается ещё такая вещь, как клановость. Клановостью может быть землячество, происхождение с одного региона. Все это разные вещи, которые часто путают, но их надо разделять.
Клановостью может быть землячество, происхождение с одного региона. Все это разные вещи, которые часто путают, но их надо разделять.
А бывают совпадения, да? Вот родились и выросли в одном районе Алматинской области, и земляки, и видели друг друга часто, и одного рода, и братья…
Возьмём классический пример Баянаула. Каныш Сатпаев и все баянаульцы, которые вместе с ним стали основой нашей Академии наук. Тут трудно разделить. С одной стороны вы видите землячество, клановость. Они все баянаульские. Там три разных рода, но они все баянаульские. С другой стороны вы видите, что все они — родственники: один — по прямой мужской линии; другой — по женской; кто-то женился успешно. Значит, мы видим одновременно три явления — трайбализм, непотизм, землячество. Все они смешались, и их трудно разделить.
Каныш Сатпаев тоже этим страдал?! Он в Академию наук брал только своих?!
Ну, как своих. Он оказывал социальную поддержку тем людям, с которыми общался. На самом деле, у нас в XIX веке были созданы две точки роста. С одной стороны Ыбырай Алтынсарин – это Торгай, Костанай, с другой стороны Муса Шорманов и его последователи в Баянауле. Эти две точки роста дали очень много интеллигенции. Там уже сложилась своя база. Понимаете, когда к вам приезжает человек свой и человек чужой, и свой всё-таки умнее оказывается, потому что они с XIX века развивались, то хочешь-не хочешь ты отбираешь человека с более сильным человеческим капиталом. И вроде кажется, что это непотизм и трайбализм, но у него человеческий капитал был сильнее.
На самом деле, у нас в XIX веке были созданы две точки роста. С одной стороны Ыбырай Алтынсарин – это Торгай, Костанай, с другой стороны Муса Шорманов и его последователи в Баянауле. Эти две точки роста дали очень много интеллигенции. Там уже сложилась своя база. Понимаете, когда к вам приезжает человек свой и человек чужой, и свой всё-таки умнее оказывается, потому что они с XIX века развивались, то хочешь-не хочешь ты отбираешь человека с более сильным человеческим капиталом. И вроде кажется, что это непотизм и трайбализм, но у него человеческий капитал был сильнее.
Поясните подробнее, почему так получилось? Почему в этих двух точках человеческий капитал оказался сильнее?
Потому что были люди, которые вкладывали деньги в образование – Ыбырай Алтынсарин и Муса Шорманов. Муса Шорманов растил людей, отправлял и оплачивал им учёбу, а Алтынсарин создавал школы. Это всё стало основой Алашорды и позже — первых советских кадров. Вот возьмём Каныша Сатпаева. Там три-четыре поколения семьи общались с Потаниным, другом Чокана Валиханова, поставляли ему информацию. Они общались с таким человеком, что многое говорит о них самих, об их уровне.
Там три-четыре поколения семьи общались с Потаниным, другом Чокана Валиханова, поставляли ему информацию. Они общались с таким человеком, что многое говорит о них самих, об их уровне.
То есть он из этого вырос, в четвёртом-пятом поколении получился выдающийся национальный учёный.
Да, у него человеческий капитал всё-таки был сильнее среднего уровня, потому что у него семья была более образованная и готовая. Она раньше остальных начала образовываться и расти.
Почему же эти две точки роста не представлены в сегодняшней политической элите, когда по всем меркам они должны там преобладать? Политолог Данияр Ашимбаев в одном интервью сказал, что в нашей управленческой элите численно преобладают выходцы совсем из другой точки – из рода шапырашты. Почему?
Относительно есть, но это относительно. Нужно всё смотреть, считать. Экспертные оценки чем плохи? К сожалению, за ними не стоит хорошей, чёткой, расписанной методологии. То есть кто эти люди с расписанными генеалогиями? Если вы так говорите, соответственно, нужно привести полный список с генеалогиями – шежіре, часто люди путают. К примеру, человека запишут к одном роду, а на самом деле он относится к другому. Всё это надо хорошо исследовать. Действительно, есть большой элемент представителей южных родов. Но тут есть два момента. Когда Алматы стал столицей, приезжать туда с окраин Алматы, из близлежащих районов стало легче. Поэтому представители родов албан и шапырашты стали сильно захватывать позиции ещё в прежней, советской Алма-Ате. Они приезжали в столицу и становились кем-то, потому что географически им было ближе и легче, чем жителям Костаная, например. Это дало определённый базис. С другой стороны, есть политические аспекты, которые тоже надо учитывать. На самом деле, тут всё очень сложно и имеет корни ещё из Советского Союза.
К примеру, человека запишут к одном роду, а на самом деле он относится к другому. Всё это надо хорошо исследовать. Действительно, есть большой элемент представителей южных родов. Но тут есть два момента. Когда Алматы стал столицей, приезжать туда с окраин Алматы, из близлежащих районов стало легче. Поэтому представители родов албан и шапырашты стали сильно захватывать позиции ещё в прежней, советской Алма-Ате. Они приезжали в столицу и становились кем-то, потому что географически им было ближе и легче, чем жителям Костаная, например. Это дало определённый базис. С другой стороны, есть политические аспекты, которые тоже надо учитывать. На самом деле, тут всё очень сложно и имеет корни ещё из Советского Союза.
Но вы согласны, что у нас шапырашты больше всех во власти? Или это не так?
Повторю, надо методологию показать: что такое самые многочисленные, что такое род, какой процент. Я процентов не вижу. Нужны чёткие исследования, методология. Возьмём все политические позиции, начиная от вице-министров, министров, премьер-министра и поставим баллы: вице-министр — один балл и т. д. Посчитаем эти баллы, роды. И только тогда увидим и поймём. Но мы провели другое исследование — сериалов, которые снимают в последние пять-десять лет наши телеканалы. И что мы увидели? Оказывается, шестьдесят процентов героев этих сериалов — представители Старшего жуза. Остальная часть – Средний жуз, и совсем чуть-чуть – Младший. Такой вот интересный перекос. Предположу, что люди, принимающие решение, какой сериал снимать, происходят из этих родов. И не обязательно это продюсер или режиссёр. Бывают другие люди. Мы же не знаем кухню. Не знаем, кто решает. Всё это может происходить хаотично. Мы не знаем процесс, но видим, что на выходе 60% – Старший жуз, 30% – Средний жуз, и совсем мало Младшего жуза.
д. Посчитаем эти баллы, роды. И только тогда увидим и поймём. Но мы провели другое исследование — сериалов, которые снимают в последние пять-десять лет наши телеканалы. И что мы увидели? Оказывается, шестьдесят процентов героев этих сериалов — представители Старшего жуза. Остальная часть – Средний жуз, и совсем чуть-чуть – Младший. Такой вот интересный перекос. Предположу, что люди, принимающие решение, какой сериал снимать, происходят из этих родов. И не обязательно это продюсер или режиссёр. Бывают другие люди. Мы же не знаем кухню. Не знаем, кто решает. Всё это может происходить хаотично. Мы не знаем процесс, но видим, что на выходе 60% – Старший жуз, 30% – Средний жуз, и совсем мало Младшего жуза.
Если посмотреть на внешность казахов, то они разные. Насколько далеко друг от друга находятся генетические маркеры разных жузов и родов?
Есть неопубликованные данные о сравнении аутосомных маркеров. Аутосомные – это общегенетические портреты казахских родов. И если мы возьмем адаев с Запада, найманов с Востока, аргынов с Севера, дулатов с Юга, то в аутосомном плане они имеют меньше разнообразия, чем башкирские рода, проживающие в Башкирии более компактно. Это говорит о том, что наша общая история XVII века, когда мы все жили возле Сырдарьи и кучковались, дала о себе знать. Ещё с тех времён мы имеем общий аутосомный, генетический портрет. Различия между родами очень маленькие, что связано ещё и с законом «Жеты ата», когда нельзя было брать в жёны и мужья своих; нужно было брать из других родов, которые разбавляли всю эту аутосомную картину для всех родов.
И если мы возьмем адаев с Запада, найманов с Востока, аргынов с Севера, дулатов с Юга, то в аутосомном плане они имеют меньше разнообразия, чем башкирские рода, проживающие в Башкирии более компактно. Это говорит о том, что наша общая история XVII века, когда мы все жили возле Сырдарьи и кучковались, дала о себе знать. Ещё с тех времён мы имеем общий аутосомный, генетический портрет. Различия между родами очень маленькие, что связано ещё и с законом «Жеты ата», когда нельзя было брать в жёны и мужья своих; нужно было брать из других родов, которые разбавляли всю эту аутосомную картину для всех родов.
Глядя на меня, вы можете сказать, к какому роду я принадлежу?
Нет, конечно. Это невозможно. Если бы я покопался и посмотрел шежіре, возможно, знал бы.
Насколько оправдано и близко к истине распространённое мнение, что Младший жуз – самый воинственный: он защищал казахов; Средний жуз – это интеллигенция: акыны, музыканты, поэты; Старший всегда управлял казахами?
На самом деле это была фраза, которую переиначили. Про Старший жуз там сказано «таяқ бер», то есть поставь пасти скот, не было ничего про управлять.
Про Старший жуз там сказано «таяқ бер», то есть поставь пасти скот, не было ничего про управлять.
То есть пастухами были?
Не пастухами, но у них были большие поголовья. С точки зрения средневекового стандарта, все три жуза – қара сүйек, чёрная кость. Не было такого, что один лучше или выше, а другие ниже. Все мы — қара сүйек для төре. Даже если вы посмотрите «Жеті Жарғы», там разные наказания для ақсүйек и қара сүйек. Поэтому когда переводят, что улы жуз – великий, величайший, это попытки сыграть на родовом уровне. Все жузы были қара сүйек.
Все кроме чингизидов?
Да, ну там ещё говорят қожа. Но по ним ещё можно спорить. Это проповедники ислама.
У меня есть подруга қожа. Она всегда посмеивается над своими родственниками из Туркестана, которые считают себя аристократами, поскольку они — қожа.
Я общался с представителями этого рода. Интересно, что у них до 1972 года старались қожа жениться на қожа. Да, есть даже такой момент. Это то, чем южные қожа отличаются от северных. Северный қожа, знакомясь с девушкой, думает «лишь бы не қожа», там стараются выйти за представителей не своего рода, а на юге — наоборот. Традиция! Был такой случай с Жалаңтөс батыром, настоящим олигархом в Бухарском ханстве, вторым человеком, которого официально приравняли к ханам. Так вот узгенский қожа, какой-то небогатый человек, не выдал за него дочку, потому что де «мы — ақсүйек, а вы — қара сүйек», отдыхайте. Жалаңтөс батыр вспомнил и сказал ему, что «150 лет назад вы же выдали дочь за наймана», а ему ответили – «а то другие времена были»!
Да, есть даже такой момент. Это то, чем южные қожа отличаются от северных. Северный қожа, знакомясь с девушкой, думает «лишь бы не қожа», там стараются выйти за представителей не своего рода, а на юге — наоборот. Традиция! Был такой случай с Жалаңтөс батыром, настоящим олигархом в Бухарском ханстве, вторым человеком, которого официально приравняли к ханам. Так вот узгенский қожа, какой-то небогатый человек, не выдал за него дочку, потому что де «мы — ақсүйек, а вы — қара сүйек», отдыхайте. Жалаңтөс батыр вспомнил и сказал ему, что «150 лет назад вы же выдали дочь за наймана», а ему ответили – «а то другие времена были»!
А что с нашими чингизидами сейчас? Они совсем исчезли?
В советское время их очень сильно преследовали, это было прямое уничтожение. Многие скрывали, многие уезжали. Например, Ермахан Бекмаханов – известный чингизид, торе. Он выходец из Баянаула, принадлежал к научной группировке Сатпаева. Из-за того, что его вечно били, он только на смертном одре признался одной своей дочери, что является чингизидом.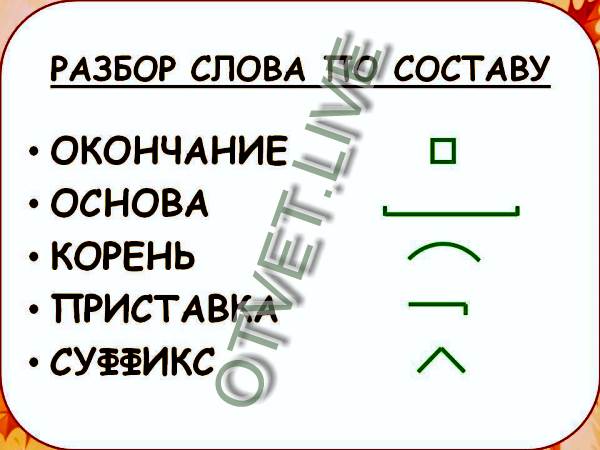 Это не поощрялось, не пролетарское происхождение. Многие чингизиды пострадали, многих расстреляли. Санжар Асфендияров был расстрелян как японский шпион. Много их было. В XIX веке они приобрели большой человеческий капитал и заняли хорошие места, потому что у них был семейный наследуемый капитал, который только усиливался. Алихан Бокейханов, Санжар Асфендияров… Все они были чингизидами.
Это не поощрялось, не пролетарское происхождение. Многие чингизиды пострадали, многих расстреляли. Санжар Асфендияров был расстрелян как японский шпион. Много их было. В XIX веке они приобрели большой человеческий капитал и заняли хорошие места, потому что у них был семейный наследуемый капитал, который только усиливался. Алихан Бокейханов, Санжар Асфендияров… Все они были чингизидами.
Алашординцы были чингизидами?
Нет-нет, алашординцы как раз были из двух точек роста — Костанай-Торгай и Баянаул. А чингизиды до революции были ақсүйек – белая кость. В XIX веке у них начали забирать власть, но всё равно они были сильнее: и в плане человеческого капитала, и в силу инерции. Советская власть уничтожила их как класс, и даже сейчас тот, кто — чингизид (например, Мухтар Джакишев), сидел. Быть чингизидом в современном Казахстане тоже может быть опасным, если ты в политику лезешь.
Джакишев – чингизид? Откуда вы знаете это?
Да, это всё есть в шежіре. Это всё публиковалось. Если вы посмотрите казахский шежіре, то много чего интересного найдёте. Но казахская шежіре – непростая база данных. Там много надо ковыряться и копаться.
Это всё публиковалось. Если вы посмотрите казахский шежіре, то много чего интересного найдёте. Но казахская шежіре – непростая база данных. Там много надо ковыряться и копаться.
Но ведь Джакишев пострадал не потому, что чингизид!
Это понятно, но это могло быть довеском.
Сейчас есть группы, сообщества, которые называются чингизидами?
Нет-нет, если даже пытаешься с ними общаться, они испытывают такую генетическую память, недоверие к власти, потому что в Советском Союзе их расстреливали, ссылали, кто-то убегал. Это сильно на них повлияло. Поэтому сейчас их почти нет во власти.
Вы в одном интервью сказали, что некий человек провёл свой генетический анализ и выяснил, что является потомком Барак хана.
Он знал, что чингизид. У него было семь колен, а дальше неизвестность. С помощью генетики он смог восстановить, к какой ветке относится, потому что появились три версии на основе имён из шежіре. И с помощью генетики одна из них подтвердилась.
И с помощью генетики одна из них подтвердилась.
Что прямой потомок Барак хана? И кто этот человек?
Да, потомок Барак султана, одного из чингизидов. Он спонсировал одну из моих книжек.
Вы сейчас проводите генетический анализ наших родов. Скажите, какая цель у вашего проекта? Это государственная программа?
Нет. Есть такой момент. Когда говорят, что такое наука, наука – это удовлетворение личного любопытства за государственный счёт. Иногда не за государственный. Когда мы начинали проект, не было никакой государственной поддержки. Это была частная инициатива. Люди тестировались и тем самым вносили вклад в общую базу данных. Это был краудсорсинг. Люди сами спонсировали это научное исследование. Сейчас же, в последние два года, с приходом Токаева, государство повернулось к учёным и финансирование увеличилось. Многие исследования по генетике теперь финансирует государство. Раньше такого не было, сейчас хорошо. Сегодня быть молодым учёным гораздо лучше, чем десять лет назад.
Генетику каких родов вы исследовали: шапырашты, албан, дулат?
Да-да, мы опубликовали две статьи со своими коллегами, с Максатом Жабагиным, про Старшие и Младшие жузы. Показали, где у них шежіре совпадает, где не совпадает, какая версия более верна или нет. Например, по роду шапырашты есть две версии, к кому он ближе. По одной, они — потомки Байдибека, великого человека из Шымкента, которому там поставили памятник. По другой, он — родственник Байдибека, но не потомок, и был принят Байдибеком, когда его отец погиб. Пока мы имеем предварительные результаты, и скорее всего вторая версия более верна. Не потомок Байдибека, но родственник. Потомки Байдибека имеют немного другие мутации.
Ещё интересный момент читала в ваших интервью, что одни рода ближе к киргизам, другие — к китайцам, европейцам. Если взять шапырашты, раз уж мы говорим о них, то какая гаплогруппа там преобладает – китайская? европейская?
Часто люди, которые только начинают увлекаться генетикой, уходят в «генетический трайбализм», когда на основе гаплогруппы делают далеко идущие выводы.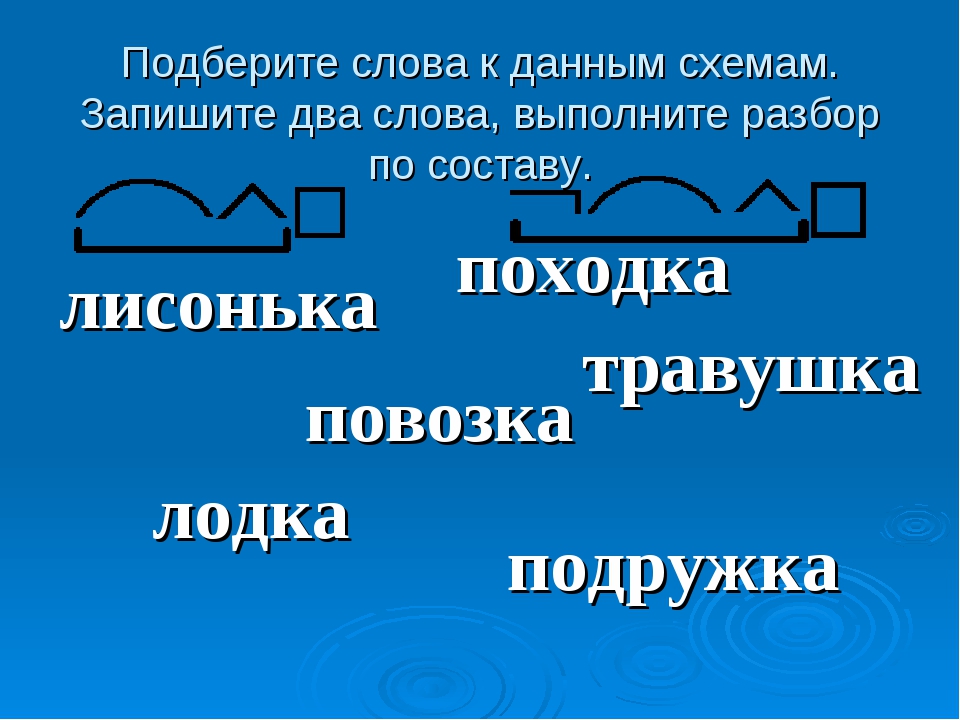 На самом деле гаплогруппа – это такая вещь, которая интересна для сравнения шежіре, но в общем генетическом портрете гаплогруппы маленькие. Это 0,3% от всего генома – всего 80 из 28 тысяч генов. Небольшая вещь, которую нельзя абсолютизировать. Гаплогруппа интересна для людей, которые занимаются шежіре, но делать на их основе выводы об этническом происхождении себя, своего рода и всего казахского народа не стоит. Это может привести к неправильным интерпретациям.
На самом деле гаплогруппа – это такая вещь, которая интересна для сравнения шежіре, но в общем генетическом портрете гаплогруппы маленькие. Это 0,3% от всего генома – всего 80 из 28 тысяч генов. Небольшая вещь, которую нельзя абсолютизировать. Гаплогруппа интересна для людей, которые занимаются шежіре, но делать на их основе выводы об этническом происхождении себя, своего рода и всего казахского народа не стоит. Это может привести к неправильным интерпретациям.
К чему может привести, я не знаю. Но вы сами сказали в недавнем интервью, что все наши олигархи – это сарты.
Нет, я сказал «с точки зрения…» . Во-первых, это сказал ещё Нурболат Масанов про современных казахов. Если мы посмотрим с точки зрения наших предков, которые были кочевниками, тогда всё население Казахстана – это сарты. Это люди, которые абсолютно не кочуют, совершенно оторвались от кочевых традиций, и с точки зрения наших предков-казахов, да, мы такие. Если бы они жили, то говорили бы, что мы — сарты.
То есть это про образ жизни, про оседлость. Но всё же в подкасте вы сказали именно про олигархов, что они — сарты. Хочу понять, что это такое.
Нет, я их сравнивал с толенгутами, наверное. Смотрите, казахское общество имело такую социальную структуру, что она исключала сильную ханскую власть. Рода были большими политическими единицами, которые многое определяли. Они могли слушать либо не слушать ханов. И он не мог их преследовать. Поэтому ханы часто набирали себе толенгутов, представителей разных родов, разных народов, которые приходили им служить и от них зависели. Эти толенгуты слушали только хана и не были связаны с казахским обществом. Они были разного происхождения. Там было много джунгаров, калмыков. Они усиливали власть хана. Наверное, я говорил о том, что наши современные олигархи похожи на тех толенгутов, потому что они напрямую зависят от правителя и не интегрированы с обществом.
Есть такая информация, что правительство Казахстана начало было один масштабный проект по исследованию генетического кода казахов, но потом бросило, потому что выяснилось, что мы, казахи, ближе к монголам и бурятам, а не тюркам, что не соответствует текущим идеологическим задачам. Это правда?
Нет, те выводы, которые вы озвучили, на самом деле не соответствуют действительности. Казахи – типичные тюрки. Самые близкие к ним народы – это каракалпаки и киргизы, дальше ногайцы, то есть не монгольские народы. Когда мы говорим про монголов и бурятов, то люди, которые не разбираются в гаплогруппах, начинают говорить: «Гаплогруппа С – это монголы, значит казахи – монголы». Это не так, это абсолютный бред! Потому что гаплогруппа С есть и у аборигенов Австралии, и у индейских племён аппачей и навахо, которые «ни фига» — не монголы. Но люди, ни черта не разбирающиеся, сразу начинают вешать ярлыки. Дилетанты. Если говорить про генетические исследования, в 2013 году был запущен один проект по исследованию трёх составляющих: палеогенетика Казахстана, современное население Казахстана и, условно говоря, национальная порода животных. Но проект, к сожалению, не выстрелил. Были потрачены деньги, но не достигнуто никаких результатов.
Почему?
Ну, кадровый голод, скорее всего. С другой стороны, в то время наука финансировалась плохо. Это сейчас она стала лучше финансироваться, а тогда по остаточному признаку и в принципе так вышло, что учёные не достигли того, что могли бы сделать.
Хочу спросить вас относительно выводов ученых, и это не только казахстанская проблема в гуманитарных исследованиях. Кто дает гранты, тот заказывает результаты и выводы, так ведь? Учёные часто подгоняют свои исследования под потребности и нужды заказчика, а ваш заказчик — государство, которое очень хочет, чтобы казахи были ближе к тюркам. Это даёт мне право подвергать сомнению выводу, которые озвучили вы?
Можете сомневаться. Мы зависим от государства, но всё равно проблема в том, что когда мы публикуем свои статьи на английском языке, их мало кто читает. Человек десять в Казахстане прочитают. Из них трое поймут, один может поспорить, максимум. Те публикации, которые мы делаем, они настолько специфичны, что с ними трудно спорить, мало кто поймет, о чём речь. Тут кроется главное зерно. Просто иногда бывают такие моменты… Люди умеющие пользоваться GOOGLE-переводчиком, берут с какой-то статьи один абзац, и в отрыве от всей статьи начинают говорить: «А вот учёные сказали». Хотя там были сказаны ещё две вещи, которые имеют совсем другую картину.
Я кое-что почитываю, но не видела там публикаций наших учёных.
Нет, есть наши исследования по палеогенетике, было несколько публикаций. В 2017 году была шикарная публикация команды, с очень хорошими данными и выводами. Надо сказать, что генетические выводы… негативные, понятно, что их очень трудно вытащить, понять. Это выводы. Бывает и так, что те выводы, которые негативные для идеологии, просто не переводят.
А какие выводы для нашей сегодняшней идеологии являются негативными?
Давайте я возьму в пример другие страны, чтобы было понятно. Например, доказано, что Рюриковичи всё-таки имеют отношение к Южной Швеции. Там куча людей, антинорманистов, которые считают, что Рюрик был свой, славянин, оказывается в пролёте. Там ещё было доказано по Ольговским князям, потомкам Чарыганских князей, что они, скорее всего, — генетически не Рюриковичи. Вышла такая публикация, но на неё мало кто реагирует. Научные публикации мало кто читает, больше смотрят Ютуб, рассылку по Ватсапу, когда тебе всю историю казахов весьма живописно и топорно объясняют на одной страничке. И люди — вау! — считают, что узнали истину. На самом деле рассылают фейки. Надо понимать, что истина сложна, многомерна, её нельзя свести к чёрно-белому «да-нет». Люди хотят простые ответы, но на самом деле все ответы сложные.
Людям в интернете не понравилось создание Института Джучи, который собирается заниматься научными исследованиями. Вы, кажется, баллотируетесь на директора?
Нет, я не баллотируюсь. Во-первых, его еще не создали. Что можно сказать про Жошы (а не Джучи). Проблема с кадровым составом в Казахстане наблюдается ещё с Советских времен. У нас с 1969 года мало что было сделано по вводу новых источников в научный оборот, очень мало. Даже вот эти программы культурного наследия, там были очень большие деньги, но они ушли как вода в песок. Мало что нужного перевели, либо переиздали то, что было издано в советское время. А надо вводить новые источники в научный оборот. Вот у нас есть источник «Иманкули хан—наме» про казахских ханов Ферганы. Два хана – отец и сын – правили в Фергане, казахи. Келдимухамед из Ташкента пришёл, потом его сын. Мы знаем этот источник с 1969 года. Пятьдесят лет прошло, но никто не перевёл. Это катастрофа с точки зрения кадрового состава. У нас, получается, нет людей, которые могут перевести? На самом деле есть. Их просто нужно организовать. Мне кажется, если центр будет создан, то его главная цель – вводить новые источники в научный оборот, потому что их очень много. И если копать, мы можем обогатить нашу историю.
Была же программа искать по всему миру в архивах любые документы, где упомянуты казахи?
Тут есть следующие моменты. Во-первых, это академический туризм. Когда выезжают в Испанию и в десятый раз привозят информацию об Аль-Фараби. Чиновник не может понять, кого привезли. Какая-то арабица, что там — непонятно. И он закрывает глаза. Всё смотрится по научному вкладу. Если после 2013 года мы не видели нормальных публикаций, о чём речь? У нас привезли «Музер Ансап», копии британские и индийские, привезли две британские копии «Кадыргали Жалаири», ещё много чего привезли, но где переводы? На русский, казахский, английский переведите! Но у нас это складируется и никому не даётся. У нас многие воспринимают это как феодальную собственность: приехало, источник имеется, но я никому не дам. Я уже просил человека, три-четыре важных источника привезли, но с тринадцатого года не дают. Феодальная собственность.
Институт Жошы этим займётся?
Думаю, что да. Если посмотрим 550-летие Казахского ханства и 750-летие Золотой Орды — это были тои по большей части, но не было научной работы. И сейчас наконец-то, кажется, власть заметила: зачем тратиться на тои, когда нужно вести научную работу. Мелковатую с точки зрения обывателей, но фундаментальную, на долгое время. На самом деле, деньги большие не нужны. Если мы посмотрим на наших татар, которые занимаются Золотой Ордой, то они имеют в 10-20 раз меньше денег, чем казахи, но переводят источники. И для казахстанских историков они сделали больше, чем целые наши институты.
Чемпионат Англии по футболу (АПЛ)
Чемпионат Англии: колыбель мирового футболаВ играх в футбол чемпионат Англии занимает особое место. Ведь именно с него началась история футбольных турниров. Документально подтверждено: чемпионат Англии по футболу стал первым в мире. Еще в 1888 г. на Туманном Альбионе состоялись первые сражения на футбольных полях за титул чемпиона.
Именно тогда была основана английская Футбольная лига. Чуть более 100 лет спустя на ее основе появилась Премьер-лига Англии. И сегодня ее клубы по праву считаются одними из самых сильных в Европе.
Главные факты об АПЛСтарт матчей | 1992 г. |
Предыдущие дивизионы |
|
Количество клубов |
|
Структура соревнований | Каждая команда играет с каждой другой командой дважды: домашний + гостевой матчи. |
Самые титулованные команды |
|
Чемпионат Англии: что это за турнир?
Внимание болельщиков не только Европы, но и всего мира уже давно завоевал футбол Англии. Большим спросом пользуются трансляции матчей и профессиональные обзоры сыгранных встреч. Из статьи вы узнаете какие особенности имеет Английская Премьер Лига и получите всю необходимую информацию про Чемпионат Англии.
Когда был основан чемпионат Англии
Год основания | 1992 |
Количество участников | 20 клубов |
Продолжительность сезона | С августа по май |
Квалификация в еврокубки | Есть |
Премьер Лига Англии славится своим динамизмом и напряженностью, ведь календарь встреч здесь всегда разнообразней, чем в других европейских лигах. При этом Премьер Лига Англии привлекает болельщиков со всего мира еще и тем, что в чемпионате играют лучшие футболисты, а тренируют их топовые наставники. За счет этого футбол Англии — это лучшая лига Европы, а значит и самая интересная для фанатов АПЛ и нейтральных зрителей.
Английская Премьер лига: регламент турнира
Английская Премьер Лига насчитывает 20 команд, которые начинают каждый новый сезон. В течение сезона каждый клуб-участник дважды играет с остальными командами: на своем поле и в гостях. То есть, Английская Премьер Лига состоит из 38 встреч для каждой команды. Победа приносит 3 очка в турнирной таблице, а ничья — 1 очко.
Английская Премьер Лига — турнир для сильнейших команд, поэтому три самые слабые клуба по результатам сезона вылетают в Чемпионшип. Их место занимают три лучшие коллектива из нижнего дивизиона. Если кандидат на вылет делит место с другой командой по количеству баллов, то назначается дополнительный матч. Команды АПЛ проводят его на нейтральном поле.
Премьер лига Англии: как определяется чемпион
Премьер Лига Англии — это турнир с регулярно меняющимся составом участников, но чемпион каждый год новый. Его определяют, в первую очередь, по количеству баллов в итоговой таблице. Если несколько клубов набрали равное количество очков, то первенство определяют по разнице мячей или по забитым голам. Первые 5 клубов из таблицы получают возможность выхода в топовые европейские турниры, в которых футбол Англии хорошо себя проявил.
Какие особенности имеет английский футбол
Английская Премьер Лига имеет свои фирменный характер, что радует болельщиков, предпочитающих активный футбол Англии, результаты которого часто непредсказуемые. Его характер довольно быстрый и силовой. При этом отличается стиль команд: некоторые ставят на контроль мяча, некоторые на сильную оборону, а кто-то стремится вести игру на половине поля противника. Чемпионат Англии по футболу настолько разнообразный из-за манер тренерского состава команд. Поскольку много клубов-участников приглашает зарубежных тренеров, Премьер лига Англии может порадовать самого требовательного болельщика.
Бомбардиры АПЛ — награда лучшему голеадору сезона
Кроме командных результатов, Английская Премьер Лига каждый сезон отмечается и высокими индивидуальными достижениями игроков. Есть даже неофициальные награды, например, гол месяца, сезона, лучшие ассистенты АПЛ. И, конечно же, существует отдельная гонка бомбардиров. Каждый игрок хочет повторить успех Алана Ширера — футбол Англии до сих пор не знает более результативного нападающего. На счету футболиста 260 забитых голов, в том числе 56 реализованных пенальти.
Английская Премьер Лига имеет свою награду для лучшего бомбардира сезона — Золотую бутсу. Отдельно существуют награды для авторов первых 10, 20 и 30 голов в сезоне. Также есть целый ряд индивидуальных наград, которые дает Премьер Лига Англии лучшему защитнику, вратарю, нападающему, есть награда игроку года и так далее. Все это также порождает азарт и конкуренцию между футболистами, так как каждый желает стать лучшим, за счет чего футбол Англии и является лучшей лигой.
Где читать новости АПЛ
Всех болельщиков интересует, где можно найти актуальные новости и разбор матчей. Весь футбол Англии результаты, обзоры, прогнозы, новости и так далее, вы найдете на нашем сайте. Здесь регулярно обновляются новости чемпионата, профессиональные аналитики готовят обзоры сыгранных встреч и делают прогнозы на грядущие события, которыми славится чемпионат Англии. К вашим услугам полные турнирные таблицы и свежее АПЛ расписание матчей.
Как формируется турнирная таблица АПЛ
В последнее время чемпионат Англии стал еще более интересным из-за своей непредсказуемости. Команды обновляют составы, совершенствуют тактику игры, из-за чего даже прошлогодние аутсайдеры имеют все шансы на победу. Более того, в футбол, особенно в чемпионат Англии, приходят все более крупные инвесторы и капиталовложения, а значит растет и уровень исполнителей, а также возрастает доминирование команд из АПЛ на европейской арене.
Турнирная таблица зависит от результатов всех матчей сезона. Поэтому нередко сделать прогноз на победителя сложно, ведь Английская Премьер Лига почти всегда имеет 5-6 команд претендентов на чемпионство. Также серьезная борьба всегда ведется и в нижней части таблицы, ведь никакая из команд не хочет покидать топовый чемпионат Англии.
Коммерческий проект и футбольная революцияВ 1992-м футбольный мир потрясла новость: ведущие клубы Англии не стали довольствоваться Футбольной лигой и основали собственную. Первоначально «Премьер-лига Футбольной ассоциации» в 2007-м сократила свое название первых двух слов.
Причина появления АПЛ прозаична: желание увеличить заработки. Клубы-основатели стали ее акционерами и смогли самостоятельно вести дела со спонсорами, продавать права на телетрансляции матчей.
Как результат, инвестиции не заставили себя ждать. Всего за 4 года клубы Премьер-лиги полностью модернизировали свою инфраструктуру. Число болельщиков резко возросло, английский футбол привлек новых дорогих игроков и поднялся со дна турнирной таблицы Европы.
Интересный факт об Английском футболеСегодня 9 команд АПЛ входят в ТОП-20 самых доходных в Европе.
Как менялась структура чемпионатаЕсли сделать краткий обзор-ретроспективу, можно отметить, что расписание первого сезона АПЛ включало игры 22 команд. Так было в Первом дивизионе Футбольной лиги до создания Премьер-лиги.
Но в 1995-м, по требованию ФИФА, все национальные первенства сократили свой календарь до 38 туров с участием 20 команд.
Корона и львы: главный трофей АПЛГлавный кубок страны выполнен из серебра, имеет малахитовое основание и весит четверть центнера. Венчает его золотая корона. А над ручками расположены символы английского футбола – львы.
Интересные факты- В 2006-м федерация потребовала уменьшить число участников первенства до 18. Но англичане на это не пошли.
- В 2018-м по всему миру разлетелись новости о том, как Александр Зинченко уронил кубок АПЛ. Инцидент произошел случайно: во время награждения защитник «горожан» столкнул трофей с тумбы (момент зафиксирован на видео и набрал миллионы просмотров онлайн).
- В 2019-м МанСити снова завладел кубком. Зинченко стал первым украинцем, который дважды удостоился победы в национальном чемпионате Англии. И трофей опять уронили! Как выяснилось, трюк был запланирован: футболисты устроили пранк с разбиванием копии кубка и пощекотали нервы болельщикам.
FAQ
⚽ Где доступен к просмотру футбол Англии онлайн?
✅ На нашем сайте вы найдете ссылки на трансляции соревнований. Кроме видео, всегда есть обзор игры и полноценная статистика.
⚽ Имеет ли отличия в правилах Премьер Лига Англии?
✅ Нет, правила игры не отличаются от других чемпионатов и соответствуют всем требованиям УЕФА.
⚽ Сколько туров имеет Премьер Лига Англии?
✅ Всего команды играют 38 туров, среди которых как домашние, так и выездные матчи.
Все права защищены. При использовании текстовых материалов сайта гиперссылка на Sport.ua обязательна. Для печатных изданий указание Sport.ua обязательно. Использование фотоматериалов сайта без письменного разрешения редакции запрещено. Редакция проекта может не разделять мнение авторов и не несет ответственности за авторские материалы.
15 модных английских фраз, чтобы лучше выразить свои эмоции
Что бы вы ответили, если вас спросят о вашем текущем настроении? Вы скажете «Счастлив», «грустен» или «зол». Но неужели вы думаете, что этого достаточно, чтобы описать свое настроение? Как бы описать невероятно удивительный отпуск? Как «счастливый»? Но сколько раз можно использовать счастье. Слово потеряет смысл. Вы можете использовать синтаксический анализ «на луну», чтобы выразить счастье и справедливо выразить свои эмоции.
Есть много слов, которыми вы можете выразить вашу текущую форму эмоций.Это поможет вам описать весь спектр ваших эмоций. Это поможет другим точно узнать, что вы чувствуете. Итак, вот несколько модных английских фраз, которые вы можете использовать, чтобы выразить весь спектр своих эмоций.
Happy1. Полет высоко:
Например: Она взлетела высоко после успешного собеседования.
2. Накаченный
- Значение: очень взволнован чем-то
Например: Он накачан своей первой зарплатой.
3. Рай для дураков:
- Значение: ситуация, когда кто-то счастлив, потому что игнорирует проблему или не осознает ее существование.
Например: Вы, должно быть, оказались в раю для дураков, если думаете, что во время такого жаркого лета пойдет дождь.
Sad4. Быть на свалке:
- Значение: чувствовать себя несчастным или без надежды
Например: Она немного подавлена, потому что ей нужно снова сдавать экзамены.
5. Будьте на конце вашей веревки
- Значение: чувствовать себя очень расстроенным из-за того, что вы больше не в состоянии справиться с трудной ситуацией
Например: Похоже, вы на краю веревки .
6. Убитый горем
Например: после того, как его жена погибла в автокатастрофе, он остался убитым горем.
Злой7. Откусить кому-нибудь голову:
- Значение: ответить кому-то гневом
Например: Я задал ему один простой вопрос, и он откусил мне голову.
8. Черное настроение:- Значение: быть раздражительным, злым или подавленным.
Например: Она боится попросить поездку на выходные, так как ее мать сегодня в плохом настроении.
9. Подъезжайте к стене:
- Значение: раздражать или раздражать кого-то.
Например: Его безвкусное пение и барабанная дробь на столе доводят меня до стены.
Испугано10. Иметь / почувствовать / почувствовать бабочек в животе:
- Значение: испытать тревогу, как правило, перед тем, как что-то делать живот, когда она собиралась идти по проходу.
11. Бояться собственной тени:
- Значение: быть очень напуганным (настолько напуганным, что вы подпрыгнете, если увидите свою собственную тень на свету).
Например: Иногда люди, которые кажутся самыми уверенными, на самом деле боятся собственной тени.
12. В окаменелости:
- Значение: очень напуган, особенно из-за того, что вы не можете двинуться с места или решить, что делать.
Например: Мысль о том, что мы живем в полной слепоте, окаменела!
Неясно13.Чувствовать себя:
- Значение: не чувствовать себя в нормальном состоянии ума.
Например: Он только что проснулся после ночи, когда был сильно пьян, и чувствовал себя совершенно не в себе.
14. Загадка:
Значение: долго хорошо думать о ком-то или о чем-то и пытаться понять их.
Например: Они долго ломали голову над этим вопросом.
15. Неоднозначное отношение к:
Значение: одновременное ощущение двух разных вещей в отношении кого-то или чего-то, например, что они вам нравятся и не нравятся.
Например: Она амбивалентна ко многим вещам, которые могут показаться читателю ужасными.
Прочитано: Список слов с альтернативным написанием
Прочитано: 40 латинских слов, чтобы сделать ваш обычный разговор действительно интересным
Прочитано: 30 распространенных английских ошибок, которые делают индийцы
Дерево синтаксического анализа для предложения ‘Фильм очень интересный ‘построен …
Эта диссертация фокусируется на двух задачах обработки естественного языка, которые требуют извлечения семантической информации из необработанных текстов: анализ тональности и обобщение текста.В этой диссертации обсуждаются вопросы и делается попытка улучшить нейронные модели для решения обеих задач, которые стали доминирующей парадигмой за последние несколько лет. Соответственно, эта диссертация состоит из двух частей: первая часть (нейронный анализ настроений) посвящена компьютерному изучению мнений, настроений людей, а вторая часть (нейронное суммирование текста) пытается извлечь важную информацию из сложного предложения и переписать ее. в удобочитаемой форме. Нейронный анализ сентиментальности. Подобно компьютерному зрению, многочисленные глубокие сверточные нейронные сети были адаптированы для анализа настроений и задач классификации текста.Однако, в отличие от области изображений, эти исследования проводятся на разных типах входных данных и на разных наборах данных, что затрудняет понимание того, действительно ли нужна глубокая сеть. В этом тезисе мы стремимся найти элементы для ответа на этот вопрос, то есть должны ли нейронные сети вычислять глубокие иерархии функций для текстовых данных так же, как они это делают в зрении. Таким образом, мы предлагаем новую адаптацию самой глубокой сверточной архитектуры (DenseNet) для классификации текста и изучаем важность глубины в сверточных моделях с различными атомными уровнями (слово или символ) ввода.Мы показываем, что глубокие модели действительно дают лучшие характеристики, чем мелкие сети, когда ввод текста представлен как последовательность символов. Однако простая неглубокая и широкая сеть превосходит глубокие модели DenseNet с вводом слов. Кроме того, для дальнейшего улучшения классификаторов настроений и их контекстуализации мы предлагаем моделировать их совместно с диалоговыми актами, которые являются фактором объяснения и коррелируют с настроениями, но, тем не менее, часто игнорируются. Мы вручную аннотировали диалоги и настроения в социальной сети, подобной Twitter, и обучаем многозадачную иерархическую повторяющуюся сеть совместному распознаванию настроений и диалогов.Мы показываем, что трансферное обучение может быть эффективно достигнуто между обеими задачами, и далее анализируем некоторые конкретные корреляции между настроениями и диалогами в социальных сетях. Обобщение нейронного текста. Выявление настроений и мнений из больших цифровых документов не всегда позволяет пользователям таких систем принимать обоснованные решения, поскольку другая важная семантическая информация отсутствует. Людям также нужны основные аргументы и подтверждающие доводы из исходных документов, чтобы по-настоящему понять и интерпретировать документ.Чтобы получить такую информацию, мы стремимся сделать нейронные модели реферирования текста более понятными. Мы предлагаем модель, которая имеет лучшие свойства объяснимости и достаточно гибкая, чтобы поддерживать различные модули поверхностного синтаксического анализа. В частности, мы линеаризуем синтаксическое дерево в форме перекрывающихся текстовых сегментов, которые затем выбираются с помощью обучения с подкреплением (RL) и регенерируются в сжатую форму. Следовательно, предлагаемая модель способна обрабатывать как экстрактивное, так и абстрактное обобщение.Кроме того, мы наблюдаем, что модели на основе RL становятся все более и более повсеместными для многих задач реферирования текста. Мы заинтересованы в лучшем понимании того, какие типы информации учитываются такими моделями, и предлагаем изучить этот вопрос с синтаксической точки зрения. Таким образом, мы предоставляем подробное сравнение как основанных на RL подходов, так и подходов с учетом синтаксиса, а также их комбинации по нескольким параметрам, которые относятся к воспринимаемому качеству сгенерированных сводок, таких как количество повторений, длина предложения, распределение тегов частей речи. , актуальность и грамматичность.Мы показываем, что при ограничении ресурсов (вычисления и память) разумно обучать модели только с RL и без какой-либо синтаксической информации, поскольку они обеспечивают почти такие же хорошие результаты, как модели с учетом синтаксиса с меньшим количеством параметров и более быстрой сходимостью обучения.
Правил разбиения слов | Советы на BestEssays.com
Правила разделения слов в конце строки в английском языке довольно сложны и во многих случаях довольно субъективны. На всякий случай — просто избегайте этого.Мы рекомендуем вам отключить автоматическую расстановку переносов в вашем текстовом редакторе, которая, вероятно, будет переноситься в американском английском, где правила гораздо более гибкие, чем в британском английском. Если разрыв слова неизбежен, убедитесь, что вы поставили дефис после полного слога: neg-li -gent. Перенос в середине слога считается ошибкой.
Для разделения строк в словах, оканчивающихся на -ing, если последняя корневая согласная удваивается перед -ing, ставьте дефис между согласными; в других случаях ставьте дефис в самом суффиксе:
e.g Dig-ging
Put-ting
Sing -ing
Vot-ing.Есть несколько правил «никогда», которые следует помнить при разбиении слов в конце строки:
- Никогда не разбивайте односложное слово.
- Никогда не переносите слова, в которых уже есть дефис.
- Никогда не разделяйте имя собственное (существительное, начинающееся с заглавной буквы).
- Никогда не оставляйте одну или две буквы в любой строке. Однако вы можете использовать дефис перед склонением для причастия прошедшего времени (например,g play-ed) с правильными глаголами, в то же время он реже встречается с неправильными глаголами (например, brok -en).
- Никогда не помещайте первую или последнюю букву слова в конец или начало строки.
- Никогда не начинайте новую строку с двухбуквенного суффикса.
Есть ли у вас проблемы с написанием эссе?
Позвольте нашим профессионалам помочь вам с исследованием и написанием статейУзнайте, чем вы можете воспользоваться в Bestessays.com
- Получите профессиональную помощь с корректурой и форматированием ваших статей всего по цене от 5,49 долларов США за стр.
- См. Образцы самых популярных научных работ
- Получите помощь в исследовании по любому предмету , если вам не хватает времени или необходимых ресурсов
% PDF-1.5 % 259 0 объект > эндобдж xref 259 89 0000000015 00000 н. 0000002181 00000 п. 0000002310 00000 н. 0000002362 00000 н. 0000003024 00000 н. 0000003480 00000 н. 0000003773 00000 н. 0000003855 00000 н. 0000003963 00000 н. 0000004124 00000 п. 0000004327 00000 н. 0000004532 00000 н. 0000004694 00000 н. 0000004856 00000 н. 0000005018 00000 н. 0000005180 00000 н. 0000005368 00000 н. 0000011160 00000 п. 0000011258 00000 п. 0000012016 00000 п. 0000012421 00000 п. 0000012594 00000 п. 0000012713 00000 п. 0000012774 00000 п. 0000013057 00000 п. 0000021225 00000 п. 0000022141 00000 п. 0000022164 00000 п. 0000022187 00000 п. 0000022243 00000 п. 0000022431 00000 п. 0000022621 00000 п. 0000022810 00000 п. 0000023007 00000 п. 0000023194 00000 п. 0000023383 00000 п. 0000023544 00000 п. 0000024177 00000 п. 0000024388 00000 п. 0000025328 00000 п. 0000025727 00000 п. 0000026039 00000 п. 0000026599 00000 н. 0000027544 00000 п. 0000028485 00000 п. 0000028771 00000 п. 0000029709 00000 п. 0000030109 00000 п. 0000030485 00000 п. 0000030780 00000 п. 0000031153 00000 п. 0000031531 00000 п. 0000031971 00000 п. 0000032918 00000 п. 0000033320 00000 п. 0000033816 00000 п. 0000034181 00000 п. 0000035121 00000 п. 0000035520 00000 п. 0000035960 00000 п. 0000036891 00000 п. 0000037624 00000 п. 0000038001 00000 п. 0000127986 00000 п. 0000228266 00000 н. 0000276351 00000 н. 0000314651 00000 н. 0000377134 00000 н. 0000395865 00000 н. 0000406830 00000 н. 0000406908 00000 н. 0000407003 00000 н. 0000407097 00000 н. 0000407211 00000 н. 0000407367 00000 н. 0000407464 00000 н. 0000407614 00000 н. 0000407723 00000 н. 0000407877 00000 н. 0000407988 00000 п. 0000408081 00000 н. 0000408240 00000 н.
Улучшение композиционности встраивания слов с использованием лексикографических определений
% PDF-1.5 % 1 0 объект > / OCG [5 0 R] >> / OpenAction 6 0 R / Контуры 7 0 R / PageLabels> / PageMode / UseOutlines / Страницы 9 0 R / Тип / Каталог >> эндобдж 10 0 obj > эндобдж 2 0 obj > / Шрифт> >> / Поля [] >> эндобдж 3 0 obj > поток application / pdf
- Thijs Scheepers, Evangelos Kanoulas и Efstratios Gavves
- Улучшение композиционности вложения слов с использованием лексикографических определений 2018-02-19T08: 22: 59ZLaTeX с acmart 2018/02/07 v1.50 наборных статей для Association for Computing Machinery and hyperref 2016/06/24 v6.83q Гипертекстовые ссылки для LaTeX2019-07-05T16: 29: 05 + 02: 002019-07-05T16: 29: 05 + 02: 00pdfTeX-1.40. 17False Это pdfTeX, версия 3.14159265-2.6-1.40.17 (TeX Live 2016 / Debian) kpathsea версия 6.2.2uuid: 87ca0d57-bbc6-4649-a016-17dfc19bc428uuid: d1671e0b-8ef6-4c24-aa836e3624a конечный поток эндобдж 4 0 obj > эндобдж 5 0 obj > >> >> эндобдж 6 0 obj > эндобдж 7 0 объект > эндобдж 8 0 объект > эндобдж 9 0 объект > эндобдж 11 0 объект > эндобдж 12 0 объект > эндобдж 13 0 объект > эндобдж 14 0 объект > эндобдж 15 0 объект > / Шрифт> / ProcSet [/ PDF / Text] / XObject> >> / Повернуть 0 / Тип / Страница >> эндобдж 16 0 объект >> эндобдж 17 0 объект >> эндобдж 18 0 объект > эндобдж 19 0 объект > эндобдж 20 0 объект > эндобдж 21 0 объект > эндобдж 22 0 объект > эндобдж 23 0 объект > / Граница [0 0 0] / C [1 0 0] /ПРИВЕТ / Rect [84.961 260,561 94,366 269,937] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 24 0 объект > / Граница [0 0 0] / C [0 1 1] /ПРИВЕТ / Rect [116,547 260,561 247,846 269,937] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 25 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [181,311 225,585 191,642 233,213] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 26 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [254,81 181,749 265,141 189,377] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 27 0 объект > / Граница [0 0 0] / C [0 1 1] /ПРИВЕТ / Rect [52.802 81,581 167,938 90,78] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 28 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [416,49 593,916 426,821 601,544] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 29 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [354,116 495,286 364,447 502,914] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 30 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [430,993 451,45 441,324 459,078] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 31 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [457.583 232,272 467,915 239,9] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 32 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [499,6 232,348 509,931 239,9] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 33 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [549.793 232.272 555.955 239.9] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 34 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [374,883 221,313 385,214 228,941] / Подтип / Ссылка / Тип / Аннотация >> эндобдж 35 0 объект > / Граница [0 0 0] / C [0 1 0] /ПРИВЕТ / Rect [463.ʚVq \% n! iɳc3 S «̙lkoGi! [}} ξW n! f9T $ c \ -,
c G, * kby0lal | Hf {6
Машинное обучение — обработка текста | by Javaid Nabi
Обработка текста — одна из наиболее распространенных задач во многих приложениях машинного обучения. Ниже приведены несколько примеров таких приложений.
• Языковой перевод: Перевод предложения с одного языка на другой. • Анализ настроений: для определения по корпусу текста, является ли отношение к какой-либо теме или продукту и т. Д. Положительным, отрицательным или нейтральным. • Фильтрация спама: обнаружение нежелательных и нежелательных сообщений электронной почты / сообщений.Предоставлено (сигмоидальная)
Эти приложения работают с огромным объемом текста для выполнения классификации или перевода и требуют большой работы на стороне сервера. Преобразование текста во что-то, что алгоритм может переварить, — сложный процесс. В этой статье мы обсудим этапы обработки текста.
Шаг 1: Предварительная обработка данных
- Токенизация — преобразование предложений в слова
- Удаление ненужных знаков препинания, тегов
- Удаление стоп-слов — частые слова, такие как «the», «is» и т. Д.которые не имеют определенной семантики.
- Stemming — слова сокращаются до корня путем удаления перегиба путем удаления ненужных символов, обычно суффикса.
- Лемматизация — Другой подход к удалению интонации путем определения части речи и использования подробной базы данных языка.
Обобщенная форма обучения: studi
Обусловленная форма обучения: study Лемматизированная форма обучения: study
Лемматизированная форма обучения: study
Таким образом, выделение корней и лемматизация помогают сократить такие слова, как «исследования», «изучение» до общей основной формы или корневого слова «учеба».Подробное обсуждение стемминга и лемматизации см. Здесь. Обратите внимание, что не все шаги являются обязательными и зависят от варианта использования приложения. Для фильтрации спама мы можем выполнить все вышеперечисленные шаги, но не в случае языкового перевода.
Мы можем использовать python для выполнения многих операций предварительной обработки текста.
- NLTK — The Natural Language ToolKit — одна из самых известных и наиболее часто используемых библиотек NLP, полезная для всех видов задач, начиная от токенизации, выделения, тегирования, синтаксического анализа и т. Д.
- BeautifulSoup — Библиотека для извлечения данных из Документы HTML и XML
# используя библиотеку NLTK, мы можем сделать много предварительной обработки текста
import nltk
from nltk.tokenize import word_tokenize
# функция для разделения текста на слово
tokens = word_tokenize («Быстрая коричневая лиса перепрыгивает через ленивую собаку»)
nltk.download ('стоп-слова')
print (tokens)
OUT: [ ‘The’, ‘quick’, ‘brown’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’, ‘dog’]
из nltk.corpus импортировать стоп-слова
stop_words = set ( stopwords.words ('english'))
tokens = [w вместо w в токенах, если не w в stop_words]
print (tokens)
OUT: [‘The’, ‘quick’, ‘brown’, ‘fox’ , ‘прыжки’, ‘ленивый’, ‘собака’]
#NLTK предоставляет несколько интерфейсов стеммера, например, стеммер Портера, #Lancaster Stemmer, Snowball Stemmer
от nltk.stem.porter import PorterStemmer
porter = PorterStemmer ()
stems = []
для t в токенах:
stems.append (porter.stem (t))
print (stem)
OUT: [‘the’, ‘ quick, brown, fox, jump, lazi, dog]
Шаг 2. Извлечение признаков
При обработке текста слова текста представляют дискретные категориальные признаки. Как мы закодируем такие данные таким образом, чтобы их могли использовать алгоритмы? Преобразование текстовых данных в векторы с действительными значениями называется извлечением признаков.Один из самых простых способов числового представления текста — Мешок слов.
Мешок слов (BOW): Мы составляем список уникальных слов в корпусе текста, называемый словарем. Затем мы можем представить каждое предложение или документ как вектор с каждым словом, представленным как 1 для настоящего и 0 для отсутствующего в словаре. Другое представление — это подсчет количества раз, когда каждое слово появляется в документе. Наиболее популярным подходом является использование метода Term Frequency-Inverse Document Frequency (TF-IDF) .
- Частота термина (TF) = (Количество раз, когда термин t появляется в документе) / (Количество терминов в документе)
- Частота обратного документа (IDF) = log (N / n), где , N — количество документов, а n — количество документов, в которых появился термин t. IDF редкого слова высокий, тогда как IDF частого слова, вероятно, будет низким. Таким образом, выделяются отдельные слова.
- Мы вычисляем TF-IDF значение термина как = TF * IDF
Давайте рассмотрим пример для вычисления TF-IDF термина в документе.
Пример текстового корпуса TF ('beautiful', Document1) = 2/10, IDF ('beautiful') = log (2/2) = 0
TF ('day', Document1) = 5/10, IDF ( 'день') = журнал (2/1) = 0,30 TF-IDF ('красивый', Документ1) = (2/10) * 0 = 0
TF-IDF ('день', Документ1) = (5/10 ) * 0,30 = 0,15
Как вы можете видеть для Документа 1, метод TF-IDF сильно наказывает слово «красивый», но придает больший вес «дню». Это связано с частью IDF, которая придает больший вес отдельным словам.Другими словами, «день» — важное слово для Document1 в контексте всего корпуса. Библиотека Python scikit-learn предоставляет эффективные инструменты для интеллектуального анализа текстовых данных и предоставляет функции для вычисления TF-IDF текстового словаря с учетом корпуса текста.
Одним из основных недостатков использования BOW является то, что он игнорирует порядок слов, тем самым игнорируя контекст и, в свою очередь, значение слов в документе. Для обработки естественного языка (НЛП) крайне важно поддерживать контекст слов.Чтобы решить эту проблему, мы используем другой подход, который называется Word Embedding.
Вложение слов: Это представление текста, в котором слова, имеющие одинаковое значение, имеют аналогичное представление. Другими словами, он представляет слова в системе координат, где связанные слова, основанные на совокупности отношений, расположены ближе друг к другу.
Давайте обсудим некоторые из хорошо известных моделей встраивания слов :
Word2VecWord2vec принимает в качестве входных данных большой корпус текста и создает векторное пространство, в котором каждому уникальному слову назначается соответствующий вектор в космос.Векторы слов располагаются в векторном пространстве таким образом, что слова, имеющие общие контексты в корпусе, располагаются в пространстве в непосредственной близости друг от друга. Word2Vec очень известен тем, что улавливает смысл и демонстрирует его на таких задачах, как вычисление вопросов по аналогии в форме a соответствует b , как c соответствует ? . Например, мужчина — женщина , как дядя — ? ( тетя ) с использованием простого метода векторного смещения на основе косинусного расстояния.Например, вот векторные смещения для трех пар слов, иллюстрирующие гендерные отношения:
векторных смещений для гендерных отношенийЭтот вид векторной композиции также позволяет нам ответить «Король — Мужчина + Женщина =?» вопрос и получите результат «Королева»! Все это действительно замечательно, если подумать, что все эти знания просто приходят из просмотра большого количества слов в контексте без какой-либо другой информации об их семантике. Подробнее см. Здесь.
ПерчаткаАлгоритм глобальных векторов для представления слов, или GloVe, является расширением метода word2vec для эффективного изучения векторов слов.GloVe создает явный контекст слова или матрицу совпадения слов, используя статистику по всему текстовому корпусу. Результатом является обучающая модель, которая в целом может улучшить встраивание слов.
Рассмотрим следующий пример:
Целевые слова: лед, пар
Контрольные слова: твердое тело, газ, вода, мода
Пусть P (k | w) будет вероятностью того, что слово k появляется в контексте слова w . Рассмотрим слово, тесно связанное с ice , но не с steam , например solid . P (solid | ice) будет относительно высоким, а P (solid | steam) будет относительно низким. Таким образом, соотношение P (твердый | лед) / P (твердый | пар) будет большим. Если мы возьмем такое слово, как газ , которое связано с паром , но не с льдом , соотношение P (газ | лед) / P (газ | пар) будет небольшим. Для слова, относящегося как к , так и к льду и к пару , например к воде , мы ожидаем, что соотношение будет близко к единице.Обратитесь сюда для получения более подробной информации.
Вложения слов кодируют каждое слово в вектор, который фиксирует некоторую связь и сходство между словами в текстовом корпусе. Это означает, что даже варианты слов, такие как регистр, орфография, пунктуация и т. Д., Будут автоматически изучены. В свою очередь, это может означать, что некоторые из описанных выше шагов по очистке текста могут больше не потребоваться.
Шаг 3: Выбор алгоритмов машинного обучения
Существуют различные подходы к построению моделей машинного обучения для различных текстовых приложений в зависимости от области проблемы и доступных данных.
Классические подходы машинного обучения, такие как «наивный байесовский» или «вспомогательные векторные машины» для фильтрации спама, получили широкое распространение. Методы глубокого обучения дают лучшие результаты для таких задач НЛП, как анализ тональности и языковой перевод. Модели глубокого обучения очень медленно обучаются, и было замечено, что для простых задач классификации текста классические подходы машинного обучения также дают аналогичные результаты с меньшим временем обучения.
Давайте построим Sentiment Analyzer на основе набора данных обзора фильмов IMDB, используя описанные выше методы.
Загрузить данные обзора фильмов IMDb
Набор обзоров фильмов IMDB можно загрузить отсюда. Этот набор данных для двоичной классификации тональности содержит набор из 25 000 высокополярных обзоров фильмов для обучения и 25 000 для тестирования. Этот набор данных использовался в очень популярной статье «Изучение векторов слов для анализа настроений».
Предварительная обработка
Набор данных структурирован как набор тестов и обучающий набор по 25000 файлов каждый. Давайте сначала прочитаем файлы в фреймворк Python для дальнейшей обработки и визуализации.Набор тестов и обучающих разделен на 12500 «положительных» и «отрицательных» отзывов каждый. Мы читаем каждый файл и помечаем отрицательный отзыв как ‘0’, а положительный отзыв как ‘1’
# преобразовать набор данных из файлов в файл Python DataFrame import pandas as pd
import os folder = 'aclImdb' labels = {'pos': 1, 'neg': 0} df = pd.DataFrame () для f in ('test', 'train'):
для l in ('pos', 'neg') :
путь = os.path.join (папка, f, l)
для файла в os.listdir (путь):
с open (os.path.join (путь, файл), 'r', encoding = 'utf-8') как infile:
txt = infile.read ()
df = df.append ( [[txt, labels [l]]], ignore_index = True) df.columns = ['review', 'sentiment']
Сохраним собранные данные как файл .csv для дальнейшего использования.
Пять обзоров и соответствующая тональность Чтобы получить частотное распределение слов в тексте, мы можем использовать функцию nltk.FreqDist () , которая перечисляет самые популярные слова, используемые в тексте, обеспечивая приблизительное представление об основных словах. в текстовых данных, как показано в следующем коде:
import nltk
from nltk.tokenize import word_tokenize reviews = df.review.str.cat (sep = '') # функция разбиения текста на слово
tokens = word_tokenize (reviews) dictionary = set (tokens)
print (len (dictionary )) frequency_dist = nltk.FreqDist (tokens)
sorted (frequency_dist, key = frequency_dist .__ getitem__, reverse = True) [0:50]
Это дает 50 первых слов, используемых в тексте, хотя это очевидно что некоторые стоп-слова, такие как и , часто встречаются в английском языке.
Присмотритесь, и вы обнаружите много ненужных знаков препинания и тегов. Исключая одно- и двухбуквенные слова, такие стоп-слова, как , , , , и , , , занимают верхнюю позицию на графике частотного распределения слов, показанном ниже.
Удалим стоп-слова для дальнейшей очистки текстового корпуса.
из nltk.corpus импортировать стоп-слова stop_words = set (stopwords.words ('english'))
tokens = [w вместо w в токенах, если не w в стоп-словах] Top 50 слов Это похоже на очищенное текстовый корпус сейчас и такие слова, как , идут , видели , фильм и т. д.занять верхние слоты, как и ожидалось.
Еще один полезный инструмент визуализации Пакет wordcloud помогает создавать облака слов путем случайного размещения слов на холсте с размерами, пропорциональными их частоте в тексте.
из wordcloud импортировать WordCloud
импортировать matplotlib.pyplot как plt wordcloud = WordCloud ().
generate_from_frequencies (frequency_dist) plt.imshow (wordcloud)
plt.axis ("off")
plt.show ()
Построение классификатора
После очистки пришло время построить классификатор для определения настроения обзор каждого фильма.Из набора данных IMDb разделите тестовые и обучающие наборы по 25000 в каждом:
X_train = df.loc [: 24999, 'review']. Values
y_train = df.loc [: 24999, 'sentiment']. Values
X_test = df.loc [25000 :, 'review']. values
y_test = df.loc [25000 :, 'sentiment']. values
scikit-learn предоставляет несколько интересных инструментов для предварительной обработки текста. Мы используем TfidTransformer , чтобы скрыть текстовый корпус в векторах функций, мы ограничиваем максимальное количество функций до 10000.Дополнительные сведения об использовании TfidTransformer см. Здесь.
из sklearn.feature_extraction.text import TfidfTransformerНабор для обучения и тестирования: 25K с 10K функций
из sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer ()
train_vectors = vectorizer.fit_transform)
train_vectors = vectorizer. shape, test_vectors.shape)
Есть много алгоритмов на выбор, мы будем использовать базовый наивный байесовский классификатор и обучить модель на обучающем наборе.
из sklearn.naive_bayes import MultinomialNB clf = MultinomialNB (). Fit (train_vectors, y_train)
Наш анализатор настроений готов и обучен. Теперь давайте проверим производительность нашей модели на тестовом наборе, чтобы предсказать метки настроения.
из sklearn.metrics import precision_score predicted = clf.predict (test_vectors) print (precision_score (y_test, predicted)) Output 0.791
Wow !!! Анализатор настроений на основе базового классификатора NB дает точность около 79%.Вы можете попробовать изменить длину вектора функций и параметры TfidTransformer , чтобы увидеть влияние на точность модели.
Заключение: Мы подробно обсудили методы обработки текста, используемые в НЛП. Мы также продемонстрировали использование обработки текста и построили анализатор настроений с классическим подходом машинного обучения, добившись довольно хороших результатов.
Спасибо, что прочитали эту статью, рекомендую и делитесь, если она вам нравится.
Дополнительная литература:
Текстовый набор данных рецептов синтеза неорганических материалов
Точность экстракции
Общий выход экстракции трубопровода составляет 28%, что означает, что из 53 538 параграфов твердого тела только 15 144 из них дают сбалансированные химическая реакция.В качестве теста полного конвейера извлечения мы случайным образом извлекли 100 абзацев из набора абзацев, классифицированных как твердотельный синтез, и проверили их на полноту извлеченных данных. Из 100 абзацев мы нашли 30, которые не содержали полного набора исходных материалов и конечных продуктов, а это означает, что эксперт-человек не сможет восстановить реакцию по этим абзацам. Остальные 70 абзацев потенциально могут внести свой вклад в набор данных, поскольку они предоставляют всю информацию о исходных материалах и конечных продуктах.Проверка этих 70 параграфов показала, что 42 потенциальных реакции не были реконструированы из-за неполного или чрезмерного набора извлеченных материалов-предшественников / мишеней или невозможности проанализировать химический состав, что делает невозможным балансировку реакции. Первая потеря возникает из-за более низкого повторного вызова алгоритма MER, который мы обменяли на более высокую точность, в то время как проблема синтаксического анализа возникает из-за сложной записи, используемой для объекта материалов.
Оценка точности записей набора данных была проведена путем случайного отбора 100 записей и ручной проверки каждого извлеченного поля по сравнению с исходным абзацем.Расчетная точность, полнота и оценка F1 для каждого атрибута ввода данных приведены в таблице 2. В целом мы достигли высокой точности при извлечении целей (точность 97%), предшественников (оценка F1 99%), операций ( F1-оценка 90%) и уравновешивающие реакции (точность 95%). Более низкая точность условий нагрева (оценка F1 <90%) в основном вызвана случаями, когда этап нагрева пропускается алгоритмом извлечения операций. Восстановление условий смешивания показывает относительно низкую точность с оценкой F1 65%.Это в значительной степени связано с неправильной идентификацией MER материала устройства или вещества среды, используемой для смешивания, а также потому, что эти условия часто не упоминаются в том же предложении, что и процедура смешивания.
Таблица 2 Производительность извлечения данных для записей набора данных.Этот анализ приводит нас к выводу, что на химическом уровне (правильные прекурсоры, мишени, реакции) точность набора данных составляет 93%. При включении всех операций и их условий точность извлечения и правильного назначения всех элементов рецепта (химии, операций и атрибутов операций) составляет 51%, что является низким показателем из-за низкой производительности при извлечении атрибутов смешивания.Для многих твердотельных рецептов особенности смешивания прекурсоров менее важны, поэтому этот сбой экстракции менее критичен. При рассмотрении только правильности рецепта без условий нагрева и смешивания (т.е. химии, операций и реакций) точность возрастает до 64%.
Стоит отметить, что для этого набора данных мы стремились достичь более высокой точности извлечения данных за счет более низкого отзыва (т.е. лучше пропустить запись данных, чем предоставить неправильную), поэтому скорость извлечения низкая.Тем не менее, построение сбалансированного химического уравнения устанавливает дополнительные ограничения для целей и прекурсоров и помогает уменьшить потенциальные ошибки, которые могли быть вызваны анализом состава. Это приводит к перекосу показателей в сторону более высокой точности идентификации целей и прекурсоров по сравнению с операциями.
Анализ набора данных
Чтобы проверить разнообразие записей, представляющих набор данных, мы сначала получили список уникальных материалов (целей и прекурсоров) и реакций.Набор данных содержит 13 009 уникальных целей, 1845 уникальных предшественников и 16 290 уникальных реакций. Почти в 10 раз меньшее разнообразие прекурсоров по сравнению с мишенями можно объяснить тем фактом, что в целом исследователи работают с набором общепринятых, хорошо зарекомендовавших себя прекурсоров. В таблице 3 представлены десять наиболее частых целей, предшественников и реакций в наборе данных. Целевые соединения точно охватывают типы материалов, наиболее часто изучаемые в последние два десятилетия с помощью твердотельного синтеза. Это катодные материалы для литий-ионных аккумуляторов (LiFePO 4 , LiMn 2 O 4 и LiNi 0.5 Mn 1.5 O 4 ), а также перовскиты для мультиферроиков, светодиодов и КМОП-приложений (BaTiO 3 , BiFeO 3 , SrTiO 3 , Y 3 Al 12634 ). Возможно, что этот список «первой десятки» материалов смещен из-за набора издателей, которые дали нам разрешение на доступ к их научному корпусу. Например, Американское физическое общество не было включено и, возможно, внесло в список другие соединения.
Таблица 3 Десять наиболее распространенных целей, предшественников и реакций, присутствующих в наборе данных.Затем мы оцениваем химическое пространство, охватываемое набором данных. Для каждого химического элемента мы вычислили количество реакций, которые включают данный элемент в мишень. Результаты отображены на рис. 2 в рамке с градиентом от желтого к зеленому в верхней части окна каждого элемента. В базе данных преобладают целевые материалы, содержащие Ti, Sr, Ba, La, Fe -> 3000 реакций включают эти мишени с этими элементами. Это также отражено в списке из десяти наиболее часто встречающихся целевых материалов, появляющихся в наборе данных (Таблица 3).Следующими по распространенности мишенями являются материалы с Li, Ca, Nb, Mn, Bi — 2 000–3 000 реакций с этими элементами в мишенях. Наименее распространенными элементами являются Au, Pt, Os, Be — <13 реакций в наборе данных содержат эти элементы. Редкие и радиоактивные элементы, такие как франций, радий, технеций или прометий, не представлены в целевых материалах набора данных.
Рис. 2Карта химического пространства, охваченного набором данных. Для каждого элемента рамка, окрашенная в градиент от желтого к зеленому, представляет собой общее количество реакций, в результате которых образуется целевое соединение, содержащее элемент.Гистограмма под каждым элементом показывает список ионов, сопряженных с элементом в соединениях-предшественниках. Длина полоски соответствует средней температуре обжига по всем реакциям с использованием данного прекурсора (то есть элемент + противоион). Элементы, встречающиеся в пяти и менее целях, отображаются серым цветом. «Ас» означает ацетатный радикал CH 3 COO — в формуле соединения.
Мы также исследовали совместное присутствие химических элементов и наиболее типичных противоионов в исходных материалах и определили среднюю температуру обжига, используемую с каждым из этих прекурсоров.Здесь мы оперативно определяем температуру обжига как температуру, используемую на последнем этапе нагрева в последовательности операций синтеза. Результаты показаны на рис. 2 в виде гистограмм для каждого элемента. Цвет полоски соответствует определенному противоиону. Чистый элемент в качестве предшественника показан пурпурным цветом. Длина полосы обозначает среднюю температуру обжига.
В этом представлении мы видим, что набор данных точно отображает известные аспекты химии твердого тела.Например, катионы щелочных и переходных металлов часто вводятся в реакцию через различные предшественники, включая бинарные оксиды, нитриды, сульфиды и т.д .; или простые соли, такие как карбонаты, фосфаты и нитраты. В то же время некоторые катионы в соединениях-предшественниках можно найти только в форме оксидов или чистых элементов (например, Be, Sc, Hf, Ru, Os, Rh, Pb, Nb, Pt, Au,…).
В твердотельном синтезе противоион управляет температурой плавления или разложения предшественника и может определять, когда предшественник становится активным во время синтеза.Распределение температур обжига на рис. 2 очень хорошо согласуется с этим утверждением и показывает, как разные прекурсоры используются в разных температурных режимах во время твердотельного синтеза. Например, синие полосы обычно имеют большую длину (высокая средняя температура), чем красные, потому что бориды, карбиды и нитриды переходных металлов часто имеют более высокие температуры реакции, чем их соответствующие оксиды, из-за тугоплавкой природы их предшественников. С другой стороны, зеленые полоски относительно короче (более низкая средняя температура обжига), чем красные, потому что, по сравнению с оксидами и сложными оксидными анионами (карбонаты, фосфаты и т. Д.), Синтез с гидроксидами, оксалатами и ацетатами способствует более низкотемпературным реакциям. поскольку они часто гомогенно смешиваются путем осаждения из раствора.Этот анализ температуры на основе данных основан на прекурсоре, и мы признаем, что температуры реакции также зависят от термической стабильности и реакционной способности целевых соединений. Тем не менее, эта цифра представляет собой полуколичественную отправную точку для исследователей: если целевой материал разлагается при относительно низкой температуре, может быть лучше выбрать прекурсор, который имеет тенденцию становиться активным при более низкой температуре.
Чтобы продемонстрировать разнообразие маршрутов синтеза, представленных в наборе данных, мы отсортировали последовательность шагов синтеза в соответствии со следующими заранее заданными шаблонами (таблица на рис.3):
одностадийный синтез состоит только из операций перемешивания / измельчения твердых веществ и не более одной стадии нагрева (окончательный обжиг) без доизмельчения,
синтез с измельчением в жидкой среде для гомогенизации ( без растворения) исходные материалы в любой жидкой среде,
синтез на основе раствора содержит любой тип растворения исходных материалов в растворителе,
синтез с промежуточным нагревом имеет одну или несколько стадий нагрева (не включая сушку после смешивания с жидкой частью) перед окончательным обжигом материалов.
Соответствие между выбором пути синтеза и исходными противоионами. В верхней таблице приведен пример четырех определенных типов синтеза: одностадийный синтез, на основе раствора, синтез с промежуточными стадиями нагрева, синтез, включая измельчение прекурсоров в жидких средах. Круговые диаграммы справа отображают долю каждого маршрута синтеза в наборе данных. Диаграммы, похожие на пончики, представляют собой доли четырех маршрутов синтеза (приведенных в таблице) для каждого противоиона, используемого в прекурсорах.«Ас» означает ацетатный радикал CH 3 COO — в формуле соединения. «Org» означает органический радикал (–CH–) в формуле соединения.
Во-первых, мы обнаружили, что различные типы синтеза представлены в базе данных почти равномерно (верхняя круговая диаграмма на рис. 3): 26% материалов синтезируются в один этап, 25% маршрутов синтеза выполняются с промежуточным нагревом. стадия (и) перед окончательным обжигом, 21% синтезов содержат измельчение (гомогенизацию) в жидкости, а 14% требуют растворения прекурсоров в растворителе.Остальные рецепты (14%) либо не содержат подробной процедуры синтеза (6%), либо путь более сложен (8%).
Поскольку выбор противоиона, используемого в прекурсоре, часто сильно зависит от метода синтеза, мы рассмотрели, какой тип синтеза является общим для конкретного иона в прекурсоре. Мы запросили подмножество реакций, которые включают данный противоион в соединении-предшественнике, и рассчитали долю каждого типа синтеза в этом подмножестве. Полученные круговые диаграммы показаны на рис.3. Возникающая картина согласуется с известными аспектами твердотельного синтеза. Например, при осаждении твердых веществ во время синтеза предшественник растворяется в растворе. Как показано на рис. 3, в синтезе на основе раствора (оранжевая фракция) часто используются растворимые предшественники с нитратами, ацетатами и органическими (СН-содержащими) радикалами. Некоторые противоионы более поддаются одностадийному синтезу, чем другие, например, хлориды, сульфиды и гидриды не требуют большой дополнительной обработки.С другой стороны, относительно стабильные предшественники, такие как оксиды и карбонаты, обрабатываются различными способами, часто требующими промежуточного нагрева и измельчения. Вероятно, это связано с обычным образованием реакционных примесей и неравновесных промежуточных продуктов во время последовательностей реакций 45,46 .
Разработанный нами конвейер экстракции позволяет автоматически обрабатывать научные абзацы и определять оттуда ключевую информацию о твердотельном синтезе. Однако конвейер по-прежнему страдает от некоторых проблем с интеллектуальным анализом текста.Во-первых, большинство ошибок в конвейере возникает из-за неправильной токенизации абзацев и предложений. Хотя токенизатор ChemDataExtractor 22 значительно превосходит другие пакеты НЛП в текстах, связанных с химией, он по-прежнему не может правильно обрабатывать формулы больших смесей и твердых растворов, а также химические названия, состоящие из нескольких слов. Мы связываем эту проблему с тем, что ChemDataExtractor был обучен на органических химических объектах, и его использование для распознавания неорганических токенов требует модификации алгоритмов.Во-вторых, не существует установленного шаблона или шаблона для описания процедуры синтеза, что приводит к значительной неоднозначности и трудностям, когда метод синтеза интерпретируется даже экспертом 47 . Это требует разработки более совершенных моделей извлечения текста, учитывающих особенности научного потока текста. В-третьих, хотя набор данных был сгенерирован из параграфов, описывающих твердотельный синтез (как определено алгоритмом классификации), он также содержит реакции для синтеза прекурсоров на основе раствора, такие как золь-гель (рис.3). Тем не менее, эти записи в основном выпадали позже, потому что в большинстве из них используются органические прекурсоры со сложными радикалами, и балансирование таких химических уравнений становится сложным. Наконец, мы обнаружили, что большинство материалов, изученных и синтезированных после 2000-х годов, часто являются модифицированными (например, легированными, замещенными элементами) соединениями, смесями, стеклами или твердыми растворами. Разбить такие материалы на состав и построить сбалансированные уравнения реакций непросто. Для некоторых соединений с легированными и замещенными элементами мы включили информацию о модифицирующих элементах и соответствующих прекурсорах в цепочку реакций (см.