Слова «имя» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «имя» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «имя» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «имя».
Содержимое:
- 1 Слоги в слове «имя» деление на слоги
- 2 Как перенести слово «имя»
- 3 Морфологический разбор слова «имя»
- 4 Разбор слова «имя» по составу
- 5 Сходные по морфемному строению слова «имя»
- 6 Синонимы слова «имя»
- 7 Антонимы слова «имя»
- 8 Ударение в слове «имя»
- 9 Фонетическая транскрипция слова «имя»
- 10 Фонетический разбор слова «имя» на буквы и звуки (Звуко-буквенный)
- 11 Предложения со словом «имя»
- 12 Сочетаемость слова «имя»
- 13 Значение слова «имя»
- 14 Склонение слова «имя» по подежам
- 15 Как правильно пишется слово «имя»
- 16 Ассоциации к слову «имя»
Слоги в слове «имя» деление на слоги
Количество слогов: 2
По слогам: и-мя
Как перенести слово «имя»
имя — слова из 3 букв и меньше не переносятся
Морфологический разбор слова «имя»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: средний;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
имя
Разбор слова «имя» по составу
| им | корень |
| я | окончание |
имя
Сходные по морфемному строению слова «имя»
Сходные по морфемному строению слова
Синонимы слова «имя»
1. название
название
2. наименование
3. кличка
4. погоняло
5. псевдоним
6. прозвище
7. идентификация
8. позывной
9. звание
10. известность
11. корифей
12. величина
13. звезда
14. знаменитость
15. светило
16. звезда первой величины
17. признание
18. популярность
Антонимы слова «имя»
1. неизвестность
Ударение в слове «имя»
и́мя — ударение падает на 1-й слог
Фонетическая транскрипция слова «имя»
[`им’а]
Фонетический разбор слова «имя» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| и | [`и] | гласный, ударный | и |
| м | [м’] | согласный, звонкий непарный (сонорный), мягкий | м |
| я | [а] | гласный, безударный | я |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 3 буквы и 3 звука.
Буквы: 2 гласных буквы, 1 согласная буква.
Звуки: 2 гласных звука, 1 согласный звук.
Предложения со словом «имя»
Меня впустили, когда я назвал имя отца-настоятеля, и оставили ждать во дворе.
Источник: Джейн Ли, Проникающий в сны.
Никогда бы не подумала, что собственное имя так меня взбудоражит.
Источник: Ян-Филипп Зендкер, Искусство слышать стук сердца, 2006.
Зато это даёт возможность сберечь заработанное годами доброе имя старого бренда в случае неуспеха на рынке новых товаров.
Источник: М. С. Клочкова, Мерчандайзинг.
Сочетаемость слова «имя»
1. новое имя
2. настоящее имя
3. собственное имя
4. имя человека
5. имя бога
имя бога
6. имя отца
7. список имён
8. множество имён
9. десятки имён
10. имя означает
11. имя прозвучало
12. имя показалось
13. назвать своё имя
14. узнать имя
15. услышать своё имя
16. (полная таблица сочетаемости)
Значение слова «имя»
И́МЯ , и́мени, мн. имена́, имён, имена́м, ср. 1. Личное название человека, даваемое ему при рождении. (Малый академический словарь, МАС)
Склонение слова «имя» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | имя | имена |
| РодительныйРод. | чего? | имени, им | имён |
| ДательныйДат. | чему? | имени | именам |
| ВинительныйВин. | что? | имя | имена |
ТворительныйТв. | чем? | именем | именами |
| ПредложныйПред. | о чём? | имени | именах |
Как правильно пишется слово «имя»
Правописание слова «имя»
Орфография слова «имя»
Правильно слово пишется: и́мя
Нумерация букв в слове
Номера букв в слове «имя» в прямом и обратном порядке:
- 3
и
1 - 2
м
2 - 1
я
3
Ассоциации к слову «имя»
Отчество
Фрунзе
Упоминание
Шевченко
Чудотворец
Киров
Фамилия
Псевдоним
Ворошилов
Доверенность
Крещение
Святитель
Колхоз
Ломоносов
Инициал
Настоящее
Прозвище
Мгу
Иегова
Лауреат
Комсомол
Кличка
Премия
Присвоение
Богородица
Титр
Табличка
Паспорт
Эпитет
Уста
Произношение
Консерватория
Калинин
Синоним
Афиша
Прошение
Апостолов
Топоним
Гагарин
Совхоз
Слог
Вымышленный
Названый
Родовой
Кодовый
Академический
Сценический
Дзержинский
Звучный
Мемориальный
Чайковский
Господний
Пресвятой
Благословенный
Регистрационный
Христов
Производный
Педагогический
Вписать
Произноситься
Назваться
Выгравировать
Выкрикивать
Назвать
Фигурировать
Окликать
Освятить
Упоминаться
Присвоить
Запятнать
Значиться
Произносить
Упоминать
Прославить
Зваться
Носить
Откликаться
Вычеркнуть
Позорить
Начертать
Трепать
Нацарапать
Подписаться
Поминать
Называть
Опозорить
Ассоциироваться
Славить
Окрестить
Переводиться
Упомянуть
Прикрываться
Крестить
Величать
Писаться
Зарегистрировать
Перечислить
Выписать
Перечислять
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова « имя», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.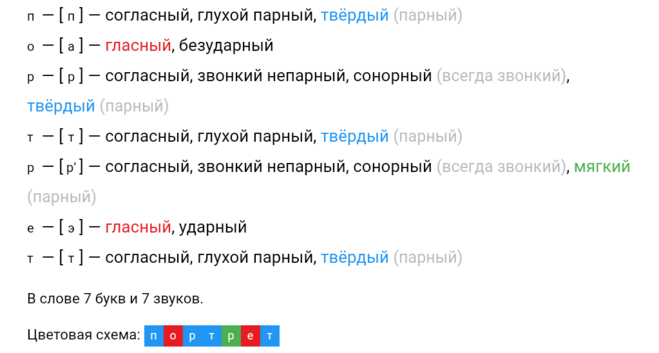
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ИМЯ, имени, мн. имена, имён, именам, ср.
1. Личное название человека, даваемое при рождении, часто вообще личное название живого существа. Собственное и. Его и. Иван. И. и отчество. Звать по имени кого-н. Имена античных богов. Как Ваше и.? Дать и. коню, кошке, щенку. Обезьянка по имени Яшка.
2. Фамилия, семейное название. На стеле имена погибших героев.
3. Личная известность; репутация. Учёный с мировым именем. Приобрести и. Порочить чьён. честное и. Доброе и.
4. Известный, знаменитый человек. Крупные имена.
5. Название предмета, явления. Растение алоэ известно под именем «столетник». Называть вещи своими именами (перен. : говорить прямо, не скрывая истины).
: говорить прямо, не скрывая истины).
6. В грамматике: разряд склоняемых слов. И. существительное. И. прилагательное. И. числительное.
7. имени кого-чего, в знач. предлога с род. п. В память, в честь кого-чего-н. Театр имени Вахтангова. Музей имени Пушкина. Канал имени Москвы.
8. именем кого-чего, в знач. предлога с род. п. На основании власти, полномочий, предоставленных кому-н. (офиц.). Действовать именем республики. Требовать именем закона.
• Во имя кого-чего, предлог с род. п. (высок.) ради кого-чего-н., в интересах кого-чего-н. Сражаться во имя славы Родины. Действовать во имя дружбы.
На имя кого-чего, в знач. предлога с род. п. предназначая, адресуя кому-н. Заявление на имя директора. Ордер на имя главы семьи.
От имени кого-чего, в знач. предлога с род. п. по поручению, ссылаясь, опираясь на кого-что-н. Говорить от имени общественности.
предлога с род. п. по поручению, ссылаясь, опираясь на кого-что-н. Говорить от имени общественности.
| прил. именной, ая, ое (к 6 знач.). Именное склонение.
Фонетический (звуко-буквенный) разбор
и́мя
имя — слово из 2 слогов: и-мя. Ударение падает на 1-й слог.
Транскрипция слова: [им’а]
и — [и] — гласный, ударный
м — [м’] — согласный, звонкий непарный, сонорный (всегда звонкий), мягкий (парный)
я — [а] — гласный, безударный
В слове 3 буквы и 3 звука.
Цветовая схема: имя
Разбор слова «имя» по составу
имя
Части слова «имя»: им/я
Состав слова:
им — корень,
я — окончание,
им — основа слова.
Основы японских имен: как они выбираются, пишутся и читаются
Японские имена для людей занимают необычную нишу, поскольку вид написанного имени не означает, что вы будете знать, как его произносить. Кроме того, то, что вы слышите имя, не означает, что вы будете знать, как его написать, даже если вы являетесь носителем японского языка!
Как же так? Давайте начнем с краткого обзора письменного японского языка.
Японский язык письменности
В японском языке для письма используются три алфавита: идеограммы и два слоговых алфавита (где каждый символ представляет собой слог).
Идеографический шрифт: японский кандзи
Кандзи — это заимствованные китайские иероглифы, которые обозначают идею, но произношение которых меняется в зависимости от контекста слова. Вот (неполная) выборка различных произношений одного иероглифа кандзи.
Символ 生 имеет основное значение «жизнь». Он имеет особенно плодовитый набор произношений.
Слово кандзи | Произношение | Пояснение |
|---|---|---|
| «сенсей» | В сочетании с кандзи 先 (что означает: раньше, впереди) 生 произносится как «сэй».先生 = «учитель» (то есть тот, кто родился раньше вас) | |
| 生 | «имя» | Самостоятельное слово, означающее «сырой», как и «сырое мясо», но при добавлении префикса к слову «трансляция» (中継 chuukei) 生中継 (nama chuukei) означает «прямая трансляция». |
| 生かす | «и(касу)» | 生 произносится как «i» для глагола, означающего «использовать» (т. е. сделать что-то «живым» с помощью этого), и сочетается с символами хираганы (слоговыми буквами) «касу». |
| 生まれる | «у(мареру)» | 生 произносится как «у» для глагола, означающего «родиться», и сочетается с символами хираганы (слоговыми) «мареру». |
Фонетические шрифты: хирагана и катакана
Два слоговых алфавита, хирагана и катакана, в японском языке представляют одни и те же 46 слогов, без привязки к какому-либо символу. Как правило, хирагана, более пышная на вид, используется для японских слов, а катакана — для заимствованных слов из других языков.
Хирагана | Катакана | Произношение |
|---|---|---|
| あ | ア | и |
| き | キ | ки |
| こ | コ | ко |
См. полную таблицу символов хираганы и катаканы здесь.
полную таблицу символов хираганы и катаканы здесь.
Неоднозначное прочтение и написание японских имен
В результате, поскольку кандзи используется для большинства имен (конечно, для всех фамилий), существует большая двусмысленность в том, как произносить имена — иначе говоря, прочтения. На самом деле, японские визитные карточки обычно включают чтение имени человека, чтобы не смущать получателя карты, и японцы привыкли включать произношение своего имени в хирагане или катакане для любой формы, которую они заполняют.
В приведенном ниже примере имя «Адзума Таро» читается хираганой (маленькая хирагана над кандзи).
В приведенной ниже таблице приведена лишь небольшая часть этого явления. В общем, в японском языке много омофонов, где одно прочтение может соответствовать множеству комбинаций кандзи, как показано ниже для мужских имен «Такеши», «Кодзи» и «Хироши».
Примеры имен кандзи с несколькими вариантами чтения
(источник)
Имена кандзи | Возможные варианты чтения (на хирагане и английском) |
|---|---|
| 光希 | こうき Коки или みつき Мицуки |
| 幸子 | ゆきこ Юкико или さちこ Сатико |
| 清一 | きよかず Kiyokazu или せいいち Seiichi |
| 裕美 | ひろみ Хироми или ゆみ Юми |
| Номер телефона | ひろし Хироси или ゆうじ Юдзи |
| 広志 広治 浩志 宏司 | ひろし Хироши или こうじ Кодзи |
| 高志 孝司 | たかしТакэси или こうじ Кодзи |
| 健司 健志 健史 | たけし Такеши или けんじ Кенджи |
Некоторые родители могут использовать только хирагану (ようこ «Ёко») или смесь кандзи и катаканы (ヨウ 子 «Ёко») или смесь кандзи и хирагана よ199 «Йоко»).
Кроме того, есть варианты произношения кандзи, которые используются ТОЛЬКО для имён.
東 означает «восток» и обычно произносится как «хигаси» или «тоу» (как в Токио 東京), но как фамилия произносится как «Адзума».
Японские прозвища
В отличие от английского, в котором много «стандартных» прозвищ (таких как Liz, Beth или Eliza для Элизабет, или добавление звука «ie» в конце (Charles > Charlie, Katherine > Kate > Katie) , Японские прозвища гораздо более случайны.Они часто представляют собой сокращение звуков в имени плюс 君(-кун) или ちゃん(-чан) (уменьшительные формы -сан, термин уважения, который используется при обращении к другому человеку) , Или для имен из двух слов может быть объединение начального звука каждого слова, например, «Брэд Питт» с «БураПи».0003
Имя | ||
|---|---|---|
| 正明 Масааки | まあくん Маакун | Ма-кун |
| 哲子 Тецуко | てっちゃん Тетчан | |
| 勝也 Кацуя | かっちゃん Катчан | |
| 安成 Ясунари | やあちゃん Я-чан | |
| 木村 拓哉 Кимура Такуя (японская знаменитость) | キムタク Кимутаку | |
| ブラッド・ピット Бураддо Питто (американский актер Брэд Питт) | ブラピ Бурапи |
Источник: https://en. wikipedia.org/wiki/Japanese_name#Nicknames
wikipedia.org/wiki/Japanese_name#Nicknames
Японские подходы к именованию
Когда родители называют своего ребенка, они могут начать с кандзи из-за его приятного значения или со звука имя, например «Йоко» или «Хироши». Неудивительно, что в списках «самых популярных имен года» есть и то, и другое. В настоящее время женские имена, оканчивающиеся на -ko 子 (что означает «ребенок»), менее популярны, чем в прошлом, как вы можете видеть ниже.
Ниже приведены пять самых популярных женских и мужских имен за 2019 и 1970 годы. Значение кандзи: солнце+мальва
2. 凛(Rin) Значение кандзи: холод
3. 紬(Tsumugi)Значение кандзи: pongee (узловатая шелковая ткань)
4. Привязано к 4-му: 莉子(Riko)Значение кандзи: жасмин+ ребенок
и 芽依(Mei)Значение кандзи: почка+зависит/зависит от
1. めい Мэй
2. あかり Акари
3. ひまり Химари
4. ゆい Юи
5.
 みお Мио
みお Мио1970 Топ -пять имен девушек
(Источник)
| от персонажа Канджи, с римлянизированным чтением 1. 直 美 (Наоми) Канджи. : мудрость+ребенок 3. 陽 子 (Ёко) Значение кандзи: солнце+ребенок 4. 裕 子 (Юко) Значение кандзи: изобилие/богатый+ребенок 5. 由美子 (Юмико) Значение кандзи: причина+красота+ребенок |
Пять лучших имен мальчиков 2019 года
(источник)
| По иероглифу кандзи, романизированное чтение 1. 蓮 (Рен) Кандзи означает: цветок или семя лотоса сбор, пирс 3. 陽翔(Haruto)Значение кандзи: солнце/залитый солнцем+полет/детальный 4. 律(Ritsu)Значение кандзи: прямой, прямой 5. 樹(Itsuki)Значение кандзи: дерево | Читая хираганой и романизированным языком はると (Харуто) そうた (Сота) みなと (Минато) ゆうと (Юто) りく (Рику) |
1970 Пять лучших имен мальчиков
(источник)
1. 健一 (ken’ichi) Значение: Здоровое, сильное 健一 (ken’ichi) Значение: Здоровое, сильное 2. 誠 (Маво) : философия, ясность 4. 剛 (Цуёси или Такеши) Значение: сильный, мужественный 5. 博 (Хироши) Значение: ученый |
Современные имена
Традиционно японские имена девочек часто оканчиваются на «-ko» (子), «-ka», «n-a» или «-e», а имена мальчиков заканчиваются на «-rou», « -о» или «-хико» (за некоторыми исключениями). Однако, как и в других культурах, имена и тенденции именования проходят циклы популярности. В 2000-х годах многие родители выбирали чтение, а затем творчески подбирали к нему символы кандзи. При этом они иногда полностью игнорировали стандартные прочтения, связанные с этими персонажами. Например, 一二三 (иероглифы кандзи для чисел «1, 2, 3» читаются как «ити, ни, сан») можно сопоставить с чтением «до ре ми». (Да, как в музыкальных нотах.) Имена такого типа называются キラキラネーム («имя кира-кира», где «кира-кира» означает «блестящий/блестящий») или, более уничижительно, DQNネーム (произносится как «имя дон кён» ).
Чтобы обуздать заблудших родителей, которые могут назвать своего ребенка «демоном» или любым другим именем, которое может подвергнуть их насмешкам, Министерство юстиции Японии ведет список допустимых кандзи для использования в японских именах.
Последние мысли
Учитывая двусмысленность японского произношения имен, им может быть чрезвычайно сложно сопоставить оригинальное японское имя и его представление латинскими буквами. Мы рассмотрим эту тему в следующем блоге.
Технический документ — Rhasspy
На высоком уровне Rhasspy преобразует аудиоданные (голосовые команды) в события JSON.
Голосовые команды указываются заранее в компактном текстовом формате:
[LightState]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
Этот формат поддерживает:
-
[дополнительные слова] -
(альтернативный | выбор) -
имя = тело— правила -
<имя правила>— ссылки на правила -
(значение) {имя}— теги -
ввод: вывод— замены -
$movies— списки слотов -
1.— числовые серии .100
.100 -
ТЕКСТ!поплавок— преобразователи
 .100
.100 Во время обучения Rhasspy генерирует артефакты, которые могут распознавать и декодировать указанные голосовые команды. Если эти команды изменятся, Rhasspy необходимо переобучить.
Основные компоненты
Основные функции Rhasspy можно разделить на компоненты распознавания речи и намерений.
Когда голосовые команды распознаются речевым компонентом, транскрипция передается распознавателю намерений для обработки. Конечным результатом является структурированное событие JSON с:
- Имя намерения
- Распознанные слоты/сущности
- Необязательные метаданные о процессе распознавания речи
- Ввод текста, времени, токенов и т. д.
Например:
{
"текст": "включи свет",
"намерение": {
"имя": "LightState"
},
"слоты": {
"состояние": "включено"
}
}
Преобразование речи в текст
Автономная транскрипция голосовых команд в Rhasspy осуществляется одной из трех систем с открытым исходным кодом:
- Pocketsphinx
- CMU (2000)
- Калди
- Джонс Хопкинс (2009)
- Глубокая речь
- Мозилла (v0. 6, 2019)
- Мозилла (v0.
 6, 2019)
6, 2019)Для Pocketsphinx и Kaldi требуется:
- Акустическая модель
- Сопоставление звуковых характеристик с фонемами
- Словарь произношения
- Преобразование фонем в слова
- Модель языка
- Описывает, как часто слова следуют за другими словами
DeepSpeech объединяет акустическую модель и словарь произношения в единую нейронную сеть. Однако он по-прежнему использует языковую модель.
Акустическая модель
Акустическая модель сопоставляет акустические/речевые характеристики с вероятными фонемами данного языка.
Обычно в качестве акустических характеристик используются коэффициенты кепстра частот Mel (сокращенно MFCC). Они математически выделяют полезные аспекты человеческой речи.
Фонемы зависят от языка (и даже от локали). Это 90 514 неделимых единиц 90 515 произношения слов. Определение фонем языка требует лингвистического анализа, и могут возникнуть споры по поводу окончательного набора. Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита.
Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита.
Акустическая модель представляет собой статистическое сопоставление между звуковыми характеристиками (MFCC) и одной или несколькими фонемами. Это сопоставление изучается из большой коллекции речевых примеров вместе с их соответствующими транскрипциями. Предварительно созданный словарь произношения необходим для сопоставления транскрипций с фонемами, прежде чем можно будет обучить модель. Сбор, расшифровка и проверка этих больших наборов речевых данных является ограничивающим фактором в распознавании речи с открытым исходным кодом.
Словарь произношений
Словарь, отображающий последовательности фонем в слова, необходим как для обучения акустической модели, так и для распознавания речи. Для каждого слова возможно более одного сопоставления (произношения).
Для практических целей давайте будем считать слово просто «вещью между пробелами» в тексте. Независимо от того, как именно вы определяете, что такое «слово», важнее всего согласованность: кто-то должен решить, являются ли составные слова (например, «предварительно построенные»), сокращения и т. д. отдельными («предварительно созданными») или составными словами ( «предварительно» и «построено»).
Независимо от того, как именно вы определяете, что такое «слово», важнее всего согласованность: кто-то должен решить, являются ли составные слова (например, «предварительно построенные»), сокращения и т. д. отдельными («предварительно созданными») или составными словами ( «предварительно» и «построено»).
Ниже приведена таблица примеров фонем для американского английского языка из Словаря произношения CMU.
| Фонема | Слово | Произношение |
|---|---|---|
| АА | нечетный | АА Д |
| АЕ | в | АЕ Т |
| АХ | хижина | ЧЧ АХ Т |
| АО | должен | АО Т |
| AW | корова | К AW |
| АЮ | скрыть | ЧЧ АУ Д |
| Б | будет | Б ИЮ |
| Ч | сыр | Ч Й З |
| Д | ди | Д ИЙ |
| ДХ | тэ | ДХ ИЮ |
| ЕН | Эд | ЭХ Д |
| ЕР | больно | HHER T |
| ЭЙ | съел | ЭЙ Т |
| Ф | плата | Ф ИГ |
| Г | зеленый | Г Р И Й N |
| ЧЧ | он | ЧН ИГ |
| ИХ | это | ИХ Т |
| ИГ | есть | ИЮ Т |
| ДЖХ | гы | JH IY |
| К | ключ | К ИЮ |
| Л | Ли | Л ИГ |
| М | я | М ИГ |
| Н | колено | Н ИЮ |
| НГ | пинг | ПИХ НГ |
| ВВ | овес | ВЛ Т |
| ОУ | игрушка | ИГРУШКА |
| Р | моча | П Й |
| Р | читать | Р ИЙ Д |
| С | море | S IY |
| Ш | она | Ш ИЮ |
| Т | чай | Т ИЙ |
| ТХ | тета | ТЭЙ Т АХ |
| UH | капот | ВН ВГ D |
| ВВ | два | Т УВ |
| В | и | В ИГ |
| Ш | мы | Вт IY |
| Д | выход | Г ИГ Л Д |
| З | зи | З IY |
| Ж | конфискация | С ИЙ Ж ЭР |
Более поздние версии этого словаря включают ударение, указывающее, на какие части слова делается ударение во время произношения.
Во время обучения Rhasspy копирует произношения для каждого слова в ваших шаблонах голосовых команд из большого предварительно созданного словаря произношений. Произношение слов, которых нет в этом словаре, угадывается с использованием предварительно обученной графемы в модель фонемы.
Графема в фонему
Модель графемы в фонему (G2P) можно использовать для угадывания фонетического произношения слов. Это статистическая модель, которая сопоставляет последовательности символов (графем) с последовательностями фонем и обычно обучается на основе большого предварительно созданного словаря произношения. Для этой цели Rhasspy использует инструмент под названием Phonetisaurus.
Модель языка
Модель языка описывает, как часто одни слова следуют за другими. Обычно можно увидеть модели, которые состоят из одного-трех слов подряд.
Языковые модели создаются из большого массива текстов, таких как книги, новостные сайты, Википедия и т. д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности должны быть предсказаны с помощью эвристики.
Ниже приведен вымышленный пример вероятностей одиночных/парных/тройных слов для корпуса, который содержит только слова «дерн», «пил», «это», «это» и «нечетный».
0,2 дерн 0,2 распиленный 0,2 что 0,2 это 0,2 нечетный 0,25 странно 0.25 что распилил 0.25 это дерьмо 0,25 странно, что 0.5 как то странно 0,5 черт возьми
При распознавании речи поступающие фонемы могут совпадать более чем с одним словом из словаря произношения. Языковая модель помогает сузить круг возможных вариантов, сообщая распознавателю речи, что некоторые сочетания слов очень маловероятны и могут быть проигнорированы.
Фрагменты предложений
Языковая модель не содержит вероятностей для целых предложений, только предложение осколков . Для получения полного предложения от распознавателя речи требуется несколько приемов:
- Добавление виртуального начала/конца предложения «слов» (
-
какое время ..» -
этоэто конец предложения «…это?»
-
- Использовать скользящие временные окна
- Фрагменты сшиваются вместе с помощью перекрывающихся окон
- «сколько времени», «время», «это» для предложения «который час»
- Прерывание звука при длительных паузах или постоянное использование одного предложения
- Вы всегда можете предположить, что первое «слово» — это
- Но куда поставить
- Вы всегда можете предположить, что первое «слово» — это
 ..»
..»При использовании этих приемов распознанные «предложения» могут оставаться бессмысленными и иметь мало общего с предыдущими предложениями. Например:
этот дерн тот тот дерн, который пилил...
Современные нейронные сети-трансформеры могут намного лучше обрабатывать долгосрочные зависимости внутри и между предложениями, но:
- Им требуется огромное количество обучающих данных
- Они могут быть медленными/ресурсоемкими для (повторного) обучения и выполнения без специального оборудования
Для предполагаемого использования Rhasspy (заранее заданные короткие голосовые команды) описанные выше приемы обычно достаточно хороши. Хотя облачные сервисы можно использовать с Rhasspy, существуют компромиссы в отношении конфиденциальности и отказоустойчивости (потеря Интернета или облачной учетной записи).
Хотя облачные сервисы можно использовать с Rhasspy, существуют компромиссы в отношении конфиденциальности и отказоустойчивости (потеря Интернета или облачной учетной записи).
Обучение языковой модели
Во время обучения Rhasspy создает пользовательскую языковую модель на основе ваших шаблонов голосовых команд (обычно в формате ARPA). Благодаря библиотеке opengrm, Rhasspy может брать промежуточный граф предложений, созданный на начальных этапах обучения, и напрямую генерировать языковую модель! Это позволяет Rhasspy обучаться за считанные секунды даже миллионам возможных голосовых команд.
Смешивание языковых моделей
Пользовательскую языковую модель Rhasspy можно дополнительно смешивать с гораздо большей заранее созданной языковой моделью. В зависимости от того, какой вес придается той или иной модели, это повысит вероятность ваших голосовых команд на фоне общих предложений на языке профиля.
При правильном смешивании Rhasspy способен к (почти) неограниченному распознаванию речи с предпочтением голосовых команд пользователя. К сожалению, это обычно приводит к снижению производительности распознавания речи и множеству других сбоев распознавания намерений (которые обучаются только на голосовых командах пользователя).
К сожалению, это обычно приводит к снижению производительности распознавания речи и множеству других сбоев распознавания намерений (которые обучаются только на голосовых командах пользователя).
Text to Intent
Система(ы) распознавания речи в Rhasspy создает текстовые транскрипции, которые затем передаются системе распознавания намерений. Когда и речь, и система намерений обучаются вместе с одним и тем же файлом шаблона, все допустимые команды (с небольшими вариациями) должны быть правильно преобразованы в события JSON.
Rhasspy преобразует набор возможных голосовых команд в граф, который действует как преобразователь конечных состояний (FST). Когда на вход подается действительное предложение, этот преобразователь выводит (преобразованное) предложение вместе с «мета»-словами, которые определяют намерение предложения и именованные объекты.
В качестве примера рассмотрим приведенный ниже шаблон предложения для намерения LightState :
[LightState]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
При обучении с этим шаблоном Rhasspy будет генерировать такой график:
Каждое состояние помечено номером, а ребра (стрелки) тоже имеют метки. Метки ребер имеют специальный формат, который представляет входные данные, необходимые для прохождения ребра, и соответствующие выходные данные. Двоеточие («:») разделяет входные/выходные слова по краю и опускается, если входные и выходные данные совпадают. Выходные «слова», начинающиеся с двух знаков подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Метки ребер имеют специальный формат, который представляет входные данные, необходимые для прохождения ребра, и соответствующие выходные данные. Двоеточие («:») разделяет входные/выходные слова по краю и опускается, если входные и выходные данные совпадают. Выходные «слова», начинающиеся с двух знаков подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Приведенный выше FST примет все возможные предложения в файле шаблона:
- включи свет
- включить свет
- выключить свет
- выключить свет
Это вывод, когда FST принимает каждое предложение:
| Ввод | Выход |
|---|---|
включи свет | __label__LightState включить __begin__state on __end__state свет |
включить свет | __label__LightState включите __begin__state on __end__state свет |
выключить свет | __label__LightState включить __begin__state выключить __end__state свет |
выключить свет | __label__LightState включить __begin__state выключить __end__state свет |
Нотация __label__ взята из fasttext, высокопроизводительной системы классификации предложений. Единая мета
Единая мета __label__ слово создается для каждого предложения, помечая его именем намерения свойства.
Метаслова __begin__ и __end__ используются Rhasspy для создания события JSON для каждого предложения. Они отмечают начало и конец помеченного блока текста в исходном файле шаблона — например, (on | off){state} . Эти начальные/конечные символы можно легко преобразовать в общую схему аннотирования корпусов текстов (IOB) для обучения распознавателя именованных сущностей (NER). Например, flair может читать такие корпуса и обучать NER с помощью PyTorch.
Библиотека Rhasspy NLU в настоящее время использует следующий набор метаслов:
-
__label__INTENT- Предложение принадлежит намерению с именем
INTENT
- Предложение принадлежит намерению с именем
-
__begin__TAG- Начало тега с именем
TAG
- Начало тега с именем
-
__end__TAG- Конец названного тега
TAG
- Конец названного тега
-
__convert__CONV- Начало преобразователя с именем
КОНВ
- Начало преобразователя с именем
-
__converted__CONV- Конец преобразователя с именем
CONV
- Конец преобразователя с именем
-
__source__SLOT- Имя списка слотов, откуда был взят текст
-
__unpack__PAYLOAD- Декодирует
PAYLOADкак строку в кодировке base64, а затем интерпретирует как метку края
- Декодирует
fsticuffs
Распознаватель намерений Rhasspy на основе FST называется fsticuffs . Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Распознавание намерений выполняется путем простого запуска транскрипции через граф намерений и анализа выходных слов (и метаслов). Транскрипция «включи свет» разбивается (по пробелам) на слова поворот на свет .
Следуя пути через приведенный выше пример графа намерений со словами в качестве входных символов, это выведет:
__label__lightstate Turn __BEGIN__STATE на __end__State . Имя намерения и именованные объекты восстанавливаются с использованием метаслов __label__ , __begin__ и __end__ . Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой:
{
"текст": "включи свет",
"намерение": {
"имя": "LightState"
},
"слоты": {
"состояние": "включено"
}
}
Fuzzy FSTs
Что, если fsticuffs должны были получить транскрипцию «не могли бы вы включить свет»? Это недопустимый пример голосовой команды, но представляется разумным принять ее с помощью ввода текста (например, в чате).