Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Окончание. Та часть слова, которая изменяется при склонении или спряжении.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Затем нужно выделить окончание. Чтобы его найти, слово нужно просклонять по падежам, если часть речи это позволяет. Например, наречие изменить никак нельзя, поэтому у него не будет окончания.
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться. Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: рапоз сейчас хрупкость 1 секунда назад б о м ь а л 2 секунды назад уловитель 2 секунды назад нбдагол 2 секунды назад в е р з и л а 4 секунды назад п о и ш н 5 секунд назад цдтнебо 6 секунд назад п е л и к а н 7 секунд назад ттеск 7 секунд назад рплтое 7 секунд назад ф е т и н с 8 секунд назад гостинар 8 секунд назад д р у ш л а г 9 секунд назад сократ 9 секунд назад
морфемный разбор — Суффиксы в слове «пловец»
Это продолжение первого ответа, поэтому кому интересно, начинайте читать с первого ответа, чтоб было понятно о чём речь.
Прошу прощения, у меня опять появился вопрос.
А почему же тогда в словах «плыву, плывет, плывущий» тоже есть суффикс «в»? Тут уже другая причина должна быть, вероятно. Продаю, продающий… там -j- .
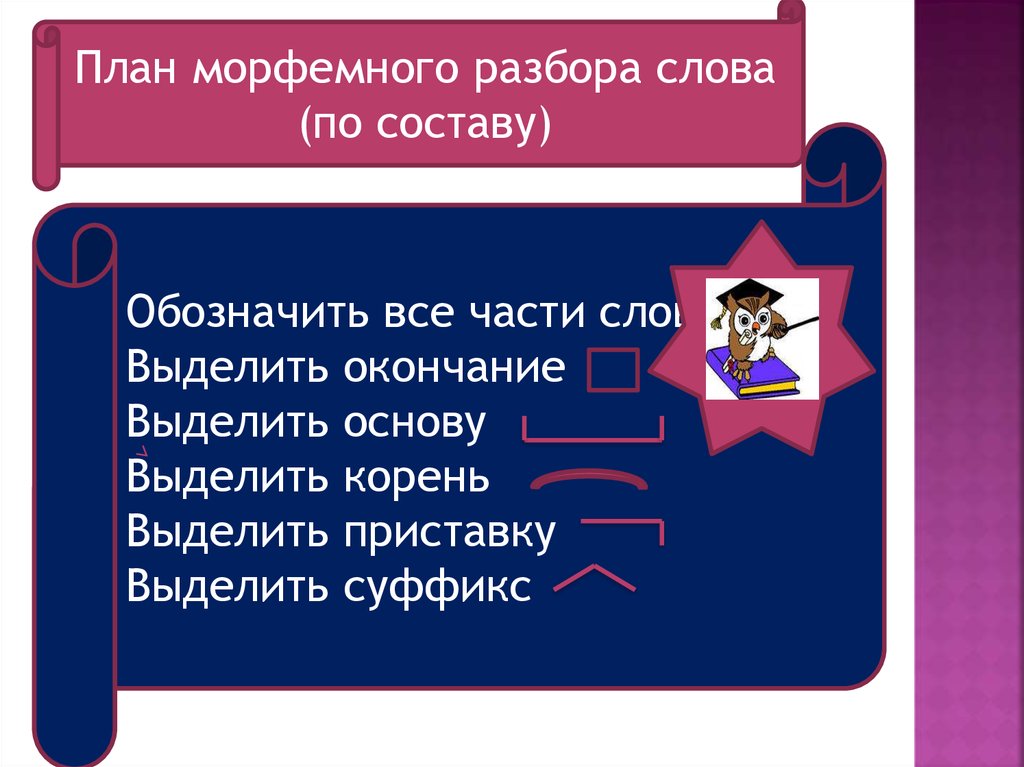 А почему же тогда в словах «плыву, плывет, плывущий» тоже есть суффикс «в»? Тут уже другая
причина должна быть, вероятно. Продаю, продающий… там -j- .
А почему же тогда в словах «плыву, плывет, плывущий» тоже есть суффикс «в»? Тут уже другая
причина должна быть, вероятно. Продаю, продающий… там -j- .С пловцом-то я разобралась, но теперь меня интересует другой вопрос.) На всякий случай галочку убрала, вдруг кто-то еще что-то знает по этому поводу. Может быть, в формах глагола «плыть» -в- взялось именно из -у- для устранения зияния гласных. Но тогда он должен, наверное, попадать в корень. Есть еще похожее слово «слывёт».
Я когда прочитал второй комментарий, уже почти дописал этот второй ответ. Но тут есть, то что подходит и под второй комментарий кроме «зияния гласных».
По поводу: плыть – плыву, плывет, плывущий.
Существует такая вещь, как альтернация или чередование:
альтернация
лингв. последовательная мена гласных или согласных в определённых позициях или в определённых морфемах; чередование [Викисловарь]
Может быть так, что в «плыть — плыву», имеет место чередование в корне, а не добавление суффикса -в-.
Это слово можно найти в книге Русская грамматика, том I. Фонетика. Фонология. Ударение. Интонация. Введение в морфемику. Словообразование. Морфология. Н. Ю. ШВЕДОВА (главный редактор).
Сокращённая цитата, многоточиями обозначены пропуски, слово «плыть» я выделил жирным, и рядом с ним есть «слыть», о котором вы спрашивали:
АЛЬТЕРНАЦИОННЫЕ РЯДЫ ФОНЕМ В ГЛАГОЛЬНЫХ ФОРМАХ
АЛЬТЕРНАЦИОННЫЕ РЯДЫ СОГЛАСНЫХ ФОНЕМ
§ 1596. В глагольном словоизменении представлены альтернационные ряды фонем, составляющие четыре группы.
…
Четвертая группа альтернац. рядов согласных фонем
§ 1601. В четвертую группу входят десять альтернац. рядов согласных фонем: |д — д’|, |т — т’|, |з — з’|, |с — с’|, |в — в’|, |к — к’|, |н — н’|, |л — л’|, |р — р’|, |м — м’|.
…
5. Альтернац. ряд |в — в’| — в гл. кл. V
…
2 (соотн. основ 4): жить, плыть, слыть:
жить, жи|в|ут — жи|в’|ёшь, жи|в’|ёт, жи|в’|ём, жи|в’|ёте; жи|в’|и(те), жи|в’|я.

Я так понимаю, что тут речь идёт о чередовании согласных в корне слова. Похожая ситуация с примером: жить, живут — живёшь, живёт, живём, живёте; живи(те), живя.
жить – живут
плыть – плывут
В статье Чередование согласных в корне слова на сайте obrazovaka.ru сказано:
В русском языке распространено такое явление, как чередование гласных в корне слова (вариантов чередования и корней с ним очень много), но встречаются и корни с чередующимися согласными. Есть несколько наиболее характерных разновидностей смены согласных и определенное объяснение данного явления в целом. Оно заслуживает отдельного внимания, поскольку такие чередования обязательно нужно запомнить.
…
На самом деле вариантов чередования согласных в корне очень много. Вот самые распространенные пары-тройки:г\ ж\ з – друг- дружить- друзья; т\ ч\ щ- свет- свеча- освещение; д\ ж\ жд- труд- тружусь- утруждать; ц\ч\к – лицо-личико-лик; с\ш\х – лес-леший, пахать-вспашка; щ\ск-ст – мощеный – мостить, лощеный – лоск; б\ бл- любовь- люблю; в\ вл- ловить- ловля; м\ мл- ломить- преломление; п\ пл- лупить- луплю; ф\ фл- графить- графлю.Объяснение этих процессов учеными-лингвистами достаточно простое: чередование образовалось в результате упрощения произношения, причем изначальный смысл звуков по мере протекания этого процесса утрачивался.

Таки образом, изменение согласной буквы с «т» на «в», можно объяснить упрощением произношения. У Шведовой четвёртая группа в которую входит «плыть» описана так:
ч е т в е р т а я г р у п п а включает ряды «твердая переднеязычная смычная шумная — мягкая переднеязычная смычная шумная», «твердая переднеязычная щелевая шумная — мягкая переднеязычная щелевая шумная», «твердая губная щелевая шумная — мягкая губная щелевая шумная», «твердая заднеязычная смычная — мягкая заднеязычная смычная», «твердая сонорная — мягкая сонорная» (например, |д — д’|, |з — з’|, |в — в’|, |к — к’|, |н — н’|).
Однако удобство произношения может быть не единственным объяснением.
Из той же статьи Чередование согласных в корне слова с сайта obrazovaka. ru:
ru:
В ученой среде бытует несколько ироническое выражение, которое звучит как “так сложилось исторически”. Оно объясняет многие непонятные явления в русском языке, в том числе и чередование согласных в корне. На самом деле такое объяснение имеет смысл – за каждой парой или тройкой чередующихся согласных в корне стоит длительный процесс языковых перемен.
Если посмотреть этимологиюслова «плыть» в этимологическом словаре Семёнова А. В.:
Плыть. Древнерусское — плоути (плыть). Слово «плыть» широко применяется в русском языке с середины XI в. Первоначально это слово значило путешествовать по воде (на лодке, плоту, корабле). Форма «плыву» появилась в XVII–XVIII вв. Интересно, что исследователи предполагают родство глагола «плыть» с латинским словом pluit (идет дождь, дождит) и с немецким flut (дождь, поток воды). Родственным является: Литовское — ploviau (полоскаю, стираю). Производные: плавать, плыву, плывун.
Можно предположить, что изначально было, что-то вроде «плоути», а потом из-за
упрощения произношения (для удобства) инфинитив превратился в «плыть»
(пропало «у»), а, например, первое лицо настоящего времени превратилось «плыву»
(пропало «т», а «у» преобразовалось в «в» — это близкие звуки).
Для сравнения в латинском языке буква «V» использовалась вместо «U»:
Непосредственно в классическом латинском языке, откуда буква V перешла в остальные языки, она использовалась также в качестве современной буквы U. В позднем латинском эти две буквы разделились для большего удобства, однако при написании слов заглавными буквами до сих пор изредка вместо U могут использовать V — например, в латинской Википедии.
[Википедия]
На латыни вода, например, «aqua» («акуа»), а говорят по-русски «аква». Таким образом, «у» вполне могла трактоваться к «в» и наоборот. А если это слово заимствованное то тем более.
Шанский в своем этимологическом словаре пишет, что «плыть» «общеслав. индоевроп. характера» и связывает его с «ср. др.-инд. plávatē». А в «plávatē», как видно, буква «v»:
Плыть. Общеслав. индоевроп. характера (ср. др.-инд. plávatē «плывет», лат. pluit «идет дождь», греч.
[Этимологический словарь Шанского Н. М.]
 pleō «плыву на судне» и т. д.).
pleō «плыву на судне» и т. д.).Как вывод: Я думаю, что в «плыть» — «плыву», имеет место не суффикс -в-, а чередование согласной в корне.
Дополнение
В книге Грамматика русского языка. Том 1. Фонетика и морфология. В.В. Виноградов, Е.С. Истрина, С. Г. Бархудров есть такой текст:
Суффикс -ец. Названия лиц с суффиксом -ец в современном русском языке распадаются на несколько словообразовательных разрядов:
- Непродуктивны образования с суффиксом -ец от глагольных основ. Слова этого типа обозначают лиц по роду занятий, по каким-нибудь действиям, определяющим их профессию и социальное положение, напр.: боре́ц (бороться), вы́ходец (выходить), гоне́ц (гнать, гоню), гребе́ц (грести, гребу), деле́ц (делать), жнец (жать, жну), косе́ц (косить), купец (купить), лове́ц (ловить), певе́ц (петь, певать), писе́ц (писать), продаве́ц (продавать), творе́ц (творить), торго́вец (торговать), чтец (честь, про-честь, про-чту), игрец (играть) (устар.
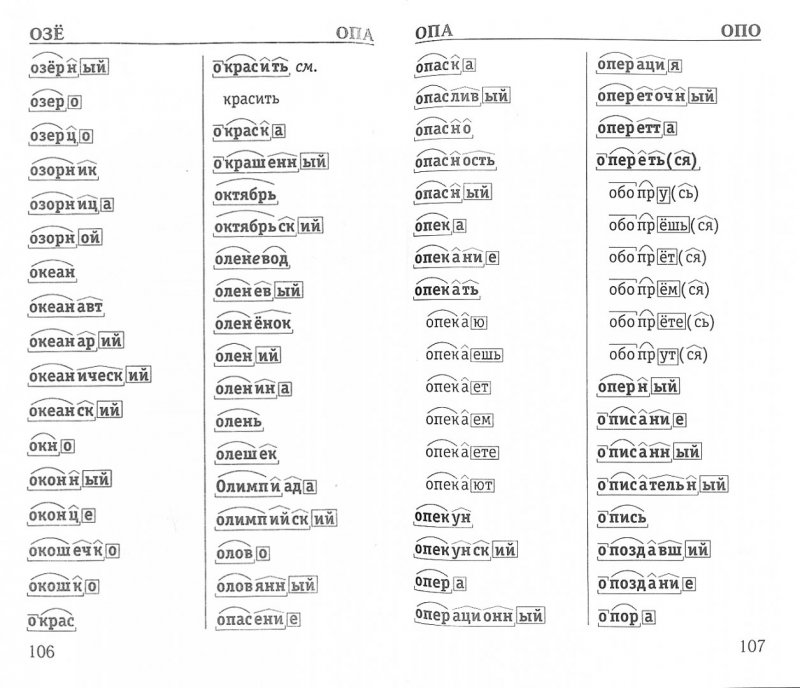 , ср. «швец, и
жнец, и в дуду игрец»).
, ср. «швец, и
жнец, и в дуду игрец»).Если посмотреть на слова в скобках, то всё-таки чаще они образованы от инфинитива и настоящего времени, а не от каких-то лиц и других времён.
Обратите внимание на слово: певе́ц (петь, певать).
Тут похожая ситуация: «петь», но «певец»; «плыть», «но пловец».
Если обратить внимание на второе слово в скобках — «певать», то можно заметить его сходство с «плавать».
ПЕВА́ТЬ, пева́л, -ла, -ло; несов.
Разг. Многокр. к петь.[Словарь русского языка Евгеньевой]
Хоть и написано, что разговорное, но при этом написано: многократно к «петь».
В повести «Детство», описывая своего отца, Лев Толстой пишет: «Он любил музыку, певал, аккомпанируя себе на фортепиано, романсы приятеля своего А…». Инициал А… обозначает Алябьева, который действительно был дружен с Николаем Ильичом Толстым. [mgpu.ru]
«Певал» — пел многократно.
Ведь тут тот же суффикс -ва-, о котором я писал в своём ответе, обозначающий многократность. И, скорей всего, именно он остался в «певец».
Корень слова: ped (корень) | Membean
Иногда английский язык импортирует слова из греческого и латинского языков, которые означают одно и то же. Это произошло в случае латинского корневого слова ped и греческого корневого слова pod , которые оба означают «ступня».
Давайте сначала посмотрим на латинский корень слова ped : «нога». А пед ал на велосипеде — это чтобы «нога» на нее напирала. Счетчик ped измеряет количество «футов», которые вы прошли. Ped эстрийцы ходят «на ногах».
Говоря о ходьбе, поскольку люди ходят на двух «ногах», мы известны как bi ped s. Некоторые животные классифицируются аналогичным образом из-за количества ног, которые у них есть. Крупный рогатый скот, собаки, лошади, овцы и им подобные — это quadru ped s, что этимологически означает «четыре ноги». Centi ped e также является насекомым со 100 «ногами»; некоторые сенти пед эс действительно обладают 100 «футами»! Милли пед e, с другой стороны, предположительно имеет тысячу «футов». На самом деле у milli ped es обычно не более 400 ножек, хотя у некоторых самых крупных может быть до 750.
Centi ped e также является насекомым со 100 «ногами»; некоторые сенти пед эс действительно обладают 100 «футами»! Милли пед e, с другой стороны, предположительно имеет тысячу «футов». На самом деле у milli ped es обычно не более 400 ножек, хотя у некоторых самых крупных может быть до 750.
Теперь давайте посмотрим на греческое корневое слово pod , которое также означает «нога». Tri pod , например, представляет собой подставку с тремя «ножками», которая устойчиво удерживает камеру. pod ium — это стойка для лекторов, имеющая одну «ногу», на которой она держится.
Вы когда-нибудь задумывались, кто находится на противоположной стороне мира от вас? Этот человек был бы на анти pod es того места, где вы находитесь, их «ноги» стоят точно напротив ваших.
pod iatrist — «ножной» врач. Представьте себе, что врачу стручка приходится заботиться о зауро стручка или ящерице «ноги», таких колоссальных динозаврах, как брахиозавр или апатозавр! И представьте, если бы у вас были только голова и ноги, и ничего между ними; тогда вы были бы cephalo pod или «головоногим», таким как осьминог или кальмар.
Не надо теперь брать экс ped в свой словарь в следующий раз, когда вы встретите слова с ped и pod в них; теперь можно просто расставить «ноги» и улыбнуться!
- педаль : часть велосипеда для ноги
- шагомер : прибор, который измеряет «ступни», по которым кто-то ходит
- пешеход : тот, кто ходит «на ногах»
- двуногое : животное, которое ходит на двух «ногах»
- четвероногое : животное, которое ходит на четырех «ногах»
- многоножка : насекомое, имеющее около 100 «ног»
- многоножка : насекомое, этимологически имеющее 1000 «ног»
- штатив : подставка с тремя «ножками»
- подиум : подставка с одной «ножкой»
- антиподы : место на Земле напротив собственных «ног»
- ортопед : стопный врач
- зауропод : ящероногий динозавр
- экспедиция : освобождение «ноги» для путешествия
Маркировка POS и синтаксический анализ с помощью R
Лаборатория языковых технологий и анализа данных
- ДОМ
- О ЛАДАЛ
- СОБЫТИЯ
- УЧЕБНЫЕ ПОСОБИЯ
- РЕСУРСЫ
- КОНТАКТ
В этом руководстве представлены теги частей речи и синтаксический анализ
с использованием R. Это руководство предназначено для начинающих и опытных пользователей R.
с целью демонстрации того, как аннотировать текстовые данные с помощью
теги части речи (pos) и как синтаксически анализировать текстовые данные
с использованием R. Цель состоит не в том, чтобы обеспечить полноценный анализ, а в том,
показать и проиллюстрировать выбранные полезные методы, связанные с
пост-тегов и синтаксического анализа. Еще один очень рекомендуемый учебник
по тегированию частей речи в R с помощью UDPipe доступно здесь и другое руководство
о пост-тегах и синтаксическом анализе Андреас Никлер и Грегор
Видеманн можно найти здесь
(см. Видеманн и Никлер, 2017 г.).
Это руководство предназначено для начинающих и опытных пользователей R.
с целью демонстрации того, как аннотировать текстовые данные с помощью
теги части речи (pos) и как синтаксически анализировать текстовые данные
с использованием R. Цель состоит не в том, чтобы обеспечить полноценный анализ, а в том,
показать и проиллюстрировать выбранные полезные методы, связанные с
пост-тегов и синтаксического анализа. Еще один очень рекомендуемый учебник
по тегированию частей речи в R с помощью UDPipe доступно здесь и другое руководство
о пост-тегах и синтаксическом анализе Андреас Никлер и Грегор
Видеманн можно найти здесь
(см. Видеманн и Никлер, 2017 г.).
Весь R Notebook для учебника можно загрузить здесь .
Если вы хотите визуализировать R Notebook на своем компьютере, т. е. связать
документ в html или pdf, вам нужно убедиться, что у вас есть R и
RStudio установлен и вам также необходимо скачать библиографию файл и сохраните его в той же папке, где вы храните
файл рмд.
Нажмите
эта ссылка, чтобы открыть интерактивную версию этого руководства на
MyBinder.org .
Этот интерактивный блокнот Jupyter позволяет
вам выполнять код самостоятельно, а также вы можете изменять и редактировать
блокнот, напр. вы можете изменить код и загрузить свои данные.
Многие анализы языковых данных требуют, чтобы мы различали разные части речи. Чтобы определить словесный класс определенного слова, мы используем процедуру, которая называется маркировкой части речи (обычно называется pos-, pos- или PoS-тегированием). пост-теги — это обычное дело процедура при работе с данными на естественном языке. Несмотря на то, что используется довольно часто это довольно сложный вопрос, требующий применение статистических методов, которые достаточно продвинуты. в далее мы рассмотрим различные варианты пост-тегов и синтаксический разбор.
Части речи или категории слов относятся к грамматической природе
или категория лексического элемента, например. в предложении Джейн нравится
девушка каждая лексическая единица может быть классифицирована в зависимости от того, является ли она
относится к группе определителей, глаголов, существительных и т.п.
относится к (вычислительному) процессу, в котором информация добавляется к
существующий текст. Этот процесс также называется аннотацией .
Аннотация может быть очень разной в зависимости от поставленной задачи. Большинство
общий тип аннотаций, когда речь идет о языковых данных,
тегирование части речи, при котором класс слова определяется для каждого слова
в тексте, а класс слов затем добавляется к слову в качестве тега.
Однако существует множество различных способов пометки или аннотирования текстов.
в предложении Джейн нравится
девушка каждая лексическая единица может быть классифицирована в зависимости от того, является ли она
относится к группе определителей, глаголов, существительных и т.п.
относится к (вычислительному) процессу, в котором информация добавляется к
существующий текст. Этот процесс также называется аннотацией .
Аннотация может быть очень разной в зависимости от поставленной задачи. Большинство
общий тип аннотаций, когда речь идет о языковых данных,
тегирование части речи, при котором класс слова определяется для каждого слова
в тексте, а класс слов затем добавляется к слову в качестве тега.
Однако существует множество различных способов пометки или аннотирования текстов.
Позиционная маркировка присваивает метки части речи строкам символов (эти
представляют в основном слова, конечно, но также включают в себя знаки препинания
и другие элементы). Это означает, что pos-теги — это один из специфических типов
аннотацию, т. е. добавление информации к данным (либо путем непосредственного добавления
информации к самим данным или путем хранения информации, например. список
который связан с данными). Важно отметить, что аннотация
охватывает различные типы информации, такие как паузы, перекрытия и т. д.
Позиционное тегирование — это лишь один из многих способов, с помощью которых данные корпуса могут быть обогащен . Анализ настроений, например, также аннотирует
тексты или слова в отношении их или их эмоциональной ценности или
полярность.
список
который связан с данными). Важно отметить, что аннотация
охватывает различные типы информации, такие как паузы, перекрытия и т. д.
Позиционное тегирование — это лишь один из многих способов, с помощью которых данные корпуса могут быть обогащен . Анализ настроений, например, также аннотирует
тексты или слова в отношении их или их эмоциональной ценности или
полярность.
Аннотация требуется во многих контекстах машинного обучения, потому что аннотированные тексты обычно используются в качестве обучающих наборов, на которых машина обучаются модели обучения или глубокого обучения, которые затем предсказывают, для неизвестные слова или тексты, какие значения им, скорее всего, будут присвоены если аннотация была сделана вручную. Также следует упомянуть, что многие онлайн-сервисы предлагают пост-теги (например, здесь или здесь.
При маркировке пример предложения может выглядеть как пример ниже.
- Джейн/ННП любит/ВБЗ девушка/ДТ девушка/НН
В приведенном выше примере NNP означает имя собственное
(единственное число), VBZ означает настоящее время от 3-го лица единственного числа
глагол времени, DT для определителя и NN для
существительное (единственное или массовое). Почтовые теги, используемые
Почтовые теги, используемые openNLPpackage являются Penn
Английские почтовые теги Treebank. Более подробное описание тегов
можно найти здесь, который кратко изложен ниже:
Tag | Description | Examples | |
|---|---|---|---|
CC | Coordinating conjunction | and, or, but | |
CD | Кардинальный номер | один, два, три | |
DT | Determiner | a, the | |
EX | Existential there | There/EX was a party in progress | |
FW | Иностранное слово | persona/FW non/FW grata/FW | |
ИН | Предлог или подчинительный con | 0007||
JJ | Adjective | good, bad, ugly | |
JJR | Adjective, comparative | better, nicer | |
JJS | Прилагательное в превосходной степени | лучший, самый приятный | |
LS | Элемент списка 9 маркер 070002 a. | ||
MD | Modal | can, would, will | |
NN | Noun, singular or mass | tree, chair | |
NNS | Noun, plural | trees, chairs | |
NNP | Proper noun, singular | John, Paul, CIA | |
NNPS | Proper noun, plural | Johns, Pauls, CIAs | |
PDT | Predeterminer | all/ PDT этот мрамор, много/PDT душа | |
POS | Притяжательное окончание | John/NNP’s/POS, the parentss/NNP ‘00009 | |
PRP | Personal pronoun | I, you, he | |
PRP$ | Possessive pronoun | mine, yours | |
RB | Adverb | Evry, достаточно, не | |
RBR | Наречие, сравнение | Поздравляем. | |
RBS | Adverb, superlative | latest | |
RP | Particle | RP | |
SYM | Symbol | CO2 | |
ТО | |||
uhm, uh | |||
VB | Verb, base form | go, walk | |
VBD | Verb, past tense | Прогулки, пила | |
VBG | Глагол, Герунд или Настоящее участие | Ходьба, видя | |
VBN | |||
VBN | |||
VBN | |||
VBN | |||
VBN | Verb, past participle | walked, thought | |
VBP | Verb, non-3rd person singular pr | walk, think | |
VBZ | глагол, 3-й человек в единственном числе представлен | Walks, считает | |
WDT | WH-Determiner | , что 9000 9000 70007 | , что 210 |
WP | Wh-pronoun | what, who, whom (wh-pronoun) | |
WP$ | Possessive wh-pronoun | whose, who (WH-Words) | |
WRB | WH-ADVERB | Как, где, почему (WH-Adverb) |
 , b., 1., 2.
, b., 1., 2. 0203
0203. Присвоение эти поставки со счетами. прямой
вперед. Тем не менее, пост-теги довольно сложны, и существуют различные
способы, с помощью которых компьютер можно обучить присваивать почтовые теги. Например,
можно использовать орфографическую или морфологическую информацию для разработки правил
такой как. . .
Присвоение эти поставки со счетами. прямой
вперед. Тем не менее, пост-теги довольно сложны, и существуют различные
способы, с помощью которых компьютер можно обучить присваивать почтовые теги. Например,
можно использовать орфографическую или морфологическую информацию для разработки правил
такой как. . .
Если слово заканчивается на ment , назначьте почтовую метку
NN(для имени нарицательного)Если слово не встречается в начале предложения, но с заглавной буквы, присвойте pos-тег
NNP(для правильного существительное)
Использование таких правил имеет тот недостаток, что почтовые теги могут быть
присваивается относительно небольшому количеству слов, так как большинство слов будет
двусмысленный — подумайте о сходстве английского множественного числа
(- (д)с ) и английское 3 rd лицо, настоящее время
ориентировочная морфема (- (e)s ), например, которые являются
орфографически идентичны. Другой вариант — использовать словарь
в котором каждому слову присваивается определенный пост-тег, и программа может
назначьте pos-тег, если слово встречается в данном тексте. Эта процедура
имеет тот недостаток, что большинство слов принадлежат более чем к одному классу слов
и пост-тегирование, таким образом, должно полагаться на дополнительную информацию.
Проблема слов, принадлежащих более чем к одному классу слов, может быть частично решена.
исправить путем включения контекстной информации, такой как. .
Другой вариант — использовать словарь
в котором каждому слову присваивается определенный пост-тег, и программа может
назначьте pos-тег, если слово встречается в данном тексте. Эта процедура
имеет тот недостаток, что большинство слов принадлежат более чем к одному классу слов
и пост-тегирование, таким образом, должно полагаться на дополнительную информацию.
Проблема слов, принадлежащих более чем к одному классу слов, может быть частично решена.
исправить путем включения контекстной информации, такой как. .
- Если предыдущее слово является определителем, а следующее слово является
имя нарицательное, присвойте pos-тег
JJ(для общего прилагательное)
Эта процедура работает достаточно хорошо, но есть и лучше
options. Лучший способ пометить текст — создать аннотированный вручную
обучающий набор, который напоминает имеющийся языковой вариант. На основе
частота ассоциации между данным словом и почтовыми тегами, которыми оно является
назначенному в обучающих данных, можно пометить слово тегом
pos-тег, который чаще всего присваивается данному слову в обучении
data.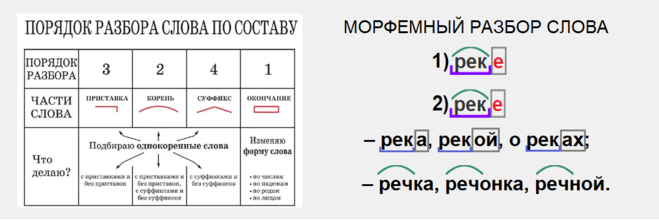 Все вышеперечисленные методы можно и нужно оптимизировать, комбинируя
их и дополнительно включая pos-n-граммы, т.е. определяя pos-тег
неизвестного слова на основе того, какая последовательность почтовых тегов наиболее похожа
к имеющейся последовательности, а также чаще всего встречается в обучающих данных.
введение является чрезвычайно поверхностным и предназначено только для того, чтобы поцарапать некоторые
основных процедур, на которые опирается пост-тегирование. Заинтересованные
читатель отсылается к введениям в области машинного обучения и пост-тегов
например, https://class.coursera.org/nlp/lecture/149.
Все вышеперечисленные методы можно и нужно оптимизировать, комбинируя
их и дополнительно включая pos-n-граммы, т.е. определяя pos-тег
неизвестного слова на основе того, какая последовательность почтовых тегов наиболее похожа
к имеющейся последовательности, а также чаще всего встречается в обучающих данных.
введение является чрезвычайно поверхностным и предназначено только для того, чтобы поцарапать некоторые
основных процедур, на которые опирается пост-тегирование. Заинтересованные
читатель отсылается к введениям в области машинного обучения и пост-тегов
например, https://class.coursera.org/nlp/lecture/149.
Существует несколько различных пакетов R, которые помогают с пост-тегированием
тексты (см. Kumar and Paul 2016). В этом уроке
мы будем использовать udpipe (Wijffels 2021). udpipe упаковка действительно великолепна, так как проста в использовании, охватывает
широкий спектр языков, очень гибкий и очень точный.
Подготовка и настройка сеанса
Это руководство основано на R.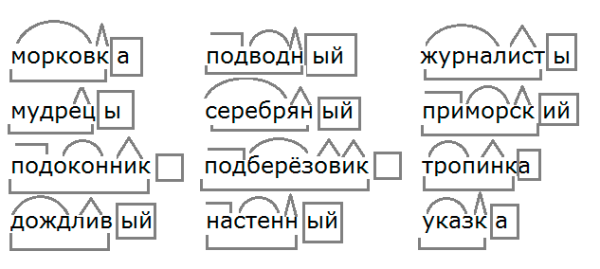 Если вы не установили R или впервые
в нем вы найдете введение и дополнительную информацию о том, как использовать
Р здесь. Для этого
учебники, нам нужно установить определенные пакеты от R библиотека , чтобы показанные ниже сценарии выполнялись без
ошибки. Прежде чем перейти к приведенному ниже коду, установите пакеты с помощью
запустив код под этим абзацем. Если вы уже установили
пакеты, упомянутые ниже, то вы можете пропустить этот раздел.
Чтобы установить необходимые пакеты, просто запустите следующий код — он
может занять некоторое время (от 1 до 5 минут, чтобы установить все
библиотеки, поэтому вам не нужно беспокоиться, если это займет некоторое время).
Если вы не установили R или впервые
в нем вы найдете введение и дополнительную информацию о том, как использовать
Р здесь. Для этого
учебники, нам нужно установить определенные пакеты от R библиотека , чтобы показанные ниже сценарии выполнялись без
ошибки. Прежде чем перейти к приведенному ниже коду, установите пакеты с помощью
запустив код под этим абзацем. Если вы уже установили
пакеты, упомянутые ниже, то вы можете пропустить этот раздел.
Чтобы установить необходимые пакеты, просто запустите следующий код — он
может занять некоторое время (от 1 до 5 минут, чтобы установить все
библиотеки, поэтому вам не нужно беспокоиться, если это займет некоторое время).
# установить пакеты
#install.packages("dplyr")
#install.packages("stringr")
#install.packages("udpipe")
#install.packages("гибкая таблица")
#install.packages("здесь")# установить klippy для кнопки копирования в буфер обмена в кусках кода
install.packages("пульты")
remotes::install_github("rlesur/klippy") Теперь, когда мы установили пакеты, мы активируем их, как показано
ниже.
# загрузить пакеты библиотека (dplyr) библиотека (строка) библиотека (водопровод) библиотека (гибкая таблица) # активировать клиппу для кнопки копирования в буфер обмена клиппи::клиппи()
После того, как вы установили R и RStudio и инициировали сеанс выполнив код, показанный выше, все готово.
UDPipe был разработан в Карловом университете в Праге и
Пакет udpipe R (Wijffels 2021) является
чрезвычайно интересный и действительно фантастический пакет, поскольку он обеспечивает очень
простой и удобный способ токенизации, не зависящей от языка, пост-тегов,
лемматизация и анализ зависимостей необработанного текста в R. Это
особенно удобен, потому что он устраняет и устраняет основные недостатки
которые были у предыдущих методов пост-тегов, а именно
- предлагает широкий выбор языковых моделей (на данный момент 64 языка). точка)
- он не зависит от внешнего программного обеспечения (например, TreeTagger, который должны были быть установлены отдельно и могли быть сложными при использовании разные операционные системы)
- действительно легко реализовать, нужно только установить и загрузить
пакет
udpipeи скачать и активировать язык модель один интересует - позволяет довольно легко обучать и настраивать собственные модели
Доступные предварительно обученные языковые модели в UDPipe:
Languages | Models | |
|---|---|---|
Afrikaans | afrikaans-afribooms | |
Ancient Greek | ancient_greek-perseus, ancient_greek-proiel | |
Arabic | arabic-padt | |
Armenian | armenian-armtdp | |
Basque | basque-bdt | |
Belarusian | belarusian- HSE | |
Bulgarian-BTB | Bulgarian-BTB | |
Buryat | Buryat-BDT 0007 | |
Catalan | catalan-ancora | |
Chinese | chinese-gsd, chinese-gsdsimp, classical_chinese-kyoto | |
Coptic | coptic-scriptorium | |
Хорватский | Хорватский навод | |
Чешский | Czech-Cac, Czech-Cltt, Czechtre, Czechtree, Czechtre0007 | |
Danish | danish-ddt | |
Dutch | dutch-alpino, dutch-lassysmall | |
English | english-ewt, english-gum Английская линия, английская партия | |
Эстониан | Эстониан-Эдт, Эстониан-Эвт | |
Finnish | 902. 0007 0007 | |
Французский | Французский GSD, французский, французский, Sequoia, французский | |
Galian-CTG, галчич German | german-gsd, german-hdt | |
Gothic | gothic-proiel | |
Greek | greek-gdt | |
Hebrew | hebrew-htb | |
Hindi | hindi-hdtb | |
Hungarian | hungarian-szeged | |
Indonesian | индонезийский-gsd | |
Ирландский гэльский | irish-idt | |
Итальянский ISDT, Итальянский Партт, Итальянская Постетва, Итальянский-Твиттиро, Итальянский Вит | ||
Японский | Японский-Гс. | |
Korean | korean-gsd, korean-kaist | |
Kurmanji | kurmanji-mg | |
Latin | latin-ittb, latin-perseus, latin-proiel | |
Latvian | latvian-lvtb | |
Lithuanian | lithuanian-alksnis, lithuanian-hse | |
Maltese | Мальтийский мудт | |
Marathi | Marathi-Ufal | |
north_sami-giella | ||
Norwegian | norwegian-bokmaal, norwegian-nynorsk, norwegian-nynorsklia | |
Old Church Slavonic | old_church_slavonic-proiel | |
Старофранцузский | old_french-srcmf | |
Старорусский | old_russian-torot | |
Persian | persian-seraji | |
Polish | polish-lfg, polish-pdb, polish-sz | |
Portugese | portuguese-bosque, portuguese- Br, Portuguese-GSD | |
Румын | Румыньяна-нондард, румын-RRT | |
русский | 07 | |
Sanskrit | sanskrit-ufal | |
Scottish Gaelic | scottish_gaelic-arcosg | |
Serbian | serbian-set | |
Slovak | словацкий-snk | |
словенский | словенский-ssj, словенский-sst | |
Spanish | spanish-ancora, spanish-gsd | |
Swedish | swedish-lines, swedish-talbanken | |
Tamil | tamil-ttb | |
Телугу | Телугу-MTG | |
Турции | ||
ukrainian-iu | ||
Upper Sorbia | upper_sorbian-ufal | |
Urdu | urdu-udtb | |
Uyghur | uyghur-udt | |
Вьетнамский | Вьетнамес-VTB | |
WOLOF | WOLOF-WTB | WOLOF-WTB | 90390710 |


Пакет udpipe R также позволяет легко обучать собственные модели,
на основе данных в формате CONLL-U, чтобы вы могли использовать их для своих собственных
коммерческих или некоммерческих целях.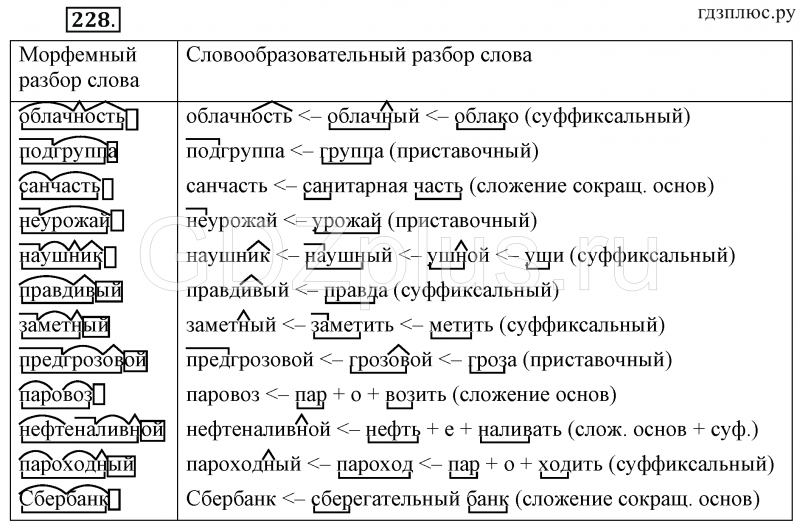 Это описано в др.
виньетка этого пакета, которую вы можете просмотреть командой
Это описано в др.
виньетка этого пакета, которую вы можете просмотреть командой
виньетка("udpipe-train", package="udpipe")
Чтобы скачать любую из этих моделей, мы можем использовать udpipe_download_model функция. Например, чтобы скачать english-ewt модель, мы бы использовали вызов: m_eng <- udpipe::udpipe_download_model(language = "english-ewt") .
Начнем с загрузки текста
# загрузить текст
текст <- readLines("https://slcladal.github.io/data/testcorpus/linguistics06.txt", skipNul = T)
# чистые данные
текст <- текст %>%
str_squish() Теперь, когда у нас есть текст, с которым мы можем работать, мы загрузим предварительно обученная языковая модель.
# скачать языковую модель m_eng <- udpipe::udpipe_download_model(language = "english-ewt")
Если вы скачали модель один раз, вы также можете загрузить модель
непосредственно из того места, где вы сохранили его на своем компьютере. В моем
случае, я сохранил модель в папке с именем udpipemodels
В моем
случае, я сохранил модель в папке с именем udpipemodels
# загрузить языковую модель с вашего компьютера после того, как вы скачали ее один раз
m_eng <- udpipe_load_model(file = here::here("udpipemodels", "english-ewt-ud-2.5-1.udpipe"))
Теперь мы можем использовать модель для комментирования текста.
# токенизация, тег, анализ зависимостей text_anndf <- udpipe::udpipe_annotate(m_eng, x = текст) %>% as.data.frame() %>% dplyr::select(-предложение) # осмотреть голова (text_andf, 10)
## doc_id параграф_id предложение_ид token_id токен лемма upos xpos ## 1 doc1 1 1 1 Лингвистика Лингвистика СУЩЕСТВИТЕЛЬНОЕ NNS ## 2 doc1 1 1 2 также АДВ РБ ## 3 doc1 1 1 3 сделки сделка СУЩЕСТВИТЕЛЬНОЕ NNS ## 4 doc1 1 1 4 with с ADP IN ## 5 doc1 1 1 5 DET DT ## 6 doc1 1 1 6 социальные социальные ADJ JJ ## 7 doc1 1 1 7 , , ПУНКТ , ## 8 doc1 1 1 8 культурный культурный ADJ JJ ## 9doc1 1 1 9 , , ПУНКТ , ## 10 doc1 1 1 10 исторический исторический ADJ JJ ## feats head_token_id dep_rel deps misc ## 1 Число=Соединение Plur 3## 2 3 advmod ## 3 Number=Plur 0 root ## 4 13 case ## 5 Definite=Def|PronType=Art 13 det ## 6 Degree=Pos 13 amod SpaceAfter=No ## 7 8 точек ## 8 Degree=Pos 6 conj SpaceAfter=No ## 9 10 пунктов ## 10 Degree=Pos 6 conj
Может быть полезно извлечь только слова и их pos-теги и
преобразовать их обратно в текстовый формат (а не в табличный формат).
tagged_text <- paste(text_anndf$token, "/", text_anndf$xpos, свернуть = " ", sep = "") # проверить помеченный текст tagged_text
## [1] "Языкознание/ННС также/РБ занимается/ННС с/В/ДТ социальные/ДЖ ,/, культурные/ДЖ ,/, исторические/ДЖ и/СС политические/ДЖ факторы/ННС что/ ВДТ влияние/ВБП язык/НН,/, через/В котором/ВДТ лингвистический/НН и/СС язык/НН -/ГИФ на основе/ВБН контекст/НН есть/ВБЗ часто/РБ определяется/ДЖ./.Исследования/ВБ на /В языке/NN через/В/ДТ подотрасли/ННС в/В историческом/JJ и/CC эволюционном/JJ лингвистике/NNS также/RB фокус/RB на/В как/WRB языки/NNS меняются/VBP и /CC расти/VBP,/, в частности/RB over/IN an/DT растянутый/JJ период/NN of/IN время/NN ./.Язык/NN документация/NN объединяет/ВБЗ антропологический/JJ запрос/NN (/- LRB- в/В/DT история/NN и/CC культура/NN/В языке/NN )/-RRB- с/В лингвистическом/JJ запрос/NN ,/, в/В порядке/NN к/Для описания /ВБ языков/ННС и/СС их/ПРП$ грамматик/ННС./. Лексикография/ННП включает/ВБЗ/ДТ документацию/НС/В слов/ННС, что/ВДТ формируют/ВБП а/ДТ словарь/ННС.
 / .Такие/ПДТ а/ДТ документация/НН г/В a/DT лингвистический/JJ словарь/NN из/IN a/DT конкретный/JJ язык/NN есть/VBZ обычно/RB составлено/VBN в/IN a/DT словарь/NN ./. Вычислительная/JJ лингвистика/NNS is/VBZ заинтересован/JJ с/IN the/DT статистический/NN или/правило CC/NN -/HYPH на основе/VBN моделирование/NN of/IN естественный/JJ язык/NN from/IN a/ DT вычислительный/JJ перспективы/NN ./. Специфические/JJ знания/NN of/В языке/NN есть/VBZ применяется/VBN by/В говорящих/NNS во время/В/ДТ действует/NN of/В переводе/NN и/CC интерпретация/NN ,/, as/ Рб ж/Рб а/В в/В языке/НН образования/НН �/$/ДТ преподавания/НН/В а/ДТ второго/ДжЖ или/СС иностранного/ДжЖ языка/НН ./. Политики/разработчики NN/работа NNS/VBP с/в правительствах/NNS для/внедрения/VB new/JJ планы/NNS в/в образовании/NN и/CC обучение/NN, на которых/WDT основаны/VBP на основе/VBN на/ В лингвистике/JJ Research/NN./."
/ .Такие/ПДТ а/ДТ документация/НН г/В a/DT лингвистический/JJ словарь/NN из/IN a/DT конкретный/JJ язык/NN есть/VBZ обычно/RB составлено/VBN в/IN a/DT словарь/NN ./. Вычислительная/JJ лингвистика/NNS is/VBZ заинтересован/JJ с/IN the/DT статистический/NN или/правило CC/NN -/HYPH на основе/VBN моделирование/NN of/IN естественный/JJ язык/NN from/IN a/ DT вычислительный/JJ перспективы/NN ./. Специфические/JJ знания/NN of/В языке/NN есть/VBZ применяется/VBN by/В говорящих/NNS во время/В/ДТ действует/NN of/В переводе/NN и/CC интерпретация/NN ,/, as/ Рб ж/Рб а/В в/В языке/НН образования/НН �/$/ДТ преподавания/НН/В а/ДТ второго/ДжЖ или/СС иностранного/ДжЖ языка/НН ./. Политики/разработчики NN/работа NNS/VBP с/в правительствах/NNS для/внедрения/VB new/JJ планы/NNS в/в образовании/NN и/CC обучение/NN, на которых/WDT основаны/VBP на основе/VBN на/ В лингвистике/JJ Research/NN./." Мы можем применить тот же метод для аннотирования, например. добавление pos-тегов, чтобы
Другие языки. Для этого мы можем обучить нашу собственную модель или использовать
одна из многих предварительно обученных языковых моделей, которые udpipe обеспечивает.
Давайте рассмотрим, как это сделать, используя примеры текстов из разных языков, здесь с немецкого и испанского (но мы могли бы также аннотировать тексты с любого из множества языков, для которых UDPipe предоставляет предварительно обученные модели.
Начнем с загрузки немецкого и голландского текста.
# загрузить тексты
gertext <- readLines("https://slcladal.github.io/data/german.txt")
duttext <- readLines("https://slcladal.github.io/data/dutch.txt")
# проверять тексты
гертекст; duttext ## [1] "Sprachwissenschaft untersucht in verschiedenen Herangehensweisen die menschliche Sprache."
## [1] «Taalkunde, ook wel taalwetenschap of linguïstiek, is de wetenschappelijke studie van de natuurlijke talen».
Далее устанавливаем предварительно обученные языковые модели.
# скачать языковую модель m_ger <- udpipe::udpipe_download_model(language = "немецкий-gsd") m_dut <- udpipe::udpipe_download_model(language = "dutch-alpino")
Или мы загружаем их с нашей машины (если мы скачали и сохранили
их раньше).
# загрузить языковую модель с вашего компьютера после того, как вы скачали ее один раз
m_ger <- udpipe::udpipe_load_model(file = here::here("udpipemodels", "german-gsd-ud-2.5-1.udpipe"))
m_dut <- udpipe::udpipe_load_model(file = here::here("udpipemodels", "голландский-alpino-ud-2.5-1
.udpipe"))
Теперь пометьте текст на немецком языке.
# tokenise, tag, парсинг зависимостей немецкого текста ger_pos <- udpipe::udpipe_annotate(m_ger, x = gertext) %>% as.data.frame() %>% dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>% dplyr::pull(уникальный(postxt)) # осмотреть ger_pos
## [1] "Sprachwissenschaft/NN untersucht/VVFIN in/APPR verschiedenen/ADJA Herangehensweisen/NN die/ART menschliche/NN Sprache/NN ./$."
И, наконец, мы также размещаем текст на голландском языке.
# tokenise, тег, разбор зависимостей немецкого текста nl_pos <- udpipe::udpipe_annotate(m_dut, x = duttext) %>% as.data.
 frame() %>%
dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>%
dplyr::pull(уникальный(postxt))
# осмотреть
nl_pos
frame() %>%
dplyr::summarise(postxt = paste(токен, "/", xpos, свернуть = " ", sep = "")) %>%
dplyr::pull(уникальный(postxt))
# осмотреть
nl_pos ## [1] "Taalkunde/N|soort|ev|basis|zijd|stan ,/LET ook/BW wel/BW taalwetenschap/N|soort|ev|basis|zijd|stan of/VG|neven linguïstiek /N|soort|ev|basis|zijd|stan ,/LET is/WW|pv|tgw|ev de/LID|bep|stan|rest wetenschappelijke/ADJ|prenom|basis|met-e|stan studie/N| soort|ev|basis|zijd|stan van/VZ|init de/LID|bep|stan|rest natuurlijke/ADJ|prenom|basis|met-e|stan talen/N|soort|mv|basis ./LET"
Помимо пост-тегов, мы также можем генерировать графики, показывающие
синтаксическая зависимость различных членов предложения. Для
при этом мы генерируем объект, содержащий предложение (в данном случае
предложение Лингвистика является научным изучением языка ), и
затем мы строим (или визуализируем) зависимости, используя функция textplot_dependencyparser .
# разобрать текст отправлено <- udpipe::udpipe_annotate(m_eng, x = "Лингвистика — это научное изучение языка") %>% as.
 data.frame()
# осмотреть
голова(отправлено)
data.frame()
# осмотреть
голова(отправлено) ## doc_id id_абзаца id_предложения ## 1 документ1 1 1 ## 2 документ1 1 1 ## 3 документ1 1 1 ## 4 документ1 1 1 ## 5 документ1 1 1 ## 6 документ1 1 1 ## предложение token_id token ## 1 Лингвистика – это научное изучение языка 1 Лингвистика ## 2 Лингвистика – это научное изучение языка 2 – это ## 3 Лингвистика – это научное изучение языка 3 ## 4 Лингвистика – это научное изучение языка 4 научное ## 5 Лингвистика – это научное изучение языка 5 изучение ## 6 Лингвистика – это научное изучение языка 6 ## lemma upos xpos feats ## 1 Лингвистическое СУЩЕСТВИТЕЛЬНОЕ NNS Number=Plur ## 2 be AUX VBZ Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin ## 3 DET DT Definite=Def|PronType=Art ## 4 научный ADJ JJ Degree=Pos ## 5 изучение СУЩЕСТВИТЕЛЬНОЕ NN Число=Петь ## 6 из ADP IN## head_token_id dep_rel deps misc ## 1 5 nsubj <нет данных> <нет данных> ## 2 5 коп ## 3 5 дет <нет данных> <нет данных> ## 4 5 amod ## 5 0 корень ## 6 7 case
Теперь создадим график.