СРОЧНО!!!Разбор слова по составу : головки, яркий, огонек.
Дам 40 баллов за «Сочинение-рассказ» Самый памятный день моей жизни.(придумайте что хотите) (в нём ОБЯЗАТЕЛЬНО должно быть 1—2числительн.)
КТО ПОМОЖЕТ ДАМ МАКС БАЛ
1. Укажите вариант ответа, в котором оба числительных имеют правильную форму:
1) семьсот тридцать семь, восьмистами пятьюдеся
… тью пятью 2) семьсот семьдесят шесть, четырьмьюстами восемьюдесятью двумя 3) девятьсот девяносто девять, двумястами семьюдесятью двумя 4) сто девяти, шестьсот семьдесят двум
2. Укажите пример с ошибкой в форме имени числительного:
1) восьмьюстами пятьюдесятью пятью дисками2) (о) девятисотах шестидесяти семи рублях3) семистам тридцати восьми детям4) четырьмястами восьмьюдесятью пятью часами
3. Укажите пример с ошибкой в форме числительного:
1) девятисот пятидесяти шести попугаев2) сто две кошки3) семьюстами тридцатью восьми обложками4) девятьсот тридцать восемь
4. Укажите пример с ошибкой в форме числительного:
1) (около) пятисот сорока девяти дней2) девятисот сорок семь тетрадок3) трёхсот семидесяти шести книг4) семисот тридцати восьми розеток
5. Укажите пример без ошибки в форме числительного:
1) семисот тридцати восьми наборов2) восьмистами сорока девятью монетами3) двести пяти книгам4) триста сорока девяти
6. Укажите пример без ошибки в форме числительного:
1) семьюстами тридцатью пятью рублями2) девятьюсотами пятьюдесяти шестью калькуляторами3) восьмистами семьюдесятью шестью телевизорами4) двадцатью семи рублями
7. Укажите пример без ошибки в форме числительного:
1) (о) девятьсот пятидесяти шести рублях2) семисот тридцать семь книг3) четырьмьюстами восьмьюдесятью пятью телефонами4) шестистам пятидесяти четырём килограммам8. Укажите пример с ошибкой в образовании имени числительного:
1) девятьюстами пятьюдесятью семью2) двумястами восьмидесятью тремя3) семьюстами двумя4) девятьюстами двумя
9. Укажите пример с ошибкой в форме числительного:
1) семьюсотами пятьюдесятью шестью2) (о) пятистах тридцати восьми3) семьюстами тридцатью пятью4) девятьюстами пятьюдесятью семью
10.
Перетишите текст 1, раскрывая скобки, вставляя,необходимо,пропущенные буквы и знаки препинания.Текст 1Двор (во)всю свою ширину засыпан пушстым снег.м. … Синеют на нёмчьи(то) (не)глубокие сляды. М.розный воздух чуть щипл..т(3) нос кол.Щ.cКИ (не)заметными иголоч..К..ми. Сарай и скотные дворы стоятпр..земистые, покрытые (серебристо)белыми шапками, будто вр..сли в снег. Какст..клян, нные, тянут..ся сл..ды полоз..ев (от)дома через весь двор.Никита радос..но (з/с)бежал с крыльца по дер..вя(Н,нным ступен..м. (6)Внизу стояли новенькие санки, ра(з/с)писные, с дли(Н,нной2) верёвкой. Никитаосмотрел (з/с)деланы проч..но, попробовал ничуть (не)тяж..лые, ск..льзятпр..красно. Он взв..лилсанки назахв..Тил лопатку, думая, чтопонадоб.т..ся, и направился к реч..ке. Там стояли гр..мадные вётлы, покрытыебл..стящим ине..м. Никита вышел на высокий берег (Ч, ч)агры сел (на)санки0..толкнулся и санки стр..лой пол..тели с крутой г..ры.(По А.Н. Толстому)ПОМОГИТЕ ПОЖАЛУЙСТА, ДАМ 10 БАЛЛОВ
ЗАПИШИТЕ в тетрадь словами дробные числительные: 2/3 4/7 78/100 7/8 0,8 0,04 5,02 78,7
1. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов. 1) Я думал, что(бы) я сам стал делать, если б меня пос..дили по
… д стекля(н, нн)ый к..лпак. (Ю. Коваль) 2) Он и песню себе специально пр..думал, что(бы) не так страшно ему на л..сной дороге было. (Ю. Макаров) 3) Я должен его разбудить во что(бы) то ни стало! (В. Медведев) 4) Бер..ги его [жеребёнка] и не б..ри за него н..чего, что(бы) тебе ни предл..гали. (Д. Мамин Сибиряк)
2. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Рябина то(же) в..сной цветёт, но какие у неё цветы? (Ю. Коваль) 2) В то(же) время вдруг ветер рванул ещё раз. (М. Пришвин) 3) И когда зажгли свет, все захлопали и зав..пили «браво», я то(же) кричал «браво». (В. Драгунский) 4) Думать можно (по)разному, а г..ворить одно и то(же). (С. Козлов)
3. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Костя стал ругать меня за(то), что я, (не)дож..даясь его, пр..вратился в воробья. (В. Медведев) 2) От боли он подпрыгнул, за(то) уб..дился, что (не)спит. (М. Сергеев) 3) Я знаю, что в..новат перед тобою; но я ж..стоко за(то) наказан! (А. Погорельский) 4) Спасибо вам ..громное за(то), что вы нас пр..дупредили об опасност.. . (В. Постников)
1) Я думал, что(бы) я сам стал делать, если б меня пос..дили по
… д стекля(н, нн)ый к..лпак. (Ю. Коваль) 2) Он и песню себе специально пр..думал, что(бы) не так страшно ему на л..сной дороге было. (Ю. Макаров) 3) Я должен его разбудить во что(бы) то ни стало! (В. Медведев) 4) Бер..ги его [жеребёнка] и не б..ри за него н..чего, что(бы) тебе ни предл..гали. (Д. Мамин Сибиряк)
2. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Рябина то(же) в..сной цветёт, но какие у неё цветы? (Ю. Коваль) 2) В то(же) время вдруг ветер рванул ещё раз. (М. Пришвин) 3) И когда зажгли свет, все захлопали и зав..пили «браво», я то(же) кричал «браво». (В. Драгунский) 4) Думать можно (по)разному, а г..ворить одно и то(же). (С. Козлов)
3. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Костя стал ругать меня за(то), что я, (не)дож..даясь его, пр..вратился в воробья. (В. Медведев) 2) От боли он подпрыгнул, за(то) уб..дился, что (не)спит. (М. Сергеев) 3) Я знаю, что в..новат перед тобою; но я ж..стоко за(то) наказан! (А. Погорельский) 4) Спасибо вам ..громное за(то), что вы нас пр..дупредили об опасност.. . (В. Постников)
11. Спишите, расставляя недостающие знаки препинания. Выделите обобща-ющие слова. Составьте схемы предложений.1) Но ни заборы ни дома ничто так не изм
… енилось, как люди. (А. Чехов)2) Книги, мебель, эскизы, наброски всё постепенно заглатывалось всеяд-ным огненным смерчем. (Ф.Ахмедзаде) 3) Настоящему рыбаку нужно мно-гое река цветы утренние зори таинственные ночи голубые вечера и тишина.(Г. Троепольский) 4) Всюду вверху и внизу пели жаворонки. (А. Чехов) 5) Вчеловеке всё должно быть прекрасно и лицо и одежда и душа и мысли.(А.Чехов) 6) Другие факторы как-то ветры разность температуры днём и но-чью летом и зимою морские брызги и прочее играют второстепенную роль.(В.Арсеньев) 7) Среди травянистых растений есть такие, что живут всегоодно лето например лебеда левкой редис просо овёс. (Л.Корчагина) 8) Ба-бушка предложила моей матери выбрать для своего помещения одну из двухКомнат или залу или гостиную.
Запишите и объясните -ТСЯ и -ТЬСЯ в глаголах. Определите вид глагола. Умеет трудит..ся, он трудит..ся с душой, нельзя ленит..ся, просыпает..ся на расс … вете, катает..ся с горы, собирает..ся поехать в Москву, общает..ся с друзьями, (не)надо ссорит..ся, (не)боит..ся ошибит..ся, надо научит..ся не раздражат..ся, он учит..ся в МГУ, ему интересно учит..ся.
Задание.
Дайте аргументированный ответ на вопрос ,что же сейчас происходит с людьми? Почему сейчас стало нормой выглядеть равнодушным?
Помогите пожал
… уйста
Недавно со мной приключилась беда. Шёл я по улице, поскользнулся и упал… Упал неудачно, хуже некуда: лицом о бордюр сломал себе нос, всё лицо разбил, рука выскочила в плече. Было это примерно в семь часов вечера, в центре города, недалеко от дома, где живу.
С большим трудом поднялся — лицо залито кровью, рука повисла плетью. Чувствовал, что держусь шоковым состоянием, боль накатывает всё сильнее и надо быстро что-то сделать. И говорить-то не могу — рот разбит.
Решил повернуть назад, домой.
Я шёл по улице, думаю, что не шатаясь, держа у лица окровавленный платок, пальто уже блестит от крови. Хорошо помню этот путь — метров примерно триста. Народу на улице было много. Навстречу прошла женщина с девочкой, какая-то парочка, пожилая
женщина, мужчина, молодые ребята, все они вначале с любопытством взглядывали на меня, а потом отводили глаза, отворачивались. Хоть бы кто на этом пути подошёл ко мне, спросил, что со мной, не нужно ли помочь. Я запомнил лица многих людей — видимо, безотчётным вниманием, обострённым ожиданием помощи…
Боль путала сознание, но я понимал, что, если лягу сейчас на тротуаре, преспокойно будут перешагивать через меня, обходить. Надо добираться до дома.
Позже я раздумывал над этой историей. Могли ли люди принять меня за пьяного? Вроде бы нет, вряд ли я производил такое впечатление. Но даже если бы и принимали за пьяного… — они же видели, что я весь в крови, что-то случилось — упал, ударился, — почему же не помогли, не спросили хотя бы, в чём дело? Значит, пройти мимо, не тратить времени, сил, стало чувством привычным?
Раздумывая, с горечью вспоминал этих людей, поначалу злился, обвинял, недоумевал, негодовал, а вот потом стал вспоминать самого себя.
За нами — Москва Эссе Срочноооо
Найдите слова, которые помогают узнать, где совершается действу508Подчеркните их как члены предложения.1) Ребята встретились возле баскетбольной площа … дки. 2)хыт записался в спортивную секцию. 3) Футбольный матч5) Шайба влетела в ворота. 6) Мяч попал в корзину.стоится на школьном стадионе. 4) Мы тренируемся в спортзале,
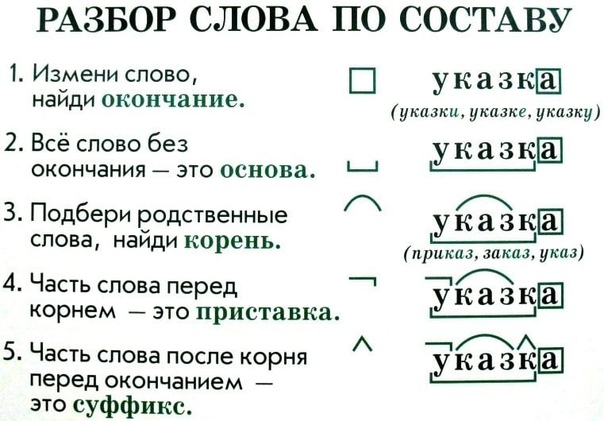
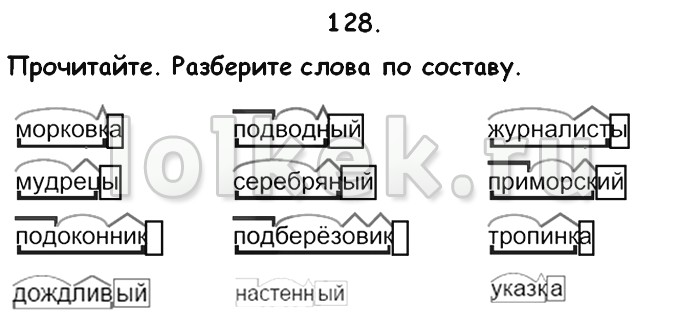
Разобрать слова по составу:полетели , головки , отцветают
Дам 40 баллов за «Сочинение-рассказ» Самый памятный день моей жизни.(придумайте что хотите) (в нём ОБЯЗАТЕЛЬНО должно быть 1—2числительн.)
КТО ПОМОЖЕТ ДАМ МАКС БАЛ
1. Укажите вариант ответа, в котором оба числительных имеют правильную форму:
1) семьсот тридцать семь, восьмистами пятьюдеся
… тью пятью 2) семьсот семьдесят шесть, четырьмьюстами восемьюдесятью двумя 3) девятьсот девяносто девять, двумястами семьюдесятью двумя 4) сто девяти, шестьсот семьдесят двум
2. Укажите пример с ошибкой в форме имени числительного:
1) восьмьюстами пятьюдесятью пятью дисками2) (о) девятисотах шестидесяти семи рублях3) семистам тридцати восьми детям4) четырьмястами восьмьюдесятью пятью часами
3. Укажите пример с ошибкой в форме числительного:
1) девятисот пятидесяти шести попугаев2) сто две кошки3) семьюстами тридцатью восьми обложками4) девятьсот тридцать восемь
4. Укажите пример с ошибкой в форме числительного:
1) (около) пятисот сорока девяти дней2) девятисот сорок семь тетрадок3) трёхсот семидесяти шести книг4) семисот тридцати восьми розеток
5. Укажите пример без ошибки в форме числительного:
1) семисот тридцати восьми наборов2) восьмистами сорока девятью монетами3) двести пяти книгам4) триста сорока девяти
6. Укажите пример без ошибки в форме числительного:
1) семьюстами тридцатью пятью рублями2) девятьюсотами пятьюдесяти шестью калькуляторами3) восьмистами семьюдесятью шестью телевизорами4) двадцатью семи рублями
7. Укажите пример без ошибки в форме числительного:
1) (о) девятьсот пятидесяти шести рублях2) семисот тридцать семь книг3) четырьмьюстами восьмьюдесятью пятью телефонами4) шестистам пятидесяти четырём килограммам8. Укажите пример с ошибкой в образовании имени числительного:
1) девятьюстами пятьюдесятью семью2) двумястами восьмидесятью тремя3) семьюстами двумя4) девятьюстами двумя
9. Укажите пример с ошибкой в форме числительного:
1) семьюсотами пятьюдесятью шестью2) (о) пятистах тридцати восьми3) семьюстами тридцатью пятью4) девятьюстами пятьюдесятью семью
10. Укажите пример с ошибкой в форме числительного:
1) четырьмьюстами восьмьюдесятью семью2) двадцатью пятью3) ста шести4) семьсот тридцать восемь11.
В чём сходство и различие в склонении количественных числительных (от 50 до 80 и от 500 до 900) в русском и украинском языках?
11. В чём сходство и различие в склонении количественных числительных (от 50 до 80 и от 500 до 900) в русском и украинском языках?
1) Склоняются одинаково
2)В русском языке склоняются обе части
3) В русском языке склоняется вторая часть
12.Запишите числа словами в творительном падеже: 345 участников, 973 экскурсии
1)триста сорока пятью участниками, девятьсот семьдесят тремя экскурсиями
2)триста сорока пятью участниками, девятьсот семьюдесятью тремя экскурсиями
3)тремястами сорока пятью участниками, девятьюстами семьюдесятью тремя экскурсиями
Укажите пример с ошибкой в форме числительного:
1) (около) пятисот сорока девяти дней2) девятисот сорок семь тетрадок3) трёхсот семидесяти шести книг4) семисот тридцати восьми розеток
5. Укажите пример без ошибки в форме числительного:
1) семисот тридцати восьми наборов2) восьмистами сорока девятью монетами3) двести пяти книгам4) триста сорока девяти
6. Укажите пример без ошибки в форме числительного:
1) семьюстами тридцатью пятью рублями2) девятьюсотами пятьюдесяти шестью калькуляторами3) восьмистами семьюдесятью шестью телевизорами4) двадцатью семи рублями
7. Укажите пример без ошибки в форме числительного:
1) (о) девятьсот пятидесяти шести рублях2) семисот тридцать семь книг3) четырьмьюстами восьмьюдесятью пятью телефонами4) шестистам пятидесяти четырём килограммам8. Укажите пример с ошибкой в образовании имени числительного:
1) девятьюстами пятьюдесятью семью2) двумястами восьмидесятью тремя3) семьюстами двумя4) девятьюстами двумя
9. Укажите пример с ошибкой в форме числительного:
1) семьюсотами пятьюдесятью шестью2) (о) пятистах тридцати восьми3) семьюстами тридцатью пятью4) девятьюстами пятьюдесятью семью
10. Укажите пример с ошибкой в форме числительного:
1) четырьмьюстами восьмьюдесятью семью2) двадцатью пятью3) ста шести4) семьсот тридцать восемь11.
В чём сходство и различие в склонении количественных числительных (от 50 до 80 и от 500 до 900) в русском и украинском языках?
11. В чём сходство и различие в склонении количественных числительных (от 50 до 80 и от 500 до 900) в русском и украинском языках?
1) Склоняются одинаково
2)В русском языке склоняются обе части
3) В русском языке склоняется вторая часть
12.Запишите числа словами в творительном падеже: 345 участников, 973 экскурсии
1)триста сорока пятью участниками, девятьсот семьдесят тремя экскурсиями
2)триста сорока пятью участниками, девятьсот семьюдесятью тремя экскурсиями
3)тремястами сорока пятью участниками, девятьюстами семьюдесятью тремя экскурсиями
Перетишите текст 1, раскрывая скобки, вставляя,необходимо,пропущенные буквы и знаки препинания. Текст 1Двор (во)всю свою ширину засыпан пушстым снег.м.
… Синеют на нёмчьи(то) (не)глубокие сляды. М.розный воздух чуть щипл..т(3) нос кол.Щ.cКИ (не)заметными иголоч..К..ми. Сарай и скотные дворы стоятпр..земистые, покрытые (серебристо)белыми шапками, будто вр..сли в снег. Какст..клян, нные, тянут..ся сл..ды полоз..ев (от)дома через весь двор.Никита радос..но (з/с)бежал с крыльца по дер..вя(Н,нным ступен..м. (6)Внизу стояли новенькие санки, ра(з/с)писные, с дли(Н,нной2) верёвкой. Никитаосмотрел (з/с)деланы проч..но, попробовал ничуть (не)тяж..лые, ск..льзятпр..красно. Он взв..лилсанки назахв..Тил лопатку, думая, чтопонадоб.т..ся, и направился к реч..ке. Там стояли гр..мадные вётлы, покрытыебл..стящим ине..м. Никита вышел на высокий берег (Ч, ч)агры сел (на)санки0..толкнулся и санки стр..лой пол..тели с крутой г..ры.(По А.Н. Толстому)ПОМОГИТЕ ПОЖАЛУЙСТА, ДАМ 10 БАЛЛОВ
Текст 1Двор (во)всю свою ширину засыпан пушстым снег.м.
… Синеют на нёмчьи(то) (не)глубокие сляды. М.розный воздух чуть щипл..т(3) нос кол.Щ.cКИ (не)заметными иголоч..К..ми. Сарай и скотные дворы стоятпр..земистые, покрытые (серебристо)белыми шапками, будто вр..сли в снег. Какст..клян, нные, тянут..ся сл..ды полоз..ев (от)дома через весь двор.Никита радос..но (з/с)бежал с крыльца по дер..вя(Н,нным ступен..м. (6)Внизу стояли новенькие санки, ра(з/с)писные, с дли(Н,нной2) верёвкой. Никитаосмотрел (з/с)деланы проч..но, попробовал ничуть (не)тяж..лые, ск..льзятпр..красно. Он взв..лилсанки назахв..Тил лопатку, думая, чтопонадоб.т..ся, и направился к реч..ке. Там стояли гр..мадные вётлы, покрытыебл..стящим ине..м. Никита вышел на высокий берег (Ч, ч)агры сел (на)санки0..толкнулся и санки стр..лой пол..тели с крутой г..ры.(По А.Н. Толстому)ПОМОГИТЕ ПОЖАЛУЙСТА, ДАМ 10 БАЛЛОВ
ЗАПИШИТЕ в тетрадь словами дробные числительные: 2/3 4/7 78/100 7/8 0,8 0,04 5,02 78,7
1. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Я думал, что(бы) я сам стал делать, если б меня пос..дили по
… д стекля(н, нн)ый к..лпак. (Ю. Коваль) 2) Он и песню себе специально пр..думал, что(бы) не так страшно ему на л..сной дороге было. (Ю. Макаров) 3) Я должен его разбудить во что(бы) то ни стало! (В. Медведев) 4) Бер..ги его [жеребёнка] и не б..ри за него н..чего, что(бы) тебе ни предл..гали. (Д. Мамин Сибиряк)
2. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Рябина то(же) в..сной цветёт, но какие у неё цветы? (Ю. Коваль) 2) В то(же) время вдруг ветер рванул ещё раз. (М. Пришвин) 3) И когда зажгли свет, все захлопали и зав..пили «браво», я то(же) кричал «браво». (В. Драгунский) 4) Думать можно (по)разному, а г..ворить одно и то(же). (С. Козлов)
3. Перепишите предложения. Объясните слитное или раздельное написание выделенных слов.
1) Костя стал ругать меня за(то), что я, (не)дож..даясь его, пр..вратился в воробья. (В. Медведев) 2) От боли он подпрыгнул, за(то) уб..дился, что (не)спит. (М. Сергеев) 3) Я знаю, что в..новат перед тобою; но я ж..стоко за(то) наказан! (А. Погорельский) 4) Спасибо вам ..громное за(то), что вы нас пр..дупредили об опасност.. . (В. Постников)
(В. Медведев) 2) От боли он подпрыгнул, за(то) уб..дился, что (не)спит. (М. Сергеев) 3) Я знаю, что в..новат перед тобою; но я ж..стоко за(то) наказан! (А. Погорельский) 4) Спасибо вам ..громное за(то), что вы нас пр..дупредили об опасност.. . (В. Постников)
11. Спишите, расставляя недостающие знаки препинания. Выделите обобща-ющие слова. Составьте схемы предложений.1) Но ни заборы ни дома ничто так не изм … енилось, как люди. (А. Чехов)2) Книги, мебель, эскизы, наброски всё постепенно заглатывалось всеяд-ным огненным смерчем. (Ф.Ахмедзаде) 3) Настоящему рыбаку нужно мно-гое река цветы утренние зори таинственные ночи голубые вечера и тишина.(Г. Троепольский) 4) Всюду вверху и внизу пели жаворонки. (А. Чехов) 5) Вчеловеке всё должно быть прекрасно и лицо и одежда и душа и мысли.(А.Чехов) 6) Другие факторы как-то ветры разность температуры днём и но-чью летом и зимою морские брызги и прочее играют второстепенную роль.(В.Арсеньев) 7) Среди травянистых растений есть такие, что живут всегоодно лето например лебеда левкой редис просо овёс. (Л.Корчагина) 8) Ба-бушка предложила моей матери выбрать для своего помещения одну из двухКомнат или залу или гостиную. (С. Аксаков)
Запишите и объясните -ТСЯ и -ТЬСЯ в глаголах. Определите вид глагола. Умеет трудит..ся, он трудит..ся с душой, нельзя ленит..ся, просыпает..ся на расс … вете, катает..ся с горы, собирает..ся поехать в Москву, общает..ся с друзьями, (не)надо ссорит..ся, (не)боит..ся ошибит..ся, надо научит..ся не раздражат..ся, он учит..ся в МГУ, ему интересно учит..ся.
Задание.
Дайте аргументированный ответ на вопрос ,что же сейчас происходит с людьми? Почему сейчас стало нормой выглядеть равнодушным?
Помогите пожал
… уйста
Недавно со мной приключилась беда. Шёл я по улице, поскользнулся и упал… Упал неудачно, хуже некуда: лицом о бордюр сломал себе нос, всё лицо разбил, рука выскочила в плече. Было это примерно в семь часов вечера, в центре города, недалеко от дома, где живу.
С большим трудом поднялся — лицо залито кровью, рука повисла плетью. Чувствовал, что держусь шоковым состоянием, боль накатывает всё сильнее и надо быстро что-то сделать. И говорить-то не могу — рот разбит.
Решил повернуть назад, домой.
Я шёл по улице, думаю, что не шатаясь, держа у лица окровавленный платок, пальто уже блестит от крови. Хорошо помню этот путь — метров примерно триста. Народу на улице было много. Навстречу прошла женщина с девочкой, какая-то парочка, пожилая
женщина, мужчина, молодые ребята, все они вначале с любопытством взглядывали на меня, а потом отводили глаза, отворачивались. Хоть бы кто на этом пути подошёл ко мне, спросил, что со мной, не нужно ли помочь. Я запомнил лица многих людей — видимо, безотчётным вниманием, обострённым ожиданием помощи…
Боль путала сознание, но я понимал, что, если лягу сейчас на тротуаре, преспокойно будут перешагивать через меня, обходить. Надо добираться до дома.
Позже я раздумывал над этой историей. Могли ли люди принять меня за пьяного? Вроде бы нет, вряд ли я производил такое впечатление. Но даже если бы и принимали за пьяного… — они же видели, что я весь в крови, что-то случилось — упал, ударился, — почему же не помогли, не спросили хотя бы, в чём дело? Значит, пройти мимо, не тратить времени, сил, стало чувством привычным?
Раздумывая, с горечью вспоминал этих людей, поначалу злился, обвинял, недоумевал, негодовал, а вот потом стал вспоминать самого себя. И нечто подобное отыскивал и в своём поведении — желание отойти, уклониться, не ввязываться… И, уличив себя, начал понимать, как привычно стало это чувство, как оно пригрелось, незаметно укоренилось.
Раздумывая, я вспоминал и другое. Вспоминал фронтовое время, когда в голодной окопной нашей жизни исключено было, чтобы при виде раненого пройти мимо него.
И после войны это чувство взаимопомощи долго оставалось среди нас. Но постепенно оно исчезло. Утратилось настолько, что человек считает возможным пройти мимо упавшего, пострадавшего, лежащего на земле.
И в самом деле, что же это с нами происходит? Как мы дошли до этого, как из нормальной отзывчивости перешли в равнодушие, в бездушие, и это тоже стало нормальным?
Чувствовал, что держусь шоковым состоянием, боль накатывает всё сильнее и надо быстро что-то сделать. И говорить-то не могу — рот разбит.
Решил повернуть назад, домой.
Я шёл по улице, думаю, что не шатаясь, держа у лица окровавленный платок, пальто уже блестит от крови. Хорошо помню этот путь — метров примерно триста. Народу на улице было много. Навстречу прошла женщина с девочкой, какая-то парочка, пожилая
женщина, мужчина, молодые ребята, все они вначале с любопытством взглядывали на меня, а потом отводили глаза, отворачивались. Хоть бы кто на этом пути подошёл ко мне, спросил, что со мной, не нужно ли помочь. Я запомнил лица многих людей — видимо, безотчётным вниманием, обострённым ожиданием помощи…
Боль путала сознание, но я понимал, что, если лягу сейчас на тротуаре, преспокойно будут перешагивать через меня, обходить. Надо добираться до дома.
Позже я раздумывал над этой историей. Могли ли люди принять меня за пьяного? Вроде бы нет, вряд ли я производил такое впечатление. Но даже если бы и принимали за пьяного… — они же видели, что я весь в крови, что-то случилось — упал, ударился, — почему же не помогли, не спросили хотя бы, в чём дело? Значит, пройти мимо, не тратить времени, сил, стало чувством привычным?
Раздумывая, с горечью вспоминал этих людей, поначалу злился, обвинял, недоумевал, негодовал, а вот потом стал вспоминать самого себя. И нечто подобное отыскивал и в своём поведении — желание отойти, уклониться, не ввязываться… И, уличив себя, начал понимать, как привычно стало это чувство, как оно пригрелось, незаметно укоренилось.
Раздумывая, я вспоминал и другое. Вспоминал фронтовое время, когда в голодной окопной нашей жизни исключено было, чтобы при виде раненого пройти мимо него.
И после войны это чувство взаимопомощи долго оставалось среди нас. Но постепенно оно исчезло. Утратилось настолько, что человек считает возможным пройти мимо упавшего, пострадавшего, лежащего на земле.
И в самом деле, что же это с нами происходит? Как мы дошли до этого, как из нормальной отзывчивости перешли в равнодушие, в бездушие, и это тоже стало нормальным?
За нами — Москва Эссе Срочноооо
Найдите слова, которые помогают узнать, где совершается действу508Подчеркните их как члены предложения. 1) Ребята встретились возле баскетбольной площа
… дки. 2)хыт записался в спортивную секцию. 3) Футбольный матч5) Шайба влетела в ворота. 6) Мяч попал в корзину.стоится на школьном стадионе. 4) Мы тренируемся в спортзале,
1) Ребята встретились возле баскетбольной площа
… дки. 2)хыт записался в спортивную секцию. 3) Футбольный матч5) Шайба влетела в ворота. 6) Мяч попал в корзину.стоится на школьном стадионе. 4) Мы тренируемся в спортзале,
Морфологический разбор слова «головке»
Часть речи: Существительное
ГОЛОВКЕ — неодушевленное
Начальная форма слова: «ГОЛОВКА»
| Слово | Морфологические признаки |
|---|---|
| ГОЛОВКЕ |
|
| ГОЛОВКЕ |
|
Все формы слова ГОЛОВКЕ
ГОЛОВКА, ГОЛОВКИ, ГОЛОВКЕ, ГОЛОВКУ, ГОЛОВКОЙ, ГОЛОВКОЮ, ГОЛОВОК, ГОЛОВКАМ, ГОЛОВКАМИ, ГОЛОВКАХ
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ГОЛОВКЕ» в конкретном предложении или тексте, то лучше использовать морфологический разбор текста.
Примеры предложений со словом «головке»
1
А хотите вот таких, – ткнул он в студента, – воспитывать, по головке гладить, по головке.
Белый Бим Черное ухо (сборник), Гавриил Троепольский2
Ну, взял я ее, да по головке, по головке.
3
Один раз погладили по головка, второй раз пожурили, погладив по головке, и парень уверился: он может делать все, что ему заблагорассудится.
Сквозь призму права. Судебные очерки, статьи, эссе, Геннадий Мурзин4
Головка, головка очень большая.
Говорит Альберт Эйнштейн, Р. Дж. Гэдни, 2018г.5
Смолокуров самодовольно улыбался, гладил умницу по головке и велел выдать Анисье Терентьевне фунт чаю да головку сахару.
На горах, Павел Мельников-Печерский, 1875-1881г.Найти еще примеры предложений со словом ГОЛОВКЕ
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Разбор слова по составу цветов, головки
бресятной — образовано от слова береста при помощи суффикса ян. При образлование корень с БЕРЕСТ заменился на БРЕСТ. Способ образования суффиксальный.
Там два наречия это тяжело и звонко
Огород, города, рога, род, дар
От духовного и нравственного развития человека зависит станет ли он цельной личностью. будут ли ему присущи такие качества как доброта,сострадание,терпимость,любовь,уважение,целомудрие.Духовность понятие сложное и многогранное,говоря о ней мы подразумеваем систему нравственных ценностей.На неё влияет и культура и искусство.Мы должны чтить и хранить свои традиции должны чтить свою культуру,свои праздники,должны любить и знать свою историю,своё наследие.Тогда конечно человек будет свободнее и в своём выборе и в суждениях.Но в наше время стоит желать лучшего,нет сейчас у подрастающего поколения ни духовного не нравственного развития.Нет тех ценностей,которые присущи человеку воспитанному в духовно нравственных традициях.Не знают они историю,а что преподносят им сильно искажено сейчас.Происходит деградация человека как личности,это на руку западным странам,что бы человек не был свободен ни в своем выборе нив своих мыслях и суждениях.
будут ли ему присущи такие качества как доброта,сострадание,терпимость,любовь,уважение,целомудрие.Духовность понятие сложное и многогранное,говоря о ней мы подразумеваем систему нравственных ценностей.На неё влияет и культура и искусство.Мы должны чтить и хранить свои традиции должны чтить свою культуру,свои праздники,должны любить и знать свою историю,своё наследие.Тогда конечно человек будет свободнее и в своём выборе и в суждениях.Но в наше время стоит желать лучшего,нет сейчас у подрастающего поколения ни духовного не нравственного развития.Нет тех ценностей,которые присущи человеку воспитанному в духовно нравственных традициях.Не знают они историю,а что преподносят им сильно искажено сейчас.Происходит деградация человека как личности,это на руку западным странам,что бы человек не был свободен ни в своем выборе нив своих мыслях и суждениях.
служба — в армии
в церкви
в офисе
свет — лунный
электрический
общество (выйти в свет)
собрание — сбор людей
сбор сочинений какого-нибудь автора
совещание какого-то важного органа власти
собрание родителей в школе
(PDF) Модель на основе графов для совместной сегментации китайских слов и анализа зависимостей
Джон Д. Лафферти, Эндрю МакКаллум и
Фернандо К. Н. Перейра. 2001. Условные случайные поля
dom: Вероятностные модели для сегмента
данных последовательности и маркировки. В материалах
Восемнадцатой Международной конференции по машинному обучению
(ICML 2001), Williams Col-
lege, Уильямстаун, Массачусетс, США, 28 июня — 1 июля,
2001.
Хаонан Ли, Чжисун Чжан, Юци Цзюй и Хай
Чжао. 2018. Зависимость на уровне нейронных символов
Анализдля китайского языка. В материалах Тридцати
Второй конференции AAAI по искусственному интеллекту —
gence (AAAI-18), 30-го инновационного приложения
искусственного интеллекта (IAAI-18) и 8-го симпозиума
AAAI по образовательным вопросам. Достижения в области искусственного интеллекта
(EAAI-18), Новый Орлеан,
Луизиана, США, 2–7 февраля 2018 г.
Чжэнхуа Ли, Минь Чжан, Вансян Че, Тин
Лю, Вэньлян Чен и Хайчжоу Ли. 2011.
Совместные модели для китайских POS-тегов и
анализа зависимостей. In Proceedings of the 2011
Conference on Empirical Methods in Natural
Language Processing, EMNLP 2011, 27–31
July 2011, John McIntyre Conference Center,
Эдинбург, Великобритания, собрание SIGDAT, a Spe-
Группа по интересам ACL.
Ван Лин, Крис Дайер, Алан В.Блэк и Изабель
Транкосо. 2015. Две / слишком простые адаптации
word2vec для синтаксических проблем. В NAACL
HLT 2015, Конференция Севера 2015 года
Американское отделение Ассоциации Com-
Предполагаемая лингвистика: человеческий язык
Technologies, Денвер, Колорадо, США, 31 мая —
5 июня 2015 года.
Илья Лощилов и Фрэнк Хаттер. 2019. De-
регуляризация спада сопряженного веса. На 7-й Международной конференции по обучению
, представленной
, ICLR 2019, Новый Орлеан, Луизиана, США,
6–9 мая 2019 г.
Джи Ма, Кузман Ганчев и Дэвид Вайс. 2018.
Современная сегментация китайских слов с помощью
bi-LSTM. In Proceedings of the 2018 Confer-
enceon Empirical Methods in Natural Language
Processing, Брюссель, Бельгия, 31 октября —
4 ноября 2018 года.
Hwee Tou Ng and Jin Kiat Low. 2004. Китайский
тегирование части речи: по одному или все —
сразу? На основе слов или символов? В материалах
Proceedings of the 2004 Conference on Em-
pirical Methods in Natural Language Pro-
cessing, EMNLP 2004, Meeting of SIGDAT,
Special Interest Group of the ACL, организованной в
совместно с ACL 2004 , 25–26 июля 2004 г. ,
,
Барселона, Испания.
Вэньчжэ Пей, Тао Гэ и Баобао Чанг. 2014.
Нейронная сеть тензора максимальной маржи для китайского языка
сегментация слов. В материалах 52-го ежегодного собрания
Ассоциации компьютерной лингвистики
, ACL 2014, 22–27 июня,
2014, Балтимор, Мэриленд, США, Том 1: Long
Papers.
Сиань Цянь и Ян Лю. 2012. Совместная китайская сегментация
слов, POS-теги и синтаксический анализ.
В материалах совместной конференции 2012 г.
по эмпирическим методам на естественном языке
Обработка и вычислительное обучение естественному языку
, EMNLP-CoNLL 2012,
12–14, 2012, остров Чеджу, Корея.
Сипенг Цю, Цзяи Чжао и Сюаньцзин Хуан.
2013. Совместная сегментация китайских слов и
тегов POS на разнородных аннотированных cor-
pora с многократным обучением. In Proceedings
of the 2013 Conference on Empirical Methods
in Natural Language Processing, EMNLP 2013,
18–21 октября 2013, Grand Hyatt Seattle, Сиэтл,
Вашингтон, США, встреча SIGDAT,
Special Группа интересов ACL.
Ян Шао, Кристиан Хардмайер, J¨
org Tiedemann,
и Йоаким Нивре. 2017. Символьная сегментация
и теги POS для китайского
с использованием двунаправленной RNN-CRF. В материалах
восьмой международной конференции по обработке естественного языка
, IJCNLP 2017,
Тайбэй, Тайвань, 27 ноября — 1 декабря,
2017 — Том 1: Длинные документы.
Тианзе Ши, Лян Хуанг и Лилиан Ли.2017.
Быстрое (er) точное декодирование и глобальное обучение
для анализа зависимостей на основе переходов через
минимальный набор функций. В материалах конференции
2017 г. по эмпирическим методам обработки естественного языка
, EMNLP 2017,
Копенгаген, Дания, 9–11 сентября 2017 г.
Ян Сун, Шумин Ши, Цзин Ли и Хайсонг
Чжан . 2018. Направленная скип-грамма: Explic-
2018. Направленная скип-грамма: Explic-
позволяет различать левый и правый контекст для
вложений слов.В материалах дела 2018 г.
91
3 Неуклюжие композиции
Марк Никол
В каждом из приведенных ниже предложений неудобный синтаксис приводит к отвлекающе неуклюжему потоку, который затрудняет понимание. Обсуждение и пересмотр каждого примера расскажет и покажет, как сделать поток утверждений более плавным.
1. Они хотели развить организацию, выходящую за рамки традиционной сети больниц, с успехом, измеряемым заполняемостью или «головами на коек».”
Когда появляется неформальное слово или фраза, используемые в качестве синонима для более формального термина, чеканка часто следует за стандартным термином в качестве аппозитива (термин, эквивалентный соседнему термину), что нелогично — зачем вводить сленговый термин после использования официальный, когда, появится он снова или нет, он сразу покажется избыточным? Единственная разумная причина для использования обоих синонимов — сначала ввести неформальный термин, который впоследствии снова появится в части содержания, а затем приукрасить (кратко определить) его формальным термином; после этого, когда читатели снова встретят этот термин, они уже будут проинформированы о его значении: «Они хотели развить организацию, выходящую за пределы ее корней, в традиционную сеть больниц с успехом, измеряемым« головами на кроватях »или занятостью.”
2. Этот вопрос был в центре внимания в Гонконге. Представитель денежно-кредитного управления Гонконга Джон Чанг прокомментировал его ответ на прошлой неделе.
В этом предложении «Гонконг» неудобно повторяется сразу же подряд, разделенных только точкой, что затрудняет чтение. Фразу, описывающую принадлежность Джона Чанга, легко изменить, чтобы она следовала за его именем, и это решение рекомендуется в целом, когда такое описание является обширным: «Проблема была в центре внимания в Гонконге. Джон Чанг, представитель денежно-кредитного управления Гонконга, прокомментировал его ответ на прошлой неделе ».
Джон Чанг, представитель денежно-кредитного управления Гонконга, прокомментировал его ответ на прошлой неделе ».
3. Методология расчета рейтинга риска клиента должна быть скорректирована с учетом любого повышенного риска финансовых преступлений.
Кластер прилагательных, предшествующий методологии , неудобен, потому что все слова в этой строке являются существительными, служащими прилагательными, и читатель может легко расстроиться из-за того, что ему нужно прерывисто читать фразу, пытаясь разобрать, где заканчивается фразовое прилагательное.Технически правильное решение — расставить строку через дефис, но результат получается громоздким. А еще лучше ослабить предложение, чтобы уменьшить количество элементов во фразовом прилагательном: «Методология расчета рейтинга риска клиента должна быть скорректирована с учетом любого повышенного риска финансовых преступлений».
Хотите улучшить свой английский за пять минут в день? Оформите подписку и начните ежедневно получать наши советы по написанию и упражнения!
Продолжайте учиться! Просмотрите категорию «Стиль», просмотрите наши популярные публикации или выберите соответствующую публикацию ниже:
Хватит делать эти досадные ошибки! Подпишитесь на Daily Writing Tips уже сегодня!
- Вы будете улучшать свой английский всего за 5 минут в день, гарантировано!
- Подписчики получают доступ к нашим архивам с более чем 800 интерактивными упражнениями!
- Вы также получите три бонусные электронные книги совершенно бесплатно!
Анализ заголовка для понимания естественного языка
Анализ заголовка для понимания естественного языкаДалее: Анализ и надежность в главном углу Up: Надежный синтаксический анализ с Предыдущая: Введение
Подразделы
Я предполагаю, что грамматики определены в Формализм грамматики с определенными предложениями [5].
 Без потери
В общем, я предполагаю, что никакие внешние вызовы Пролога (те, которые
определены в {и}). Более того, я предполагаю, что
такая грамматика представлена несколько иначе, чтобы
определение парсера проще, и убедиться, что правила
проиндексировано соответствующим образом. Это представление будет в
Практика может быть составлена из представления в удобной для пользователя нотации.
Без потери
В общем, я предполагаю, что никакие внешние вызовы Пролога (те, которые
определены в {и}). Более того, я предполагаю, что
такая грамматика представлена несколько иначе, чтобы
определение парсера проще, и убедиться, что правила
проиндексировано соответствующим образом. Это представление будет в
Практика может быть составлена из представления в удобной для пользователя нотации.Более конкретно, я предполагаю, что правила грамматики представлены предикат Head_rule / 4, в котором первым аргументом является глава правила, второй аргумент — материнский узел правила, третий аргумент — это перевернутый список дочерей слева от головы, и четвертый аргумент — это список дочери справа от головы.
Например, правило DCG
| (1) |
| (2) |
Кроме того, я предполагаю, что лексический поиск был выполняется уже другим модулем.В этом модуле есть утвержденные пункты для предиката lexical_analysis / 3, где первые два Аргументы — это позиции строки, а третий аргумент — это (лексическая) категория. Для предложения ввода «Время летит, как стрела» этот модуль может создавать следующий набор предложений:
| (3) |
 lexical_analysis (2,3, подготов.).lexical_analysis (2,3, глагол). lexical_analysis (3,4, дет).
lexical_analysis (4,5, существительное).
lexical_analysis (2,3, подготов.).lexical_analysis (2,3, глагол). lexical_analysis (3,4, дет).
lexical_analysis (4,5, существительное).
| (4) |
| (5) |
| (6) |

| (7) |
| (8) |
- использование нисходящей информации таблицей, представляющей
отношение голова-угол.Кроме того, индексация используется для эффективного
поиск по таблице.
 Отношение голова-угол включает информацию о
начальная и конечная позиции (например, требование, чтобы руководитель
sbar - это комплементатор в самой левой позиции этого
фраза sbar.
Отношение голова-угол включает информацию о
начальная и конечная позиции (например, требование, чтобы руководитель
sbar - это комплементатор в самой левой позиции этого
фраза sbar. - использование неполного указания информации о местоположении в случай пустых производств (правила эпсилона).
- (ограниченное) использование запоминания. Запоминание применяется только
для предиката parse / 5. Это означает, что каждые максимальных
проекция вычисляется только один раз; частичные проекции головы
могут быть построены во время синтаксического анализа любое количество раз, как и
последовательности категорий (рассматриваемые как сестры главе).Активный
парсеры диаграмм `запоминают 'все; неактивные парсеры диаграмм только памятка
категории, а не последовательности категорий. В нашем предложении мы
запоминайте только те категории, которые являются "максимальными проекциями", т.е.
проекции головы, которые объединяются с высшей категорией (начало
символ) или с дочерью правила, не являющейся главой.
Обратите внимание, что ничто не помешает нам запоминать и другие предикаты. Опыт показывает, что стоимость обслуживания таблиц, например, то отношение head_corner (намного) выше, чем связанное выгода.Использование мемоизации только для синтаксического анализа / 5 целей подразумевает, что требования к памяти парсера головного угла в с точки зрения количества записываемых элементов намного меньше чем в обычных парсерах диаграмм. Мы не только воздерживаемся от утверждая так называемые активных пунктов, но мы также воздерживаемся от утверждение неактивных пунктов для немаксимальных проекций голов. На практике разница в требованиях к пространству огромна (2 порядки величины). Эта разница, в свою очередь, может быть значительной. причина практической эффективности парсера головного угла. 1
- использование ослабляющих цели . Понимание того, что стоит за `goal
ослабление »в контексте запоминания состоит в том, что мы можем объединить
количество немного разных целей в одну более общую цель.
Очень часто решить этот сингл намного дешевле (но больше
общая) цель, чем решать каждую из конкретных целей по очереди.
Ясно, что нужно быть осторожным, чтобы не удалить важную информацию.
от цели (в худшем случае это может даже привести к
не прекращение работы программ с хорошим поведением).
В зависимости от свойств конкретной грамматики он может Например, стоит обратить внимание на , чтобы ограничить данную категорию ее синтаксических функций, прежде чем мы попытаемся решить задачу синтаксического анализа этого категория. Оператор ограничения Шибера [6] может быть здесь используется. Таким образом, мы, по сути, отбрасываем некоторую информацию перед тем, как сделана попытка решить (запомненную) цель. Например, категория
можно разложить на:х (A, B, f (A, B), g (A, h (B, i (C))))
(9) Обратите внимание, что ослабление цели - это разумно.Ответ на ослабленную цель g рассматривается как ответ для g , только если a и g объединяются. Также обратите внимание, что ослабление цели является полным в том смысле, что для ответ a на цель g всегда будет ответ a ' на ослабление г таким образом, что a ' включает a . Для практических реализаций можно использовать ослабление цели. чрезвычайно важно.По моему опыту, хорошо выбранная цель Оператор ослабления может сократить время синтаксического анализа на порядок величина.
- Компактное представление деревьев разбора упаковкой Неясность .
 Отношение голова-угол включает информацию о
начальная и конечная позиции (например, требование, чтобы руководитель
sbar - это комплементатор в самой левой позиции этого
фраза sbar.
Отношение голова-угол включает информацию о
начальная и конечная позиции (например, требование, чтобы руководитель
sbar - это комплементатор в самой левой позиции этого
фраза sbar.В этой системе вход для парсера - это не простой список слов, а скорее слово-граф: ориентированный ациклический граф, в котором состояния - моменты времени, а края помечены словесными гипотезами и соответствующая им вероятность.Таким образом, такие словесные графы являются ациклические весовые конечные автоматы.
В некоторых подходах к обработке некорректных входных данных желание обобщение от входных строк до входных конечных автоматов также явно присутствует. Например, в [3] фреймворк для описана некорректная обработка ввода, в которой некоторые общие ошибки моделируются как (взвешенные) преобразователи с конечным числом состояний. В композиция входного предложения с этими преобразователями дает (взвешенный) конечный автомат, который затем вводится для синтаксического анализатора.
Обобщение от строк до весовых автоматов вводит по сути две сложности. Во-первых, мы не можем использовать строковые индексы больше. Во-вторых, нам нужно отслеживать вероятности слова, используемые в определенном происхождении.
Парсинг на основе конечного автомата можно рассматривать как вычисление пересечения этого автомата с грамматикой. Можно показать, что если грамматика с определенными предложениями отключена анализируемый, и если конечный автомат ациклический, то этот вычисление может быть гарантированно завершено [7].Moverover, существующие методы парсинга на основе строки можно легко обобщить, используя имена состояний в автомат вместо обычных строковых индексов.
В парсере head-corner это приводит к изменению определения предикат между / 4. Вместо простого целого числа сравнения, теперь нам нужно проверить, что производная от P0 до P может быть расширен до производной от E0 до E с помощью проверка наличия путей в словесном графе от E0 до P0 и от P до E.
Предикат между / 4 реализован с использованием мемоизации как
следует. Предполагается, что названия состояний являются целыми числами; чтобы исключить
В циклических графах слов мы также требуем, чтобы для всех переходов от P0 к P выполнялось условие P0 Синтаксический и семантический синтаксический анализ исследуется десятилетиями,
что является одной из основных тем в сообществе разработчиков естественного языка.Эта статья предназначена для краткого обзора по этой теме.
Сообщество парсинга включает в себя множество задач,
которые трудно охватить полностью.
Здесь мы сосредоточимся на двух наиболее популярных формализации парсинга:
составной синтаксический анализ и анализ зависимостей.
Составной синтаксический анализ в основном нацелен на синтаксический анализ,
а анализ зависимостей может обрабатывать как синтаксический, так и семантический анализ.
В этой статье кратко рассматриваются репрезентативные модели составного синтаксического анализа и анализа зависимостей.
а также анализ графа зависимостей с богатой семантикой.Кроме того, мы также рассматриваем тесно связанные темы, такие как модели междоменного, кросс-языкового и совместного анализа,
приложение парсера, а также разработка корпуса синтаксического анализа в статье. Синтаксический и семантический анализ на уровне предложений - одна из основных тем в сообществе обработки естественного языка (NLP),
который направлен на раскрытие внутренних структурных отношений в предложениях [manning1999foundations, kubler2009dependency, zcq2013, jurafsky2019speech] .С точки зрения лингвистики,
цель синтаксического анализа - раскрыть, как слова объединяются в предложения, а также правила, которые управляют формированием предложений.
С другой стороны, с точки зрения приложений НЛП,
парсинг может быть полезен для ряда задач,
такие как машинный перевод, ответы на вопросы, извлечение информации, анализ тональности и генерация Синтаксический анализ широко изучается на протяжении десятилетий.
Цель синтаксического анализа - получить синтаксическую информацию в предложениях,
такие как предметы, объекты, модификаторы и темы.
Для этой задачи был достигнут ряд достижений,
и уже доступны крупномасштабные корпуса для ряда языков.
По сравнению с синтаксическим анализом,
семантический синтаксический анализ намного сложнее из-за сложной структуры различной семантики, такой как предикат-аргумент,
и это также долгосрочная цель НЛП.Благодаря недавнему прогрессу в моделях машинного обучения на основе данных,
семантический синтаксический анализ привлекает все больший интерес, особенно в нейронной среде.
Для облегчения исследования было разработано несколько наборов данных на основе определенных формализаций. При синтаксическом анализе часто используются определенные грамматики,
которые используются для уточнения структуры вывода синтаксиса и семантики.
Существует множество сложных грамматик для точного выражения синтаксической и семантической информации на уровне предложения.В этой статье мы сосредоточимся на двух популярных грамматиках, которые больше всего интересуют нас.
Контекстно-свободная грамматика (CFG), известная как составной синтаксический анализ (или синтаксический анализ структуры фраз) [jurafsky2019speech] (таким образом, также как составная грамматика или грамматика структуры фраз), принимает иерархические структурные деревья фраз для организации синтаксической информации на уровне предложений,
который интенсивно исследуется с самого начала.
Грамматика зависимостей - еще одна широко используемая грамматика для синтаксического и семантического разбора,
где слова напрямую связаны ссылками зависимости, с метками, указывающими их синтаксические или семантические отношения [kubler2009dependency] .Благодаря лаконичности и простоте аннотации структур зависимостей,
синтаксическому анализу зависимостей уделялось больше внимания, чем синтаксическому анализу составляющих. Кроме того, есть много других замечательных грамматик.
Репрезентативные темы включают комбинаторно-категориальную грамматику (CCG),
грамматика структуры фраз, управляемая головой (HPSG),
лексико-функциональная грамматика (ЛФГ),
представление абстрактного значения (AMR),
семантика минимальной рекурсии (MRS),
универсальная концептуальная когнитивная аннотация (UCCA)
а также несколько формализаций, ориентированных на логику.Все эти категории исследуются давно.
и, в частности, некоторые из них сейчас быстро развиваются из-за мощи нейронных сетей.
а также предварительно обученные контекстуализированные представления слов.
Однако в данной статье эти исследования оставлены для будущих более всеобъемлющих обзоров. Здесь мы делаем краткий обзор синтаксического и семантического синтаксического анализа на основе составной грамматики и двулексикализованной грамматики зависимостей.
В разделах 2 и 3 мы рассматриваем исследования составного синтаксического анализа и анализа зависимостей соответственно.
где анализ зависимостей основан на древовидной структуре и специально нацелен на синтаксис.
Мы дополнительно исследуем семантически-ориентированный синтаксический анализ графа зависимостей в разделе 4.
В разделах 5 и 6 рассматривается кросс-доменный и кросс-языковой синтаксический анализ, который является одним из горячих направлений.В разделе 7 рассматриваются совместные модели, которые нацелены на анализ в качестве конечной цели.
в то время как в разделе 8 рассматриваются стратегии приложений синтаксического анализатора, в которых анализаторы оцениваются в последующих приложениях.
Раздел 9 знакомит с работой связанного с ним банка деревьев, который служит основным корпусом обучения для различных синтаксических анализаторов, а также для оценки модели синтаксического анализатора.
Наконец, в Разделе 10 резюмируются выводы и будущая работа. Составной синтаксический анализ - одна из основных задач синтаксического анализа,
который вызывает большой интерес на протяжении десятилетий [manning1999foundations, zcq2013, jurafsky2019speech] .На рисунке 1 показан пример составного дерева,
где узлы в дереве составных частей являются составными промежутками, также известными как фразы.
Цель составного синтаксического анализа - выявить эти фразы, а также их отношения.
Стандартный метод оценки составляющих синтаксических анализаторов основан на распознавании фраз,
где точность, отзывчивость и оценка F1-меры приняты в качестве основных показателей. Основные подходы к составному синтаксическому анализу включают модели, основанные на диаграммах и переходах.Современные нейронные модели достигли высочайшего уровня производительности при использовании обоих двух методов.
Фактически, анализ нейронных составляющих начинается очень рано, до процветания глубокого обучения Первые успешные модели анализа составляющих используют продуктивные правила CFG для управления генерацией составляющих деревьев.
Алгоритмы синтаксического анализа диаграммы используются повсеместно для декодирования,
и большая часть усилий сосредоточена на уточнении правил CFG, которые служат основными источниками оценки параметров. Указанные выше модели страдают от сложности интеграции нелокальных функций.
поскольку будущие решения невидимы во время декодирования, что имеет решающее значение для глобального вывода.Условное случайное поле (CRF) - это один из способов глобального моделирования. hall-etal-2014-less ( hall-etal-2014-less ) [hall-etal-2014-less] предлагает сильную модель анализа компонентов путем адаптации стандартных n-граммовых моделей CRF для CFG ,
и тем временем представляя богатые сложные функции.
Можно смоделировать зависимости между смежными правилами CFG,
которые используются для глобального вывода. socher2010learning ( socher2010learning ) [socher2010learning] - первая работа, в которой рекурсивные нейронные сети определяют оценки по фразам.Таким образом можно естественным образом смоделировать составные деревья на основе CFG.
Соответственно, нейронный анализ CRF предлагается durrett-klein-2015-neural ( durrett-klein-2015-neural ) [durrett-klein-2015-neural] ,
что можно рассматривать как нейронное усиление hall-etal-2014-less ( hall-etal-2014-less ) [hall-etal-2014-less] .
В работе просто используются нейронные сети с прямой связью для кодирования элементарных функций вместо человеческого состава.Обратите внимание, что он отличается от stern-etal-2017-minimal ( stern-etal-2017-minimal ) [stern-etal-2017-minimal] предлагают современные нейронные модели на основе диаграмм.
С одной стороны, они используют нейронные сети с глубокой двунаправленной долговременной памятью (LSTM) для улучшения представления предложений,
разработка сложных стратегий для представления диапазона.С другой стороны, они также применяют нисходящий инкрементный синтаксический анализ для декодирования,
который размывает различия между подходами, основанными на диаграммах и переходах.
В то же время их результаты очень хороши по сравнению с современными методами, основанными на переходах.
Далее следуют Модели на основе переходов демонстрируют высокую перспективность для анализа составляющих [ratnaparkhi-1997-linear, sagae-lavie-2005-classifier] .Ключевая идея - определить систему переходов с переходными состояниями и действиями,
где состояния обозначают результаты частичного синтаксического анализа,
а действия определяют операции перехода между состояниями следующего шага.
Действия перехода указывают на процесс построения инкрементного дерева.
Для составного синтаксического анализа типичные действия включают смещение на построение оконечных узлов, унарных на построение унарных узлов,
и двоичный код для построения двоичных узлов.
Детали могут упоминаться как sagae-lavie-2005-classifier ( sagae-lavie-2005-classifier ) [sagae-lavie-2005-classifier] .Модель также обычно называют моделью сдвига-уменьшения, где унарный и двоичный являются действиями сокращения.
Преобразуя составной синтаксический анализ в предсказание последовательности действий перехода,
дискриминантные классификаторы, такие как максимальная энтропия и машина опорных векторов (SVM), могут применяться для прогнозирования,
с богатыми функциями, созданными вручную. Исходная модель сокращения сдвига классифицирует последовательность действий для одного составляющего дерева отдельно,
жадно ищет лучшее дерево выходных составляющих,
который может страдать от проблемы распространения ошибки, поскольку ошибки на раннем этапе могут повлиять на более поздние прогнозы.С этой целью предлагается глобальное моделирование с поиском луча, чтобы облегчить проблему,
который декодирует полную последовательность действий для всего составляющего дерева в целом [zhang-clark: 2009: IWPT09, zhu-etal-2013-fast] .
Онлайн-обучение в стиле различительного перцептрона в значительной степени способствует этому направлению работы watanabe-sumita-2015-transition ( watanabe-sumita-2015-transition ) [watanabe-sumita-2015-transition] и wang-etal-2015-feature ( wang-etal-2015- feature ) [wang-etal-2015-feature] может быть прямым расширением zhu-etal-2013-fast ( zhu-etal-2013-fast ) [zhu-etal-2013-fast] с помощью нейронных сетей.
Состав атомарных функций достигается с помощью нейронных сетей с прямой связью. cross-huang-2016-incremental ( cross-huang-2016-incremental ) [cross-huang-2016-incremental] обнаружили, что декодирование в жадном стиле также может обеспечить высокую конкурентоспособность при использовании глубокого кодировщика LSTM .
Затем несколько исследований предлагают динамические оракулы для оптимизации жадных составляющих синтаксических анализаторов. [cross-huang-2016-span, coavoux-crabbe-2016-neural] .
Основная идея состоит в том, чтобы позволить моделям принимать оптимальные решения, когда они сталкиваются с ошибочными переходными состояниями [goldberg-nivre-2012-dynamic] .Часть обучающих экземпляров с ошибочными переходными состояниями и их действиями оракула добавляется в исходный обучающий корпус. Было проведено несколько исследований, в которых использовались различные стратегии перехода. dyer-etal-2016-recurrent ( dyer-etal-2016-recurrent ) [dyer-etal-2016-recurrent] предполагает повторяющуюся грамматику нейронной работы (RNNG),
которая представляет собой систему, основанную на переходе сверху вниз. liu-zhang-2017-order ( liu-zhang-2017-order ) [liu-zhang-2017-order] разработать систему перехода по порядку, чтобы найти компромисс между нисходящим и восходящим переходы. coavoux-etal-2019-unlexicalized ( coavoux-etal-2019-unlexicalized ) [coavoux-etal-2019-unlexicalized] представляет новую систему с дополнительным действием GAP для прерывистого синтаксического анализа избирательных округов,
они также обнаружили, что нелексикализованные модели обеспечивают лучшую производительность. fernandez2019faster ( fernandez2019faster ) [fernandez2019faster] оптимизировать действия перехода для облегчения построения небинаризованных составляющих узлов,
избегая предварительной обработки бинаризации для составляющих деревьев. Нейронные сети, такие как глубокий LSTM и самовнимание с несколькими головами
способны неявно кодировать глобальные функции в их окончательные представления,
что ослабляет роль декодирования как источника наведения признаков.Основываясь на наблюдении,
в нескольких исследованиях делается попытка использовать простые рамки,
стремясь к широкому сообществу для синтаксического анализа. Одна репрезентативная попытка состоит в использовании нейронных моделей последовательностей для структурного анализа составляющих [vinyals2015grammar, choe-charniak-2016-parsing] .
Ключевая идея состоит в том, чтобы сначала линеаризовать структурно-фразовое составляющее дерево в последовательность символов с помощью определенных стратегий обхода,
а затем напрямую подать пару входных слов и выходных символов в стандартную модель «последовательность-последовательность».Эти модели требуют больших корпусов для обучения,
которые могут быть получены с помощью автоматического анализа составляющих деревьев с высокой степенью достоверности из других современных синтаксических анализаторов. Модели маркировки нейронных последовательностей также были исследованы для анализа составляющих [gomez-rodriguez-vilares-2018-constituent] . гомес-родригес-виларес-2018-составляющая ( гомес-родригес-виларес-2018-составляющая ) [гомес-родригес-виларес-2018-составляющая] предлагаю первую работу этой линии,
который использует наименьшего общего предка между соседними словами в качестве ключей для кодирования ролей слов. vilares2020parsing ( vilares2020parsing ) [vilares2020parsing] расширяет работу с помощью языкового моделирования и улучшает синтаксический анализ с помощью предварительного обучения.
Кроме того, были предложены более прямые схемы с локальным моделированием для составного анализа. shen-etal-2018-прямой ( shen-etal-2018-прямой ) [shen-etal-2018-прямой] напрямую предсказывает расстояние составляющих фраз
а затем жадно декодировать сверху вниз для получения полного дерева компонентов.Аналогичным образом, teng-zhang-2018-two ( teng-zhang-2018-two ) [teng-zhang-2018-two] предлагает две модели, основанные на локальном прогнозе пролета,
достижение высокой конкурентоспособности на уровне моделей, основанных на переходе.
Недавно была представлена zhou-zhao-2019-head ( zhou-zhao-2019-head ) [zhou-zhao-2019-head] для использования основанной на HPSG грамматики для составного синтаксического анализа,
и дополнительно снабдите модель представлениями слов XLNet [yang2019xlnet] ,
достижение максимальной производительности для наборов данных CTB и PTB. mrini2019rethinking ( mrini2019rethinking ) [mrini2019rethinking] пересмотр механизма самовнимания с несколькими головками в zhou-zhao-2019-head ( zhou-zhao-2019-head -head --) -заголовок] ,
что приводит к аналогичной производительности с меньшим количеством слоев. Полууправляемая архитектура направлена на улучшение контролируемой модели за счет статистической информации, извлеченной из необработанного текста. mcclosky-etal-2006-effective ( mcclosky-etal-2006-effective ) [mcclosky-etal-2006-effective] представляет первую работу, в которой достигается улучшенная производительность для анализа составляющих путем самообучения,
и mcclosky-etal-2008-self ( mcclosky-etal-2008-self ) [mcclosky-etal-2008-self] эмпирически изучают самообучение, чтобы показать условия полезности. candito2009improving ( candito2009improving ) [candito2009improving] использовать неконтролируемые кластеры слов, полученные из необработанного текста, для улучшения составного синтаксического анализа.
В то время как недавние исследования переходят к настройке нейронной сети, граница между полу-контролируемым и контролируемым становится нечеткой.
поскольку предварительное обучение на основе необработанного текста является критически важным для успешности нейронных моделей. Ансамбль моделей - один из эффективных способов повысить производительность анализа компонентов.Первоначальная работа сосредоточена на изменении ранжирования выходных данных [collins-koo-2005-discinative, huang-2008-forest] .
В качестве входных данных мы можем взять либо k-лучшие выходы составного синтаксического анализатора, либо одни лучшие выходы из разнородных анализаторов,
а затем построить новое дерево составляющих, используя многофункциональную модель переориентации.
Воспользовавшись сложными нелокальными функциями, созданными вручную,
фреймворк может значительно улучшить производительность парсера.
Однако связанные с ней исследования в нейронных сетях вызвали гораздо меньшее беспокойство,
что потенциально может быть связано с тем, что большинство современных нейронных моделей используют одни и те же кодировщики предложений,
что указывает на сходство функций в разных типах моделей, а между тем на однородный ансамбль (например,г., разные случайные семена)
простым голосованием можно добиться непревзойденных результатов. Разбор зависимостей разработан для синтаксического и семантического анализа с использованием билексикализованной грамматики зависимостей,
где все синтаксические и семантические явления представлены билексикализованными зависимостями [kubler2009dependency] .
На рисунке 2 показан пример дерева анализа зависимостей.
Для оценки различных анализаторов зависимостей в качестве основного показателя используется точность зависимостей,
с точки зрения немаркированной оценки привязанности (UAS) и маркированной оценки привязанности (LAS).На ранней стадии синтаксический анализ зависимостей ограничен деревьями, проективными или непроективными [hajic-etal-2009-conll1] .
Недавно несколько исследований были посвящены синтаксическому анализу зависимостей по графам [oepen2015semeval] .
С одной стороны, исходные деревья зависимостей в основном ориентированы на синтаксис,
в то время как в последнее время растет интерес к семантическим отношениям между словами [hajic-etal-2009-conll1, oepen2015semeval] .
Этот раздел в основном посвящен синтаксическому анализу дерева зависимостей,
а анализ графа зависимостей будет обсуждаться в следующем разделе. Большинство моделей анализа зависимостей можно разделить на два типа:
на основе графов и переходов [nivre-mcdonald-2008-integration] ,
оба из них были тщательно исследованы в традиционных статистических условиях [mcdonald-etal-2005-online, XavierCarreras2007, nivre-iwpt03, Yamada2003] и
нейронная установка [nivre-mcdonald-2008-integration] .
Существуют также другие интересные подходы к синтаксическому анализу зависимостей за пределами двух категорий [li-etal-2018-seq2seq] .Таблица 2 показывает общую картину производительности нескольких типичных анализаторов зависимостей.
и все модели ансамбля исключены в этой таблице.
Модели на основе графиков и переходов практически сопоставимы (модели на основе графиков немного выше) как в традиционных статистических, так и в нейронных настройках,
и другие типы моделей достигают хорошей производительности благодаря поддержке сложных нейронных сетей.
В настоящее время нейронные модели достигают самых современных характеристик при синтаксическом анализе зависимостей [kulmizev-etal-2019-deep] . Графические методы используют алгоритм максимального связующего дерева (MST) для декодирования,
который разбивает полное дерево зависимостей на небольшие факторы, такие как края зависимостей,
и оценивает все дерево путем суммирования оценок всех включенных факторов.
Оценка каждого фактора может быть рассчитана независимо по извлеченным из него характеристикам.
Модели, использующие ребра зависимости в качестве основного скорингового фактора, называются моделями первого порядка.
где порядок указывает максимальное количество ребер в множителе. Позже были изучены MST-синтаксические анализаторы более высокого порядка.
При больших факторах модели синтаксического анализа могут использовать более сложные функции и, таким образом, потенциально могут улучшить производительность.
Модели синтаксического анализа MST второго порядка были тщательно изучены [mcdonald-06-phd-thesis, McDonald2006, XavierCarreras2007, Bohnet2010] ,
где недавно добавленные функции включают отношения из факторов родитель-брат и родитель-ребенок-внук.Обратите внимание, что декодирование MST более высокого порядка может иметь более высокую временную сложность (то есть от O (n3) до O (n4)),
что может привести к невыносимой скорости синтаксического анализа.
Проблема может быть решена с помощью Bohnet2010 ( Bohnet2010 ) [Bohnet2010] с хешированием функций. koo-collins-2010-effective ( koo-collins-2010-effective ) [koo-collins-2010-effective] предложит эффективную модель анализа зависимостей третьего порядка,
который добавляет в модель функции старшего брата и тройного брата. lei-etal-2014-low ( lei-etal-2014-low ) [lei-etal-2014-low] использовать тензор низкого ранга для облегчения бремени проектирования функций.
Анализ зависимостей четвертого порядка был исследован pei-etal-2015-эффективный ( pei-etal-2015-эффективный ) [pei-etal-2015-эффективный] представляет нейронную модель на основе графов
путем встраивания всех дискретных атомарных характеристик в традиционные статистические модели MST и
затем составление этих вложений с аналогичной сетью прямой связи ( chen-manning-2014-fast , chen-manning-2014-fast ) [chen-manning-2014-fast] .Затем сверточная нейронная сеть применяется для композиции нейронных признаков в dozat2016deep ( dozat2016deep ) [dozat2016deep] предлагает глубокий биаффиновый синтаксический анализатор, который достигает впечатляющих характеристик,
повышение количества UAS и LAS до нового уровня.
Парсер использует трехуровневый двунаправленный LSTM в качестве кодировщика,
и двунаправленная операция в качестве декодера для оценки всех возможных краев зависимости.
Эта работа использует несколько приемов для достижения их окончательного результата,
например, выпадение на уровне узла и одна и та же маска выпадения на каждом повторяющемся временном шаге. li2019self ( li2019self ) [li2019self] дальнейшее усовершенствование синтаксического анализатора biaffine с помощью кодировщика с самовниманием и
контекстуализированные представления слов, такие как ELMo и BERT [peters-etal-2018-deep, devlin-etal-2019-bert] . ji-etal-2019-graph ( ji-etal-2019-graph ) [ji-etal-2019-graph] используют нейронные сети графа для улучшения кодировщика входных предложений. Модели на основе переходов добились больших успехов в синтаксическом анализе зависимостей.В некоторой степени основанной на переходе структуре затем уделяется большое внимание другим задачам НЛП, связанным со структурным обучением.
из-за успешности синтаксического анализа зависимостей.
Например, анализ составляющих на основе переходов изначально основан на анализе зависимостей на основе переходов.
С одной стороны, модели на основе переходов могут получить почти эквивалентную производительность по сравнению с методами на основе графов.
С другой стороны, эти модели очень эффективны, что позволяет достичь линейной временной сложности.Модели на основе переходов преобразуют анализ зависимостей в инкрементный процесс перехода между состояниями,
где состояния обозначают частичные выходы, и они продвигаются шаг за шагом предопределенными действиями перехода. Начальная работа по синтаксическому анализу зависимостей на основе переходов предлагается nivre-iwpt03 ( nivre-iwpt03 ) [nivre-iwpt03] и Yamada2003 ( Yamada2003 )
а затем тщательно исследуется структура [nivre-cl08, gomez-rodriguez-nivre-2013-divisible] .Существуют две типичные переходные конфигурации: стандартная дуга и режим готовности к дуге, соответственно.
которые сопоставимы по производительности синтаксического анализа.
Обычно действия перехода включают в себя операцию , сдвиг, (с целью запуска следующей обработки текста), arc-left (с целью построения зависимости направления влево),
и arc-right (стремясь к правильным направленным зависимостям).
Кроме того, некоторые исследователи предлагают другие конфигурации перехода [nivre-2009-non, sartorio-etal-2013-transition, gomez-rodriguez-nivre-2013-divisible, noji-miyao-2014-left] ,
который может обрабатывать различные сложные случаи, такие как непроективные зависимости. Ранние методы, основанные на переходах, обычно используют дискриминантные классификаторы для предсказания действий, когда задано определенное состояние перехода,
который обрабатывает синтаксический анализ локально.
В схеме может возникнуть проблема распространения ошибок, когда ранние ошибки могут повлиять на будущие прогнозы.
Чтобы решить эту проблему, одним из эффективных способов является глобальное обучение с поиском луча. Чжан-Кларк-2008-Сказка ( Чжан-Кларк-2008-Сказка ) [Чжан-Кларк-2008-Сказка] сначала примените стратегию.Богатые глобальные функции, которые использовались в анализаторах зависимостей на основе графов высокого порядка, также могут быть интегрированы.
в модель [zhang-nivre-2011-transition] .
Стратегию также можно улучшить с помощью динамического программирования [huang-sagae-2010-dynamic, kuhlmann-etal-2011-dynamic] . Другая альтернативная стратегия - динамический оракул,
который впервые предлагается goldberg-nivre-2012-dynamic ( goldberg-nivre-2012-dynamic ) [goldberg-nivre-2012-dynamic] для моделей на основе переходов с использованием arc-eager.Метод определяет динамический оракул золотого стандарта на основе выборки ошибочных состояний,
а затем добавьте эти экземпляры для улучшения обучения модели.
Таким образом, мы можем минимизировать глобальные потери производительности при возникновении ошибок.
Хотя стратегия дает несколько худшую производительность, чем zhang-nivre-2011-transition ( zhang-nivre-2011-transition ) [zhang-nivre-2011-transition] ,
он обеспечивает жадный анализ зависимостей, значительно повышая эффективность синтаксического анализа.
Стратегия была исследована в нескольких исследованиях с различными конфигурациями,
например, стандартный и непроективный синтаксический анализ [goldberg-etal-2014-tabular, gomez-rodriguez-etal-2014-polynomial] . ( chen-manning-2014-fast , chen-manning-2014-fast ) [chen-manning-2014-fast] - это одна жернова для анализа нейронной зависимости,
который заменяет традиционные, созданные вручную дискретные функции нейронными функциями.
В работе используются простые нейронные сети с прямой связью, чтобы автоматически составлять вложения всех атомарных функций,
и, таким образом, не требует разработки функций.
Наконец, предложенная модель показала намного лучшие характеристики, чем соответствующий базовый статистический показатель.Предварительно обученные вложения слов и функция нейронной композиции - ключи к успеху. Существует несколько направлений повышения производительности анализа зависимостей на основе нейронных переходов.
Во-первых, мы можем использовать более совершенные структуры нейронной сети.
Stack-LSTM представлен dyer-etal-2015-transition ( dyer-etal-2015-transition ) [dyer-etal-2015-transition] , за которым следуют несколько исследований [ballesteros-etal-2015 -улучшенный, ballesteros-etal-2017-greedy, de-lhoneux-etal-2019-recursive] ,
которые могут представлять переходные состояния, используя частичную структурную информацию.Параллельно исследуется глубокий двунаправленный LSTM [kiperwasser-goldberg-2016-simple, ma-etal-2018-stack] . ma-etal-2018-stack ( ma-etal-2018-stack ) [ma-etal-2018-stack] использует кодировщик, аналогичный dozat2016deep ( dozat2016deep ) [dozat2016deep] , достижение немного лучших характеристик, чем ( dozat2016deep , dozat2016deep ) [dozat2016deep] .
Фактически, с помощью мощных нейронных кодировщиков, особенно предварительно обученных контекстуализированных представлений слов,
разница в производительности между графами и переходами очень незначительна [kulmizev-etal-2019-deep] . Несколько исследователей предлагают глобальное обучение со стратегией поиска луча в ( zhang-nivre-2011-transition , zhang-nivre-2011-transition ) [zhang-nivre-2011-transition] в нейронной среде. zhou-etal-2015-neural ( zhou-etal-2015-neural ) [zhou-etal-2015-neural] сделать пионерские попытки для достижения этой цели,
который дополнительно усовершенствован с теоретической гарантией andor-etal-2016-global ( andor-etal-2016-global ) [andor-etal-2016-global] .Эти модели достигли высочайшего уровня производительности до синтаксического анализатора biaffine [dozat2016deep] .
Одним из основных недостатков является то, что стратегия страдает проблемой эффективности из-за поиска луча.
Также применяется стратегия динамического оракула, позволяющая создавать жадные анализаторы нейронных зависимостей на основе переходов. [Fernandez-gonzalez-gomez-rodriguez-2018-dynamic-oracle] .
В последнее время как глобальное обучение, так и динамический оракул трудно дать значительно улучшенные возможности.
когда используются предварительно обученные контекстуализированные представления слов. Также рассматриваются несколько интересных моделей вне рамок на основе графов и переходов.
Например, основанная на грамматике структура также может применяться к синтаксическому анализу зависимостей.
Во-первых, дерево зависимостей преобразуется в эквивалентное структурно-фразовое составное дерево,
а затем модель анализа составляющих на основе грамматики может быть применена для анализа зависимостей.
Метод предложен в первую очередь mcdonald-06-phd-thesis ( mcdonald-06-phd-thesis ) [mcdonald-06-phd-thesis] ,
а также сильно подчеркнута в kubler2009dependency ( kubler2009dependency ) [kubler2009dependency] .В нескольких исследованиях этот метод использовался как один из компонентов для ансамбля модели [sun-wan-2013-data] .
Недавно, zhou-zhao-2019-head ( zhou-zhao-2019-head ) [zhou-zhao-2019-head] и mrini2019rethinking ( mrini2019rethinking ) rething2010 грамматика для той же цели,
достижение очень конкурентоспособных результатов. goldberg-elhadad-2010-effective ( goldberg-elhadad-2010-effective ) [goldberg-elhadad-2010-effective] представляет собой простую модель синтаксического анализа зависимостей, которая обрабатывает входные предложения в не- направленный путь.Выходное дерево зависимостей строится рекурсивно, при этом дуга зависимости с наивысшей степенью достоверности выбирается каждый раз.
Нейронная версия работы используется kiperwasser-goldberg-2016-easy ( kiperwasser-goldberg-2016-easy ) [kiperwasser-goldberg-2016-easy] с использованием иерархических LSTM.
Последовательное обучение может также применяться к синтаксическому анализу нейронных зависимостей, где линеаризация на основе переходов может служить одним естественным решением. li-etal-2018-seq2seq ( li-etal-2018-seq2seq ) [li-etal-2018-seq2seq] представляет собой строгую модель последовательности с предсказанием заголовка для каждого слова. strzyz-etal-2019-viable ( strzyz-etal-2019-viable ) [strzyz-etal-2019-viable] предлагают модель маркировки последовательностей для анализа зависимостей. Здесь мы вкратце предлагаем обзор полууправляемого синтаксического анализа зависимостей при традиционной статистической настройке,
который использует статистическую информацию, извлеченную из необработанного текста, для улучшения базовой модели.
Эта схема не получила должного внимания в нейронных сетях из-за предварительного обучения.В целом, полууправляемые модели синтаксического анализа зависимостей можно разделить на три типа.
согласно извлеченной информации из необработанного текста,
а именно методы уровня слова, уровня частичного дерева и уровня предложения. Для информации на уровне слов одна репрезентативная работа: ( koo-etal-2008-simple , koo-etal-2008-simple ) [koo-etal-2008-simple] ,
который дополняет элементарные особенности базовой модели кластерами слов. zhou-etal-2011-exploiting ( zhou-etal-2011-exploiting ) [zhou-etal-2011-exploiting] использовать информацию о предпочтениях выбора из веб-текстов для улучшения анализа зависимостей.Фактически, вложения слов можно также рассматривать как своего рода полу-контролируемую информацию на уровне слов,
который был предложен turian-etal-2010-word ( turian-etal-2010-word ) [turian-etal-2010-word] для НЛП, но не экспериментировал с анализом зависимостей. chen-etal-2014-feature ( chen-etal-2014-feature ) [chen-etal-2014-feature] еще больше расширяет идею до встраивания функций, встраивая все функции, включая слова. Для интеграции на уровне частичного дерева chen2008dependency ( chen2008dependency ) [chen2008dependency] использовать высокочастотные автоматически анализируемые билексические зависимости для улучшения базовой контролируемой модели.Кроме того, chen-etal-2009-Superior ( chen-etal-2009-Superior ) [chen-etal-2009-Improvement] расширяют работу, используя поддеревья более высокого порядка. chen-etal-2012-using ( chen-etal-2012-using ) [chen-etal-2012-using] можно рассматривать как общую основу для частичной интеграции на уровне дерева,
за счет использования моделей языка зависимостей, полученных из автоматически анализируемых деревьев зависимостей. Самостоятельное обучение, совместное обучение, а также тройное обучение - простые методы для уровня предложения
полуконтрольное обучение Эффективно комбинируя разнородные модели,
производительность анализа зависимостей может быть дополнительно увеличена. nivre-mcdonald-2008-integration ( nivre-mcdonald-2008-integration ) [nivre-mcdonald-2008-integration] сначала проанализируйте различия между моделями на основе графов и на основе переходов
а затем объедините два типа моделей, чтобы использовать их дополнительную информацию,
что приводит к лучшим характеристикам. sun-wan-2013-data ( sun-wan-2013-data ) [sun-wan-2013-data] выполняет анализ ансамбля, дополнительно включая грамматические модели,
которые сильно различаются между моделями на основе графов и переходов.
При нейронной настройке простое голосование может дать очень хорошие результаты. Все вышеперечисленные исследования нацелены на разные модели синтаксического анализа, основанные на одном и том же банке деревьев.
Есть несколько исследований, направленных на ансамбль парсеров на основе разнородных групп деревьев,
чьи правила аннотации сильно различаются. li-etal-2012-exploiting ( li-etal-2012-exploiting ) [li-etal-2012-exploiting] использовать многослойное обучение в сочетании с квазисинхронными грамматиками для эффективной интеграции. guo-etal-2016-universal ( guo-etal-2016-universal ) [guo-etal-2016-universal] изучить аналогичный ансамбль с помощью глубокого многозадачного обучения,
где также есть берега деревьев на разных языках. jiang-etal-2018-под наблюдением ( jiang-etal-2018-supervised ) [jiang-etal-2018-supervised] представляет и изучает задачу контролируемого преобразования банка деревьев,
который может служить одним из методов интеграции. Все модели анализа зависимостей, упомянутые в предыдущем разделе, предназначены для синтаксического анализа дерева зависимостей,
который в основном отражает синтаксическую и поверхностно-семантическую информацию в предложениях.
Поскольку требования к глубокому семантическому синтаксическому анализу растут,
что трудно выразить только деревом зависимостей,
Парсинг графа зависимостей вызывает растущий интерес [oepen-etal-2014-semeval, oepen2015semeval, che-etal-2016-semeval] ,
что позволяет использовать несколько (включая ноль) заголовков для одного слова в предложениях.Обратите внимание, что семантический граф по-прежнему формализован набором билексикализованных зависимостей,
с узлами, соответствующими поверхностным лексическим словам, и ребрами, указывающими семантические отношения между узлами. Существуют разные формализации графа семантических зависимостей.
Мы можем комбинировать синтаксический анализ зависимостей на основе дерева и семантическую маркировку ролей (SRL), чтобы получить граф зависимостей,
который называется синтаксисом совместной зависимости и SRL [surdeanu-EtAl: 2008: CONLL, hajic-etal-2009-conll1] .Недавно была представлена концепция синтаксического анализа семантических зависимостей (SDP) [oepen-etal-2014-semeval, oepen2015semeval, che-etal-2016-semeval] ,
который обеспечивает различные представления семантических отношений, такие как DELPH-IN MRS (DM), структуры предиката-аргумента (PDS) и семантические зависимости Праги (PSD).
Далее мы рассмотрим исследования двух типов разбора семантического графа зависимостей. На рисунке 3 показан пример графа зависимостей совместных синтаксических и семантических зависимостей.Здесь мы не собираемся знакомить с моделями трубопроводов,
которые тренируют синтаксические и семантические модели отдельно,
а затем вывести график зависимостей либо в два этапа, либо вместе [che-EtAl: 2009: CoNLL-2009-ST, johansson-2009-statistics] .
Хотя эти модели могут выполнять синтаксический анализ графа зависимостей,
им уделяется меньше внимания, чем этой теме.
Мы ориентируемся на модели совместного обучения и декодирования для полного разбора графа зависимостей.
В таблице 3 показаны результаты нескольких исследований по этой линии. titov2009online ( titov2009online ) [titov2009online] расширяет анализ зависимостей на основе переходов с помощью конкретной операции swap ,
позволяют модели обрабатывать непланарность нескольких графов совместно,
и, таким образом, синтаксический анализ графа зависимостей может выполняться совместно. henderson-etal-2013-multingual ( henderson-etal-2013-multingual ) [henderson-etal-2013-multingual] также используют структуру на основе переходов для получения синтаксических и семантических
зависимости, одновременно основанные на такой же переходной системе, что и titov2009online ( titov2009online ) [titov2009online] ,
но принять другую модель оценки, используя инкрементную сигмовидную сеть убеждений со скрытыми переменными. lluis-etal-2013-Joint ( lluis-etal-2013-Joint ) [lluis-etal-2013-Joint] представляет модель на основе графа с алгоритмом двойной декомпозиции для декодирования,
одновременное присвоение синтаксических и семантических зависимостей. Все вышеупомянутые исследования основаны на традиционных статистических условиях.
В нейронной среде мало внимания уделяется задаче, за одним исключением. swayamdipta-etal-2016-greedy ( swayamdipta-etal-2016-greedy ) [swayamdipta-etal-2016-greedy] представляет основанную на переходах модель stack-LSTM для совместных синтаксических и семантических зависимостей,
где в основном соблюдается их переходная система ( henderson-etal-2013-многоязычный , henderson-etal-2013-многоязычный ) [henderson-etal-2013-multingual] .С тех пор нейронные модели анализа зависимостей графа зависимостей сосредоточены на других наборах данных. SDP можно рассматривать как расширение синтаксического анализа зависимостей.
охарактеризовав более семантические отношения над билексическими зависимостями [sun-etal-2014-grammatical, che-etal-2016-semeval] ,
который может быть очень извлечен из усовершенствований анализа зависимостей.В то время как недавно были выпущены oepen-etal-2014-semeval ( oepen-etal-2014-semeval ) [oepen-etal-2014-semeval] и oepen2015semeval ( oepen2015semeval eval) [oepen2015semeval eval]
Чтобы учесть вероятности деривации (определяемой как
произведение вероятностей, связанных со всеми переходами из
слово-граф, участвующий в выводе), мы предполагаем, что предикат
lexical_analysis представляет вероятность того, что кусок
граф слов, который он покрывает дополнительным аргументом.Во время первого
фазовые вероятности игнорируются. На втором этапе (когда
построен частный вывод) вероятности складываются.
между (L0, R0, L, R): - соединение (L, L0), соединение (R0, R).соединение (A, B): -
(var (A) -> истина
; var (B) -> истина
; A =: = B -> верно
; B fail% словарные графы ациклические
; ok_conn (A, B) -> истина
; fail_conn (A, B) -> сбой
; граф слов: транс (A, _, X, _),
соединение (X, B) -> assertz (ok_conn (A, B))
; assertz (fail_conn (A, B)),
неудача
).
(11)
Далее: Анализ и надежность в главном углу Up: Надежный синтаксический анализ с Предыдущая: Введение Noord G.J.M. фургон
1998-09-25 Обзор синтаксико-семантического разбора на основе структур составляющих и зависимостей
Реферат
1 Введение
2 Составной синтаксический анализ
2.1 Анализ на основе диаграмм
2.1.1 Статистические модели
2.1.2 Нейронные модели
2.2 Анализ на основе переходов
2.2.1 Статистические модели
2.2.2 Нейронные модели
2.3 Другие фреймворки
2.4 Полууправляемые модели
2.5 Ансамбль моделей
3 Анализ зависимостей
3.1 Анализ на основе графиков
3.1.1 Статистические модели
3.1.2 Нейронные модели
3.2 Анализ на основе переходов
3.2.1 Статистические модели
3.2.2 Нейронные модели
3.3 Другие фреймворки
3.4 Полу-контролируемые модели
3.5 Ансамбль моделей
4 График семантических зависимостей
4.1 Синтаксис совместной зависимости и SRL
4.2 Анализ семантических зависимостей
4.2.1 Графический
Существует ряд моделей SDP на основе графов для общих задач SDP в SemEval [thomson-etal-2014-cmu, almeida2015lisbon] . Как правило, сложно разработать алгоритм декодирования на основе графов, ориентированный на произвольные графы зависимостей.Таким образом, большинство моделей налагают определенные ограничения. kuhlmann-jonsson-2015-parsing ( kuhlmann-jonsson-2015-parsing ) [kuhlmann-jonsson-2015-parsing] представляет алгоритм вывода точного кубического времени для непересекающихся графов зависимостей. cao-etal-2017-parsing ( cao-etal-2017-parsing ) [cao-etal-2017-parsing] и cao-etal-2017-quasi ( cao-etal-2017-quasi ) [cao-etal-2017-quasi] исследуют алгоритм максимального подграфа для графов с пересечением 1-конечной точки, номер страницы-2. sun-etal-2017-parsing ( sun-etal-2017-parsing ) [sun-etal-2017-parsing] попытка решить анализ графа зависимостей путем декомпозиции и слияния подграфов. sun-etal-2017-semantic ( sun-etal-2017-semantic ) [sun-etal-2017-semantic] предлагают интересную стратегию встраивания книги для SDP.
Во всех вышеперечисленных моделях используются отдельные элементы, созданные вручную. В нейронной настройке peng-etal-2017-deep ( peng-etal-2017-deep ) [peng-etal-2017-deep] представляют структуру многозадачного обучения для различных взглядов на SDP. dozat-manning-2018-simpler ( dozat-manning-2018-simpler ) [dozat-manning-2018-simpler] расширяет синтаксический анализ биаффинных зависимостей для SDP. Недавно wang-etal-2019-second ( wang-etal-2019-second ) [wang-etal-2019-second] предложили модель SDP второго порядка, основанную на ( dozat-manning-2018- проще , dozat-manning-2018-simpler ) [dozat-manning-2018-simpler] . В целом нейронные модели могут улучшить производительность для SDP.
4.2.2 На основе переходного периода
Модели SDP, основанные на переходе, также могут обеспечить конкурентоспособную производительность, и в то же время эти модели более эффективны и свободны от ограничений, таким образом они привлекли большое внимание [ribeyre-etal-2014-alpage, kanerva-etal-2015-turku] . Фактически, анализ графа зависимостей на основе переходов может быть датирован sagae-tsujii-2008-shift ( sagae-tsujii-2008-shift ) [sagae-tsujii-2008-shift] , а модель дополнена динамическим оракулом на tokgoz2015transition ( tokgoz2015transition ) [tokgoz2015transition] . sun-etal-2014-grammatical ( sun-etal-2014-grammatical ) [sun-etal-2014-grammatical] определяют систему перехода K-перестановки для обработки генерации графа зависимостей. zhang2016transition ( zhang2016transition ) [zhang2016transition] представляют две новые системы переходов для глубокого анализа семантических зависимостей. gildea-etal-2018-cache ( gildea-etal-2018-cache ) [gildea-etal-2018-cache] представляет систему на основе переходов, включая кэш для захвата графов зависимостей,
Недавно, wang2018neural ( wang2018neural ) [wang2018neural] предложили сильную модель SDP на основе переходов с использованием нейронных сетей.Они используют глубокий двунаправленный LSTM в качестве кодировщика сообщений вместе со stack-LSTM для лучшего представления переходных состояний. buys-blunsom-2017-robust ( buys-blunsom-2017-robust ) [buys-blunsom-2017-robust] представляет модель на основе переходов для общего разбора семантического графа, который также подходит для SDP.
4.2.3 Другие методы
Анализ графа зависимостей с использованием аппроксимации дерева и постобработки также может обеспечить конкурентоспособную производительность.Эти типы моделей сначала преобразуют графы зависимостей в деревья, а затем можно применить синтаксический анализ на основе деревьев [agic-koller-2014-potsdam, schluter-etal-2014-copenhagen] . du2015peking ( du2015peking ) [du2015peking] объедините несколько стратегий аппроксимации дерева и добейтесь максимальной производительности в SemEval 2015 [oepen2015semeval] . agic2015semantic ( agic2015semantic ) [agic2015semantic] провести всестороннее исследование разбора графа семантических зависимостей с использованием аппроксимации дерева.
Рисунок 5: Архитектура междоменного анализа.5 Междоменный анализ
Междоменная адаптация - одна из горячих тем в сообществе НЛП, особенно для задач синтаксического и семантического анализа, где аннотирование данных чрезвычайно трудоемко и дорого. В настоящее время контролируемый синтаксический анализ достиг невероятно высокой производительности благодаря последним достижениям нейронных сетей. Однако производительность может значительно снизиться, если хорошо обученные парсеры будут применяться к текстам в разных доменах в качестве обучающего корпуса.Аннотировать наборы обучающих данных для всех доменов непрактично. Таким образом, кросс-доменная адаптация очень важна для того, чтобы синтаксический анализатор был применим. Исследования междоменного синтаксического анализа в основном сосредоточены на двух параметрах: неконтролируемая адаптация домена, где нет доступного набора данных для обучения целевой области, и полууправляемая адаптация домена, где для целевого домена доступны небольшие обучающие экземпляры. На рисунке 5 показана архитектура междоменного анализа, где показаны различия между двумя параметрами.
5.1 Адаптация неконтролируемого домена
Самообучение - одна из полезных стратегий для адаптации парсера между доменами, хотя он достиг очень ограниченного прироста при полу-контролируемой настройке в домене. Первоначальная работа в основном сосредоточена на составном синтаксическом анализе. mcclosky-etal-2006-reranking ( mcclosky-etal-2006-reranking ) [mcclosky-etal-2006-reranking] использовать стратегию изменения рейтинга, чтобы получить набор автоматически проанализированных выходных данных с высокой степенью достоверности, а затем добавить их в учебный корпус. sagae-2010-self ( sagae-2010-self ) [sagae-2010-self] показывает, что само по себе самообучение без повторного ранжирования также может дать значительные улучшения. kawahara-uchimoto-2008-learning ( kawahara-uchimoto-2008-learning ) [kawahara-uchimoto-2008-learning] сначала успешно примените самообучение при синтаксическом анализе зависимостей, который использует дополнительный классификатор для определения надежности проанализированного дерева. chen-etal-2008-Learning ( chen-etal-2008-learning ) [chen-etal-2008-learning] используют только частичные зависимости с высокой степенью достоверности для обучения на следующем этапе. yu2015domain ( yu2015domain ) [yu2015domain] предлагает новый метод оценки достоверности, что привело к повышению производительности набора данных вне домена.
Помимо самообучения, существует несколько других методов неконтролируемой адаптации домена. steedman-etal-2003-example ( steedman-etal-2003-example ) [steedman-etal-2003-example] применить совместное обучение к составному синтаксическому анализу, что аналогично самообучению но отличие в том, что выборка примера выполняется двумя парсерами. sagae-tsujii-2007-dependency ( sagae-tsujii-2007-dependency ) [sagae-tsujii-2007-dependency] использовать аналогичный метод совместного обучения для синтаксического анализа зависимостей. Далее, sogaard-rishoj-2010-semi ( sogaard-rishoj-2010-semi ) [sogaard-rishoj-2010-semi] использовать три-обучение для адаптации предметной области при синтаксическом анализе зависимостей, расширение двух парсеров до парсеров. Интересно, что планк-ван-норд-2011-эффективный ( планк-ван-норд-2011-эффективный ) [планк-ван-норд-2011-эффективный] избранные обучающие примеры вместо этого из набора данных исходного домена, где выбираются экземпляры, наиболее релевантные для целевого домена. yang-etal-2015-domain ( yang-etal-2015-domain ) [yang-etal-2015-domain] использовать нейронные сети глубокого убеждения для повышения производительности анализа зависимостей на тестовых данных вне домена , который может эффективно извлекать полезную информацию из необработанных текстов целевой области.
Адаптация домена с несколькими источниками также является многообещающим направлением, что предполагает наличие обучающих корпусов из нескольких исходных доменов. Сеттинг полностью соответствует реальному практическому сценарию. mcclosky-etal-2010-automatic ( mcclosky-etal-2010-automatic ) [mcclosky-etal-2010-automatic] представляет первую работу этого параметра для анализа зависимостей. Они линейно комбинируют модели синтаксического анализа разных доменов. с весами, полученными из регрессионной модели, учитывая производительность каждого парсера в целевом домене.
5.2 Адаптация полууправляемого домена
При небольшом количестве обучающих данных целевой области, reichart-rappoport-2007-self ( reichart-rappoport-2007-self ) [reichart-rappoport-2007-self] показывают, что самообучение может эффективно улучшить производительность составного синтаксического анализа.В последнее время большая часть работы сосредоточена на эффективном обучении на смешанных исходных и целевых экземплярах обучения. путем разделения доменно-зависимых и доменно-инвариантных признаков [daume-iii-2007-frustratingly] . Если рассматривать эти особенности по-разному, окончательная модель может точно передать полезные знания. из исходного домена в целевой. finkel-manning-2009 -ierarchical ( finkel-manning-2009 -ierarchical ) [finkel-manning-2009 -ierarchical] расширить идею иерархической байесовской моделью и оцените его при синтаксическом анализе зависимостей, добившись лучшей производительности в целевом домене. чем обучение только с данными целевой области.В нейронной среде состязательное обучение является одним из эффективных методов для той же цели [ganin2015unsupervised] . sano2017adversarial ( sano2017adversarial ) [sano2017adversarial] сначала примените метод анализа зависимостей.
Активное обучение может быть одним из многообещающих подходов к адаптации к полунезависимой предметной области. Учитывая, что синтаксис / семантическая аннотация полного предложения чрезвычайно дороги, частичная аннотация может быть предпочтительнее.Для составного синтаксического анализа joshi-etal-2018-extends ( joshi-etal-2018-extends ) [joshi-etal-2018-extends] предлагает частичную аннотацию составляющих скобок для улучшения адаптации домена. Для синтаксического анализа зависимостей flannery2015combining ( flannery2015combining ) [flannery2015combining] использовать частичную аннотацию в сочетании с активным обучением синтаксическому анализу междоменных зависимостей на японском языке. Недавно, li-etal-2019-semi-supervised ( li-etal-2019-semi-supervised ) [li-etal-2019-semi-supervised] всесторонне исследовали стратегию синтаксического анализа зависимостей Китая. под нейронной сетью.
Рисунок 6: Архитектура межъязыкового синтаксического анализа.6 Межъязычный анализ
Межъязыковой синтаксический анализ, целью которого является синтаксический анализ структур предложений языков с низким уровнем ресурсов. с помощью богатых ресурсами языков, таких как английский. Для этой задачи был проведен ряд исследований, и большая часть работы сосредоточена на разборе зависимостей благодаря относительно структурной лаконичности, а также хорошо развитым универсальным зависимостям. В частности, с недавним развитием межъязыкового или универсального представления слов на основе нейронных методов предварительного обучения, задача была связана с возрастающими интересами.Задача включает в себя две основные настройки, неконтролируемая настройка, предполагающая, что для целевых языков нет учебного корпуса, и установка с частично контролируемым / контролируемым обучением, где существует определенная шкала корпусов для целевых языков. Архитектура межъязыкового синтаксического анализа показана на рисунке 6, где также проиллюстрирована подробная разница между неконтролируемыми и частично контролируемыми / контролируемыми настройками.
6.1 Неконтролируемая настройка
Для неконтролируемого межъязыкового синтаксического анализа, основные методы можно разделить на две категории: перенос модели и проекция аннотации, где первая категория обучает модель в корпусе обучения исходному языку, а затем напрямую использует его для анализа текстов на целевом языке, и вторая категория проецирует аннотации синтаксического анализа исходного языка на целевой язык с помощью параллельного корпуса, в результате получается корпус псевдообучения для целевого языка, а затем обучает модель синтаксического анализа целевого языка на псевдокорпусе.
6.1.1 Перенос модели
Подход с переносом модели прост для межъязыкового синтаксического анализа. Наибольшее внимание уделяется функциям, не зависящим от языка, которые выполняют согласованные функции на разных языках. Первоначально это направление работы представлено zeman-resnik-2008-cross ( zeman-resnik-2008-cross ) [zeman-resnik-2008-cross] , который предлагает делексициализированные модели для межъязыкового анализа зависимостей, и доработан mcdonald-etal-2011-multi ( mcdonald-etal-2011-multi ) [mcdonald-etal-2011-multi] для передачи из нескольких источников, где несколько исходных языков используются для улучшения целевого языка.Некоторые исследователи прибегают к различным нелексическим функциям для улучшения делексикализованных кросс-языковых моделей. [cohen-etal-2011-unsupervised, naseem-etal-2012-selected] .
Недавно tackstrom-etal-2012-cross ( tackstrom-etal-2012-cross ) [tackstrom-etal-2012-cross] используют кросс-языковые кластеры слов, который является одним из королей кросс-языковых представлений слов. Под нейронной сетью значительно упрощается изучение кросс-языковых представлений слов. guo-etal-2015-cross ( guo-etal-2015-cross ) [guo-etal-2015-cross] предлагают использовать межъязыковые вложения слов для лексикализованного анализа межъязыковых зависимостей. Затем этому методу уделяется много внимания и могут быть дополнительно улучшены различными способами, например улучшенными нейронными структурами [zhang-barzilay-2015 -ierarchical] и адаптация с несколькими источниками [guo2016presentation, wick2016minimally] .
Кросс-язычные предварительно обученные контекстуализированные представления слов дают самые современные возможности этой категории. schuster-etal-2019-cross ( schuster-etal-2019-cross ) [schuster-etal-2019-cross] предоставляет метод эффективного изучения контекстных представлений ELMO и затем примените представления к задаче, добившись гораздо лучших результатов, чем кросс-языковые вложения слов. wang-etal-2019-cross ( wang-etal-2019-cross ) [wang-etal-2019-cross] и wu-dredze-2019-beto ( wu-dredze-2019-beto ) [wu-dredze-2019-beto] применить межъязычный mBERT к беспроблемному синтаксическому анализу межъязыковых зависимостей. lample2019cross ( lample2019cross ) [lample2019cross] представляет XLM одновременно с mBERT, что также является своего рода сильные многоязычные контекстуализированные представления слов для межъязыкового синтаксического анализа [wu2019emerging] . Все эти недавние исследования привели к появлению новейших достижений в литературе этой категории.
6.1.2 Проекция аннотации
Метод проецирования аннотаций требует немного больше усилий по сравнению с переносом модели, который направлен на создание корпуса псевдотренировок с помощью битекстовой проекции.С корпусом псевдообучения окончательная модель может захватывать богатые характеристики целевого языка. Метод основан на наборе параллельных предложений между исходным и целевым языками. Исходный синтаксический анализатор, обученный на исходном древовидном банке, используется для синтаксического анализа исходных предложений параллельного корпуса, а затем автоматические исходные аннотации проецируются на предложения целевого языка в соответствии с выравниванием слов, в результате получается окончательный корпус псевдотренировок. Для достижения цели существует ряд стратегий.Например, мы можем использовать разные типы параллельных корпусов, такие как EuroParl и книга Библия, а также может использовать различные сложные методы для улучшения качества проецирования.
Для составного синтаксического анализа, snyder-etal-2009-unsupervised ( snyder-etal-2009-unsupervised ) [snyder-etal-2009-unsupervised] использует метод неконтролируемого составного синтаксического анализа, и обнаружил, что он может значительно превзойти модели без учителя. jiang-etal-2011-relaxed ( jiang-etal-2011-relaxed ) [jiang-etal-2011-relaxed] предлагает алгоритм ЭМ для постепенного повышения качества проецируемых составляющих деревьев с ослаблением ограничений.Количество исследований по составному синтаксическому анализу относительно невелико, что может быть возможно из-за того, что проекция составляющих структур очень сложна.
Для анализа зависимостей, hwa2005bootstrapping ( hwa2005bootstrapping ) [hwa2005bootstrapping] представляет первую работу в этой категории, а затем этот подход был тщательно изучен в различных условиях, таких как уверенное обучение [li-etal-2014-soft] , улучшение нейронной сети [ma-xia-2014-unsupervised, schlichtkrull-sogaard-2017-cross] , и адаптация для нескольких источников [rasooli-collins-2015-density, agic-etal-2016-multingual] .Интересно, что jiang2015joint ( jiang2015joint ) [jiang2015joint] предлагают совместную модель для кросс-языкового анализа компонентов и зависимостей с проекцией аннотации. Подход имеет большой успех при разборе межъязычных зависимостей.
6.1.3 Другие методы
Существует также несколько других методов неконтролируемого межъязыкового синтаксического анализа. Перевод Treebank - это одна из типичных стратегий, что по сути очень похоже на проекцию аннотации.Подход также направлен на построение корпуса псевдообучения. В отличие от проекции аннотаций, он напрямую переводит исходный обучающий корпус на целевой язык. Помимо проецирования битекста, для создания предложений на целевом языке требуется перевод. tiedemann2014treebank ( tiedemann2014treebank ) [tiedemann2014treebank] сначала предложите этот метод и их метод усовершенствован в более поздних исследованиях [tiedemann2016synthetic] . zhang-etal-2019-cross ( zhang-etal-2019-cross ) [zhang-etal-2019-cross] изучить подход в нейронной среде с частичной трансляцией, и совместить их модель с переносом модели.
Методы, используемые в междоменном анализе, также могут быть подходящими (например, самообучение) для этой настройки. из-за межъязыкового представления слов. Однако такие методы редко изучались. rasooli-collins-2017-cross ( rasooli-collins-2017-cross ) [rasooli-collins-2017-cross] сочетают в себе преимущества переноса модели, проекции аннотаций, перевод дерева деревьев, а также самообучение для получения очень сильной модели для межъязыкового синтаксического анализа зависимостей.
Переупорядочивание предложений - это один из недавно представленных интересных методов, цель которого переупорядочить синтаксические деревья исходного языка ввода, чтобы сделать его максимально похожим на целевой язык. Идея впервые была изучена wang-eisner-2018-Synthetic ( wang-eisner-2018-Synthetic ) [wang-eisner-2018-Synthetic] . rasooli-collins-2019-low ( rasooli-collins-2019-low ) [rasooli-collins-2019-low] использовать метод с двумя сильными стратегиями переупорядочения, получение очень конкурентоспособной производительности по сравнению с даже контролируемыми моделями синтаксического анализа.
6.2 Полу-контролируемая / контролируемая настройка
Поскольку доступность дерева деревьев для ряда языков, как эффективно использовать древовидный банк как исходного, так и целевого языков это одна интересная проблема. С самого начала несколько исследований показали, что для синтаксического анализа два языка лучше, чем один язык. smith3004bilingual ( smith3004bilingual ) [smith3004bilingual] показывают, что совместное обучение английскому и корейскому синтаксическому анализатору может повысить производительность. burkett-klein-2008-two ( burkett-klein-2008-two ) [burkett-klein-2008-two] также демонстрирует то же наблюдение.
При нейронной настройке это направление работы может выполняться более удобно благодаря кросс-языковым представлениям слов. ammar-etal-2016-many ( ammar-etal-2016-many ) [ammar-etal-2016-many] предлагают использовать одну универсальную модель для синтаксического анализа всех языков. Однако их окончательные показатели все еще ниже соответствующих индивидуальных базовых показателей. smith-etal-2018-82 ( smith-etal-2018-82 ) [smith-etal-2018-82] обучить 34 модели для 46 различных языков. За счет объединения нескольких древовидных структур с одного языка или близкородственных языков, мы можем добиться конкурентоспособных показателей и при этом значительно сократить количество требуемых моделей. Совсем недавно в публикации kondratyuk-straka-2019-75 ( kondratyuk-straka-2019-75 ) [kondratyuk-straka-2019-75] предлагается сложная стратегия обучения одной универсальной модели для 75 языков с использованием многоязычного BERT самовнимание, который обеспечивает лучшие характеристики, чем соответствующие отдельные модели.
7 совместных моделей
В этом разделе мы обсуждаем совместные модели парсинга, фокусируясь только на конечной цели - задаче синтаксического анализа. В следующем разделе будут представлены исследования совместного моделирования синтаксико-семантического синтаксического анализа, а также целевых последующих задач. Разработка совместных моделей в основном мотивирована проблемой исключения ошибок в предварительно обусловленных задачах. Маркировка POS - одна из основных предварительных задач, поскольку теги POS являются одним из ценных источников функций для анализа.Перед добавлением тегов POS на нескольких языках, например в китайском, в качестве обязательного шага требуется сегментация слов. Синтаксический анализ обычно выполняется на основе слов, в то время как предложения этих языков не имеют явных границ слов. Таким образом, здесь мы кратко исследуем два типа совместных моделей: совместная маркировка POS и синтаксический анализ, совместная сегментация, теги и парсинг, и мы показываем их взаимосвязь на Рисунке 7.
Рисунок 7: Архитектура совместных моделей, предназначенных для синтаксического анализа, где сегментация слов доступна только для китайского языка.Примечательно, что существует несколько исследований совместного синтаксического и семантического синтаксического анализа. Совместные модели на основе зависимостей уже были описаны в разделе 4.1. Таким образом, здесь можно найти подробности. Для совместного анализа составляющих и присвоения семантических ролей, исследований очень мало. Репрезентативная работа: ли-этал-2010-сустав ( ли-этал-2010-сустав ) [ли-этал-2010-сустав] , это первая работа такого рода с использованием сложных, созданных вручную функций.Работа показывает, что их совместная модель может дать лучшие характеристики как для китайского составного синтаксического анализа, так и для SRL.
7.1 Совместная маркировка и анализ POS
Для совместной маркировки POS и составного синтаксического анализа, анализ PCFG на основе диаграмм естественным образом выполняет две задачи одновременно [collins-1997-three, Charniak2000, petrov-klein-2007-Superior] , где теги POS могут быть непосредственно вызваны из нижних лексических правил. На основе структуры на основе переходов совместная маркировка POS и составной синтаксический анализ могут быть легко достигается с помощью операции сдвига с одним дополнительным параметром для указания тега POS слова обработки. wang-xue-2014-Joint ( wang-xue-2014-Joint ) [wang-xue-2014-Joint] исследовать совместную задачу и представить ряд нелокальных особенностей.
li-etal-2011-Joint ( li-etal-2011-Joint ) [li-etal-2011-Joint] предлагает первую совместную модель тегов POS и синтаксического анализа зависимостей на основе факторинга графов, где базовые единицы оценки дополняются тегами POS. li-etal-2012-отдельно ( li-etal-2012-отдельно ) [li-etal-2012-отдельно] улучшите модель с помощью лучших стратегий обучения. hatori-etal-2011-incremental ( hatori-etal-2011-incremental ) [hatori-etal-2011-incremental] - это первая основанная на переходах модель для совместной маркировки POS и синтаксического анализа зависимостей. bohnet-nivre-2012-transition ( bohnet-nivre-2012-transition ) [bohnet-nivre-2012-transition] расширить модель на основе переходов для непроективного анализа зависимостей. Эти два типа моделей обеспечивают сопоставимые характеристики для обеих задач.
Под нейронной сетью, alberti-etal-2015-Superior ( alberti-etal-2015-Superior ) [alberti-etal-2015-Superior] исследовать модель bohnet-nivre-2012-transition ( bohnet-nivre-2012-transition ) [bohnet-nivre-2012-transition] с нейронными функциями. zhang-weiss-2016-stack ( zhang-weiss-2016-stack ) [zhang-weiss-2016-stack] предлагает совместную модель POS-тегов и анализа зависимостей путем распространения стека. yang2017joint ( yang2017joint ) [yang2017joint] дальнейшее исследование задачи нейронного сустава с помощью LSTM с помощью фреймворков на основе графов и переходов соответственно. Фактически, важность совместного моделирования значительно ослабла. поскольку синтаксический анализ без тегов POS также может обеспечить высокую производительность, близкую к той же модели с тегами POS [dozat2016deep] .
7.2 Совместная сегментация, теги и синтаксический анализ
Задача совместной сегментации, тегов и синтаксического анализа в основном нацелена на китайский синтаксический анализ. Серия этой работы начинается в самом начале [Luo: 2003: EMNLP] с синтаксического анализа на уровне персонажа. Позже zhao-2009-character ( zhao-2009-character ) [zhao-2009-character] демонстрирует, что синтаксический анализ зависимостей китайского языка на основе символов лучше, который естественным образом может выполнять три задачи.Недавно, hatori-etal-2012-incremental ( hatori-etal-2012-incremental ) [hatori-etal-2012-incremental] предложили основанную на переходах объединенную модель для сегментации слов, тегов POS и анализа зависимостей. li-zhou-2012-unified ( li-zhou-2012-unified ) [li-zhou-2012-unified] предлагает аналогичную совместную модель на основе переходов с использованием неделимых подслов, а также их внутренней структуры. zhang-etal-2013-chinese ( zhang-etal-2013-chinese ) [zhang-etal-2013-chinese] и zhang-etal-2014-character ( zhang-etal-2014-character ) [zhang-etal-2014-character] выполняет синтаксический анализ составляющих и зависимостей на уровне символов, расширяя аннотации на уровне слов на символы, достижение высочайшего уровня производительности для обеих задач в дискретных условиях.Все четыре модели используют структуру, основанную на переходах. zhang-etal-2015-randomized ( zhang-etal-2015-randomized ) [zhang-etal-2015-randomized] предлагает первую работу с использованием графического вывода с эффективным декодированием при подъеме на холм.
zheng2015character ( zheng2015character ) [zheng2015character] - это первая работа по внедрению нейронных сетей для анализа составляющих на уровне символов, достижение сопоставимости с современной дискретной моделью с помощью простой сверточной нейронной сети. li2018neural ( li2018neural ) [li2018neural] представляет нейронную модель для синтаксического анализа зависимостей на уровне символов. yan2019unified ( yan2019unified ) [yan2019unified] предлагает сильную совместную модель только для сегментации слов и анализа зависимостей, В этой работе используются современный синтаксический анализатор биаффина и предварительно обученный BERT. Под нейронной сетью совместная структура может быть очень сложной, поскольку базовые параметры сильны, а нейронные сети могут неявно изучать глобальные высокоуровневые функции.
8 Приложение парсера
Когда доступен хорошо обученный синтаксический / семантический синтаксический анализатор, как эффективно использовать его для получения выгоды для последующих приложений - одна из важных тем в сообществе синтаксического анализа, что также связано с проверкой полезности синтаксического и семантического разбора. На самом деле эта тема широко изучена, результаты синтаксического анализа продемонстрировали свою эффективность для ряда задач, таких как обозначение семантических ролей [johansson-nugues-2008-dependency, Strubell-etal-2018-linguistically] , извлечение отношения [zhang-etal-2006-explore, miwa-bansal-2016-end] , анализ тональности [zou2015sentiment, tai-etal-2015-Superior] и машинный перевод [yamada-knight-2001-syntax, zhang-etal-2019-syntax-Enhanced-neural] .Методы разведки существенно отличаются от статистических дискретных моделей. к нейронным моделям. Здесь мы кратко резюмируем основные подходы к исследованию парсера с точки зрения двух настроек.
8.1 Статистические методы, основанные на признаках
При традиционной статистической настройке исследование парсеров прибегает к дискретным функциям, созданным вручную, которые в большинстве своем разработаны с учетом поставленных задач. Мы кратко суммируем здесь широко используемые функции.Для составляющих деревьев такие функции включают нетерминальные категории, Правила CFG, словарные нграммы на уровне фраз, синтаксические пути к корню или какому-либо другому слову, сопоставление с завершенной фразой. Для деревьев зависимостей, ngram на основе зависимостей, меток зависимостей, путей зависимостей являются широко используемыми функциями. Все эти функции дополнительно адаптируются к различным задачам, направленным на для эффективного получения большей части информации для синтаксического анализа [liu-etal-2006-tree, johansson-nugues-2008-dependency, chan-roth-2011-exploiting, qiu-zhang-2014-zore, zou2015sentiment] .Кроме того, подход, основанный на древовидном ядре, также может быть хорошей альтернативой. [che-etal-2006-hybrid, yang-etal-2006-kernel, zhang-etal-2006-explore, zhou-etal-2007-tree, zhang-li -2009-дерево] . Несколько подходов предлагают использовать несколько разнородных парсеров для повышения производительности. включая интеграцию составных парсеров и анализаторов зависимостей, а также парсеров, обученных на гетерогенных банках деревьев [johansson-nugues-2008-effect] .
8.2 Репрезентативное обучение с помощью нейронных сетей
Одним из простых способов использования функций синтаксического анализа на основе нейронных сетей является внедрение всех атомарных функций, а затем использовать сложные нейронные сети для их автоматического создания.Наиболее представительный метод такого рода - LSTM на основе путей, которые используют LSTM на последовательных путях составляющих или зависимостей [xu-etal-2015-classifying, roth-lapata-2016-neural] . Недавняя тенденция использования сквозного фреймворка для большинства задач НЛП приводит к универсальным представлениям на основе выходных данных парсера. Мы создаем универсальный кодировщик со структурными выходами синтаксического анализатора, а затем адаптируем их для различных задач с помощью декодеров, как показано на рисунке 8. Есть несколько способов собрать кодировщик.Здесь мы делим методы на четыре типа: рекурсивная нейронная сеть; на основе линеаризации; подразумевает структурно-ориентированные представления слов и нейронные сети графов (GNN).
Рисунок 8: Расширенный универсальный кодировщик Parser для задач нисходящего потока.Рекурсивная нейронная сеть - один из естественных методов моделирования выходных данных с древовидной структурой. который составляет дерево входных данных снизу вверх или сверху вниз с приращением. Мы можем использовать различные операции композиции, что приводит к более сложным нейронным сетям на уровне дерева. такие как свертки деревьев, предложенные mou-etal-2015-дискриминационный ( mou-etal-2015-дискриминационный ) [mou-etal-2015-дискриминационный] и Tree-LSTM, предложенный tai-etal-2015- улучшенный ( tai-etal-2015-better ) [tai-etal-2015-better] .Все эти сопутствующие исследования позволяют улучшить выполнение ряда задач [zhang-etal-2016-top, teng-zhang-2017-head] .
Ключевая идея методов, основанных на линеаризации, состоит в том, чтобы преобразовать структурные входы в последовательность символов, а затем использовать стандартные последовательные кодеры для непосредственного моделирования новой последовательности [li-etal-2017-models, wu2017improved] . Обычно преобразование можно назвать процессом линеаризации синтаксических анализаторов на основе переходов, или мы можем постепенно перемещаться по дереву или графу разными способами.Метод вызывал меньше проблем, что могло быть связано с его крайней простотой, хотя он эффективен и в то же время очень эффективен [zhang-etal-2019-syntax-Enhanced-neural] .
Неявные структурно-ориентированные представления слов, впервые представленные zhang-etal-2017-end ( zhang-etal-2017-end ) [zhang-etal-2017-end] для извлечения отношений, аналогичны идея контекстуализированных представлений слов, которые используют скрытые выходные данные хорошо подготовленного синтаксического анализатора в качестве входных данных для последующих задач [yu-etal-2018-transition, zhang-etal-2019-syntax-Enhanced-neural] .Этот метод также может эффективно представлять структурную информацию, такую как синтаксис и семантика. Кроме того, метод может быть легко адаптирован к стратегии многозадачного обучения для приложение синтаксического анализатора [Strubell-etal-2018-linguistically] , в то время как парсер требует совместного обучения многозадачному обучению.
В последнее время возрос интерес к теме графовых нейронных сетей, который естественным образом может быть применен для кодирования структурных синтаксических и семантических графов. Действительно, уже было проведено несколько исследований. с использованием либо сверточных сетей графа, либо сетей внимания графа [bastings-etal-2017-graph, zhang-etal-2018-graph, marcheggiani-etal-2018-exploiting] , и все эти работы демонстрируют эффективность GNN для кодирования структур.
9 Корпус и общие задачи
Наконец, мы рассматриваем работу по разработке корпуса в синтаксическом и семантическом разборе, что критично для выполнения контролируемого синтаксического анализа. Есть несколько классических берегов деревьев, таких как Penn Treebanks английского и китайского языков, которые значительно способствуют развитию сообщества парсеров. На самом деле есть банки деревьев для разных языков, и здесь мы в основном ориентируемся на китайский и английский берега деревьев. Кроме того, есть ряд общих задач, которые также предлагают ценные корпуса для синтаксического и семантического разбора.
9.1 Penn Treebank
Английский Penn Treebank (PTB), автор marcus-etal-1993-building ( marcus-etal-1993-building ) [marcus-etal-1993-building] может быть самым известным ресурсом для синтаксического анализа, который аннотирует заключенные в квадратные скобки синтаксические структуры фраз для более чем 40 000 предложений, охватывающих около 4,5 миллионов слов. Кроме того, xuexia2005 ( xuexia2005 ) [xuexia2005] аннотирует Penn Treebank для китайского языка, сокращенно CTB, и теперь существует более 130 000 предложений с аннотациями фразеологической структуры, охватывающими более 2 миллионов слов.Оба набора данных также имеют аннотированные теги POS, которые важны для автоматического синтаксического анализа. Для китайского языка сегментация слов золотого стандарта также была аннотирована в CTB.
Два набора данных также преобразуются в банки деревьев зависимостей для анализа зависимостей, чего можно достичь с помощью лексикализации заголовка на основе правил над составляющими деревьями [Yamada2003, johansson2007extended, johansson2007lth, zhli2018convert, zhang-clark-2008-tale] . В последнее время зависимости Стэнфорда используются наиболее популярно, особенно для английского языка, где правила преобразования относительно более детализированы [de2006generating] и тем временем могут отражать больше синтаксических и семантических явлений.
Существует несколько небольших групп деревьев с такими же рекомендациями по аннотации, что и PTB, которые могут быть полезными ресурсами для изучения адаптации к предметной области при синтаксическом анализе компонентов и зависимостей, При этом PTB ориентируются на данные по жанрам новостей. Например, Brown Treebank чаще всего используется для междоменного синтаксического анализа как жанр литературы. tateisi2005syntax ( tateisi2005syntax ) [tateisi2005syntax] предлагает древовидный банк биомедицинской области.Два банка деревьев предназначены для исследований по составному синтаксическому анализу. Недавно, kong-etal-2014-dependency ( kong-etal-2014-dependency ) [kong-etal-2014-dependency] аннотировали древовидный банк текстов твиттера на основе грамматики зависимостей.
9.2 Универсальные зависимости
Настоящее время универсальных зависимостей (UD) привлекло большое внимание для облегчения многоязычных исследований, который направлен на разработку кросс-лингвистически согласованной аннотации банка деревьев для нескольких языков.UD может фиксировать сходства, а также идиосинкразии между типологически разными языками, такими как англоязычные языки, морфологически богатые языки. и языки pro-drop. Разработка UD изначально основана на типизированных зависимостях Стэнфорда [de2014universal] и универсальной схеме зависимостей Google [petrov2012universal, mcdonald-etal-2013-universal1] . Сейчас он проходит несколько версий [nivre2015universal, nivre2017universal] , со значительными изменениями в руководящих принципах, также при необходимости поддерживает расширения для конкретных языков.В настоящее время версия 2.5 древовидного банка UD включает 157 древовидных банков для более чем 90 языков. Помимо многоязычного синтаксического анализа зависимостей, растет тенденция использовать их для оценки одноязычного анализа зависимостей на основе наборов данных, а также [ji-etal-2019-graph, kulmizev-etal-2019-deep] .
9.3 Китайский банк деревьев
Для китайских языков развитие банка деревьев было связано с несколькими исследованиями, помимо CTB. Sinica Treebank предлагает синтаксические деревья с синтаксической структурой фраз более чем из 360 000 слов в традиционном китайском языке [chen2003sinica] . qiang2004annotation ( qiang2004annotation ) [qiang2004annotation] выпускает составной древовидный банк, охватывающий около миллиона слов для упрощенного китайского языка. zhan2012application ( zhan2012application ) [zhan2012application] также аннотирует составляющие деревья в масштабе 0,9 миллиона слов для китайского языка. Руководящие принципы всех этих структурных древовидных банков фраз совершенно разные.
Существует несколько ресурсов банка деревьев, непосредственно основанных на структуре зависимостей, поскольку считается, что грамматика зависимостей проще и легче в разработке. liu2006building ( liu2006building ) [liu2006building] и che2012chinese ( che2012chinese ) [che2012chinese] создают банк зависимостей для китайского языка, занимающий более 1,1 миллиона слов. qiu-etal-2014-multi ( qiu-etal-2014-multi ) [qiu-etal-2014-multi] создать многовидовой банк дерева зависимостей для китайцев, содержащий 14 463 предложений, который дополнительно дополняется информацией предиката-аргумента на qiu2016dependency ( qiu2016dependency ) [qiu2016dependency] для семантически-ориентированного банка дерева зависимостей.Совсем недавно li-etal-2019-semi-supervised ( li-etal-2019-semi-supervised ) [li-etal-2019-semi-supervised] выпустили крупномасштабный банк зависимостей китайского языка, охватывающий около 3 миллион слов, а также разные домены, в том числе новости, веб-блоги, литературные тексты.
9.4 Общие задачи
Почти все общие задачи сосредоточены на разборе зависимостей, и большая часть из которых посвящена многоязычному синтаксическому анализу с поддержкой нескольких групп деревьев на разных языках.Эти общие задачи, с одной стороны, могут оценивать текущие современные модели синтаксического анализа, и, с другой стороны, предлагают ценные наборы данных для анализа, облегчение будущей исследовательской работы.
ConLL06 организует первую общую задачу для синтаксического анализа зависимостей с участием 13 языков [buchholz-marsi: 2006: CoNLL-X] , а адаптация домена рассматривается позже в ConLL07 [nivre-etal-2007-conll] . В ConLL08 и ConLL09 семантические зависимости, извлеченные из SRL, интегрируются, что приводит к совместному синтаксико-семантическому синтаксическому анализу [surdeanu-EtAl: 2008: CONLL, hajic-etal-2009-conll1] .В последнее время общая задача ConLL 2017 начинает принимать универсальные зависимости для анализа зависимостей [zeman-etal-2017-conll1] , и на ConLL 2018 82 дерева UD на 57 языках включены в оценку [zeman-etal-2018-conll] . Помимо ConLL, SANCL 2012 организует общую задачу по синтаксическому анализу английского веб-текста [petrov-mcdonald: 2012: SANCL] , который предлагает набор данных для анализа междоменных зависимостей на английском языке. Кроме того, общая задача NLPCC 2019 по синтаксическому анализу междоменных зависимостей также предлагает ценный набор данных на китайском языке [peng2019overview] .
Указанные выше общие задачи сосредоточены на синтаксическом анализе зависимостей. Для синтаксического анализа семантических зависимостей che-EtAl: 2012: STARSEM-SEMEVAL ( che-EtAl: 2012: STARSEM-SEMEVAL ) [che-EtAl: 2012: STARSEM-SEMEVAL] представляет первую общую задачу для китайских текстов в SemEval, где в оценке используются деревья зависимостей. che-etal-2016-semeval ( che-etal-2016-semeval ) [che-etal-2016-semeval] начинают использовать графы зависимостей для формального семантического представления.Для английского языка oepen-etal-2014-semeval ( oepen-etal-2014-semeval ) [oepen-etal-2014-semeval] организуют общую задачу для семантического синтаксического анализа широкого охвата с использованием трех различных зависимостей. семантические формализации. Графы зависимостей используются для представления различной семантики. oepen2015semeval ( oepen2015semeval ) [oepen2015semeval] расширить общую задачу ( oepen-etal-2014-semeval , oepen-etal-2014-semeval ) [oepen--etal] [oepen-etal] с большим количеством языков, включая китайский и чешский. oepen-etal-2019-mrp ( oepen-etal-2019-mrp ) [oepen-etal-2019-mrp] охватывает больше тем синтаксического анализа семантического графа для глубокой семантики, включая не только графы на основе зависимостей, но также и несколько других формализаций, таких как UCCA и AMR.
10 Заключение и дальнейшие направления
В этой статье мы сделали тщательный обзор прошлой работы по синтаксическому и семантическому синтаксическому анализу, уделяя особое внимание синтаксическому синтаксическому анализу и синтаксическому анализу зависимостей. Были обобщены как традиционные статистические модели, так и доминирующие в настоящее время методы нейронных сетей.Во-первых, для моделей синтаксического анализа методы нейронной сети с предварительно обученными контекстуализированными представлениями слов достигли наивысшей производительности. почти для всех наборов данных. Растет тенденция к использованию простых фреймворков кодировщика-декодера для синтаксического анализа, так что можно применять хорошо изученные стратегии обучения. Во-вторых, все большее внимание уделяется семантическому синтаксическому анализу с широким охватом, который может стать темой перехода на следующем этапе. Выполнение задач теперь постепенно приемлемо. благодаря моделям нейронных сетей, а также развитию языковых ресурсов.
Междоменные и кросс-языковые настройки являются важными сценариями для синтаксического анализа, которые трудно разрешить, но они играют ключевую роль в реальных приложениях. Для междоменной настройки все еще существует большой спрос на ресурсы. Хотя для межъязыкового синтаксического анализа существует ряд методов. Может оказаться полезным всестороннее и справедливое сравнение этих методов, а также их интеграции. Кроме того, разница между междоменным и кросс-языковым становится меньше. из-за универсальных словесных представлений.С технической точки зрения кросс-языковой синтаксический анализ можно рассматривать как частный случай кросс-доменного анализа.
Значение совместных моделей снижается. Используя нейронные сети, глобальные функции для различных задач могут быть непосредственно захвачены сложными нейронными структурами, такими как глубокий LSTM и самовнимание, и, с другой стороны, мы можем создать один общий кодировщик для разных задач, чтобы уменьшить влияние распространения ошибок. Для приложения парсера, которое можно рассматривать как обратное направление совместных моделей, кодеры нейронных сетей могут привести к высокоэффективным и элегантным универсальным представлениям с синтаксической и семантической информацией.Кроме того, все современные методы по-прежнему требуют всестороннего и справедливого сравнения.
Наконец, развитие банка деревьев является основным источником достижений синтаксического и семантического синтаксического анализа. что может быть самой сложной и очень ценной работой. В частности, семантическое знание одного предложения может иметь несколько разных точек зрения. Подробные аннотации требуют чрезвычайно высоких затрат. Как эффективно выполнять аннотацию банка деревьев - одна из задач, заслуживающих исследования.
Для будущих направлений предстоит еще много работы.Самое главное, что синтаксический анализ более сложных грамматик получит повышенное внимание, хотя этот обзор не покрывается. Что касается синтаксического синтаксического анализа, производительность синтаксического анализа CCG, HPSG и LFG все еще неудовлетворительна, особенно для неанглийских языков. Для семантического синтаксического анализа грамматики на основе зависимостей недостаточно для богатой семантики, даже будучи ослабленным ограничениями графа. Нелексикализованные узлы необходимы для выражения нескольких сложных семантик. Таким образом, AMR, UCCA и MRS могут быть многообещающими для практического глубокого семантического синтаксического анализа.На основе CFG и грамматик зависимостей, следует обратить внимание на междоменные и межъязыковые настройки, которые могут быть далее объединены. Практическим решением могут быть модели с небольшим контролем или без выстрела. Для совместных моделей, а также для приложений парсеров, многозадачное обучение и предварительное обучение могут стать более популярными архитектурами адаптации.
Глобальная структура документа HTML
Глобальная структура документа HTML7.1 Введение в структуру HTML документ
Документ HTML 4 состоит из трех частей:
- строка, содержащая версию HTML информация,
- декларативный раздел заголовка (разделенный заголовком HEAD элемент),
- тело, которое содержит фактическое содержимое документа.Тело может быть реализуется элементом BODY или Элемент FRAMESET .
Пробелы (пробелы, символы новой строки, табуляции и комментарии) могут появляться перед или после каждого раздела. Разделы 2 и 3 должны быть разделены кодом HTML . элемент.
Вот пример простого HTML-документа:
<ГОЛОВА>
Мой первый HTML-документ
<ТЕЛО>
Привет, мир!