Однокоренные слова — словарь и онлайн подбор
Однокоренные (родственные) слова — это слова с одним корнем. Корень — основная часть слова, в которой заключается главный смысл всех родственных слов. Как и человек, слова образуют целые семьи. Такие слова называются однокоренными (родственными).
Например: берёз-а — берёз-овый — под-берёз-овик. Здесь корень означает всё, связанное с этим деревом.
Берёзовый. Относящийся к берёзе (например сок, ствол).
Подберёзовик. Гриб, который растёт в соседстве с этим деревом.
Однокоренные слова и формы слова
Однокоренные слова нужно отличать от форм одного и того же слова. Как это сделать?
Во-первых, по лексическому значению, т. е. по смыслу слова. У форм слова одинаковое лексическое значение, то есть смысл, а у однокоренных слов значения отличаются.
Например
| Падеж | Вопрос | Форма слова |
|---|---|---|
| именительный падеж | кто? что? | вертолёт |
| родительный падеж | кого? чего? | вертолёт-а |
| дательный падеж | кому? чему? | вертолёт-у |
| винительный падеж | кого? что? | вертолёт |
| творительный падеж | кем? чем? | вертолёт-ом |
| предложный падеж | о ком? о чем? | о вертолёт-е |
Перед нами в воображении предстаёт одна и та же картинка летающего аппарата с пропеллером. Это формы одного и того же слова, так как лексическое значение одно и то же, разные только грамматические значения (у существительных — падежа и числа), выражающиеся окончаниями.
Это формы одного и того же слова, так как лексическое значение одно и то же, разные только грамматические значения (у существительных — падежа и числа), выражающиеся окончаниями.
А теперь сравним: вертолёт и вертолёт-чик. Перед нами в воображении предстают две абсолютно разные картинки. Это однокоренные слова, так как лексическое значение у слов разное. Слово вертолётчик обозначает уже человека, управляющего этим летающим аппаратом с пропеллером.
Кстати, обратите внимание, что в словах вертолёт и вертолётчик два корня. Какие? Что они обозначают? Правильно, -верт- — «вертеть», -лёт- — «лететь».
Можно продолжить группу однокоренных слов для каждого из этих корней:
-верт- — верт-олёт, верт-олётчик, верт-ушка, раз-верт-еться, по-верт-еть;
-лёт- — верто-лёт, верто-лёт-чик, само-лёт, лет-еть, лет-ать, по-лет-еть, по-лёт, вы-лет, от-лёт, лет-ун, лет-яга.
Общее лексическое значение у всех однокоренных слов с корнем -верт- — связано с глаголом «вертеть», а общее лексическое значение всех однокоренных слов с корнем -лёт- связано с глаголом «лететь».
Во-вторых, отличить однокоренные слова и формы одного и того же слова можно по структуре. Однокоренные слова образуются с помощью приставок и суффиксов. В формах слова изменяются только окончания.
Например
| формы слова, меняются только окончания | |
| дом, домишко, домище, надомный, домовой, домоводство | однокоренные слова с разными приставками и суффиксами |
Использование однокоренных слов
Грамотность человека зависит от того, насколько хорошо он умеет определять корень слова, понимать его лексическое значение, подбирать однокоренные слова. Зная правописание слова, легко ориентироваться в написании всех его однокоренных (родственных) слов.
Когда гласные или согласные буквы оказываются в слабой позиции, появляются сомнения в выборе этих букв.
Например
Л..с-ник — мы пишем через букву -е-, потому что все однокоренные слова этого ряда проверяются словом лес, где сомнительная гласная корня оказалась в сильной позиции, под ударением.
Хле.. — мы пишем через букву -б-, потому что сомнительную согласную проверяем однокоренным словом хлебушек, где эта согласная оказалась в сильной позиции, перед гласной буквой.
Слова с омонимичными корнями.
Следует отличать однокоренные слова от слов с омонимичнымые корнями. Омонимичные корни одинаково пишутся, но имеют разные лексические значения. А у однокоренных слов корни имеют одинаковые лексические значения.
Например
| вод-а, над-вод-ный, под-вод-ник, при-вод-ниться, вод-яной, водолаз, водоросли | однокоренные. Лексическое значение корня -вод- связано со значением слова «вода». |
| про-вод-ка | слово с корнем -вод- имеет другое лексическое значение, связанное со словом «проводить», поэтому слова проводка и вода не являются однокоренными, то есть родственными, их корни омонимичные, то есть имеют разные лексические значения. |
Для чего это нужно знать? Вслушиваясь в слова, всматриваясь в их структуру, можно догадаться о смысле незнакомых слов. Догадайтесь, что означает слово бор-овик? Догадались?
Догадайтесь, что означает слово бор-овик? Догадались?
Разбор слов по составу
Разбор слова по составу
Тип лингвистического анализа, в результате которого определяется структура слова, а также его состав, называется морфемным анализом.
Виды морфем
В русском языке используются следующие морфемы:
— Корень. В нем заключается значение самого слова. Слова, у которых есть общий корень, считаются однокоренными. Иногда слово может иметь два и даже три корня.
— Суффикс. Обычно идет после корня и служит инструментом для образования других слов. К примеру, «гриб» и «грибник». В слове может быть несколько суффиксов, а может не быть совсем.
— Приставка. Находится перед корнем. Может отсутствовать.
— Основа. Часть слова, к которой относятся все морфемы, кроме окончания.
Важность морфемного разбора
В русском языке разбор слова по составу очень важен, ведь нередко для правильного написания слова необходимо точно знать, частью какой морфемы является проверяемая буква. Многие правила русского языка построены на этой зависимости.
Многие правила русского языка построены на этой зависимости.
Пример
В качестве примера можно взять два слова: «чёрный» и «червячок». Почему в первом случае на месте ударной гласной мы пишем «ё», а не «о», как в слове «червячок»? Нужно вспомнить правило написания букв «ё», «е», «о» после шипящих, стоящих в корне слова. Если возможно поменять форму слова либо подобрать родственное ему так, чтобы «ё» чередовалась с «е», тогда следует ставить букву «ё» (чёрный — чернеть). Если чередование отсутствует, тогда ставится буква «о» (например, чокаться, шорты).
В случае же со словом «червячок» «-ок-» — это суффикс. Правило заключается в том, что в суффиксах, если стоящая после шипящих букв гласная находится под ударением, всегда пишется «о» (зрачок, снежок), в безударном случае — «е» (платочек, кармашек).
Как разобрать слово по составу
Для помощи начинающим существуют морфемно-орфографические словари. Можно выделить книги таких авторов, как Тихонов А.Н. , Ожегов С.И., Рацибурская Л.В.
, Ожегов С.И., Рацибурская Л.В.
В любом слове непременно должны присутствовать корень и основа. Остальных морфем может и не быть. Иногда слово целиком может состоять из корня (или основы): «гриб», «чай» и т.д.
Этапы морфемного анализа
Чтобы морфемный разбор слов было легче осуществить, следует придерживаться определенного алгоритма:
— Сначала нужно определить часть речи, задав вопрос к слову. Для прилагательного это будет вопрос «какой?», для существительного — «что?» или «кто?».
— Далее нужно выделить основу у слова. Все, кроме окончания, — основа.
— Потом следует определить корень, подобрав родственные однокоренные слова.
— Определяется приставка, а потом суффиксы (при их наличии).
Особенности разбора
Иногда подход к морфемному разбору в программах университета и школы может отличаться.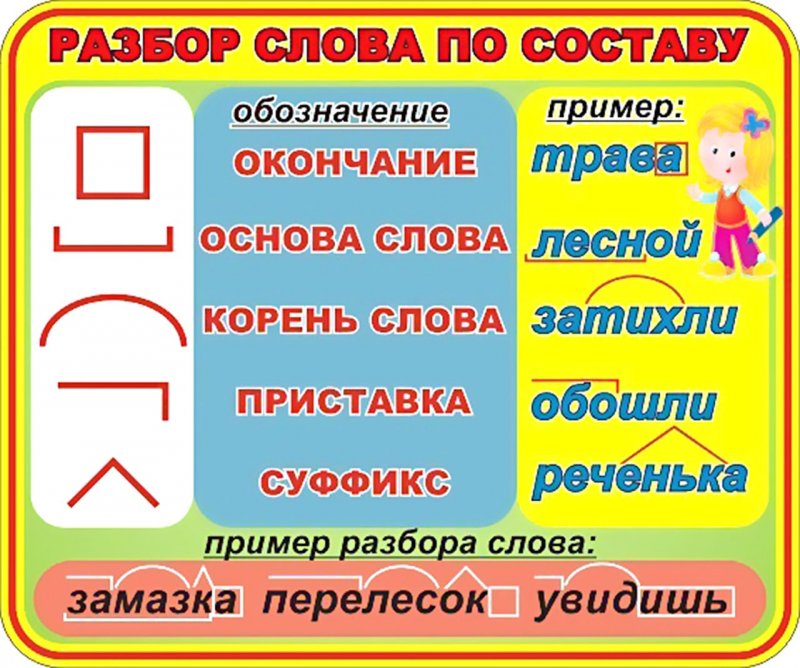 Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Во всех случаях различия аргументированы и имеют право на существование. Поэтому стоит ориентироваться на морфемный словарь, рекомендованный в конкретном учебном заведении.
Только что искали: лебидон 1 секунда назад эмират 1 секунда назад т о л к б с 1 секунда назад одкал 1 секунда назад с а т и 1 секунда назад магррмоап 1 секунда назад выкупс 1 секунда назад с имптом 2 секунды назад р я м е т л а 2 секунды назад сужаесрри 2 секунды назад р у б с е л к 2 секунды назад к о н т у р 2 секунды назад т р е щ и н а 2 секунды назад компандер 2 секунды назад влетевние 2 секунды назад
Написание контента · Nuxt Content
Прежде всего, создайте каталог content/ в вашем проекте:
content/ article/ article-1.md article-2.md home.md
Этот модуль будет анализировать .,  MD
MD .yaml , .yml , .CSV , .JSON , .JSON5 , .XML и генерируйте следующие свойства:
-
- 59999444444444444444444994444444444444444444994449
4444444444499444499444994444444499. -
slug -
extension(ex:.md) -
createdAt -
updatedAt
The createdAt and updatedAt properties are based on the file's actual created & updated datetime, but вы можете переопределить их, определив свои собственные значения createdAt и updatedAt . Это особенно полезно, если вы переносите свои прошлые сообщения в блоге, где
Это особенно полезно, если вы переносите свои прошлые сообщения в блоге, где createdAt может быть несколько месяцев или лет назад.
Этот модуль преобразует ваши файлы .md в древовидную структуру JSON AST, хранящуюся в переменной body .
Обязательно используйте компонент для отображения тела содержимого уценки, см. Отображение содержимого.
Вы можете обратиться к руководству по основному синтаксису, чтобы помочь вам освоить Markdown
Вступительная часть
Вы можете добавить блок вступительной части YAML в файлы уценки. Вступительная часть должна быть первой в файле и должна иметь форму допустимого YAML, заключенного между линиями с тройным пунктиром. Вот простой пример:
Вот простой пример:
---title: Introductiondescription: Узнайте, как использовать @nuxt/content.---
Эти переменные будут введены в документ:
{ body: Выдержка из объекта: Название объекта: «Введение» описание: «Узнайте как использовать @nuxt/content». dir: "/" extension: ".md" path: "/index" slug: "index" toc: Array createdAt: DateTime updatedAt: DateTime} Excerpt
Выдержка из содержимого или сводка могут быть извлечены из содержимого с помощью < !--подробнее--> как разделитель.
---title: Introduction---Узнайте, как использовать @nuxt/content.Полный объем контента за пределами разделителя more.
Свойство Description будет содержать содержимое выдержки, если оно не определено в реквизитах Front Matter.
В документ будут внедрены переменные примера:
{ body: Object title: «Introduction» description: «Узнайте, как использовать @nuxt/content». dir: "/" выдержка: Расширение объекта: ".md" путь: "/index" slug: "index" toc: Array createdAt: DateTime updatedAt: DateTime}
dir: "/" выдержка: Расширение объекта: ".md" путь: "/index" slug: "index" toc: Array createdAt: DateTime updatedAt: DateTime}  dir: "/" выдержка: Расширение объекта: ".md" путь: "/index" slug: "index" toc: Array createdAt: DateTime updatedAt: DateTime}
dir: "/" выдержка: Расширение объекта: ".md" путь: "/index" slug: "index" toc: Array createdAt: DateTime updatedAt: DateTime} Заголовки
Этот модуль автоматически добавляет идентификатор и ссылку к каждому заголовку.
Скажем, у нас есть следующий файл уценки:
home.md
# Lorem ipsum## dolor—sit—amet### consectetur & adipisicing#### elit##### elit
Он будет преобразован в свою структуру JSON AST и с помощью компонента nuxt-content будет отображать HTML следующим образом:
Lorem ipsumdolor—sit—ametconsectetur & жиросжиганиеэлит< a href="#elit-1" aria-hidden="true" tabindex="-1">elit
Ссылки в заголовках пусты и поэтому скрыты, так что вам решать, как их стилизовать.
 Например, попробуйте навести курсор на один из заголовков в этих документах.
Например, попробуйте навести курсор на один из заголовков в этих документах.Ссылки
Ссылки преобразуются для добавления действительных атрибутов target и rel с использованием замечаний-внешних-ссылок. Вы можете проверить здесь, чтобы узнать, как настроить этот плагин.
Относительные ссылки также автоматически преобразуются в nuxt-ссылки, чтобы обеспечить навигацию между компонентами страницы с повышенной производительностью благодаря интеллектуальной предварительной выборке.
Вот пример использования внешних, относительных, уцененных и HTML-ссылок:
---title: Home---## LinksNuxt Link to Blog Html-ссылка на блог[Markdown-ссылка на блог](/articles)Внешняя html-ссылка[ Уценка внешней ссылки](https://nuxtjs.
 org)
org) Сноски
Этот модуль поддерживает расширенный синтаксис уценки для сносок с использованием сносок-примечаний. Вы можете проверить здесь, чтобы узнать, как настроить этот плагин. 9bignote]: Вот пример с несколькими абзацами и кодом. Сделайте отступ для абзацев, чтобы включить их в сноску. `{ мой код }` Добавьте столько абзацев, сколько хотите.
Дополнительную информацию о сносках можно найти в расширенном руководстве по синтаксису.
Кодовые блоки
Этот модуль автоматически упаковывает кодовые блоки и применяет классы PrismJS (см. подсветку синтаксиса).
Кодовые блоки в Markdown заключаются в 3 обратных кавычки. При желании вы можете определить язык кодового блока, чтобы включить подсветку синтаксиса.
Первоначально уценка не поддерживала имена файлов или выделение определенных строк внутри кодовых блоков.
- Выделенные номера строк в фигурных скобках
- Имя файла в квадратных скобках
```js{1,3-5}[server.js]
константный http = требуется('http')
const bodyParser = требуется ('тело-парсер')
http.createServer((req, res) => {
bodyParser.parse(req, (ошибка, тело) => {
рез.конец(тело)
})
}).слушай(3000)
```
После рендеринга с компонентом nuxt-content это должно выглядеть так (пока без имени файла):
server.js
server.js...
Номера строк добавляются к тегу pre в атрибуте data-line .
Ознакомьтесь с этим комментарием о том, как отображать номера линий призмы.

Имя файла будет преобразовано в диапазон с классом имени файла . Это зависит от вас, чтобы стилизовать его.
Ознакомьтесь с файлом main.css этой документации, чтобы посмотреть пример оформления имен файлов.
Подсветка синтаксиса
По умолчанию он поддерживает подсветку кода с использованием PrismJS и внедряет тему, определенную в параметрах, в ваше приложение Nuxt.js, см. конфигурацию.
HTML
Вы можете писать HTML в Markdown:
home.md
---title: Home---## HTMLСочетание Markdown и HTML.
Имейте в виду, что при размещении Markdown внутри компонента ему должна предшествовать и следовать пустая строка, иначе весь блок будет рассматриваться как пользовательский HTML.
Это не сработает:
*Markdown* и HTML.
Но это сработает:
*Markdown* и < em>HTML.
Как и это :
*Markdown* и HTML. Компоненты Vue
Вы можете использовать глобальные компоненты Vue или локально зарегистрировать на странице, которую вы повторно отображая вашу уценку.
Существует проблема с локально зарегистрированными компонентами и динамическим редактированием в процессе разработки. Начиная с версии v1.5.0 ее можно отключить, установив liveEdit: false (см. конфигурацию
).
Начиная с @nuxt/content работает в предположении, что весь Markdown предоставляется автором (а не через стороннее представление пользователя), исходники обрабатываются полностью (включая теги), с парой оговорок от rehype-raw:
- Вам нужно ссылайтесь на свои компоненты и их реквизиты по имени kebab case:
Используйтевместо
- Вы не можете использовать самозакрывающиеся теги , то есть это не сработает :
<мой-компонент/>
Но это будет :
<мой-компонент>
Пример
Пример: Vtiselect, называемый M
home. md
md
Выберите *framework*:
Результат
Пожалуйста, выберите платформу :
Не работает с документами Content v2!
Вы также можете определить параметры компонентов во вступительной части:
home.md
---multiselectOptions: - VuePress - Gridsome - Nuxt---
Не работает с документами Content v2!
Шаблоны
Вы можете использовать теги шаблона для распространения контента внутри компонентов Vue.js:
Содержимое именованного слота.
Однако вы не можете визуализировать
динамический контент и не использовать
слот реквизит. то есть, это не сработает :
то есть, это не сработает :
{{ slotProps.someProperty }}
Глобальные компоненты
Начиная с v1.4.0 и Nuxt v2.13.0 теперь вы можете помещать свои компоненты в каталог components/global/, чтобы вам не приходилось импортировать их на свои страницы.
components/ global/ Hello.vuecontent/ home.md
Затем в content/home.md вы можете использовать компонент , не беспокоясь об его импорте на свою страницу.
Содержание
При извлечении документа у нас есть доступ к свойству toc, которое представляет собой массив всех заголовков. Каждый заголовок имеет идентификатор
Каждый заголовок имеет идентификатор id , так что на него можно ссылаться, глубина, которая является типом заголовка. Для оглавления используются только заголовки h3 и h4. Существует также свойство text, которое является текстом заголовка.
{ "toc": [{ "id": "добро пожаловать", "depth": 2, "text": "Добро пожаловать!" }]} Взгляните на правую часть этой страницы для примера.
Пример
Файл content/home.md :
---title: Home---## Добро пожаловать!
Будет преобразовано в:
{ "dir": "/", "slug": "home", "path": "/home", "extension": ".md", "title": "Home ", "toc": [ { "id": "добро пожаловать", "depth": 2, "text": "Добро пожаловать!" } ], "body": { "type": "root", "children": [ { "type": "element", "tag": "h3", "props": { "id": "welcome" }, "children": [ { "type": "element", "tag": "a", "props": { "ariaHidden": "true", "href": "#welcome", "tabIndex": -1 }, "дети": [ { "тип": "элемент", "тег": "диапазон", "реквизит": { "имя_класса": [ "значок", "значок-ссылка" ] }, "дети ": [] } ] }, { "type": "text", "value": "Добро пожаловать!" } ] } ] }} Мы внутренне добавляем ключ text с телом уценки, которое будет использоваться для поиска или расширения.
Определенные данные будут вставлены в документ.
Тело не будет создано.
Массивы
v0.10.0+
Теперь вы можете использовать массивы внутри файлов .json . Объекты будут сведены и вставлены в коллекцию. Вы можете получать свой контент так же, как и раньше.
С slug по умолчанию берется из пути и отсутствует, в этом случае вы должны определить его в своих объектах, чтобы эта функция работала правильно.
Посмотрите наш пример со статьями и авторами.
Пример
Файл content/home.json :
{ "title": "Главная", "description": "Добро пожаловать!"} Будет преобразовано в:
{ "dir": "/", "slug": "home", "path": "/home", "extension": ". json", "title": "Home", "description": "Добро пожаловать!"}  json", "title": "Home", "description": "Добро пожаловать!"}
json", "title": "Home", "description": "Добро пожаловать!"} Файл content/authors.json :
[ { "name": "Себастьян Шопен", "slug": "atinux" }, { "name": "Крути Патель", "slug": "крутипатель " }, { "name": "Сергей Бедрицкий", "slug": "sergeybedritsky" }] Будет преобразовано в:
[ { "name": "Себастьян Шопен", "slug": "atinux", "dir": "/authors", "path": "/authors/atinux", "extension": ".json" }, { "name": "Крути Пател", "slug": "Крутиепатель", "каталог ": "/authors", "path": "/authors/крутипатель", "extension": ".json" }, { "name": "Сергей Бедрицкий", "slug": "сергейбедрицкий", "dir": "/authors", "путь": "/authors/сергейбедрицкий", "расширение": ".json" }] Строки будут присвоены переменной body.
Пример
Файл content/home.csv :
заголовок, описание Домой, добро пожаловать!
Будет преобразовано в:
{ "dir": "/", "slug": "home", "path": "/home", "extension": ".