Слова «множество» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «множество» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «множество» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «множество».
Содержимое:
- 1 Слоги в слове «множество» деление на слоги
- 2 Как перенести слово «множество»
- 3 Разбор слова «множество» по составу
- 4 Сходные по морфемному строению слова «множество»
- 5 Синонимы слова «множество»
- 6 Антонимы слова «множество»
- 7 Ударение в слове «множество»
- 8 Фонетическая транскрипция слова «множество»
- 9 Фонетический разбор слова «множество» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «множество»
- 11 Сочетаемость слова «множество»
- 12 Значение слова «множество»
- 13 Склонение слова «множество» по подежам
- 14 Как правильно пишется слово «множество»
Слоги в слове «множество» деление на слоги
Количество слогов: 3
По слогам: мно-же-ство
По правилам школьной программы слово «Множество» можно поделить на слоги разными способами. Допускается вариативность, то есть все варианты правильные. Например, такой:
Допускается вариативность, то есть все варианты правильные. Например, такой:
мно-жес-тво
По программе института слоги выделяются на основе восходящей звучности:
мно-же-ство
Ниже перечислены виды слогов и объяснено деление с учётом программы института и школ с углублённым изучением русского языка.
с примыкает к этому слогу, а не к предыдущему, так как не является сонорной (непарной звонкой согласной)
Как перенести слово «множество»
мно—жество
множе—ство
множес—тво
множест—во
Разбор слова «множество» по составу
| множ | корень |
| еств | суффикс |
| о | окончание |
множество
Сходные по морфемному строению слова «множество»
Сходные по морфемному строению слова
Синонимы слова «множество»
1. прорва
прорва
2. раздолье
3. разнообразие
4. обилие
5. изобилие
6. море
7. масса
8. тьма
9. бездна
10. пропасть
11. уйма
12. куча
13. гора
14. скопище
15. стая
16. рой
17. туча
18. полчище
19. табун
20. сонм
21. сонмище
22. армия
23. полк
24. легион
25. воз
26. вагон
27. арсенал
28. груда
29. ворох
30. множественность
31. уймища
32. бесчисленность
33. тьма-тьмущая
34. тьма тем
35. сила
36. подмножество
37. град
38. лик
39. мириады
40. пучок
41. силища
42. континуум
43. строй
44. лес
45. несметное количество
46. большое количество
47. огромное количество
48. великое множество
49. поток
50. каскад
51. лавина
52. разливанное море
53. большое число
54. огромное число
55. несметное число
56. миллионы
миллионы
57. гибель
58. чертова гибель
59. многое множество
60. премножество
61. короб
62. батарея
63. кипа
64. много
65. армада
66. кодла
67. целый ряд
68. полно
69. немало
70. без числа
71. без счета
72. предостаточно
73. сколько угодно
74. сколько душе угодно
75. более чем достаточно
76. сколько хочешь
77. без счету
78. в избытке
79. косяк
80. навал
81. хор
82. кодло
83. палестина
84. целый короб
Антонимы слова «множество»
1. меньшинство
Ударение в слове «множество»
мно́жество — ударение падает на 1-й слог
Фонетическая транскрипция слова «множество»
[мн`ожыства]
Фонетический разбор слова «множество» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| м | [м] | согласный, звонкий непарный (сонорный), твёрдый | м |
| н | [н] | согласный, звонкий непарный (сонорный), твёрдый | н |
| о | [`о] | гласный, ударный | о |
| ж | [ж] | согласный, звонкий парный, твёрдый, шипящий, шумный | ж |
| е | [ы] | гласный, безударный | е |
| с | [с] | согласный, глухой парный, твёрдый, шумный | с |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| в | [в] | согласный, звонкий парный, твёрдый, шумный | в |
| о | [а] | гласный, безударный | о |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 9 букв и 9 звуков.
Буквы: 3 гласных буквы, 6 согласных букв.
Звуки: 3 гласных звука, 6 согласных звуков.
Предложения со словом «множество»
Пища современного человека содержит множество жиров, но чаще не тех, которые полезны, а как раз тех, которые следует избегать.
Источник: Анатолий Будниченко, Как правильно питаться успешному человеку, 2013.
Причин для осуществления подобной цели имелось великое множество.
Источник: Павел Амитов, Преодоление лжи.
А вот мои прекрасные, изумрудные глаза поменяли цвет на бледно синий, совершенно не выразительный, плюс появилось множество мелких веснушек.
Источник: Е. В. Березовская, Трактир под «знаком качества».
Сочетаемость слова «множество»
1. великое множество
великое множество
2. бесчисленное множество
3. бесконечное множество
4. множество людей
5. множество вопросов
6. множество вещей
7. топот множества ног
8. теория множеств
9. в окружении множества
10. множество примет
11. увидеть множество
12. иметь множество
13. состоять из множества
14. (полная таблица сочетаемости)
Значение слова «множество»
МНО́ЖЕСТВО , -а, ср. 1. Очень большое количество, число кого-, чего-л. (Малый академический словарь, МАС)
Склонение слова «множество» по подежам
| Падеж | Вопрос | Единственное числоЕд.ч. | Множественное числоМн.ч. |
|---|---|---|---|
| ИменительныйИм. | что? | множество | множества |
| РодительныйРод. | чего? | множества | множеств |
| ДательныйДат. | чему? | множеству | множествам |
ВинительныйВин. | что? | множество | множества |
| ТворительныйТв. | чем? | множеством | множествами |
| ПредложныйПред. | о чём? | множестве | множествах |
Как правильно пишется слово «множество»
Орфография слова «множество»Правильно слово пишется: мно́жество
Нумерация букв в слове
Номера букв в слове «множество» в прямом и обратном порядке:
- 9
м
1 - 8
н
2 - 7
о
3 - 6
ж
4 - 5
е
5 - 4
с
6 - 3
т
7 - 2
в
8 - 1
о
9
Опубликовано: 2020-06-11
Популярные слова
проскользнет , забежал , сопредельный , антивибраторы , астропрогнозу , брахиоподах , бульдозерные , взывайте , внутрикомнатным , возродившеюся , вспухают , выменивающую , выминавшим , вышучивайте , гидробионту , горчицам , государственностью , дедуля , жижесборник , заготовившем , отсевают , отсеиваемом , перехваленным , пиронафте , подлезаете , позанести , покормившему , полуфинальный , поспешают , пристыдим , проливавшему , прорубки , пятнистых , разведавшею , разворотившие , разлучило , расквартированными , расстыковываются , тенденциозность , цементировавший
Фонетический разбор слова / Русский на 5
Есть языки, в которых слова пишутся так, как слышатся. Но русский язык не такой. Многие слова произносятся и пишутся по-разному. Понимать звуко-буквенные соответствия учит фонетический разбор. Он повышает грамотность письменной речи. Именно поэтому в школе фонетическому разбору уделяют много внимания.
Но русский язык не такой. Многие слова произносятся и пишутся по-разному. Понимать звуко-буквенные соответствия учит фонетический разбор. Он повышает грамотность письменной речи. Именно поэтому в школе фонетическому разбору уделяют много внимания.
Поскольку эта статья вызывает большой интерес, было решено расширить её и представить в виде рубрики. В новой версии больше слов для разбора, интерактивные тренинги и тесты. Стало возможным многократно открывать и закрывать ответы, открыть ответы на несколько заданий одновременно, сравнивать разборы разных примеров.
Особенности фонетического разбора
Что такое фонетический разбор, в чём его специфика.
Что нужно знать и уметь делать. Порядок разбора
Советы. Как приступить к делу
О чём важно подумать перед разбором слова, что с чем не перепутать, в чём не ошибиться
Примеры и комментарии
Это то, чего не хватает в учебниках. Здесь на конкретных образцах показано, как разбирать слова
Типичные ошибки
Разберись с типичными ошибками и не повторяй их. Без этого знания будут неполными
Без этого знания будут неполными
Первые шаги — подготовительные задания
Учись выполнять отдельные важные операции, простые действия. Это поможет избежать множества проблем.
Темы:
Деление слов на слоги и определение ударного слога. Тесты № 1 — № 2
Соотношение букв и звуков. Характеристика звуков. Тесты № 1 — № 2
Чтение транскрипция
Составление транскрипции
Итоговые тесты «Фонетический анализ в формате ЕГЭ»
Пройди итоговые тесты по теме: Фонетический разбор слова. Тесты №1 — №4
Старая версия
Фонетический разбор. Особенности
Данный вид разбора вызывает множество затруднений. Мало кому удаётся избежать в нём ошибок. Почему?
Дело в том, что для его выполнения нужны знания и предельное внимание: мелочей в фонетике не бывает.
Необходимо знать правила транскрипции, уметь её писать. Нужно понимать, что делать и в какой последовательности.
Перед тренировкой:
- узнай порядок разбора,
- внимательно изучи примеры и комментарии,
- проанализируй типичные ошибки.


В учебниках примеров транскрипции и фонетического разбора слов слишком мало. Поэтому здесь приводится много примеров, в десятки раз больше. Я вижу свою задачу в том, чтобы с максимальной наглядностью показать, что от тебя требуется. Но если ты не знаешь базовых понятий фонетики, не понимаешь различия между буквами и звуками, не умеешь определять гласные и согласные, отличать глухие от звонких, твёрдые от мягких и т.п., то тебе лучше начать с рубрики Глава 2. Фонетика
ПОМНИ:
приступать к фонетическому разбору без знаний — только терять время.
Порядок разбора
- Запишите слово, обозначая деление на слоги, сосчитайте количество слогов.
- Определите ударный слог, поставьте ударение.
- Запишите слово в столбик буквами и транскрипцией. Обратите внимание на соотношение букв и звуков. Подсчитайте количество букв и звуков. Запишите эти данные.
- Дайте характеристику звукам: гласным и согласным.
Полезные советы:
- Когда транскрипция уже написана, не спеши переходить к характеристике звуков. Произнеси слово несколько раз. Не утрируй произношение: при этом звучание будет искажено. Слушай себя внимательно.
- Проверь транскрипцию ещё раз. Если в транскрибировании слова допущена ошибка, она повлечёт за собой следующие ошибки в характеристике звуков.
- Выработай чёткую последовательность действий, чтобы не пропустить какой-либо обязательный этап разбора.
- Приучи себя с особенной тщательностью относиться к словам, если в них есть стечение гласных или стечение согласных, шипящие согласные, непарные согласные по твёрдости-мягкости и/или глухости-звонкости.
- Особо внимательно отнесись к словам, вызывающим орфографические трудности: в них всегда звуко-буквенные соотношения будут иметь какие-то особенности.
 Произнеси слово несколько раз. Не утрируй произношение: при этом звучание будет искажено. Слушай себя внимательно.
Произнеси слово несколько раз. Не утрируй произношение: при этом звучание будет искажено. Слушай себя внимательно.
Примеры и комментарии:
Пример 1: ель — слово из одного слога.
е — [й’] — согл., зв. непарн., мягк. непарн.
\ [э] — гл. ударн.
л — [л’] — согл. , зв. непарн., мягк.
, зв. непарн., мягк.
ь — [-]
_______
3 б., 3 зв.
Комментарий:
- буква е в начале слова обозначает два звука: [й’] и [э]
- буква ь обозначает мягкость предшествующего согласного
- звук [й’] — непарный по глухости-звонкости и по твёрдости-мягкости
- звук [л’] — непарный по глухости-звонкости
Пример 2: вы-со´-кий — слово из трёх слогов, второй слог ударный.
в — [в] — согл., зв., тв.
ы — [ы] — гл. безуд.
с — [с] — согл., глух., тв.
о — [о´] — гл. ударн.
к — [к’] — согл., глух., мягк.
й — [й’] — согл., зв. непарн., мягк. непарн.
________
7 б., 7 зв.
Комментарий:
- гласные [ы] и [и] — в безударном положении произносятся короче, слабее, но не меняют своего качества
- звук [й’] — непарный по глухости-звонкости и по твёрдости-мягкости
Пример 3: объ-е´зд — слово из двух слогов, второй слог ударный.
о — [a] — гл. безуд.
б — [б’] — согл., зв., тв.
ъ — [-]
е — [й’] — согл., зв. непарн., мягк. непарн.
\ [э´] — гл. ударн.
з — [с] — согл., гл., тв.
д — [т] — согл., гл., тв.
________
6 б., 6 зв.
Комментарий:
- буква е после разделительного твёрдого знака обозначает два звука: [й’] и [э]
- звук [т] — пример оглушения звонких на конце слова
- звук [c] — пример оглушения звонкого в позиции пред глухим
- слово может произноситься и по-другому: [абй’эст], т.е. с твёрдым произношением [б]
Пример 4: лы´-жи — слово из двух слогов, первый слог ударный.
л — [л] — согл., зв. непарн., тв.
ы — [ы´] — гл. ударн.
ж — [ж] — согл., зв., тв. непарн.
и — [ы] — гл. безуд.
________
4 б., 4зв.
Комментарий:
- звук [л] — непарный по глухости-звонкости
- звук [ж] — непарный по твёрдости-мягкости, написание после него буквы и — это традиционное написание
- буква и обозначает звук [ы], согласный [ж] — твёрдый, написание и после ж традиционное.

Пример 5: вью´-га — слово из двух слогов, первый слог ударный.
в — [в’] — согл., зв., мягк.
ь — [-]
ю — [й’] — согл., зв. непарн., мягк. непарн.
\ [у´] — гл. ударн.
г — [г] — согл., зв., тв.
а — [ъ] — гл. безуд.
________
5 б., 5 зв.
Комментарий:
- буква ь здесь разделительный мягкий знак
- буква ю после разделительного мягкого знака обозначает два звука: [й’] и [у]
- звук [й’] — непарный по глухости-звонкости и по твёрдости-мягкости
- конечный гласный звук в слабой заударной позиции подвергается редукции: [ъ]
Пример 6: е-го´ – слово из двух слогов, второй слог ударный.
е-[й’] – согл., зв. непарн., мягк. непарн.
\[и] — гл. безуд.
г- [в] – согл., зв., тв.
о-[о´] – гл. ударн.
__________
3 б., 4 зв.
Комментарий:
- Буква е в начале слова обозначает два звука: [й’] и безударный [и]
- буква г пишется по традиции в окончаниях прилагательных, числительных местоимений: ого, его – нового, синего, первого. Пишем г, произносим [в]
 Пишем г, произносим [в]
Пишем г, произносим [в]
Пример 7: пра´-здный – слово из двух слогов, первый слог ударный.
п-[п] – согл., глух., тв
р-[р] – согл., зв. непарн., тв.
а-[а´] – гл. ударн.
з-[з] – согл., зв, тв.
д-[-]
н-[н] – согл., зв. непарн., тв.
ы-[ы] – гл. безуд.
й-[й’] – согл., зв. непарн., мягк. непарн.
___________
8 б., 7 зв.
Комментарий:
- звуки [р] и [н] непарные по глухости-звонкости
- буква д пишется, потому что в сильной позиции в корне праздн есть [д]: празден (краткая форма прилагательного, ед.ч., м.р.)
- звук [й’] непарный по глухости-звонкости и по твёрдости-мягкости
Пример 8: ве-сти´ – слово из двух слогов, второй слог ударный.
в-[в’] – согл., зв., мягк.
е-[и] – гл. безуд.
с-[с’] – согл., глух., мягк.
т-[т’] – согл., глух., мягк.
и-[и´] – гл. ударн.
_________
5 б., 5 зв.
Комментарий:
- Звук [с’] – пример позиционного изменения согласных по твёрдости-мягкости
- Буквы е и и показывают, что согласные перед ними мягкие
Пример 9: ве-зти´ – слово из двух слогов, второй слог ударный.
в-[в’] – согл, зв., мягк.
е-[и] – гл. безуд.
з-[с’] – согл., глух., мягк.
т-[т’] — согл., глух., мягк.
и-[и´] — гл. ударн.
________
5 б., 5 зв.
Комментарий:
- Звук [c’] – пример позиционных изменений согласных по глухости-звонкости и по твёрдости-мягкости
- Буквы е и и показывают, что согласные перед ними мягкие
Пример 10: ре-во-лю´-ци-я — слово из 5 слогов
р — [р’] — согл., зв. непарн., мягк. непарн.
е — [ь] — гл. безуд.
в — [в] — согл., зв., тв.
о — [а] — гл. безуд.
л — [л’] — согл. , зв. непарн., мягк.
, зв. непарн., мягк.
ю — [у´] — гл. ударн.
ц — [ц] — согл., глух. непарн., тв. непарн.
и — [ы] — гл. безуд.
я — [й’] — согл., зв. непарн., мягк. непарн.
\ [a] — гл. безуд.
_________
9 б., 10 зв.
Комментарий:
- звуки [р’] и [л’] — непарные по глухости-звонкости
- звук [ь] — так обозначается безударный гласный, произносимый в заударных и предударных слогах (кроме 1-го предударного) после мягких согласных
- звук [ц] — непарный по обоим признакам: по твёрдости-мягкости и по глухости-звонкости
- буква и обозначает звук [ы], потому что в корне слова после буквы ц пишется и: революция – [р’ьвал’уцый’а] .
- буква я после гласных произносится как два звука: [й’] и [a]. Гласный находится в слабой позиции, заударном слоге, подвергается редукции.
Типичные ошибки
В обозначении ударения:
1. Неправильно проставленное ударение, например, в словах: феномен, каталог, алфавит.
2. Ударение не обозначено.
ПРАВИЛЬНО:
фено´мен, катало´г, алфави´т
Списки ошибкоопасных слов см. в разделе ЕГЭ: «А, В, С» — всё для подготовки, а также в разделе Ликбез: уроки правильной речи для родителей
В транскрипции:
1. Неправильное обозначение в транскрипции ударных гласных.
Смешение звуков и букв:
- ошибочное обозначение гласными буквами е, ё, ю, я звуков [э], [о], [у], [а], например, в словах: шёл, щель, Люба, мясо
- ошибочное обозначение гласной буквой и звука [ы] после шипящих и ц, например, в словах: машина, цирк
- ошибочное обозначение гласными буквами я и ю звуков [a] и [у] после ч и щ , например, в словах: чашка, чудо
- ошибочное обозначение гласной буквой е звука [э] после шипящих, например в словах: шесть, жест.
ПРАВИЛЬНО:
- [шол], [ш’:эл’], [л’у´бъ], [м’а´съ]
- [машы´нъ], [цырк]
- [ч’а´шкъ], [ч’у´дъ]
- [шэс’т’], [жэст]
2. Неправильное обозначение безударных гласных.
Неправильное обозначение безударных гласных.
Игнорирование или незнание правил редукции гласных в безударных слогах:
ошибочное обозначение звуков буквами в заударных и предударных слогах после твёрдых согласных, например, в словах: плохо, хорошо, карандаш
ошибочное обозначение звуков буквами в заударных и предударных слогах после мягких согласных, например, в словах: мячом, мечом, девять, десять
ошибочное обозначение звука буквами в позиции начала слова, например, в словах: окно, остановка
ошибочное обозначение звуков буквами в позиции после шипящих, например, в словах: шоссе, шинель
ошибочное обозначение звуков в позиции конца слова, например, в словах: по´ле, по´ля, здание, здания
ПРАВИЛЬНО:
- [пло´хъ], [хърашо´], [къранда´ш]
- [м’ич’о´м], [м’ич’о´м], [ д’э´в’ьт’], [д’э´с’ьт’]
- [акно´], [астано´фкъ]
- [шас:э´], [шын’э´л’]
- [по´л’э], [по´л’а], [зда´н’ий’э], [зда´н’ий’а]
3. Неправильное обозначение звонких согласных, например, в словах: косьба, сделать, экзамен. Правильно: [каз’ба´], [з’д’э´лът’], [игза´м’ьн]
Неправильное обозначение звонких согласных, например, в словах: косьба, сделать, экзамен. Правильно: [каз’ба´], [з’д’э´лът’], [игза´м’ьн]
4. Неправильное обозначение глухих согласных, например, в словах: варежки, сказки, встать. Правильно: [ва´р’ьшк’и], [ска´ск’и], [фстат’]
5. Неправильное обозначение непарных твёрдых согласных, например, в словах: цирк, машины, жить. Правильно: [цырк], [машы´ны], [жыт’]
6. Неправильное обозначение непарных мягких согласных, например, в словах: чаша, чушь, щит. Правильно: [ч’а´шъ], [ч’уш], [ш’:ит]
7. Неправильное обозначение звука, например, в словах: что, считать, его. Правильно: [што], [ш’:ита´т’]
8. Неправильный подсчёт звуков.
9. Смешение букв и звуков.
В характеристике звуков:
1. Гласных – ошибочные характеристики, смешение ударных и безударных гласных.
2. Согласных – ошибочные характеристики из-за незнания, какие звуки звонкие, а какие глухие, какие твёрдые, а какие мягкие.
3. Групп согласных – ошибочные характеристики из-за незнания позиционных изменений согласных.
4. Долгих согласных – пропуск символа, обозначающего долготу звука, например: учиться, учится, щит, счёт, Алла. Правильно: [у´ч’иц:ъ], [уч’и´ц:ъ], [ш’:ит], [ш’:от], [А´л:ъ]
Если ты не понимаешь, почему транскрипция примеров выполнена именно так, то, по-видимому, у тебя есть пробелы в знаниях. Рекомендую обратиться к рубрике: Русская грамматика. Раздел 2. Фонетика
Подготовительные задания1. Деление слов на слоги, выделение ударного слога.
Раздели слова на слоги с помощью символа: —
Затем выдели ударный слог. Проверь себя по ключу.
Пример:
Дано: дома.
Действие 1: на месте слогораздела поставь символ «-«: до-ма.
Действите 2: кликнуть на ударный слог, который при этом выделится.
После выполнения правильные ответы обозначаются зелёным цветом, неправильные – красным.
Слова:
семья, домик, праздник, окошко, диван, потолок, радость, лужа, деревня, лампа, круг, тишина
Ключ: Семь-я´, до´-мик, пра´-здник, о-ко´-шко, ди-ва´н, по-то-ло´к, ра´-дость, лу´-жа, де-ре´-вня, ла´м-па, круг, ти-ши-на´
ВНИМАНИЕ!
Не путай: слова для переноса делятся по-другому.
2. Транскрипция.
Запиши слова в транскрипции. Проверь себя по ключам.
Дано: слова.
Действие: транскрибирование слов.
- Пол, дом, курс, зуб, дам, мать, вот, лгать, знать, слон
- Вода, дома, сама, окно, возил, носил, водил, носы, душа, лыжи
- Мяч, меч, речь, течь, течёт, мячом, мечом, тенью, дядей, витязь, север
- Хорошо, холодно, запад, карандаш, колбаса, самовар, радость, садовый, прогулка, парашют
- Экран, этаж, этикет, эстетика, экономика, оса, автобус, остановка, аквариум, осторожность
- Я, ёж, её, июль, юла, яблоко, ёлка, подъём, подъезд, съёжиться, вьюга
Ключи:
1. [пол], [дом], [курс], [зуп], [дам], [мат’], [вот], [лгат’], [знат’], [слон]
2. [вада´], [дама´], [сама´], [акно´], [ваз’и´л], [нас’и´л], [вад’и´л], [насы´], [душа´], [лы´жы]
3. [м’ач’], [м’эч’], [р’эч’], [т’эч’], [т’ич’о´т], [м’ич’о´м], [м’ич’о´м], [т’э´н’й’у], [д’а´д’ьй’], [в’и´ т’ьс’], [c’э´в’ьр]
4. [хърашо´], [хо´лъднъ], [за´път], [къранда´ш], [кълбаса´], [съмава´р], [ра´дъс’т’], [садо´вый’], [прагу´лкъ], [пърашу´т]
5. [икра´н], [ита´ш], [ит’ик’э´т], [истэ´т’икъ], [икано´м’икъ], [аса´], [афто´бус], [астано´фкъ], [аква´р’иум], [астаро´жнъс’т’]
6. [й’а], [й’ош], [й’ий’о´], [ий’у´л’], [й’у´ла], [й’a´блъкъ], [й’о´лкъ], [пад’й’о´м], [пад’й’э´cт], [c’й’о´жыц:ъ], [в’й’у´гъ]
3. Определите звуки, обозначенные выделенными буквами и охарактеризуйте их:
- Съёмка, привёзти, сито
- Шёл, что, шорох
- Отца, стараться, улыбается
- Подпол, пот, тратить
- Экономия, игра, история
- Вскоре, факт, Коровьев
- Майка, строй, йод
- Ем, подъезд, ездить
- Гриб, грипп, тулуп
- Сыр, лыжи, шин
Ключи:
- [с’] – согл. , глух., мягк.
- [ш] – согл., глух., тв. непарн.
- [ц:] – согл., глух. непарн., тв. непарн.
- [т] – согл., гл., тв.
- [и] – гл. безударн.
- [ф] – согл., глух., тв.
- [й’] – cогл., зв. непарн., мягк. непарн.
- Звуки [й’] и [э] – согл., зв. непарн., мягк. непарн.; гл. ударн.
- [п] – согл., глух., тв.
- [ы] – гл. ударн.
 , глух., мягк.
, глух., мягк.4. Прочитайте транскрипцию, определи, какие слова представлены и запиши их буквами:
[с’й’э´л’и], [c’н’эк], [пърас’´онък], [пъзнако´м’иц:ъ], [м’ит’э´л’], [бас’э´й’н], [бъгаты´р’], [л’ингв’и´с’т’икъ], [аб’й’о´м], [кам’п’й’у´тър], [фай’л], [тр’э´н’инк], [с’э´рцъ], [дрост], [й’у´пкъ], [т’и´х’ий’], [ш’от]
Ключи:
съели, снег, поросёнок, познакомиться, метель, бассейн, богатырь, лингвистика, объём, компьютер, файл, тренинг, сердце, дрозд, юбка, тихий, счёт
Фонетический разбор слова.
 КлючиЗадание 1:
КлючиЗадание 1:Слова для разбора:
1) деньги, 2) луч, 3) солнце, 4) синим, 5) ложка
Ответ:
1) де´ньги — 2 слога, 1-й ударный
д-[д’] — согл., зв., мягк.
е-[э´] — гл. ударн.
н-[н’] — согл., зв. непарн., мягк.
ь-[-]
г-[г’] — согл., зв., мягк.
и-[и] — гл. безуд.
_______
6 б., 5 зв.
2) луч — 1 слог
л — [л] — согл., зв. непарн., тв.
у — [у] — гл. ударн.
ч — [ч’] — согл., глух. непарн., мягк. непарн.
_______
3 б., 3 зв.
3) со´лнце — 2 слога, 1-й ударный
с — [с] — согл., глух., тв.
о — [о´] — гл. ударн.
л — [-]
н — [н] — согл., зв. непарн., тв.
ц — [ц] — согл., глух. непарн., тв. непарн.
е — [э] — гл. безударн.
________
6 б., 5 зв.
4) си´ний — 2 слога, 1-й ударный
с — [с’] — согл., глух., мягк.
и — [и´] — гл. ударн.
н — [н’] — согл., зв. непарн., мягк.
и — [и] — гл. безударн.
й — [й’] — согл., зв. непарн., мягк. непарн.
_________
5 б., 5 зв.
5) ло´жка — 2 слога, 1-й ударный
л — [л] — согл., зв. непарн., тв.
о — [о´] — гл. ударн.
ж — [ш] — согл., глух., тв. непарн.
к — [к] — согл., глух., тв.
а — [а] — гл. безударн.
_________
5 б., 5 зв.
Задание 2:
Слова для разбора:
1) проспект, 2) окно, 3) груз, 4) грузчик, 5) мышь
Ответ:
1) проспе´кт — 2 слога, 2-ой ударный
п — [п] — согл., глух., тв.
р — [р] — согл., зв. непарн., тв.
о — [а] — гл. безударн.
с — [с] — согл., глух., тв.
п — [п’] — согл., глух., мягк.
е — [э´] — гл. ударн.
к — [к] — согл., глух., тв.
т — [т] — согл., глух., тв.
_________
8 б., 8 зв.
2) окно´ — 2 слога, 2-й ударный
о — [а] — гл. безударн.
к — [к] — согл., глух., тв.
н — [н] — согл., зв. непарн., тв.
о — [о´] — гл. ударн.
ударн.
_________
4 б, 4 зв.
3) груз — 1 слог
г — [г] — согл., зв., тв.
р — [р] — согл., зв. непарн., тв.
у — [у] — гл. ударн.
з — [с] — согл., глух., тв.
_________
4 б., 4 зв.
4) грузчик — 2 слога, 1-й ударный
г — [г] — согл., зв., тв.
р — [р] — согл., зв. непарн., тв.
у — [у´] — гл. ударн.
з — [ш’:] — согл., глух. непарн., мягк. непарн., долгий
ч/
и — [и] — гл. безударный
к — [к] — согл., глух., тв.
_________
7 б., 6 зв.
5) мышь — 1 слог
м — [м] — согл., зв. непарн., тв.
ы — [ы] — гл. ударн.
ш — [ш] — согл., гл., тв.
ь — [-]
___________
4 б., 3 зв.
Задание 3:
Слова для разбора:
1) еда, 2) въезд, 3) местный, 4) глушь, 5) разжечь
Ответ:
1) еда´- 2 слога, 2-й ударный
е — [й’] — согл., зв. непарн., мягк. непарн.
\ [и] — гл. безударн.
д — [д] — согл., зв., тв.
а — [а´] — гл.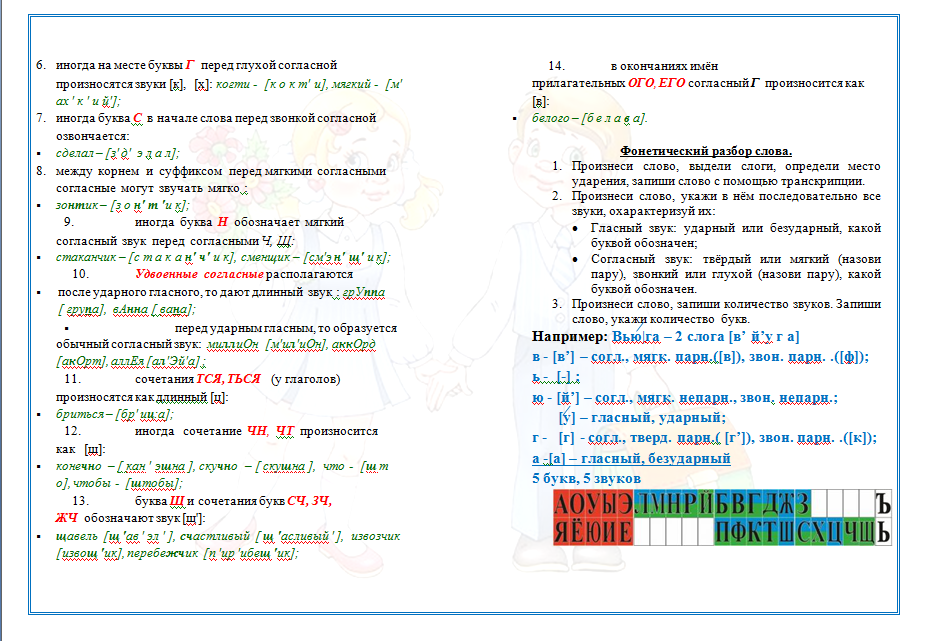 ударн.
ударн.
__________
3 б., 4 зв.
2) въезд — 1 слог
в -[в] — согл., зв., тв.
ъ — [-]
е — [й’] — согл., зв. непарный, мягк. непарн.
\ [э] — гл. ударн.
з — [с] — согл.,глух., тв.
д — [т] — согл., глух., тв.
___________
5 б., 5 зв.
3) ме´стный — 2 слога, 1-й ударный
м — [м’] — согл., зв. непарн., мягк.
е — [э´] — гл. ударн.
с — [с] — согл., глух., тв.
т — [-]
н — [н] — согл., зв. непарн., тв.
ы — [ы] — гл. безударн.
й — [й] — согл., зв.непарн., мягк. непарн.
__________
7 б., 6 зв.
4) глушь — 1 слог
г — [г] — согл., зв., тв.
л — [л] — согл., зв. непарн., тв.
у — [у] — гл. ударн.
ш — [ш] — согл., глух., тв
ь — [-]
___________
5 б., 4 зв.
5) разже´чь — 2 слога, 2-ой ударный
р — [р] — согл., зв. непарн., тв.
а — [а] — гл. безударн.
з — [ж:] — согл., зв., тв., долгий
ж/
е — [э´] — гл. ударн.
ч — [ч’] — согл. , глух. непарн., мягк. непарн.
, глух. непарн., мягк. непарн.
ь — [-]
___________
7 б., 5 зв.
Задание 4:
Слова для разбора:
1) ателье, 2) цифры, 3) сшить, 4) ночной, 5) опоздав
Ответ:
1) ателье´ — 3-х слога, 3-й ударный
а — [а] — гл. безударн.
т — [т] — согл., глух., тв.
е — [э] — гл. безударн.
л — [л’] — согл., зв. непарн., мягк.
ь — [-]
е — [й’] — согл., зв. непарн., мягк. непарн.
\ [э´] — гл. ударн.
_________
6 б., 6 зв.
2) ци´фры — 2 слога, 1-й слог ударный
ц — [ц] — согл., глух. непарн., тв. непарн.
и — [ы] — гл. ударн.
ф — [ф] — согл., глух., тв.
р — [р] — согл., зв. непарн., тв.
ы — [ы] — гл. безударн.
____________
5 б., 5 зв.
3) сшить — 1 слог
с — [ш:] — согл., глух., тв., долгий
ш/
и- [ы] — гл. ударн.
т — [т’] — согл., глух., мягк.
ь — []
__________
5 б., 3 зв.
4) ночно´й — 2 слога, 2-ой слог ударный.
н — [н] — согл., зв. непарн., тв.
о — [а] — гл. безударн.
ч — [ч’] — согл., глух. непарн., мягк. непарн.
н — [н] — согл., зв. непарн., тв.
о — [о´] — гл. ударн.
й — [й’] — согл., зв.непарн., мягк. непарн.
_________
6 б, 6 зв.
5) опозда´в — 3 слог, 3-й слог ударный.
о -[а] — гл. безударн.
п — [п] — согл., глух, тв.
о — [а] — гл. безударн.
з — [з] — согл., зв., тв.
д — [д] — согл., зв., тв.
а — [а´] — гл. ударн.
в — [ф] — согл., глух., тв.
__________
7 б., 7 зв.
Задание 5:
Слова для разбора:
1) обыскать, 2) объёмный, 3) ружьё, 4) (много) туч, 5) ложь
Ответ:
1) обыска´ть — 3 слога, 3-ий ударный
о — [а] — гл. безударн.
б — [б] — согл., зв., тв.
ы — [ы] — гл. безударн.
с — [с] — согл., глух., тв.
к — [к] — согл., глух., тв.
а — [а´] — гл. ударн.
т — [т’] — согл., глух., мягк.
ь — [-]
__________
8 б. , 7 зв.
, 7 зв.
2) объёмный — 3 слога, 2-ой ударный
о — [а] — гл. безударн.
б — [б] — согл., зв, тв.
ъ — [-]
ё — [й’] — согл., зв. непарн., мягк. непарн.
\ [о´] — гл. ударн.
м — [м] — согл., зв. непарн., тв.
н — [н] — согл., зв. непарн., тв.
ы — [ы] — гл. безударн.
й — [й’] — согл., зв. непарн., мягк. непарн.
___________
8 б., 8 зв.
3) ружьё — 2 слога, 2-ой слог ударный
р — [р] — согл., зв. непарн., тв.
у — [у] — гл. безударн.
ж — [ж] — согл., зв., тв.
ь — [-]
ё — [й’] — согл., зв. непарн., мягк. непарн.
\ [о´] — гл. ударн.
___________
5 б., 5 зв.
4) туч — 1 слог
т — [т] — согл., глух., тв.
у — [у] — гл. ударн.
ч — [ч’] — согл., глух. непарн., мягк. непарн.
_________
3 б., 3 зв.
5) ложь — 1 слог
л — [л] — согл., зв. непарн., тв.
о — [о] — гл. ударн.
ж — [ш]- согл., глух., тв. непарн.
ь — [-]
_________
4 б. , з зв.
, з зв.
Задание 6:
Слова для разбора:
1) властный, 2) его, 3) тест, 4) поезд, 5)вокзальный
Ответ:
1) вла´стный — 2 слога, 1-й ударный
в — [в] — согл., зв., тв.
л -[л] — согл., зв. непарн., тв.
а — [а´] — гл. ударн.
с — [с] -согл., глух., тв.
т — [-]
н — [н] — согл., зв. непарн., тв.
ы — [ы] — гл. безударн.
й — [й’] — согл., зв. непарн., мягк. непарн.
__________
8 б., 7 зв.
2) его´- 2 слога, 2-ой ударный
е — [й’] — согл., зв. непарн., мягк. непарн.
\ [и] — гл. безударн.
г — [в] — согл., зв., тв.
о — [о´] — гл. ударн.
_________
3 б., 4 зв.
3) тест — 1 слог
т — [т] — согл., глух., тв.
е — [э] — гл. ударн.
с — [с] — согл., гл., тв.
т — [т] — согл., гл., тв.
_________
4 б., 4 зв.
4) по´езд — 2 слога, 1-й ударный
п — [п] — согл., глух., тв.
о — [о´] — гл. ударн.
е — [й’] — согл. , зв. непарн., мягк. непарн.
, зв. непарн., мягк. непарн.
\ [и] — гл. безударн.
з — [с] — согл., глух., тв.
д — [т] — согл., глух., тв.
_________
5 б., 6 зв.
5) вокза´льный — 3 слога, 2-ой ударный
в — [в] — согл., зв., тв.
о — [а] — гл. безударн.
к — [г] — согл., зв., тв.
з — [з] — согл., зв., тв.
а — [а´] — гл. ударн.
л — [л’] — согл., зв. непарн., мягк.
ь — [-]
н — [н] -согл., зв. непарн., тв.
ы — [ы] — гл. безударн.
й — [й’] — согл., зв. непарн., мягк. непарн.
__________
10 б., 9 зв.
Фонетические алгоритмы / Хабр
Фонетические алгоритмы сопоставляют двум словам со схожим произношением одинаковые коды, что позволяет осуществлять сравнение и индексацию множества таких слов на основе их фонетического сходства.
Часто довольно трудно найти в базе нетипичную фамилию, например:
— Леха, поищи в нашей базе Адольфа Швардсенеггера,
— Шворцинегира? Нет такого!
В этом случае использование фонетических алгоритмов (особенно в сочетании с алгоритмами нечеткого сопоставления) может значительно упростить задачу.
Такие алгоритмы очень удобно использовать при поиске в базах по спискам людей, в программах проверки орфографии. Зачастую они используются совместно с алгоритмами нечеткого поиска (которые, несомненно, заслуживают отдельной статьи), предоставляя пользователям удобный поиск по именам и фамилиям в различных базах данных, списках сотрудников и так далее.
В этой статье я рассмотрю наиболее известные алгоритмы, такие как Soundex, Daitch-Mokotoff Soundex, NYSIIS, Metaphone, Double Metaphone, русский Metaphone, Caverphone.
Soundex
Одним из первых был алгоритм Soundex, изобретенный еще в 10-x годах прошлого века Робертом Расселом. Этот алгоритм (а точнее, его американская версия) сопоставляет словам численный индекс вида A126. Принцип его работы основан на разбиении согласных букв на группы с порядковыми номерами, из которых затем и составляется результирующее значение. Позднее также был предложен ряд улучшений.
Позднее также был предложен ряд улучшений.
Первая буква сохраняется, последующие буквы сопоставляются цифрам по таблице. Символы, не представленные в таблице (а это все гласные и некоторые согласные), игнорируются. Смежные символы, или символы, разделенные буквами H или W, входящие в одну и ту же группу, записываются как один. Результат обрезается до 4 символов. Недостающие позиции заполняются нулями. Несложно заметить, что после всех этих процедур остается всего лишь 7 тысяч различных вариаций такого кода, что влечет за собой множество совершенно ничем не похожих друг на друга слов, имеющих одинаковый Soundex-код. Таким образом, результат в большинстве случаев включает в себя большое количество «ложноположительных» значений.
В улучшенной версии, как можно заметить, буквы разбиты на большее количество групп. Помимо этого, никакого особого внимания буквам H и W не уделяется, они просто игнорируются. Кроме того, никаких операций с длиной результата не производится — код не имеет фиксированной длины и не обрезается.
Примеры
Оригинальный Soundex:
D341 → Дедловский, Дедловских, Дидилев, Дителев, Дудалев, Дудолев, Дутлов, Дыдалев, Дятлов, Дятлович.
N251 → Нагимов, Нагмбетов, Назимов, Насимов, Нассонов, Нежнов, Незнаев, Несмеев, Нижневский, Никонов, Никонович, Нисенблат, Нисенбаум, Ниссенбаум, Ногинов, Ножнов.
Улучшенный Soundex:
N8030802 → Насимов, Нассонов, Никонов.
N80308108 → Нисенбаум, Ниссенбаум.
N8040802 → Нагимов, Нагонов, Неганов, Ногинов.
N804810602 → Нагмбетов.
N8050802 → Назимов, Нежнов, Ножнов.
В среднем, на одно значение кода Soundex приходится 21 фамилия. В случае же улучшенной версии Soundex, к одному и тому же коду преобразуются всего 2-3 фамилии.
NYSIIS
Разработанный в 1970 году как часть системы «New York State Identification and Intelligence System», этот алгоритм дает несколько лучшие результаты относительно оригинального Soundex, используя более сложные правила преобразования исходного слова в результирующий код. Этот алгоритм разработан для работы именно с американскими фамилиями.
Этот алгоритм разработан для работы именно с американскими фамилиями.
Алгоритм вычисления кода NYSIIS
- Преобразовать начало слова по следующим правилам:
MAC → MCC
KN → N
K → C
PH, PF → FF
SCH → SSS - Преобразовать конец слова по следующим правилам:
EE → Y
IE → Y
DT, RT, RD, NT, ND → D - Затем все буквы, кроме первой, преобразуются по следующим правилам:
EV → AF
A, E, I, O, U → A
Q → G
Z → S
M → N
KN → N
K → C
SCH → SSS
PH → FF
После гласных: удалить H, преобразовать W → A - Удалить S на конце
- Преобразуем AY на конце → Y
- Удалить A на конце
- Обрезать до 6 символов (необязательный шаг).
Примеры
CASPARAVAS → Каспаравичус, Касперович, Каспирович.
CATNACAV → Катников, Цитников, Цотников.
LANSANC → Ленченко, Леонченко, Линченко, Лунченко, Лямзенко.
PRADSC → Приходский, Проходский, Прудский, Прудских, Прудской.
STADNACAV → Стадников.
NYSIIS преобразует к одному и тому же коду немногим более двух фамилий.
Daitch-Mokotoff Soundex
Этот алгоритм в 1985 году разработали два генеалога — Гарри Мокотофф и Рэнди Дэйч, стремясь достичь лучших, относительно оригинального Soundex, результатов при работе со восточно-европейскими (в том числе русскими) фамилиями.
Этот алгоритм имеет мало общего с оригинальным Soundex, разве что результатом всё так же остается последовательность цифр, однако теперь первая буква также кодируется.
Он имеет значительно более сложные правила конверсии — теперь в формировании результирующего кода участвуют не только одиночные символы, но и последовательности из нескольких символов. Кроме того, результат вида 023689 обеспечивает около 600 тысяч различных вариаций кода, что вкупе с усложненными правилами уменьшает количество «лишних», т. е. «ложноположительных» слов в результирующем множестве.
е. «ложноположительных» слов в результирующем множестве.
Преобразования осуществляются по следующей таблице (порядок преобразований соответствует порядку буквосочетаний в таблице):
| Исходные буквосочетания | В начале | За гласной | Остальное |
| AI, AJ, AY, EI, EY, EJ, OI, OJ, OY, UI, UJ, UY | 0 | 1 | |
| AU | 0 | 7 | |
| IA, IE, IO, IU | 1 | ||
| EU | 1 | 1 | |
| A, UE, E, I, O, U, Y | 0 | ||
| J | 1 | 1 | 1 |
| SCHTSCH, SCHTSH, SCHTCH, SHTCH, SHCH, SHTSH, STCH, STSCH, STRZ, STRS, STSH, SZCZ, SZCS | 2 | 4 | 4 |
| SHT, SCHT, SCHD, ST, SZT, SHD, SZD, SD | 2 | 43 | 43 |
| CSZ, CZS, CS, CZ, DRZ, DRS, DSH, DS, DZH, DZS, DZ, TRZ, TRS, TRCH, TSH, TTSZ, TTZ, TZS, TSZ, SZ, TTCH, TCH, TTSCH, ZSCH, ZHSH, SCH, SH, TTS, TC, TS, TZ, ZH, ZS | 4 | 4 | 4 |
| SC | 2 | 4 | 4 |
| DT, D, TH, T | 3 | 3 | 3 |
| CHS, KS, X | 5 | 54 | 54 |
| S, Z | 4 | 4 | 4 |
| CH, CK, C, G, KH, K, Q | 5 | 5 | 5 |
| MN, NM | 66 | 66 | |
| M, N | 6 | 6 | 6 |
| FB, B, PH, PF, F, P, V, W | 7 | 7 | 7 |
| H | 5 | 5 | |
| L | 8 | 8 | 8 |
| R | 9 | 9 | 9 |
«Альтернативные» варианты буквосочетаний (используются для генерации нескольких альтернативных кодов из исходного слова):
CH → TCH
CK → TSK
C → TZ
J → DZH
Примеры
095747 → Архипцев, Архипцов, Архипычев, Арцыбасов, Арцыбашев, Арчибасов
095757 → Архипков, Архипцев, Архипцов, Архипычев
584360 → Галстян, Галустян, Гильштейн, Глистин, Глуздань, Голштейн, Гольдштеин, Гольдштейн, Калустьян, Хлистун, Хлыстун, Хлюстин.
К одному и тому же коду этот алгоритм преобразует в среднем 5 фамилий.
Впоследствии Александр Бейдер и Стивен Морзе разработали Beider-Morse Name Matching Algorithm, нацеленный на уменьшение количества «ложноположительных» значений относительно Daitch-Mokotoff Soundex при работе с еврейскими (ашкенази) фамилиями.
Metaphone
Несколько лучшими характеристиками обладает алгоритм Metaphone (1990 год), отличающийся от предыдущих алгоритмов несколько иным подходом к процессу кодирования: он преобразует исходное слово с учетом правил английского языка, используя заметно более сложные правила, и при этом теряется значительно меньше информации, так как буквы не разбиваются на группы. Итоговый код представляет собой набор символов из множества 0BFHJKLMNPRSTWXY, в начале слова также могут быть гласные из множества AEIOU.
Алгоритм вычисления кода Metaphone
- Удаляем все повторяющиеся соседние буквы, за исключением буквы C.
- Начало слова преобразовать по следующим правилам:
KN → N
GN → N
PN → N
AE → E
WR → R - Удаляем на конце букву B, если она идет после M.
- Заменяем C по следующим правилам
На Х: CIA → XIA, SCH → SKH, CH → XH
На S: CI → SI, CE → SE, CY → SY
На K: C → K - Заменяем D по следующим правилам
На J: DGE → JGE, DGY → JGY, DGI → JGY
На T: D → T - Заменяем GH → H, если это буквосочетание стоит не в конце и не перед гласной.
- Заменяем GN → N и GNED → NED, если эти буквосочетания стоят в конце.
- Заменяем G по следующим правилам
На J: GI → JI, GE → JE, GY → JY
на K: G → K - Удаляем все H, идущие после гласных, но не перед гласными.
- Выполняем последующие преобразования по правилам:
CK → K
PH → F
Q → K
V → F
Z → S - Заменяем S на X:
SH → XH
SIO → XIO
SIA → XIA - Заменяем T по следующим правилам
На X: TIA → XIA, TIO → XIO
На 0: TH → 0
Удаляем: TCH → CH - В начале слова преобразовать WH → W. Если после W нет гласной, то удалить W.
- Если X в начале слова, то преобразовать X → S, иначе X → KS
- Удалить все Y, которые не находятся перед гласными.
- Удалить все гласные, кроме начальной.

 Если после W нет гласной, то удалить W.
Если после W нет гласной, то удалить W.Примеры
AKXN → Агашин, Акаченок, Акишин, Аксионенко, Аксионов, Акчунаев, Акшанов, Акшенцев, Акшинский, Акшинцев, Акшонов.
FSLX → Василишин, Васильчак, Васильченко, Васильчик, Васильчиков, Васильченко, Васильчук, Василющенко.
SRFM → Серафимов, Серафимский, Серафимчук, Церейфман.
Одно и то же значение кода Metaphone имеют в среднем 6 фамилий.
Double Metaphone
Double Metaphone (2000 год) несколько отличается от других фонетических алгоритмов, генерируя из исходного слова не один, а два кода (оба длиной до 4 символов) — один отражает основной вариант произношения слова, другой же — альтернативную версию. Он имеет большое количество различных правил, учитывающих, помимо всего прочего, различное происхождение слов, уделяя внимание восточно-европейским, итальянским, китайским словам и так далее. Правила преобразований достаточно многочисленны, я не буду их публиковать, а желающие смогут прочитать о них в статье журнала Dr Dobbs.
Правила преобразований достаточно многочисленны, я не буду их публиковать, а желающие смогут прочитать о них в статье журнала Dr Dobbs.
Примеры
JXRF → Гишаров.
KKRF → Гагаров, Кагаров, Качаровский, Качеровский, Качуривский, Качуров, Качуровский, Кичеров, Кокарев, Кокоуров, Кокоуров, Кочаров, Кочуров, Кукарев, Цакиров, Цокуров, Цугров.
KXRF → Гишаров, Гочаров, Качеров, Качеровский, Кашаревский, Кочаров, Кочерев, Кочеряев, Кочураев, Кошарев, Кошеров.
PNFS → Бановский, Бахновский, Биневский, Бинявский, Буйновский, Буяновский, Паневский, Пановский, Пановских, Пеньевский, Пиневский, Пиуновский, Пихновский.
Double Metaphone сопоставляет в среднем 8-9 фамилий одному и тому же коду.
Русский Metaphone
В 2002 году в 8-ом выпуске журнала «Программист» была опубликована статья Петра Каньковски, рассказывающая о его адаптации английской версии алгоритма Metaphone к суровым сибирским морозам, медведям и балалайкам. Этот алгоритм преобразует исходные слова в соответствии с правилами и нормами русского языка, учитывая фонетическое звучание безударных гласных и возможные «слияния» согласных при произношении. Он показывает очень хорошие результаты на практике, несмотря на то, что основывается на довольно простых правилах. Все буквы разбиты на группы по звучанию — гласные и согласные (vowels и consonants соответственно в английской терминологии), глухие и звонкие. Звонкие согласные преобразуются в соответствующие им парные глухие, объединяются «сливающиеся» при произношении последовательности букв, и проводятся некоторые другие манипуляции. Ниже я приведу немного доработанный вариант, который, в отличие от оригинала Петра Каньковски, привносит правила, связанные с фонетической эквивалентностью Ц и ТС или ДС, и не сжимает окончания — байты экономить — это не наша задача.
Этот алгоритм преобразует исходные слова в соответствии с правилами и нормами русского языка, учитывая фонетическое звучание безударных гласных и возможные «слияния» согласных при произношении. Он показывает очень хорошие результаты на практике, несмотря на то, что основывается на довольно простых правилах. Все буквы разбиты на группы по звучанию — гласные и согласные (vowels и consonants соответственно в английской терминологии), глухие и звонкие. Звонкие согласные преобразуются в соответствующие им парные глухие, объединяются «сливающиеся» при произношении последовательности букв, и проводятся некоторые другие манипуляции. Ниже я приведу немного доработанный вариант, который, в отличие от оригинала Петра Каньковски, привносит правила, связанные с фонетической эквивалентностью Ц и ТС или ДС, и не сжимает окончания — байты экономить — это не наша задача.
Алгоритм вычисления кода русского Metaphone
- Для всех гласных букв проделать следующие операции.
ЙО, ИО, ЙЕ, ИЕ → И
О, Ы, Я → А
Е, Ё, Э → И
Ю → У - Для всех согласных букв, за которыми следует любая согласная, кроме Л, М, Н или Р, либо же для согласных на конце слова, провести оглушение:
Б → П
З → С
Д → Т
В → Ф
Г → К - Склеиваем ТС и ДС в Ц:
ТС → Ц

В итоге, алгоритм очень хорошо справляется со своей задачей — в результирующем наборе содержатся действительно фонетически схожие слова. И при этом остается довольно мало лишних слов, в основном благодаря тому, что гласные не игнорируются, а преобразуются и используются в итоговом коде. Однако же, есть некоторые слова, которые, не смотря на свою фонетическую схожесть, не попадают в результирующий набор из-за слишком «строгих» правил алгоритма.
В случае Адольфа Швардсенеггера результатом работы алгоритма русского Metaphone будет:
Таким образом, алгоритм в данном случае отражает реальное фонетическое сходство этих двух фамилий.
Примеры
ВИТАФСКИЙ → Витавский, Витовский.
ВИТИНБИРК → Витенберг, Виттенберг.
НАСАНАФ → Насанов, Насонов, Нассонов, Носонов.
ПИРМАКАФ → Пермаков, Пермяков, Перьмяков.
Этот алгоритм преобразует к одному и тому же коду в среднем 1-2 фамилии.
Caverphone
Алгоритм Caverphone был разработан в 2002 году в рамках одного из новозеландских проектов для сопоставления данных в старых и новых электоральных списках, потому он наиболее ориентирован на местное произношение, хотя и для русских фамилий он дает вполне приемлемые результаты.
Алгоритм вычисления кода Caverphone
- Преобразовать имя или фамилию в нижний регистр (алгоритм чувствителен к регистру).
- Удалить буквы e на конце.
- Преобразовать начало слова по следующей таблице (актуально для местных новозеландских имен и фамилий). При этом цифра 2 означает временную метку для согласной буквы, которая впоследствии будет удалена.
cough rough tough enough gn mb cou2f rou2f tou2f enou2f 2n m2 - Провести замены символов по следующей таблице:
cq ci ce cy tch c q x v dg tio tia d ph b sh z 2q si se sy 2ch k k k f 2g sio sia t fh p s2 s - Заменить все гласные в начале слова на A, в остальных случаях — на 3. h
h r3 r$ r l3 l$ l N W3 Wh4 3 2 A 2 R3 3 2 L3 3 2 - Удалить все цифры 2. Если на конце слова осталась цифра 3, то заменить её на A. Затем удалить все цифры 3.
- Обрезать слово до 10 символов, либо же дополнить до 10 символов единицами.

 h
h
Примеры
KPRLN11111 → Габрелян, Габриэлян, Габриэльян, Капарулин, Капралин, Капрелян.
MSRFK11111 → Мейзерович, Мисарович, Мисюревич.
PLLF111111 → Балалаев, Балалиев, Балалуев, Билалиев, Билалов, Билялов, Болелов, Палилов, Полилов, Полуляхов.
Caverphone сопоставляет одному и тому же коду около 4-5 фамилий.
Итого
Большая часть этих алгоритмов реализована на множестве языков, в том числе на C, C++, Java, C# и PHP. Некоторые из них, например Soundex и Metaphone, интегрированы или реализованы в виде плагинов для многих популярных СУБД, а также используются в составе полноценных поисковых движков, например, Apache Lucene. Область их применения довольно специфична, ведь значительного повышения удобства для пользователей можно добиться лишь при поиске фамилий, но тем не менее грамотное их использование — это плюс для поисковых систем.
Ссылки
- Код на Java к статье. Яндекс.Диск
- Реализации Soundex, Refined Soundex, Metaphone, Double Metaphone, Caverphone на Java.
Apache Commons Codec - Реализация NYSIIS на Java. Проект Egothor
- Реализация Daitch-Mokotoff Soundex на Java. http://joshualevy.tripod.com/genealogy/dmsoundex/dmsoundex.zip
- Описание Soundex. http://en.wikipedia.org/wiki/Soundex
- Описание Daitch-Mokotoff Soundex. http://www.jewishgen.org/infofiles/soundex.html
- Описание NYSIIS.
http://en.wikipedia.org/wiki/New_York_State_Identification_and_Intelligence_System - Описание Metaphone. http://en.wikipedia.org/wiki/Metaphone
- Описание Double Metaphone. http://www.drdobbs.com/article/184401251
- Описание русского Metaphone. http://forum.aeroion.ru/topic461.html
- Описание Caverphone. http://en.wikipedia.org/wiki/Caverphone
- Онлайн-демо Soundex. http://www.gedpage.com/soundex.html
- Онлайн-демо NYSIIS. http://www.dropby.com/NYSIIS.html
- Онлайн-демо Daitch-Mokotoff Soundex. http://stevemorse.org/census/soundex.html
- Онлайн-демо Metaphone. http://www.searchforancestors.com/utility/metaphone.php
 http://www.jewishgen.org/infofiles/soundex.html
http://www.jewishgen.org/infofiles/soundex.htmlРабота № 20. Повторение изученного в 5 классе. Фонетика. Лексика. Словообразование
Вариант 1
Прочитайте текст.
(1) Уже давно в ожидании большой воды лежат штабелями дрова. (2) У нас было твёрдое намерение и..пользовать эти дрова. (3) Но за несколько лет бе..полезной лёжки эти дрова потемнели, многие ра..сыпались. (4) Множество насекомых ра..велось в дровах, и в огромном числе поселились трясогузки. (5) Нам захотелось сфотографировать этих маленьких птичек на близком ра..стоянии. (6) Если трясогузка сидит на далёком ра..стоянии, то для этого надо показаться и..дали и тут же спрятаться от неё.
(2) У нас было твёрдое намерение и..пользовать эти дрова. (3) Но за несколько лет бе..полезной лёжки эти дрова потемнели, многие ра..сыпались. (4) Множество насекомых ра..велось в дровах, и в огромном числе поселились трясогузки. (5) Нам захотелось сфотографировать этих маленьких птичек на близком ра..стоянии. (6) Если трясогузка сидит на далёком ра..стоянии, то для этого надо показаться и..дали и тут же спрятаться от неё.
(По М. Пришвину)
Выполните задания
1. Из предложений 1 — 4 выпишите слова, в которых происходит оглушение согласного.
2. Из предложений 5 и 6 выпишите слова, в которых буква обозначает два звука.
3. Произведите фонетический разбор слова большой.
4. Из предложений 1 — 4 выпишите синонимы.
5. Из предложений 4 — 6 выпишите антонимы.
6. Из предложений 2 и 3 выпишите слово, употреблённое в переносном значении.
7. Какой орфограмме соответствуют пропущенные в словах буквы? Вставьте буквы, обозначьте графически эту орфограмму, запишите её название.
8. Из предложений 2 — 4 выпишите слова, состоящие из приставки, корня, суффикса и окончания.
9. Из предложения 5 выпишите слово, образованное приставочным способом.
Ответ:
1. Лёжки, трясогузки
2. Расстоянии, неё
3. Большой — [болʹшо́йʹ] — 2 слога
Б [б] — согл., тв. парн., зв. парн.
о [о] — гл., безуд.
л [лʹ] — согл., мяг., парн., зв. непар.
ь [-] — не обозначает звука
ш [ш] — согл., тв. непарн., гл. парн.
о [о́] — гл., ударн.
й [йʹ] — согл., мягк. непарный, зв. непарн.
В слове 7 букв, 6 звуков
4. Большой — огромный
5. Близком — далёком
6. Твёрдое
7. Использовать (ис — приставка), бесполезной (бес — пр.), рассыпались (рас — пр.), развелось (раз — пр.), расстоянии (рас — пр.), издали (из — пр.).
Правило: если после приставки идет глухой звук, то в приставке тоже пишется буква с глухим звуком, если после приставки идет звонкий звук, то и в приставке тоже пишется буква со звонким звуком.
8. Бесполезной (бес — приставка, полез — корень, н — суффикс, ой — окончание), использовать (ис — приставка, польз — корень, ова, ть — суффиксы, нулевое окончание).
9. Захотелось.
Вариант 2
Прочитайте текст.
(1) Жемчужные лепестки ра..сыпались по травке: отцветает черёмуха. (2) Зато ра..цвела бузина и под нею внизу земляника, привлекающая своим ароматом. (3) Бутоны ландышей тоже почти все ра..крылись, бурые листья осин и берёз стали зелёными. (4) Взошедший овёс солдатиками ра..ставился по полю. (5) Иду вверх по тропе и наслаждаюсь запахами леса. (6) Мне всё интересно: каждая мелочь в жизни бе..численных птиц ра..сказывает о движении жизни на земле.
(По М. Пришвину)
Выполните задания
1. Из предложений 1 — 4 выпишите слова, в которых происходит оглушение согласного.
2. Из предложений 1 и 2 выпишите слова, в которых есть буква, обозначающая два звука.
3. Произведите фонетический разбор слова листья.
4. Из предложений 2 — 5 выпишите синонимы.
5. Из предложений 1 — 4 выпишите антонимы.
6. Из предложений 1 — 2 выпишите слово, употреблённое в переносном значении.
7. Какой орфограмме соответствуют пропущенные в тексте буквы? Вставьте буквы, обозначьте графически эту орфограмму, запишите её название.
8. Из предложения 1 выпишите слово, состоящее из приставки, корня, суффикса и окончания.
9. Из предложений 5 и 6 выпишите слово, образованное с помощью приставки.
Ответ:
1. Травке, берёз
2. Жемчужные, отцветают, нею
3. Листья — [лʹи́стʹйʹа] — 2 слога
Л [лʹ] — согл., мягк. пар., зв. непарн.
и [и́] — гл., ударн.
с [с] — согл., тв. парн., гл. парн.
т [тʹ] — согл., мягк. парн., гл. парн.
ь [-] — не обозначает звука
я [йʹ] — согл., мягк. непарн., зв. непарн.
[а] — гл., безуд.
В слове 6 букв, 6 звуков
4. Ароматом — запахами
Ароматом — запахами
5. Отцветает — расцвела
6. Рассыпались
7. Расцвела (рас — приставка), раскрылись (рас), рассыпались (рас), расставился (рас), бесчисленных (бес), рассказывает (рас)
Правило: если после приставки идет глухой звук, то в приставке тоже пишется буква с глухим звуком, если после приставки идет звонкий звук, то в приставке тоже пишется буква со звонким звуком.
8. Отцветает (от — приставка, цвет — корень, а — суффикс, ет — окончание)
9. Рассказывают
Фонетический разбор — Стоматология в Химках
Русский язык звуко буквенный разбор
Если произнести вслух слова «въехать» и «прекрасный», можно заметить, что «е» в них звучит по-разному, хотя это одна и та же буква. И таких примеров в русском языке великое множество. Чтобы разобраться, почему так происходит, придумали фонетический разбор слов. Сейчас расскажем, что это такое, и покажем на примерах, как принято разбирать слова на слоги, звуки и буквы.
О чем эта статья:
Что такое фонетический разбор
Фонетический, или Звуко-буквенный, разбор слова — это анализ звуков и букв, из которых это слово состоит.
В русском языке 33 буквы, из которых мы составляем слова и записываем их на бумаге. Когда мы произносим слово, то слышим звуки — это то, как звучат буквы в его составе. В некоторых словах одна и та же буква может обозначать два звука одновременно либо не звучать вообще. Здесь и пригодится звуко-буквенный разбор: он нужен затем, чтобы мы могли анализировать звуки и буквы, грамотно писать, а также произносить слова.
Как делается фонетический разбор слова
Звуко-буквенный разбор принято делать по такому алгоритму:
Количество слогов, ударение.
Полная транскрипция слова.
Гласные звуки: ударный или безударный, какой буквой обозначен.
Согласные звуки: звонкий, сонорный или глухой, парный или непарный; твердый или мягкий, парный или непарный; какой буквой обозначен.
Общее количество букв и звуков.
Разбирать слова по звукам и буквам можно устно или письменно. Эти способы немного отличаются друг от друга, поэтому рассмотрим каждый отдельно
Образец письменного фонетического разбора
На письме звуко-буквенный разбор слова делают так:
Транскрипция слова. Записываем слово и все звуки, которые в него входят.
Слоги и ударение. Считаем и записываем количество слогов в слове, обозначаем тот, на который падает ударение.
Звуки. Со следующей строки в столбик переписываем все буквы в том порядке, в котором они стоят в слове. Напротив каждой из них записываем звук и заключаем в квадратные скобки.
Гласные звуки. Рядом с каждым гласным звуком пишем, ударный он или безударный. А после указываем, какой буквой он обозначен.
Согласные звуки. Рядом с каждым согласным звуком указываем, звонкий он или глухой. Далее — парный или непарный по глухости-звонкости. После этого пишем, твердый звук или мягкий, а следом — парный или непарный по мягкости-твердости. В конце нужно указать, какой буквой обозначен звук.
После этого пишем, твердый звук или мягкий, а следом — парный или непарный по мягкости-твердости. В конце нужно указать, какой буквой обозначен звук.
Число букв, звуков. Считаем и записываем количество букв и звуков в слове.
Теперь используем этот алгоритм на примерах.
Пример № 1. Письменный фонетический разбор глагола обыскивать
Обыскивать [абыск’иват’] — 4 слога, 2-й ударный.
О — [а] — гл., безударн.
Б — [б] — согл., зв. парн., тв. парн.
С — [с] — согл., глух. парн., тв. парн.
К — [к’] — согл., глух. парн., мягк. парн.
И — [и] — гл., безударн.
В — [в] — согл., зв. парн., тв. парн.
А — [а] — гл., безударн.
Т — [т’] — согл., глух. парн., мягк. парн.
Пример № 2. Письменный фонетический разбор прилагательного весенний
Весенний [в’ис’эн’:ий’] — 3 слога, 2-й ударный.
В — [в’] — согл., зв. парн., мягк. парн.
Е — [и] — гл., безударн.
С — [с’] — согл. , глух. парн., мягк. парн.
, глух. парн., мягк. парн.
Н — [н’:] — согл., сонорн. непарн., мягк. парн.
И — [и] — гл., безударн.
Й — [й’] — согл., сонорн. непарн., мягк. непарн.
Пример № 3. Письменный фонетический разбор существительного профессор
Профессор [праф’эс:ар] — 3 слога, 2-й ударный.
П — [п] — согл., глух. парн., тв. парн.
Р — [р] — согл., сонорн. непарн., тв. парн.
О — [а] — гл., безударн.
Ф — [ф’] — согл., глух. парн., мягк. парн.
С — [с:] — согл., глух. парн., тв. парн.
О — [а] — гл., безударн.
Р — [р] — согл., сонорн. непарн., тв. парн.
Образец устного фонетического разбора
Если нужно сделать звуко-буквенный разбор устно, придерживайтесь такого алгоритма:
Слоги и ударение. Посчитайте и назовите количество слогов в слове, обозначьте тот, на который падает ударение.
Гласные звуки. Назовите гласные звуки в том порядке, в котором они звучат в слове. Для каждого из них определите, является он ударным или безударным. После уточните буквы, которыми они обозначены.
После уточните буквы, которыми они обозначены.
Согласные звуки. Для каждого из согласных звуков определите, звонкий он или глухой, а затем — парный или непарный по глухости-звонкости. После этого установите, твердый это звук или мягкий, а также парный или непарный по мягкости-твердости. В конце разбора каждого из согласных звуков уточните, какой буквой он обозначен в слове.
Число букв, звуков. Посчитайте и назовите количество букв и звуков в слове.
Потренируемся в устном фонетическом разборе на примере тех же слов, что мы разобрали выше.
Пример № 1. Устный фонетический разбор глагола обыскивать
1. В слове обыскивать 4 слога, ударение падает на второй: о-бы-ски-вать.
2. Гласные звуки:
Первый — безударный [а], обозначен буквой о;
Второй — ударный [ы], обозначен буквой ы;
Третий — безударный [и], обозначен буквой и;
Четвертый — безударный [а], обозначен буквой а.
3. Согласные звуки:
[б] — звонкий парный, твердый парный, обозначен буквой б;
[с] — глухой парный, твердый парный, обозначен буквой с;
[к’] — глухой парный, мягкий парный, обозначен буквой к;
[в] — звонкий парный, твердый парный, обозначен буквой в;
[т’] — глухой парный, мягкий парный, обозначен буквой т;
Буква ь не обозначает звука.
4. В слове обыскивать 10 букв и 9 звуков.
Пример № 2. Устный фонетический разбор прилагательного весенний
1. В слове весенний 3 слога, ударение падает на второй: ве-сен-ний.
2. Гласные звуки:
Первый — безударный [и], обозначен буквой е;
Второй — ударный [э], обозначен буквой е;
Третий — безударный [и], обозначен буквой и.
3. Согласные звуки:
[в’] — звонкий парный, мягкий парный, обозначен буквой в;
[с’] — глухой парный, мягкий парный, обозначен буквой с;
[н’] — звонкий непарный (сонорный), мягкий парный, обозначен буквой н. Вторая н в слове не образует звука;
[й’] — звонкий непарный (сонорный), твердый непарный, обозначен буквой й.
4. В слове весенний 8 букв и 7 звуков.
Пример № 3. Устный фонетический разбор существительного профессор
1. В слове профессор 3 слога, ударение падает на второй: про-фе-ссор.
2. Гласные звуки:
Первый — безударный [а], обозначен буквой о;
Второй — ударный [э], обозначен буквой е;
Третий — безударный [а], обозначен буквой о.
3. Согласные звуки:
[п] — глухой парный, твердый парный, обозначен буквой п;
[р] — звонкий непарный (сонорный), твердый парный, обозначен буквой р;
[ф’] — глухой парный, мягкий парный, обозначен буквой ф;
[с] — глухой парный, твердый парный, обозначен буквой с. Вторая с в слове не образует звука;
[р] — звонкий непарный (сонорный), твердый парный, обозначен буквой р.
4. В слове профессор 9 букв и 8 звуков.
Проверьте себя
Давайте узнаем, насколько хорошо вы поняли, что такое фонетический разбор. Ниже вы найдете три задания, с помощью которых можно потренировать этот навык.
Задание 1
Разберите по звуковому составу следующие слова: занятой, постоялец, вакансия, произносить, говорящий.
Задание 2
Выполните устный фонетический разбор слов: коробочный, больница, идти, союз, морская.
Задание 3
Прочтите короткий текст ниже и выполните письменный фонетический разбор всех существительных в нем.
Мы бродили весной в лесу и наблюдали жизнь дупляных птиц: дятлов, сов. Вдруг в той стороне, где у нас раньше было намечено интересное дерево, мы услышали звук пилы. То была, как нам говорили, заготовка дров из сухостойного леса для стеклянного завода.
Вдруг в той стороне, где у нас раньше было намечено интересное дерево, мы услышали звук пилы. То была, как нам говорили, заготовка дров из сухостойного леса для стеклянного завода.
Впервые делать фонетической разбор слов ученики начинают в 3-м классе начальной школы. Со временем задания на уроках усложняются, поэтому важно вовремя понять тему. Если после прочтения этой статьи у вас еще остались вопросы — приглашаем за знаниями в онлайн-школу русского языка Skysmart. На занятиях преподаватель расскажет, что такое фонетический (звуко-буквенный) разбор слова и как его правильно делать, чтобы повысить оценку в школе.
Слоги и ударение.
Skysmart. ru
17.09.2018 19:01:01
2018-09-17 19:01:01
Источники:
Https://skysmart. ru/articles/russian/foneticheskij-razbor
Звуко-буквенный (фонетический) разбор слов онлайн » /> » /> .keyword { color: red; }
Русский язык звуко буквенный разбор
Фонетический разбор слова — анализ звукового состава слова, позволяет вычленить в слове звуки и определить их характеристики. Также его называют звуко-буквенным разбором. Фонетический разбор отражает фонетику русского слова — его «звучание», правильное произношение с учётом сложившихся правил и традиций русской речи. Слово для фонетического разбора в школьных учебниках обозначается цифрой 1.
Также его называют звуко-буквенным разбором. Фонетический разбор отражает фонетику русского слова — его «звучание», правильное произношение с учётом сложившихся правил и традиций русской речи. Слово для фонетического разбора в школьных учебниках обозначается цифрой 1.
На сайте можно сделать фонетический разбор любого русского слова в режиме онлайн — введите слово в форму поиска и нажмите кнопку.
Чаще всего разбирают слова (в скобках показано, сколько раз посетители сайта разбирали слово):
- (7066) (5601) (4673) (4118) (4012) (3592) (3419) (3359) (3329) (3308) (3294) (3249) (3187) (3079) (3052) (2951) (2809) (2778) (2753) (2696) (2575) (2528) (2522) (2093)
Последние разобранные слова:
Смотрите также примеры фонетических разборов простых и сложных случаев с объяснениями. Разборы делаются с учётом требований современной школьной программы русского языка. На сайте также даются справочные материалы по звукам, транскрипции с правилами и примерами.
Разборы слов на сайте делаются в автоматическом режиме на основе алгоритма, поэтому могут быть недостоверными. Используйте разборы исключительно для самопроверки.
Используйте разборы исключительно для самопроверки.
Frazbor. ru — фонетический разбор слов, составление транскрипции, определение звуков
Фонетический разбор.
Frazbor. ru
14.10.2019 10:32:37
2019-10-14 10:32:37
Источники:
Https://frazbor. ru/
Звуко-буквенный разбор слова «русский» / Справочник: Бингоскул » /> » /> .keyword { color: red; }
Русский язык звуко буквенный разбор
Слово РУССКИЙ состоит из двух слогов, первый из которых ударный. Количество букв и звуков не совпадает (7 букв, 6 звуков), т. к. присутствует удвоенная согласная, обозначающая один звук. Слово является словарным. Правописание удвоенной согласной нужно запомнить.
Звуко-буквенный разбор
Ру’с-ский — [рус:кий`], 2 слога
- Р — [р] – согласный, звонкий, непарный, твердый, парный, сонорный; У — [у] – гласный, ударный; С — [с:] – согласный, глухой, парный, твердый, парный; С — [-] К — [к`] м — согласный, глухой, парный, мягкий, парный; И — [и] – гласный, безударный; Й — [й`] – согласный, звонкий, непарный, мягкий, непарный, сонорный;
Цветовая схема слова:
Цветовая схема слова:
Слово РУССКИЙ состоит из двух слогов, первый из которых ударный. Количество букв и звуков не совпадает (7 букв, 6 звуков), т. к. присутствует удвоенная согласная, обозначающая один звук. Слово является словарным. Правописание удвоенной согласной нужно запомнить.
Количество букв и звуков не совпадает (7 букв, 6 звуков), т. к. присутствует удвоенная согласная, обозначающая один звук. Слово является словарным. Правописание удвоенной согласной нужно запомнить.
Ру’с-ский — [рус:кий`], 2 слога
- Р — [р] – согласный, звонкий, непарный, твердый, парный, сонорный; У — [у] – гласный, ударный; С — [с:] – согласный, глухой, парный, твердый, парный; С — [-] К — [к`] м — согласный, глухой, парный, мягкий, парный; И — [и] – гласный, безударный; Й — [й`] – согласный, звонкий, непарный, мягкий, непарный, сонорный;
Цветовая схема слова:
И — и гласный, безударный;.
Bingoschool. ru
21.07.2020 21:29:50
2020-07-21 21:29:50
Источники:
Https://bingoschool. ru/manual/foneticheskij-razbor-slova-russkij/
WALS Online — Глава описи качества гласных
1.
 Введение
Введение В этой главе обсуждается количество контрастов гласных в инвентаре звуков в языках. Она дополняет главу 1, посвященную инвентаризации согласных, хотя в этой главе количество рассматриваемых элементов подсчитывается несколько иначе. Гласные — это виды звуков, которые обычно встречаются в качестве основных центров слогов; во многих языках самое короткое слово состоит всего из одной гласной, как во французском слове eau «вода», произносится как один гласный звук /о/. Как показывает этот пример, устоявшаяся система правописания часто предполагает очень косвенную связь между используемыми буквами и гласными звуками языка. Следовательно, набор используемых гласных должен быть установлен таким же образом, как это обсуждалось для согласных, в данном случае путем сравнения наборов слов, в которых различаются только гласные звуки. Английские слова seat, sit, sate, set, sat, sot, soot, suit показывают, что в английском языке есть как минимум 8 различных гласных звуков. Рассматривая дополнительные наборы слов с другими согласными, можно установить полный набор английских гласных (который будет варьироваться в зависимости от рассматриваемого варианта английского языка).
Рассматривая дополнительные наборы слов с другими согласными, можно установить полный набор английских гласных (который будет варьироваться в зависимости от рассматриваемого варианта английского языка).
Как и в случае с согласными, для многих языков довольно просто решить, сколько гласных есть, но в других случаях приходится решать некоторые трудные вопросы, особенно когда возникает вопрос о том, следует ли признать данный центр слога состоящим из из одной или двух (а то и более) частей. Есть несколько типов случаев, которые ставят эту проблему, из которых только три основных будут рассмотрены здесь довольно кратко. Это касается длины гласных 9.0006 , назализация гласных и дифтонгов .
Во многих языках гласная, которая удерживается в течение более длительного времени, контрастирует с более короткой версией той же гласной (или достаточно похожей, чтобы считаться в основном эквивалентной). Например, на языке тлинкитов (на-дене; Аляска) слово, написанное t’a /t’a/, означает «королевский лосось», тогда как t’aa /t’aː/ означает «доска, доска». Такая долгая гласная может рассматриваться как две последовательные копии одной и той же гласной, как предполагает написание, или рассматриваться как единое целое. Соображения, которые привели бы к тому или иному выбору, часто тщательно сбалансированы и приводят разных ученых к разным выводам.
Такая долгая гласная может рассматриваться как две последовательные копии одной и той же гласной, как предполагает написание, или рассматриваться как единое целое. Соображения, которые привели бы к тому или иному выбору, часто тщательно сбалансированы и приводят разных ученых к разным выводам.
Назальная гласная — это гласная, в которой воздух выходит не только через рот, но и через нос. Во многих языках произношение одного и того же слова может различаться в разных контекстах между произнесением носовой гласной и произнесением гласной и носовой согласной, как в различном произношении французского bon в bon cafe «хороший кофе» и bon ami. ‘хороший друг’, /bɔ̃ kafe/ против /bɔn ami/. Опять же, разные соображения могут привести к разному выбору, либо интерпретируя такой падеж как содержащий единицу, которая является носовой гласной, либо как состоящую из двух частей, а именно гласной, сопровождаемой носовым элементом.
Дифтонги, такие как виды звуков, слышимых между согласными в английских словах лгал /laid/ и громко /laud/, включают перемещение гласных из начальной позиции в другую конечную позицию. Опять-таки можно рассматривать такие случаи как отдельные звуки с присущим им движением или рассматривать их как результат последовательного произнесения двух разных гласных.
Опять-таки можно рассматривать такие случаи как отдельные звуки с присущим им движением или рассматривать их как результат последовательного произнесения двух разных гласных.
Согласно решениям, принятым по подобным вопросам, количество гласных, встречающихся в том или ином языке, может значительно различаться. Более последовательный способ сравнить инвентарь гласных — провести сравнение на несколько более абстрактном уровне. Фонетики выделяют три свойства, которые определяют основное качество или «тембр» гласного звука. это его высота (примерно, насколько открытой должна быть челюсть, чтобы произнести гласную), ее положение в прямом направлении (примерно, нужно ли выдвигать язык вперед, оставаться более или менее в положении в котором она отдыхает при нормальном дыхании или притягивается к задней части рта для этой гласной), и положение губ (независимо от того, выдвинуты ли губы вперед и сужены или нет). Существует гораздо больше согласия относительно того, сколько типов гласных, различающихся по одному или нескольким из этих основных параметров, встречается в любом данном языке. Долгие и краткие варианты одной и той же гласной всегда учитываются один раз, носовые гласные не добавляются к инвентарю, пока встречается неназальный аналог, и так далее. По этой причине в этой главе рассматривается количество основных качеств гласных в каждом языке. Таким образом, считается, что в испанском языке пять гласных, которые обычно довольно просто обозначаются буквами 9.0007 i, e, a, o, u в испанской орфографии. Дифтонги, встречающиеся в таких словах, как puerta «дверь» или siempre «всегда», могут быть решены как комбинации двух этих основных гласных, встречающихся в одном слоге. Для пяти общепризнанных качеств гласных в испанском языке можно дать простую фонетическую классификацию с точки зрения основных свойств следующим образом: две гласные, представленные /i, u/, являются высокими гласными, /e, o/ — средними гласными и /a/. это низкий гласный. Гласные /i, e/ передние, /a/ центральные, /o, u/ задние; / o / и / u / также округляются, в то время как остальные три испанских гласных не округляются.
Долгие и краткие варианты одной и той же гласной всегда учитываются один раз, носовые гласные не добавляются к инвентарю, пока встречается неназальный аналог, и так далее. По этой причине в этой главе рассматривается количество основных качеств гласных в каждом языке. Таким образом, считается, что в испанском языке пять гласных, которые обычно довольно просто обозначаются буквами 9.0007 i, e, a, o, u в испанской орфографии. Дифтонги, встречающиеся в таких словах, как puerta «дверь» или siempre «всегда», могут быть решены как комбинации двух этих основных гласных, встречающихся в одном слоге. Для пяти общепризнанных качеств гласных в испанском языке можно дать простую фонетическую классификацию с точки зрения основных свойств следующим образом: две гласные, представленные /i, u/, являются высокими гласными, /e, o/ — средними гласными и /a/. это низкий гласный. Гласные /i, e/ передние, /a/ центральные, /o, u/ задние; / o / и / u / также округляются, в то время как остальные три испанских гласных не округляются.
2. Установление значений. 14. В выборке 4 языка только с двумя контрастными качествами гласных; это языки, в которых только высота гласного имеет какую-либо отличительную функцию в соответствии по крайней мере с одной возможной интерпретацией их фонетических моделей. Примером такой крайности является Йимас (Нижний Сепик-Раму; Папуа-Новая Гвинея). Только один язык в выборке, немецкий, использует 14 качеств гласных, и только 2 используют 13, а именно включенную здесь разновидность британского английского и Bété (Kru, Нигер-Конго; Кот-д’Ивуар). Значительно больше языков имеют набор из пяти гласных, чем любое другое число — 188 или немногим более одной трети. Следующим наиболее часто встречающимся размером инвентаря является шесть качеств гласных для 100 языков (или 17,8% выборки). Таким образом, при нанесении данных на Карту 2А инвентаризация качества гласных с 5 или 6 элементами была сгруппирована вместе в категорию «средних», в то время как те, у которых 4 или меньше, классифицируются как «малые», а те, у которых 7 или более, классифицируются как «средние».
 большой». Языки со «средним» размером инвентаря качества гласных составляют более половины всей выборки (51,2%), около трети (32,5%) имеют «большой» инвентарь качества гласных, и только 16,3% имеют «маленький» инвентарь качества гласных.
большой». Языки со «средним» размером инвентаря качества гласных составляют более половины всей выборки (51,2%), около трети (32,5%) имеют «большой» инвентарь качества гласных, и только 16,3% имеют «маленький» инвентарь качества гласных.| Перейти к карте | ||
|---|---|---|
| Значение | Представление | |
| Инвентарь малых гласных (2-4) | 93 | |
| Средний запас гласных (5-6) | 287 | |
| Перечень больших гласных (7-14) | 184 | |
| Итого: | 564 | |
3. Географическое распределение
Существуют четкие территориальные закономерности в распределении кадастров качества гласных. Неудивительно, что языки со средним объемом инвентаря разбросаны наиболее широко. Всего в нескольких районах, в том числе в Южной Африке, они встречаются почти за исключением двух других типов. С другой стороны, малые и большие запасы заметно асимметричны в своем географическом распределении. Языки с небольшим запасом часто встречаются в Америке. Языки коренных народов Америки довольно часто имеют четыре гласных в наборе, аналогичном испанскому, за исключением отсутствия гласной, подобной / u /. Примерами языков, имеющих такую систему, являются восточный оджибва (алгонкинский; Онтарио), навахо (атапаскский; юго-запад США), северный пуэбла-науатль (уто-ацтекский; Мексика) и такана (таканский; Боливия). Другие из этих языков, такие как аймара, чероки и хайда, имеют трехгласные системы, обычно имеющие две высокие гласные /i, u/ и низкую центральную гласную /a/. В Австралии преобладают малые гласные, и эта особенность является лишь одним из многих свойств, которые придают языкам, родным для этой части мира, особый характер с точки зрения их звуковых моделей.
Неудивительно, что языки со средним объемом инвентаря разбросаны наиболее широко. Всего в нескольких районах, в том числе в Южной Африке, они встречаются почти за исключением двух других типов. С другой стороны, малые и большие запасы заметно асимметричны в своем географическом распределении. Языки с небольшим запасом часто встречаются в Америке. Языки коренных народов Америки довольно часто имеют четыре гласных в наборе, аналогичном испанскому, за исключением отсутствия гласной, подобной / u /. Примерами языков, имеющих такую систему, являются восточный оджибва (алгонкинский; Онтарио), навахо (атапаскский; юго-запад США), северный пуэбла-науатль (уто-ацтекский; Мексика) и такана (таканский; Боливия). Другие из этих языков, такие как аймара, чероки и хайда, имеют трехгласные системы, обычно имеющие две высокие гласные /i, u/ и низкую центральную гласную /a/. В Австралии преобладают малые гласные, и эта особенность является лишь одним из многих свойств, которые придают языкам, родным для этой части мира, особый характер с точки зрения их звуковых моделей. Инвентарь малых гласных редко встречается в остальных частях мира, то есть в Африке, на всей материковой части Евразии, в Новой Гвинее и на островах Тихого океана, хотя существуют некоторые специфические небольшие языковые группы, такие как берберские языки Северной Африки и берберские языки. Языки Северо-Западного Кавказа, на которых говорят вблизи границы России и Грузии, могут иметь эту особенность.
Инвентарь малых гласных редко встречается в остальных частях мира, то есть в Африке, на всей материковой части Евразии, в Новой Гвинее и на островах Тихого океана, хотя существуют некоторые специфические небольшие языковые группы, такие как берберские языки Северной Африки и берберские языки. Языки Северо-Западного Кавказа, на которых говорят вблизи границы России и Грузии, могут иметь эту особенность.
Африка поразительно отмечена зоной прямо через «средний пояс», примерно между экватором и Сахарой, в которой преобладают большие запасы гласных. Этот пояс охватывает языки, принадлежащие к трем основным семьям: нигеро-конголезской, нило-сахарской и афро-азиатской. Относительно большое количество гласных в этих языках, по-видимому, связано с преобладанием моделей гармонии гласных в той же области. Когда говорят, что в языке есть гармония гласных, это обычно означает, что в слове, включая любые аффиксы, можно комбинировать только члены определенных подмножеств гласных вместе. Такие ограничения очень распространены как в нигеро-конголезских, так и в нило-сахарских языках в этой области. Поскольку его эффект заключается в уменьшении количества правильных слов, которые могут быть составлены из набора доступных звуков, наличие гармонии гласных может облегчить переносимость большего, чем обычно, количества различных гласных в языке, поскольку это снижает риск неправильное расслышание и неправильное определение слова. Это связано с тем, что в языке с гармонией гласных данную гласную в слове не нужно выделять среди набора всех возможных гласных, а только среди гласных подмножества.
Такие ограничения очень распространены как в нигеро-конголезских, так и в нило-сахарских языках в этой области. Поскольку его эффект заключается в уменьшении количества правильных слов, которые могут быть составлены из набора доступных звуков, наличие гармонии гласных может облегчить переносимость большего, чем обычно, количества различных гласных в языке, поскольку это снижает риск неправильное расслышание и неправильное определение слова. Это связано с тем, что в языке с гармонией гласных данную гласную в слове не нужно выделять среди набора всех возможных гласных, а только среди гласных подмножества.
Кроме того, во внутренних районах Юго-Восточной Азии и на юге Китая, в большей части Европы и, в меньшем масштабе, во внутренних районах Новой Гвинеи наблюдается концентрация гласных, превышающая средний показатель. Европейская территория также включает в себя ряд языков с ограничениями гармонии гласных на распределение их гласных, таких как финский и венгерский, а также турецкий и его родственники (которые простираются далеко в Среднюю Азию и в западный Китай). Однако большое количество гласных в некоторых других языках этой области появилось (по крайней мере, частично) в результате того, что ранее различия между наборами долгих и кратких гласных превратились в контрасты качества гласных. Это произошло (с учетом других влияний) среди прочего на английском, немецком и итальянском языках.
Однако большое количество гласных в некоторых других языках этой области появилось (по крайней мере, частично) в результате того, что ранее различия между наборами долгих и кратких гласных превратились в контрасты качества гласных. Это произошло (с учетом других влияний) среди прочего на английском, немецком и итальянском языках.
4. Дискуссия
В затронутой азиатской области ряд языков хорошо известен тем, что они претерпели исторические звуковые изменения, в результате которых их слова сократились так, что многие из них стали длиной всего в один слог, и часто в то же время сократилось количество слов. различия между согласными, особенно на концах слов. По крайней мере, в некоторых случаях эти изменения также привели к увеличению количества отдельных гласных. Такие модели взаимосвязанных изменений иногда предполагают, что языки поддерживают общий баланс сложности своих фонологических систем. Поэтому интересно проверить, не обнаруживается ли в данных этого исследования тенденция уравновешивать небольшое количество согласных большим количеством гласных и, наоборот, уравновешивать большее количество согласных меньшим количеством контрастов гласных. В наборе 559языков, для которых доступны как размер инвентаря согласных, так и размер инвентаря качества гласных, абсолютно никакой корреляции между количеством гласных и количеством согласных обнаружено не было (для статистически мыслящих коэффициент корреляции между двумя рядами чисел равен -. 004). Отсутствие какой-либо существенной взаимосвязи между этими свойствами также становится очевидным при рассмотрении широких категорий размеров, обсуждаемых в этой главе и в главе 1. Например, из 167 языков с «умеренно большим» и «большим» набором согласных, как определено в главе 1, 33 имеют «маленький» набор качества гласных и 50 — «большой» набор качества гласных, или 19 языков.0,8% и 29,9% соответственно. Эти пропорции очень похожи на общие частоты, обнаруженные во всей выборке. Поэтому в качестве общего принципа нельзя сказать, что числа гласных и согласных в инвентаре, подсчитанные здесь, имеют отношение друг к другу. Существует много различных возможных балансов между этими двумя аспектами звуковой системы языка, и все они служат для создания удовлетворительного инструмента для человеческого использования.
В наборе 559языков, для которых доступны как размер инвентаря согласных, так и размер инвентаря качества гласных, абсолютно никакой корреляции между количеством гласных и количеством согласных обнаружено не было (для статистически мыслящих коэффициент корреляции между двумя рядами чисел равен -. 004). Отсутствие какой-либо существенной взаимосвязи между этими свойствами также становится очевидным при рассмотрении широких категорий размеров, обсуждаемых в этой главе и в главе 1. Например, из 167 языков с «умеренно большим» и «большим» набором согласных, как определено в главе 1, 33 имеют «маленький» набор качества гласных и 50 — «большой» набор качества гласных, или 19 языков.0,8% и 29,9% соответственно. Эти пропорции очень похожи на общие частоты, обнаруженные во всей выборке. Поэтому в качестве общего принципа нельзя сказать, что числа гласных и согласных в инвентаре, подсчитанные здесь, имеют отношение друг к другу. Существует много различных возможных балансов между этими двумя аспектами звуковой системы языка, и все они служат для создания удовлетворительного инструмента для человеческого использования.
Связь между количеством гласных и количеством согласных обсуждается с другой точки зрения в Главе 3, а связь между системами гласных и системами тонов обсуждается в Главе 13.
Домен 2 — Вы RICA
Компетенция 3: Ключевые термины Прямое обучение
Differentiation
Учителя должны специально обучать EL фонемам, которых нет в их родном языке.
Учитель произносит вслух 22 слова, и ученик должен ответить разными звуками каждого слова отдельными частями. Эта оценка должна быть дана первой, а в случае неудачи следует протестировать другие компоненты. Если учащийся хорошо справляется с этой оценкой, можно предположить, что он преуспеет и в других областях фонематического восприятия.
| Компетенция 4: Ключевые термины Прямые инструкции
Учителя используют большие книги для обмена опытом. Во-первых, следует начинать с заголовка на лицевой стороне и продолжать до титульного листа и остального текста. Каждая строка должна быть прочитана, и учитель должен пальцем указать, где он читает. Каждая вещь, на которую указывает учитель при чтении, должна быть подробно объяснена и обучена ученикам. Это хороший способ для студентов изучить концепции печати.
Если учащиеся читают и изучают азбуку, а также тренируются в написании букв, это помогает учащимся распознавать буквы. Дифференциация
take advantage of transfer between first language and English (i.e. same directionality and similarities in letters in Spanish and English) Assessment
Пример теста Йоппа-Зингера:  youtube.com/embed/tJdw-kxnXM0?wmode=opaque» frameborder=»0″ allowfullscreen=»»> youtube.com/embed/tJdw-kxnXM0?wmode=opaque» frameborder=»0″ allowfullscreen=»»> |
 графемы могут представлять фонемы несколькими различными способами. (т.е. ск, к, в)
графемы могут представлять фонемы несколькими различными способами. (т.е. ск, к, в) 





Компетенция 5: Ключевые термины
декодируемый текст — текст, который можно разбить на части, чтобы понять его смысл.
| Компетенция 6: Ключевые термины
от целого к части — инструкция, которая начинается с предложений, затем рассматривает слова и завершается изучением связи звука и символа, на которой делается акцент. Прямое обучение
Оценка
Учащиеся читают слова из списка, а учитель анализирует, с какими звуками у каждого учащегося возникают проблемы. Это может помочь оценить как фонетику, так и зрительные слова.
Учащиеся читают часть рассказа или статьи вслух, а учитель ведет учет ошибок учащихся и неправильно идентифицированных слов. |





 Затем учитель может проанализировать результаты чтения.
Затем учитель может проанализировать результаты чтения. Компетенция 7: Ключевые термины
(слон — одна морфема, а стулья — две (стул+ы)) Direct Instruction
Отслеживание заглавных букв Песня: |

 Затем учитель работал с учениками, чтобы выяснить, что означает префикс, суффикс или корень.
Затем учитель работал с учениками, чтобы выяснить, что означает префикс, суффикс или корень. Дифференциация
Assessment
|
 Учитель записывает все допущенные ошибки.
Учитель записывает все допущенные ошибки. << Домен 1 | Домен 3 >> |
5 Занятия по фонологическому и фонематическому восприятию
«Фонологическая осведомленность», «фонематическая осведомленность» и «фоника» — термины грамотности, которые мы часто слышим одновременно и, возможно, даже взаимозаменяемо! Однако, работая с детьми, помогая им развить прочную основу грамотности и языковых навыков, мы должны осознавать важное различие между этими терминами.
Что такое фонематический слух?
Фонологическая осведомленность — это способность слышать и манипулировать частями разговорной речи. Навыки находятся на уровне аудирования/слухового и разговорного/вербального – НЕТ печатных слов – произносимые слова, требующие только ушей!
Это широкий термин, включающий группу навыков, которые развиваются в процессе развития, но, конечно же, перекрываются по мере взросления детей. По мере развития навыков фонологического восприятия дети начнут обращать внимание, различать, запоминать и манипулировать (сегментировать/смешивать) слова и звуки на следующих уровнях или фрагментах:
- Приговор
- Понимание того, что услышанное ими предложение «Thecatisfat» состоит из четырех отдельных слов «The cat is fat».
- Слово
- Понимание рифмы слов «кошка» и «толстый».
- Понимание того, что два слова становятся одним в сложном слове: кошка + рыба = сом
- Слог
- Понимание слова «кошка» как одного слога.
- Понимание слова «кошка» как одного слога.
- Фонематическая осведомленность
- Понимание трех звуков в слове «кошка» и управление ими = /k/ /a/ /t/

Давайте подробнее рассмотрим фонематический слух. Это особый навык, относящийся к широкой категории фонологической осведомленности. Если мы поместим навыки фонологического восприятия в континуум, фонематическое восприятие будет самым сложным и последним для развития.
Ниже приведен список конкретных навыков фонематического восприятия. Имейте в виду, что все это делается на аудиальном/разговорном уровне, БЕЗ печати:
- Распознавать слова в наборе, начинающиеся с одного и того же звука (кошка, торт, воздушный змей, все начинаются со звука /k/)
- Выделение и произнесение первого/последнего/среднего звука/ов в слове (кошка начинается со звука /к/ и заканчивается звуком /т/ и т. д.)
- Слияние отдельных звуков (фонем) в слова (/k/- /a/ — /t/ = кошка)
- Разделить слова на звуки (cat = /k/- /a/ — /t/)
- Удалить/изменить звуки в произносимых словах (Что такое «кошка» без /k/? — «at»
В основном, навыки фонематического восприятия включают в себя обучение тому, как разбивать (сегментировать) и комбинировать (смешивать) звуки в словах. Фонематическая осведомленность должна начинаться в Pre-K с акцентом на более простые фонематические навыки выделения и определения начальных и конечных звуков. Поскольку фонематическая осведомленность является более продвинутым навыком фонологической осведомленности, развитие продолжается в детском саду и в начальной школе.
Фонематическая осведомленность должна начинаться в Pre-K с акцентом на более простые фонематические навыки выделения и определения начальных и конечных звуков. Поскольку фонематическая осведомленность является более продвинутым навыком фонологической осведомленности, развитие продолжается в детском саду и в начальной школе.
Почему навыки фонематического восприятия так важны?
Что ж, детям, которые не могут слышать и манипулировать фонемами произносимых слов, будет очень трудно научиться связывать фонемы с буквами, когда они видят их в написанных словах, Фонетика. Таким образом, навыки фонологического восприятия являются основополагающими для фонетики.
Что такое фонетика?
Фонематическая осведомленность, однако, не фонетика.
Развитие фонетических навыков направлено на то, чтобы помочь детям понять взаимосвязь между звуками письменных букв, буквосочетаниями и словами. Фонетика имеет дело с письменной речью, поэтому нам нужно использовать наши уши И глаза, в то время как фонологическая осведомленность (и фонематическая осведомленность) не включает печать, а только прослушивание и произнесение звуков и слов. Чтобы не упускать это из виду, я думаю о действиях по фонологическому осознанию как о действиях, которые можно выполнять с закрытыми глазами, в то время как действия по фонетике требуют, чтобы мы видели написанные буквы и слова, поэтому глаза должны быть открыты.
Чтобы не упускать это из виду, я думаю о действиях по фонологическому осознанию как о действиях, которые можно выполнять с закрытыми глазами, в то время как действия по фонетике требуют, чтобы мы видели написанные буквы и слова, поэтому глаза должны быть открыты.
И фонематический слух, и фонетика взаимосвязаны, являются основополагающими навыками и необходимы для чтения. Тем не менее, важно понимать, что прежде чем интенсивно концентрироваться на фонетике, необходимо создать основу для всех навыков фонологического восприятия.
Преимущества фонематической и фонологической осведомленности
PreK — это время, чтобы начать закладывать основу для сильных навыков чтения, и важно начать с концентрации на развитии навыков фонологической осведомленности. Кроме того, если мы не поможем детям обрести базовое понимание звуков, которое дает фонематическое осознание, фоника (присвоение букве звука, правописание и чтение) не будет иметь большого смысла. И исследования подтверждают это.
- «Фонологическая осведомленность имеет решающее значение для обучения чтению любой алфавитной системы письма». Рвы, Л., и Толман, К. (2009). Отрывок из «Основы языка для учителей чтения и правописания» (LETRS): «Звуки речи английского языка: фонетика, фонология и знание фонем» (модуль 2). Бостон: Соприс Вест.
- Также установлено, что фонематические знания являются основой навыков правописания и распознавания слов. «Фонематическая осведомленность — один из лучших показателей того, насколько хорошо дети научатся читать в первые два года обучения в школе». Чтение ракет / WETA.
Подводя итог, можно сказать, что фонематическая осведомленность имеет решающее значение для чтения. Он подготавливает читателей к преобразованию речи в печатный текст, соединению звуков с письменными символами, а также дает детям возможность приблизиться к звучанию, смешиванию звуков для создания и чтения новых слов.
Упражнения и стратегии фонологического восприятия
В Pre-K фонологическому восприятию, безусловно, нужно обучать в явном виде, но в любое время можно вплести забавную дополнительную практику.
Упражнение 1: Игры, в которые можно играть в очереди
Вот несколько идей для простых игр, в которые дети могут играть, пока дети ждут в очереди:
- Игра в предложения: произнесите предложение «Кошка толстая». Постукивайте первых 4 детей по голове, произнося каждое слово предложения. Спросите: «Сколько слов?», четыре! Повторяйте это предложение или произносите другое предложение, пока вы идете по цепочке детей.
- Игра в рифмы: Произнесите несколько слов, которые рифмуются со словами «кошка, жир, летучая мышь». Предложите детям включиться в игру. Возможно, вам придется подсказывать, произнося некоторые начальные звуки: /p/ — ат, /s/ — ат и т. д. Включайте глупые слова (/z/ — ат) и сочетания (/th/ — ат)!
- Игра «Моя очередь/Твоя очередь» на подсчет слогов: (Моя очередь) Моделируйте аплодисменты/топание/стуки по слогам объектов, которые вы видите в классе (потолок, пол, стол, компьютер). (Ваша очередь) Предложите детям подражать вам. Спрашивайте после каждого слова: «Сколько слогов?»
- Повторить начало звуковой игры: /с/ — /с/ — кот, /с/ — /с/ — торт, /с/ — /с/ — машина. Предложите детям присоединиться к ним другими словами.
Учебная программа «Подготовка к школе» предлагает множество мероприятий, способствующих раннему развитию языковых навыков и навыков грамотности у детей в классах дошкольного образования.
Вот несколько дополнительных примеров занятий и продуктов, предназначенных для подробного обучения юных учащихся некоторым ключевым навыкам фонологической осведомленности.
Упражнение 2: Различение рифм
В каждой из четырех книг о Матмене есть любимый персонаж, Матмен. Рифмованные стихи во всех книгах помогают детям различать и узнавать рифмы.
Mat Man помогает учащимся узнать о формах, профессиях, рифмах, расширяя при этом их воображение, исследования и осведомленность общества.
Щелкните здесь, чтобы увидеть больше образцов страниц из серии книг Mat Man.
Упражнение 3. Различение звуков окружающей среды и звуков речи
Дети узнают важные социальные, математические, грамотные и языковые понятия, когда они двигаются и поют веселые песни в музыкальном альбоме «Пой, звучи и считай со мной»
Для например, песня «Syllable Sound Off» помогает развивать у детей понимание слогов, когда они слушают и двигаются, чтобы определить слова из 2, 3 и 4 слогов… и все это в одной песне!
Стихи учат в веселой игровой форме в песне «Rhyming Riddles». На самом деле, большинство песен на музыкальном альбоме содержат куплеты с рифмованными словами!
Упражнение 4. Определение звуков и их источников
Sound Around Box — это универсальное учебное пособие, которое поможет вам обучать раннему языку и основам грамотности в веселой и практической форме. Это дает возможность для многих групповых занятий, которые помогут детям развить важные социальные навыки, поскольку они участвуют в мультисенсорной игре с рифмами, слогами, начальными звуками, знанием алфавита, букв, частей слова и проверяют свои навыки памяти!
Упражнение 5. Развитие языковых, грамотных, моторных и социальных навыков в раннем возрасте
Line It Up вовлекает детей в веселые интерактивные занятия, которые развивают ранние языковые, грамотные, моторные и социальные навыки. В набор входит монтируемая магнитная панель для хранения карточек с историями, буквами и раскрасками.
26 карточек-раскрасок имеют простые изображения. Картинка может быть цветной, но также может использоваться для облегчения занятия «Повторение слога». Например, на карте «А»: ал-ли-га-тор .
26 карточек с картинками можно использовать для фонематических занятий, поскольку дети называют каждую картинку и определяют те, которые начинаются с целевого звука. Например:
- Покажите сторону изображения карты Letter A. Назовите каждое изображение.
- Аллигатор начинается с /ă/. Скажи это со мной, /ă/, аллигатор.
- Скрипка начинается с /ă/? Нет, скрипка начинается с /v/.
- Начинается ли астронавт с /ă/? Да, /ă/, космонавт.
- Продолжайте с бананом и яблоком.
- Пусть дети обведут начало /ă/ картинки.
Все продукты Get Set for School поддерживают различные возможности обучения для ваших развивающихся детей. Представленные здесь продукты и виды деятельности — это всего лишь краткий обзор многих навыков, которым эти продукты могут способствовать.
Чтобы узнать больше об этих и других мероприятиях и продуктах Get Set for School, посетите наш веб-сайт.
A—Z для Mat Man and Me
Плавно воплотите в жизнь азбуку, развивая базовые навыки грамотности с помощью нашей новой серии букварей. Каждая из наших иллюстрированных буквенных книг представляет букву алфавита и подчеркивает связанные с ней звуки с помощью увлекательных визуальных историй. Увлекательные истории в каждой книге захватывают воображение детей и знакомят их с социально-эмоциональными навыками и разнообразными культурами.
Подробнее → .
Морфофонология | Психология Вики | Фэндом
Оценка |
Биопсихология |
Сравнительный |
Познавательный |
Развивающие |
Язык |
Индивидуальные различия |
Личность |
Философия |
Социальные |
Методы |
Статистика |
Клинический |
Образовательные |
промышленный |
Профессиональные товары |
Мировая психология |
Язык: Лингвистика · семиотика · Речь
Морфофонология (также морфофонема , морфофонология ) — раздел языкознания, изучающий в целом взаимодействие морфологических и фонетических процессов. Когда морфема присоединена к слову, она может изменить фонетическое окружение других морфем в этом слове. Морфофонемика пытается описать этот процесс. Морфофонематическая структура языка обычно описывается серией правил, которые в идеале могут описывать каждое морфофонемное чередование, имеющее место в языке.
В качестве примера морфофонологического чередования в английском языке возьмем суффикс множественного числа. Написанная как «-s» или «-es», но обычно понимаемая как имеющая основное представление / z /, морфема множественного числа чередуется между [s], [z] и [əz], как в кошек , собак , и лошадей соответственно. Суффикс множественного числа «-s» также может изменять фонемы, непосредственно окружающие его. Например, слово «лист» [liːf] принимает форму множественного числа, чередуя [f] с [v] и добавляя суффикс множественного числа, на этот раз записываемый как «-es», но произносимый как [z]. В результате получаются «листья» [liːvz]. Другие слова, такие как «нож», «файф» и «карлик», также демонстрируют это чередование. Это может быть связано с тем, что последняя фонема в этих словах на самом деле является архифонемой /F/, которая может быть реализована как [f] или [v] в зависимости от контекста, даже если эти фонемы обычно контрастируют. Архифонема для голоса не указывается по правилу: /F/ -> [αголос] / __ [αголос]. Поскольку основным представлением английского суффикса множественного числа является звонкий согласный /z/, архифонема /F/ реализуется как звонкий аллофон [v].
Другим примером может быть различное произношение маркера прошедшего времени «-ed». После глухого звука «-ed» обычно реализуется как [t], например, шел , надеялся на , желал и так далее.
Флективные и агглютинирующие языки могут иметь чрезвычайно сложные системы морфофонемы. Примеры сложных морфофонологических систем включают:
- Градация согласных, встречающаяся в некоторых уральских языках, таких как финский, эстонский, северносаамский и нганасанский.
- Гармония гласных, встречающаяся в разной степени в языках по всему миру, особенно в тюркских языках.
- Sandhi, явление, стоящее за приведенными выше английскими примерами множественного числа и прошедшего времени, в той или иной степени встречается практически во всех языках. Даже мандарин, о котором иногда говорят, что он не имеет морфологии, тем не менее демонстрирует тон сандхи, морфофонематическое чередование.
- Аблаут встречается на английском и других германских языках. Аблаут — это явление, при котором гласные основы меняют форму в зависимости от контекста, как в английском языке 9.0007 поет , поет , поет .
Содержание
- 1 Морфофонематический анализ
- 1.1 Ярлык формы изоляции и почему он иногда не работает
- 1.2 Терминология порядка правил
- 1.2.1 Орфографический контекст
- 2 Каталожные номера
Морфофонематический анализ
Морфофонематический анализ обозначает аналитические процедуры, посредством которых парадигмы с фонологическими чередованиями сводятся к базовым представлениям и фонологическим правилам. Термин «морфофонематический анализ» имеет в настоящее время неясное происхождение. В 19В 40-х и 1950-х годах многие фонологи работали с теорией, в которой (примерно) предполагалось, что все нейтрализующие правила применяются до всех аллофонических правил. Это фактически разделило фонологию на два компонента: нейтрализующий компонент, единицы которого были названы «морфофонемами», и ненейтрализующий компонент, который имел дело с фонемами и аллофонами. Эта теория раздвоенной фонологии сегодня широко считается несостоятельной, но «морфофонемия» остается полезным термином для характеристики изучения нейтрализующих фонологических правил, применяемых в парадигмах.
- Метод морфофонического анализа
Проводя морфофонемный анализ, мы стремимся установить связь между данными и теорией. Рассматриваемая теория состоит в том, что морфемы хранятся в лексиконе в инвариантной фонематической форме. Затем они связываются вместе по морфологическим и синтаксическим правилам. Наконец, они преобразуются в свои поверхностные формы последовательностью (часто нейтрализующих) фонологических правил, применяемых в определенном порядке. Цель морфофонематического анализа состоит в том, чтобы обнаружить набор основных форм и упорядоченных правил, которые согласуются с данными; и выигрыш в том, что кажущиеся сложными шаблоны часто сводятся к простоте.
Морфофонематический анализ можно противопоставить фонематическому анализу. Фонематический анализ — это более ограниченная форма фонологического анализа, которая направлена только на обнаружение ненейтрализующих (аллофонических) правил фонологии. При фонематическом анализе изучается только распределение и сходство телефонов. Следовательно, данные не обязательно группировать по парадигмам, а нужно лишь содержать достаточно большой и репрезентативный набор слов.
Подобно фонематическому анализу, морфофонемный анализ можно проводить систематическим методом.
- Процедура морфофонемного анализа
- Изучите данные, обращаясь к толкованиям, и сделайте предварительное разделение форм на морфемы.
- Найдите каждую чередующуюся морфему и найдите все ее алломорфы.
- В каждом алломорфе найдите конкретный сегмент или сегменты, которые чередуются.
- Принимая во внимание логические возможности, настройте основные представления так, чтобы все алломорфы каждой морфемы могли быть получены из одного основного представления по общим фонологическим правилам.
- Общая схема подробно описана ниже.
- Предварительная обработка данных: фонемизация
Почти всегда легче проводить морфофонемный анализ с данными, которые уже выражены в виде фонем, поэтому, если это еще не сделано, рекомендуется сначала свести данные к фонемам.
- Деление морфем
Следующим шагом является разбиение форм на составляющие их морфемы. Потенциальная сложность заключается в том, что фонологические чередования могут скрыть это разделение. В сложных случаях нужно попробовать несколько вариантов «расстановки дефисов», в конечном итоге выбрав тот вариант, который дает рабочий анализ. Поскольку слова делятся на морфемы, обычно также можно указать и упорядочить действующие правила морфологии.
- Установка лежащих в основе репрезентаций
Как и в случае деления морфем, проблема выбора лежащих в основе репрезентаций часто включает рассмотрение более чем одной гипотезы, при этом окончательный выбор защищается тем, что он ведет к рабочему анализу. Следующая стратегия часто оказывается полезной. Предположим, что сегмент A чередуется с сегментом B в данных. В таком случае аналитик должен рассмотреть две возможности:
- Сегменты, показывающие чередование A ~ B, в основе своей представляют собой /A/, который преобразуется в [B] в определенных контекстах по одному или нескольким фонологическим правилам.
- Сегменты, показывающие чередование A ~ B, в основе своей являются /B/, которые преобразуются в [A] в определенных контекстах по одному или нескольким фонологическим правилам.
- Другими словами, всегда учитывайте оба направления.
- Приведу конкретный пример: если бы мы анализировали Chimwiini, мы бы нашли много примеров чередования долгих гласных с краткими, как в
- [x-soːm-a] ‘читать’
- [x-som-oːw-a] ‘для чтения’
- Мы бы рассмотрели возможность того, что в основе таких падежей лежат долгие гласные («read» = /soːm/), и рассмотрели бы правила сокращения (это оказывается правильным), а также возможность того, что в основе этих падежей лежат короткие гласные («read» = /soːm/). ‘ = /som/) и рассмотрите возможность удлинения правил.
- Построение лежащих в основе репрезентаций согласно конкретной гипотезе ) и пробуем его, следующим шагом будет построение базовых представлений. Вот рекомендуемая процедура:
- Сегменты, которые не чередуются, могут (обычно) считаться фонематически идентичными в их основном представлении их поверхностному представлению. (Это предполагает, как уже отмечалось, что фонематический анализ уже выполнен, поэтому любые позиционные аллофоны уже будут появляться в своей основной форме. )
- Для сегментов, которые чередуются, следуйте гипотезе, которую вы выдвинули о базовых формах, последовательно реализуя ее через данные. Таким образом, если вы предполагаете, что чередование A ~ B, найденное в конкретном контексте, лежит в основе A, вы должны установить /A/ в базовом представлении для всех таких чередований в этом контексте.
- Убедитесь, что лежащее в основе представление каждой морфемы единообразно через ее парадигму — это основная гипотеза теории, которую вы принимаете.
- В нашем примере [x-soːm-a] ~ [x-som-oːw-a] при гипотезе о том, что это правило является правилом сокращения, эти принципы вынуждают нас устанавливать базовые представления /soːm/ для корня и /-oːw/ для неизменно длинного пассивного суффикса.
- Конечный гласный /-а/ оказывается особым случаем: его поверхностная длина фактически не различительна, полностью определяется фонологическими правилами. Наша грамматика будет работать независимо от того, какая базовая длина назначена этому суффиксу.
- Конечный гласный /-а/ оказывается особым случаем: его поверхностная длина фактически не различительна, полностью определяется фонологическими правилами. Наша грамматика будет работать независимо от того, какая базовая длина назначена этому суффиксу.
- Разработка правил
Когда у вас есть подходящий набор гипотетических базовых форм, полезно расположить их в ряд, выровняв соответствующие поверхностные формы под ними следующим образом:
«читать» ‘для чтения’ ‘остановиться на раз’ /x-soːm-a/ /x-soːm-o:wa/ / ку-ребэб-эɺ-ан-а / основные формы … … … добавьте сюда правила [xsoːma] [xsomoːwa] [куребеана] формы поверхности Затем нужно придумать единую систему правил, которая будет выводить нижний ряд из верхнего. Если вы застряли на этом, вы можете попробовать собрать локальных сред для звуков, которые изменяются, как описано выше для фонематического анализа.
- Подсказка для выбора базовых представлений
Когда вы решаете, установить ли базовый A и вывести из него B, или наоборот, в данных часто есть подсказка, которая поможет вам, а именно: контекстуально ограниченный контраст.
В данном случае обратите внимание, что, хотя длина гласных является фонематической в Chimwiini, разрешены только короткие гласные, когда более трех слогов от конца фразы или когда следует долгая гласная. Такие ограничения являются убедительным признаком того, что должно существовать правило, стирающее контраст в этих средах.Другой способ сказать то же самое: не анализируйте в направлении, противоположном направлению нейтрализации. Когда мы анализируем Chimwiini с сокращением, или анализ хорошо сочетается с контекстуально нейтрализованным распределением долгих и кратких гласных в языке. Если, однако, мы попытаемся проанализировать Chimwiini с удлинением, фонологическое распределение поставит нас в тупик. Следующая четверка форм должна прояснить этот момент.
[x-k uː l-a] ‘извлекать’ [x-k u l-oːw-a] ‘быть извлеченным’
[xk u l-a] ‘выращивать’ [xk u l-oːw-a] ‘выращивать’Верхний ряд форм показывает чередование [uː] и [u], которое мы ранее проанализировали, предполагая лежащий в основе /uː/ и нейтрализующее правило Pre-Long Shortening.
Ясно, что предварительное длинное сокращение нейтрализует, поскольку пассивная форма [x-ku:l-a], [x-kul-oːw-a] идентична пассивной форме [x-kul-a], что означает « расти’. Если бы мы неправильно выбрали лежащий в основе /u/ корень, означающий «извлечь», мы потерпели бы поражение: какое бы правило удлинения мы ни пробовали, оно не смогло бы вывести [x-kuːl-a] для «извлечения» и [x -kul-a] для «расти», поскольку эти две формы будут иметь одно и то же основное представление.Ярлык для изолированной формы и почему он иногда не работает
Ярлык формы изоляции
- «Основная форма основы — это просто то, как основа появляется изолированно (без учета влияния любых аллофонических правил)».
Эта стратегия особенно актуальна для таких языков, как английский, где основы часто встречаются поодиночке. Услышав чередование типа [ˈplænt] ~ [ˈplænɪŋ] [Как сослаться и сделать ссылку на резюме или текст] ( растение ~ посадка; у нас возникает соблазн принять свидетельство изолированной формы [ˈplænt] как свидетельство, достаточное само по себе, чтобы оправдать лежащую в основе форму /ˈplænt / Это отлично работает для этого конкретного случая.
Однако в целом ярлык формы изоляции не работает. Причина этого кроется в том, как устроена система, и в простой логике: вполне возможно, что могут применяться правила нейтрализации на всякий случай, если к основе не добавляется аффикс. Мы бы сказали, что в таких случаях аффикс «защищает» основу от нейтрализующего правила, выступая своего рода буфером.
Чтобы быть более точным: нейтрализующие фонологические правила часто обусловлены краем слова; то есть у них есть такие окружения, как /___] word . Когда присутствует аффикс, основа будет буферизована этим аффиксом, и ключевое правило не будет применяться. Действительно, правило будет применяться только к тем членам парадигмы, где нет аффикса, , чтобы эффект буферизации отсутствовал.
Фонологии, имеющие такое явление, довольно распространены и встречаются в корейском, японском, английском, немецком, русском и многих других языках.
Терминология упорядочения правил
- Подача
Обратите внимание, что Apocope, когда он предоставляет кластер сокращения согласных в конце слова, тем самым позволяет применить кластер .
Об этом свидетельствует следующий сокращенный вывод:/jukaɾpa/ основная форма jukaɾp Апокоп jukaɾ Уменьшение кластера [jukaɾ] форма поверхности Говорят, что это случай кормления : Apocope «кормит» сокращение Кластера. В целом термин определяется следующим образом:
Правило A подает правило B, когда:
– A заказывается раньше B, и
– A создает новые конфигурации, к которым может применяться B.
- Кровотечение
Далее рассмотрим взаимодействие /w/ эпентезы и удаления гласных, показанное в следующем сокращенном производном:
/папи-уɻ/ основная форма папиву /в/ Эпентезис − Удаление гласных [papiwuɻ] форма поверхности Ясно, что , если бы /w/ Эпентезис не применялся, , то удаление гласных имело бы дополнительный шанс примениться, создавая *[papiɻ].
Таким образом, мы могли бы сказать, что /w/ эпентезис в этом конкретном выводе «блокирует» или «упреждает» удаление гласных. Однако стандартный используемый термин — кровотечений; /w/ Эпентезис кровоточит Удаление гласных. В более общем смысле:Правило А кровотечения правило B, когда:
– A заказывается раньше B, и
— A удаляет конфигурации, к которым в противном случае мог бы быть применен B.
Орфографический контекст
- См. также: Морфо-фонематическая орфография
Английская морфема множественного числа s пишется одинаково независимо от произношения: Это морфофонемное написание. Если бы в английском языке использовалась чисто фонематическая орфография (та же самая система без каких-либо морфемных соображений), их можно было бы написать 9.0007 кошки и dogz, , потому что /s/ и /z/ в английском языке являются отдельными фонемами.
В какой-то степени английская орфография отражает этимологию его слов и поэтому является частично морфофонемной.
Это объясняет не только CAT S /S /и DOG S /Z /, но также SCI ENCE /SAɪ /VS. UNCON SCI OUS /ʃ /, pre judice /prɛ/ vs. pre quel /PRIː /, CHAS ED /T /VS. LOAD ED /ɪD /, Знак /SAɪN / Знак ATUR и т. д.Однако большинство морфофонемных орфографий отражают только активную морфологию, например, кошек против собак, или преследуемых, против загруженных. Турецкий и немецкий языки имеют широко фонематическую систему письма, но в то время как немецкий язык является морфофонемным, транскрибирующим «основные» фонемы, турецкий является чисто фонематическим, транскрибирующим только поверхностные фонемы (по крайней мере, традиционно; это, кажется, меняется). Например, в турецком есть два слова, /et/ «мясо» и /et/ «делать», которые по отдельности кажутся омонимами. Однако, когда следует гласная, корни расходятся: /eti/ ‘его мясо’, а /edir/ ‘он делает’.
В турецком языке, когда корень, оканчивающийся на /d/, появляется без следующей гласной, /d/ становится /t/ (последнее затруднительное озвучивание), и это отражается в написании: эт, эт, эти, эдир .Немецкий имеет аналогичную связь между /t/ и /d/. Слова для «ванны» и «совета» — это /bat/ и /rat/, но глагольные формы — это /badən/ «купать» и /ratən/ «советовать». Однако они пишутся Bad, baden и Rat, raten , как будто согласные вообще не изменились. Действительно, говорящий может почувствовать, что конечная согласная в Bad отличается от конечной согласной в Rat , потому что интонации различаются, даже если они произносятся одинаково. Подобная морфофонемная орфография имеет то преимущество, что сохраняет орфографическую форму корня независимо от перегиба, что облегчает распознавание при чтении.
В Международном фонетическом алфавите вертикальные черты (| |) часто используются для обозначения морфофонемного, а не фонематического представления.
Еще одно распространенное соглашение — двойная косая черта (// //), символически подразумевающая, что транскрипция «более фонематическая, чем просто фонематическая». Иногда встречаются и другие соглашения: двойная вертикальная черта (|| ||) и фигурные скобки ({}).- Табл. , лежащий в основе (морфо-фонематический), фонематический, и фонетический представлений четырех немецких и турецких слов. (В турецких примерах //Ü// представляет основную высокую гласную, которая в результате гармонии турецких гласных может проявляться как любая из четырех фонем /i y ɯ u/.)
слово морфо-
фонематическийфонематический фонетический Немецкий Плохой //плохо// /летучая мышь/ [летучая мышь] Баден //бадан// /баден/ [баден] Крыса //крыса// /крыса/ [ат] ставка //ratən// /ratən/ [ʀatən] Турецкий и //ред// /et/ [ɛт] редирек //edÜr// /ред. /[ред.] и //и// /et/ [ɛт] эти //etÜ// /эти/ [эти]
Другим примером морфофонемной орфографии является современный хангыль, и тем более устаревшая северокорейская Chosŏn-ŏ sinch’ŏlchabŏp орфография.
Ссылки
- Хейс, Брюс (2009). «Морфофонематический анализ» Введение в фонологию , стр. 161–185. Blackwell
На этой странице используется лицензированный Creative Commons контент из Википедии (просмотр авторов). Ингибирующее и облегчающее влияние фонологического и орфографического сходства на распознавание слов L2 в разных модальностях у двуязычных что двуязычие — это не просто два одноязычных в одном теле
1 . Эта идея подчеркивается концепцией языковой коактивации, которая предполагает, что ни один язык билингва никогда не бывает полностью неактивным или «выключенным». Настоящее исследование исследует эту идею, оценивая, влияет ли фонологическое и орфографическое сходство между эквивалентами перевода на распознавание слов второго языка (L2) — как визуальное, так и слуховое.При изучении существования совместной активации, а именно активации нецелевого языка при обработке целевого языка, одним из наиболее частых доказательств является родственный эффект. Родственные переводы определяются как переводы, которые имеют общую форму и значение в разных языках (например, «бумага» и «бумага» на английском и испанском языках соответственно), в отличие от неродственных переводов, которые имеют только общее значение в разных языках (например, «книга»). и «либро»). Родственный эффект относится к идее о том, что слова, похожие по форме в разных языках, часто оказывают облегчающее воздействие на распознавание слов в одноязычном контексте 2,3,4,5,6,7,8,9 . Обратите внимание, что существует также частный случай родственных слов, в которых слова не просто пишутся одинаково в разных языках, а скорее являются точными совпадениями или орфографически идентичными словами (идентичные родственные слова).
Считается, что эти совершенные или идентичные родственники имеют особый статус, вызывая больший эффект, чем неидентичные родственники 10 .Несмотря на большое количество литературы, посвященной изучению эффекта родственных слов, основное внимание уделялось орфографическому сходству и использованию парадигм визуального распознавания слов 11,12,13,14,15 . Манипуляции орфографическим сходством в визуальной модальности неизменно приводят к эффекту облегчения родственных слов в восприятии. Это родственное преимущество — или родственный эффект облегчения — интерпретируется как совместная активация обоих языков (целевого и нецелевого). Поскольку родственные слова имеют общую форму и значение в разных языках, связанная активация между этими словами выше (активация с более высоким уровнем покоя) по сравнению с неродственными словами (активация с более низким уровнем покоя), что объясняет их более высокую скорость обработки 5,10,16,17 .
Хотя эффект орфографического сходства в визуальной модальности хорошо задокументирован, фонологическому сходству уделялось мало внимания, и очень мало исследований изучали родственный эффект на слух.
В рамках нескольких исследований, изучающих эффект родственных слов на слух, в большинстве из них определялся родственный статус слов на основе орфографического сходства, и результаты не являются окончательными. Некоторые исследования показали, что родственные слова не всегда облегчают и даже могут тормозить. В частности, одно исследование показало, что владение L2 модулирует эффект орфографического сходства при устной речи, при этом участники с более высоким уровнем владения демонстрируют облегчение, а участники с более низким уровнем владения демонстрируют торможение с повышенным сходством 18 . Таким образом, мы знаем, что при манипулировании орфографическим сходством существует эффект родственности в визуальной модальности, но необходимо исследовать эффект родственности в слуховой модальности при манипулировании фонологическим сходством независимо от орфографии. Это одна из основных задач данного исследования.В рамках ряда исследований, проверяющих эффект родственности с учетом фонологического сходства, большинство из них были сосредоточены на производстве, в частности, с использованием задач наименования изображений.
Садат и его коллеги 19 обнаружили фонологический облегчающий родственный эффект при назывании латентных периодов с использованием расстояния ALINE для измерения фонологического сходства. Они заметили, что изображения родственных слов создавались быстрее, чем изображения неродственных. Шварц, Кролл и Диас 8 ортогонально манипулировали фонологическим и орфографическим сходством между родственными и совершенными родственными словами (орфографически идентичными словами, имеющими одинаковое значение) в задаче наименования изображений. Они обнаружили, что при высоком орфографическом сходстве задержки называния замедлялись из-за разной фонологии. Следует отметить, что они сравнивали только родственные и совершенные родственные слова, поэтому их результаты нелегко обобщить на всю лексику. В одном из немногих исследований, изучающих эффекты фонологического сходства в восприятии, Дейкстра и его коллеги 5 оценили носителей нидерландского языка с высоким уровнем владения английским языком в задаче визуального лексического решения (LDT). Они манипулировали фонологическим и орфографическим сходством между голландским и английским языками и обнаружили облегчение в производительности LDT — как по времени ответа, так и по процентным ошибкам — для слов, которые имеют либо только форму — а именно, ложные друзья, — либо и форму, и значение — т. языки. С другой стороны, задержки распознавания задерживались, когда слова имели общую фонологию, а не орфографию, в разных языках. Хотя они ортогонально манипулировали фонологией и орфографией, они обеспечивали только попарные сравнения и не содержали информации о взаимодействии между двумя типами сходства. Поэтому, основываясь на нескольких предыдущих исследованиях, фонологическое сходство может быть не столь последовательно способствующим, как орфографическое сходство, и некоторые результаты предполагают, что фонологическое и орфографическое сходство могут даже взаимодействовать. Это указывает на необходимость дальнейших исследований, изучающих как фонологическое сходство, так и взаимосвязь между орфографическим и фонологическим сходством как в визуальной, так и в слуховой модальностях.Еще одна проблема работы со аудиальной модальностью — установление мер сходства. В тех исследованиях, которые оценивали родственный эффект на слух, измерения сходства сильно различались по уровню объективности и часто были сосредоточены на орфографическом сходстве, как упоминалось выше. Например, Грассо и его коллеги 20 рассматривали элементы, которые были фонологически родственными или неродственными, на основе субъективных оценок трех двуязычных патологов. Шварц и Кролл 21 использовали комбинацию субъективной оценки экспериментаторов, двух двуязычных и одноязычных носителей английского языка с объективной оценкой, основанной на орфографическом сходстве 14 . Другие использовали более объективные меры, используя так называемое выравнивание строк. Эти меры количественно определяют количество операций (вставок, удалений и замен), необходимых для преобразования одной строки — например, графемы или фонемы — в другую. Некоторые авторы предложили использовать расстояние Левенштейна, которое использует выравнивание графем 22,23 , в то время как Садат и его коллеги 19 использовали расстояние ALINE, которое вместо этого выравнивает строки фонем с учетом особенностей сравниваемых фонем 24 .
Упомянутая ранее формула расстояния Левенштейна является наиболее распространенным алгоритмом, используемым для определения орфографического сходства, но, к сожалению, он аппроксимирует фонологическое сходство из орфографического сходства. Если два сравниваемых языка имеют общие сопоставления графемы и фонемы — или, по крайней мере, они имеют в основном взаимно-однозначные соответствия между фонемами и графемами — тогда это не будет серьезной проблемой, поскольку орфографическое и фонологическое сходство будут хорошо согласованы. Тем не менее, это часто не так, поскольку многие языки не имеют прямого взаимно однозначного соответствия между орфографией и фонологией, как в случае с английским языком, например, с «написать», «правильно» и «обряд». все произносятся одинаково. Кроме того, даже если в языках есть прямые соответствия между фонемами и графемами, они могут различаться между языками — например, «piano» в испанском и «πιάνο» в греческом или «sh» в английском и «sch» в немецком, где каждая пара произносится одинаково, но пишется по-разному.
Наконец, аппроксимация фонологического сходства на основе орфографического сходства также важна для случаев, когда языки имеют общую орфографическую систему, но фонологический репертуар совершенно другой. Так обстоит дело между испанским и английским языками, в которых слово «скрипка» (в обоих языках пишется одинаково) произносится как /bio’lin/ и /’vaɪəlɪn/ соответственно. Здесь сходство, измеренное с помощью орфографического расстояния Левенштейна, говорит о том, что эти слова идентичны, но на самом деле в слуховой модальности у них есть только две общие фонемы. Использование орфографического сходства при слуховом распознавании слов может быть не очень хорошим приближением. Это особенно касается часто используемой языковой пары, английского и испанского.Важно отметить, что описанные выше случаи, когда орфографическое и фонологическое сходство не совпадают, могут нести в себе взаимодействие между этими степенями сходства, что еще больше усложняет картину. Это предполагает необходимость изучения не только эффекта фонологического сходства, но и его возможного взаимодействия с орфографическим сходством как в визуальной модальности, так и в малоизученной слуховой модальности.
Это будет нашей второй целью.Настоящее исследование
Для достижения вышеупомянутых целей нам в идеале нужна пара языков, которые следуют разным правилам преобразования фонем в графемы, что позволяет нам ортогонально управлять орфографическим и фонологическим сходством. Хотя орфография и фонология, как правило, соответствуют друг другу, английский язык с его непрозрачной орфографией, т. Е. Соответствиями фонем к графемам «один ко многим» и «многие к одному», позволяет отделить их друг от друга. Кроме того, английский и испанский языки имеют один и тот же алфавит, но имеют много различий в количестве и идентичности фонем. Таким образом, мы протестировали испано-английских билингвов, используя английский в качестве целевого языка. Мы проверили эту группу участников на задачах лексического решения в двух модальностях — визуальной и слуховой — чтобы сравнить результаты участников по одним и тем же предметам в разных модальностях.
Родственные слова, которые орфографически — хотя и не обязательно фонологически — строго идентичны между языками (например, «скрипка», /’vaɪəlɪn/ в английском языке и /bio’lin/ в испанском языке), будут упоминаться в текущем тексте как орфографически идентичные слова чтобы выделить фонологические различия в нашей языковой паре.
Как упоминалось ранее, некоторые исследователи утверждают, что переводы, орфографически идентичные между языками (часто называемые совершенными родственными), имеют особый статус 3,10 , тогда как другие считают их частью спектра орфографического сходства 8,11 . В качестве дополнительной цели мы включили орфографически идентичные слова, чтобы проверить, отличаются ли они категорически от неидентичных родственных слов. Обратите внимание, что мы сосредоточились только на идентичных орфографических родственных словах, а не на идентичных фонологических родственных словах, учитывая, что последняя группа крайне редко встречается в испано-английской языковой комбинации.Мы использовали расстояние ALINE в качестве объективной меры фонологического сходства, поскольку было показано, что оно лучше, чем те, которые использовались в предыдущих исследованиях 25,26,27,28,29 . Частично его преимущество заключается в том, что он учитывает особенности фонем и, таким образом, обеспечивает более точное сравнение фонологических строк, чем, например, расстояние Левенштейна.
ALINE также выравнивает строки, а не просто сравнивает их, что позволяет лучше сравнивать, когда различия между словами в двух языках подразумевают вставку или удаление нескольких фонем или графем 29 .Таким образом, целью настоящего исследования было (1) проверить влияние фонологического сходства на слуховое распознавание слов, (2) оценить влияние фонологического и орфографического сходства между модальностями — визуальной и слуховой — и (3) оценить, имеют ли орфографически идентичные слова особый статус.
Метод
Участники
Участниками были 55 носителей испанского языка (Ж = 34 года, М возраст = 26,25 [SD = 6,01]) из Мадрида и Мурсии со средним уровнем владения английским языком (их вторым языком). Участники набрали минимум 40 баллов по английскому языку BEST 30 — задание по названию картинок с максимальным баллом 65 — и 60% по английскому LexTALE (словарный тест), что соответствует примерно B2 (выше среднего).
уровень 31 . Средний балл участников по BEST составил 57,58 (SD = 5,86) с диапазоном от 40 до 64. Что касается LexTALE, их средний балл составил 77% (SD = 10%) с диапазоном от 60 до 9.9%. Участники сами сообщали о своем среднем ежедневном общении на английском языке, которое составляло в среднем 34% времени (SD = 22%). По их самооценке, средний возраст овладения английским языком составлял 6,5 (SD = 2,5) года, при этом минимальный возраст составлял 3 года. Все участники дали информированное согласие перед тем, как принять участие в эксперименте, который был проведен в соответствии с Хельсинкской декларацией и одобрен комитетом по этике Баскского центра познания, мозга и языка (номер одобрения 9994). Участникам платили за участие в эксперименте.Стимулы
Стимулы состояли из 300 слов и 300 псевдослов. Слова были разделены на шесть категорий. Четыре из них состояли из латинского квадрата между орфографическим и фонологическим сходством. Еще одна группа содержала элементы, находящиеся в крайней степени распределения орфографического сходства — орфографически идентичные слова, — а последняя группа состояла из крайне несходных.
Рисунок 1 Последняя группа была включена, чтобы сбалансировать количество элементов с высоким и низким сходством, и в дальнейшем считается группой наполнителей (пример каждого из них см. на рис. 1). Для основной манипуляции у нас было четыре группы: высокое фонологическое и орфографическое сходство (P High O High ), высокое фонологическое сходство и низкое орфографическое сходство (P High O Low ), низкое фонологическое сходство и высокое орфографическое сходство (P Low O High ), низкое фонологическое и орфографическое сходство сходство (P Low O Low ). Помимо этих 4 основных групп, существовала орфографически идентичная группа перевода (P High O Iden ), которая была включена для оценки «особого статуса» этих элементов по каждому из модальностей. Обратите внимание, что группа с идентичными фонологическими данными (или фонологически идентичными) не была включена, поскольку различия в фонологии между языками не позволяли найти достаточно элементов. Высокое и низкое фонологическое и орфографическое сходство определяли по медианному расщеплению. Для фонологии мы использовали обратное расстояние Алине со средним разделением 0,74. Диапазон высокого сходства значений обратного расстояния Алина составлял от 0,741 до 0,9.51, а для группы с низким сходством диапазон составлял от 0,195 до 0,736. Для орфографии мы использовали ту же меру (обратное расстояние Алине) с разделением медианы на 0,77. Диапазон высокого сходства обратного значения расстояния Алина составлял от 0,771 до 0,982, а для группы с низким сходством диапазон составлял от 0,360 до 0,769.Распределение орфографического и фонологического сходства и примеры слов в каждой категории. Сообщаемые фонологические транскрипции соответствуют общему американскому английскому акценту, который является акцентом говорящего, записавшего стимулы. Псевдослова были записаны в соответствии с транскрипцией IPA, а не с орфографией псевдослова.
Все транскрипции были проверены лингвистом на соответствие стимулам. Каждая строка представляет уровень фонологического сходства, а каждый столбец представляет уровень орфографического сходства. Каждая ячейка содержит 50 элементов.Полноразмерное изображение
Все шесть групп элементов были сопоставлены по следующим переменным: частота слов (необработанная и логарифмическая), частота испанского перевода (необработанная и логарифмическая), количество слогов, количество букв и количество фонем. (Средние значения, стандартные отклонения и статистические данные см. в Таблице 1), все они взяты из CLEARPOND 32 . Псевдослова были созданы путем замены двух последних фонем (2 или 3 буквы) между словами, использованными в задании (например, линза/lɛnz изменена на lert/lɛrt, а airport/ɛrpɔrt на airpons/ɛrpɔnz). Таким образом, количество букв и фонем оставалось постоянным, и все элементы нужно было прослушивать до предпоследней фонемы, чтобы отличить слово от псевдослова.
Таблица 1 Были сопоставлены средние значения, стандартные отклонения и статистические данные для переменных стимулов. Другими словами, мы поддерживали точку уникальности целевых слов постоянной между стимулами и как можно позже. Кроме того, мы использовали орфографическую аппроксимацию этих слов для визуальных стимулов, чтобы поддерживать условия двух модальностей как можно более похожими. Наконец, этот способ создания стимулов позволил нам сопоставить псевдослова с каждой из целевых категорий слов и, таким образом, рассчитать A’ для каждой группы для оценки производительности.Полноразмерная таблица
Всего было 50 слов на каждое условие, всего 300 слов. Также было 50 псевдослов для каждого условия — по одному для каждого слова. Все слова и псевдослова предъявлялись один раз в каждой модальности.
Слуховые стимулы были записаны в тихой комнате для записи носителем английского языка с общим американским акцентом 33 и в соответствии с произношением, указанным в словаре CMU Карнеги-Меллона 34 .
Они были нормализованы до 1 дБ и вырезаны с 500 мс тишины до и после с помощью Audacity 35 . Они были записаны на частоте 44,1 кГц и 32 бит.Процедура
Основным заданием было задание на лексическое решение. Участники видели фиксационный крест в течение 500 мс, а затем либо слышали последовательность фонем, либо видели буквенную цепочку и должны были решить, настоящее ли это слово. Слова визуально отображались на 17-дюймовом экране с разрешением 1024 на 768 пикселей, шрифтом без засечек размером 70 пикселей (белый текст на черном фоне). Слуховые стимулы предъявлялись с использованием наушников, воспроизводящих их в 16-битном формате WAV с частотой дискретизации 44,1 кГц. У участников было 2500 мс, чтобы отреагировать на слуховые стимулы (начиная с начала слова) и 1500 мс, чтобы отреагировать на визуальные стимулы. Они ответили, используя клавиши клавиатуры F (настоящее слово) и J (псевдослово). Перед тем, как перейти к основному заданию (без обратной связи), участники прошли шесть практических испытаний с обратной связью.
Они провели эксперимент в два сеанса с интервалом от одной недели до 10 дней. На каждом занятии участники выполняли либо слуховое, либо зрительное задание (уравновешенное между участниками). Эксперимент имел продолжительность 40 минут на сеанс, всего 2 сеанса. Каждая сессия состояла из 4 блоков с паузами между ними.Анализы
Влияние орфографического и фонологического сходства на LDT оценивалось с использованием двустороннего дисперсионного анализа (ANOVA), а также линейных моделей смешанных эффектов (LME), представленных в дополнительных материалах.
Для дисперсионного анализа, во-первых, мы рассмотрели влияние фонологического и орфографического сходства на A’ — индекс чувствительности, который учитывает совпадения и ложные тревоги — с использованием пакета Psycho в R 36 . Это было выполнено один раз для каждой модальности. A’ был рассчитан с использованием точности слов для расчета частоты попаданий и ошибок псевдослов для расчета ложных тревог.
Затем мы провели дисперсионный анализ влияния фонологического и орфографического сходства на время отклика.
Для слуховой модальности мы вычли продолжительность стимула из записанного времени отклика, измеренного от начала стимула до ответа, чтобы нейтрализовать эффект длительности стимула. Что касается времени отклика в целом, учитывались только правильные ответы, а любые ответы менее 150 мс или более чем на 2 стандартных отклонения от среднего значения в каждой категории для каждого участника исключались. Для орфографически идентичных слов мы провели односторонний ANOVA для основного эффекта орфографического сходства, сохранив только группы с высоким фонологическим сходством. Это означает, что мы сравнивали следующие три группы: P High O Low , P High O High и P High O Iden . Это было сделано для того, чтобы сопоставить 3 группы по фонологическому сходству, поскольку в орфографически идентичной группе не было элементов с низким фонологическим сходством.Наконец, мы провели те же тесты по участникам и по пунктам, и для всех тестов мы провели последующие наблюдения с использованием поправок Бонферрони.
Все значения p для апостериорных тестов приводятся с рассчитанной поправкой Бонферрони (т. е. p значение умножается на количество тестов). Следовательно, порог значимости остается равным 0,05. Во всех случаях рассчитывались F1 и F2, но следует отметить, что анализы участников были значительно более мощными. Это связано с тем, что F1 был внутри предметов, тогда как F2 был между предметами, с меньшим количеством предметов (50), чем участников (55).Недавняя работа показала, что дисперсионный анализ устойчив к нарушениям нормальности 37,38 . Таким образом, мы не исправили нарушения предположения о нормальности.
Существовал общий эффект местоположения, так что участники в Мадриде показали лучшие результаты, чем в Мурсии, но результаты качественно не изменились, когда мы включили местоположение в качестве фактора. Поскольку это не была интересующая переменная, мы свернули данные по местоположениям. Все тесты проводились с использованием JASP 39 .
Результаты
Все участники показали лучшие результаты в любых условиях (средняя производительность в аудио: 77,25% [9,01%] и в визуальном: 89,33% [6,12%]). Используя наши критерии, мы исключили 5,09% (0,64%) ответов — количество удаленных предметов не менялось в зависимости от условий, слуховые: Ж 1 (4, 216) = 1,973, p = 0,10, зрительные:
7
8
8 (4, 216) = 1,132, p = 0,342. Аудиальное задание
Эффекты орфографического и фонологического сходства
Для A’ в слуховой модальности мы обнаружили основной эффект фонологического сходства участников, так что высокое фонологическое сходство привело к более высокому обнаружению сигнала (M = 0,86, SD = 0,07 ), чем низкое сходство (M = 0,84, SD = 0,09), F 1 (1, 54) = 18,349, P <0,001, η P 2 = 0,254; По сложности этот фонологический эффект не был значимым, F 2 (1, 196) = 0,478, P = 0,490, η P 2 4444444444,0,002.
Таблица 2 Средние значения по субъектам и стандартные отклонения. Был также основной эффект орфографического сходства участников, так что высокое орфографическое сходство приводило к более низкому обнаружению сигнала (M = 0,85, SD = 0,08), чем низкое сходство (M = 0,86, SD = 0,08), F 1 (1, 54) = 6,211, P = 0,016, η P 2 = 0,103 (No Effect по элементу, F = 0,103 (No Effect, Eitmer, F = 0,103 (NO. (1, 196) = 1,273, p = 0,261, η p 2 0= 06). Наконец, между двумя факторами не было взаимодействия, F 1 (1, 54) = 0,838, p = 0,364, η P 2 = 0,015, F 2 (1, 196) = 0,518, P = 0,472, η 97777777777797777797777797779777977797797779779779779777977977977977977979779779779779779779779779797979797977977979797979797979779н. = 0,003. См. Таблицу 2 и Рис. 2 для статистики по субъектам.Полноразмерная таблица
Рисунок 2Результаты задачи лексического решения в аудиальной модальности. ( а ) Время отклика в миллисекундах и ( b ) A’ по фонологическому (группы полос) и орфографическому (цвет полос) сходству для слухового задания. Столбики погрешностей соответствуют 95% доверительным интервалам.
Полноразмерное изображение
Для времени отклика в слуховой модальности мы не обнаружили основного эффекта фонологического сходства, F 1 (1, 54) = 1,707, P = 0,197, η , P = 0,197, η , P = 0,197, η . р 2 = 0,031, F 2 (1, 296) = 0,721, P = 0,396, η P 2 = 0,002.
Был основной эффект орфографического сходства, так что высокое орфографическое сходство приводило к более длительному времени реакции (M = 445,84, SD = 102,99), чем низкое сходство (M = 428,83, SD = 98,29), F 1 ( 1, 54) = 12,078, p < 0,001, η p 2 = 0,183 (незначительно значимый по стимулу, F 2 (1, 196) = 2,840, P = 0,094, η P 7 P 7 2 P 77
2 . . Наконец, между двумя факторами не было взаимодействия, F 1 (1, 54) = 1,360, P = 0,249, η P 24444444444444444 гг. Ф
2 (1, 196) = 0,558, p = 0,456, η p 2 0= 3. См. Таблицу 2 и Рис. 2 для статистики по субъектам.Идентичные элементы орфографии (орфографически идентичные слова)
Для А’ в слуховой модальности мы не обнаружили эффектов орфографического сходства при потемном анализе, р = 0,483, η р 2 = 0,013, NOR в анализе BY-EITEM, F 2 (2, 147) = 0,037, P = 0,963, η P 77777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777777779679679679679679679н.
< 0,001.In the response time analysis, we found an effect of orthographic similarity, F 1 (2, 108) = 25.801, p < 0.001, η p 2 = 0,323, F 2 (2, 147) = 5,6730, P = 0,004, η P 2 = 0,072. В апостериорных тестах по предметам мы обнаружили, что идентичные элементы (M = 480,01, SD = 104,12) реагировали медленнее, чем оба с высоким сходством (M = 439,32, SD = 104,00), t (54) = 5,865 , p < 0,001, коэффициент Коэна D = 0,791 и элементы с низким сходством (M = 427,89, SD = 94,80), t (54) = 6,102, p < 0,001, Коэн D = 0,823, но элементы высокого и низкого сходства не различались, t (54) = 1,563, p = 0,371, Коэн D = 0,211. См. Таблицу 2 и Рис. 3 для средних значений и стандартных отклонений по субъектам. Точно так же, что касается поэлементного анализа, в апостериорных тестах мы заметили, что одинаковые элементы (M = 506,62, SD = 93,68) реагировали медленнее, чем оба высоких (M = 458,89, SD = 103,37), t (54) = 2,507, p = 0,040, D Коэна = 0,484 и элементы с низким сходством (M = 445,26, SD = 87,87), T (54) = 3,224, P = 0,005, Cohen’s D = 0,676, но элементы высокого и низкого сходства не отличались, T (54) = -0,716, P = 1, Cohen’s D = 0,142 .
Рисунок 3Влияние орфографического сходства на задачу лексического решения в слуховой модальности. ( a ) Время отклика в миллисекундах и ( b ) A’ по орфографическому сходству (низкое, высокое и идентичное) для слухового задания. Столбики погрешностей соответствуют 95% доверительным интервалам. Н.С.: p > .1; + : p < .1; *: р < .05; **: p < .01, ***: p < .001.
Изображение в натуральную величину
Зрительное задание
Орфографическое и фонологическое сходство.
Для «В визуальном модальности» был основной эффект от орфографического сходства, F 1 (1, 54) = 4,962, P = 0,030, η P 9777777777 P 77777777 P 77777777777 P 77777777 2 = 0,084, так что высокое орфографическое сходство приводило к более высокому обнаружению сигнала (M = 0,94, SD = 0,04), чем низкое сходство (M = 0,93, SD = 0,05).
Рисунок 4 In the by-item analysis, we did not find this orthographic similarity effect, F 2 (1, 196) = 0.434, p = 0.511, η p 2 = 0,002. Мы обнаружили маргинальный основной эффект фонологического сходства в анализе по субъектам, F 1 (1, 54) = 2,982, P = 0,090, η P 2 = 0,052, такой, что высокая фонологическая сходность сходности к приведению к нижнему сигналу (M = 0 = 0,052, такой, что высокая фонологическая сходность сходности к приведению к нижнему сигналу (M = 0,052, такой, что высокая фонологическая сходность к приведению к нижнему сигналу (M = 0,052, такой, что высокая фонологическая сходность к приведению к нижнему сигналу (M = 0,052. 0,93, SD = 0,04), чем низкое сходство (M = 0,94, SD = 0,04) (отсутствие влияния в поэлементном анализе, F 2 (1, 196) 78= 0,072, η p 2 < 0,001). Наконец, не было никакого взаимодействия между двумя факторами, F 1 (1, 54) = 1.896, p = 0.174, η p 2 = 0.034, F 2 (1, 196 ) = 0,143, p = 0,706, η p 2 < 0,001. См. Таблицу 2 и Рис. 4 для статистики по субъектам.Результаты задачи лексического решения в визуальной модальности. ( a ) Время отклика в миллисекундах и ( b ) A’ по фонологическому (группы полос) и орфографическому (цвет полос) сходству для визуальной задачи. Столбики погрешностей соответствуют 95% доверительным интервалам.
Полноразмерное изображение
Для времени отклика В визуальной модальности не было никакого основного эффекта орфографического сходства, F 1 (1, 54) = 2,319, P = 0,134, η , P = 0,134, η , P = 0,134, η , P = 0,134, η , P = 0,134, η , P = 0,134, η , .
p 2 = 0,041, F 2 (1, 196) = 1,033, p = 0,311, η p 2 0= 5. Мы обнаружили основной эффект фонологического сходства в анализе по субъекту, F 1 (1, 54) = 6,889, P = 0,011, η P 2 P 2 P 2 . = 0,113, так что высокое фонологическое сходство приводило к более медленному времени отклика (M = 678,60, SD = 73,97), чем низкое сходство (M = 669,87, SD = 71,47), (отсутствие эффекта при анализе по стимулу, F 2 (1, 196) = 2,484, P = 0,117, η P 2 = 0,012). Также не было взаимодействия между двумя факторами, F 1 (1, 54) = 1,946, P = 0,169, η P 2 4444035, 2 444444035, 2 , 2 . 2 (1, 196) = 0,902, p = 0,343, η p 2 = 0,005. См. Таблицу 2 и Рис. 4 для статистики по субъектам.Идентичные орфографические элементы (орфографически идентичные слова)
Был эффект орфографического сходства на A ‘, F 1 (2, 95,304) = 32,325, P <0,001, η 97959595959595959595959599595995995995995995995995995995995995995995995995995995995995929н. p 2 = 0,374, F 2 (2, 147) = 6,204, p = 0,003, η p 2 = 0,078. В апостериорных тестах мы обнаружили, что идентичные элементы имели более высокое обнаружение сигнала (M = 0,96, SD = 0,03), чем оба элемента с высоким сходством (M = 0,94, SD = 0,04), t (54) = 6,535, p < 0,001, Коэн D = 0,881 и элементы с низким сходством (M = 0,93, SD = 05), t (54) = 6,699, p 3,09’0s= 0,000, Элементы с высоким сходством также имели более высокое обнаружение сигнала, чем элементы с низким сходством, t (54) = 2,274, p = 0,081, коэффициент Коэна D = 0,307 — см.
Рисунок 5 Таблицу 2 и Рис. 5 для статистики по субъектам.Влияние орфографического сходства на задачу лексического решения в визуальной модальности. ( a ) Время отклика в миллисекундах и ( b ) A’ по орфографическому сходству (низкое, высокое и идентичное) для визуальной задачи. Столбики погрешностей соответствуют 95% доверительным интервалам. N.s.: p > .1; + : p < .1; *: р < .05; **: p < .01, ***: p < .001.
Полноразмерное изображение
Мы обнаружили влияние орфографического сходства на время отклика, F 1 (2, 108) = 75,689, P <0,001, η P
77777777777777777777777777777777777008 P
7777777777777777777777777 P
77777777777777777779000 . 2 = 0,584, F 2 (2, 147) = 25,164, P <0,001, η P η P 2 = 0,255.
В апостериорных тестах мы обнаружили, что идентичные предметы распознавались быстрее (M = 626,78, SD = 70,26), чем оба высоких (M = 673,83, SD = 74,23), t (54) = 10,430, p 0,0001 , коэффициент Коэна D = 1,406 и элементы с низким сходством (M = 683,38, SD = 77,88), t (54) = 10,426, p < 0,001, элементы с низким сходством не отличались, t (54) = 1,994, p = 0,154, коэффициент Коэна D = 0,269 — см. Таблицу 2 и Рис. 5 для статистики по субъектам.Обсуждение
Настоящее исследование преследовало три цели: оценить эффекты фонологического сходства в слуховой модальности, оценить эффекты фонологического и орфографического сходства и их взаимодействие между модальностями и оценить, являются ли орфографически идентичные слова особым случаем. в пределах спектра орфографического сходства. Мы попросили участников выполнить две задачи на лексическое решение — одну в визуальной, а другую в слуховой модальности — в своем L2, в уравновешенном порядке.
Мы обнаружили, что фонологическое сходство вызывает облегчение в слуховой модальности, как орфографическое сходство в визуальной модальности. Мы также обнаружили, что эффекты орфографического и фонологического сходства вызывают тормозящие эффекты в разных модальностях, то есть фонологическое сходство вызывает торможение в визуальной модальности, а орфографическое сходство — в слуховой модальности. Следует отметить, что эти эффекты могут быть квалифицированы тройным взаимодействием, обнаруженным в LME (приведенным в дополнительных материалах для обеспечения более полной картины данных, с одновременным контролем случайных эффектов по участникам и по предметам). В этих анализах мы обнаружили взаимодействие между модальностью, орфографическим сходством и фонологическим сходством. Это взаимодействие предполагало, что в визуальной модальности фонологическое сходство ухудшало производительность (более низкая точность и более медленное время отклика), но орфографическое сходство не имело никакого эффекта, в то время как в слуховой модальности было такое взаимодействие, что орфографическое сходство ухудшало производительность (снижение точности и увеличение времени отклика).
время отклика) в условиях низкого фонологического сходства, но не повлияло на условие высокого сходства. Принимая во внимание оба анализа, возможно, что эффекты орфографии и фонологии не совсем симметричны между модальностями. Наконец, мы обнаружили, что орфографически идентичные слова на самом деле имеют особый статус, проявляя непропорционально большие эффекты в обеих модальностях — облегчающей в случае визуальной модальности и тормозящей в случае слуховой модальности.В визуальной модальности мы обнаружили эффект облегчения орфографического сходства для A’, но не для времени отклика. Этот результат частично согласуется с предыдущими исследованиями, описывающими родственный эффект облегчения 2,3,4,5,6,7,8,9,40 , обнаруженный в различных областях. Например, некоторые нашли его по времени отклика только 2,8,9 , другие по точности только 7 , и, наконец, третьи по времени отклика и точности 3,5,6 . Важно отметить, что мы обнаружили, что фонологическое сходство имело несколько парадоксальный эффект, при котором более высокое фонологическое сходство мешало производительности в визуальной модальности (как во времени отклика, так и незначительно в A’).
Эти результаты уже наблюдались ранее в исследовании Dijkstra et al. 5 , в котором они обнаружили, что фонологическое сходство препятствует работе в визуальной модальности. Наши результаты выходят за рамки этого и показывают те же тормозящие эффекты для орфографического сходства в слуховой модальности (см. ниже дальнейшее обсуждение эффектов орфографического сходства в слуховой модальности).Следует отметить, что не все эффекты, которые были значимы в обоих анализах, были значимыми побочными элементами. Вероятно, на это повлиял тот факт, что мы были недостаточно сильны в анализе по пунктам (который был между пунктами и имел только 50 пунктов в каждой категории). Тем не менее, результаты нашей модели линейных смешанных эффектов, которые учитывали случайные эффекты отдельных элементов, соответствовали результатам анализа отдельных участников.
Наши результаты предоставляют дополнительные доказательства кросс-модальной природы языка, а также предполагают, что влияние L1 во время обработки L2 не ограничивается модальностью, относящейся к задаче.
Во-первых, мы показываем, что фонологическое сходство влияет на визуальное распознавание слов и наоборот (см. ниже), показывая, что нецелевой язык влияет на обработку целевого языка не только внутри, но и между модальностями. Кроме того, хотя интуитивно можно подумать, что фонологическое сходство должно улучшить производительность независимо от модальности, глядя на особенности языков, которые мы тестировали, это не так просто. В случае непрозрачного языка, такого как английский, кросс-модальное влияние прозрачного языка с другой фонологией, такого как испанский, будет мешать производительности. В этих двух языках фонологические и орфографические соответствия сильно различаются, что, естественно, внесет путаницу и распространит активацию на другие слова, кроме целевого, вместо того, чтобы помочь участнику отточить правильный ответ.В слуховой модальности мы обнаружили, что фонологическое сходство влияет на обнаружение сигнала (A’), но не на время отклика, при этом элементы с высоким сходством распознаются лучше, чем с низким сходством.
Это согласуется с представлением о том, что сходство между L1 и L2 помогает обработке текстов, но что касается слуховой модальности, это было показано только в производственных задачах 8,19 . Наши результаты по слуховой модальности совпадают с результатами Садата и его коллег 19 , которые обнаружили, что фонологическое сходство облегчает производство слов у билингвов. Наше исследование распространяет эти результаты на восприятие и совмещает эффекты с эффектами орфографического сходства. Мы обнаружили, что орфографическое сходство препятствует обработке в слуховой модальности, при этом элементы с высоким сходством распознаются медленнее и менее точно, чем с низким сходством, хотя, опять же, в точности мы обнаружили возможное взаимодействие между типами сходства в слуховом состоянии. Эти результаты аналогичны результатам, упомянутым ранее Dijkstra et al. 5 , которые показали, что фонологическое сходство препятствует визуальной обработке. Хотя аналогичный ингибирующий эффект был обнаружен для продукции у участников с низким уровнем владения 18 , этот эффект не был описан ни в восприятии, ни у высоко владеющих билингвами. Это также контрастирует с традиционным родственным эффектом, когда орфографически похожие элементы имеют преимущество в обработке по сравнению с разнородными. Возможно, этот контраст с литературой отражает объединенное определение сходства, включающее как фонологическое, так и орфографическое сходство. Более конкретно, использование стимулов, которые совпадают в обеих областях, может указывать на облегчающий эффект орфографии в слуховой модальности, который на самом деле мог быть вызван фонологией. В более общем плане наши результаты указывают на разделение между орфографическими и фонологическими представлениями слов, на которые полагаются по-разному в соответствии со схемой задачи. Подтверждая предыдущие исследования, сходство между языками способствует обработке в рамках одной и той же модальности и показывает, что оба языка активны даже в одноязычных задачах 10 .Орфографически идентичные слова продемонстрировали эффекты, превышающие эффекты слов с высоким сходством.
Другими словами, хотя увеличение сходства между высоким орфографическим сходством и идентичными элементами часто было минимальным — например, «группа» (испанский: «банда») не тождественно, а «такси» (испанский: «такси») — эффект сходства было непропорционально больше для орфографически идентичных слов. В случае облегчения визуальной модальности (как для A’, так и для времени ответа) этот результат согласуется с предыдущими выводами, которые показали больший эффект облегчения для орфографически идентичных слов по сравнению с элементами с высоким сходством 9.1677 8,10,13 . Текущее исследование распространяет эти результаты на слуховую модальность, в которой мы обнаружили непропорциональный уровень торможения орфографически идентичными словами, замедление времени отклика по сравнению с элементами с высоким сходством, которые не отличались от элементов с низким сходством. Важно отметить, что это предполагает нелинейную связь, которая помещает идентичные элементы в специальную категорию. С другой стороны, наши орфографические и фонологические результаты контрастируют с результатами Шварца и его коллег 8 , которые обнаружили взаимодействие между орфографическим и фонологическим сходством. Но, что важно, они смешали идентичные элементы и элементы с высоким орфографическим сходством и обнаружили, что слова с очень высоким сходством (включая идентичные элементы) производились быстрее, чем элементы с высоким орфографическим сходством, но это фонологическое несходство снижало производительность. Хотя Шварц и его коллеги наблюдали облегчение в этой производственной задаче, другие обнаружили торможение для родственных в производственной задаче, в зависимости от сложности задачи 9.1677 41 . Следовательно, этот контраст с нашими результатами может быть связан с различиями в задаче (производство по сравнению с восприятием) или может быть связан со сложностью задачи. Это согласуется с предыдущими одноязычными исследованиями, показывающими как облегчающие, так и тормозящие эффекты семантического сходства 42,43 , фонологического сходства 44 и плотности фонологического соседства 45 в зависимости от различных факторов. Это различие также предполагает, что, возможно, на орфографически идентичные слова из-за их «особого статуса» влияет фонологическое сходство иначе, чем на элементы, которые имеют сильное орфографическое сходство в разных языках.Также важно отметить, что в нашем исследовании есть несколько уникальных аспектов, которые могли повлиять на обнаруженные нами эффекты. Во-первых, целевой язык был непрозрачен, но родной язык участников был прозрачен. Когда участник услышал строку, он построил прогнозируемое орфографическое представление на основе подлексических фонологических единиц («транскрипцию»), которое нужно было сравнить с лексическим представлением. В прозрачных языках, таких как испанский или итальянский, это довольно простой процесс, в основном с однозначными соответствиями между фонемами и графемами. С другой стороны, в английском языке этот процесс более сложен, особенно для участников с прозрачным Я1, которые привыкли полагаться в основном на взаимно-однозначные отношения между фонемами и графемами.
Если бы прозрачный целевой язык использовался в качестве целевого языка в подобном эксперименте, могло бы произойти одно из двух: если соответствия графемы/фонемы совпадают между языками, это должно привести к облегчающим, а не тормозящим эффектам в разных модальностях; если они не совпадают, это все равно может привести к путанице и задержкам в обработке. Еще одним интересным продолжением будет тестирование участников с непрозрачным L1. Их может вообще не беспокоить несовпадение, и они могут не демонстрировать влияния орфографического сходства на слуховую модальность и наоборот.Другая проблема связана с акцентом, так как звуковые элементы были записаны с акцентом носителей языка, который участники не привыкли слышать (испанцы больше привыкли слушать английский язык с испанским акцентом, чем английский язык, произносимый носителями языка). Акцент, используемый в стимулах настоящего исследования, является родным акцентом, то, что они слышали, вероятно, не соответствовало тому, что они привыкли слышать, и тому, как они произносили это слово.
У носителей испанского языка, вероятно, были представления английских слов, построенные путем прослушивания большинства не носителей языка из их страны и под влиянием фонологии их L1. Неясно, были бы результаты такими же, если бы стимулы были произведены с иностранным акцентом, соответствующим их L1. Будущие исследования должны проверить относительное влияние этого фактора.Насколько нам известно, это первый эксперимент по ортогональному манипулированию орфографическим и фонологическим сходством между модальностями, чтобы проверить влияние межъязыкового сходства на восприятие в слуховой модальности и показать, что орфографическое сходство мешает слуховой работе и наоборот. Наши результаты согласуются с отчетом о совместной активации, часто упоминаемым в литературе, показывающим эффекты языка без присмотра в обеих модальностях с обеими мерами межъязыкового сходства (орфографическим и фонологическим). Главный вопрос, который остается, заключается в том, почему внутри модальности есть облегчение — фонологическое в слуховой модальности и орфографическое в визуальной — но торможение в разных модальностях — орфографическая в слуховой и фонологическая в визуальной.
В соответствии с моделями BIA и BIA + последействие языковой коактивации происходит, когда орфография, фонология и семантические характеристики в языках схожи 10 . Эти модели предполагают, что оба языка билингва активируются параллельно, когда они выполняют одноязычную задачу. Как следствие, любое сходство между словами в обоих языках должно способствовать распознаванию слов, поскольку совместная активация языка должна помочь этому процессу, что не полностью согласуется с нашими выводами. Стоит отметить, что эти модели не учитывают различий между модальностями и, таким образом, предполагают одинаковые эффекты. В нашем эксперименте мы обнаружили, что эффект сходства зависел от модальности представления и от того, соответствовал ли тип сходства поставленной задаче, т. е. орфографическое с визуальным и фонологическое со слуховым. На теоретическом уровне наши результаты показывают, что модели двуязычной обработки, такие как модель BIA + , должны рассматривать обработку в слуховой модальности, а также проводить различие между орфографией и фонологией.
Другими словами, они должны учитывать модальность и кросс-модальные взаимодействия: модели должны учитывать тот факт, что репрезентации на другом языке активируются не только в модальности задачи, но также и в нерелевантной модальности, и что облегчающие/ тормозные взаимодействия происходят через модальности. В то же время прозрачная или непрозрачная природа каждого языка может также иметь значение для понимания влияния одного языка на другой: чтобы понять двуязычную обработку текстов, нам необходимо включить характеристики языков — как независимо, так и в отношении друг к другу. друг к другу — к нашим моделям.Кроме того, аналогичный ингибирующий эффект был приписан усиленной конкуренции между словами в целевом и нецелевом языках 18 , что также объясняет наши результаты, особенно в случае орфографически идентичных слов с разной фонологией. Это делает взаимосвязь между языками и особенности каждого языка важными факторами при изучении их коактивации. В частности, эффекты орфографического и фонологического сходства могут различаться в зависимости от того, имеют ли языки общие соответствия графем фонем или они фонетически похожи.
Как мы упоминали ранее, учитывая, что в других исследованиях фонологическое и орфографическое сходство не ортогонально манипулировали, трудно сравнивать результаты, поскольку в предыдущих исследованиях эффекты орфографии могли быть замаскированы эффектами фонологии, или наоборот.Что касается методологии, это исследование показывает, что при тестировании билингвов нам необходимо количественно определять и контролировать сходство слов в кажущейся нерелевантной модальности. Тормозящие эффекты разных модальностей подчеркивают важность учета того, как соотносятся фонологические и орфографические коды каждого из языков билингва при их тестировании. Недостаточно просто сказать, что слово «похоже по форме» на свой переводной эквивалент, как часто определяют однокоренные слова. Необходимо определить, какие аспекты формы — будь то фонологические или орфографические — схожи, а также согласуется ли это с модальностью представления.
В заключение, результаты этого исследования предполагают интерференцию между репрезентациями лексических единиц в различных модальностях у билингвов.
Кроме того, это исследование прокладывает путь для дальнейших исследований диссоциации между орфографическими и фонологическими представлениями и соответствующих эффектов орфографического и фонологического сходства внутри модальностей и между ними. Понимание того, как различные представления слова взаимодействуют между языками, важно для нашего понимания того, как двуязычный разум приспосабливает два полных языка с их соответствующими орфографическими и фонологическими кодами.Ссылки
Грожан, Ф. Двуязычный как компетентный, но специфический говорящий-слушатель. Дж. Мультилинг. Мультикульт. Дев. 6 , 2 (1985).
Артикул Google ученый
Карамазца А. и Бронс И. Лексический доступ у билингвов. Бык. Психон. соц. https://doi.org/10.3758/BF03335062 (1979).
Артикул Google ученый
де Гроот, А.М.Б. и Нас, Г.Л.Дж. Лексическое представление родственных и неродственных слов в сложных двуязычных языках. Дж. Мем. Ланг. 30 , 90–123 (1991).
Артикул Google ученый
Дейкстра, Т., Грейнджер, Дж. и Ван Хеувен, В. Дж. Б. Распознавание родственных и межъязыковых омографов: пренебрегаемая роль фонологии. Дж. Мем. Ланг. https://doi.org/10.1006/jmla.1999.2654 (1999).
Артикул Google ученый
Дейкстра, Т., Ван Яарсвельд, Х. и Бринке, С. Т. Распознавание межъязыковых омографов: влияние требований к задачам и языкового смешения.
Билинг. Ланг. Познан. https://doi.org/10.1017/s1366728998000121 (1998).Артикул Google ученый
Санчес-Касас, Р. М., Дэвис, К. В. и Гарсия-Албеа, Дж. Э. Двуязычная лексическая обработка: изучение различий родственных и неродственных. евро. Дж. Когн. Психол. 4 , 293–310 (1992).
Артикул Google ученый
Шварц А.И., Кролл Дж.Ф. и Диас М. Чтение слов на испанском и английском языках: сопоставление орфографии с фонологией на двух языках. Ланг. Познан. Процесс. 22 , 106–129 (2007).
Артикул Google ученый
Voga, M. & Grainger, J. Cognate status и подготовка к переводу кросс-сценариев. Мем. Когнит. 35 , 938–952 (2007).
Артикул Google ученый
Poort, E.D. & Rodd, J.M. Эффект родственного облегчения в двуязычном лексическом решении зависит от состава списка стимулов. Acta Psychol. (Амст) 180 , 52–63 (2017).
Артикул Google ученый
Ван Аше, Э., Дриге, Д., Дайк, В., Велварт, М. и Хартсуикер, Р. Дж. Влияние семантических ограничений на распознавание двуязычных слов во время чтения предложений. Дж. Мем. Ланг. 64 , 2 (2011).
Google ученый
Дайк, В., Ван Аш, Э., Дриге, Д. и Харцуикер, Р. Дж. Визуальное распознавание слов билингвами в контексте предложения: свидетельство неселективного лексического доступа.
Дж. Эксп. Психол. Учиться. Мем. Познан. https://doi.org/10.1037/0278-7393.33.4.663 (2007 г.).Артикул пабмед Google ученый
van Orden, G.C. РЯДЫ — это РОЗА: правописание, звук и чтение. Мем. Когнит. 15 , 2 (1987).
Google ученый
Van Assche, E., Duyck, W. & Hartsuiker, RJ. Двуязычное распознавание слов в контексте предложения. Фронт. Психол. 3 , 1–8 (2012).
Артикул Google ученый
Van Heuven, WJB, Dijkstra, T. & Grainger, J. Эффекты орфографического соседства при распознавании двуязычных слов. Дж. Мем. Ланг. 39 , 2 (1998).
Google ученый
Лемхёфер, К. и др. Влияние родного языка на распознавание слов на втором языке: мегаисследование.
Дж. Эксп. Психол. Учиться. Мем. Познан. https://doi.org/10.1037/0278-7393.34.1.12 (2008 г.).Артикул пабмед Google ученый
Броерсма, М., Картер, Д. и Ачесон, Д. Дж. Затраты на родственные связи при воспроизведении двуязычной речи: данные по переключению языка. Фронт. Психол. 7 , 2 (2016).
Артикул Google ученый
Садат, Дж., Мартин, К.Д., Магнусон, Дж.С., Аларио, Ф.С. и Коста, А. Анализ стоимости двуязычного производства речи. Познан. науч. 40 , 2 (2016).
Артикул Google ученый
Грассо, С. М., Пенья, Э. Д., Бедоре, Л. М., Хиксон, Дж. Г. и Гриффин, З. М. Кросс-лингвистическое родственное производство у испано-английских двуязычных детей с определенными языковыми нарушениями и без них.
J. Язык речи. Слышать. Рез. 2 , 2. https://doi.org/10.1044/2017_JSLHR-L-16-0421 (2018).Артикул Google ученый
Шварц, А. И. и Кролл, Дж. Ф. Двуязычная лексическая активация в контексте предложения. Дж. Мем. Ланг. 55 , 197–212 (2006).
Артикул Google ученый
Schepens, J., Dijkstra, T. & Grootjen, F. Распределение родственников в Европе на основе расстояния Левенштейна. Билингвизм 15 , 2 (2012).
Артикул Google ученый
Вилинг, М., Маргарета, Э. и Нербонн, Дж. Определение степени фонетического сходства на основе вариаций произношения. Дж. Телефон. 40 , 2 (2012).
Артикул Google ученый
Ковингтон, Массачусетс. Алгоритм выравнивания слов для исторического сравнения. Расчет. Лингвист. 22 , 481–496 (1996).
Google ученый
Гилдеа, Д. и Джурафски, Д. Предвзятость обучения и индукция фонологических правил. Вычисл. Лингвист. 22 , 497–530 (1996).
Google ученый
Нербонн, Дж. и Херинга, В. Фонетическое измерение диалектной дистанции. в Третье собрание Специальной группы ACL по компьютерной фонологии (SIGPHON-97). 11–18 (1997).
Somers, H. L. Показатели сходства для сопоставления данных артикуляции детей. в COLING-ACL’98: 36-е ежегодное собрание Ассоциации компьютерной лингвистики и 17-я Международная конференция по компьютерной лингвистике 1227–1232 (1998).
doi: https://doi.org/10.3115/980432.980769.Кондрак Г. Выравнивание фонетических последовательностей . http://www.cs.utoronto.ca/csri/reports.html (1999).
де Брюин, А., Каррейрас, М. и Дуньябеития, Дж. А. ЛУЧШИЙ набор данных о владении языком. Фронт. Психол. 8 , 2 (2017).
Артикул Google ученый
Lemhöfer, K. & Broersma, M. Представляем LexTALE: быстрый и достоверный лексический тест для продвинутых изучающих английский язык. Поведение. Рез. Методы 44 , 325–343 (2012).
Артикул Google ученый
Мариан, В., Бартолотти, Дж., Чабал, С. и Шук, А. Клирпонд: кросс-лингвистический ресурс с легким доступом для фонологической и орфографической плотности соседства. PLoS ONE 7 , 2 (2012).
Артикул Google ученый
Лабов В., Эш С. и Боберг К. Атлас североамериканского английского: фонетика, фонология и изменение звука . (Вальтер де Грюйтер, 2006).
Карнеги-Меллон: словарь произношения CMU.
Команда Audacity. Смелость (R). (2018).
Маковски, Д. Пакет Psycho: эффективный и ориентированный на публикации рабочий процесс для психологических наук. J. Программное обеспечение с открытым исходным кодом. 3 , 470 (2018).
Артикул ОБЪЯВЛЕНИЯ Google ученый
Бланка, М. Дж., Аларкон, Р., Арнау, Дж., Боно, Р. и Бендаян, Р. Нет нормальных данных: ¿es el ANOVA una opción valida?. Псикотема 29 , 552–557 (2017).
ПабМед Google ученый
Команда JASP. JASP (версия 0.9). (2018).
Дюфур, Р. и Кролл, Дж. Ф. Сопоставление слов с понятиями на двух языках: тест модели посредничества понятий двуязычного представления. Мем. Когнит. https://doi.org/10.3758/BF03197219 (1995).
Артикул пабмед Google ученый
Мартин, К. Д. и Нозари, Н. Языковой контроль в двуязычном производстве: информация о частоте ошибок и типах ошибок в построении предложений. Билингвизм https://doi.org/10.1017/S13667280590 (2020).
Артикул Google ученый
Рабовский, М., Шад, Д. Дж. и Абдель Рахман, Р. Речевому производству способствует семантическое богатство, но препятствует семантическая плотность: свидетельство именования изображений. Познание 146 , 240–244 (2016).
Артикул Google ученый
Нозари, Н., Фройнд, М., Брейнинг, Б., Рапп, Б. и Гордон, Б. Когнитивный контроль во время выбора и исправления в производстве слов. Ланг. Познан. Неврологи. 31 , 886–903 (2016).
Артикул Google ученый
«>
Кристоффанини, П., Кирснер, К. и Милех, Д. Двуязычное лексическое представление: статус испано-английских родственных слов. QJ Exp. Психол. Разд. А 38 , 367–393 (1986).
Артикул Google ученый
«>
Дейкстра, Т. и ван Хеувен, В. Дж. Б. Архитектура двуязычной системы распознавания слов: от идентификации к решению. Билинг. Ланг. Познан. 5 , 175–197 (2002).
Артикул Google ученый
«>
Кондрак Г. Новый алгоритм выравнивания фонетических последовательностей. Проц. Первая встреча. Север Ам. Глава доц. вычисл. Лингвист. 288–295 (2000).
«>
Шмидер, Э., Циглер, М., Данай, Э., Бейер, Л. и Бюнер, М. Действительно ли это надежно?: повторное исследование устойчивости дисперсионного анализа к нарушениям предположения о нормальном распределении. Методология 6 , 147–151 (2010).
Артикул Google ученый
«>
Блум, И., ван ден Бугаард, С. и Ла Хейдж, В. Семантическое облегчение и семантическая интерференция в языковом производстве: еще одно доказательство концептуальной модели выбора лексического доступа. Дж. Мем. Ланг. 51 , 307–323 (2004).
Артикул Google ученый
«>
Буз, Э. и Джагер, Т. Ф. (Не)зависимость артикуляции и лексического планирования во время изолированного производства слов. Ланг. Познан. Неврологи. 31 , 404–424 (2016).
Артикул Google ученый
Скачать ссылки
Что такое лексический набор?
`;
А. ЛеверкунЛексический набор – это группа слов. Многие определения этого лингвистического понятия определяют группы слов, которые имеют одну и ту же тему, имеют одинаковую конструкцию или функционируют одинаково.
Различные виды лексических наборов полезны для различных лингвистических задач или в разговорных или языковых моделях, применяемых к таким технологиям, как искусственный интеллект.Одним из способов анализа лексического набора является понимание частей речи в языке. Лексический набор может быть достаточно широким, чтобы включать все элементы определенного класса, например, существительные, глаголы или прилагательные. Другие лексические наборы могут включать более узкие категории частей речи. Например, конкретный лексический набор, используемый в образовательных проектах, может включать только фразовые глаголы, вспомогательные или вспомогательные глаголы или другие виды специальных глагольных конструкций.
Как ограниченный набор слов, лексический набор может быть полезен в определенных видах обучающих игр или других языковых действий. Другое применение лексических наборов — это научное наблюдение за тем, как люди используют язык. Факультеты лингвистики верхнего уровня или компьютерных наук могут использовать лексические наборы как часть анализа использования языка, для завершения лингвистических исследований или для построения компьютерных моделей языка. Лексический набор также применим к изучению фонологии или фонетических систем.
Семантика фреймов — это область, в которой лексические наборы особенно полезны.
В этом конкретном типе семантического исследования ученые исходят из теории, что одно слово бесполезно без большей категории слов. В такого рода научном процессе лексический набор является важной частью установления того, какие наборы слов дополняют друг друга с точки зрения значения.Лингвисты также получают пользу от сравнения и противопоставления лексических наборов. Например, лингвист мог бы рассмотреть два разных лексических набора, представляющих ассоциации слов. Они могут использовать эти модели для сравнения того, как говорящие или писатели связывают два разных набора отдельных слов, чтобы сформировать уникальные передаваемые понятия, или как конечные результаты каждого набора воспринимаются слушателем или читателем.
- Сегменты, которые не чередуются, могут (обычно) считаться фонематически идентичными в их основном представлении их поверхностному представлению. (Это предполагает, как уже отмечалось, что фонематический анализ уже выполнен, поэтому любые позиционные аллофоны уже будут появляться в своей основной форме.