ГДЗ по русскому языку 3 класс учебник Канакина, Горецкий 1 часть – стр 122
- Тип: ГДЗ, Решебник.
- Автор: Канакина В. П., Горецкий В. Г.
- Год: 2019.
- Издательство: Просвещение.
Подготовили готовое домашнее задание к упражнениям на 6 странице по предмету русский язык за 3 класс. Ответы на вопросы к заданиям 234, 235 и 236.
Учебник 1 часть – Страница 122.
Ответы 2022 года.
Номер 234.
Прочитайте.
Аппетит, троллейбус, грамматика, теннис, суббота, бассейн, терраса, дрожжи, коллектив, хоккей, колледж, кроссворд, пассажир, кросс, антенна, коллекция.
- Объясните лексическое значение каждого слова.
Ответ:
Аппетит — желание есть.
Троллейбус — безрельсовое механическое транспортное средство.
Грамматика — раздел науки о языке, изучающий правила строения слов, предложений, словосочетаний.
Теннис — большая игра с ракетками и мячами.
Суббота — шестой день недели.
Бассейн — плавательная ванна, сооружение для плавания.
Терраса — открытый настил на основании с опорами.
Дрожжи — грибы, используемые в кулинарии.
Коллектив — группа лиц, объединенных общей деятельностью.
Хоккей — игра на ледовой арене.
Колледж — образовательное заведение.
Кроссворд — головоломка с буквенно-клеточными заданиями.
Пассажир — участник дорожного движения, пользователь транспорта.
Кросс — бег по пересеченной местности.
Антенна — устройство для принятия сигнала.
Коллекция — собрание чего-либо.
- Запишите слова в алфавитном порядке. Подчеркните в них удвоенные согласные.
Ответ:
Антенна
Аппетит
Бассейн
Грамматика
Дрожжи
Колледж
Коллектив
Кросс
Кроссворд
Пассажир
Суббота
Теннис
Терраса
Троллейбус
Хоккей
- Образуйте от выделенных слов однокоренные слова — названия лиц, которые занимаются этим видом спорта.

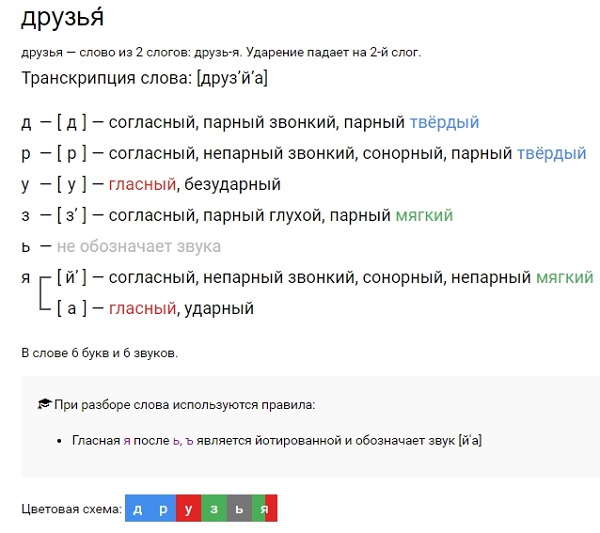
Ответ:
Теннис — теннисист
Хоккей — хоккеист
Номер 235.
Прочитайте.
Машина — машинный, луна, камень, длина, сон, окно, лимон, конь, осень.
- Образуйте от каждого слова однокоренное имя прилагательное при помощи суффикса -н-. Запишите пары слов.
Ответ:
Машина — машинный, луна — лунный, камень — каменный, длина — длинный, сон — сонный, окно — оконный, лимон — лимонный, конь — конный, осень — осенний.
- Почему в именах прилагательных пишутся две буквы н?
Ответ:
В прилагательных пишутся две буквы н, потому что одна буква н в корне, а вторая н — это суффикс.
- Дайте совет однокласснику, как перенести слова с удвоенными согласными с одной строки на другую.
Ответ:
Чтобы перенести слова с удвоенными согласными с одной строки на другую, нужно разбить слово так, чтобы часть с одной буквой н осталась на одной строке, а часть с другой н была на другой строке.
Фонетический разбор
Окно [акно´] — 2 слога.
о — [а] — гласн., безуд.
к — [к] — согл., глух. парн., тв. парн.
н — [н] — согл., зв. непарн., тв. парн.
о — [о´] — гласн., ударн.
4 буквы, 4 звука.
Номер 236.
Задание в вашем учебнике может отличаться!
2021Старое издание
Прочитайте.
Беззвёздный, перрон, картинный, ванна, матросский, ввозить, шоссе, аккуратный, суффикс, рассказать, коллектив, осинник, ссора.
- Спишите. Подчеркните в словах удвоенные согласные.
Ответ:
Беззвёздный, перрон, картинный, ванна, матросский, ввозить, шоссе, аккуратный, суффикс, рассказать, коллектив, осинник, ссора.
- Назовите слова c удвоенными согласными:
а) в корне;
б) на стыке приставки и корня;
в) на стыке корня и суффикса.

Ответ:
а) Перрон, ванна, шоссе, аккуратный, суффикс, коллектив, ссора.
в) Картинный, матросский, осинник.
- Подберите синоним к выделенному слову.
Ответ:
Аккуратный — опрятный, чистоплотный.
Разбор слова
Беззвёздный — прил., картинный — прил.
Прочитайте.
Беззвёздный, перрон, картинный, ванна, матросский, ввозить, шоссе, аккуратный, суффикс, рассказать, коллектив, осинник, ссора.
- Спишите слова в алфавитном порядке. Подчеркните в словах удвоенные согласные.
Ответ:
А ккуратный, беззвёздный, ванна, ввозить, картинный, коллектив, матросский, осинник, перрон, рассказать, ссора, суффикс, шоссе. p>
- Назовите слова c удвоенными согласными:
а) в корне;
б) на стыке приставки и корня;
в) на стыке корня и суффикса.

Ответ:
а) Перрон, ванна, шоссе, аккуратный, суффикс, коллектив, ссора.
б) Беззвездный, ввозить, рассказать.
в) Картинный, матросский, осинник.
- Подберите синоним к выделенному слову.
Ответ:
Аккуратный — опрятный, чистоплотный.
Разбор слова
Беззвёздный — прил., картинный — прил.
фонетических вложений слов | DeepAI
1 Введение
ВложенияWord стали незаменимым элементом любого конвейера обработки естественного языка (NLP). Этот метод преобразует написанные слова в подпространство более высокого измерения, обычно на основе семантики, предоставляя алгоритмам преимущества векторных пространств, такие как сложение и проецирование при работе со словами. В настоящее время они используются для различных задач, таких как системы ответов на вопросы
(Zhou et al. , 2015)
, 2015)
, анализ настроений
(Giatsoglou et al., 2017) , распознавание речи (Bengio and Heigold, 2014) и многие другие. Эти пространства вложений обычно изучаются на основе значения слова, как подчеркнуто в основополагающей работе word2vec (Миколов и др., 2013) .
В этой работе мы исследовали параллельную идеологию изучения пространств встраивания слов, основанную на фонетической подписи слов. Эта методология помещает два слова в пространство для встраивания ближе, если они звучат одинаково. Такое вложение находит применение в различных задачах, таких как обнаружение ключевых слов (Sacchi et al., 2019) и поколение поэзии (Parrish, 2017) . В (Parrish, 2017) автор четко определяет понятие фонетического сходства:
Аллитерация, ассонанс, созвучие и рифма — все это фигуры речи, используемые в художественном письме для создания звуковых паттернов, либо для привлечения внимания, либо для вызова синтетических ассоциаций.
 Все эти рисунки, по сути, представляют собой методы введения фонетического сходства в текст, независимо от того, является ли это сходство локальным для одного слова или распределено по более крупным участкам текста.
Все эти рисунки, по сути, представляют собой методы введения фонетического сходства в текст, независимо от того, является ли это сходство локальным для одного слова или распределено по более крупным участкам текста. (Пэрриш, 2017) представляет стратегию использования биграмм фонетических признаков для вычисления векторного представления слова. Это объединяет представление о том, что фонемы можно отличить друг от друга с помощью ограниченного набора свойств (Теория отличительных признаков 
Вклад этой статьи заключается в следующем: (i) алгоритм сходства между двумя фонемами, основанный на четко определенных фонетических характеристиках; (ii) подход на основе расстояния редактирования Wagner and Fischer (1974) для вычисления акустического сходства между двумя словами; (iii) новый недиагональный штраф за совпадение фонетической последовательности двух слов; (iv) новый коэффициент взвешивания телефона в конце слова, который фиксирует способность людей воспринимать звуковое сходство; и (v) результаты представлены на двух языках: английском и хинди. Результаты для английского языка уверенно превосходят предыдущие лучшие результаты, и это первый случай, когда такие результаты сообщаются для хинди, насколько нам известно.
Остальная часть статьи организована следующим образом: мы представляем обзор литературы в разделе 2, в разделе 3 подробно обсуждается предлагаемый подход, проведенные эксперименты и результаты обсуждаются в разделе 4, и, наконец, работа завершается в разделе 5.
Исходный код предлагаемого метода наряду с экспериментами опубликован в открытом доступе и доступен по адресу https://github.com/rahulsrma26/phonetic-word-embedding
2 Связанная работа
В литературе имеется множество работ, в которых используются методы фонетического сходства для различных последующих задач, таких как изучение языковых сходств, диахроническое языковое изменение, сравнение фонетического сходства с перцептивным сходством и т.д. Это разнообразное использование служит для нас сильной мотивацией для разработки более точного и надежного алгоритма встраивания слов на основе фонетического сходства.
(Bradlow et al., 2010) исследует методы представления языков в пространстве перцептивного сходства на основе их общего фонетического сходства. Он направлен на использование этого фонетического и фонологического сходства любых двух языков для изучения моделей межъязыкового и второго языка восприятия и производства речи. Важно отметить, что их внимание сосредоточено не на словах в языке, а на использовании пространства подобия для изучения отношений между языками. (Мильке, 2012) рассказывает о количественной оценке фонетического сходства и о том, чем фонологические понятия сходства отличаются от артикуляционного, акустического и перцептивного сходства. Предложенная метрика, основанная на фонетических признаках, сравнивалась с показателями фонологического сходства, рассчитываемыми путем подсчета совпадений пар звуков в одних и тех же фонологически активных классах. В экспериментах, проведенных (Vitz and Winkler, 1973) , небольшие группы носителей американского английского языка L1 попросили оценить фонетическое сходство «стандартного» слова со списком слов сравнения по шкале от 0 (нет сходства) до 4 (очень похоже). Было проведено несколько экспериментов с разными стандартными словами и словами сравнения. Витц и Винклер сравнили полученные оценки с результатами собственной процедуры определения фонетического сходства (называемой «прогнозируемой фонематической дистанцией», сокращенно здесь PPD). (Parrish, 2017) предлагает новый метод использования биграмм фонетических признаков для вычисления векторного представления слова.
(Мильке, 2012) рассказывает о количественной оценке фонетического сходства и о том, чем фонологические понятия сходства отличаются от артикуляционного, акустического и перцептивного сходства. Предложенная метрика, основанная на фонетических признаках, сравнивалась с показателями фонологического сходства, рассчитываемыми путем подсчета совпадений пар звуков в одних и тех же фонологически активных классах. В экспериментах, проведенных (Vitz and Winkler, 1973) , небольшие группы носителей американского английского языка L1 попросили оценить фонетическое сходство «стандартного» слова со списком слов сравнения по шкале от 0 (нет сходства) до 4 (очень похоже). Было проведено несколько экспериментов с разными стандартными словами и словами сравнения. Витц и Винклер сравнили полученные оценки с результатами собственной процедуры определения фонетического сходства (называемой «прогнозируемой фонематической дистанцией», сокращенно здесь PPD). (Parrish, 2017) предлагает новый метод использования биграмм фонетических признаков для вычисления векторного представления слова. Было показано, что в некоторых случаях этот метод работает лучше, чем подход (Vitz and Winkler, 1973) PPD. Автор работает с версией 0.7b Словаря произношения CMU Carnegie Mellon Speech Group (2014) , который состоит из 133852
Было показано, что в некоторых случаях этот метод работает лучше, чем подход (Vitz and Winkler, 1973) PPD. Автор работает с версией 0.7b Словаря произношения CMU Carnegie Mellon Speech Group (2014) , который состоит из 133852
статей, добавляет токен «BEG» к началу и «END» к концу фонетической транскрипции. все слова и вычисляет чередующиеся биграммы признаков для каждого из них. Используя тот факт, что их может быть 949 уникальных перемежающихся биграмм признаков по всему набору данных, автор представляет признаки, извлеченные для всех слов, в виде матрицы размера
133852 (количество слов в словаре) × 949 (количество уникальных признаков). PCA применяется к приведенной выше матрице, чтобы получить 50-мерное вложение для каждого слова в наборе данных, которое мы называем в этой статье PSSVec, сокращенно от вектора подобия поэтического звука. Чтобы зафиксировать сходство слов независимо от порядка фонем, автор дополнительно вычисляет признаки для обратного порядка фонем и добавляет их к исходному признаку слова. Таким образом, недостатком этого подхода является то, что встраивание не зависит от положения фонемы в слове, например, вложение для фонемных последовательностей ‘AY P N OW’ и ‘OW N P AY’ оказалось бы одинаковым, что является нелогичным, поскольку они не звучат похоже. Следовательно, мы постулируем, что положение фонем также играет важную роль в том, чтобы два слова звучали одинаково (и, следовательно, были ближе друг к другу в пространстве вложений), и мы решаем эту проблему в нашем предложенном алгоритме подобия.
Таким образом, недостатком этого подхода является то, что встраивание не зависит от положения фонемы в слове, например, вложение для фонемных последовательностей ‘AY P N OW’ и ‘OW N P AY’ оказалось бы одинаковым, что является нелогичным, поскольку они не звучат похоже. Следовательно, мы постулируем, что положение фонем также играет важную роль в том, чтобы два слова звучали одинаково (и, следовательно, были ближе друг к другу в пространстве вложений), и мы решаем эту проблему в нашем предложенном алгоритме подобия.
| Таблица 1: Полное описание признаков английских согласных (* обозначает многократное использование данной фонемы) |
| Таблица 2: Полное описание свойств английских гласных (* обозначает многократное использование данной фонемы) |
| Таблица 3: Полное описание признаков согласных хинди |
| Таблица 4: Полное описание функции для гласных хинди |
3 Предлагаемый подход
Лингвисты твердо установили, что некоторые фонемы более похожи, чем другие, в зависимости от вариаций артикуляционных позиций, задействованных при их воспроизведении Хомский и Галле (1968) , и эти вариации улавливаются особенностями фонем. По этим признакам фонемы можно разделить на группы.
Наш метод предполагает, что каждой фонеме можно сопоставить набор соответствующих фонетических признаков. Для английского языка мы используем сопоставление, предложенное в спецификации для X-SAMPA 9.0007 Kirshenbaum (2001) , адаптированный к схеме транскрипции Arpabet. Сопоставление английских фонем признакам показано в таблицах 2 и 2.
По этим признакам фонемы можно разделить на группы.
Наш метод предполагает, что каждой фонеме можно сопоставить набор соответствующих фонетических признаков. Для английского языка мы используем сопоставление, предложенное в спецификации для X-SAMPA 9.0007 Kirshenbaum (2001) , адаптированный к схеме транскрипции Arpabet. Сопоставление английских фонем признакам показано в таблицах 2 и 2.
После мандаринского, испанского и английского языков хинди является самым родным языком в мире, на котором, по данным Ethnologue (2014) , говорят почти 260 миллионов человек. Для хинди мы используем отображение, предложенное Malviya et al. (2016) и добавил некоторые из недостающих, используя фонетические особенности IPA Mortensen et al. (2016) . Сопоставление фонем хинди с используемыми нами признаками показано в таблицах 2 и 2.
3.1 Сходство фонем
Фонетическое расстояние (сходство) S между парой фонем Pa и Pb измеряется с использованием набора признаков двух фонем и вычисления сходства Жаккара.
| S(Pa,Pb)=|F(Pa)∩F(Pb)||F(Pa)∪F(Pb)| | (1) |
Здесь F(P) — множество всех характеристик телефона P. Например, F(R)={apr,alv} (из таблицы 2). Мы можем распространить эту логику и на биграммы. Чтобы вычислить набор функций биграммы (Pa1, Pa2), мы просто возьмем объединение функций для обоих телефонов.
| F(Па1,Па2)=F(Па1)∪F(Па2) | (2) |
И Сходство S между парами биграмм (Pa1,Pa2) и (Pb1,Pb2), можно рассчитать как:
| S((Pa1,Pa2),(Pb1,Pb2))=|F(Pa1,Pa2)∩F(Pb1,Pb2)||F(Pa1,Pa2)∪F(Pb1,Pb2)| | (3) |
Гласные в речи обычно длиннее согласных Umeda (1975) Umeda (1977) и далее восприятие сходства сильно зависит от гласных Raphael (1972) . По этой причине, если две биграммы оканчиваются на одну и ту же гласную, то они звучат почти одинаково, несмотря на то, что начинаются с разных согласных.
По этой причине, если две биграммы оканчиваются на одну и ту же гласную, то они звучат почти одинаково, несмотря на то, что начинаются с разных согласных.
Мы можем взвесить нашу оценку подобия, чтобы отразить эту идею.
| Зв((Pa1,Pa2),(Pb1,Pb2))=⎧⎪ ⎪ ⎪⎨⎪ ⎪ ⎪⎩√S((Pa1,Pa2),(Pb1,Pb2)), если Pa2 – гласная и Pa2=Pb2S((Pa1,Pa2),(Pb1,Pb2))2, иначе | (4) |
Здесь Sv — взвешенное по гласным подобие для биграмм (Pa1,Pa2) и (Pb1,Pb2).
3.2 Сходство слов 90 129
Мы предлагаем новый метод сравнения слов, учитывающий сходство фонем, а также их последовательность. Симметричное расстояние подобия между словом a, заданным в виде последовательности фонем a1,a2,a3…an, и словом b, заданным в виде последовательности фонем b1,b2,b3…bm, равно dnm, определяемому повторением:
| d1,1=S(a1,b1) |
| di,1=di−1,1+S(ai,b1)для 2≤i≤n |
| d1,j=d1,j−1+S(a1,bj)для 2≤j≤m |
| ди, j=⎧⎪ ⎪ ⎪ ⎪⎨⎪ ⎪ ⎪ ⎪⎩S(ai,bj)+di−1,j−1, если S(ai,bj)=1S(ai,bj)/p+min{di−1,jdi,j−1, иначе при 2≤i ≤n,2≤j≤m | (5) |
Здесь p — недиагональный штраф. Поскольку мы вычисляем баллы для всех возможных путей, это позволяет нам препятствовать тому, чтобы алгоритм использовал запутанные недиагональные пути, которые в противном случае будут набирать лучшие баллы, поскольку они длиннее. Сходство слов WS между словами a и b можно рассчитать как:
Поскольку мы вычисляем баллы для всех возможных путей, это позволяет нам препятствовать тому, чтобы алгоритм использовал запутанные недиагональные пути, которые в противном случае будут набирать лучшие баллы, поскольку они длиннее. Сходство слов WS между словами a и b можно рассчитать как:
| WS(a,b)=dn,m/max(n,m) | (6) |
Установив недиагональный штраф p≥2, мы можем гарантировать, что сходство слов WS будет находиться в диапазоне 0≤WS≤1.
Кроме того, оценка может быть рассчитана для последовательности биграмм вместо последовательности униграмм с помощью уравнения 3. В случае биграмм мы вставляем две новые лексемы: «BEG» в начале и «END» в конец фонемной последовательности. Для слова a, определенного исходной последовательностью a1,a2,a3…an, последовательность биграмм будет (BEG,a1),(a1,a2),(a2,a3),(a3,a4)…(an −1,an),(an,END). Здесь «BEG» и «END» — это фиктивные телефоны, которые отображаются на отдельные фиктивные фонетические функции «beg» и «end» соответственно.
Мы также можем использовать преимущества концепции веса гласных, которые мы установили в уравнении 4. Единственное изменение, которое необходимо внести в уравнение 3.2, — это использовать Sv вместо S при вычислении симметричного расстояния подобия dn,m. Сходство слов, полученное с помощью этого метода, мы обозначаем в этой статье как WVS (сходство слов, взвешенных по гласным).
3.3 Внедрение расчета
Используя алгоритм, упомянутый в предыдущем разделе, мы можем получить сходство между любыми двумя словами, если у нас есть их фонематическая разбивка. В этом разделе мы расскажем о подходе, использованном для создания пространства для встраивания слов. Вложения слов предлагают множество преимуществ, таких как более быстрое вычисление и независимая обработка, в дополнение к другим преимуществам векторных пространств, таким как сложение, вычитание и проецирование.
Для словаря k слов мы можем получить матрицу подобия M∈Rk∗k, вычислив сходство слов между всеми парами слов.
| Mi,j=WVS(wordi,wordj) | (7) |
Поскольку эта матрица сходства M будет симметричной неотрицательной матрицей, можно использовать факторизацию неотрицательной матрицы Yang et al. (2008) или аналогичный метод для получения вложения слова d измерения V∈Rk∗d
. Использование стохастического градиентного спуска (SGD)
Koren et al. (2009) На основе метода мы можем узнать матрицу вложения V, минимизировав:
| ||М-В.ВТ||2 | (8) |
Мы выбираем метод на основе SGD, так как матричная факторизация и другие подобные методы становятся неэффективными из-за требований к памяти по мере увеличения количества слов k. Например, чтобы разместить в памяти матрицу сходства M для k слов, потребуется пространство порядка O(k2). Но, используя метод на основе SGD, нам не нужно предварительно вычислять матрицу M, мы можем просто вычислить необходимые значения, используя уравнение 7 на лету.
Но, используя метод на основе SGD, нам не нужно предварительно вычислять матрицу M, мы можем просто вычислить необходимые значения, используя уравнение 7 на лету.
4 эксперимента и результаты
4.1 Эксперименты
Мы реализовали запомненную версию алгоритма с помощью динамического программирования. Для двух слов a и b с последовательностями фонем a=a1,a2,a3…an и b=b1,b2,b3…bm сложность алгоритма составляет O(n.m). Алгоритм реализован на языке Python и CMU Pronouncing Dictionary 0.7b Carnegie Mellon Speech Group (2014) используется для получения последовательности фонем для данного слова.
Как описано ниже, для сравнения предлагаемого нами подхода с существующей работой мы рассчитали корреляцию между человеческими оценками и оценками, полученными PSSVec, и нашим методом для всех стандартных слов, как указано в (Vitz and Winkler, 1973) .
Сначала мы используем наш алгоритм WS на униграммах, а затем на биграммах. Для биграмм мы использовали 3 варианта: один без недиагонального штрафа (т.е. p=1), один с p=2,5 и один с весами гласных (WVS). Мы сравнили корреляцию между методами и результатами опроса людей Витц и Винклер (1973) . Мы масштабировали результаты опроса людей от 0-4 до 0-1. Как видно на рисунке 1, отдав предпочтение совпадающим элементам, установив p=2,5, мы увеличили количество баллов. Эффект недиагонального штрафа p можно увидеть на рисунке 3. Это также показывает, что присвоение большего веса одинаковым гласным в конце еще больше повысило производительность.
После этого мы сравнили наш метод (биграммы с WVS и p=2,5) с существующей работой. Как видно из рисунка 2, наш метод выполняет существующую работу во всех 4 случаях.
Как видно из рисунка 2, наш метод выполняет существующую работу во всех 4 случаях.
4.2 Расчет пространства для встраивания
Поскольку взвешенный по гласным биграммный метод WVS с недиагональным штрафом p = 2,5 дал нам наилучшие результаты, мы используем его для изучения вложений, решая уравнение 8
. Tensorflow v2.1
Абади и др. (2016) использовался для реализации нашего кода матричной факторизации.
Поскольку реализация Python медленная, мы также реализовали наш алгоритм на C++ и использовали его в Tensorflow (для пакетных вычислений на лету), представив его как модуль Python с помощью Cython 9.0007 Сельеботн (2009) . В однопоточном сравнении мы получили среднее ускорение примерно в 300 раз от реализации C++ по сравнению с реализацией Python. Реализация выигрывает от встроенных функций компилятора для подсчета битов Muła et al. (2018) , которые ускоряют вычисление сходства Жаккара. Результаты были получены на процессоре Intel(R) Xeon(R) E5-2690 v4 с тактовой частотой 2,60 ГГц и 440 ГБ ОЗУ, работающем под управлением Ubuntu 18.04. Чтобы сравнить производительность, мы используем время, затраченное на вычисление сходства между данным словом и каждым словом в словаре. Опыты повторяли 5 раз и для исследований брали их среднее значение.
Результаты были получены на процессоре Intel(R) Xeon(R) E5-2690 v4 с тактовой частотой 2,60 ГГц и 440 ГБ ОЗУ, работающем под управлением Ubuntu 18.04. Чтобы сравнить производительность, мы используем время, затраченное на вычисление сходства между данным словом и каждым словом в словаре. Опыты повторяли 5 раз и для исследований брали их среднее значение.
Как и в случае с PSSVec, мы также использовали 50-мерные вложения для объективного сравнения. Английские эмбеддинги обучены на 133859 словах из словаря CMU 0.7b Carnegie Mellon Speech Group (2014) . На рис. 4 показано сравнение PSSVec и наших вложений.
Для языка хинди мы используем набор данных Kunchukuttan (2020) и тренируемся на 22877 словах.
Мы также можем проводить звуковые аналогии (которые выявляют фонетические отношения между словами) с полученными вложениями слов, используя векторную арифметику, чтобы продемонстрировать эффективность изученного пространства вложений. Предположим, что V(W) представляет изученный вектор вложения для слова W. Если Wa связано с Wb тем же отношением, которым Wc связано с Wd (Wa:Wb::Wc:Wd), учитывая вложение слов Wa,Wb,Wc, мы можем получить Wd как:
Если Wa связано с Wb тем же отношением, которым Wc связано с Wd (Wa:Wb::Wc:Wd), учитывая вложение слов Wa,Wb,Wc, мы можем получить Wd как:
| Wd=N(V(Wb)−V(Wa)+V(Wc)) | (9) |
, где функция N(v) возвращает ближайшее слово из вектора v в изученном пространстве вложения. Результаты для некоторых пар задокументированы в следующих таблицах:
Таблица 5: Звуковые аналогии для английского языка Таблица 6: Звуковые аналогии для хинди Чтобы помочь визуальному пониманию этого пространства вложений, мы выбрали несколько слов из английского и хинди языков и спроецировали их вложения в двумерное пространство, используя t-распределенное стохастическое вложение соседей (Маатен и Хинтон, 2008) . Спроецированные векторы представлены в виде двумерного графика на рисунке 5 для английского языка и на рисунке 6 для хинди. Мы четко отмечаем, что похожие по звучанию слова встречаются в сюжете вместе, тем самым подтверждая нашу гипотезу о том, что предлагаемое нами пространство для встраивания способно уловить фонетическое сходство слов.
4.3 Оценка на основе каламбура
Каламбур — это форма игры слов, которая использует различные возможные значения слова или тот факт, что существуют слова, которые звучат одинаково, но имеют разные значения, для предполагаемого юмористического или риторического эффекта Миллер и др. (2017) . Первая категория, в которой каламбур использует различные возможные значения слова, называется омографическим каламбуром, а вторая категория, опирающаяся на слова со схожим звучанием, называется гетерографическим каламбуром. Ниже приведен пример гетерографического каламбура:
.Я переименовал свой iPod в «Титаник»,
, поэтому, когда я подключаю его, он говорит:
«Титаник синхронизируется».
Гетерографические каламбуры основаны на схожих по звучанию словах и, таким образом, служат идеальным набором данных для сравнительного анализа алгоритмов акустического встраивания. Для демонстрации эффективности нашего подхода мы использовали 3-ю подзадачу (гетерографическое обнаружение каламбуров) набора данных SemEval-2017 Task 7 9. 0007 Миллер и др. (2017) . Этот тестовый набор содержит 1098 пар слов с гетографическими каламбурами, такими как синхронизация и погружение. После взятия всех пар слов, которые присутствуют в CMU Pronouncing Dictionary Carnegie Mellon Speech Group (2014)
0007 Миллер и др. (2017) . Этот тестовый набор содержит 1098 пар слов с гетографическими каламбурами, такими как синхронизация и погружение. После взятия всех пар слов, которые присутствуют в CMU Pronouncing Dictionary Carnegie Mellon Speech Group (2014)
, и удаления повторяющихся записей, у нас осталось 778 пар слов. В идеале, для хорошего алгоритма акустического встраивания мы ожидаем, что распределение косинусного сходства этих пар слов будет точным гауссовским со значениями
→ 1.
Чтобы еще больше наглядно подчеркнуть эффективность нашего подхода, для 778 пар слов мы представляем в таблице 7 разницу оценок косинусного сходства, полученных с помощью нашего алгоритма и PSSVec (отсортированных по разнице). Как мы видим, несмотря на то, что слова бормотание и мать относительно похожи по звучанию, PSSVec приписывает отрицательное сходство. Для сравнения, наш метод более надежен, правильно фиксируя акустическое сходство между словами.
Рисунок 7
показывает распределение плотности косинусного сходства между тестовыми парами слов для предложенного нами алгоритма и PSSVec. Замечено, что наше распределение очень похоже на гауссово, с меньшей дисперсией и более высоким средним значением по сравнению с вложениями PSSVec.
Рисунок 7: Сравнение распределения подобия косинуса5 Заключение
В этой работе мы предлагаем метод получения сходства между парой слов с учетом их фонемной последовательности и отображением фонетических признаков для языка. Преодолевая недостаток предыдущих решений, основанных на встраивании, наш алгоритм также можно использовать для сравнения сходства новых слов, поступающих на лету, даже если они не видны в обучающих данных.
Кроме того, поскольку встраивания оказались полезными в различных случаях, мы также представляем алгоритм встраивания слов, использующий нашу метрику сходства. Показано, что наши вложения работают лучше, чем результаты, о которых сообщалось ранее в литературе. Мы утверждаем, что наш подход является общим и может быть распространен на любой язык, для которого можно получить последовательности фонем для всех его слов. Чтобы продемонстрировать это, результаты представлены для 2 языков — английского и хинди.
Мы утверждаем, что наш подход является общим и может быть распространен на любой язык, для которого можно получить последовательности фонем для всех его слов. Чтобы продемонстрировать это, результаты представлены для 2 языков — английского и хинди.
В будущем мы хотим применить наш подход к большему количеству индийских языков, используя тот факт, что в большинстве из них не требуется сложное преобразование графемы в фонему, поскольку большинство индийских языков имеют орфографии с высоким коэффициентом преобразования графемы в фонему. и соответствие фонем графемам. Этот подход становится более ценным для хинди и других индийских языков, поскольку для них делается очень мало работы, а адаптация общей структуры обеспечивает разнообразие и инклюзивность. Мы также хотим воспользоваться этой мерой подобия и создать систему распознавания речи на основе слов, которая может быть полезна для различных задач, таких как ASR с ограниченным словарным запасом, обнаружение ключевых слов и обнаружение пробуждающих слов.
Ссылки
- М. Абади, А. Агарвал, П. Бархам, Э. Бревдо, З. Чен, К. Ситро, Г. С. Коррадо, А. Дэвис, Дж. Дин, М. Девин и др. (2016)
Tensorflow: крупномасштабное машинное обучение в гетерогенных распределенных системах
. Препринт arXiv arXiv: 1603.04467. Цитируется по: §4.2. - С. Бенжио и Г. Хейгольд (2014) Вложения слов для распознавания речи. Цитируется по: §1.
- А. Брэдлоу, К. Клоппер, Р. Смильяник и М. А. Уолтер (2010 г.) Пространство перцептивного фонетического сходства языков: данные пяти групп слушателей, говорящих на родном языке. Речевое общение 52 (11-12), стр. 930–942. Цитируется по: §2.
- К. П. Броуман и Л. Гольдштейн (1992) Артикуляционная фонология: обзор. Фонетика 49 (3–4), стр. 155–180. Цитируется по: §1.
- Речевая группа Карнеги-Меллона (2014) Орфоэпический словарь CMU 0.7b. Внешние ссылки: ссылка Цитируется по: §2, §4.1, §4.2, §4.3.
- Н. Хомский и М. Галле (1968)
Звуковая модель английского языка. Цитируется по: §1,
§3.
- Этнолог (2014) Самые распространенные языки в мире. Внешние ссылки: ссылка Цитируется по: §3. 904:30
- М. Гиатсоглу, М. Г. Возалис, К. Диамантарас, А. Вакали, Г. Саригианнидис и К. К. Чатзисаввас (2017) Анализ настроений с использованием эмоций и встраивания слов. Экспертные системы с приложениями 69, стр. 214–224. Цитируется по: §1.
- Э. Киршенбаум (2001) Представление фонетики IPA в ascii. URL: http://www.kirshenbaum.net/IPA/ascii-ipa.pdf (неопубликовано), Hewlett-Packard Laboratories. Цитируется по: §3.
- Ю. Корен, Р. Белл и К. Волински (2009 г.) Методы матричной факторизации для рекомендательных систем. Компьютер 42 (8), стр. 30–37. Цитируется по: §3.3. 904:30
- А. Кунчукуттан (2020) Библиотека IndicNLP. Примечание: https://github.com/anoopkunchukuttan/indic_nlp_library/blob/master/docs/indicnlp.pdf Цитируется по: §4.2.
- Л. в. д. Маатен и Г. Хинтон (2008)
Визуализация данных с помощью t-sne.
Журнал исследований машинного обучения 9 (ноябрь), стр. 2579–2605.
Цитируется по: §4.2.
- С. Мальвия, Р. Мишра и У. С. Тивари (2016 г.) Структурный анализ фонетики хинди и метод извлечения фонетически богатых предложений из очень большого корпуса текстов на хинди. В 2016 году Конференция Восточного отделения Международного комитета по координации и стандартизации речевых баз данных и методов оценки (O-COCOSDA), стр. 188–19.3. Цитируется по: §3.
- Дж. Мильке (2012) Метрика звукового сходства, основанная на фонетике. Lingua 122 (2), стр. 145–163. Цитируется по: §2.
- Т. Миколов, И. Суцкевер, К. Чен, Г. С. Коррадо и Дж. Дин (2013) Распределенные представления слов и фраз и их композиционность. В Достижениях в области нейронных систем обработки информации, стр. 3111–3119. Цитируется по: §1.
- Т. Миллер, К. Ф. Хемпельманн, И. Гуревич (2017)
SemEval-2017 задание 7: обнаружение и интерпретация английских каламбуров.
В материалах 11-го Международного семинара по семантической оценке (SemEval-2017),
стр. 58–68.
Цитируется по: §4.3,
§4.3.
904:30
- Д. Р. Мортенсен, П. Литтелл, А. Бхарадвадж, К. Гоял, К. Дайер и Л. Левин (2016) Panphon: ресурс для сопоставления сегментов ipa с векторами артикуляционных признаков. В материалах COLING 2016, 26-й Международной конференции по компьютерной лингвистике: технические документы, стр. 3475–3484. Цитируется по: §3.
- В. Мула, Н. Курц и Д. Лемир (2018) Более быстрый подсчет населения с использованием инструкций avx2. Компьютерный журнал 61 (1), стр. 111–120. Цитируется по: §4.2.
- А. Пэрриш (2017)
Векторы подобия поэтического звука с использованием фонетических признаков.
В
Тринадцатая конференция по искусственному интеллекту и интерактивным цифровым развлечениям
, Цитируется по: §1, §2. - LJ Рафаэль (1972)
Продолжительность предшествующей гласной как сигнал к восприятию звуковой характеристики согласных в конце слова в американском английском.
Журнал Акустического общества Америки 51 (4B), стр. 1296–1303. Цитируется по: §3.1.
- Н. Сакки, А. Нанчен, М. Джагги и М. Чернак (2019 г.) Обнаружение ключевых слов с открытым словарем с встраиванием аудио и текста. В ИНТЕРСПИЧ 2019-Международная конференция IEEE по акустике, обработке речи и сигналов, Цитируется по: §1.
- Д. С. Сельеботн (2009) Быстрые численные вычисления с cython. В материалах 8-й конференции Python в науке, Том. 37. Цитируется по: §4.2.
- Н. Умеда (1975) Длительность гласных в американском английском. Журнал Акустического общества Америки 58 (2), стр. 434–445. Цитируется по: §3.1.
- Н. Умеда (1977) Длительность согласных в американском английском. Журнал Акустического общества Америки 61 (3), стр. 846–858. Цитируется по: §3.1. 904:30
- ПК Витц и Б. С. Винклер (1973) Предсказание предполагаемого «похожести звучания» английских слов. Журнал вербального обучения и вербального поведения 12 (4), стр. 373–388. Цитируется по: §2, §4.1, §4.1.
- Р. А. Вагнер и М. Дж. Фишер (1974)
Задача исправления строки в строку. Журнал ACM (JACM) 21 (1), стр. 168–173.
Цитируется по: §1.
- Дж. Ян, С. Ян, Ю. Фу, С. Ли и Т. Хуан (2008 г.)
Вложение неотрицательного графа.
В
2008 г. Конференция IEEE по компьютерному зрению и распознаванию образов
, стр. 1–8. Цитируется по: §3.3. - Г. Чжоу, Т. Хэ, Дж. Чжао и П. Ху (2015) Изучение непрерывного встраивания слов с метаданными для поиска вопросов в ответах на вопросы сообщества. В материалах 53-го ежегодного собрания Ассоциации компьютерной лингвистики и 7-й Международной объединенной конференции по обработке естественного языка (Том 1: Длинные статьи), стр. 250–259. Цитируется по: §1.
 Цитируется по: §1,
§3.
Цитируется по: §1,
§3. 2579–2605.
Цитируется по: §4.2.
2579–2605.
Цитируется по: §4.2. 58–68.
Цитируется по: §4.3,
§4.3.
904:30
58–68.
Цитируется по: §4.3,
§4.3.
904:30 Цитируется по: §3.1.
Цитируется по: §3.1. Журнал ACM (JACM) 21 (1), стр. 168–173.
Цитируется по: §1.
Журнал ACM (JACM) 21 (1), стр. 168–173.
Цитируется по: §1.Готов | Университет Висконсина
Поиск
Полный сайт
Каталог
Программы
Майоры и несовершеннолетние
Ищи сейчасОнлайн степени
Учить большеОплата колледжа
Стипендии и многое другое!Дружественный к трансферу прием
Трансфер в СтаутКампус Туры
Совершите тур!Наше политехническое преимущество
Наше преимуществоОткройте для себя путь карьеры в UW-Stout
Искусство, дизайн и графикаИскусство, дизайн и графика
Посмотреть кластер
Управление бизнесомБизнес и управление
Посмотреть кластер
ОбразованиеОбразование
Посмотреть кластер
Гуманитарные и социальные наукиГуманитарные и социальные науки
Посмотреть кластер
Информационные технологии и коммуникацииИнформационные технологии и связь
Посмотреть кластер
Наука, инженерия и математикаНаука, инженерия и математика
Посмотреть кластер
Студенты и семьи
Начни здесьСотрудники факультета
Найдите это здесьСообщество и посетители
Учить большеПродвигайтесь дальше по карьерной лестнице!
Ученая степень
Продвиньтесь по карьерной лестнице, занимаясь профессиональным развитием, получением степени, степенью или сертификатами.
Поиск ученых степеней
Лайф@Стаут
We Are Stout Proud
Одно дело найти школу, в которой есть ваша степень; представлять себя есть другое. Узнайте, почему мы #StoutProud!
Подробнее
Особенности UW-Stout
Центр новостейДень Stout Proud: выпускной празднует самоотверженность, мужество и успех 594 выпускников
Две церемонии вручения дипломов 17 декабря в UW-Stout ознаменовали особый день «Stout Proud» в жизни 594 выпускников.
Продолжить чтениеИз Сирии на начальный этап братья выйдут вместе 17 декабря
Абдул и Карам Мунир вдохновляют своей историей о том, «как человеческий дух может преодолевать бурные испытания»
Магистерская программа школьного консультирования, центры удовлетворения критических потребностей в Висконсине, сообщество
Реконструкция Зала наследия для обеспечения междисциплинарного обучения и повышения доступности услуг