Слова «алгоритм» морфологический и фонетический разбор
Объяснение правил деление (разбивки) слова «алгоритм» на слоги для переноса.
Онлайн словарь Soosle.ru поможет: фонетический и морфологический разобрать слово «алгоритм» по составу, правильно делить на слоги по провилам русского языка, выделить части слова, поставить ударение, укажет значение, синонимы, антонимы и сочетаемость к слову «алгоритм».
Содержимое:
- 1 Слоги в слове «алгоритм» деление на слоги
- 2 Как перенести слово «алгоритм»
- 3 Морфологический разбор слова «алгоритм»
- 4 Разбор слова «алгоритм» по составу
- 5 Сходные по морфемному строению слова «алгоритм»
- 6 Синонимы слова «алгоритм»
- 7 Ударение в слове «алгоритм»
- 8 Фонетическая транскрипция слова «алгоритм»
- 9 Фонетический разбор слова «алгоритм» на буквы и звуки (Звуко-буквенный)
- 10 Предложения со словом «алгоритм»
- 11 Сочетаемость слова «алгоритм»
- 12 Значение слова «алгоритм»
- 13 Как правильно пишется слово «алгоритм»
- 14 Ассоциации к слову «алгоритм»
Слоги в слове «алгоритм» деление на слоги
Количество слогов: 3
По слогам: а-лго-ритм
л — непарная звонкая согласная (сонорная), примыкает к текущему слогу
Как перенести слово «алгоритм»
ал—горитм
алго—ритм
Морфологический разбор слова «алгоритм»
Часть речи:
Имя существительное
Грамматика:
часть речи: имя существительное;
одушевлённость: неодушевлённое;
род: мужской;
число: единственное;
падеж: именительный, винительный;
отвечает на вопрос: (есть) Что?, (вижу/виню) Что?
Начальная форма:
алгоритм
Разбор слова «алгоритм» по составу
| алгоритм | корень |
| ø | нулевое окончание |
алгоритм
Сходные по морфемному строению слова «алгоритм»
Сходные по морфемному строению слова
Синонимы слова «алгоритм»
1. алгорифм
алгорифм
Ударение в слове «алгоритм»
алгори́тм — ударение падает на 3-й слог
Фонетическая транскрипция слова «алгоритм»
[алгар’`итм]
Фонетический разбор слова «алгоритм» на буквы и звуки (Звуко-буквенный)
| Буква | Звук | Характеристики звука | Цвет |
|---|---|---|---|
| а | [а] | гласный, безударный | а |
| л | [л] | согласный, звонкий непарный (сонорный), твёрдый | л |
| г | [г] | согласный, звонкий парный, твёрдый, шумный | г |
| о | [а] | гласный, безударный | о |
| р | [р’] | согласный, звонкий непарный (сонорный), мягкий | р |
| и | [`и] | гласный, ударный | и |
| т | [т] | согласный, глухой парный, твёрдый, шумный | т |
| м | [м] | согласный, звонкий непарный (сонорный), твёрдый | м |
Число букв и звуков:
На основе сделанного разбора делаем вывод, что в слове 8 букв и 8 звуков.
Буквы: 3 гласных буквы, 5 согласных букв.
Звуки: 3 гласных звука, 5 согласных звуков.
Предложения со словом «алгоритм»
Водителю — выработать посадку и алгоритмы действий, чувство автомобиля.
Источник: Николай Додонов, Антитайм-менеджмент, 2015.
На механической материи и на её полевых формах закреплены жёсткие алгоритмы поведения, известные как фундаментальные законы.
Источник: Н. Н. Мальцев, Инопланетяне и земные аборигены. Перспективы межпланетной экспансии и бессмертия, 2013.
Поисковые подсказки «Яндекса» формируются по сложным алгоритмам, проходя десятки фильтров.
Источник: Михаил Боде, Раскрутка: секреты эффективного продвижения сайтов, 2013.
Сочетаемость слова «алгоритм»
1. новый алгоритм
новый алгоритм
2. определённый алгоритм
3. адаптивные алгоритмы
4. алгоритм действий
5. алгоритм работы
6. алгоритм решения
7. на основе алгоритмов
8. теория алгоритмов
9. суть алгоритма
10. создать алгоритм
11. действовать по алгоритму
12. составить алгоритм
13. (полная таблица сочетаемости)
Значение слова «алгоритм»
АЛГОРИ́ТМ , -а, м. Мат. Система вычислений по строго определенным правилам, которая после последовательного их выполнения приводит к решению поставленной задачи. Алгоритм извлечения корня из числа. Построение системы алгоритмов. (Малый академический словарь, МАС)
Как правильно пишется слово «алгоритм»
Орфография слова «алгоритм»Правильно слово пишется: алгори́тм
Нумерация букв в слове
Номера букв в слове «алгоритм» в прямом и обратном порядке:
- 8
а
1 - 7
л
2 - 6
г
3 - 5
о
4 - 4
р
5 - 3
и
6 - 2
т
7 - 1
м
8
Ассоциации к слову «алгоритм»
Вычисление
Программирование
Бит
Моделирование
Нахождение
Реализация
Шифр
Матрица
Последовательность
Построение
Преобразование
Сложность
Взлом
Кода
Параметр
Производительность
Обработка
Процессор
Теорема
Бита
Гост
Вектор
Программист
Уравнение
Разработчик
Разложение
Метода
Метод
Пользователь
Стандарт
Использование
Целостность
Модификация
Эффективность
Коэффициент
Функционирование
Массив
Сервер
Расшифровка
Стойкость
Математика
Простейшее
Функция
Проектирование
Файл
Сдвиг
Тестирование
Анализ
Конфигурация
Пароль
Патент
Математик
Расчёт
Устойчивость
Раунд
Формат
Потоков
Диаграмма
Синтез
Выработка
Вычислительный
Симметричный
Оптимальный
Динамический
Квантовый
Программный
Произвольный
Математический
Цифровой
Эволюционный
Линейный
Заданный
Исходный
Эффективный
Графический
Генетический
Применимый
Численный
Переменный
Последовательный
Блоковый
Базовый
Структурный
Машинный
Целевой
Компьютерный
Сетевой
Специализированный
Универсальный
Параллельный
Функциональный
Зашифровать
Реализовать
Выполняться
Разработать
Использоваться
Упорядочить
Вычислить
Улучшить
Применяться
Этапы урока | Деятельность учителя | Деятельность обучающихся | Задания для учащихся, выполнение которых приведет к достижению запланированных результатов | УУД |
1. Мотивация познавательной деятельности | Приветствие. Мотивация класса к активной деятельности на уроке. | Подготовка класса к уроку. Настраиваются на учебную деятельность. | Урок погружения в разнообразный мир звуков, окружающий нас со всех сторон. Давайте погрузимся в этот мир и попробуем в нем разобраться. | Л -самоопределение К — планирование учебного сотрудничества с учителем и сверстниками |
2. Актуализация необходимых знаний | Предлагает записать транскрипцию слов. Предлагает игру «Фонетический опрос» | Выполняют работу, записывают транскрипцию слов, объясняют. Отвечают на вопросы. | -Что такое транскрипция? Спишите слова, расставьте ударение, запишите транскрипцию. Земля, лев, цветок, открыть, мороз, очки 2) Вопросы (слайд): — Как называется раздел науки о языке, изучающий звуки речи? — Какие звуки являются гласными, согласными? — Каким буквам отведена двойная роль? — В чем разница между буквой и звуком? — Сколько парных согласных по глухости – звонкости, назовите? — Сколько непарных глухих? — Сколько непарных мягких, твердых согласных? | П — осуществляют для решения учебных задач мыслительные операции. Р — принимают и сохраняют учебную задачу. К — формулируют собственные мысли, высказывают и обосновывают свою точку зрения. Л — развитие интереса к языку, положительное отношение к процессу познания. |
3. Постановка учебной задачи Цель: помочь ребятам поставить цель | Сообщает тему урока. | Отвечают на вопрос, ставят цель, формулируют учебную задачу: учиться выполнять фонетический разбор слова (устный и письменный). | — Какую цель мы поставим себе сегодня на уроке? — Какие задачи необходимо решить для достижения нашей цели? Что необходимо для выполнения любого разбора? (план, алгоритм) | Р – целеполагание, совместное с учителем планирование и прогнозирование результатов деятельности на уроке. К – умение точно выражать свои мысли в соответствии с задачами и условиями коммуникации. |
4. Этап первичного закрепления с проговариванием во внешней речи. Работа с учебником. | Предлагает познакомиться с порядком фонетического разбора (стр.146). • Предлагает познакомиться с устным и письменным фонетическим разбором слова. • Предлагает выполнить разбор слова: пень | •Читают порядок фонетического разбора. • Знакомятся с устным и письменным фонетическим разбором слова. Обращают внимание, что устный разбор подробнее письменного. В письменном разборе подводится итог в виде количественного соотношения букв и звуков. •Читают задание. Комментируют порядок действий. Выполняют фонетический разбор слова. Комментируют выполнение задания вслух по желанию | Порядок фонетического разбора слова. Написать слово Поставить знак ударения. Определить, сколько в слове слогов. Записать слово в транскрипции. Последовательно охарактеризовать все звуки. На лесной поляне стоял старый пень1. | П — извлекают необходимую информацию, систематизируют знания. Р — планируют необходимые действия, операции, действуют по плану. |
5. Организация познавательной деятельности. | Организует работу по активизации мыслительной и познавательной деятельности учащихся, предлагает работу по карточкам и разгадывание ребуса, разбор слов. Организует деятельность по обобщению и включению знаний в систему. Предлагает рассмотреть домашнее задание: выполнить фонетический разбор слов: ёж, медведь, цирк. | Разгадывают ребусы и делают разбор слов, учатся рассуждать. Комментируют выполнение задания вслух по желанию. По окончании проводят самопроверку. Корректируют написанное. При необходимости задают уточняющие вопросы. | Работа по карточкам. Орфоэпическая разминка. Спишите слова, расставьте ударение. Алфавит, каталог, библиотека, красивее, звонит, договор, средства, километр, свекла, творог. Разгадать ребусы и выполнить фонетический разбор слов. Запишите в три колонки слова, распределив их по принципу: 1) звуков букв; 2) звуков Пьеса, звёздный, объём, льдины, ёжик, каюта. При необходимости задают уточняющие вопросы. | П – анализ, построение логической цепи рассуждения, выдвижение гипотез, установление причинно-следственных связей, аналогии, создание способов решения проблем. Р – планирование своей деятельности для решения поставленной задачи и контроль полученного результата, познавательная инициатива, умение осуществлять саморегуляцию. К — сотрудничество в поиске и выборе информации. |
6. Подведение итогов | Уточняет, достигли ли цели, поставленной в начале урока, достиг ли её каждый из учеников, предлагает оценить свою деятельность на уроке. Создает условия для рефлексии. Дает оценку работе учащихся. | Осуществляют самооценку собственной деятельности | 1. Тема сегодня на уроке была: сложная/простая 2. Я на уроке работал(а): активно/пассивно 3. Новая тема мне: понятна/непонятна 4. | К — умение выражать свои мысли. Р – рефлексия. Л- смыслообразование. |
 Тема: Фонетический разбор слова.
Тема: Фонетический разбор слова.


 В парах проговаривают алгоритм его выполнения.
В парах проговаривают алгоритм его выполнения.

 В целом уроком я: доволен/не доволен
В целом уроком я: доволен/не доволенЧтение алгоритма «Как выполнять фонетический анализ слова». — Студопедия.Нет
Артикуляционная гимнастика.
Учащиеся 5–7 раз повторяют скороговорку.
У пеньков опять пять опят.
Физкультминутка
Проведение фонетического анализа слов по алгоритму.
Учащиеся, выполняют фонетический анализ слова, рассуждают и действуют последовательно, согласно указаниям алгоритма:
1) Запишем слово, разделим на слоги, запишем его с помощью транскрипции: Ракета, ра-ке-та, [рак’э́та].
2) Запишем слово по буквам в столбик и рядом транскрипцию [ ] звука.
3) Дадим характеристику звукам.
4) Подсчитаем количество букв и звуков.
р – [р] – согласный, твердый, непарный.
a – [а] – гласный, безударный.
к – [к’] – согласный, глухой, парный ([г]).
е – [э] – гласный, ударный.
т – [т] – согласный, глухой, парный ([д]).
а – [а] – гласный, безударный.
| 6 букв, 6 звуков. |
Учащиеся делают фонетический анализ слова луна.
IV. Итог урока.
Учитель. Как вы думаете, для чего надо уметь выполнять фонетический разбор слов?
Слова различаются правописанием и произношением. И редко, когда произношение и написание совпадают, чаще всего они различаются. Для того, чтобы правильно писать слова, надо уметь различать их на слух, характеризовать звуки, знать их буквенное обозначение и еще очень многое, что нам предстоит изучать на уроках русского языка.
Домашнее задание: внимательно прочитайте алгоритм в учебнике.
Русский язык 3 класс 1 четвертьУМК «Начальная школа 21 века»
Урок 5 Тема: Повторяем: текст, его признаки и типы
Цели: закрепить знания учащихся о типах текста; развивать речь, обогащать словарный запас учащихся.
Ход урока
I. Чистописание.
с ж Самуил Яковлевич Маршак
II. Повторение изученного материала.
Учитель. Сегодня на уроке мы с вами повторим известные сведения о тексте, его признаках и типах.
Послушайте несколько текстов.
В следующий раз я попал на Светлое озеро уже поздней осенью, когда выпал первый снег. Лес и теперь был хорош. Кое-где на березках еще оставался желтый лист. Сухая осенняя травка выглядывала из-под снега желтой щеткой. Светлое озеро казалось больше, потому что не стало прибрежной зелени…
Вопросы по тексту:
– О чем я вам прочитала?
– Какой это тип текста?
– По каким признакам вы определили, что это текст-описание?
Том окунул кисть в ведро и провел ею по верхней доске забора, повторил эту операцию, проделал ее снова, сравнил выбеленную полоску с необозримым материком неокрашенного забора и уселся на загородку под деревом в полном унынии.
Вопросы по тексту:
– Какой тип текста я прочитала?
– Какие признаки текста-повествования вам известны?
Лес приносит человеку большую пользу. Он прежде всего – хранитель воды. Деревья защищают землю от знойных лучей солнца и от ветров, а потому прохлада и сырость сохраняются долго в тени деревьев. Весной снег в лесу тает не вдруг, но постепенно, влага долго сохраняется в лесу и питает ручьи и речки в продолжение лета…
Вопросы по тексту:
– Какой тип текста я прочитала?
– По каким признакам вы определили, что это текст-рассуждение?
Физкультминутка
III. Определение типа текстов.
1. Выполнение упражнения 1 устно(учебник).
– Можно ли стихотворение назвать текстом? Проблема!
Учащиеся находят в стихотворении элементы текста, доказывают, что это – текст-повествование.
2. Анализ текста из упражнения 2(учебник).
Учащиеся работают в парах.
– Можно ли сказать, что это текст-описание?
– Как вы его озаглавите? (Звуки осени. Голос осени.)
– А теперь посоветуйтесь и выберите окончание текста из предложенных вариантов. Запишите в тетрадь заголовок и текст с тем окончанием, которое вы выбрали.
IV. Итог урока.
– Можно ли определить содержание текста по его окончанию?
Домашнее задание: подберите примеры разных типов текста и определите их признаки.
Русский язык 3 класс 1 четвертьУМК «Начальная школа 21 века»
Урок 6 Тема: Фонетический анализ слов ………………………..
Цели: закрепить знания об омонимах; учить выполнять фонетический анализ слова по алгоритму.
Ход урока
I. Чистописание.
Туман, зонт, дождь, шарф, пруд.
II. Повторение изученного материала.
На доске записаны стихотворения В.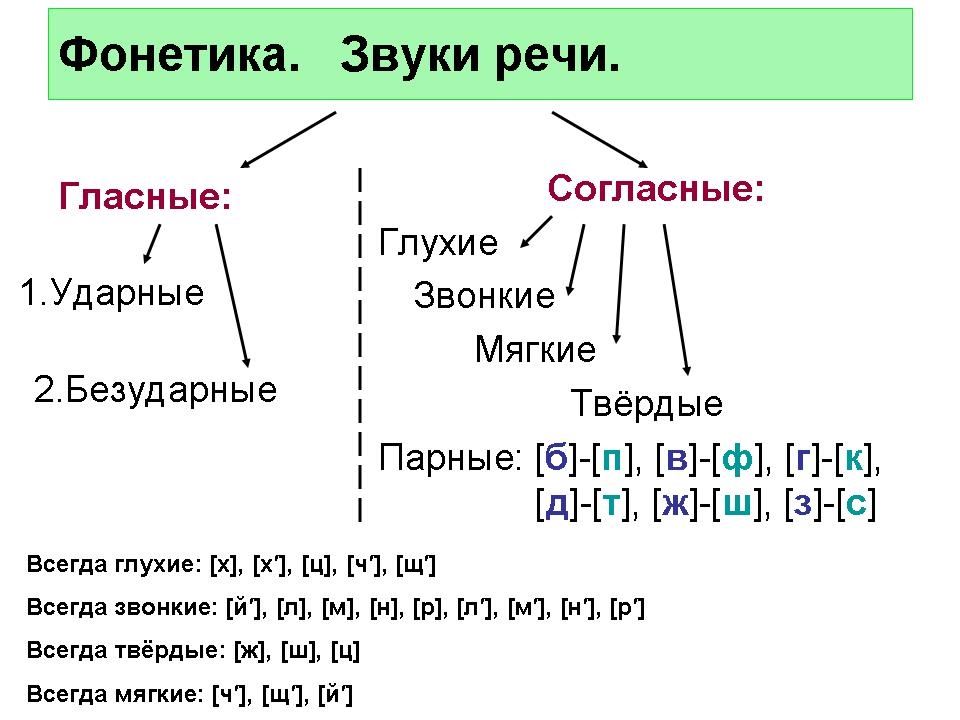 Волиной:
Волиной:
Пересохла глина,
Рассердилась Нина:
– Не мука, а мука,
Поварам наука.
Скорей, сестра, на рыб взгляни,
Попались на крючок они.
В ведерко руку окуни,
Не бойся, это окуни.
Учитель. Найдите одинаковые по написанию слова.
– Чего не хватает в словах, чтобы был понятен смысл?
Поставьте ударение. Прочитайте стихи.
– Вспомните, как называются слова одинаковые по написанию, но разные по произношению?
Приведите примеры омонимов.
Фонетический разбор слова пирог
Главная » Разное » Фонетический разбор слова пирог
пирог — фонетический (звуко-буквенный) разбор слова
Cлово имеет 2 разбора, так как ударение может падать на разные слоги (ударения были указаны пользователями сайта).
Разбор №1пи́рог
пирог — слово из 2 слогов: пи-рог. Ударение падает на 1-й слог.
Транскрипция слова: [п’ирак]
п — [п’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, ударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [а] — гласный, безударный
г — [к] — согласный, глухой парный, твёрдый (парный)
В слове 5 букв и 5 звуков.
Цветовая схема: пирог
27285 / Слово разобрано с помощью программы. Результат разбора используется вами на свой страх и риск.
Разбор №2пиро́г
пирог — слово из 2 слогов: пи-рог. Ударение падает на 2-й слог.
Транскрипция слова: [п’ирок]
п — [п’] — согласный, глухой парный, мягкий (парный)
и — [и] — гласный, безударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
о — [о] — гласный, ударный
г — [к] — согласный, глухой парный, твёрдый (парный)
В слове 5 букв и 5 звуков.
Цветовая схема: пирог
27284 / Слово разобрано с помощью программы. Результат разбора используется вами на свой страх и риск.
Печатать
dmort27 / epitran: Инструмент для расшифровки орфографического текста как IPA (международный фонетический алфавит)
перейти к содержанию Зарегистрироваться- Почему именно GitHub? Особенности →
- Обзор кода
- Управление проектами
- Интеграции
- Действия
- Пакеты
- Безопасность
- Управление командой
- Хостинг
- мобильный
- Истории клиентов →
- Безопасность →
- команда
- предприятие

Фонетический алфавит — Лондонская школа английского языка
Международный фонетический алфавит (IPA) — это система, в которой каждый символ связан с определенным английским звуком. Используя IPA, вы можете точно знать, как произносится определенное слово на английском языке. Это помогает улучшить английское произношение и чувствовать себя более уверенно, говоря на английском, независимо от того, изучаете ли вы английский самостоятельно или под руководством преподавателя-специалиста в индивидуальном классе обучения английскому акценту.
Вот примеры использования IPA в общеупотребительных английских словах.Вы можете практиковать различные гласные и согласные звуки, произнося слова. Это один из способов улучшить английское произношение.
Скачать примеры звуков IPA (PDF)
Международный фонетический алфавит звучит в повседневной речи
Краткие гласные
| IPA Symbol | Примеры слов |
| e | |
| æ | Кошка, рука, ворс, плоский, есть. |
| ʌ | Веселье, любовь, деньги, один, Лондон, давай. |
| ʊ | Ставить, смотреть, надо, готовить, заказывать, смотреть. |
| ɒ | Роб, топ, часы, приседание, колбаса. |
| ə | Жива, опять мать. |
 =»»> Пошел, намереваюсь, отправлю, письмо.
=»»> Пошел, намереваюсь, отправлю, письмо.Долгие гласные
| Символ IPA | Примеры слов |
| i: | Потребность, победа, команда. |
| ɜ: | Медсестра, слышно, третья, очередь. |
| ɔ: | Разговор, закон, скука, зевота, челюсть. |
| u: | Немного, сапог, проиграть, мрачно, фрукты, жевать. |
| : | Быстро, в машине, жестко, в бане. |
Гласные дифтонга
| Символ IPA | Примеры слов |
| ɪə | Рядом, ухо, ясно, слеза, пиво, страх |
| eə | |
| eɪ | Лицо, космос, дождь, чемодан, восьмерка |
| 23 | Радость, найми, игрушка, катушка, устрица. |
| aɪ | Мой взгляд, гордость, добрый, полет |
| əʊ | Нет, не надо, камни, в одиночестве, дыра |
| aʊ | Рот, дом, коричневый, корова, вон |
 =»» care=»» bear=»» air=»»> Волосы, там, уход, лестница, груша
=»» care=»» bear=»» air=»»> Волосы, там, уход, лестница, грушаСогласные Звуки: Fricatives
| Символ IPA | Примеры слов |
| f | Полный, пятница, рыба, нож. |
| в | Жилет, деревня, вид, пещера. |
| θ | Мысли, думай, баня. |
| ð | Вот те, братья, другие. |
| z | Зоопарк, сумасшедший, ленивый, зигзаг, нос. |
| ʃ | Рубашка, риш, магазин, наличка. |
| ʒ | Телевидение, заблуждение, случайное |
| h | Высокий, помогите, привет. |
Согласные Звуки: Взрывчатые вещества
| Обозначение IPA | Примеры слов |
| p | Штифт, заглушка, назначение, пауза. |
| б | Сумка, пузырь, сборка, халат. |
| т | Время, поезд, буксировка, поздно. |
| d | Дверь, день, привод, вниз, подача. |
| k | Cash, quick, cricket, sock. |
| г | Девушка, зеленая, трава, флаг. |
Согласные Звуки: Аффрикаты
| Символ IPA | Примеры слов |
| ʈʃ | Выбирайте, сыр, церковь, часы. |
| dʒ | Радость, жонглирование, сок, сцена. |
Согласные Звуки: Носовые
| IPA Symbol | Примеры слов |
| м | Комната, мама, безумная, еще. |
| n | Вот, никто, не знал, очередь. |
| ŋ | Король, вещь, песня, плавание. |
Согласные Звуки: Приближенные
| Символ IPA | Примеры слов |
| r | Дорога, розы, река, кольцо, поездка. |
| j | Желтый, обычный, мелодия, вчера, двор. |
| w | Стена, прогулка, вино, мир. |
| l и ɫ | Law, lot, leap, long, pill, cold, chill, melt. |
Мы поможем вам говорить по-английски более четко и уверенно:
Посмотрите наше видео с одним из наших тренеров:
Добавлено: 16 августа 2017
Категории: Коммуникативные навыки
.Векторизованный подход в Python
В предыдущей статье я познакомил вас с фонетическими алгоритмами и показал их разнообразие. Более подробно мы рассмотрели расстояние редактирования, которое также известно как расстояние Левенштейна. Этот алгоритм был разработан для того, чтобы подсчитать количество замен букв для перехода от одного слова к другому.
Этот алгоритм был разработан для того, чтобы подсчитать количество замен букв для перехода от одного слова к другому.
Как вы, возможно, уже заметили в предыдущей статье, существуют различные методы для расчета звучания слова, такие как Soundex, Metaphone и Match Rating codex.Некоторые из них встречаются чаще, чем другие. Например, реализация Soundex является частью каждого языка программирования, а также систем управления базами данных (СУБД), таких как Oracle, MySQL и PostgreSQL. В отличие от этого кодекс Metaphone и Match Rating используется редко и в большинстве случаев требует установки дополнительных программных библиотек в вашей системе.
Рассматриваемая как предложение, эта статья демонстрирует, как комбинировать разные фонетические алгоритмы в векторизованном подходе и использовать их особенности для достижения лучшего результата сравнения, чем использование отдельных алгоритмов по отдельности.Для реализации этого в игру вступает библиотека на основе Python под названием AdvaS Advanced Search на SourceForge. AdvaS уже включает в себя метод, позволяющий вычислить несколько фонетических кодов слова за один шаг.
AdvaS уже включает в себя метод, позволяющий вычислить несколько фонетических кодов слова за один шаг.
Разъяснение фонетических алгоритмов
Если быть более точным, каждый из этих алгоритмов создает определенное фонетическое представление отдельного слова. Обычно такое представление представляет собой либо строку фиксированной длины, либо строку переменной длины, состоящую только из букв, либо комбинацию букв и цифр.Подробная структура представления зависит от алгоритма. Фактически, если два представления, рассчитанные с использованием одного и того же алгоритма, похожи, два исходных слова произносятся одинаково, независимо от того, как они пишутся. На самом деле это помогает обнаруживать похожие по звучанию слова, даже если они написаны по-разному — независимо от того, сделано ли это намеренно или случайно.
Каждый из этих алгоритмов был разработан с учетом определенного языка или цели и не подходит для языков друг друга одинаково.Имейте в виду, что изображения не всегда оптимальны, но предназначены для максимального соответствия. Например, оригинальный алгоритм Soundex ориентирован на английский язык, тогда как Kölner Phonetik фокусируется на немецком языке, который содержит умляуты и другие специальные символы, такие как «ß».
Например, оригинальный алгоритм Soundex ориентирован на английский язык, тогда как Kölner Phonetik фокусируется на немецком языке, который содержит умляуты и другие специальные символы, такие как «ß».
Далее мы кратко рассмотрим набор фонетических алгоритмов. Для более подробного описания перейдите по ссылкам, приведенным ниже. Предупреждаем, что уровень документации алгоритмов очень разный — от очень детального до весьма скудного.
Soundex
Результирующее представление алгоритма Soundex представляет собой четырехбуквенное слово. Это основано на символе, за которым следуют три числовые цифры. Например, значение Soundex для «Knuth» составляет K530, что аналогично «Kant». Эта простота приводит к появлению множества ошибочных представлений. Хотя в целом результаты неплохие. Первоначально разработанный для американского английского, Soundex сегодня доступен в различных языковых версиях, таких как французский, немецкий и иврит.
Разработанный Робертом Расселом и Маргарет Кинг Оделл в начале 20 века, Soundex был разработан с учетом английского языка. Он широко использовался для обнаружения похожих по звучанию фамилий в рамках переписи населения США в 1930-х годах.
Он широко использовался для обнаружения похожих по звучанию фамилий в рамках переписи населения США в 1930-х годах.
Метафон
Разработанный Лоуренсом Филлипсом в 1990 году, Metaphone был разработан с учетом английского языка. Он попытался улучшить механизм Soundex, используя информацию о вариациях и несоответствиях в английском написании / произношении, чтобы получить более точные кодировки.В результате фонетическое представление представляет собой слово переменной длины на основе 16 согласных «0BFHJKLMNPRSTWXY». 5 гласных «AEIOU» тоже разрешены, но только в начале представления.
Первоначальное описание алгоритма Метафона было довольно неточным и привело к разработке как Двойного Метафона, так и Метафона 3. Последний может исправлять тысячи неправильных кодировок, которые производятся первыми двумя версиями. Metaphone 3 доступен как коммерческое программное обеспечение и поддерживает немецкое и испанское произношение.
Рисунок 1 ниже — это снимок экрана, сделанный с голландского генеалогического веб-сайта, на котором показаны различные представления Soundex, Metaphone и Double Metaphone для имени «Knuth». Кроме того, на рисунке показан набор слов, которые представлены одинаково и имеют одинаковый фонетический код («Gleiche Kodierung wie»). Чем отчетливее алгоритм, тем лучше меньше слов с одинаковым фонетическим кодом.
Кроме того, на рисунке показан набор слов, которые представлены одинаково и имеют одинаковый фонетический код («Gleiche Kodierung wie»). Чем отчетливее алгоритм, тем лучше меньше слов с одинаковым фонетическим кодом.
Рисунок 1
Алгоритм Метафон является стандартной частью только нескольких языков программирования, например PHP.Для Python и Метафон, и Двойной Метафон являются частью
.Введение в фонетическую транскрипцию | Антимун
Томаш П. Шинальски
© Томаш П. Шинальски, Antimoon.com
Связанные страницы
Демонстрация фонетической транскрипции
Словари с фонетической транскрипцией расскажут вам о произношение слов. В английских словарях фонетическая транскрипция необходима, потому что написание английского слова не скажи тебе, как ты должен произнести это.
Фонетические транскрипции обычно пишутся в международном фонетическом алфавите (IPA), в котором каждому английскому звуку соответствует свой символ. (Вы можете посмотреть на график со всеми Английские звуки и их символы IPA.)
(Вы можете посмотреть на график со всеми Английские звуки и их символы IPA.)
Например, фонетическая транскрипция слова на основе IPA дом это hoʊm , а транскрипция прийти составляет км . Обратите внимание, что в написании эти слова похожи. Оба они оканчиваются на или . Но их фонетические транскрипции разные, потому что они выраженный по-другому.
Фонетическая транскрипция обычно приводится в скобках, например: / hom / , / km / .В словаре это выглядит так:
(Кстати, не все словари дают произношения слов. Если вы серьезно относитесь к изучению английского языка, вам следует купите словарь, в котором есть эта информация.)
Словесное ударение
Когда в слове много слогов, один из них всегда выраженный сильнее. Это называется ударением слова , и мы говорим, что это слог с ударением . Например, в слове становится , усиленный слог приходят . Если бы ударный слог был , будет , станет . выраженный
Если бы ударный слог был , будет , станет . выраженный нравится .
Словари подскажут, на каком слоге делается ударение. Самая популярная система — нанесение вертикальной линии ( ˈ ) перед ударным слогом в фонетической транскрипции слова. Например, транскрипция для становится это / bɪˈkʌm / .
Если в слове только один слог (примеры: pen , watch ), словари обычно не ставят перед ним ударение ˈ .Так они не пишут / ˈpen / — просто пишут / pen / .
Некоторые словари используют другие системы для выделения словесного ударения. Например, они могут поставить ˈ после ударного слога, или они могут подчеркивать ударный слог.
Демонстрация
Взгляните на наши демонстрация системы фонетической транскрипции. Вы можете прочитать транскрипции несколько английских слов и одновременно слушайте их произношение.
Представление различий между британским и американским английским языком
Многие слова в британском и американском английском произносятся по-разному. Конечно, эти отличия должны быть отражены в фонетической транскрипции. Это можно сделать двумя основными способами:
Конечно, эти отличия должны быть отражены в фонетической транскрипции. Это можно сделать двумя основными способами:
Отдельные транскрипции для британского и американского английского, например:
точка BrE / dɒt /, AmE/ dɑːt /ферма BrE / fɑːm /, AmE/ fɑːrm /идти BrE / gəʊ /, AmE/ goʊ /мама BrE / m /, AmE/ mʌðər /(или/ mʌðɚ /)Эта система используется в словарях для продвинутых учащихся из Лонгмана, Оксфорда и Кембриджа.Проблема с этой системой заключается в том, что вам нужно написать две транскрипции для большинства слов, что занимает много места.
Одна «компромиссная» транскрипция для британского и американского английского. Это делается с использованием в основном британских символов фонем и символа
ʳ.
точка / dɒt /ферма / фɑːʳм /идти / goʊ /мама / мкм /В этой системе транскрипции короче, но читатель должен знать, что в американском английском
ɒменяется наɑ:иʳменяется наr.Эта система используется, например, в Collins COBUILD Английский словарь для продвинутых изучающих, и во многих местах на Antimoon.

Следует ли вам заботиться о фонетической транскрипции?
Сегодня почти все хорошие английские словари имеют аудиозаписи. Если вы можете слушать любое английское слово как оно есть произносится носителем языка, почему вы должны заботиться о фонетической транскрипции? Вот несколько причин:
- Если вы хотите иметь хорошее английское произношение, вам все равно придется выучить и практиковать все английские звуки. Если ты будешь учить каждый звук в таблице звуков английского языка вы можете также выучить его символ — , это не означает столько дополнительных усилий . Для вас это даже не обязательно должен быть специальный проект — все, что вам нужно сделать, это обратить внимание на фонетические транскрипции в вашем словаре. Так вы постепенно узнаете символы.
Предположим, вы ищете слово boot и слушаете его запись *. Теоретически, если вы знакомы со звуками английского языка, вы должны быть в состоянии заметить что boot имеет звук «длинное u» , и скоро , а не «Короткий u» хорошо и книга .Но на практике вы можете упустить этот факт, особенно если вы новичок или не уделяете достаточно внимания. Если вы также прочитаете фонетическую транскрипцию
Есть еще слова, написание которых может заставить вас услышать то, чего нет./ buːt /и увидите символuː(и знаете, что он означает), есть больший шанс, что Вы заметите и запомните правильное произношение . Например, многие учащиеся могут «услышать», что панда оканчивается на гласную ɑː, что ha w k имеет звукw, и что syst e m имеет звукe.Во всех таких случаях фонетическая транскрипция может помочь избежать иллюзий. (К сожалению, они могут создавать свои собственные иллюзии.)Транскрипции также могут избавить вас от галлюцинаций. Позвольте мне объяснить, что я имею в виду. Вот английское слово: полковник . А вот его звуковое произношение. Вы заметили что-нибудь необычное в этом слове и его произношении? Если вы ничего не заметили, вот подсказка: сколько на нем
l, когда вы это говорите? Правильно — всего одинл.Однако это очень легко пропустить, потому что написание полковник заставляет вас ожидать двухлитров. Это ожидание может повлиять на ваше восприятие — когда вы слушаете запись, очень легко услышать дваl, даже если есть только один! Просмотр фонетической транскрипции/ ˈkɜːn ə l /может помочь вам заметить что первые l , полковник молчит.- В словарях больше транскрипций, чем записей.Например, транскрипции могут покажите два способа произнести слово, но запись покажет только один. Если вы умеете читать фонетические транскрипции, вы можете получить больше информации из словаря.
- В Интернете люди используют фонетическую транскрипцию по номеру обсудить проблемы с произношением . Если вы хотите присоединиться к дискуссии или задать вопросы, вы должны знать систему транскрипции.
- Есть ситуаций, когда вы не можете слушать звук — например, на вашем компьютере нет динамиков, вы не хотите беспокоить других людей, вы находитесь в шумной обстановке и не слышите звук, у вас есть доступ только к бумажному словарю и т. д.Даже если вы можете использовать аудио, взгляните на транскрипцию может быть быстрее, чем нажатие кнопки и прослушивание записи.
- Если вы создаете свои собственные элементы SRS, вы можете добавлять фонетические транскрипции легче (и быстрее), чем аудиозаписи. См. Также: элементы произношения.
 Если ты будешь учить каждый звук в таблице звуков английского языка вы можете также выучить его символ — , это не означает столько дополнительных усилий . Для вас это даже не обязательно должен быть специальный проект — все, что вам нужно сделать, это обратить внимание на фонетические транскрипции в вашем словаре. Так вы постепенно узнаете символы.
Если ты будешь учить каждый звук в таблице звуков английского языка вы можете также выучить его символ — , это не означает столько дополнительных усилий . Для вас это даже не обязательно должен быть специальный проект — все, что вам нужно сделать, это обратить внимание на фонетические транскрипции в вашем словаре. Так вы постепенно узнаете символы. Например, многие учащиеся могут «услышать», что панда оканчивается на гласную
Например, многие учащиеся могут «услышать», что панда оканчивается на гласную 
 См. Также: элементы произношения.
См. Также: элементы произношения.Короче говоря, вы можете выучить хорошее английское произношение, не зная символов IPA для английских звуков, но изучение этих символов не так уж и сложно, и вы получите взамен несколько приятных преимуществ.
Если вы собираетесь использовать фонетические транскрипции, вам следует кое-что о них знать.
.фонетический разбор и этапы его проведения :: SYL.ru
Улучшаем пасту шпинатом и тыквой: способы приготовления здоровых блюд
В клетку и не только: самые модные модели штанов на осень 2022
Кешью и не только: 5 источников углеводов, которые действительно полезны
Салфетки, розовая вода и не только: делаем эффективную косметическую маску-вуаль
Что есть каждому женскому знаку зодиака на завтрак, чтобы зарядиться энергией
Запеченный лосось со спаржей: 8 идей блюд на противне, уменьшающих воспаление
Улыбнулась в ответ: женщины склонны заражаться чужими чувствами сильнее мужчин
Запеченная тыква на тосте с сыром: три вкусных осенних рецепта из тыквы
Подплечники в версии XXL и корсет: обязательные тренды осени-зимы 2022/2023
Кожаная куртка: что еще надеть, когда уходишь в 9:00, а возвращаешься в 21:00
Автор Ольга Иванова
В школьную программу, помимо овладения навыками грамотного письма и связного изложения мыслей, входит обучение разного рода разборам слов, словосочетаний и предложений. У каждого вида есть свои задачи и алгоритм действия.
У каждого вида есть свои задачи и алгоритм действия.
Понятие фонетического разбора
Фонетический разбор представляет собой анализ звуковой оболочки слова. Он даёт представление о том, из скольких слогов слово состоит, на какой из них падает ударение, каково соотношение в слове звуков и букв, каков их качественный состав. Подобный разбор напрямую связан с фонетикой – разделом, посвящённым изучению звукового строя языка. Также фонетический разбор предполагает элементарное владение навыками транскрибирования – записи слова по принципу «как слышится».
Принципы обучения и подачи материала
Системно и подробно фонетический анализ изучается в 5 классе. Эта тема идёт в качестве обобщающей по всему разделу. К тому времени школьники уже знают о системе гласных и согласных в русском языке, имеют представление об ударной и безударной позициях звука, о системе звонких и глухих согласных, сонорных, мягких и твёрдых и отношениях парности и непарности между ними. Также грамотный фонетический разбор невозможен без понимания того, что такое йотированные гласные и когда одна буква обозначает несколько звуков. Все эти сведения впоследствии не повторяются специально. Чтобы ученики не забыли материал, его следует регулярно закреплять на практике. Следовательно, хотя бы раза два в неделю надо давать общие или индивидуальные задания, куда обязательно будет входить фонетический разбор. Касается это не только 5 класса, но и всех последующих лет обучения русскому языку. Поэтому педагогу следует действовать целенаправленно, планируя учебный процесс по своему предмету. И если пятиклассники будут тренироваться на простых примерах, то в следующих классах учитель должен давать им задания посложнее. Вначале, конечно, идёт фонетический разбор слов. В 6-7 классах школьники могут анализировать буквенно-звуковую оболочку словосочетаний. Так будут отрабатываться навыки транскрибирования, шлифоваться алгоритмы производимых операций. Дети научатся слышать слово, его характерные особенности.
Также грамотный фонетический разбор невозможен без понимания того, что такое йотированные гласные и когда одна буква обозначает несколько звуков. Все эти сведения впоследствии не повторяются специально. Чтобы ученики не забыли материал, его следует регулярно закреплять на практике. Следовательно, хотя бы раза два в неделю надо давать общие или индивидуальные задания, куда обязательно будет входить фонетический разбор. Касается это не только 5 класса, но и всех последующих лет обучения русскому языку. Поэтому педагогу следует действовать целенаправленно, планируя учебный процесс по своему предмету. И если пятиклассники будут тренироваться на простых примерах, то в следующих классах учитель должен давать им задания посложнее. Вначале, конечно, идёт фонетический разбор слов. В 6-7 классах школьники могут анализировать буквенно-звуковую оболочку словосочетаний. Так будут отрабатываться навыки транскрибирования, шлифоваться алгоритмы производимых операций. Дети научатся слышать слово, его характерные особенности. А в старшем звене – 8-9 и следующие классы – ученикам можно всё чаще предлагать произвести фонетический разбор предложения.
А в старшем звене – 8-9 и следующие классы – ученикам можно всё чаще предлагать произвести фонетический разбор предложения.
Конкретные примеры фонетического анализа
Давайте рассмотрим фонетический анализ слова «ветер». Оно состоит из двух слогов, ударение падает на первую букву «е». Транскрибируем слово, проставляем ударение. Транскрипция оформляется в квадратные скобки: [в’э´т’ир]. Как видим, сразу следует отметить имеющиеся в слове фонетические явления. В данном случае это наличие мягких звуков. Теперь под анализируемым словом проводим вертикальную черту и записываем в столбик каждую букву, а после неё – звук с подробной характеристикой:
- в – [в’] согласный, звонкий, парный, [ф’], в данной позиции является мягким, парным [в];
- е – [э´] гласный, ударный;
- т – [т’] согласный, всегда глухой, есть звонкая пара [д’], мягкий, парный, [т];
- е – [и] гласный, безударный;
- р – [р] согласный, сонорный, твёрдый, парный, [р’].
Таким образом, слово состоит из 5 букв, 5 звуков. Данный пример продемонстрировал особенности оформления фонетического анализа в письменном виде.
Данный пример продемонстрировал особенности оформления фонетического анализа в письменном виде.
Похожие статьи
- Фонетическая транскрипция — это очень просто
- Звуковой анализ слова: что это и как правильно его делать
- Анатомия женщины: внутренние органы
- Что такое образные выражения в баснях Крылова
- Исконно русские слова: история, особенности и примеры
- Что такое муниципалитет? Значение, происхождение, перевод слова
- Что такое портрет? Значение слова, определение
Также читайте
Этапы урока | Обучающие и развивающие компоненты, задания и упражнения | Деятельность учителя | Осуществляемая деятельность учащихся | Формирование УУД |
1. | Эмоциональная, психологическая и мотивационная подготовка учащихся к усвоению изучаемого материала | Вступительное слово. Люблю грозу в начале мая, Когда весенний первый гром, Как бы резвяся и играя, Грохочет в небе голубом. Гремят раскаты молодые… (г, р) Определите, как сочетанием звуков, их повторением передаёт поэт грохот грома?
Сегодня у нас необычное занятие — урок погружения в разнообразный мир звуков, окружающий нас со всех сторон. -Какой раздел науки о языке изучает звуки? | Слушают выразительное чтение стихотворения, участвуют в диалоге с учителем. Размещают учебные материалы на рабочем месте, демонстрируют готовность к уроку | Познавательные: осознают учебно-познавательную задачу. Регулятивные:планируют необходимые действия, операции. Коммуникативные: работают в группах (обмениваются мнениями, учатся понимать позицию партнера, в том числе и отличную от своей) |
II. Актуализация знаний по теме «Фонетика» | Воспроизведение ранее изученного, установление преемственных связей прежних и новых знаний и применение их в новых ситуациях. Эвристическая беседа, обсуждение результатов работы по заданиям | Лингвистическая задача 1группа Орфоэпическая разминка. 3 группа Прочитайте слова в транскрипции и запишите орфографически правильно: [баица] [ваз’м’ом] [л’охк’ий’] [сй’эст] [сонцэ] [вышыфка] [скаска] 4 группа Запишите в три колонки слова, распределив их по принципу: 1) звуков букв; 2) звуков Пьеса, звёздный, объём, льдины, ёжик, каюта | Работа в группах. У доски запись коллективной работы (от группы по одному человеку) | Познавательные: осуществляют для решения учебных задач операции анализа, синтеза, сравнения, классификации, следственные связи. Регулятивные: принимают и сохраняют учебную задачу. Коммуникативные: формулируют собственные мысли, высказывают и обосно-вывают свою точку зрения Личностные: осознают свои трудности и стремятся к их преодолению; проявляют способность к самооценке своих действий, поступков. Познавательные: устанавливают причинно-следственные связи, делают выводы. Регулятивные: осознают недостаточность своих знаний. Коммуникативные: задают вопросы с целью получения необходимой для решения проблемы информации |
3. Выявление места и причины затруднения | Беседа, ответы на вопросы, обсуждение результатов предыдущего этапа. | Для чего нужно изучать фонетику? Какие действия вы производили со словом? Или Назовите вид разбора над которым мы работали? | Обдумывают ответы на вопросы, воспринимают на слух информацию, осваивают лингвистические термины. Осознают, что знаний недостаточно для полных ответов | |
4. | Сформулируйте тему урока. Что необходимо для выполнения любого разбора? (план, алгоритм) | Формулируют тему, цели урока. | Регулятивные УУД 1. Высказывать предположения на основе наблюдений. Искать пути решения проблемы. Познавательные УУД 1. Выделять главное, свёртывать информацию. 2. Анализировать, сравнивать, делать выводы. 3. Преобразовывать информацию из одной формы в другую (план, схема). | |
. Что мы понимаем под словосочетанием «фонетический разбор»? (Определение признаков всех звуков, из которых состоит слово)
гласные – ударный, безударный; согласные – звонкий, глухой; твёрдый, мягкий; сонорный. 6.Определить количество букв и звуков. | Коллективная работа, индивидуальная, работа в группах | |||
6. Первичное закрепление с комментированием во внешней речи. Работа по учебнику 7. Самостоятельная работа с взаимопроверкой по эталону | Обобщение, систематизация знаний и формирование рациональных способов применения их на практике. Выполнение разноуровневых обучающих упражнений на основе текстов учебника | Отгадайте загадку, сделайте фонетический разбор слова Загадка. Загадка. Самостоятельная работа. Что же это за девица, Ни швея, ни мастерица, Ничего сама не шьёт, А в иголках круглый год? Стоял жаркий июльский день. Косыми жаркими лучами солнце жгло сухую землю. Густая пыль поднималась по дороге и наполняла воздух. Облака объединялись в большую тучу. Прогремел дальний гром. Произвести фонетический разбор выделенных слов. | Ёжик ё-жик, 2 слога [й’ожык] Ё [й’] — согласный, звонкий, мягкий, сонорный [о] — гласный, ударный; Ж [ж] — согласный, звонкий, твёрдый; И [ы] — гласный, безударный; К [к] — согласный, глухой, твёрдый. ____________ 4 буквы, 5 звуков Ель 1 слог [й’эл’] Е [й’] — согласный, звонкий, мягкий, сонорный [э] — гласный, ударный; Л [л’] — согласный, звонкий, мягкий, сонорный Ь [–] ____________ 3 буквы, 3 звука | Личностные: осознают свои возможности в учении; способны адекватно рассуждать о причинах своего успеха или неуспеха в учении, связывая успехи с усилиями, трудолюбием. Регулятивные: планируют необходимые действия, операции, действуют по плану. Коммуникативные: осуществляют совместную деятельность в парах и рабочих группах с учётом конкретных учебнопознавательных задач |
8. Домашнее задание | 1.Контрольные вопросы на стр. 2.По желанию. Найдите строки стихотворения, в которых используется приём звукописи. | |||
9.Рефлексия |
Дайте оценку своей работе. | Определяют свое эмоциональное состояние на уроке. | Регулятивные УУД Соотносить цели и результаты своей деятельности. Вырабатывать критерии оценки и определять степень успешности работы. Познавательные: приобретают умения мотивированно организовывать свою деятельность. Коммуникативные: строят небольшие монологические высказывания |
 Мотивация (самоопределение) к учебной деятельности
Мотивация (самоопределение) к учебной деятельности Звуки «живут» и внутри нас самих. Давайте же погрузимся в этот мир и попробуем в нем разобраться.
Звуки «живут» и внутри нас самих. Давайте же погрузимся в этот мир и попробуем в нем разобраться. Прочитайте слова. Поставьте знак ударения. Произнесите правильно.
Прочитайте слова. Поставьте знак ударения. Произнесите правильно.
 Введение в тему с последующим планированием деятельности на уроке.
Введение в тему с последующим планированием деятельности на уроке.

 Познавательные: извлекают необходимую информацию из высказываний одноклассников, систематизируют собственные знания.
Познавательные: извлекают необходимую информацию из высказываний одноклассников, систематизируют собственные знания.

Векторизованный подход в Python
В предыдущей статье я дал вам введение в фонетические алгоритмы и показал их разнообразие. Более подробно мы рассмотрели расстояние редактирования, также известное как расстояние Левенштейна. Этот алгоритм был разработан для подсчета количества замен букв для перехода от одного слова к другому.
Как вы, возможно, уже заметили в предыдущей статье, существуют разные методы расчета звучания слова, такие как Soundex, Metaphone и кодекс Match Rating. Некоторые из них более распространены, чем другие. Например, реализация Soundex является частью каждого языка программирования, а также систем управления базами данных (СУБД), таких как Oracle, MySQL и PostgreSQL. Напротив, и Metaphone, и кодекс Match Rating редко используются и в большинстве случаев требуют установки в вашей системе дополнительных программных библиотек.
Эта статья, рассматриваемая как предложение, демонстрирует, как объединить различные фонетические алгоритмы в векторном подходе и использовать их особенности для достижения лучшего результата сравнения, чем при использовании отдельных алгоритмов по отдельности. Для реализации этого в игру вступает основанная на Python библиотека AdvaS Advanced Search на SourceForge. AdvaS уже включает метод для вычисления нескольких фонетических кодов для слова за один шаг.
Для реализации этого в игру вступает основанная на Python библиотека AdvaS Advanced Search на SourceForge. AdvaS уже включает метод для вычисления нескольких фонетических кодов для слова за один шаг.
Объяснение фонетических алгоритмов
Чтобы быть более точным, каждый из этих алгоритмов создает определенное фонетическое представление одного слова. Обычно такое представление представляет собой либо строку фиксированной длины, либо строку переменной длины, состоящую только из букв, либо комбинацию букв и цифр. Детальная структура представления зависит от алгоритма. На самом деле, если два представления, рассчитанные с использованием одного и того же алгоритма, похожи, два исходных слова произносятся одинаково, независимо от того, как они написаны. На самом деле, это помогает обнаруживать слова с похожим звучанием, даже если они пишутся по-разному, независимо от того, сделано это намеренно или случайно.
Каждый из этих алгоритмов был разработан с учетом определенного языка или цели и не подходит для других языков точно так же.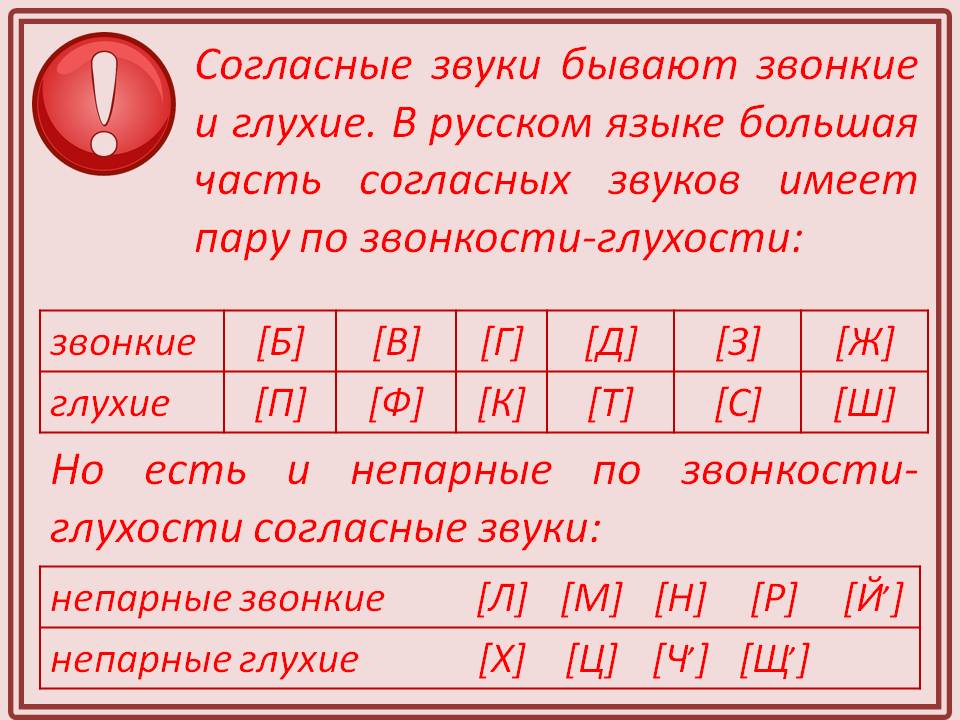 Имейте в виду, что представления не всегда оптимальны, но предназначены для максимально точного соответствия. Например, исходный алгоритм Soundex ориентирован на английский язык, тогда как Kölner Phonetik ориентирован на немецкий язык, который содержит умлауты и другие специальные символы, такие как «ß».
Имейте в виду, что представления не всегда оптимальны, но предназначены для максимально точного соответствия. Например, исходный алгоритм Soundex ориентирован на английский язык, тогда как Kölner Phonetik ориентирован на немецкий язык, который содержит умлауты и другие специальные символы, такие как «ß».
Далее мы кратко рассмотрим некоторые фонетические алгоритмы. Для более подробного описания перейдите по ссылкам, указанным ниже. Имейте в виду, что уровень документирования алгоритмов весьма разный — от очень подробного до весьма скудного.
Soundex
Результирующее представление алгоритма Soundex представляет собой четырехбуквенное слово. Это основано на символе, за которым следуют три цифры. Например, значение «Кнут» на Soundex равно K530, что похоже на «Кант». Эта простота приводит к целому ряду вводящих в заблуждение представлений. Хотя в целом результаты неплохие. Первоначально разработанный для американского английского, Soundex сегодня доступен в различных языковых версиях, таких как французский, немецкий и иврит.
Разработанный Робертом С. Расселом и Маргарет Кинг Оделл в начале 20-го века, Soundex был разработан с учетом английского языка. Он широко использовался для обнаружения похожих по звучанию фамилий в рамках переписи населения США в 1930-х годах.
Metaphone
Разработанный Лоуренсом Филлипсом в 1990 году, Metaphone также был разработан с учетом английского языка. Он попытался улучшить механизм Soundex, используя информацию о вариациях и несоответствиях в английской орфографии/произношении для создания более точных кодировок. В результате фонетическое представление представляет собой слово переменной длины, основанное на 16 согласных «0BFHJKLMNPRSTWXY». Допускаются и 5 гласных «AEIOU», но только в начале представления.
Первоначальное описание алгоритма Метафона было довольно неточным и привело к разработке как Двойного Метафона, так и Метафона 3. Последний может исправить тысячи неверных кодов, порожденных первыми двумя версиями. Metaphone 3 доступен как коммерческое программное обеспечение и поддерживает как немецкое, так и испанское произношение.
Рисунок 1 ниже представляет собой снимок экрана, сделанный с веб-сайта голландской генеалогии, и показывает различные представления Soundex, Metaphone и Double Metaphone для имени «Knuth». Кроме того, на рисунке показан набор слов, представленных одинаковым образом и имеющих одинаковый фонетический код («Gleiche Kodierung wie»). Чем четче алгоритм, тем меньше слов с одинаковым фонетическим кодом.
Рисунок 1
Алгоритм Metaphone является стандартной частью лишь нескольких языков программирования, например PHP. Для Python и Metaphone, и Double Metaphone являются частью пакета Phonetics. Коммерческие реализации доступны для языков программирования C++, C#, Java, Python и Ruby.
Caverphone
Алгоритм Caverphone был создан Дэвидом Худом в 2002 году. Переработанная версия была выпущена в 2004 году. Средой проекта является проект Caversham Project в Университете Отаго, Новая Зеландия. Предыстория алгоритма заключалась в том, чтобы помочь сопоставить данные списков избирателей между концом 19го века и начала 20 века, когда имена должны были быть только в «общеузнаваемой форме». Алгоритм назван в честь муниципалитета, в котором расположен университет, и оптимизирован для языковых комбинаций букв, в которых проводилось исследование названий.
Алгоритм назван в честь муниципалитета, в котором расположен университет, и оптимизирован для языковых комбинаций букв, в которых проводилось исследование названий.
По умолчанию представление Caverphone состоит из шести символов и цифр. Некоторые реализации позволяют увеличить длину до десяти символов и цифр. Например, «Томпсон» трансформируется в код «TMPSN1». В настоящее время алгоритм доступен для C#, Python (пересмотренная версия), Java (как исходная, так и переработанная версия) и R.
Система идентификации и разведки штата Нью-Йорк
Этот алгоритм был разработан в 1970-х годах как часть Системы идентификации и разведки штата Нью-Йорк (NYSIIS). Говорят, что он все еще используется сегодня, его качество близко к алгоритму Soundex.
Дизайн специально оптимизирован для соответствия американским именам. Итак, два имени «Уэбберли» и «Вибберли» представлены фонетическим кодом «ВАБАРЛИ».
Kölner Phonetik
На основе алгоритма Soundex, в 1969 Ганс Иоахим Постель разработал Kölner Phonetik. Он ориентирован на немецкий язык и позже стал частью систем SAP. Фонетическое представление — это просто строка цифр переменной длины.
Он ориентирован на немецкий язык и позже стал частью систем SAP. Фонетическое представление — это просто строка цифр переменной длины.
В настоящее время известны реализации на Perl, PHP и JavaScript.
Подход к оценке соответствия
Кодекс подхода к оценке соответствия (MRA) был разработан в 1977 г. компанией Western Airlines. Идея заключалась в том, чтобы обнаруживать гомофонные имена в списках пассажиров с упором на английский язык. Например, для «Смит» используется «SMTH», тогда как «Smyth» кодируется как «SMYTH».
В настоящее время MRA доступен в виде реализации C# на заархивированном веб-сайте и в виде метода Python в модуле Jellyfish.
Реализация
Расчет степени сходства основан на трех векторах, обозначенных как codeList1 , codeList2 и вес в листинге исходного кода ниже. В Python вектор можно реализовать как массив, например, с помощью пакета NumPy. Векторы номер один и два представляют собой фонетический код двух разных слов. Вектор номер три представляет конкретный вес алгоритма и содержит дробное значение от 0 до 1 для описания этого веса. Сумма отдельных значений вектора три является точным значением 1 и не должна быть ни ниже, ни выше этого значения. В этом случае отдельные значения третьего вектора должны быть предварительно нормализованы.
Вектор номер три представляет конкретный вес алгоритма и содержит дробное значение от 0 до 1 для описания этого веса. Сумма отдельных значений вектора три является точным значением 1 и не должна быть ни ниже, ни выше этого значения. В этом случае отдельные значения третьего вектора должны быть предварительно нормализованы.
На рисунке 2 показаны три вектора.
Рисунок 2 Три вектора, используемые для хранения данных
Рассчитанная степень сходства между двумя словами представляет собой десятичное значение, основанное на расчете по фонетическому алгоритму (промежуточный итог). Каждая промежуточная сумма является произведением расстояния Левенштейна между конкретным фонетическим представлением codeList1 и codeList2 и соответствующим весом для конкретного фонетического алгоритма. Для NYSIIS он рассчитывается следующим образом:
nysiis = Левенштейн(кодСписок1["нисис"], кодСписок2["нисис"]) * вес["нисис"]
= Левенштейн("Кнат", "Канд") * 0,1
= 3 * 0,1
= 0,3
Как описано в предыдущей статье, расстояние Левенштейна возвращает количество правок, необходимых для перехода от одного слова к другому. В нашем случае два слова представляют собой фонетические коды, вычисляемые по алгоритму. Чем меньше количество изменений (правок) между кодами, тем выше уровень фонетического сходства исходных слов с точки зрения алгоритма.
В нашем случае два слова представляют собой фонетические коды, вычисляемые по алгоритму. Чем меньше количество изменений (правок) между кодами, тем выше уровень фонетического сходства исходных слов с точки зрения алгоритма.
Приведенный ниже код Python использует класс Phonetics из модуля AdvaS, а также модуль NumPy. Определение функции Левенштейна похоже на предыдущую статью о расстоянии Левенштейна и включено только для полноты картины. Затем три вектора инициализируются, как показано на рис. 2 , промежуточные итоги вычисляются в цикле, и итог выводится на стандартный вывод.
# --*- кодировка: utf-8 --*-
из импорта фонетики Фонетика
импортировать numpy как np
определение Левенштейна (seq1, seq2):
size_x = длина (seq1) + 1
size_y = длина (seq2) + 1
матрица = np.zeros ((size_x, size_y))
для x в xrange (size_x):
матрица [х, 0] = х
для y в xrange (size_y):
матрица [0, у] = у
для x в xrange (1, size_x):
для y в xrange(1, size_y):
если seq1[x-1] == seq2[y-1]:
матрица [x,y] = мин(
матрица [х-1, у] + 1,
матрица [х-1, у-1],
матрица [х, у-1] + 1
)
еще:
матрица [x,y] = мин(
матрица [х-1, у] + 1,
матрица [х-1, у-1] + 1,
матрица [х, у-1] + 1
)
возврат (матрица [size_x - 1, size_y - 1])
# -- инициализируем фонетический объект
word1 = Фонетика ("Кнут")
word2 = Фонетика ("Кант")
print("Сравнение %s с %s" % (word1. getText(), word2.getText())))
# -- фонетический код
codeList1 = word1.phoneticCode()
codeList2 = word2.phoneticCode()
# -- масса
вес = {
"саундекс": 0,2,
"каверфон": 0,2,
"метафон": 0,5,
«нисис»: 0,1
}
# -- алгоритмы
алгоритмы = ["саундекс", "каверфон", "метафон", "нисис"]
# -- общий
всего = 0,0
для входа в алгоритмы:
код1 = кодСписок1[запись]
код2 = кодСписок2[запись]
лев = левенштейн (код1, код2)
currentWeight = вес[вход]
print ("сравнение %s с %s для %s (%0.2f: вес %0.2f)" % (code1, code2, entry, lev, currentWeight))
промежуточный итог = уровень * текущий вес
итог += промежуточный итог
печать ("всего: %0.2f" % всего)
 getText(), word2.getText())))
# -- фонетический код
codeList1 = word1.phoneticCode()
codeList2 = word2.phoneticCode()
# -- масса
вес = {
"саундекс": 0,2,
"каверфон": 0,2,
"метафон": 0,5,
«нисис»: 0,1
}
# -- алгоритмы
алгоритмы = ["саундекс", "каверфон", "метафон", "нисис"]
# -- общий
всего = 0,0
для входа в алгоритмы:
код1 = кодСписок1[запись]
код2 = кодСписок2[запись]
лев = левенштейн (код1, код2)
currentWeight = вес[вход]
print ("сравнение %s с %s для %s (%0.2f: вес %0.2f)" % (code1, code2, entry, lev, currentWeight))
промежуточный итог = уровень * текущий вес
итог += промежуточный итог
печать ("всего: %0.2f" % всего)
getText(), word2.getText())))
# -- фонетический код
codeList1 = word1.phoneticCode()
codeList2 = word2.phoneticCode()
# -- масса
вес = {
"саундекс": 0,2,
"каверфон": 0,2,
"метафон": 0,5,
«нисис»: 0,1
}
# -- алгоритмы
алгоритмы = ["саундекс", "каверфон", "метафон", "нисис"]
# -- общий
всего = 0,0
для входа в алгоритмы:
код1 = кодСписок1[запись]
код2 = кодСписок2[запись]
лев = левенштейн (код1, код2)
currentWeight = вес[вход]
print ("сравнение %s с %s для %s (%0.2f: вес %0.2f)" % (code1, code2, entry, lev, currentWeight))
промежуточный итог = уровень * текущий вес
итог += промежуточный итог
печать ("всего: %0.2f" % всего)
Предполагая, что исходный код хранится в файле phonetics-vector.py, вывод будет следующим:
$ python phonetics-vector.py Сравнение Кнута с Кантом сравнение K530 с K530 для soundex (0,00: вес 0,20) сравнение KNT1111111 с KNT1111111 для каверфона (0,00: вес 0,20) сравнение n0h с nt для метафона (2,00: вес 0,50) сравнение Кнатта с Кандом для nysiis (3,00: вес 0,20) всего: 1,60 $
Чем меньше степень сходства, тем более идентичны два слова с точки зрения произношения. Как показано в приведенном выше примере «Кнут» и «Кант», расчетное значение равно 1,6 и является довольно низким.
Как показано в приведенном выше примере «Кнут» и «Кант», расчетное значение равно 1,6 и является довольно низким.
Заключение
Описанный здесь подход помогает найти решение, позволяющее сбалансировать особенности различных фонетических методов. Пока что первый результат многообещающий, но, возможно, еще не оптимальный. Весовой вектор используется для регулирования влияния каждого конкретного фонетического алгоритма. Необходимы дальнейшие исследования, чтобы найти соответствующее распределение весовых значений для каждого языка. Кроме того, список алгоритмов, которые учитываются, может быть легко расширен.
Благодарности
Автор выражает благодарность Gerold Rupprecht и Zoleka Hatitongwe за поддержку при подготовке статьи.
Фонетические алгоритмы — deparkes
Фонетические алгоритмы помогают сравнивать и сопоставлять слова по их произношению, а не только по написанию. Ранние фонетические алгоритмы были введены для помощи в анализе данных переписи населения США. Фонетические алгоритмы и другие методы «нечеткого сопоставления» с тех пор играют важную роль во многих действиях, включая исправление орфографии, связывание записей базы данных и рекомендации по поиску. В этом посте рассматривается, как работают фонетические алгоритмы, их ограничения и некоторые альтернативы.
Фонетические алгоритмы и другие методы «нечеткого сопоставления» с тех пор играют важную роль во многих действиях, включая исправление орфографии, связывание записей базы данных и рекомендации по поиску. В этом посте рассматривается, как работают фонетические алгоритмы, их ограничения и некоторые альтернативы.
Фонетические алгоритмы работают, разбивая слова на звуки, а не на написание. Одним из наиболее часто используемых фонетических алгоритмов является «Soundex», который был создан для помощи в анализе данных переписи населения США в начале 20-го века. Другие фонетические алгоритмы часто являются развитием и усовершенствованием Soundex, и он может служить примером того, как работают фонетические алгоритмы в целом.
Алгоритм Soundex кодирует слова (обычно имена) в виде буквы, за которой следуют три цифры. Числовое группирование цифр определяется местом артикуляции различных звуков в английском языке. Например, b, f, p и v получают кодовый номер 1, а d и t — кодовый номер 3.
Например, b, f, p и v получают кодовый номер 1, а d и t — кодовый номер 3.
Чтобы построить полный Soundex для слова, первая буква сохраняется, а затем удаляются все гласные звуки (включая h и w). Затем существуют дополнительные правила для работы с дубликатами и другими особыми случаями. Результатом является буква плюс три цифры кода исходной строки. Это упрощенное представление языка делает Soundex и другие подобные фонетические алгоритмы мощным инструментом для сравнения слов.
Фонетическое кодирование
Вы можете попробовать Soundex, используя онлайн-кодер Soundex. Запуск Soundex для слова или фразы создаст четырехсимвольный код. Поэкспериментируйте, и вы увидите некоторые потенциальные ловушки с кодированием типа Soundex.
Вы увидите, что «Robert» и «Ropert» дают один и тот же код Soundex (R163), который был бы полезен, если бы «Ropert» было ошибкой в написании «Robert». У Руперта также есть код «R163», и менее вероятно, что Руперт просто ошибся в написании Роберта, поэтому это может быть неверный результат.
Коды Soundex также плохо работают с более длинными строками. Джонс и Джонсон дают J520 и J525 соответственно, и это нормально. Если мы включим их в качестве фамилий, чтобы различать двух людей с именем «Роберт», Soundex перестанет быть полезным. Роберт Джонс и Роберт Джонсон по-прежнему будут возвращать код R163, поскольку код Soundex учитывает только первые несколько символов строки.
Ограничения фонетических алгоритмов
Фонетические алгоритмы могут быть чрезвычайно полезны для поиска документов и сопоставления данных. Однако у них есть свои ограничения, особенно когда речь идет о культурных различиях в звуках и латинизированном написании — фонетические алгоритмы довольно грубы и очень специфичны для языков, для которых они были разработаны, обычно для английского или немецкого. Фонетические алгоритмы «из коробки» также уязвимы для опечаток и других ошибок ввода и не имеют способов определить близость совпадений.
Ограничения на ввод
Некоторые входные данные для фонетических алгоритмов могут быть особенно сложными. К ним относятся:
К ним относятся:
- Зависимость от начальной буквы (например, f против ph): Фонетические алгоритмы обычно строят код на основе первой буквы имени или интересующего слова. Этот подход можно легко реализовать с помощью имен с разными буквами для одного и того же звука: например, «Кэтрин» (Soundex: K365) и «Кэтрин» (Soundex: C365).
- Ограничение на количество символов в коде Soundex (четыре) означает, что более длинные слова могут использовать один и тот же код, даже если они сильно различаются.
- В реальных данных часто используются инициалы, а не полное имя, например, «Дж. К. Роулинг», а не «Джоан Роулинг». Фонетический алгоритм не смог бы сопоставить эти два имени.
- Непереносимость шума (опечатки): фонетические алгоритмы по своей природе не устойчивы к опечаткам в словах, введенных в базу данных. Некоторые опечатки, такие как «Карл» и «Крал», могут быть идентифицированы, но такие опечатки, как «геоге» вместо «геордж», дают очень разные результаты.

Вопросы культуры
Фонетические алгоритмы разработаны для звуков определенного языка. Другие культурные проблемы включают в себя:
- Эквивалентность имен или прозвища. Например, Джека и Джона можно обменять .
- Заказ имени. Не во всех культурах используется порядок имен «первый-средний-фамилия». Непоследовательность в том, как они были записаны в базу данных, может легко обмануть фонетический алгоритм.
- Причуды английского языка означают, что в имени или слове часто встречаются немые согласные. Эти имена не должны последовательно записываться в интересующие записи имен. Например, «Дейтон» или «Дейтон», «Крайтон» или «Крайтон», «Синджин» или «Св. Джон» и так далее. Различия в том, как записываются эти имена, запутают фонетический алгоритм.
- Различия в латинском написании. Существует несколько способов написания или написания имен с использованием латинских букв и английских звуков. Это также может происходить из-за различий в слухе или понимании. Часто имена вносятся в базу данных после прослушивания того, как кто-то произносит их имя — это может создать дополнительные сложности, если имя будет расслышано неправильно.
- Имена, содержащие частицы. Довольно часто встречаются имена, содержащие «частицы» или артикли. Это дополнительные части имени, такие как «фон», «де», «ал». Довольно часто они опускаются или объединяются с остальной частью имени — это может
 Часто имена вносятся в базу данных после прослушивания того, как кто-то произносит их имя — это может создать дополнительные сложности, если имя будет расслышано неправильно.
Часто имена вносятся в базу данных после прослушивания того, как кто-то произносит их имя — это может создать дополнительные сложности, если имя будет расслышано неправильно.Ограничения процесса
Существуют также некоторые ограничения в работе фонетических алгоритмов.
- Возвращает без ранжирования: Фонетические алгоритмы обычно не имеют концепции ранжирования подобия. Единственное, что имеет значение, это то, что кодировка одинакова. Часто бывает полезнее знать, какие возвращенные записи ближе всего к поисковому запросу.
- Плохая точность: упрощающий эффект фонетических алгоритмов типа Soundex может чрезмерно упростить имена до такой степени, что этот метод перестанет быть полезным. Ввод нескольких имен в кодировщик Soundex быстро покажет, что часто возвращается много нерелевантных имен. Это снижает эффективность любых последующих поисков или обработки данных.
 Это снижает эффективность любых последующих поисков или обработки данных.
Это снижает эффективность любых последующих поисков или обработки данных.Более продвинутые фонетические алгоритмы
Soundex хорошо известен и широко распространен, но многие разработки были реализованы в более поздних фонетических алгоритмах. Возможно, стоит изучить некоторые из этих альтернатив, прежде чем искать что-то другое.
Система идентификации и разведки штата Нью-Йорк (NYSIIS) была введена в 1970-х годах как усовершенствование Soundex. Основные улучшения включали в себя предоставление латиноамериканских имен и таблицы вероятностей, относящиеся к именам, ожидаемым в штате Нью-Йорк в то время. Daitch-Mokotoff Soundex был разработан в 1980-х лучше разбираться с германскими и славянскими фамилиями. Metaphone и Double Metaphone разрабатывались с 1990-х по 2000-е годы и пытались улучшить Soundex, используя информацию о вариациях и несоответствиях в написании. Другим вариантом является подход с рейтингом соответствия, который также позволяет измерить, насколько похожи два имени или слова.
Фонетические алгоритмы ElasticSearch | Даниэль Раналло
Воспроизведение проиндексированных версий записей переписи можно значительно улучшить с помощью фонетических алгоритмов Фонетические алгоритмы — это преобразования индексируемого текста, которые изменяют текст, как правило, до закодированного преобразования, основанного на произношении слова. Это позволяет преобразовывать входящие запросы таким же образом и в идеале достигать желаемого результата. В плагин фонетического анализа ElasticSearch встроено несколько фонетических алгоритмов, таких как Soundex, Metaphone, nysiis и каверфон. В основном эти фонетические алгоритмы используются для кодирования сложных для написания и необычных слов на основе их звучания, чтобы их можно было найти по тому, как они звучат. Эта уникальная схема кодирования делает их особенно полезными для индексации и поиска по имени человека. На самом деле как минимум две схемы в плагине были специально разработаны для решения проблемы поиска имен людей; Система идентификации и разведки штата Нью-Йорк (nysiis) и Soundex. Эти алгоритмы жертвуют некоторой точностью результатов в пользу улучшения отзыва (способности находить) системы.
Эти алгоритмы жертвуют некоторой точностью результатов в пользу улучшения отзыва (способности находить) системы.
Имена сложные. Представьте, что вы создаете систему, в которой пользователям нужно будет искать других пользователей по имени, например, в LinkedIn или Facebook есть функции поиска друзей. Возможно, вы сможете найти своих близких друзей, набрав их имя так, как пишет ваш друг. Поскольку это близкий друг, у вас по крайней мере есть шанс написать его правильно. А как насчет того парня, которого вы встретили на той конференции, Джона Смита, или это был Джон Смит, или Джин Смит? В сочетании с другими условиями поиска, такими как гипотетическая компания Джона, это может быть очень полезной функцией. Кроме того, попробуйте найти какие-либо очень интересные и информативные выступления Венката Субраманиама. Вы можете искать его имя с терминами Sbraminem, Subraminem или даже subramen, все из которых приводят к коду Soundex S165, что означает, что вы получите хиты, что означает высокий отзыв. Если кто-то с именем Sbraminem произведет множество выступлений, используя только Soundex, вы получите плохую точность; многие результаты вам не нужны, а некоторые нужны.
Если кто-то с именем Sbraminem произведет множество выступлений, используя только Soundex, вы получите плохую точность; многие результаты вам не нужны, а некоторые нужны.
Плагин ElasticSearch с открытым исходным кодом поддерживает множество алгоритмов. Ниже приведен синтез каждого алгоритма, включенного в плагин, о котором я могу найти информацию:
- Metaphone — улучшение Soundex, учитывающее различные варианты написания и произношения слов на английском языке. Ranallo стал RNL
- Double Metaphone — усовершенствование Metaphone, которое кодирует английские слова несколькими различными способами, в результате чего на вход можно ввести до двух кодов, что помогает охватить больше вариантов происхождения слов. Любопытно, что Раналло становится RNL при обоих преобразованиях.
- Soundex — фонетический алгоритм, используемый для анализа записей переписи населения США; учитывая его историю, ожидайте, что он хорошо сработает для американских фамилий. Раналло становится R540.
- Refined Soundex — усовершенствование Soundex, которое уменьшает количество имен, которые приводят к одному и тому же коду. Смещает соотношение точность/отзыв в сторону более высокой точности с меньшим отзывом.
- NYSIIS — алгоритм, разработанный специально для работы с американскими именами. Эмпирически это немного лучше, чем soundex. Раналло становится RANAL
- Caverphone1 и Caverphone2 — Алгоритмы, созданные в ходе работы, связанной с переписью в Новой Зеландии. Оптимизировано для английских имен, произносимых с особым акцентом (Данедин, Новая Зеландия). Раналло становится RNLA111111 в обеих версиях.
- Кёльн — Преобразование слова в числительное в соответствии с предопределенными правилами пути, например, A-> 0, F-> 3. Ranallo становится 7060550
- Diatch Mokotoff — усовершенствование Soundex, настроенное для славянских и идишских имен. Раналло становится 968800
- Beider Morse — Аналогичен Soundex, но спроектирован так, чтобы быть независимым от языка и более общим с более низким уровнем ложных срабатываний.
- Два дополнительных алгоритма, Koelner и Haase, встроены в подключаемый модуль, хотя мне было трудно найти достоверную информацию о том, что делает их уникальными.


Теперь, когда мы знаем, что такое фонетический алгоритм, и некоторые факты, которые могут помочь решить, какой фонетический алгоритм лучше всего подходит для конкретного случая; пришло время попробовать это. Первым шагом является включение плагина фонетики для вашего сервера ElasticSearch. В документации показан один из способов сделать это, выполнив некоторые команды на вашем сервере. Я предпочитаю неизменяемую инфраструктуру почти во всех случаях; это ничем не отличается. Чтобы включить Docker во время сборки образа, вы можете добавить следующую строку в свой Dockerfile:
RUN bin/elasticsearch-plugin install analysis-phonetic
Далее вам нужно настроить шаблон для индексации определенных полей с помощью выбранного фонетического алгоритма. В приведенном ниже примере документа:
{
"id": "aa936e9c-c436-4337-a15e-5a224da7214b",
"name": "Daniel Ranallo"
} Шаблон указателя, аналогичный следующему, активирует фонетические алгоритмы в поле имени с использованием динамического шаблона для поля с именем имя:
{
"index_patterns": [
"человек"
],
"настройки": {
"анализ": {
"анализатор": {
"метафон": {
"тип": "пользовательский",
"токенизатор" : "стандартный",
"фильтр": [
"строчные буквы",
"пример_метафона"
]
},
"soundex": {
"тип": "пользовательский",
"токенизатор": "стандартный",
"filter": [
"нижний регистр",
"refined_soundex_example"
]
},
"nysiis": {
"type": "пользовательский",
"tokenizer": "стандартный",
"filter": [
"нижний регистр",
"nysiis_example"
]
}
},
"фильтр": {
"metaphone_example": {
"кодировщик": "двойной метафон",
"заменить": false,
"тип": " фонетический"
},
"refined_soundex_example": {
"тип": "фонетический",
"кодировщик": "уточненный звук",
"заменить": false
},
"nysiis_example": {
"тип": " фонетический",
"кодировщик": "nysiis",
"заменить": false
}
},
"нормализатор": {
"lowercase_normalizer": {
"type": "custom",
"char_filter": [],
"filter": [
"нижний регистр"
]
}
}
}
},
"mappings": {
"_doc": {
"dynamic_templates": [
{
"фонетический": {
"match_mapping_type": "строка",
"match": "имя",
"mapping": {
"type": "текст",
"анализатор ": "стандарт",
"поля": {
"метафон": {
"тип": "текст",
"анализатор": "метафон"
},
"саундекс": {
"тип": " текст",
"анализатор": "soundex"
},
"nysiis": {
"type": "text",
"analyzer": "nysiis"
}
}
}
}
}
]
}
}
} 7 Установить этот шаблон скручивание PUT на адрес сервера
/templates/example_template . Это необходимо сделать перед индексацией данных, поскольку сопоставления типов неизменяемы для существующих полей. После того, как шаблон установлен и некоторые данные проиндексированы, вы готовы запрашивать некоторые документы. В зависимости от того, что важнее для вашего варианта использования — оптимизация отзыва или точности, вы можете использовать одно фонетическое поле, все поля или даже ни одно из полей. При оптимизации отзыва может быть достаточно запроса, подобного следующему: {
"запрос": {
"bool": {
"следует": [
{
"multi_match": {
"запрос": "ранали",
"поля": [
"имя",
"name.soundex",
"name.metaphone",
"name.nysiis"
]
}
}
]
}
}
} Замена значения запроса из ranali на другие распространенные варианты написания моей фамилии, такие как renali и rinala по-прежнему приводят к ожидаемому документу.
Большая часть работы по преобразованию во всех алгоритмах довольно незначительна и будет выполняться во время индексации, что снизит производительность индексации. Это может быть приемлемо для ваших бизнес-требований. При выполнении запросов также наблюдается небольшое снижение производительности цепочки анализатора, поскольку запрос должен пройти такое же преобразование. Самый большой скачок производительности, который я наблюдал, связан с использованием поиска по нескольким полям. Пример запроса ищет 4 поля, что означает поиск 4 инвертированных индексов для определения соответствия документа. ElasticSearch хорошо справляется с такой работой, но если возникают неприемлемые задержки, рассмотрите возможность настройки запроса, удалив лишние поля.
Я обнаружил, что плагин фонетических алгоритмов в ElasticSearch очень эффективен, позволяя мне начать работу за короткий период времени и сопоставлять некоторые очень сложные для написания имена. Недостатком является то, что компромисс между полнотой и точностью в некоторых случаях приводил к очень странным результатам. Например, в исходной реализации Soundex имена Джессика и Джошуа сопоставлялись с одним и тем же кодом Soundex. Это может сбить пользователей с толку, но, используя более новые версии алгоритмов и собирая данные о том, что работает для ваших пользователей, а что нет, вы обычно можете обойти эту проблему. Приведенные выше фонетические алгоритмы могут значительно повысить производительность поисковых алгоритмов, особенно при поиске имен людей.
Изображение на обложке из https://cityofgatonia.news/1920-census-unc-digitalinnovationlab/
Реализация фонетического поиска в Python с помощью алгоритма Soundex
В этой статье мы рассмотрим сопоставление слов с использованием алгоритма Soundex в Питон.
Что такое алгоритм Soundex и как он работает?
Soundex — это фонетический алгоритм, который может находить фразы с похожими звуками. Метод поиска Soundex принимает слово в качестве входных данных, например, имя человека, и выводит строку символов, которая идентифицирует группу слов, которые (примерно) фонетически похожи или звучат (приблизительно) одинаково.
Что такое стемминг и лемматизация в НЛП?
Стемминг и лемматизация — это два метода, используемые в обработке естественного языка (NLP) для стандартизации текста и подготовки слов или документов к дополнительной обработке машинным обучением.
Хотя это два самых популярных метода канонизации, они имеют определенные ограничения. Наша задача состоит в том, чтобы привести слова к их корневой форме для предварительной обработки, и этот метод известен как канонизация. Канонизация — это метод преобразования данных с множеством представлений в стандартную или нормальную форму. В этой статье мы попытаемся разобраться в этих ограничениях и понять, как на помощь приходит фонетическое хеширование.
В чем разница между стеммингом и лемматизацией? Stemming — это метод канонизации, который пытается сократить слово до его корневой формы, отбрасывая его аффиксы. Лемматизация — это еще один метод канонизации, который пытается сопоставить слово с его леммой — таким образом, для правильных результатов с использованием лемматизации слова должны быть правильно написаны в корпусе.
Ограничения стемминга и лемматизации В обоих методах возникает серьезная проблема при работе со словами с несколькими вариантами написания из-за разного произношения. Например, слова «Цвет» и «Цвет» могут обрабатываться стеммером по-разному, хотя оба они означают одно и то же. Точно так же «путешествие» и «путешествие» породили бы две основы/леммы, несмотря на то, что являются вариациями одного и того же слова.
Фонетическое хеширование
Фонетическое хеширование — это метод, используемый для канонизации слов, имеющих одинаковые фонетические характеристики. В результате фонетического хеширования каждому слову присваивается хеш-код на основе его фонемы, которая является наименьшей звуковой единицей. Таким образом, слова, являющиеся фонетическими вариантами друг друга, обычно имеют одинаковый код. Фонетическое хеширование достигается с помощью алгоритмов Soundex, доступных для разных языков. В этом разделе мы рассмотрим алгоритм
American Soundex
9. 0002 Американский алгоритм Soundex, который выполняет фонетическое хэширование англоязычного слова, т. е. берет слово на английском языке и генерирует его хэш-код. Полный алгоритм American Soundex для поиска кода Soundex выглядит следующим образом:
Шаг 1: Сохраните начальную букву
Этот шаг основан на рассуждениях о том, что в английском языке первая буква любого слова определяет его произношение. и является обязательным условием понятности слова. На этом шаге мы сохраняем первую букву слова, как она есть в хэш-коде.
Шаг 2: Кодирование согласных
Этот шаг основан на фонетических исследованиях английского языка. Он пытается заменить согласные с одинаковыми фонетическими характеристиками одной и той же буквой. Кодирование выполняется следующим образом:
 Это необходимо сделать перед индексацией данных, поскольку сопоставления типов неизменяемы для существующих полей. После того, как шаблон установлен и некоторые данные проиндексированы, вы готовы запрашивать некоторые документы. В зависимости от того, что важнее для вашего варианта использования — оптимизация отзыва или точности, вы можете использовать одно фонетическое поле, все поля или даже ни одно из полей. При оптимизации отзыва может быть достаточно запроса, подобного следующему:
Это необходимо сделать перед индексацией данных, поскольку сопоставления типов неизменяемы для существующих полей. После того, как шаблон установлен и некоторые данные проиндексированы, вы готовы запрашивать некоторые документы. В зависимости от того, что важнее для вашего варианта использования — оптимизация отзыва или точности, вы можете использовать одно фонетическое поле, все поля или даже ни одно из полей. При оптимизации отзыва может быть достаточно запроса, подобного следующему:  Это может быть приемлемо для ваших бизнес-требований. При выполнении запросов также наблюдается небольшое снижение производительности цепочки анализатора, поскольку запрос должен пройти такое же преобразование. Самый большой скачок производительности, который я наблюдал, связан с использованием поиска по нескольким полям. Пример запроса ищет 4 поля, что означает поиск 4 инвертированных индексов для определения соответствия документа. ElasticSearch хорошо справляется с такой работой, но если возникают неприемлемые задержки, рассмотрите возможность настройки запроса, удалив лишние поля.
Это может быть приемлемо для ваших бизнес-требований. При выполнении запросов также наблюдается небольшое снижение производительности цепочки анализатора, поскольку запрос должен пройти такое же преобразование. Самый большой скачок производительности, который я наблюдал, связан с использованием поиска по нескольким полям. Пример запроса ищет 4 поля, что означает поиск 4 инвертированных индексов для определения соответствия документа. ElasticSearch хорошо справляется с такой работой, но если возникают неприемлемые задержки, рассмотрите возможность настройки запроса, удалив лишние поля. Это может сбить пользователей с толку, но, используя более новые версии алгоритмов и собирая данные о том, что работает для ваших пользователей, а что нет, вы обычно можете обойти эту проблему. Приведенные выше фонетические алгоритмы могут значительно повысить производительность поисковых алгоритмов, особенно при поиске имен людей.
Это может сбить пользователей с толку, но, используя более новые версии алгоритмов и собирая данные о том, что работает для ваших пользователей, а что нет, вы обычно можете обойти эту проблему. Приведенные выше фонетические алгоритмы могут значительно повысить производительность поисковых алгоритмов, особенно при поиске имен людей.

 0002 Американский алгоритм Soundex, который выполняет фонетическое хэширование англоязычного слова, т. е. берет слово на английском языке и генерирует его хэш-код.
0002 Американский алгоритм Soundex, который выполняет фонетическое хэширование англоязычного слова, т. е. берет слово на английском языке и генерирует его хэш-код.- б, е, р, v → 1
- в, ж, к, к, к, с, х, г → 2
- г, т → 3
- л → 4
- m, n → 5
- r → 6
- h, w, y → не закодировано
Шаг 3. Отбросьте гласные
Отбросьте гласные
Этот шаг выполняется, поскольку гласные в английском языке не сильно влияют на фонетическое различие слова. Таким образом, все гласные прямо опускаются из слова.
Шаг 4: Сделайте длину кода равной 4
Последний шаг основан на стандарте, согласно которому хеш-коды должны иметь длину 4. Чтобы сделать код длиной четыре, мы делаем следующее:
- Если длина меньше 4, в конце дополняются нулями.
- Если длина превышает 4, обрезать хэш-код после позиции 4.
Пример американского алгоритма Soundex
Например, предположим, что нам нужно найти хэш-код слова Бангалор.
Шаг 1: Сохранить первую букву
Хэш-код : B
Шаг 2: Кодировать согласные
, l5 → Хэш-код: [n r →6] = Ba524o6e
Шаг 3: Теперь отбросьте все гласные
Хэш-код: B5246
Шаг 4: Укажите длину кода 4
Хэш-код: B524 [Усекая все после позиции 4]
Шаг 5: Окончательный вывод
Хэш-код Бангалора: B524
Аналогично, если мы вычислим хэш-код Бангалор (фонетический вариант 904 804), оказывается одинаковым, т. е. B524
е. B524
Реализация кода
Пример 1:
Теперь применим американский алгоритм Soundex в Python. Мы создаем функцию soundex_generator, которая генерирует хэш-код любого введенного в нее слова. Мы видим, что приведенный ниже код дает Soundex для Бангалора как B524, что совпадает с тем, который мы рассчитали вручную.
Python3
|
 ". ".
". ".  ljust(
ljust( Output:
B524600
Пример 2:
В этом примере мы передаем GeeksforGeeks в качестве аргумента, который дает результат как G216200. Здесь мы Trim or Pad, чтобы сделать Soundex 7-значным кодом.
Python3
|
 upper()
upper()  66666666666666666666666666669 ". "
66666666666666666666666666669 ". " :
G216200
00 S095265720056200
00 S0952657200566200
00. % 1 0 объект > эндообъект 7 0 объект > эндообъект 2 0 объект > эндообъект 3 0 объект > эндообъект 4 0 объект > ручей Acrobat Distiller 7.0.5 (Windows)2020-10-22T14:13:19+05:01Arbortext Advanced Print Publisher 10.0.1465/W Unicode2020-10-22T14:31:44+05:012021-07-07T17:05:47 +00:00приложение/pdf
, 17:05:47, в соответствии с условиями использования Cambridge Core, доступными по адресу https://www.cambridge.org/core/terms.API фонетического кодирования: как использовать API с бесплатным ключом API
Доступные алгоритмы:
- SOUNDEX
- КАВЕРФОН
- ТЕЛЕФОН 2
- КЕЛЬН_ФОНЕТИЧЕСКИЙ
- DAITCH_MOKOTOFF_SOUDEX
- МЕТАФОН
- МЕТАФОН2
- МЕТАФОН3
- НСИИС
- REFINED_SOUNDEX
- MATCH_RATING_APPROACH
- БЕЙДЕР_МОРСЕ
SOUNDEX
Soundex — это фонетический алгоритм индексации имен по звукам, произносимым на английском языке. Цель состоит в том, чтобы омофоны были закодированы в одном и том же представлении, чтобы их можно было сопоставить, несмотря на незначительные различия в написании. Алгоритм в основном кодирует согласные; гласная не будет закодирована, если это не первая буква. Soundex — наиболее широко известный из всех фонетических алгоритмов. Усовершенствования Soundex являются основой для многих современных фонетических алгоритмов
https://en.wikipedia.org/wiki/Soundex. и 1938 г. в южном Данидине, Новая Зеландия. Начав с концепции, аналогичной метафону, с тех пор он был разработан для обработки общего английского языка.
https://en.wikipedia.org/wiki/Caverphone
CAVERPHONE 2.0
Обновленный алгоритм 2.0 представляет собой систему фонетического сопоставления английского языка общего назначения.
https://en.wikipedia.org/wiki/Caverphone
COLOGNE PHONETIC
Кельнская фонетика (также Kölner Phonetik, Кёльнский процесс) — это фонетический алгоритм, который присваивает словам последовательность цифр, фонетический код. Цель этой процедуры состоит в том, чтобы идентичным по звучанию словам присваивался одинаковый код. Алгоритм можно использовать для поиска сходства между словами. Например, в списке имен можно найти такие записи, как «Meier», с разными вариантами написания, такими как «Maier», «Mayer» или «Mayr». Кёльнская фонетика связана с хорошо известным фонетическим алгоритмом Soundex, но оптимизирована для соответствия немецкому языку. Алгоритм был опубликован в 1969 Ганса Иоахима Постеля.
https://en.wikipedia.org/wiki/Cologne_phonetics
DAITCH-MOKOTOFF SOUDEX
Daitch-Mokotoff Soundex (D-M Soundex) — это фонетический алгоритм, изобретенный в 1985 году еврейскими генеалогами Гэри Мокотоффом и Рэнди Дейчем. Это усовершенствование алгоритмов Russell и American Soundex, предназначенное для обеспечения большей точности сопоставления славянских и идишских фамилий с похожим произношением, но с различиями в написании.
Daitch-Mokotoff Soundex иногда называют «еврейским Soundex» и «восточноевропейским Soundex», хотя авторы не одобряют использование этих прозвищ для алгоритма, поскольку сам алгоритм не зависит от того факта, что мотивация создания новой системы была плохой результат систем-предшественников при работе со славянскими и еврейскими фамилиями.
https://en.wikipedia.org/wiki/Daitch–Mokotoff_Soundex
МЕТАФОН
Метафон — это фонетический алгоритм, опубликованный Лоуренсом Филипсом в 1990 году для индексации слов по их английскому произношению. Он существенно улучшает алгоритм Soundex за счет использования информации о вариациях и несоответствиях в написании и произношении английского языка для получения более точной кодировки, которая лучше справляется с сопоставлением слов и имен, которые звучат одинаково. Как и в случае с Soundex, похожие по звучанию слова должны иметь одни и те же ключи. Метафон доступен как встроенный оператор в ряде систем.
https://en.wikipedia.org/wiki/Metaphone
ДВОЙНОЙ МЕТАФОН (МЕТАФОН 2.0)
В отличие от исходного алгоритма, применение которого ограничено только английским языком, эта версия учитывает особенности правописания ряда других языков .
https://en.wikipedia.org/wiki/Metaphone
METAPHONE 3.0
Metaphone 3 обеспечивает точность примерно 99% для английских слов, неанглийских слов, знакомых американцам, а также имен и фамилий, обычно встречающихся в Соединенные Штаты, разработанные в соответствии с современными инженерными стандартами на основе тестового набора подготовленных правильных кодировок.