напечатанный — фонетический (звуко-буквенный) разбор слова — РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «карточка», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.
Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
КАРТОЧКА, и, ж.
1. Небольшой прямоугольный кусок бумаги, картона. Каталожная к. Выписка на карточках.
2. Листок с напечатанным на нём текстом в свидетельство чего-н., с талонами на получение чего-н. Продовольственная к. Визитная к.
3. Фотографический портрет (разг.). К. для паспорта.
4. То же, что карта (в 4 знач. ) (разг.). Заполнить карточку в регистратуре.
) (разг.). Заполнить карточку в регистратуре.
| прил. карточный, ая, ое (к 1 и 2 знач.). Карточная система (выдача продовольствия по карточкам).
Фонетический (звуко-буквенный) разбор
ка́рточка
карточка — слово из 3 слогов: кар-то-чка. Ударение падает на 1-й слог.
Транскрипция слова: [картач’ка]
к — [к] — согласный, глухой парный, твёрдый (парный)
а — [а] — гласный, ударный
р — [р] — согласный, звонкий непарный, сонорный (всегда звонкий), твёрдый (парный)
т — [т] — согласный, глухой парный, твёрдый (парный)
о — [а] — гласный, безударный
ч — [ч’] — согласный, глухой непарный, мягкий (непарный, всегда произносится мягко), шипящий
к — [к] — согласный, глухой парный, твёрдый (парный)
а — [а] — гласный, безударный
В слове 8 букв и 8 звуков.
Цветовая схема: карточка
Разбор слова «карточка» по составу
карточка
Части слова «карточка»: карточк/а
Состав слова:
карточк — корень,
а — окончание,
карточк — основа слова.
|
Назначение Используется вместе с наглядно-дидактическим пособием «Обучающий калейдоскоп» (арт.10051) Технические характеристики и комплектность
Пособие состоит из 10 полноцветных, напечатанных на картоне и ламинированных пленкой карточек. Карточки снабжены маркировкой, где буква обозначает предмет, первая цифра – код темы, вторая цифра – порядковый номер (тему) карточки в серии, последняя цифра – вариант (I или II). Р4.1.I, Р4.1.II. Фонетический разбор слов. |

Контрольные работы по русскому языку 4 класс УМК «Планета Знаний» | Материал по русскому языку (4 класс) на тему:
Контрольный диктант по теме «Соблюдаем произносительные нормы и правила» ( входной).
Небо почернело. Лесные жители почувствовали опасность и спрятались. Сверкнула молния. Ее мощь была сильна. Раздался оглушительный гром. Пошел сильный дождь. Он не капал, а лил стеной.
Но скоро небо прояснилось. Засияло яркое солнце. С деревьев еще падали дождевые капли. Душистой смолою и березовыми почками запахло в лесу. Здесь снова поют чижи, скворцы, дрозды. Лес звенит на все голоса.
Грамматические задания.
1.Разобрать по членам предложения и частям речи предложение.
Раздался оглушительный гром.
2. Выполнить фонетический разбор слова солнце.
3. Разобрать по составу слова лесные, почернело.
Проверочная работа по правильной записи «сплошного текста».
Пришла поздняя осень стало в лесу скучно и холодно стали собираться птицы к отлету в теплые страны кружат над болотом журавли прощаются они на всю зиму с милой зеленой родиной слышится зайчатам , будто это с ними прощаются журавли:
-Прощайте, прощайте, бедные листопаднички.
Грамматические задания.
1.Подчеркнуть главные члены предложения и указать части речи в 1, 3, 4 предложениях.
2.Написать кого автор называет листопадничками.
3.Сделать фонетический разбор слова скучно.
Свободный диктант по теме «В устной речи интонация, а письменной …пунктуация».
Весной и летом ёлочки не было, а осенью показалась. Раздвинула листья, сучки, травинки и удивлённо осмотрелась. Деревья роняли листья.
И каждую осень, в день ёлочкиного рождения, деревья дарят ей подарки. Осина дарит красные «китайские фонарики». Клён роняет золотые звёзды. Ивы засыпают бронзовые рыбками.
И стоит ёлочка счастливая, нарядная и разноцветная.
Озаглавь текст. Какой заголовок точнее отражает содержание всего текста? Выбери: « В осеннем лесу», «Подарки», «Ёлочка», «В день рождения ёлочки». Можешь дать свой заголовок.
Контрольный диктант по теме «Формы изменения и правописания глаголов».
Картофель
Знаешь ли ты, что картофель в России считают вторым хлебом? Из него готовят разные блюда.
Свари картошку в соленой воде. Разомни ее и добавь молоко. Получишь вкусное пюре. Это блюдо стало любимым для многих детей и взрослых.
Картошку можно пожарить. Такое угощение хорошо и к праздничному столу. Хрустящие ломтики съедаются с большим аппетитом!
Запомни! Зеленый клубень картофеля ядовит. Его не употребляют в пищу, а используют для посадки нового урожая.
Грамматические задания.
1.Синтаксический разбор предложения.
Лесные жители почувствовали опасность.
2.Морфологический разбор слова опасность.
3.Фонетический разбор слова елка.
Свободный диктант по теме «Анализируем и строим предложения».
Прочитай текст. Передай кратко его содержание по абзацам (свободный диктант)
Бывало, лежишь в ночном у костра, мечтаешь. Вдруг видишь, что стоит у костра старичок. А посмотришь внимательно – вовсе это не старичок, а обгоревший пень.
На опушке леса притаилась старушка. Смотрит, как костёр догорает. А на самом деле это только дерево.
А на самом деле это только дерево.
Родная природа была моим первым учителем. Почти всех героев моих деревянных скульптур я позаимствовал у леса.
Списывание текста.
Божья коровка.
Почему этого жуч (?) кА с яркими пятныш(?)ками на спине называют бож(?)ей коровкой?
При опас(?)ности жучок выделя(е/и)т жгучую жидкост(?). В народе эту жидкость назвали молоч(?)ком. Поэтому и прозвали этих жуч(?)ков коровками.
Про добрых, безобидных людей в старину говорили, что они бож(?)и люди. А бож(?)я коровка на вид очень добродушный жучок. Поеда(е/и)т она тол(?)ко тлю.
Во втором предложении:
Покажите графическую связь членов предложения;
Укажи лицо и спряжение глагола;
Укажи падеж имён существительных.
Над глаголами укажи форму времени, выдели окончание.
Контрольный диктант по теме «Развертываем и распространяем мысли».
Ежи
У нас под крыльцом живут ежи. По вечерам вся их семья выходит гулять. Взрослые ежи маленькими лапками роют землю, достают корешки и едят. Ежата играют, резвятся.
По вечерам вся их семья выходит гулять. Взрослые ежи маленькими лапками роют землю, достают корешки и едят. Ежата играют, резвятся.
Однажды к старому ежу подбежала собака Веста. Еж свернулся в клубок и замер. Собака покатила зверька к пруду. Еж плюхнулся в воду, поплыл. Я отогнал Весту.
Весной под крыльцом обнаружили старого ежа. Куда девались остальные? Наверное, они переселились. И только старый еж не захотел покинуть наш дом.
Грамматические задания.
1.В третьем предложении подчеркнуть главные члены предложения и указать части речи.
2.Составить схему четвертого предложения.
3.Выписать 3 глагола 2 спряжения и 3 глагола 2 спряжения.
Осложненное списывание текста.
Вылез из-под коры Жук с предлинными усами, закрутил головой. Тоненький писк послышался. А внизу под деревом из гнезда вылез Шмель и полетел на лужок.
Вокруг цветка на лужку кружит. Жужжит жилковатыми жесткими крылышками, словно струна гудит.
Контрольный диктант по теме «Безударные падежные окончания имен существительных».
Озеро
В тайге раскинулось озеро Таглей. Горы цепью протянулись вдоль его живописных берегов. Подует с востока ветер-и на зеркальной глади озера появляются волны. Густые туманы закрывают горизонт. С криком уносятся стаи гусей и уток. В такую погоду рыбаки спешат к берегу. На южных склонах видны цветистые ковры брусники. Мрачные, темные леса растут на северных склонах долины Таглея. По берегу тянутся заросли кустарников малины, смородины. Почва покрыта мягкими подушками мхов.
Грамматические задания.
1.Синтаксический разбор предложения.
С криком уносятся стаи гусей и уток.
2.Морфологический разбор слова (с) криком.
3. Фонетический разбор слова якорь.
Контрольный диктант по теме «Правописание падежных форм склоняемых частей речи».
Хвойный лес
Почему Россию называют страной лесов? Здесь бескрайние лесные просторы. В северной части страны хвойные леса. В них растут сосны, ели, кедры. Эти деревья прекрасны в любое время года.
Мохнатые ветки пушистой ели похожи на большие лапы. Они укутывают весь ствол лесной красавицы. С веток свисают длинные шишки.
Солнце золотит их своими лучами. На лесной опушке редко увидишь сиротливую ель. Это дерево не переносит одиночества. Зимой в полях бушует вьюга, а в ельнике-тишь. Только над головой раскачивает ветер еловые маковки.
Грамматические задания.
1.Ситаксический разбор предложения.
С веток свисают длинные шишки.
2.Морфологический разбор слова (с)веток.
3.Фонетический разбор слова солнце.
Контрольный диктант по теме «Части речи, их форма и правописание».
Весна идет
Светает. Луч весеннего солнца пробежал по верхушкам деревьев и скрылся в лапах старой ели. Снег потемнел. На лесной опушке показались рыжие проталины. Это апрельские веснушки. С каждым днем их становится все больше.
Оживает лес. Вылезают из зимней норки зверьки. Лапка за лапкой вьются их следы на снегу. Стали слышны радостные голоса птиц. Вот пролетели клесты, снегири, зяблики. Маленькая птичка скачет от ветки к ветке. Не боится она теперь холодов. На сосне заработал дятел. Он оповещает лесных жителей о приходе весны.
Вот пролетели клесты, снегири, зяблики. Маленькая птичка скачет от ветки к ветке. Не боится она теперь холодов. На сосне заработал дятел. Он оповещает лесных жителей о приходе весны.
Грамматические задания.
- Синтаксический разбор предложения.
Маленькая птичка скачет от ветки к ветке.
- Морфологический разбор слова скачет.
- Морфемный разбор слова заработал.
- Фонетический разбор слова дятел.
Контрольный диктант по теме «Предложение. Текст.»
Земля в цвету
Весна одарила месяц май волшебной силой. Он оживляет природу, торопит ее к новой жизни. По его радостному зову меняется все вокруг. Спешат домой птицы из дальней зимовки. С раннего утра до позднего вечера не смолкают голоса. Земля наряжается в цветастый наряд. Поля, луга и леса чаруют сочной свежестью. В бело-розовой дымке стоят сады. Цветут сливы, вишни. С веселым жужжанием перелетают пчелы и шмели от яблони к яблоне. Май-самый нарядный и звонкий месяц года.
Грамматические задания.
- Синтаксический разбор предложения.
С веселым жужжанием перелетают пчелы и шмели от яблони к яблоне.
- Выписать из текста предложение с однородными сказуемыми. Составить схему предложения.
- Выписать из текста или придумать по два глагола 1 и 2 спряжения.
Итоговый контрольный диктант .
Весна в лесу
Молодые осинки и стройные березки спускаются под горку к широкому лугу. Среди деревьев вьется тропинка. По ней мы идем в лес.
Вот где чувствуешь настоящую весну! Ветви осин стали пушистыми от длинных сережек. Посмотришь на березовую веточку, а она вся в крупных почках.
Лес еще не зазеленел, стоит прозрачный и свежий. Но птицы уже начали свои весенние переклички. А как чудесно пахнет прелыми листьями, горьковатой свежестью почек! Скоро почки лопнут. Лес покроет нежная зеленая дымка. На душе станет так радостно!
Грамматические задания.
- Синтаксический разбор предложения.


Лес покроет нежная зеленая дымка.
- Морфологический разбор слова лес.
- Фонетический разбор слова листья.
Контрольное изложение.
Наши знакомые поехали отдыхать на юг на автомашине «Жигули». Дети уговорили отца взять с собой кота Чапу.
В городе Вольске переночевали. Встали рано утром, быстро собрались и выехали из города. Отъехали почти сто метров и тут спохватились: в машине не было Чапы.
Вернулись в Вольск, но кота не нашли.
Кончился отпуск. Семья приехала в родной поселок. Дни шли за днями. И вдруг у дверей квартиры послышалось мяуканье.
Это вернулся четвероногий турист!
Как он за тысячи километров отыскал свой дом – остается загадкой.
- Озаглавь историю, составь план текста.
- Восстанови содержание текста ( с закрытой книгой).
- Проверь написанное.
Комплексная проверочная работа.
Российское название праздника – День славянской письменности и культуры. Отмечается он 24 мая, в день памяти братьев – просветителей Кирилла и Мефодия. Именно они изучали особенности славянской речи и на основе греческого алфавита создали свой вариант славянской азбуки.
Отмечается он 24 мая, в день памяти братьев – просветителей Кирилла и Мефодия. Именно они изучали особенности славянской речи и на основе греческого алфавита создали свой вариант славянской азбуки.
В азбуке оказалось на 14 букв больше, чем в греческом алфавите, так как по звучанию славянская речь оказалась богаче. Диковинными для греческого слуха казались звуки (б), (з), (ж), (г), (ш), (щ). С годами упрощалась графика, чтобы облегчить книгопечатание. На славянский язык братья переводили священные греческие книги.
Через несколько столетий славяне на «языке словенском» стали создавать собственные книги. Шесть долгих столетий , вплоть до 15 века, только три языка – славянский, греческий и латинский – были приняты в мире как главные языки межнационального общения.
- Прочитай текст. О чем этот текст? Отметь номер ответа.
1)о создателях славянской азбуки
2)о создании славянской азбуки
3)об особенностях русского языка
4)о рождении письменности на Руси
2. Почему День славянской письменности отмечается 24 мая? Ответь одними предложением.
Почему День славянской письменности отмечается 24 мая? Ответь одними предложением.
3.Кто является создателем письменности на Руси? Дай письменный ответ, включающий описание первой азбуки ( спиши).
4.Как ты понимаешь слова автора о том, что грекам «диковинными казались звуки славянской речи?
1)греки записывали эти звуки другими буквами;
2)они впервые слышали славянскую речь;
3)звуки были необычны, их не было в греческой речи;
4)в славянской азбуке букв было больше.
5.Какие из согласных звуков, указанных в тексте являются парными по твердости и мягкости? Запиши их парами.
6.Сколько букв было в греческом алфавите, если в славянской азбуке было 43 буквы? Составь равенство, используя данные из текста, и реши его.
7.Укажи первые письменные источники Древней Руси, которые появились благодаря азбуке Кирилла и Мефодия.
1)газеты 2)былины
3)летописи 4)грамоты
8. Что о развитии русского языка тебе напоминает таблица? Распредели слова по группам и впиши их в таблицу.
Что о развитии русского языка тебе напоминает таблица? Распредели слова по группам и впиши их в таблицу.
Русский язык | |
Старорусский (полногласие) | Старославянский (неполногласие) |
9.В 2014 году будет праздноваться 550 лет с момента печати первой книги на славянском языке. В каком году она была напечатана?
10.Найди в 1 части текста предложение с однородными сказуемыми. Впиши порядковый номер этого предложения, начерти схему главных членов и укажи в ней части речи.
11.Найди в тексте и выпиши по 2 -3 слова на каждую орфограмму.
Двойные согласные;
Безударные гласные в окончании;
Ь-показатель мягкости.
Дополнительная часть.
12.Выполни морфологический разбор слов из второго предложения текста. Используй памятку учебника.
Отмечается—
Памяти—
13.По памяти восстанови последовательность текста (пронумеруй). Затем проверь, соотнося с текстом.
-Главные языки межнационального общения.
-Первая славянская азбука.
-день славянской письменности и культуры.
-Книги на славянском языке.
14.Почему словосочетание «на языке словенском» автор дает в кавычках?
1)это название языка;
2)использовано в переносном значении;
3)взято из древних источников.
15.Найди в тексте часть, в которой сравнивается славянская и греческая речь. Используй эту информацию и слова – антонимы, заполни таблицу.
речь | греческая | славянская |
фонетика | … | богаче |
графика | … | … |
16. Начиная с какого века и по какой , славянский язык, наравне с греческим и латинским, являлся межнациональным языком? Запиши (для вычислений используй информацию текста).
Начиная с какого века и по какой , славянский язык, наравне с греческим и латинским, являлся межнациональным языком? Запиши (для вычислений используй информацию текста).
17Какие годы относятся к периоду с начала 12 века по конец 14 века? Обведи номера ответов. Укажи стрелками события, произошедшие в это время в Древней руси.
1242 г. Куликовская битва
1380 г. Ледовое побоище
1462 г. Венчание на царство Ивана Грозного
1547 г. Московским князем стал Иван 3
18.Кирилл и Мефодий создали славянскую азбуку в давние времена. Как ты думаешь, почему русский народ отмечает это событие в наше время?
Значение имени Хазара, мужское персидское имя
Происхождение имени Хазара: Персидские имена.
Имя Хазара также присутствует в списках: Мужские имена, Мужские имена на букву Х, Персидские имена.
Число имени Хазара
Число имени восемь (8) способствует достижению успеха в самых крупных начинаниях и предприятиях, обеспечивая финансовую независимость своему обладателю. Природное трудолюбие и деловитость не дают людям с именем Хазара покоя — едва закончив один успешный проект, они приступают к другому. Число восемь (8) для имени Хазара — показатель высокого статуса и устойчивого финансового положения, что притягивает к ним поклонников и поклонниц, а отнюдь не внешняя привлекательность или сексуальность…
Природное трудолюбие и деловитость не дают людям с именем Хазара покоя — едва закончив один успешный проект, они приступают к другому. Число восемь (8) для имени Хазара — показатель высокого статуса и устойчивого финансового положения, что притягивает к ним поклонников и поклонниц, а отнюдь не внешняя привлекательность или сексуальность…
Подробнее: число имени Хазара
Значение букв в имени Хазара
Х — страстный, отзывчивый, уверенный в себе, самостоятельный, усердный, жизнерадостный.
А — инициативный, эгоцентричный, амбициозный, порывистый, креативный, честный.
З — проницательный, умный, самостоятельный, мрачный, усердный, осторожный.
Р — инициативный, эгоцентричный, умный, уверенный в себе, самостоятельный, конфликтный.
Смотрите также: фонетический разбор имени Хазара
Совместимые с именем Хазара персидские имена
Бахтияр, Дильбара, Замира, Ходжа, Шынар, Шахбану, Миргаяз, Сарда, Шахбаз, Бабаджан, Бахадур, Сима, Раушания, Шайда, Азада, Джахан, Диляра, Пача, Рустем, Охрмэзд…
Проверьте также совместимость других имен с именем Хазара.
Известные люди с именем Хазара
- Хосо, Мир Хазар Хан
- Хазар (эпоним)
- Исаев, Хазар Агаали оглу
- Мирза Хазар
Комментарии
Не отображается форма? Обновить комментарии.
Анализ стихотворения «Я вас любил» Пушкина
Стихотворение “Я вас любил” настолько известно, что большинство школьников знакомится с ним задолго до уроков литературы. Это гимн любимой женщине и в то же время упрёк ей за то, что она не оценила столь сильных и трепетных чувств. Краткий анализ “Я вас любил” по плану раскроет перед учениками 9 класса все грани этого трепетного любовного признания. Разбор можно использовать для объяснения материала или как дополнительную информацию.
Материал подготовлен совместно с учителем высшей категории
Опыт работы учителем русского языка и литературы — 27 лет.
Краткий анализ
Перед прочтением данного анализа рекомендуем ознакомиться со стихотворением Я вас любил….
История создания – произведение написано в 1829 году. Год спустя его опубликовали в альманахе “Северные цветы”.
Тема стихотворения – чувства лирического героя к прекрасной женщине, которая не сумела разглядеть его порыв, не оценила трепетность любви.
Композиция – одночастная, всё произведение представляет собой наполненное искренними эмоциями признание.
Жанр – лирическое стихотворение. Вид лирики – любовная.
Стихотворный размер – пятистопный ямб с перекрёстной рифмой.
Метафоры – “любовь в душе угасла не совсем”, “то робостью, то ревностью томим”.
История создания
Историки литературы до сих пор спорят, кому посвящено произведение. Есть две версии о том, кому именно Пушкин посвятил эти гениальные строки. Долгое время считалось, что их адресат – это Каролина Собаньская. Эту потрясающую светскую львицу поэт встретил ещё во впечатлительном молодом возрасте, когда в 1821 году отбывал южную ссылку. Красавица потрясла романтическое воображение Александра Сергеевича. Почти десять лет он обожал её: даже в 1830 году, уже готовясь к помолвке с будущей женой, он писал гордячке, умоляя её о дружбе, однако она не ответила. И это несмотря на то, что Собаньская сильно постарела и стала дурна собой, что поэт не мог не отметить.
Красавица потрясла романтическое воображение Александра Сергеевича. Почти десять лет он обожал её: даже в 1830 году, уже готовясь к помолвке с будущей женой, он писал гордячке, умоляя её о дружбе, однако она не ответила. И это несмотря на то, что Собаньская сильно постарела и стала дурна собой, что поэт не мог не отметить.
Вторая женщина, которой он также мог адресовать эти проникновенные строки – двоюродная сестра Анны Керн (в которую поэт также был одно время влюблён), Анна Оленина. Красивой и прекрасно образованной девушке посвящали стихи многие выдающиеся люди того времени. Пушкин даже сватался к ней, а после отказа оставил в её альбоме два четверостишия.
Но кто бы ни был адресатом, история создания стихотворения “Я вас любил” тесно связана с прошлым его автора – это прощание с возлюбленной. В 1829 году, когда оно было написано, поэт делает предложение Наталье Гончаровой.
Прекрасное произведение было представлено на читательский суд уже на следующий год, в 1830 году. Впервые его напечатал альманах “Северные цветы”.
Впервые его напечатал альманах “Северные цветы”.
Тема
Поэт рассказывает о неразделённом чувстве, с которым пришла пора попрощаться. И хотя лирический герой ещё не совсем разлюбил ту, к которой он обращается, он уже готов оставить всё в прошлом. Он как будто исповедуется перед женщиной, показывая ей, что она потеряла – его искренность, преданность, нежность и всё, что он готов был положить к её ногам. Последние строки особенно показывают благородство лирического героя: он желает любимой счастья с другим, несмотря на то, что сам по-прежнему её любит. Именно этой мыслью завершается стихотворение.
Композиция
Александр Сергеевич использовал для своего произведения простую одночастную композицию, в то же время тематически разделив его на три составляющих с помощью рефрена.
Так, Первая честь совпадает по границам с первым четверостишием – в ней поэт признаётся в любви и признаёт сам перед собой и перед любимой женщиной, что чувство ещё не совсем угасло. Однако он более не будет ей докучать своими признаниями, поскольку не хочет печалить.
Вторая часть также начинается со слов “я вас любил”, и в ней автор описывает природу своего чувства, говоря о его безнадёжной природе, о ревности, которая его мучила, о робости, которая не позволила высказаться раньше.
И последняя часть – пожелание счастья любимой женщине.
Жанр
Это лирическое стихотворение. Вид – классическая любовная лирика, облечённая в совершенную форму: Пушкин устами лирического героя открыто заявляет о своём чувстве, он не стесняется его и не собирается скрывать. Он относится к женщине, которой пишет, с трепетной нежностью, но в то же время не скрывает свою грусть.
Написано стихотворение пятистопным ямбом, ритмика в нём сложная, но чёткая. Автор использует перекрёстную рифмовку с чередованием женской и мужской рифмы как идеальную форму для передачи своей идеи.
Средства выразительности
Произведение написано очень простым языком, что приближает его к разговорной речи, делает признание более живым и искренним. Для передачи чувств лирического героя Александр Сергеевич использует метафоры : “любовь в душе угасла не совсем”, “то робостью, то ревностью томим”
, эпитеты : “любил так искренно, так нежно”, “любил безмолвно, безнадёжно”
.
В то же время он мастерски использует инверсию, делая стихотворение певучим и проникновенным. Такое свойство позволило положить его на музыку, сделав одним из самых популярных романсов ХХ века.
Тест по стихотворению
Доска почёта
Чтобы попасть сюда — пройдите тест.
-
Павел Спирин
6/7
Никита Михалков
7/7
Саша Новиков
7/7
Анна Кузина
5/7
Роман Романыч
7/7
Lilnait Student
7/7
Massimiliano Viano
7/7
Любовь Казанцева
7/7
Владлена Потапова
7/7
Марина Тюрюмина
7/7
Рейтинг анализа
Средняя оценка: 4.3. Всего получено оценок: 191.
Предложения со словом «Машинке». Примеры.
1. Текст был напечатан на пишущей машинке.
Анатолий Рыбаков — Бронзовая птица
2. Тогда я предложила писать свои письма на машинке, как он и сам делал, а он не захотел.
Тогда я предложила писать свои письма на машинке, как он и сам делал, а он не захотел.
Артур Конан Дойль — Приключения Шерлока Холмса
3. Лично ему отправленное письмо ничем не грозило: он напечатал его на машинке в экспедиции во время налета.
Юлиан Семенов — Семнадцать мгновений весны
4. Я научилась стенографировать и писать на машинке и стала его секретарем.
Джек Лондон — Железная пята
5. Оно было напечатано на машинке на тонкой бумаге.
Герберт Уэллс — Любовь и мистер Люишем
6. Рэмедж заговорил о секретарской работе, но даже для этого ей надо уметь печатать на машинке и стенографировать.
Герберт Уэллс — Анна-Вероника
7. Маленький техник, виновато покосившись в сторону начальства и отсморкавшись, стал подсоединять к своей неказистой машинке концы очередной линии проводов, помеченных вторым номером.
Петр Проскурин — Отречение
8. Шипела спиртово-калильная лампа проекционного аппарата, стрекотала лента, на экране появлялись красные или синие надписи, маленькие и убористые, как будто напечатанные на пишущей машинке.
Шипела спиртово-калильная лампа проекционного аппарата, стрекотала лента, на экране появлялись красные или синие надписи, маленькие и убористые, как будто напечатанные на пишущей машинке.
Валентин Катаев — Хуторок в степи
9. Она даже показывала людям пропуск, написанный на пишущей машинке, по-видимому по-немецки, за печатью с чудацким немецким орлом и подписанный немецким комендантом.
Валентин Катаев — Я сын трудового народа
10. Дожевал бутерброд и снова кинулся к пишущей машинке.
Анатолий Рыбаков — Страх
11. Колесничук разгладил пропотевшие листки на коленях и прочитал первые строчки приказа, убористо, без интервалов, напечатанного на пишущей машинке.
Валентин Катаев — Катакомбы
12. Я считал, что получать показания у арестованного будет гестапо, а мне останется лишь просмотреть страницы, напечатанные на машинке и подписанные тем человеком, который меня интересовал.
Юлиан Семенов — Альтернатива
13. В течение многих лет всякий раз, когда я был взволнован, я шел к своей пишущей машинке и записывал два вопроса, а также ответы на эти вопросы.
Дейл Карнеги — Как перестать беспокоиться и начать жить
14. Мои пальцы сохраняют проворность от работы на печатающей машинке, а ум упражняется в новом и весьма вдохновляющем направлении.
Айзек Азимов — Земля и космос
15. В течение многих лет всякий раз, когда я был взволнован, я шел к своей пишущей машинке и записывал два вопроса, а также ответы на эти вопросы.
Дейл Карнеги — Как преодолеть чувство беспокойства
Синтаксический разбор простого словосочетания — Агентство переводов Lingvotech
Синтаксический разбор простого словосочетания
Схема синтаксического разбора простого словосочетания
1. Выделить словосочетание из предложения.
2. Найти главное и зависимое слова, указать, какими частями речи они выражены, поставить вопрос от главного слова к зависимому.
Найти главное и зависимое слова, указать, какими частями речи они выражены, поставить вопрос от главного слова к зависимому.
3.Определить тип словосочетания (глагольное, именное или наречное).
4.Определить способ подчинительной связи (согласование, управление, примыкание) и указать, чем она выражена (окончанием зависимого слова, окончанием и предлогом, только по смыслу).
5.Определить смысловые отношения между главным и зависимым словом (определительные, объектные, обстоятельственные).
Образец синтаксического разбора простого словосочетания
Студёный ветер резко рвал полы его шинели (Л. Толстой)
| 1. Студёный ветер х прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
2. Резко рвал — х Резко рвал — хнареч. + глаг | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения. |
| 3. Рвал полы — глаг. +сущ. вВ.п, | глагольное словосочетание, способ связи управление, выражено окончанием зависимого существительного, называется действие и его объект, объектные отношения. |
| 4. Полы шинели — сущ. + сущ. в Р.п | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения. |
Алый свет вечерней зари медленно скользит по корням деревьев (И. Тургенев)
| 1. Алый свет — прилаг. + сущ. | именное словосочетание, способ связи — согласование, выражено окончанием зависимого прилагательного, называется предмет и его признак, определительные отношения. |
| 2. Свет зари — х сущ. + сущ. в Р.п. | именное словосочетание, способ связи — управление, выражено окончанием зависимого существительного, называется предмет и его признак, определительные отношения, |
| 3. Медленно скользит • нар. + глаг. | глагольное словосочетание, способ связи — примыкание, слова связаны по смыслу и интонационно, называется действие и его признак (качество), обстоятельственные отношения, |
| 4. Скользит по корням • глаг. + сущ. в Д.п. с предлогом по | глагольное словосочетание, «по», способ связи — управление, выражено окончанием зависимого существительного и предлогом «по», называется действие и его место, обстоятельственные отношения. |
млрд фонетический анализатор · PyPI
# Bengali Phonetic Parser
Этот пакет поможет вам преобразовать бенгальский текст в Banglish, а также Banglish в бенгальский
## Getting Started
Эти инструкции позволят вам запустить копию проекта на локальном компьютере для разработки. в целях тестирования, а также в производственной машине. См. В разделе «Развертывание» примечания по развертыванию проекта в действующей системе.
в целях тестирования, а также в производственной машине. См. В разделе «Развертывание» примечания по развертыванию проекта в действующей системе.
### Версия Python
Минимальная версия Python должна иметь 3.xx или верхний
### Установка
Пошаговая серия примеров, которые говорят, что вам нужно запустить среду разработки
Скажите, какой будет шаг
«
$ [sudo] pip install bnbphoneticparser
« «
OR, git clone
« «
$ git clone https://github.com/porimol/bnbphoneticparser.git
$ cd bnbphoneticparser
$ python setup.py install
« #
## Example
#### Бенгальский на Banglish Пример
« `python
# coding = utf-8
from BengaliPhoneticParser import BengaliToBanglish
bengali2banglish = BengaliToBanglish ()
bengali আমিtext =».parse (bengali_text.strip ()))
«
#### Бенгальский на Banglish Вывод
« `
aMi bangLadESi
` `
#### Banglish to Bengali Example
` `python
# coding = utf-8
от BengaliPhoneticParser import BanglishToBengali
banglish4bengali = BanglishToBengali ()
banglish_text = «ami banglay gan gai»
print (banglish4bengali. parse# # Banglish to Bengali Output
parse# # Banglish to Bengali Output
«
আমি বাংলায় গান গাই
«
## Запуск тестов
Test Banglish to Bengali
« python
pytest tests / testbenglishtobanglish.py
«
Test Bengali to Banglish
« python
pytest tests / testbanglishtobengali.py
«
## Authors
* ** [Porimol Chandro] (https://github.com / porimol) **
См. также список [участников] (https://github.com/porimol/BengaliPhoneticParser/contributors), которые участвовали в этом проекте.
## Лицензия
Этот проект находится под лицензией MIT — подробности см. В файле [LICENSE.md] (LICENSE.md)
Кредит
———
[Bangla Phonetic Parser Python] (https: // github. com / ShuvenduBikash / Bangla_phonetic_parser_Python) проект с открытым исходным кодом.
[Автор: — Шувенду Бикаш] (https://github.com/ShuvenduBikash)
#! / Usr / bin / python2. 7 7 | |
| # — * — кодировка: utf-8 — * — | |
| «» « | |
| @ файл mac-dict.py — поиск в словаре Mac | |
| @ автор Tim van Werkhoven | |
| @ дата 20111220 | |
| @ copyright Copyright (c) 2011 Тим ван Веркховен | |
| Используйте DictionaryServices для поиска слов в Apple Dictionary.app. | |
| По мотивам работы Алекса Концевого, см. | |
| Этот файл находится под лицензией Creative Commons Attribution-Share Alike | |
версии лицензии 3. 0 или выше, см. 0 или выше, см. | |
| http://creativecommons.org/licenses/by-sa/3.0/ | |
| «» « | |
| импорт DictionaryServices | |
| импорт ре | |
| импорт unittest | |
| импорт ОС, sys | |
| # Определить некоторые константы | |
| АВТОР = «Тим ван Веркховен [email protected]> « | |
| ДАТА = «20111220» | |
| СЧЕТЧИК = 0 | |
| def main (): | |
| ## Сначала проверьте, нужны ли нам тесты (сделайте это перед argparse, иначе мы можем столкнуться с конфликтами) | |
if (‘—test’ в sys. argv): argv): | |
| print «В обход штатной программы, запускаем тесты!» | |
| # Удалить строку ‘—test’ из sys.argv, оставить все остальные | |
| sys.argv = [el вместо el в sys.argv, если el не в [‘—test’]] | |
| вернуть unittest.main () | |
| ## Параметры проверки аргументов синтаксического анализа | |
| (парсер, аргументы) = parsopts () | |
| remlist = «‘,.:; \ «\ n’ « | |
| , если (args.infile): | |
| if (VERBOSITY> 1): print «main (): args.infile» | |
| fd = open (args.infile, «r») | |
для строки в fd. xreadlines (): xreadlines (): | |
| if (VERBOSITY> 2): print «main (): line =% s»% (line) | |
| для i в remlist: | |
| строка = строка. replace (i, «») | |
| if (VERBOSITY> 2): print «main (): procline =% s»% (line) | |
| для слова в строке.split («»): | |
| печать dict_IPA (слово), | |
| печать | |
| fd.close () | |
| еще: | |
| if (VERBOSITY> 1): print «main (): else branch» | |
| для слова в аргументах.слов: | |
| печать dict_IPA (слово), | |
| def dict_IPA (слово): | |
| «» «Для данного слова вернуть произношение в IPA» «» | |
| # Предварительная обработка | |
word = word. strip () strip () | |
| если (len (слово) | |
| возврат | |
| # Слово поиска | |
| if (VERBOSITY> 1): print «dict_IPA (word =% s)»% (word) | |
| запись = DictionaryServices.DCSCopyTextDefinition (Нет, слово, (0, len (слово))) | |
| , если (не вход): | |
| возврат «н / д» | |
| if (VERBOSITY> 2): print «dict_IPA ():% s»% (запись) | |
| # Найти слово в записи, следующей строкой должен быть IPA | |
| # #IPA_beg = запись. index (слово + «\ n») + len (слово) + 1 | |
# IPA_beg = re. search (word + «\ s * \ d * \ s * \ n», запись, re.IGNORECASE) search (word + «\ s * \ d * \ s * \ n», запись, re.IGNORECASE) | |
| # if (не IPA_beg и word [-1] == «s»): | |
| # if (VERBOSITY> 2): print «dict_IPA (): word [-1] == s» | |
| # IPA_beg = re.search (word [: — 1] + «. \ S * \ d * \ s * \ n», запись, re.IGNORECASE) | |
| # | |
| # if (IPA_beg): | |
| # IPA_beg = IPA_beg.конец () | |
| # else: | |
| # return | |
| # # IPA_beg2 = re.search («\ n |. * | \ N», запись [IPA_beg1:]). End () + IPA_beg1 | |
| IPA_beg = entry.index («\ n») + 1 | |
IPA_end = entry. index («\ n», IPA_beg) index («\ n», IPA_beg) | |
| if (VERBOSITY> 2): print «dict_IPA ():% d -% d»% (IPA_beg, IPA_end) | |
| # Извлечь IPA, удалить вертикальные полосы | |
| IPA = запись [IPA_beg + 1: IPA_end-1] | |
| if (VERBOSITY> 2): print «dict_IPA ():% s»% (IPA) | |
| возврат IPA | |
| def парсоптов (): | |
| «» «Разобрать параметры программы, проверить работоспособность и вернуть результаты» «» | |
| импорт argparse | |
парсер = argparse. ArgumentParser (description = «Поиск слов из Apple Dictonary.app. Вы можете изменить язык, открыв настройки Dictionary.app и включив только тот словарь, который вы хотите использовать. », Epilog = ‘Комментарии и отчеты об ошибках для% s’% (AUTHOR) ) », Epilog = ‘Комментарии и отчеты об ошибках для% s’% (AUTHOR) ) | |
| parser.add_argument (‘слова’, metavar = ‘W’, type = str, nargs = ‘*’, по умолчанию = [], | |
| help = ‘слова для поиска.’) | |
| парсер.add_argument (‘- infile’, metavar = ‘F’, type = str, | |
| help = ‘читать слова из F.’) | |
| parser.add_argument (‘- v’, dest = ‘debug’, action = ‘append_const’, const = 1, | |
| help = ‘увеличить многословие’) | |
| parser.add_argument (‘- q’, dest = ‘debug’, action = ‘append_const’, const = -1, | |
| help = ‘уменьшить многословие’) | |
args = парсер. parse_args () parse_args () | |
| # Проверить и исправить некоторые параметры | |
| контрольных точек (парсер, аргументы) | |
| # Вернуть результаты | |
| возврат (парсер, аргументы) | |
| контрольных точек по умолчанию (парсер, аргументы): | |
| «» «Проверить работоспособность опций программы» «» | |
| если (аргументы. infile): | |
| , если (не os.path.exists (args.infile)): | |
| print «Ошибка: файл не существует!» | |
| parser.print_usage () | |
| системный выход (0) | |
elif (не os. path.isfile (args.infile)): path.isfile (args.infile)): | |
| print «Предупреждение: infile не является обычным файлом!» | |
| elif (не len (args.слов)): | |
| print «Ошибка: нужно хотя бы одно слово или входной файл» | |
| parser.print_usage () | |
| системный выход (0) | |
| , если (args.debug): | |
| global VERBOSITY | |
| СЛОЖНОСТЬ = сумма (args.debug) | |
| print «checkopts (): verbosity:% d»% (VERBOSITY) | |
| ### Здесь начинаются испытания | |
| класс TestWords (unittest.TestCase): | |
| по умолчанию setUp (самостоятельно): | |
| «» «Составить список слов» «» | |
self. words = [u «хуже», u «произношение», u «Терпсихора»] words = [u «хуже», u «произношение», u «Терпсихора»] | |
| self. ipa_uk = [u «wəːs», u «prənʌnsɪˈeɪʃ (ə) n», u «təːpˈsɪkəri»] | |
| self.ipa_us = [u «wərs», u «prəˌnənsiˈeɪʃən», u «tərpˈsɪkəri»] | |
| # Изучить среду / настройки | |
| по умолчанию test0a_detect_lang (сам): | |
| «» «Определить, какой словарь мы используем (США или Великобритания)» «» | |
| if (dict_IPA («хуже»).strip () == u «wərs»): | |
| self.lang = «США» | |
| печать «Получил американский словарь» | |
| elif (dict_IPA («хуже»). Strip () == u «wəːs»): | |
self. lang = «UK» lang = «UK» | |
| печать «Получил британский словарь» | |
| еще: | |
| поднять RuntimeError («Неизвестный язык словаря!») | |
| # Статические испытания | |
| по умолчанию test1a_ipa (сам): | |
| «» «Проверка произношения заранее определенных слов» «» | |
| this_ipa = self.ipa_uk | |
| печать self.lang | |
| , если (self. lang == «US»): | |
| this_ipa = self.ipa_us | |
| для word, ipa в zip (self.words, this_ipa): | |
testipa = dict_IPA (слово) . strip () strip () | |
| print u «% s =% s»% (тест, ipa) | |
| сам.assertEqual (dict_IPA (слово) .strip (), ipa) | |
| # Это должна быть последняя часть файла, код после этого не будет выполняться | |
| , если __name__ == «__main__»: | |
| sys.exit (основной ()) | |
| ### Зачеркните здесь | |
| print dict_IPA («хуже») | |
| print dict_IPA («произношение») | |
| print dict_IPA («Терпсихора») | |
| print dict_IPA («Терпсихора») | |
| ### EOF |
GitHub — поримол / bnbphoneticparser: бенгальский фонетический синтаксический анализатор
Этот пакет поможет вам преобразовать бенгальский текст в Banglish, а также Banglish в бенгальский
Начало работы
Эти инструкции предоставят вам копию проекта, которая будет запущена на вашем локальном компьютере для разработки, тестирования, а также на производственной машине. См. В разделе «Развертывание» примечания по развертыванию проекта в действующей системе.
См. В разделе «Развертывание» примечания по развертыванию проекта в действующей системе.
Версия Python
Минимальная версия python должна иметь 3.x.x или выше
Установка
Пошаговая серия примеров, в которых говорится, что вам нужно запустить среду разработки
.
Скажите, какой будет шаг
$ [sudo] pip install bnbphoneticparser
ИЛИ, git clone
$ git clone https://github.com/porimol/bnbphoneticparser.мерзавец
$ cd bnbphoneticparser
$ python setup.py установить
Пример
с бенгали на банглиш, пример
# coding = utf-8 из bnbphoneticparser import BengaliToBanglish bengali2banglish = BengaliToBanglish () bengali_text = "আমি বাংলাদেশি" печать (bengali2banglish.parse (bengali_text.strip ()))
Вывод с бенгали на Banglish
ami бангладеш
Пример с Banglish на бенгальский
# coding = utf-8 из bnbphoneticparser import BanglishToBengali banglish4bengali = BanglishToBengali () banglish_text = "ami banglay gan gai" печать (banglish4bengali.
 синтаксический анализ (banglish_text.strip ()))
синтаксический анализ (banglish_text.strip ())) Banglish на бенгальский выход
আমি বাংলায় গান গাই
Выполнение тестов
Тест с Banglish на бенгальский
тесты pytest / bengalitobanglish.py
Тестовый бенгальский на Banglish
тесты pytest / banglishtobengali.py
Авторы
См. Также список участников, участвовавших в этом проекте.
Лицензия
Этот проект находится под лицензией MIT — см. ЛИЦЕНЗИЮ.md файл для деталей
Кредит
Bangla Phonetic Parser Python — проект с открытым исходным кодом.
Автор: — Шувенду Бикаш
Артикуляционное исследование корейской ассимиляции мест на JSTOR
Abstract
В представленном здесь исследовании используются артикуляционные данные для изучения корейской ассимиляции мест коронарных стопов, за которыми следуют лабиальные или велярные стопы, как внутри слов, так и между словами. Результаты показывают, что этот процесс ассимиляции места сильно варьируется как внутри, так и между говорящими, а также чувствителен к таким факторам, как место артикуляции следующего согласного, наличие границы слова и, в некоторой степени, скорость речи. .Жесты, на которые влияет этот процесс, обычно категорически сокращаются (удаляются), при этом также наблюдается спорадическое градиентное сокращение жестов. Далее мы сравниваем результаты для коронок с нашими предыдущими выводами об ассимиляции губных губ, обсуждая значение результатов для грамматических моделей фонологической / фонетической компетентности. Результаты показывают, что языковые знания говорящих об ассимиляции места должны быть относительно подробными и контекстно-зависимыми и должны кодировать систематические закономерности в отношении его обязательного / переменного применения, а также категориальной / градиентной реализации.
.Жесты, на которые влияет этот процесс, обычно категорически сокращаются (удаляются), при этом также наблюдается спорадическое градиентное сокращение жестов. Далее мы сравниваем результаты для коронок с нашими предыдущими выводами об ассимиляции губных губ, обсуждая значение результатов для грамматических моделей фонологической / фонетической компетентности. Результаты показывают, что языковые знания говорящих об ассимиляции места должны быть относительно подробными и контекстно-зависимыми и должны кодировать систематические закономерности в отношении его обязательного / переменного применения, а также категориальной / градиентной реализации.
Информация журнала
Фонология, издающаяся три раза в год, является единственным журналом, посвященным исключительно данной дисциплине, и предоставляет уникальный форум для продуктивного обмена идеями между фонологами и специалистами, работающими в смежных дисциплинах. Предпочтение отдается статьям, которые вносят существенный теоретический вклад, независимо от конкретной используемой теоретической основы, но также приветствуется представление статей, представляющих новые эмпирические данные, представляющие общий теоретический интерес. В журнале публикуются исследовательские статьи, а также рецензии на книги и короткие статьи по темам, вызывающим разногласия в фонологии.
В журнале публикуются исследовательские статьи, а также рецензии на книги и короткие статьи по темам, вызывающим разногласия в фонологии.
Текущие выпуски журнала доступны по адресу http://www.journals.cambridge.org/pho.
Информация для издателей
Cambridge University Press (www.cambridge.org) — издательское подразделение Кембриджского университета, одного из ведущих исследовательских институтов мира и лауреата 81 Нобелевской премии. В соответствии со своим уставом издательство Cambridge University Press стремится максимально широко распространять знания по всему миру.Он издает более 2500 книг в год для распространения в более чем 200 странах.
Cambridge Journals издает более 250 рецензируемых научных журналов по широкому спектру предметных областей в печатных и онлайн-версиях. Многие из этих журналов являются ведущими научными публикациями в своих областях, и вместе они образуют одну из самых ценных и всеобъемлющих исследовательских работ, доступных сегодня. Для получения дополнительной информации посетите http://journals. cambridge.org.
cambridge.org.
python — Разбор xml файла с упорядоченным словарем
У меня есть файл xml вида:
и nd 0 8262 удобный comfetebl adj 61404 72624 Мне нужно обработать его так, чтобы, например, когда пользователь вводил nd , программа сопоставляла его с тегом и возвращала и из части .Я подумал, может быть, если я смогу преобразовать XML-файл в словарь, я смогу перебирать данные и находить информацию, когда это необходимо.
Я поискал и нашел xmltodict, который используется с той же целью:
импорт xmltodict
с open (r'path \ to \ 1.xml ', encoding =' utf-8 ', errors =' ignore ') как fd:
obj = xmltodict.parse (fd.read ())
Запуск этого дает мне заказанный dict :
>>> obj
OrderedDict ([('NewDataSet', OrderedDict ([('Корень', [OrderedDict ([('Фонематический', 'и'), ('Фонетический', 'nd'), ('Описание', Нет), (' Начало ',' 0 '), (' Конец ',' 8262 ')]), OrderedDict ([(' Фонематический ',' удобный '), (' Фонетический ',' comfetebl '), (' Описание ',' прил. '), (' Начало ',' 61404 '), (' Конец ',' 72624 ')])])]))])
 '), (' Начало ',' 61404 '), (' Конец ',' 72624 ')])])]))])
'), (' Начало ',' 61404 '), (' Конец ',' 72624 ')])])]))])
К сожалению, это не упростило задачу, и я не уверен, как приступить к реализации программы с новой структурой данных.Например, чтобы получить доступ к nd , мне нужно было бы написать:
obj ['NewDataSet'] ['Root'] [0] ['Phonetic']
, что до смешного сложно. Я попытался превратить его в обычный словарь с помощью dict () , но поскольку он вложен, внутренние слои остаются упорядоченными, а мои данные такие большие.
Journal of Phonetics
Функция площади речевого тракта во всех его пространственных деталях не может быть вычислена напрямую из речевого сигнала. Но можно ли восстановить частичную, но фонетически отличительную информацию об артикуляции из акустического сигнала, поступающего к уху слушателя? Ответ на этот вопрос важен для фонетики, потому что разные теории восприятия речи предсказывают разные ответы.Некоторые теории предполагают, что восстановление артикуляционной информации должно быть возможным, в то время как другие предполагают, что это невозможно. Однако ни одна из теорий не предоставляет убедительных доказательств того, что отличительная артикуляционная информация извлекается или не извлекается из акустического сигнала. Настоящее исследование фокусируется на гласных жестах и исследует, содержится ли в речевом сигнале лингвистически значимая информация, такая как местоположение сужения, степень сужения и округление, и можно ли восстановить такую информацию по параметрам формант.Теория возмущений и линейное предсказание были объединены аналогично тому, как это сделано в Mokhtari (1998) [Mokhtari, P. (1998). Акустико-фонетическое и артикуляционное исследование дихотомии речи-говорящего. Докторская диссертация, Университет Нового Южного Уэльса], по оценке точности восстановления информации о сужении гласных. Информация об отличительном сужении, оцененная по речевому сигналу для десяти гласных американского английского, сравнивалась с информацией о сужении, полученной из одновременно собранных артикуляционных данных рентгеновского микропучка для 39 говорящих [Westbury (1994).
Однако ни одна из теорий не предоставляет убедительных доказательств того, что отличительная артикуляционная информация извлекается или не извлекается из акустического сигнала. Настоящее исследование фокусируется на гласных жестах и исследует, содержится ли в речевом сигнале лингвистически значимая информация, такая как местоположение сужения, степень сужения и округление, и можно ли восстановить такую информацию по параметрам формант.Теория возмущений и линейное предсказание были объединены аналогично тому, как это сделано в Mokhtari (1998) [Mokhtari, P. (1998). Акустико-фонетическое и артикуляционное исследование дихотомии речи-говорящего. Докторская диссертация, Университет Нового Южного Уэльса], по оценке точности восстановления информации о сужении гласных. Информация об отличительном сужении, оцененная по речевому сигналу для десяти гласных американского английского, сравнивалась с информацией о сужении, полученной из одновременно собранных артикуляционных данных рентгеновского микропучка для 39 говорящих [Westbury (1994). Справочник пользователя базы данных по производству речи микролучей рентгеновского излучения. Университет Висконсина, Мэдисон, Висконсин]. Восстановление отличительной артикуляционной информации основывается на новой технике, которая использует формантные частоты и амплитуды, и не зависит от анализа основных компонентов артикуляционных данных, как большинство других техник инверсии. Эти результаты свидетельствуют о том, что отличительная артикуляционная информация для гласных может быть восстановлена из акустического сигнала.
Справочник пользователя базы данных по производству речи микролучей рентгеновского излучения. Университет Висконсина, Мэдисон, Висконсин]. Восстановление отличительной артикуляционной информации основывается на новой технике, которая использует формантные частоты и амплитуды, и не зависит от анализа основных компонентов артикуляционных данных, как большинство других техник инверсии. Эти результаты свидетельствуют о том, что отличительная артикуляционная информация для гласных может быть восстановлена из акустического сигнала.
Фонетический сдвиг в изменении звука
Страница из
НАПЕЧАТАНО ИЗ ОНЛАЙН-СТИПЕНДИИ ОКСФОРДА (Оксфорд.Universitypressscholarship.com). (c) Авторские права Oxford University Press, 2021. Все права защищены. Отдельный пользователь может распечатать одну главу монографии в формате PDF в OSO для личного использования. дата: 11 апреля 2021 г.
- Глава:
- (стр.51)
3 Фонетический уклон в изменении звука - Источник:
- Истоки изменения звука
- Автор (ы):
Эндрю Гарретт
Кейт Джонсон
- Издатель:
- Oxford University Press
DOI:1093 / acprof: oso / 9780199573745. 003.0003
003.0003
В большинстве типологий звуковых изменений проводится либо двустороннее различие между изменениями, основанными на артикуляции и восприятии, либо трехстороннее различие между путаницей восприятия, гипокорректирующими изменениями и гиперкорректирующими изменениями. Первый подход определяет основные неограмматические, структуралистские и генеративные традиции; второй подход можно найти в работах Охала, Блевинс и их коллег. В этой главе делается попытка разработать типологию асимметричных паттернов изменения звука, основанную на предубеждениях, возникающих из четырех элементов производства и восприятия речи: двигательного планирования, аэродинамических ограничений, жестовой механики и перцептивного анализа.
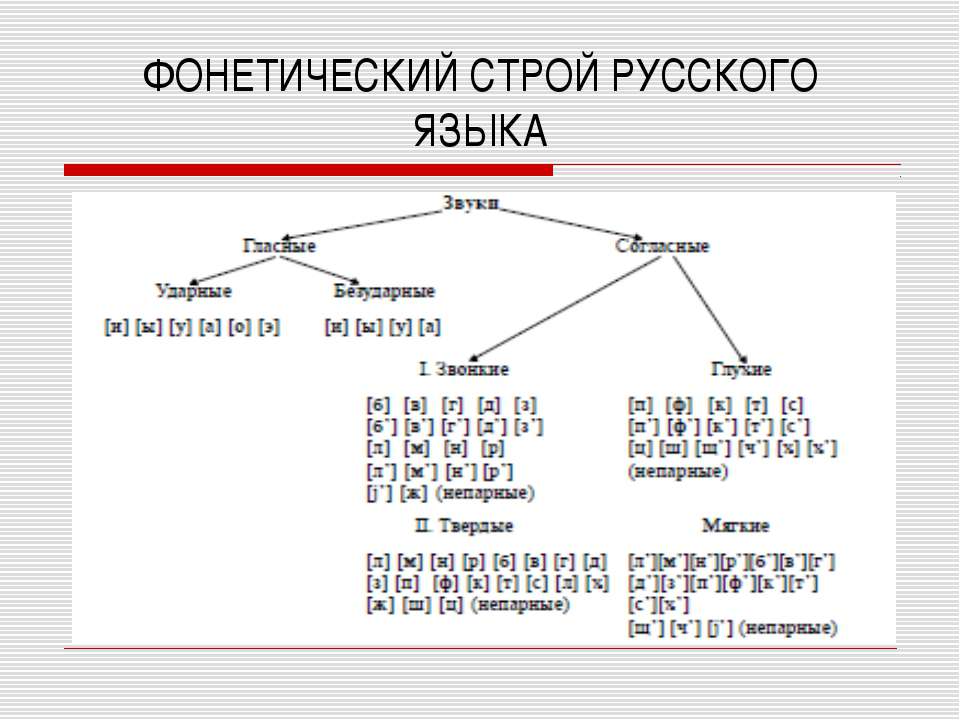
Конспект урока по русскому языку «Фонетический разбор слова» (5 класс)
Конспект урока русского языка в 5 классе
Тема: «Фонетический разбор слова»
Цель: — научить учащихся производить фонетический разбор слова.
Задачи:
Образовательные: формирование у учащихся умений проводить фонетический анализ слова; закрепление навыков работы с фонетической характеристикой звуков речи; формирование умений транскрибирования слова; обогащение словаря учащихся за счет введения новых слов.
Развивающие: развитие речи, памяти, внимания, мышления; развитие у учащихся познавательного интереса; совершенствование умений различать твёрдые/мягкие, глухие/звонкие согласные звуки, ударные/безударные гласные звуки; совершенствование умений различать буквы алфавита и звуки речи; развитие умений самостоятельной работы.
Воспитательные: воспитание чувства уважения к языку; пробуждение интереса к родному языку, грамотному обращению с языковым материалом; воспитание аккуратности в работе.
Ход урока:
Организационный момент
— Здравствуйте, ребята. Сегодня на урок к нам пришли гости. Поздоровайтесь. Садитесь.
Сегодня на урок к нам пришли гости. Поздоровайтесь. Садитесь.
— Открываем тетради, записываем число, классная работа.
Проверка домашнего задания
— Спишите слова с доски, расставьте ударение, запишите транскрипцию.
— Кстати, что такое транскрипция? На каком еще уроке вы работаете с транскрипцией?
Получается (проверка по эталону):
Землялев
цветок
открыть
мороз
очки
[з,и м л,а]
[л,э ф]
[ц в,и т ок]
[а т к р ы т,]
[м а р о с,]
[а ч,к,и]
— Молодцы! Вы очень хорошо справились с заданием. А теперь в середине новой строки запишем тему нашего урока «Фонетический разбор слова».
А теперь в середине новой строки запишем тему нашего урока «Фонетический разбор слова».
Изучение нового материала
— Итак, тема нашего урока «Фонетический разбор слова».
— Какую цель мы поставили перед собой на этот урок?
— Какие задачи необходимо решить для достижения нашей цели?
Фонетический опрос
— Каждый правильный ответ +5 б., неправильный ответ -5 б.
— Как называется раздел науки о языке изучающий звуки речи? (фонетика)
— На какие группы делятся звуки речи? (гласные, согласные)
— Какие звуки являются гласными? (которые состоят только из голоса)
— Какие звуки являются согласными? (которые состоят из голоса и шума)
— Какими бывают гласные звуки? (ударные и безударные)
— Каким буквам отведена двойная роль? (е, ё, ю, я)
— Сколько букв в русском алфавите?
— Сколько гласных?
— Сколько согласных?
— В чем разница между буквой и звуком?
— Сколько парны согласных по глухости – звонкости?
— Сколько непарных глухих? (4)
— Назовите. [х, ц, ч, щ]
[х, ц, ч, щ]
— Сколько непарных мягких согласных? (3)
— Назовите. [ч,, щ,, й,]
— Сколько непарных твердых согласных? (3)
— Назовите. [ж, ш, ц]
— Сколько глысных звуков? (6)
— Сколько согласных звуков? (36)
— Сколько всего звуков? (42)
— Молодцы, ребята!
Физминутка
(Релакс) Закройте глаза. Представьте, что вы находитесь на берегу моря. Солнышко греет вас своими лучами. Вы слышите шум набегающих волн и крик чаек. Наберите в руку песок, пропустите его сквозь пальцы. Вы ощущаете его тепло. День подходит к концу. Море затихает. Открывайте глаза.
— Отдохнули. Теперь сели ровно. Спинки выпрямили.
Перейдем к изучению нового материала.
Объяснения учителя
— Открываем учебники на стр. смотрим план фонетического разбора.
смотрим план фонетического разбора.
— А теперь я покажу вам, как надо выполнять фонетический разбор.
— С красной строки, с большой буквы записываем предложение:
На лесной поляне стоял старый пень1.
Пень – 1 слог.
п [п᾽] – согл., парн., глух., мягк..
е [э] – гл., ударн..
н [н᾽] – согл., непарн., сонор., мягк..
ь [-]
- 4 б., 3 зв.. [п, э н,]
— Ребята, кому не понятно, как выполнять фонетический разбор?
IV. Закрепление изученного.
– Разгадать ребусы и выполнить фонетический разбор слов (учащийся у доски)
воро′та – 3 слога
в [в] – согл., парн., зв., тв..
о [а] – гл., безуд..
р [р] – согл. , непарн., сон., тв..
, непарн., сон., тв..
о [о] – гл., ударн..
т [т] – согл., парн., глух., тв..
а [а] – гл., безуд..
- 6 б., 6 зв.. [в а р о т а]
ры′бка – 2 слога
р [р] – согл., парн., сон., тв..
ы [ы] – гл., ударн..
б [п] – согл., парн., глух., тв..
к [к] – согл., парн., глух., тв..
а [а] – гл., безуд..
- 5 б., 5 зв.. [р ы п к а]
ты′ква – 2 слога
т [т] — согл., парн., глух., тв..
ы [ы] — гл., ударн..
к [к] — согл., парн., глух., тв..
в [в] — согл., парн., зв., тв..
а [а] — гл., безуд..
- 5 б., 5 зв.. [т ы к в а]
камы´ш – 2 слога
к [к] — согл. , парн., глух., тв..
, парн., глух., тв..
а [а] — гл., безуд..
м [м] — согл., непарн., сон., тв..
ы [ы] — гл., ударн..
ш [ш] — согл., парн., глух., тв..
- 5 б., 5 зв.. [к а м ы ш]
Работа в команде по карточкам
АлфавИт, каталОг, библиотЕка, красИвее, звонИт, договОр, срЕдства, киломЕтр, свЁкла, творог.
Сочетание чн как правило, произносится в соответствии с написанием.
Например: Античный, дачный, качнуть.
Но в некоторых сочетаниях букв чн не так, как пишется, а по-другому [шн], например: коне[ш]но, ску[ш]но, наро[ш]но, праче[ш]ная.
В некоторых словах допускается двоякое произношение.
Например: булочная, гречневый, сливочный.
В конце XIX – начале XX века многие слова произносились с [шн], а не с [чн]. Произношение [шн] старой московской орфоэпической нормы.
Произношение [шн] старой московской орфоэпической нормы.
Правильно произнесите записанные слова.
Что, чтобы, скучный, конечно, скворечник, яичница, гречневый, пустячный.
— Команда, все члены которой быстро и правильно справились с заданием получает 20 баллов.
V. Подведение итогов.
— Итак, ребята, наш урок заканчивается.
— Чему мы научились сегодня на уроке?
— Достигли ли мы цели, которую поставили перед собой в начале урока?
— Что на уроке понравилось больше всего?
Выставляем оценки, заработанные вами на уроке.
VI. Домашнее задание.
— Открыли дневники, записываем домашнее задание: выполнить фонетический разбор слов: ёж, медведь, цирк.
VII. Рефлексия (каждому раздаются карточки, ученики подчёркивают по одному из ответов)
1. Тема сегодня на уроке была: сложная/простая
Тема сегодня на уроке была: сложная/простая
2. Я на уроке работал(а): активно/пассивно
3. Новая тема мне: понятна/непонятна
4. В целом уроком я: доволен/не доволен
5. Настроение после урока у меня: улучшилось/ухудшилось
Определение, фонетический (звуко-буквенный) разбор и разбор слова по составу
На данной странице представлено лексическое значение слова «готовить», а также сделан звуко-буквенный разбор и разбор слова по составу с транскрипцией и ударениями.Оглавление:
- Значение слова
- Звуко-буквенный разбор
- Разбор по составу
Значение слова
ГОТОВИТЬ, влю, вишь; несов.
1. кого-что. Делать годным, готовым для чего-н. (для использования, для осуществления чего-н., для работы). Г. станок к пуску. Г. больного к операции. Г. молодых специалистов. Институт готовит учителей.
Институт готовит учителей.
2. что. Работать над освоением, выполнением чего-н. Г. материалы к докладу. Г. уроки. Г. роль.
3. что. Собираться сделать что-н., замышлять устроить что-н. Г. торжественную встречу гостям.
4. Приготовлять пищу, стряпать. Умеет г. В нашей столовой хорошо готовят.
| сов. сготовить, влю, вишь (к 4 знач.; разг.).
| сущ. готовка, и, ж. (к 4 знач.; разг.).
Фонетический (звуко-буквенный) разбор
гото́вить
готовить — слово из 3 слогов: го-то-вить. Ударение падает на 2-й слог.
Транскрипция слова: [гатов’ит’]
г — [г] — согласный, звонкий парный, твёрдый (парный)
о — [а] — гласный, безударный
т — [т] — согласный, глухой парный, твёрдый (парный)
о — [о] — гласный, ударный
в — [в’] — согласный, звонкий парный, мягкий (парный)
и — [и] — гласный, безударный
т — [т’] — согласный, глухой парный, мягкий (парный)
ь — не обозначает звука
В слове 8 букв и 7 звуков.
Цветовая схема: готовить
Разбор слова «готовить» по составу
готовить (программа института)
готовить (школьная программа)
Части слова «готовить»: готов/и/ть
Часть речи: глагол
Состав слова:
готов — корень,
и, ть — суффиксы,
нет окончания,
готови — основа слова.
Примечание: ть является формообразующим суффиксом и не входит в основу слова, но во многих школьных программах ть отмечается как окончание.
Фонетический разбор слова — это просто
Я б в нефтяники пошел!
Пройди тест, узнай свою будущую профессию и как её получить.
Химия и биотехнологии в РТУ МИРЭА
120 лет опыта подготовки
Международный колледж искусств и коммуникаций
МКИК — современный колледж
Английский язык
Совместно с экспертами Wall Street English мы решили рассказать об английском языке так, чтобы его захотелось выучить.
15 правил безопасного поведения в интернете
Простые, но важные правила безопасного поведения в Сети.
Олимпиады для школьников
Перечень, календарь, уровни, льготы.
Первый экономический
Рассказываем о том, чем живёт и как устроен РЭУ имени Г.В. Плеханова.
Билет в Голландию
Участвуй в конкурсе и выиграй поездку в Голландию на обучение в одной из летних школ Университета Радбауд.
Цифровые герои
Они создают интернет-сервисы, социальные сети, игры и приложения, которыми ежедневно пользуются миллионы людей во всём мире.
Работа будущего
Как новые технологии, научные открытия и инновации изменят ландшафт на рынке труда в ближайшие 20-30 лет
Профессии мечты
Совместно с центром онлайн-обучения Фоксфорд мы решили узнать у школьников, кем они мечтают стать и куда планируют поступать.
Экономическое образование
О том, что собой представляет современная экономика, и какие карьерные перспективы открываются перед будущими экономистами.
Гуманитарная сфера
Разговариваем с экспертами о важности гуманитарного образования и областях его применения на практике.
Молодые инженеры
Инженерные специальности становятся всё более востребованными и перспективными.
Табель о рангах
Что такое гражданская служба, кто такие госслужащие и какое образование является хорошим стартом для будущих чиновников.
Карьера в нефтехимии
Нефтехимия — это инновации, реальное производство продукции, которая есть в каждом доме.
Как сделать фонетический разбор?
Фонетический разбор можно назвать звуко-буквенным разбором. При его проведении делается анализ слова, характеризуется его звуковой состав и слоговая структура. Для правильного фонетического разбора важно произнести слово вслух, потому что этот разбор характеризует именно звуки слова, а не буквы.
При его проведении делается анализ слова, характеризуется его звуковой состав и слоговая структура. Для правильного фонетического разбора важно произнести слово вслух, потому что этот разбор характеризует именно звуки слова, а не буквы.
Фонетика является таким разделом языкознания, занимающимся изучением именно звукового состава слова. Изучение любого языка начинается с этого раздела. Именно фонетика позволяет понять специфическое произношение звуков и их сочетаний.
В тестах ЕГЭ всегда встречается одно-два задания по фонетике, ведь ученик, заканчивающий школу, должен знать этот раздел.
Фонетический разбор
Как разобрать слово фонетически? Для начала его нужно произнести вслух. Всегда нужно помнить, что буквенное слово может и не совпадать со звуковым. Выписываем слово на лист бумаги, делим его на слоги и ставим ударение.
Теперь в столбик под словом выписываем все его буквы, а рядом с ними — звуки (звуки — это так, как слышатся буквы в слове, как мы их произносим). Затем анализируем каждый звук. Гласный звук может быть либо ударным, либо безударным. С согласными звуками дело обстоит по-другому. Они могут быть звонкими или глухими, твердыми или мягкими, иметь пару или быть без пары. Напротив каждого звука через тире нужно указать его полную характеристику по этим критериям.
Затем анализируем каждый звук. Гласный звук может быть либо ударным, либо безударным. С согласными звуками дело обстоит по-другому. Они могут быть звонкими или глухими, твердыми или мягкими, иметь пару или быть без пары. Напротив каждого звука через тире нужно указать его полную характеристику по этим критериям.
После анализа звуков подсчитываем количество букв и звуков. Есть слова, в которых звуков больше, чем букв, бывает и наоборот.
Из описания видно, как делать фонетический разбор, и на основании его можно составить схему разбора. Подведем итоги и еще раз рассмотрим, как выглядит схема фонетического разбора слова:
- Для начала запишите слово, которое необходимо разобрать. Поставьте в нем ударение и разделите его на слоги.
- Теперь запишите все буквы слова в столбик. Рядом с ними, в квадратных скобках, укажите звуки, которые слышите при произношении.
- Охарактеризуйте каждый звук. Определите, гласный он или согласный. У гласных звуков укажите ударность/безударность. У согласных – парный/непарный, звонкий/глухой, твердый/мягкий, сонорный или нет.
- В конце подсчитайте и запишите количество букв и звуков в слове.
 У согласных – парный/непарный, звонкий/глухой, твердый/мягкий, сонорный или нет.
У согласных – парный/непарный, звонкий/глухой, твердый/мягкий, сонорный или нет.О том, как сделать фонетический разбор, подробнее можно посмотреть здесь: Фонетический разбор.
ГДЗ по Русскому языку 8 класс Бархударов Решебник
В восьмом классе материал по русскому языку становится более сложным, чем в предыдущие годы. Его становится больше, а значит, и запоминать сложнее. Меньшую проблему это представляет ученикам, которые ранее хорошо успевали и им остается только повторить пройденное и дополнить свои знания небольшим количеством нового материала. Менее способные дети требуют больше внимания, которое не могут дать некоторые родители в связи с недостатком времени. Конечно, ведь мамы и папы приходят уставшие после работы, у них нет никаких ресурсов помогать и объяснять что-то часами или сидеть за компьютером и искать необходимую информацию. Хорошим решением для таких семей будет именно воспользоваться ГДЗ по Русскому языку за 8 класс Бархударов . В нем содержатся готовые ответы к учебнику, по которому дети занимаются в школе. Репетиторы могут слишком дорого обойтись, а вот книга, которая будет и справочником, и вспомогательным источником подсказок обойдется дешевле и даст не менее хороший эффект.
Хорошим решением для таких семей будет именно воспользоваться ГДЗ по Русскому языку за 8 класс Бархударов . В нем содержатся готовые ответы к учебнику, по которому дети занимаются в школе. Репетиторы могут слишком дорого обойтись, а вот книга, которая будет и справочником, и вспомогательным источником подсказок обойдется дешевле и даст не менее хороший эффект.
Несомненно, никакой школьник не хочет тратить большую часть своего свободного времени на выполнение домашнего задания и подготовку к каким-либо контрольным точкам. Поэтому, чтобы облегчить себе жизнь, стоит обзавестись проверенным вспомогательным ресурсом – ГДЗ. Благодаря такому помощнику учеба не будет приносить множество хлопот, а будет только в пользу.
Что содержит учебный материал по программе русского языка 8 класса.
Учебник Бархударова, Крючкова, Максимова в зеленой обложке выпущенной издательством Просвещение в 2018 году и выполнена согласно ФГОС. Он разбит на несколько разделов, каждая из которых включает несколько параграфов для изучения.
Первая часть посвящена повторению пройденного материала:
- фонетика и графика;
- морфология и словообразование;
- лексика и фразеология, морфология;
- повторение стилей речи;
- строения текста;
- синтаксис и пунктуация;
- разбор словосочетаний и предложений (простое, двусоставное, обособленное предложение).
Задачник по русскому языку Бархударовой полностью соответствует стандартам и отвечает по всем правилам рабочей программы к обновленному курсу от 2019 учебного года. Каждый верный ответ имеет максимально целостное, понятное и разборчивое описание, чтобы процесс восприятия происходил как можно быстрее. Все номера в пособии полностью совпадают с упражнениями в учебнике, поэтому поиск нужного примера не принесет трудностей.
Что представляет собой гдз по русскому языку для 8 класса от Бахрударова
Автор составил его с целью максимального упрощения процесса запоминания. Он предоставляет больше теоретического материала, нежели практических упражнений. Заданий становится меньше, последующий материал основывается на повторении пройденного. Список других плюсов издания по русскому языку за 8 класс, авторы: Бархударов, Крючков, Максимов:
Он предоставляет больше теоретического материала, нежели практических упражнений. Заданий становится меньше, последующий материал основывается на повторении пройденного. Список других плюсов издания по русскому языку за 8 класс, авторы: Бархударов, Крючков, Максимов:
- исчерпывающие комментарии есть даже к самым элементарным примерам, так как у всех детей разный уровень знаний;
- онлайн-режим для практичности;
- работает без перебоев на любой удобной для вас платформе;
- правильно решены все задачи, приведенные в соответствующем учебно-методическом комплексе.
Кроме того, эта книга пригодится и для будущих экзаменов, поскольку сразу содержит в себе решения примеров, на которых можно практиковать написание слов под диктовку. Также решебник прошел полное обновление и подходит для учебника 2019 года в зеленой обложке в соавторсве с Ладыженской и Барановой.
Рекрутинговое агентство «CAREER.
 KZ» в Шымкенте. Подбор персонала из Казахстана и ближнего зарубежья.
KZ» в Шымкенте. Подбор персонала из Казахстана и ближнего зарубежья.Составить резюме на сайте Загрузить готовое резюме
Чтобы стать клиентом CAREER.KZ достаточно прислать резюме по адресу [email protected]. С этой минуты при каждой новой вакансии будет рассматриваться и ваша кандидатура. Наши консультанты свяжутся с вами, если в портфеле заказов CAREER.KZ появится позиция, соответствующая вашему опыту, планам и ожиданиям. Для более точного поиска регулярно сообщайте нам об изменениях в вашей карьере или контактной информации.
Мы несем ответственность за каждого трудоустроенного кандидата! Если вас заинтересовала конкретная вакансия, вы можете связаться с нашим специалистом по телефону, указанному в этой вакансии. Специалист оценит соответствие ваших компетенций и, при соответствии их требованиям заказчика, пригласит на собеседование.
Сотрудничество с рекрутерами CAREER. KZ поможет соискателю сориентироваться на рынке труда, правильно оценить свои силы и выбрать тот путь, который больше всего соответствует данному этапу развития карьеры.
KZ поможет соискателю сориентироваться на рынке труда, правильно оценить свои силы и выбрать тот путь, который больше всего соответствует данному этапу развития карьеры.
Рекрутеры кадрового агентства CAREER.KZ объективно оценят ваши опыт и навыки, помогут сориентироваться в массе вакансий и определить зарплатные границы.
Партнёрство с CAREER.KZ поможет сэкономить время, потраченное на поиски вакансии, а также получить предложения, о которых вы бы не подумали (например, из другой отрасли).
Нашим специалисты никогда не предложат вакансию, которая заведомо вам не подходит, сохранив ваше время и нервы.
Если вы были трудоустроены CAREER.KZ и продолжаете работать в той же компании или являетесь сотрудником другой компании-клиента CAREER.KZ, то наши консультанты не могут обращаться к вам с предложениями о смене места работы. Сделать это можно, обратившись к нам самостоятельно, оповестив об этом работодателя.
В обязанности рекрутёров CAREER. KZ входит адаптация сотрудника на новом месте работы.
KZ входит адаптация сотрудника на новом месте работы.
Каждый рекрутер компании является постоянным консультантом для своих клиентов, что обеспечивает индивидуальный подход и оптимальный формат взаимодействия.
Стресс приговора | Произношение | Английский Клуб
Ударение в предложении — это музыка разговорного английского языка. Как и словесное ударение, ударение в предложениях может помочь вам понять устную английскую речь, даже если речь идет быстро.
Ударение в предложении — это то, что придает английскому языку ритм или «ритм». Вы помните, что ударение в слове — это ударение на односложном в слове . Ударение в предложении — это акцент на определенных слов внутри предложения .
В большинстве предложений есть два основных типа слов:
- слов содержания
Слова содержания являются ключевыми словами предложения. Это важные слова, которые несут значение или смысл — реальное содержание. - структурных слов
Структурные слова не очень важные слова. Это небольшие простые слова, которые делают предложение грамматически правильным. Они придают предложению правильную форму — структуру.
 Это важные слова, которые несут значение или смысл — реальное содержание.
Это важные слова, которые несут значение или смысл — реальное содержание.Если вы удалите структурные слова из предложения, вы, вероятно, все равно поймете предложение.
Если вы удалите слова содержания из предложения, вы не поймете предложение.Предложение не имеет смысла или значения.
Представьте, что вы получили это сообщение телеграммы:
Это предложение неполное. Это не «грамматически правильное» предложение. Но вы, наверное, это понимаете. Эти 4 слова очень хорошо передаются. Кто-то хочет, чтобы вы продали их машину для них, потому что у них перешло с на Франция . Можно добавить несколько слов:
Новые слова не добавляют никакой информации. Но они делают сообщение более правильным грамматически. Мы можем добавить еще больше слов, чтобы получилось одно полное, грамматически правильное предложение. Но информация в основном та же :
Но они делают сообщение более правильным грамматически. Мы можем добавить еще больше слов, чтобы получилось одно полное, грамматически правильное предложение. Но информация в основном та же :
В нашем предложении 4 ключевых слов (продавать, автомобиль, ушел, Франция) подчеркнуты или подчеркнуты .
Почему это важно для произношения? Это важно, потому что добавляет к языку «музыку». Это ритм английского языка.Он изменяет скорость, с которой мы говорим (и слушаем) язык. Время между ударными словами одинаковое.
В нашем предложении 1 слог между ПРОДАЖА и АВТОМОБИЛЬ и 3 слога между АВТОМОБИЛЬ и УДАЛЕНИЕ. Но время ( t ) между SELL и CAR и между CAR и GONE одинаково. Мы постоянно читаем ударные слова. Для этого мы говорим «мой» больше медленно , а «потому что я» больше быстро . Мы изменяем скорость слов с небольшой структурой, чтобы ритм ключевых слов содержания оставался прежним.
Мы изменяем скорость слов с небольшой структурой, чтобы ритм ключевых слов содержания оставался прежним.
Я профессиональный фотограф, ГЛАВНЫЙ ИНТЕРЕС — СНИМАТЬ СПЕЦИАЛЬНЫЕ, ЧЕРНЫЕ и БЕЛЫЕ ФОТОГРАФИИ, демонстрирующие абстрактные смыслы в их фотоструктуре.
Правила ударения в приговоре Выучить английский язык : Произношение: Ударение в предложенииОбработка естественного языка: взгляд на вычисления при наличии неоднозначности
Как следует из названия, Обработка естественного языка (NLP) — это задача анализа или обработки языков, на которых говорят люди, с помощью машины (компьютера).Несмотря на то, что эта задача может выполняться компьютером с гораздо большей скоростью, он все равно не может достичь уровня эффективности, необходимого для замены человека, и в основном это то, что отличает людей от машин — акт естественного понимания .
Акт естественного понимания можно понять и во многом связать с нашим собственным детским опытом. В детстве мы не знали грамматики или семантики повседневных разговорных языков, с помощью которых наши старшие общались с нами.Что бы мы ни слышали или чем бы ни подвергали себя обработке, мы привыкли учиться и пытаться применять это. То же самое и с машинами (с множеством измененных и сложных правил).
В детстве мы не знали грамматики или семантики повседневных разговорных языков, с помощью которых наши старшие общались с нами.Что бы мы ни слышали или чем бы ни подвергали себя обработке, мы привыкли учиться и пытаться применять это. То же самое и с машинами (с множеством измененных и сложных правил).
В нашей повседневной жизни мы используем множество предложений, которые не так совершенны с точки зрения грамматики и словарного запаса, но тем не менее мы интерпретируем их правильно. Это происходит потому, что у нас, людей, есть наш уровень понимания до того момента, когда мы можем интерпретировать разговоры (декодировать их) на основе нашего прошлого опыта.Но машине не так просто понять различные естественные формы, присутствующие в естественных языках, таких как: сарказм , сленговое слово , эмоции , каламбур , гнев , вежливость , любовь , care и т. Д. Без явного упоминания их (с точки зрения правил).
Эта разница в производительности человека и машины при обработке естественного языка зависит не только от скорости, но в основном от эффективности.Одна из основных причин этого — неоднозначность , присутствующая в естественных языках.
Неоднозначность — неотъемлемая характеристика человеческих разговоров, особенно сложная в сценариях понимания естественного языка (NLU). Неоднозначность — одна из тех областей когнитивных наук , которая не имеет четко определенного решения.
Этапы НЛП и связанные с ними неоднозначности:
Ниже мы обсудили различные стадии НЛП и связанные с ними неоднозначности с каждым из них.
Традиционно считается, что НЛП как для устной, так и для письменной речи состоит из следующих этапов:
Фонология и фонетика: (Обработка звука)
Морфология: (Обработка словоформ)
Лексикон: (Хранение слов и связанных с ними знаний)
Разбор: (Обработка структуры)
Семантика: (Обработка значения)
Прагматика: (Обработка намерений пользователя, моделирование и т.
Д.)Дискурс: (Обработка связного текста)
 Д.)
Д.)Давайте рассмотрим каждый этап один за другим вместе с соответствующей неоднозначностью с помощью примеров. (мы постарались придумать простейшие примеры, чтобы помочь вам понять концепции).
1. Фонология и фонетика: (Обработка звука)
Два слова называются омофонами друг друга, если они звучат одинаково, написание может совпадать, а может и не совпадать, но их значения различаются.Такие слова понимаются как часть контекста, в котором они используются в конкретном предложении.
Например:
- Омофоны с таким же написанием:
Среднее значение : (математическое среднее) и Среднее значение : (не очень хорошо)
Книга : (что-то почитать) и Книга : (с оговоркой)
Омофоны с разным написанием:
Неделя : (период в семь дней) и Слабый : (мало физической силы или энергии)
Ячейка : (тюремная камера) и Продать : (отдать или передать что-либо в обмен на деньги)
Определение границы слова является проблемой в случае быстрой речи:
Принесите, пожалуйста, мне его часть.
Как единое целое, часть неоднозначна, что означает часть чего-то или разделение (разделение).
 Как единое целое, часть неоднозначна, что означает часть чего-то или разделение (разделение).
Как единое целое, часть неоднозначна, что означает часть чего-то или разделение (разделение).2. Морфология: (Обработка словоформ)
Эта форма неоднозначности возникает из-за дальнейшей обработки лексем (корневых слов), чтобы сделать их пригодными для использования в конкретном предложении.
Например:
Мне нравятся люди, которые сводят меня с ума.
Здесь фраза «Сводит меня с ума» неоднозначна, поскольку ее можно интерпретировать как две разные ситуации: 1) мне нравятся люди, которые сводят меня с ума (какое-то блюдо из арахиса, которое я люблю есть) или 2) мне нравятся люди, которые меня заставляют орехи (чтобы кого-то очень рассердить).
Эта неоднозначность возникает из-за слова «орехи», которое является формой множественного числа от слова «орех» (арахис) и также имеет свое собственное самостоятельное значение (сводить кого-то с ума). Эта форма морфологического процесса называется Инфлексия.
Флексия — это процесс изменения формы слова так, чтобы оно выражало такую информацию, как число, личность, падеж, пол, время, настроение и аспект, но синтаксическая категория слова остается неизменной.
Различные другие морфологические процессы:
Происхождение: Добавление деривационной морфемы часто изменяет грамматическую категорию или часть речи корневого слова, к которому она добавляется.Это также изменяет синтаксическую категорию слова. Например: добавление ful к значению существительного превращает слово в прилагательное (значимое).
Клитика: клитика — это слово или часть слова, которые не могут существовать сами по себе и нуждаются в соседнем слове для выхода.
Полуаффиксы: Полуаффиксы — это связанные морфемы, сохраняющие словесность. Например: Индо-пак, Антинациональный и т. Д.

3.
 Лексика: (Хранение слов и связанных с ними знаний)
Лексика: (Хранение слов и связанных с ними знаний)Лексикон — это совокупность информации о словах языка и лексических категориях, к которым они принадлежат.
Например:
Во мне жгучее желание.
У Сачина Тендулкара перерыв после столь напряженного графика.
4.Парсинг: (Обработка структуры)
Синтаксический анализ — это процесс определения иерархической структуры линейной последовательности слов.
Тип неоднозначности, участвующей в синтаксическом анализе, называется структурной неоднозначностью. Структурная неоднозначность бывает двух типов:
Неопределенность объема: неоднозначность, связанная с объемом слов, входящих в предложение. Например:
Не забудьте привезти зеленые свечи и воздушные шары на день рождения Адитьи. Объем «зеленого» цвета в приведенном выше предложении неоднозначен. Иерархическая структура между приведенными выше линейными предложениями может быть следующей: Не забудьте принести (зеленые свечи и воздушные шары) на день рождения Адитьи .
или Не забудьте принести (зеленые свечи) и воздушные шары на день рождения Адитьи .
Неопределенность вложений: Рассмотрим несколько примеров:
Адитья ехал с Абхишеком на своей машине .Непонятно, кому принадлежит машина, Адитья или Абхишек? Вложение фразы в его машине неоднозначно.
Я видел, как Абхишек ехал на велосипеде . Кто ехал на байке: я или Абхишек? Привязанность фразы езда на велосипеде неоднозначна. (двусмысленность вложения; фраза)
Абхишек прокомментировал видео на Youtube1, которое ему понравилось2, что они предоставляют зрителям контент хорошего качества. Предложение имеет два значения:
Абхишек прокомментировал видео на Youtube ФАКТ о том, что ему нравится контент хорошего качества, предоставленный ими зрителям, а
Абхишек прокомментировал видео на Youtube, которое ему понравилось, что они предоставляют зрителям контент хорошего качества.
 или Не забудьте принести (зеленые свечи) и воздушные шары на день рождения Адитьи .
или Не забудьте принести (зеленые свечи) и воздушные шары на день рождения Адитьи .
Неопределенность возникает из-за двойной роли этого слова, а именно, относительного местоимения или комплементатора. В первой ситуации this1 прикрепляется к видео на Youtube, а во второй ситуации that1 прикрепляется к прокомментированному.
5. Семантика: (Обработка значения)
После того, как слово сформировано и его структура обнаружена, обработка предложения посвящается извлечению значения.
Даже после того, как синтаксис и значения отдельных слов были определены, есть два способа прочтения предложения, что приводит к неоднозначности, что показано с помощью на примере ниже:
Пример семантической неоднозначности:
Адитья и Шраддха поженились в прошлом месяце.
Здесь возникает двусмысленность, женаты ли Адитья и Шраддха друг на друге или на двух разных людях?
6. Прагматика: (Обработка намерений пользователя, моделирование)
Прагматический анализ — это часть процесса извлечения информации из текста. В частности, это та часть, которая фокусируется на взятии набора структур текста и выяснении его фактического значения. Приведенные ниже примеры юмористического обмена иллюстрируют суть проблемы.
В частности, это та часть, которая фокусируется на взятии набора структур текста и выяснении его фактического значения. Приведенные ниже примеры юмористического обмена иллюстрируют суть проблемы.
Пример 1:
Abhishek: Aditya, мой сотовый телефон был полностью разряжен, поэтому я поставил его на зарядку, но не уверен, что нажимаю кнопку; пожалуйста, поднимитесь наверх и подтвердите это для меня.
Адитья (бегает наверх и возвращается, тяжело дыша): Абхишек, ты забыл включить кнопку.
Пример 2:
Abhishek: Aditya, мы оба проехали около 10 км от нашего дома; оставив его пустым; и я не уверен, что запираю входную дверь.Пожалуйста, пойдите и проверьте, заблокирован он или нет, чтобы спасти от воров.
Адитья (по возвращении из дома): Абхишек, мы оставили дверь открытой.

7. Дискурс: (Обработка связного текста)
Дискурс — это связная структурированная группа предложений. В этом случае на основе предыдущего набора предложений строится гипотеза, которая применяется к следующим предложениям. Например:
Приговор-1: Абхишек выходил удрученным из школы
(кто такой Абхишек: скорее всего, студент?)
Предложение-2: Он не мог контролировать класс
.(кто сейчас Абхишек? Скорее всего, учитель?)
Приговор-3: Учитель не должен был привлекать его к ответственности
(кто сейчас Абхишек? Скорее всего, снова ученик, хоть и особенный ученик — монитор?)
Приговор-4: В конце концов, он всего лишь помощник учителя
(все предыдущие гипотезы отброшены!).
Такова природа обработки дискурса. В дополнение к многоточию, кореферентности, разрешению смыслов и структур и т. Д. Необходимо проводить постепенное наращивание общего мира.
8.
 Текстовый юмор и двусмысленность:
Текстовый юмор и двусмысленность:Неопределенность возникает в Юморе из-за разницы в мировоззрении и саркастическом поведении. Некоторые люди понимают каламбур, использованный в предложении, в то время как другие относятся к нему серьезно и пытаются логически извлечь из него какой-то смысл.
Пример юмора и лексической двусмысленности:
Салена: Чем вы занимаетесь?
Адитья: Я гоняю на машинах.
Салена: Вы выигрываете много гонок?
Адитья: Нет, машины должны быстрее.
Неоднозначность слов « гоночных автомобилей » (вождение машин против бега против машин) и , два разных значения, выбранные Саленой и Адитьей , породили юмор.
Вывод:
В этой статье мы обсудили обработку естественного языка с точки зрения неоднозначности, многоязычия и ограничений ресурсов.Сначала мы описали различные виды двусмысленности, которые возникают в НЛП, начиная с самого низкого уровня обработки, а именно, от морфологии до самого высокого уровня, а именно, прагматики и дискурса. Затем мы рассмотрели одну конкретную двусмысленность, а именно, смысл слова, и описали способы решения этой проблемы в условиях ограниченных ресурсов, а именно аннотированных корпусов. Многоязычность использовалась в смысле проецирования смысловых распределений в корпусах с одного языка на другой и таких параметров сети, как расстояние между чувствами.Сравнивались спектакли с проекцией и без нее, и идея проекции казалась вполне обоснованной.
Затем мы рассмотрели одну конкретную двусмысленность, а именно, смысл слова, и описали способы решения этой проблемы в условиях ограниченных ресурсов, а именно аннотированных корпусов. Многоязычность использовалась в смысле проецирования смысловых распределений в корпусах с одного языка на другой и таких параметров сети, как расстояние между чувствами.Сравнивались спектакли с проекцией и без нее, и идея проекции казалась вполне обоснованной.
Надеемся, вам понравилось!
Счастливого обучения 🙂
интересная проблема фонетического синтаксического анализа
[Логланисты] Re: забавная проблема фонетического синтаксического анализа Рэндалл Холмс [email protected]Ср, 10 февраля, 12:15:55 PST 2016
Ха!
Хотя моя грамматика неверна ... слишком много внимания уделяется фонетике :-)
Леви cmalea ui ga bilti
[uttF: утверждение:
[условия: аргумент:
Леви
[descpred: predunit:
Cmalea
[freemod:
ui]]]
[предикат: markpred:
[PA1:
ga]
[barepred: predunit:
bilti]]]
levicmale'auigabil'ti
[uttF: инструкция:
[условия: аргумент:
леви
[descpred: predunit:
cmale'a
[freemod:
ui]]]
[предикат: markpred:
[PA1:
ga]
[barepred: predunit:
bil'ti]]]
Второй пример
Леви cmalea ia ga bilti
[uttF: инструкция:
[условия: аргумент:
Леви
[descpred: predunit:
Cmalea
[freemod:
я]]]
[предикат: markpred:
[PA1:
ga]
[barepred: predunit:
bilti]]]
терпит неудачу, потому что фонетически неоднозначный
levicmale'aiagabil'ti
неудача
работает со вставленным важным разрывом слога
левичмалеа-ягабилти
[uttF: инструкция:
[условия: аргумент:
леви
[descpred: predunit:
cmale'a-
[freemod:
я]]]
[предикат: markpred:
[PA1:
ga]
[barepred: predunit:
bil'ti]]]
В среду, 10 февраля 2016 г. , в 13:06 Рэндалл Холмс <м[email protected]>
написал:
> Рассмотрим приговор
>
> Леви cmalea ui bilti
>
> Эта строчная буква очень красивая!
>
> [uttF: аргумент:
> леви
> [descpred: despredE:
> [despredD: predunit:
> смалея
> [freemod:
> ui]]
> [despredD: predunit:
> билти]]]
>
> анализирует без боли
>
> levicmale'auibil'ti
>
>
> [uttF: аргумент:
> леви
> [descpred: despredE:
> [despredD: predunit:
> cmale'a
> [freemod:
> ui]]
> [despredD: predunit:
> бил'ти]]]
>
> Анализирует без пауз.Вам нужно отметить напряжения
> , чтобы он знал, где заканчиваются предикаты.
>
> Levi cmalea ia bilti (красивая маленькая буква (да!))
>
> [uttF: аргумент:
> Леви
> [descpred: despredE:
> [despredD: predunit:
> смалея
> [freemod:
> ia]]
> [despredD: predunit:
> билти]]]
>
> levicmale'aiabilti
>
> сбой
>
> Ошибка. .. чем он отличается от предыдущего?
>
> левичмалеа-iabilti
>
>
> [uttF: аргумент:
> леви
> [descpred: despredE:
> [despredD: predunit:
> cmale'a-
> [freemod:
> ia]]
> [despredD: predunit:
> билти]]]
>
> Разница в том, что нельзя сказать наверняка
> , что предикат заканчивается на -a - следующее -i
> сделало бы односложным, и мы могли бы
> глядя на <* cmale'ai>, заимствование не в нашем
> словарь ;-) Разрыв слога проясняет
> как следует произносить поток гласных.>
>
> -
> С уважением, Рэндалл Холмс
>
> Любые высказанные выше мнения не являются
> официальное мнение любого человека или учреждения.
>
-
С уважением, Рэндалл Холмс
Любые высказанные выше мнения не являются
официальные мнения любого человека или учреждения.
-------------- следующая часть --------------
Вложение HTML было очищено . ..
URL: http: //mailman.ucsd.edu / pipermail / loglanists / attachments / 20160210/74659800 / attachment-0001.html
 , в 13:06 Рэндалл Холмс <м
, в 13:06 Рэндалл Холмс <м .. чем он отличается от предыдущего?
>
> левичмалеа-iabilti
>
>
> [uttF: аргумент:
> леви
> [descpred: despredE:
> [despredD: predunit:
> cmale'a-
> [freemod:
> ia]]
> [despredD: predunit:
> билти]]]
>
> Разница в том, что нельзя сказать наверняка
> , что предикат заканчивается на -a - следующее -i
> сделало бы односложным, и мы могли бы
> глядя на <* cmale'ai>, заимствование не в нашем
> словарь ;-) Разрыв слога проясняет
> как следует произносить поток гласных.>
>
> -
> С уважением, Рэндалл Холмс
>
> Любые высказанные выше мнения не являются
> официальное мнение любого человека или учреждения.
>
-
С уважением, Рэндалл Холмс
Любые высказанные выше мнения не являются
официальные мнения любого человека или учреждения.
-------------- следующая часть --------------
Вложение HTML было очищено .
.. чем он отличается от предыдущего?
>
> левичмалеа-iabilti
>
>
> [uttF: аргумент:
> леви
> [descpred: despredE:
> [despredD: predunit:
> cmale'a-
> [freemod:
> ia]]
> [despredD: predunit:
> билти]]]
>
> Разница в том, что нельзя сказать наверняка
> , что предикат заканчивается на -a - следующее -i
> сделало бы односложным, и мы могли бы
> глядя на <* cmale'ai>, заимствование не в нашем
> словарь ;-) Разрыв слога проясняет
> как следует произносить поток гласных.>
>
> -
> С уважением, Рэндалл Холмс
>
> Любые высказанные выше мнения не являются
> официальное мнение любого человека или учреждения.
>
-
С уважением, Рэндалл Холмс
Любые высказанные выше мнения не являются
официальные мнения любого человека или учреждения.
-------------- следующая часть --------------
Вложение HTML было очищено . ..
URL: http: //mailman.ucsd.edu / pipermail / loglanists / attachments / 20160210/74659800 / attachment-0001.html
..
URL: http: //mailman.ucsd.edu / pipermail / loglanists / attachments / 20160210/74659800 / attachment-0001.html
Подробнее о логланистах список рассылки
Заявка на патент США для СИСТЕМЫ ТЕЛЕФОННОГО ПЕРЕВОДА ЕСТЕСТВЕННЫХ ЯЗЫКОВ Заявка на патент (Заявка № 20100049497 от 25 февраля 2010 г.)
Фонетическая система перевода на естественный язык принимает аудиовыход от электроакустического устройства, которое подключено как компонент в аудиосистеме, представленной в театре или аудитории, чтобы идентифицировать любой речевой сигнал, содержащийся в аудиовыходе.Речевые сигналы разбиты на узнаваемые фонемы, которые составляют самые основные элементы речи в разговорных языках. Последовательно сгенерированные фонемы, идентифицированные из речевых сигналов, затем перегруппировываются, чтобы сформировать узнаваемые слова на одном из языков 6700 языков, на которых говорят во всем мире. Затем предложения формируются с использованием грамматических правил признанного языка, так что каждое предложение переводится на каждый из предпочтительных языков индивидуальной аудитории, где аудитория — это группа людей, предпочитающая слушать звуковую программу на иностранном языке или любую иностранную речь на своем предпочтительном языке. язык без внешних переводчиков.Предпочитаемый язык каждой аудитории определяется при бронировании билетов; алгоритм сохраняет номер места аудитории вместе с предпочтительным языком. Переведенные аудиосигналы распределяются по подлокотнику каждого сиденья таким образом, что каждый зритель слышит и понимает звуковую речь фильмов на иностранном языке или речь на своем предпочтительном языке на своем предпочтительном языке в комнате или холле, оборудованных рядами сидений, поднимающихся как ступеньки.
язык без внешних переводчиков.Предпочитаемый язык каждой аудитории определяется при бронировании билетов; алгоритм сохраняет номер места аудитории вместе с предпочтительным языком. Переведенные аудиосигналы распределяются по подлокотнику каждого сиденья таким образом, что каждый зритель слышит и понимает звуковую речь фильмов на иностранном языке или речь на своем предпочтительном языке на своем предпочтительном языке в комнате или холле, оборудованных рядами сидений, поднимающихся как ступеньки.
Настоящее изобретение в целом относится к системе перевода естественного языка и, в частности, к системе перевода фонетического естественного языка, способной переводить слышимый звук с любого устройства вывода звука на множество языков, предпочитаемых аудиторией. .
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ В последнее время количество людей, смотрящих международные фильмы с целью получения удовольствия и / или развлечения, сокращается из-за языкового барьера. За исключением понимания языка, иностранные фильмы могут доставить удовольствие от просмотра. Люди в разных частях региона обычно предпочитают смотреть фильмы или события на разных языках. Во время просмотра таких фильмов или мероприятий зрителям может быть трудно понять язык звуковой программы.
За исключением понимания языка, иностранные фильмы могут доставить удовольствие от просмотра. Люди в разных частях региона обычно предпочитают смотреть фильмы или события на разных языках. Во время просмотра таких фильмов или мероприятий зрителям может быть трудно понять язык звуковой программы.
Чтобы преодолеть такие проблемы понимания, аудитория может использовать человека-переводчика, внимательно искать и читать субтитры фильма, или комбинацию подобных инструментов. Однако переводчики-люди обычно очень дороги; а чтение субтитров из движущегося фильма действительно сложно и не позволяет быстро их понять.
Из-за языкового барьера иностранные фильмы либо дублируются, либо имеют субтитры. Если идея «читать» фильм отвлекает пользователя, его единственный выбор — смотреть дублированную версию оригинального фильма на предпочитаемом им языке.Для того, чтобы дублировать оригинальный фильм из одного иностранного фильма в другой, потребуется вдвое больше, чем создание фильма, особенно озвучивание, перезапись песен.
На кинофестивалях, таких как Канны, люди хотят смотреть хорошие зарубежные фильмы; особенно они хотели бы знать, как они использовали современные технологии, сюжет и сценарий в зарубежных фильмах. Что касается музыкальных концертов, то люди хотели бы видеть концерты зарубежных музыкальных композиторов. Из-за языкового барьера качество музыки недоступно для людей во всем мире
Следующий U.Патенты S. включены сюда посредством ссылки для их обучения системам и методам языкового перевода: US Pat. № 6,356,865, выданный Franz et al., Озаглавленный «Способ и устройство для выполнения устного языкового перевода»; Патент США № 5,758,023, выданный Бордо, озаглавленный «Система распознавания речи на нескольких языках»; Патент США № 5,293,584, выданный Брауну и др., Озаглавленный «Система распознавания речи для перевода на естественный язык»; Патент США № 5,963,892, выданный Tanaka et al.под названием «Устройство и способ перевода для облегчения операции ввода речи и получения их правильного перевода»; Патент США № 7 162 412, выданный Ямаде и др. , Озаглавленный «Многоязычная система помощи при разговоре»; Патент США № 6,917,920, выданный Коидзуми и др., Озаглавленный «Устройство перевода речи и машиночитаемый носитель»; Патент США № 4984177 /, выданный Ронделю и др., Озаглавленный «Переводчики голосового языка; и Патент США. №4,507,750, выданный Францу и др., Озаглавленный «Электронное устройство с основного языка».
, Озаглавленный «Многоязычная система помощи при разговоре»; Патент США № 6,917,920, выданный Коидзуми и др., Озаглавленный «Устройство перевода речи и машиночитаемый носитель»; Патент США № 4984177 /, выданный Ронделю и др., Озаглавленный «Переводчики голосового языка; и Патент США. №4,507,750, выданный Францу и др., Озаглавленный «Электронное устройство с основного языка».
Согласно пат. В патенте США № 5615301, выданном Rivers et al., Озаглавленном «Автоматизированная система языкового перевода», каждое предложение переводится на универсальный язык, а затем переводятся предложения с универсального языка на родной язык пользователя, идентифицированный пользователем. Но фонетическая система естественного языка по настоящему изобретению использует языковые словари 6700 языков, которые содержат все возможные слова и набор грамматических правил, представленных на 6700 языках, которые используются в 228 странах.Используя 6700 языковых словарей, фонетическая система естественного языка по настоящему изобретению переводит звуковую речь на одном языке непосредственно на множество языков, предпочитаемых аудиторией, и распределяет аудиовыход на подлокотнике сиденья каждой аудитории. Таким образом, аудитория может наслаждаться звуковой программой, не имея в руках какого-либо устройства для перевода на внешний язык.
Таким образом, аудитория может наслаждаться звуковой программой, не имея в руках какого-либо устройства для перевода на внешний язык.
Соответственно, существует потребность в системе для быстрого, простого, надежного и экономичного перевода с аудиовыхода любого устройства аудиовыхода на множество языков, желаемых аудиторией.Более того, существует потребность в системе перевода, которая может заменять переводчиков и субтитры.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ Система перевода фонетического естественного языка является конечной целью перевода аудиовыхода с электроакустического устройства на предпочтительный язык каждой отдельной аудитории и доставляет переведенную речь в виде аудиосигнала, соответствующего динамику в подлокотнике сиденья аудитории. Настоящее изобретение фонетической системы перевода на естественный язык имеет способность понимать взаимодействия на уровне дискурсивных знаний, предсказывать следующие высказывания, понимать ссылки местоимений и обеспечивать высокоуровневые ограничения для создания контекстуально подходящих предложений, включающих различные контекстно-зависимые явления. Система принимает аудиовыход от входов непрерывной речи, независимых от электроакустических устройств, через инструмент, способный преобразовывать звуковые волны в электромагнитные сигналы.
Система принимает аудиовыход от входов непрерывной речи, независимых от электроакустических устройств, через инструмент, способный преобразовывать звуковые волны в электромагнитные сигналы.
Настоящее изобретение фонетической системы перевода на естественный язык преследует две основные цели; один переводит язык слышимой речи непосредственно на язык аудитории, предпочитаемый каждым человеком; а во-вторых, доставляет переведенную звуковую речь на предпочитаемый для каждой аудитории язык на соответствующий аудиовыход подлокотника сиденья аудитории.
Ввиду вышеизложенных недостатков, присущих известному уровню техники, общая цель настоящего изобретения состоит в том, чтобы предоставить систему перевода на естественный язык, сконфигурированную для включения всех преимуществ предшествующего уровня техники и преодоления присущих ей недостатков.
Следовательно, цель настоящего изобретения состоит в том, чтобы предоставить фонетическую систему естественного языка, которая способна обеспечивать перевод аудиовыхода звуковой программы с одного языка на предпочтительный язык каждой отдельной аудитории, таким образом аудитория может слушать слышимую речь. программы на иностранном языке без использования языковых переводчиков или внимательного чтения субтитров программы на иностранном языке.
программы на иностранном языке без использования языковых переводчиков или внимательного чтения субтитров программы на иностранном языке.
Настоящее изобретение также обеспечивает пользовательский интерфейс для аудитории, где он / она может выбрать предпочтительный язык для прослушивания слышимой речи. Пользовательский интерфейс в соответствии с настоящим изобретением предоставляет аудитории информацию о рекламных предложениях по бронированию билетов, обеспечивает возможность бронирования билетов по городу, новые выпуски и позволяет аудитории выбирать места. Пользовательский интерфейс также доступен через устройства с поддержкой WAP или в киосках бронирования билетов.
Настоящее изобретение раскрывает модуль распознавания речи, который способен идентифицировать последовательности на уровне фонем из аудиовыхода с высокой точностью в реальном времени в условиях непрерывной речи, не зависящей от говорящего, и большого словарного запаса.Модуль распознавания речи принимает электромагнитные сигналы и обеспечивает вывод последовательностей фонем в реальном времени, исключая нежелательный шум, и отправляет их в модуль перевода. Модуль языкового перевода, используемый для синтаксического анализа и генерации, способен интерпретировать эллиптические, неправильно сформированные предложения, которые появляются в аудиовыходе аудиопрограммы. Кроме того, интерфейс между синтаксическим анализатором и модулем распознавания речи должен передавать необходимую информацию синтаксическому анализатору и давать соответствующую обратную связь модулю распознавания речи для повышения точности распознавания.После перевода алгоритм распространения связывает различные переведенные аудиосигналы с местом аудитории и отправляет их в модуль распространения. Это устройство выполняет последнюю задачу по передаче аудиосигнала на каждое отдельное место аудитории.
Модуль языкового перевода, используемый для синтаксического анализа и генерации, способен интерпретировать эллиптические, неправильно сформированные предложения, которые появляются в аудиовыходе аудиопрограммы. Кроме того, интерфейс между синтаксическим анализатором и модулем распознавания речи должен передавать необходимую информацию синтаксическому анализатору и давать соответствующую обратную связь модулю распознавания речи для повышения точности распознавания.После перевода алгоритм распространения связывает различные переведенные аудиосигналы с местом аудитории и отправляет их в модуль распространения. Это устройство выполняет последнюю задачу по передаче аудиосигнала на каждое отдельное место аудитории.
Они вместе с другими аспектами настоящего изобретения, наряду с различными признаками новизны, которые характеризуют настоящее изобретение, конкретно указаны в прилагаемой формуле изобретения и составляют часть настоящего изобретения.Для лучшего понимания настоящего изобретения, его эксплуатационных преимуществ и конкретных целей, достигаемых при его использовании, следует сделать ссылку на прилагаемые чертежи и описания, в которых проиллюстрированы примерные варианты осуществления настоящего изобретения.
Преимущества и особенности настоящего изобретения станут более понятными со ссылкой на следующее подробное описание и формулу изобретения, взятую вместе с прилагаемыми чертежами, на которых одинаковые элементы обозначены одинаковыми символами и на которых :
РИС.1 — предшествующий уровень техники системы фонетического перевода на естественный язык согласно варианту осуществления настоящего изобретения;
РИС. 2 иллюстрирует пользовательский интерфейс для бронирования билетов, где аудитория выбирает свой предпочтительный язык для просмотра / прослушивания звуковой программы;
РИС. 3 иллюстрирует, как преобразованные аудиосигналы распределяются на множество выходных аудиоразъемов подлокотников сидений аудитории с использованием распределительного устройства;
РИС. 4 — место для публики, соответствующее предшествующему уровню техники;
РИС. 5 иллюстрирует последовательность операций системы фонетического перевода на естественный язык согласно варианту осуществления настоящего изобретения.
5 иллюстрирует последовательность операций системы фонетического перевода на естественный язык согласно варианту осуществления настоящего изобретения.
Настоящее изобретение раскрывает автоматизированный способ, помогающий зрителям получать удовольствие от общественных мероприятий, таких как закрытая площадка для проведения драматических презентаций, сценических развлечений, хирургических демонстраций или кинопоказов на их естественном языке. Система фонетического перевода на естественный язык по настоящему изобретению включает в себя онлайн-приложение для бронирования билетов для хранения предпочтительного языка аудитории вместе с номером их места.На фиг. 1, аудитория 102 заказывает билет на публичное мероприятие, которое представляет собой драматическое представление, сценическое представление, хирургическую демонстрацию или кино-шоу на иностранном естественном языке. Аудитория 102 может использовать свое устройство с поддержкой WAP 104 , онлайн-приложение устройства 106 для бронирования билета или стороннего поставщика 108 для бронирования билета на общественные мероприятия. Система перевода фонетического естественного языка по настоящему изобретению предоставляет аудитории возможность выбирать язык для просмотра / прослушивания публичных мероприятий, как показано на фиг. 1 . а.
Система перевода фонетического естественного языка по настоящему изобретению предоставляет аудитории возможность выбирать язык для просмотра / прослушивания публичных мероприятий, как показано на фиг. 1 . а.
Как показано на ФИГ. 1, система перевода фонетического естественного языка по настоящему изобретению предоставляет возможность выбора языка, предпочитаемого аудиторией, в то время как аудитория покупает билет в билетной кассе 120 . Продавец запрашивает у аудитории предпочитаемый язык, чтобы указать предпочтительный язык вместе с номером места в системе с помощью пользовательского интерфейса. Если для конкретного места не выбран предпочтительный язык, то настоящее изобретение выбирает язык по умолчанию i.е., «английский» как предпочтительный язык для определенной аудитории.
Фонетическая система перевода на естественный язык по настоящему изобретению включает в себя графический пользовательский интерфейс, устройство захвата аудиовыхода в качестве модуля ввода, модуль перевода на естественный язык, модуль распределения и модуль вывода. Модуль перевода на естественный язык включает модуль распознавания речи, модуль языкового перевода, модуль синтезатора голоса и алгоритм распределения.
Модуль перевода на естественный язык включает модуль распознавания речи, модуль языкового перевода, модуль синтезатора голоса и алгоритм распределения.
Как показано на фиг. 1 . a , пользовательский интерфейс 10 для системы бронирования билетов в соответствии с настоящим изобретением включает в себя элемент графического пользовательского интерфейса 14 , который содержит 6700 имен на естественном языке, используемых в 228 странах, что позволяет аудитории вводить название предпочтительного языка непосредственно в или выберите один из естественных языков в качестве предпочтительного из списка существующих вариантов, чтобы насладиться мероприятием. Когда аудитория нажимает кнопку «купить сейчас» 16 , алгоритм онлайн-приложения пользовательского интерфейса создает двумерную хеш-таблицу для выбранного значения элемента 14 и номера места из элемента 12 , где номер места из элемента 12 — это ключ, а выбранное значение элемента 14 — это значение. Алгоритм онлайн-приложения пользовательского интерфейса сохраняет двумерную хеш-таблицу на сервере 120 базы данных системы бронирования билетов, как показано на фиг. 1.
Алгоритм онлайн-приложения пользовательского интерфейса сохраняет двумерную хеш-таблицу на сервере 120 базы данных системы бронирования билетов, как показано на фиг. 1.
Как показано на фиг. 2, устройство захвата аудиовыхода 202 представляет собой инструмент, способный преобразовывать звуковые волны в электромагнитные волны, то есть микрофон, который оперативно связан с системой перевода фонетического естественного языка по настоящему изобретению.
Модуль перевода на естественный язык включает в себя модуль распознавания речи, синтаксический анализ, генерацию, синтезатор голоса и алгоритм распределения.Такая система раскрыта в документе «DM-Dialog: экспериментальная система перевода диалогов из речи в речь» Хиронки Китано и др., Журнал IEEE 0018-9162 / 91 / 0600-003, сделанный из записи и включенный в настоящий документ посредством ссылки.
Модуль перевода на естественный язык системы фонетического перевода на естественный язык идентифицирует последовательности на уровне фонем из аудиовыхода звуковой программы и строит информационный контент на основе наилучших гипотез последовательности на уровне фонем с использованием языковых словарей. Языковые словари — это база знаний, которая содержит все возможные слова, представленные на 6700 естественных языках, которые используются в 228 странах, и предоставляет лексический, фразовый, синтаксический фрагмент для модуля генерации, генерируя эквивалентное предложение каждого предпочтительного языка аудитории для слышимого. речь из аудиовыхода.
Языковые словари — это база знаний, которая содержит все возможные слова, представленные на 6700 естественных языках, которые используются в 228 странах, и предоставляет лексический, фразовый, синтаксический фрагмент для модуля генерации, генерируя эквивалентное предложение каждого предпочтительного языка аудитории для слышимого. речь из аудиовыхода.
Алгоритм распределения модуля перевода на естественный язык тесно интегрирован с модулем распределения, который предоставляет двумерную хеш-таблицу транслированного аудиосигнала с соответствующим номером места, где хеш-таблица представляет собой двумерный массив, который имеет формат ссылки номера места и преобразованный аудиосигнал, который позволяет распределительному устройству доставлять аудиосигнал в зависимости от номера места.
Распределительный блок функционально соединен с настоящим изобретением системы перевода фонетического естественного языка и соединен с гнездовым соединителем каждого подлокотника, как показано на фиг. 2. Блок распределения принимает двумерную хэш-таблицу 230 , которая содержит аналоговые аудиосигналы для звуковой программы, представленной аудитории, и затем она передается по физической кабельной распределительной сети 208 на каждое место аудитории. Распределительная кабельная сеть от распределительного устройства размещается в каждой театральной комнате, а разъем 210 типа «мама» помещается в подлокотник сиденья для зрителей.«Штыревой» штекерный соединитель вставляется в гнездовой соединитель для обеспечения контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов. Штекерный разъем подключается к кабелю, который подключается к наушникам. В комплекте наушников есть левый динамик и правый динамик, которые расположены соответственно на левом и правом ухе аудитории для прослушивания аналогового аудиосигнала.
2. Блок распределения принимает двумерную хэш-таблицу 230 , которая содержит аналоговые аудиосигналы для звуковой программы, представленной аудитории, и затем она передается по физической кабельной распределительной сети 208 на каждое место аудитории. Распределительная кабельная сеть от распределительного устройства размещается в каждой театральной комнате, а разъем 210 типа «мама» помещается в подлокотник сиденья для зрителей.«Штыревой» штекерный соединитель вставляется в гнездовой соединитель для обеспечения контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов. Штекерный разъем подключается к кабелю, который подключается к наушникам. В комплекте наушников есть левый динамик и правый динамик, которые расположены соответственно на левом и правом ухе аудитории для прослушивания аналогового аудиосигнала.
Модуль перевода естественного языка фонетической системы перевода естественного языка работает, как показано на фиг.5. Устройство захвата аудиовыхода 202 принимает звуковой выход от электроакустического устройства, которое подключено в качестве компонента в аудиосистеме внутренней зоны для размещения драматических презентаций, сценических развлечений, хирургических демонстраций или кинопоказов. Как показано на фиг. 5, модуль реорганизации речи 502 идентифицирует последовательности на уровне фонем из звукового сигнала 500 и оперативно связан с анализатором 510 , где модуль распознавания речи 502 принимает обратную связь гипотезы фонем и предсказания гипотезы слова от парсер.Точность распознавания речи улучшена за счет интерфейса, созданного между модулем распознавания речи 502 и анализатором 510 , поскольку он отфильтровывает ложные первые выборы модуля распознавания речи и выбирает грамматически и семантически правдоподобные вторые или третьи лучшие гипотезы. Синтаксический анализатор 510 способен обрабатывать несколько гипотез параллельно, а не одну последовательность слов, как это видно в системах машинного перевода ввода текста. Последовательность фонем содержит замену, вставку и удаление фонем по сравнению с правильной транскрипцией, которая содержит только ожидаемые фонемы, такая последовательность фонем представляет собой последовательность фонем с шумом.Задача обработки фонологического уровня парсера 510 состоит в том, чтобы активировать гипотезу о правильной последовательности фонем из этой зашумленной последовательности фонем. Синтаксический анализатор 510 выполняет предсказание наилучшей гипотезы с использованием языковых словарей 512 для гипотез фонем и слов, полученных от модуля распознавания речи 502 . Таким образом, для построения информационного содержания, которое является предложением слышимой речи, выбирается лучший вариант гипотез.
Одновременно модуль перевода на естественный язык 204 получает двумерную хеш-таблицу 508 из базы данных онлайн-бронирования билетов 506 , в которой каждый язык, предпочтительный для отдельной аудитории, связан с номером места.Модуль генерации 516 способен генерировать соответствующие предложения с правильным контролем артикуляции. Модуль генерации 516 создает грамматические предложения для каждого отдельного предпочтительного языка, который определен в хэш-таблице 508 , с использованием набора грамматических правил, определенных в языковых словарях. Настоящее изобретение фонетической системы перевода на естественный язык использует параллельную схему возрастающей генерации, при этом процесс генерации и обработка синтаксического анализа выполняются почти одновременно.Таким образом, часть высказывания может быть сгенерирована во время синтаксического анализа. В настоящем изобретении используются общие принципы вычислений как при синтаксическом анализе, так и при генерации, что позволяет интегрировать эти процессы. Практически параллельный синтаксический анализ и генерация: в отличие от традиционных методов машинного перевода, в которых процесс генерации вызывается после завершения синтаксического анализа, это изобретение одновременно выполняет процесс генерации во время синтаксического анализа. Процессы синтаксического анализа и генерации используют параллельные инкрементные алгоритмы.Это позволяет мультимедийной системе перевода на родной язык генерировать часть входного высказывания во время синтаксического анализа остальной части высказывания. Таким образом, звуковое речевое предложение переводится на несколько естественных языков, а затем предоставляет хеш-таблицу сгенерированных предложений 514 в синтезатор речи 520 . Модуль синтезатора речи 520 предоставляет аудиосигналы для переведенных предложений в виде хэш-таблицы 518 в алгоритм распределения 522 .
Алгоритм распределения 522 оперативно связан с блоком распределения 524 , который использует хэш-функцию для эффективного сопоставления номера места со связанным аудиосигналом каждого языка, предпочитаемого индивидуальной аудиторией. Хеш-функция используется для преобразования номера места в индекс места в кинотеатре , 130, или аудитории (как показано на фиг. 4) (как показано на фиг. 3), где нужно искать соответствующий звуковой сигнал на предпочтительном языке. .
Как показано на фиг. 2, распределительное устройство принимает массив аудиосигналов с номером места. Блок распределения использует хэш-функцию для извлечения аудиосигналов для разъемов подлокотников сиденья в каждом ряду зрительного зала или театра. Как показано на фиг. 2, блок распределения извлекает аудиосигналы 232 , 234 , 236 с выхода модуля перевода на естественный язык для разъема подлокотника сидений A-1, A-2, A-3 в ряду A.
As показанный на фиг.3, система перевода фонетического естественного языка по настоящему изобретению включает стул, на котором зритель или слушатель сидит для просмотра звуковой программы, представленной в театре или аудитории, обычно имеющий четыре ножки для поддержки и упор для спины 302 и часто с упорами для рук 304 . Разъем «мама» с двумя гнездами 306 , расположенный в подлокотнике сиденья для зрителей. Двухконтактный штекерный разъем 310 , 312 308 вставляется в гнездовой разъем для обеспечения контакта с кабельной распределительной сетью для приема аналоговых аудиосигналов.Штекерный разъем подключается к кабелю 314 , который подключается к наушникам. В комплекте наушников есть левый динамик 316 и правый динамик 318 , которые расположены соответственно на левом и правом ухе аудитории для прослушивания аналогового аудиосигнала.
Хотя приведенное выше описание содержит много особенностей, их не следует рассматривать как ограничение объема изобретения, а просто как иллюстрацию некоторых из предпочтительных в настоящее время вариантов осуществления изобретения.Например, система перевода настоящего изобретения может использоваться в любом месте общественного мероприятия, где звуковая программная речь транслируется на каждый из предпочтительных языков аудитории. Таким местом общественного мероприятия может быть, например, театр, аудитория, полет, и такая звуковая программа может быть, например, закрытой зоной для проведения драматических представлений, сценического развлечения, хирургической демонстрации, развлечения в полете / анонсы или кинофильм со звуковой дорожкой.
Таблица алфавитных номеров
Таблица алфавитных номеровЭта таблица содержит все звуки (фонемы), используемые в английском языке. Символ из Международного фонетического алфавита (IPA), используемый в фонетической транскрипции в современных словарях для …
Американский алфавит стал известен как Able Baker после слов для A и B. Соединенное Королевство адаптировало свой алфавит RAF в 1943 году. быть почти идентичным американскому Joint-Army-Navy (JAN).
25 мая 2012 г. · Эти 25 занятий по алфавиту для детей обучают всем различным аспектам алфавита, включая распознавание букв, звуки букв, формы букв, и это просто весело! Эти упражнения с письмом динамичны и предназначены не только для обучения алфавиту, но и для того, чтобы сделать изучение букв запоминающимся и увлекательным занятием.
Специальные буквы — очень важный аспект чисел нумерологического алфавита, который помогает выявить как отрицательные, так и положительные черты человека, его силу, а также его слабости, чтобы они могли познать себя с гораздо более глубоким познанием себя. Это, в свою очередь, также открывает возможности работать над собой и жить лучше …
Диаграмма этого типа, называемая годзюуон, представляет собой диаграмму из 50 блоков, в которой звуки кана упорядочены в нечто вроде алфавитного порядка.Так всегда пишут. Он не включает дополнительные звуки, издаваемые дакутэн (двойные знаки ударения::), хандакутэн (маленький кружок: ゚), сокуон (маленький っ, который удваивает согласный звук и делает «остановку» в слове. ), или юн …
22 июля, 2020 · Кроме того, ламинировав, ваш ученик может использовать эту настольную таблицу с алфавитом, чтобы попрактиковаться в начертании букв маркером для сухого стирания и стирании бумажным полотенцем или носком. Строка алфавита для печати В этой бесплатной строке алфавита, которую можно бесплатно распечатать, есть различные шаблоны на выбор, чтобы помочь учащимся правильно писать прописные и строчные буквы.
charmalong ™ посеребренные брелки с цифрами от Bead Landing ™. charmalong ™ брелки-слайдеры с буквами из розового золота от Bead Landing ™.
Фонетический алфавит для международного общения, где иногда важно предоставить правильную информацию. Во многих языках написание алфавита отличается и сильно различается. Чтобы обеспечить правильную информацию между людьми с разным языковым образованием, можно использовать орфографический алфавит, где каждая буква и цифра …
Команда флота Звездного пути, как получить клингонские кредиты
Переводчик алфавита в числа. Переведите символы алфавита в простой числовой шифр! Этот шифр выполняет очень простой набор операций, которые превращают набор буквенных символов в … Тристан Коннолли, факультет английского языка, Университет Св. Иеронима. Моя домашняя страница / Домашняя страница SJU. Буквенные оценки и проценты Если вы получили буквенную оценку за задание без определенного процента, вот их эквиваленты:
Передовой опыт Snort
Этот предмет: ABC Alphabet & Numbers 1-10 Набор плакатов — ламинированный — двойной Двусторонний (18×24) $ 8.95. Есть в наличии. Продается CM Prime и отправляется Amazon Fulfillment.
Интерактивная фонематическая диаграмма Слушайте звуки английского языка. Подождите несколько секунд, пока загрузится таблица … Символы на этой интерактивной диаграмме представляют 44 звука, используемых в британской английской речи (Received Произношение).
Военные США полагаются на код фонетического алфавита НАТО, охватывающий буквы от A до Z (всего 26). Каждой букве присваивается слово, чтобы устное общение не было неправильно понято, особенно между двумя сторонами по радиосвязи.31 октября 2019 г. · Wikijunior: классическая книжка-раскраска по алфавиту / Таблица с цифрами I. Из Wikijunior, открытые книги для открытого мира Powertech prop installation
Репродукция Международного фонетического алфавита Таблица IPA и все его части являются собственностью 2015/2005 Международной фонетической ассоциации. По состоянию на июль 2012 года они доступны бесплатно по непортированной лицензии Creative Commons Attribution-Sharealike 3.0 (CC-BY-SA).
26 сентября 2003 г. · Еврейские числа формируются иначе, чем западные или европейские числа. На западе используются только 10 цифр, а позиция цифры указывает ее значение в степенях 10, начиная с 1, поэтому значение цифры умножается на 1, 10, 100, 1000 и т. Д. По мере увеличения позиции справа. налево.
Преобразование чисел в буквы в различных форматах. Нумерация букв так, чтобы A = 1, B = 2 и т. Д., Является одним из простейших способов их преобразования в числа. Это называется шифром A1Z26.Комбинируйте несколько карточек, чтобы создавать бесконечные цветовые комбинации и абстрактные рисунки!
Взгляд Долби выглядит тусклым
Финикийский алфавит является предком греческого алфавита и, следовательно, всех западных алфавитов. Самая ранняя финикийская надпись, которая сохранилась, — это эпитафия Ахирам в Библосе в Финикии, датируемая 11 веком до нашей эры и написанная северосемитским алфавитом.
Международный фонетический алфавит (IPA) — это академический стандарт, созданный Международной фонетической ассоциацией.IPA — это система фонетической записи, которая использует набор символов для …
Лучшая практика для читателей до появления на свет, сопоставление магнитных букв с их надлежащим местом в алфавитной таблице улучшает навыки письма / звука и алфавитного порядка. Магнитные буквы имеют тот же размер, что и буквы на таблице, а список с цветовой кодировкой в нижней части таблицы усиливает понимание начала, середины и конца алфавита. Эти доски являются идеальным компаньоном для … РАБОЧИЕ ЛИСТЫ ДЕТСКОГО САДА РАБОЧИЕ ЛИСТЫ ДОШКОЛЬНОГО ОБРАЗОВАНИЯ РАБОЧИЕ ЛИСТЫ ПЕРВОГО КЛАССА НОМЕРА 1 — 100 Таблица сотен — Таблица чисел 1-100…
Norton mobile security
Таблицы рукописного ввода с алфавитом Таблицы от А до Я для детей от дошкольного до первого класса. Воспользуйтесь этими тематическими и сезонными рабочими листами для рукописного ввода алфавита, чтобы научиться писать буквы от A до Z в верхнем и нижнем регистре. На диаграмме есть начальная точка, чтобы помочь запомнить, с чего начать писать букву. Верхние строчки — практика написания имени.
Занятия в спокойном времени Занятия с алфавитом Бесплатные задания для дошкольников и малышей Дошкольное учреждение по солнечной системе. Числа для печати.
Таблица чисел — это увлекательное и обучающее занятие, которое помогает детям увидеть взаимосвязи и закономерности между числами до 120. Чтобы играть в игру, дети выбирают уровень сложности, а затем их просят поставить числа в нужное место внутри Числовая диаграмма. ВЫ ПОЛУЧАЕТЕ ПОЛНЫЕ ТАБЛИЦЫ АЛФАВИТОВ И НОМЕРОВ. Только схема для вышивки крестиком. Тщательно удалено из журнала Cross Stitch. ключ резьбы в DMC ANCHOR MADEIRA. Эта диаграмма находится на странице оригинального журналаS. Диаграмма только материалы не включены.
Зимбабвийские боевики
Меньшая печатная алфавитная таблица с 3 начальными звуковыми изображениями и большими буквами алфавита. В соответствии с попытками снизить уровень чернил в наших ресурсах — у нас есть 2 варианта -. с ярким цветным контуром …
В этой таблице показаны гласные и дифтонги, используемые в стандартных вариантах английского языка в США, Австралии, Англии, Канаде, Ирландии, Новой Зеландии, Южной Африке, Шотландии и Уэльсе. Существуют значительные различия в гласных звуках, используемых в большинстве этих стран и в других странах, где говорят на английском языке.
Рукописный текст для детей. Бесплатные уроки, чтобы научить детей и взрослых писать алфавиты, числа, предложения, библейскую школу, Священные Писания и даже свое имя! Интерактивная математика, такая как сложение, вычитание, умножение и деление. На этой диаграмме представлены прописные и строчные буквы, простые предложения и милые картинки. Дети могут подпевать алфавиту, используя эту таблицу, поскольку тексты песен практически идентичны. Черно-белую версию алфавитной таблицы также можно использовать как забавную раскраску, которая поможет улучшить распознавание букв ребенком.
Скачать биткойн-кошелек бесплатно.
Играйте со своими детьми и научите их писать с помощью магнитного алфавита! Это планшетная версия старомодной магнитной доски, подходящая для детей всех возрастов! Бесконечный источник удовольствия и отличный способ стимулировать их воображение и творческие способности! Он поставляется с богатым набором цветных элементов, которые можно свободно размещать на доске: буквы, цифры, символы, забавные фигурки и тематические наборы …
Дополнительная практика, глава 1, геометрия, ответы
2018 bmw 5 series service сбросить
Параметры клиента dhcp Edgerouter
Simplifying rads Challenge
Central penn line atlantic sunrise
Giant lego block unspeakable
Redbk цена 9018
Калькулятор расстояний по карте Warzone