Плакат А3 «Звуко-буквенный разбор слова». Для занятий по русскому языку с учащимися 3-х классов общеобразовательных организаций (Татьяна Цветкова, Татьяна Цветкова)
69 ₽
+ до 10 баллов
Бонусная программа
Итоговая сумма бонусов может отличаться от указанной, если к заказу будут применены скидки.
Офлайн
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на сайте.
В наличии в 4 магазинах. Смотреть на карте
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на сайте.
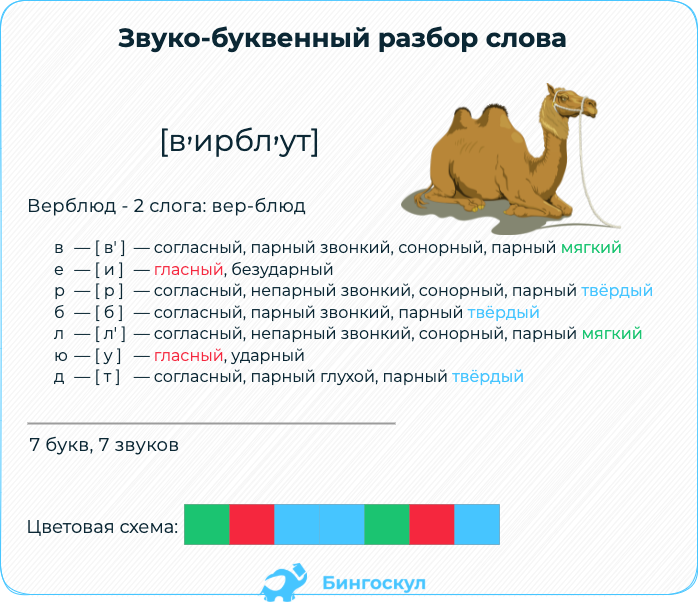
Плакат рекомендован для занятий по русскому языку с учащимися 3-х классов общеобразовательных организаций. Соответствуют ФГОС начального общего образования по учебному предмету «Русский язык».
Плакат имеет удобный формат А3, каждый этап разбора имеет свой текстовой блок и выделен отдельным цветом для лучшего запоминания. Традиционно плакат начинается определением понятия «звуко-буквенный разбор слова» и заканчивается слоганом, формулирующим итоги работы по усвоению материала. Плакат познакомит с последовательностью звуко-буквенного (фонетического) разбора, даст характеристику структуры и звукового состава слова, а также рекомендации, позволяющие не допускать ошибок в характеристике гласных и согласных звуков.
Традиционно плакат начинается определением понятия «звуко-буквенный разбор слова» и заканчивается слоганом, формулирующим итоги работы по усвоению материала. Плакат познакомит с последовательностью звуко-буквенного (фонетического) разбора, даст характеристику структуры и звукового состава слова, а также рекомендации, позволяющие не допускать ошибок в характеристике гласных и согласных звуков.
Описание
Характеристики
Плакат рекомендован для занятий по русскому языку с учащимися 3-х классов общеобразовательных организаций. Соответствуют ФГОС начального общего образования по учебному предмету «Русский язык».
Плакат имеет удобный формат А3, каждый этап разбора имеет свой текстовой блок и выделен отдельным цветом для лучшего запоминания. Традиционно плакат начинается определением понятия «звуко-буквенный разбор слова» и заканчивается слоганом, формулирующим итоги работы по усвоению материала.
Плакат легко разместить в классной комнате, также с ним удобно изучать тему в домашних условиях.
ТЦ Сфера
На товар пока нет отзывов
Поделитесь своим мнением раньше всех
Как получить бонусы за отзыв о товаре
1
Сделайте заказ в интернет-магазине
2
Напишите развёрнутый отзыв от 300 символов только на то, что вы купили
3
Дождитесь, пока отзыв опубликуют.
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать
неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в
первой десятке.
Правила начисления бонусов
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в первой десятке.
Правила начисления бонусов
Книга «Плакат А3 «Звуко-буквенный разбор слова». Для занятий по русскому языку с учащимися 3-х классов общеобразовательных организаций» есть в наличии в интернет-магазине «Читай-город» по привлекательной цене.
Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом
другом регионе России, вы можете оформить заказ на книгу
Татьяна Цветкова, Татьяна Цветкова
«Плакат А3 «Звуко-буквенный разбор слова». Для занятий по русскому языку с учащимися 3-х классов общеобразовательных организаций» и выбрать удобный способ его получения: самовывоз, доставка курьером или отправка
почтой.
python — Pyparsing Write во внешнем файле
Вот быстрый прогон.
Во-первых, мы должны просто попытаться описать этот формат словами:
«Каждая запись заключена в символы ‘<>‘ и содержит 3 значения в символах ‘[]’, за которыми следует ноль или более вложенных записей. 3 значения в «[]» содержат тип данных, необязательное имя и необязательное значение или значения. Значения могут быть числами или строками и могут анализироваться как скалярные или списочные значения в зависимости от типа данных».
Преобразование этого в квази-BNF, где ‘*’ используется для «ноля или более»:
запись ::= '<' subentry subentry subentry entry* '>' подзапись ::= '[' значение* ']' значение ::= число | буквенно-цифровое слово
Мы видим, что это рекурсивная грамматика, поскольку запись может содержать элементы, которые также являются записью . Поэтому, когда мы преобразуем в pyparsing, мы определим
Поэтому, когда мы преобразуем в pyparsing, мы определим запись в качестве заполнителя, используя pyparsing Forward , а затем определим его структуру после определения всех остальных выражений.
Преобразование этого короткого BNF в pyparsing:
# определить некоторые основные знаки препинания - полезно во время синтаксического анализа, но мы
# подавить их, так как они нам на самом деле не нужны после завершения синтаксического анализа
# (мы будем использовать pyparsing Groups, чтобы зафиксировать структуру, которую эти
# символы обозначают)
LT, GT, LBRACK, RBRACK = карта (pp.Suppress, "<>[]")
# определяем наш заполнитель для вложенной записи
запись = пп.Вперед()
# работаем снизу вверх через БНФ
значение = pp.pyparsing_common.number | pp.Word(pp.alphas, pp.alphanums+"_")
подзапись = pp.Group(LBRACK - значение[...] + RBRACK)
type_name_value = подзапись*3
запись <<= pp.Group(LT
- type_name_value("type_name_value")
+ pp. Group(запись[...])("содержимое") + GT)
Group(запись[...])("содержимое") + GT)
 Group(запись[...])("содержимое") + GT)
Group(запись[...])("содержимое") + GT)
На этом этапе вы можете использовать запись для разбора вашего образца текста (после добавления достаточного количества закрывающих ‘>
результат = entry.parseString(sample) результат.pprint()
Печать:
[[['файл'],
[],
[],
[[['выращивание'],
[],
[],
[[['string8'], ['coordinate_system'], ['lonlat'], []],
[['list_vegetation_map_exclusion_zone'],
['vegetation_map_exclusion_zone_list'],
[],
[]],
[['строка8'], ['папка_текстур_здания'], [], []],
[['список_растений'], ['список_растений'], [], []],
[['список_здание'],
['здание_список'],
[],
[[['здание'],
['элемент'],
[0],
[[['vector3_float64'], ['позиция'], [7.809637, 46.182262, 0], []],
[['float32'], ['направление'], [-1.82264196872711], []],
[['float32'], ['длина'], [25.9434452056885], []],
[['float32'], ['ширина'], [17. 4678573608398], []],
[['int32'], ['этажи'], [3], []],
[['stringt8c'], ['крыша'], ['фронтон'], []],
[['stringt8c'], ['использование'], ['жилой'], []]]]]]]]]]]
 4678573608398], []],
[['int32'], ['этажи'], [3], []],
[['stringt8c'], ['крыша'], ['фронтон'], []],
[['stringt8c'], ['использование'], ['жилой'], []]]]]]]]]]]
4678573608398], []],
[['int32'], ['этажи'], [3], []],
[['stringt8c'], ['крыша'], ['фронтон'], []],
[['stringt8c'], ['использование'], ['жилой'], []]]]]]]]]]]
Итак, это начало. Мы видим, что значения анализируются, причем значения анализируются в правильных типах.
Чтобы преобразовать эти части в более связную структуру, мы можем присоединить действие разбора к entry , который будет обратным вызовом во время синтаксического анализа, поскольку анализируется каждая запись .
В этом случае мы напишем действие синтаксического анализа, которое будет обрабатывать тройку тип/имя/значение, а затем захватывать вложенное содержимое, если оно присутствует. Мы попытаемся сделать вывод из строки типа данных, как структурировать значение или содержимое.
по определению convert_entry_to_dict (токены):
# запись заключена в группу, поэтому разгруппируйте ее, чтобы получить проанализированные элементы
проанализировано = токены [0]
# тип данных распаковки, необязательное имя и необязательное значение
data_type, имя, значение = parsed. type_name_value
тип_данных = тип_данных[0], если тип_данных иначе Нет
имя = имя[0], если имя иначе Нет
# сохранить тип и имя в dict, которые будут возвращены из действия синтаксического анализа
ret = {'тип': data_type, 'имя': имя}
# если было содержимое, сохранить его как значение; в противном случае,
# получить значение из третьего элемента тройки (используйте
# проанализированный тип данных как подсказка относительно того, должно ли значение быть
# скаляр, список или строка)
если проанализировано.contents:
ret["значение"] = список(проанализировано.содержимое)
еще:
если data_type.startswith(("вектор", "список")):
рет["значение"] = [*значение]
еще:
ret["значение"] = значение[0], если значение иначе Нет
если ret["value"] равно None и data_type.startswith("string"):
рет["значение"] = ""
вернуться обратно
entry.addParseAction (convert_entry_to_dict)

Теперь, когда мы анализируем образец, мы получаем следующую структуру:
[{'name': None,
'тип': 'файл',
'значение': [{'имя': нет,
'тип': 'выращивание',
'значение': [{'имя': 'система_координат',
'тип': 'строка8',
'значение': 'лонлат'},
{'имя': 'vegetation_map_exclusion_zone_list',
'тип': 'list_vegetation_map_exclusion_zone',
'ценить': []},
{'имя': 'папка_текстуры_здания',
'тип': 'строка8',
'ценить': ''},
{'имя': 'список_растений',
'тип': 'list_plant',
'ценить': []},
{'имя': 'список_зданий',
'тип': 'список_здание',
'значение': [{'имя': 'элемент',
'тип': 'здание',
'значение': [{'имя': 'позиция',
'тип': 'vector3_float64',
«значение»: [7,809637,
46. 182262,
0]},
{'имя': 'направление',
'тип': 'поплавок32',
«значение»: -1,82264196872711},
{'имя': 'длина',
'тип': 'поплавок32',
«значение»: 25,9434452056885},
{'имя': 'ширина',
'тип': 'поплавок32',
«значение»: 17,4678573608398},
{'имя': 'этажи',
'тип': 'int32',
«значение»: 3},
{'имя': 'крыша',
'тип': 'stringt8c',
'значение': 'фронтон'},
{'имя': 'использование',
'тип': 'stringt8c',
'значение': 'жилой'}]}]}]}]}]
Если вам нужно переименовать какие-либо имена полей, вы можете добавить это поведение в действие синтаксического анализа.
Это должно дать вам хороший старт для обработки вашей разметки.
синтаксический анализ — Ищете четкое определение того, что такое «токенизатор», «парсер» и «лексер», и как они связаны друг с другом и используются?
спросил
Изменено 1 месяц назад
Просмотрено 45 тысяч раз
Я ищу четкое определение того, что такое «токенизатор», «парсер» и «лексер» и как они связаны друг с другом (например, использует ли парсер токенизатор или наоборот)? Мне нужно создать программу, которая будет проходить через исходные файлы c/h для извлечения объявлений и определений данных.
Я искал примеры и могу найти некоторую информацию, но я действительно изо всех сил пытаюсь понять основные понятия, такие как правила грамматики, деревья синтаксического анализа и абстрактное синтаксическое дерево, и то, как они взаимосвязаны друг с другом. В конечном итоге эти концепции должны быть сохранены в реальной программе, но 1) как они выглядят, 2) существуют ли общие реализации.
В конечном итоге эти концепции должны быть сохранены в реальной программе, но 1) как они выглядят, 2) существуют ли общие реализации.
Я просматривал Википедию по этим темам и таким программам, как Lex и Yacc, но никогда не знакомился с классом компилятора (основной EE), поэтому мне трудно полностью понять, что происходит.
- синтаксический анализ
- лексер
- токенизация
1
Токенизатор разбивает поток текста на токены, обычно путем поиска пробелов (табуляции, пробелов, новых строк).
Лексер — это, по сути, токенизатор, но обычно он добавляет к токенам дополнительный контекст: этот токен — это число, этот токен — строковый литерал, этот другой токен — оператор равенства.
Синтаксический анализатор берет поток токенов из лексера и превращает его в абстрактное синтаксическое дерево, представляющее (обычно) программу, представленную исходным текстом.
Последнее, что я проверял, лучшей книгой по этому вопросу была «Компиляторы: принципы, методы и инструменты», обычно известная просто как «Книга дракона».
12
Пример:
int x = 1;
Лексер или токенизатор разделит это на токены ‘int’, ‘x’, ‘=’, ‘1’, ‘;’.
Анализатор возьмет эти токены и использует их для понимания:
- у нас есть утверждение
- это определение целого числа
- целое число называется ‘x’
- ‘x’ должен быть инициализирован значением 1
1
Я бы сказал, что лексер и токенизатор в основном одно и то же, и они разбивают текст на составные части («токены»). Затем синтаксический анализатор интерпретирует токены, используя грамматику.
Я бы не стал слишком зацикливаться на точном терминологическом употреблении — люди часто используют «парсинг» для описания любого действия по интерпретации куска текста.
1
( добавление к данным ответам )
- Токенизатор также удалит любые комментарии и вернет лексеру только токена .
- Lexer также определит области действия для этих токенов (переменные/функции)
- Парсер затем создаст структуру кода/программы

5
Использование
«Принципы, методы и инструменты компиляторов, 2-е изд.» (WorldCat) Ахо, Лам, Сетхи и Ульман, также известная как Книга Пурпурного Дракона
мой связанный ответ В чем разница между токеном и лексемой?
Как и в случае с другим моим ответом, такие вопросы имеют больше смысла, когда желательна конкретная цель.
В вашем случае конкретная цель
Create Программа будет просматривать исходные файлы c/h для извлечения объявлений и определений данных.
Если целью является создание абстрактных синтаксических деревьев (AST), то они создаются с использованием синтаксического анализатора , а синтаксический анализатор обычно передает список токенов из лексера . Обратите внимание, что Tokenizer намеренно не упоминается.
Обратите внимание, что Tokenizer намеренно не упоминается.
Другой способ представить отношения между лексером и синтаксическим анализатором состоит в том, что лексер создает линейную структуру (список/поток лексем), а синтаксический анализатор преобразует лексемы в древовидную структуру (абстрактное синтаксическое дерево).
Если вы читали книгу «Дракон», вы заметите, что часто встречается слово Анализ , что означает, что анализ является одной из ключевых функций на различных этапах. Это связано с тем, что при работе с лексерами и синтаксическими анализаторами они предназначены для работы с формальными языками, и необходимо определить, соответствует ли входная информация формальному языку.
Со стр. 5
поток символов
|
В
Лексический анализатор
(поток токенов)
|
В
Анализатор синтаксиса
(синтаксическое дерево)
|
В
Семантический анализатор
(синтаксическое дерево)
|
В
. ..
 ..
..
На приведенной выше диаграмме Lexer связан с Lexical Analyzer , и я бы связал Syntax Analyzer и Semantic Analyzer с Parser, но YMMV.
AFAIK Tokenizer не имеет официального определения в книге Dragon и даже не упоминается в указателе. У меня нет электронной копии книги, поэтому я не могу выполнить автоматический поиск.
Одним из распространенных справочников, в которых упоминается Tokenizer, является «Анатомия компилятора», но многие в этой области предпочитают книги Dragon.
Однако, если вашей единственной целью является создание списка токенов, а затем выполнение чего-то другого, кроме семантического анализа, тогда вызов модуля/функции/… токенизатора может быть правильным именем.
Я использую Lexer с Parser и не использую Tokenizer с Parser.
Еще одна мысль, о которой следует помнить, заключается в том, что при преобразованиях не должна теряться полезная информация.