Что значит разобрать слово по составу — «Семья и Школа»
Содержание
Узнаем как разобрать слово по составу
Давая задание разобрать слово по составу, многие учителя сталкиваются с тем, что не все дети справляются с этим правильно и быстро. На самом деле алгоритм этой процедуры достаточно прост. Важно изначально сформировать у школьников данное умение, чтобы в последующем у них не возникало проблем.
Разобрать слово по составу означает выделить в нем значимые части. Умение выполнять данное действие пригодится при освоении многих правил правописания. Основными приемами являются подбор форм, а также нахождение одноструктурных и однокоренных слов. Рекомендуется, выделяя ту или иную морфему, определять ее грамматическое значение.
Перед тем как разобрать слово по составу, нужно определить, к какой части речи оно относится. Сделать это необходимо для того, чтобы понять, изменяемо оно или нет (в последнем случае у него не будет окончания). Далее выделяется основа слова. В таких частях речи, как междометие, наречие или предлог окончания нет, и оно никак не отмечается. Если же оно предположительно может быть, но в слове его не имеется (например, мост), то его обозначают, как «нулевое». Оставшаяся часть носит название «основа». Для выделения окончания слово изменяют (существительные — по падежам, прилагательные — по родам и т. д.).
В таких частях речи, как междометие, наречие или предлог окончания нет, и оно никак не отмечается. Если же оно предположительно может быть, но в слове его не имеется (например, мост), то его обозначают, как «нулевое». Оставшаяся часть носит название «основа». Для выделения окончания слово изменяют (существительные — по падежам, прилагательные — по родам и т. д.).
В основе слова заключается его лексическое значение. Из нее, в свою очередь, выделяются оставшиеся части. Основная лексическая нагрузка находится в корне. Это неизменяемая часть, считающаяся главной. Группы слов, имеющие одинаковый корень, носят название «однокоренные». К примеру: раст-и, раст-ение, под-раст-ать и т. д.
Если разобрать по составу слово «подготовка», то можно увидеть, что окончанием здесь является морфема -а, корнем -готов-. Далее нужно обратить внимание на суффикс и приставку. Стоит отметить, что они различаются в основном в зависимости от части речи. Для того чтобы их выявить, необходимо подобрать группу одноструктурных слов.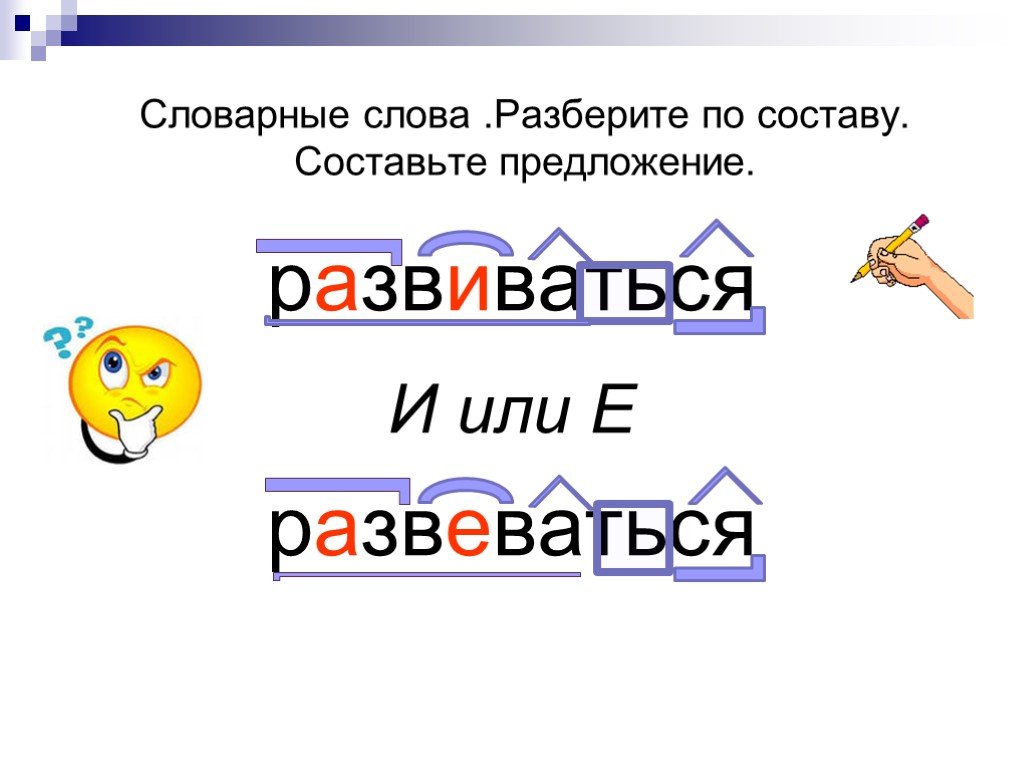 Так, для нашего существительного можно взять такие примеры, как «подставка», «подсказка» и др.
Так, для нашего существительного можно взять такие примеры, как «подставка», «подсказка» и др.
Приставка считается значимой частью. Ее используют с целью образования слов, которые имеют другое значение.
Суффиксы находятся после корня. В существительном «подготовка» это -к-. Данная часть служит для образования нового слова или его формы.
Нужно отметить, что в некоторых случаях может быть несколько корней, например, пар-о-ход, верт-о-лет и т. д.
В других ситуациях слово может быть образовано с помощью нескольких приставок или суффиксов.
Их необходимо выделять все. Если разобрать слово по составу затруднительно, следует еще раз обратиться к тому, какая это часть речи.
Ведь для большинства групп характерны свои морфемы. Стоит упомянуть и постфикс, часть слова, которая встречается в конце глаголов (-ся, -ка, -те) и некоторых местоимений (-либо, -то).
Его не относят к флексиям (окончанию). В школьных учебниках постфикс называют суффиксом и обозначают таким же знаком. К примеру, в слове «смеялась» будет окончание -а- («смеялись», «смеялось»).
К примеру, в слове «смеялась» будет окончание -а- («смеялись», «смеялось»).
Постфикс в данном случае -сь. При разборе данного слова нужно не забыть включить его в основу.
Урок русского языка в 5 классе «Морфемный разбор слова»
Тема: МОРФЕМНЫЙ РАЗБОР СЛОВА.
Цели:
- дидактическая: продолжить формирование навыка морфемного разбора слова;
- коррекционно-развивающая: коррекция логического мышления на основе упражнений и воспитание внимания и усидчивости у учащихся;
- воспитательная: формировать мотивацию к учению.
Оборудование: мультимедиапроектор, презентация по теме морфемный разбор слова, карточки индивидуальной работы.
ХОД УРОКА.
I. Организационный момент.
1. Приветствие.
2. Целеполагание.
II. Изучение нового материала (с использованием мультимедиапроектора).
Тема изложена на слайдах презентации, которые комментируются учителем.
Учащиеся записывают материал в тетради по ходу объяснения.
1. Фронтальный опрос.
— Кто мне скажет, что обозначает слово морфемика? Знаком ли вам этот термин? (слайд 3)
Морфемика – это раздел, который изучает морфемный разбор, иначе разбор слова по составу.
— Помните ли вы, что такое морфемный анализ слов? Как он проводится?
— Чтобы сделать морфемный разбор слова или разобрать слово по составу, необходимо знать из каких частей (морфем) строятся слова.
-Давайте дадим определение каждой морфеме.
— Что такое корень? (слайд 4)
Корень – главная значимая часть слова, в которой заключено лексическое значение, общее для всех однокоренных слов: вода, водяной, паводок, водный.
— Приведите ваши примеры однокоренных слов.
— Что такое приставка? (слайд 5)
Приставка – значимая часть слова, которая служит для образования новых однокоренных слов: ехать – приехать, уехать, заехать, переехать. Приставка находится перед корнем.
— Приведите примеры однокоренных слов с разными приставками.
— Итак, мы сделаем разбор слова по составу на слове «прекрасна».
— Что такое суффикс? (слайд 6)
Суффикс – значимая часть слова, которая, как правило, служит для образования новых однокоренных слов: человек, человечек, человеческий. Суффикс находится после корня.
— Приведите примеры однокоренных слов с разными суффиксами.
— Что такое окончание? (слайд 7)
Окончание – изменяемая часть слова, которая служит для образования грамматических форм существительных, прилагательных, числительных, местоимений и глаголов: терем¨, у терема, к терему; я тужу, ты тужишь, он тужит. Таким образом, окончание имеет грамматическое значение.
— Дайте примеры форм одного слова с разными окончаниями.
— Теперь, когда мы вспомнили морфемы, мы можем перейти к морфемному разбору.
2. Морфемный разбор слова. (слайд 8)
(слайд 2) «Я ль, скажи мне всех милее,
Всех румяней и белее? »
Что же зеркальце в ответ?
«Ты прекрасна, спору нет…»
— Кто вспомнит, из какого произведения эти строки?
— А вот и слово, которое мы будем разбирать «прекрасна».
Шаг 1. (слайд 10)
— Выделяем окончание и определяем его грамматическое значение.
— Что нужно сделать, чтобы выделить окончание слова «прекрасна»?
— Нужно изменить его. Это краткое прилагательное, оно изменяется по числам и родам. ( Прекрасен, прекрасно, прекрасны).
— Мы видим часть слова, которая меняется (по окончаниям на сноске)
Следовательно, в слове «прекрасна» окончание–«а».
— Оно имеет грамматическое значение единственного числа женского рода. Обратите внимание на то, как обозначается окончание.
— Если мы выделили окончание, нам легко определить основу слова. (слайд 11)
— Почему?
Основа – это часть слова без окончания: у терема, пирожок¨.
— Основа прекрасн—.
— Итак, в слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде.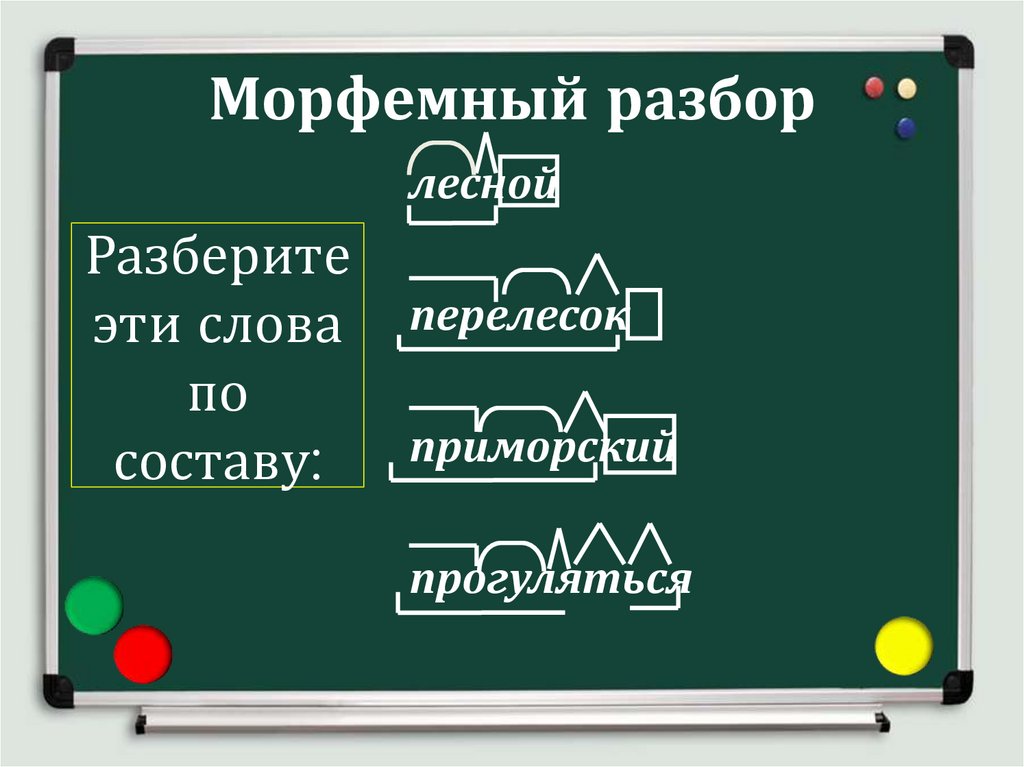
Основа – прекрасн а .
Продолжаем наш разбор .
Шаг 2. (слайд 12)
— Определим корень слова.
— Как это сделать?
— Нужно подобрать однокоренные слова: красный, краса, красивый.
— Мы видим, что их общая часть, а значит, корень -крас-. В нем заключено общее для всех этих слов лексическое значение. Я думаю, вы знаете, что в старину слово «красный» имело значение «красивый».
Итак, корень в слове «прекрасна» – —крас-. Однокоренными словами являются красный, краса, красивый.
Шаг 3. (слайд 13)
— Нужно определить, какие ещё морфемы есть в слове.
— Есть ли приставка в этом слове?
— Да, перед корнем приставка пре-.
— Какое значение она придаёт прилагательному?
— Образуем другие прилагательные с такой же приставкой: предобрый, премилый, премудрый. Очевидно, что приставка «пре» во всех этих прилагательных имеет значение «весьма», «очень».
— Есть ли в слове суффикс?
— Да, это суффикс н. Он стоит после корня перед окончанием.
— Какова его роль?
— Мы видим, что с помощью этого суффикса от существительных образуются прилагательные: беда – бедный; вред – вредный; честь – честный
и… краса – красный.
— Вот мы и сделали морфемный разбор слова «прекрасна».
Выводы на доску. (слайд 14)
(слайд 15). В слове «прекрасна» окончание –а. Проверяем с помощью форм прекрасен, прекрасно, прекрасны. Окончание обозначает, что краткое прилагательное стоит в единственном числе женском роде. Основа – прекрасн-.
(слайд 16). Корень в слове прекрасна – -крас-. Однокоренными словами являются красный, краса, красивый.
(слайд 17). В слове прекрасна есть приставка пре-, она имеет значение «очень», «весьма».
(слайд 18). В слове прекрасна есть суффикс –н-. С помощью этого суффикса от существительного образовалось прилагательное.
Итак, Порядок разбора: (слайд 19)
Шаг 1. Выделить окончание, объяснить его значение. Выделить основу слова.
Шаг 2. Выделить корень слова, подобрав однокоренные слова.
Шаг 3. Выделить приставки и суффиксы. Объяснить, если возможно значение приставок и суффиксов.
III. Физминутка. (Выполняется стоя).
1). Сделать 3-4 раза круговые движения головой.
2). 1. – Руки согнуты перед грудью. 1-2 — два пружинящих рывка назад согнутыми руками. 3-4 – то же прямыми руками. Повторить 5-7 раз. Темп средний.
3). Несколько раз открыть/закрыть глаза.
IV. Закрепление изученного материала.
1. Морфемный разбор слова.
Один учащийся работает у доски, остальные самостоятельно.
Лесной, перелесок, приморский, прогуляться, многолетний.
2. Работа с отрывком из сказки «Сказка о мёртвой царевне и семи богатырях».
Долго царь был неутешен Но как быть? И он был грешен; Год прошёл, как сон пустой, Царь женился на другой. | Правду молвит молодица Уж и впрямь была царица: Высока, стройна, бела, И умом и всем взяла… |

Сделайте морфемный разбор выделенных в тексте слов. Впишите части слов в таблицу. Если в слове нет какой-нибудь морфемы, напишите: нет. Если окончание нулевое, так и напишите.
слова для разбора | окончание | основа | корень | суффикс | |
неутешен | нулевое | неутешен | теш | не, у | ен |
прошёл | нулевое | прошёл | шё | про | л |
пустой | ой | пуст | пуст | нет | нет |
молодица | а | молодиц | молод | нет | иц |
умом | ом | ум | ум | нет | нет |
3. Работа со схемами.
Работа со схемами.
Нужно подобрать слова, которые подходят к схемам.
V. Итог урока.
— Что же такое морфемный разбор слова?
— В какой последовательности нужно его выполнять?
VI. Домашнее задание.
Упр. 178 на с.74, сделать морфемный разбор слов: пришкольный, бегает, новизна.
Выставление оценок.
Скачать>>>
Разобрать Определение и значение
- Лучшие определения
- Викторина
- Связанный контент
- Примеры
- Идиомы и фразы
Сохраните это слово!
См. синонимы к слову разбирать на Thesaurus.com
глагол (tr, наречие)
разделять (что-то) на составные части
критиковать или строго наказыватьрецензенты разобрали новую пьесу ПЛАВАТЬ ИЛИ НАТЯНУТЬСЯ НА ЭТИ ВОПРОСЫ ПО ГРАММАТИКЕ?
Плавно переходите к этим распространенным грамматическим ошибкам, которые ставят многих людей в тупик. Удачи!
Удачи!
Вопрос 1 из 7
Заполните пропуск: Я не могу понять, что _____ подарил мне этот подарок.
Слова рядом разобрать
снять с себя груз, взять с собой, посмотреть, разобрать, поинтересоваться, разобрать, сфотографировать, потыкать, взять порошок, взять дождь проверьте, примите как Евангелие
Английский словарь Коллинза — полное и полное цифровое издание 2012 г. © William Collins Sons & Co. Ltd. 1979, 1986 © HarperCollins Publishers 1998, 2000, 2003, 2005, 2006, 2007, 2009, 2012
Слова, относящиеся к разбирать
разъединять, откладывать, распускать, демонтировать, рассеивать, разрушать, растворять, разделять, останавливать, положить конец, разделять, расколоть, остановить, приостановить, прекратить, уничтожить, снести, раздавить, уничтожить, опустошить
Как использовать в предложении слово «разобрать»
И все же это, в конце концов, книга, из которой выходишь грустный, мрачный, разочарованный , по крайней мере, если мы согласимся отнестись к этому серьезно.

Зажигательный роман Уэльбека изображает Францию с президентом-мусульманином|Пьер Ассулин|9 января 2015|DAILY BEAST
А теперь точно так же бывший губернатор Арканзаса Майк Хакаби: «Нагнись и возьми, как пленный!»
Huckabee 2016: Нагнись и возьми, как пленник!|Оливия Нуцци|8 января 2015 г.|DAILY BEAST
РИМ — Что нужно звезде Голливуда, чтобы получить частную аудиенцию у Папы Франциска?
Папа Франциск имел удовольствие встретиться с Анджелиной Джоли на несколько секунд|Барби Лаца Надо|8 января 2015 г.|DAILY BEAST
Хотя снисходительный тон Хакаби, как у учителя истории начальной школы, мешает воспринимать его всерьез.
Huckabee 2016: Нагнись и возьми как пленник!|Оливия Нуцци|8 января 2015|DAILY BEAST
Несмотря на кликбейтное название, наклонись и возьми как пленник!
Хакаби 2016: Нагнись и возьми как пленницу!|Оливия Нуцци|8 января 2015 г.|DAILY BEAST
Я беру Экстремальные Колокола и наношу на них шесть Изменений таким образом.
Тинтинналогия, или Искусство звенеть|Ричард Дакворт и Фабиан Стедман
Более того, большинство нор находились всего в нескольких футах друг от друга, и никакого агрессивного поведения не наблюдалось.
Летние птицы с полуострова Юкатан|Эрвин Э. Клаас
Уиклиф переводит Вульгату: «И это как модир onourid schal mete hym, и как женщина fro virgynyte schal возьми его».
Соломон и соломонова литература|Moncure Daniel Conway
Но нужно было взять Силан, который спешили укрепить повстанцы, преследуемые испанцами.
Филиппинские острова|Джон Форман
И этим летом ей казалось, что она никогда не сможет должным образом заботиться о своем гнездышке детей.
Сказка о дедушке Кроте|Артур Скотт Бейли

Другие идиомы и фразы с разобрать
разобрать
1
Разобрать или разобрать, как в Им пришлось разобрать стерео, прежде чем они смогли его переместить.
2
Тщательно изучить, проанализировать или разобрать, как в «Учитель смутил Тома, разобрав его диссертацию на части перед классом». [Середина 1900-х]
3
Бить, бить, как в Тебе лучше быть осторожным; эти мальчики разберут вас на части. [Сленг; mid-1900s]
Словарь идиом Американского наследия® Авторское право © 2002, 2001, 1995, издательство Houghton Mifflin Harcourt Publishing Company. Опубликовано издательством Houghton Mifflin Harcourt Publishing Company.
TAKE APART – фразовый глагол – значения и примеры Woodward English
Английский фразовый глагол TAKE APART имеет следующие значения:
1. Разобрать (что-то) = разобрать что-то
(переходный) Этот фразовый глагол используется, когда вы разбираете что-то на составные части.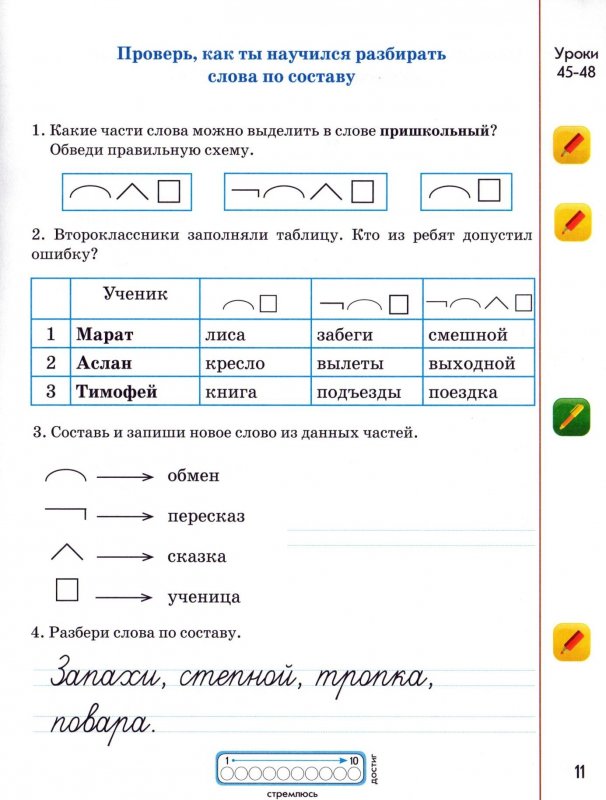 Это когда машина (или устройство и т. д.) разбирается на разные части, иногда для того, чтобы выяснить, что с ней не так. Разобрать и разобрать – это синонимы разобрать .
Это когда машина (или устройство и т. д.) разбирается на разные части, иногда для того, чтобы выяснить, что с ней не так. Разобрать и разобрать – это синонимы разобрать .
- Механику пришлось взять двигатель , разобрать , чтобы посмотреть, что издает шум.
- Им пришлось взять кровать отдельно потому что она не проходила через дверь.
- Она взяла свой ноутбук на части , чтобы посмотреть, сможет ли она его починить.
- Когда ты в армии, ты узнаешь, как разобрать пистолет очень быстро.
- я взял мой велосипед отдельно чтобы хорошо почистить.
- Он легко снял часы разобрал но не смог собрать их обратно.
Обратите внимание, как в этом значении объект находится между двумя частями этого фразового глагола.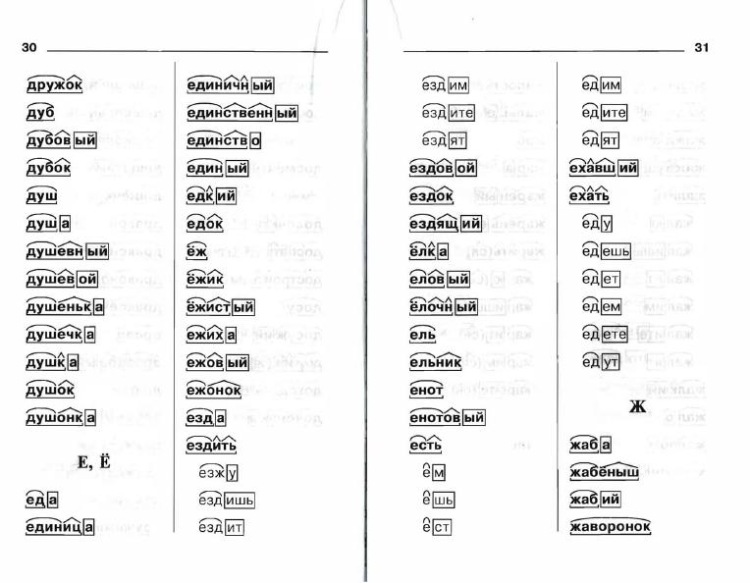
Разобрать мотор , разобрать кровать , разобрать ее ноутбук … разобрать что-то .
2. Разбирать = анализировать и критиковать (что-то или кого-то)
(переходный – неформальный) Это используется, когда кто-то говорит о различных частях чего-либо (например, романа или фильма) с целью критики. Вещь или человек обычно анализируются, чтобы обнаружить недостатки или слабости.
- Предложение кандидата в президенты было разобрано в ходе прений.
- Критики приняли новую пьесу отдельно от и оставили ужасные отзывы.
- Мой учитель разобрал мое эссе на части , сказав все, что в нем было не так.
- Мой босс разобрал бюджет, который я составил, сказав, что это слишком дорого для компании.
3. Разобрать = легко победить кого-то или команду
(переходный – неформальный) Это еще один способ сказать, чтобы разбить кого-то или легко победить кого-то в игре, обычно с большим счетом.
в R с помощью UDPipe — около слова
В продолжение моего предыдущего поста (POS-теги в R с помощью UDPipe) я исследую пакет udpipe , сосредоточившись на этот раз на разборе зависимостей. Разбор зависимостей — это процесс анализа грамматической структуры предложений, установления отношений между словами в предложениях и маркировки этих отношений с помощью грамматических зависимостей. Прежде чем продолжить, рекомендуется ознакомиться с философией универсальных зависимостей (UD).
Анализ зависимостей
Доступ к грамматической структуре предложения полезен для различных задач НЛП, таких как: кусочки информации. Например, вы можете использовать синтаксический анализ зависимостей для определения субъекта и объекта предложения или для извлечения имен людей или организаций, упомянутых в тексте.
Конвейер
Мы собираемся повторно использовать часть кода POS-тегов в R с UDPipe, а именно части, предназначенные для:
- загрузки и загрузки языковых моделей UDPipe с помощью
udpipe_download_model()ифункции udpipe_load_model(); - аннотировать предложение-кандидат с помощью
функции udpipe_annotate().

Новая часть кода включает отправку предложения-кандидата и визуализацию токенов, тега POS и зависимостей с помощью мощного и универсального пакета textplot .
(Down)загрузить языковую модель
# загрузить необходимые пакеты библиотека (водопровод) библиотека (текстовый сюжет) # скачать языковую модель (english-ewt) и сохранить путь m_eng_ewt <- udpipe_download_model(language = "english-ewt") m_eng_ewt_path <- m_eng_ewt$file_model # загрузить выбранную языковую модель m_eng_ewt_loaded <- udpipe_load_model(file = m_eng_ewt_path)
Аннотировать предложение
Пришло время разобрать предложение-кандидат, а именно: «Мертвый воздух формирует мертвую тьму дальше, чем зрение формирует мертвую землю» (Фолкнер, Когда я умирал, ). Предложение аннотируется, и выходные данные преобразуются во фрейм данных.
предложение <- udpipe::udpipe_annotate(m_eng_ewt_loaded, x = "Мертвый воздух формирует мертвую тьму, дальше, чем зрение формирует мертвую землю")
%>%
as. data.frame()  data.frame()
data.frame() Вы можете просмотреть аннотированное предложение с помощью head(sentence) . Я не делаю этого здесь, потому что вывод слишком широкий.
Построение графика зависимостей
Для построения графика зависимостей мы используем функцию textplot_dependencyparser() пакета textplot .
textplot_dependencyparser(sentence, size = 3)Анализатор зависимостей с моделью
english-ewt Два аргумента: аннотированное предложение ( предложение ) и размер этикетки ( размер ).
Интерпретация графа
Имейте в виду, что деревья UD аннотированы грамматическими зависимостями между словами в предложении. В UD каждому слову назначается отношение зависимости к одному из других слов в предложении. Слово, на которое указывает отношение, называется заголовком отношения, а слово, из которого исходит отношение, называется зависимым.
Чтобы понять зависимости, вам нужно обратиться к описи зависимостей. Я рекомендую этот, адаптированный из de Marneffe et al (2014). Характер каждой зависимости выделен красным цветом. В приведенном выше предложении имеем:
Я рекомендую этот, адаптированный из de Marneffe et al (2014). Характер каждой зависимости выделен красным цветом. В приведенном выше предложении имеем:
-
detdeterminer -
amodadjectival modifier -
nsubjnominal subject -
objobject -
punctpunctuation -
advmodadverbial modifier -
advcladverbial clause modifier -
csubjclausal subject -
меткамаркер
Чтобы оценить, насколько хорошо синтаксический анализатор работает, полезно знать, что происходит в предложении. Здесь первое появление глагола формы является корнем первого предложения, а второе вхождение того же глагола является корнем второго предложения. В первом предложении говорится, что мертвый воздух формирует мертвая тьма , а во втором предложении говорится, что номинальный глагол видеть формирует мертвая земля . В первом предложении определяет существительное воздух , а мертвый является прилагательным, модифицирующим воздух и тьма . Воздух является субъектом глагола формы , а тьма является объектом. Во втором предложении наречие в дальнейшем изменяет наречие вдали . Оба наречия изменяют форму глагола . Than здесь помечен как «маркер» (
В первом предложении определяет существительное воздух , а мертвый является прилагательным, модифицирующим воздух и тьма . Воздух является субъектом глагола формы , а тьма является объектом. Во втором предложении наречие в дальнейшем изменяет наречие вдали . Оба наречия изменяют форму глагола . Than здесь помечен как «маркер» ( отметка ). Дуга от , затем от до формирует , сигнализируя о том, что это подчинительное соединение. Seeing является подлежащим глагола формы и земля это объект. Хотя придирчивые грамматики могут предложить альтернативные теги и синтаксический анализ, мы можем сказать, что english-ewt проделал достаточно хорошую работу.
Выбор правильной языковой модели
Вы должны сопоставить модель с текстовыми данными, с которыми работаете. Помимо english-ewt , есть еще три модели, которые стоит рассмотреть для английского языка: english-gum , english-lines и english-partut . Они обучены на разных наборах данных и могут иметь немного разные характеристики производительности. Вот краткий обзор каждой модели:
Они обучены на разных наборах данных и могут иметь немного разные характеристики производительности. Вот краткий обзор каждой модели:
-
english-ewtобучен работе с English Web Treebank (EWT), который представляет собой набор предложений из Интернета; -
english-gumобучается на GUM Corpus, который представляет собой большой аннотированный вручную корпус английского языка, включающий широкий спектр типов и жанров текстов; -
english-linesобучается на корпусе LINES, который представляет собой набор предложений из Интернета; -
english-partutобучается на ParTUT Corpus, который изначально представляет собой набор итальянских предложений. Он был адаптирован для использования с текстом на английском языке с применением методов межъязыкового переноса обучения.
Если вы работаете с текстом определенного типа (например, веб-текстом, новостными статьями и т. д.), вы можете выбрать модель, обученную на аналогичном наборе данных, например, english-ewt или английские линии . Если вы работаете со смесью типов текста, вы можете выбрать более универсальную модель, например,
Если вы работаете со смесью типов текста, вы можете выбрать более универсальную модель, например, english-gum .
При этом ни один синтаксический анализатор не идеален. График ниже основан на english-gum , что априори является лучшей моделью для предложения Фолкнера. Удивительно, но синтаксический анализатор неправильно истолковал грамматический статус второго вхождения 9.0049 формирует , которое он считает существительным, а не глаголом. Эта ошибка возникает из-за того, что на первый взгляд фигур можно считать существительными или глаголами.
english-gum Та же проблема возникает с english-lines …
english-lines модель … и english-partut .
english-partut Таким образом, есть три решения: (а) сравнить парсеры на серии тестовых предложений и выбрать тот, который работает лучше всего, (б) принять, что ваш парсер будет генерировать определенное количество неправильные теги и зависимости, или (c) обучать собственную модель на ваших конкретных данных, функция, также предлагаемая удпайп пакет.
Де Марнефф, М. К., Доза, Т., Сильвейра, Н., Хаверинен, К., Гинтер, Ф., Нивр, Дж., и Мэннинг, К. Д. (2014). Универсальные зависимости Стэнфорда: межъязыковая типология. В Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14) (стр. 4585-4592).
Нивр, Дж., де Марнефф, М.К., Гинтер, Ф., Хаич, Дж., Мэннинг, К.Д., Пюйсало, С., Шустер, С., Тайерс, Ф. и Земан, Д. 2020. Универсальные зависимости v2 : постоянно растущая многоязычная коллекция Treebank. В Материалы Двенадцатой конференции по языковым ресурсам и оценке , стр. 4034–4043, Марсель, Франция. Европейская ассоциация языковых ресурсов.
Цитируйте эту статью как: Гийом Дезагюлье, «Синтаксический анализ зависимостей в R с помощью UDPipe», в Около слова , 20/12/2022, https://corpling.hypotheses.org/4178.
новый оператор - Что такое синтаксический анализ в терминах, понятных начинающему программисту?
Что такое синтаксический анализ? 9n
(что означает одинаковое количество символов A, за которым следует такое же количество символов B). Синтаксический анализатор для этого языка примет ввод
Синтаксический анализатор для этого языка примет ввод AABB и отклонит ввод AAAB . Это то, что делает парсер. Кроме того, во время этого процесса может быть создана структура данных для дальнейшей обработки. В моем предыдущем примере можно, например, хранить AA и BB в двух отдельных стопках.
Все, что происходит после этого, например, придание значения AA или BB , или преобразовать его во что-то другое, не является разбором. Придание смысла частям входной последовательности токенов называется семантическим анализом.
Что не анализируется?
- Разбор — это не преобразование одного в другое. Преобразование A в B — это, по сути, то, что делает компилятор. Компиляция выполняется в несколько шагов, синтаксический анализ — только один из них.
- Парсинг не извлекает смысл из текста. Это семантический анализ, этап процесса компиляции.

Как проще всего это понять?
Я думаю, что лучший способ понять концепцию синтаксического анализа — начать с более простых понятий. Простейшим в предмете языковой обработки является конечный автомат. Это формализм для анализа обычных языков, таких как регулярные выражения.
Все очень просто, у вас есть вход, набор состояний и набор переходов. Рассмотрим следующий язык, построенный на основе алфавита {A, B} , L = {w | w начинается с «AA» или «BB» в качестве подстроки } . Приведенный ниже автомат представляет собой возможный синтаксический анализатор для этого языка, все допустимые слова которого начинаются с «AA» или «BB».
А-->(q1)--А-->(qf)
/
(q0)
\
B-->(q2)--B-->(qf)
Это очень простой синтаксический анализатор для этого языка. Вы начинаете с (q0) , начального состояния, затем вы читаете символ из ввода, если это A , то вы переходите в состояние (q1) , в противном случае (это B , помните помните алфавит только A и B ) вы переходите в состояние (q2) и так далее.