Государственное казенное учреждение социального обслуживания Ростовской области центр помощи детям, оставшимся без попечения родителей, "РОСТОВСКИЙ ЦЕНТР ПОМОЩИ ДЕТЯМ № 7"
Большая разбор слова фонетический разбор: Фонетический разбор слова большая — звуки и буквы, транскрипция
фонетика — это раздел науки о языке, в котором изучаются звуки
Современный русский алфавит состоит из 33 букв,
10 из которых предназначены для обозначения гласных звуков и соответственно называются гласными.
21 согласная буква служит для обозначения согласных звуков.
Кроме того, в современном русском языке есть две буквы, которые никаких звуков не обозначают: ъ (твёрдый знак), ь (мягкий знак).
Звуки речи на письме заключаются в квадратные скобки. Это транскрипция. В транскрипции не принято писать прописные буквы и ставить знаки препинания. Все звуки русского языка делятся на гласные и согласные. 1. Гласные звуки — это звуки, которые образуются при участии голоса.
В русском языке их шесть: [а], [э], [и], [о], [у], [ы]. 2. Согласные звуки — это звуки, которые образуются при участии голоса и шума или только шума.
а) Согласные звуки делятся на твердые и мягкие.
Большинство твердых и мягких согласных образуют пары
Памятка: Звуки [й], [л], [м], [н], [р] — звонкие, сонорные (не имеют пары по звонкости-глухости) Звуки [х], [ц], [ч], [ш’] — глухие (не имеют пары по твердости-мягкости) Звуки [ж], [ш], [ц] — всегда твёрдые. Звуки [й], [ч], [щ] — всегда мягкие.
Звуковое значение букв е, ё, ю, я
1. Буквы е, ё, ю, я могут обозначать два звука:
[йэ], [йо], [йу], [йа].
Происходит это в следующих случаях:
в начале слова: например, ель — [йэ]ль, ёж — [йо]ж, юла — [йу]ла, яма — [йа]ма;
после гласного звука: моет — мо[йэ]т, поёт — по[йо]т, дают — да[йу]т, лаять — ла[йа]ть;
Конспект урока русского языка в 5 классе «Обобщение по теме «Фонетика» «
Тема урока:Обобщение
по теме «Фонетика»
Цели:
1. повторить, обобщить и углубить сведения о звуках и буквах
русского
алфавита, закрепить навык их произношения и написания;
совершенствовать
полученные учащимися умения и навыки; закрепить изученные орфограммы; знать
порядок фонетического разбора;
2.
освоить новые знания о неизвестных сторонах русского языка
3.
прививать любовь к родному слову, русской речи.
Тип урока: повторение и обобщение знаний.
Ход урока
1. Организационная
часть.
Сегодня у нас не совсем обычный урок. Он
превратился в заседание Клуба знатоков Фонетики русского языка. А вы,
соответственно, знатоки, которым предстоит решить массу сложных вопросов. Цель
нашего заседания: обобщение знаний, полученных путем наисложнейших исследований
и опытов, проведенных вами на предыдущих уроках.
2. Актуализация опорных знаний.
Фронтальный
опрос:
-Какой
раздел науки о языке изучает звуки речи?
(Фонетика
знакомит со звуками речи, учит правильно произносить их. )
-Что
такое звук? ( минимальная единица языка)
-На
какие две группы делятся все звуки речи?
-Перечислите
сонорные звуки?
-Какие
звуки всегда мягкие? ч, щ, й
—
А какие разделы языка связаны с фонетикой?
Графика,
орфоэпия, орфография.
Продолжите
фразу: Начертания букв, их виды изучает…
(Графика)
-А
кто подскажет, как называется раздел науки о языке, в котором содержатся
правила произношения звуков и ударения в словах?
(Орфоэпия)
Как
называется фонетическая запись на письме?
Для
чего нужно знать алфавит?
3. Выполнение и распределение заданий
Задание №1(инд) Объяснить
написание слов, определить части речи, назвать фонетические процессы в словах)
Чтобы не ошибиться
в произношении, в какой словарик мы можем посмотреть?
А в нашем
конспекте? ( Произноси правильно)
10. А теперь, уважаемые знатоки, вам
необходимо разбить слова, продиктованные мной на две группы. В первую группу вы
включите слова, где буквы Е,Ё,Ю,Я дают один звук, а во второй – два звука.
Осетр,
тюки, ряженый, зябко, лепесток
Ерунда,
вьюга, затмение, янтарь, ёмкость.
При каких
условиях буквы Е,Ё,Ю,Я дают два звука, а при каких один?
Ну что ж,
уважаемые знатоки, мы с вами подошли к наиболее сложному вопросу нашего
заседания – фонетическому разбору. Что это такое?
Посмотрите
внимательно на экран. Перед вами фонетический разбор слова село. Проверьте,
правильно ли произведен этот разбор.
СЕЛО се-ло
2 слога
Село
Сʼ — согл,
звонкий парный, мягкий парный.
Е –
гласный, безударный.
Л – согл,
глухой парный, твердый парный.
О –
гласный, ударный.
4буквы,
4звука.
А теперь
сами разберите слова юга, ежи, Яга. (по вариантам).
Сегодня
наше заседание знатоков проходит очень плодотворно. В наш клуб обратился агент
по рекламе и попросил подредактировать рекламные тексты.
Покупайте
бигудя
Завивайте
все кудря.
Сто⁄ляр
устранит поломку
И починит
вашу полку.
Зимние
польта согреют вам душу,
Не дадут
замерзнуть в зимнюю стужу.
Д/з повторить
слова в конспекте «Произноси правильно»
На
выбор: 1.Составить вопросы по нашей теме (6-7)
2.Упр № 316
Тренажёр ( презентация- задания по теме :
Фонетика) -13 вопросов
Рефлексия.
Какое
задание было интересным?
Что
нового вы узнали?
Чему
научился?
Что
было трудно?
Что
же мы сегодня повторили?
Что
вам понравилось на уроке?
Надеюсь,
вы убедились, как важно знать законы фонетики и графики, чтобы правильно говорить
и писать
Доп.задание.
упр-316.
Международный фестиваль «Россия — Казахстан: культурное наследие» пройдет в Астане и Алматы
С 28 сентября по 8 октября в Казахстане пройдет фестиваль «Россия — Казахстан: культурное наследие», приуроченный к 30-летию установления дипломатических отношений между Российской Федерацией и Республикой Казахстан.
Наши страны объединяет не только общая история, но и общее культурное наследие. Традиции многовековых контактов и значительный период общей государственности сформировали уникальную культурную ткань, в которой переплетены традиции двух народов.
Фестиваль призван рассказать о диалоге культур России и Казахстана, длящемся не одно столетие, и познакомить широкую аудиторию с деятелями культуры, оставившим свой след в нашей общей истории. Насыщенная концертная и лекционная программа фестиваля состоит из культурно-просветительских мероприятий, ориентированных на широкую публику, все мероприятия бесплатны.
Фестиваль проводится в 30-летнюю годовщину установления дипломатических отношений между Россией и Казахстаном и посвящен изучению и популяризации общего культурно-исторического наследия наших стран. Программа мероприятий, организованных совместными усилиями казахстанских и российских творческих коллективов в Астане и Алматы, станет еще одним шагом к укреплению культурных связей между нашими странами. Работа нашего фонда в Республике Казахстан не ограничивается рамками фестиваля. В 2022-2023 гг. планируется поддержка Книжного уголка России в Национальной библиотеке РК, пополнение русскоязычного библиотечного фонда казахских библиотек, сохранение русского некрополя в городе Кызылорде, поддержка театрального проекта в Костанае и другие проекты», — говорит Елена Чернышкова, руководитель Фонда наследия русского зарубежья.
За 30 лет дипломатических отношений Казахстан и Россия стали не просто соседями и партнерами, а друзьями, практически родственниками! Для которых важны такие семейные ценности, как доверие, взаимное уважение, умение слушать и слышать друг друга, вместе находить общие решения. Которые помнят и чтят общую историю, ценят культуру и традиции друг друга, берегут то, что их накрепко связало в прошлом и связывает сегодня. Фестиваль «Россия — Казахстан: культурное наследие» станет ярким примером культурного обмена между нашими странами, сплотит наши многочисленные народы, взаимно обогатит и укрепит целостность каждой из культур», — считает Татьяна Барышникова, представитель Россотрудничества в Алматы.
Фестиваль откроется в Астане концертом талантливого московского коллектива классической музыки «Новое трио». В Государственном театре оперы и балета «Астана-опера» 28 сентября прозвучат камерные произведения С. Рахманинова, Н. Метнера, И. Стравинского и других композиторов, составивших славу русской музыки за рубежом.
С 29 сентября фестиваль переместится в Алматы. В Национальной библиотеке Республики Казахстан пройдет церемония открытия обновленного Книжного уголка России и передача в дар библиотеке книжного собрания по истории русского зарубежья. После официальной части гостей будет ждать уникальный концерт «Русские корни американского джаза», рассказывающий о малоизвестных страницах джазовой музыки. Поведает эти почти детективные истории и исполнит произведения популярная казахстанская певица Ирэна Аравина в сопровождении квартета JAZZ HOUSE.
Театральный перформанс-читка от талантливого молодого независимого режиссера Камиллы Рашид Dombrovski (от третьего лица) по мотивам произведения «Ручка, ножка, огуречик» и биографии Ю. Домбровского в период нахождения в городе Алма-Ате пройдет 30 сентября на малой сцене культурного пространства «ТРАНСФОРМА». Спектакль подготовлен специально для российско-казахстанского фестиваля и в нем, помимо самой Камиллы Рашид, примут участие популярные алматинские артисты Куантай Абдимади и Лаура Турсунканова.
1 октября в Алматы состоится камерный концерт «Русская музыка в эмиграции», где ведущие солисты Казахского национального театра оперы и балета имени Абая Наталья Мезина и Эмиль Сакавов исполнят романсы и оперные арии известных композиторов, оказавшихся в изгнании, но продолживших лучшие традиции русской классической музыки. Концерт пройдет в необычной обстановке — в одном из выставочных залов ведущего художественного музея страны — Государственного музея искусств РК имени А. Кастеева.
Также музей проведет цикл лекций руководителя отдела зарубежного искусства и увлеченного исследователя Галины Сырлыбаевой. Слушатели откроют для себя малоизвестные, но захватывающие сюжеты, связанные с жизнью и творчеством замечательных русских художников, открывавших Казахстан для России и всего мира (1 и 8 октября).
Необычный вечер пройдет 2 октября в Алматы в арт-пространстве Hazbin в формате «Поэтического кабаре»: «Поэзия русского зарубежья». Со сцены стихотворения будут читать не только профессиональные артисты, но и простые алматинцы, любящие поэзию.
Фестиваль проходит при поддержке посольства России и представительства Россотрудничества в Республике Казахстан.
Полная программа фестиваля и бесплатная регистрация доступны по ссылке: fest.fnrz.ru/kazakhstan2022.
Для связи:
Дополнительная информация, получение фото и видеозаписей с фестиваля и из архива Фонда, организация интервью и съемок:
[email protected]
[email protected]
Справка об организаторах:
Фонд наследия русского зарубежья — некоммерческая организация, основана в начале 2020 года по инициативе Дома русского зарубежья им. А. Солженицына и государственной корпорации развития ВЭБ. РФ.
Деятельность Фонда направлена на сохранение и популяризацию культурного и исторического наследия русской эмиграции. Среди основных задач — приобретение и возвращение в Россию архивов и ценностей музейного значения, поддержка мероприятий, посвященных изучению и популяризации истории и современности русского зарубежья для широкой, в том числе молодежной, аудитории.
Дом русского зарубежья имени А. Солженицына — государственное бюджетное учреждение культуры города Москвы, уникальный комплекс, состоящий из музея, архива, библиотеки, научно-исследовательского, информационно-издательского и культурно-просветительского центров, чья деятельность нацелена на сосредоточение и изучение культурного наследия русского зарубежья, развитие отношений и укрепление связей с соотечественниками за пределами России.
[PDF] Надежный синтаксический анализ сильно искаженных устных высказываний
title={Надежный анализ сильно искаженных высказываний},
автор = {Эджидио П.
Гиачин и Клаудио Руллент},
booktitle={ЦВЕТ},
год = {1988}
}
Э. Гиачин, К. Руллент
Опубликовано в COLING 22 августа 1988 г.
Лингвистика
В этой статье описывается метод, позволяющий системе понимания речи работать с предложениями, в которых некоторые односложные слова не распознаются. Предполагается, что такие слова действуют как простые синтаксические маркеры внутри языковой области системы. Этот результат достигается за счет сочетания модифицированного подхода caseframe к представлению лингвистических знаний со стратегией синтаксического анализа, способной интегрировать ожидания от языковой модели и предсказания от слов. Экспериментальные результаты показывают, что…
View on ACL
dl.acm.org
Efficient Representation of Linguistic Knowledge for Continuous Speech Understanding
P. Baggia, Elisabetta Gerbino, E. Giachin, C. Rullent
Computer Science
IJCAI
1991
Цель состоит в том, чтобы при использовании мощных и гибких формализмов для синтаксиса и семантики генерировать «компактные» гипотезы фраз, каждая из которых учитывает множество синтаксических правил одновременно.
Glr*: надежный синтаксический анализатор, ориентированный на грамматику, для спонтанной речи
А. Лави, М. Томита
Информатика
1996
Общая структура для объединения набора показателей оценки синтаксического анализа в интегрированную эвристику для оценки и ранжирования синтаксических анализов, созданных синтаксическим анализатором GLR*, он был разработан, чтобы быть устойчивым к двум конкретным типам экстраграмматичности: шуму во входных данных и ограниченному охвату грамматики.
Лингвистическая обработка в системе понимания речи
E. Giachin, C. Rullent
Информатика
1992
Целью системы распознавания речи является правильное определение действия, которое должно быть выполнено в ответ на озвученный запрос пользователя, и лингвистические ограничения интегрированы в распознаватель, который декодирует одну строку слов, обрабатываемую интерфейсом на естественном языке.
Улучшение понимания речи посредством проверки обратной связи
П. Баггиа, Л. Фиссор, Элизабетта Гербино, Э. Гиачин, К. Руллент
Информатика
Речь Комм.
1992
Experimental results on large vocabulary continuous speech understanding
Miriam De Mattia, E. Giachin
Computer Science
International Conference on Acoustics, Speech, and Signal Processing,
1989
Авторы сосредотачиваются на недавних улучшениях, добавленных на уровне понимания, состоящих из нового статистического моделирования правильного соседства слов и потери служебных слов, что позволяет решать основные проблемы коартикуляции между словами и обеспечивает существенные успехи с точки зрения точности распознавания на уровне понимания. низкая вычислительная стоимость.
Параллельный анализатор для разговорного естественного языка
E. Giachin, C. Rullent
Компьютерная наука
IJCAI
1989
. в параллельной вычислительной среде, характеризующейся подходом, основными новыми особенностями которого являются резкое сокращение времени простоя и высокая модульность.
Интерактивное понимание речи
Hiroaki Saito
Информатика
COLING
1992
В этой статье представлен надежный интерактивный метод понимания речи, способный обрабатывать неизвестные слова, что важно в практических системах.
Алгоритмы понимания
Р. Гемелло, Э. Гиачин, К. Руллент
Информатика
1990
Оба вида деятельности, распознавание слов и понимание, должны быть доступны. о словах, языке и домене и должны использовать эти знания в качестве источника ограничений для устранения неоднозначности слов.
ДВУПОВАТЕЛЬНЫЙ СПАСПРАВЛЕНИЕ LR от якорного слова для распознавания речи
Hiroaki Saito
Коллекционирование
Coling
1990
. надежными или семантически важными. Этот метод использует эффективный метод синтаксического анализа LR и использует…
Проектирование и разработка систем синтаксического анализа диалогов на естественном языке
Д. Р. Хипп
Информатика
1992
В этой диссертации описывается новая стратегия синтаксического анализа, направленная на преодоление неправильности диалоговой речи, и описывается подсистема, которая использует вывод поддиалогов проверки для выборочной проверки значений. парсер.
ПОКАЗАНЫ 1-10 ИЗ 16 ССЫЛОК
СОРТИРОВАТЬ ПОРелевантности Наиболее влиятельные документыНедавность
Как разобрать пробелы в устных высказываниях
Günther Görz, C. Beckstein
Информатика
EACL
1983
Мы описываем GLP, синтаксический анализатор диаграмм, который будет использоваться в качестве модуля SYNTAX системы распознавания речи Erlangen. GLP реализует многопроцессорную схему на основе повестки дня, которая позволяет легко применять…
Роль семантической обработки в системе автоматического понимания речи
A. Brietzmann, U. Ehrlich
Информатика
COLING
40011 1986
Представляем семантический компонент системы понимания речи и диалога, разработанной в нашем институте. Из -за изменений произношения и неопределенности процесса распознавания слов…
Модифицированный диаграмма речевого кафедра для систем понимания речи
Массимо Поэзио, C. rullent
Computer Science
IJCAI
1987
. Понимание систем представляет собой стратегию параграфирования esseframe, которая отличается от «чистого» разбора casefrsme как минимум в двух отношениях: параграфирование не основывается исключительно на нисходящем…
Разговорной язык синтаксический анализ устного ввода с ограниченным доменом, и применяет грамматику caseframe совершенно по-другому, подчеркивая остров, растущий из заголовков caseframe.
Объединение акустики и лингвистики в понимании речи
G. Niedermair
Лингвистика
1988
В статье представлено предложение тесно связанного контролируемого взаимодействия между лингвистическим прогнозированием, акустическим распознаванием и лингвистической проверкой в понимании речи.
Экспериментальные результаты по задаче доступа к большому словарю
P. Laface, G. Micca, R. Pieraccini
Лингвистика
ICASSP ’87. Международная конференция IEEE по акустике, речи и обработке сигналов
1987
В статье рассматривается проблема лексического доступа к большим словарям посредством грубого фонетического описания слов. Используется метод создания и тестирования: сначала набор слов-кандидатов…
Оптимальные стратегии поиска для контроля понимания речи
W. Woods
Информатика
Artif. Интел.
1982
Взвешенное взаимодействие синтаксиса и семантики в анализе естественного языка
L. Lesmo, P. Torasso
Компьютерные науки, лингвистика
IJCAI
1985
был добавлен в синтаксический анализатор, чтобы можно было параллельно исследовать несколько разных гипотез и выбирать лучшую на основе сложного взаимодействия между синтаксисом и семантикой.
A Композиционная семантика для модификаторов направления — повторное открытие местного падежа —
E. Hinrichs
Лингвистика
COLING
1986
Семантическая теория, предложенная для анализа, представляет собой теорию строго направленной композиции в английской грамматике, которая позволяет разработать модификатор Монтегю.
Эффективный алгоритм синтаксического анализа без дополненного контекста
М. Томита
Информатика
Вычисл. Лингвистика
1987
Вводится эффективный алгоритм разбора расширенных контекстно-свободных грамматик и обсуждается его применение к интерактивным интерфейсам на естественном языке. Алгоритм представляет собой обобщенный разбор LR…
разбор – corp.ling.stats
SeanОставить комментарий
Свидетельства из словосочетаний с предлогом (al)
Аннотация Полный документ (PDF)
Одна из наиболее сложных задач в лингвистических исследованиях касается определения того, как ограничения могут применяться к процессу построения фраз и предложений в естественном языке. В предыдущей работе (Уоллис, 2019 г.) мы рассмотрели ряд операций модификации именных словосочетаний, в том числе последовательную и встроенную модификацию с постмодифицирующими предложениями. Примечательно, что мы обнаружили паттерн убывающей аддитивной вероятности для каждого решения о встраивании постмодифицирующих предложений, хотя паттерн различался в устной и письменной речи.
В этой статье мы используем ту же исследовательскую парадигму для исследования встраивания более простой структуры: постмодифицирующих существительных с предложными фразами. Они встречаются примерно в два раза чаще, а структуры демонстрируют целых пять уровней встраивания в ICE-GB (на два больше, чем для предложений). Наконец, модель встраивания упрощается, потому что в каждой предложной фразе можно найти только одну именную группу. Мы обнаруживаем разные начальные нормы и закономерности для имен нарицательных и собственных, а также для некоторых подмножеств местоимений и числительных. Нарицательные существительные (80 % существительных в корпусе), по-видимому, вызывают постоянное снижение аддитивной вероятности встроенных предложных фраз, в то время как эквивалентная скорость для имен собственных повышается из-за низкой начальной вероятности, факт, который, по-видимому, сильно зависит от наличие титулов.
В целом можно предположить, что, как и придаточные предложения, фразы с предлогами являются по существу независимыми единицами. Тем не менее, мы находим доказательства из ряда источников, которые указывают на то, что некоторые двухслойные конструкции могут быть добавлены как отдельные единицы. Помимо заглавий, к этим конструкциям относятся схематические или идиоматические выражения, в начале которых стоит «неопределенное» местоимение или числительное. Продолжить чтение «Являются ли решения о встраивании независимыми?» →
Это очень широкий вопрос, на который в конечном счете можно ответить эмпирическим путем в зависимости от производительности конкретного синтаксического анализатора.
Однако, чтобы спрогнозировать производительность, мы можем рассмотреть типы структур, которые синтаксический анализатор, вероятно, сочтет трудными, а затем изучить проанализированный корпус речи и письма для получения ключевых статистических данных.
Переменные, такие как средняя длина предложения или сложность главного предложения, часто указываются в качестве показателя сложности синтаксического анализа. Однако в этом случае длина и сложность предложения, скорее всего, будут плохими ориентирами. Произносимые данные не разбиваются на предложения говорящим, скорее, сегментация высказывания является вопросом выбора расшифровщика/аннотатора. Чтобы повысить производительность, аннотатор может просто увеличить количество подразделов предложения. Сложность «на одно предложение» также потенциально может ввести в заблуждение.
В оригинальном London Lund Corpus (LLC) разговорные данные были разделены по оборотам динамика, а единицы фонетического тона были отмечены. В случае с речами обороты оратора могут быть очень длинными составными предложениями. На практике, когда тексты анализировались, обороты говорящих могли быть разделены на координаторов или после наречия предложения.
В этом дискуссионном документе мы будем использовать британский компонент Международного корпуса английского языка (ICE-GB, Nelson et al. 9).0368 2002) в качестве тестового корпуса разобранной речи и письма. Стоит отметить, что оба компонента анализировались одними и теми же инструментами и исследовательской группой.
Очень четкое различие между речью и письмом в ICE-GB можно найти в степени самокоррекции . Средняя скорость самокоррекции в устных данных ICE-GB составляет 3,5% слов (скорость для письма составляет 0,4%). Разговорный жанр с наименьшим уровнем самокоррекции – выпуск новостей (0,7%). Напротив, в сценариях студенческих экзаменов авторами вычеркнуто около 5% слов, за ними следуют социальные письма и студенческие эссе, в которых около 0,8% слов помечены для удаления.
Однако к самоисправлению можно обратиться на этапе аннотирования, удалив его из входных данных синтаксического анализатора, проанализировав это упрощенное предложение и воссоединив вывод с исходной строкой корпуса. Чтобы выявить проблемы сложности синтаксического анализа, поэтому нам нужно рассмотреть предложение без каких-либо самоисправлений. Существуют ли другие факторы, которые могут затруднить разбор входного потока по сравнению с записью? Продолжить чтение «Почему синтаксический анализ устных данных может представлять более сложные задачи, чем синтаксический анализ письма?» →
В этой статье обобщается методологическая перспектива корпусной лингвистики, которая является объединяющей и критической. В нем подчеркивается, что процессы, связанные с аннотированием корпусов и проведением исследований с корпусами, принципиально циклический , т. е. включающий как восходящие, так и нисходящие процессы. Знания обязательно частичны и опровержимы.
Эта точка зрения объединяет исследования, основанные на корпусе, и исследования, основанные на теории, как два аспекта исследовательского цикла. Мы выделяем три различных, но связанных циклических процесса: аннотацию, абстракцию и анализ. Эти циклы существуют на разных уровнях и выполняют разные задачи, но связаны друг с другом таким образом, что результат одного обеспечивает вход следующего.
Такое разделение исследовательской деятельности на интегрированные циклы особенно важно в случае работы с устными данными. Акт транскрипции сам по себе является аннотацией, и решения по структурной идентификации отдельных предложений лучше всего понимать как неотъемлемую часть синтаксического анализа. В лингвистических исследованиях следует отдавать предпочтение устным данным, но в современных корпусах преобладают большие объемы письменного текста. Мы отмечаем, что это не является обязательным аспектом корпусной лингвистики, и вводим два анализируемых корпуса, содержащие устные транскрипции.
Мы выделяем три типа свидетельств, которые можно получить из корпуса: фактические, частотные и интерактивные, представляющие различные логические утверждения о данных. Каждый из них может существовать на любом уровне иерархии 3А. Кроме того, обогащение аннотации корпуса позволяет получать доказательства на основе этих более богатых аннотаций. Мы демонстрируем это, обсуждая синтаксический анализ корпуса данных разговорной речи и два недавних исследования, которые иллюстрируют эту точку зрения. Продолжить чтение «Что может сказать нам о языке корпус проанализированных устных данных?» →
Нравится:
Нравится Загрузка. ..
Рубрика: Экспериментальный дизайн, методологияTagged 3A цикл, абстракция, анализ, аннотация, корпус, корпусная лингвистика, эпистемология, лингвистика, синтаксический анализ, философия науки, психолингвистика, речь
Как работает voice2json | voice2json
На высоком уровне voice2json преобразует аудиоданные (голосовые команды) в события JSON.
Голосовые команды указываются заранее в компактном текстовом формате:
[Состояние света]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
Этот формат поддерживает:
[дополнительные слова]
(альтернативный | выбор)
имя = тело — правила
<имя правила> — ссылки на правила
(значение) {имя} — теги
ввод: вывод — замены
$movies — список слотов
1. .100 — числовые серии
ТЕКСТ!поплавок — преобразователи
Во время обучения voice2json генерирует артефакты, которые могут распознавать и декодировать указанные голосовые команды. Если эти команды изменятся, необходимо заново обучить voice2json .
Основные компоненты
Основные функции
voice2json можно разделить на компоненты распознавания речи и намерений.
Когда голосовые команды распознаются речевым компонентом, транскрипция передается распознавателю намерений для обработки. Конечным результатом является структурированное событие JSON с:
Имя намерения
Распознанные слоты/сущности
Необязательные метаданные о процессе распознавания речи
Автономная транскрипция голосовых команд в voice2json обрабатывается одной из трех систем с открытым исходным кодом:
Карманный сфинкс
КМУ (2000)
Калди
Джонс Хопкинс (2009)
Глубокая речь
Мозилла (v0. 6, 2019)
Для Pocketsphinx и Kaldi требуется:
Акустическая модель
Сопоставляет звуковые функции с фонемами
Словарь произношения
Преобразование фонем в слова
Языковая модель
Описывает, как часто слова следуют за другими словами
DeepSpeech объединяет акустическую модель и словарь произношения в единую нейронную сеть. Однако он по-прежнему использует языковую модель.
Акустическая модель
Акустическая модель сопоставляет акустические/речевые характеристики с вероятными фонемами данного языка.
Обычно в качестве акустических признаков используются коэффициенты кепстра частот Mel (сокращенно MFCC). Они математически выделяют полезные аспекты человеческой речи.
Фонемы зависят от языка (и даже от локали). Это 90 367 неделимых единиц 90 368 словесного произношения. Определение фонем языка требует лингвистического анализа, и могут возникнуть споры по поводу окончательного набора. Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита.
Акустическая модель представляет собой статистическое сопоставление между звуковыми характеристиками (MFCC) и одной или несколькими фонемами. Это сопоставление изучается из большой коллекции речевых примеров вместе с их соответствующими транскрипциями. Предварительно созданный словарь произношения необходим для сопоставления транскрипций с фонемами, прежде чем можно будет обучить модель. Сбор, расшифровка и проверка этих больших наборов речевых данных является ограничивающим фактором в распознавании речи с открытым исходным кодом.
Словарь произношений
Словарь, отображающий последовательности фонем в слова, необходим как для обучения акустической модели, так и для распознавания речи. Для каждого слова возможно более одного сопоставления (произношения).
Для практических целей давайте будем считать слово просто «вещью между пробелами» в тексте. Независимо от того, как именно вы определяете, что такое «слово», важнее всего последовательность: кто-то должен решить, являются ли составные слова (например, «предварительно построенные»), сокращения и т. д. отдельными («предварительно построенными») или составными словами ( «предварительно» и «построено»).
Ниже приведена таблица примеров фонем для американского английского языка из Словаря произношения CMU.
Фонема
Слово
Произношение
АА
нечетный
АА Д
АЭ
на
АЕ Т
АХ
хижина
НХ АХ Т
АО
должен
АО Т
АВ
корова
К AW
АЮ
скрыть
ЧЧ АУ Д
Б
будет
Б ИЮ
СН
сыр
Ч Й З
Д
ди
Д ИЙ
ДХ
тэ
ДХ ИЮ
ЕН
Эд
ЕН Д
ЕР
ранить
HHER T
ЭЙ
съел
ЭЙ Т
Ф
плата
Ф 1Г
Г
зеленый
Г Р И Я N
НН
он
ЧГ ИГ
ИХ
это
ИХ Т
ИГ
есть
ИЮ Т
ДЖХ
гы
JH IY
К
ключ
К ИЮ
Л
ли
Л ИЙ
М
я
М ИГ
Н
колено
Н ИЮ
НГ
пинг
П ИХ НГ
ОВ
овес
ВЛ Т
ОУ
игрушка
ТОЙ
Р
моча
П ИЙ
Р
читать
Р ИЙ Д
С
море
S IY
Ш
она
Ш ИЮ
Т
чай
Т ИЮ
ТГ
тета
ТЭЙ Т АХ
UH
капот
ЧХ УХ Д
УВ
два
Т УВ
В
и
В ИГ
Ш
мы
В ИГ
Д
выход
Г ИГ Л Д
З
зи
З ИЮ
Ж
изъятие
С ИЙ Ж ЭР
Более поздние версии этого словаря включают ударение, указывающее, на какие части слова делается ударение во время произношения.
Во время обучения voice2json копирует произношения для каждого слова в ваших шаблонах голосовых команд из большого предварительно созданного словаря произношений. Произношение слов, которых нет в этом словаре, угадывается с использованием предварительно обученной модели графемы в фонему.
Графема в фонему
Модель графема-фонема (G2P) может использоваться для угадывания фонетического произношения слов. Это статистическая модель, которая сопоставляет последовательности символов (графем) с последовательностями фонем и обычно обучается на основе большого предварительно созданного словаря произношения. voice2json использует для этой цели инструмент под названием Phonetisaurus.
Модель языка
Языковая модель описывает, как часто одни слова следуют за другими. Обычно можно увидеть модели, которые состоят из одного-трех слов подряд.
Языковые модели создаются из большого массива текстов, таких как книги, новостные сайты, Википедия и т. д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности должны быть предсказаны с помощью эвристики.
Ниже приведен вымышленный пример вероятностей одиночных/парных/тройных слов для корпуса, который содержит только слова «sod», «sawed», «that», «that’s» и «odd».
0,2 дерн
0,2 распиленный
0,2 что
0,2 это
0,2 нечетный
0,25 странно
0.25 что распилил
0.25 это дерьмо
0,25 странно, что
0.5 как то странно
0,5 черт возьми
Во время распознавания речи входящие фонемы могут соответствовать более чем одному слову из словаря произношения. Языковая модель помогает сузить круг возможных вариантов, сообщая распознавателю речи, что некоторые сочетания слов очень маловероятны и могут быть проигнорированы.
Фрагменты предложения
Языковая модель не содержит вероятности целых предложений, только фрагментов предложения . Для получения полного предложения от распознавателя речи требуется несколько приемов:
Добавление виртуального начального/конечного предложения «слова» ( , )
what time — начало предложения «what time…»
is it — конец предложения «…is it?»
Использовать скользящие временные окна
Фрагменты сшиваются с помощью перекрывающихся окон
«который час», «время», «это» для предложения «который час»
Прерывание звука при длительных паузах или постоянное использование одного предложения
Вы всегда можете предположить, что первое «слово» (начало предложения)
Где поставить (конец предложения)?
При использовании этих приемов распознанные «предложения» могут оставаться бессмысленными и иметь мало общего с предыдущими предложениями. Например:
тот дерн, тот дерн, который пилил...
Современные нейронные сети-трансформеры могут намного лучше обрабатывать долгосрочные зависимости внутри и между предложениями, но:
Им требуется огромное количество обучающих данных
Они могут быть медленными/ресурсоемкими для (повторного) обучения и выполнения без специального оборудования
Для предполагаемого использования voice2json (заранее заданные короткие голосовые команды) приведенные выше приемы обычно достаточно хороши. Хотя облачные сервисы можно использовать с voice2json , есть компромисс между конфиденциальностью и отказоустойчивостью (потеря Интернета или облачной учетной записи).
Обучение языковой модели
Во время обучения voice2json создает пользовательскую языковую модель на основе ваших шаблонов голосовых команд (обычно в формате ARPA). Благодаря библиотеке opengrm, voice2json может взять граф промежуточных предложений, созданный на начальных этапах обучения, и напрямую сгенерировать языковую модель ! Это включает voice2json для обучения за считанные секунды даже миллионам возможных голосовых команд.
Смешивание языковых моделей
Настраиваемая языковая модель voice2json при желании может быть смешана с гораздо большей заранее созданной языковой моделью. В зависимости от того, какой вес придается той или иной модели, это повысит вероятность ваших голосовых команд на фоне общих предложений на языке профиля.
При правильном смешивании voice2json способен к (почти) неограниченному распознаванию речи с предпочтением голосовых команд пользователя. К сожалению, это обычно приводит к снижению производительности распознавания речи и множеству других сбоев распознавания намерений (которые обучаются только на голосовых командах пользователя).
Текст для намерения
Система(ы) распознавания речи в voice2json создает текстовые транскрипции, которые затем передаются в систему распознавания намерений. Когда и речь, и система намерений обучаются вместе с одним и тем же файлом шаблона, все допустимые команды (с небольшими вариациями) должны быть правильно преобразованы в события JSON.
voice2json преобразует набор возможных голосовых команд в граф, который действует как преобразователь конечного состояния (FST). При получении действительного предложения в качестве входных данных этот преобразователь будет выводить (преобразованное) предложение вместе с «мета»-словами, которые определяют намерение предложения и именованные сущности.
В качестве примера рассмотрим приведенный ниже шаблон предложения для намерения LightState :
[Состояние света]
состояния = (вкл | выкл)
включите (<состояния>){состояние} [the] свет
При обучении с помощью этого шаблона voice2json сгенерирует такой график:
Каждое состояние помечено цифрой, а ребра (стрелки) тоже имеют метки. Метки ребер имеют специальный формат, который представляет входные данные, необходимые для прохождения ребра, и соответствующие выходные данные. Двоеточие («:») разделяет входные/выходные слова по краю и опускается, если входные и выходные данные совпадают. Выходные «слова», начинающиеся с двух символов подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Приведенный выше FST примет все возможные предложения в файле шаблона:
включить свет
включить свет
выключить свет
выключить свет
Это вывод, когда каждое предложение принимается FST:
Вход
Выход
включи свет
__label__LightState включить __begin__state on __end__state свет
включить свет
__label__LightState включите __begin__state on __end__state свет
выключить свет
__label__LightState включить __begin__state выключить __end__state свет
выключить свет
__label__LightState включить __begin__state выключить __end__state свет
Нотация __label__ взята из fasttext, высокопроизводительной системы классификации предложений. Для каждого предложения создается одно мета-слово __label__ , помечающее его именем намерения свойства.
Метаслова __begin__ и __end__ используются voice2json для создания события JSON для каждого предложения. Они отмечают начало и конец помеченного блока текста в исходном файле шаблона — например, (вкл | выкл) {состояние} . Эти начальные/конечные символы можно легко преобразовать в общую схему аннотирования корпусов текстов (IOB) для обучения распознавателя именованных сущностей (NER). Например, flair может читать такие корпуса и обучать NER с помощью PyTorch.
Библиотека voice2json NLU в настоящее время использует следующий набор метаслов:
__label__INTENT
Предложение принадлежит намерению с именем НАМЕРЕНИЕ
__begin__TAG
Начало тега с именем TAG
__end__TAG
Конец тега с именем TAG
__convert__CONV
Начало преобразователя имени CONV
__converted__CONV
Конец преобразователя с именем CONV
__source__SLOT
Имя списка слотов, откуда был взят текст
__unpack__PAYLOAD
Декодирует PAYLOAD как строку в кодировке base64, а затем интерпретирует как метку края
фастфуды
voice2json Распознаватель намерений на основе FST называется fsticuffs . Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Распознавание намерений выполняется путем простого запуска транскрипции через граф намерений и анализа выходных слов (и метаслов). Транскрипция «включи свет» разбивается (по пробелам) на слова поворот на свет .
Следуя пути через приведенный выше пример графа намерений со словами в качестве входных символов, это выведет:
__метка__LightState очередь __begin__state на __end__state свет
Довольно простой конечный автомат получает эти символы/слова и создает структурированное намерение, которое в конечном итоге преобразуется в JSON. Имя намерения и именованные объекты восстанавливаются с использованием метаслов __label__ , __begin__ и __end__ . Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой:
Что, если fsticuffs получить транскрипцию «не могли бы вы включить свет»? Это недопустимый пример голосовой команды, но представляется разумным принять ее с помощью ввода текста (например, в чате).
Поскольку будет , а вы не являются словами, закодированными в намерении, FST не сможет его распознать. Чтобы справиться с этим, voice2json позволяет молча пропускать стоп-слова во время распознавания, если они не были бы приняты. Этот «нечеткий» режим распознавания работает медленнее, но позволяет принять больше предложений.
Заключение
При обучении voice2json выдает следующие артефакты:
Словарь произношения, содержащий только слов из ваших шаблонов голосовых команд
Произношение слов, отсутствующих в словаре, угадывается с использованием модели графемы к фонеме
Граф намерений, который используется для распознавания намерений из предложений
При желании можно игнорировать общие слова, чтобы обеспечить более «нечеткое» распознавание
Языковая модель, сгенерированная непосредственно из графа намерений с помощью opengrm
Это может быть опционально смешано с большой предварительно созданной языковой моделью
ТЕМА: Обзор статей конференции, отсортированных по темам
A-C-D-E-G-H-I-K-L-M-N-O-P-Q-S-T-U-V-W
А
Приобретение
Модель на основе нейронной сети для идентификации заимствованных слов в уйгурском языке Оценка фонематической транскрипции тональных языков с низким уровнем ресурсов для языковой документации Контекстный выбор материала на основе использования CBFC: параллельный речевой корпус L2 для изучающих корейский и французский языки Большой ресурс шаблонов для словесных перефраз 2-й продольный корпус для детского письма с расширенным выводом для определенных моделей правописания Автоматическая аннотация типов семантических терминов в полном справочном корпусе антологии ACL Индекс понимания слов для младенцев, примененный к исследованию преобладания изучения существительных с использованием межъязыковой базы данных CDI Использование английских приманок для ловли сербской многословной терминологии BioRo: Биомедицинский корпус для румынского языка Анализ индекса общности словарного запаса с использованием крупномасштабной базы данных развития детской речи KIT-Multi: ориентированный на перевод многоязычный корпус для встраивания Многоязычные аргументные корпуса на английском, турецком, греческом, албанском, хорватском, сербском, македонском, болгарском, румынском и арабском языках Распределение и просодическая реализация глагольных форм в немецкой детской речи Большой многоязычный и многодоменный набор данных для рекомендательных систем Межъязыковые сети малого мира повсеместно распространены в детской речи Параллельное дерево L1-L2 для изучающих китайский язык: чрезмерное и недостаточное использование синтаксических структур Использование выравнивания текста в полуавтоматическом анализе ошибок: вариант использования при разработке корпуса изучающих латышский язык Аннотация к ошибке в корпусе учащихся португальского языка Берега деревьев AnnCor CHILDES г. Говорящий атлас региональных языков Франции. BabyCloud, технологическая платформа для родителей и исследователей
Анафора, Кореферентность
Когерентность дискурса через призму корпуса аннотированных текстов: тематическое исследование Классификация случаев шлюза в диалоге Слой аннотаций Gold Anaphora на корпусе движений глаз Аннотирование нулевой анафоры для ответов на вопросы На пути к диагностике текстовых трудностей у детей с дислексией Междокументная, межъязыковая корреферентная аннотация событий с использованием бункеров событий BASHI: Сборник статей Wall Street Journal, аннотированный связующими ссылками Глубокие нейронные сети для разрешения кореферентности для польского языка SzegedKoref: Венгерский корпус основных ссылок Корпус для изучения относительных отношений для именных имен Sanaphor++: объединение глубоких нейронных сетей с семантикой для разрешения кореферентности АНКОР-АС: обогащение корпуса АНКОР синтаксическими аннотациями ParCorFull: параллельный корпус, аннотированный полной кореферентностью Разрешение базовой ссылки в FreeLing 4. 0 SACR: инструмент на основе перетаскивания для аннотаций кореференсов
С
Когнитивные методы
Слой аннотаций Gold Anaphora на корпусе движений глаз Корпус естественных историй Контекстный выбор материала на основе использования Раскрытие внешнего поведения и внутреннего аффективного состояния товарищей по команде с помощью ансамблевого обучения: экспериментальные данные диадического коллектива Определенное описание Лексический выбор: учет личности говорящего Генерация выражения обращения в связи с ограничением по времени Мультимодальное расстояние — подход к генерации стеммы с взвешиванием Знать автора по компании Его слова держат Fluid Annotation: инструмент аннотации с учетом детализации для текучести китайских слов Rollenwechsel-English: крупномасштабный корпус семантических ролей Создание набора данных по знанию английской лексики для изучающих японский английский как второй язык с помощью краудсорсинга Автоматическая маркировка диалогов по решению проблем для вычислительной микрогенетической аналитики обучения CoLoSS: корпус когнитивной нагрузки с данными о речи и производительности из символьно-цифрового двойного задания Модель лингвистической категории на польском языке (LCM-PL) Этикетки межличностных отношений для CALLHOME Corpus WordKit: пакет Python для орфографической и фонологической детализации
Компьютерное изучение языка (звонок)
Контекстуальный выбор материала на основе использования На пути к диагностике текстовых трудностей у детей с дислексией SW4ALL: Классифицированный и согласованный корпус CEFR для изучения языков Набор данных лексического упрощения на основе CEFR Semi-supervised Clustering for Short Answer Scoring Создание учебного корпуса TOCFL для диагностики китайских грамматических ошибок MIAPARLE: онлайн-тренинг по различению контрастов стресса Уровневый корпус для чтения современного стандартного арабского языка Параллельное дерево L1-L2 для изучающих китайский язык: чрезмерное и недостаточное использование синтаксических структур Генерация корпуса испанских искусственных ошибок словосочетаний Создание набора данных по лексике английского языка для изучающих японский английский как второй язык с использованием краудсорсинга Аннотация к ошибке в корпусе учащихся португальского языка Корпус SLA, аннотированный педагогически значимыми грамматическими структурами EFLLex: оцениваемый лексический ресурс для изучающих английский язык как иностранный ESCRITO — набор инструментов для оценки образования, дополненный НЛП Revita: языковая платформа на пересечении ITS и CALL Разработка мобильной системы поддержки наблюдения для учащихся: FishWatchr Mini
Контролируемые языки
Реальный корпус сообщений управления воздушным движением с французским акцентом Упрощенный корпус с основным словарем
Корпус (создание, аннотация и т. д.)
Когерентность дискурса через призму корпуса аннотированных текстов: тематическое исследование Создание параллельного одноязычного корпуса ганьских диалектов китайского языка FrameNet для информации о раке в клинических рассказах: схема и аннотация MOCCA: мера достоверности для анализа корпуса — автоматическая проверка надежности стенограммы и автоматическая сегментация Записанный набор данных для дебатов Связывание, поиск и визуализация сущностей в Википедии Многоязычный параллельный корпус для глобального коммуникационного плана Open Subtitles Paraphrase Corpus для шести языков Включение глобальных контекстов во встраивание предложений для реляционного извлечения на уровне абзаца с дистанционным контролем Классификация случаев шлюза в диалоге Корпус для моделирования важности слов в стенограммах разговорных диалогов Создание корпуса из рукописных открыток с картинками: транскрипция, аннотация и маркировка частями речи Аннотирование высокоуровневых структур коротких рассказов и личных анекдотов Обнаружение темпоральности на уровне предложения с использованием неявного ресурса с определением времени Создание корпуса с анализом зависимостей в веб-масштабе из CommonCrawl MCScript: новый набор данных для оценки машинного понимания с использованием знаний сценариев Новый корпус для поддержки интеллектуального анализа текста для курирования метаболитов в базе данных ChEBI Оценка новизны свода метафор для синтаксически связанных пар слов Сбор данных мультимодального диалога и анализ результата аннотации уровня интереса пользователей Многослойная аннотация Ригведы Universal Dependencies Version 2 для японского языка ESCAPE: крупномасштабный синтетический корпус для автоматического постредактирования OpenSubtitles2018: Статистическая переоценка выравнивания предложений в больших, шумных параллельных корпусах Создание банка дерева зависимостей китайского языка с поддержкой многоточия для веб-текста MPST: свод синопсисов сюжетов фильмов с тегами EuroGames16: оценка обнаружения изменений в онлайн-разговоре Корпус естественных историй Корпус арабских диалектов MADAR и лексикон Полуавтоматическая корейская аннотация FrameNet по KAIST Treebank Большой параллельный корпус полнотекстовых научных статей Разработка дерева рассуждений Bangla RST Компьютерная диаризация говорящего: как оценить человеческие исправления На пути к стандарту ISO для аннотаций количественного анализа Распространение эмоциональных реакций на новостные статьи в Twitter Облегченная грамматическая аннотация в TEI: новые перспективы Детальное семантическое текстовое сходство для сербского языка Составление лексикона относительных существительных TAP-DLND 1. 0: корпус для обнаружения новизны на уровне документа Оценка фонематической транскрипции тональных языков с низким уровнем ресурсов для языковой документации NegPar: параллельный корпус, аннотированный для отрицания SPADE: оценочный набор данных для одноязычного выравнивания фраз Распознавание поведенческих факторов во время вождения: реальный мультимодальный корпус для мониторинга эмоционального состояния водителя Аннотирование нулевой анафоры для ответов на вопросы Восстановление диакритических знаков с помощью нейронных сетей Комплексная аннотация различных типов временной информации на оси времени EmotionLines: корпус эмоций многосторонних разговоров Сравнение методов обнаружения каламбура с использованием японского корпуса каламбуров Золотой стандарт многоязычного автоматического извлечения терминов из сопоставимых корпусов: структура терминов и эквиваленты перевода На пути к эпическому эпиграфу Типы ошибок связывания именованных объектов Китайско-португальский машинный перевод: исследование построения параллельных корпусов из сопоставимых текстов Дополнение Librispeech французскими переводами: мультимодальный корпус для оценки прямого перевода речи T-REx: крупномасштабное согласование естественного языка с тройками базы знаний PoSTWITA-UD: итальянский банк деревьев Twitter в универсальных зависимостях ETPC — Корпус идентификации парафраз, аннотированный расширенной типологией парафраз и отрицанием Аннотация структуры диалога для многоэтажного взаимодействия г. Извлечение англо-персидского параллельного корпуса из сопоставимых корпусов Свод комментариев пользователей к электронному правилу для измерения оцениваемости аргументов Речевой корпус языка с очень низким ресурсом для экспериментов по документированию вычислительных языков Многослойный аннотированный корпус аргументативного текста: от схем аргументации к дискурсивным отношениям Новая версия базы данных польского языка Składnica, гармонизированная со словарем Валентности Валентности Лексический инструмент для академического письма на испанском языке на основе корпусов экспертов и новичков Создание матрицы перевода библейских имен на 591 язык Набор данных для извлечения связи между предложениями с использованием удаленного контроля Французско-алжирский аудиокорпус с переключением кода (FACST) Чахта Анумпа: мультимодальный корпус языка чокто SumeCzech: большой набор данных на основе чешских новостей IIT Bombay English-Hindi Parallel Corpus Параллельные корпуса для биомедицинской области Улучшение машинного перевода образовательного контента с помощью краудсорсинга Абстрактное значение Представление конструкций: чем больше мы включаем, тем лучше представление Корпус хинди-английского кода со смешанными данными, аннотированный агрессией Диахронический корпус для анализа литературного стиля CBFC: параллельный речевой корпус L2 для изучающих корейский и французский языки Системные соглашения и разногласия во временной обработке: подробный анализ ошибок задачи TempEval-3 На пути к диагностике текстовых трудностей у детей с дислексией Автоматическое сопоставление Wordnet: от CoreNet до Princeton WordNet Представляем NIEUW: новые стимулы и рабочие процессы для получения лингвистических данных BULBasaa: Двуязычный басаа-французский речевой корпус для оценки инструментов языковой документации Обработка проблемы с редкими словами с использованием синтетических обучающих данных для сингальского и тамильского нейронного машинного перевода Аннотирование временно привязанных пространственных знаний с использованием синтаксических зависимостей Исследование малообеспеченных языков — DigiSami Corpus Семантические сверхчувства для английских притяжательных имен Мультимодальный корпус для взаимного взгляда и совместного внимания в многостороннем ситуационном взаимодействии Аннотирование образовательных вопросов для анализа ответов учащихся Аннотирование, если авторы твита находятся в местах, о которых они твитят SW4ALL: Классифицированный и согласованный корпус CEFR для изучения языков Простые семантические аннотации и ситуационные фреймы: два подхода к базовому пониманию текста в LORELEI Разбери меня, если сможешь: искусственные деревья для экспериментов по разбору эллиптических конструкций Создание основы для заполнения базы знаний: девять лет лингвистических ресурсов для TAC KBP Корпус отношений атрибуции для политических новостей Хватит ходить вокруг да около: шаг к обработке идиом для НЛП индийского языка Упрощение текста на основе профессионально подготовленных корпусов Новый Propbank: согласование Propbank с AMR посредством унификации POS CONDUCT: набор данных выразительных дирижерских жестов для управления звуком Интертекстуальная корреспонденция для интеграции корпусов Medical Entity Corpus с элементами PICO и анализом настроений Основанный на зрении набор данных для прогнозирования типичных местоположений глаголов Оценка хорватских вложений слов BlogSet-BR: корпус блогов на бразильском португальском языке Преобразование Википедии в крупномасштабный детальный корпус типов сущностей Многоязычный подход к классификации вопросов Корпус характеристик динамиков Nautilus: записи речи и метки характеристик динамиков и описания голоса SMILE Набор данных швейцарско-немецкого жестового языка JESC: Корпус японско-английских субтитров Создание корпуса для личностно-зависимого понимания и генерации естественного языка Набор данных для первой оценки понимания машинного чтения на китайском языке Многодоменная структура для текстового сходства. Практический пример задач на сходство «вопрос-вопрос» и «вопрос-ответ» Генерация выражения обращения в связи с ограничением по времени Проектирование и разработка речевых корпусов для обучения авиадиспетчеров BiLSTM-CRF для распознавания именованных сущностей на персидском языке ArmanPersonERCorpus: первый персидский набор данных с аннотациями сущностей Приложение для построения корпуса польской телефонной речи Аннотирование выражений модальности и достоверность событий для корпуса комментариев к японским шахматам Использование дискурсивной информации для образования с испано-китайским параллельным корпусом 2-й продольный корпус для детского письма с расширенным выводом для определенных моделей правописания CPJD Corpus: краудсорсинговый параллельный речевой корпус японских диалектов BKTreebank: создание вьетнамского дерева зависимостей Анонимизация данных для анализа качества требований: воспроизводимая задача автоматического обнаружения ошибок WorldTree: свод графиков пояснений к элементарным научным вопросам, поддерживающим многошаговый вывод Аннотирование отношений атрибуции на арабском языке BASHI: Корпус статей Wall Street Journal, аннотированный связующими ссылками Немецкий корпус для детального распознавания именованных сущностей и извлечения отношений трафика и отраслевых событий Исследование корпуса и схема аннотаций для распознавания именованных сущностей и извлечения отношений бизнес-продуктов Тегирование части речи на албанском языке: золотой стандарт и оценка Первый южноафриканский корпус многоязычной мыльной оперы с переключением кодов Сбор данных с кодовой коммутацией из социальных сетей Устранение многозначности слов, состоящих из всех слов, с использованием встраивания понятий Англо-баскский статистический и нейронный машинный перевод Реальный корпус сообщений управления воздушным движением с французским акцентом Исправление ошибок сегментации слов OCR в статьях из коллекции ACL с помощью методов нейронного машинного перевода Набор данных Sentiment-Stance-Specific (SSS): выявление зависимостей, основанных на поддержке, среди мнений. «Портретный» подход к многоканальному дискурсу Улучшение модели нейронного машинного перевода с несколькими источниками с расширением корпуса для языков с низким уровнем ресурсов Многоязычное расширение аннотаций в стиле PDTB: пример TED Multilingual Discourse Bank Создание диалектных подкорпусов путем кластеризации: пример адаптивного метода в японском языке Создание ресурсов для автоматического анализа настроений на телугу (язык с низким уровнем ресурсов) и интеграция нескольких доменных источников для улучшения прогнозирования настроений Построение древовидной базы макрокитайского дискурса Морфо-синтаксическая аннотация Animacy для анализатора зависимостей Автоматическая аннотация типов семантических терминов в полном справочном корпусе антологии ACL Большой самоаннотированный корпус для сарказма JAIST Аннотированный корпус свободной беседы Корпус стажеров по дебатам о металоге: сбор данных и аннотации MYCanCor: видеокорпус разговорного малайзийского кантонского диалекта AET: веб-инструмент для изучения прилагательных для немецкого языка HappyDB: собрание 100 000 счастливых моментов, созданных с помощью краудсорсинга Преобразование текстов в скрипты: исследование последствий Лингвистическая и социолингвистическая аннотация голландских писем 17 века Неконтролируемое устранение неоднозначности корейского смысла слов с использованием CoreNet Идентификация арабского диалекта в контексте бивалентности и переключения кодов Набор данных лексического упрощения на основе CEFR Аннотация структуры дискурса и информационной структуры на основе QUD: инструмент и оценка UFSAC: объединение смысловых аннотированных корпусов и инструментов Классификация информативного поведения эмодзи в микроблогах MIsA: многоязычное извлечение «IsA» из корпусов Создание литовских и латышских речевых корпусов из неточно аннотированных веб-данных KTH Tangrams: набор данных для исследования выравнивания и концептуальных договоров в диалоге, ориентированном на задачу Аннотирование конструкций легких глаголов китайского языка в соответствии с рекомендациями PARSEME Предсказание словарного запаса корейского языка L2: можно ли использовать большой аннотированный корпус для обучения более совершенных моделей предсказания неизвестных слов? Новый аннотированный португальско-испанский корпус для задачи сжатия нескольких предложений Аннотирование спина в биомедицинских научных публикациях : случай случайных контролируемых испытаний (РКИ) Упрощенный корпус с основным словарем Золотой стандарт высокого качества для задач на основе цитирования Корпуса с аннотациями частей речи для трех региональных языков Франции: эльзасского, окситанского и пикардийского Прагматический подход к сегментации слов в классическом китайском языке Корпус описаний природных мультимодальных пространственных сцен ZAP: многоязычная среда проецирования аннотаций с открытым исходным кодом Расширение набора терминов распространения О векторном представлении высказываний в контексте диалога Таксономия для углубленной оценки нормализации пользовательского контента Шведский корпус по краже печенья Live Blog Corpus для обобщения FEIDEGGER: Мультимодальный корпус изображений и описаний моды на немецком языке ES-Port: спонтанный разговорный корпус технической поддержки для исследований диалога на испанском языке SzegedKoref: венгерский корпус Coreference Краудсорсинговый корпус упрощения предложений с основным словарным запасом . Корпус для изучения относительных отношений для именных имен. Влияние выбора одномодального представления на мультимодальное обучение Структура намерения диалога: иерархическая схема связанных действий диалога Анализ неявных условий в диалогах поиска в базе данных JDCFC: корпус японских диалогов с изменениями функций Получение и потеря влияния в онлайн-разговоре Обнаружение юмора в контенте социальных сетей, смешанном с кодом на английском и хинди: корпус и базовая система Навстречу AMR-BR: SemBank для бразильского португальского языка На пути к золотому стандарту корпуса для обнаружения переменных и связывания в публикациях по социальным наукам На пути к языковым технологиям для микмак ASAP++: обогащение набора данных ASAP для автоматизированной оценки эссе баллами атрибутов эссе Создание набора изображений рукописных клинописных символов Перенос фреймов из английского FrameNet в Construct китайский FrameNet: подход на основе двуязычного корпуса Создание универсальных банков деревьев зависимостей на корейском языке Создание корпуса настроений из твитов на бразильском португальском языке Взгляд с высоты птичьего полета на проекты языковой обработки в Румынской академии Построение крупномасштабного англоязычного вербального многословного выражения с аннотациями Унифицированные рекомендации и ресурсы для арабской диалектной орфографии Параллельный корпус арабо-японских новостных статей EMTC: многокомпонентный корпус в домене фильмов для анализа эмоций в диалоговом тексте Корпус диалогов диадического социального текста ADELE: аннотация диалогового акта с ISO 24617-2 Корпус «Найди отличия»: мультимодальный корпус спонтанных устных взаимодействий, ориентированных на задачу. На пути к моделированию нейронных динамиков в многостороннем разговоре: задача, набор данных и модели Автоматическая аннотация семиотического типа жестов рук в юмористических речах Обамы Подготовка данных психотерапии для обработки естественного языка Справочный корпус современного румынского языка (CoRoLa) BioRo: Биомедицинский корпус для румынского языка Различение похожих языков в несбалансированных разговорных текстах Изучение верхушки айсберга: набор данных для перевода идиом KRAUTS: Немецкий корпус новостей с временными аннотациями Перемещение ТИГР за пределы уровня предложения Протокол выявления и материал для корпуса длинных подготовленных монологов на языке жестов MirasVoice: двуязычный (англо-персидский) речевой корпус Семантическая связанность концепций Википедии — эталонные данные и рабочее решение Сложные и точные аннотации к фильмам и книгам на французском языке для анализа тональности на основе аспектов Набор многоязычных тестов для семантического поиска категорий сущностей От анализа к моделированию взаимодействия как последовательности мультимодального поведения Сценарий диалога Сборник убедительных диалогов с эмоциональными выражениями с помощью краудсорсинга Японский диалоговый корпус информационной навигации и внимательного слушания, аннотированный расширенными тегами диалогового акта ISO-24617-2 Японский корпус для анализа информации о лояльности клиентов Deep JSLC: коллекция мультимодальных корпусов для управляемой данными генерации выражений японского языка жестов FooTweets: двуязычный параллельный корпус твитов о чемпионатах мира Edit me: Корпус и основа для понимания редактирования изображений на естественном языке Корпус Ники и Джули: совместные мультимодальные диалоги между людьми, роботами и виртуальными агентами Маркировка части речи для диалекта арабского залива с использованием Bi-LSTM Создание разговорного корпуса китайской медицины с аннотациями разговорных структур и действий Прогнозирование кивков с помощью диалоговых действий в диалоге J-MeDic: словарь названий японских болезней, основанный на реальном клиническом использовании Проект «Карцинологический индекс серьезности речи»: База данных о нарушениях речи для оценки качества жизни, связанного с речью после рака The WAW Corpus: Первый корпус устных речей и их переводов на английский и арабский языки Многоязычный викифицированный набор учебных материалов TSix: набор данных с участием человека для обобщения твитов Оценка явных меж- и внутрипредметных дискурсивных связок в банке турецких дискурсов Arap-Tweet: большой многодиалектный корпус Twitter для идентификации пола, возраста и языкового разнообразия Анализ семантического фрейма для извлечения информации: корпус CALOR Обогащение лексикона дискурсивных связок корпусными данными Морфологически аннотированный корпус эмиратского арабского языка Составление списка синонимичных слов и фраз японских составных глаголов Создание учебного корпуса TOCFL для диагностики китайских грамматических ошибок Эксперименты со свёрточными нейронными сетями для определения авторства нескольких меток На пути к автоматической оценке краудсорсинговых данных для NLU SimPA: корпус упрощений на уровне предложений для домена государственного управления Испанский банк деревьев HPSG на основе AnCora Corpus Корпуса SSIX: три золотых стандартных корпуса для анализа настроений на английском, испанском и немецком языках Финансовые микроблоги Универсальные зависимости для амхарского языка Предварительный анализ телесных взаимодействий между научными коммуникаторами и посетителями на основе мультимодального корпуса японских разговоров в музее науки Первые 100 дней: свод политических программ в Твиттере Использование корпуса политических выступлений на английском и китайском языках для анализа метафор Медицинский анализ настроений с использованием социальных сетей: на пути к созданию системы помощи пациентам Автоматическая идентификация диалектов Магриба с использованием подхода на основе словаря Улучшение SMT для предметной области для языков с низким уровнем ресурсов с использованием данных из разных предметных областей Моделирование совместного мультимодального поведения в групповых диалогах: Корпус MULTISIMO Корпус brWaC: новый открытый ресурс для бразильского португальского языка Многоязычный анализ зависимостей для малоресурсных языков: тематические исследования северносаамского и коми-зырийского языков Обнаружение параллельных языковых ресурсов для обучения машин машинного перевода Подробный анализ ошибок выходных данных NMT, SMT и RBMT для перевода с английского на голландский Китайский набор данных с отрицательными полными формами для общего прогнозирования сокращений Уровневый корпус для чтения современного стандартного арабского языка Аннотация и количественный анализ информации о говорящем в новых разговорных предложениях на японском языке Мультимодальный лексический перевод Улучшение аннотации японских дискурсивных отношений на основе краудсорсинга Дерево LIA разговорных норвежских диалектов Польский корпус аннотированных описаний изображений Чаты и фрагменты: аннотация и анализ многосторонних длинных случайных бесед Полуавтономная система для создания корпуса взаимодействия человека и машины в виртуальной реальности: приложение к системе ACORFORMed для обучения врачей сообщать плохие новости Корпус чешских текстовых документов v 2. 0 Аннотированный вручную корпус польских текстов, опубликованных между 1830 и 1918 годами Краудсорсинг перевода: создание многоязычного корпуса образовательного онлайн-контента M-CNER: корпус для распознавания именованных сущностей на китайском языке в нескольких доменах Статистический анализ пропущенного перевода в синхронном переводе с использованием крупномасштабного двуязычного речевого корпуса Корпус глаголов действия Первоначальная тестовая коллекция для ранжированного поиска SMS-разговоров Совместное использование копий синтетических клинических корпусов без физического распространения — тематическое исследование по обходу прав интеллектуальной собственности и ограничений конфиденциальности с участием немецкого корпуса JSYNCC Профилирование статей в медицинских журналах с использованием семантического тега Gene Ontology FrNewsLink : свод, связывающий новостные сегменты телепередач и статьи в прессе. Итальянский твиттер-корпус речей ненависти против иммигрантов Полуконтролируемая генерация обучающих данных для многоязычных ответов на вопросы FARMI: платформа для записи мультимодальных взаимодействий EMO&LY (EMOtion и AnomaLY): новый корпус для обнаружения аномалий в аудиовизуальном потоке с эмоциональным контекстом. Корпуса типичных предложений Аннотирование мнений и целевых мнений в отзывах учащихся о курсе FastSense: эффективный классификатор устранения неоднозначности смысла слов Немецкий справочный корпус DeReKo: новые разработки – новые возможности Аннотирование представлений абстрактного значения для испанского языка Risamálheild: очень большой исландский текстовый корпус ASR для документирования языков коренных народов, испытывающих острую нехватку ресурсов Построение англо-французского мультимодального аффективного разговорного корпуса из телевизионных драм SandhiKosh: эталонный корпус для оценки санскритских инструментов Sandhi PhotoshopQuiA: свод вопросов и ответов, не относящихся к фактам, для ответа на вопрос «почему?» Изучение создания разговорного языка для расширенного контента об отелях Автоматизация обнаружения документов в процессе систематического обзора: как использовать мякину для извлечения пшеницы Многоязычные аргументные корпуса на английском, турецком, греческом, албанском, хорватском, сербском, македонском, болгарском, румынском и арабском языках На пути к разговорно-аналитической таксономии речевого перекрытия BioRead: новый набор данных для биомедицинского понимания прочитанного Чешский юридический текст Treebank 2. 0 Разработка аннотированного мультимодального набора данных для исследования классификации и обобщения презентаций с использованием паралингвистических функций высокого уровня Шами: корпус левантийских арабских диалектов Корпус академического письменного итальянского языка ICoN (L1 и L2) Аннотированный корпус домашних страниц научных конференций для извлечения информации Ключевые семейства ресурсов CLARIN Аннотации и анализ экстрактивных аннотаций для Kyutech Corpus NoReC: Норвежский обзорный корпус Оценка производительности машинного перевода в различных жанрах и языках На пути к связанному изданию Sumerian Corpora с открытыми данными HiNTS: набор тегов для средне-нижненемецкого языка Идентификация личной информации, передаваемой в чат-ориентированном диалоге SentiArabic: анализатор настроений для стандартного арабского языка На пути к выводу семантических отношений в сложных именных: экспериментальное исследование Кросс-лингвистические сети малого мира повсеместно распространены в детской речи Репозиторий корпусов для обобщения АНКОР-АС: обогащение корпуса АНКОР синтаксическими аннотациями Параллельное дерево L1-L2 для изучающих китайский язык: чрезмерное и недостаточное использование синтаксических структур Rollenwechsel-English: крупномасштабный корпус семантических ролей База данных MonPaGe_HA для документации разговорного французского во взрослом возрасте Вы пишете в Твиттере то, что говорите: набор данных арабских диалектов на уровне города Использование выравнивания текста в полуавтоматическом анализе ошибок: вариант использования при разработке корпуса изучающих латышский язык На пути к стандартизированному набору данных для толкования составных существительных ParCorFull: параллельный корпус, аннотированный полной кореферентностью Корпус акта о вьетнамском диалоге на основе стандарта ISO 24617-2 Многоязычный набор данных для оценки извлечения параллельных предложений из сопоставимых корпусов Построение корпуса и оценка мнений на основе аспектов из твитов на испанском языке Генерация корпуса испанских искусственных ошибок словосочетаний Постобработка зашумленного вывода OCR с низким уровнем ресурсов для оцифровки исторического корпуса
Наборы тестов для разбора нелокальных зависимостей на китайском языке Структурированная интерпретация временных отношений Аннотирование размышлений для терапии изменения поведения в отношении здоровья Добавление синтаксических аннотаций в корпус сущностей Flickr30k для разрешения мультимодальных неоднозначных вложений с предложными фразами Аннотация к ошибке в корпусе учащихся португальского языка Визуализация «Словаря регионализмов Франции» (DRF) CoLoSS: корпус когнитивной нагрузки с данными о речи и производительности из символьно-цифрового двойного задания SB-CH: швейцарско-немецкий корпус с аннотациями настроений DART: большой набор данных диалектных арабских твитов VAST: корпус видеоаннотаций для речевых технологий Auto-hMDS: автоматическое построение большого разнородного многоязычного корпуса для обобщения нескольких документов Корпус парламентских протоколов GermaParl Анализ качества консультационных бесед: явные признаки качественного консультирования Идентификация говорящих и адресатов в диалогах, извлеченных из художественной литературы Сбор и анализ корпуса египетской арабо-английской речи с переключением кодов Повышение воспроизводимости аннотаций аргументов за счет использования соглашения между аннотаторами для улучшения рекомендаций Корпус SLA, аннотированный педагогически значимыми грамматическими структурами Сегментация многоязычных слов: плавное обучение многих языковых токенизаторов благодаря универсальному корпусу зависимостей Этикетки межличностных отношений для CALLHOME Corpus Text Mining for History: первые шаги по созданию большого набора данных Проектирование русского идиоматического аннотированного корпуса Ручное и автоматическое извлечение битекста Обман синтаксического анализатора до смерти: передача аннотаций между банками деревьев на основе данных Универсальные зависимости и количественные типологические тенденции. Практический пример порядка слов Создание наборов данных оценки для поиска культурных микроблогов Transc&Anno: графический инструмент для расшифровки и оперативного комментирования рукописных документов Машинный перевод малоресурсных разговорных диалектов: стратегии нормализации швейцарского немецкого языка Сборник немецких политических выступлений 21 века. На пути к легкому решению для языков с ограниченными ресурсами: создание POS-теггера для эльзасского языка с использованием добровольного краудсорсинга Palmyra: независимый от платформы инструмент аннотирования зависимостей для морфологически богатых языков Записи коллекции метаданных для языковых ресурсов Веб-система для древовидного банка зависимостей Crowd-in-the-Loop Свод руководств по употреблению наркотиков, аннотированный типом рекомендаций ChAnot: Интеллектуальный инструмент аннотации для коренных и сильно агглютинативных языков в Перу Составление корпуса повседневной японской речи: промежуточный отчет Сборник корпусов для изучения интерфейса информационная структура-просодия Абхазский национальный корпус CATS: инструмент для индивидуального выравнивания корпусов упрощения текста Параллельные корпуса в Мбоши (банту C25, Конго-Браззавиль) Карта мастерских LREC Errator: инструмент для обнаружения ошибок аннотаций в проекте универсальных зависимостей Не аннотировать, а проверять: метод преобразования данных в текст для сбора данных о событиях База данных определяющих контекстов немецкого языка из избранных веб-источников. PDFAnno: веб-инструмент лингвистических аннотаций для PDF-документов TriMED: многоязычная терминологическая база данных Создание синтаксического анализатора грамматики ограничений для глаголов и аргументов Plains Cree Переработка данных для генерации естественного языка NL2Bash: корпусной и семантический парсер для интерфейса естественного языка с операционной системой Linux Краудсорсинговый инструмент сбора мультимодальных корпусов Разрешение базовой ссылки в FreeLing 4.0 Разработка мобильной системы поддержки наблюдения для учащихся: FishWatchr Mini Расширение набора данных AI2 Diagrams с помощью теории риторической структуры SACR: инструмент на основе перетаскивания для аннотаций кореференсов На пути к непрерывному созданию корпуса диалога: запись в корпус и генерация из него К обработке устных исторических интервью и связанных с ними печатных документов Manzanilla: инструмент аннотации изображений для TKB Building Помимо общего суммирования: многогранный корпус иерархического суммирования больших разнородных данных BabyCloud, технологическая платформа для родителей и исследователей Интервью с немецким радио: выпуск GRAIN коллекции Silver Standard SFB732 Создание литературного корпуса для вычислительного литературного анализа — прототип для преодоления разрыва между CL и DH MirasText: автоматически генерируемый текстовый корпус для персидского языка WASA: веб-приложение для аннотации последовательности Облегченное промежуточное ПО моделирования для корпусной обработки Создание крупномасштабных структур аргументации для диалоговых систем ILCM — виртуальная исследовательская инфраструктура для крупномасштабных качественных данных SlugNERDS: инструмент распознавания именованных сущностей для диалоговых систем с открытым доменом Веб-инструмент для создания аннотаций к ресурсам на флективных языках Повышение доступности выровненных по времени речевых корпусов с помощью Spokes Mix Подход к обучению с полуучителем на основе графов для POS-тегов на тамильском языке Создание сбалансированного современного многослойного корпуса для NLU Применение и анализ многослойной схемы иронии в итальянском корпусе Twitter TWITTIRÒ Аннотации эмоций на уровне предложений и пунктов, обнаружение и классификация в многожанровом корпусе Создание быстрой и точной лемматизации для арабского языка Производство эталонов при взаимодействии человека с компьютером: проблемы для генерации выражений ссылок на основе корпуса База данных персидского дискурса и корреферентный корпус
Краудсорсинг
JFCKB: База знаний об изменении функций японского языка Количественная оценка качественных данных для понимания спорных вопросов Краудсорсинг данных о региональных различиях и автоматическая геолокализация носителей европейского французского языка Улучшение машинного перевода образовательного контента с помощью краудсорсинга Стратегии и задачи краудсорсинга данных о восприятии региональных диалектов для швейцарского немецкого и швейцарского французского языков Предсказание корейского словаря L2: можно ли использовать большой аннотированный корпус для обучения лучших моделей для предсказания неизвестных слов? Краудсорсинговая аннотация бухгалтерских регистров итальянской комедии Краудсорсинговый корпус упрощения предложений с основным словарным запасом Использование Crowd Agreement для локализации Wordnet Улучшение аннотации японских дискурсивных отношений на основе краудсорсинга Краудсорсинг перевода: создание многоязычного корпуса онлайн-образовательного контента Создание набора данных по знанию английской лексики для изучающих японский английский как второй язык с помощью краудсорсинга Веб-система для древовидного банка зависимостей Crowd-in-the-Loop Краудсорсинговый инструмент сбора мультимодальных корпораций Помимо общего суммирования: многогранный корпус иерархического суммирования больших разнородных данных
Д
Диалог
Аннотация структуры диалога для многоэтажного взаимодействия Влияние гендерных стереотипов на доверие и симпатию в разговорном взаимодействии человека и робота Мультимодальный корпус для взаимного взгляда и совместного внимания в многостороннем ситуационном взаимодействии Что вызывает различия в стилях общения? Мультикультурное исследование прямоты и продуманности Экспертная оценка системы разговорного диалога в клинической операционной Аннотированный корпус свободной беседы JAIST KTH Tangrams: набор данных для исследования выравнивания и концептуальных договоров в диалоге, ориентированном на задачу ES-Port: спонтанный разговорный корпус технической поддержки для исследований диалога на испанском языке Структура намерения диалога: иерархическая схема связанных действий диалога JDCFC: корпус японских диалогов с изменениями функций Корпус «Найди отличия»: мультимодальный корпус спонтанных устных взаимодействий, ориентированных на задачу. Закрытый корпус взаимодействия человека и агента, предоставляющий информацию Dialogue Scenario Сборник убедительных диалогов с эмоциональными выражениями через краудсорсинг Японский диалоговый корпус информационной навигации и внимательного слушания, аннотированный расширенными тегами диалогового акта ISO-24617-2 Корпус Ники и Джули: совместные мультимодальные диалоги между людьми, роботами и виртуальными агентами Создание разговорного корпуса китайской медицины с аннотациями разговорных структур и действий Предсказание кивков с помощью диалоговых действий в диалоге Моделирование совместного мультимодального поведения в групповых диалогах: Корпус MULTISIMO Чаты и фрагменты: аннотация и анализ многосторонних длинных случайных бесед Идентификация личной информации, передаваемой в чат-ориентированном диалоге Аннотирование размышлений для терапии изменения поведения в отношении здоровья Автоматическая маркировка диалогов по решению проблем для вычислительной микрогенетической аналитики обучения Создание крупномасштабных структур аргументации для диалоговых систем
Электронные библиотеки
На пути к эпическому эпиграфу Анализ сетей Citation-Distance для оценки влияния публикации Золотой стандарт высокого качества для задач на основе цитирования Краудсорсинговая аннотация бухгалтерских регистров итальянской комедии Измерение инноваций в публикациях по обработке речи и языка. PDFdigest: адаптивный инструмент для извлечения текстового содержимого PDF-to-XML с поддержкой макета для научных статей
Аннотация дискурса, представление и обработка
Когерентность дискурса через призму корпуса аннотированных текстов: тематическое исследование Классификация случаев шлюза в диалоге Автоматическое предсказание дискурсивных связок Разработка дерева рассуждений Bangla RST Интегрированное представление лингвистических и социальных функций переключения кода Адаптация серьезной игры для ложной аргументации к немецкому языку: подводные камни, идеи и передовой опыт Оценка представлений значений с областью видимости . Сборник комментариев пользователей по разработке электронных правил для измерения оцениваемости аргументов. Многослойный аннотированный корпус аргументативного текста: от схем аргументации к дискурсивным отношениям Интертекстуальная корреспонденция для интеграции корпусов Аннотирование отношений атрибуции на арабском языке BASHI: Сборник статей Wall Street Journal, аннотированный связующими ссылками «Портретный» подход к многоканальному дискурсу Многоязычное расширение аннотации в стиле PDTB: пример TED Multilingual Discourse Bank Построение древовидной базы макрокитайского дискурса Корпус стажеров по дебатам о металоге: сбор данных и аннотации Аннотация структуры дискурса и информационной структуры на основе QUD: инструмент и оценка О векторном представлении высказываний в контексте диалога Структура намерения диалога: иерархическая схема связанных действий диалога Получение и потеря влияния в онлайн-разговоре Корпус диалогов диадического социального текста ADELE: аннотация диалогового акта с ISO 24617-2 Корпус «Найди отличия»: мультимодальный корпус спонтанных устных взаимодействий, ориентированных на задачу. Внимание для распознавания имплицитных дискурсивных отношений Создание разговорного корпуса китайской медицины с аннотациями разговорных структур и действий Оценка явных меж- и внутрипредметных дискурсивных связок в банке турецких дискурсов Контекстный подход к распознаванию акта диалога с использованием простых рекуррентных нейронных сетей Предварительный анализ телесных взаимодействий между научными коммуникаторами и посетителями на основе мультимодального корпуса японских разговоров в музее науки Аннотация и количественный анализ информации о говорящем в новых разговорных предложениях на японском языке Улучшение аннотации японских дискурсивных отношений на основе краудсорсинга Чаты и фрагменты: аннотация и анализ многосторонних длинных случайных бесед Аннотирование представлений абстрактного значения для испанского языка PhotoshopQuiA: свод вопросов и ответов, не относящихся к фактам, для ответа на вопрос «почему?» На пути к разговорно-аналитической таксономии перекрытия речи Лексикон дискурсивных маркеров для португальского языка – LDM-PT Аннотации и анализ экстрактивных аннотаций для Kyutech Corpus Структурированная интерпретация временных отношений Автоматическая маркировка диалогов по решению проблем для вычислительной микрогенетической аналитики обучения Малоресурсные методы анализа разделов средневековых документов Идентификация говорящих и адресатов в диалогах, извлеченных из художественной литературы Повышение воспроизводимости аннотаций аргументов за счет использования соглашения между аннотаторами для улучшения рекомендаций Расширение набора данных диаграмм AI2 с использованием теории риторической структуры SACR: инструмент на основе перетаскивания для аннотаций кореференсов TreeAnnotator: универсальная визуальная аннотация иерархических текстовых отношений Создание крупномасштабных структур аргументации для диалоговых систем PyrEval: автоматизированный метод сводного анализа контента База данных персидского дискурса и корреферентный корпус
Классификация документов, категоризация текста
Обнаружение конфликта интересов на основе контента в Википедии TAP-DLND 1. 0: корпус для обнаружения новизны на уровне документа Знакомство с языком винных обзоров: учетная запись интеллектуального анализа текста Корпус для многоязычной классификации документов на восьми языках Анализ сетей Citation-Distance для оценки влияния публикации Аннотирование образовательных вопросов для анализа ответов учащихся Многозначность вербальных оборотней Многоязычная многоклассовая классификация тональности с использованием сверточных нейронных сетей Большой самоаннотированный корпус для сарказма Аннотированный корпус свободной беседы JAIST HappyDB: собрание 100 000 счастливых моментов, собранных с помощью краудсорсинга MultiBooked: свод баскских и каталонских отзывов об отелях с аннотациями для классификации тональности на уровне аспектов Идентификация арабского диалекта в контексте бивалентности и переключения кодов Улучшение обнаружения языка ненависти с помощью ансамблей глубокого обучения Расширение набора терминов распространения Можно ли рассматривать адаптацию домена как аналогию? Влияние выбора одномодального представления на мультимодальное обучение Профилирование авторов из Facebook Corpora Подготовка данных психотерапии для обработки естественного языка Полуконтролируемая кластеризация для подсчета кратких ответов Перемещение ТИГР за пределы уровня предложения Семантическая связь концепций Википедии — эталонные данные и рабочее решение Внимание для распознавания имплицитных дискурсивных отношений Эксперименты со свёрточными нейронными сетями для определения авторства нескольких меток Медицинский анализ настроений с использованием социальных сетей: на пути к созданию системы помощи пациентам Сегментация потока страниц с помощью сверточных нейронных сетей, сочетающих текстовые и визуальные функции Чешский корпус текстовых документов v 2. 0 Язык аннотаций для семантического поиска юридических источников «Да» или «Нет»? Анализ настроений на уровне речи в стенограммах парламентских дебатов Hansard в Великобритании Автоматизация обнаружения документов в процессе систематического обзора: как использовать мякину для извлечения пшеницы Два многоязычных корпуса извлечены из электронных ежедневных тендеров для приложений машинного обучения и машинного перевода. NoReC: Норвежский обзорный корпус Использование состязательных примеров в обработке естественного языка Улучшение неконтролируемого извлечения ключевых фраз с использованием фоновых знаний Моделирование троллинга в социальных сетях Многоязычный набор данных для оценки извлечения параллельных предложений из сопоставимых корпусов Аннотирование размышлений для терапии изменения поведения в отношении здоровья SB-CH: швейцарско-немецкий корпус с аннотациями настроений Анализ качества консультационных бесед: явные признаки качественного консультирования ярлыка межличностных отношений для CALLHOME Corpus Разработка аннотированного корпуса русских идиом Классификация близкородственных субдиалектов арабского языка с использованием машин опорных векторов DeepTC — расширение текстовой классификации DKPro для повышения воспроизводимости экспериментов по глубокому обучению Arabic Data Science Toolkit: API для извлечения признаков арабского языка
К
Обнаружение/представление знаний
Простое крупномасштабное извлечение отношений из неструктурированного текста Сетевые функции на основе обнаружения когипонимов Связывание, поиск и визуализация сущностей в Википедии Обучение отображению выражений на естественном языке в представления базы знаний для построения базы знаний Построение графа знаний из определений естественного языка для распознавания интерпретируемого текста MCScript: новый набор данных для оценки машинного понимания с использованием знаний сценариев Модель на основе нейронной сети для идентификации заимствованных слов в уйгурском языке Совместное изучение смысловых и словесных вложений Сочетание подходов на основе правил и встраивания для нормализации текстовых объектов с помощью онтологии Преодоление проблемы «длинного хвоста»: тематическое исследование оценки выбросов CO2 для рецептов с использованием информационного поиска Комплексная аннотация различных типов временной информации на оси времени T-REx: крупномасштабное согласование естественного языка с тройками базы знаний Абстрактное значение Представление конструкций: чем больше мы включаем, тем лучше представление Сравнение предварительно обученных многоязычных вложений слов в задаче выравнивания онтологии Междокументная, межъязыковая корреферентная аннотация событий с использованием бункеров событий Интеграция структур событий генеративного лексикона в VerbNet Основанный на видении набор данных для прогнозирования типичных местоположений глаголов. Большой ресурс шаблонов для словесных перефраз Межъязыковая генерация и оценка обширного лексико-семантического ресурса Создание высококачественного смыслового корпуса и встраивания слов посредством неконтролируемого устранения псевдомногосмысла ScholarGraph: график знаний китайских ученых по китайскому языку Автоматическая аннотация типов семантических терминов в полном справочном корпусе антологии ACL Преобразование текстов в скрипты: исследование последствий MIsA: многоязычное извлечение «IsA» из корпусов Обогащение представлений кадров с помощью смыслов, индуцированных распределением Перекрестная проверка WordNet и SUMO с использованием меронимии Навстречу AMR-BR: SemBank для бразильского португальского языка От анализа к моделированию взаимодействия как последовательности мультимодального поведения Контролируемый подход к извлечению таксономии с использованием встраивания слов Онтология косвенных событий (CEO) и ECB+/CEO: онтология и корпус для неявных причинно-следственных связей между событиями Китайский набор данных с отрицательными полными формами для общего прогнозирования сокращений Korean TimeBank, включая относительную временную информацию Язык аннотаций для семантического поиска юридических источников Масштабируемая визуализация настроений и позиций Разработка аннотированного мультимодального набора данных для исследования классификации и обобщения презентаций с использованием паралингвистических функций высокого уровня На пути к достоверной визуализации глобального языкового разнообразия Просмотр терминологической структуры специализированной области: метод, основанный на лексических функциях и их классификации Большой многоязычный и многодоменный набор данных для рекомендательных систем Кросс-лингвистические сети малого мира повсеместно распространены в детской речи Tel(s)-Telle(s)-Signs: высокоточное автоматическое межъязыковое обнаружение гиперонимов World Knowledge для синтаксического анализа представления абстрактного значения The LODeXporter: гибкое создание связанных троек открытых данных из платформ NLP для автоматического построения базы знаний Одно событие, много представлений. Отображение концепций действий с помощью визуальных функций. Revita: языковая платформа на пересечении ITS и CALL Расширение набора данных AI2 Diagrams с помощью теории риторической структуры Графики текстовых аннотаций: аннотирование сложных явлений естественного языка Manzanilla: инструмент аннотации изображений для TKB Building Модернизация представлений слов для неконтролируемых сходств слов с учетом смысла Улучшение извлечения гипернимов с помощью распределенных семантических классов
л
Идентификация языка
Построение параллельного одноязычного корпуса ганьских диалектов китайского языка Краудсорсинг данных о региональных различиях и автоматическая геолокация носителей европейского французского языка Сбор данных с кодовой коммутацией из социальных сетей Создание диалектных подкорпусов путем кластеризации: пример адаптивного метода в японском языке Различение похожих языков в несбалансированных разговорных текстах Автоматическая идентификация диалектов Магриба с использованием подхода на основе словаря Шами: Корпус левантийских арабских диалектов Корпус академического письменного итальянского языка ICoN (L1 и L2) Вы пишете в Твиттере то, что говорите: набор данных арабских диалектов на уровне города DART: большой набор данных диалектных арабских твитов VAST: корпус видеоаннотаций для речевых технологий Классификация близкородственных субдиалектов арабского языка с использованием машин опорных векторов
Языковое моделирование
Слой аннотаций Gold Anaphora на корпусе движений глаз Облегченная грамматическая аннотация в TEI: новые перспективы Сравнение методов обнаружения каламбура с использованием японского корпуса каламбуров Изучение векторов слов для 157 языков Лексическое профилирование экологических корпусов г. Вычислительная архитектура для морфологии Верхней Тананы. Влияние гендерных стереотипов на доверие и симпатию в разговорном взаимодействии человека и робота Заземление оцениваемых прилагательных с помощью краудсорсинга TF-LM: набор инструментов для языкового моделирования на основе TensorFlow Анонимизация данных для анализа качества требований: воспроизводимая задача автоматического обнаружения ошибок Осведомленность на уровне графем в вложениях слов для морфологически богатых языков Портативный корректор орфографии для менее ресурсоемкого языка: амхарский Создание диалектных подкорпусов путем кластеризации: пример адаптивного метода в японском языке Dynamic Oracle для нейронного машинного перевода на этапе декодирования Интегрированное формальное представление терминологических и лексических данных, включенных в схемы классификации Расширение набора терминов распространения Корпус для изучения относительных отношений для именных имен На пути к языковым технологиям для микмаков На пути к моделированию нейронных динамиков в многостороннем разговоре: задача, набор данных и модели Тщательно настроенные вложения слов на основе 2 миллиардов токенов для португальского языка Анализ индекса общности словарного запаса с использованием крупномасштабной базы данных развития детской речи Нейронные модели селективных предпочтений для неявной маркировки семантических ролей SimLex-999 для польского языка Автоматическая оценка внеконтекстных ошибок Корпус глаголов действия Моделирование французского жестового языка: предложение по семантически-композиционной системе Межъязыковая оценка флективной сложности: перспектива обработки Моделирование морфологии глагола северной хайда
Наборы тестов для разбора нелокальных зависимостей на китайском языке Составление корпусов для изучения интерфейса информационная структура-просодия Создание синтаксического анализатора грамматики ограничений для глаголов и аргументов Plains Cree MirasText: автоматически генерируемый текстовый корпус для персидского языка Получение информации из французской лексической сети в формате RDF/OWL
Менее ресурсоемкие языки
FonBund: библиотека для объединения данных межъязыковых фонологических сегментов Создание открытых корпусов яванского и суданского языков для многоязычного преобразования текста в речь
Лексикон, Лексическая база данных
Создание лексикона синонимов глаголов на основе параллельного корпуса Сетевые функции на основе обнаружения когипонимов г. Представляем лексикон словесных переключателей полярности для английского языка. Полуавтоматическое построение сетей словообразования (для польского и испанского языков) JFCKB: База знаний об изменении функций на японском языке Корпус арабских диалектов MADAR и лексикон Полуавтоматическая корейская аннотация FrameNet по KAIST Treebank Разработка совместного процесса создания двуязычных словарей индонезийских этнических языков Отображение представлений: новый подход к созданию высококачественных многоязычных словарей эмоций Автоматическое построение тезауруса для современного иврита Составление лексикона относительных существительных Краудсорсинг данных о региональных различиях и автоматическая геолокализация носителей европейского французского языка Большой автоматически получаемый список всех слов многословных выражений, оцениваемых по композиционности Многоязычный сборник CoNLL-U-совместимых морфологических лексиконов Лексическое профилирование экологических корпусов Новая версия базы данных польского языка Składnica, гармонизированная со словарем Валентности Валентности UniMorph 2. 0: универсальная морфология Автоматическое сопоставление Wordnet: от CoreNet до Princeton WordNet Создание крупномасштабных многоязычных родственных таблиц Гибридный подход к автоматическому извлечению двуязычных многословных выражений из параллельных корпусов Интеграция структур событий генеративного лексикона в VerbNet FontLex: типографский лексикон, основанный на аффективных ассоциациях Новый Propbank: согласование Propbank с AMR посредством унификации POS LIdioms: многоязычный набор связанных идиом Морфологический анализ конечного состояния для гагаузов GeCoTagger: аннотация немецких глагольных дополнений с условными случайными полями Расширение золотого стандарта для задачи лексической замены: оно того стоит? IPSL: База данных паттернов иконичности в жестовых языках. Создание и использование Недостаточная выборка улучшает обучение прототипированию гипернимии Морфологическая инъекция для англо-малаяламского статистического машинного перевода
9Наборы данных оценки встраивания слов 1293 и встраивание заголовков Википедии для китайского языка Автоматическое изучение лексикона алжирского диалекта с использованием многоязычных вложений слов Неконтролируемое устранение неоднозначности корейского смысла слов с использованием CoreNet Эксперименты по языковой адаптации посредством межъязыкового встраивания родственных языков Крупномасштабные лексические ресурсы для улучшения китайского и японского машинного перевода Аннотирование конструкций легких глаголов китайского языка в соответствии с рекомендациями PARSEME Упрощенный корпус с основным словарем Прагматический подход к сегментации слов в классическом китайском языке Перекрестная проверка WordNet и SUMO с использованием меронимии Оценка методов создания словарей для языков финно-угорских меньшинств Краудсорсинговый корпус упрощения предложений с основным словарным запасом инструмента для создания аналоговых сеток и ресурс N-граммных аналоговых сеток на 11 языках Объединение понятий и их переводы из структурированных словарей языков уральских меньшинств Перенос фреймов из английского FrameNet в Construct китайский FrameNet: подход на основе двуязычного корпуса Создание универсальных банков деревьев зависимостей на корейском языке Единые рекомендации и ресурсы для арабской диалектной орфографии словаря произношения эльзасских диалектов для анализа правописания и фонетических вариаций Konbitzul: база данных MWE для испано-баскского языка Сложные и точные аннотации к фильмам и книгам на французском языке для анализа тональности на основе аспектов J-MeDic: словарь названий японских болезней, основанный на реальном клиническом использовании Arap-Tweet: большой мультидиалектный корпус Twitter для идентификации пола, возраста и языкового разнообразия Обогащение лексикона дискурсивных связок корпусными данными Составление списка синонимичных слов и фраз японских составных глаголов Автоматическое обогащение терминологических ресурсов: пример IATE RDF Автоматическая идентификация диалектов Магриба с использованием подхода на основе словаря Использование Crowd Agreement для локализации Wordnet Датский лексикон FrameNet и аннотированный корпус, используемые для обучения и оценки семантического классификатора фреймов точно настроенных, 2 миллиарда токенов встраивания слов для португальского языка СЛАЙД — лексикон общих идиом для настроений CoNLL-UL: универсальные морфологические решетки для универсального анализа зависимостей PronuncUR: Генератор лексикона произношения урду SimLex-999 для польского языка Профилирование статей в медицинских журналах с использованием семантического тега Gene Ontology SandhiKosh: эталонный корпус для оценки санскритских инструментов Sandhi Подготовка и использование лексикографических данных коса для многоязычной федеративной среды Лексикон дискурсивных маркеров для португальского языка – LDM-PT Просмотр терминологической структуры специализированной области: метод, основанный на лексических функциях и их классификации Один язык, чтобы управлять всеми: моделирование морфологических паттернов в крупномасштабном лексиконе итальянского языка с помощью SWRL SenSALDO: создание лексикона настроений для шведского языка SentiArabic: Анализатор настроений для стандартного арабского языка Использование лексических ресурсов и грамматики ограничений для основанной на правилах маркировки частей речи в валлийском языке Wordnet на индийском языке и их связи с Princeton WordNet Распространение полярности на основе классификатора в WordNet Визуализация «Словаря регионализмов Франции» (DRF) Модель лингвистической категории на польском языке (LCM-PL) Массовый транслингвальный составной анализ и обнаружение перевода Обзор автоматически создаваемых сетей WordNet и их оценка: подходы на основе лексики и встраивания слов Универсальные зависимости для айнов WordNet-Shp: на пути к созданию лексической базы данных для перуанского языка меньшинства Создание морфологического дерева для немецкого языка из лингвистической базы данных Быстрый и гибкий веб-интерфейс для исследования диалектов в Нидерландах Инструменты для создания взаимосвязанной сети лексикона синонимов EFLLex: оцениваемый лексический ресурс для изучающих английский язык как иностранный Signbank: программное обеспечение для поддержки интернет-словарей жестового языка Нормализация биомедицинских терминов EHR с помощью UMLS База данных определяющих контекстов немецкого языка из избранных веб-источников. языка жестов и всемирные онлайн-словари и лексикостатистика Оценка EcoLexiCAT: CAT-инструмент с улучшенной терминологией Extended HowNet 2.0 — модель представления здравого смысла между сущностью и отношением Предложения по метафорам на основе репозитория семантических метафор Улучшение извлечения гипернимов с помощью распределенных семантических классов
Связанные данные
Обучение отображению выражений на естественном языке в представления базы знаний для построения базы знаний LIdioms: многоязычный набор связанных идиом EventWiki: База знаний о крупных событиях Совместимость языковой информации: сопоставление тезауруса BLL с Lexvo и Glottolog Структура потребностей различных типов пользователей в многоязычном семантическом обогащении Универсальные морфологии для Кавказского региона J-MeDic: словарь названий японских болезней, основанный на реальном клиническом использовании PMKI: действие Европейской комиссии по функциональной совместимости, ремонтопригодности и устойчивости языковых ресурсов. Автоматическое обогащение терминологических ресурсов: пример IATE RDF Sanaphor++: объединение глубоких нейронных сетей с семантикой для разрешения кореферентности Подготовка и использование лексикографических данных коса для многоязычной федеративной среды Один язык, чтобы управлять всеми: моделирование морфологических паттернов в крупномасштабном лексиконе итальянского языка с помощью SWRL На пути к связанному изданию Sumerian Corpora с открытыми данными Wordnet на индийском языке и их связи с Princeton WordNet Teanga: платформа на основе связанных данных для обработки естественного языка The LODeXporter: гибкое создание связанных троек открытых данных из платформ NLP для автоматического построения базы знаний Библиотеки ACoLi CoNLL: помимо значений, разделенных табуляцией Создание литературного корпуса для вычислительного литературного анализа — прототип для преодоления разрыва между CL и DH Автоматические и ручные веб-аннотации в инфраструктуре для обработки фейковых новостей и других феноменов онлайн-медиа LiDo RDF: от реляционной базы данных к графику связанных данных лингвистических терминов и библиографических данных
Lr инфраструктуры и архитектуры
Построение параллельного одноязычного корпуса ганьских диалектов китайского языка План управления данными (DMP) для языковых данных в соответствии с новым Общим регламентом защиты данных (GDPR) Обработка больших данных и конфиденциальных данных с использованием универсальной платформы выполнения EUDAT и механизма рабочего процесса WebLicht. Извлеченные уроки: о проблемах переноса репозитория исследовательских данных из исследовательского учреждения в университетскую библиотеку. Новые направления в деятельности ELRA CLARIN: На пути к СПРАВЕДЛИВОЙ и ответственной науке о данных с использованием языковых ресурсов От «решенных проблем» к новым вызовам: отчет о деятельности НРС . Фреймворк для разработки многоязычных сервисов с языковой сеткой Языковые технологии для многоязычной Европы: анализ крупномасштабного исследования проблем, требований, пробелов и потребностей Представляем NIEUW: новые стимулы и рабочие процессы для получения лингвистических данных Структура для нужд различных типов пользователей в многоязычном семантическом обогащении LREMap, песня ресурсов и оценки Объединение понятий и их переводы из структурированных словарей языков уральских меньшинств Подготовка данных психотерапии для обработки естественного языка Универсальные морфологии для Кавказского региона Управление данными государственного сектора для разработки многоязычных приложений FARMI: платформа для записи мультимодальных взаимодействий Fluid Annotation: инструмент аннотации с учетом детализации для текучести китайских слов группы ключевых ресурсов CLARIN Представляем Центр знаний CLARIN по языковому разнообразию и языковой документации Сбор языковых ресурсов от государственных администраций в странах Северной Европы и Балтии Записи коллекции метаданных для языковых ресурсов Публикации по биомедицине в горнодобывающей промышленности с использованием сети LAPPS Разработка новых лингвистических ресурсов и инструментов для галисийского языка Интероперабельность ресурсов для устойчивого сравнительного анализа: случай событий Библиотеки ACoLi CoNLL: помимо значений, разделенных табуляцией На пути к непрерывному созданию корпуса диалога: запись в корпус и генерация из него Расширение системы поиска на основе интерактивной визуализации для корпусов речи MirasText: автоматически генерируемый текстовый корпус для персидского языка Объединение сети LAPPS и CLARIN E-magyar — Цифровая система обработки языка ILCM — виртуальная исследовательская инфраструктура для крупномасштабных качественных данных Что случилось, Питон? — Библиотека Visual Differ и Graph для НЛП на Python Indra: сервер встраивания слов и семантического родства Интерфейс базы данных UIMA для управления текстовыми аннотациями, связанными с NLP
Lr Национальные/международные проекты, вопросы инфраструктуры/политики
План управления данными (DMP) для языковых данных в соответствии с новым Общим регламентом защиты данных (GDPR) Извлеченные уроки: о проблемах переноса репозитория исследовательских данных из исследовательского учреждения в университетскую библиотеку. Новые направления в деятельности ELRA CLARIN: На пути к СПРАВЕДЛИВОЙ и ответственной науке о данных с использованием языковых ресурсов От «решенных проблем» к новым вызовам: отчет о деятельности НРС Языковые технологии для многоязычной Европы: анализ крупномасштабного исследования проблем, требований, пробелов и потребностей Представляем NIEUW: новые стимулы и рабочие процессы для получения лингвистических данных Исследование малообеспеченных языков — DigiSami Corpus Взгляд с высоты птичьего полета на проекты языковой обработки в Румынской академии Справочный корпус современного румынского языка (CoRoLa) PMKI: действие Европейской комиссии по функциональной совместимости, ремонтопригодности и устойчивости языковых ресурсов. Управление данными государственного сектора для разработки многоязычных приложений Краудсорсинг перевода: создание многоязычного корпуса образовательного онлайн-контента Опрос DLDP по цифровому использованию и удобству использования региональных языков и языков меньшинств ЕС Представляем Центр знаний CLARIN по языковому разнообразию и языковой документации Юридический взгляд на модели обучения для обработки естественного языка Корпус парламентских протоколов GermaParl Сбор языковых ресурсов от государственных администраций в странах Северной Европы и Балтии Координация европейских языковых ресурсов: сбор языковых ресурсов для управления многоязычной информацией в государственном секторе Объединение сети LAPPS и CLARIN E-magyar — Цифровая система обработки языка
М
Машинный перевод, Речевой перевод
Многоязычный параллельный корпус для глобального коммуникационного плана ESCAPE: крупномасштабный синтетический корпус для автоматического постредактирования Оценка производительности машинного перевода китайских идиом с помощью метода черного списка Оценка адаптации домена для машинного перевода в разных сценариях Китайско-португальский машинный перевод: исследование построения параллельных корпусов из сопоставимых текстов Дополнение Librispeech французскими переводами: мультимодальный корпус для оценки прямого перевода речи Большой автоматически получаемый список всех слов многословных выражений, оцениваемых по композиционности Повышение ставки: на пути к лучшему эталону машинного перевода с китайского на английский Улучшение машинного перевода образовательного контента с помощью краудсорсинга Гибридный подход к автоматическому извлечению двуязычных многословных выражений из параллельных корпусов Обучение и адаптация многоязычного NMT для менее ресурсоемких и морфологически богатых языков Англо-баскский статистический и нейронный машинный перевод Морфологическая инъекция для англо-малаяламского статистического машинного перевода Dynamic Oracle для нейронного машинного перевода на этапе декодирования Изучение верхушки айсберга: набор данных для перевода идиом Улучшение SMT для предметной области для языков с низким уровнем ресурсов с использованием данных из разных предметных областей Подробный анализ ошибок выходных данных NMT, SMT и RBMT для перевода с английского на голландский Мультимодальный лексический перевод Сравнительное исследование крайне малоресурсной транслитерации языков мира Машинный перевод малоресурсных разговорных диалектов: стратегии нормализации швейцарского немецкого языка TQ-AutoTest — набор автоматизированных тестов для качества (машинного) перевода Одно предложение, одна модель для нейронного машинного перевода
Метаданные
LREMap, песня ресурсов и оценки
Морфология
Полуавтоматическое построение сетей словообразования (для польского и испанского языков) UniMorph 2. 0: универсальная морфология Вычислительная архитектура для морфологии Верхней Тананы Расширение аббревиатур в сильно флективном языке: достаточно ли морфосинтаксических тегов? Быстрый и точный сегментатор вьетнамских слов Морфологический анализ конечного состояния для гагаузов Создание набора данных сходства японских слов Морфологическая инъекция для англо-малаяламского статистического машинного перевода Осведомленность на уровне графем в вложениях слов для морфологически богатых языков Морфо-синтаксическая аннотация Animacy для парсера зависимостей Инструменты для создания аналоговых сеток и ресурс аналоговых сеток с N-граммами на 11 языках Универсальные морфологии для Кавказского региона Морфологически аннотированный корпус эмиратского арабского языка ForFun 1. 0: Пражская база данных форм и функций — бесценный ресурс для лингвистических исследований CoNLL-UL: универсальные морфологические решетки для универсального разбора зависимостей Аннотированный вручную корпус польских текстов, опубликованных между 1830 и 1918 годами Межъязыковая оценка флективной сложности: перспектива обработки SandhiKosh: эталонный корпус для оценки санскритских инструментов Sandhi Комбинаторы парсера для морфологии тигринья и оромо Один язык, чтобы управлять всеми: моделирование морфологических паттернов в крупномасштабном лексиконе итальянского языка с помощью SWRL Моделирование морфологии глагола северной хайда Создание морфологического дерева для немецкого языка из лингвистической базы данных MADARI: веб-интерфейс для совместной арабской морфологической аннотации и исправления правописания Морфологический анализатор острова Св. Лаврентия / среднесибирского юпика Абхазский национальный корпус Веб-инструмент для создания аннотаций к ресурсам на флективных языках Parsivar: набор инструментов для обработки персидского языка BPEmb: Предварительно обученные вложения подслов без токенизации на 275 языках Создание быстрой и точной лемматизации для арабского языка
Многоязычие
Boarnsterhim Corpus: двуязычная фризско-голландская панель и исследование тенденций Open Subtitles Paraphrase Corpus для шести языков Включение контекстной информации для независимых от языка динамических задач устранения неоднозначности OpenSubtitles2018: Статистическая переоценка выравнивания предложений в больших, шумных параллельных корпусах Большой параллельный корпус полнотекстовых научных статей Интегрированное представление лингвистических и социальных функций переключения кода : Мы истощаем наш предмет исследования по мере его изучения: в языковых технологиях требуется больше репликации и разнообразия Отображение представлений: новый подход к созданию высококачественных многоязычных словарей эмоций NegPar: параллельный корпус с аннотациями для отрицания Изучение векторов слов для 157 языков Корпус для многоязычной классификации документов на восьми языках Многоязычный сборник CoNLL-U-совместимых морфологических лексиконов Огромные автоматически извлекаемые обучающие наборы для многоязычного слова SenseDisambiguation Создание матрицы перевода библейских имен на 591 язык UniMorph 2. 0: универсальная морфология Французско-алжирский аудиокорпус с переключением кода (FACST) Языковые технологии для многоязычной Европы: анализ крупномасштабного исследования проблем, требований, пробелов и потребностей г. Чахта Анумпа: мультимодальный корпус языка чокто. Сравнение предварительно обученных многоязычных вложений слов в задаче выравнивания онтологии Создание крупномасштабных многоязычных родственных таблиц Фонетически сбалансированный кодовый смешанный речевой корпус для хинди-английского автоматического распознавания речи Построение тегов распознавания именованных сущностей с помощью Parallel Corpora Хватит ходить вокруг да около: шаг к обработке идиом для НЛП индийского языка Анализ ошибок тегирования уйгурских имен: языковые методы и остающиеся проблемы Многоязычный подход к классификации вопросов Базовые показатели и тестовые данные для межъязыкового вывода Обучение и адаптация многоязычного NMT для менее ресурсоемких и морфологически богатых языков Первый южноафриканский корпус многоязычной мыльной оперы с переключением кодов IPSL: База данных шаблонов иконичности в жестовых языках. Создание и использование Получение классов глаголов с помощью восходящей семантической кластеризации глаголов Многоязычное расширение аннотаций в стиле PDTB: пример TED Multilingual Discourse Bank Китайская классификация отношений с использованием сетей долговременной памяти Автоматическое изучение лексикона алжирского диалекта с использованием многоязычных вложений слов Эксперименты по языковой адаптации посредством межъязыкового встраивания родственных языков Новый аннотированный португальско-испанский корпус для задачи сжатия нескольких предложений Обнаружение канонических индийских английских акцентов: подход на основе краудсорсинга Интегрированное формальное представление терминологических и лексических данных, включенных в схемы классификации ZAP: многоязычная среда проецирования аннотаций с открытым исходным кодом Обнаружение юмора в контенте социальных сетей, смешанном с кодом на английском и хинди: корпус и базовая система Индекс понимания слов для младенцев, примененный к исследованию преобладания изучения существительных с использованием межъязыковой базы данных CDI Konbitzul: база данных MWE для испано-баскского языка MirasVoice: двуязычный (англо-персидский) речевой корпус GenDR: универсальный глубокий реализатор со сложной лексикализацией Автоматическое обогащение терминологических ресурсов: пример IATE RDF Использование Crowd Agreement для локализации Wordnet Многоязычный анализ зависимостей для малоресурсных языков: тематические исследования северносаамского и коми-зырийского языков Статистический анализ пропущенного перевода в синхронном переводе с использованием крупномасштабного двуязычного речевого корпуса KIT-Multi: ориентированный на перевод многоязычный корпус для встраивания Корпуса типичных предложений Сравнительное исследование крайне малоресурсной транслитерации языков мира Два многоязычных корпуса извлечены из электронных ежедневных тендеров для приложений машинного обучения и машинного перевода. Большой многоязычный и многодоменный набор данных для рекомендательных систем SemR-11: многоязычный золотой стандарт семантического сходства и родства для одиннадцати языков Wordnets на индийском языке и их связи с Princeton WordNet ParCorFull: параллельный корпус, аннотированный полной кореферентностью Многоязычный набор данных для оценки извлечения параллельных предложений из сопоставимых корпусов Массовый транслингвальный составной анализ и обнаружение перевода Сегментация многоязычных слов: плавное обучение многих языковых токенизаторов благодаря универсальному корпусу зависимостей Универсальные зависимости и количественные типологические тенденции. Практический пример порядка слов Координация европейских языковых ресурсов: сбор языковых ресурсов для управления многоязычной информацией в государственном секторе Рабочее место для быстрого создания многоязычных сводок CATS: инструмент для индивидуального выравнивания корпусов упрощения текста TriMED: многоязычная терминологическая база данных Создание новых языковых и голосовых компонентов для обновленной платформы синтеза речи MaryTTS Просмотр и поддержка Pluricentric Global Wordnet или просто интересующей вас Wordnet BPEmb: Предварительно обученные вложения подслов без токенизации на 275 языках
Обработка мультимедийных документов
Face2Text: сбор аннотированного корпуса описаний изображений для создания подробных описаний лиц Обработка звукового сигнала с помощью сети Seq2Tree Теги социальных изображений как источник встраивания слов: оценка, ориентированная на задачу Влияние выбора одномодального представления на мультимодальное обучение Польский корпус аннотированных описаний изображений На пути к сопоставлению музыкального языка На пути к обработке устных исторических интервью и связанных с ними печатных документов
Многословные выражения и словосочетания
Подход к встраиванию слов для извлечения синонимов многословных терминов Оценка производительности машинного перевода китайских идиом с помощью метода черного списка Большой автоматически получаемый список всех слов многословных выражений, оцениваемых по композиционности Лексический инструмент для академического письма на испанском языке на основе корпусов экспертов и новичков Гибридный подход к автоматическому извлечению двуязычных многословных выражений из параллельных корпусов Хватит ходить вокруг да около: шаг к обработке идиом для НЛП индийского языка LIdioms: многоязычный набор связанных идиом Аннотирование выражений модальности и достоверность событий для корпуса комментариев к японским шахматам Аннотирование конструкций легких глаголов китайского языка в соответствии с рекомендациями PARSEME Использование английских приманок для ловли сербской многословной терминологии Построение крупномасштабного англоязычного вербального многословного выражения с аннотациями Изучение верхушки айсберга: набор данных для перевода идиом Konbitzul: база данных MWE для испано-баскского языка GenDR: универсальный глубокий реализатор со сложной лексикализацией Многоязычная тестовая коллекция для семантического поиска категорий сущностей Составление списка синонимичных слов и фраз японских составных глаголов СЛАЙД — лексикон общих идиом для настроений Стоит ли? Метрики оценки, связанные с бюджетом, для выбора модели Корпус академического письменного итальянского языка ICoN (L1 и L2) На пути к выводу семантических отношений в сложных именных: экспериментальное исследование На пути к стандартизированному набору данных для толкования составных существительных Генерация корпуса испанских искусственных ошибок словосочетаний Улучшение тега на основе нейронных сетей для идентификации многословных выражений Разработка аннотированного корпуса русских идиом
О
Онтологии
Сравнение предварительно обученных многоязычных вложений слов в задаче выравнивания онтологии Недостаточная выборка улучшает обучение прототипированию гипернимии Совместимость языковой информации: сопоставление тезауруса BLL с Lexvo и Glottolog Перекрестная проверка WordNet и SUMO с использованием меронимии Онтология косвенных событий (CEO) и ECB+/CEO: онтология и корпус для неявных причинно-следственных связей между событиями Профилирование статей в медицинских журналах с использованием семантического тега Gene Ontology На пути к разговорно-аналитической таксономии перекрытия речи Идентификация личной информации, передаваемой в чат-ориентированном диалоге Обзор автоматически создаваемых сетей WordNet и их оценка: подходы на основе лексики и встраивания слов Tel(s)-Telle(s)-Signs: высокоточное автоматическое межъязыковое обнаружение гиперонимов Одно событие, много представлений. Отображение концепций действий с помощью визуальных функций. Переработка данных для генерации естественного языка Просмотр и поддержка Pluricentric Global Wordnet или просто интересующей вас Wordnet Extended HowNet 2.0 – модель представления здравого смысла между сущностью и отношением Получение информации из французской лексической сети в формате RDF/OWL
Анализ мнений / анализ настроений
Представляем лексикон Verbal Polarity Shifters для английского языка Количественная оценка качественных данных для понимания спорных вопросов Интенсивность влияния слов Распространение эмоциональных реакций на новостные статьи в Twitter Понимание эмоций: набор твитов для изучения взаимодействий между категориями эмоций Medical Entity Corpus с элементами PICO и анализом настроений Многозначность вербальных оборотней Аннотирование отношений атрибуции на арабском языке Начальная загрузка полярно противоположных измерений эмоций из онлайн-обзоров Создание ресурсов для автоматического анализа настроений на телугу (язык с низким уровнем ресурсов) и интеграция нескольких доменных источников для улучшения прогнозирования настроений Многоязычная многоклассовая классификация тональности с использованием сверточных нейронных сетей Большой самоаннотированный корпус для сарказма MultiBooked: свод баскских и каталонских отзывов об отелях с аннотациями для классификации тональности на уровне аспектов Можно ли рассматривать адаптацию домена как аналогию? Создание корпуса настроений из твитов на бразильском португальском языке EMTC: многокомпонентный корпус в домене фильмов для анализа эмоций в диалоговом тексте Сложные и точные аннотации к фильмам и книгам на французском языке для анализа тональности на основе аспектов Lingmotif-lex: современный лексикон с широким охватом для анализа настроений Японский корпус для анализа информации о лояльности клиентов FooTweets: двуязычный параллельный корпус твитов о чемпионатах мира Корпуса SSIX: три золотых стандартных корпуса для анализа настроений на английском, испанском и немецком языках Финансовые микроблоги Идентификация цели сарказма: набор данных и вводный подход СЛАЙД — лексикон общих идиом для настроений Подход с несколькими классификаторами в сравнении с подходом с одним классификатором для определения модальности в португальском языке Итальянский твиттер-корпус речей ненависти против иммигрантов Аннотирование мнений и целевых мнений в отзывах учащихся о курсе «Да» или «Нет»? Анализ настроений на уровне речи в стенограммах парламентских дебатов Hansard в Великобритании Масштабируемая визуализация настроений и позиций NoReC: Норвежский обзорный корпус SenSALDO: создание лексикона настроений для шведского языка RtGender: корпус для изучения дифференциальных реакций на пол Корпус акта о вьетнамском диалоге на основе стандарта ISO 24617-2 Построение корпуса и оценка мнений на основе аспектов из твитов на испанском языке WikiArt Emotions: аннотированный набор данных об эмоциях, вызванных искусством Распространение полярности на основе классификатора в WordNet Использование больших корпораций Twitter для создания настроений Lexica г. Создание золотого стандарта шведского лексикона чувств Применение и анализ многослойной схемы иронии в итальянском корпусе Twitter TWITTIRÒ
Оптическое распознавание символов
Создание набора изображений рукописных клинописных символов Сегментация потока страниц с помощью сверточных нейронных сетей, сочетающих текстовые и визуальные функции Малоресурсная постобработка зашумленного вывода OCR для оцифровки исторического корпуса PDFdigest: адаптивный инструмент для извлечения текстового содержимого PDF-to-XML с поддержкой макета для научных статей
Другой
Создание лексикона синонимов глаголов на основе параллельного корпуса Многоязычный параллельный корпус для глобального коммуникационного плана DeModify: набор данных для анализа контекстных ограничений на удаление модификатора Когда ACE встретился с KBP: сквозная оценка заполнения базы знаний с аннотацией на уровне компонентов Аннотирование высокоуровневых структур коротких рассказов и личных анекдотов Обнаружение темпоральности на уровне предложения с использованием неявного ресурса с определением времени Создание корпуса с анализом зависимостей в веб-масштабе из CommonCrawl Face2Text: сбор аннотированного корпуса описаний изображений для создания расширенных описаний лиц Полуавтоматическое построение сетей словообразования (для польского и испанского языков) Оценка новизны свода метафор для синтаксически связанных пар слов Оценка доменных вложений Word с использованием ресурсов знаний Сбор данных мультимодального диалога и анализ результата аннотации уровня интереса пользователей Многослойная аннотация Ригведы Универсальные зависимости версии 2 для японского языка ESCAPE: крупномасштабный синтетический корпус для автоматического постредактирования Включение контекстной информации для независимых от языка динамических задач устранения неоднозначности Модель на основе нейронной сети для идентификации заимствованных слов в уйгурском языке OpenSubtitles2018: Статистическая переоценка выравнивания предложений в больших, шумных параллельных корпусах . Создание китайского дерева зависимостей с многоточием для веб-текста План управления данными (DMP) для языковых данных в соответствии с новым Общим регламентом защиты данных (GDPR) Количественная оценка качественных данных для понимания спорных вопросов Интенсивность воздействия слов Полуавтоматическая корейская аннотация FrameNet по KAIST Treebank Обработка проблем нормализации для маркировки частей речи разговорного онлайн-текста Большой параллельный корпус полнотекстовых научных статей Разработка дерева рассуждений Bangla RST Компьютерная диаризация говорящего: как оценить человеческие исправления Мы истощаем наш предмет исследования по мере того, как мы его изучаем: в языковых технологиях требуется больше репликации и разнообразия Пересмотр удаленного контроля для извлечения отношений Автоматическое построение тезауруса для современного иврита Подход, основанный на глубокой нейронной сети, для извлечения сущностей в тексте индийских социальных сетей со смешанным кодом Адаптация серьезной игры для ложной аргументации к немецкому языку: подводные камни, идеи и передовой опыт Знакомство с языком винных обзоров: учетная запись интеллектуального анализа текста Извлеченные уроки: о проблемах переноса репозитория исследовательских данных из исследовательского учреждения в университетскую библиотеку. новых направления в деятельности ELRA Распознавание поведенческих факторов во время вождения: реальный мультимодальный корпус для мониторинга эмоционального состояния водителя BDPROTO: База данных фонологических инвентарей древних и реконструированных языков Маркировка POS на нескольких диалектах арабского языка: подход CRF Оценка адаптации домена для машинного перевода в разных сценариях CLARIN: На пути к СПРАВЕДЛИВОЙ и ответственной науке о данных с использованием языковых ресурсов EmotionLines: корпус эмоций многосторонних разговоров Золотой стандарт многоязычного автоматического извлечения терминов из сопоставимых корпусов: структура терминов и эквиваленты перевода На пути к эпическому эпиграфу Китайско-португальский машинный перевод: исследование построения параллельных корпусов из сопоставимых текстов Изучение векторов слов для 157 языков Создание сегментатора слов для санскрита за одну ночь Аннотация структуры диалога для многоэтажного взаимодействия Извлечение англо-персидского параллельного корпуса из сопоставимых корпусов Повышение ставки: на пути к лучшему эталону машинного перевода с китайского на английский Свод комментариев пользователей к электронному правилу для измерения оцениваемости аргументов Лексическое профилирование экологических корпусов Новая версия базы данных польского языка Składnica, гармонизированная со словарем Валентности Валентности . Создание матрицы перевода библейских имен на 591 язык. От «решенных проблем» к новым вызовам: отчет о деятельности НРС Влияние на производительность, вызванное скрытой погрешностью обучающих данных для распознавания текстового дополнения Набор данных для извлечения связи между предложениями с использованием удаленного контроля Вычислительная архитектура для морфологии Верхней Тананы IIT Bombay English-Hindi Parallel Corpus Параллельные корпуса для биомедицинской области Диахронический корпус для анализа литературного стиля CBFC: параллельный речевой корпус L2 для изучающих корейский и французский языки Системные соглашения и разногласия во временной обработке: подробный анализ ошибок задачи TempEval-3 Стратегии и задачи краудсорсинга данных о восприятии региональных диалектов для швейцарского немецкого и швейцарского французского языков Создание крупномасштабных многоязычных родственных таблиц BULBasaa: Двуязычный басаа-французский речевой корпус для оценки инструментов языковой документации Обработка проблемы с редкими словами с использованием синтетических обучающих данных для сингальского и тамильского нейронного машинного перевода Три измерения воспроизводимости при обработке естественного языка Исследование малообеспеченных языков — DigiSami Corpus Понимание эмоций: набор твитов для изучения взаимодействий между категориями эмоций Расширение аббревиатур в сильно флективном языке: достаточно ли морфосинтаксических тегов? Заземление оцениваемых прилагательных с помощью краудсорсинга Простые семантические аннотации и ситуационные фреймы: два подхода к базовому пониманию текста в LORELEI Разбери меня, если сможешь: искусственные деревья для экспериментов по разбору эллиптических конструкций Закладка основы для заполнения базы знаний: девять лет лингвистических ресурсов для TAC KBP Корпус отношений атрибуции для политических новостей FontLex: типографский лексикон, основанный на аффективных ассоциациях Упрощение текста на основе профессионально подготовленных корпусов Лингвистически управляемая платформа для вычислительно эффективного и масштабируемого распознавания знаков ПОВЕДЕНИЕ: набор данных выразительных дирижерских жестов для управления звуком Основанный на зрении набор данных для прогнозирования типичных местоположений глаголов Улучшение классификации Закона о диалогах для спонтанной арабской речи и мгновенных сообщений на уровне произнесения Большой ресурс шаблонов для словесных перефраз Анализ ошибок тегирования уйгурских имен: языковые методы и остающиеся проблемы Корпус характеристик динамиков Nautilus: записи речи и метки характеристик динамиков и описания голоса JESC: Корпус японско-английских субтитров Приложение для построения корпуса польской телефонной речи Базовые показатели и тестовые данные для межъязыкового вывода Быстрый и точный сегментатор вьетнамских слов 2-й продольный корпус для детского письма с расширенным выводом для определенных моделей правописания CPJD Corpus: краудсорсинговый параллельный речевой корпус японских диалектов Морфологический анализ конечного состояния для гагаузов Анонимизация данных для анализа качества требований: воспроизводимая задача автоматического обнаружения ошибок GeCoTagger: аннотация дополнений немецких глаголов с условными случайными полями Тегирование части речи на албанском языке: золотой стандарт и оценка Сбор данных с кодовой коммутацией из социальных сетей Включение семантического внимания в генерацию описания видео Исправление ошибок сегментации слов OCR в статьях из коллекции ACL с помощью методов нейронного машинного перевода Набор данных Sentiment-Stance-Specific (SSS): выявление зависимостей, основанных на поддержке, среди мнений. Использование предварительного заказа для нейронного машинного перевода Портативный корректор орфографии для менее ресурсоемкого языка: амхарский Улучшение модели нейронного машинного перевода с несколькими источниками с расширением корпуса для языков с низким уровнем ресурсов Лексические и семантические признаки для классификации повторного использования межъязыкового текста: эксперимент с английскими и латинскими перефразами Построение древовидной базы макрокитайского дискурса Вложения слов на урду Dynamic Oracle для нейронного машинного перевода на этапе декодирования Обработка звукового сигнала с помощью сети Seq2Tree Что вызывает различия в стилях общения? Мультикультурное исследование прямоты и продуманности Экспертная оценка системы разговорного диалога в клинической операционной Глубокие нейронные сети для разрешения кореферентности для польского языка Корпус стажеров по дебатам о металоге: сбор данных и аннотации AET: веб-инструмент для изучения прилагательных для немецкого языка Open ASR для исландского языка: ресурсы и базовая система Корпус неопределенности UIR для китайского языка: аннотирование корпуса микроблогов китайского языка для выявления неопределенности в социальных сетях Лингвистическая и социолингвистическая аннотация голландских писем 17 века Обнаружение семантической эквивалентности: вопросительные формы сложнее декларативных? Идентификация арабского диалекта в контексте бивалентности и переключения кодов Исследование влияния двуязычного MWU на качество перевода стажеров Извлечение межъязыковой терминологии для оценки качества перевода Крупномасштабные лексические ресурсы для улучшения китайского и японского машинного перевода Совместимость языковой информации: сопоставление тезауруса BLL с Lexvo и Glottolog KTH Tangrams: набор данных для исследования выравнивания и концептуальных договоров в диалоге, ориентированном на задачу Обнаружение канонических индийских английских акцентов: подход, основанный на краудсорсинге Мультимодальное расстояние — подход к генерации стеммы с взвешиванием Улучшение обнаружения языка ненависти с помощью ансамблей глубокого обучения Корпус описаний природных мультимодальных пространственных сцен LREMap, песня ресурсов и оценки ZAP: многоязычная среда проецирования аннотаций с открытым исходным кодом О векторной репрезентации высказываний в контексте диалога Шведский корпус по краже файлов cookie От рукописей к архетипам посредством итеративной кластеризации FEIDEGGER: Мультимодальный корпус изображений и описаний моды на немецком языке ES-Port: спонтанный разговорный корпус технической поддержки для исследований диалога на испанском языке ASAP++: обогащение набора данных ASAP для автоматизированной оценки эссе баллами атрибутов эссе Создание набора изображений рукописных клинописных символов Индекс понимания слов для младенцев, примененный к исследованию преобладания изучения существительных с использованием межъязыковой базы данных CDI Единые рекомендации и ресурсы для арабской диалектной орфографии Параллельный корпус арабо-японских новостных статей Корпус диалогов диадического социального текста ADELE: аннотация диалогового акта с ISO 24617-2 Справочный корпус современного румынского языка (CoRoLa) Различение похожих языков в несбалансированных разговорных текстах KRAUTS: Немецкий корпус новостей с временными аннотациями Перемещение ТИГР за пределы уровня предложения Протокол выявления и материал для корпуса длинных подготовленных монологов на языке жестов Семантическая связь концепций Википедии — эталонные данные и рабочее решение Lingmotif-lex: современный лексикон с широким охватом для анализа настроений. На пути к валлийской системе семантических аннотаций FooTweets: двуязычный параллельный корпус твитов о чемпионатах мира Edit me: Корпус и основа для понимания редактирования изображений на естественном языке Корпус Ники и Джули: совместные мультимодальные диалоги между людьми, роботами и виртуальными агентами Маркировка части речи для диалекта арабского залива с использованием Bi-LSTM Оценка речи при дизартрии: автоматический и перцептивный подходы Прогнозирование кивков с помощью диалоговых действий в диалоге Проект индекса карцинологической тяжести речи: База данных о нарушениях речи для оценки качества жизни, связанного с речью после рака The WAW Corpus: Первый корпус устных речей и их переводов на английский и арабский языки Многоязычный викифицированный набор учебных материалов Оценка явных меж- и внутрипредметных дискурсивных связок в банке турецких дискурсов Создание учебного корпуса TOCFL для диагностики китайских грамматических ошибок SimPA: корпус упрощений на уровне предложений для домена государственного управления MIAPARLE: онлайн-тренинг по различению контрастов стресса Визуальный выбор правдоподобных альтернатив: оценка причинно-следственных рассуждений на основе здравого смысла Универсальные зависимости для амхарского языка Первые 100 дней: свод политических программ в Твиттере Использование корпуса политических выступлений на английском и китайском языках для анализа метафор Идентификация цели сарказма: набор данных и вводный подход Моделирование совместного мультимодального поведения в групповых диалогах: Корпус MULTISIMO Корпус brWaC: новый открытый ресурс для бразильского португальского языка Обнаружение параллельных языковых ресурсов для обучения машин машинного перевода Китайский набор данных с отрицательными полными формами для общего прогнозирования сокращений Уровневый корпус для чтения современного стандартного арабского языка CoNLL-UL: универсальные морфологические решетки для универсального анализа зависимостей Аннотация и количественный анализ информации о говорящем в новых разговорных предложениях на японском языке Дерево LIA разговорных норвежских диалектов Польский корпус аннотированных описаний изображений Управление данными государственного сектора для разработки многоязычных приложений Korean TimeBank, включая относительную временную информацию Аннотированный вручную корпус польских текстов, опубликованных между 1830 и 1918 годами Опрос DLDP по цифровому использованию и удобству использования региональных языков и языков меньшинств ЕС SimLex-999 для польского языка Корпус глаголов действия Совместное использование копий синтетических клинических корпусов без физического распространения — тематическое исследование по обходу прав интеллектуальной собственности и ограничений конфиденциальности с участием немецкого корпуса JSYNCC EMO&LY (EMOtion и AnomaLY): новый корпус для обнаружения аномалий в аудиовизуальном потоке с эмоциональным контекстом. Fluid Annotation: инструмент аннотации с учетом детализации для текучести китайских слов Немецкий справочный корпус DeReKo: новые разработки – новые возможности Risamálheild: очень большой исландский текстовый корпус Построение англо-французского мультимодального аффективного разговорного корпуса из телевизионных драм Изучение создания разговорного языка для расширенного контента об отелях Сравнительное исследование крайне малоресурсной транслитерации языков мира многоязычных аргументных корпуса на английском, турецком, греческом, албанском, хорватском, сербском, македонском, болгарском, румынском и арабском языках. Комбинаторы парсера для морфологии тигринья и оромо Подготовка и использование лексикографических данных коса для многоязычной федеративной среды Преобразование запросов веб-поиска в вопросы на естественном языке Буквальность и когнитивные усилия: японский и испанский языки Шами: Корпус левантийских арабских диалектов Ключевые семейства ресурсов CLARIN На пути к сопоставлению музыкального языка Два многоязычных корпуса извлечены из электронных ежедневных тендеров для приложений машинного обучения и машинного перевода. Оценка производительности машинного перевода в различных жанрах и языках HiNTS: набор тегов для средне-нижненемецкого языка Улучшение неконтролируемого извлечения ключевых фраз с использованием фоновых знаний Передача обучения для распознавания именованных объектов с помощью нейронных сетей Оценка адаптации динамиков Feature-Space для сквозных акустических моделей Использование лексических ресурсов и грамматики ограничений для основанной на правилах маркировки частей речи в валлийском языке Репозиторий корпусов для обобщения WikiDragon: платформа Java для диахронического контента и сетевого анализа MediaWikis Моделирование троллинга в социальных сетях Контекстные зависимости в непрерывном во времени многомерном распознавании воздействия Вы пишете в Твиттере то, что говорите: набор данных арабских диалектов на уровне города Корпус акта о вьетнамском диалоге на основе стандарта ISO 24617-2 WikiArt Emotions: аннотированный набор данных об эмоциях, вызванных искусством
Наборы тестов для разбора нелокальных зависимостей на китайском языке г. Изучение мусульманских стереотипов посредством извлечения микропортретов Добавление синтаксических аннотаций в корпус сущностей Flickr30k для разрешения мультимодальных неоднозначных вложений с предложными фразами Представляем Центр знаний CLARIN по языковому разнообразию и языковой документации DART: большой набор данных диалектных арабских твитов Модель лингвистической категории на польском языке (LCM-PL) Массовый транслингвальный составной анализ и обнаружение перевода Универсальные зависимости для айнов Идентификация говорящих и адресатов в диалогах, извлеченных из художественной литературы Сбор и анализ корпуса египетской арабо-английской речи с переключением кодов Расчет скорости речи с короткими высказываниями: исследование на основе задачи преобразования речи в речь, опосредованной машинным переводом Автоматическая идентификация областей исследований в научных статьях Создание морфологического дерева для немецкого языка из лингвистической базы данных Сбор языковых ресурсов от государственных администраций в странах Северной Европы и Балтии Ручное и автоматическое извлечение битекста Обман синтаксического анализатора до смерти: передача аннотаций между банками деревьев на основе данных Teanga: платформа на основе связанных данных для обработки естественного языка инструмента для создания взаимосвязанной сети лексикона синонимов Машинный перевод малоресурсных разговорных диалектов: стратегии нормализации швейцарского немецкого языка Сборник немецких политических выступлений 21 века. Записи коллекции метаданных для языковых ресурсов MADARI: веб-интерфейс для совместной арабской морфологической аннотации и исправления правописания Морфологический анализатор острова Св. Лаврентия / среднесибирского юпика ChAnot: Интеллектуальный инструмент аннотации для коренных и сильно агглютинативных языков в Перу ESCRITO — набор инструментов для оценки образования, дополненный НЛП Параллельные корпуса в Мбоши (банту C25, Конго-Браззавиль) Карта мастерских LREC Errator: инструмент для обнаружения ошибок аннотаций в проекте универсальных зависимостей Сохранение воспроизводимости рабочего процесса: клиент RePlay-DH как инструмент документирования процесса Matic Software Suite: новые инструменты для оценки и исследования данных Повторный анализ преобразования PDF в текст для интеллектуального анализа лингвистических данных Наведение порядка в хаосе: непоследовательный подход к просмотру больших наборов найденных аудиоданных MGAD: многоязычная генерация наборов аналоговых данных QUEST: интерфейс на естественном языке для реляционных баз данных На пути к непрерывному созданию корпуса диалога: запись в корпус и генерация из него Одно предложение, одна модель для нейронного машинного перевода Графики текстовых аннотаций: аннотирование сложных явлений естественного языка Расширение системы поиска на основе интерактивной визуализации для корпусов речи Интервью с немецким радио: выпуск GRAIN коллекции Silver Standard SFB732 Создание литературного корпуса для вычислительного литературного анализа — прототип для преодоления разрыва между CL и DH языка жестов и всемирные онлайн-словари и лексикостатистика WASA: веб-приложение для аннотации последовательности Объединение сети LAPPS и CLARIN Облегченное промежуточное ПО моделирования для корпусной обработки SlugNERDS: инструмент распознавания именованных сущностей для диалоговых систем с открытым доменом MMQA: многодоменная многоязычная структура вопросов и ответов для английского и хинди Parsivar: набор инструментов для обработки персидского языка Подход к обучению с полуучителем на основе графов для POS-тегов на тамильском языке Создание сбалансированного современного многослойного корпуса для NLU Аннотации эмоций на уровне предложений и пунктов, обнаружение и классификация в многожанровом корпусе База данных персидского дискурса и корреферентный корпус
п
Разбор
Включение контекстной информации для независимых от языка динамических задач устранения неоднозначности Оценка адаптации домена для машинного перевода в разных сценариях Ансамбль румынского разбора зависимостей с помощью нейронных сетей PoSTWITA-UD: итальянский банк деревьев Twitter в универсальных зависимостях BKTreebank: создание вьетнамского дерева зависимостей Внимание для распознавания имплицитных дискурсивных отношений Многоязычный анализ зависимостей для малоресурсных языков: тематические исследования северносаамского и коми-зырийского языков АНКОР-АС: обогащение корпуса АНКОР синтаксическими аннотациями Мировые знания для разбора абстрактного представления смысла Берега деревьев AnnCor CHILDES Анализ синтаксиса средневерхненемецкого языка с помощью RDF и SPARQL
Маркировка части речи
Создание корпуса из рукописных открыток с картинками: транскрипция, аннотация и маркировка частями речи Universal Dependencies Version 2 для японского языка Обработка проблем нормализации для маркировки частей речи разговорного онлайн-текста Маркировка POS на нескольких диалектах арабского языка: подход CRF Многоязычная коллекция CoNLL-U-совместимых морфологических словарей Расширение аббревиатур в сильно флективном языке: достаточно ли морфосинтаксических тегов? BKTreebank: создание вьетнамского дерева зависимостей Маркировка албанскими частями речи: золотой стандарт и оценка Морфо-синтаксическая аннотация Animacy для анализатора зависимостей Лингвистическая и социолингвистическая аннотация голландских писем 17 века Корпуса с аннотациями частей речи для трех региональных языков Франции: эльзасского, окситанского и пикардийского BioRo: Биомедицинский корпус для румынского языка Маркировка части речи для диалекта арабского залива с использованием Bi-LSTM Морфологически аннотированный корпус эмиратского арабского языка Использование лексических ресурсов и грамматики ограничений для основанной на правилах маркировки частей речи в валлийском языке Модель нейронной сети для маркировки частей речи текстов социальных сетей На пути к легкому решению для языков с ограниченными ресурсами: создание POS-теггера для эльзасского языка с использованием добровольного краудсорсинга EFLLex: оцениваемый лексический ресурс для изучающих английский язык как иностранный SoMeWeTa: Теггер частей речи для немецких социальных сетей и веб-текстов Веб-инструмент для создания аннотаций к ресурсам на флективных языках Подход к обучению с полуучителем на основе графов для POS-тегов на тамильском языке
Идентификация человека
Delta и N-Gram Tracing: оценка надежности методов атрибуции авторства Создание корпуса для личностно-зависимого понимания и генерации естественного языка Повторно используемые рабочие процессы для предсказания пола На пути к моделированию нейронных динамиков в многостороннем разговоре: задача, набор данных и модели Эксперименты со свёрточными нейронными сетями для определения авторства нескольких меток База данных MonPaGe_HA для документации разговорного французского во взрослом возрасте Arabic Data Science Toolkit: API для извлечения признаков арабского языка
Фонетические базы данных, Фонология
Boarnsterhim Corpus: двуязычная фризско-голландская панель и исследование тенденций BDPROTO: База данных фонологических инвентарей древних и реконструированных языков Сравнение методов обнаружения каламбура с использованием японского корпуса каламбуров Оценка автоматических средств отслеживания формант Моделирование произношения швейцарско-немецкой диалектной речи на основе данных для автоматического распознавания речи Мультимодальный корпус экспертного взгляда и поведения во время задач фонетической сегментации Варианты произношения и ASR разговорной речи: пример чешского языка Распределение и просодическая реализация глагольных форм в немецкой детской речи Epitran: Precision G2P для многих языков Составление корпуса повседневной японской речи: промежуточный отчет Говорящий атлас региональных языков Франции WordKit: пакет Python для орфографической и фонологической детализации Языки жестов и онлайновые мировые онлайн-словари и лексикостатистика
Профилирование
Что вызывает различия в стилях общения? Мультикультурное исследование прямоты и продуманности Повторно используемые рабочие процессы для предсказания пола Arap-Tweet: большой мультидиалектный корпус Twitter для идентификации пола, возраста и языкового разнообразия Корпус SLA, аннотированный педагогически значимыми грамматическими структурами
просодия
«Портретный» подход к многоканальному дискурсу SynPaFlex-Corpus: Выразительный корпус французских аудиокниг, посвященный выразительному синтезу речи. Распределение и просодическая реализация глагольных форм в немецкой детской речи Повышение доступности выровненных по времени речевых корпусов с помощью Spokes Mix
С
Семантическая сеть
Включение глобальных контекстов во встраивание предложений для реляционного извлечения на уровне абзаца с дистанционным контролем Интегрированное формальное представление терминологических и лексических данных, включенных в схемы классификации PMKI: действие Европейской комиссии по функциональной совместимости, ремонтопригодности и устойчивости языковых ресурсов. RDF2PT: создание текстов на бразильском португальском языке из данных RDF На пути к связанному изданию Sumerian Corpora с открытыми данными The LODeXporter: гибкое создание связанных троек открытых данных из платформ NLP для автоматического построения базы знаний Анализ синтаксиса средневерхненемецкого языка с помощью RDF и SPARQL Автоматические и ручные веб-аннотации в инфраструктуре для обработки фейковых новостей и других феноменов онлайн-медиа LiDo RDF: от реляционной базы данных к графику связанных данных лингвистических терминов и библиографических данных
Семантика
Создание лексикона синонимов глаголов на основе параллельного корпуса Подход к встраиванию слов для извлечения синонимов многословных терминов FrameNet для информации о раке в клинических рассказах: схема и аннотация Сетевые функции на основе обнаружения когипонимов Представляем лексикон словесных переключателей полярности для английского языка DeModify: набор данных для анализа контекстных ограничений на удаление модификатора Аннотирование высокоуровневых структур коротких рассказов и личных анекдотов Обнаружение темпоральности на уровне предложения с использованием неявного ресурса, чувствительного к времени Создание корпуса с анализом зависимостей в веб-масштабе из CommonCrawl Оценка новизны свода метафор для синтаксически связанных пар слов Оценка доменных вложений Word с использованием ресурсов знаний Интегрированное представление лингвистических и социальных функций переключения кода Совместное изучение смысловых и словесных вложений На пути к стандарту ISO для аннотаций количественного анализа Детальное семантическое текстовое сходство для сербского языка Автоматическое построение тезауруса для современного иврита NegPar: параллельный корпус с аннотациями для отрицания Оценка представлений значений с областью видимости ETPC — Корпус идентификации парафраз, аннотированный расширенной типологией парафраз и отрицанием Достижения в предварительном обучении распределенных представлений слов Огромные автоматически извлекаемые обучающие наборы для многоязычного слова SenseDisambiguation SentEval: набор инструментов для оценки универсальных представлений предложений C-HTS: концептуальный подход к иерархической сегментации текста Абстрактное значение Представление конструкций: чем больше мы включаем, тем лучше представление Системные соглашения и разногласия во временной обработке: подробный анализ ошибок задачи TempEval-3 Аннотирование временно привязанных пространственных знаний с использованием синтаксических зависимостей Семантические сверхчувства для английских притяжательных имен Междокументная, межъязыковая корреферентная аннотация событий с использованием бункеров событий Простые семантические аннотации и ситуационные фреймы: два подхода к базовому пониманию текста в LORELEI Интеграция структур событий генеративного лексикона в VerbNet Новый Propbank: согласование Propbank с AMR посредством унификации POS Оценка хорватских вложений слов Межъязыковая генерация и оценка обширного лексико-семантического ресурса Аннотирование выражений модальности и достоверность событий для корпуса комментариев к японским шахматам Расширение золотого стандарта для задачи лексической замены: оно того стоит? Создание набора данных сходства японских слов Улучшение современных контролируемых моделей устранения неоднозначности смысла слов с помощью семантических лексических ресурсов Получение классов глаголов с помощью восходящей семантической кластеризации глаголов Создание высококачественного смыслового корпуса и встраивания слов посредством неконтролируемого устранения псевдомногосмысла Недостаточная выборка улучшает обучение прототипированию гипернимии вложения слов на урду Китайская классификация отношений с использованием сетей долговременной памяти
Наборы данных оценки встраивания слов и встраивание заголовков Википедии для китайского языка Обнаружение семантической эквивалентности: вопросительные формы сложнее декларативных? Теги социальных изображений как источник встраивания слов: оценка, ориентированная на задачу SzegedKoref: венгерский корпус Coreference Зная Автора Компанией Его Слова Сохраняются Навстречу AMR-BR: SemBank для бразильского португальского языка Перенос фреймов из английского FrameNet в Construct китайский FrameNet: подход на основе двуязычного корпуса Автоматическая аннотация семиотического типа жестов рук в юмористических речах Обамы На пути к валлийской системе семантических аннотаций Система оценки мультимодального взаимодействия Анализ семантического фрейма для извлечения информации: корпус CALOR Испанский банк деревьев HPSG на основе AnCora Corpus Использование корпуса политических выступлений на английском и китайском языках для анализа метафор Датский лексикон FrameNet и аннотированный корпус, используемые для обучения и оценки семантического классификатора фреймов Тщательно настроенные вложения слов на основе 2 миллиардов токенов для португальского языка Подход с несколькими классификаторами в сравнении с подходом с одним классификатором для определения модальности в португальском языке Нейронные модели селективных предпочтений для неявной маркировки семантических ролей KIT-Multi: ориентированный на перевод многоязычный корпус для встраивания Моделирование французского жестового языка: предложение по семантически-композиционной системе Аннотирование представлений абстрактного значения для испанского языка Лексикон дискурсивных маркеров для португальского языка — LDM-PT Моделирование ошибок ASR для обучения систем SLU Просмотр терминологической структуры специализированной области: метод, основанный на лексических функциях и их классификации SemR-11: многоязычный золотой стандарт семантического сходства и родства для одиннадцати языков На пути к выводу семантических отношений в сложных именных: экспериментальное исследование Rollenwechsel-English: крупномасштабный корпус семантических ролей На пути к стандартизированному набору данных для интерпретации сложных существительных World Knowledge для синтаксического анализа представления абстрактного значения Неконтролируемая система устранения неоднозначности слов для языков с ограниченными ресурсами Парсер для LTAG и семантики кадров Не аннотировать, а проверять: метод преобразования данных в текст для сбора данных о событиях База данных определяющих контекстов немецкого языка из избранных веб-источников. Одно событие, много представлений. Отображение концепций действий с помощью визуальных функций. NL2Bash: корпусной и семантический парсер для интерфейса естественного языка с операционной системой Linux Модернизация представлений слов для неконтролируемых сходств слов с учетом смысла Indra: сервер встраивания слов и семантического родства Создание сбалансированного современного многослойного корпуса для NLU Предложения по метафорам на основе репозитория семантических метафор BPEmb: Предварительно обученные вложения подслов без токенизации на 275 языках Производство эталонов при взаимодействии человека с компьютером: проблемы для генерации выражений ссылок на основе корпуса
Распознавание/генерация языка жестов
Лингвистически управляемая платформа для вычислительно эффективного и масштабируемого распознавания знаков SMILE Набор данных швейцарско-немецкого жестового языка Реальный корпус сообщений управления воздушным движением с французским акцентом Протокол выявления и материал для корпуса длинных подготовленных монологов на языке жестов Deep JSLC: коллекция мультимодальных корпусов для управляемой данными генерации выражений японского языка жестов Моделирование французского языка жестов: предложение семантически-композиционной системы.
Обработка социальных сетей
Создание банка дерева зависимостей китайского языка для веб-текста с поддержкой многоточия EuroGames16: оценка обнаружения изменений в онлайн-разговоре Подход, основанный на глубокой нейронной сети, для извлечения сущностей в индийском тексте социальных сетей со смешанным кодом Многодиалектная арабская маркировка POS: подход CRF PoSTWITA-UD: итальянский банк деревьев Twitter в универсальных зависимостях Корпус хинди-английского кода со смешанными данными, аннотированный агрессией Семантические сверхчувства для английских притяжательных имен Аннотирование, если авторы твита находятся в местах, о которых они твитят Сравнение схем аннотирования эмоций и нового набора аннотированных данных Автоматическое изучение лексикона алжирского диалекта с использованием многоязычных вложений слов. Теги социальных изображений как источник встраивания слов: оценка, ориентированная на задачу Классификация информативного поведения эмодзи в микроблогах Улучшение обнаружения языка ненависти с помощью ансамблей глубокого обучения Визуализация тенденции возникновения инфекционных заболеваний с помощью Twitter Таксономия для углубленной оценки нормализации пользовательского контента Можно ли рассматривать адаптацию домена как аналогию? Профилирование авторов из Facebook Corpora Получение и потеря влияния в онлайн-разговоре Обнаружение юмора в содержимом социальных сетей, смешанном с кодом на английском и хинди: корпус и базовая система Создание корпуса настроений из твитов на бразильском португальском языке Lingmotif-lex: современный лексикон с широким охватом для анализа настроений. Корпуса SSIX: три золотых стандартных корпуса для анализа настроений на английском, испанском и немецком языках Финансовые микроблоги Первые 100 дней: свод политических программ в Твиттере Медицинский анализ настроений с использованием социальных сетей: на пути к созданию системы помощи пациентам Итальянский Твиттер-корпус речей ненависти против иммигрантов RtGender: корпус для изучения дифференциальных реакций на пол Модель нейронной сети для маркировки частей речи текстов социальных сетей Использование больших корпораций Twitter для создания настроений Lexica Создание наборов данных оценки для поиска культурных микроблогов Применение и анализ многослойной схемы иронии в итальянском корпусе Twitter TWITTIRÒ
Распознавание/понимание речи
Записанный набор данных для дебатов Оценка фонематической транскрипции тональных языков с низким уровнем ресурсов для языковой документации Фонетически сбалансированный кодовый смешанный речевой корпус для хинди-английского автоматического распознавания речи BULBasaa: Двуязычный басаа-французский речевой корпус для оценки инструментов языковой документации Закон об улучшении классификации диалогов для спонтанной арабской речи и мгновенных сообщений на уровне произнесения Проектирование и разработка речевых корпусов для обучения авиадиспетчеров Веб-служба для предварительной сегментации очень длинных расшифрованных записей речи Улучшенная расшифровка и индексация интервью по устной истории для цифровых гуманитарных исследований Open ASR для исландского языка: ресурсы и базовая система Создание литовских и латышских речевых корпусов из неточно аннотированных веб-данных На пути к автоматической оценке краудсорсинговых данных для NLU Моделирование произношения швейцарско-немецкой диалектной речи на основе данных для автоматического распознавания речи Моделирование ошибок ASR для обучения систем SLU Варианты произношения и ASR разговорной речи: пример чешского языка Оценка адаптации динамика Feature-Space для сквозных акустических моделей Epitran: Precision G2P для многих языков Matic Software Suite: новые инструменты для оценки и исследования данных
Речевой ресурс/база данных
Boarnsterhim Corpus: двуязычная фризско-голландская панель и исследование тенденций Дополнение Librispeech французскими переводами: мультимодальный корпус для оценки прямого перевода речи Речевой корпус языка с очень низким ресурсом для экспериментов по документированию вычислительных языков Фонетически сбалансированный кодовый смешанный речевой корпус для хинди-английского автоматического распознавания речи Мультимодальный корпус для взаимного взгляда и совместного внимания в многостороннем ситуативном взаимодействии Корпус характеристик говорящих Nautilus: записи речи и метки характеристик говорящих и описания голоса Оценка автоматических средств отслеживания формант Приложение для построения корпуса польской телефонной речи Первый южноафриканский корпус многоязычной мыльной оперы с переключением кодов Веб-служба для предварительной сегментации очень длинных расшифрованных записей речи MYCanCor: видеокорпус разговорного малайзийского кантонского диалекта. Open ASR для исландского языка: ресурсы и базовая система Создание литовских и латышских речевых корпусов из неточно аннотированных веб-данных Обнаружение канонических индийских английских акцентов: подход на основе краудсорсинга Корпус описаний природных мультимодальных пространственных сцен Взгляд с высоты птичьего полета на проекты языковой обработки в Румынской академии словаря произношения эльзасских диалектов для анализа правописания и фонетических вариаций MirasVoice: двуязычный (англо-персидский) речевой корпус Японский диалоговый корпус информационной навигации и внимательного слушания, аннотированный расширенными тегами диалогового акта ISO-24617-2 Проект индекса карцинологической тяжести речи: База данных о нарушениях речи для оценки качества жизни, связанного с речью после рака Управляемое данными моделирование произношения швейцарско-немецкой диалектной речи для автоматического распознавания речи Предварительный анализ телесных взаимодействий между научными коммуникаторами и посетителями на основе мультимодального корпуса японских разговоров в музее науки Анализ индекса общности словарного запаса с использованием крупномасштабной базы данных развития детской речи PronuncUR: Генератор лексикона произношения урду Мультимодальный корпус экспертного взгляда и поведения во время задач фонетической сегментации Статистический анализ пропущенного перевода в синхронном переводе с использованием крупномасштабного двуязычного речевого корпуса EMO&LY (EMOtion и AnomaLY): новый корпус для обнаружения аномалий в аудиовизуальном потоке с эмоциональным контекстом. SynPaFlex-Corpus: Выразительный корпус французских аудиокниг, посвященный выразительному синтезу речи. ASR для документирования языков коренных народов с острой нехваткой ресурсов Варианты произношения и ASR разговорной речи: пример чешского языка База данных MonPaGe_HA для документации разговорного французского во взрослом возрасте CoLoSS: корпус когнитивной нагрузки с данными о речи и производительности из символьно-цифрового двойного задания VAST: корпус видеоаннотаций для речевых технологий Сбор и анализ корпуса египетской арабо-английской речи с переключением кодов Составление корпуса повседневной японской речи: промежуточный отчет Параллельные корпуса в Мбоши (банту C25, Конго-Браззавиль) Наведение порядка в хаосе: непоследовательный подход к просмотру больших наборов найденных аудиоданных Расширение системы поиска на основе интерактивной визуализации для корпусов речи BabyCloud, технологическая платформа для родителей и исследователей Повышение доступности выровненных по времени речевых корпусов с помощью Spokes Mix
Синтез речи
Проектирование и разработка речевых корпусов для обучения авиадиспетчеров SynPaFlex-Corpus: Выразительный корпус французских аудиокниг, посвященный выразительному синтезу речи. Epitran: Precision G2P для многих языков Создание новых языковых и голосовых компонентов для обновленной платформы синтеза речи MaryTTS
Стандарты для Lrs
На пути к стандарту ISO для аннотаций количественного анализа Облегченная грамматическая аннотация в TEI: новые перспективы Интероперабельность ресурсов для устойчивого сравнительного анализа: случай событий
Статистические и машинные методы обучения
Простое крупномасштабное извлечение отношений из неструктурированного текста Корпус для моделирования важности слов в стенограммах разговорных диалогов EuroGames16: оценка обнаружения изменений в онлайн-разговоре Сочетание подходов на основе правил и встраивания для нормализации текстовых объектов с помощью онтологии Ансамбль румынского разбора зависимостей с помощью нейронных сетей Восстановление диакритических знаков с помощью нейронных сетей Создание сегментатора слов для санскрита за одну ночь Достижения в предварительном обучении распределенных представлений слов Нейронная генерация подписей к новостным изображениям SumeCzech: большой набор сводных данных на основе чешских новостей Аннотирование образовательных вопросов для анализа ответов учащихся SW4ALL: Классифицированный и согласованный корпус CEFR для изучения языков Лингвистически управляемая платформа для вычислительно эффективного и масштабируемого распознавания знаков Межъязыковая генерация и оценка обширного лексико-семантического ресурса Набор данных SMILE по швейцарско-немецкому языку жестов TF-LM: набор инструментов для языкового моделирования на основе TensorFlow Устранение многозначности слов, состоящих из всех слов, с использованием встраивания понятий Англо-баскский статистический и нейронный машинный перевод Улучшение современных контролируемых моделей устранения неоднозначности смысла слов с помощью семантических лексических ресурсов Использование предварительного заказа для нейронного машинного перевода Портативный корректор орфографии для менее ресурсоемкого языка: амхарский Улучшенная расшифровка и индексация интервью по устной истории для цифровых гуманитарных исследований Вложения слов на урду Обработка звукового сигнала с помощью сети Seq2Tree Эксперименты по языковой адаптации посредством межъязыкового встраивания родственных языков Изучение влияния двуязычного MWU на качество перевода стажеров Классификация информативного поведения эмодзи в микроблогах Предсказание словарного запаса корейского языка L2: можно ли использовать большой аннотированный корпус для обучения более совершенных моделей предсказания неизвестных слов? Распознавание именованных объектов на португальском языке с использованием условных случайных полей и локальных грамматик Автоматическая аннотация семиотического типа жестов рук в юмористических речах Обамы Полуконтролируемая кластеризация для подсчета кратких ответов От анализа к моделированию взаимодействия как последовательности мультимодального поведения Контекстный подход к распознаванию акта диалога с использованием простых рекуррентных нейронных сетей Анализ семантического фрейма для извлечения информации: корпус CALOR Улучшение SMT для предметной области для языков с низким уровнем ресурсов с использованием данных из разных предметных областей Датский лексикон FrameNet и аннотированный корпус, используемые для обучения и оценки семантического классификатора фреймов Стоит ли оно того? Метрики оценки, связанные с бюджетом, для выбора модели Подход с несколькими классификаторами в сравнении с подходом с одним классификатором для определения модальности в португальском языке Подробная оценка нейронных моделей последовательностей последовательностей для внутридоменного и междоменного упрощения текста Сегментация потока страниц с помощью сверточных нейронных сетей, сочетающих текстовые и визуальные функции Полуконтролируемая генерация обучающих данных для многоязычных ответов на вопросы Кросслингвистическая оценка флективной сложности: перспектива обработки BioRead: новый набор данных для биомедицинского понимания прочитанного Моделирование ошибок ASR для обучения систем SLU Использование состязательных примеров в обработке естественного языка Модель нейронной сети для маркировки частей речи текстов социальных сетей Добавление синтаксических аннотаций в корпус сущностей Flickr30k для разрешения мультимодальных неоднозначных вложений с предложными фразами Распространение полярности на основе классификатора в WordNet Юридический взгляд на модели обучения для обработки естественного языка Использование больших корпораций Twitter для создания настроений Lexica Улучшение тега на основе нейронных сетей для идентификации многословных выражений Сегментация многоязычных слов: плавное обучение многих языковых токенизаторов благодаря универсальному корпусу зависимостей Ручное и автоматическое извлечение битекста Наведение порядка в хаосе: непоследовательный подход к просмотру больших наборов найденных аудиоданных NL2Bash: корпусной и семантический парсер для интерфейса естественного языка с операционной системой Linux MGAD: многоязычная генерация наборов аналоговых данных DeepTC — расширение текстовой классификации DKPro для повышения воспроизводимости экспериментов по глубокому обучению SoMeWeTa: Теггер частей речи для немецких социальных сетей и веб-текстов
Подведение итогов
Нейронная генерация подписей к новостным изображениям SumeCzech: большой набор данных на основе чешских новостей Новый аннотированный португальско-испанский корпус для задачи сжатия нескольких предложений Live Blog Corpus для обобщения TSix: набор данных с участием человека для обобщения твитов Масштабируемая визуализация настроений и позиций RDF2PT: создание текстов на бразильском португальском языке из данных RDF Аннотации и анализ экстрактивных аннотаций для Kyutech Corpus Репозиторий корпусов для обобщения Построение корпуса и оценка мнений на основе аспектов из твитов на испанском языке Auto-hMDS: автоматическое построение большого разнородного многоязычного корпуса для обобщения нескольких документов Рабочее место для быстрого создания многоязычных сводок Помимо общего суммирования: многогранный корпус иерархического суммирования больших разнородных данных PyrEval: автоматизированный метод сводного анализа контента
Т
Интеллектуальный анализ текста
Подход к встраиванию слов для извлечения синонимов многословных терминов Записанный набор данных для дебатов Новый корпус для поддержки интеллектуального анализа текста для курирования метаболитов в базе данных ChEBI Обнаружение конфликта интересов на основе контента в Википедии MPST: свод синопсисов сюжетов фильмов с тегами TAP-DLND 1. 0: корпус для обнаружения новизны на уровне документа Знакомство с языком винных обзоров: учетная запись интеллектуального анализа текста Достижения в предварительном обучении распределенных представлений слов Нейронная генерация подписей к новостным изображениям Анализ сетей Citation-Distance для оценки влияния публикации C-HTS: концептуальный подход к иерархической сегментации текста Диахронический корпус для анализа литературного стиля Три измерения воспроизводимости при обработке естественного языка Medical Entity Corpus с элементами PICO и анализом настроений BlogSet-BR: корпус блогов на бразильском португальском языке Начальная загрузка полярно противоположных измерений эмоций из онлайн-обзоров Набор данных Sentiment-Stance-Specific (SSS): выявление зависимостей, основанных на поддержке, среди мнений. Лексические и семантические признаки для классификации повторного использования межъязыкового текста: эксперимент с английскими и латинскими перефразами Создание ресурсов для автоматического анализа тональности на телугу (язык с низким уровнем ресурсов) и интеграция нескольких доменных источников для улучшения прогнозирования тональности Многоязычная многоклассовая классификация тональности с использованием сверточных нейронных сетей HappyDB: собрание 100 000 счастливых моментов, собранных с помощью краудсорсинга EventWiki: База знаний о крупных событиях MultiBooked: свод баскских и каталонских отзывов об отелях с аннотациями для классификации тональности на уровне аспектов Извлечение межъязыковой терминологии для оценки качества перевода Аннотирование спина в биомедицинских научных публикациях : случай случайных контролируемых испытаний (РКИ) Шведский корпус по краже печенья Повторно используемые рабочие процессы для предсказания пола От рукописей к архетипам посредством итеративной кластеризации Знать автора по компании Его слова держат Профилирование авторов из Facebook Corpora Японский корпус для анализа информации о лояльности клиентов Пересмотр задачи оценки открытых отношений IE Контролируемый подход к извлечению таксономии с использованием встраивания слов Онтология косвенных событий (CEO) и ECB+/CEO: онтология и корпус для неявных причинно-следственных связей между событиями Аннотирование мнений и целевых мнений в отзывах учащихся о курсе «Да» или «Нет»? Анализ настроений на уровне речи в стенограммах парламентских дебатов Hansard в Великобритании Risamálheild: очень большой исландский текстовый корпус Автоматизация обнаружения документов в процессе систематического обзора: как использовать мякину для извлечения пшеницы Аннотированный корпус домашних страниц научных конференций для извлечения информации RtGender: корпус для изучения дифференциальных реакций на пол Изучение мусульманских стереотипов посредством извлечения микропортретов Юридический взгляд на модели обучения для обработки естественного языка Анализ качества консультационных бесед: контрольные признаки качественного консультирования Публикации по биомедицине в горнодобывающей промышленности с использованием сети LAPPS PyRATA, анализ структуры функций на основе правил Python CogCompNLP: ваш швейцарский армейский нож для НЛП ILCM — виртуальная исследовательская инфраструктура для крупномасштабных качественных данных
Текстовое сопровождение и перефразирование
DeModify: набор данных для анализа контекстных ограничений на удаление модификатора Open Subtitles Paraphrase Corpus для шести языков Построение графа знаний из определений естественного языка для распознавания интерпретируемого текста Автоматическое предсказание дискурсивных связок Детальное семантическое текстовое сходство для сербского языка SPADE: оценочный набор данных для одноязычного выравнивания фраз ETPC — Корпус идентификации парафраз, аннотированный расширенной типологией парафраз и отрицанием Влияние на производительность, вызванное скрытой погрешностью обучающих данных для распознавания текстового дополнения Многодоменная структура для текстового сходства. Практический пример задач на сходство «вопрос-вопрос» и «вопрос-ответ» Базовые показатели и тестовые данные для межъязыкового вывода Преобразование текстов в скрипты: исследование последствий Обнаружение семантической эквивалентности: вопросительные формы сложнее декларативных? Набор данных лексического упрощения на основе CEFR На пути к золотому стандарту корпуса для обнаружения переменных и связывания в публикациях по социальным наукам Набор многоязычных тестов для семантического поиска категорий сущностей
Инструменты и платформы для сбора данных
Краудсорсинг, управляемый сообществом: сбор данных с местными разработчиками
Инструменты, системы, приложения
Оценка системы преобразования текста в сцену WordsEye: творческие и реалистичные предложения Создание корпуса из рукописных открыток с картинками: транскрипция, аннотация и маркировка частями речи Разработка совместного процесса создания двуязычных словарей индонезийских этнических языков Преодоление проблемы «длинного хвоста»: тематическое исследование оценки выбросов CO2 для рецептов с использованием информационного поиска Обработка больших данных и конфиденциальных данных с использованием универсальной платформы выполнения EUDAT и механизма рабочего процесса WebLicht. Ансамбль румынского разбора зависимостей с помощью нейронных сетей Восстановление диакритических знаков с помощью нейронных сетей Создание сегментатора слов для санскрита за одну ночь Многослойный аннотированный корпус аргументативного текста: от схем аргументации к дискурсивным отношениям SentEval: набор инструментов для оценки универсальных представлений предложений Лексический инструмент для академического письма на испанском языке на основе корпусов экспертов и новичков . Фреймворк для разработки многоязычных сервисов с языковой сеткой FontLex: типографский лексикон, основанный на аффективных ассоциациях Интертекстуальная корреспонденция для интеграции корпусов Оценка автоматических средств отслеживания формант Быстрый и точный сегментатор вьетнамских слов TF-LM: набор инструментов для языкового моделирования на основе TensorFlow GeCoTagger: аннотация дополнений немецких глаголов с условными случайными полями Обучение и адаптация многоязычного NMT для менее ресурсоемких и морфологически богатых языков Исправление ошибок сегментации слов OCR в статьях из коллекции ACL с помощью методов нейронного машинного перевода Улучшенная расшифровка и индексация интервью по устной истории для цифровых гуманитарных исследований ScholarGraph: график знаний китайских ученых по китайскому языку Экспертная оценка системы разговорного диалога в клинической операционной Глубокие нейронные сети для разрешения кореферентности для польского языка Рейтинг кандидатов на обслуживание онлайн-словаря Аннотация структуры дискурса и информационной структуры на основе QUD: инструмент и оценка UFSAC: объединение смысловых аннотированных корпусов и инструментов Структура для нужд различных типов пользователей в многоязычном семантическом обогащении Мультимодальное расстояние — подход к генерации стеммы с взвешиванием Прагматический подход к сегментации слов в классическом китайском языке Визуализация тенденции возникновения инфекционных заболеваний с помощью Twitter От рукописей к архетипам посредством итеративной кластеризации Live Blog Corpus для обобщения Инструменты для создания аналоговых сеток и ресурс аналоговых сеток с N-граммами на 11 языках Объединение понятий и их переводы из структурированных словарей языков уральских меньшинств На пути к валлийской системе семантических аннотаций Система оценки мультимодального взаимодействия Оценка речи при дизартрии: автоматический и перцептивный подходы Корпус brWaC: новый открытый ресурс для бразильского португальского языка Обнаружение параллельных языковых ресурсов для обучения машин машинного перевода ForFun 1. 0: Пражская база данных форм и функций — бесценный ресурс для лингвистических исследований Подробная оценка нейронных моделей последовательностей последовательностей для внутридоменного и междоменного упрощения текста Нейронные модели селективных предпочтений для неявной маркировки семантических ролей PronuncUR: Генератор лексикона произношения урду Полуавтономная система для создания корпуса взаимодействия человека и машины в виртуальной реальности: приложение к системе ACORFORMed для обучения врачей сообщать плохие новости FARMI: платформа для записи мультимодальных взаимодействий Немецкий справочный корпус DeReKo: новые разработки – новые возможности Разработка аннотированного мультимодального набора данных для исследования классификации и обобщения презентаций с использованием паралингвистических функций высокого уровня На пути к достоверной визуализации глобального языкового разнообразия Улучшение неконтролируемого извлечения ключевых фраз с использованием фоновых знаний WikiDragon: Java-фреймворк для диахронического контента и сетевого анализа MediaWikis Моделирование троллинга в социальных сетях Контекстные зависимости в непрерывном во времени многомерном распознавании воздействия Использование выравнивания текста в полуавтоматическом анализе ошибок: вариант использования при разработке корпуса изучающих латышский язык Корпус парламентских протоколов GermaParl WordNet-Shp: на пути к созданию лексической базы данных для перуанского языка меньшинства Расчет скорости речи с короткими высказываниями: исследование на основе задачи преобразования речи в речь, опосредованной машинным переводом Улучшение тега на основе нейронных сетей для идентификации многословных выражений Transc&Anno: графический инструмент для расшифровки и оперативного комментирования рукописных документов Неконтролируемая система устранения неоднозначности слов для языков с ограниченными ресурсами Быстрый и гибкий веб-интерфейс для исследования диалектов в Нидерландах Инструменты для создания взаимосвязанной сети лексикона синонимов Palmyra: независимый от платформы инструмент аннотирования зависимостей для морфологически богатых языков Веб-система для древовидного банка зависимостей Crowd-in-the-Loop MADARI: веб-интерфейс для совместной арабской морфологической аннотации и исправления правописания Морфологический анализатор острова Св. Лаврентия / среднесибирский юпик Свод руководств по употреблению наркотиков, аннотированный типом рекомендаций ChAnot: Интеллектуальный инструмент аннотации для коренных и сильно агглютинативных языков в Перу Signbank: программное обеспечение для поддержки интернет-словарей жестового языка Нормализация биомедицинских терминов EHR с помощью UMLS Сборник корпусов для изучения интерфейса информационная структура-просодия Парсер для LTAG и семантики кадров Рабочее место для быстрого создания многоязычных сводок ESCRITO — набор инструментов для оценки образования, дополненный НЛП CATS: инструмент для индивидуального выравнивания корпусов упрощения текста Errator: инструмент для обнаружения ошибок аннотаций в проекте универсальных зависимостей Публикации по биомедицине в горнодобывающей промышленности с использованием сети LAPPS PDFAnno: веб-инструмент лингвистических аннотаций для PDF-документов Сохранение воспроизводимости рабочего процесса: клиент RePlay-DH как инструмент документирования процесса TriMED: многоязычная терминологическая база данных PyRATA, анализ структуры функций на основе правил Python Matic Software Suite: новые инструменты для оценки и исследования данных Revita: языковая платформа на пересечении ITS и CALL Разработка новых лингвистических ресурсов и инструментов для галисийского языка Библиотеки ACoLi CoNLL: помимо значений, разделенных табуляцией Повторный анализ преобразования PDF в текст для интеллектуального анализа лингвистических данных PDFdigest: адаптивный инструмент для извлечения текстового содержимого PDF-to-XML с поддержкой макета для научных статей Создание новых языковых и голосовых компонентов для обновленной платформы синтеза речи MaryTTS QUEST: Интерфейс естественного языка для реляционных баз данных Краудсорсинговый инструмент сбора мультимодальных корпораций Разрешение базовой ссылки в FreeLing 4. 0 DeepTC — расширение текстовой классификации DKPro для повышения воспроизводимости экспериментов по глубокому обучению SoMeWeTa: Теггер частей речи для немецких социальных сетей и веб-текстов TQ-AutoTest — набор автоматизированных тестов для качества (машинного) перевода CogCompNLP: ваш швейцарский армейский нож для НЛП Разработка мобильной системы поддержки наблюдения для учащихся: FishWatchr Mini Manzanilla: инструмент аннотации изображений для TKB Building WordKit: пакет Python для орфографической и фонологической детализации Просмотр и поддержка Pluricentric Global Wordnet или просто интересующей вас Wordnet Автоматические и ручные веб-аннотации в инфраструктуре для обработки фейковых новостей и других феноменов онлайн-медиа WASA: веб-приложение для аннотации последовательности Оценка EcoLexiCAT: CAT-инструмент с улучшенной терминологией Extended HowNet 2. 0 — модель представления здравого смысла между сущностью и отношением TreeAnnotator: универсальная визуальная аннотация иерархических текстовых отношений Облегченное промежуточное ПО моделирования для корпусной обработки E-magyar — цифровая система обработки языка : Что случилось, Питон? — Библиотека Visual Differ и Graph для НЛП на Python Parsivar: набор инструментов для обработки персидского языка Indra: сервер встраивания слов и семантического родства Интерфейс базы данных UIMA для управления текстовыми аннотациями, связанными с NLP Предложения по метафорам на основе репозитория семантических метафор Аннотации эмоций на уровне предложений и пунктов, обнаружение и классификация в многожанровом корпусе
Обнаружение темы и отслеживание
C-HTS: концептуальный подход к иерархической сегментации текста Многоязычный викифицированный набор учебных материалов Измерение инноваций в публикациях по обработке речи и языка. FrNewsLink : свод, связывающий новостные сегменты телепередач и статьи в прессе. Малоресурсные методы анализа разделов средневековых документов Сборник немецких политических выступлений 21 века. MMQA: многодоменная многоязычная структура вопросов и ответов для английского и хинди
Типологические базы данных
BDPROTO: База данных фонологических инвентарей древних и реконструированных языков Осведомленность на уровне графем в вложениях слов для морфологически богатых языков На пути к достоверной визуализации глобального языкового разнообразия Универсальные зависимости и количественные типологические тенденции. Практический пример порядка слов QUEST: интерфейс на естественном языке для реляционных баз данных
Основные проблемы обработки естественного языка (NLP)
Искусственный интеллект стал частью нашей повседневной жизни — Alexa и Siri, автокоррекция текста и электронной почты, чат-боты обслуживания клиентов. Все они используют алгоритмы машинного обучения и обработку естественного языка (NLP) для обработки, «понимания» и реагирования на человеческий язык, как письменный, так и устный.
Попробуйте этот анализатор настроений НЛП, чтобы увидеть, как НЛП автоматически понимает и анализирует настроения в тексте (положительные, нейтральные, отрицательные).
Хотя НЛП и родственное ему исследование «Понимание естественного языка» (NLU) постоянно развиваются огромными скачками благодаря своей способности вычислять слова и текст, человеческий язык невероятно сложен, подвижен и непоследователен и представляет собой серьезные проблемы, с которыми НЛП пока не справляется. полностью преодолеть.
Давайте рассмотрим некоторые из этих проблем ниже.
Проблемы обработки естественного языка (NLP)
НЛП — мощный инструмент с огромными преимуществами, но все еще существует ряд ограничений и проблем обработки естественного языка:
Контекстуальные слова и фразы и омонимы Сарказм
Неоднозначность
Ошибки в тексте или речи
Разговорные выражения и сленг
Язык, специфичный для предметной области
Языки с низким уровнем ресурсов
Отсутствие исследований и разработок
Контекстуальные слова и фразы и омонимы
Одни и те же слова и фразы могут иметь разное значение в зависимости от контекста предложения, и многие слова, особенно в английском языке, имеют точно такое же произношение, но совершенно разные значения.
Например:
Я побежал в магазин, потому что у нас закончилось молоко .
Могу ли я пробежать что-нибудь мимо вас очень быстро?
Дом действительно выглядит запустить вниз.
Их легко понять людям, потому что мы читаем контекст предложения и понимаем все различные определения. И хотя языковые модели НЛП, возможно, усвоили все определения, различие между ними в контексте может вызвать проблемы.
Омонимы — два или более слова, которые произносятся одинаково, но имеют разные определения — могут создавать проблемы для ответов на вопросы и приложений преобразования речи в текст, поскольку они не записываются в текстовой форме. Использование их и там , например, это даже обычная проблема для человека.
Синонимы
Синонимы могут привести к проблемам, подобным контекстуальному пониманию, потому что мы используем много разных слов для выражения одной и той же идеи. Кроме того, некоторые из этих слов могут иметь точно такое же значение, в то время как некоторые могут быть уровнями сложности (маленький, маленький, крошечный, крошечный), и разные люди используют синонимы для обозначения немного разных значений в своем личном словаре.
Итак, для построения систем НЛП важно включить все возможные значения слова и все возможные синонимы. Модели анализа текста все еще могут время от времени ошибаться, но чем больше релевантных обучающих данных они получат, тем лучше они смогут понимать синонимы.
Ирония и сарказм
Ирония и сарказм создают проблемы для моделей машинного обучения, поскольку они обычно используют слова и фразы, которые строго по определению могут быть положительными или отрицательными, но на самом деле означают противоположное.
Модели можно обучать с помощью определенных сигналов, которые часто сопровождают ироничные или саркастические фразы, такие как «да, верно», «что угодно» и т. д., а также встраивания слов (где слова, имеющие одинаковое значение, имеют сходное представление), но все равно непростой процесс.
Неоднозначность
Неоднозначность в НЛП относится к предложениям и фразам, которые потенциально могут иметь две или более возможных интерпретации.
Лексическая неоднозначность: слово, которое может использоваться как глагол, существительное или прилагательное.
Семантическая двусмысленность: интерпретация предложения в контексте. Например: Я видел мальчика на пляже в бинокль. Это может означать, что я видел мальчика в свой бинокль или у мальчика был с собой мой бинокль. Фраза с моим биноклем может изменить глагол «пила» или существительное «мальчик».
Даже человеку трудно интерпретировать это предложение без контекста окружающего текста. Тегирование POS (часть речи) — это одно из решений НЛП, которое может отчасти помочь решить проблему.
Ошибки в тексте и речи
Ошибки или неправильное использование слов могут создать проблемы для анализа текста. Приложения для автозамены и исправления грамматики могут обрабатывать распространенные ошибки, но не всегда понимают намерение автора.
В разговорной речи неправильное произношение, разные акценты, заикание и т. д. могут быть трудны для понимания машиной. Однако по мере роста языковых баз данных и обучения интеллектуальных помощников их отдельными пользователями эти проблемы можно свести к минимуму.
Разговорные выражения и сленг
Неформальные фразы, выражения, идиомы и культурно-специфический жаргон создают ряд проблем для НЛП, особенно для моделей, предназначенных для широкого использования. Потому что как формальный язык разговорные выражения могут вообще не иметь «словарного определения», и эти выражения могут даже иметь разное значение в разных географических областях. Кроме того, культурный сленг постоянно трансформируется и расширяется, поэтому каждый день появляются новые слова.
Здесь может помочь обучение и регулярное обновление пользовательских моделей, хотя часто для этого требуется довольно много данных.
Язык для предметной области
Различные предприятия и отрасли часто используют очень разные языки. Например, модель обработки NLP, необходимая для здравоохранения, будет сильно отличаться от модели, используемой для обработки юридических документов. В наши дни, однако, существует ряд аналитических инструментов, подготовленных для конкретных областей, но в крайне нишевых отраслях может возникнуть необходимость в создании или обучении своих собственных моделей.
Языки с низким уровнем ресурсов
Машинное обучение ИИ Приложения НЛП в основном созданы для наиболее распространенных и широко используемых языков. И просто поразительно, насколько точными стали системы перевода. Однако многие языки, особенно те, на которых говорят люди с ограниченным доступом к технологиям, часто упускаются из виду и недостаточно обрабатываются. Например, по некоторым оценкам (в зависимости от языка и диалекта) только в Африке насчитывается более 3000 языков. По многим из этих языков просто не так много данных.
Однако новые методы, такие как многоязычные преобразователи (с использованием Google BERT «Двунаправленные представления кодировщиков из преобразователей») и встраивание многоязычных предложений направлены на выявление и использование универсальных сходств, существующих между языками.
Отсутствие исследований и разработок
Машинному обучению требуется МНОГО данных, чтобы функционировать до предела — миллиарды обучающих данных. Чем на большем количестве данных обучаются модели НЛП, тем умнее они становятся. Тем не менее, данные (и человеческий язык!) только растут с каждым днем, как и новые методы машинного обучения и пользовательские алгоритмы. Все вышеперечисленные проблемы потребуют дополнительных исследований и новых методов для их улучшения.
Передовые методы, такие как искусственные нейронные сети и глубокое обучение, позволяют множеству техник, алгоритмов и моделей НЛП работать постепенно, как это делает человеческий разум. По мере их роста и укрепления у нас могут появиться решения для некоторых из этих проблем в ближайшем будущем.
Платформы анализа текста SaaS, такие как MonkeyLearn, позволяют пользователям обучать свои собственные модели машинного обучения NLP, часто всего за несколько шагов, что может значительно облегчить многие из ограничений обработки NLP, описанных выше. Инструменты без кода MonkeyLearn, обученные специфике языка и потребностям вашего бизнеса, предлагают огромные преимущества NLP для оптимизации процессов обслуживания клиентов, выяснения того, что клиенты говорят о вашем бренде в социальных сетях, и замыкания цикла обратной связи с клиентами.
Резюме
Хотя обработка естественного языка имеет свои ограничения, она по-прежнему предлагает огромные и широкие преимущества для любого бизнеса. И с появлением новых методов и новых технологий каждый день многие из этих барьеров будут преодолены в ближайшие годы.
Машинное обучение НЛП можно использовать для анализа огромных объемов текста в режиме реального времени для получения ранее недостижимых сведений.
Хотите попробовать анализ текста НЛП? Посетите MonkeyLearn, чтобы узнать, как легко начать работу с НЛП.
Инес Ролдос
22 декабря 2020 г.
Основы преобразования речи в текст | Облачная документация по преобразованию речи в текст
Обзор
Этот документ представляет собой руководство по основам использования преобразования речи в текст. В этом концептуальном руководстве рассматриваются типы запросов, которые вы можете сделать
к преобразованию речи в текст, как составить эти запросы и как
обрабатывать их ответы. Мы рекомендуем всем пользователям Speech-to-Text
прочтите это руководство и одно из связанных руководств, прежде чем погрузиться в
сам API.
Примечание: Все пользователи могут отправлять до 60 минут аудио в Speech-to-Text для
бесплатно каждый месяц . Если вы превысите эту сумму, понесены расходы. См.
страницу с ценами для деталей.
Попробуйте сами
Если вы новичок в Google Cloud, создайте учетную запись, чтобы оценить, как
Преобразование речи в текст работает в реальном мире
сценарии. Новые клиенты также получают бесплатные кредиты в размере 300 долларов США для запуска, тестирования и
развертывание рабочих нагрузок.
Попробуйте Преобразование речи в текст бесплатно
Речевые запросы
Преобразование речи в текст имеет три основных метода распознавания речи. Это
перечислены ниже:
Синхронное распознавание (REST и gRPC) отправляет аудиоданные в API преобразования речи в текст,
выполняет распознавание этих данных и возвращает результаты после всех звуковых
обработан. Запросы синхронного распознавания ограничены звуком
данные длительностью 1 минута или менее.
Асинхронное распознавание (REST и gRPC) отправляет аудиоданные в API преобразования речи в текст.
и инициирует длительную операцию . С помощью этой операции вы можете
периодически опрашивать результаты распознавания. Используйте асинхронные запросы для
аудиоданные любой продолжительности до 480 минут.
Потоковое распознавание (только gRPC) выполняет распознавание аудиоданных
предоставляется в течение
Двунаправленный поток gRPC.
Потоковые запросы предназначены для целей распознавания в реальном времени, таких как
захват живого звука с микрофона. Потоковое распознавание обеспечивает
промежуточные результаты во время захвата звука, позволяющие отображать результат,
например, пока пользователь все еще говорит.
Запросы содержат параметры конфигурации, а также аудиоданные. Следующее
разделы описывают эти типы запросов на признание, ответы на них
генерировать и как обрабатывать эти ответы более подробно.
Распознавание Speech-to-Text API
Запрос на синхронное распознавание Speech-to-Text API — самый простой метод для
выполнение распознавания речевых аудиоданных. Преобразование речи в текст может обрабатывать до
1 минута речевых аудиоданных, отправленных в синхронном запросе. После преобразования речи в текст
обрабатывает и распознает все аудио, возвращает ответ.
Синхронный запрос блокируется, это означает, что преобразование речи в текст должно
вернуть ответ перед обработкой следующего запроса. Преобразование речи в текст
обычно обрабатывает звук быстрее, чем в реальном времени, обрабатывая 30 секунд звука
в среднем за 15 секунд. В случае плохого качества звука ваше признание
запрос может занять значительно больше времени.
Преобразование речи в текст имеет методы REST и gRPC для вызова
Синхронные и асинхронные запросы Speech-to-Text API. В этой статье демонстрируется
REST API, потому что так проще показать и объяснить основы использования API.
Однако базовая структура запроса REST или gRPC очень похожа.
Запросы на потоковое распознавание
поддерживается gRPC.
Запросы синхронного распознавания речи
Синхронный запрос Speech-to-Text API состоит из конфигурации распознавания речи,
и звуковые данные. Образец запроса показан ниже:
Все запросы на синхронное распознавание Speech-to-Text API должны включать распознавание речи config поле (типа
Конфигурация распознавания). А RecognitionConfig содержит следующие подполя:
encoding — (обязательно) указывает схему кодирования поставляемого
аудио (типа AudioEncoding ). Если у вас есть выбор в кодеке, предпочитайте
кодирование без потерь, такое как FLAC или LINEAR16 для лучшей производительности.
(Дополнительную информацию см. в разделе Кодирование аудио.)
Поле кодировки является необязательным для FLAC 9.0412 и файлы WAV , где
кодировка включена в заголовок файла.
sampleRateHertz — (обязательно) указывает частоту дискретизации (в герцах)
поставляемый звук. (Для получения дополнительной информации о частотах дискретизации см.
Примерные цены ниже. )
Поле sampleRateHertz является необязательным для файлов FLAC и WAV , где
частота дискретизации включена в заголовок файла.
languageCode — (обязательно) содержит язык + регион/локаль для использования
распознавание речи поставляемого аудио. Код языка должен быть
Идентификатор BCP-47.
Обратите внимание, что языковые коды обычно
состоят из тегов основного языка и подтегов дополнительного региона для обозначения
диалекты (например, «en» для английского и «US» для Соединенных Штатов в
приведенный выше пример.) (Список поддерживаемых языков см.
Поддерживаемые языки.)
maxAlternatives — (необязательно, по умолчанию 1 ) указывает количество
альтернативные транскрипции предоставить в ответ. По умолчанию
API преобразования речи в текст обеспечивает одну первичную транскрипцию. Если вы хотите оценить
различные альтернативы, установите maxAlternatives на более высокое значение. Обратите внимание, что
Преобразование речи в текст будет возвращать альтернативы только в том случае, если распознаватель определит
альтернативы должны быть достаточного качества; в общем альтернативы
больше подходят для запросов в реальном времени, требующих обратной связи с пользователем (для
например, голосовые команды) и поэтому больше подходят для стриминга
запросы на признание.
profanityFilter — (необязательно) указывает, следует ли отфильтровывать ненормативную лексику.
слова или фразы. Отфильтрованные слова будут содержать первую букву
и звездочки для остальных символов (например, f***). Ненормативная лексика
фильтр работает по отдельным словам, он не обнаруживает оскорбительные или оскорбительные
речь, представляющая собой фразу или сочетание слов.
speechContext — (необязательно) содержит дополнительную контекстную информацию
для обработки этого звука. Контекст содержит следующее подполе:
фразы — содержит список слов и фраз, дающих подсказки
к задаче распознавания речи. Для получения дополнительной информации см.
информация о
контекст речи.
Звук подается в преобразование речи в текст через параметр audio типа
Распознавание аудио. аудио поле содержит либо из следующих подполей:
контент содержит аудио для оценки, встроенное в запрос.
Дополнительные сведения см. в разделе «Встраивание аудиоконтента» ниже.
Продолжительность звука, передаваемого непосредственно в этом поле, ограничена 1 минутой.
uri содержит URI, указывающий на аудиоконтент. Файл не должен быть
сжатый (например, gzip). В настоящее время это
Поле должно содержать URI Google Cloud Storage (в формате gs:// имя-корзины / путь_к_аудио_файлу ). Видеть
Передача ссылки на аудио по указанному ниже URI.
Дополнительные сведения об этих параметрах запроса и ответа приведены ниже.
Частота дискретизации
Вы указываете частоту дискретизации вашего аудио в sampleRateHertz поле
конфигурации запроса, и он должен соответствовать частоте дискретизации связанного аудио
контент или поток. Поддерживаются частоты дискретизации от 8000 Гц до 48000 Гц.
в Преобразовании речи в текст. Вы можете указать частоту дискретизации для FLAC или WAV в заголовке файла вместо использования поля sampleRateHertz . Файл FLAC должен содержать частоту дискретизации в заголовке FLAC , чтобы быть
переданный в API преобразования речи в текст.
Если у вас есть выбор при кодировании исходного материала, записывайте звук с помощью
частота дискретизации 16000 Гц. Значения ниже этого могут ухудшить распознавание речи.
точность, а более высокие уровни не оказывают заметного влияния на распознавание речи.
качественный.
Однако, если ваши аудиоданные уже были записаны в существующем семпле
частоту, отличную от 16 000 Гц, не передискретизируйте звук до 16 000 Гц. Самое наследие
телефонный звук, например, использует частоту дискретизации 8000 Гц, что может дать меньше
точные результаты. Если вы должны использовать такое аудио, предоставьте аудио для речи.
API с собственной частотой дискретизации.
Языки
Механизм распознавания речи в текст поддерживает различные языки и
диалекты. Вы указываете язык (и национальный или региональный диалект) вашего
аудио в поле languageCode конфигурации запроса, используя
Идентификатор BCP-47.
Полный список поддерживаемых языков для каждой функции
доступен на странице языковой поддержки.
Смещение времени (метки времени)
Преобразование речи в текст может включать значения смещения времени (метки времени)
для начала
и конец каждого произнесенного слова, которое распознается в предоставленном аудио. Время
значение смещения представляет количество времени, прошедшее с начала
звука с шагом 100 мс.
Сдвиги по времени особенно полезны для анализа более длинных аудиофайлов, когда вы
может потребоваться поиск определенного слова в распознанном тексте и
найти его (искать) в оригинальном аудио. Смещение времени поддерживается для всех
наши методы распознавания: распознает , потоковое распознавание и долговременное распознавание .
Значения смещения времени включаются только для первого варианта, указанного в
ответ узнавания.
Чтобы включить временные сдвиги в результаты вашего запроса, установите Параметр enableWordTimeOffs установлен в true в конфигурации вашего запроса. За
примеры использования REST API или клиентских библиотек см.
Использование временных смещений (временных меток).
Например, вы можете включить параметр enableWordTimeOffsets в
запросить конфигурацию, как показано здесь:
Преобразование речи в текст может использовать один из нескольких методов машинного обучения моделей для расшифровки вашего аудиофайла. Google обучил их
модели распознавания речи для определенных типов аудио и источников.
Когда вы отправляете запрос на расшифровку аудио
Speech-to-Text, вы можете улучшить результаты, которые вы получаете
путем указания источника исходного звука. Это позволяет
Speech-to-Text API для обработки ваших аудиофайлов с помощью
модель машинного обучения, обученная распознавать речевой звук из этого
конкретный тип источника.
Чтобы указать модель для распознавания речи, включите поле модель в объекте RecognitionConfig для вашего
запрос, указав модель, которую вы хотите использовать.
Преобразование речи в текст может использовать следующие типы машин
обучающие модели для расшифровки ваших аудиофайлов.
Примечание: См.
страницу поддерживаемых языков, чтобы узнать, какие модели
доступны для вашего языка.
Тип
Константа перечисления
Описание
Последняя длинная
последний_длинный
Используйте эту модель для любого вида
длинное содержание, такое как средства массовой информации или спонтанная речь и
разговоры. Рассмотрите возможность использования этой модели вместо модели видео.
особенно если модель видео недоступна на вашем целевом языке.
Вы также можете использовать это вместо модели по умолчанию.
Последний короткий
последний_короткий
Используйте эту модель для краткости
высказывания длительностью в несколько секунд. Это полезно для попытки
команды захвата или другие случаи использования однократной направленной речи.
Рассмотрите возможность использования этой модели вместо команды и поиска
модель.
Видео
видео
Используйте эту модель для расшифровки звука из видеоклипов или других источников
(например, подкасты) с несколькими динамиками. Эта модель также часто
лучший выбор для аудио, записанного с высоким качеством
микрофон или имеет много фонового шума. Для лучших результатов,
обеспечить звук, записанный с частотой дискретизации 16 000 Гц или выше.
Примечание: Это модель премиум-класса, которая стоит
больше стандартной ставки.
Телефон
phone_call
Используйте эту модель для расшифровки аудио из телефонного звонка.
Обычно звук телефона записывается с частотой дискретизации 8000 Гц.
Примечание: Усовершенствованная модель телефона является премиальной.
модель, которая стоит дороже стандартной цены.
ASR: команда и поиск
команда_и_поиск
Используйте эту модель для расшифровки коротких аудиоклипов. Немного
примеры включают голосовые команды или голосовой поиск.
ASR: по умолчанию
по умолчанию
Используйте эту модель, если ваш звук не подходит ни к одной из других моделей.
описано в этой таблице. Например, вы можете использовать это для длинной формы
аудиозаписи, в которых присутствует только один динамик. Модель по умолчанию
будет производить транскрипцию для любого типа аудио, включая
аудио, такие как видеоклипы, которые имеют отдельную модель специально
приспособлены к нему. Однако распознавание звука видеоклипа с использованием стандартного
модель хотела бы давать результаты более низкого качества, чем при использовании модели видео.
В идеале звук должен быть качественным, записанным с частотой 16 000 Гц или выше.
частота выборки.
Медицинский диктант
медицинский_диктант
Используйте эту модель для расшифровки заметок, продиктованных медицинским работником.
Медицинская беседа
медицинский_разговор
Используйте эту модель, чтобы расшифровать разговор между медицинским
профессионал и пациент.
Встроенное аудиосодержание
Встроенное аудио включается в запрос распознавания речи при передаче параметр содержимого в поле аудио запроса. Для встроенного звука
предоставляется как контент в запросе gRPC, этот звук должен быть совместим для
Прото3
сериализации и предоставляется в виде двоичных данных. Для встроенного звука, предоставляемого как
контент в запросе REST, этот звук должен быть совместим с JSON
сериализации и сначала закодировать в Base64. Видеть
Base64 Encoding Your Audio для получения дополнительной информации.
При построении запроса с использованием
клиентская библиотека Google Cloud,
обычно вы будете записывать эти двоичные (или закодированные в base-64) данные
непосредственно в поле содержимого .
Передать звук, на который ссылается URI
Как правило, вы передаете параметр uri в запросе речи.
Поле audio , указывающее на аудиофайл (в двоичном формате, а не в base64)
расположен в Google Cloud Storage следующего вида:
gs:// имя-ковша / путь_к_аудио_файлу
Например, следующая часть речевого запроса ссылается на образец аудио
файл, используемый в Quickstart:
У вас должны быть соответствующие права доступа для чтения файлов Google Cloud Storage, таких как
как одно из следующих:
Общедоступный (например, наши образцы аудиофайлов)
Доступно для чтения вашей служебной учетной записи, если используется авторизация служебной учетной записи.
Доступно для чтения учетной записи пользователя, если для учетной записи пользователя используется трехсторонний протокол OAuth.
авторизация.
Дополнительную информацию об управлении доступом к Google Cloud Storage можно найти по адресу
Создание и управление списками контроля доступа
в документации Google Cloud Storage.
Ответы API преобразования речи в текст
Как указывалось ранее, синхронный ответ API преобразования речи в текст может занять некоторое время
для возврата результатов, пропорциональных длине предоставленного аудио. Один раз
обработано, API вернет ответ, как показано ниже:
результаты содержит список результатов (типа SpeechRecognitionResult )
где каждый результат соответствует сегменту аудио (сегменты аудио
разделены паузами). Каждый результат будет состоять из одного или нескольких следующих полей:
альтернативы содержит список возможных транскрипций типа Альтернативы распознавания речи . Наличие более одной альтернативы
появляется зависит как от того, запрашивали ли вы более одной альтернативы
(установив для maxAlternatives значение больше 1 ) и от того,
Speech-to-Text производил альтернативы достаточно высокого качества. Каждый
альтернатива будет состоять из следующих полей:
стенограмма содержит расшифрованный текст. Видеть
Обработка транскрипций ниже.
достоверность содержит значение от 0 до 1, указывающее, как
уверен, что Speech-to-Text имеет заданную транскрипцию. Видеть
Интерпретация значений достоверности ниже.
Если невозможно распознать речь из предоставленного аудио, то
возвращенный список результатов не будет содержать элементов. Нераспознанная речь обычно является результатом очень плохого качества звука,
или из кода языка, кодировки или значений частоты дискретизации, которые не совпадают
прилагаемый звук.
Компоненты этого ответа объясняются в следующих разделах.
Каждый синхронный ответ Speech-to-Text API возвращает список результатов,
а не один результат, содержащий все распознанные аудио. Список
распознанное аудио (в пределах элементов расшифровки ) появится в
смежный порядок.
Выбрать альтернативы
Каждый результат успешного ответа синхронного распознавания может содержать
одна или несколько альтернатив (если maxAlternatives значение для запроса
больше, чем 1 ). Если функция преобразования речи в текст определяет, что альтернатива
имеет достаточно
значение достоверности, то эта альтернатива включается в
ответ. Первая альтернатива в ответе всегда лучшая
(скорее всего) альтернатива.
Настройка maxAlternatives на более высокое значение, чем 1 не означает и не гарантирует
что будет возвращено несколько альтернатив. В общем, более одного
альтернатива больше подходит для предоставления пользователям возможностей в реальном времени, получающих
результаты через запрос на потоковое распознавание.
Обработка транскрипций
Каждая альтернатива, указанная в ответе, будет содержать транскрипцию содержащий распознанный текст. При наличии последовательных альтернатив,
вы должны объединить эти транскрипции вместе.
Следующий код Python перебирает список результатов и объединяет
транскрипции вместе. Обратите внимание, что мы берем первую альтернативу (нулевую) в
все случаи.
ответ = service_request. execute()
распознанный_текст = 'Транскрибированный текст: \n'
для i в диапазоне (len (ответ ['результаты'])):
распознанный_текст += ответ['результаты'][i]['альтернативы'][0]['стенограмма']
Значения достоверности
Значение достоверности является оценкой от 0,0 до 1,0. Это рассчитано
путем агрегирования значений «вероятности», присвоенных каждому слову в
аудио. Более высокое число указывает на предполагаемую большую вероятность того, что
отдельные слова были распознаны правильно. Обычно это поле
предоставляется только для верхней гипотезы и только для результатов, где is_final=истина . Например, вы можете использовать значение достоверности .
решить, показывать ли
альтернативные результаты
пользователю или запросить подтверждение у пользователя.
Однако имейте в виду, что модель определяет «лучший» результат с наивысшим рейтингом на основе
на большем количестве сигналов, чем только достоверности баллов (например, контекст предложения). Из-за этого иногда бывают случаи, когда лучший результат не
имеют наивысший показатель достоверности. Если вы не запрашивали несколько альтернатив
результаты, единственный возвращенный «лучший» результат может иметь более низкое значение достоверности
чем предполагалось. Это может произойти, например, в тех случаях, когда редкие слова
использовался. Редко используемому слову можно присвоить низкое значение «вероятности».
даже если он распознан правильно. Если модель определяет редкое слово как
наиболее вероятный вариант, основанный на контексте, этот результат возвращается даже наверху
если результат достоверность Значение ниже, чем у альтернативных вариантов.
Примечание: Ваш код не должен ожидать достоверности в качестве обязательного поля, так как это не так.
гарантированно будет точным или даже установленным в любом из результатов.
Асинхронные запросы и ответы
Асинхронный запрос API преобразования речи в текст к методу LongRunningRecognize
по форме идентичен синхронному
Запрос API преобразования речи в текст. Однако,
вместо возврата ответа асинхронный запрос инициирует Длительная работа (типа
Операция)
и немедленно вернуть эту операцию вызываемому объекту. Вы можете использовать асинхронный
распознавание речи со звуком любой продолжительности до 480 минут.
Обратите внимание, что результатов пока нет. Преобразование речи в текст продолжит
обработайте звук и используйте эту операцию для сохранения результатов. Результаты будут
появляются в поле ответа операция
возвращается, когда LongRunningRecognize запрос завершен.
Полный ответ после завершения запроса отображается ниже:
Обратите внимание, что выполнено установлено значение True и что ответ операции содержит набор результатов типа
Результат Распознавания Речи
тот же тип, который возвращается синхронным запросом на распознавание Speech-to-Text API.
По умолчанию асинхронный ответ REST будет установлен выполнено от до False , значение по умолчанию; однако, потому что
JSON не требует наличия значений по умолчанию в поле при тестировании. завершена ли операция, вы должны проверить, что done Поле присутствует и установлено на True .
Запросы на распознавание потокового API преобразования речи в текст
Вызов распознавания потокового API преобразования речи в текст предназначен для захвата и
распознавание аудио в двунаправленном потоке. Ваша заявка может быть отправлена
аудио в потоке запроса и получать промежуточное и окончательное распознавание
результаты в потоке ответов в режиме реального времени. Промежуточные результаты представляют
текущий результат распознавания участка аудио, а окончательный
результат распознавания представляет собой последнее, наилучшее предположение для этого фрагмента аудио.
Потоковые запросы
В отличие от синхронных и асинхронных вызовов, при которых вы отправляете как
конфигурация и аудио в одном запросе, вызывая потоковую речь
API требует отправки нескольких запросов. Первый StreamingRecognizeRequest должен содержать конфигурацию типа
StreamingRecognitionConfig
без какого-либо сопутствующего звука. Последующие StreamingRecognizeRequest отправлены
над одним и тем же потоком будет состоять из последовательных кадров необработанных аудиобайтов.
A StreamingRecognitionConfig состоит из следующих полей:
config — (обязательно) содержит информацию о конфигурации аудио,
типа
Конфигурация распознавания
и такое же, как показано в синхронных и асинхронных запросах.
single_utterance — (необязательно, по умолчанию false ) указывает, является ли это
запрос должен автоматически завершиться после того, как речь больше не будет обнаружена. Если установлено,
Преобразование речи в текст обнаружит паузы, тишину или неречевой звук, чтобы определить
когда прекратить признание. Если не установлено, поток будет продолжать слушать и
обрабатывать звук до тех пор, пока либо поток не будет закрыт напрямую, либо
предельная длина превышена. Настройка single_utterance от до true is
полезно для обработки голосовых команд.
interim_results — (необязательно, по умолчанию false ) указывает, что это
потоковый запрос должен возвращать временные результаты, которые могут быть уточнены в любое время.
позднее время (после обработки большего количества аудио). Промежуточные результаты будут отмечены
в ответах через настройку is_final на false .
Потоковые ответы
Потоковые результаты распознавания речи возвращаются в серии ответов
типа
StreamingRecognitionResponse.
Такой ответ состоит из следующих полей:
speechEventType содержит события типа
SpeechEventType.



 Соответствие безударных гласных и обозначающих их букв (ударные соответствуют буквам)
Соответствие безударных гласных и обозначающих их букв (ударные соответствуют буквам)

 повторить, обобщить и углубить сведения о звуках и буквах
повторить, обобщить и углубить сведения о звуках и буквах )
)



 Традиции многовековых контактов и значительный период общей государственности сформировали уникальную культурную ткань, в которой переплетены традиции двух народов.
Традиции многовековых контактов и значительный период общей государственности сформировали уникальную культурную ткань, в которой переплетены традиции двух народов. В 2022-2023 гг. планируется поддержка Книжного уголка России в Национальной библиотеке РК, пополнение русскоязычного библиотечного фонда казахских библиотек, сохранение русского некрополя в городе Кызылорде, поддержка театрального проекта в Костанае и другие проекты», — говорит Елена Чернышкова, руководитель Фонда наследия русского зарубежья.
 В 2022-2023 гг. планируется поддержка Книжного уголка России в Национальной библиотеке РК, пополнение русскоязычного библиотечного фонда казахских библиотек, сохранение русского некрополя в городе Кызылорде, поддержка театрального проекта в Костанае и другие проекты», — говорит Елена Чернышкова, руководитель Фонда наследия русского зарубежья.
В 2022-2023 гг. планируется поддержка Книжного уголка России в Национальной библиотеке РК, пополнение русскоязычного библиотечного фонда казахских библиотек, сохранение русского некрополя в городе Кызылорде, поддержка театрального проекта в Костанае и другие проекты», — говорит Елена Чернышкова, руководитель Фонда наследия русского зарубежья.
 Домбровского в период нахождения в городе Алма-Ате пройдет 30 сентября на малой сцене культурного пространства «ТРАНСФОРМА». Спектакль подготовлен специально для российско-казахстанского фестиваля и в нем, помимо самой Камиллы Рашид, примут участие популярные алматинские артисты Куантай Абдимади и Лаура Турсунканова.
Домбровского в период нахождения в городе Алма-Ате пройдет 30 сентября на малой сцене культурного пространства «ТРАНСФОРМА». Спектакль подготовлен специально для российско-казахстанского фестиваля и в нем, помимо самой Камиллы Рашид, примут участие популярные алматинские артисты Куантай Абдимади и Лаура Турсунканова.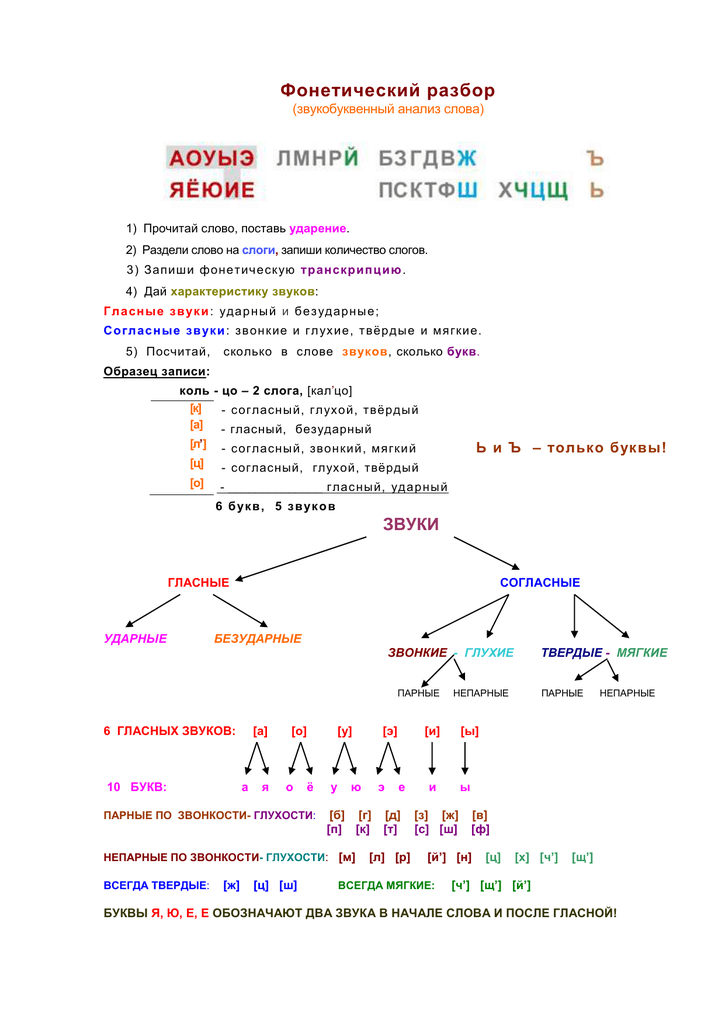
 РФ.
РФ.  Гиачин и Клаудио Руллент},
booktitle={ЦВЕТ},
год = {1988}
}
Гиачин и Клаудио Руллент},
booktitle={ЦВЕТ},
год = {1988}
} 

 Giachin, C. Rullent
Giachin, C. Rullent
 GLP реализует многопроцессорную схему на основе повестки дня, которая позволяет легко применять…
GLP реализует многопроцессорную схему на основе повестки дня, которая позволяет легко применять…

 Томита
Томита Примечательно, что мы обнаружили паттерн убывающей аддитивной вероятности для каждого решения о встраивании постмодифицирующих предложений, хотя паттерн различался в устной и письменной речи.
Примечательно, что мы обнаружили паттерн убывающей аддитивной вероятности для каждого решения о встраивании постмодифицирующих предложений, хотя паттерн различался в устной и письменной речи.
 Сложность «на одно предложение» также потенциально может ввести в заблуждение.
Сложность «на одно предложение» также потенциально может ввести в заблуждение. Разговорный жанр с наименьшим уровнем самокоррекции – выпуск новостей (0,7%). Напротив, в сценариях студенческих экзаменов авторами вычеркнуто около 5% слов, за ними следуют социальные письма и студенческие эссе, в которых около 0,8% слов помечены для удаления.
Разговорный жанр с наименьшим уровнем самокоррекции – выпуск новостей (0,7%). Напротив, в сценариях студенческих экзаменов авторами вычеркнуто около 5% слов, за ними следуют социальные письма и студенческие эссе, в которых около 0,8% слов помечены для удаления. Акт транскрипции сам по себе является аннотацией, и решения по структурной идентификации отдельных предложений лучше всего понимать как неотъемлемую часть синтаксического анализа. В лингвистических исследованиях следует отдавать предпочтение устным данным, но в современных корпусах преобладают большие объемы письменного текста. Мы отмечаем, что это не является обязательным аспектом корпусной лингвистики, и вводим два анализируемых корпуса, содержащие устные транскрипции.
Акт транскрипции сам по себе является аннотацией, и решения по структурной идентификации отдельных предложений лучше всего понимать как неотъемлемую часть синтаксического анализа. В лингвистических исследованиях следует отдавать предпочтение устным данным, но в современных корпусах преобладают большие объемы письменного текста. Мы отмечаем, что это не является обязательным аспектом корпусной лингвистики, и вводим два анализируемых корпуса, содержащие устные транскрипции. ..
.. .100
.100  6, 2019)
6, 2019) Определение фонем языка требует лингвистического анализа, и могут возникнуть споры по поводу окончательного набора. Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита.
Определение фонем языка требует лингвистического анализа, и могут возникнуть споры по поводу окончательного набора. Отдельные человеческие языки обычно имеют не более нескольких десятков фонем. Набор всех возможных фонем может быть представлен с помощью Международного фонетического алфавита. Для каждого слова возможно более одного сопоставления (произношения).
Для каждого слова возможно более одного сопоставления (произношения).
 д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности должны быть предсказаны с помощью эвристики.
д. Не все комбинации будут присутствовать в обучающем материале, поэтому их вероятности должны быть предсказаны с помощью эвристики. Например:
Например:

 Выходные «слова», начинающиеся с двух символов подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении.
Выходные «слова», начинающиеся с двух символов подчеркивания («__»), являются «мета»-словами, предоставляющими дополнительную информацию о распознанном предложении. Для каждого предложения создается одно мета-слово
Для каждого предложения создается одно мета-слово  Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON.
Он берет граф намерений, сгенерированный во время обучения, и использует его для преобразования транскрипций из речевой системы в события JSON. Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой:
Все немета-слова собираются для окончательной текстовой строки, включая замены и преобразования. Окончательный результат примерно такой: lrec-conf.org/proceedings/lrec2018/img/ombre_left.gif»>
lrec-conf.org/proceedings/lrec2018/img/ombre_left.gif»> Говорящий атлас региональных языков Франции.
Говорящий атлас региональных языков Франции.  0
0  д.)
д.) 0: корпус для обнаружения новизны на уровне документа
0: корпус для обнаружения новизны на уровне документа  Извлечение англо-персидского параллельного корпуса из сопоставимых корпусов
Извлечение англо-персидского параллельного корпуса из сопоставимых корпусов  Практический пример задач на сходство «вопрос-вопрос» и «вопрос-ответ»
Практический пример задач на сходство «вопрос-вопрос» и «вопрос-ответ» 
 Корпус для изучения относительных отношений для именных имен.
Корпус для изучения относительных отношений для именных имен. 
 0
0 
 0
0  Практический пример порядка слов
Практический пример порядка слов 
 полностью преодолеть.
полностью преодолеть.