Морфологический разбор слова «дети»
Часть речи: Существительное
ДЕТИ — слово может быть как одушевленное так и неодушевленное, смотрите по предложению в котором оно используется.
Начальная форма слова: «РЕБЕНОК»
| Слово | Морфологические признаки |
|---|---|
| ДЕТИ |
|
Все формы слова ДЕТИ
РЕБЕНОК, РЕБЕНКА, РЕБЕНКУ, РЕБЕНКОМ, РЕБЕНКЕ, ДЕТИ, ДЕТЕЙ, ДЕТЯМ, ДЕТЬМИ, ДЕТЯХ
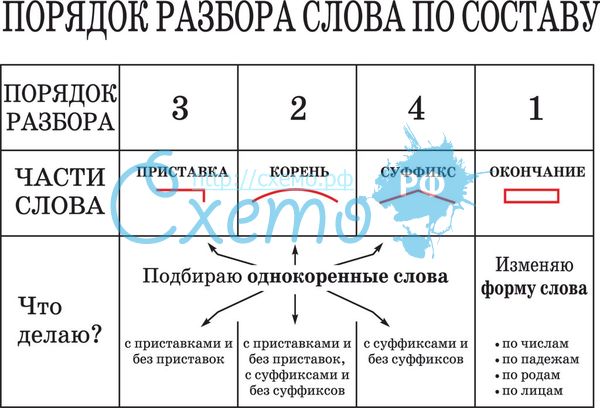
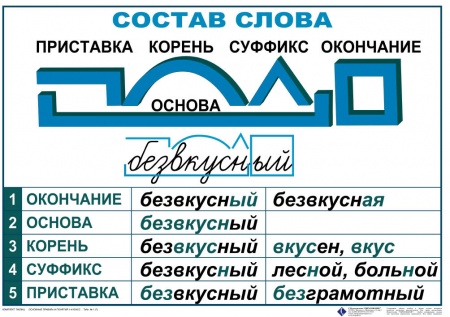
Разбор слова по составу дети
| Основа слова | дет |
|---|---|
| Корень | дет |
| Окончание | и |
Разобрать другие слова
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ДЕТИ» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Найти синонимы к слову «дети»
Примеры предложений со словом «дети»
1
Только и слышишь нынче по радио и телевидению: безнадзорные дети, дети-сироты, опекаемые дети, сиротские приюты.
Философия крутых ступеней, или Детство и юность Насти Чугуновой, Альберт Карышев, 2013г.
2
Полтысячи детей – теперь заметней стало, что это дети, – самые обыкновенные дети, бесились среди развалин, дорвавшись до купания.
Ночевала тучка золотая, Анатолий Приставкин, 1987г.
3
но нам хочется знать, почему дети этих героев и мы, дети их детей, не имеем теперь ни демократии, ни хоть какого-нибудь прогресса в нашей жизни?
Заговорщики. Преступление, Ник. Шпанов, 1951г.
Преступление, Ник. Шпанов, 1951г.
4
И дети у него вышли отличные – вентиль содержали в порядке со всеми вытекающими для их детей и детей их детей последствиями.
Мало ли что говорят, Татьяна Соломатина, 2012г.
5
У кого-то дети маленькие, у кого-то средние, у кого-то большие, кто-то сам еще ребенок, а кто-то не собирается заводить детей.
Новый мир. Сборник статей, Игорь Власьев
Найти еще примеры предложений со словом ДЕТИ
Весенние акции! Детский клуб «ИНДИГО» дарит подарки родителям и детям
Новости / Перед фактомВчера, 09:00
Подарки бывают разные: малышня всегда рада игрушкам, шарикам и новым знакомствам, а для родителей наиболее приятны скидки на качественный продукт.

Настоящим подарком от детского клуба «ИНДИГО» выступает проводимая акция на обучение дошкольников.
Детский клуб «ИНДИГО» не первый год успешно набирает активную и любознательную команду на каждое из двух образовательных направлений: «Развитие маленьких гениев» (3-4 года) и «Подготовка к школе в малых группах» (5-6 лет).
Родители и дети несколько раз в неделю спешат на двухчасовой комплекс увлекательных занятий, который включает обучение грамоте и развитие речи, математику и логику, музыкальный английский. Здесь готовят руку к письму и фантазируют в творческой мастерской.
Занятия в клубе в основном начинаются в 18.00, когда рабочий день у родителей уже закончен, а дети еще полны энергии и сил, – самое время окунуться в атмосферу ненавязчивого обучения в игровой форме, соответствующей определенному возрасту.
Малыши трех-четырех лет порой не замечают, что игра направлена на усвоение сложных математических или грамматических понятий.
Ребята постарше уже больше мотивированы на получение энциклопедических знаний – они помогут им при прохождении увлекательного квеста, принесут победу в «Индиго-поединке» или будут оценены смайликом на футболке. Скучать не приходится никому, ведь уроки по 30 минут быстро сменяют друг друга, комплекс «Подготовка к школе в малых группах» длится два часа. Нужно успеть почитать, разбить слова на слоги, разобрать состав числа, спеть песню на английском языке и выполнить упражнение в тетради. Не беда, если кто-то не успел – в группе из восьми человек в приоритете индивидуальный подход.
В «ИНДИГО» очень ответственно подходят к охране здоровья детей и взрослых, антивирусные мероприятия и рециркуляторы помогают заботиться об этом.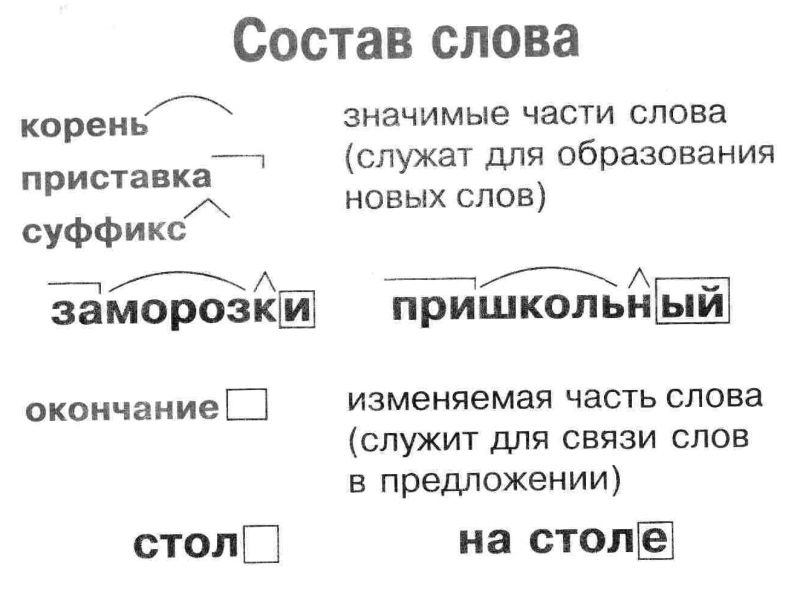
Безусловным плюсом обучения в ЧДОУ Детский Клуб «ИНДИГО» является наличие образовательной лицензии, и, соответственно, родители имеют возможность получить с оплаченных услуг налоговый вычет.
Все подробности об акциях – по телефону 43-07-66 и в группе.
Читайте нас в Telegram
Поделиться новостью
Служба новостей «Верстов.Инфо»
Если вы заметили ошибку в тексте, выделите ее и нажмите Ctrl+Enter
Смотрите также
Новости партнеров
5 февраля 2023
Вниманию горожан! Информация о плановых отключениях электроэнергии
Новости партнеров
Авто
10 февраля 2023
В Магнитогорске у ТРК «Континент» эвакуировали автомобили нарушителей
Авто
ВИП-новость
17 февраля 2023
Посёлок спит – «Алмаз» дымит: магнитогорский завод не испугался главы СК Бастрыкина
ВИП-новость
Перед фактом
5 февраля 2023
Под Магнитогорском простятся с двумя военнослужащими, погибшими в зоне СВО
Перед фактом
NLP: анализ предложения путем анализа зависимостей с помощью Spacy | Кундан Джоши | Январь 2023 г.

При обработке естественного языка нам часто приходилось приступать к подробной семантической анатомии грамматического состава предложений. В то время как модели машинного обучения помогают решать проблемы классификации и категоризации текста на широком уровне, навязчивый анализ предложений становится неизбежным для точного анализа намерений и других параметров для различных целей. Здесь нам нужно будет перейти к грамматическим нюансам конкретного языка, с которым мы имеем дело — подумайте о глаголах, прилагательных, существительных и т. д., которые так часто освещаются в различных блогах и сообщениях о батареях, включая такие функции, как POS, NER. и т. д. Этот бит посвящен не очень распространенной конструкции деконструкции предложения, называемой синтаксическим анализом зависимостей.
Разбор зависимостей — это тип лингвистического представления грамматических составляющих путем разделения предложений на бинарные отношения «голова-и-зависимость» между токенами. Простая комбинация, зависящая от головы, содержит всю структуру отношений предложения, сжимая ее в рудиментарную и асимметричную ассоциацию, не вдаваясь в какую-либо продвинутую лексикологию.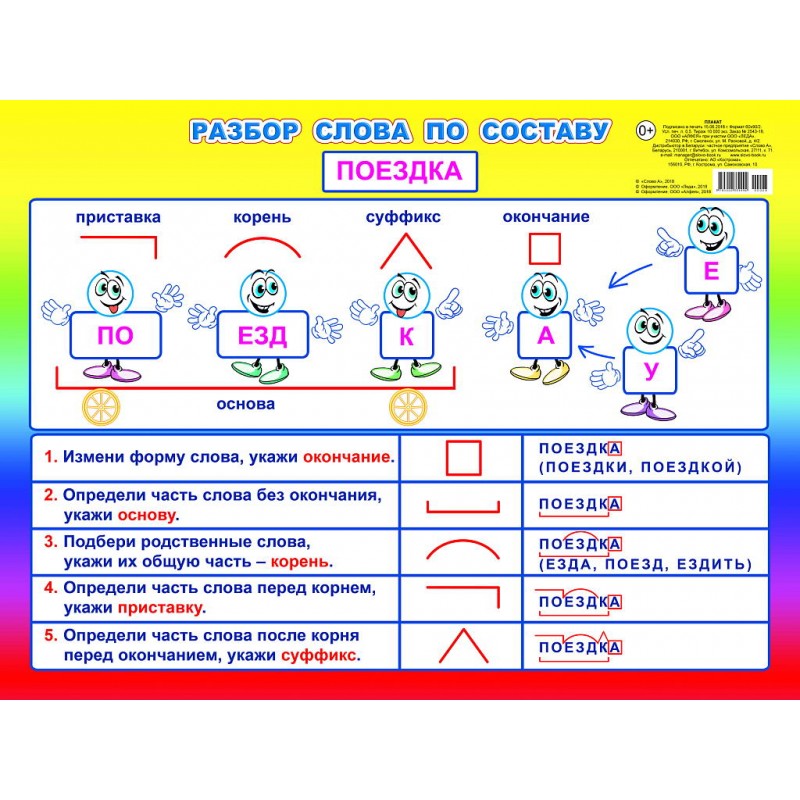 Хотя это в большей степени относится к языкам, не зависящим от порядка слов, это в значительной степени применимо и к английскому языку.
Хотя это в большей степени относится к языкам, не зависящим от порядка слов, это в значительной степени применимо и к английскому языку.
Корень обычно является основным глаголом (в глагольной фразе) — каждое проанализированное отношение зависимости имеет единственный корень, голову дерева; дерево представляет собой ориентированный граф пар головка-впадина, изображенный дугами/стрелками от головок к зависимым и квалифицированный функциональными аннотациями. Например, если у нас есть предложение
«Пожалуйста, запишитесь на срочную встречу в 16:30 на пятницу с доктором Бэннером».
Типичный граф/дерево зависимостей показан как ориентированный граф вершин и дуг с одним корнем.
Лексические элементы, связанные с глаголом «книга», связаны с ним, как показано в проанализированном дереве зависимостей. Чтобы проиллюстрировать, «срочно» — это модификатор «назначения», связанный непосредственно в структуре зависимости, так что мы можем установить связь относительно типа встречи (модификатор прилагательного).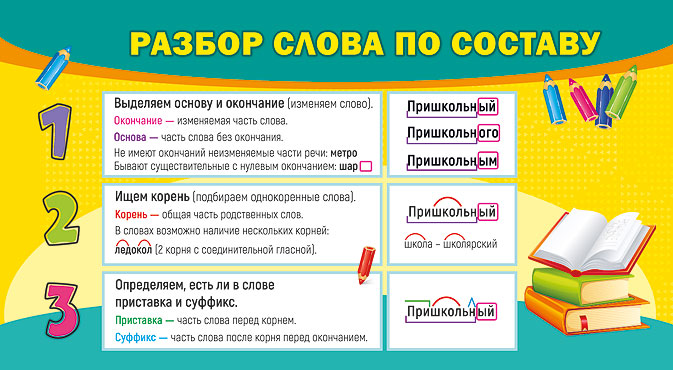
Таким образом, мы видим, что для извлечения из предложения элементов, представляющих значимую информацию, нам достаточно одного отношения, основанного на ссылке. Это обычно применимо к языкам, которые демонстрируют более гибкий порядок слов, отсутствие которого в противном случае потребовало бы множественных условных проверок или регулярных выражений на основе правил для определения намерений и параметров.
Синтаксический анализ на основе дерева зависимостей больше не учитывает порядок слов или линейный порядок. Языки со свободным порядком слов выигрывают от синтаксического анализа зависимостей. Чешский и персидский, вероятно, подходят лучше всего, потому что они являются языками со свободным порядком слов, но тогда я уступаю кандидату на докторскую литературу, чтобы он еще взвесил этот вопрос. 🙂
Итак, хватит теории; давайте приступим к гайкам и болтам.
Для тех, кто опоздал — создайте виртуальную среду python и активируйте ее.
python3 -m venv tutorial-env
source tutorial-env/bin/activate
Установите spacy и загрузите маленькую модель — для этой цели должно подойти.
pip install -U pip setuptools колесо
pip install -U spacy
python -m spacy загрузить en_core_web_sm
Отлично! Теперь перейдем к делу…
Быстрый и базовый анализ зависимостей… давайте вернемся к предыдущему ежедневному заявлению… «Пожалуйста, запишитесь на срочную встречу в пятницу в 16:30 к доктору Бэннеру». (хотя и не обычный врач).
Теперь давайте разберем его со Спейси. Очень элементарная пара строк Spacy, как показано ниже:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Пожалуйста, запишитесь на срочную встречу в пятницу в 16:30 с доктором Бэннером.")print("{:25} {:10} {:10} {:20} {:10} {:10} {:50} {:50}".format('Token','Pos-Tag',' Dep','Head','Pos-Head','NER', 'Lefts', 'Rights'))
print("_" * 150)
для токена в документе:
print("{:25} { :10} {:10} {:20} {:10} {:10} {:50} {:50}".format(token.text, token.pos_, token.dep_, token.head.text, token .head.pos_, token.ent_type_, "-".join([w.text для w в token.lefts]), "-".join([w.text для w в token.rights])))
 text для w в token.lefts]), "-".join([w.text для w в token.rights])))
text для w в token.lefts]), "-".join([w.text для w в token.rights]))) дает нам этот вывод:
Не вдаваясь в NER и POS, поскольку это в любом случае часто обсуждаемая тема, давайте прямо рассмотрим токены, проанализированные зависимостями. Корневой токен предложения обычно является глаголом действия — по крайней мере, для предложения, ориентированного на глагольную фразу. Это становится жизненно важным, поскольку большую часть времени нам может понадобиться повернуть наш анализ предложения вокруг этого корневого токена.
Набор типичных/наиболее часто встречающихся определений или грамматических отношений DEP:
NSUBJ Номинальный подлежащий
DOBJ Прямой объект
NMOD Номинальный модификатор
AMOD Модификатор прилагательного
NUMMOD Числовой модификатор
APPOS Модификатор аппозиции показанный ранее график будет выглядеть следующим образом:
from spacy import displacy
displacy.serve(doc, options={"distance": 120})
Анализ зависимостей лучше всего решать путем более глубокого анализа с помощью анализа тегов DEP. на другом примере.
на другом примере.
import spacy
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("merge_noun_chunks")
doc = nlp("NewYork-Presbyterian щедро заплатил доктору Стрэнджу 500000$, в то время как Kamartaj заплатил ему только 100$")print("{:25} {:10} {:10} {:20} {:10} {:10} {:50} {:50}".format('Token','Pos-Tag',' Dep','Head','Pos-Head','NER', 'Lefts', 'Rights'))
print("_" * 150)
для токена в документе:
print("{:25} { :10} {:10} {:20} {:10} {:10} {:50} {:50}".format(token.text, token.pos_, token.dep_, token.head.text, token .head.pos_, token.ent_type_, "-".join([w.text для w в token.lefts]), " ".join([w.text для w в token.rights])))для токена в документе:
, если token.pos_ == "NUM" и token.dep_ == "dobj":
работодатель = [w.text для w в token.head.lefts, если w.dep_ == "nsubj "]
, если работодатель:
print(" Работодатель: {:20s} \tSalary: {:10}".format(employer[0], token.text))
else:
obj = [[r для r в w .
if obj:
print(" Работодатель: {:20s} \tSalary: {:10 }".format(str(obj[0][0]), token.text))
 rights if r.dep_ == 'pobj'] for w in token.head.rights if w.dep_ == "agent"]
rights if r.dep_ == 'pobj'] for w in token.head.rights if w.dep_ == "agent"] Здесь мы реализуем простые условные проверки на основе правил в токенах, которые мы итерируем; если указанный токен является числом и прямым дополнением, то:
— прямое дополнение глагольной фразы — это именное словосочетание, которое является явно подразумеваемым или обвинительным дополнением глагола, в этом случае «NY-Pres оплачено 500000» означает, что глагол «оплачивается», а прямое дополнение — « 500000′.
— после того, как мы находим начало числа, которое является глагольной фразой, мы смотрим налево, чтобы найти именной подлежащий (существительное/деятель) глагольного действия, в данном случае «NY-Pres»
— в пассивный залог, как во 2-м падеже / еще предложении, нам нужно искать pobj, так как это косвенная ссылка, чтобы найти именную группу, которая не является прямой головой, но следует (справа) от предлога (‘ by’) — что по существу является предложным дополнением в страдательном залоге — в данном случае «Камартай».
Немного запутанно, но эффективно в подобных случаях.
Возьмем другой пример.
import spacy
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe("merge_noun_chunks")
doc = nlp("Хороший доктор сейчас живет в Непале, но раньше жил в Нью-Йорке")print ("{:25} {:10} {:10} {:20} {:10} {:10} {:50}".format('Token','Pos-Tag','Dep','Head ','Pos-Head','NER', 'Дети'))
для токена в документе:
print("{:25} {:10} {:10} {:20} {:10} {:10 } {:50}".format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_, token.ent_type_, ":".join([w.text для w в токен.дети])))для токена в документе:
, если token.ent_type_ == 'GPE':
head = token.head
, если head.dep_ == 'prep':
grand_head = head.head
, если grand_head.tag_ in ('VBG ','VBZ','VBP'):
, если есть ([Истинно для дочернего элемента в grand_head.children, если child.dep_ == 'aux' и child.tag_ in ('VBD')]):
print("previous location = {}".format(token.
else:
print("current location = {}".format(token.text))
elif grand_head.tag_ in ('VBD','VBN'):
, если есть ([Верно для дочернего элемента в grand_head.children, если child.dep_ == 'auxpass' и child.tag_ in ('VBP')]):
print("текущее местоположение = {}".format(token.text))
else:
print("предыдущее местоположение = {}".format(token.text))
 text))
text)) что приводит к —
Деконструировать предложения с информацией о сущностях, таких как местоположения или организации, мы можем повернуть анализ вокруг рассматриваемого NER, в данном случае геополитической сущности, а затем проследить наш путь вокруг лингвистических элементов, окружающих ее. Как видно из предложений if-else, информационный блок типа «живет в Непале» имеет ООП с элементом HEAD в качестве предлога («в»). Отслеживание в обратном направлении от предлога (grand_head) показывает тег POS (часть речи) дедушки и бабушки, который представляет собой ГЛАГОЛ в единственном числе настоящего («VBZ»), что помогает нам определить текущее место жительства субъекта («врач») .
Однако это может быть очень ограничивающим условным ограничением, так как в случаях, когда используется форма причастия настоящего времени («VBG») — поскольку причастие настоящего времени будет подразумевать настоящее продолженное время, только если после вспомогательного «быть» (есть, есть и т. д.), что само по себе является настоящим временем. «Дополнительно», если оно присутствует, будет дочерним элементом причастия настоящего времени, поэтому мы можем проверить это и сделать вывод, является ли оно настоящим временем/местом жительства или прошедшим временем (если вспомогательное слово имеет прошедшее время, как в этом случае).
Как мы видели, это может превратиться в настоящий лабиринт условных конструкций, которые необходимо сплести вместе, чтобы анатомировать предложение и разобраться в хитросплетениях хронологии, сущностей и ассоциаций. Хотя это действительно относится к области обработки предложений на основе правил, это дает нам лучшее представление о точности анализа контекста и намерений.
Сочетание этого с богатством морфологии, NER, POS и т. д. элементов, которые допускает Spacy, дает гораздо более точное НЛП-рассечение.
Да, и кстати, все имена людей, мест, организаций, включая цифры вознаграждения в примерах текстовых предложений, являются чисто вымышленными и не имеют никакого сходства или корреляции с какими-либо живыми, реальными или иным образом широко вымышленными существами. …. 🙂
Удачного разбора!
Цитаты: Фото Финна Мунда на Unsplash
Спасибо, что являетесь частью нашего сообщества! Перед тем, как уйти:
- 👏 Хлопайте в ладоши и следите за автором 👉
- 📰 Смотрите больше контента в публикации Level Up Coding
- 🔔 Следуйте за нами: Twitter | Линкедин | Информационный бюллетень
🚀👉 Присоединяйтесь к коллективу талантов Level Up и найдите прекрасную работу
Анализ зависимостей в НЛП. Синтаксический анализ или анализ зависимостей… | Шириш Кадам
Синтаксический анализ или Анализ зависимостей — это задача распознавания предложения и присвоения ему синтаксической структуры.
Теперь задача синтаксического разбора довольно сложна из-за того, что данное предложение может иметь несколько деревьев разбора, которые мы называем неоднозначностями. Рассмотрим предложение « Забронируйте этот рейс. », который может формировать несколько деревьев синтаксического анализа на основе его неоднозначной части речевых тегов, если эти неоднозначности не будут разрешены.
В этом посте мы попытаемся реализовать несколько синтаксических анализаторов из разных библиотек:
Анализатор зависимостей spaCy предоставляет свойства токена для навигации по сгенерированному дереву разбора зависимостей. Использование атрибута dep дает отношение синтаксической зависимости между головным токеном и его дочерним токеном. Схема синтаксической зависимости используется от ClearNLP. Сгенерированное дерево синтаксического анализа соответствует всем свойствам дерева, и каждый дочерний токен имеет только один головной токен, хотя головной токен может иметь несколько дочерних элементов. Мы можем получить жетон головы с помощью 9Свойство 0165 token.
token.children . Поддерево маркера также можно извлечь с помощью свойства token.subtree . Точно так же предков для токена можно получить с помощью token.ancestors . Чтобы получить крайний правый и крайний левый токен синтаксических потомков токена, можно использовать token.right_edge и token.left_edge . Также стоит упомянуть, что для извлечения соседнего токена мы можем использовать токен.номер . spaCy не предоставляет встроенного древовидного представления, хотя вы можете использовать древовидное представление NLTK. Вот фрагмент кода для этого:def tok_format(tok):
return "_".join([tok.orth_, tok.tag_, tok.dep_])def to_nltk_tree(node):
if node.n_lefts + node.n_rights > 0:
return Tree(tok_format(node), [to_nltk_tree(child) для потомка в node.children])
else:
return tok_format(node)command = "Отправьте журналы отладки руководителю проекта сегодня в 9:00 AM"
en_doc = en_nlp(u'' + команда)[to_nltk_tree(sent.
 root).pretty_print() для отправки в en_doc.sents]
root).pretty_print() для отправки в en_doc.sents] Вот формат вывода ( Token_POS Tags_Dependency Tag ): —
Давайте попробуем извлечь заглавное слово из вопроса, чтобы понять, как работает зависимость.Заглавное слово в вопросе может быть извлечено с использованием различных отношений зависимости.Но сейчас мы попробуем извлечь Номинальный субъект nsubj
head_word = "null"
question = "В каких фильмах фигурирует персонаж Попай Дойл?"
en_doc = en_nlp(u'' + question)
для отправленных в en_doc.sents:
для токенов в отправленных:
если token.dep == nsubj и (token.pos == NOUN или token.pos == PROPN):
head_word = token.text
elif token.dep == attr and (token.pos == NOUN или token.pos == PROPN):
head_word = token.text
print(question+" ("+head_word+")")
Здесь мы получаем вывод с заглавным словом «фильмы», который довольно близок, и вы можете повысить его точность, обнаружив больше отношений зависимости и правил заглавных слов:
В каких фильмах фигурировал персонаж Попай Дойл? (фильмы)
spaCy также имеет визуализатор зависимостей displaCy вот демо с нашим входным вопросом:
displaCyполучить дерево зависимостей с помощью spaCy? [Обсуждение переполнения стека]
Работаете над похожей постановкой задачи? Хотите обсудить это? Свяжитесь со мной mail@5hirish.